
A Hybrid Analysis-Based Approach to Android Malware Family Classification


Abstract
:1. Introduction
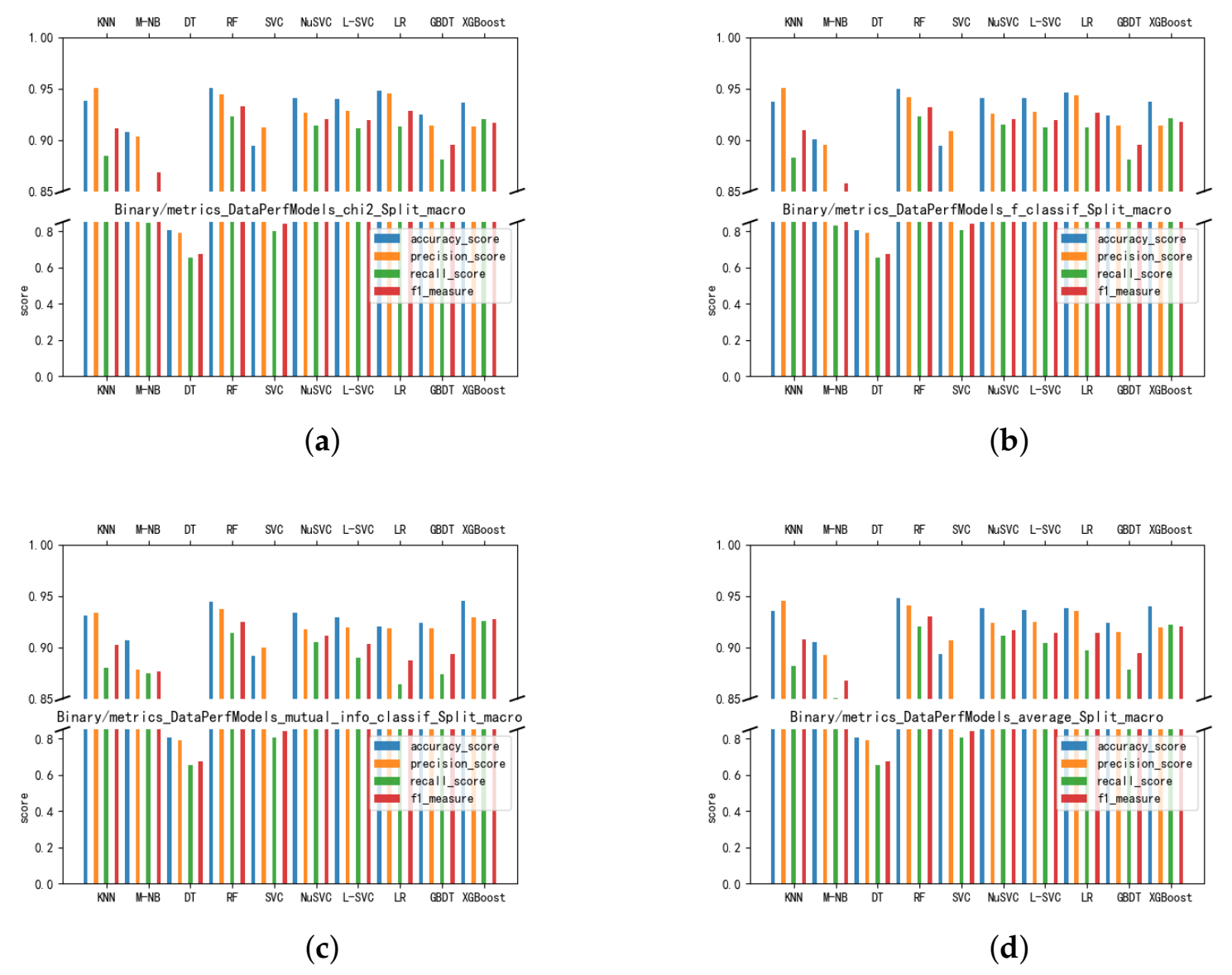
- The static detection of Android malware based on permissions and intents has been improved. We applied three feature selection methods, which eliminated more redundant features; a subset of candidate features was input to multiple machine learning methods, and the random forest was compared to yield the best detection results. The chi-square test is the optimal feature selection method and is briefly analyzed. Afterwards, we analyze the top 20 features in the optimal feature subset and one feature associated with them;
- The classification of Android malware families based on network traffic has been updated. In the dynamic analysis of Android malware, focusing on "sessions and all layers of protocols” in network traffic and applying Res7LSTM is considered feasible compared to focusing only on HTTPS in the application layer;
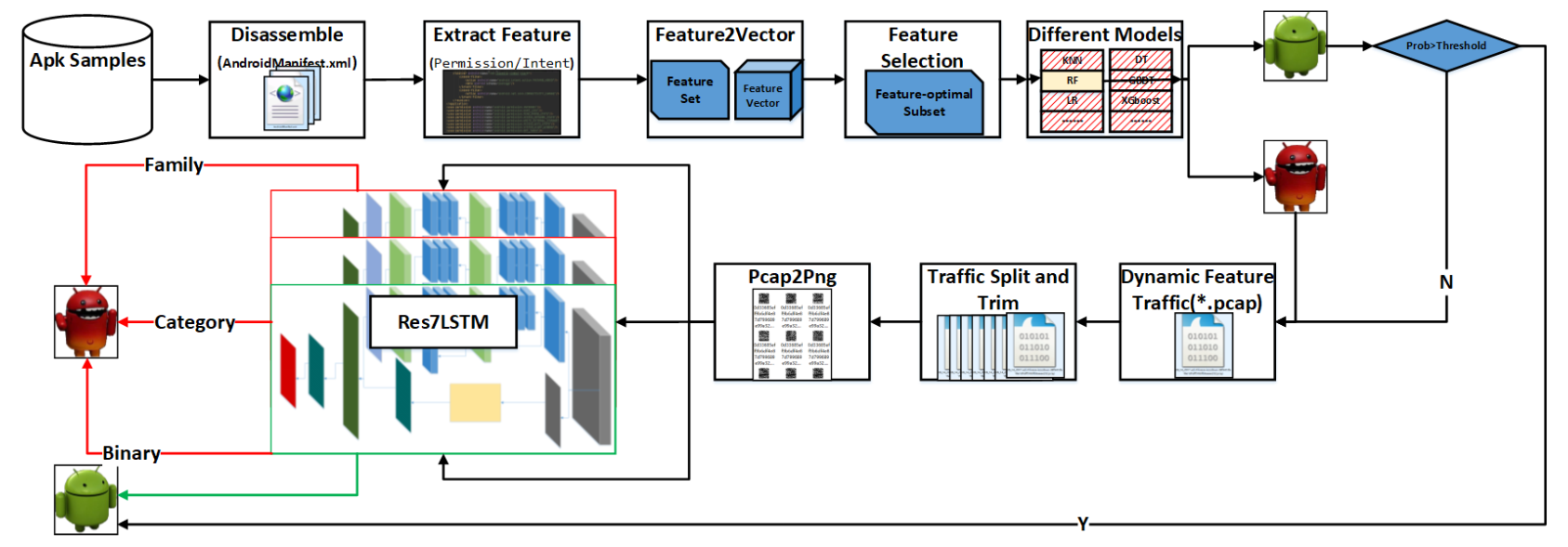
- Detection and classification processes are based on hybrid analysis. Permissions and intents are selected as static features and, after feature selection, different algorithms are applied to select the optimal algorithm and the optimal feature subset, and the results are directly output or input to the dynamic detection layer according to their prediction probability. In dynamic analysis, network traffic is split and imaged as “sessions and all layers of protocols”, and Res7LSTM is used for detection and classification.
2. Related Work
3. Modeling
3.1. Static Features-Manifest File Characterization
3.1.1. Sample Decompiling and Obtaining Features
3.1.2. Initialize Static Feature Space and Obtain Numerical Feature Expression
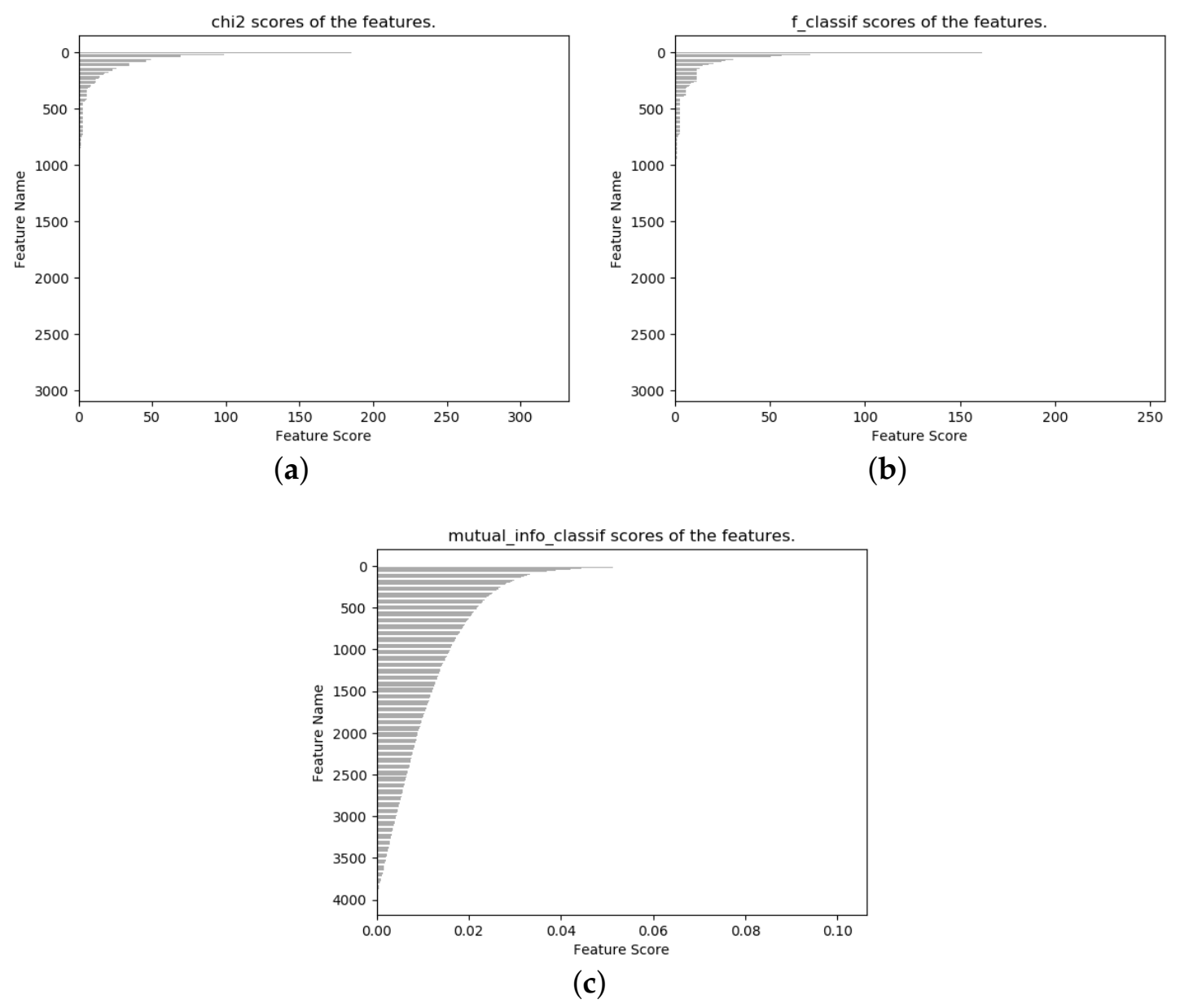
3.1.3. Feature Selection and Mobile Malware Detection
| Algorithm 1 Feature Selection. |
| Input: Training set with permissions and intent static features; |
| Output: Optimal subset of features after selection; 1 |
| 1: Step1: Feature importance ranking |
| 2: The feature importance scores were calculated using chisquare test, analysis of variance Fvalue, and mutual information, respectively.; |
| 3: Removal of features with scores of Nan and 0; |
| 4: Obtain the corresponding candidate feature sets separately; |
| 5: EndStep |
| 6: Step2: Comparing the average performance of different algorithms |
| 7: Apply some detection algorithms to the three candidate feature sets; |
| 8: Calculate the average performance of each algorithm on the three feature sets; |
| 9: EndStep |
| 10: Step3: Obtain the optimal subset of features |
| 11: Compare the average performance and find the best-performing detection algorithm; |
| 12: Compare the performance of this optimal detection algorithm on three feature subsets and find the best performing feature set; |
| 13: EndStep |
| 14: Return the optimal subset of features. |
3.2. Dynamic Features—Mobile Network Traffic Data Mining
3.2.1. Dataset
3.2.2. Preprocessing
- (1)
- Labeling and Pcap2Session.To slice the traffic file, Wang et al. [24] proposed a new traffic classification method for malware traffic based on convolutional neural networks using traffic data as images. USTC-TK2016, the paper’s publicly available traffic handling tool, is based on SplitCap.exe and integrates applications such as finddupe.exe. When all layers are preserved, the data link header contains information about the physical link. This information, such as the media access control (MAC) address, is essential for forwarding frames over the network, but it has no information for application identification or traffic characterization tasks [25]. Since the MAC address changes when crossing domain gateways, causing inconsistency problems, we filter the source and destination addresses as traffic packets for MAC addresses. The traffic files are organized in a structure of “two-classification-labels/four-classification-category-labels/forty-classification-family-labels/network-traffic-files” (the four classification and forty classification labels for a benign sample are all None) to facilitate subsequent labeling. The resulting folder has the same name as the pcap file and maintains its folder organization.
- (2)
- Pcap2Png and Png2Mnist.This step first divides the sliced and filtered mac address pcap files randomly into training and test sets at a ratio of 9:1. The divided pcap files are then unified to the same length. The work of Wang Wei et al. [24] shows that trimming the cut pcap file to 784 bytes leads to better results, and that dividing by session is better than dividing by flow. Therefore, the choice was made to slice by session with the the length = 784. The obtained pcap file in the previous step is converted to a single-channel grayscale png image with three kinds of label (benign–malicious labels, category labels and family labels). Three kinds of ubyte dataset file were constructed with reference to the Mnist dataset format [26].
3.2.3. Dynamic Analysis, Training and Evaluation
3.3. Detection and Classification
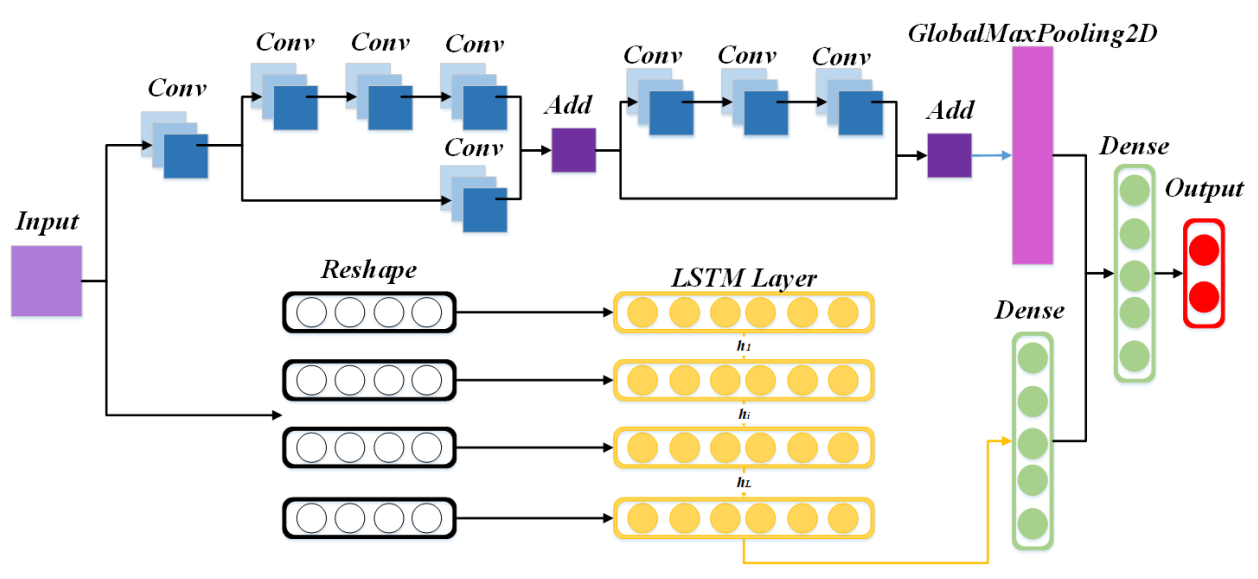
3.3.1. Residual Network
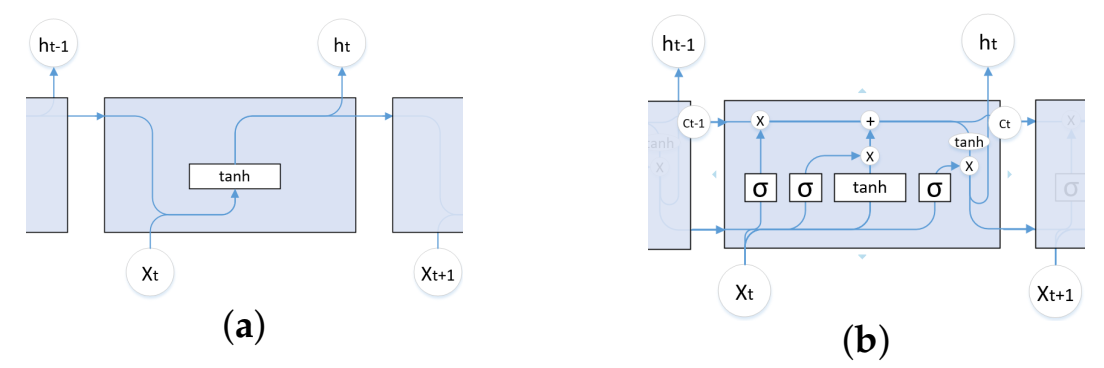
3.3.2. Long Short-Term Memory
3.3.3. Malware Category and Family Classification
4. Experimental
4.1. Complete Dataset Description
4.2. Static and Dynamic Feature Data Preprocessing
4.3. Evaluation Metrics
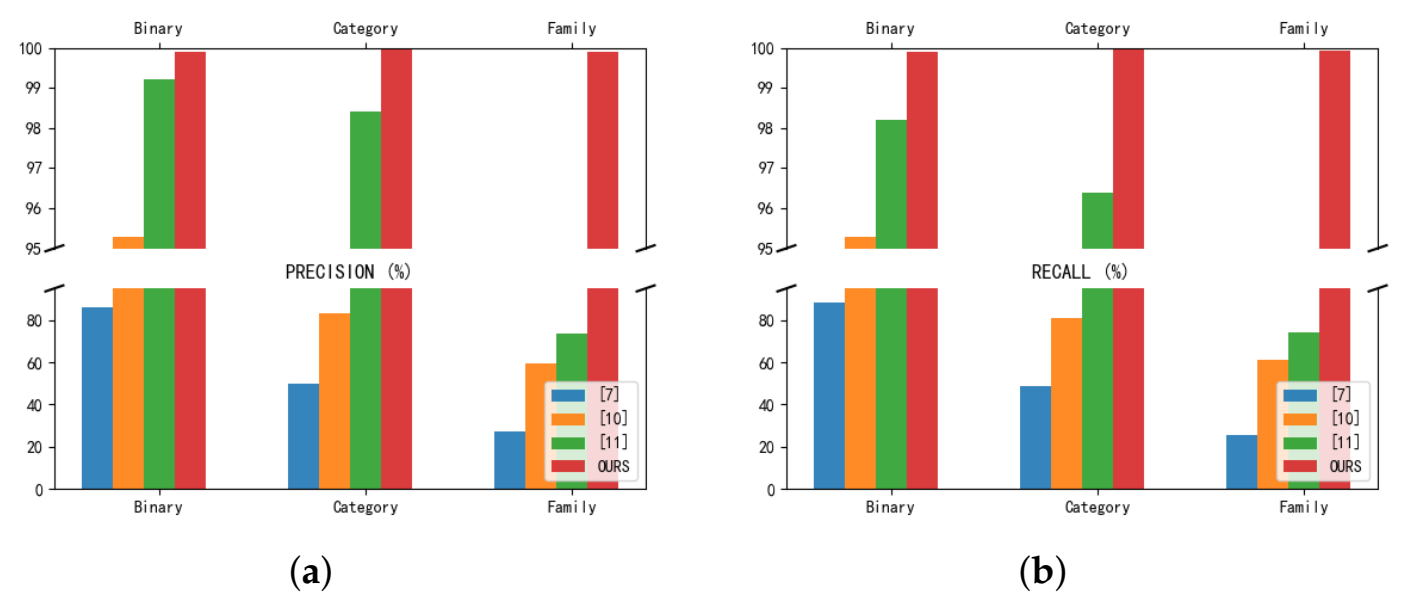
4.4. Feature Selection and Detection Algorithm Comparison
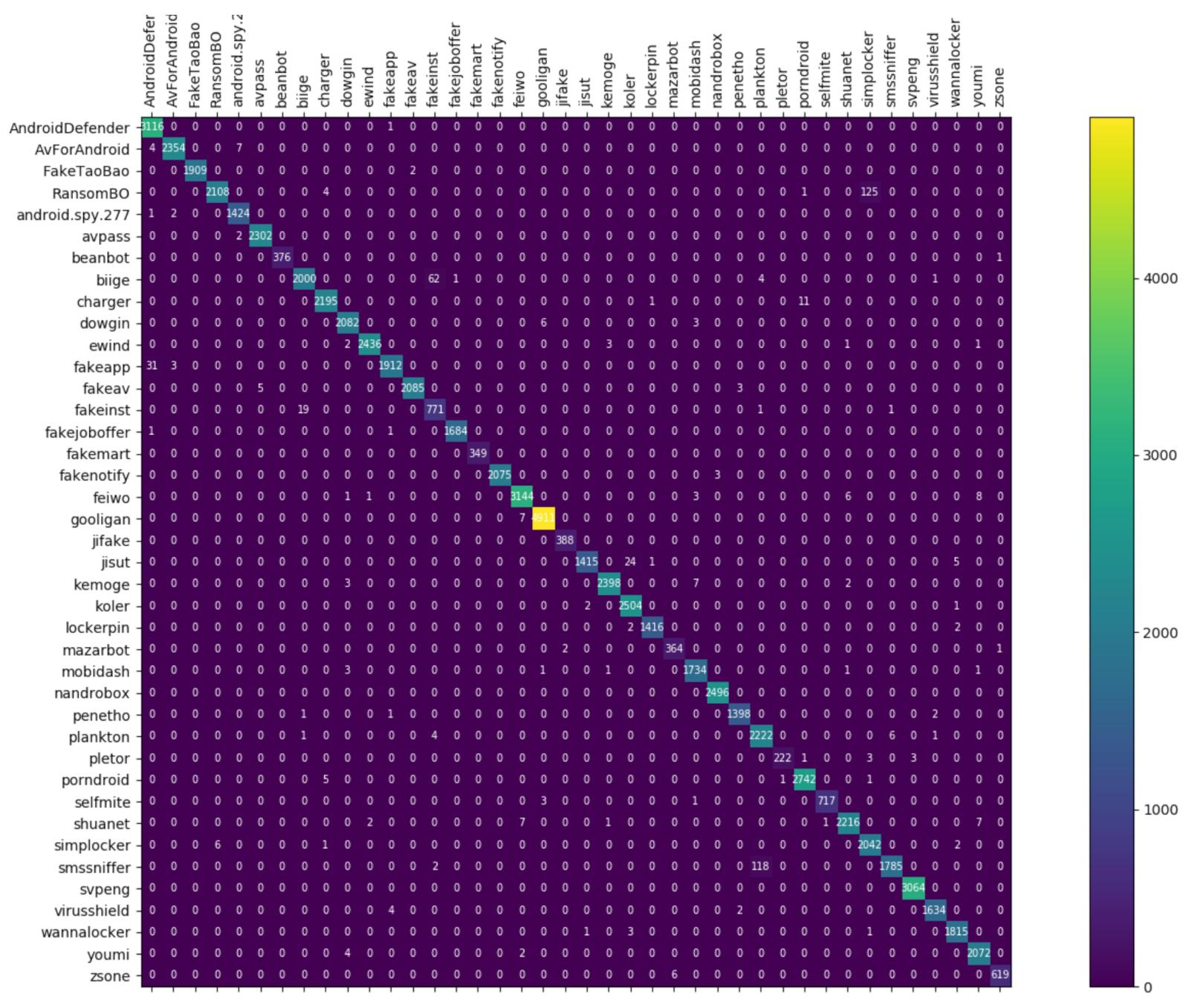
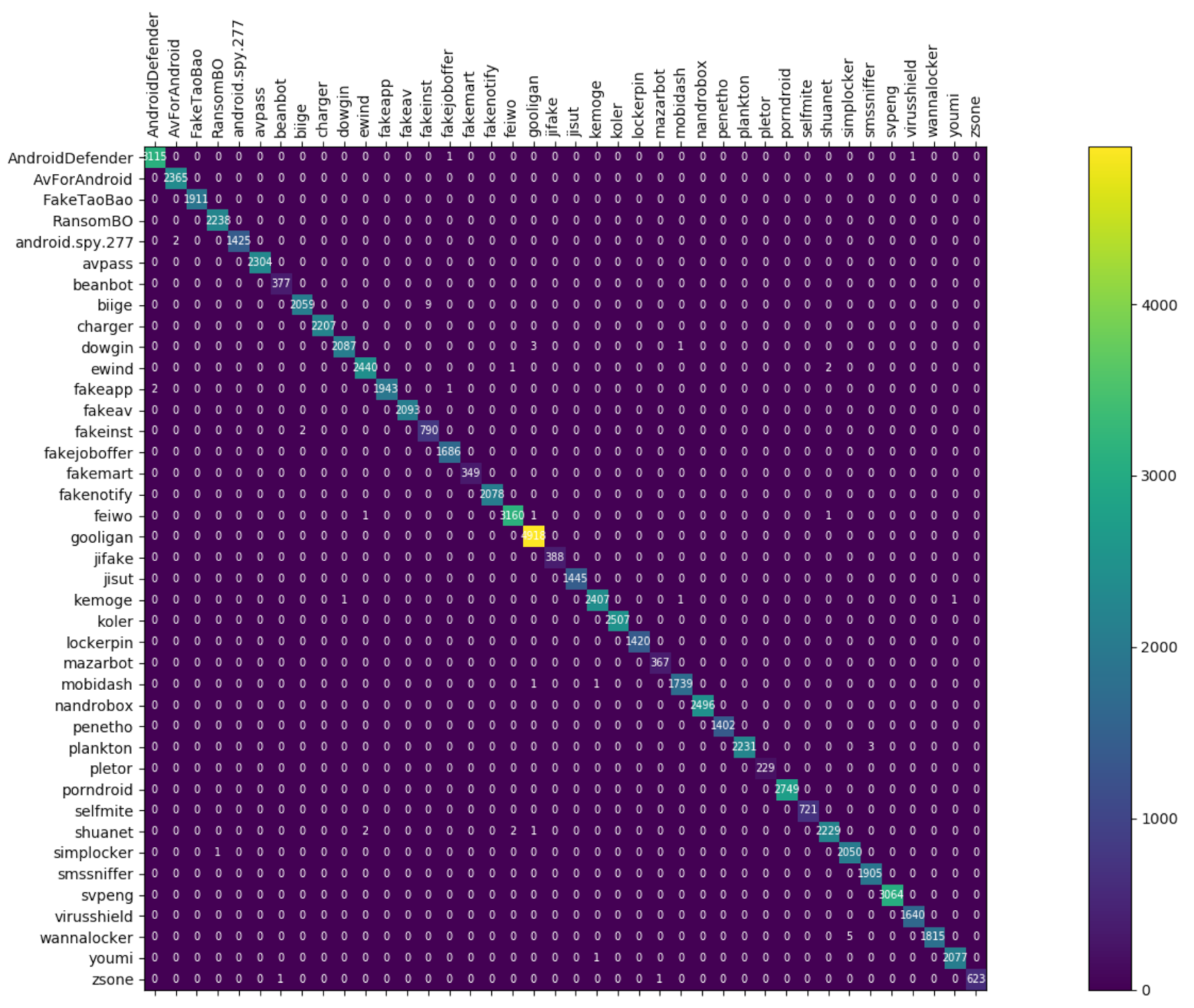
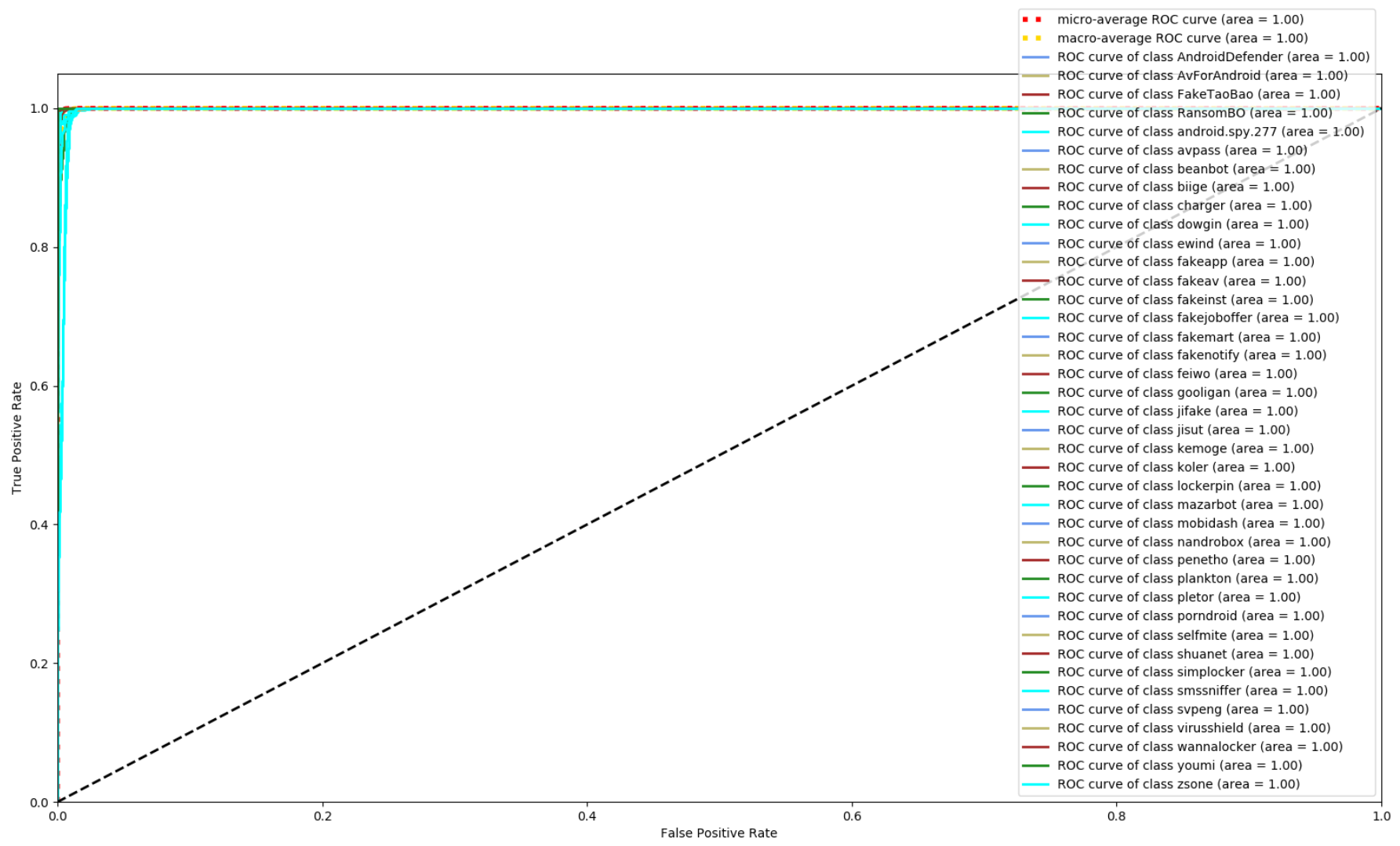
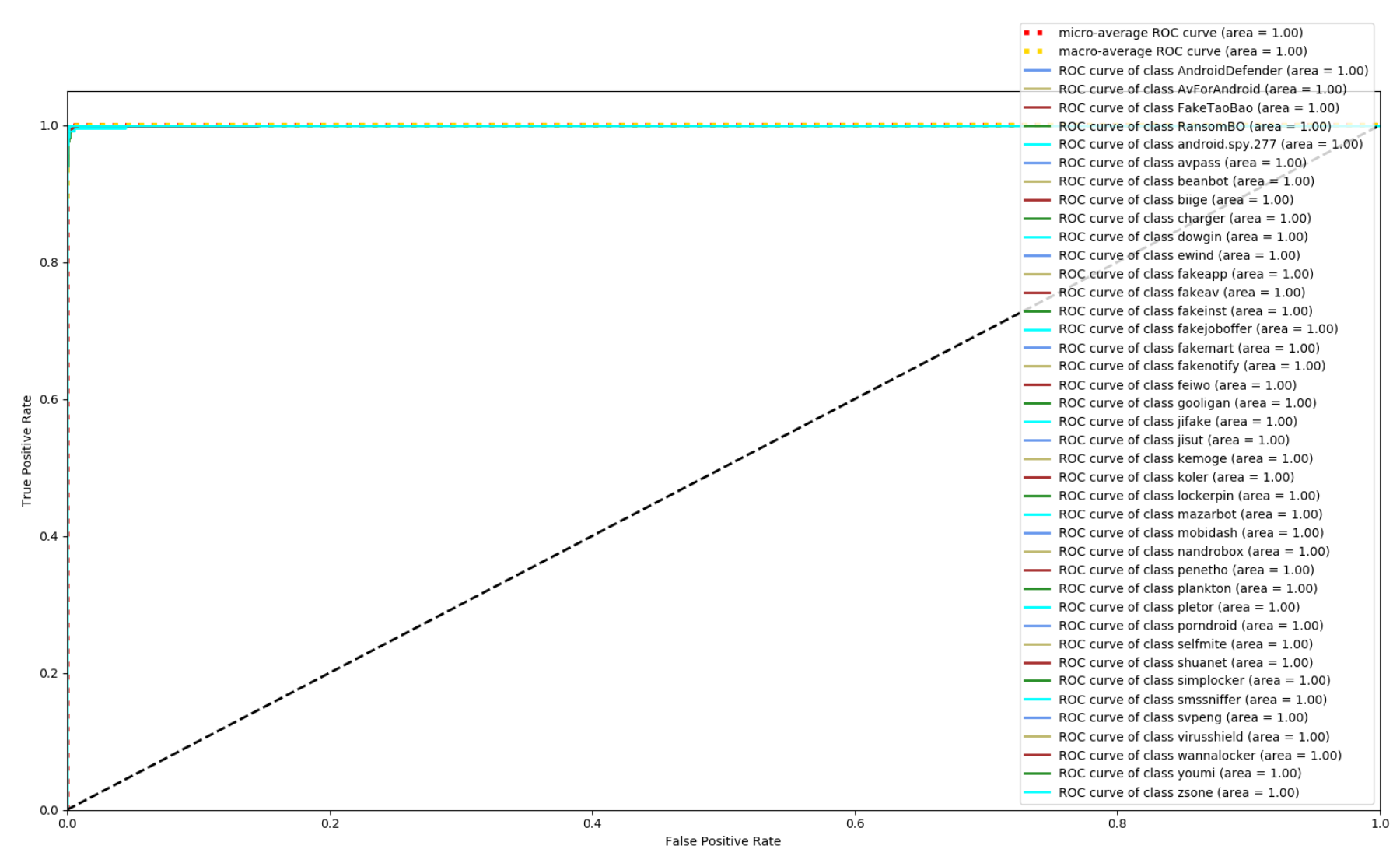
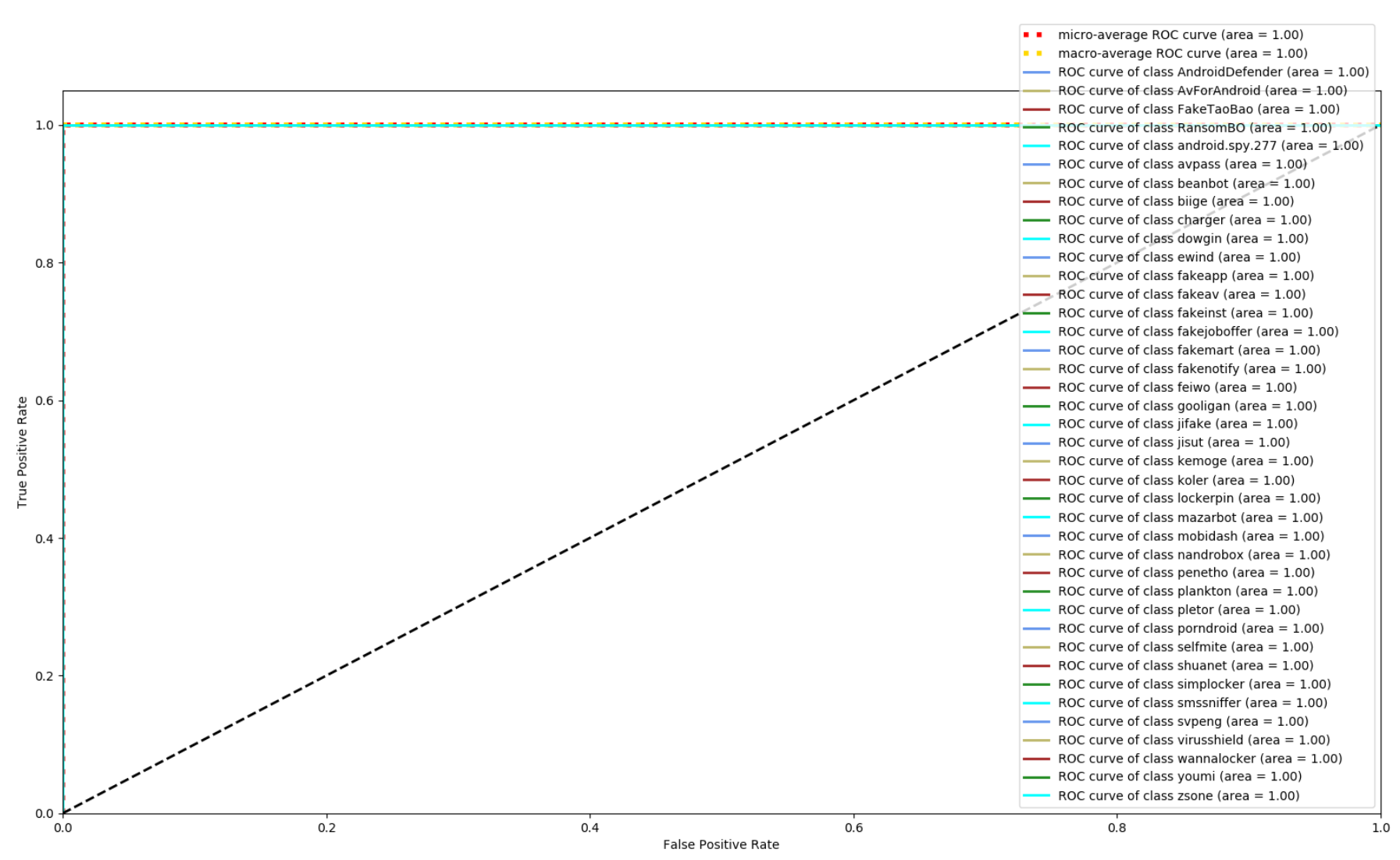
4.5. Res7LSTM Performance Comparison
5. Conclusions and Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SMS | Short Message Service |
| NuSVC | Nuclear Support Vector Classification |
| ResNet | Residual Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long short-term Memory Network |
| RF | Random Forest |
| KNN | k-nearest neighbor |
| GBDT | Gradient Boosting Decision Tree |
| XGBoost | eXtreme Gradient Boosting |
| TP | True Positives |
| TN | True Negatives |
| FP | False Positives |
| FN | False Negatives |
References
- Ericsson Mobility Report June 2020. Ericsson Mobility Report. Available online: https://www.ericsson.com/49da93/assets/local/mobility-report/documents/2020/june2020-ericsson-mobility-report.pdf (accessed on 27 July 2020).
- Smartphone Market Share. Available online: https://www.idc.com/promo/smartphone-market-share/os (accessed on 5 April 2021).
- Symantec, I. Internet Security Threat Report 2019. Available online: https://docs.broadcom.com/doc/istr-24-executive-summary-en (accessed on 15 March 2012).
- 2019 Android Malware Special Report by 360 Security Brain. Available online: https://blogs.360.cn/post/review_android_malware_of_2019.html (accessed on 5 April 2021).
- 2019 Mobile Ad Supply Chain Safety Report. Available online: http://info.pixalate.com/mobile-advertising-supply-chain-safety-report-2019 (accessed on 5 April 2021).
- Liu, X.; Liu, J. A Two-Layered Permission-Based Android Malware Detection Scheme. In Proceedings of the 2014 2nd IEEE International Conference on Mobile Cloud Computing, Services, and Engineering, Oxford, UK, 8–11 April 2014; pp. 142–148. [Google Scholar]
- Noorbehbahani, F.; Rasouli, F.; Saberi, M. Analysis of machine learning techniques for ransomware detection. In Proceedings of the 2019 16th International ISC (Iranian Society of Cryptology) Conference on Information Security and Cryptology (ISCISC), Mashhad, Iran, 28–29 August 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 128–133. [Google Scholar]
- Blanc, W.; Hashem, L.G.; Elish, K.O.; Almohri, M.J.H. Identifying android malware families using android-oriented metrics. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 4708–4713. [Google Scholar]
- Gao, H.; Cheng, S.; Zhang, W. GDroid: Android malware detection and classification with graph convolutional network. Comput. Secur. 2021, 106, 102264. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Nisa, M.; Shah, J.H.; Kanwal, S.; Raza, M.; Khan, M.A.; Damaševičius, R.; Blažauskas, T. Hybrid Malware Classification Method Using Segmentation-Based Fractal Texture Analysis and Deep Convolution Neural Network Features. Appl. Sci. 2020, 10, 4966. [Google Scholar] [CrossRef]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-Based Classification Using Neural Networks and Machine Learning Models for Windows PE Malware Detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Zhao, S.; Li, X.; Xu, G.; Zhang, L.; Feng, Z. Attack tree based android malware detection with hybrid analysis. In Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications, Beijing, China, 24–26 September 2014; IEEE: New York, NY, USA, 2014; pp. 380–387. [Google Scholar]
- Arshad, S.; Shah, M.A.; Wahid, A.; Mehmood, A.; Song, H.; Yu, H. Samadroid: A novel 3-level hybrid malware detection model for android operating system. IEEE Access 2018, 6, 4321–4339. [Google Scholar] [CrossRef]
- Fauskrud, J. Hybrid Analysis for Android Malware Family Classification in a Time-Aware Setting. Master’s Thesis, NTNU, Trondheim, Norway, 2019. [Google Scholar]
- Lashkari, A.H.; Kadir, A.F.A.; Taheri, L.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark android malware datasets and classification. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Taheri, L.; Kadir, A.F.A.; Lashkari, A.H. Extensible android malware detection and family classification using network-flows and api-calls. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- X Developers. Xgboost Python Package. XGBoost Developers. Available online: https://xgboost.readthedocs.io/en/latest/python/python_intro.html (accessed on 20 July 2020).
- Feng, J.; Shen, L.; Chen, Z.; Wang, Y.; Li, H. A two-layer deep learning method for android malware detection using network traffic. IEEE Access 2020, 8, 125786–125796. [Google Scholar] [CrossRef]
- Winsniewski, R. Apktool: A Tool for Reverse Engineering Android apk Files. Available online: https://ibotpeaches.github.io/Apktool/ (accessed on 27 July 2016).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; IEEE: New York, NY, USA, 2017; pp. 712–717. [Google Scholar]
- Lotfollahi, M.; Siavoshani, M.J.; Zade, R.S.H.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y. The Mnist Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 July 1998).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 5353–5360. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Total, V. Virus Total. Available online: https://www.virustotal.com (accessed on 20 July 2013).
- Powers, D.M.W. Evaluation: From precision, recall and f-measure to roc, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- API Android. Available online: http://developer.android.com/reference/packages.html (accessed on 14 October 2015).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Score |
|---|---|
| <actionandroid:name=“android.intent.action.USER_PRESENT”/> | 316.54 |
| <actionandroid:name=“android.net.conn.CONNECTIVITY_CHANGE”/> | 259.02 |
| <actionandroid:name=“android.intent.action.VIEW”/> | 243.52 |
| android.permission.SYSTEM_ALERT_WINDOW | 225.62 |
| <actionandroid:name=“android.app.action.DEVICE_ADMIN_ENABLED”/> | 185.42 |
| android.permission.READ_PHONE_STATE | 185.31 |
| android.permission.SEND_SMS | 175.83 |
| <actionandroid:name=“android.intent.action.PACKAGE_ADDED”/> | 175.34 |
| android.permission.CHANGE_NETWORK_STATE | 150.87 |
| android.permission.RECEIVE_SMS | 150.55 |
| android.permission.MOUNT_UNMOUNT_FILESYSTEMS | 140.80 |
| <actionandroid:name=“android.provider.Telephony.SMS_RECEIVED”/> | 138.15 |
| android.permission.GET_TASKS | 136.95 |
| <actionandroid:name=“android.intent.action.BOOT_COMPLETED”/> | 124.74 |
| android.permission.READ_SMS | 123.28 |
| android.permission.RECEIVE_BOOT_COMPLETED | 122.16 |
| android.permission.CHANGE_WIFI_STATE | 113.41 |
| android.permission.WRITE_SMS | 106.71 |
| <actionandroid:name=“android.intent.action.MAIN”/> | 104.34 |
| <actionandroid:name=“.ACTION_DECABDCE”/> | 103.92 |
| …… | …… |
| <actionandroid:name=“android.permission.BIND_DEVICE_ADMIN"/> | 0.35 |
| Binary | Category | Family | Samples | Number of Traffic Pcap/Png | ||
|---|---|---|---|---|---|---|
| Train | Test | Total | ||||
| Benign | None | None | 1190 | 393,364 | 44,418 | 437,782 |
| Malware | Adware | dowgin | 10 | 18,785 | 2091 | 20,876 |
| ewind | 10 | 21,950 | 2443 | 24,393 | ||
| feiwo | 15 | 28,390 | 3163 | 31,553 | ||
| gooligan | 14 | 44,211 | 4918 | 49,129 | ||
| kemoge | 11 | 21,663 | 2410 | 24,073 | ||
| mobidash | 10 | 15,618 | 1741 | 17,359 | ||
| selfmite | 4 | 6472 | 721 | 7193 | ||
| shuanet | 10 | 20,060 | 2234 | 22,294 | ||
| youmi | 10 | 18,650 | 2078 | 20,728 | ||
| TOTAL | 94 | 195,799 | 21,799 | 217,598 | ||
| Ransomware | charger | 10 | 19,807 | 2207 | 22,014 | |
| jisut | 10 | 12,951 | 1445 | 14,396 | ||
| koler | 10 | 22,516 | 2507 | 25,023 | ||
| lockerpin | 10 | 12,732 | 1420 | 14,152 | ||
| pletor | 10 | 2027 | 229 | 2256 | ||
| porndroid | 10 | 24,692 | 2749 | 27,441 | ||
| RansomBO | 10 | 20,090 | 2238 | 22,328 | ||
| simplocker | 10 | 18,394 | 2051 | 20,445 | ||
| svpeng | 11 | 27,512 | 3064 | 30,576 | ||
| wannalocker | 10 | 16,352 | 1820 | 18,172 | ||
| TOTAL | 101 | 177,073 | 19,730 | 196,803 | ||
| Scareware | android.spy.277 | 6 | 12,815 | 1427 | 14,242 | |
| AndroidDefender | 17 | 27,976 | 3117 | 31,093 | ||
| AvForAndroid | 10 | 21,246 | 2365 | 23,611 | ||
| avpass | 10 | 20,695 | 2304 | 22,999 | ||
| fakeapp | 10 | 17,469 | 1946 | 19,415 | ||
| fakeav | 9 | 18,790 | 2093 | 20,883 | ||
| fakejoboffer | 9 | 15,124 | 1686 | 16,810 | ||
| FakeTaoBao | 9 | 17,171 | 1911 | 19,082 | ||
| penetho | 10 | 12,576 | 1402 | 13,978 | ||
| virusshield | 10 | 14,728 | 1640 | 16,368 | ||
| TOTAL | 100 | 178,590 | 19,891 | 198,481 | ||
| SMS | beanbot | 9 | 3349 | 377 | 3726 | |
| biige | 11 | 18,563 | 2068 | 20,631 | ||
| fakeinst | 10 | 7080 | 792 | 7872 | ||
| fakemart | 10 | 3095 | 349 | 3444 | ||
| fakenotify | 10 | 18,653 | 2078 | 20,731 | ||
| jifake | 10 | 3442 | 388 | 3830 | ||
| mazarbot | 9 | 3267 | 367 | 3634 | ||
| nandrobox | 11 | 22,426 | 2496 | 24,922 | ||
| plankton | 10 | 20,065 | 2234 | 22,299 | ||
| smssniffer | 9 | 17,102 | 1905 | 19,007 | ||
| zsone | 10 | 5587 | 625 | 6212 | ||
| TOTAL | 109 | 122,629 | 13,679 | 136,308 | ||
| TOTAL | NaN | 404 | 674,091 | 75,099 | 749,190 | |
| TOTAL | NaN | NaN | 1594 | 1,067,455 | 119,517 | 1,186,972 |
| Binary | Category | Samples | % |
|---|---|---|---|
| Malware | Ransomware | 34 | 43.0 |
| Scareware | 21 | 26.6 | |
| Adware | 12 | 15.2 | |
| SMS | 6 | 7.6 | |
| Begin | None | 6 | 7.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Luktarhan, N.; Lu, B.; Zhang, W. A Hybrid Analysis-Based Approach to Android Malware Family Classification. Entropy 2021, 23, 1009. https://doi.org/10.3390/e23081009
Ding C, Luktarhan N, Lu B, Zhang W. A Hybrid Analysis-Based Approach to Android Malware Family Classification. Entropy. 2021; 23(8):1009. https://doi.org/10.3390/e23081009
Chicago/Turabian StyleDing, Chao, Nurbol Luktarhan, Bei Lu, and Wenhui Zhang. 2021. "A Hybrid Analysis-Based Approach to Android Malware Family Classification" Entropy 23, no. 8: 1009. https://doi.org/10.3390/e23081009
APA StyleDing, C., Luktarhan, N., Lu, B., & Zhang, W. (2021). A Hybrid Analysis-Based Approach to Android Malware Family Classification. Entropy, 23(8), 1009. https://doi.org/10.3390/e23081009