1. Introduction
Deep learning (DL) is becoming increasingly ubiquitous in the task of image classification due to its ability to extract desired features from raw data [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. DL is created through cascading non-linear layers that progressively produce multi-layers of representations with increasing levels of abstraction, starting from the raw input data and ending with the predicted output label [
5,
7,
11,
12,
13,
14,
15,
16]. These multi-layers of representations are features not designed by human engineers with considerable domain expertise, but they are learned from the raw data through a backpropagation learning algorithm.
In image classification, the raw data fed into a DL machine are the pixel values of an image to be classified. Note that the meaning of raw data in the context of DL here is with respect to subsequently extracted features but not in the context of compression. In the whole pipeline of data acquisition, data encoding (i.e., compression), data transmission, and data processing/utilization, the raw data fed into a DL machine are not “raw”; instead, they are generally compressed in a lossy manner. Since lossy compression is about the trade-off between compression ratio (CR) and compression quality, many versions of compressed raw data in the context of DL can be produced with each version having a different compression ratio and compression quality. This in turn brings forth the following interesting question to DL:
- Question 1
Which version of compressed raw data is good for DL and its related applications?
In practice, images are often compressed by JPEG encoders [
17,
18,
19]. For most practical applications with JPEG, both the CR and compression quality of a JPEG image are controlled by a parameter called the quality factor (QF); the higher is the QF, the lower is the CR and the better is the compression quality. With the maximum value of QF at 100, the majority of JPEG images in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012 dataset [
20,
21] have high QF values ranging from 91 to 100, implying that they all have high compression quality.
In the literature, Question 1 is investigated to some extent on the basis of constant QFs which are the same for all images in a whole set of JPEG images [
22,
23,
24,
25,
26,
27], as shown in
Figure 1. Specifically, four deep neural network (DNN) models were tested by Dodge et al. [
23] on a subset of the validation set of the ILSVRC 2012 dataset [
20]. To evaluate the impact of compression on the classification performance of these four DNN models, all images in the subset were further compressed by JPEG with the same constant QF. These compressed images with the constant QF were then fed into each of these four DNN models. Both the Top 1 classification accuracy and the Top 5 classification accuracy were recorded. As the value of the constant QF decreases, the curves of the Top 1 classification accuracy vs. QF and the Top 5 classification accuracy vs. QF were plotted by Dodge et al. [
23] in the QF range from 20 to 2. It was shown by Dodge et al. [
23] that both the Top 1 classification accuracy and the Top 5 classification accuracy of each of the four DNN models decay as the value of the constant QF decreases. This phenomenon of negative impact of compression on the classification performance of DNN models was also reported by Liu et al. [
27].
To alleviate the negative impact of JPEG compression on the classification performance of DNN models to some extent, several methods were proposed in the literature, including data augmentation, stability training, and due-channel training with preprocessing [
24,
27,
28,
29,
30,
31]. For example, stability training was proposed by Zheng et al. [
24], where, during the training stage of a DNN model, both the original image and its distorted version are fed into the model, and training is performed to minimize a modified cost function which takes stability into consideration. Although these methods improve the classification robustness of DNN models against JPEG compression and other types of distortion, there is still a significant degradation (as high as 10%) in the classification accuracy when these newly trained DNN models are applied to low-quality JPEG compressed images. Based on these findings, it is generally believed that compression, especially JPEG compression, would hurt the classification accuracy of deep learning in image classification.
In this paper, we investigate Question 1 in the context of JPEG compression from a different perspective. Instead of using a constant QF in JPEG compression for all images in the ILSVRC 2012 dataset, we would allow each image to be compressed first with a possibly different QF and then fed into a DNN. Specifically, let QF take values from
(This set of QF values is simply used as an example. The idea of this paper, however, can be applied to any set of QF values. In addition,
is regarded in this example as the lowest compression quality acceptable to humans.) We associate each original image in the ILSVRC 2012 dataset with its 10 compressed versions, each compressed version corresponding to a different QF from
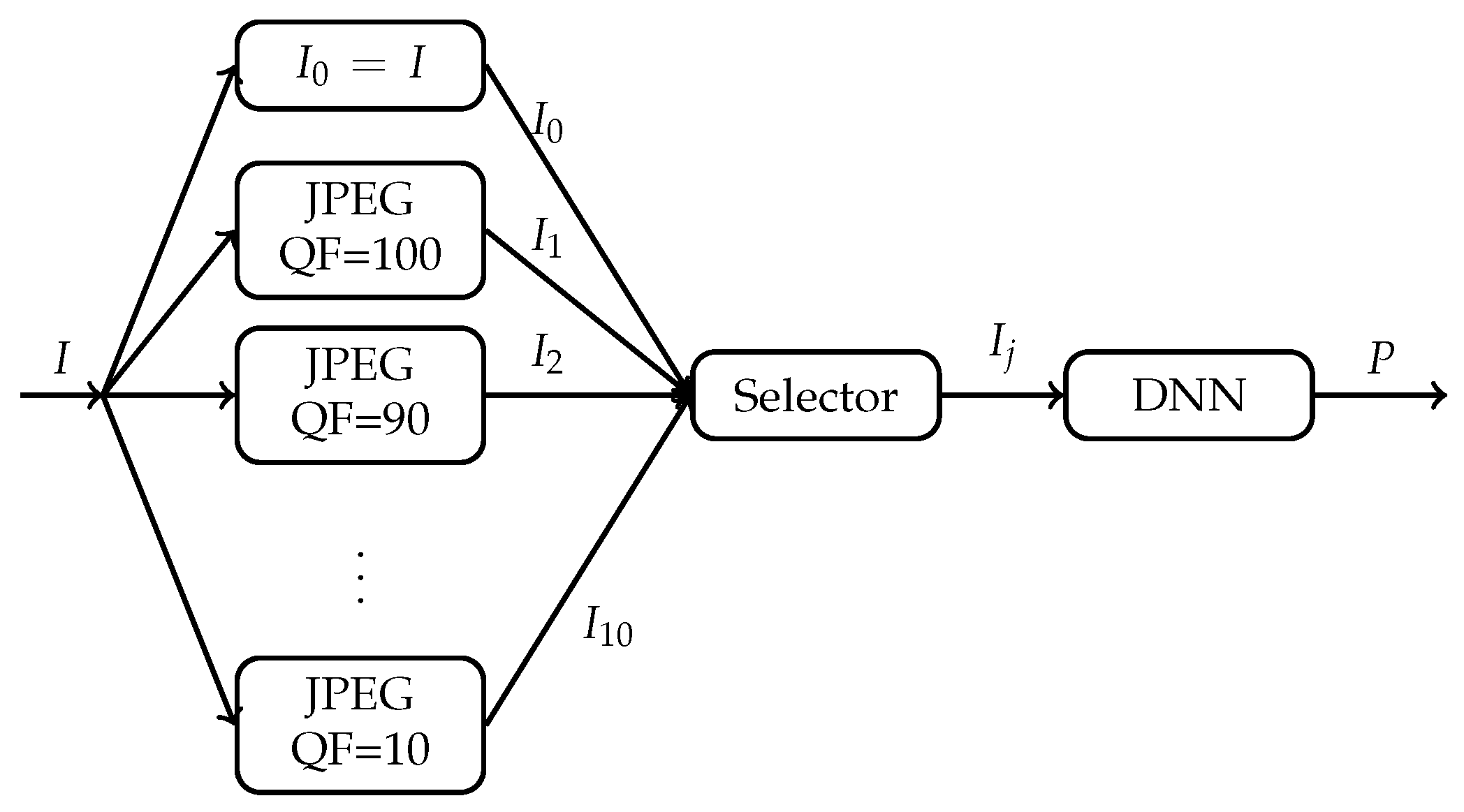
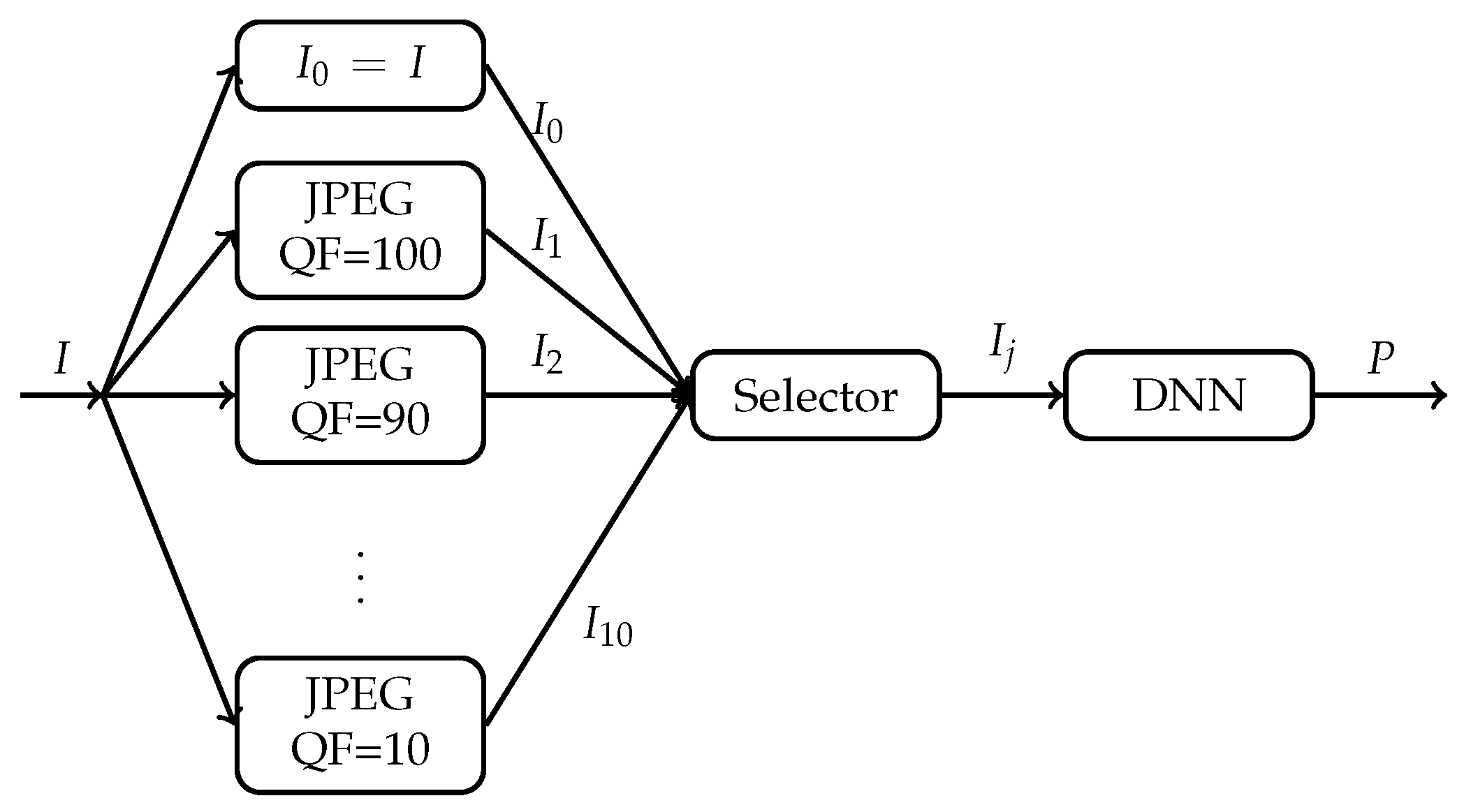
. For each image, there are now 11 different versions: 1 original version and 10 compressed versions. As shown in
Figure 2, for each original image
I, we now have freedom to select one version
out of its 11 versions
,
, to be fed into the DNN. Is there any selector that can select, for each original image
I, a suitable version
to be fed into the DNN so that both the Top 1 classification accuracy and Top 5 classification accuracy of the DNN can be improved significantly while the size (in bits) of the input image to the DNN can be reduced dramatically in general?
One of our purposes in this paper is to settle the above question. We show that the answer to the above question turns out to be positive. Therefore, in contrast to the conventional understanding, compression, if used in the right manner, actually improves the classification accuracy of a DNN significantly while also reducing dramatically the number of bits needed to be fed into the DNN. Specifically, a DNN pre-trained with pristine ImageNet images is fixed. That is, the DNN is trained with the original images in the training set of the ILSVRC 2012 dataset. Suppose that the ground truth label of each original image
I is known to the selector in
Figure 2, but it is unknown to the DNN. Under this assumption, we propose a selector called Highest Rank Selector (HRS). For each original image
I, HRS works as follows. Examine the prediction vector
of the DNN in response to each version
; determine the rank of the ground truth label in the sorted
, where labels in
are sorted according to their probabilities in descending order with rank 1 being the highest ranking; and then select the compressed version
as the desired input to the DNN if the rank of the ground truth label in the sorted
is the highest among all sorted
, where, in the case of tie, HRS selects the compressed version with the lowest QF. It can be shown that, among all selectors one could possibly design, HRS achieves the highest Top 1 and Top 5 classification accuracy and hence is optimal. When applied to Inception V3 and ResNet-50 V2 architectures pre-trained with pristine ImageNet images [
32,
33], HRS improves, on average, the Top 1 classification accuracy by 5.6% and the Top 5 classification accuracy by 1.9% on the whole ImageNet validation set. In addition, compared with the original image, the compressed version selected by HRS also achieves, on average, the CR of 8.
When the ground truth label of each input image is unknown to the selector in
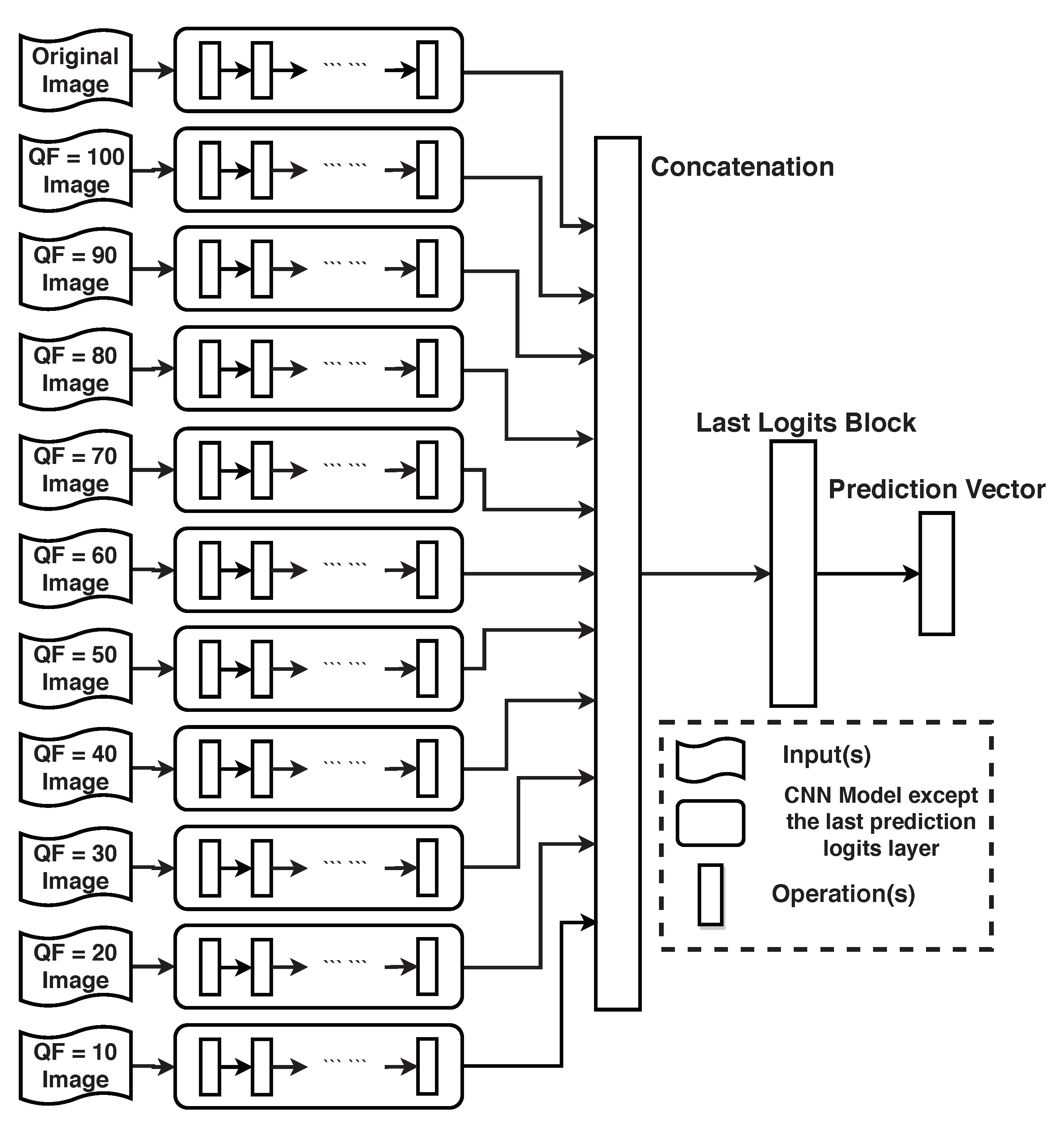
Figure 2 as well, HRS is not applicable. To demonstrate that compression still improves the classification accuracy of DL in this case, we propose a new convolutional neural network (CNN) topology based on a given DNN. Consider the main architecture of the DNN without its last fully connected layer. As shown in Figure 12, the new CNN topology based on the given DNN consists of 11 parallel main architectures of the DNN followed by the last fully connected layer at which the logit blocks from the 11 parallel main architectures are concatenated. The original image and its 10 compressed versions are inputs to the 11 parallel main architectures of the given DNN, respectively. These 11 parallel identical main architectures are first pre-trained with the original images in the training set of the ILSVRC 2012 dataset. The last a few layers of the new CNN topology are then re-trained. Experimental results show that, when compared with the given underlying DNN, the new CNN topology improves the Top 1 classification accuracy and the Top 5 classification accuracy by 0.4% and 0.3%, respectively, when the given underlying DNN is Inception V3 and by 0.4% and 0.2%, respectively, when the given underlying DNN is ResNet-50 V2.
In another direction, when the ground truth label of each input image is unknown to the selector in
Figure 2, we also propose a selector which can maintain the same the Top 1 classification accuracy and Top 5 classification accuracy as those of the given DNN with the original image as its input. When applied to Inception V3 and ResNet-50 V2, the compressed version selected by the proposed selector achieves, on average, the CR of 3.1 in comparison with the original image.
The remainder of the paper is organized as follows.
Section 2 provides a case study that motivates the research work in this paper. In
Section 3, we describe HRS in detail, demonstrate its optimality, and analyze why it improves classification accuracy significantly while achieving dramatic reduction in bits.
Section 4 and
Section 5 are devoted to the case where the ground truth label of each input image is unknown to the selector in
Figure 2, with
Section 4 focusing on the new CNN topology.
Section 5 is devoted to the proposed selector maintaining classification accuracy while achieving significant reduction in bits. Finally,
Section 6 concludes the paper.
2. Motivation: Case Study
This section motivates our approach to Question 1 as illustrated in
Figure 2. Let us first reproduce results which lead people to the conventional understanding that JPEG compression generally degrades classification performance of DNNs.
The conventional understanding is based on the approach shown in
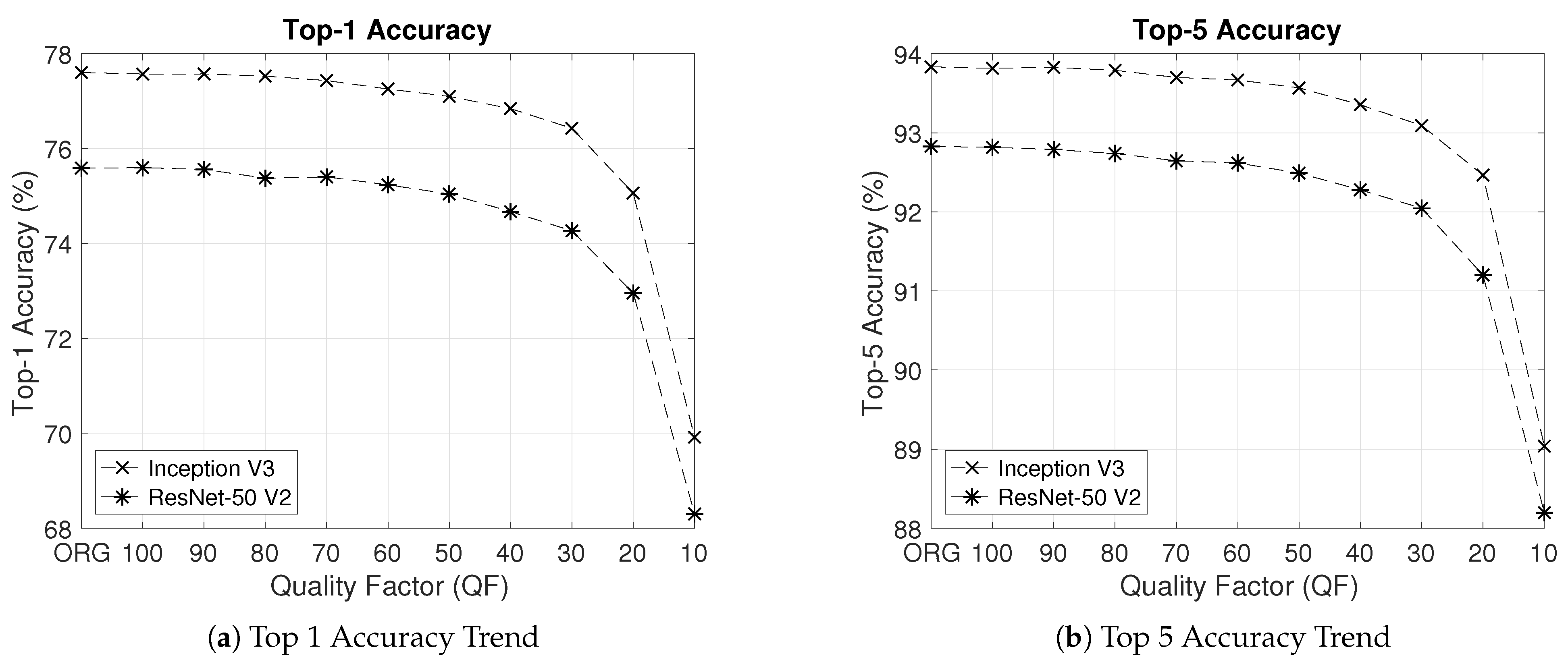
Figure 1, where a constant QF is used to compress all images in a whole set of images. This approach can be dubbed as “one QF vs. all images”. For Inception V3 and ResNet-50 V2 pre-trained with the original images in the training set of the ILSVRC 2012 dataset,
Figure 3 shows their respective curves of the Top 1 classification accuracy and Top 5 classification accuracy on the whole ImageNet validation dataset vs. the constant QF as the value of the constant QF in
Figure 1 decreases from 100 to 10 with a step size of 10. From the results in
Figure 3, it is clear that classification performance deteriorates as the value of the constant QF decreases, hereby reconfirming the conventional understanding.
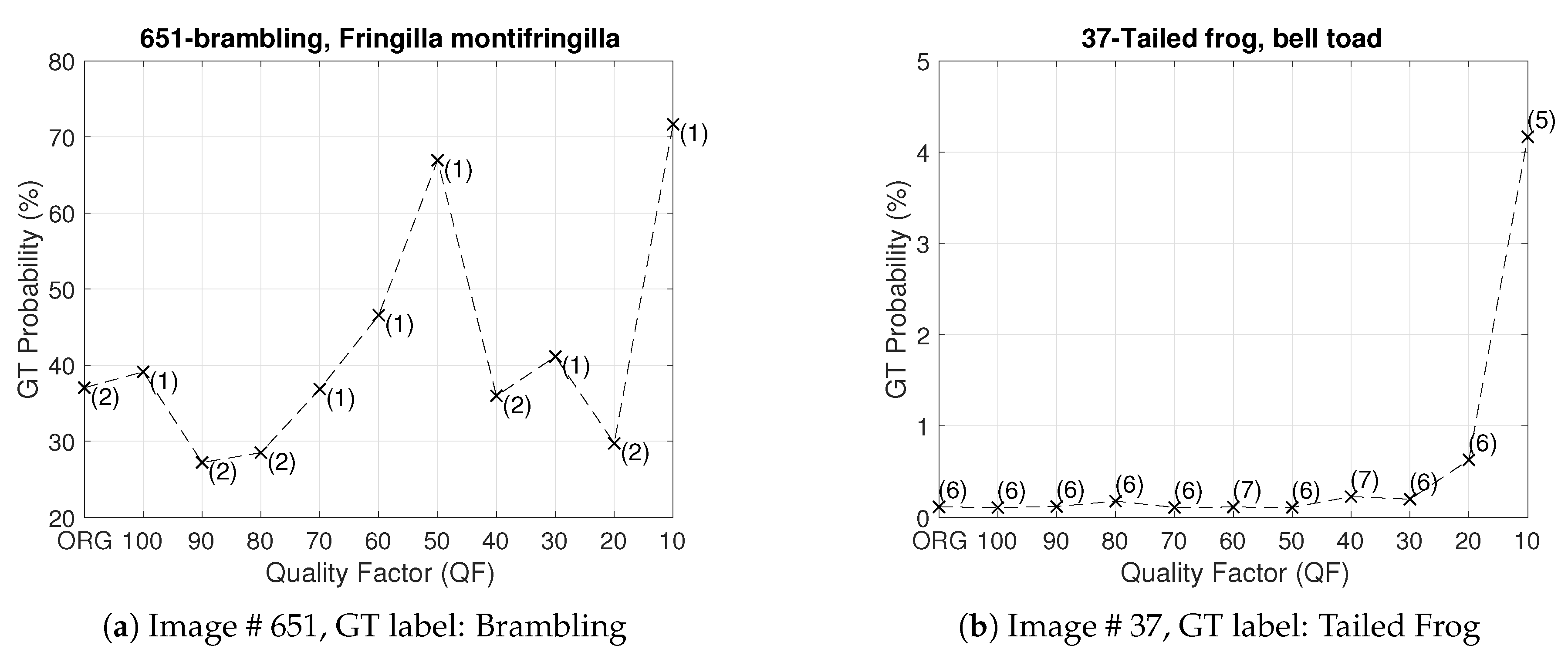
Note that the concept of classification accuracy is a group notion with respect to a whole set of images. If, however, we focus on a particular image and examine the impact of JPEG compression with different QFs on the predicted vector of the underlying DNN—such a perspective is dubbed as “one image vs. all QFs”—then the rank and probability of the ground truth (GT) label of the image in the predicted vector do not necessarily go down as the value of QF decreases. This is indeed confirmed by
Figure 4. With Inception V3 pre-trained with ImageNet pristine images as the underlying DNN,
Figure 4 shows the ranks and probabilities of the GT labels of Images #651 and #37 in the ImageNet validation set as the value of QF decreases. In this Figure, it is clear that, for a given image, a JPEG compressed version with a lower QF could yield a higher rank of the GT label and a larger probability of the GT label in comparison with the original image. For example, for Image #651 shown in
Figure 5, when the original image is fed into the underlying DNN, the GT label ranks second with probability 37% in the corresponding predicted vector. On the other hand, when its JPEG compressed version with
shown in
Figure 5 is fed into the underlying DNN, the GT label ranks first with probability 72% in the corresponding predicted vector; both the rank and probability of the GT label are improved. The same phenomenon is observed for Image #37 and in the case of the ResNet-50 V2 architecture as well.
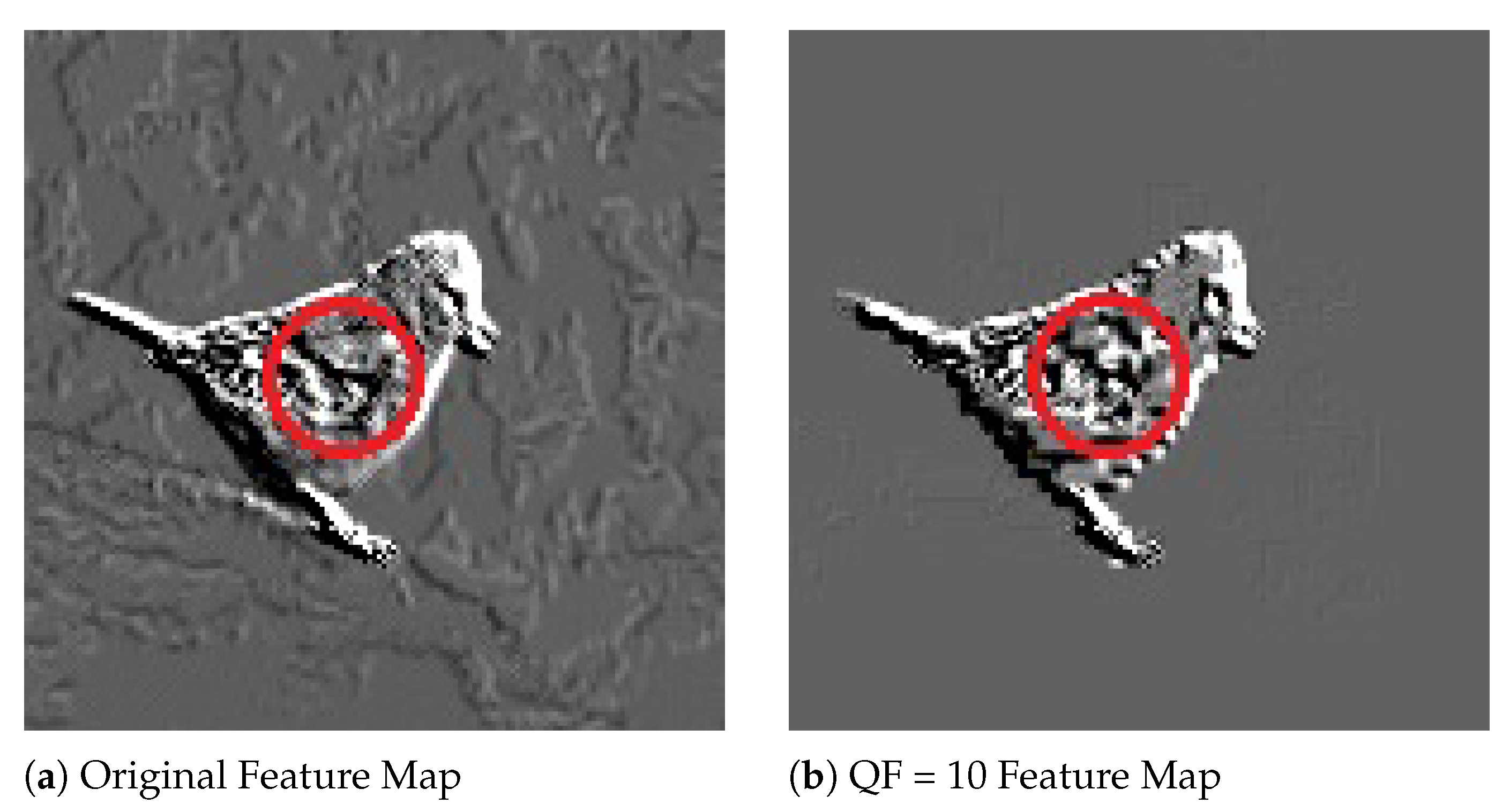
To shed light on why, for a particular image, both the rank and probability of its GT label resulting from a JPEG compressed version with a low QF could be higher than those resulting from the original image,
Figure 6 shows a pair of corresponding feature maps extracted from the original Image #651 and its JPEG compressed version with
, respectively, by Layer 1 of Inception V3. In
Figure 6, the feature map extracted from the JPEG compressed image with
is a lot of cleaner and has much better contrast between the foreground and background than the one extracted from the original image. This is likely due to the unequal quantization performed by JPEG on different discrete cosine transform (DCT) coefficients, which is non-linear and reduces more energy in the background than the foreground. This, combined with the subsequent rectified linear unit (ReLU) function in Inception V3, essentially wipes out the background information.
The above case study suggests that, if for any image, one can select, among its many compressed versions including its original version, a suitable version as an input to the underlying DNN, then the classification accuracy of the underlying DNN could be improved. In addition, if a highly compressed version is selected most of the time, then the size in bits of the input is also reduced dramatically in comparison with the original image. The question, of course, is how to select such a compressed version, which is addressed in the next section when the GT label of the image is known to the selector.
5. Selectors Maintaining Classification Accuracy While Reducing Input Size
Let us now go back to
Figure 2 and continue to assume that the GT label of the original image is unknown to the selector therein. In this section, we present three selectors which maintain the same Top 1 accuracy, the same Top 5 accuracy, and the same Top 1 accuracy and Top 5 accuracy as those of the underlying DNN, respectively, while reducing the size in bits of the input image to the underlying DNN to some degree. These three selectors are referred to as Top 1 Keeper (T1K), Top 5 Keeper (T5K), and Top 1 and Top 5 Keeper (TTK), respectively.
For any original image I, T1K selects as an input to the underlying DNN if and only if is the largest integer such that the Top 1 label in the sorted is the same as that in the sorted . Similarly, for any original image I, T5K selects as an input to the underlying DNN if and only if is the largest integer such that the set of Top 5 labels within the sorted is the same as that in the sorted . Likewise, TTK selects as an input to the underlying DNN if and only if is the largest integer such that both the Top 1 label in and the set of Top 5 labels within the sorted are the same as those in the sorted , respectively. It is clear that, on any set of images, T1K achieves the same Top 1 accuracy as that of the underlying DNN, T5K achieves the same Top 5 accuracy as that of the underlying DNN, and TTK achieves the same Top 1 accuracy and Top 5 accuracy as those of the underlying DNN.
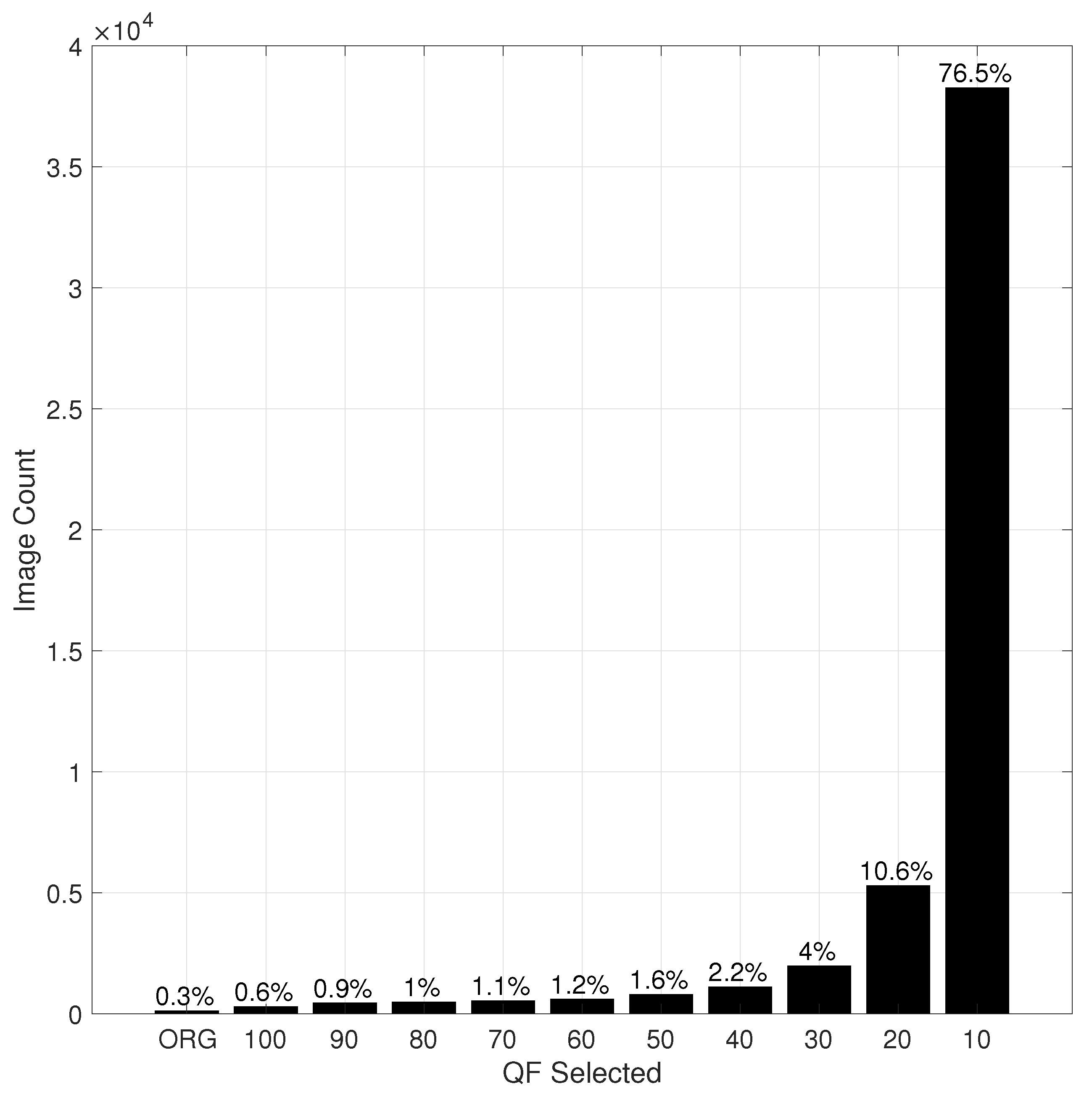
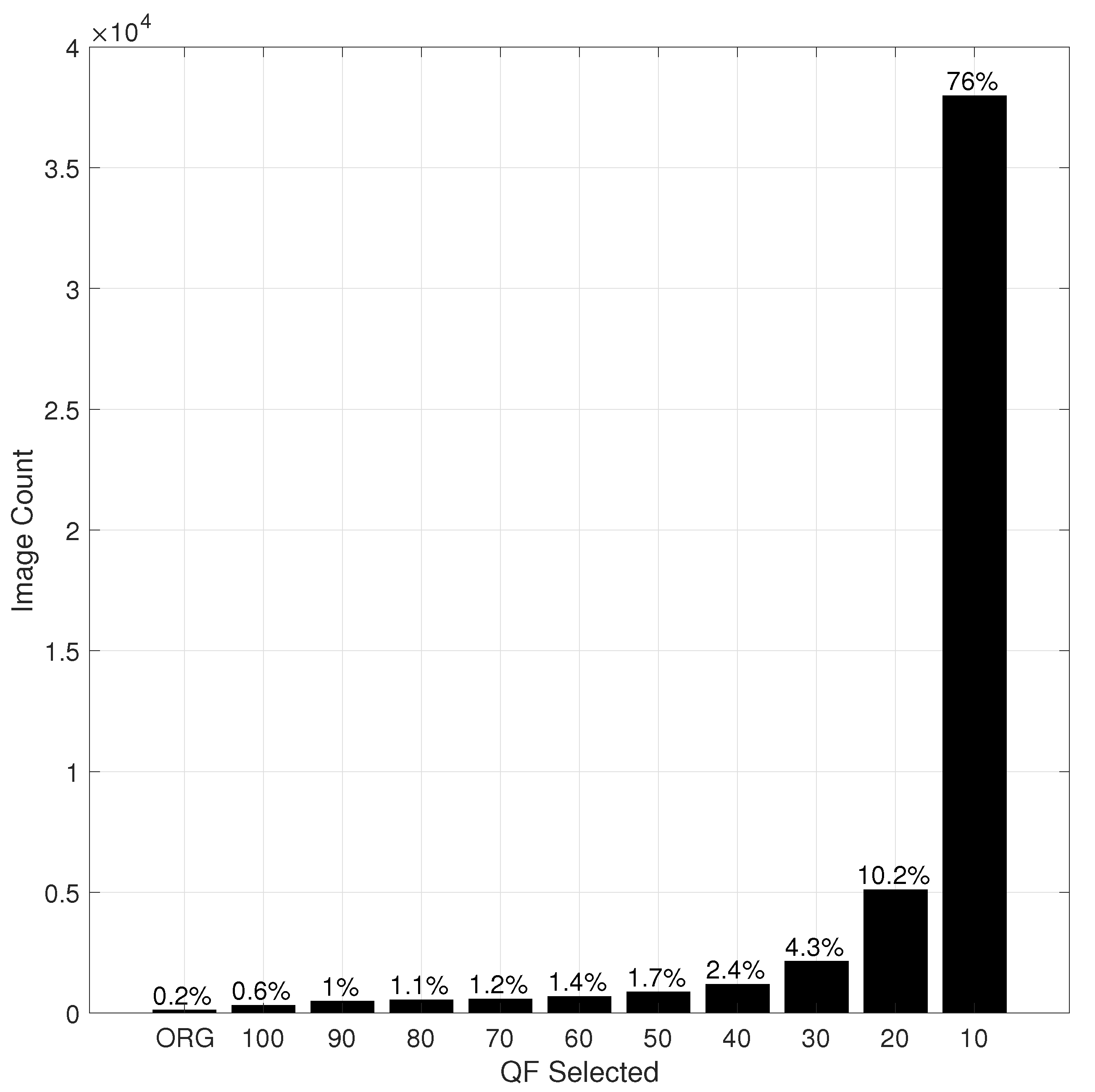
Table 6 shows the Top 1 accuracy and Top 5 accuracy of T1K and T5K on the whole ImageNet validation dataset when the underlying DNN is Inception V3 and ResNet-50 V2 pre-trained with the original images in the training set of the ILSVRC 2012 dataset, respectively. As seen in this table, T1K degrades the Top 5 accuracy by up to 1.5%, while T5K reduces the Top 1 accuracy by up to 1.26%. However, the advantage is the dramatic reduction in the input size in bits.
Table 7 and
Table 8 show CR results of T1K, T5K, and TTK for the whole ImageNet validation dataset when the underlying DNN is Inception V3 and ResNet-50 V2, respectively. In
Table 7 and
Table 8, the default size is the total size in GB of all original images in ImageNet validation dataset, while the new size is the total size of all selected input images by T1K, T5K, or TTK as the case may be. As seen in these tables, the compression ratios achieved by T1K, T5K, and TTK are on average 8.8, 3.3, and 3.1, respectively.
These results demonstrate the advantage of selectors in
Figure 2 in terms of input storage savings while roughly maintaining the classification accuracy of the underlying DNN. Applications that require long-term storage of multimedia such as image surveillance will benefit from these selectors.
6. Conclusions
In this paper, we formulate a new framework to investigate the impact of JPEG compression on deep learning (DL) in image classification. An underlying deep neural network (DNN) pre-trained with pristine ImageNet images is fixed. For any original image, the framework allows one to select, among many JPEG compressed versions of the original image including possibly the original image itself, a suitable version as an input to the underlying DNN. It was demonstrated that, within the framework, a selector can be designed so that the classification accuracy of the underlying DNN can be improved significantly, while the size in bits of the selected input is, on average, reduced dramatically in comparison with the original image. Therefore, compression, if used in the right manner, helps DL in image classification, which is in contrast to the conventional understanding that JPEG compression generally degrades the classification accuracy of DL.
In the case where the ground truth label of the original image is known to the selector but unknown to the underlying DNN, a selector called Highest Ranking Selector (HRS) is presented and shown to be optimal in the sense of achieving the highest Top k accuracy on any set of images for any k among all possible selectors. When the selection is made among the original image and its 10 JPEG compressed versions with their quality factor (QF) values ranging from 100 to 10 with a step size of 10, HRS improves, on average, the Top 1 accuracy and Top 5 accuracy of Inception V3 and ResNet-50 on the whole ImageNet validation set by 5.6% and 1.9%, respectively, while reducing the input size in bits dramatically—the compression ratio (CR) between the size of the original images and the size of the selected input images by HRS is 8 for the whole ImageNet validation dataset.
In the case where the ground truth label of the original image is unknown to the selector as well, we also propose a new convolutional neural network (CNN) topology which is based on the underlying DNN and takes the original image and its 10 JPEG compressed versions as 11 parallel inputs. It was demonstrated that the proposed new CNN topology, even when partially trained, can consistently improve the Top 1 accuracy of Inception V3 and ResNet-50 V2 by approximately 0.4% and the Top 5 accuracy of Inception V3 and ResNet-50 V2 by 0.32% and 0.2%, respectively.
Selectors without the knowledge of the ground truth label of the original image are also proposed. They maintain the Top 1 accuracy, Top 5 accuracy, or Top 1 and Top 5 accuracy of the underlying DNN. It was shown that, when applied to Inception V3 and ResNet-50, these selectors achieve CRs of 8.8, 3.3, and 3.1, respectively, for the whole ImageNet validation dataset.
The results in this paper could motivate further developments in at least two directions. First, it would be desirable to develop new compression theory and algorithms for DL to achieve good trade-offs among the compression rate, compression distortion, and classification accuracy, where the compression distortion is for human, and the classification accuracy is for DL machines. Second, the results in this paper imply that the current CNN classifiers are not smart enough and behave as a short-sighted person—if the main features of an object are relatively enhanced and the disturbing features surrounding the object are removed, all through compression, then the CNN classifiers can see the object better. It would be interesting to investigate whether this could be theorized to any Turing classifier (i.e., computable classifier). This first author of the paper believes that this would still be the case, based on insights gained from lossless compression of individual sequences through the lens of Kolmogorov complexity [
38].

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}