
On the Performance of Video Resolution, Motion and Dynamism in Transmission Using Near-Capacity Transceiver for Wireless Communication


Abstract
1. Introduction
- H.264 and H.265 source compression standard has been incorporated in order to visualize the quality of the highly compressed video stream at the receiver.
- SP modulation are included in order to observe the performance of the proposed systems on fading channel.
- SP modulation is inspired by space time modulation and provides the diversity and coding gain for the proposed system in order to efficiently estimate and recover the actual transmitted information.
- DSTS scheme is included to remove the Channel State Information (CSI) estimation dependency and the receiver does not required to know the channel fade.
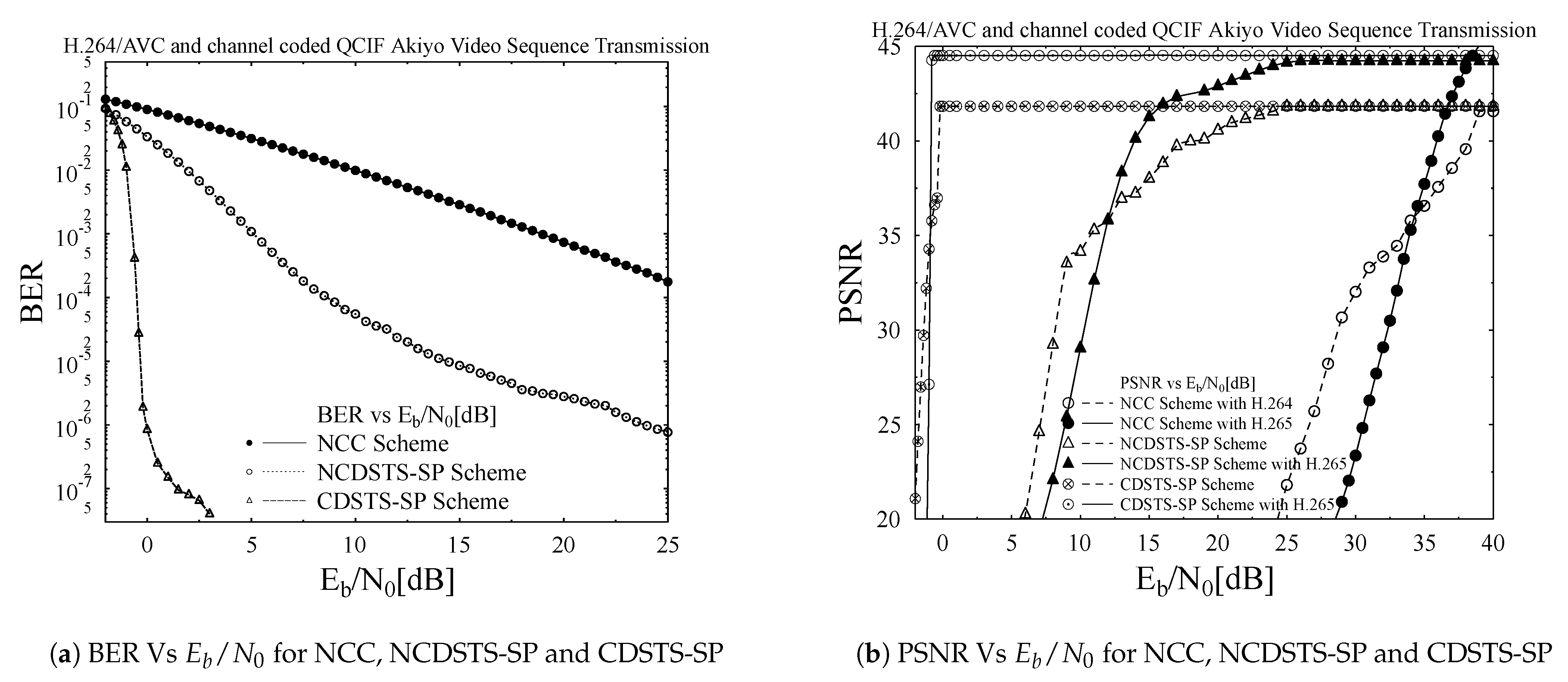
- Different inner and outer code rates are used in the concerned schemes to visualize the effect of code rates on the convergence property of iterative schemes.
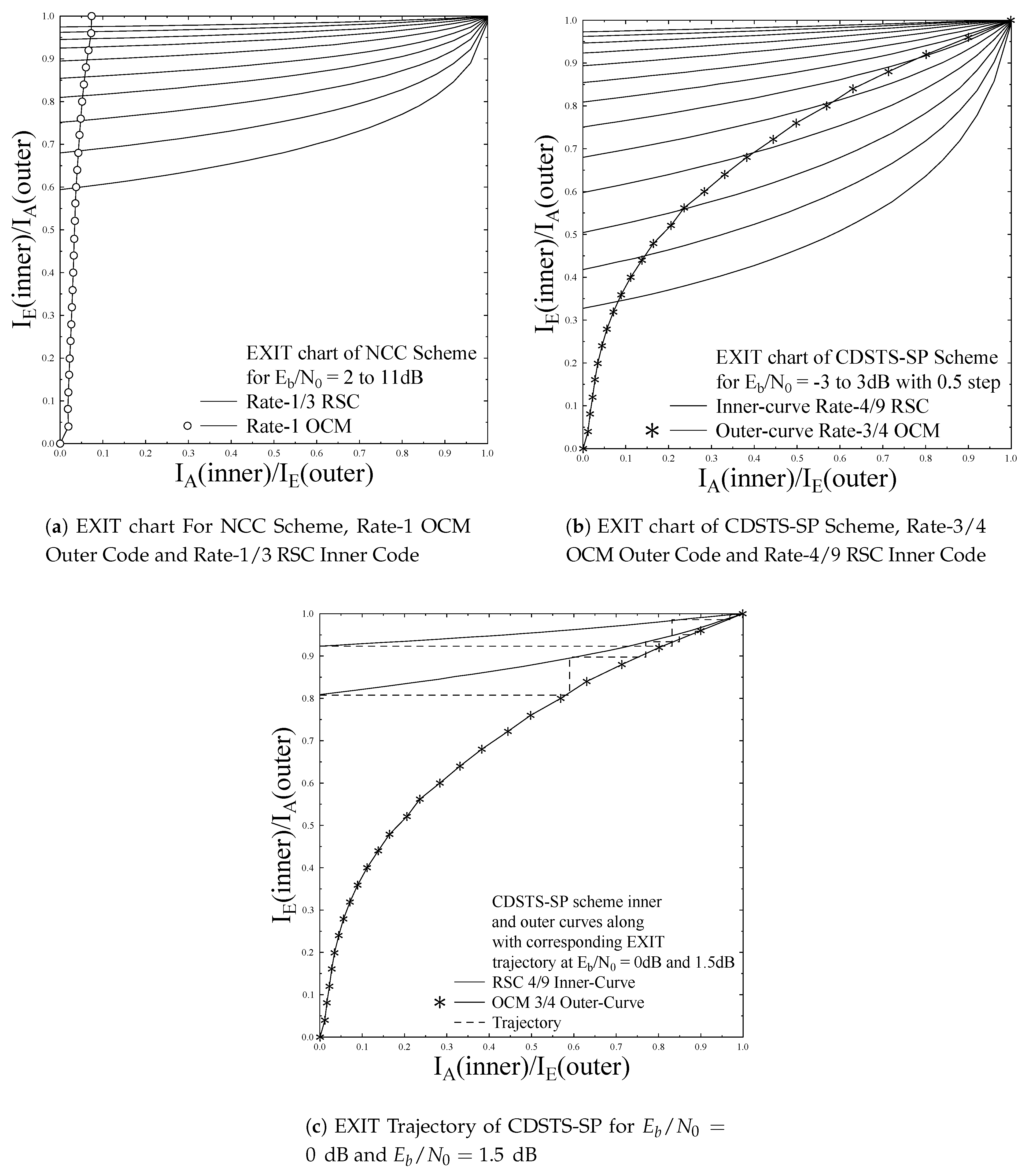
- EXIT chart are used for finding the number of profitable iterations in the decoding process.
- Diverse video sequences have been tested to measure the role of the static objects having fine details, dynamism and motion of the object in the background, on the performance metrics.
- To the best of our knowledge, this is distinctive research study to transmit the highest compression efficient coded video using the H.265/HEVC standard while employing the advocated wireless transmission setup.
2. Preliminaries & System Design Criteria
3. Proposed System Model
3.1. H.264 and H.265 Source Video Coding Standard
- Parameter set structure, containing sharable information deployed in the decoding process. The new Video Parameter Set (VPS) is based on the concepts of sequence and picture parameter sets used in H.264.
- Network Abstraction Layer (NAL) unit is retained which is helpful in identification of the purpose of payload data.
- In case of data losses, synchronization is done in H.265 with the help of slices. The same concept of slices is followed in H.264.
- Information about the timing of a video picture, interpretation of the color space and other display related information is provided by Supplemental Enhancement Information (SEI) and Video usability Information (VUI) metadata, adopted in H.265 and H.264.
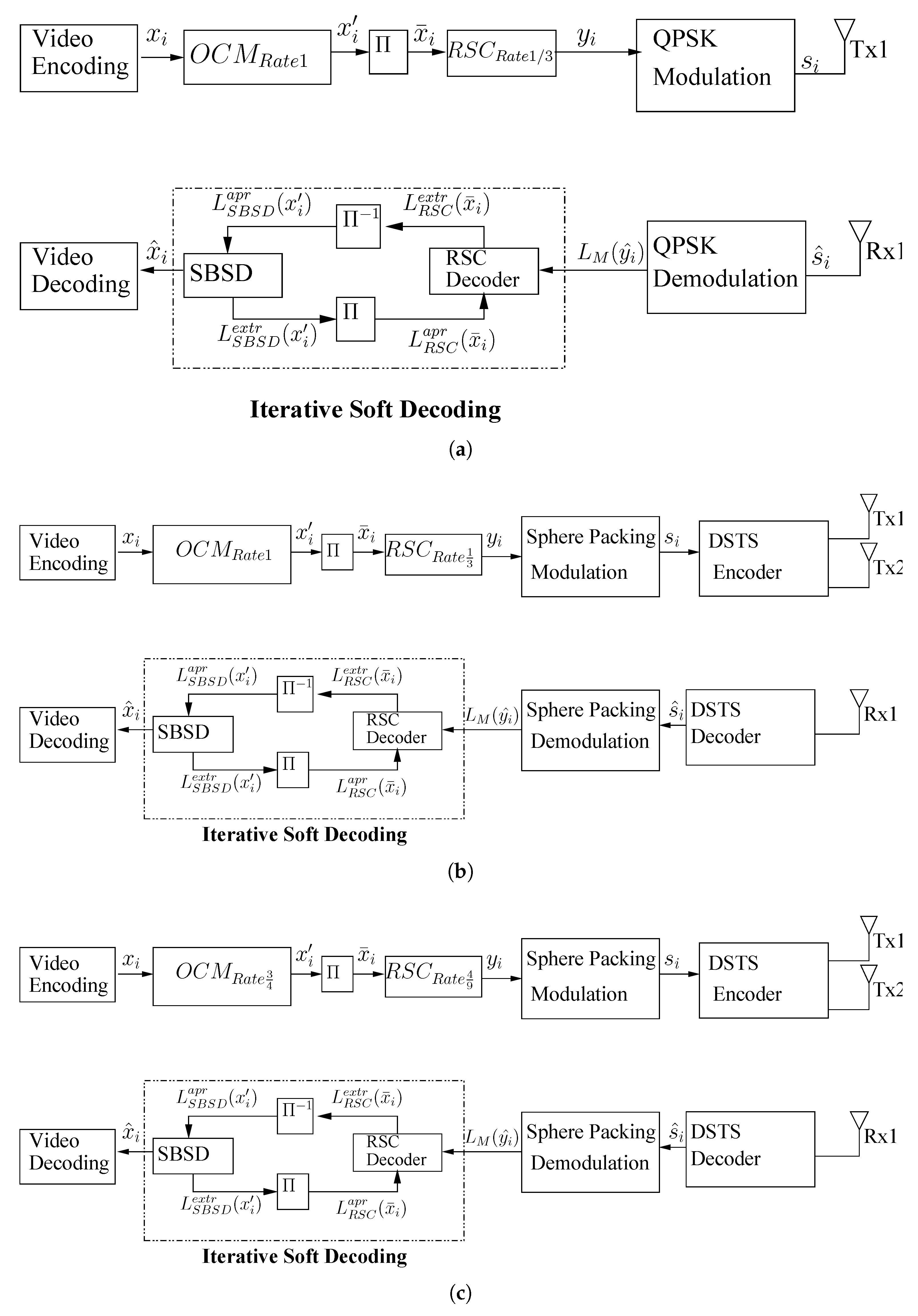
3.2. Source Channel Encoding
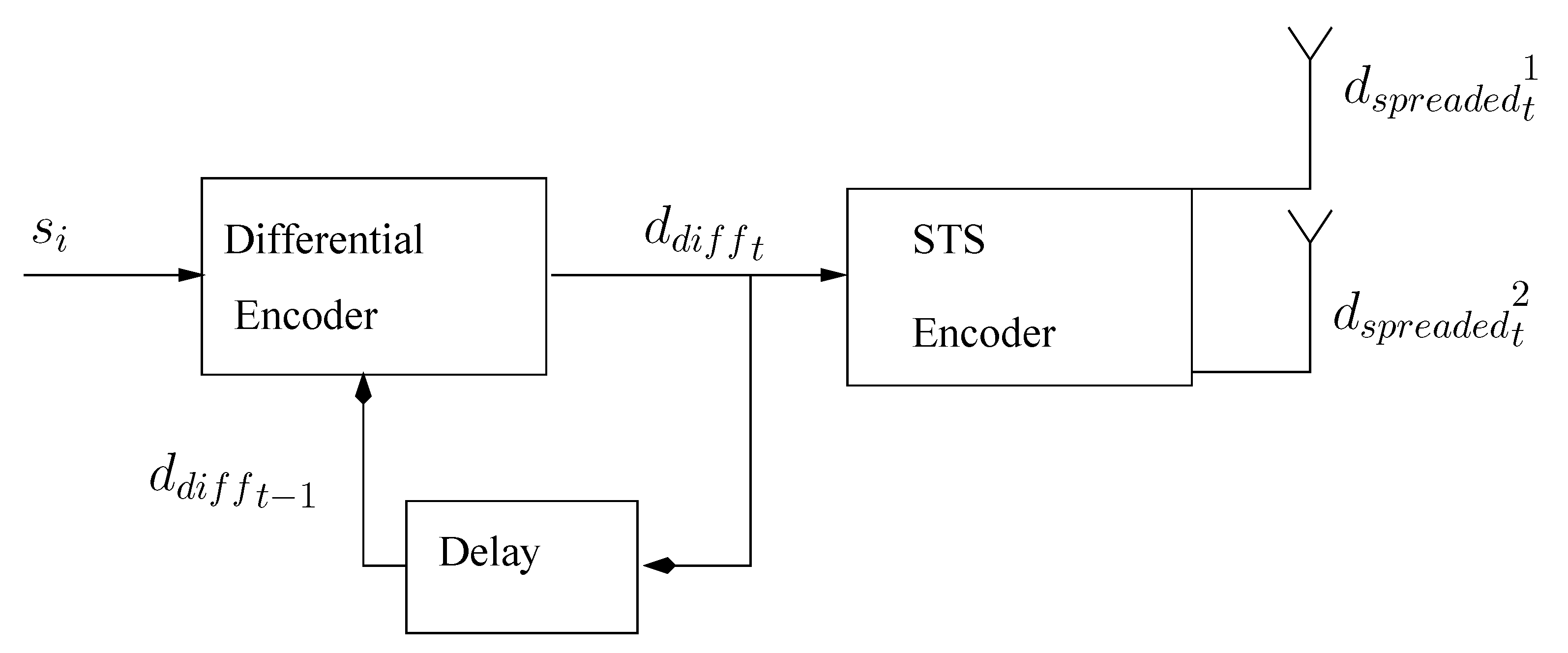
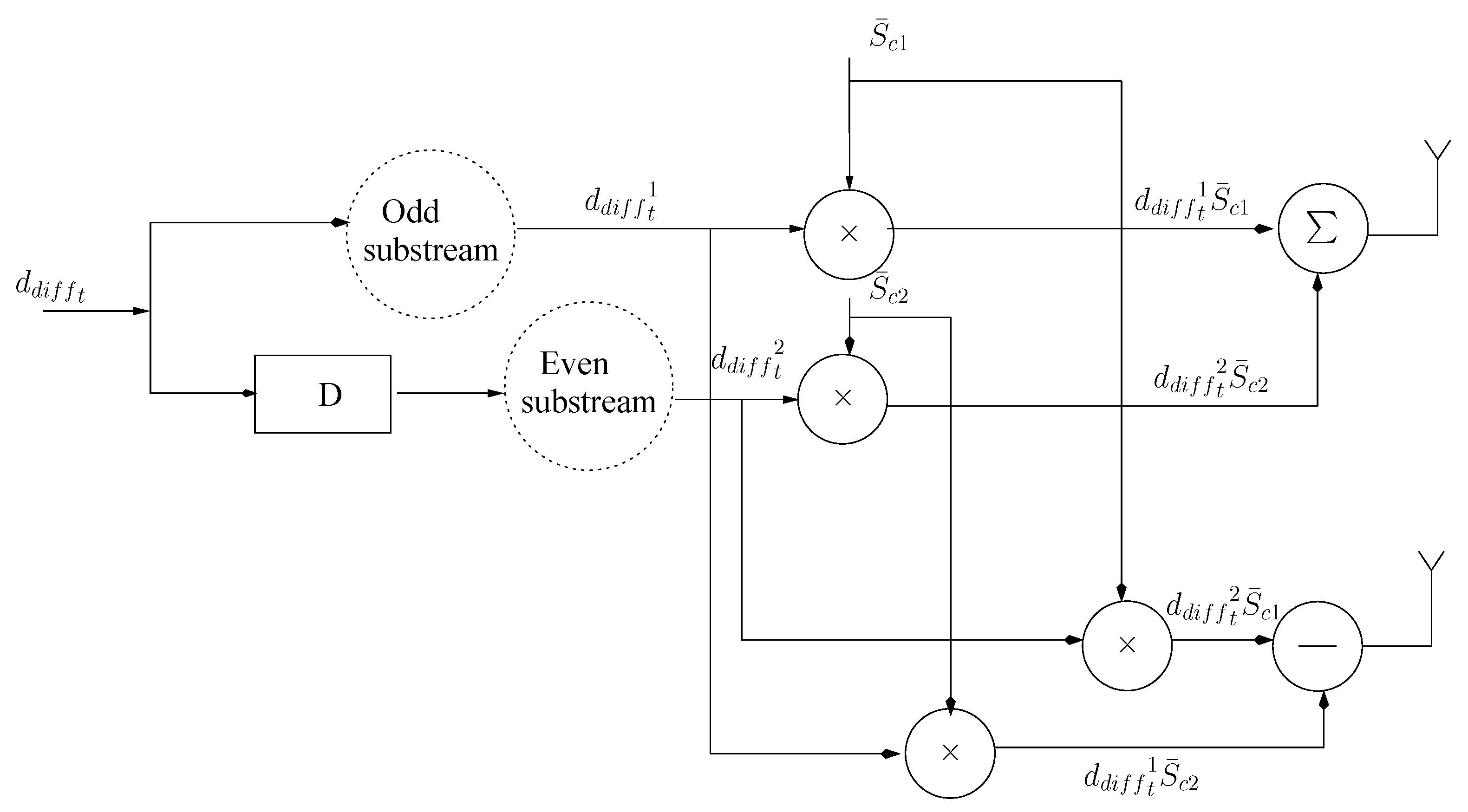
3.3. Modulation and Transmission
3.4. Iterative Soft Decoding
4. Simulations Results and Analysis
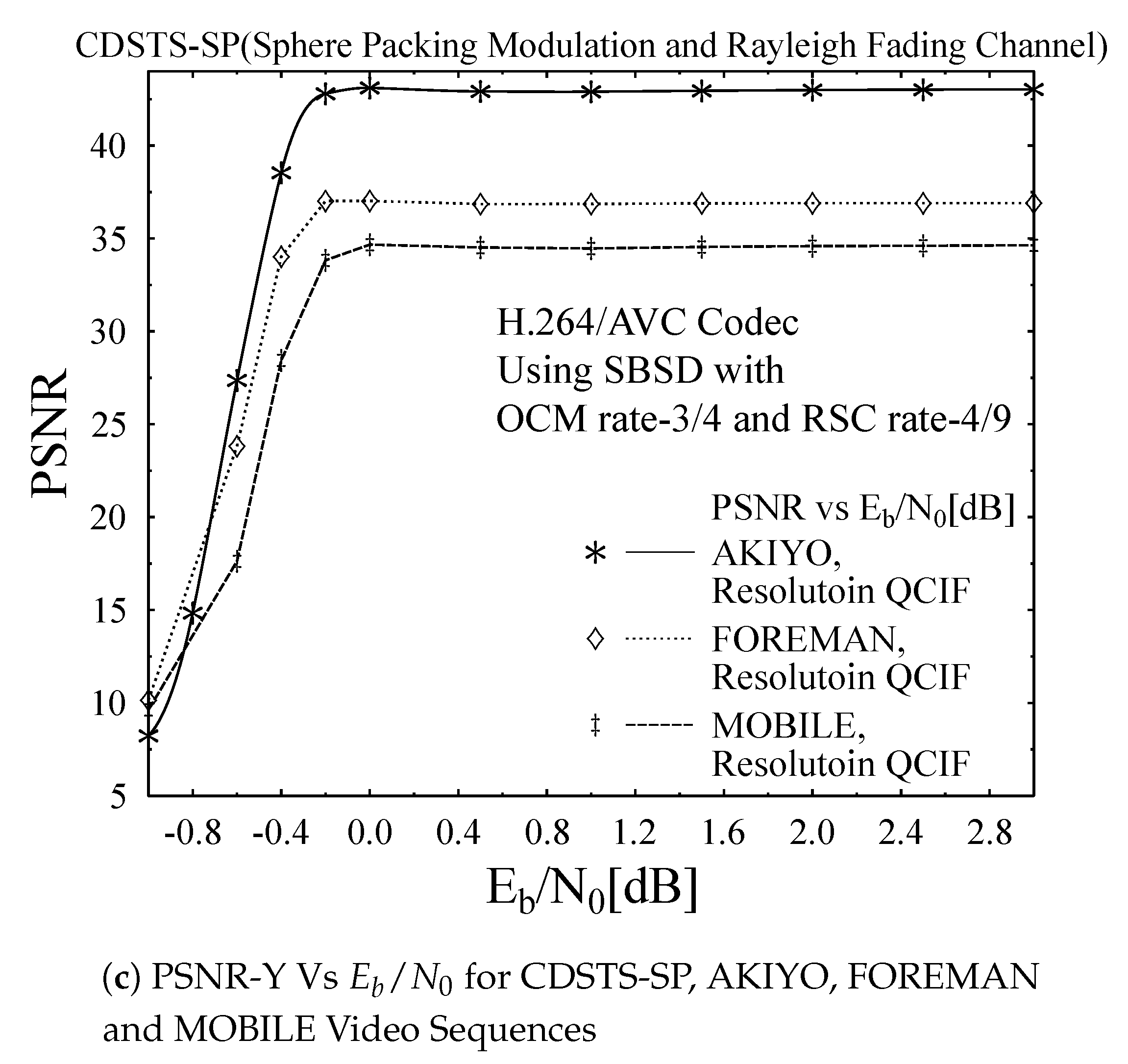
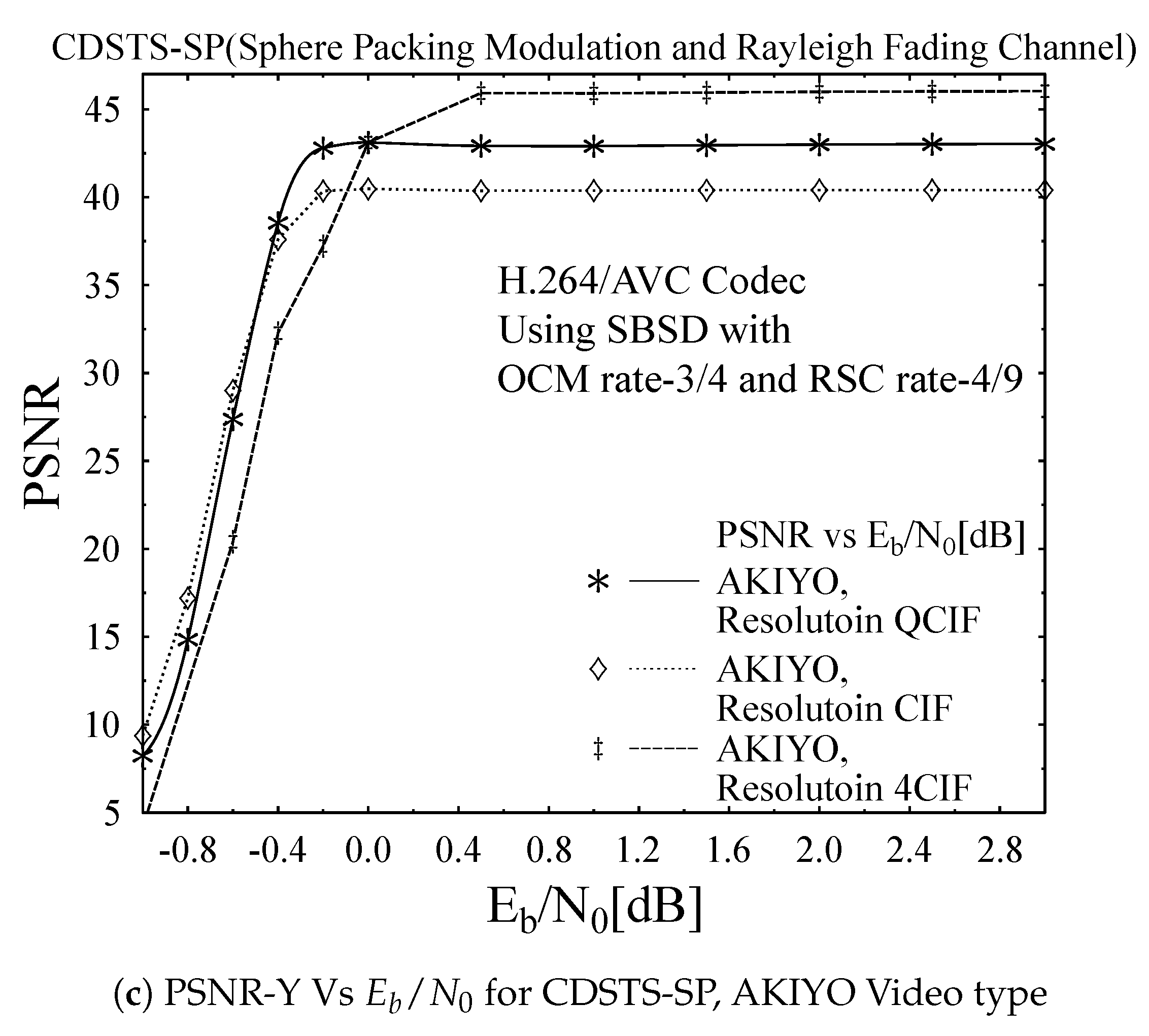
- Akiyo: This is a video of newscaster with extremely negligible movement and less details in the background.
- Foreman: This is a video of a foreman with rapidly moving face, extensive zoom out, average details and regular structures.
- Mobile: This is a video of a moving toy train with high details and dynamism.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Index, C. Cisco visual networking index: Global mobile data traffic forecast update, 2015–2020. In Cisco Technical Report; White Paper; Cisco System: San Jose, CA, USA, 2016. [Google Scholar]
- Global Mobile Data Traffic Forecast. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2018–2023; White Paper; Cisco System: San Jose, CA, USA, 2020. [Google Scholar]
- Björnson, E.; Hoydis, J.; Sanguinetti, L. Massive MIMO networks: Spectral, energy, and hardware efficiency. Found. Trends Signal Process. 2017, 11, 154–655. [Google Scholar] [CrossRef]
- Pirinen, P. A brief overview of 5G research activities. In Proceedings of the 1st International Conference on 5G for Ubiquitous Connectivity, Akaslompolo, Finland, 26–28 November 2014; pp. 17–22. [Google Scholar]
- Richardson, I.E. H. 264 and MPEG-4 Video Compression: Video Coding for Next-Generation Multimedia; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shannon, C.E. Communication in the Presence of Noise. Proc. IRE 1949, 37, 10–21. [Google Scholar] [CrossRef]
- Hamming, R.W. Error Detecting and Error Correcting Codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Elias, P. Coding for noisy channels. In IRE Convention Record; Technical Report; Butterworth Scientific Publications: London, UK, 1955; pp. 37–47. [Google Scholar]
- Nguyen, H.V.; Xu, C.; Ng, S.X.; Hanzo, L. Near-capacity wireless system design principles. IEEE Commun. Surv. Tutor. 2015, 17, 1806–1833. [Google Scholar] [CrossRef]
- Hagelbarger, D.W. Recurrent Codes: Easily Mechanized, Burst-Correcting, Binary Codes. Bell Syst. Tech. J. 1959, 38, 969–984. [Google Scholar] [CrossRef]
- Wozencraft, J.M.; Reiffen, B. Sequential Decoding; The MIT Press: Cambridge, MA, USA, 1961; Volume 10. [Google Scholar]
- Fano, R. A heuristic discussion of probabilistic decoding. IEEE Trans. Inf. Theory 1963, 9, 64–74. [Google Scholar] [CrossRef]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef]
- Forney, G.D. The viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Forney, G.D., Jr. The viterbi algorithm: A personal history. arXiv 2005, arXiv:cs/0504020. [Google Scholar]
- Forney, G. Maximum-likelihood sequence estimation of digital sequences in the presence of intersymbol interference. IEEE Trans. Inf. Theory 1972, 18, 363–378. [Google Scholar] [CrossRef]
- Bahl, L.; Cullum, C.; Frazer, W.; Jelinek, F. An efficient algorithm for computing free distance (Corresp.). IEEE Trans. Inf. Theory 1972, 18, 437–439. [Google Scholar] [CrossRef]
- Bahl, L.; Cocke, J.; Jelinek, F.; Raviv, J. Optimal decoding of linear codes for minimizing symbol error rate (Corresp.). IEEE Trans. Inf. Theory 1974, 20, 284–287. [Google Scholar] [CrossRef]
- Berrou, C.; Glavieux, A.; Thitimajshima, P. Near Shannon limit error-correcting coding and decoding: Turbo-codes. 1. In Proceedings of the ICC 93—IEEE International Conference on Communications, Geneva, Switzerland, 23–26 May 1993. [Google Scholar] [CrossRef]
- Berrou, C.; Glavieux, A. Near optimum error correcting coding and decoding: Turbo-codes. In The Best of the Best: Fifty Years of Communications and Networking Research; Wiley-IEEE Press: Hoboken, NJ, USA, 2007. [Google Scholar]
- Steele, R.; Hanzo, L. Mobile Radio Communications: Second and Third Generation Cellular and WATM Systems, 2nd ed.; IEEE Press-John Wiley: Chichester, UK, 1999. [Google Scholar]
- Koch, W.; Baier, A. Optimum and sub-optimum detection of coded data disturbed by time-varying intersymbol interference (applicable to digital mobile radio receivers). In Proceedings of the GLOBECOM 90: IEEE Global Telecommunications Conference and Exhibition, San Diego, CA, USA, 2–5 December 1990. [Google Scholar] [CrossRef]
- Chen, C.; Wang, L.; Lau, F.C. Joint optimization of protograph LDPC code pair for joint source and channel coding. IEEE Trans. Commun. 2018, 66, 3255–3267. [Google Scholar] [CrossRef]
- Burth Kurka, D.; Gündüz, D. Joint Source-Channel Coding of Images with (not very) Deep Learning. In International Zurich Seminar on Information and Communication (IZS 2020) Proceedings; ETH Zurich: Zürich, Switzerland, 2020; pp. 90–94. [Google Scholar]
- Minallah, N.; Ullah, K.; Frnda, J.; Cengiz, K.; Awais Javed, M. Transmitter Diversity Gain Technique Aided Irregular Channel Coding for Mobile Video Transmission. Entropy 2021, 23, 235. [Google Scholar] [CrossRef]
- Minallah, N.; Butt, M.F.U.; Khan, I.U.; Ahmed, I.; Khattak, K.S.; Qiao, G.; Liu, S. Analysis of Near-Capacity Iterative Decoding Schemes for Wireless Communication Using EXIT Charts. IEEE Access 2020, 8, 124424–124436. [Google Scholar] [CrossRef]
- Minallah, N.; Ahmed, I.; Ijaz, M.; Khan, A.S.; Hasan, L.; Rehman, A. On the Performance of Self-Concatenated Coding for Wireless Mobile Video Transmission Using DSTS-SP-Assisted Smart Antenna System. Wirel. Commun. Mob. Comput. 2021, 2021, 8836808. [Google Scholar] [CrossRef]
- Brejza, M.F.; Maunder, R.G.; Al-Hashimi, B.M.; Hanzo, L. A High-Throughput FPGA Architecture for Joint Source and Channel Decoding. IEEE Access 2017, 5, 2921–2944. [Google Scholar] [CrossRef]
- Balsa, J.; Domínguez-Bolaño, T.; Fresnedo, Ó.; García-Naya, J.A.; Castedo, L. Transmission of Still Images Using Low-Complexity Analog Joint Source-Channel Coding. Sensors 2019, 19, 2932. [Google Scholar] [CrossRef]
- Bourtsoulatze, E.; Burth Kurka, D.; Gündüz, D. Deep Joint Source-Channel Coding for Wireless Image Transmission. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 567–579. [Google Scholar] [CrossRef]
- Yang, H.; Qing, L.; He, X.; Ou, X.; Liu, X. Robust distributed video coding for wireless multimedia sensor networks. Multimed. Tools Appl. 2018, 77, 4453–4475. [Google Scholar] [CrossRef]
- Cai, S.; Lin, W.; Yao, X.; Wei, B.; Ma, X. Systematic Convolutional Low Density Generator Matrix Code. arXiv 2020, arXiv:2001.02854. [Google Scholar]
- Hagenauer, J. The exit chart—Introduction to extrinsic information transfer in iterative processing. In Proceedings of the 2004 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004; pp. 1541–1548. [Google Scholar]
- Brink, S. Designing iterative decoding schemes with the extrinsic information chart. AEU Int. J. Electron. Commun 2000, 54, 389–398. [Google Scholar]
- Du, J.; Yang, L.; Yuan, J.; Zhou, L.; He, X. Bit Mapping Design for LDPC Coded BICM Schemes with Multi-Edge Type EXIT Chart. IEEE Commun. Lett. 2017, 21, 722–725. [Google Scholar] [CrossRef]
- Stockhammer, T.; Hannuksela, M.; Wiegand, T. H. 264/AVC in wireless environments. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 657–673. [Google Scholar] [CrossRef]
- Nam, C.; Chu, C.; Kim, T.; Han, S. A novel motion recovery using temporal and spatial correlation for a fast temporal error concealment over H. 264 video sequences. Multimed. Tools Appl. 2020, 79, 1221–1240. [Google Scholar] [CrossRef]
- Nie, H.; Jiang, X.; Tang, W.; Zhang, S.; Dou, W. Data security over wireless transmission for enterprise multimedia security with fountain codes. Multimed. Tools Appl. 2020, 79, 10781–10803. [Google Scholar] [CrossRef]
- Yuan, J. Video data wireless transmission method based on cross-layer bitrate adaptation and error control. Multimed. Tools Appl. 2019, 79, 9255–9266. [Google Scholar] [CrossRef]
- Ibrahim, S.K.; Khamiss, N.N. A new wireless generation technology for video streaming. J. Comput. Netw. Commun. 2019, 2019, 3671826. [Google Scholar] [CrossRef]
- Ma, Z.; Sun, S. Research on HEVC screen content coding and video transmission technology based on machine learning. Ad Hoc Netw. 2020, 107, 102257. [Google Scholar] [CrossRef]
- Choi, Y.; Joo, J. Exploration of practical HEVC/H. 265 sample adaptive offset encoding policies. IEEE Signal Process. Lett. 2014, 22, 465–468. [Google Scholar] [CrossRef]
- Ichigaya, A.; Nishida, Y. Required bit rates analysis for a new broadcasting service using HEVC/H. 265. IEEE Trans. Broadcast. 2016, 62, 417–425. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, K.; Yuan, S.; Kuo, S. Moving Object Counting Using a Tripwire in H.265/HEVC Bitstreams for Video Surveillance. IEEE Access 2016, 4, 2529–2541. [Google Scholar] [CrossRef]
- Hsieh, J.; Cai, J.; Wang, Y.; Guo, Z. ML-Assisted DVFS-Aware HEVC Motion Estimation Design Scheme for Mobile APSoC. IEEE Syst. J. 2019, 13, 4464–4473. [Google Scholar] [CrossRef]
- Singhadia, A.; Mamillapalli, M.; Chakrabarti, I. Hardware-efficient 2D-DCT/IDCT architecture for portable HEVC-compliant devices. IEEE Trans. Consum. Electron. 2020, 66, 203–212. [Google Scholar] [CrossRef]
- Coding, H.E.V.; Series, H. Audiovisual and Multimedia Systems. In Infrastructure of Audiovisual Services Coding Moving Video; ITU Recommendation: Geneva, Switzerland, 2013; Volume 265. [Google Scholar]
- Jafarkhani, H. Space-Time Coding: Theory and Practice; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Kułakowski, P. The Multiple-Input Multiple-Output Systems in Slow and Fast Varying Radio Channels. Ph.D. Thesis, AGH University of Science and Technology, Kraków, Poland, 2006. [Google Scholar]
- Tarokh, V.; Seshadri, N.; Calderbank, A.R. Space-time codes for high data rate wireless communication: Performance criterion and code construction. IEEE Trans. Inf. Theory 1998, 44, 744–765. [Google Scholar] [CrossRef]
- Su, W.; Safar, Z.; Liu, K.R. Space-time signal design for time-correlated Rayleigh fading channels. IEEE Int. Conf. Commun. 2003, 5, 3175–3179. [Google Scholar]
- Su, W.; Xia, X.G. On space-time block codes from complex orthogonal designs. Wirel. Pers. Commun. 2003, 25, 1–26. [Google Scholar] [CrossRef]
- El-Hajjar, M.H. Near-Capacity MIMOs Using Iterative Detection. Ph.D. Thesis, University of Southampton, Southampton, UK, 2008. [Google Scholar]
- Ohm, J.R.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the coding efficiency of video coding standards—Including high efficiency video coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Boyce, J.M.; Chen, Y.; Ohm, J.R.; Segall, C.A.; Vetro, A. Standardized extensions of high efficiency video coding (HEVC). IEEE J. Sel. Top. Signal Process. 2013, 7, 1001–1016. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Pourazad, M.T.; Doutre, C.; Azimi, M.; Nasiopoulos, P. HEVC: The new gold standard for video compression: How does HEVC compare with H. 264/AVC? IEEE Consum. Electron. Mag. 2012, 1, 36–46. [Google Scholar] [CrossRef]
- Telecommunication Standardization Sector. ITU-T Recommendation H. 265: High Efficiency Video Coding; Telecommunication Standardization Sector: Geneva, Switzerland, 2013. [Google Scholar]
- El-Hajjar, M.; Alamri, O.; Ng, S.X.; Hanzo, L. Turbo Detection of Precoded Sphere Packing Modulation Using Four Transmit Antennas for Differential Space-Time Spreading. IEEE Trans. Wirel. Commun. 2008, 7, 943–952. [Google Scholar] [CrossRef]
- Adrat, M.; Vary, P. Iterative source-channel decoding: Improved system design using EXIT charts. EURASIP J. Adv. Signal Process. 2005, 2005, 178541. [Google Scholar] [CrossRef][Green Version]
- Ten Brink, S. Convergence behavior of iteratively decoded parallel concatenated codes. IEEE Trans. Commun. 2001, 49, 1727–1737. [Google Scholar] [CrossRef]
- RECOMMENDATION ITU-R BT. Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunication Union: Geneva, Switzerland, 2002. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Coding | Parameters |
|---|---|
| Compression standard | H.264 & H.265 |
| Date-Rate for both H.264 and H.265 | 64 kbps |
| Frame-Rate | 15 fps |
| Number of Slices Per frame in H.264 | 9 |
| Macro-Blocks Per Slice in H.264 | 11 |
| Macro-Blocks per frame in Intra-frame in H.264 | 3 |
| Profile in H.264 | Extended |
| IntraPeriod of I-pictures | 15 |
| PartitionMode in H.264 | 3 Partitions per Slice |
| Entropy coding method in H.264 | UVLC |
| SliceMode in H.264 | Fixed # of MBs in slice |
| SOA | 1 |
| Slice Mode | 1 |
| Number of CTUs in slice 1 and slice 2 | 99 |
| MaxCUWidth | 64 |
| MaxCUHeight | 64 |
| Quantization Parameter | 32 |
| Symbols | OCM Rate-1 | OCM Rate- |
|---|---|---|
| 000 | 000 | 0000 |
| 001 | 001 | 1001 |
| 010 | 010 | 1010 |
| 011 | 011 | 0011 |
| 100 | 100 | 1100 |
| 101 | 101 | 0101 |
| 110 | 110 | 0110 |
| 111 | 111 | 1111 |
| System | Parameters | ||
|---|---|---|---|
| NCC | NCDSTS-SP | CDSTS-SP | |
| Ourter Code | Rate-1 OCM | Rate-1 OCM | Rate-3/4 OCM |
| Inner Code | Rate-1/3 RSC | Rate-1/3 RSC | Rate-4/9 RSC |
| Modulation | QPSK | SP | SP |
| MIMO Scheme | Nill | DSTS | DSTS |
| Tx | 1 | 2 | 2 |
| Rx | 1 | 1 | 1 |
| Channel | Rayleigh | Rayleigh | Rayleigh |
| Doppler Frequency | 0.01 | 0.01 | 0.01 |
| Scheme | Bit Rate | Modulation | |
|---|---|---|---|
| Outer Code | Inner Code | ||
| NCC | Rate-1 OCM | Rate-1/3 RSC code | QPSK |
| NCDSTS-SP | Rate-1 OCM | Rate-1/3 RSC code | Sphere Packing |
| CDSTS-SP | Rate-3/4 OCM | Rate-4/9 RSC code | Sphere Packing |
| Sampling Format | Video Sequence Resolution | Luminance (Y) Resolution | Luminance Bits per Frame | Chrominance (Cb & Cr) Resolution | Chrominance Bits per Frame |
|---|---|---|---|---|---|
| YUV(4:4:4) | QCIF | 176 × 144 | 608,256 | 176 × 144 | 608,256 |
| CIF | 352 × 288 | 2,433,024 | 352 × 288 | 2,433,024 | |
| 4CIF | 704 × 576 | 9,732,096 | 704 × 576 | 9,732,096 | |
| YUV(4:2:2) | QCIF | 176 × 144 | 405,504 | 88 × 144 | 202,752 |
| CIF | 352 × 288 | 1,422,016 | 176 × 288 | 811,008 | |
| 4CIF | 704 × 576 | 6,488,064 | 352 × 576 | 3,244,032 | |
| YUV(4:2:0) | QCIF | 176 × 144 | 304,128 | 88 × 72 | 76,032 |
| CIF | 352 × 288 | 1,216,512 | 176 × 144 | 304,128 | |
| 4CIF | 704 × 576 | 4,866,044 | 352 × 288 | 1,216,512 | |
| Video Sequence (VS) | Frames | Frame rate | Reason for a selection | ||
| AIYO | 45 | 15 fps | Low motion and dynamism | ||
| FOREMAN | Medium motion and dynamism | ||||
| MOBILE | High motion and dynamism | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minallah, N.; Ullah, K.; Frnda, J.; Hasan, L.; Nedoma, J. On the Performance of Video Resolution, Motion and Dynamism in Transmission Using Near-Capacity Transceiver for Wireless Communication. Entropy 2021, 23, 562. https://doi.org/10.3390/e23050562
Minallah N, Ullah K, Frnda J, Hasan L, Nedoma J. On the Performance of Video Resolution, Motion and Dynamism in Transmission Using Near-Capacity Transceiver for Wireless Communication. Entropy. 2021; 23(5):562. https://doi.org/10.3390/e23050562
Chicago/Turabian StyleMinallah, Nasru, Khadem Ullah, Jaroslav Frnda, Laiq Hasan, and Jan Nedoma. 2021. "On the Performance of Video Resolution, Motion and Dynamism in Transmission Using Near-Capacity Transceiver for Wireless Communication" Entropy 23, no. 5: 562. https://doi.org/10.3390/e23050562
APA StyleMinallah, N., Ullah, K., Frnda, J., Hasan, L., & Nedoma, J. (2021). On the Performance of Video Resolution, Motion and Dynamism in Transmission Using Near-Capacity Transceiver for Wireless Communication. Entropy, 23(5), 562. https://doi.org/10.3390/e23050562