
Learn Quasi-Stationary Distributions of Finite State Markov Chain


Abstract
1. Introduction
| Algorithm 1: (ac- method) Actor-critic algorithm for quasi-stationary distribution |
 |
2. Problem Setup and Review
2.1. Quasi-Stationary Distribution
2.2. Review of Simulation Methods for Quasi-Stationary Distribution
3. Learn Quasi-Stationary Distribution
3.1. Formulation of RL and Policy Gradient Theorem
- 1.
- reaches its maximal value 0 at ;
- 2.
- in for any ;
- 3.
- ;
- 4.
- .
- 1.
- At any θ, for any , the following Bellman-type equation holds for the value function V and the average reward :
- 2.
- The gradient of the average reward is the following:
3.2. Learn QSD
3.3. Actor-Critic Algorithm
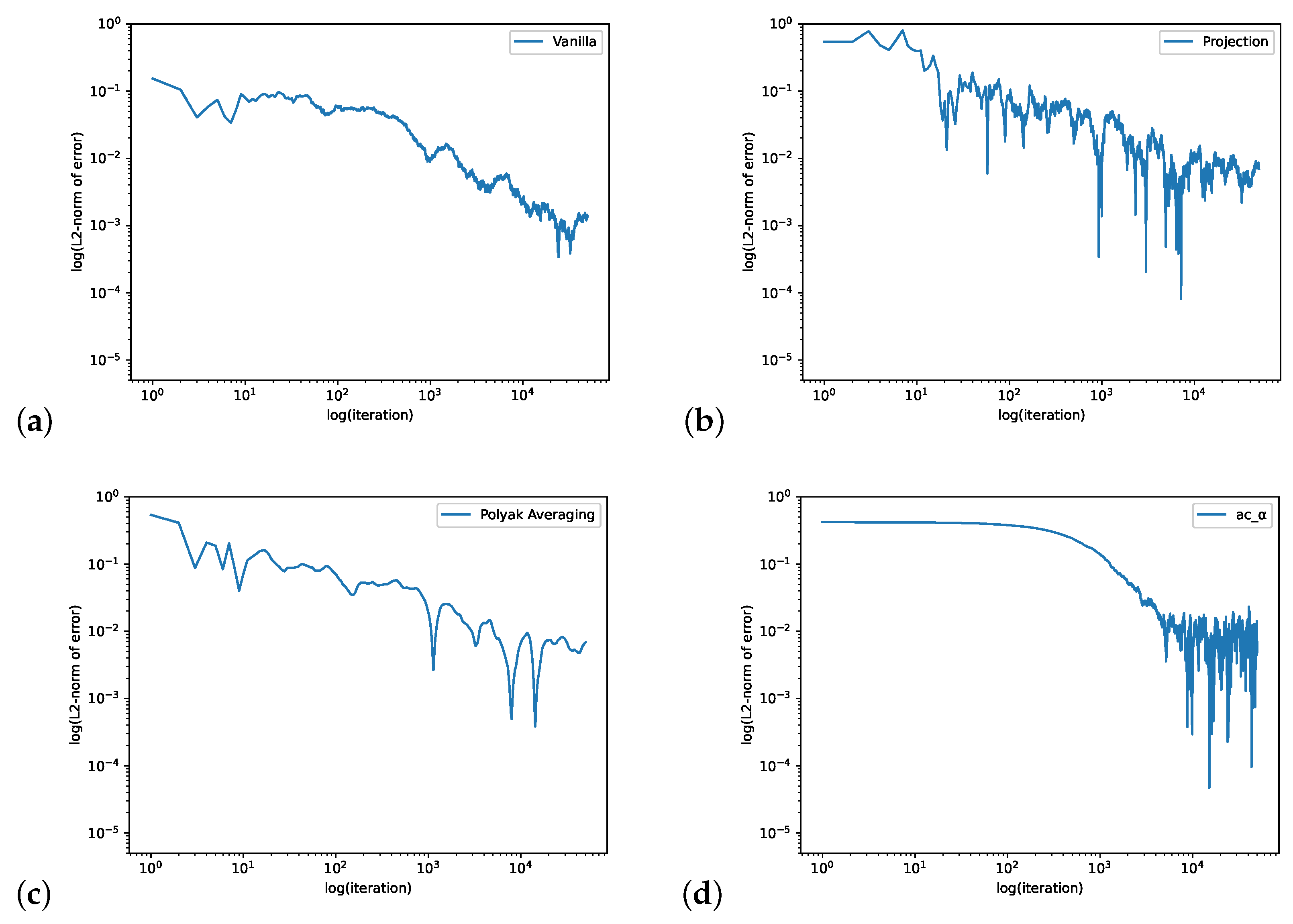
4. Numerical Experiment
4.1. Loopy Markov Chain
4.2. M/M/1/N Queue with Finite Capacity and Absorption
5. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Collet, P.; Martínez, S.; Martín, J.S. Quasi-Stationary Distributions: Markov Chains, Diffusions and Dynamical Systems; Springer Science & Business Media: Cham, Switzerlands, 2012. [Google Scholar]
- Buckley, F.; Pollett, P. Analytical methods for a stochastic mainland–island metapopulation model. Ecol. Model. 2010, 221, 2526–2530. [Google Scholar] [CrossRef]
- Lambert, A. Population dynamics and random genealogies. Stoch. Model. 2008, 24, 45–163. [Google Scholar] [CrossRef]
- De Oliveira, M.M.; Dickman, R. Quasi-stationary distributions for models of heterogeneous catalysis. Phys. Stat. Mech. Appl. 2004, 343, 525–542. [Google Scholar] [CrossRef][Green Version]
- Dykman, M.I.; Horita, T.; Ross, J. Statistical distribution and stochastic resonance in a periodically driven chemical system. J. Chem. Phys. 1995, 103, 966–972. [Google Scholar] [CrossRef][Green Version]
- Artalejo, J.R.; Economou, A.; Lopez-Herrero, M.J. Stochastic epidemic models with random environment: Quasi-stationarity, extinction and final size. J. Math. Biol. 2013, 67, 799–831. [Google Scholar] [CrossRef] [PubMed]
- Clancy, D.; Mendy, S.T. Approximating the quasi-stationary distribution of the sis model for endemic infection. Methodol. Comput. Appl. Probab. 2011, 13, 603–618. [Google Scholar] [CrossRef]
- Sani, A.; Kroese, D.; Pollett, P. Stochastic models for the spread of hiv in a mobile heterosexual population. Math. Biosci. 2007, 208, 98–124. [Google Scholar] [CrossRef]
- Chan, D.C.; Pollett, P.K.; Weinstein, M.C. Quantitative risk stratification in markov chains with limiting conditional distributions. Med. Decis. Mak. 2009, 29, 532–540. [Google Scholar] [CrossRef]
- Berglund, N.; Landon, D. Mixed-mode oscillations and interspike interval statistics in the stochastic fitzhugh–nagumo model. Nonlinearity 2012, 25, 2303. [Google Scholar] [CrossRef]
- Landon, D. Perturbation et Excitabilité Dans des Modeles Stochastiques de Transmission de l’Influx Nerveux. Ph.D. Thesis, Université d’Orléans, Orléans, France, 2012. [Google Scholar]
- Gesù, G.D.; Lelièvre, T.; Peutrec, D.L.; Nectoux, B. Jump markov models and transition state theory: The quasi-stationary distribution approach. Faraday Discuss. 2017, 195, 469–495. [Google Scholar] [CrossRef]
- Lelièvre, T.; Nier, F. Low temperature asymptotics for quasistationary distributions in a bounded domain. Anal. PDE 2015, 8, 561–628. [Google Scholar] [CrossRef]
- Pollock, M.; Fearnhead, P.; Johansen, A.M.; Roberts, G.O. The scalable langevin exact algorithm: Bayesian inference for big data. arXiv 2016, arXiv:1609.03436. [Google Scholar]
- Wang, A.Q.; Roberts, G.O.; Steinsaltz, D. An approximation scheme for quasi-stationary distributions of killed diffusions. Stoch. Process. Appl. 2020, 130, 3193–3219. [Google Scholar] [CrossRef]
- Watkins, D.S. Fundamentals of Matrix Computations; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 64. [Google Scholar]
- Bebbington, M. Parallel implementation of an aggregation/disaggregation method for evaluating quasi-stationary behavior in continuous-time markov chains. Parallel Comput. 1997, 23, 1545–1559. [Google Scholar] [CrossRef]
- Pollett, P.; Stewart, D. An efficient procedure for computing quasi-stationary distributions of markov chains by sparse transition structure. Adv. Appl. Probab. 1994, 26, 68–79. [Google Scholar] [CrossRef]
- Martinez, S.; Martin, J.S. Quasi-stationary distributions for a brownian motion with drift and associated limit laws. J. Appl. Probab. 1994, 31, 911–920. [Google Scholar] [CrossRef]
- Aldous, D.; Flannery, B.; Palacios, J.L. Two applications of urn processes the fringe analysis of search trees and the simulation of quasi-stationary distributions of markov chains. Probab. Eng. Inform. Sci. 1988, 2, 293–307. [Google Scholar] [CrossRef]
- Benaïm, M.; Cloez, B. A stochastic approximation approach to quasi-stationary distributions on finite spaces. Electron. Commun. Probab. 2015, 20, 1–13. [Google Scholar] [CrossRef]
- De Oliveira, M.M.; Dickman, R. How to simulate the quasistationary state. Phys. Rev. E 2005, 71, 016129. [Google Scholar] [CrossRef]
- Blanchet, J.; Glynn, P.; Zheng, S. Analysis of a stochastic approximation algorithm for computing quasi-stationary distributions. Adv. Appl. Probab. 2016, 48, 792–811. [Google Scholar] [CrossRef]
- Zheng, S. Stochastic Approximation Algorithms in the Estimation of Quasi-Stationary Distribution of Finite and General State Space Markov Chains. Ph.D. Thesis, Columbia University, New York, NY, USA, 2014. [Google Scholar]
- Kushner, H.; Yin, G.G. Stochastic Approximation and Recursive Algorithms and Applications; Springer Science & Business Media: Cham, Switzerlands, 2003; Volume 35. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control. Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Jordan, M.I.; Ghahramani, Z.; Jaakkola, T.S.; Saul, L.K. An Introduction to Variational Methods for Graphical Models. Mach. Learn. 1999, 37, 183–233. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Bach, F., Blei, D., Eds.; Volume 37, pp. 1530–1538. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Popova, M.; Isayev, O.; Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 2018, 4, eaap7885. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Rose, D.C.; Mair, J.F.; Garrahan, J.P. A reinforcement learning approach to rare trajectory sampling. New J. Phys. 2021, 23, 013013. [Google Scholar] [CrossRef]
- Méléard, S.; Villemonais, D. Quasi-stationary distributions and population processes. Probab. Surv. 2012, 9, 340–410. [Google Scholar] [CrossRef]
- Blanchet, J.; Glynn, P.; Zheng, S. Empirical analysis of a stochastic approximation approach for computing quasi-stationary distributions. In EVOLVE—A Bridge between Probability, Set Oriented Numerics, and Evolutionary Computation II; Schütze, O., Coello, C.A.C., Tantar, A.-A., Tantar, E., Bouvry, P., Moral, P.D., Legrand, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 19–37. [Google Scholar]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Wang, W.; Carreira-Perpinán, M.A. Projection onto the probability simplex: An efficient algorithm with a simple proof, and an application. arXiv 2013, arXiv:1309.1541. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Vanilla | Projection | Polyak Averaging | ac_ |
|---|---|---|---|---|
| Time (s) | 1038.3279 | 429.6304 | 505.2299 | 186.9280 |
| Time (s) | 753.9503 | 259.0671 | 268.5476 | 251.5370 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Z.; Lin, L.; Zhou, X. Learn Quasi-Stationary Distributions of Finite State Markov Chain. Entropy 2022, 24, 133. https://doi.org/10.3390/e24010133
Cai Z, Lin L, Zhou X. Learn Quasi-Stationary Distributions of Finite State Markov Chain. Entropy. 2022; 24(1):133. https://doi.org/10.3390/e24010133
Chicago/Turabian StyleCai, Zhiqiang, Ling Lin, and Xiang Zhou. 2022. "Learn Quasi-Stationary Distributions of Finite State Markov Chain" Entropy 24, no. 1: 133. https://doi.org/10.3390/e24010133
APA StyleCai, Z., Lin, L., & Zhou, X. (2022). Learn Quasi-Stationary Distributions of Finite State Markov Chain. Entropy, 24(1), 133. https://doi.org/10.3390/e24010133