1. Introduction
Given a set of sources and a target variable Y, we study how information about the target Y is distributed among the sources: different sources may contain information that no other source has (“unique information”), contain information that is common to other sources (“redundant information”), or contain complementary information that is only accessible when considered jointly with other sources (“synergistic information”). Such a decomposition of the information across the sources can inform the design of multi-sensor systems (e.g., to reduce redundancy between sensors), or support research in neuroscience, where neural activity is recorded from two areas during a behavior. For example, a detailed understanding of the role and relationship between brain areas during a task requires understanding how much unique information about the behavior is provided by each area that is not available to the other area, how much information is redundant (or common) to both areas, and how much additional information is present when considering the brain areas jointly (i.e., information about the behavior that is not available when considering each area independently).
Standard information–theoretic quantities conflate these notions of information. Williams and Beer [
1] therefore proposed the Partial Information Decomposition (PID), which provides a principled framework for decomposing how the information about a target variable is distributed among a set of sources. For example, for two sources
and
, the PID is given by
where
represents the “unique” information,
the “synergistic” information, and
represents the redundant information, shown in
Figure A1. We provide details in
Appendix C.1, describing how standard information–theoretic quantities, such as the mutual information
and conditional mutual information
, are decomposed in terms of the PID constituents.
Despite efforts and proposals for defining the constituents [
2,
3,
4,
5,
6,
7], existing definitions involve difficult optimization problems and remain only feasible in low-dimensional spaces, limiting their practical applications. One way to sidestep these difficult optimization problems is to assume a joint Gaussian distribution over the observations [
8], and this approach has been applied to real-world problems [
9]. To enable optimization for high-dimensional problems with arbitrary distributions, we reformulate the redundant information through a variational optimization problem over a restricted family of functions. We show that our formulation generalizes existing notions of redundant information. Additionally, we show that it correctly computes the redundant information on canonical low-dimensional examples and demonstrate that it can be used to compute the redundant information between different sources in a higher-dimensional image classification and motor-neuroscience task. Importantly, RINE is computed using samples from an underlying distribution, which does not need to be known.
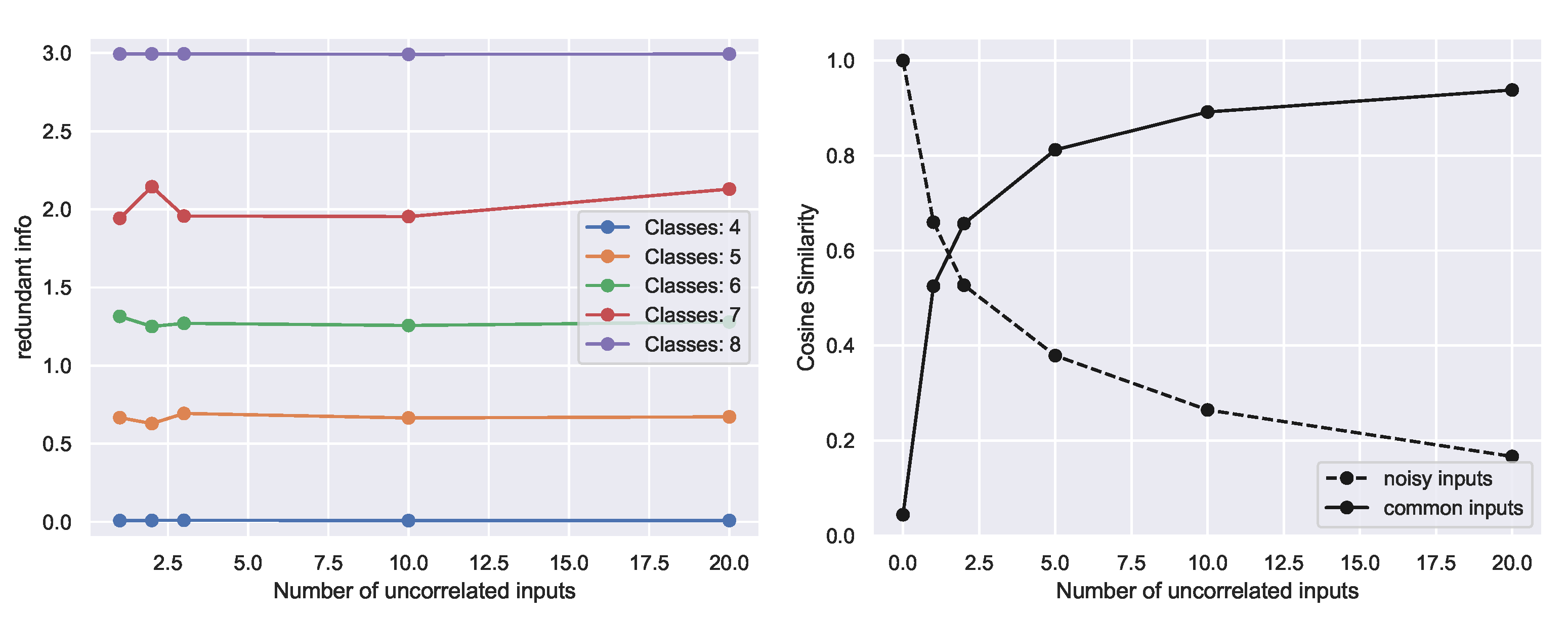
Through RINE, we introduce a similarity metric between sources which is task dependent, applicable to continuous or discrete sources, invariant to reparametrizations, and invariant to addition of extraneous or noisy data.
2. Related Work
Central to the PID is the notion of redundant information
, and much of the work surrounding the PID has focused on specifying the desirable properties that a notion of redundancy should follow. Although there has been some disagreement as to which properties a notion of redundancy should follow [
1,
4,
7], the following properties are widely accepted:
Symmetry: is invariant to the permutation of .
Self-redundancy: .
Monotonicity: .
Several notions of redundancy have been proposed that satisfy these requirements, although we emphasize that these notions were generally not defined with efficient computation in mind.
Griffith et al. [
2] proposed a redundancy measure
, defined through the optimization problem:
where
Q is a random variable and
is a deterministic function. The redundant information is thus defined as the maximum information that a random variable
Q, which is a deterministic function of all
, has about
Y. This means that
Q captures a component of information common to the sources
.
An alternative notion of redundant information
[
5,
10] with a less restrictive constraint is defined in terms of the following optimization problem:
reflects the maximum information between
Y and a random variable
Q such that
forms a Markov chain for all
, relaxing the constraint that
Q needs to be a deterministic function of
.
We show in
Section 3 that our definition of redundant information is a generalization of
and can be extended to compute
.
The main hurdle in applying these notions of information to practical problems is the difficulty of optimizing over all possible random variables
Q in a high-dimensional setting. Moreover, even if that was possible, such unconstrained optimization could recover degenerate forms of redundant information that may not be readily “accessible” to any realistic decoder. In the next section we address both concerns by moving from the notion of Shannon Information to the more general notion of Usable Information [
11,
12,
13].
3. Redundant Information Neural Estimator
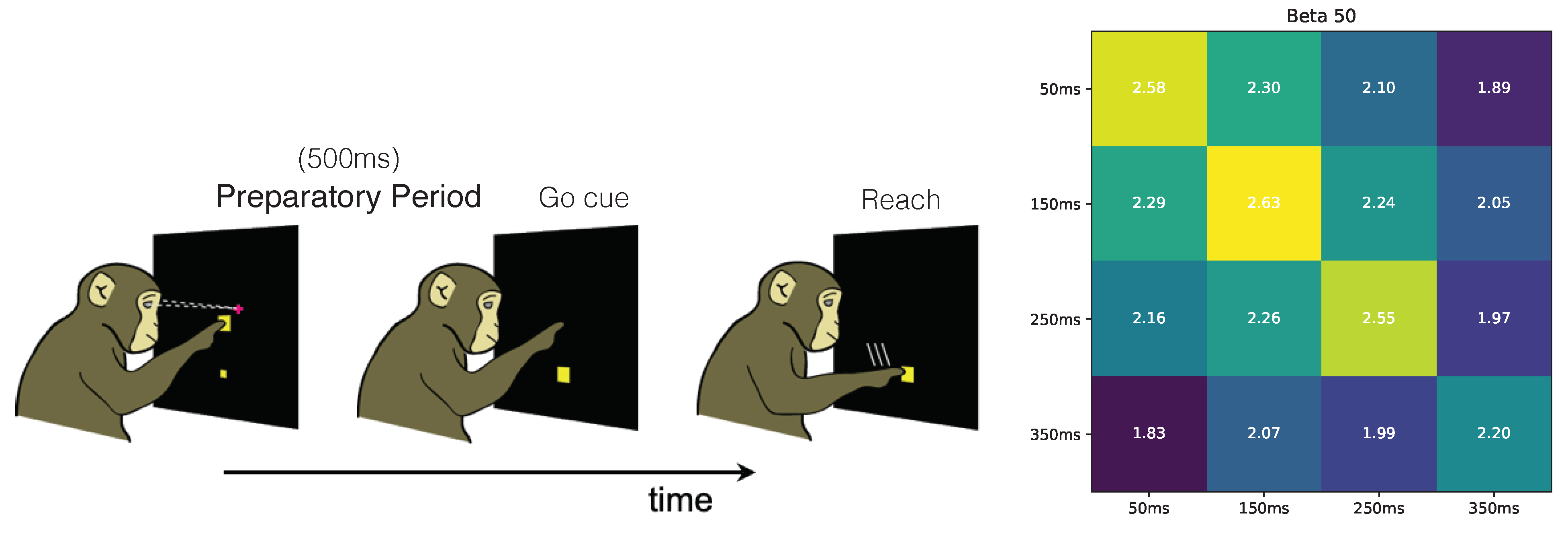
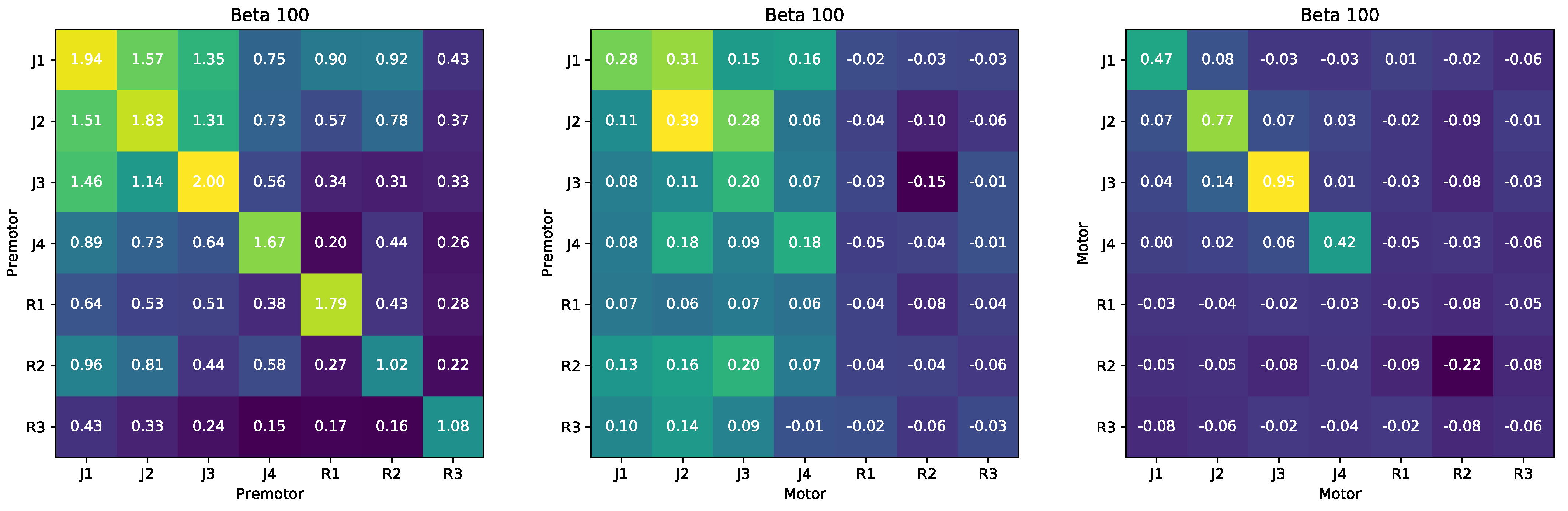
We introduce the Redundant Information Neural Estimator (RINE), a method that enables the approximation of the redundant information that high-dimensional sources contain about a target variable. In addition to being central for the PID, the redundant information also has direct applicability in that it provides a task-dependent similarity metric that is robust to noise and extraneous input, as we later show in
Section 4.4.
Our approximation leverages the insight that existing definitions of redundancy can be recast in terms of a more general optimization over a family of functions, similar to how the “usable information” was defined above. To this end, given two sources, we define a notion of redundancy, RINE, through the following optimization over models
.
where
denotes the cross-entropy when predicting
Y using the decoder
and
denotes the expected difference of the predictions of the two decoders. Importantly, the model family
can be parametrized by neural networks, enabling optimization over the two model families with backpropagation. In general, one can optimize over different model families
and
, but for notational simplicity we assume we optimize over the same model family
in the paper. Note that here we constrained the predictions directly, as opposed to using an intermediate random variable
Q. In contrast, direct optimization of Equations (
2) and (
3) is only feasible for discrete sources with small alphabets [
7]. Our formulation can be naturally extended to
n sources (
Appendix C.8) and other divergence measures between decoders. Since our formulation involves learning decoders that map the sources to target predictions, the learned decoder can safely ignore task-irrelevant variability, such as noise, as we demonstrate in
Section 4.4.
To solve the constrained minimization problem in Equations (
6) and (7), we can minimize the corresponding Lagrangian:
When the solution to the Lagrangian is such that , thus satisfying the constraints of the original problem. In practice, when optimizing this problem with deep networks, we found it useful to start the optimization with a low value of , and then increase it slowly during training to some sufficiently high value ( in most of our experiments). Note that while does not appear in the Lagrangian, it is still used to compute , as in Equation (8). The Lagrangian is optimized, using samples from an underlying distribution ; importantly, the underlying distribution can be continuous or discrete.
Our definition of
-redundant information (Equation (8)) is a generalization of
(
Section 2) as shown by the following proposition:
Proposition 1 (
Appendix B).
Let consist of the family of deterministic functions from X to distributions over . Then . Our formulation involving a constrained optimization over a family of functions is general: indeed, optimizing over stochastic functions or channels with an appropriate constraint can recover
or
[
7] (described in the Appendix) but the computation in practice becomes more difficult.
Our definition of redundant information is also invariant to reparametrization of the sources as shown by the following proposition:
Proposition 2 (
Appendix B).
Let be any invertible transformation in . Then, Note that when , is invariant to any invertible transformation. In practice, when optimizing over a subset , our definition is invariant to transformations that preserve the usable information (this accounts for practical transformations, for example the reflection or rotation of images). As an example of transformations that lie in , consider the case in which is a set of linear decoders. This model family is closed under any linear transformation applied to the source, since the composition of linear functions is still a linear function.
As an additional example, the family of fully connected networks is closed to permutations of the pixels of an image since there exists a corresponding network that would behave the same on the transformed image. The family of convolutional networks, for a given architecture on the other hand, is not closed under arbitrary transformations of the pixels, but it is closed, e.g., under rotations/flips of the image.
In contrast, complex transformations such as encryption or decryption (which preserve Shannon’s mutual information) can decrease or increase respectively the usable information content with respect to the model family . Arguably, such complex transformations do modify the “information content” or the “usable information” (in this case measured with respect to ) even though they do not affect Shannon’s mutual information (which assumes an optimal decoder in that may not be in ).
Implementation Details
In our experiments, we optimize over a model family of deep neural networks, using gradient descent. In general, the model family to optimize over should be selected such that it is not so complicated that it overfits to spurious features of the finite training set, but has high enough capacity to learn the mapping from source to target.
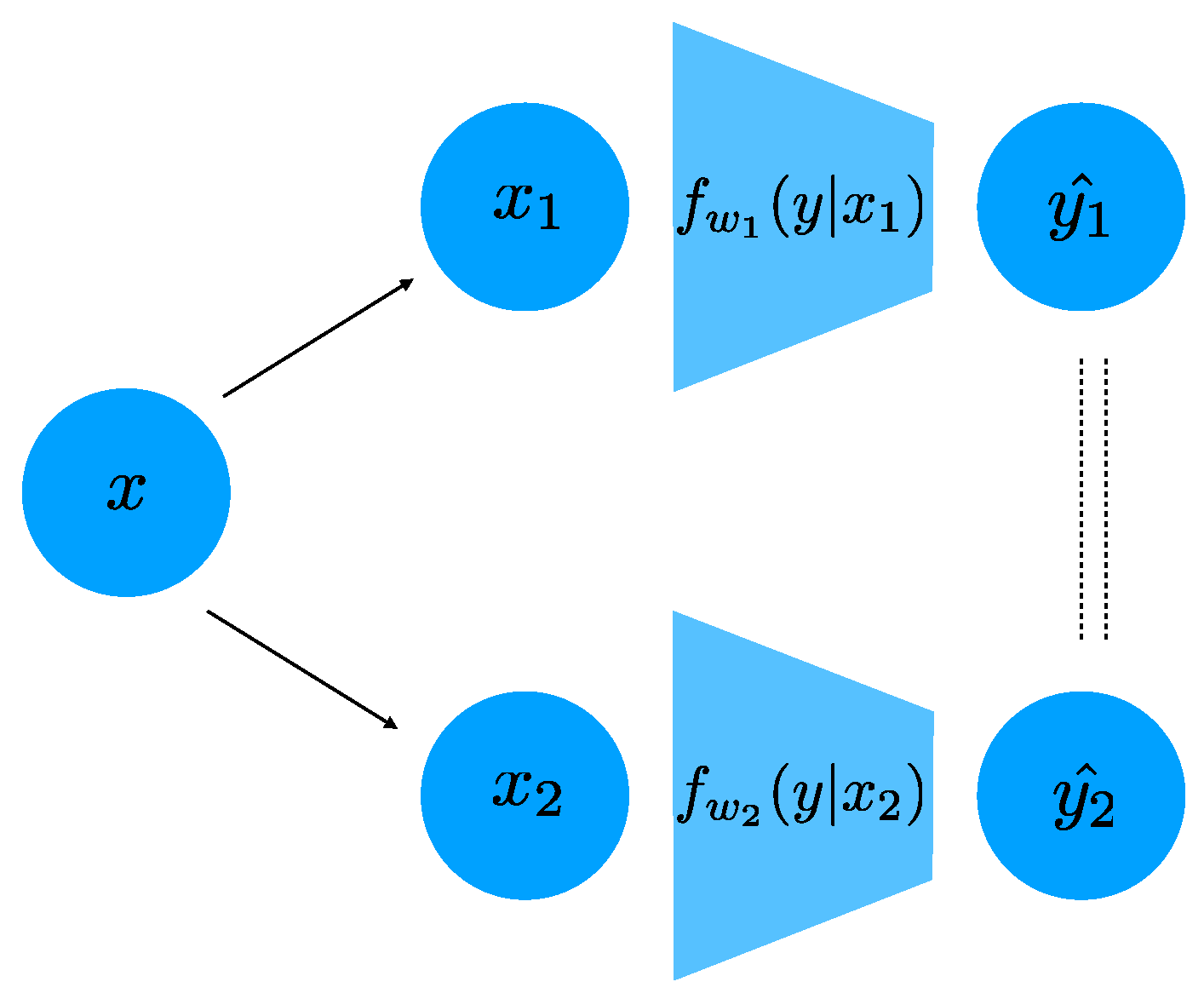
We parametrize the distribution
in Equation (
9), using a deep neural network. In particular, in the case that
y is discrete (which is the case in all our experiments), the distribution
is parametrized as the softmax of the output of a deep network with weights
. In this case, the distance
can be readily computed as the average
distance between the softmax outputs of the two networks
and
for different inputs
and
. If the task label
y is continuous, for example in a regression problem, one can parametrize
using a Normal distribution whose means is the output of a DNN. We optimize over the weights parametrizing all
jointly, and we show a schematic of our architecture in
Figure 1.
Once we parametrize
and
, we need to optimize the weights in order to minimize the Lagrangian in Equation (
9). We do so using Adam [
14] or stochastic gradient descent, depending on the experiment. For images we optimize over ResNet-18’s [
15], and for other tasks we optimize over fully-connected networks. The hyperparameter
needs to be high enough to ensure that the constraint is approximately satisfied. However, we found that starting the optimization with a very high value for
can destabilize the training and make the network converge to a trivial solution, where it outputs a constant function (which trivially satisfies the constraint). Instead, we use a reverse-annealing scheme, where we start with a low beta and then slowly increase it during training up to the designated value (
Appendix C.3). A similar strategy is also used (albeit in a different context) in optimizing
-VAEs [
16].
5. Discussion
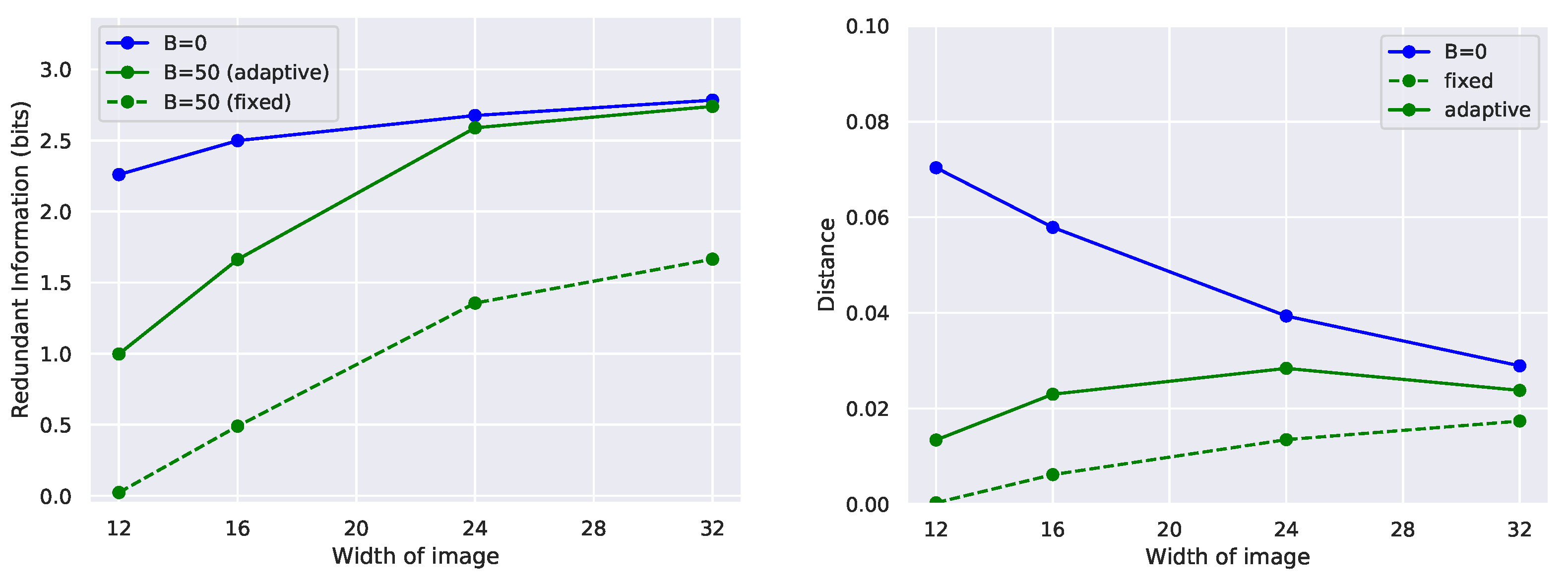
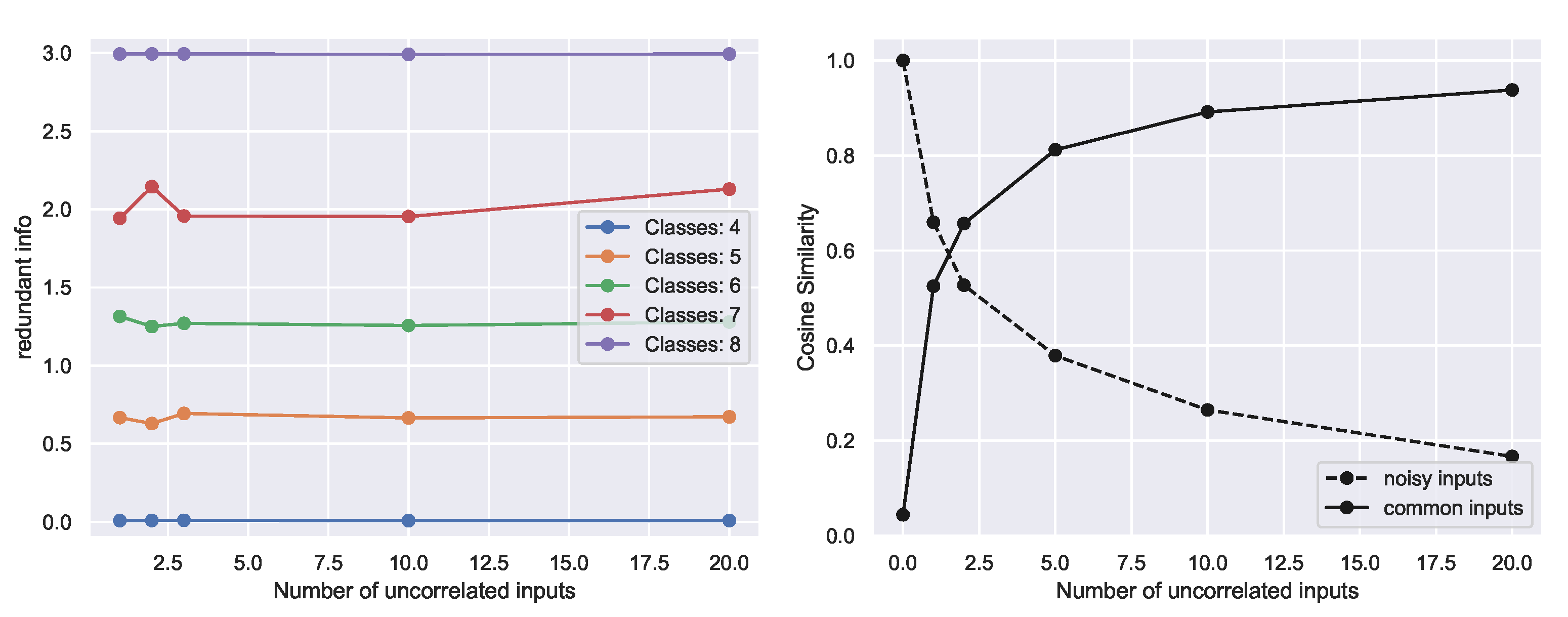
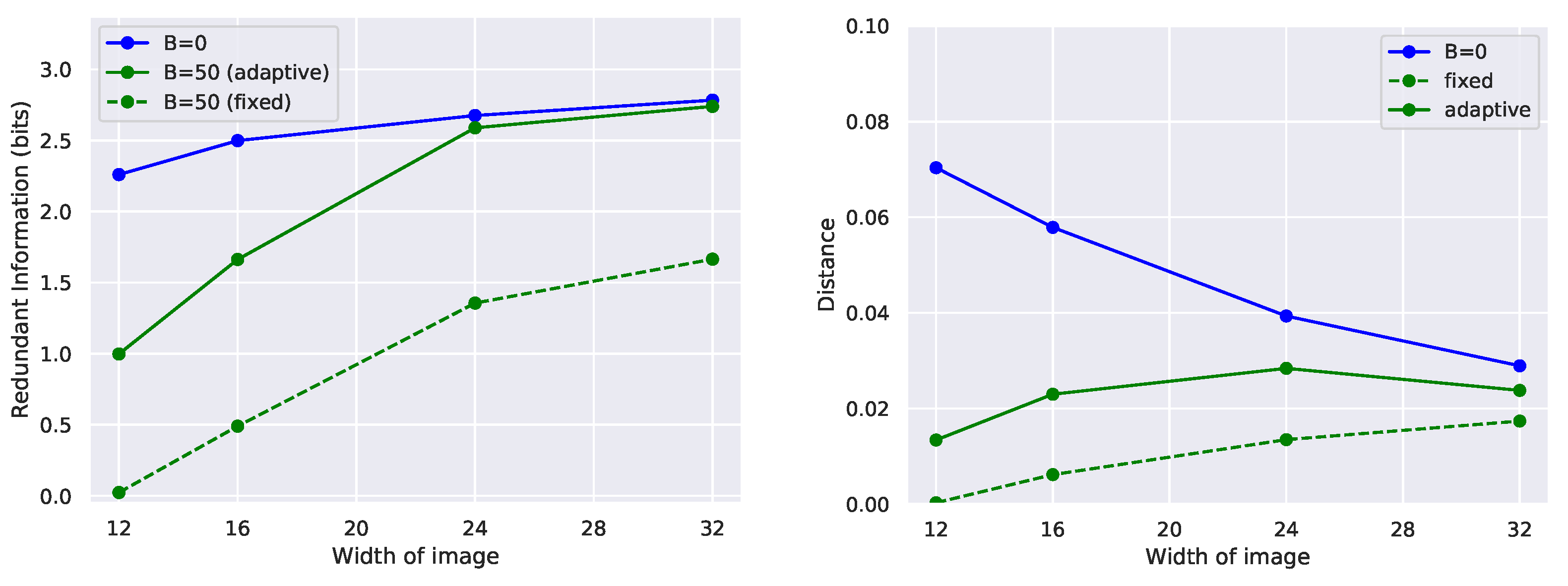
Central to the Partial Information Decomposition, the notion of redundant information offers promise for characterizing the component of task-related information present across a set of sources. Despite its appeal for providing a more fine-grained depiction of the information content of multiple sources, it has proven difficult to compute in high-dimensions, limiting widespread adoption. Here, we show that existing definitions of redundancy can be recast in terms of optimization over a family of deterministic or stochastic functions. By optimizing over a subset of these functions, we show empirically that we can recover the redundant information on simple benchmark tasks and that we can indeed approximate the redundant information for high-dimensional predictors.
Although our approach correctly computes the redundant information on canonical examples as well as provides intuitive values on higher-dimensional examples when ground-truth values are unavailable, with all optimization of overparametrized networks on a finite training set, there is the possibility of overfitting to features in the training set and having poor generalization on the test set. This is not just a problem for our method, but is a general feature of many deep learning systems, and it is common to use regularization to help mitigate this. PAC-style bounds on the test set risk that factor in the finite nature of the training set exist [
23], and it would be interesting to derive similar bounds that could be applied on the distance term to bound the deviation on the test set. Additionally, future work should investigate the properties arising from the choice of distance term since other distance terms could have preferable optimization properties or desirable information-theoretic interpretations, especially when it is non-zero. Last, the choice of beta-schedule beginning with a small value and increasing during training was important (
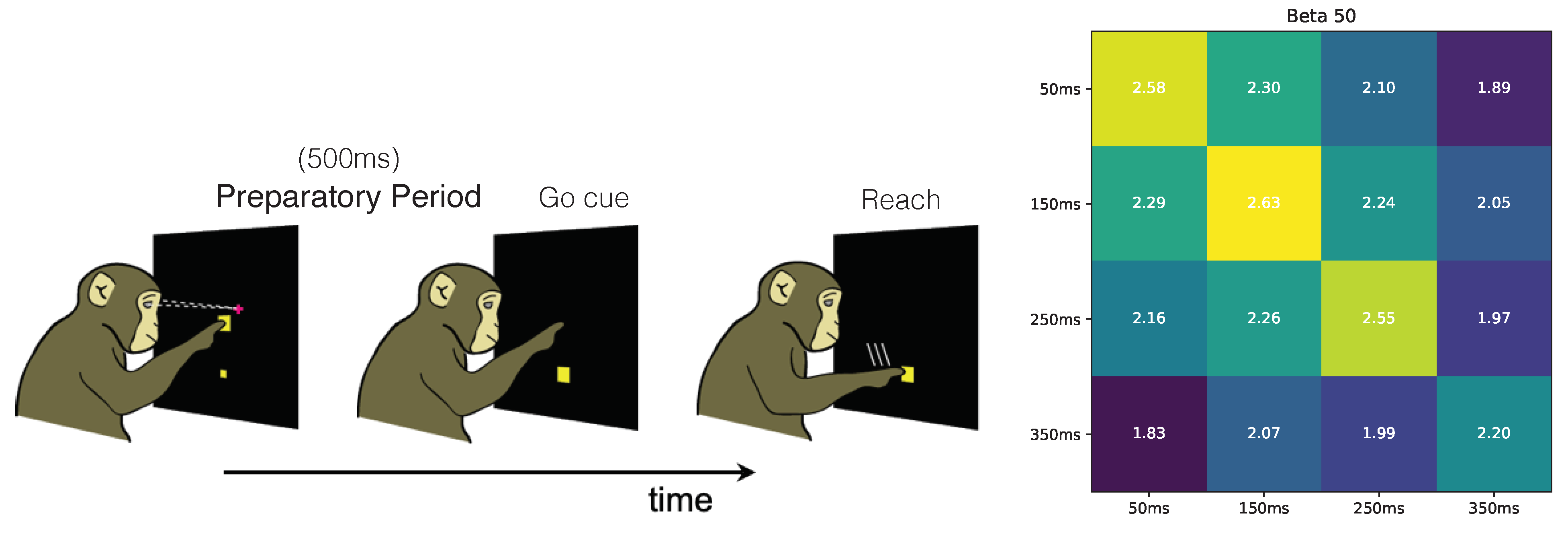
Figure A2), and may need to be tuned to a particular task.
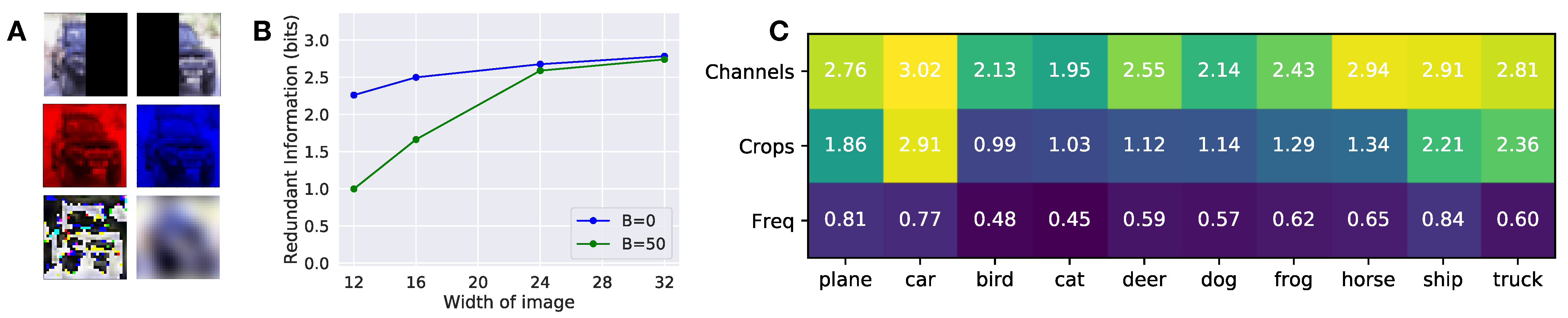
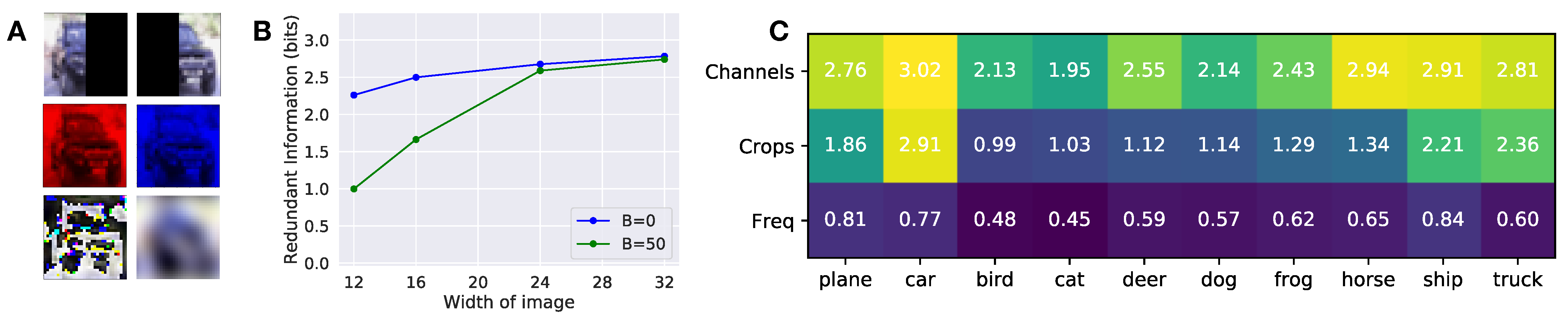
Our approach only provides a value summarizing how much of the information in a set of sources is redundant, and it does not detail what aspects of the sources are redundant. For instance, when computing the redundant information in the image classification tasks, we optimized over a high-dimensional parameter space, learning a complicated nonlinear function. Although we know the exact function mapping the input sources to prediction, it is difficult to identify the “features” or aspects of the input that contributed most to the prediction. Future work should try to extend our work to describe not only how much information is redundant, but what parts of the sources are redundant.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
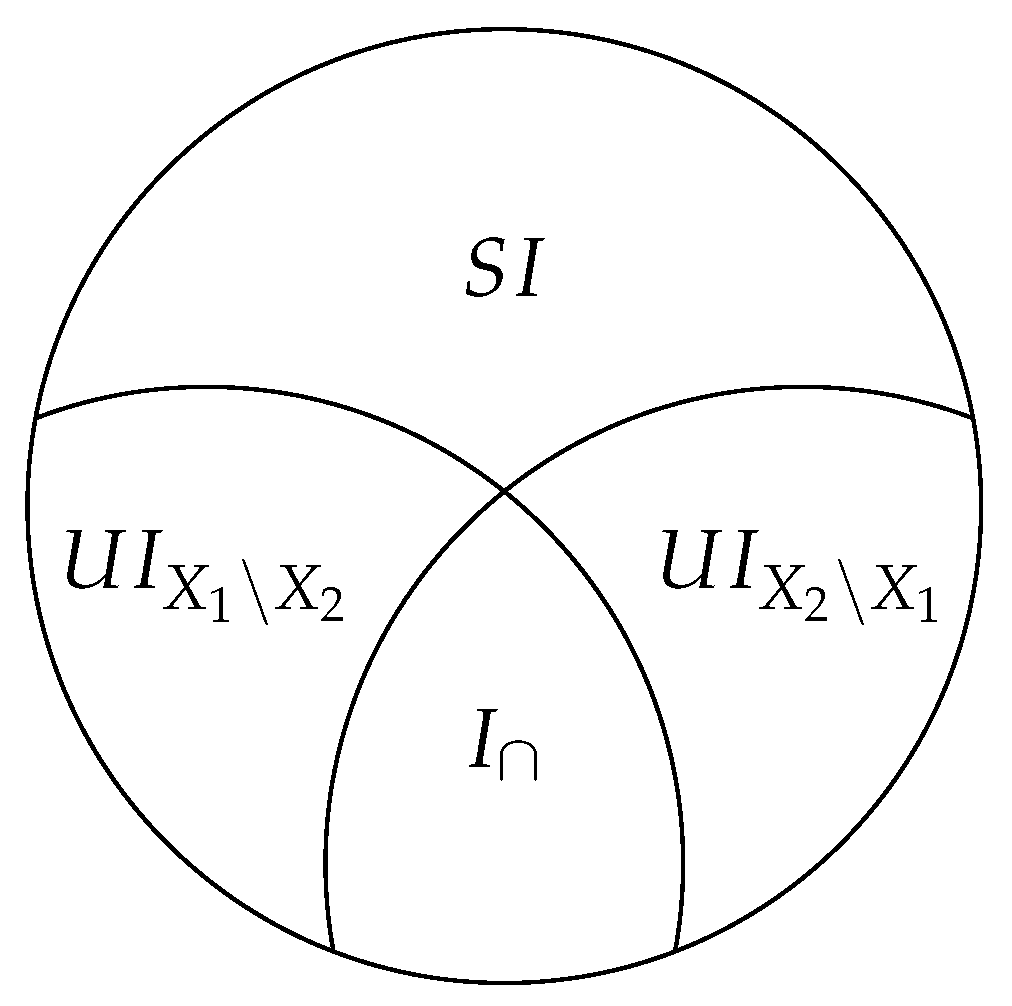{kind=link}
{kind=link}
{kind=link}