
Generalized Reversible Data Hiding with Content-Adaptive Operation and Fast Histogram Shifting Optimization


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
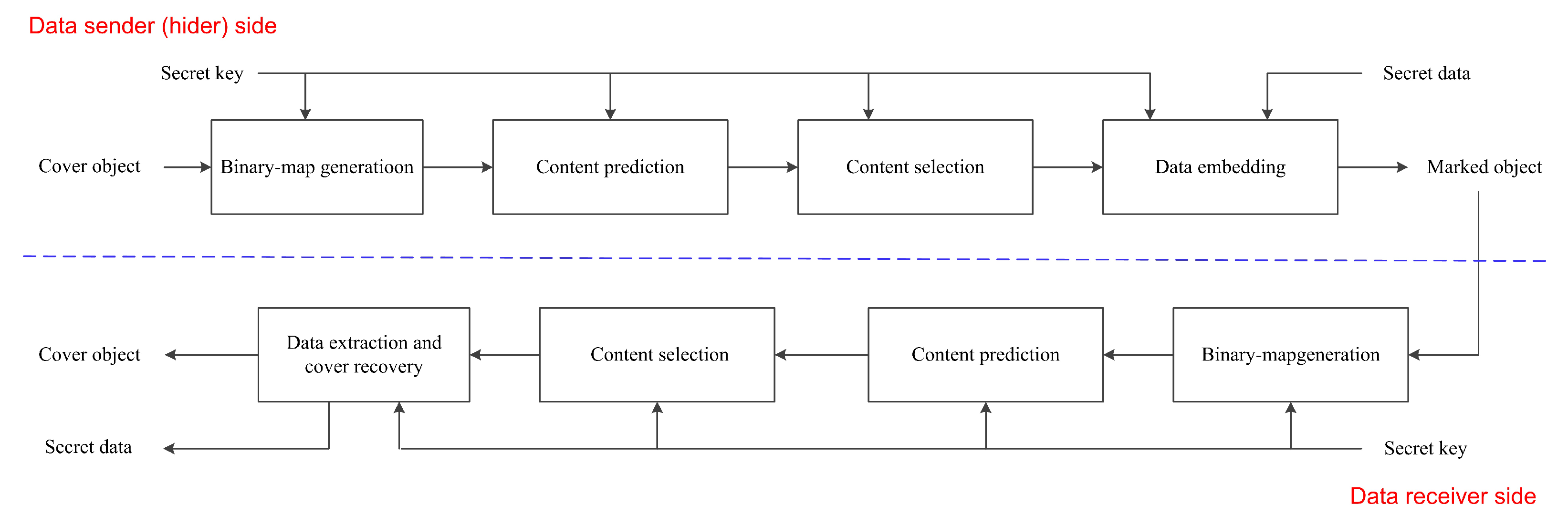
- We propose a general framework dividing the PE-based RDH design into four parts so that we can easily design or improve an RDH system. The four parts are named as binary-map generation, content prediction, content selection, and data embedding. To ensure the security, we use a secret key to control the binary-map generation, and a dynamic predictor for content prediction. For content selection, we use a local-complexity evaluation function to preferentially use smooth elements.
- We propose a fast histogram shifting optimization algorithm to determine the near-optimal embedding parameters for HS-based RDH. A significant advantage is that the embedding performance can be kept sufficient, while the computational cost is low.
- We present two detailed RDH methods to demonstrate the generalization ability of the proposed framework. Extensive experiments are also conducted to verify the superiority and applicability of the proposed work.
2. Sketch of Proposed Framework
2.1. LC-Based RDH
2.2. Ni et al’s Method
2.3. Tsai et al.’s Method
2.4. Sachnev et al.’s Method
2.5. Transformed Domain-Based RDH
2.6. Expansion-Based RDH
3. Details of Proposed Framework
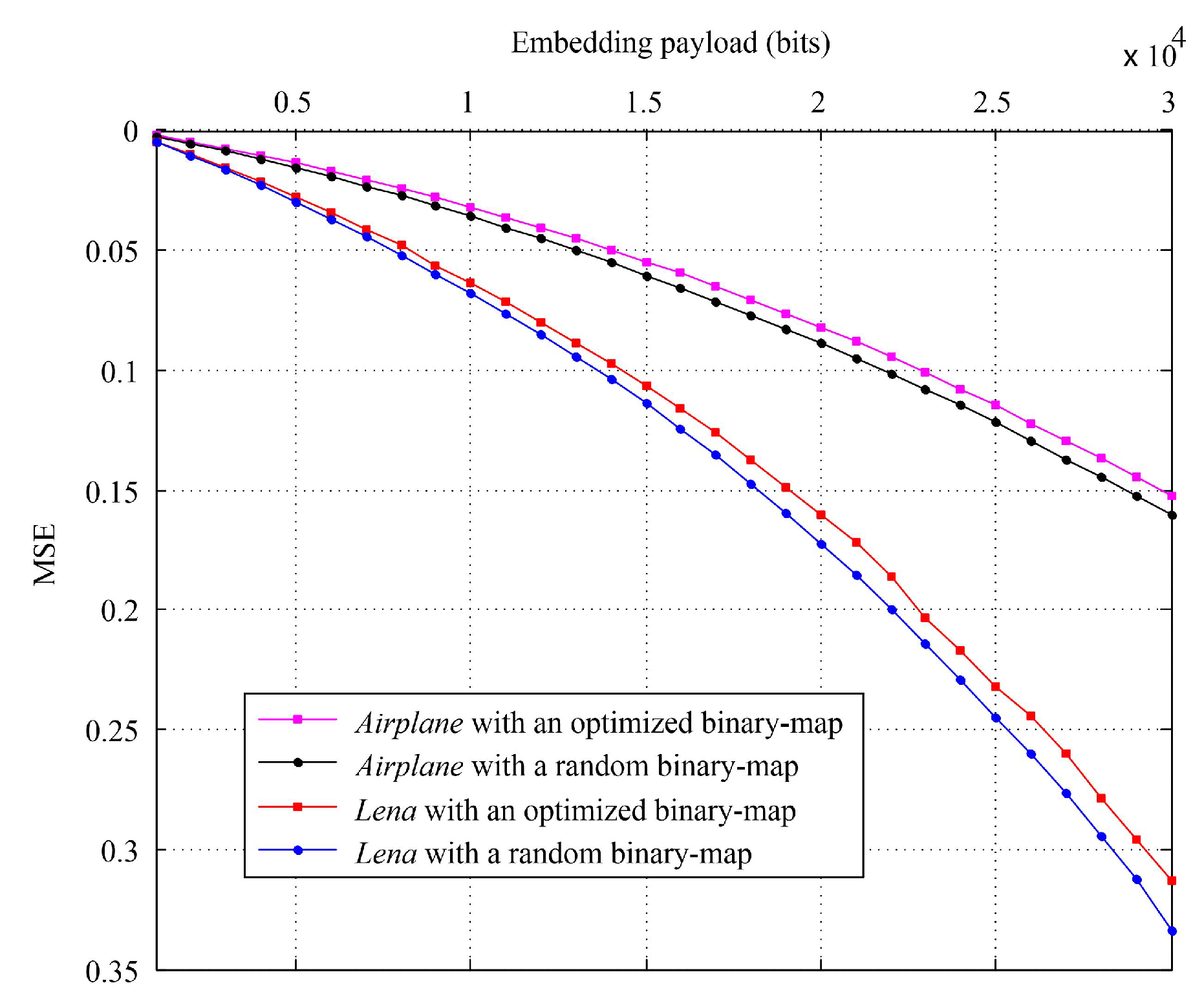
3.1. Binary-Map Generation
| Algorithm 1 Binary-map generation procedure |
| Input: A cover and a secret key. |
| Output: A binary-map and the side information (if any). |
| 1: Initialize a binary-map |
| 2: while need optimization do |
| 3: Optimize the binary-map |
| 4: end while |
| 5: return final binary-map and side information (if any) |
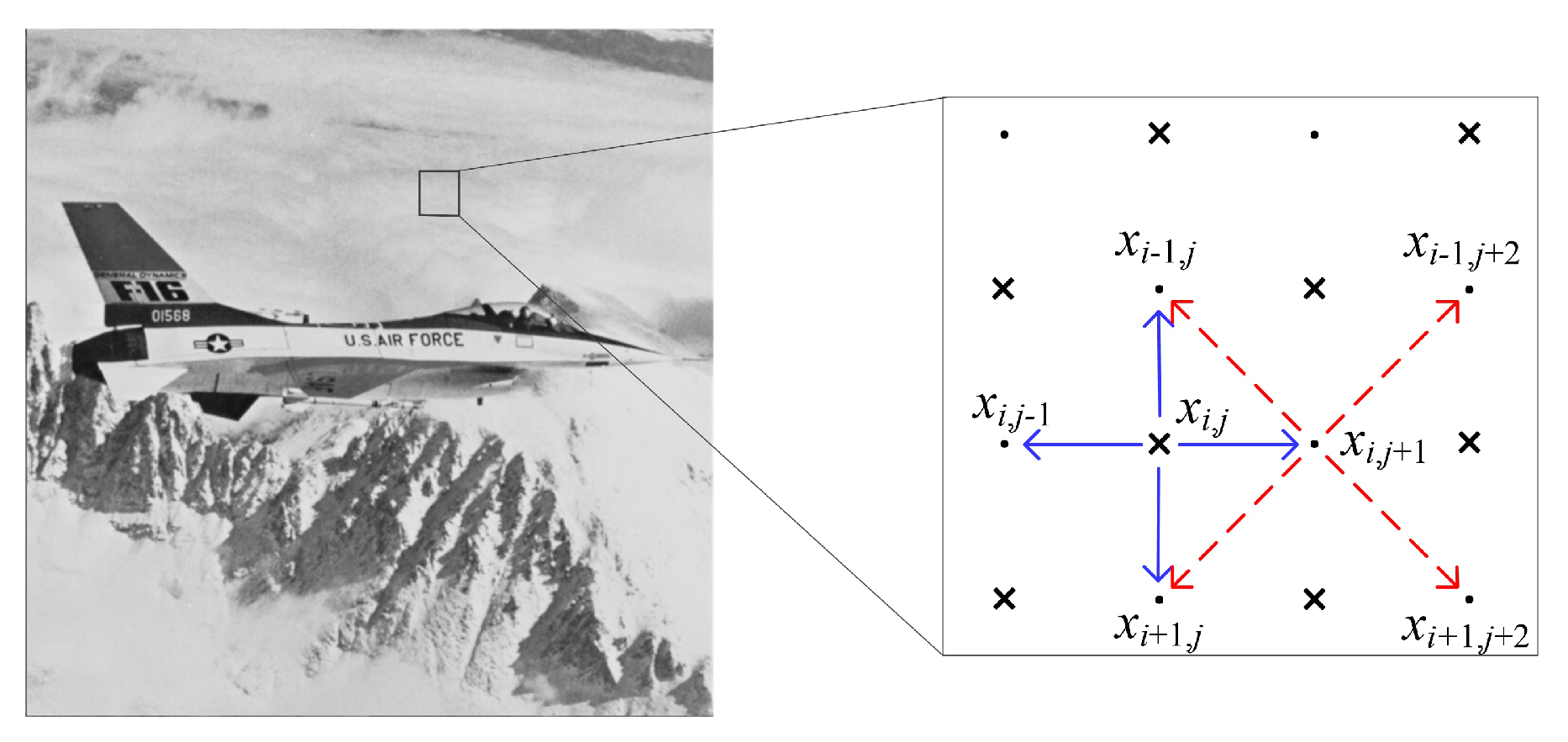
3.2. Content Prediction
| Algorithm 2 Degree-first prediction (DFP) procedure |
| Input: A cover, a binary-map and a secret key. |
| Output: A prediction version of the cover. |
| 1: Initialization |
| 2: while exist an element to be processed do |
| 3: Choose an unprocessed element that has a largest degree |
| 4: Find the prediction value (with a dynamic predictor) |
| 5: Record the prediction value |
| 6: Mark the element as processed |
| 7: Update the degrees of the rest elements to be processed |
| 8: end while |
| 9: return the prediction version of the cover |
3.3. Content Selection
| Algorithm 3 Local-complexity-based selection procedure |
| Input: A cover, a binary-map, the corresponding prediction version of the cover and the secret key. |
| Output: An ordered element sequence. |
| 1: Initialization (e.g., empty the sequence) |
| 2: while exist an element to be processed do |
| 3: Find/update all required local-complexity values |
| 4: Select an element with a smallest complexity value |
| 5: Append the element to the sequence |
| 6: Mark the element as processed |
| 7: end while |
| 8: return the ordered sequence |
3.4. Data Embedding
| Algorithm 4 Fast histogram shifting optimization (FastHiSO) |
| Input: The ordered cover sequence , the original sequence , the prediction sequence , and the payload size . |
| Output: |
| 1: Empty |
| 2: for do |
| 3: Find and |
| 4: Set |
| 5: end for |
| 6: Find the near-optimal with Equations (8)–(11), subject to the payload size . |
| 7: return |
| Algorithm 5 Data embedding procedure |
|
3.5. Data Extraction and Cover Recovery
3.6. Relationships between Different Parts
3.6.1. Relationship between Binary-Map Generation, Content Prediction, and Content Selection
| Algorithm 6 Binary-map generation using Algorithms 2 and 3 |
|
3.6.2. Relationship between Content Prediction and Content Selection
3.7. Other Perspectives
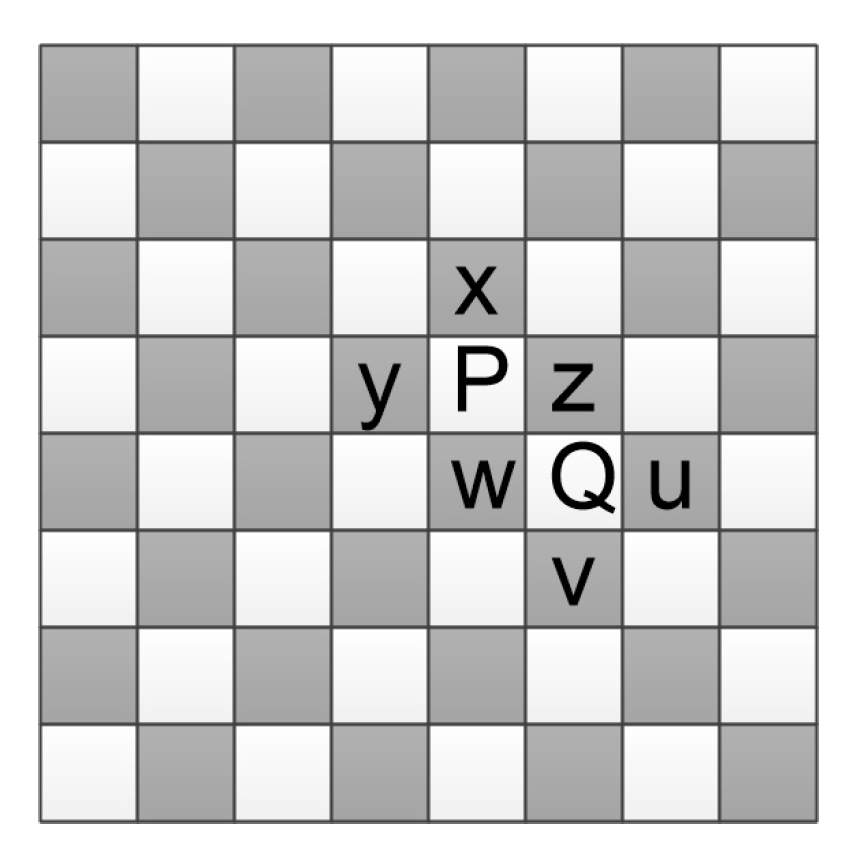
- Fusion of multiple subpredictors: The conventional methods use a single predictor. Actually, they can be treated as a fusion of multiple subpredictors. We take median edge detector (MED) [13] for explanation, i.e.,where , , and are specific neighbors of x. It can be seen that the MED essentially uses three subpredictors, i.e., , , and . Therefore, it is inferred that a dynamic predictor corresponds to a fusion of multiple subpredictors. A key work is to choose the suitable subpredictor according to the local context.
- Fusion of multiple subhistograms: The histogram to be embedded also can be regarded as a fusion of multiple subhistograms as a subpredictor corresponds to a subhistogram. Though we may not directly use the subhistograms separately, it inspires us to divide a histogram into multiple subhistograms for payload-distortion optimization, which has been exploited by Li et al. [18].
- Fusion of multiple subcovers: Different subhistograms are corresponding to different subcovers even though the elements belonging to a subcover may be widely or near-randomly distributed in the original cover. In other words, we may divide the cover into subcovers for payload-distortion optimization since different subcovers may have different texture characteristics. For example, a cover image may be divided into disjoint blocks. Notice that this perspective no longer focuses on only the dynamic predictor, but rather the design of an RDH system, e.g., as in Reference [19].
4. Two Examples Based on Proposed Framework
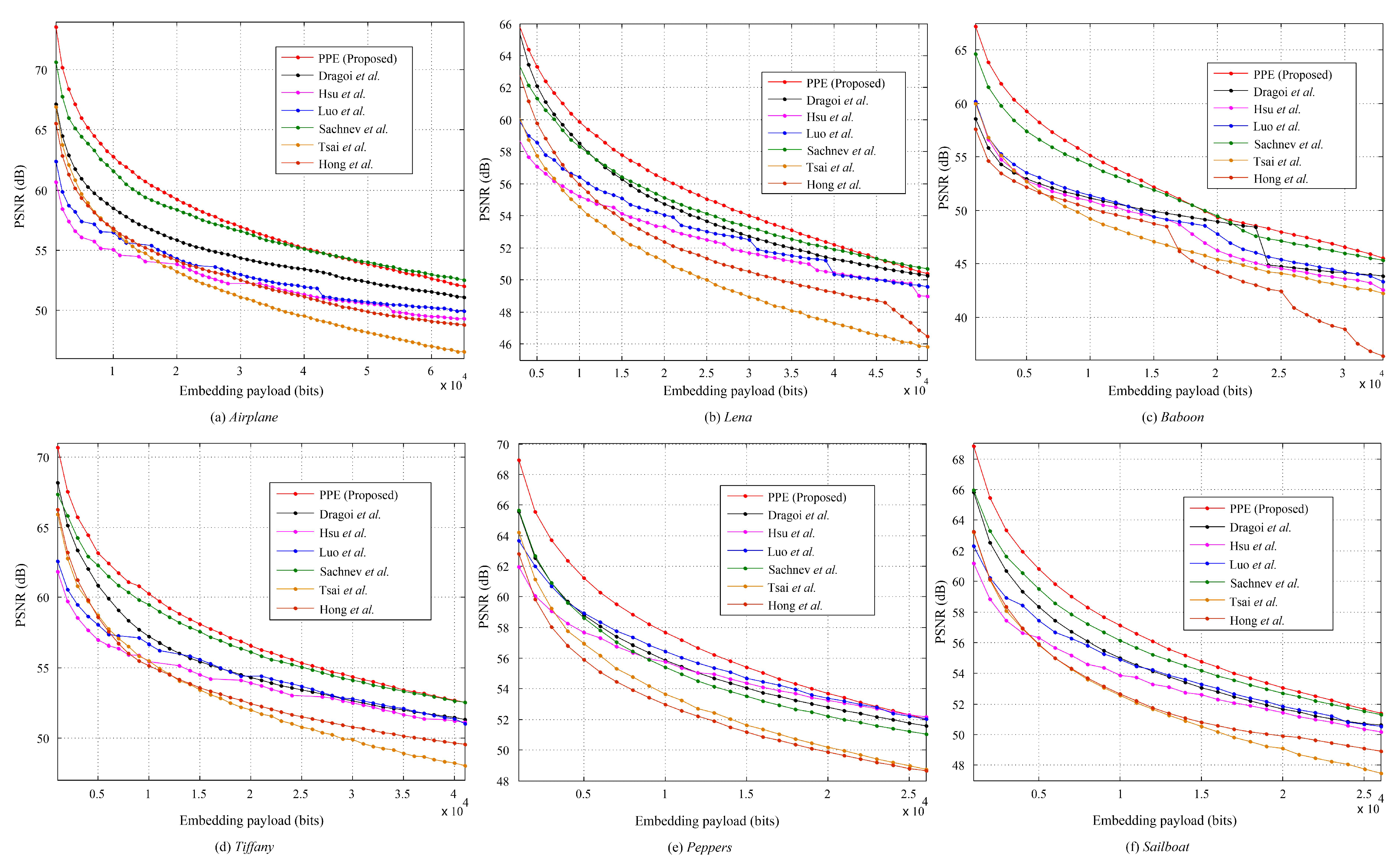
4.1. Prediction-Error of Prediction Error (PPE)-Based RDH
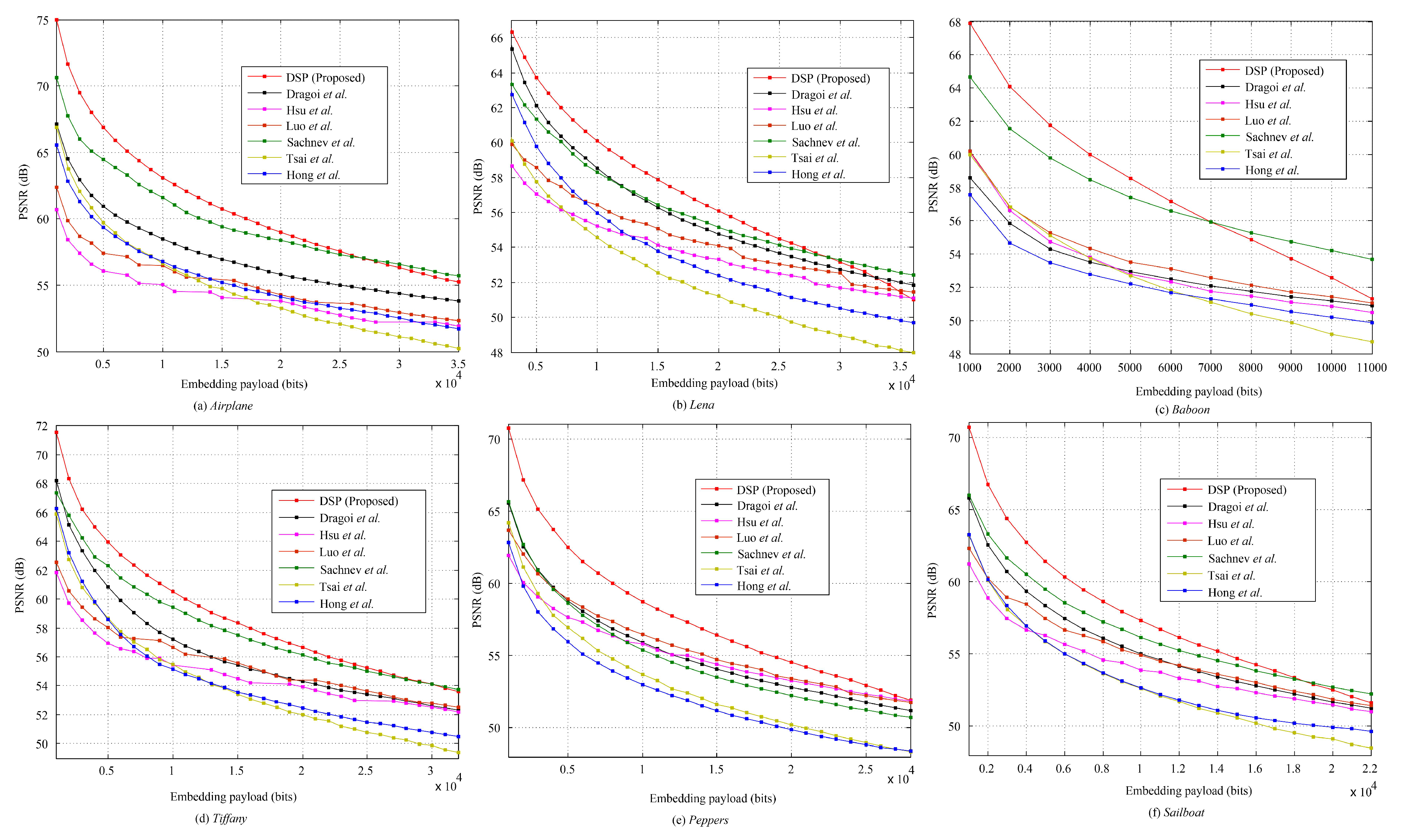
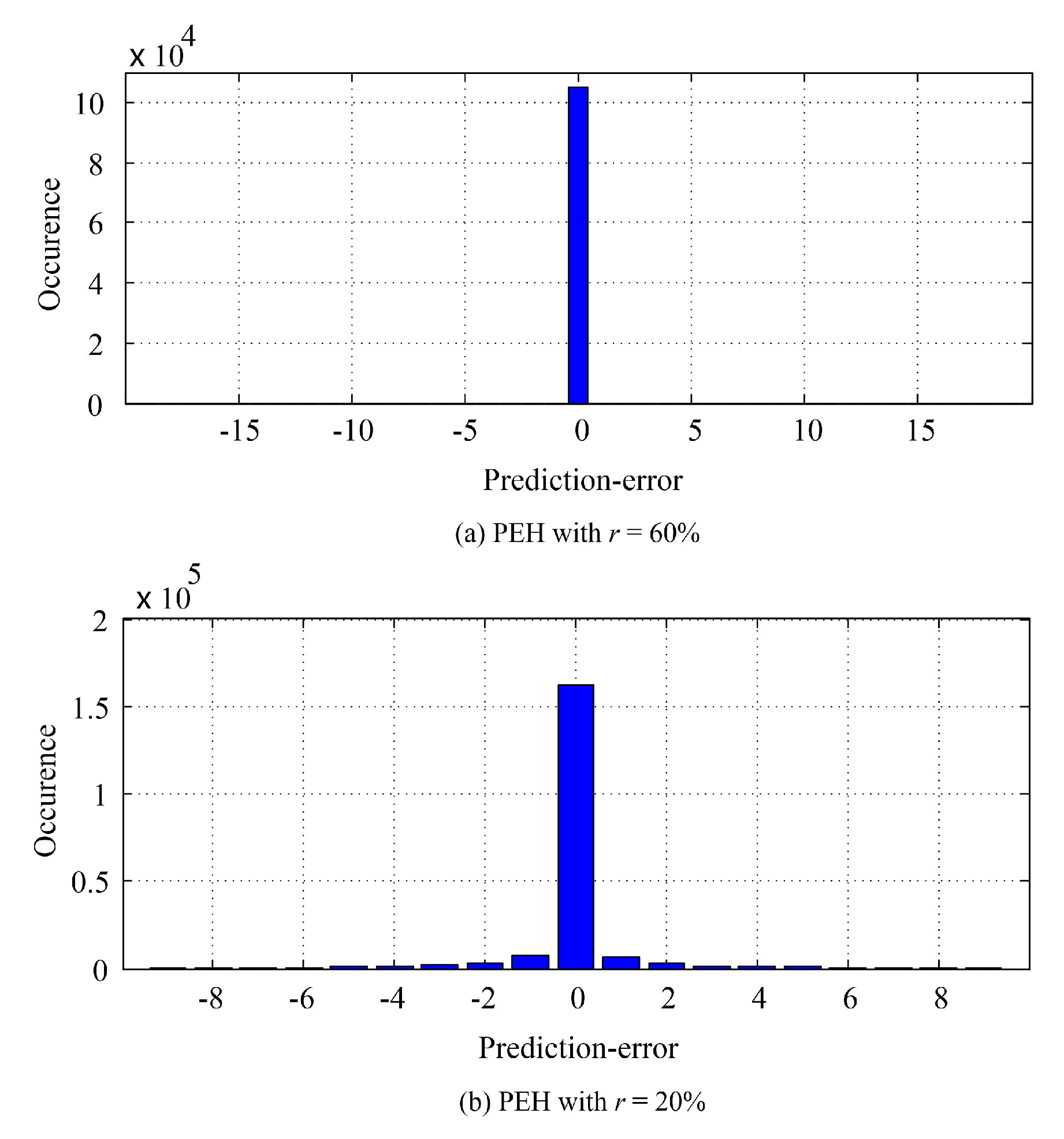
4.2. Dynamic Selection-and-Prediction (DSP)-Based RDH
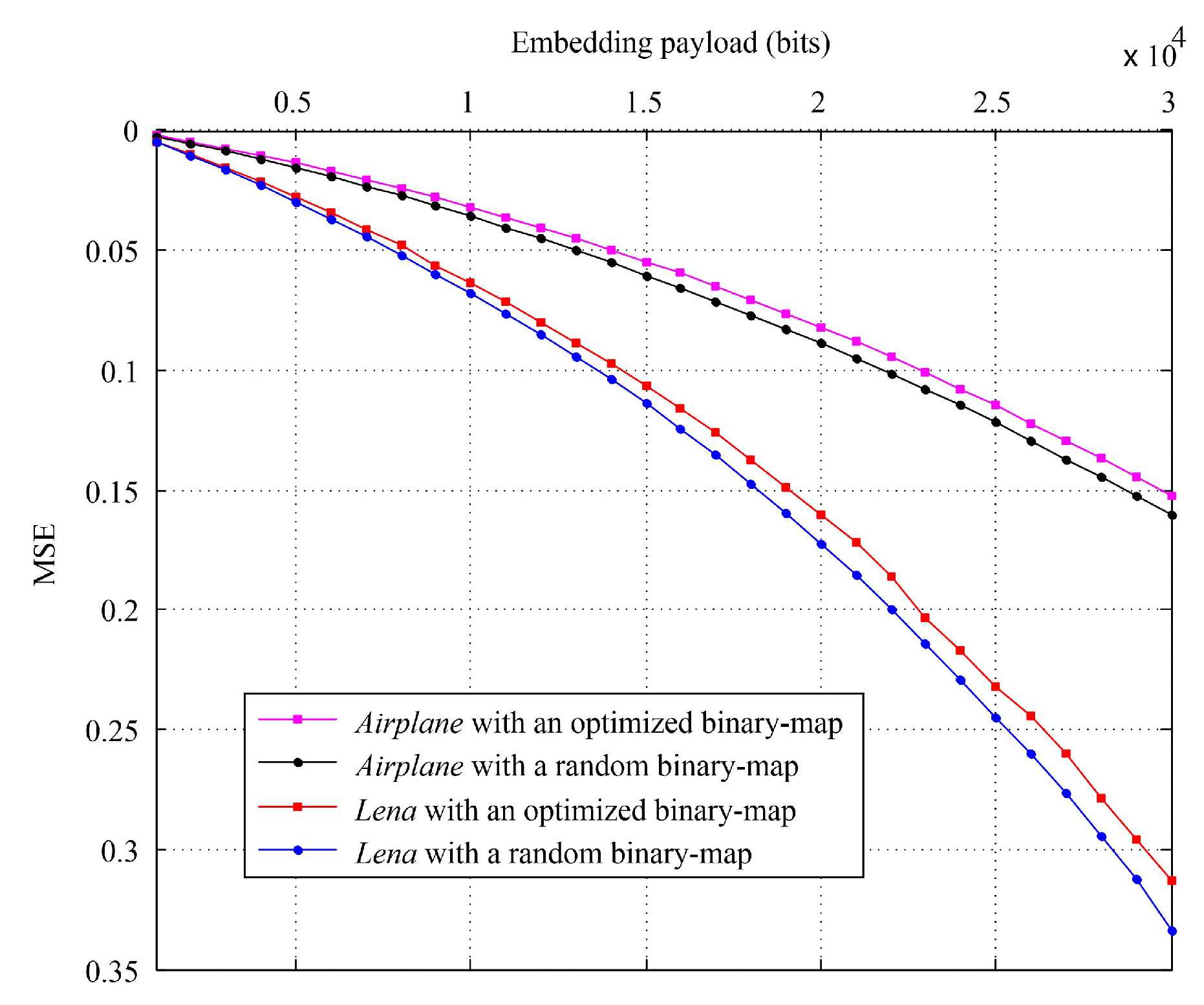
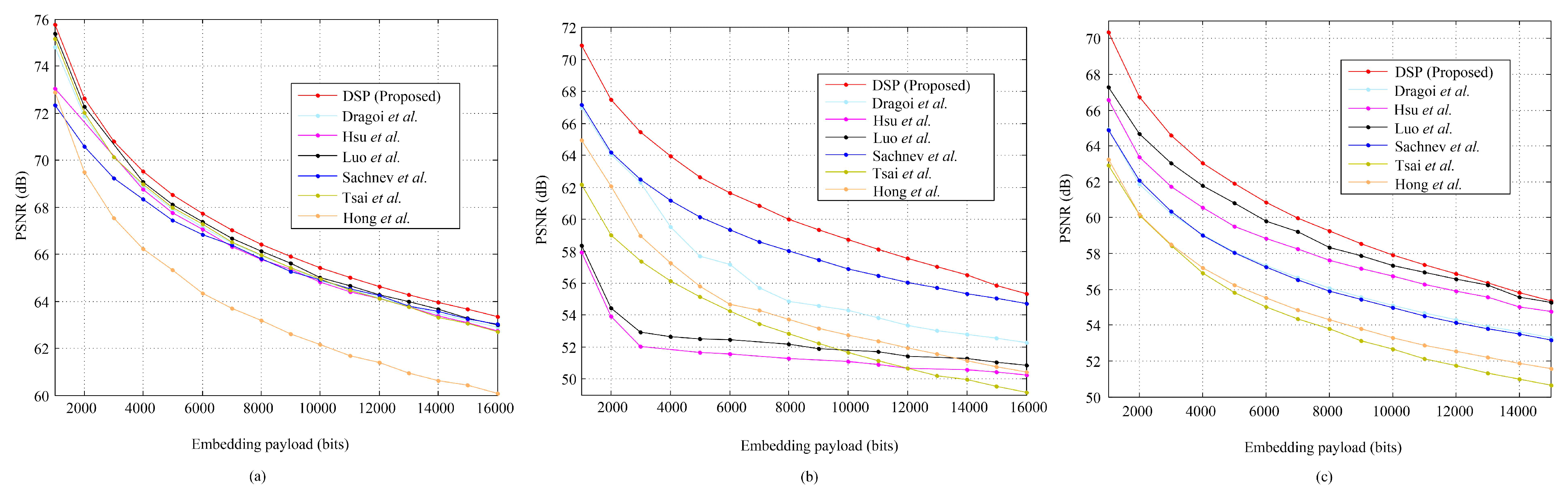
4.2.1. Evaluation on Standard Images
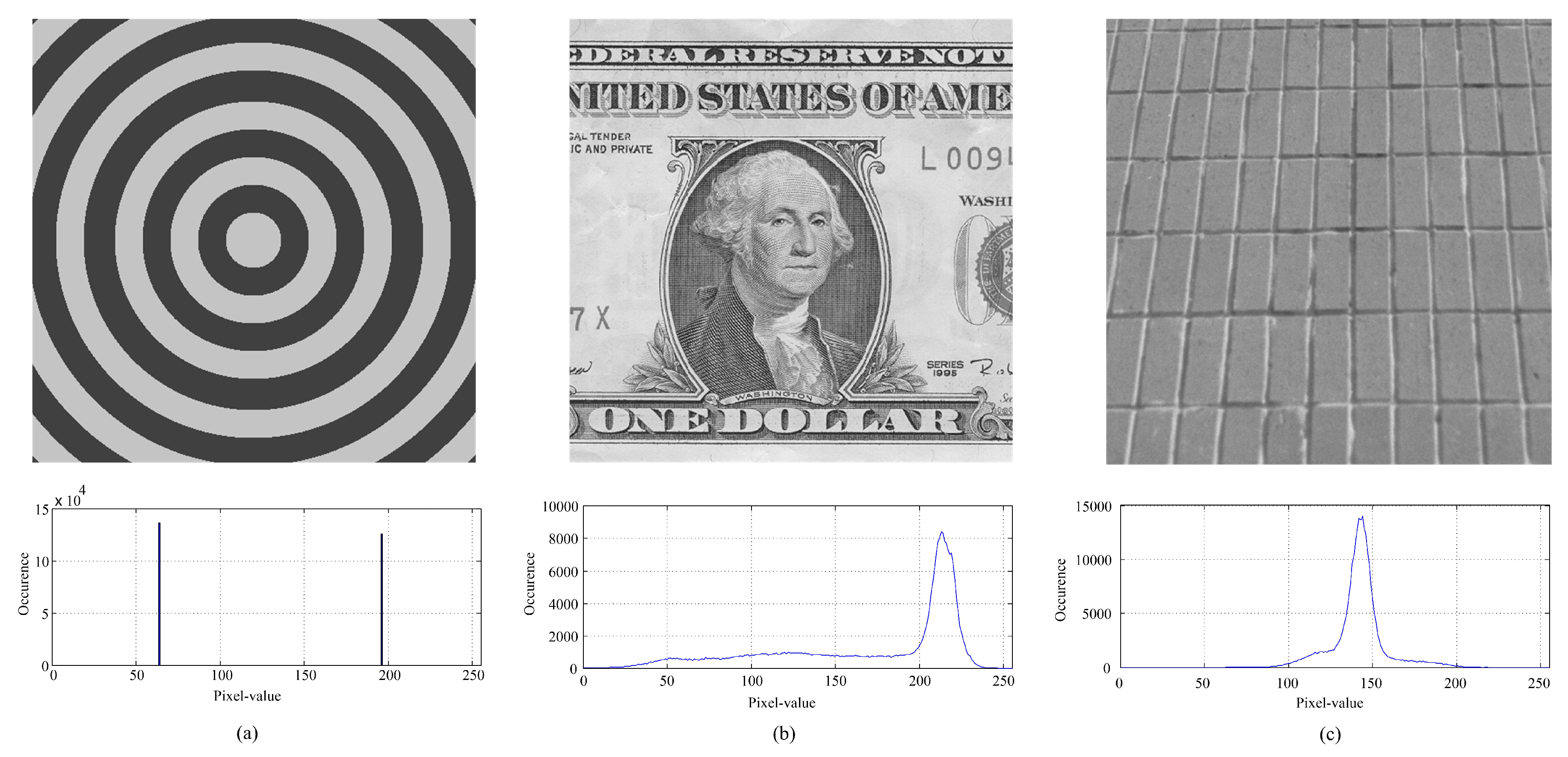
4.2.2. Evaluation on Special Images
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef] [Green Version]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Wu, H.T.; Wu, Y.; Guan, Z.H.; Cheung, Y.M. Lossless contrast enhancement of color images with reversible data hiding. Entropy 2019, 21, 910. [Google Scholar] [CrossRef] [Green Version]
- Lu, T.C.; Yang, P.C.; Jana, B. Improving the reversible LSB matching scheme based on the likelihood re-encoding strategy. Entropy 2021, 23, 577. [Google Scholar] [CrossRef] [PubMed]
- Fridrich, J.; Goljan, M.; Du, R. Invertible authentication. In Proceedings of the SPIE Security Watermarking Multimed Contents, San Jose, CA, USA, 20–26 January 2001; pp. 197–208. [Google Scholar]
- Celik, M.U.; Sharma, G.; Tekalp, A.M. Lossless watermarking for image authentication: A new framework and an implementation. IEEE Trans. Image Process. 2006, 15, 1042–1049. [Google Scholar] [CrossRef] [PubMed]
- Dragoi, I.; Coltuc, D. Local-prediction-based difference expansion reversible watermarking. IEEE Trans. Image Process. 2014, 23, 1779–1790. [Google Scholar] [CrossRef] [PubMed]
- Tsai, P.; Hu, Y.; Yeh, H. Reversible image hiding scheme using predictive coding and histogram shifting. Signal Process. 2009, 89, 1129–1143. [Google Scholar] [CrossRef]
- Thodi, D.M.; Rodríguez, J.J. Expansion embedding techniques for reversible watermarking. IEEE Trans. Image Process. 2007, 16, 721–730. [Google Scholar] [CrossRef] [PubMed]
- Sachnev, V.; Kim, H.J.; Nam, J.; Suresh, S.; Shi, Y.Q. Reversible watermarking algorithm using sorting and prediction. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 989–999. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.S.; Shiu, C.W. Reversible data hiding for high quality images using modification of prediction errors. J. Syst. Softw. 2009, 82, 1833–1842. [Google Scholar] [CrossRef]
- Luo, L.; Chen, Z.; Chen, M.; Zeng, X.; Xiong, Z. Reversible image watermarking using interpolation technique. IEEE Trans. Inf. Forensics Secur. 2010, 5, 187–193. [Google Scholar]
- Li, X.; Yang, B.; Zeng, T. Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection. IEEE Trans. Image Process. 2011, 20, 3524–3533. [Google Scholar] [PubMed]
- Wu, H.Z.; Wang, H.X.; Shi, Y.Q. PPE-Based Reversible Data Hiding. In Proceedings of the ACM Workshop Inf. Hiding Multimed. Security (Two-Page Summary, On-Going Work), Vigo Galicia, Spain, 20–22 June 2016; pp. 187–188. [Google Scholar]
- Wu, H.Z.; Wang, H.X.; Shi, Y.Q. Dynamic content selection-and-prediction framework applied to reversible data hiding. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Abu Dhabi, United Arab Emirates, 4–7 December 2016. [Google Scholar]
- Yang, C.; Tsai, M. Improving histogram-based reversible data hiding by interleaving prediction. IET Image Process. 2010, 4, 223–234. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Li, B.; Yang, B.; Zeng, T. General framework to histogram-shifting-based reversible data hiding. IEEE Trans. Image Process. 2013, 22, 2181–2191. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. Efficient reversible data hiding based on multiple histogram modification. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2016–2027. [Google Scholar]
- Wu, H.Z.; Wang, W.; Dong, J.; Wang, H.X. Ensemble reversible data hiding. In Proceedings of the International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2676–2681. [Google Scholar]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R.; Shi, Y. Pairwise prediction-error expansion for efficient reversible data hiding. IEEE Trans. Image Process. 2013, 22, 5010–5021. [Google Scholar] [CrossRef]
- Pevny, T.; Bas, P.; Fridrich, J. Steganalysis by subtractive pixel adjacency matrix. IEEE Trans. Inf. Forensics Secur. 2010, 5, 215–224. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.Z.; Wang, H.X.; Shi, Y.Q. Prediction-error of prediction error (PPE)-based reversible data hiding. arXiv 2016, arXiv:1604.04984. [Google Scholar]
- Hsu, F.; Wu, M.; Wang, S. Reversible data hiding using side-match predictions on steganographic images. Multimed. Tools Appl. 2013, 67, 571–591. [Google Scholar] [CrossRef]
- Dragoi, I.; Coltuc, D.; Caciula, I. Gradient based prediction for reversible watermarking by difference expansion. In Proceedings of the 2nd ACM Workshop on Information Hiding and Multimedia Security, Salzburg, Austria, 11–13 June 2014; pp. 35–40. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Han, H.; Wu, H. Generalized Reversible Data Hiding with Content-Adaptive Operation and Fast Histogram Shifting Optimization. Entropy 2021, 23, 917. https://doi.org/10.3390/e23070917
Zhou L, Han H, Wu H. Generalized Reversible Data Hiding with Content-Adaptive Operation and Fast Histogram Shifting Optimization. Entropy. 2021; 23(7):917. https://doi.org/10.3390/e23070917
Chicago/Turabian StyleZhou, Limengnan, Hongyu Han, and Hanzhou Wu. 2021. "Generalized Reversible Data Hiding with Content-Adaptive Operation and Fast Histogram Shifting Optimization" Entropy 23, no. 7: 917. https://doi.org/10.3390/e23070917
APA StyleZhou, L., Han, H., & Wu, H. (2021). Generalized Reversible Data Hiding with Content-Adaptive Operation and Fast Histogram Shifting Optimization. Entropy, 23(7), 917. https://doi.org/10.3390/e23070917