1. Introduction
Most, if not all, biometric algorithms have a common thread of steps. The first step is the generation of a secondary data structure that is usually called the template. Then, the identity recognition is done by comparing the templates in question. For example, in the case of human iris recognition, the Gabor sine and cosine transforms are used to generate the templates [
1,
2,
3,
4,
5,
6]; similarly, for animal nose pattern recognition, a similar Gabor transform is used [
7].
Figure 1a shows an example of a human iris template, and
Figure 1b shows that of an animal nose image. Each of these templates is a two-dimensional array of 0 s (black) and 1 s (white). One salient characteristic one can easily discern from these templates is that the 0 s and 1 s are clustered together to form a certain coherent structure that is supposed to be responsible for each individual’s biometric unique pattern.
C.Y. Han and the authors of this paper—Choi, Lee, Wee and Kwon—have studied this clustering phenomenon in light of the Ising model [
8]. In it, they proposed a new Ising model, called the Seeded Ising Model, which is a variant of the Ising model. In this model, certain bits are fixed while other bits are allowed to change according to the Ising Model dynamics. Biometric patterns such as iris and nose pattern are the result of the embryonic development of mesoderm and ectoderm with the initial condition, which is presumed to be random. The Seeded Ising Model proposed in [
8] can be viewed as a mathematical abstraction of the biometric pattern formation in which the randomly chosen seeds represent the random initial condition and the pattern formation is modeled as an Ising model’s dynamic process. They have discovered several interesting results, one of which is what they call the
effective statistical degree of freedom. In particular, they showed, using the Seeded Ising Model dynamic evolution, that if the total number of bits in the template is 2048, one only needs 342 bits as seeds to recover quite faithfully the information content of the original template. They showed this result by devising what they call the reconstructed template, which is an artificial template constructed using only a small number of seeds. This reconstructed template opens a door to a would-be attacker in that only a small portion of template information is needed for the identity fake. The purpose of this paper is to study in detail how such security hole may occur and how one can prevent such a security breach from the point of view of the Seeded Ising Model.
There are several studies addressing the security issues related to the biometric templates. Among the notable are the approaches of cancelable biometrics and the schemes of biometric cryptosystem. In the methods of cancelable biometrics, biometric templates are transformed by one-way function, and the transformed templates are stored and served as a means of identifiers [
9,
10,
11,
12,
13,
14,
15,
16]. (For an extensive survey, see [
17].) With cancelable iris templates [
14,
15,
16], biometric information would be kept securely even when the cancelable iris templates are leaked, since biometric information can not be recovered from cancelable iris templates. In the methods of biometric cryptosystems, transformed biometric templates are combined with cryptographic keys to generate secure templates [
18,
19,
20].
On the other hand, various biometric algorithms using watermarking [
21,
22,
23,
24,
25,
26] have also been proposed to secure biometric data. In the scheme proposed by Abdullah et al. [
26], iris templates are divided into two shares, and one share is stored in the database, whereas the other share is stored on user’s smart card. When it comes to comparing iris templates, two shares are combined into the original iris template beforehand.
As an alternative approach for enhancing the safety and security of biometric data, some national governments and financial institutions are now beginning to devise a new scheme of dividing the biometric templates and storing the divided partial templates in separate locations. The recent initiative of the Korea Financial Telecommunication & Clearing Institute, a governmental agency of Korea, is one such example. However, many fundamental issues concerning this scheme are not fully studied. For example, consider the following: into how many partial templates should the whole template be divided to ensure the integrity if some storage location were to be hacked and the stored partial templates are leaked? Moreover, there are other theoretical and practical issues related to this kind of division scheme.
In this paper, we systematically study the following problems: how to divide a biometric template into several partial templates and how many such partial templates are needed to guarantee the integrity of the system; how to store such partial templates in separate silos and how to match such partial templates in the confine of each silo; and how to combine the matching results of partial templates without requiring the reconstruction of the whole template in a central location. In this paper, we use iris templates as an illustrative example of our methods, but the same can be applied to other biometrics such the animal nose biometrics. For the basics of iris recognition algorithms, refer to [
1,
2,
3,
4,
5,
6]. In particular, as is the standard practice in iris recognition, the iris template is generated by applying the Gabor sine and cosine transforms.
The matching between two templates
A and
B is done by computing the following Hamming distance, which is also called the dissimilarity score:
where
and
are the phase codes of
A and
respectively;
and
are the occlusion masks of
A and
respectively; and ⊗ is the bitwise Boolean Exclusive-OR operator, whereas ∩ is the bitwise AND operator and
is the norm of a bit vector. For more details, refer to [
1,
2,
3,
4,
5,
6].
2. Distributed Template Storage and Matching scheme
The iris template is a two-dimensional array of complex binary numbers. By a complex binary number, we mean a complex number whose real and imaginary parts are 0 s and 1 s. By taking the real and imaginary parts separately, the iris template can be thought of as a pair of two-dimensional array of 0 s and 1 s of the same dimension. These real and imaginary parts come from the Gabor transform. However, for the simplicity of discussion, we take for the template the real part of the two-dimensional array. (There is no preference for the real part, and one may just as well take the imaginary part. It should be pointed out that we assume that real and imaginary parts are used independently in full implementation. In this sense, it is not congruent with the dominant iris2pi like algorithms. However, with slight modification of the algorithm, our proposed method still remains valid.) An auxiliary information that goes with the template is the occlusion mask, which is also a two-dimensional array of 0 s and 1 s of the same dimension. The occlusion mask contains the information on which parts of the iris is occluded by something other than the iris such as eyelids, eyelashes, specular reflection, and so on that act as a hindrance to the correct matching.
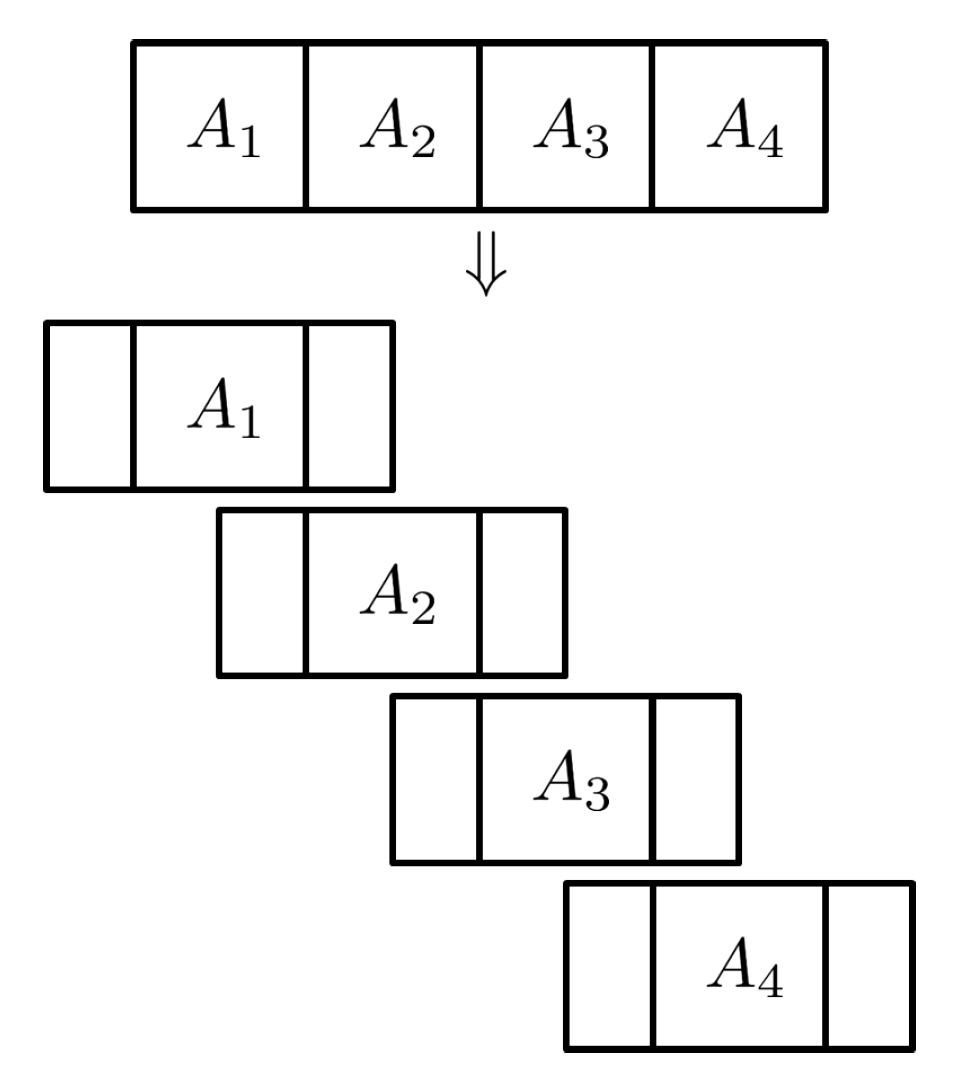
The basic scheme we use in this paper is to divide the template into several smaller units, called
partial templates, and to store and compare them separately. The ways in which the template is divided can be diverse. One way of division is to divide a template into predetermined rectangular blocks, which we call the
block-form division.
Figure 2, on the other hand, shows a different manner in which a template is divided into partial templates. Unlike the block-form division, each partial template in this case is a collection of dispersed entries of the original template. For this reason, we call this way of dividing the template into partial templates a
dispersed-form division. In this case, though, there are two different ways of creating partial templates: one way is to choose for each partial template the entries of the original template that contains only 0 s or 1 s; the other is to choose the entries without regard to its value of 0 s and 1 s. The former is called the
Z-dispersion and the latter
R-dispersion. It should be noted that the occlusion mask is also divided in exactly the same manner as the template is divided into partial templates. Since each partial template is stored separately, we need to keep track of which entry of the original template each element of a partial template corresponds to. In fact, from now on, by a
partial template, we mean the collection of these three ingredients:
divided template, occlusion mask divided accordingly and the information with regard to the entry position on the original template.
2.1. Storage of Partial Templates
Our partial template storage scheme is that after a whole template is divided, each of the resulting partial templates is stored in a different location. The different location could mean physically distant location, or it can be a logically separate location such that even if one location is attacked by a hacker, the other locations still remain relatively safe. The question then is whether the whole identity verification system is still integrally safe even if one partial template is leaked out.
2.2. Comparison
The conventional method of comparison requires comparing two whole templates (e.g., a biometric probe and a biometric reference). However, if the hacker gets hold of the biometric server performing the comparison, he/she can steal such templates. Normally the biometric server performing the comparison and template database are well guarded to prevent such mishaps. Nonetheless, such attacks do happen, and if so, the consequence is dire because biometric data, unlike passwords, cannot be revoked. Such concern has been one of the key reasons why there has been strong resistance against the wide-spread acceptance of biometric national ID. However, with the proliferation of identity theft and fraud, the world is gradually moving toward biometric IDs. The question is how to provide safeguard it in such an environment. Our scheme is designed to address such problem.
There are many national or semi-national entities that are keenly aware of the danger of whole-sale template hacking. For instance, for this reason, Korea Financial Telecommunications & Clearings Institute requires the participating biometric vendors to divide the biometric references and store the divided biometric references in separate locations. Although the divided biometric references are stored in separate locations, when it comes to comparison, they perform the comparison on the whole biometric reference: the central biometric server has to collect the divided biometric references from all of the storage locations and stitch them together to create a whole biometric reference and then do the comparison using the whole biometric reference.
In this paper, we propose a novel scheme that avoids such stitching in a central location. It works as follows. When a biometric probe arrives at the biometric server, it is divided into partial templates with some padding, called a
padded partial template, to accommodate for the rotation angle variation. (
Figure 3 briefly illustrates how to generate padded partial templates from a biometric template.) Then, such a padded partial template is sent to the appropriate storage location. The storage location has its own local biometric server, and this local biometric server compares the sent-down padded partial biometric probe with the partial biometric reference. This comparison process is called a
partial comparison.
Figure 4 shows how partial comparison is done for a rotation angle
For each angle, the resulting partial dissimilarity score is computed and forwarded to the central biometric server. The central biometric server then collects all the partial dissimilarity scores per angle and computes the dissimilarity score of the whole template per angle. The final dissimilarity score is the minimum of the dissimilarity scores taken for all angles. It should be noted that the central biometric server is not actually doing any comparison per se. Rather, it is serving as an arbiter based on the partial dissimilarity scores per angle. It should also be noted that the partial templates once stored in a storage location will never leave that location, and all the computation is done inside that storage location.
When the fractional Hamming distance
is used as a dissimilarity score, the explicit formula for partial comparison is as follows. The dissimilarity score
between a biometric probe
A and a biometric reference
B is given by
where
are rotation angles to be allowed in comparison. Suppose that
denote all the partial biometric templates from a biometric reference
where
m is the number of local biometric servers. Then,
the dissimilarity score between
A and
B with rotation angle
is computed by
where
is the partial dissimilarity score between the padded partial template from
A and the partial biometric reference
with angle
computed at the
i-th local biometric server,
is the number of bits whose masking bit value is 1 in both of the padded partial template and the partial biometric reference with angle
It should also be noted that the padding and unpadding decision can be reversed. Specifically, one may store padded partial templates in the storage location and create unpadded partial templates from the biometric probe and send down such unpadded template to each storage location. The rest of the comparison proceeds the same way. Which one is more preferable depends on the trade-off between storage efficiency and the safety of the biometric probe.
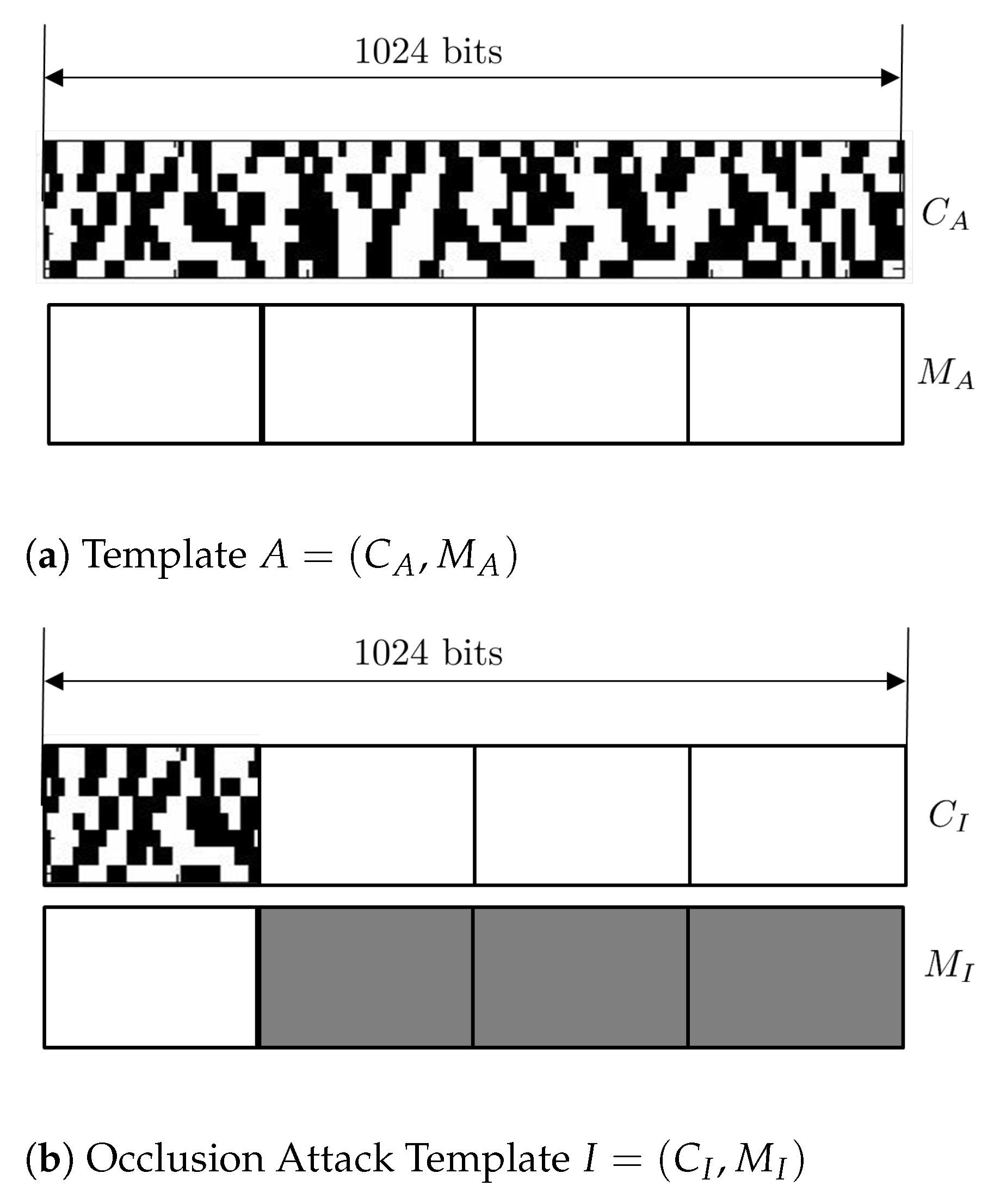
3. Occlusion Attack
Suppose a partial biometric reference is leaked out from a system with distributed storages of divided partial biometric references as this paper is proposing. Then, the most simple attack with the leaked partial biometric reference would be the so-called “occlusion attack” by which one may submit to the iris recognition system the leaked partial biometric reference with the intentionally modified occlusion mask of which every bit value is marked as a damaged or occluded bit; i.e., the value of 0 except the bits contained in the leaked partial biometric reference. If the partial template
p of a full template
x is leaked out and the biometric reference
x still remains in the system, then this occlusion attack would be always successful since the Hamming distance between
x and
p with the modified mask would be zero. Even if the template
x is replaced by another template
of the same person, this occlusion attack would still be successful with high probability, since the Hamming distance between
and
p with the modified occlusion mask is very close to the Hamming distance between
x and
which would be less than the given threshold of the system with very high probability. Thus, the distributed storage of templates alone does not provide the necessary safety measure when any partial biometric reference is leaked out. To protect the system against this occlusion attack, the system must utilize a new distance measure that penalizes the occlusion bits. For this purpose, we introduce a novel distance, the modified fractional Hamming distance, or simply the modified Hamming distance
given by
with the consideration of how many valid (i.e., mask bit value 1) bits two templates
A and
B have in common. In the definition of the modified fractional Hamming distance
∼ is the bitwise NOT operator, and
N denotes the number of bits in a phase code. The basic idea of this new distance is to give the dissimilarity score of 0.5 for each invalid (i.e., mask bit value 0) bit.
The modified Hamming distance
is related with the Hamming distance
through the equation:
where
is the number of bits that are actually compared between two templates
A and
For an illustration of how differently
and
behave, we suppose that
, where templates
A and
of length 1024 have no occlusion at all, and a partial template
whose length is 256, of
is leaked out. In an occlusion attack, an intruder template
from the leaked partial template
p is constructed with the mask
, whose bit values are 0 except where phase bit is available. For schematic diagrams of templates
A and
I, see
Figure 5. Then, it is on the average that
This means that the Hamming distance of the intruder template is the same as that of the original template; hence, the occlusion attack should be successful. On the other hand,
This higher number implies that the occlusion attack is more likely to fail (see Table 3). Thus, an occlusion attack would be successful with high probability when the fractional Hamming distance is employed, while with the modified Hamming distance, it is much less likely to succeed.
We shoud note that some commercial implementations of iris comparison enforce a minimum number of unmasked bits in the code in order to make a recognition decision. Such a requirement on the number of available blocks of iris codes can be a practical remedy to the occlusion attack.
4. Seeded Ising Model and Intruder Template
Besides occlusion attacks, the next plausible attack would be the reconstruction of iris templates based on a leaked partial biometric reference, so that the reconstructed templates are very close to real human templates of the same person whose partial biometric reference is leaked. For such attacks to succeed, one may need a model of human iris templates, which explains how human iris templates would be generated. Han et al. [
8] investigated the statistical natures of human iris templates and proposed the
Seeded Ising Model. This is a variant of the Ising model [
27] where bits in given locations stay fixed throughout the Ising model dynamic evolution. With this Seeded Ising Model, a full template can be reconstructed from partial information of the whole template. In contrast to iris image reconstruction from full biometric templates [
28], iris templates, not iris images, can be reconstructed through the Seeded Ising Model from partial template information. In the subsequent paragraph, we briefly restate the Seeded Ising Model proposed in [
8] to fix notational conventions for template representation and template reconstruction.
First, a real or imaginary part of the human iris template is modeled by a binary random field
x on an
regular lattice. Although each bit of iris template is binary with value 0 or
when it comes to the Seeded Ising Model presentation, we use the convention that each bit has a value
or
instead. Therefore according to this convention, 0 in an iris template is replaced with
for the Ising model and vice versa. With this notational convention, the space of all iris templates is denoted by
To simplify the representation of the position in a regular lattice, we use the univariate indexing scheme by utilizing a mapping, for example, With the univariate indexing scheme, the space of iris templates can be simply written by
For a given subset a map is regarded as “partial template data” specifying the value of the template at positions in Therefore, the set of templates that have the same partial template data as s is denoted by
For a given seed
we model the probability distribution
on the space of
by
where
means the positions
i and
j are adjacent to each other; thus, the sum is done over all adjacent positions;
is a constant parameter for the adjacent positions
i and
j; and
Z is the partition function given by
Since we use different
depending on whether
i and
j are horizontally or vertically adjacent to each other, we say the relation
means that two positions
i and
j are vertically adjacent to each other, and the relation
that two positions
i and
j are horizontally adjacent to each other with circular-end conditions employed for each row of a template. Note that we think of the first column and the last column in a regular lattice to be adjacent to each other with circular-end conditions employed. In this paper, we set
when two positions
i and
j are adjacent vertically, and
when two positions
i and
j are adjacent horizontally. With these conventions,
can be written as
This probabilistic model of the space of templates with seed s is called the Seeded Ising Model.
In [
8], the best parameter of
was found to be
and we use the same value for the parameter
J in this paper as well.
We will now discuss how to reconstruct iris templates when only a partial template
s is available. In this paper, the templates reconstructed from a partial template will be called
Intruder Templates since we are supposing the case in which the partial template is leaked out, and reconstructed templates are used to intrude into the iris recognition system. By the partial template
we mean partial information of a template
which tells us the locations of available bit values of
s in
x as well as bit values of
Thus, we can treat a partial template
s as a function
, where
is the set of locations on which bit values of
s are located. Then, by treating a given partial template
s as a seed, we can now model the probabilistic space of iris templates that have the same partial template information as
s with the Seeded Ising Model. Thus, we may reconstruct intruder templates from the partial template
s by sampling iris templates from the space
via the Metropolis algorithm [
29] adapted for the Seeded Ising Model as stated in [
8].
4.1. Sampling via Metropolis Algorithm
First note that, under the Seeded Ising Model, the probability
is proportional to
where
denotes the number of disagreeing vertical edges in template
x and
denotes the number of disagreeing horizontal edges. Thus,
is also proportional to the un-normalized probability
, which is given by
Let a template
be represented by a vector
Then, the Metropolis algorithm modified for our context would have the following steps:
Start with an initial template
Select randomly a
non-seed indexPropose a new template
as
Define the proposal probability of
moving from a template
t to a template
by
Then, accept
with probability
where
is the un-normalized probability of
Since
differ in exactly one non-seed index
k by the construction of
from
we thus get
The ratio in
is
where
is the number of disagreeing vertical edges between the index
k and its vertically adjacent indices in template
and
is the number of agreeing vertical edges for
x at
and
are defined similarly.
Generate a uniform random number and accept as the current template if Otherwise, keep x as the current template and go to Step 2.
4.2. Generating Intruder Templates
The procedure for obtaining an intruder template in [
8] is briefly summarized here: Let
be an initial template for the Metropolis algorithm, and
be the template obtained after
n iterations by the Metropolis algorithm. Then, for predetermined positive integers
L and
’s for
with the condition that
we define the intruder template
whose value
at position
i is given by the following:
where
denotes the vector of
Note that in the above procedure, we need a partial template
s initially, and the resulting templates of
or
naturally depend on
To denote this dependency more clearly, we may use the notations of
or
in the subsequent discussion.
For real human iris templates, it is observed that the positions of bits whose values are 0 are randomly distributed over a template, and thereby the number of 0s in a template is about 50% of the total number of bits in the template. For this reason, the number of 0s in a partial template s is also about 50% of the total number of bits in s when s is obtained by the division methods of block-form or R-dispersion. This property still remains true for intruder templates if the partial template s has this property. However, intruder templates do not have such a property if almost all bit values of the partial template s are 0s (or 1s). Thus, we need additional treatment to generate reasonably realistic intruder templates when a partial template is obtained by the method of Z-Dispersion.
Let be a partial template obtained by the method of Z-Dispersion. To generate reasonably good intruder templates, first we randomly select a subset so that and where denotes the cardinality of a set With this s is extended to a partial template so that the restriction of on I is identical with s, i.e., and the number of bits whose values are 0s is 50% of This new partial template is called a complementary partial template and is denoted by Then, intruder templates are generated from this complementary partial template via the same procedure as the above. By this process, we can obtain intruder templates or To simplify these notations, we denote intruder templates by or rather than or in the case where s is a partial template obtained by Z-Dispersion.
In the above procedure, we randomly select a complementary partial template
to generate intruder templates. Thus, intruder templates
or
clearly depend on
, which may contain wrong information about the real template from which
s came from. To minimize this effect, we may apply again the idea of bagging (
bootstrap
aggregat
ing) [
30] in machine learning. In other words, we randomly select multiple complementary partial templates
rather than just one complementary partial template. Then, we define a intruder template
whose value at position
i is given by
where
k is the number of multiple complementary partial templates. Similarly,
the value of the intruder template
at position
i, is also defined by
where
denotes the vector of
5. Intruder Attack Analysis
To analyze the integrity of the distributed template storage and comparison schemes depending on the division schemes and/or the size of partial templates, we performed statistical experiments. In the experiments, we used the algorithm developed by [
31] for iris template generation with slight modification of template size. The size of iris templates generated by the modified algorithm is
and the size of the real (or imaginary) part of the templates is
The dataset used in this paper for statistical experiments consists of reasonably good images selected from ICE2005 Dataset, which was used for Iris Challenge Evaluation 2005 [
32]. Since ICE2005 Dataset contains highly occluded images, we only selected images with a good enough iris pattern to minimize any side effects.
Table 1 shows basic statistics of the ICE2005 Dataset, and
Table 2 shows basic statistics of the dataset used in this paper.
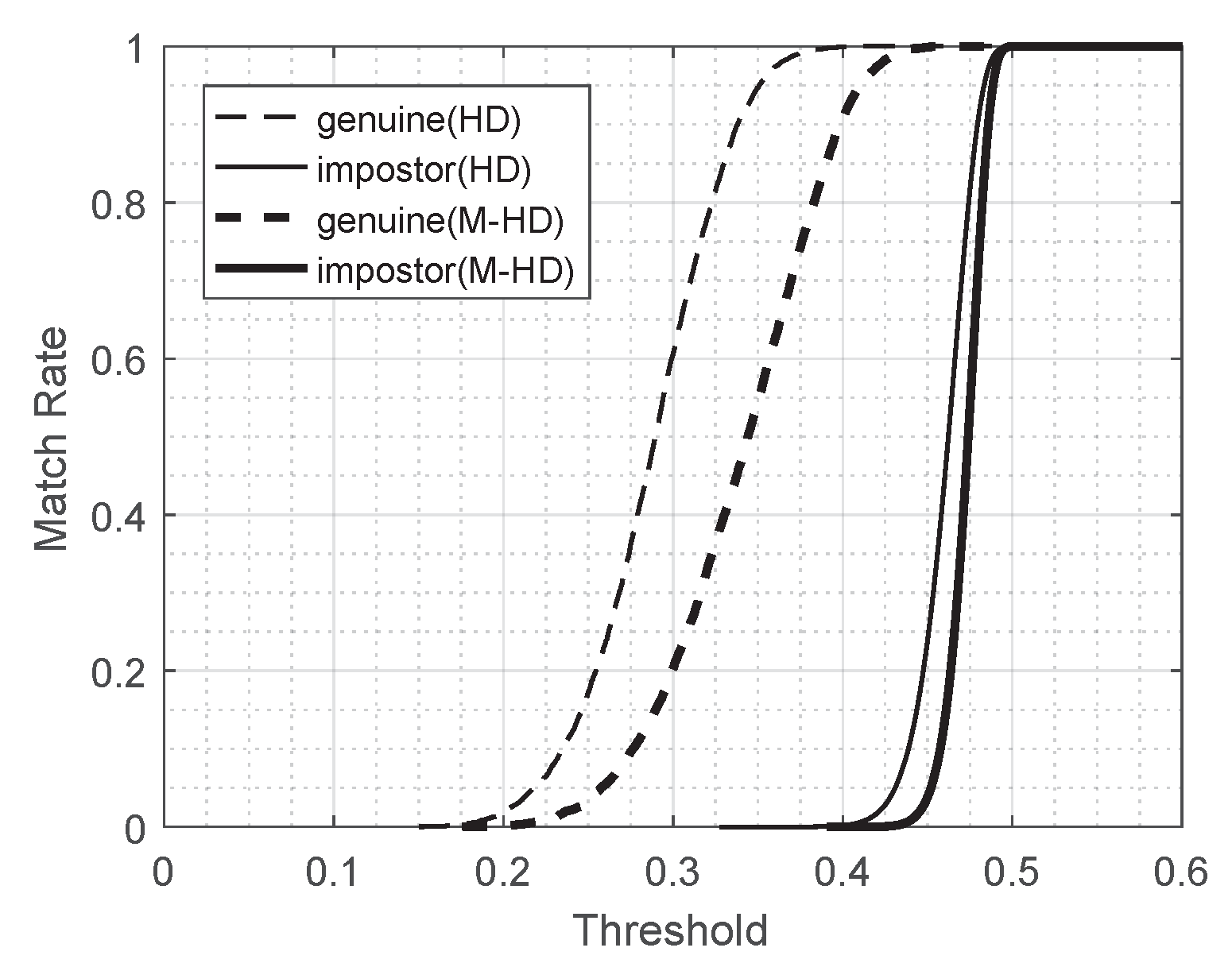
Figure 6 shows the comparison results of the dataset for the two dissimilarity metrics: the Hamming distance and the modified Hamming distance.
From the distributions in
Figure 6, we may observe that the most genuine comparison has a Hamming distance less than
and most impostor comparison has a Hamming distance greater than
Therefore, roughly speaking, the best threshold that distinguishes whether a given pair of iris templates comes from the same person or not would be around
when Hamming distance is used as a metric. However, when the modified Hamming distance is used, the best threshold would be a little bigger since the modified Hamming distance is higher than the Hamming distance when the Hamming distance is less than 0.5.
Table 3 shows the False Match Rate and False Non-Match Rate when Hamming distance (HD) and modified Hamming distance (M-HD) are used as a metric for each value of thresholds
and
From the table, we may choose the threshold value of 0.431 for the modified Hamming distance as a metric as a comparable threshold for the threshold value of 0.4 for the Hamming distance as a metric. For reference,
Table 3 also shows the Equal Error Rate (EER) for HD and M-HD.
With a match rate
defined as the ratio of the number of comparison trials with Hamming distance (or modified Hamming distance) less than or equal to
for a given collection of
M comparison scores
the differences in the characteristics of the Hamming distance and the modified Hamming distance are shown as
Figure 7. In fact, the match rate
is the empirical cumulative distribution of a collection of comparison scores.
Figure 7 shows match rate curves for several different collections of comparison scores. The thin and thick dashed curves represent the match rates for genuine comparisons of 948 images with the Hamming distance and the modified Hamming distance used, respectively. The thin and thick solid curves represent the match rates for impostor comparisons of the same dataset with the Hamming distance and the modified Hamming distance used, respectively. (See
Table 2 for the details of the number of comparisons.) Note that dashed curves represent the positive match rates, and solid curves show the false match rates.
For the statistical experiments, 948 templates from the 948 images are divided into partial templates by each scheme of three division methods of block-form division (B), R-dispersion (R-D), and Z-dispersion (Z-D), with three different sizes of partial templates: 1/4, 1/8, and 1/16 of the undivided full template size. For each case of division method and the size of partial templates, one partial template is selected for each full template, and 10 intruder templates (or ) and 10 intruder templates (or ) are generated. For the case of Z-dispersion division, 100 intruder templates of and 100 of are also additionally generated for each partial template. In the generation of intruder templates, parameters of used are as follows: and
In the experiments, we suppose two different scenarios: one is the case where a partial template
s of a full template
x is leaked, and
x is not replaced in the iris recognition system; thus intruder templates reconstructed from
s are compared with
The other scenario is the case where a partial template
s of a full template
x is leaked, and
x is replaced by another template
of the same person. Thus, intruder templates reconstructed from
s are compared with
The first scenario is simply denoted by
Leaked Template Not Replaced, and the second scenario by
Leaked Template Replaced. In order to perform statistical experiments for the scenario of Leaked Template Not Replaced, each intruder template from a partial template
s is compared with the original template
x from which
s is taken, and Hamming distance (HD) and the modified Hamming distance (M-HD) are computed for the dissimilarity scores. This distance score is called intruder distance score. For the other scenario of Leaked Template Replaced, each intruder template from
s is compared with a template
, which is another template of the same person to whom
x belongs.
Table 4 shows the numbers of intruder comparisons for each case. To compare the safety of distributed template storage and comparison schemes when partial templates are leaked, we define the Intruder Match Rate, IMR(
d) as the match rate
of the collection of intruder distance scores for a threshold
Table 5 shows intruder match rates in all cases with threshold 0.4. For each case, IMR(
d) is computed for the Hamming distances (HD) of intruder comparison. In addition, IMR(
d) for the modified Hamming distances (M-HD) of intruder comparison is computed.
Table 6 also shows intruder match rates with threshold 0.431.
From the intruders’ point of view, they will try to intrude into an iris recognition system using reconstructed iris templates with the highest IMR when a partial template
s is available. Thus, for the division methods of block-form and R-dispersion, intruders will try to intrude into the system with
and with
for the division method of Z-dispersion. Thus, the safety of distributed template storage and comparison schemes may be measured by the IMR of
or
: the lower the IMR is, the safer the system is. For a given scheme of dividing a full template into partial templates including the method of division and the size of partial templates, the IMR of
or
is defined as the
risk of leakage for the scheme. Except for the scheme
B16 of the block-form, division in which the full template is divided into 16 partial templates, the risk of leakage is more than 3%, which is not acceptable for systems of high security, when the system uses Hamming distance as a metric with the threshold of 0.4 and a leaked template is not replaced in the system. For the scheme of B16, the same risk of leakage is 0.0527%, which is less than 0.1766% of False Match Rate in
Table 3. This implies that the system of distributed template storage and comparison with the scheme of B16 is safer than most iris recognition systems, even when a partial template is leaked and it still remains in the system in terms of Hamming distance with the threshold of 0.4.
However, the system with Hamming distance as a metric is vulnerable to the occlusion attack as stated in
Section 3. For this reason, we suggest the modified Hamming distance be used in the system of high security. When using the modified Hamming distance in the system, the threshold should be adapted properly to maintain the system’s operating characteristics, for example, the False Match Rate. From
Table 3, the threshold of 0.431 for the modified Hamming distance would be equivalent to the threshold of 0.4 for Hamming distance for the dataset we used in terms of FMR.
Table 6 shows that with this threshold value and the modified Hamming distance, the scheme of B16 is still found to be as secure as usual iris recognition systems with the same metric and the same threshold even when a leaked partial template is not replaced.
This observation remains true for different values of threshold when it is in a reasonably good range.
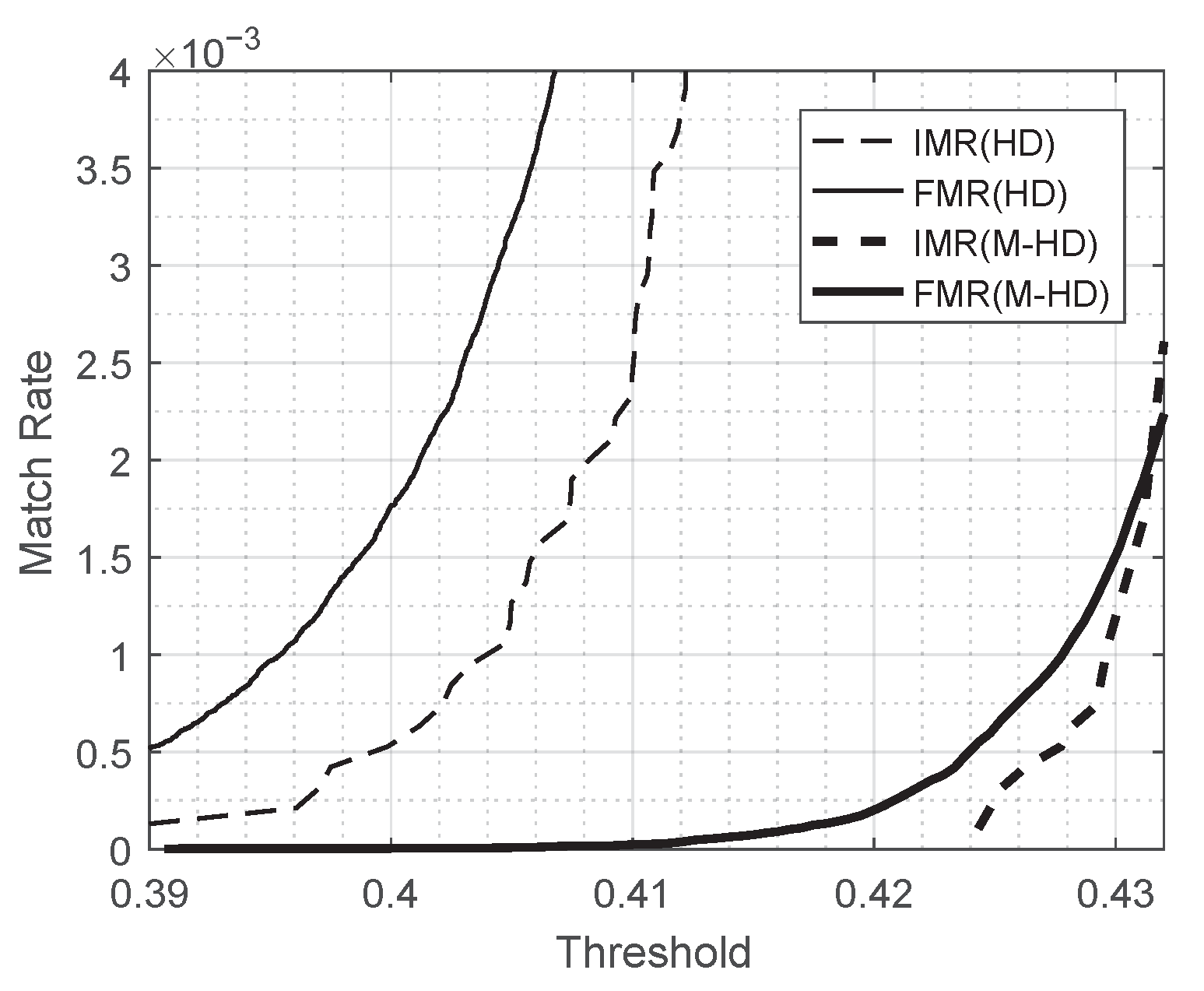
Figure 8 shows the risk of leakage for the scheme B16 for different values of threshold compared with FMR at the corresponding threshold. In
Figure 8, the thin and thick solid curves represent FMR measured by Hamming distance and FMR by the modified Hamming distance, respectively, and the thin and thick dashed curves represent the risk of leakage for the scheme B16 with Hamming distance and with the modified Hamming distance used, respectively, in the scenario of Leaked Template Not Replaced. FMR and the risk of leakage looks comparable for all values of threshold for both of metrics, Hamming distance and the modified Hamming distance.
Figure 9 is the magnified figure of
Figure 8 around the range of threshold
It shows that the risk of leakage for the scheme of B16 is less than or comparable with FMR for all values in the range of threshold.
6. Conclusions and Policy Recommendations
In this paper, we study the safety issues concerning the schemes of distributed iris template storage and comparison.
In particular, we investigate the risk of leakage for several schemes: all the combinations of division methods including block-form division, R-dispersion, Z-dispersion. and the sizes of subtemplates including 1/4, 1/8, and 1/16. To analyze the safety issues that arise when a partial template is leaked, multiple methods of generating intruder templates from a leaked partial template are proposed based on the Seeded Ising Model, and Intruder Match Rates are measured for every case of schemes in two different scenarios: Leaked Template Not Replaced and Leaked Template Replaced. Statistical experiments show that the scheme of B16 is as secure as most iris recognition systems with no leaked templates even when partial templates leaked in one location are not replaced.
We also propose the modified Hamming distance against the occlusion attack. From the analysis of our experiments, the system of distributed template storage and comparison is recommended to use the scheme of B16 with the modified Hamming distance as a metric.
There have been many studies including the approaches of cancelable biometric and the methods of biometric cryptosystem to resolve the security issues of biometric systems. Our methods and the current state-of-the-art schemes are not in any way contradictory or in competition, but rather complementary. In other words, the methods of cancelable biometrics or the biometric cryptosystems can be applied to our distributed template storage and comparison to further enhance its security.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}