Information Flows of Diverse Autoencoders


Abstract
:1. Introduction
2. Representation Learning in Autoencoders
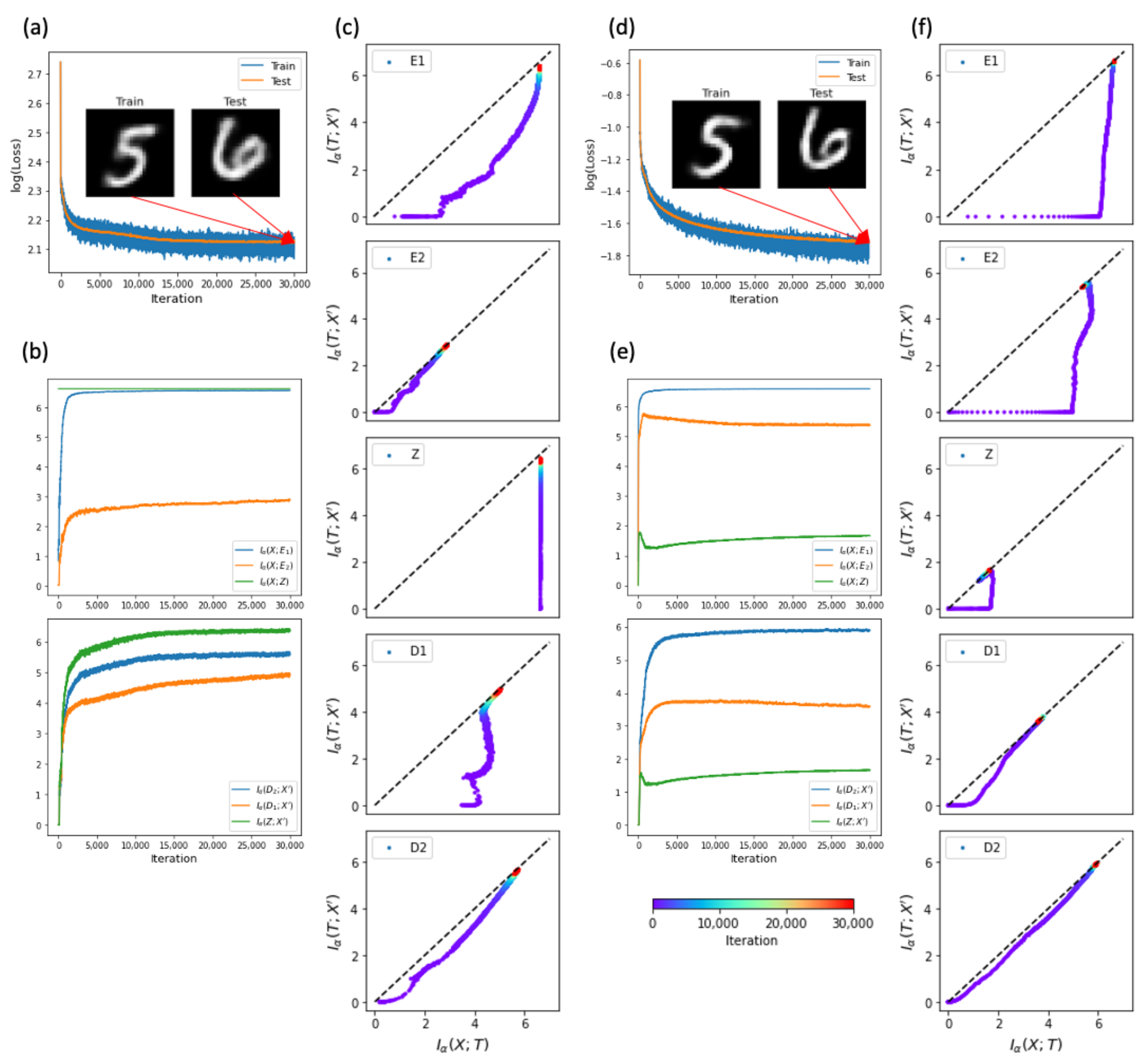
2.1. Information Plane of Autoencoders
2.2. Various Types of Autoencoders
- SAE was proposed to avoid overfitting by imposing sparsity in the latent space. The sparsity penalty is considered a regularization term of the Kullback–Leibler (KL) divergence between the activity of bottleneck layer Z and sparsity parameter , a small value close to zero.
- TAE shares the weights for the encoder and decoder part (), where superscript T depicts the transpose of a matrix. This model is widely used to reduce the number of model parameters while maintaining the training performance. Owing to its symmetrical structure, it can be interpreted as a deterministic version of restricted Boltzmann machines (RBMs), a representative generative model for unsupervised learning; consequently, the duality between TAE and RBM has been identified [27]. Compared to the vanilla AE, SAE and TAE have regularizations for the degrees of freedom for nodes and weights, respectively. Later, we visually validate how these constraints lead to a difference in the information flow of IP trajectories.
- The ultimate goal of AEs is to obtain richer expressions in the latent space. Therefore, an AE is not a mere replica model, but a generative model that designs a tangible latent representation to faithfully reproduce the input data as output. VAE is one of the most representative generative models with a similar network structure to AE; however, its mathematical formulation is fundamentally different. The detailed derivation of the learning algorithm of VAE is beyond the scope of this study, and thus it will be omitted [24]. In brief, the encoder network of VAE realizes an approximate posterior distribution for variational inference, whereas the decoder network realizes a distribution for generation. The loss of VAE, known as the evidence lower bound (ELBO), is decomposed into a reconstruction error given by the binary cross entropy (BCE) between the desired output X and predicted output , and the regularization of KL divergence between the approximate posterior distribution and prior distribution . As tangible Gaussian distributions are usually adopted as the approximate posterior and prior distributions of and , respectively, VAE has a special manifold of the latent variable Z.
- AEs do not use data labels. Instead, inputs work as self labels for supervised learning. Here, to design the latent space using label guides, we consider another AE, called label AE (LAE). LAE forces the input data to be mapped into the latent space with the corresponding label classifications. Then, the label-based internal representation is decoded to reproduce input data. Although the concept of regularization using labels has been proposed [25,26], LAE has not been considered as a generative model. Unlike vanilla AEs that use a sigmoid activation function, LAE uses a softmax activation function, , to impose the regularization of the internal representation Z to follow the true label Y as the cross entropy (CE) between Y and Z. Once LAE is trained, it can generate learned data or images using its decoder, starting from one-hot vector Z of labels with the addition of noise. Additional details of LAE are provided in Appendix B. Later, we compare the IP trajectories of VAE and LAE with those of vanilla AE in a deep structure to examine how the information flow varies depending on the latent space of generative models.
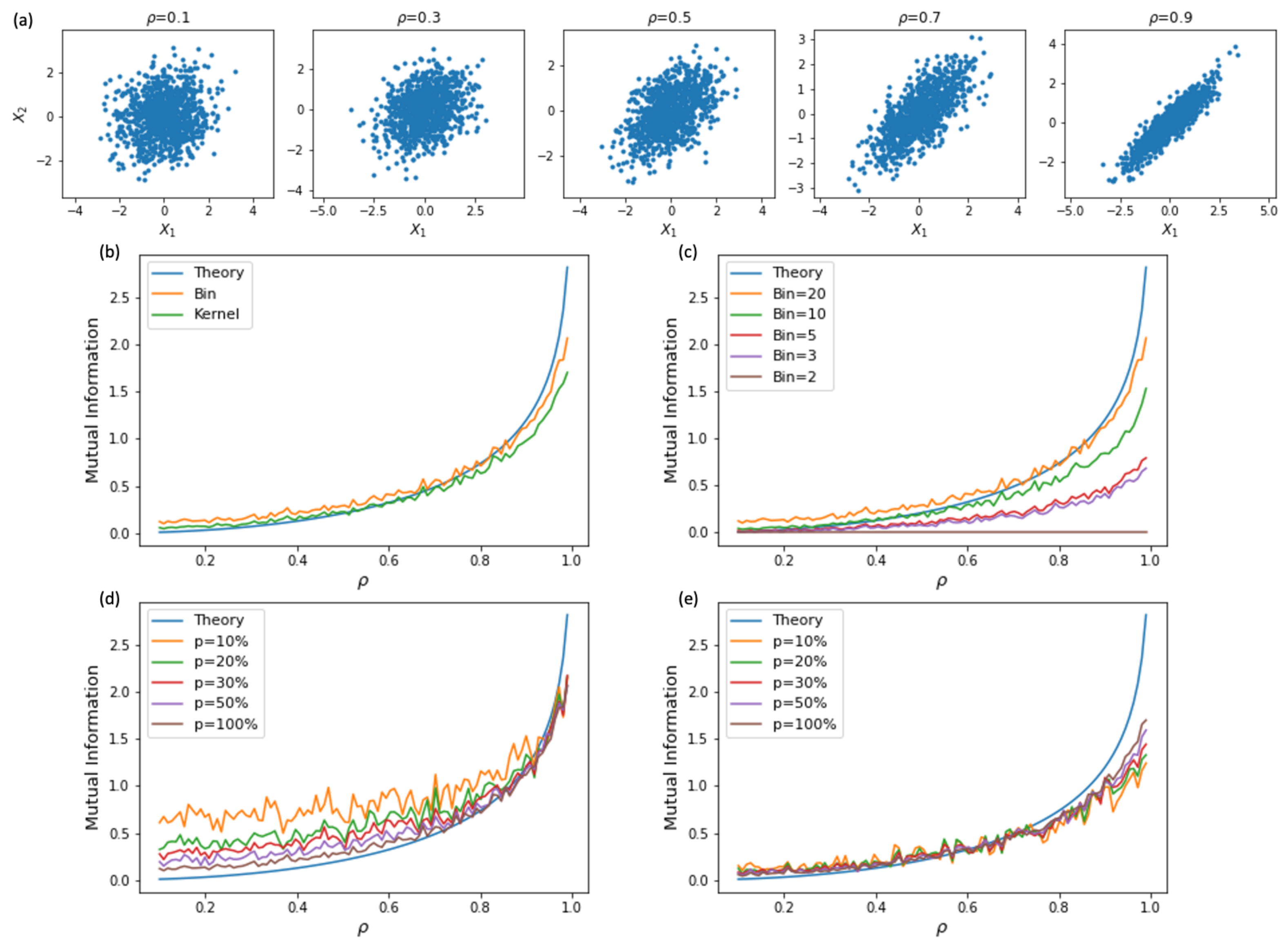
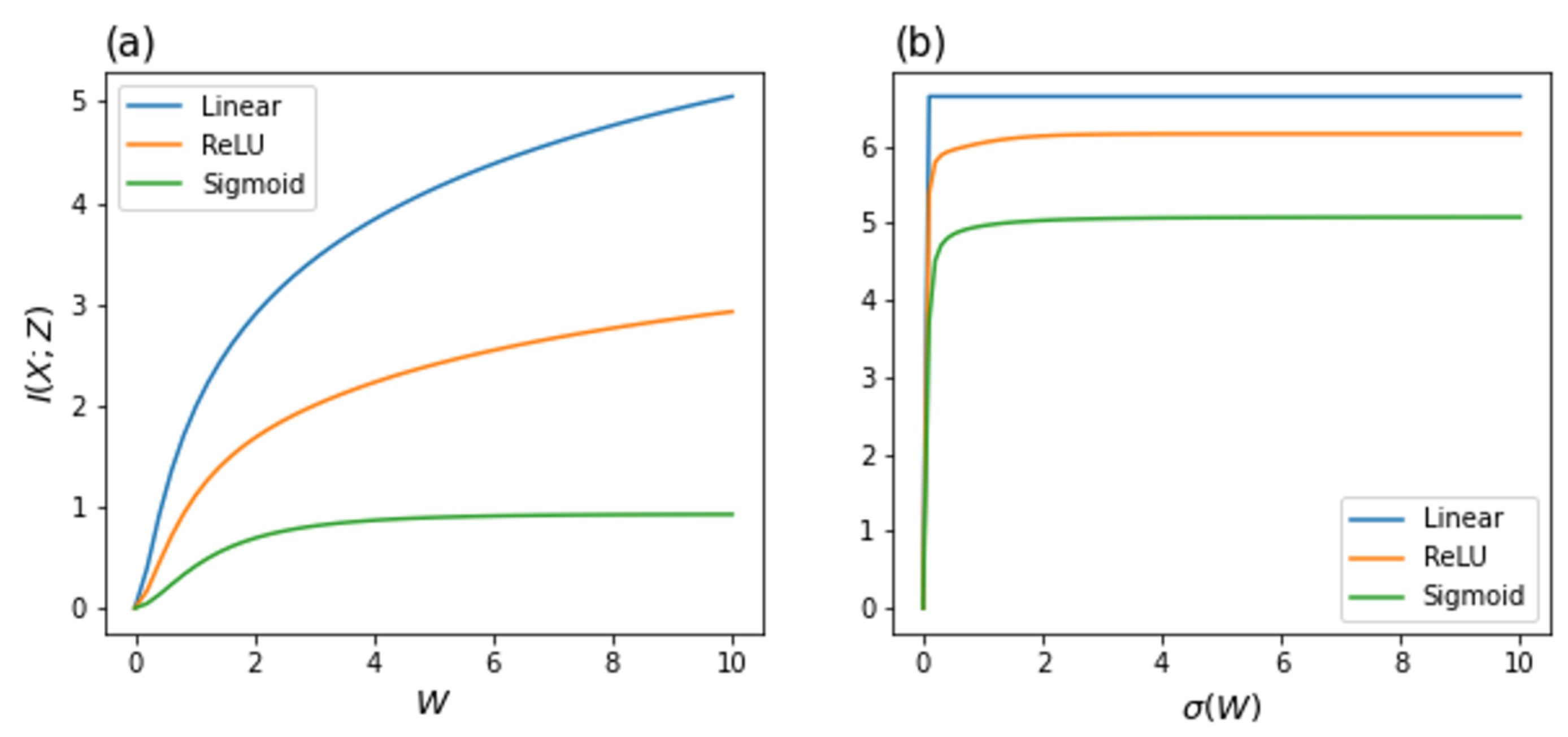
3. Estimation of Mutual Information
4. Results
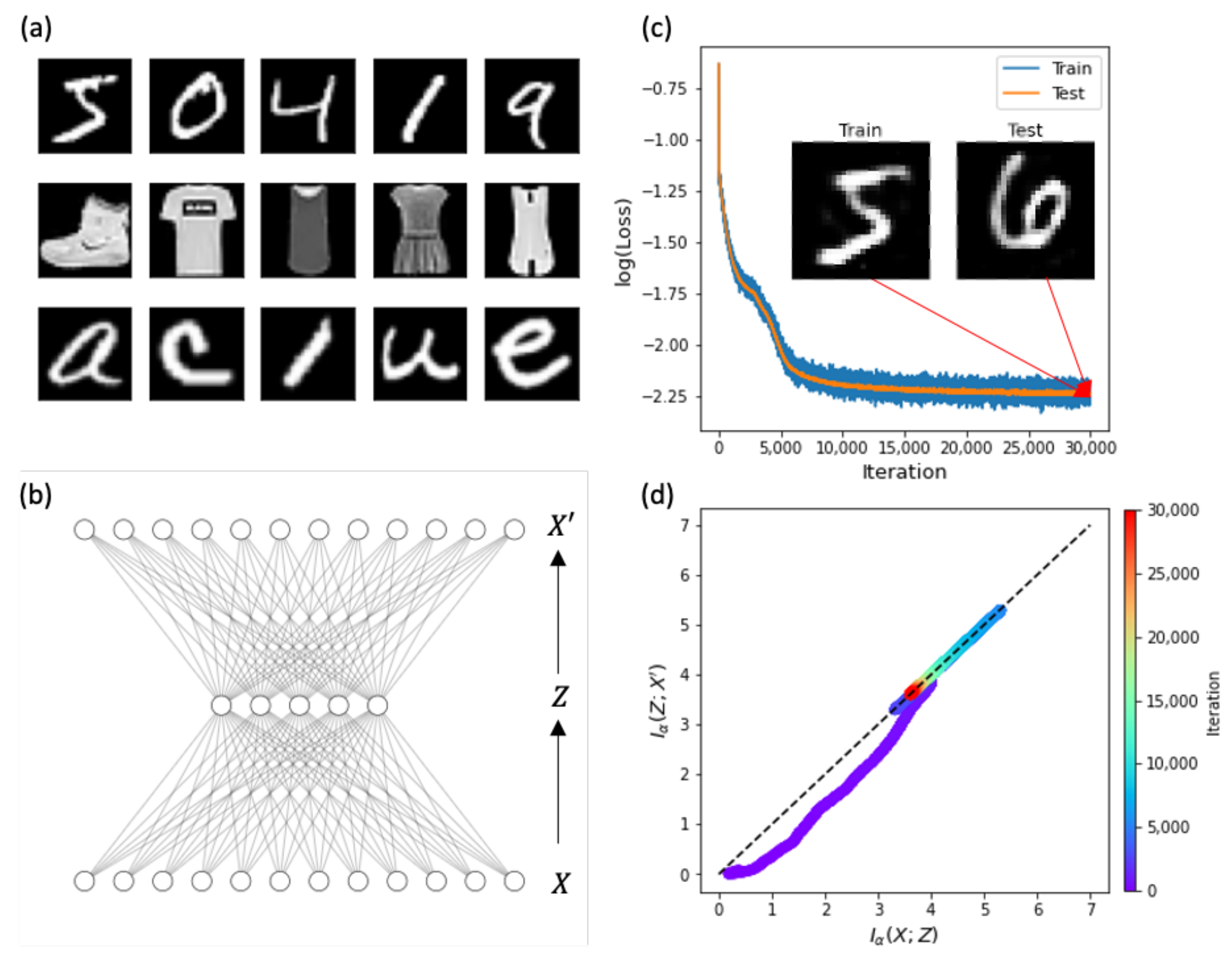
4.1. Information Flows of Autoencoders
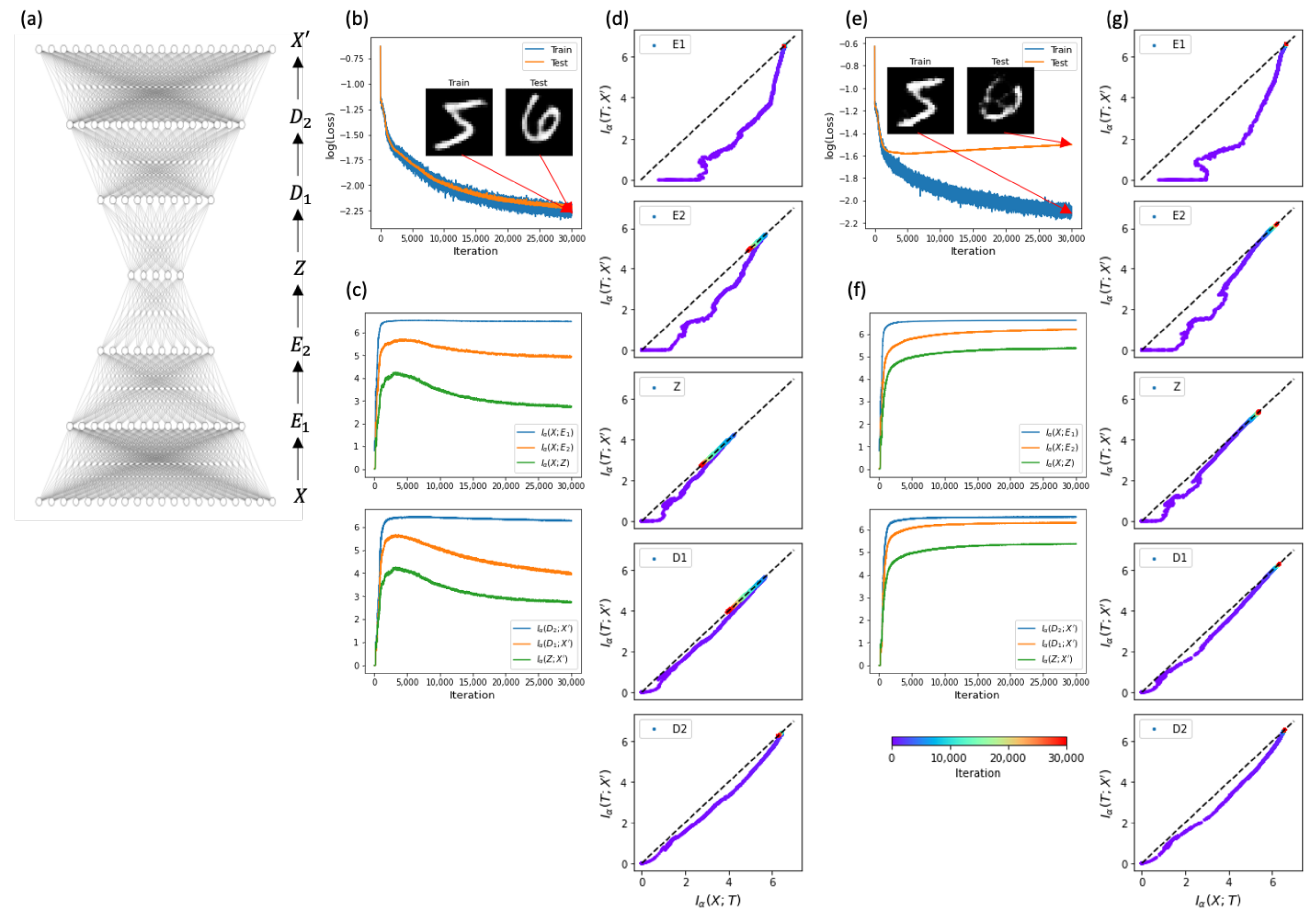
4.2. Sparse Activity and Constrained Weights
4.3. Constrained Latent Space
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| BCE | Binary Cross Entropy |
| CE | Cross Entropy |
| DPI | Data Processing Inequality |
| ELBO | Evidence Lower Bound |
| IB | Information Bottleneck |
| IP | Information Plane |
| KL | Kullback–Leibler |
| LAE | Label Autoencoder |
| MSE | Mean Squared Error |
| PCA | Principal Component Analysis |
| RBMs | Restricted Boltzmann Machines |
| ReLU | Rectified Linear Unit |
| RKHS | Reproducing Kernel Hilbert Space |
| SAE | Sparse Autoencoder |
| TAE | Tied Autoencoder |
| VAE | Variational Autoencoder |
Appendix A. Matrix-Based Kernel Estimator of Mutual Information
Appendix B. LAE: Label Autoencoder

References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Yockey, H.P. Information Theory, Evolution, and the Origin of Life; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- MacKay, D.J.; Mac Kay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. arXiv 2000, arXiv:0004057. [Google Scholar]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef] [Green Version]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Aguerri, I.E.; Zaidi, A. Distributed variational representation learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 120–138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uğur, Y.; Aguerri, I.E.; Zaidi, A. Vector Gaussian CEO problem under logarithmic loss and applications. IEEE Trans. Inf. Theory 2020, 66, 4183–4202. [Google Scholar]
- Zaidi, A.; Estella-Aguerri, I. On the information bottleneck problems: Models, connections, applications and information theoretic views. Entropy 2020, 22, 151. [Google Scholar] [CrossRef] [Green Version]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and information bottleneck principle. In Proceedings of the IEEE Information Theory Workshowp (ITX), Jeju Island, Korea, 11–16 October 2015; pp. 1–5. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Chelombiev, I.; Houghton, C.; O’Donnell, C. Adaptive estimators show information compression in deep neural networks. arXiv 2019, arXiv:1902.09037. [Google Scholar]
- Wickstrøm, K.; Løkse, S.; Kampffmeyer, M.; Yu, S.; Principe, J.; Jenssen, R. Information plane analysis of deep neural networks via matrix-based Renyi’s entropy and tensor kernels. arXiv 2019, arXiv:1909.11396. [Google Scholar]
- Yu, S.; Principe, J.C. Understanding autoencoders with information theoretic concepts. Neural Netw. 2019, 117, 104–123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tapia, N.I.; Estévez, P.A. On the Information Plane of autoencoders. In Proceedings of the International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Bourlard, H.; Kamp, Y. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 1988, 59, 291–294. [Google Scholar] [CrossRef]
- Baldi, P.; Hornik, K. Neural networks and principal component analysis: Learning from examples without local minima. Neural Netw. 1989, 2.1, 53–58. [Google Scholar] [CrossRef]
- Ng, A. Sparse Autoencoder. CS294A Lecture Notes. 2011. Available online: https://web.stanford.edu/class/cs294a/sparseAutoencoder.pdf (accessed on 5 July 2021).
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning a useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic autoencoder for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3174–3183. [Google Scholar]
- Le, L.; Patterson, A.; White, M. Supervised autoencoders: Improving generalization performance with unsupervised regularizers. Adv. Neural Inf. Process. Syst. 2018, 31, 107–117. [Google Scholar]
- Kamyshanska, H.; Memisevic, R. The potential energy of an autoencoder. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1261–1273. [Google Scholar] [CrossRef] [Green Version]
- Kolchinsky, A.; Tracey, B.D. Estimating mixture entropy with pairwise distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef] [Green Version]
- Giraldo, L.G.S.; Rao, M.; Principe, J.C. Measures of entropy form data using infinitely divisible kernels. IEEE Trans. Inf. Theory 2014, 61, 535–548. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Giraldo, L.G.S.; Jenssen, R.; Principe, J.C. Multivariate extension of matrix-based Rényi’s α-order entropy functional. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2960. [Google Scholar] [CrossRef] [PubMed]
- Geiger, B.C. On information plane analyses of neural network classifiers—A review. arXiv 2020, arXiv:2003.09671. [Google Scholar]
- Lee, S.; Jo, J. 2021. Available online: https://github.com/Sungyeop/IPRL (accessed on 16 February 2021).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; 26; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Main Loss | Constraint | Bottleneck Activation |
|---|---|---|---|
| AE | MSE | None | sigmoid |
| SAE | MSE | KL | sigmoid |
| TAE | MSE | sigmoid | |
| VAE | BCE | KL | Gaussian sampling |
| LAE | MSE | CE | softmax |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Jo, J. Information Flows of Diverse Autoencoders. Entropy 2021, 23, 862. https://doi.org/10.3390/e23070862
Lee S, Jo J. Information Flows of Diverse Autoencoders. Entropy. 2021; 23(7):862. https://doi.org/10.3390/e23070862
Chicago/Turabian StyleLee, Sungyeop, and Junghyo Jo. 2021. "Information Flows of Diverse Autoencoders" Entropy 23, no. 7: 862. https://doi.org/10.3390/e23070862
APA StyleLee, S., & Jo, J. (2021). Information Flows of Diverse Autoencoders. Entropy, 23(7), 862. https://doi.org/10.3390/e23070862