1. Introduction and Main Result
Consider a system of K nodes, denoted by , each of which have (not necessarily uniform) storage. The nodes can communicate with each other through a noiseless bus link, in which transmissions of any node is received by all others. Each node possesses a collection of data symbols (represented in bits) in its local storage and demands another set of symbols present in other nodes. We formalize this as a data exchange problem.
Definition 1. A data exchange problem on a set of K nodes involving a collection B of information bits is given by the following:
a collection where denotes the subset of data present in node i,
a collection where denotes the set of bits demanded by node i.
The above data exchange problem models a number of cache-enabled multi-receiver communication problems studied recently in the coding theory community, including Coded Caching [
1], Coded Distributed Computing [
2,
3], Coded Data Shuffling [
4,
5,
6], and Coded Data Rebalancing [
7]. In [
8], a special case of our general problem here was considered in the name of
cooperative data exchange, where the goal was to reach a state in which all nodes have all the data in the system.
A solution to a given data exchange problem involves communication between the nodes. Each node i encodes the symbols in into a codeword of length and sends it to all other nodes. The respective demanded symbols at any node is then to be decoded using the received transmissions from all the other nodes and the node’s own content.
Formally, a
communication scheme for the given data exchange problem consists of a set of encoding functions
and decoding functions
, defined as follows.
such that
The
communication load of the above scheme is defined as the total number of bits communicated, i.e.,
The optimal communication load is then denoted by
The central result in this work is Theorem 1 in
Section 1.1, which is a lower bound on the optimal communication load
. Using this lower bound, we recover several important converse results of cache-enabled communication problems studied in the literature, including Coded Caching (
Section 2), Data Shuffling (
Section 3), and Distributed Computing (
Section 4). In each of these sections, we briefly review each setting and then apply Theorem 1 to recover the respective converses. As a result, the proofs of these existing converses are also made simpler than what is already available in the literature for the respective settings. The generic structure of the converse proofs obtained using our data exchange bound is presented in
Section 1.2. This structure includes three steps, which we also highlight at the appropriate junctures within the proofs themselves. The close relationship between these problems is quite widely known. This work gives a further formal grounding to this connection, by abstracting the common structure of these converses into a general form, which can potentially be applied to other new data exchange problems as well.
Apart from recovering existing results, more importantly we also use our data exchange lower bound to obtain
new tight converse results for some settings, while improving tightness results of some known bounds. Specifically, we present a new converse for a generic coded caching setting with multi-level cache sizes. Using this, we are able to close the gap to optimality for some known special cases of this generic setting (
Section 2.1). In
Section 5, we show the relationship between a “centralized” version of our data exchange lower bound and an existing bound for index coding known as the
-bound or the generalized independence number bound [
9]. In general, we find that our bound is weaker than the
-bound. However, for unicast index coding problems, we identify the precise conditions under which our data exchange bound is equal to the
-bound. In
Section 6, we discuss the application of our data exchange lower bound to more generalized index coding settings, specifically distributed index coding [
10,
11] and embedded index coding [
12].
Notation: For positive integer a, let . For a set S, we denote by the set of items in S except for the item k, and represent the union as . The binomial coefficient is denoted by , which is zero if The set of all t-sized subsets of a set A is denoted by
1.1. A Converse for the Data Exchange Problem
In this subsection, we will obtain a lower bound on the optimal communication load of the general data exchange problem defined in
Section 1. This is the central result of this work. The predecessor to the proof technique of our data exchange lower bound is in [
3], which first presented an induction based approach for the converse of the coded distributed computing setting. Our proof uses a similar induction technique.
Given a data exchange problem and for
such that
, let
denote the number of bits which are stored in every node in the subset of nodes
Q and stored in no other node, and demanded by every node in the subset
P and demanded by no other node, i.e.,
Note that, by definition, under the following conditions.
If , as the bits demanded by any node are absent in the same node.
If , by Definition 1.
Theorem 1 gives a lower bound on the optimal communication load of a given data exchange problem. The proof of the theorem is relegated to
Appendix A. The idea of the proof is as follows. If we consider only two nodes in the system, say
, then each of the 2 nodes has to transmit whatever bits it has which are demanded by the other node, i.e.,
. The proof of the theorem uses this as a base case and employs an induction technique to obtain a sequence of cut-set bounds leading to the final expression.
Theorem 1. Theorem 1, along with the observation that gives us the following corollary, which is a restatement of Theorem 1.
Corollary 1. Letdenote the total number of bits present exactly in q nodes and demanded exactly by p (other) nodes. Then, Remark 1. In [13], the authors presented an essentially identical bound (Lemma 1, [13]) as Corollary 1 in the setting of coded distributed computing. The proof given in [13] for this lemma also generalizes the arguments presented in [3], as does this work. Our present work considers a general data exchange problem and derives the lower bound in Theorem 1 for the communication load in such a setting. We had derived this lower bound independently in the conference version of this paper [14], and only recently came to know about the bound in [13]. In subsequent sections, we show how to use this bound to recover converses for various multi-terminal communication problems considered in the literature in recent years, and also obtain new converses for some settings. We also discuss, in Section 5, the looseness of Theorem 1 by considering a centralized version of the data exchange problem and comparing our bound with the generalized independence number bound in index coding. In Section 6, we discuss the application of our data exchange bound to more generalized index coding settings. These are the novel features of our present work, compared to the bound in Lemma 1 of [13]. 1.2. A Generic Outline of the Converse Proofs Presented in This Paper
In this work, we derive converse bounds for various settings in coded caching, coded distributed computing, and coded data shuffling using the bound in Theorem 1. Some of these converse bounds are already available in the literature, while others are novel. Each setting enjoins some constraints on the size of the demands and the size of the pre-stored content at each node. The bound in Theorem 1 applies for the setting in which the nodes have some predetermined local storage and some specific demanded bits. However, the settings of coded caching, coded distributed computing, and coded data shuffling permit the design of the initial storage so that the communication load is minimized. Further, the optimal communication load as defined in the literature for some of these settings involves maximization over all possible demand configurations, keeping only the size of the demands fixed. Keeping with these specifics, our bound in Theorem 1 must be tuned for each setting to obtain the respective converse, as captured by the three following steps which describe the generic structure behind our converse proofs.
Applying Theorem 1 to the present setting, we obtain a lower bound expression on the communication load, assuming an arbitrary choice of demands across the nodes and some arbitrary but fixed storage across the nodes.
“Symmetrization” step: In this step, the lower bound expression obtained in the previous step is averaged over some carefully chosen configurations of demanded bits at the nodes. This step helps to remove the dependency of the lower bound on the specific choice of demands.
Refine the averaged bound by imposing the constraints on the size of the initial storage at the nodes, and using convexity of terms inside the averaged bound to obtain the final expression of the bound. This step helps to remove the dependency of the converse on the specific initial storage configuration at the nodes.
These three steps enable us to give simpler proofs to those in the literature for known converses, and also obtain novel converses for some variants of the same problems. Further, it also illustrates the generic nature of the data exchange bound of Theorem 1. In the converse proofs that are to follow in this paper, we will highlight these steps at the appropriate junctures.
2. Coded Caching
In this section, we apply Theorem 1 to recover the lower bound obtained in [
15] for the problem of coded caching introduced in [
1]. Further, using Theorem 1, we prove in
Section 2.1 a new converse for a generic coded caching problem under multiple cache size settings. This provides new converses for some existing settings in literature, and also tightens bounds in some others. In
Section 2.2, we recover a converse for coded caching with multiple file requests. In
Section 2.3, we recover the converse for coded caching with decentralized cache placement.
We now describe the main setting of this section. In the coded caching system introduced in [
1], there is one server connected via a noiseless broadcast channel to
K clients indexed as
. The server possesses
N files, each of size
F bits, where the files are indexed as
. Each client contains local storage, or a
cache, of size
bits, for some
. We call this a
coded caching system.
Figure 1 illustrates this system model.
The coded caching system operates in two phases: in the caching phase which occurs during the low-traffic periods, the caches of the clients are populated by the server with some (uncoded) bits of the file library. This is known as uncoded prefetching. In this phase, the demands of the clients are not known. We denote the caching function for node k as and thus the cache content at client k at the end of the caching phase is denoted as .
In the delivery phase which occurs during the high-traffic periods, each client demands one file from the server, and the server makes transmissions via the broadcast channel to satisfy the client demands. Let the demanded file at client k be , where The server uses an encoding function to obtain coded transmissions such that each client can employ a decoding function to decode its demanded file using the coded transmissions and its cache content, i.e.,
The communication load
of the above coded caching scheme is the number of bits transmitted in the delivery phase (i.e., the length of
X) in the worst case (where “worst case” denotes maximization across all possible demands). The optimal communication load denoted by
, is then defined as
For this system model, when
,the work in [
1] proposed a caching and delivery scheme which achieves a communication load (normalized by the size of the file
F) given by
. In [
15], it was shown that, for any coded caching scheme with uncoded cache placement, the optimal communication load is lower bounded by
. Therefore, it was shown that, when
and
, the scheme in [
1] is optimal.
In the present section, we give another proof of the lower bound for coded caching derived in [
15]. We later discuss the case of arbitrary
in Remark 2.
We now proceed with restating the lower bound from [
15]. Note that these converses are typically normalized by the file size in literature, however we recall them in their non-normalized form, in order to relate them with our data exchange problem setting.
Theorem 2 ([
15])
. Consider a coded caching system with . The optimal communication load in the delivery phase satisfies Proof based on Theorem 1. We assume that the caching scheme and delivery scheme of the coded caching scheme are designed such that the communication load is exactly equal to the optimal load Let the K client demands in the delivery phase be represented by a demand vector , where denotes the index of the demanded file of the client k. We are interested in the worst case demands scenario; this means we can assume that all the demanded files are distinct, i.e., for all to bound from below, without loss of generality.
We observe that a
coded caching problem during the delivery phase satisfies Definition 1 of a data exchange problem on
nodes indexed as
, where we give the index 0 to the server node and include this in the data exchange system. Before proceeding, we remark that the below proof gives a lower bound where all
nodes in the system
may transmit, whereas in the coded caching system of [
1]
only the server
can transmit. Thus, any lower bound that we obtain in this proof applies to the setting in [
1] also.
Clearly in the equivalent data exchange problem, the node 0 (the server) does not demand anything, but has a copy of all the bits in the entire system. With these observations, we have by definition of
in (
1)
where the quantities
clearly depend on the demand vector
.
We thus use a new set of variables: for each
,
, and given demands
, let
denote the number of bits demanded by receiver node
k that are available only at the nodes
, i.e.,
Using these definitions, we proceed following the three steps given in
Section 1.2.
Applying Theorem 1: By Theorem 1, we have the following lower bound for demand vector
where (
6) is obtained from (
4) and (
5).
“Symmetrizing” (6) over carefully chosen demand vectors: We now consider the averaging of bounds of type (
6) over a chosen collection of
N demand vectors, given by
where
That is, contains the demand vectors consisting of consecutive K files, starting with each of the N files as the demand of the first client.
Averaging (
6) through the set of
N demand vectors in
, the lower bound we obtain is
Let
denote the number of bits of file
n stored only in
. Then, in the above sum,
if and only if
. This happens precisely once in the collection of
N demand vectors in
. Thus, we have
where (
10) follows as for a fixed
n and
Q,
in (
9), and by multiplying and dividing by
F.
Refining the bound (10) by using the constraints of the setting: Now, by definition,
, and thus
, denotes a probability mass function. Furthermore,
As
is a convex decreasing function for
, using Jensen’s inequality, we have
, where
Thus, we get
which completes the proof. □
Remark 2. In the previous part of this section, we have shown the converse for the worst case communication load for coded caching in the regime of . We now consider a general coded caching setup with arbitrary values and cache size M. Consider a positive integer For a fixed caching scheme denoted by let the minimum communication load for satisfying the clients, maximized across all possible demand vectors with exactly distinct files in each of the demand vectors, be denoted as
In the work [16], it was shown that for where is defined as the lower convex envelope of the pointsNote that is independent of For this general setting, the optimal worst case load , as defined in (3), satisfiesThus, from (11), we getwhich is the converse bound on the worst case communication load proved in [16] for this general scenario. In Appendix B, we use our data exchange bound in Theorem 1 to recover (11), which therefore shows (12). 2.1. Server-Based and Server-Free Coded Caching with Heterogeneous Cache Sizes at Clients
So far we have discussed the coded caching scenario where there is a central server containing the entire file library and the client cache sizes are homogeneous, i.e., the same at all clients. We now describe a generalization of the result in Theorem 2 to the case of systems in which the clients have heterogeneous cache sizes, with either a centralized server present or absent. The proof of this is easily obtained from our data exchange bound in Theorem 1. To the best of our knowledge, a converse for this general setting is not known in the literature. Using this converse, we can derive new converses and tighten existing converses for various special cases of this setting, which include widely studied coded caching settings, such as device-to-device coded caching [
17].
Consider a coded caching system with N files (each of size F) with K client nodes denoted by a set . We shall indicate by the value the presence () or absence () of a centralized server in the system containing the file library. For the purpose of utilizing our data exchange bound, we assume that all the nodes in the system are capable of transmissions; thereby, any converse for this scenario is also valid for the usual coded caching scenario in which only the server (if it is present) does transmissions in the delivery phase. The set of clients is partitioned into subsets where the nodes in subset can store a fraction of the file library. Let We now give our converse for this setting. The caching and the delivery scheme, as well as the optimal communication load , are defined as in the case of coded caching with homogeneous cache sizes.
Proposition 1. For the above heterogeneous cache sizes setting, assuming , the optimal communication load for uncoded cache placement is lower bounded as follows. Before giving the proof of Proposition 1, we give the following remarks regarding the generality of Proposition 1, the new results which arise by applying Proposition 1 and various results from existing literature that are subsumed or improved by it.
Heterogeneous Cache Sizes: There exists a number of works discussing distinct or heterogenous client cache sizes, for instance, in [
18,
19]. However, closed form expressions for the lower bound on the load seem to be lacking for such scenarios, to the best of our knowledge. Proposition 1 gives a lower bound for all such settings.
Device-to-Device Coded Caching: Suppose there is no designated server in a coded caching setup, but the client nodes themselves are responsible for exchanging the information to satisfy their demands. This corresponds to the case of Device-to-Device (D2D) coded caching, first explored in [
17]. In [
17], an achievable scheme was presented for the case when each (client) node has equal cache fraction
, and this scheme achieves a communication load of
bits. In the work [
20], it was shown that this communication load is optimal (for the regime of
) over all possible “one shot” schemes (where “one shot” refers to those schemes in which each demanded bit is decoded using the transmission only from one server), and further it was shown that the load is within a multiplicative factor of 2 of the optimal communication load under the constraint for uncoded cache placement. We remark that the D2D setting of [
17] corresponds to the special case of our current setting, with
and
. By this correspondence, by applying Proposition 1, we see that the load in this case is lower bounded as
thus showing that the achievable scheme in [
17] is exactly optimal under uncoded cache placement. The D2D scenario with heterogeneous cache sizes was explored in [
21], in which the optimal communication load was characterized as the solution of an optimization problem. However, no closed form expression of the load for such a scenario is mentioned. Clearly, our Proposition 1 gives such a lower bound, when we fix
, for any number of levels
t of the client-side cache sizes.
Further, the result for coded caching with a server and equal cache sizes at receivers, as in Theorem 2, is clearly obtained as a special case of Proposition 1 with and .
We now proceed to prove Proposition 1. The proof is similar to that of Theorem 2.
Proof of Proposition 1. As in the proof of Theorem 2, we will denote the server node as the node 0 and assume a caching and delivery scheme which achieves the optimal load for worst case client demands.
Applying Theorem 1, for our setting, we have
Note that if
(i.e., the server is present), then
whenever
For a specific demand vector
consisting of distinct demands and for some
, we define the quantity
as follows.
Symmetrization over appropriately chosen demand vectors: Choosing the same special set of demand vectors
as in (
7) and averaging the above lower bound over the demand vectors in
similar to the proof of Theorem 2, we obtain a bound similar to (
8):
Combining the two expressions in (
14), we can write a single equation which holds for
,
We now define the term
as follows.
Using the above definition of
and observing that each demand vector in
has distinct components, Equation (
15) can be written as
Refining the bound in (19) using setting constraints and convexity: By the definition of
in (
16), we have
. Further,
. Furthermore, for
, the function
is a convex decreasing function in
x for
Thus, using Jensen’s inequality, we have
where
This completes the proof. □
Remark 3. Proposition 1 holds when . This scenario is the most studied case in the literature and is practically more relevant than the case . We now provide lower bounds for the heterogeneous cache sizes setting for general values of , which includes the case . As before, we consider two cases: indicates the presence of a centralized server in the system and indicates its absence.
Case 1,
:
For the case where a centralized server is present, i.e., , we havewhere the function is defined in Remark 2. The derivation of this lower bound follows the steps in Appendix B until (
A21)
, where we choose . Without loss of generality, we assume that all caches are fully populated with uncoded bits from the library, thus the total memory occupied by the cached bits is equal to the sum of all the cache memory available in the system . Applying Jensen’s inequality on (
A21)
and using the fact , we immediately arrive at the lower bound (
20)
.Case 2,
:
In this case, the optimal worst-case communication load can be lower bounded as follows:The proof of this lower bound follows similar approach as Appendix B and is outlined in Appendix C. Note that when , both (
20)
and (
21)
become identical to the inequality in Proposition 1. 2.2. Coded Caching with Multiple File Requests
In [
22], coded caching with multiple file requests was considered, in which each client requests any
files out of the
N files in the delivery phase. It was shown in [
22] (Section V.A) that if the
, then the optimal worst case communication load can be lower bounded as
The work in [
22] also gives an achievable scheme based on the scheme in [
1] which meets the above bound. The same lower bound can be derived using Theorem 1 also, by following a similar procedure as that of the proof of Theorem 2.
Applying Theorem 1, we give the proof in brief. The demand vector assumed in proof of Theorem 1 becomes a
-length vector in this case, consisting of
K subvectors, each of length
, capturing
distinct demands for each client. The proof proceeds as is until (
6).
Symmetrization: The set
in (
7) now contains the
-length vectors of consecutive file indices, cyclically constructed, starting from
, i.e.,
Thus, if the demand vector considered is
then the indices of the demanded files at client
, denoted by
is given by
The averaged lower bound expression similar to (
8) is then obtained as
In this expression, we have
which now indicates the number of bits of
distinct and consecutive files indexed by
and available exclusively at the nodes in
(0 denoting the server).
Observation: where denotes the number of bits of file available exclusively in the nodes , as in the proof of Theorem 2.
Now,
if and only if the file
is demanded by client
k. By definition of
, the event
happens for precisely
values of index
j. From (
24), applying the above observation, we have the following.
Refining the bound in (25) using the setting constraints: We use the constraints of the setting and the convexity of the resultant expression to refine (
25). This refinement essentially follows similar subsequent steps as in the proof of Theorem 2 following (
9), and leads finally to (
22).
Remark 4. The work in [23] considers a coded caching setup in which Λ
caches () are shared between the K clients. The special case when Λ
divides K and each cache is serving exactly clients is equivalent to the scenario of the multiple file requests in [22] with Λ
clients, each demanding files. The above proof then recovers the converse for this setting, which is obtained in [23] (Section III.A in [23]). 2.3. Coded Caching with Decentralized Caching
Theorem 2 and the subsequent results discussed above hold for the
centralized caching framework, in which the caching phase is designed carefully in a predetermined fashion. In [
24], the idea of decentralized placement was introduced, in which the caching phase is not coordinated centrally (this was called “decentralized coded caching” in [
24]). In this scenario, each client, independently of others, caches a fraction
of the bits in each of the
N files in the file library, chosen uniformly at random. For this scenario, the server (which has the file library) is responsible for the delivery phase. The optimal communication load
is defined as the minimum worst case communication load over all possible delivery schemes for a given caching configuration, randomly constructed as given above. For the case of
, the authors of [
24] show a scheme which achieves the worst case communication load
. This was shown to be optimal for large
F in [
16] and also in [
25] via a connection to index coding. In the following, we show that the same optimality follows easily via our Theorem 1.
Assume that we have distinct demands at the
K clients, as in the proof of Theorem 1, given by the demand vector
. We first note that by the law of large numbers, as
F increases, for the decentralized cache placement, for any
, we have
with probability close to 1, where
is as defined in (
5). This observation enables us to avoid the steps 2 and 3 mentioned in
Section 1.2, as the value of
is independent of the specific random cache placement or the demands chosen (as long as they are distinct). Using this in (
6), we get
where the last step follows as
Thus, we have given an alternate proof of the optimality of the decentralized scheme in [
24].
3. Decentralized Coded Data Shuffling
In distributed machine learning systems consisting of a master and multiple worker nodes, data are distributed to the workers by the master in order to perform training of the machine learning model in a distributed manner. In general, this training process takes multiple iterations, with the workers doing some processing (like computing gradients) on their respective training data subsets. In order to ensure that the training data subset at each node are sufficiently representative of the data, and to improve the statistical performance of machine learning algorithms, shuffling of the training data between the worker nodes is implemented after every training iteration. This is known as data shuffling.
A coding theoretic approach to data shuffling, which involves the master communicating coded data to the workers was presented in [
4]. The setting in [
4] was
centralized, which meant that there is a master node communicating to the servers to perform the data shuffling.
The work in [
5] considered the data shuffling problem in which there is no master node, but the worker nodes exchange the training data among themselves, without involving the master node, to create a new desired partition in the next iteration. This was termed as
decentralized data shuffling in [
5]. Note that these notions of “centralized” and “decentralized” in the data shuffling problem are different from those in the coded caching [
24], in which these terms were used to define the deterministic and random design of the caching phase, respectively. In this section, we look at the work in [
5] and give a new simpler proof of the lower bound on the communication load for decentralized data shuffling.
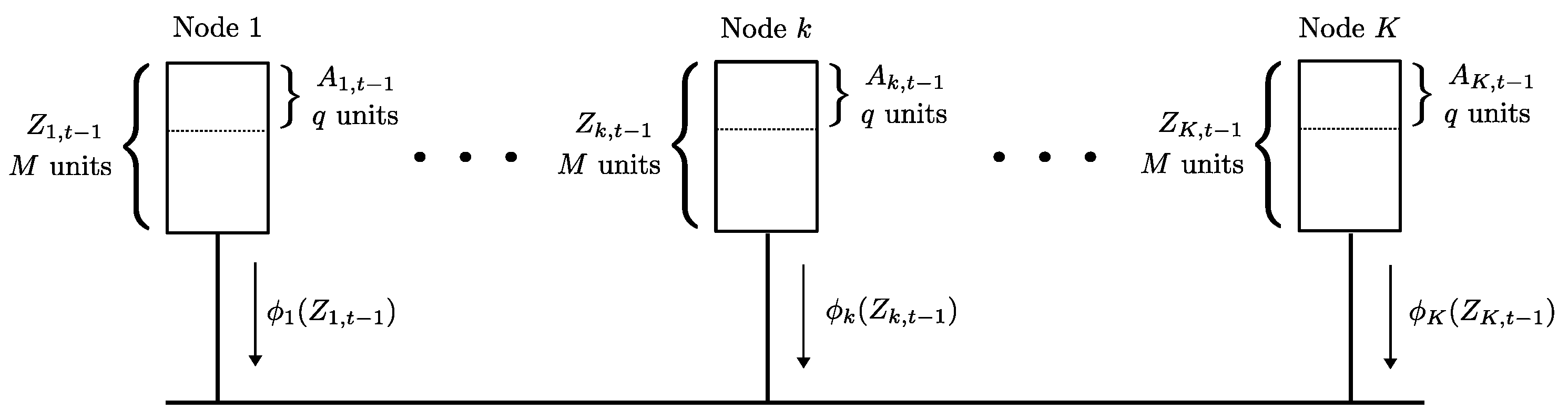
We first review the setting in [
5]. Consider
K workers in the system, where each worker node is required to process
q data units at any given time. The total dataset
consists of
data units
, with a size of
B bits per data unit. The collection of data units to be processed by worker node
k at time
t is denoted as
. The collection of data units
must form a partition of the dataset
for every time instant
t, i.e., for any time
t and any choice of
with
we have
Each node
k has a local cache of size
bits (such that
) that can hold
M data units. Out of these
M units
q units are the current “active” data
at any time step which are required to be processed by the node
k. The contents of the cache of node
k at time
t is denoted as
. Therefore, for each choice of
and any time
t, we have
At each time instance
t, a new partition
is to be made active at the nodes
, where this new partition is made known to the workers only at time step
t. Note that the contents of the nodes at time
are
, and the active partition at time
is
. The worker nodes communicate with each other over a common broadcast link, as shown in
Figure 2, to achieve the new partition. The decentralized data shuffling problem is to find a delivery scheme (between workers) to shuffle the collection of active data units
to a new partition
. Each worker
k computes a function
of its cache contents and broadcasts it to the other workers. Using these transmissions and the locally available cache content
each node
k is required to decode
As in the case of coded caching, one seeks to reduce the worst-case communication load by designing the initial storage and coded transmissions carefully. The communication load of this data shuffling scheme, denoted by
, is the sum of the number of bits broadcast by all the
K nodes in the system, i.e.,
. The optimal communication load of data shuffling
(for the worst case data shuffle) is defined as
where the maximization is over all possible choices for
and
, and the minimization is over all possible choices for the cache placement
and the delivery scheme
.
For the above setting, the following bound on the communication load
was shown in [
5].
The above bound was shown to be optimal for some special cases of the parameters, and order-optimal otherwise.
Proof of the Decentralized Data Shuffling Converse
We now recover the bound (
26) by a simple proof using our generic lower bound in Theorem 1. We assume that the cache placement and delivery scheme of the data shuffling scheme are designed such that the communication load of the data shuffling scheme is exactly equal to
We proceed as per the three steps in
Section 1.2.
Applying Theorem 1: For and let denote the subset of bits of available exactly at the nodes in Q and not anywhere else. Note that if , as each bit is necessarily present in at least one of the K nodes.
As per our bound in Theorem 1, we have
Symmetrization by averaging over appropriately chosen set of shuffles: Let the set of circular permutations of , apart from the identity permutation, be denoted by . There are of them clearly. We denote an arbitrary permutation in by , and by we denote the coordinate of .
Now, consider the shuffle given by
, i.e., for each
k,
. For this shuffle, we have by the above equation that
Now, averaging (
28) over all permutations in
, we get
As we go through all choices of
we see that
takes every value except
k, i.e.,
assumes each value in
exactly once. Moreover,
is the collection of bits of
present only in
Q. However, the bits
are already presented in
. Hence,
if
. Therefore, we have
Refining the bound using setting constraints and convexity: Now, we have the following observations as
form a partition of all the
bits.
Utilizing the above, and the fact that
is a convex decreasing function in
(for
), we have
Thus, we have recovered (
26).
Remark 5. We have considered the decentralized version of the coded data shuffling problem in this subsection. The centralized version of the data shuffling problem was introduced in [4] and its information theoretic limits were studied elaborately in [6]. Our data exchange bound, when applied to the setting in [6], results in a looser converse result than that in [6]. The reasons for this is explored in Section 5 using the connection between our data exchange bound and the bound for index coding known in literature. 4. Coded Distributed Computing
In a distributed computing setting, there are
N files on which the distributed computing task has to be performed by
K nodes. The job at hand is divided into three phases: Map, Shuffle, and Reduce. In the shuffle phase, the nodes that are assigned to perform the distributed computing task exchange data. In [
3], the authors proposed coded communication during the shuffle phase to reduce the communication load. We recollect the setting and the main converse result from [
3], which we recover using our data exchange bound.
A subset
of
N files is assigned to
node and the
node computes the map functions on this subset in the map phase (see
Figure 3). We assume that the total number of map functions computed at the
K nodes is
, where
r is referred to as the
computation load. In the reduce phase, a total of
W reduce functions is to be computed across the
K nodes corresponding to the
N files. Each node is assigned the same number of functions. Obtaining the output of the reduce functions at all the nodes will complete the distributed computing task. In this work, as in [
3], we consider two scenarios: in the first one, each reduce function is computed exactly at one node and in the second, each reduce function is computed at
s nodes, where
.
Each map function output (also referred to as intermediate output) corresponds to a particular file and a particular reduce function. For each file and each reduce function, an intermediate output of T bits is obtained. To compute an assigned reduce function, each node requires the intermediate outputs of all the files corresponding to the assigned reduce function. This means each node is missing the intermediate outputs (corresponding to the assigned reduce functions) of those files that are not assigned to it in the map phase.
The intermediate outputs of each file assigned to node i corresponding to all the reduce functions are available at node i at the end of the map phase and denoted by . These intermediate outputs at the end of the map phase are encoded as follows: and broadcasted to the remaining nodes, in the shuffle phase (in order to deliver the missing intermediate outputs at the nodes). Let be the total number of bits broadcasted by the K nodes in the shuffle phase, minimized over all possible map function assignments, reduce function assignments, and shuffling schemes, with a computation load r. We refer to as the minimum communication load.
To obtain similar expressions for the communication load as in [
3], we normalize the communication load by the total number of intermediate output bits (=
). We consider the first scenario now, where each reduce function is computed exactly at one node.
Theorem 3 ([
3])
. The minimum communication load incurred by a distributed computing system of K nodes for a given computation load r, where every reduce function is computed at exactly one node and each node computes reduce functions, is bounded as Proof. We resort to two of the three steps of
Section 1.2 to complete this proof. The symmetrization step, which involves averaging over demand configurations, is not applicable in the present setting because the definition of
involves minimization over the reduce function assignment as well.
Applying Theorem 1: Let
denote a given map function assignment to the nodes, where
. Let
denote the communication load associated with the map function assignment
. We will prove that
where
denotes the number of files which are mapped at exactly
j nodes in
. It is easy to see that
and
. We will apply Theorem 1 to this setting. Recall that each reduce function is computed exactly at one node in our present setup. To apply Theorem 1, we need to ascertain the quantities
for
being disjoint subsets of
. To do this, we first denote by
the number of files whose intermediate outputs are demanded by some node
k and available exclusively in the nodes of
Q. Note that
is the same for any
, as each node demands intermediate outputs of
all the files that are not mapped at the node itself.
As the number of reduce functions assigned to node
k is
(as each reduce function is computed at exactly one node) and each intermediate output is
T bits, the number of intermediate output bits which are demanded by any node
k and available exclusively in the nodes of
Q are
. Thus, for any
, the quantities
in Theorem 1 are given as follows.
Further note that
by definition of
Using these and applying Theorem 1 with the normalization factor
, we have the following inequalities.
Refining the bound using convexity and setting constraints: Using definition of
, noting that
is a convex decreasing function of
j and that
, we have that
□
Now, we consider the case in which each reduce function has to be computed at s nodes. The total number of reduce functions is assumed to be W. In addition, the following assumption is made to keep the problem formulation symmetric with respect to reduce functions: every possible s sized subset of K nodes is assigned reduce functions (we assume divides W). As in the previous case, we will denote the communication load for a given map function assignment by and the optimal communication load with computation load r by . We will prove the following result which gives a lower bound on .
Proposition 2 ([
3])
. The communication load corresponding to a map function assignment when each reduce function has to be computed at s nodes is lower bounded as Proof. As before, we will denote by
the number of files whose map function outputs are available exclusively in the nodes of
Q. Furthermore, we will denote the number of intermediate output bits which are demanded exclusively by the nodes in
P and available exclusively in the nodes of
Q by
. Then, applying Theorem 1, the lower bound on the communication load in terms of
is given by
We first interchange the above summation order and consider all sets
Q with
and all sets
P such that
. For
, we need to count the subsets of size
s, which form a subset of
. Thus, for a fixed
j, we can see that the range of
l can vary from
to
. For a given subset
P of size
l, the number of
s sized subsets which are contained within
and contain
P are
. Therefore, the number of intermediate output bits demanded exclusively by the nodes in
P and available exclusively in
Q,
, is given by
. This is because each of the
s-sized subset has to reduce
functions. Using this relation, the above inequality can be rewritten as follows.
where (
40) follows as
. This completes the proof. □
The above lemma along with certain convexity arguments resulting from the constraints imposed by the computation load can be used to prove the lower bound on
. The interested reader is referred to the converse proof of Theorem 2 in [
3] for the same.
5. Relation to Index Coding Lower Bound
We now consider the “centralized” version of the data exchange problem, where one of the nodes has a copy of all the information bits and is the lone transmitter in the system. We will use the index 0 for this server node, and assume that there are
K other nodes in the system, with index set
, acting as clients. In terms of Definition 1, this system is composed of
nodes
, the demand
of the server is empty, while the demands
and the contents
of all the clients are subsets of the contents of the server, i.e.,
for all
. Without loss of generality, we assume that only the server performs all the transmissions as any coded bit that can be generated by any of the client nodes can be generated at the server itself. Clearly, this is an index coding problem [
26] with
K clients or receivers, the demand of the
receiver is
, and its
side information is
. When applied to this scenario, our main result Theorem 1 therefore provides a lower bound on the index coding communication cost.
The maximum acyclic induced subgraph (MAIS) and its generalization, which is known as the generalized independence number or the
-bound, are well-known lower bounds in index coding [
9,
26]. In this section, we describe the relation between the
-bound of index coding and the centralized version of Theorem 1. We show that the latter is in general weaker, and identify the scenarios when these two bounds are identical. We then use these observations to explain why Theorem 1 cannot provide a tight lower bound for the centralized data shuffling problem [
6].
Let us first apply Theorem 1 to the centralized data exchange problem. As node 0 contains all the information bits and its demand is empty, we have if or . Using and defining the variable , we obtain
Theorem 4. The centralized version of our main result Theorem 1 is Note that it is possible to have when .
In
Section 5.1, we express the generalized independence number
in terms of the parameters
, and in
Section 5.2, we identify the relation between our lower bound Theorem 4 and the index coding lower bound
.
5.1. The Generalized Independence Number Bound
Let be any permutation of , where is the coordinate of the permutation. Applying similar ideas as in the proof of Theorem 1 to the centralized scenario, we obtain the following lower bound on . This lower bound considers the nodes in the order , and for each node in this sequence it counts the number of bits that are demanded by this node which are neither demanded by and nor available as side information in any of the earlier nodes.
Proposition 3. For any permutation γ of , A direct consequence of Proposition 3 is
where the maximization is over all possible permutations on
.
We now recall the definition of the generalized independence number [
9]. Denote the collection of the
information bits available exclusively at the nodes
and demanded exclusively by the nodes
P as
. Therefore, the set of all the information bits present in the system is
Note that each bit is identified by a triple
.
Definition 2. A subset of B is a generalized independent set if and only if every subset satisfies the following:
The generalized independence number α is the size of the largest generalized independent set.
We next show that the lower bound in (
42) is in fact equal to the generalized independence number
of this index coding problem.
Theorem 5. The generalized independence number α satisfieswhere the maximization is over all permutations of . 5.2. Relation to the Index Coding Lower Bound
Proposition 3 serves as the platform for comparing Theorem 4 and the -bound. While equals the maximum value of the bound in Proposition 3 over all permutations on , our bound in Theorem 4 equals the average value of the lower bound given in Proposition 3 over all permutations on . We will show this relation between Theorem 4 and Proposition 3 now.
Taking the average of the right hand side of (
41) with respect to all
, we obtain
For each choice of
with
, we now count the number of times
appears in this sum. For a given
, the inner summations include the term
if and only if the following holds:
i.e., if we consider the elements
in that order, the first element from
to be observed in this sequence belongs to
P. Thus, for a given pair
the probability that a permutation
chosen uniformly at random includes the term
in the inner summation is
. Therefore, the average of the lower bound in Proposition 3 over all possible
is
which is exactly the bound in Theorem 4.
As the bound in Theorem 4 is obtained by averaging over all , instead of maximizing over all , we conclude that this is in general weaker than the -bound of index coding. The two bounds are equal if and only if the bound in Proposition 3 has the same value for every permutation .
Although weaker in general, we note that the bound of Theorem 4 is easier to use than the
-bound. As demonstrated by (
2), in order to use Theorem 4, we only need to know, for each information bit, the number of nodes that contain this bit and the number of nodes that demand this bit. In comparison, this information is insufficient to evaluate the
-bound, which also requires the identities of these nodes.
5.3. On the Tightness of Theorem 4
We now consider the class of unicast problems, i.e., problems where each bit is demanded by exactly one of the nodes. For this class of problems, we characterize when Theorem 4 yields a tight bound.
Theorem 6. For unicast problems the bound in Theorem 4 equals if and only if every with satisfies the following, for every .
Proof. See
Appendix F. When the lower bound of Theorem 4 is tight, the clique-covering based index coding scheme (see in [
26,
27]) yields the optimal communication cost. □
Our main result in Theorem 1, or equivalently, Theorem 4, does not provide a tight lower bound for centralized data shuffling problem [
6], because this problem involves scenarios that do not satisfy the tightness condition of Theorem 6. For instance, consider the simple canonical data shuffling setting, where the system has exactly
K files, all of equal size
F bits, and each node stores exactly one of these files, i.e., the entirety of the contents of the
node
is the
file. Here,
for all
, and
for all
. Assume that the shuffling problem is to move the file
to node
k, i.e.,
, where we consider the index
to be equal to 1. This is a worst-case demand for data shuffling incurring the largest possible communication cost. For this set of demands, we have
for all
, and
for all other choices of
. In particular,
. Clearly, the condition in Theorem 6 does not hold for
. Therefore, our lower bound is strictly less than
for this data shuffling problem, and therefore is not tight.



{kind=link}
{kind=link}
{kind=link}


