
Biases and Variability from Costly Bayesian Inference

 , , and
, , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Results
2.1. Costly Bayesian Inference
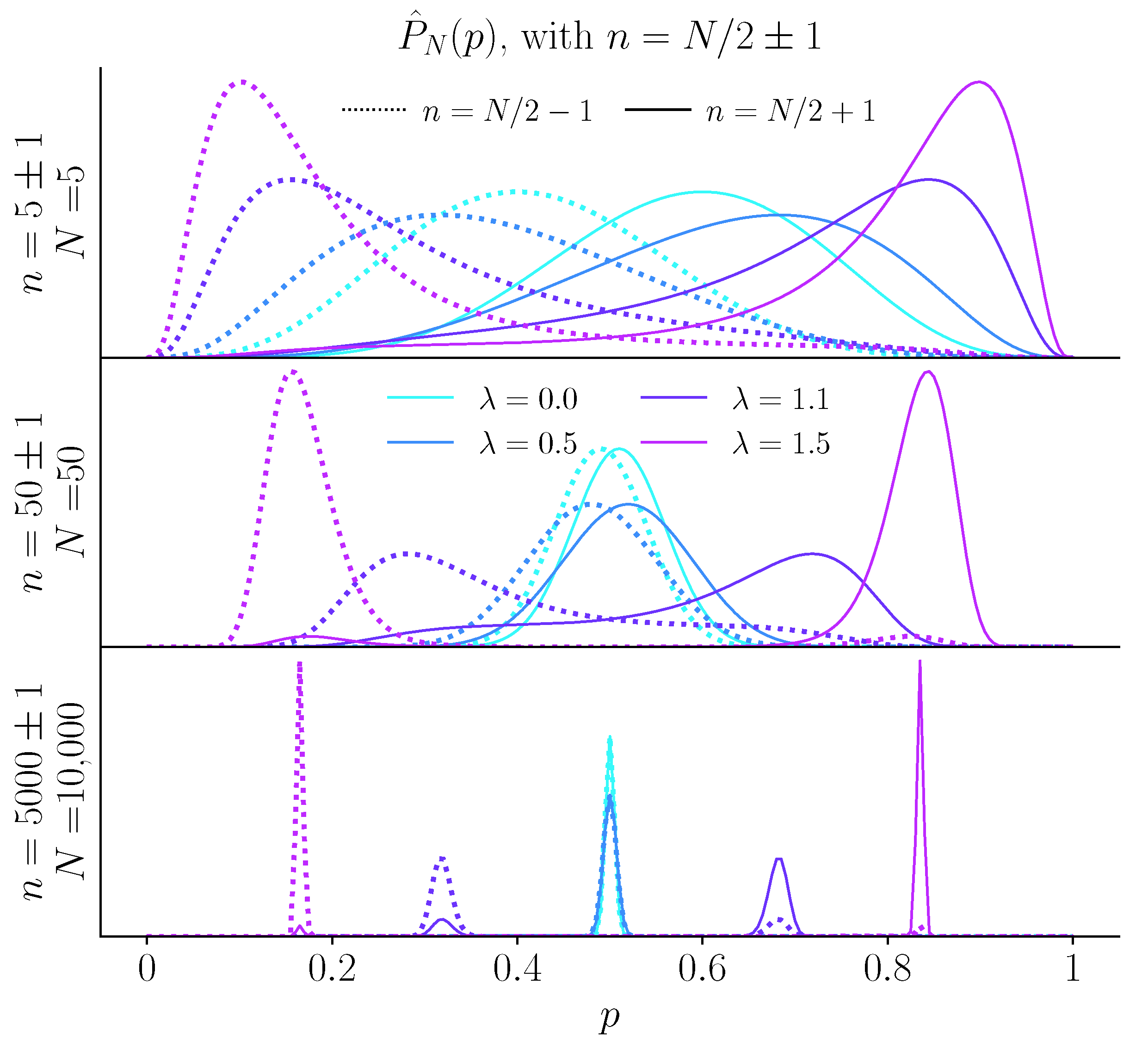
2.2. Inference of Probability under a Precision Cost
2.3. Inference of Probability under an Unpredictability Cost
2.4. The Case of a Fair Coin: Fluctuating and Biased Beliefs
3. Discussion
3.1. Summary
3.2. Costly Inference vs. Erroneous Beliefs
3.3. Costly Inference vs. Variational Inference
3.4. Costly Inference and Human Behavior
4. Methods
4.1. Precision Cost: Variance of the Posterior
4.2. Precision Cost: Autoregressive Process
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wikipedia. List of Cognitive Biases. Wikipedia, The Free Encyclopedia. 2016. Available online: https://en.wikipedia.org/wiki/List_of_cognitive_biases (accessed on 19 September 2020).
- Hubel, D.H. Eye, Brain, and Vision; Scientific American Library/Scientific American Books: New York, NY, USA, 1995. [Google Scholar]
- Baron, J. Thinking and Deciding; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Wendt, D.; Vlek, C. Utility, Probability, and Human Decision Making: Selected Proceedings of an Interdisciplinary Research Conference, Rome, 3–6 September, 1973; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 11. [Google Scholar]
- Gilovich, T.; Griffin, D.; Kahneman, D. Heuristics and Biases: The Psychology of Intuitive Judgment; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Hilbert, M. Toward a synthesis of cognitive biases: How noisy information processing can bias human decision making. Psychol. Bull. 2012, 138, 211. [Google Scholar] [CrossRef]
- Group, T.M.A.D.; Fawcett, T.W.; Fallenstein, B.; Higginson, A.D.; Houston, A.I.; Mallpress, D.E.; Trimmer, P.C.; McNamara, J.M. The evolution of decision rules in complex environments. Trends Cogn. Sci. 2014, 18, 153–161. [Google Scholar]
- Summerfield, C.; Tsetsos, K. Do humans make good decisions? Trends Cogn. Sci. 2015, 19, 27–34. [Google Scholar] [CrossRef]
- Meyniel, F.; Maheu, M.; Dehaene, S. Human Inferences about Sequences: A Minimal Transition Probability Model. PLoS Comput. Biol. 2016, 12, 1–26. [Google Scholar] [CrossRef]
- Gonzalez, R.; Wu, G. On the Shape of the ProbabilityWeighting Function. Cogn. Psychol. 1999, 38, 129–166. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Ren, X.; Maloney, L.T. The bounded rationality of probability distortion. Proc. Natl. Acad. Sci. USA 2020, 117, 22024–22034. [Google Scholar] [CrossRef] [PubMed]
- Hertwig, R.; Barron, G.; Weber, E.U.; Erev, I. Decisions from experience and the effect of rare events in risky choice. Psychol. Sci. 2004, 15, 534–539. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.J. Organizing probabilistic models of perception. Trends Cogn. Sci. 2012, 16, 511–518. [Google Scholar] [CrossRef] [PubMed]
- Weiss, Y.; Simoncelli, E.P.; Adelson, E.H. Motion illusions as optimal percepts. Nat. Neurosci. 2002, 5, 598–604. [Google Scholar] [CrossRef] [PubMed]
- Stocker, A.A.; Simoncelli, E.P. Noise characteristics and prior expectations in human visual speed perception. Nat. Neurosci. 2006, 9, 578–585. [Google Scholar] [CrossRef] [PubMed]
- Khaw, M.W.; Stevens, L.; Woodford, M. Discrete adjustment to a changing environment: Experimental evidence. J. Monet. Econ. 2017, 91, 88–103. [Google Scholar] [CrossRef]
- Acerbi, L.; Vijayakumar, S.; Wolpert, D.M. On the origins of suboptimality in human probabilistic inference. PLoS Comput. Biol. 2014, 10, e1003661. [Google Scholar] [CrossRef]
- Drugowitsch, J.; Wyart, V.; Devauchelle, A.D.; Koechlin, E. Computational Precision of Mental Inference as Critical Source of Human Choice Suboptimality. Neuron 2016, 92, 1398–1411. [Google Scholar] [CrossRef]
- Prat-Carrabin, A.; Wilson, R.C.; Cohen, J.D.; da Silveira, R.A. Human Inference in Changing Environments With Temporal Structure. Psychol. Rev. 2021. [Google Scholar] [CrossRef]
- Gigerenzer, G.; Gaissmaier, W. Heuristic decision making. Annu. Rev. Psychol. 2011, 62, 451–482. [Google Scholar] [CrossRef] [PubMed]
- Gallistel, C.R.; Krishan, M.; Liu, Y.; Miller, R.; Latham, P.E. The perception of probability. Psychol. Rev. 2014, 121, 96–123. [Google Scholar] [CrossRef] [PubMed]
- Icard, T.F.; Goodman, N.D. A Resource-Rational Approach to the Causal Frame Problem. In Proceedings of the 37th Annual Meeting of the Cognitive Science Society, Pasadena, CA, USA, 22–25 July 2015; pp. 962–967. [Google Scholar]
- Benjamin, D.J. Errors in probabilistic reasoning and judgment biases. In Handbook of Behavioral Economics; Elsevier B.V.: Amsterdam, The Netherlands, 2019; Volume 2, pp. 69–186. [Google Scholar] [CrossRef]
- Feller, W. An Introduction to Probability Theory and Its Application, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1967; Volume 1, pp. 1–525. [Google Scholar]
- Novikov, A.; Kordzakhia, N. Martingales and first passage times of AR(1) sequences. Stochastics 2007, 80, 197–210. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Banavar, J.R.; Maritan, A.; Volkov, I. Applications of the principle of maximum entropy: From physics to ecology. J. Phys. Condens. Matter 2010, 22, 063101. [Google Scholar] [CrossRef] [PubMed]
- Rushworth, M.F.; Behrens, T.E. Choice, uncertainty and value in prefrontal and cingulate cortex. Nat. Neurosci. 2008, 11, 389–397. [Google Scholar] [CrossRef]
- Mathys, C.; Daunizeau, J.; Friston, K.J.; Stephan, K.E. A Bayesian foundation for individual learning under uncertainty. Front. Hum. Neurosci. 2011, 5, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Commons, M.L.; Woodford, M.; Ducheny, J.R. How Reinforcers are Aggregated in Reinforcement-density discrimination and Preference Experiments. In Quantitative Analyses of Behavior: Volume 2, Matching and Maximizing Accounts; Ballinger: Cambridge, MA, USA, 1982; Volume 2, pp. 25–78. [Google Scholar]
- Commons, M.L.; Woodford, M.; Trudeau, E.J. How Each Reinforcer Contributes to Value: “Noise” Must Reduce Reinforcer Value Hyperbolically. In Signal Detection: Mechanisms, Models, and Applications; Commons, M.L., Nevin, J.A., Davison, M.C., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1991; pp. 139–168. [Google Scholar]
- Sozou, P.D. On hyperbolic discounting and uncertain hazard rates. Proc. R. Soc. B Biol. Sci. 1998, 265, 2015–2020. [Google Scholar] [CrossRef]
- Green, L.; Myerson, J. A discounting framework for choice with delayed and probabilistic rewards. Psychol. Bull. 2004, 130, 769–792. [Google Scholar] [CrossRef] [PubMed]
- Gabaix, X.; Laibson, D. Myopia and Discounting; NBER Working Paper No. 23254; NBER: Cambridge, MA, USA, 2017. [Google Scholar] [CrossRef]
- Yu, A.J.; Cohen, J.D. Sequential effects: Superstition or rational behavior? Adv. Neural Inf. Process. Syst. 2008, 21, 1873–1880. [Google Scholar]
- Brown, L.D. A Complete Class Theorem for Statistical Problems with Finite Sample Spaces. Ann. Stat. 2007, 9, 1289–1300. [Google Scholar] [CrossRef]
- Wald, A. An Essentially Complete Class of Admissible Decision Functions. Ann. Math. Stat. 1947, 18, 549–555. [Google Scholar] [CrossRef]
- Penny, W. Bayesian Models of Brain and Behaviour. ISRN Biomath. 2012, 2012, 785791. [Google Scholar] [CrossRef]
- Pouget, A.; Beck, J.M.; Ma, W.J.; Latham, P.E. Probabilistic brains: Knowns and unknowns. Nat. Neurosci. 2013, 16, 1170–1178. [Google Scholar] [CrossRef]
- Sanborn, A.N. Types of approximation for probabilistic cognition: Sampling and variational. Brain Cogn. 2015, 8–11. [Google Scholar] [CrossRef]
- Gershman, S.J.; Beck, J.M. Complex Probabilistic Inference: From Cognition to Neural Computation. In Computational Models of Brain and Behavior; John Wiley & Sons: Hoboken, NJ, USA, 2016; pp. 1–17. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Lieder, F.; Goodman, D. Rational Use of Cognitive Resources: Levels of Analysis Between the Computational and the Algorithmic. Top. Cogn. Sci. 2015, 7, 217–229. [Google Scholar] [CrossRef]
- Lieder, F.; Griffiths, T.L. Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources. Behav. Brain Sci. 2019. [Google Scholar] [CrossRef]
- Griffiths, T.L. Understanding Human Intelligence through Human Limitations. Trends Cogn. Sci. 2020, 24, 873–883. [Google Scholar] [CrossRef] [PubMed]
- Bhui, R.; Lai, L.; Gershman, S.J. Resource-rational decision making. Curr. Opin. Behav. Sci. 2021, 41, 15–21. [Google Scholar] [CrossRef]
- Summerfield, C.; Parpart, P. Normative principles for decision-making in natural environments. PsyArXiv 2021. [Google Scholar] [CrossRef]
- Simon, H.A. A Behavioral Model of Rational Choice. Q. J. Econ. 1955, 69, 99–118. [Google Scholar] [CrossRef]
- Simon, H.A. Models of Bounded Rationality: Empirically Grounded Economic Reason; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Ma, W.J.; Woodford, M. Multiple conceptions of resource rationality. Behav. Brain Sci. 2020, 43, e15. [Google Scholar] [CrossRef] [PubMed]
- Ghahramani, Z.; Jordan, M.I. Factorial Hidden Markov Models. Mach. Learn. 1997, 29, 245–273. [Google Scholar] [CrossRef]
- Dauwels, J. On variational message passing on factor graphs. IEEE Int. Symp. Inf. Theory Proc. 2007, 2546–2550. [Google Scholar] [CrossRef]
- Beal, M.J. Variational Algorithms for Approximate Bayesian Inference. Ph.D. Thesis, University College London, London, UK, 2003. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Winn, J.; Bishop, C. Variational message passing. J. Mach. Learn. Res. 2005, 6, 661–694. [Google Scholar]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Cho, R.Y.; Nystrom, L.E.; Brown, E.T.; Jones, A.D.; Braver, T.S.; Cohen, J.D. Mechanisms underlying dependencies of performance on stimulus history in a two-alternative forced-choice task. Cogn. Affect. Behav. Neurosci. 2002, 2, 283–299. [Google Scholar] [CrossRef] [PubMed]
- Gökaydin, D.; Ejova, A. Sequential effects in prediction. In Proceedings of the Annual Conference Cognitive Science Society, London, UK, 26–29 July 2017; pp. 397–402. [Google Scholar]
- Stephan, K.E.; Mathys, C. Computational approaches to psychiatry. Curr. Opin. Neurobiol. 2014, 25, 85–92. [Google Scholar] [CrossRef]
- Adams, R.A.; Huys, Q.J.; Roiser, J.P. Computational Psychiatry: Towards a mathematically informed understanding of mental illness. J. Neurol. Neurosurg. Psychiatry 2016, 87, 53–63. [Google Scholar] [CrossRef] [PubMed]
- Schwartenbeck, P.; Friston, K. Computational phenotyping in psychiatry: A worked example. eNeuro 2016, 3, 47. [Google Scholar] [CrossRef]
- Ashinoff, B.K.; Singletary, N.M.; Baker, S.C.; Horga, G. Rethinking delusions: A selective review of delusion research through a computational lens. Schizophr. Res. 2021. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prat-Carrabin, A.; Meyniel, F.; Tsodyks, M.; Azeredo da Silveira, R. Biases and Variability from Costly Bayesian Inference. Entropy 2021, 23, 603. https://doi.org/10.3390/e23050603
Prat-Carrabin A, Meyniel F, Tsodyks M, Azeredo da Silveira R. Biases and Variability from Costly Bayesian Inference. Entropy. 2021; 23(5):603. https://doi.org/10.3390/e23050603
Chicago/Turabian StylePrat-Carrabin, Arthur, Florent Meyniel, Misha Tsodyks, and Rava Azeredo da Silveira. 2021. "Biases and Variability from Costly Bayesian Inference" Entropy 23, no. 5: 603. https://doi.org/10.3390/e23050603
APA StylePrat-Carrabin, A., Meyniel, F., Tsodyks, M., & Azeredo da Silveira, R. (2021). Biases and Variability from Costly Bayesian Inference. Entropy, 23(5), 603. https://doi.org/10.3390/e23050603