1. Introduction
Building models from data is at the core of both science and engineering applications. The search for good models requires a performance measure that scores how well a particular model
m captures the hidden patterns in a data set
D. In a Bayesian framework, that measure is the
Bayesian evidence , i.e., the probability that model
m would generate
D if we were to draw data from
m. The art of modeling is then the iterative process of proposing new model specifications, evaluating the evidence for each model and retaining the model with the most evidence [
1].
Unfortunately, Bayesian evidence is intractable for most interesting models. A popular solution to evidence evaluation is provided by
variational
inference, which describes the process of Bayesian evidence evaluation as a (free energy) minimization process, since the variational free energy (VFE) is a tractable upper bound on Bayesian (negative log-)evidence [
2]. In practice, the model development process then consists of proposing various candidate models, minimizing VFE for each model and selecting the model with the lowest minimized VFE.
The difference between VFE and negative log-evidence (NLE) is equal to the Kullback–Leibler divergence (KLD) [
3] from the (perfect) Bayesian posterior distribution to the variational distribution for the latent variables in the model. The KLD can be interpreted as the cost of conducting variational rather than Bayesian inference. Perfect (Bayesian) inference would lead to zero inference costs (KLD
), and the KLD increases as the variational posterior diverges further from the Bayesian posterior. As a result, model development in a variational inference context is a balancing act, where we search for models that have both large amounts of evidence for the data and small inference costs (small KLD). In other words, in a variational inference context, the researcher has two knobs to tune models. The first knob alters the model specification, which affects model evidence. The second knob relates to constraining the search space for the variational posterior, which may affect the inference costs.
In this paper, we are concerned with developing algorithms for tuning the second knob. How do we constrain the range of variational posteriors so as to make variational inferences both tractable and accurate (resulting in low KLD)? We present our framework in the context of a (Forney-style) factor graph representation of the model [
4,
5]. In that context, variational inference can be understood as an automatable and efficient message passing-based inference procedure [
6,
7,
8].
Traditional constraints include mean-field [
6] and Bethe approximations [
9,
10]. However, more recently it has become clear how alternative local constraints, such as posterior factorization [
11], expectation and chance constraints [
12,
13], and local Laplace approximation [
14], may impact both tractability and inference accuracy, and thereby potentially lead to lower VFE. The main contribution of the current work lies in unifying the various ideas on local posterior constraints into a principled method for deriving variational message passing-based inference algorithms. The proposed method derives existing message passing algorithms, but also supports the development of new message passing variants.
Section 2 reviews Forney-style Factor Graphs (FFGs) and variational inference by minimizing the Bethe Free Energy (BFE). This review is continued in
Section 3, where we discuss BFE optimization from a Lagrangian optimization viewpoint. In
Appendix A, we include an example to illustrate that the Bayes rule can be derived from Lagrangian optimization with data constraints. Our main contribution lies in
Section 4, which provides a rigorous treatment of the effects of imposing local constraints on the BFE and the resulting message update rules. We build upon several previous works that describe how manipulation of (local) constraints and variational objectives can be employed to improve variational approximations in the context of message passing. For example, ref. [
12] shows how inference algorithms can be unified in terms of hybrid message passing by Lagrangian constraint manipulation. We extend this view by bringing form (
Section 4.2) and factorization constraints (
Section 4.1) into a constrained optimization framework. In [
15], a high-level recipe for generating message passing algorithms from divergence measures is described. We apply their general recipe in the current work, where we adhere to the view on local stationary points for region-based approximations on general graphs [
16]. In
Appendix B, we also show that locally stationary solutions are also the global stationary solutions. In
Section 5, we develop an algorithm for VFE evaluation in an FFG. In previous work, ref. [
17] describes a factor softening approach to evaluate the VFE for models with deterministic factors. We extend this work in
Section 5, and show how to avoid factor softening for both free energy evaluation and inference of posteriors. We show an example of how to compute VFE for a deterministic node in
Appendix C. A more detailed comparison to related work is given in
Section 7.
In the literature, proofs and descriptions of message passing-based inference algorithms are scattered across multiple papers and varying graphical representations, including Bayesian networks [
6,
18], Markov random fields [
16], bi-partite (Tanner) factor graphs [
12,
17,
19] and Forney-style factor graphs (FFGs) [
5,
11]. In
Appendix D, we provide first-principle proofs for a large collection of familiar message passing algorithms in the context of Forney-style factor graphs, which is the preferred framework in the information and communication theory communities [
4,
20].
2. Factor Graphs and the Bethe Free Energy
2.1. Terminated Forney-Style Factor Graphs
A Forney-style factor graph (FFG) is an undirected graph with nodes and edges . We denote the neighboring edges of a node by . Vice versa, for an edge , the notation collects all neighboring nodes. As a notational convention, we index nodes by and edges by , unless stated otherwise. We will mainly use a and i as summation indices and use the other indices to refer to a node or edge of interest.
In this paper, we will frequently refer to the notion of a subgraph. We define an edge-induced subgraph by , and a node-induced subgraph by . Furthermore, we denote a local subgraph by , which collects all local nodes and edges around i and a, respectively.
An FFG can be used to represent a factorized function,
where
collects the argument variables of factor
. We assumed that all the factors are positive. In an FFG, a node
corresponds to a factor
, and the neighboring edges
correspond to the variables
that are the arguments of
.
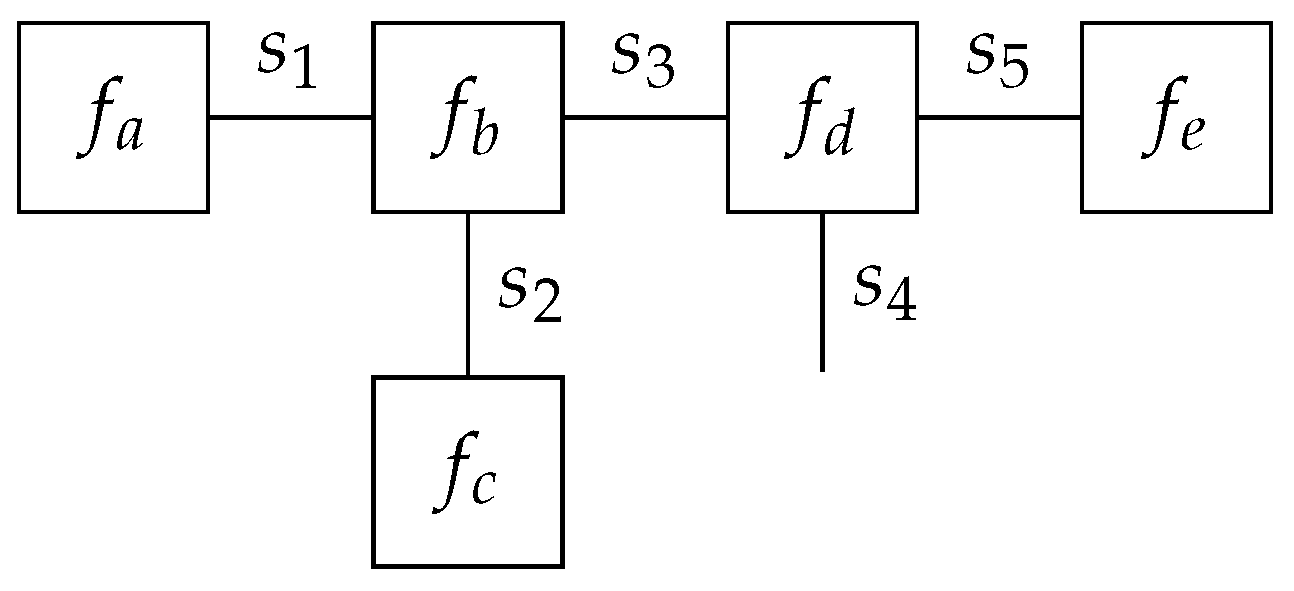
As an example model, the following factorization (
2), the corresponding FFG of which is shown in
Figure 1.
The FFG of
Figure 1 consists of five nodes
, as annotated by their corresponding factor functions, and five edges
as annotated by their corresponding variables. An edge that connects to only one node (e.g., the edge for
) is called a half-edge. In this example, the neighborhood
and
.
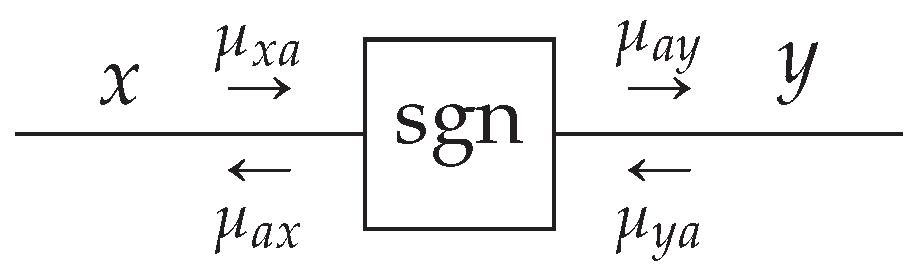
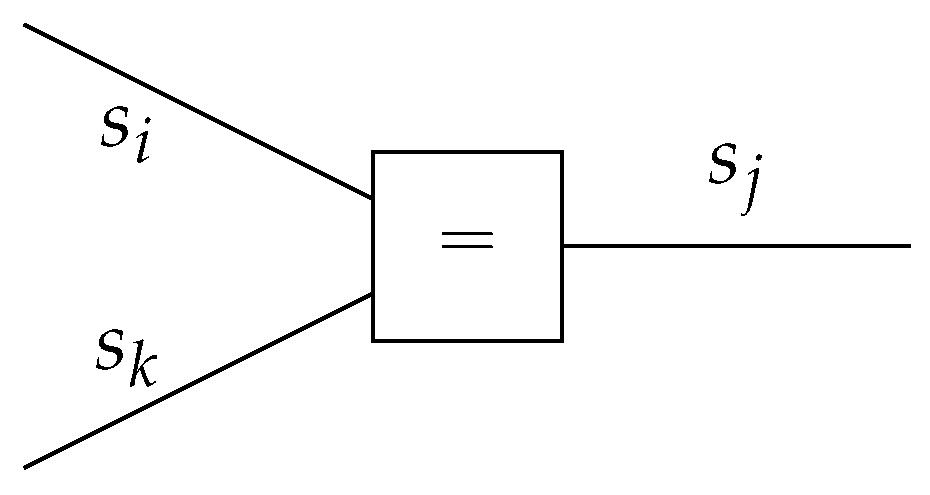
In the FFG representation, a node can be connected to an arbitrary number of edges, while an edge can only be connected to at most two nodes. Therefore, FFGs often contain “equality nodes” that constrain connected edges to carry identical beliefs, with the implication that these beliefs can be made available to more than two factors. An equality node has the factor function
for which the node-induced subgraph
is drawn in
Figure 2.
If every edge in the FFG has exactly two connected nodes (including equality nodes), then we designate the graph as a terminated FFG (TFFG). Since multiplication of a function by 1 does not alter the function, any FFG can be terminated by connecting any half-edge i to a node a that represents the unity factor .
In
Section 4.2 we discuss form constraints on posterior distributions. If such a constraint takes on a Dirac-delta functional form, then we visualize the constraint on the FFG by a small circle in the middle of the edge. For example, the small shaded circle in Figure 11 indicates that the variable has been observed. In
Section 4.3.2 we consider form constraints in the context of optimization, in which case the circle annotation will be left open (see, e.g., Figure 14).
2.2. Variational Free Energy
Given a model
and a (normalized) probability distribution
, we can define a Variational Free Energy (VFE) functional as
Variational inference is concerned with finding solutions to the minimization problem
where
imposes some constraints on
q.
If
q is unconstrained, then the optimal solution is obtained for
, with
being the exact posterior, and
a normalizing constant that is commonly referred to as the evidence. The minimum value of the free energy then follows as the negative log-evidence (NLE),
which is also known as the surprisal. The NLE can be interpreted as a measure of model performance, where low NLE is preferred.
As an unconstrained search space for
q grows exponentially with the number of variables, the optimization of (
5) quickly becomes intractable beyond the most basic models. Therefore, constraints and approximations to the variational free energy (
4) are often utilized. As a result, the
constrained
variational free energy with
bounds the NLE by
where the latter term expresses the divergence from the (intractable) exact solution to the optimal variational belief.
In practice, the functional form of
is often parameterized, such that gradients of
F can be derived w.r.t. the parameters
. This effectively converts the variational optimization of
to a parametric optimization of
as a function of
. This problem can then be solved by a (stochastic) gradient descent procedure [
21,
22].
In the context of variational calculus, while form constraints may lead to interesting properties (see
Section 4.2), they are generally not required. Interestingly, in a variational optimization context, the functional form of
q is often not an
assumption, but rather a
result of optimization (see
Section 4.3.1). An example of variational inference is provided in
Appendix A.
2.3. Bethe Free Energy
The Bethe approximation enjoys a unique place in the landscape of
, because the Bethe free energy (BFE) defines the fundamental objective of the celebrated belief propagation (BP) algorithm [
17,
23]. The origin of the Bethe approximation is rooted in tree-like approximations to subgraphs (possibly containing cycles) by enforcing local consistency conditions on the beliefs associated with edges and nodes [
24].
Given a TFFG
for a factorized function
(
1), the Bethe free energy (BFE) is defined as [
25]:
such that the factorized beliefs
satisfy the following constraints:
Together, the normalization constraint (
9a) and marginalization constraint (9b) imply that the edge marginals are also normalized:
The Bethe free energy (
7) includes a local free energy term
for each node
, and an entropy term
for each edge
. Note that the local free energy also depends on the node function
, as specified in the factorization of
f (
1), whereas the entropy only depends on the local belief
.
The Bethe factorization (
8) and constraints are summarized by the local polytope [
26]
which defines the constrained search space for the factorized variational distribution (
8).
2.4. Problem Statement
In this paper, the problem is to find the beliefs in the local polytope that minimize the Bethe free energy
where
q is defined by (
8), and where
offers a shorthand notation for optimizing over the individual beliefs in the local polytope. In the following sections, we will follow the Lagrangian optimization approach to derive various message passing-based inference algorithms.
2.5. Sketch of Solution Approach
The problem statement of
Section 2.4 defines a global minimization of the beliefs in the Bethe factorization. Instead of solving the global optimization problem directly, we employ the factorization of the variational posterior and local polytope to subdivide the global problem statement in multiple
interdependent
local objectives.
From the BFE objective (
12) and local polytope of (
11), we can construct the Lagrangian
where the Lagrange multipliers
,
and
enforce the normalization and marginalization constraints of (9). It can be seen that this Lagrangian contains local beliefs
and
, which are coupled through the
Lagrange multipliers. The Lagrange multipliers
are doubly indexed, because there is a multiplier associated with each marginalization constraint. The Lagrangian method then converts a constrained optimization problem of
to an unconstrained optimization problem of
. The total variation of the Lagrangian (
13) can then be approached from the perspective of variations of the individual (coupled) local beliefs.
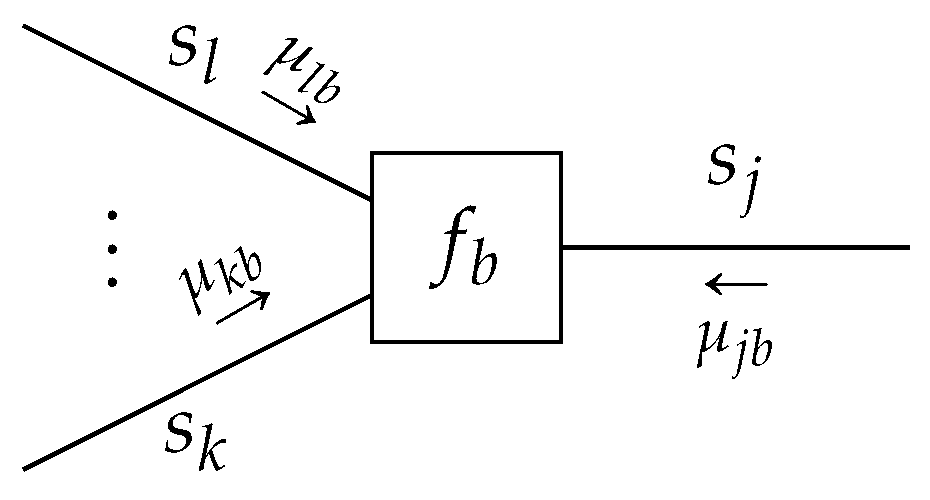
More specifically, given a locally connected pair
, we can rewrite the optimization of (
12) in terms of the local beliefs
, and the constraints in the local polytope
that pertains to these beliefs. The problem then becomes finding local stationary solutions
Using (
13), the optimization of (
15) can then be written in the Lagrangian form
where the Lagrangians
and
include the local polytope of (
14) to rewrite (
13) as an explicit functional of beliefs
and
(see, e.g., Lemmas 1 and 2). The combined stationary solutions to the local objectives then also comprise a stationary solution to the global objective (
Appendix B).
The current paper shows how to identify stationary solutions to local objectives of the form (
15), with the use of variational calculus, under varying constraints as imposed by the local polytope (
14). Interestingly, the resulting fixed-point equations can be interpreted as message passing updates on the underlying TFFG representation of the model. In the following
Section 3 and
Section 4, we derive the local stationary solutions under a selection of constraints and show how these relate to known message passing update rules (
Table 1). It then becomes possible to derive novel message updates and algorithms by simply altering the local polytope.
4. Message Passing Variations through Constraint Manipulation
For generic node functions with arbitrary connectivity, there is no guarantee that the sum-product updates can be solved analytically. When analytic solutions are not possible, there are two ways to proceed. One way is to try to solve the sum-product update equations numerically, e.g., by Monte Carlo methods. Alternatively, we can add additional constraints to the BFE that leads to simpler update equations at the cost of inference accuracy. In the remainder of the paper, we explore a variety of constraints that have proven to yield useful inference solutions.
4.1. Factorization Constraints
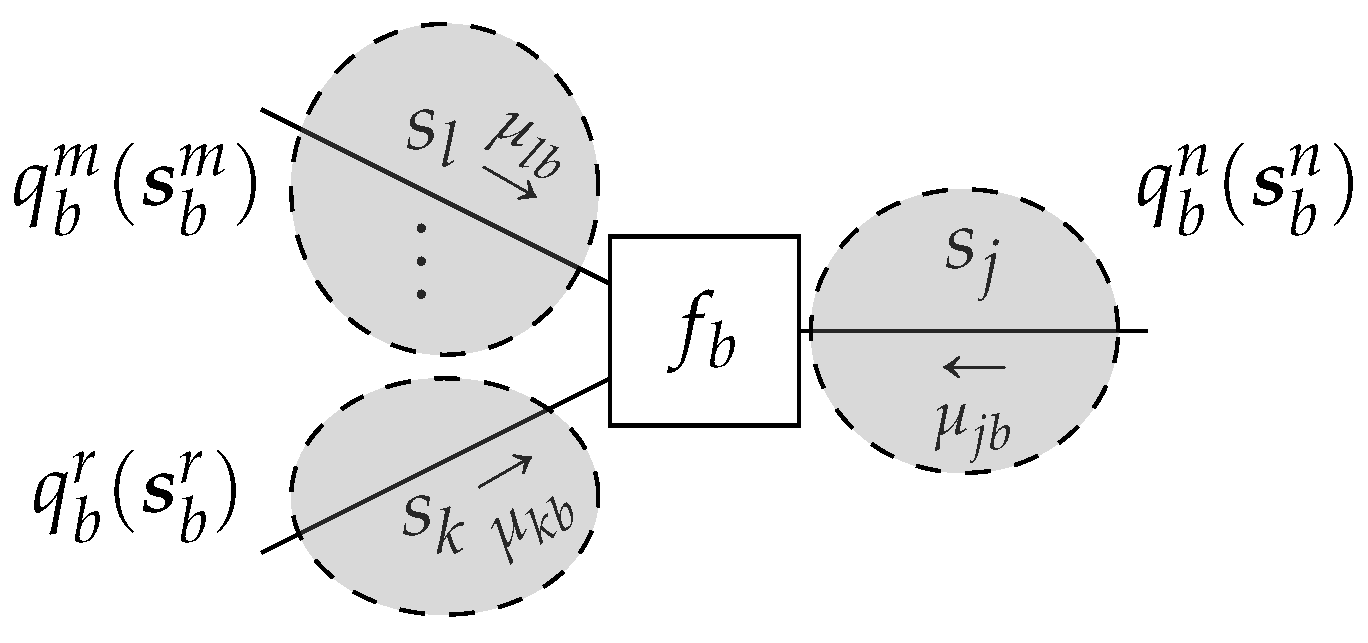
Additional factorizations of the variational density
are often assumed to ease computation. In particular, we assumed a
structured mean-field factorization
such that
where
n indicates a local cluster as a set of edges. To define a local cluster rigorously, let us first denote by
the power set of an edge set
, where the power set is the set of all subsets of
. Then, a mean-field factorization
can be chosen such that all elements in
are included in
exactly once. Therefore,
is defined as a set of one or multiple sets of edges. For example, if
, then
is allowed, as is
itself, but
is not allowed, since the element
j occurs twice. More formally, in (
26), the intersection of the super- and subscript collects the required variables, see
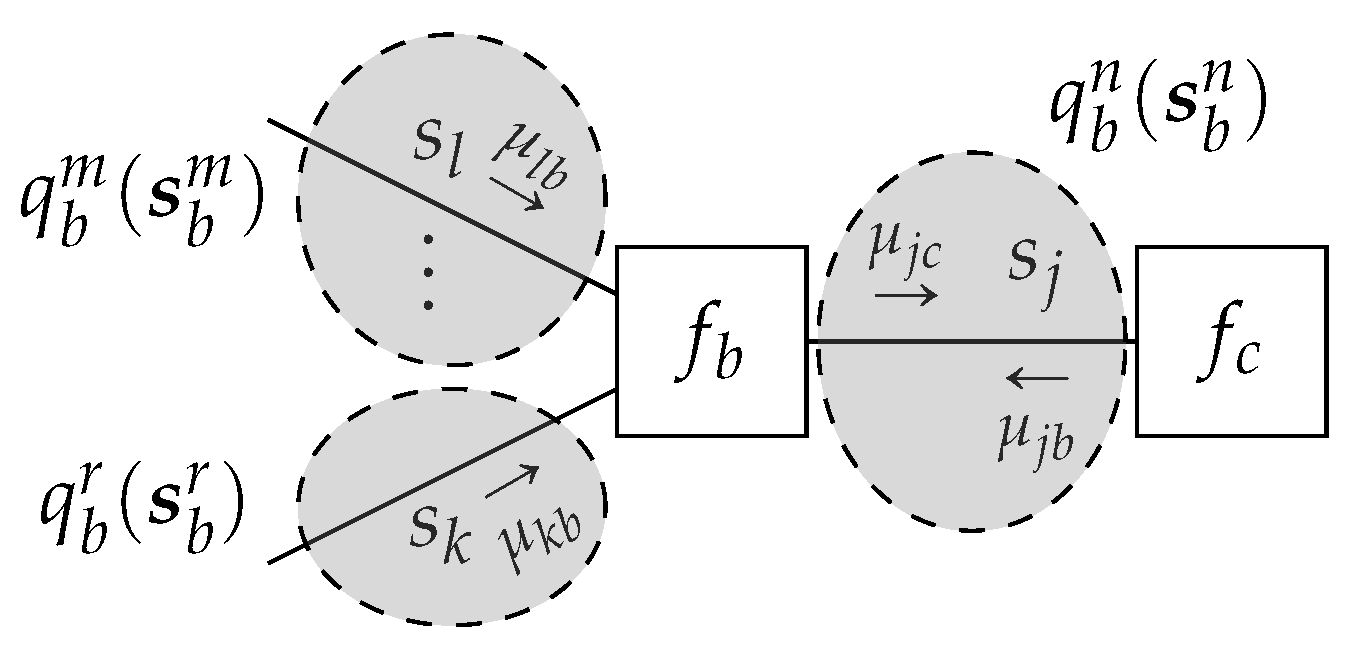
Figure 7 for an example. The special case of a fully factorized
for all edges
is known as the
naive mean-field factorization
[
11,
24].
We will analyze the effect of a structured mean-field factorization (
26) on the Bethe free energy (
7) for a specific factor node
. Substituting (
26) in the local free energy for factor
b yields
We are then interested in
where the Lagrangian
(Lemma 3) enforces the normalization and marginalization constraints
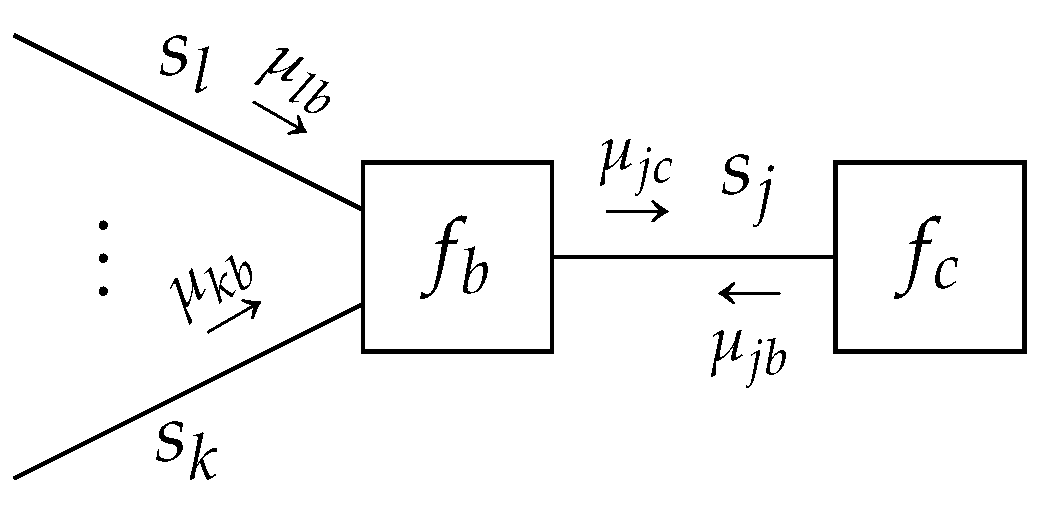
Lemma 3. Given a terminated FFG, consider a node-induced subgraphwith a structured mean-field factorization(e.g., Figure 7). Then, local stationary solutions to the Lagrangianwherecollects all terms independent of, which are of the formwhere 4.1.1. Structured Variational Message Passing
We now combine Lemmas 2 and 3 to derive the structured variational message passing algorithm.
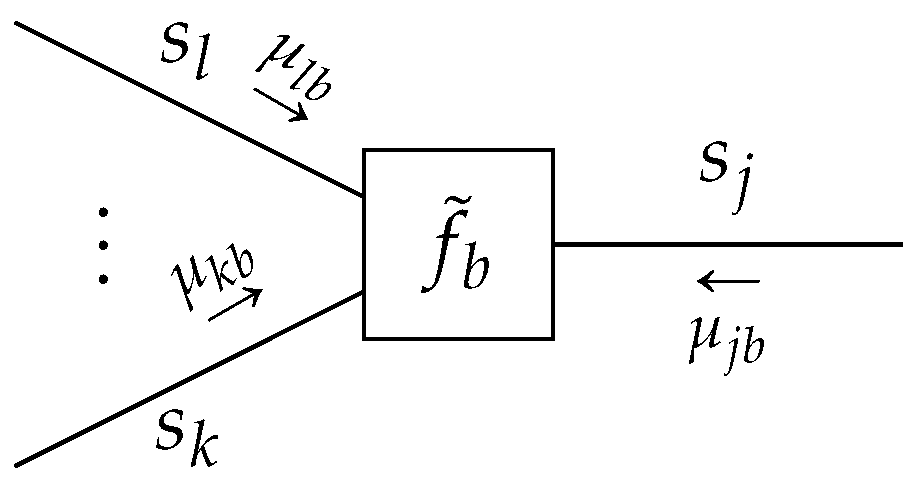
Theorem 2. Structured variational message passing: Given a TFFG, consider the induced subgraphwith a structured mean-field factorization, with local clusters. Letbe the cluster where(see, e.g., Figure 8). Given the local polytopethen local stationary solutions toare given bywith messagescorresponding to the fixed points ofwith iteration index k, and where The structured mean-field factorization applies the marginalization constraint only to the local cluster beliefs, as opposed to the joint node belief. As a result, computation for the local cluster beliefs might become tractable [
24] (Ch.5). The practical appeal of Variational Message Passing (VMP) based inference becomes evident when the underlying model is composed of conjugate factor pairs from the exponential family. When the underlying factors are conjugate exponential family distributions, the message passing updates (
36) amounts to adding natural parameters [
35] of the underlying exponential family distributions. Structured variational message passing is popular in acoustic signal modelling, e.g., [
36], as it allows one to be able to keep track of correlations over time. In [
37], a stochastic variant of structured variational inference is utilized for Latent Dirichlet Allocation. Structured approximations are also used to improve inference in auto-encoders. In [
38], inference involving non-parametric Beta-Bernoulli process priors is improved by developing a structured approximation to variational auto-encoders. When the data being modelled are time series, structured approximations reflect the transition structure over time. In [
39], an efficient structured black-box variational inference algorithm for fitting Gaussian variational models to latent time series is proposed.
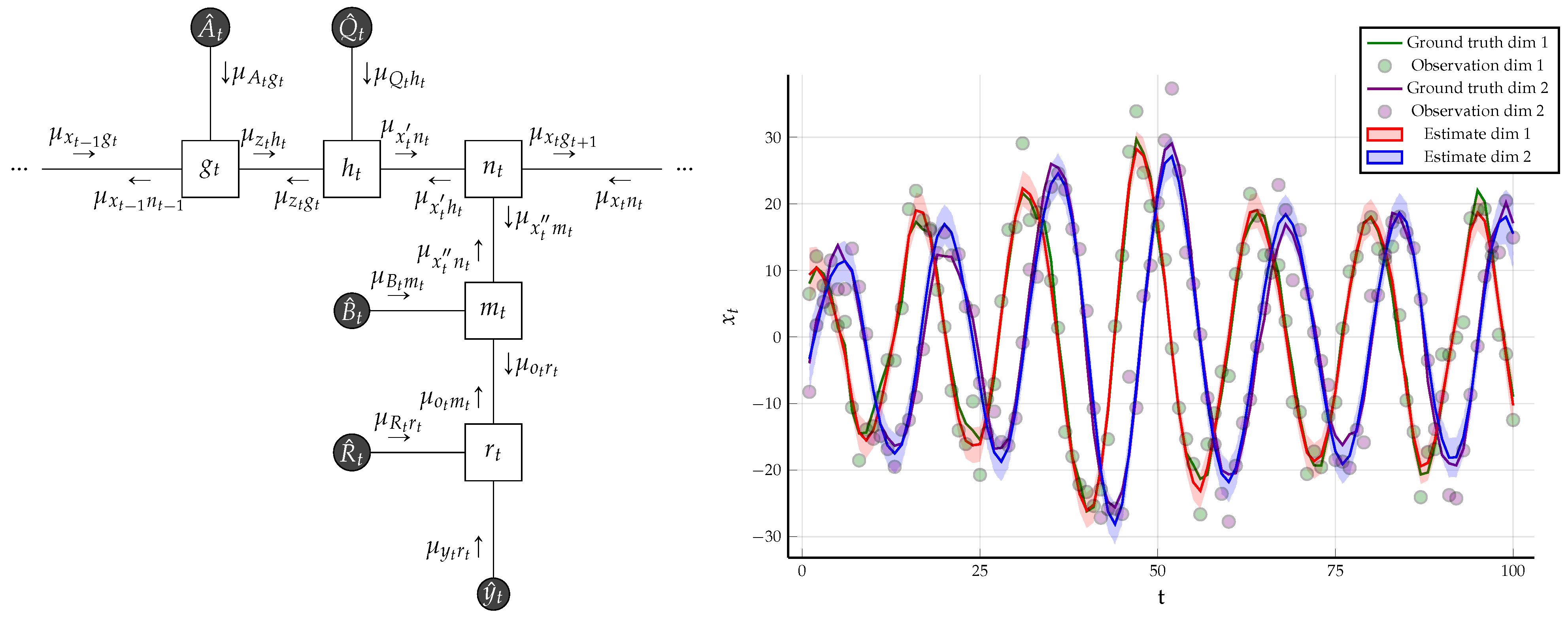
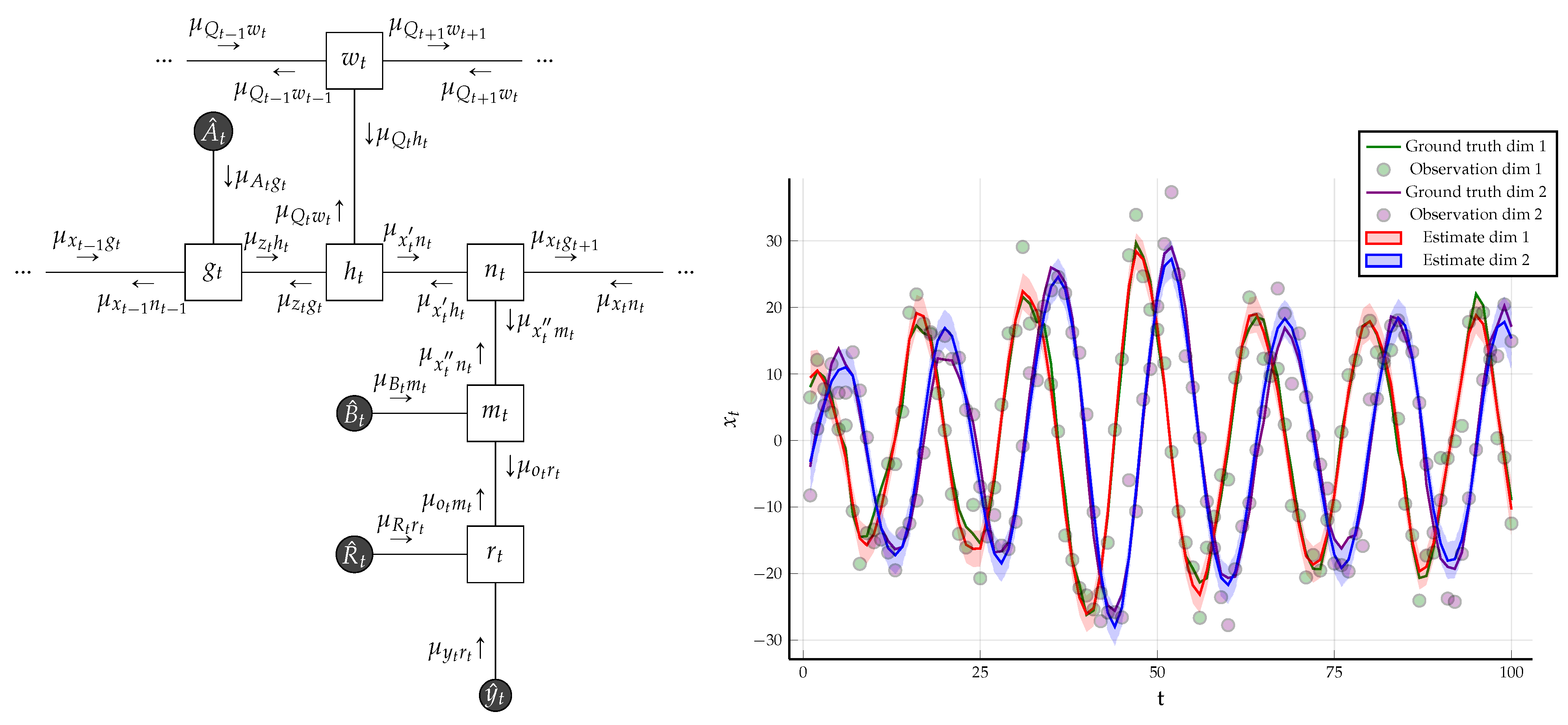
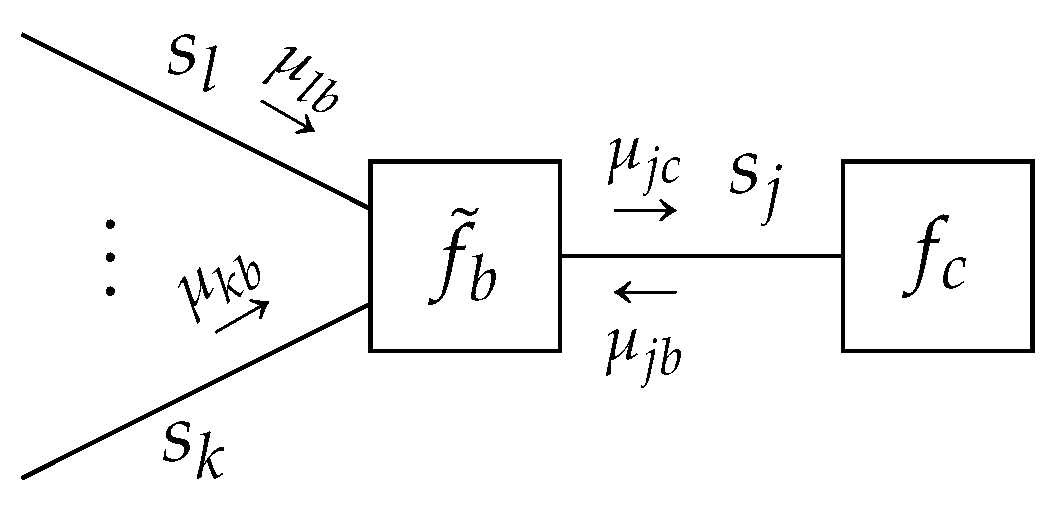
Example 2. Consider the linear Gaussian state space model of Example 1. Let us assume that the precision matrix for latent-state transitionsis not known and can not be constrained by data. Then, we can augment state space model by including a prior forand try to infer a posterior overfrom the observations. Sinceis the precision of a normal factor, we chose a conjugate Wishart prior and assumed thatis time-invariant by adding the following factorsIt is certainly possible to assume a time-varying structure for; however, our purpose is to illustrate a change in constraints rather than analyzing time-varying properties. This is why we assume time-invariance. In this setting, the sum-product equations around the factorare not analytically tractable. Therefore, we changed the constraints associated with (25b)
to those given in Theorem 2 as followsWe removed the data constraint on and instead included data constraints on the hyper-parametersWith the new set of constraints ((39a) and (39b)), we obtained a hybrid of the sum-product and structured VMP algorithm, where structured messages around the factor are computed by (
36)
and the rest of the messages are computed by the sum-product (
22)
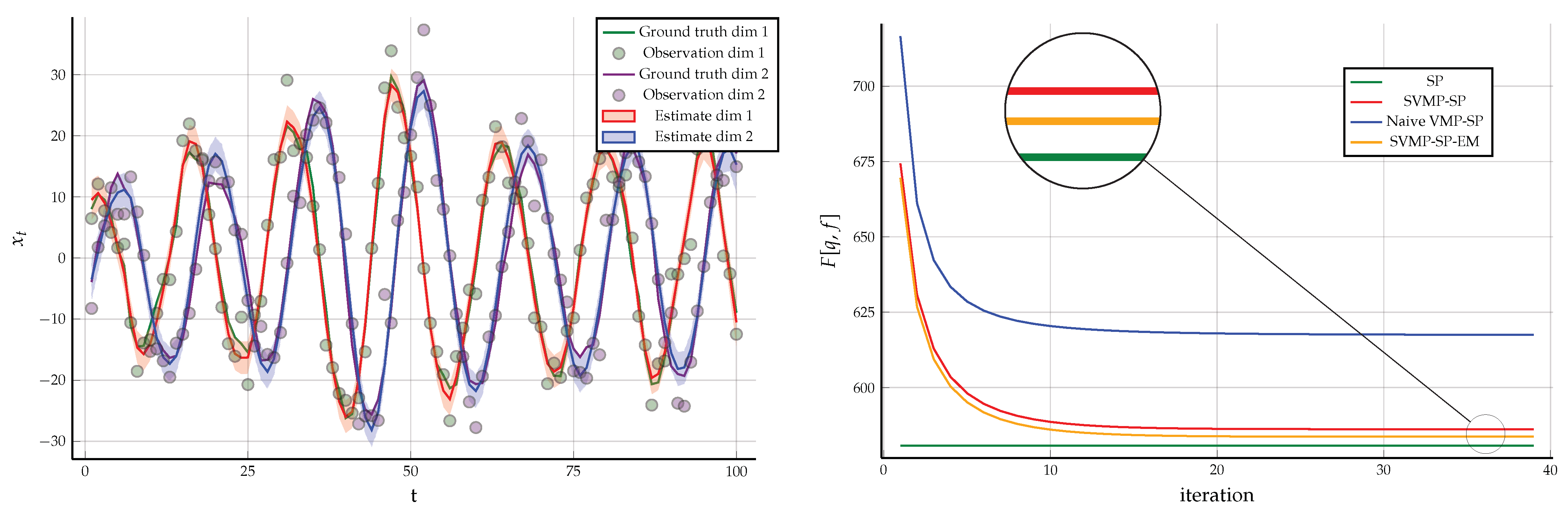
. One time segment of the modified FFG along with the messages is given Figure 9. We used the same observations that were generated in Example 1 and the same initialization for the hidden states. For the hyper-parameters of the Wishart prior, we chose and . Under these constraints, the result of structured variational message passing results along with the Bethe free energy evaluation is given in Figure 9. 4.1.2. Naive Variational Message Passing
As a corollary of Theorem 2, we can consider the special case of a naive mean-field factorization, which is defined for node
b as
The naive mean-field constraint (
41) transforms the local free energy into
Corollary 1. Naive Variational Message Passing: Given a TFFG , consider the induced subgraph with a naive mean-field factorization . Let be the cluster where . Given the local polytope of (33), the local stationary solutions to (34) are given by
where the messages
are the fixed points of the following iterations
where
k is an iteration index.
The naive mean-field factorization limits the search space of beliefs by imposing strict constraints on the variational posterior. As a result, the variational posterior also loses flexibility. To improve inference performance for sparse Bayesian learning, the authors of [
40] proposes a hybrid mechanism by augmenting naive mean-field VMP with sum-product updates. This hybrid scheme reduces the complexity of the sum-product algorithm, while improving the accuracy of the naive VMP approach. In [
41], naive VMP is applied to semi-parametric regression and allows for scaling of regression models to large data sets.
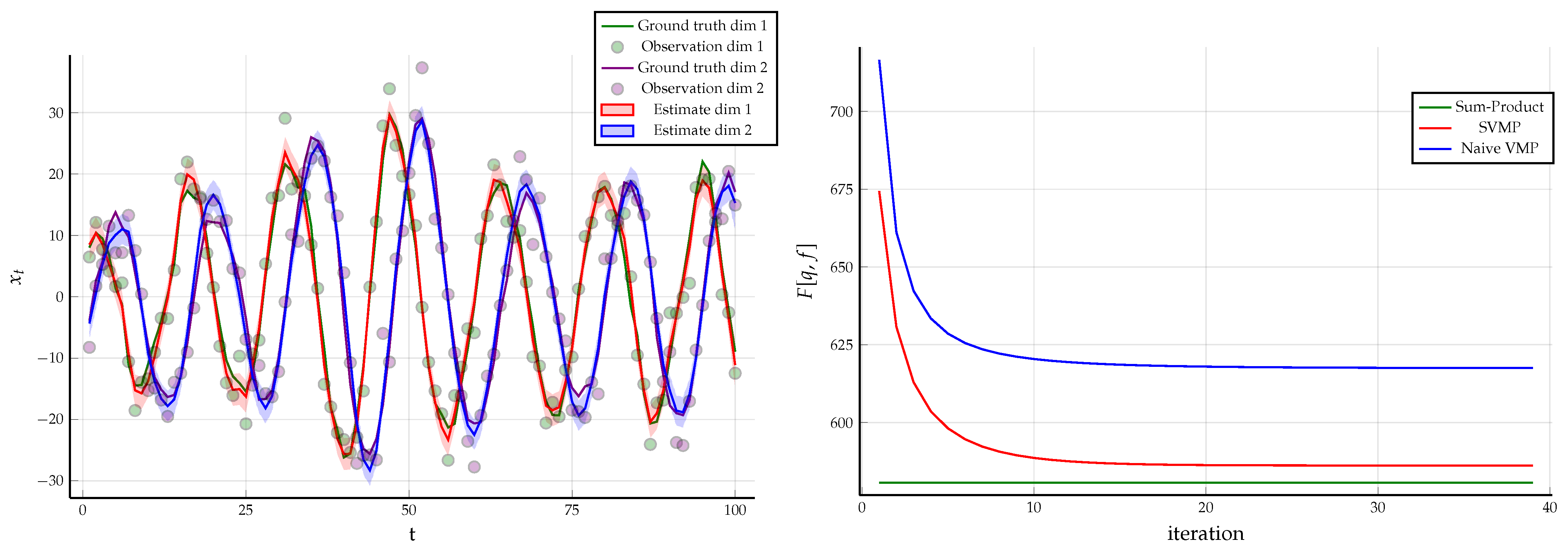
Example 3. As a follow up on Example 2, we relaxed the constraints in ((39a) and (39b)) to the following constraints presented in Corollary 1 asThe FFG remains the same and we use identical data constraints as in Example 2. Together with constraint (44)
, we obtained a hybrid of naive variational message passing and sum-product message passing algorithm where the messages around the factor are computed by (
43)
and the rest of the messages by sum-product (
22)
. Using the same data as in Example 1, the results for naive VMP are given in Figure 10 along with the evaluated Bethe free energy. 4.2. Form Constraints
Form constraints limit the functional form of the variational factors
and
. One of the most widely used form constraints, the data constraint, is also illustrated in
Appendix A.
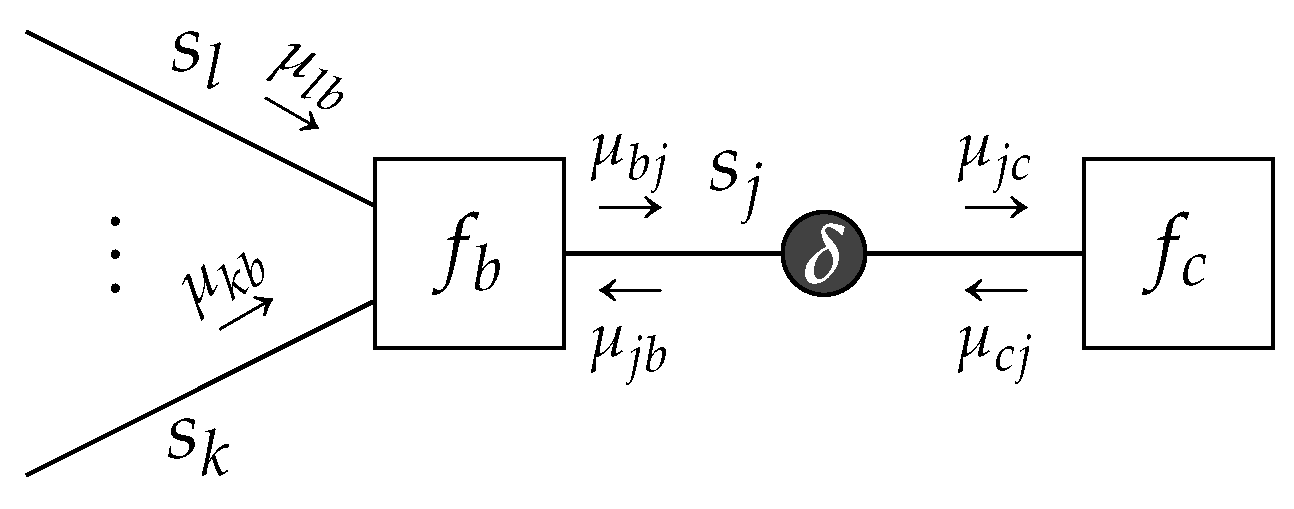
4.2.1. Data Constraints
A data constraint can be viewed as a special case of (9b), where the belief
is constrained to be a Dirac-delta function [
42], such that
where
is a known value, e.g., an observation.
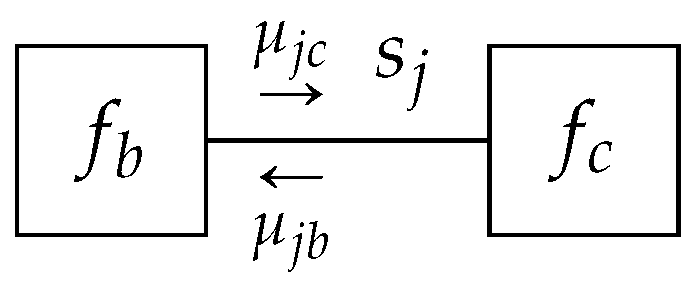
Lemma 4. Given a TFFG, consider the node-induced subgraph(Figure 3). Then local stationary solutions to the Lagrangianwherecollects all terms that are independent of, are of the form Theorem 3. Data-Constrained Sum-Product: Given a TFFG, consider the induced subgraph(Figure 11). Given the local polytopethe local stationary solutions toare of the formwith message Note that the resulting message
to node
b does not depend on messages from node
c, as would be the case for a sum-product update. By the symmetry of Theorem 3 for the subgraph
, (
A32) identifies
This implies that messages incoming to a data constraint (such as
) are not further propagated through the data constraint. The data constraint thus effectively introduces a conditional independence between the variables of neighboring factors (conditioned on the shared constrained variable). Interestingly, this is similar to the notion of an intervention [
43], where a decision variable is externally forced to a realization.
Data constraints allow information from data sets to be absorbed into the model. Essentially, (variational) Bayesian machine learning is an application of inference in a graph with data constraints. In our framework, data are a constraint, and machine learning via Bayes rule follows naturally from the minimization of the Bethe free energy (see also
Appendix A).
4.2.2. Laplace Propagation
A second type of form constraint we consider is the Laplace constraint, see also [
14]. Consider a second-order Taylor approximation on the local log-node function
around an approximation point
, as
From this approximation, we define the Laplace-approximated node function as
which is substituted in the local free energy to obtain the Laplace-encoded local free energy as
It follows that the Laplace-encoded optimization of the local free energy becomes
where the Lagrangian
imposes the marginalization and normalization constraints of (9) on (
54).
Lemma 5. Given a TFFG, consider the node-induced subgraph(Figure 12). The stationary points of the Laplace-approximated Lagrangian (
55)
as a functional of ,where collects all terms that are independent of , which are of the form We can now formulate Laplace propagation as an iterative procedure, where the approximation point is chosen as the mode of the belief .
Theorem 4.
Laplace Propagation: Given a TFFG, consider the induced subgraph(Figure 13) with the Laplace-encoded factoras per (
53)
. We write the model (
1)
with the Laplace-encoded factor substituted for , as . Given the local polytope of (
14)
, the local stationary solutions toare given bywith and the messages the fixed points of A Laplace propagation is introduced in [
14] as an algorithm that propagates mean and variance information when exact updates are expensive to compute. Laplace propagation has found applications in the context of Gaussian processes and support vector machines [
14]. In the jointly normal case, Laplace propagation coincides with sum-product and expectation propagation [
14,
18].
4.2.3. Expectation Propagation
Expectation propagation can be derived in terms of constraint manipulation by relaxing the marginalization constraints to expectation constraints. Expectation constraints are of the form
for a given function (statistic)
. Technically, the statistic
can be chosen arbitrarily. Nevertheless, they are often chosen as sufficient statistics of an exponential family distribution. An exponential family distribution is defined by
where
is the natural parameter,
is the partition function,
is the sufficient statistics and
is a base measure [
24]. The reason
is a sufficient statistic is because if there are observed values of the random variable
, then the parameter
can be estimated by using only the statistics
. This means that the estimator of
will depend only on the statistics.
The idea behind expectation propagation [
18] is to relax the marginalization constraints with moment-matching constraints by choosing sufficient statistics from exponential family distributions [
12]. Relaxation allows approximating the marginals of the sum-product algorithm with exponential family distributions. By keeping the marginals within the exponential family, the complexity of the resulting computations is reduced.
Lemma 6. Given a TFFG, consider the node-induced subgraph(Figure 3). The stationary points of the Lagrangianwith sufficient statistics, and wherecollects all terms that are independent of, are of the formwith incoming exponential family message Lemma 7.
Given a TFFG , consider an edge-induced subgraph (Figure 4). The stationary solutions of the Lagrangianwith sufficient statistics , and where collects all terms that are independent of , are of the form Theorem 5. Expectation Propagation: Given a TFFG, consider the induced subgraph(Figure 5). Given the local polytopeandan exponential family message (from Lemma 6). Then, the local stationary solutions to (
15)
are given bywith and being the fixed points of the iterationsBy moment-matching on , we obtain the natural parameter . The message update then follows from Moment-matching can be performed by solving [
24] (Proposition 3.1)
for
, where
In practice, for a Gaussian approximation, the natural parameters can be obtained by converting the matched mean and variance of
to the canonical form [
18]. Computing the moments of
is often challenging due to lack of closed form solutions of the normalization constant. In order to address the computation of moments in EP, Ref. [
44] proposes to evaluate challenging moments by quadrature methods. For multivariate random variables, moment-matching by spherical radial cubature would be advantageous as it will reduce the computational complexity [
45]. Another popular way of evaluating the moments is through importance sampling [
46] (Ch. 7) and [
47].
Expectation propagation has been utilized in various applications ranging from time series estimation with Gaussian processes [
48] to Bayesian learning with stochastic natural gradients [
49]. When the likelihood functions for Gaussian process classification are not Gaussian, EP is often utilized [
50] (Chapter 3). In [
51], a message passing-based expectation propagation algorithm is developed for models that involve both continuous and discrete random variables. Perhaps the most practical applications of EP are in the context of probabilistic programming [
52], where it is heavily used in real-world applications.
4.3. Hybrid Constraints
In this section, we consider hybrid methods that combine factorization and form constraints, and formalize some well-known algorithms in terms of message passing.
4.3.1. Mean-Field Variational Laplace
Mean-field variational Laplace applies the mean-field factorization to the Laplace-approximated factor function. The appeal of this method is that all messages outbound from the Laplace-approximated factor can be represented by Gaussians.
Theorem 6. Mean-field variational Laplace: Given a TFFG, consider the induced subgraph(Figure 13) with the Laplace-encoded factoras per (
53)
. We write the model (
1)
with substituted Laplace-encoded factor for , as . Furthermore, assume a naive mean-field factorization . Let be the cluster where . Given the local polytope of (
33)
, the local stationary solutions toare given bywhere represents the fixed points of the following iterationswith Conveniently, under these constraints, every outbound message from node
b will be proportional to a Gaussian. Substituting the Laplace-approximated factor function, we obtain:
Resolving this expectation yields a quadratic form in
, which after completing the square leads to a proportionally Gaussian message
. This argument holds for any edge adjacent to
b, and therefore for all outbound messages from node
b. Moreover, if the incoming messages are represented by Gaussians as well (e.g., because these are also computed under the mean-field variational Laplace constraint), then all beliefs on the adjacent edges to
b will also be Gaussian. This significantly simplifies the procedure of computing the expectations, which illustrates the computational appeal of mean-field variational Laplace.
Mean-field variational Laplace is widely used in dynamic causal modeling [
53] and more generally in cognitive neuroscience, partly because the resulting computations are deemed neurologically plausible [
54,
55,
56].
4.3.2. Expectation Maximization
Expectation Maximization (EM) can be viewed as a hybrid algorithm that combines a structured variational factorization with a Dirac-delta constraint, where the constrained value itself is optimized. Given a structured mean-field factorization
, with a single-edge cluster
, then expectation maximization considers local factorizations of the form
where the belief for
is constrained by a Dirac-delta distribution, similar to
Section 4.2.1. In (
69), however, the variable
represents a random variable with (unknown) value
, where
d is the dimension of the random variable
. We explicitly use the notation
(as opposed to
for the data constraint in
Section 4.2.1) to clarify that this value is a parameter for the constrained belief over
that will be optimized—that is,
does not represent a model parameter in itself. To make this distinction even more explicit, in the context of optimization, we will refer to Dirac-delta constraints as point-mass constraints.
The factor-local free energy then becomes a function of the parameter.
Theorem 7. Expectation maximization: Given a TFFG, consider the induced subgraph(Figure 14) with a structured mean-field factorization, with local clusters. Letbe the cluster where. Given the local polytopethe local stationary solutions toare given by the fixed points of Expectation maximization was formulated in [
57] as an iterative method that optimizes log-expectations of likelihood functions, where each EM iteration is guaranteed to increase the expected log-likelihood. Moreover, under some differentiability conditions, the EM algorithm is guaranteed to converge [
57] (Theorem 3). A detailed overview of EM for exponential families is available in [
24] (Ch. 6). A formulation of EM in terms of message passing is given by [
58], where message passing for EM is applied in a filtering and system identification context. In [
58], derivations are based on [
57] (Theorem 1), whereas our derivations directly follow from variational principles.
Example 4. Now suppose we do not know the anglefor the state transition matrixin Example 2 and would like to estimate the value of. Moreover, further suppose that we are interested in estimating the hyper-parameters for the priorand, as well as the precision matrix for the state transitions. For this purpose, we changed the constraints of (
25a)
into EM constraints in accordance with Theorem 7:where we optimize and with EM ( is further constrained to be positive definite during the optimization procedure). With the addition of the new EM constraints, the resulting FFG is given in Figure 15. The hybrid message passing algorithm consists of structured variational messages around the factor , and sum-product messages around , , and , and EM messages around and . We used identical observations as in the previous examples. The results for the hybrid SVMP-EM-SP algorithm are given in Figure 16 along with the evaluated Bethe free energy over all iterations. 4.4. Overview of Message Passing Algorithms
In
Section 4.1,
Section 4.2 and
Section 4.3, following a high-level recipe pioneered by [
15], we presented first-principle derivations of some of the popular message passing-based inference algorithms by manipulating the local constraints of the Bethe free energy. The results are summarized in
Table 1.
Crucially, the method of constrained BFE minimization goes beyond the reviewed algorithms. Through creating a new set of local constraints and following similar derivations based on variational calculus, one can obtain new message passing-based inference algorithms that better match the specifics of the generative model or application.
6. Implementation of Algorithms and Simulations
We have developed a probabilistic programming toolbox
ForneyLab.jl in the Julia language [
61,
62]. The majority of algorithms that are reviewed in
Table 1 have been implemented in ForneyLab along with variety of demos (
https://github.com/biaslab/ForneyLab.jl/tree/master/demo, accessed on 23 June 2021). ForneyLab is extendable and supports postulating new local constraints of the BFE for the creation of custom message passing-based inference algorithms.
In order to limit the length of this paper, we refer the reader to the demonstration folder of ForneyLab and to several of our previous papers with code. For instance, our previous work in [
63] implemented a mean-field variational Laplace propagation for the hierarchical Gaussian filter (HGF) [
64]. In the follow-up work [
65], inference results improved by changing to structured factorization and moment-matching local constraints. In that case, modification of local constraints created a hybrid EP-VMP algorithm that better suited the model. Moreover, in [
13], we formulated the idea of
chance constraints
in the form of violation probabilities leading to a new message passing algorithm that supports goal-directed behavior within the context of active inference. A similar line of reasoning led to improved inference procedures for auto-regressive models [
66].
7. Related Work
Our work is inspired by the seminal work [
17], which discusses the equivalence between the fixed points of the belief propagation algorithm [
32] and the stationary points of the Bethe free energy. This equivalence is established through a Lagrangian formalism, which allows for the derivation of Generalized Belief Propagation (GBP) algorithms by introducing region-based graphs and the region-based (Kikuchi) free energy [
16].
Region graph-based methods allows for overlapping clusters (
Section 4.1) and thus offer a more generic message passing approach. The selection of appropriate regions (clusters), however, proves to be difficult, and the resulting algorithms may grow prohibitively complex. In this context, Ref. [
67] addresses how to manipulate regions and manage the complexity of GBP algorithms. Furthermore, Ref. [
68] also establishes a connection between GBP and expectation propagation (EP) by introducing structured region graphs.
The inspirational work of [
15] derives message passing algorithms by minimization of
-divergences. The stationary points of
-divergences are obtained by a fixed point projection scheme. This projection scheme is reminiscent of the minimization scheme of the expectation propagation (EP) algorithm [
18]. Compared to [
15], our work focuses on a single divergence objective (namely, the VFE). The work of [
12] derives the EP algorithm by manipulating the marginalization and factorization constraints of the Bethe free energy objective (see also
Section 4.2.3). The EP algorithm is, however, not guaranteed to converge to a minimum of the associated divergence metric.
To address the convergence properties of the algorithms that are obtained by region graph methods, the outstanding work of [
33] derives conditions on the region counting numbers that guarantee the convexity of the underlying objective. In general, however, the constrained Bethe free energy is not guaranteed to be convex and therefore the derived message passing updates are not guaranteed to converge.
8. Discussion
The key message in this paper is that a (variational) Bayesian model designer may tune the tractability-accuracy trade-off for evidence and posterior evaluation through constraint manipulation. It is interesting to note that the technique to derive message passing algorithms is always the same. We followed the recipe pioneered in [
15] to derive a large variety of message passing algorithms solely through minimizing constrained Bethe free energy. This minimization leads to local fixed-point equations, which we can interpret as message passing updates on a (terminated) FFG. The presented lemmas showed how the constraints affect the Lagrangians locally. The presented theorems determined the stationary solutions of the Lagrangians and obtained the message passing equations. Thus, if a designer proposes a new set of constraints, then the first place to start is to analyze the effect on the Lagrangian. Once the effect of the constraint on the Lagrangian is known, then variational optimization may result in stationary solutions that can be obtained by a fixed-point iteration scheme.
In this paper, we selected the Forney-style factor graph framework to illustrate our ideas. FFGs are mathematically comparable to the more common bi-partite factor graphs that associate round nodes with variables and square nodes with factors [
20]. Bi-partite factor graphs require two distinct types of message updates (one leaving variable nodes and one leaving factor nodes), while message passing on a (T)FFG requires only a single type of message update [
69]. The (T)FFG paradigm thus substantially simplifies the derivations and resulting message passing update equations.
The message passing update rules in this paper are presented without guarantees on convergence of the (local) minimization process. In practice, however, algorithm convergence can be easily checked by evaluating the BFE (Algorithm 1) after each belief update.
In future work, we plan on extending the treatment of constraints to formulate sampling-based algorithms such as importance sampling and Hamiltonian Monte Carlo in a message passing framework. While introducing SVMP, we have limited the discussion to local clusters that are not overlapping. We plan to extend variational algorithms to include local clusters that are overlapping without altering the underlying free-energy objective or the graph structure [
16,
67].




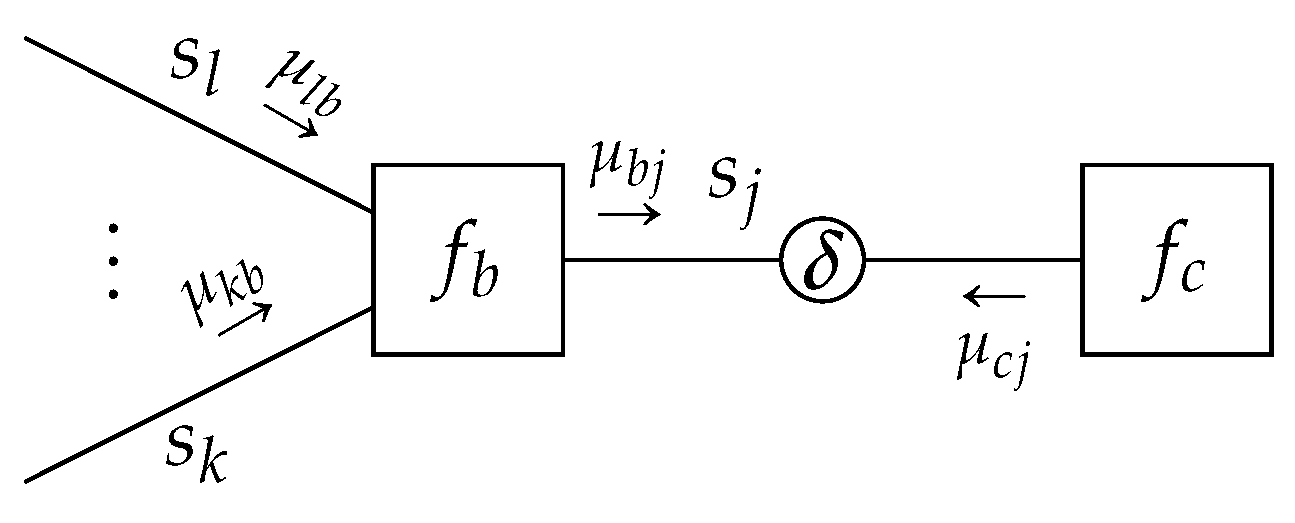


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}