Abstract
Clustering algorithms for multi-database mining (MDM) rely on computing pairwise similarities between n multiple databases to generate and evaluate candidate clusterings in order to select the ideal partitioning that optimizes a predefined goodness measure. However, when these pairwise similarities are distributed around the mean value, the clustering algorithm becomes indecisive when choosing what database pairs are considered eligible to be grouped together. Consequently, a trivial result is produced by putting all the n databases in one cluster or by returning n singleton clusters. To tackle the latter problem, we propose a learning algorithm to reduce the fuzziness of the similarity matrix by minimizing a weighted binary entropy loss function via gradient descent and back-propagation. As a result, the learned model will improve the certainty of the clustering algorithm by correctly identifying the optimal database clusters. Additionally, in contrast to gradient-based clustering algorithms, which are sensitive to the choice of the learning rate and require more iterations to converge, we propose a learning-rate-free algorithm to assess the candidate clusterings generated on the fly in fewer upper-bounded iterations. To achieve our goal, we use coordinate descent (CD) and back-propagation to search for the optimal clustering of the n multiple database in a way that minimizes a convex clustering quality measure in less than iterations. By using a max-heap data structure within our CD algorithm, we optimally choose the largest weight variable at each iteration i such that taking the partial derivative of with respect to allows us to attain the next steepest descent minimizing without using a learning rate. Through a series of experiments on multiple database samples, we show that our algorithm outperforms the existing clustering algorithms for MDM.
1. Introduction
Large multi-branch companies need to analyze multiple databases to discover useful patterns for the decision-making process. To make global decisions for the entire company, the traditional approach suggests to merge and integrate the local branch-databases into a huge data warehouse, and then one can apply data mining algorithms [1] to the accumulated dataset to mine the global patterns useful for all the branches of the company. However, there are some limitations associated with this approach. For instance, the cost of moving the data over the network, and integrating and storing potentially heterogeneous databases could be expensive. Moreover, some branches may not accept sharing their raw data due to the underlying privacy issues. More crucially, integrating a large amount of irrelevant data can easily disguise some essential patterns hidden in multiple databases. To tackle the latter problems, it is suggested to keep the transactional data stored locally and only forward the local patterns mined at each branch database to a central site where they will be clustered into disjoint cohesive pattern-base groups for knowledge discovery. In fact, analyzing the local patterns present in each individual cluster of the multiple databases (MDB) enhances the quality of aggregating novel relevant patterns, and also facilitates the parallel maintenance of the obtained database clusters.Various clustering algorithms and models have been introduced in the literature, namely spectral-based models [2], hierarchical [3], partitioning [4], competitive learning-based models [5,6,7] and artificial neural networks (ANNs) based clustering [8,9,10]. Additionally, clustering could be applied in many domains [11,12] including community discovery in social networks [13,14], image segmentation [15,16] and recommendation systems [17,18,19]. In this article, we focus on exploring similarity-based clustering models for multi-database mining [20,21,22,23], due to their stability, simplicity [24] and robustness in partitioning graphs of n multiple databases into k connected components consisting of similar database objects. Nevertheless, the existing clustering quality measures in [20,21,22,23] are non-convex objectives suffering from the existence of local optima. Consequently, identifying the optimal clustering may be a difficult task, as it requires evaluating all the candidate clusterings generated at all the local optima in order to find the ideal clustering.
To address the issues associated with clustroid initialization, preselection of a suitable number of clusters and non-convexity of the clustering quality objectives, we proposed in [25,26] an algorithm named GDMDBClustering, which minimizes a quasi-convex loss function quantifying the quality of the multi-database clustering, without a priori assumptions about which number of clusters should be chosen. Therefore, in contrast to the clustering models proposed in [20,21,22,23], GDMDBClustering [25] does not require us to produce and assess all the possible candidate classifications in order to find the optimal partitioning. Alternatively, each partitioning is assessed on the fly as it is generated and the clustering algorithm terminates right after attaining the global minimum of the objective function. However, the existing gradient-based clustering algorithms [25,26] are strongly dependent on the choice of the learning rate , which influences the number of learning cycles required to find the optimal partitioning. In fact, selecting a larger value may cause global minimum overshooting and setting a smaller value may necessitate many learning iterations for the algorithm to converge.
In this paper, we improve upon previous work [25,26] and propose a learning-rate-free (i.e., independent of the learning rate ) algorithm requiring fewer upper-bounded iterations (i.e., the maximum number of iterations is at most ) to minimize a clustering convex loss function using coordinate descent (CD) and back-propagation. Precisely, our proposed algorithm minimizes a quadratic hinge-based loss over the first largest coordinate variable while keeping the rest of the variables fixed. Then, it minimizes over the second largest coordinate variable while keeping the rest of the variables fixed, and so on until convergence or until cycling through all the coordinate variables. Consequently, our algorithm becomes faster than GDMDBClustering [25] which is dependent on a learning rate and also requires us to minimize the cost over a large set of variables at each iteration. This can be a very challenging problem in contrast to minimizing the loss over one single variable at a time while keeping all the other dimensions fixed.
On the other hand, existing clustering algorithms for multi-database mining (MDM) [20,21,22,23,25,26] proceed by computing pairwise similarities between n multiple databases, and then use these values to generate and evaluate candidate clusterings in order to select the ideal partitioning optimizing a given goodness measure. However, when () are distributed around the mean value , the fuzziness index of the similarity matrix increases and the clustering algorithm becomes uncertain when choosing what database pairs are considered similar and hence eligible to be put into the same cluster. Consequently, a trivial result is produced, i.e., putting all the n databases in one cluster or returning n singleton clusters. To tackle the latter problem, we propose a learning algorithm to reduce the fuzziness in the pairwise similarities by minimizing a weighted binary entropy loss function via gradient descent and back-propagation. Precisely, the learned model will force the similarity values above 0.5 to go closer to their maximum value (≈1), and let those below 0.5 go closer to their minimum value (≈0) in a way that minimizes . This will significantly reduce the associated fuzziness and improve the certainty of the clustering algorithm to correctly identify the optimal database clusters. The main contributions of this article are listed as follows:
- Unlike the existing algorithms proposed in [20,21,22,23,25,26] where one-class trivial clusterings are produced when the similarity values are centered around the mean value, we have added a preprocessing layer prior to clustering where the pairwise similarities are adjusted to reduce the associated fuzziness and hence improve the quality of the produced clustering. Our experimental results show that reducing the fuzziness of the similarity matrix helps generating meaningful relevant clusters that are different to the one-class trivial clusterings.
- Unlike the multi-database clustering algorithms proposed in [20,21,22,23], our approach uses a convex objective function to assess the quality of the produced clustering. This allows our algorithm to terminate just after attaining the global minimum of the objective function (i.e., after exploring fewer similarity levels). Consequently, this avoids generating unnecessary candidate clusterings, and hence reduces the CPU overhead. On the other hand, the clustering algorithms in [20,21,22,23] use non-convex objectives (i.e., they suffer from the existence of local optima due to the use of more than two monotonic functions), and therefore require generating and evaluating all the local candidate clustering solutions in order to find the clustering located at the global optimum.
- Furthermore, unlike the previous gradient-based clustering algorithms [25,26], our proposed algorithm is leaning-rate-free (i.e., independent of the learning rate), and needs at most (in the worst case) iterations to converge. That is why our proposed algorithm is faster than GDMDBClustering [25], which is strongly dependent on the learning step size and its decay rate.
- Additionally, unlike the similarity measure proposed in [20], which assumes that the same threshold was used to mine the local patterns from the n transactional databases, our proposed similarity measure takes into account the existence of n different local thresholds, which are then combined to calculate a new threshold for each cluster. Afterward, using the new thresholds, our similarity measure accurately estimates the valid patterns post-mined from each cluster in order to compute the pairwise similarities.
- The experiments carried out on real, synthetic and randomly generated datasets show that the proposed clustering algorithm outperforms the compared clustering models in [20,21,22,23,25,26], as it has the shorted average running time and the lowest average clustering error.
The remainder of this paper is organized as follows: Section 2 presents an example motivating the importance of clustering for multi-database mining (MDM) and also reviews traditional clustering algorithms for MDM. Section 3 defines the main concepts related to similarity-based clustering and then introduces the proposed approach and its main components. Section 4 presents and analyzes the experimental results. Finally, Section 5 draws conclusions and highlights potential future work.
2. Motivation and Related Work
2.1. Motivating Example
Prior to mining the multiple databases (MDB) of a multi-branch enterprise, it is essential to cluster these MDB into disjoint and cohesive pattern-base groups sharing an important number of local patterns in common. Then, using local pattern analysis and pattern synthesizing techniques [27,28,29,30], one can examine the local patterns in each individual cluster to discover novel patterns, including the exceptional patterns [31] and the high-vote patterns [32], which are extremely useful when it comes to making special targeted decisions regarding each cluster of branches of the same corporation. In the following example, we show the impact of clustering the multi-databases of a multi-branch corporation prior to multi-database mining. Consider the six transactional databases shown in Table 1, where each database records a set of transactions enclosed in parentheses and each transaction contains a set of items separated by commas. Consider a minimum support threshold . The local frequent itemsets, denoted by , and discovered from each database are shown in Table 2, such that in each tuple of is the frequent itemset name and , named , is the ratio of the number of transactions in containing to the total number of transactions in .

Table 1.
Six transactional databases , for .
Table 2.
The frequent itemsets (FIs) discovered from each transactional database in Table 1 under a threshold .
Now, the global support of each itemset is calculated via the synthesizing equation [33] defined as follows:
where is the total number of databases in and is the number of transactions in . For instance, we can calculate the global support of the itemset A as follows:
After computing the global supports of the rest of the itemsets using (1), no single novel pattern has been found, i.e., ). The reason is that irrelevant patterns were involved in the synthesizing procedure. Now, if we examine the frequent itemsets in Table 2, we observe that some databases share many patterns in common. Precisely, the six databases seem to form two clusters, = and = , where each cluster of databases tend to share similar frequent itemsets.
Next, let us use the synthesizing Equation (1) on the frequent itemsets coming from every single cluster , such that for cluster and for cluster . This time, new valid frequent itemsets having a support value above the minimum threshold are discovered in the two clusters. In fact, = and = . The obtained patterns show that a percentage of more than of the total transactions in the cluster include the itemsets C, B and A. More than of the total transactions in the cluster include , F and H. Moreover, some associations between itemsets could be derived as well, such that the itemset suggests that on average, if a customer collects the item H at one of the branches in , they are likely to also buy the item F with a confidence.
The above example demonstrates the importance of clustering the multi-databases into disjoint cohesive clusters before synthesizing the global patterns. In fact, when the local patterns mined from the six databases were analyzed all together, no global pattern could be synthesized. On the other hand, when the six databases were divided into two different clusters and then each cluster was analyzed individually, useful and novel patterns (knowledge) were discovered. Actually, from the discovered knowledge, decision makers and stakeholders are going to have a clear vision about the branches that exhibit similar purchasing behaviors, and hence take useful decision accordingly. In fact, appropriate business decisions may be taken regarding each group of similar branches in order to predict potential purchasing patterns, increase the customer retention rate and convince customers to purchase more services in the future. Consequently, exploring and examining individual clusters of similar local patterns is going to help the discovery of new and relevant patterns capable of improving the decision-making quality.
2.2. Prior Work
The authors in [34] have adopted a divide and conquer mono-database mining approach to accelerate mining global frequent itemsets (FIs) in large transactional databases. In [35,36], the authors have proposed similar work where big transactional databases are divided into k disjoint transaction partitions whose sizes are small enough to be read and loaded to the random access memory. Then, the frequent itemsets (FIs) mined from all the k partitions are synthesized into global FIs using an aggregation function such as the one suggested by the authors in [33]. It is worth noting that for mono-database mining applications, we usually have direct access to the raw data stored in big transactional databases. On the other hand, for multi-database mining (MDM) applications, it is suggested to keep the transactional data stored locally and only forward the local patterns mined at each branch database to a central site where they will be clustered into disjoint cohesive pattern-base groups for knowledge discovery. As a result, the confidential raw data are kept safe, and also the cost associated with transmitting a large amount of data over the network is cut off. Hence, in contrast to clustering the transactional data stored in a single data warehouse, our approach consists of clustering the local patterns mined and forwarded from multi-databases without requiring the number of clusters to be set a priori. Our purpose is to identify the group of databases that share similar patterns, such as the high-vote patterns [32] and the exceptional patterns [31,37,38] that can be used to make specific decisions regarding their corresponding branches. In the traditional clustering approach [34,35,36] applied for mono-database mining, we can only mine the global patterns that are supported by the whole multi-branch company.
The existing clustering algorithms for multi-database [20,21,23,39,40] are based on an agglomerative process that generates hierarchical partitionings at different levels of similarity, where each cluster in a given candidate partitioning is included in another cluster of a partitioning produced at the next similarity level. Regardless of the latter observation, each candidate partitioning is produced without taking into account the use of the clusters generated at the previous similarity levels. As a result, the clustering algorithms in [20,21,23,39,40] unnecessarily reconstruct clusters that have been built at the previous similarity levels. The latter limitation inspired the authors in [22] to design a graph-based algorithm, which maintains the classes produced at prior similarity levels in order to produce new subsequent classes out of them. Despite the fact that the experiments done in [22] showed promising results against the prior work [20,21,23,39,40], these algorithms are based on non-convex functions to evaluate the quality of the produced candidate clusterings. Consequently, finding the ideal clustering for which a non-convex function is optimal may be a difficult problem to solve in a short time.
To face the latter problem, the authors in [26] have transformed the clustering problem into a quasi-convex optimization problem solvable via gradient descent and back-propagation. Consequently, an early stopping of the clustering process occurs right after converging to the global minimum. Hence, by avoiding generating and evaluating unnecessary candidate clusterings, we can significantly reduce the CPU execution time. Even though traditional clustering algorithm such as k-means [4,41] are intuitive, popular and not hard to implement, they remain sensitive to clustroid initialization, preselection of a suitable number of clusters and non-convexity of the clustering quality objective [42]. The silhouette plot [43] could be used to find an appropriate number of clusters, but this requires executing k-means multiple times with different number of clusters in order to find the ideal partitioning maximizing the silhouette objective. As a result, the time performance will be influenced in the case of clustering big high-dimensional datasets. Slightly different, hierarchical-based clustering algorithms [3] build nested hierarchical levels to visualize the relationships between different objects in the form of dendrograms. Then, it is up to the domain expert or to some non-convex metrics to determine at which level the tree diagram should be cut.
Conversely, the optimization problem formulated in [25,26] is quasi-convex. Therefore, convergence to the global optimum is independent of the initial settings. Furthermore, the proposed gradient-based clustering GDMDBClustering [25] does not need to have the number of clusters as a parameter. Alternatively, the number of clusters becomes a parametric function in the main objective. However, GDMDBClustering is based on the choice of a suitable learning rate, i.e., choosing a small learning rate may increase the number of iterations and slow down learning the optimal weights, whereas a large may let the algorithm overshoot the global minimum. To overcome the latter limitation, we propose in this paper a learning-rate-free clustering algorithm, named CDClustering, which minimizes a convex objective function quantifying the clustering quality. For this purpose, we use coordinate descent (CD) and back-propagation to search for the optimal clustering of n multiple database in less than iterations and without using a learning rate. This makes our algorithm faster than the previous gradient-based clustering algorithm [25,26] which remains dependent on a learning rate defined based on some prior knowledge of the properties of the loss function. On the other hand, due to the fuzziness of the similarity matrix, which increases when the pairwise similarities are distributed around the mean value, the clustering algorithm becomes indecisive when grouping similar databases together. To face this problem, we design a learning algorithm to adjust the pairwise similarities between n multiple databases, in a way which minimizes a binary entropy loss function quantifying the fuzziness associated with the similarity matrix. Thus, the proposed algorithm becomes crisp in discriminating between the different database clusters.
3. Materials and Methods
In this section, we present our fuzziness reduction model applied to the pairwise similarities between n multiple databases and describe in details our coordinate descent-based clustering approach. Some definitions and notions relevant to this work need to be presented first.
3.1. Background and Relevant Concepts
In this subsection, we define the similarity measure between two transaction databases and present the process of generating and evaluating a given candidate clustering. We also define four clustering validity functions used to evaluate the clustering quality.
3.1.1. Similarity Measure
Each transactional database is encoded as a hash-table to be defined as follows:
where , n is the number of transactional databases, m is the number of frequent itemsets in , is the name of the k-th frequent itemset, is the support of , which is the ratio of the number of rows in containing to the total number of rows in , and is the minimum support threshold corresponding to , such that . In this paper, FP-Growth [1] algorithm is used to mine the frequent itemsets in each database as it only requires two passes over the whole database. Our proposed similarity measure is based on maximizing the number of global frequent itemsets (FIs) synthesized from the local FIs in each cluster. Precisely, to measure the similarity between two transactional databases and , for , we define the following function:
where
such that
and
We note that the operator is the cardinality of the set passed in as argument. Multiplying by returns the minimum number of transactions in which a frequent itemset should occur in . Therefore, is the minimum percentage of transactions from the cluster containing the itemset , i.e., . In fact, the similarity measure in Formula (3) takes into account the local minimum support threshold at each database to calculate a new threshold for each cluster. In this paper, instead of writing ’the similarity measure in Formula (3)’, we often write (3).
3.1.2. Clustering Generation and Evaluation
Let = be a candidate clustering of = produced at a given level of similarity , such that and . From a graph-theoretic perspective, each cluster represents a connected component in a similarity graph , and an edge is added to the list of edges E if and only if , where .
Initially, has no edge, i.e., . Then, at a given similarity level , edges satisfying , are added to E. The level of similarity () is chosen from the list of the m unique sorted pairwise similarities computed between the n transaction databases, such that and . After adding all the edges at , each graph component will be representing one database cluster in our candidate partitioning . One can then use one of the clustering goodness measures shown in Table 3 to assess the quality of .
Table 3.
A summary of the clustering quality measures mentioned in this paper.
Once we generate and evaluate all the candidate clusterings, we report the global optimum (minimum or maximum) of the goodness measure and compare its corresponding clustering with the ground truth if it is known or with the clustering generated at the maximum point of the silhouette coefficient when the ground truth is unknown. In fact, the silhouette coefficient proposed in [43,44] (See the last row in Table 3) could be used to verify the correctness of the cluster labels assigned to the n transactional databases. Precisely, a value suggests that the n transactional databases are highly matched to their own clusters and loosely matched to their neighboring clusters.
We should note that each clustering goodness measure in Table 3 depends on more than two monotonic functions. For instance, the quality measure (see the first row in Table 3) proposed in [20] is based on maximizing both the intra-cluster similarity (which is a non-decreasing function on the interval [0,1]) and the inter-cluster distance (which is a non-increasing function on the interval [0,1]), while minimizing the number of clusters (which is a non-increasing function on the interval [0,1]). Consequently, as it was shown via the experiments done in [25,26], most of the time, the graphs of the objectives functions in Table 3 show a non-convex behavior, which makes identifying the ideal partitioning a hard problem to solve without generating and evaluating all the candidate clusterings generated at the local optima.
3.2. Similarity Matrix Fuzziness Reduction
In this subsection, we present our fuzziness reduction model applied to the pairwise similarities between n multiple databases. Let be a weighted similarity, such that is the similarity value between and using Formula (3) and is the weight value associated with where . Let be a continuous piecewise linear activation function and be its partial derivative defined as follows:
The graph plots of and with respect to are depicted in Figure 1a. The parameter ensures that each value is within the range such that is a very small number (e.g., –7) forcing to be always above 0 and below 1, so that it can be plugged into our log-based loss function defined in (10).
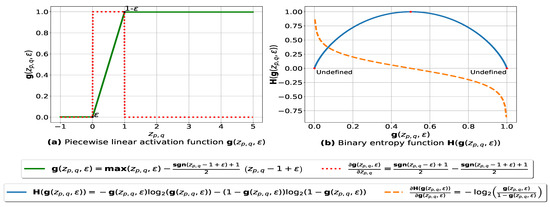
Figure 1.
(a): represents (in green) the graph of the piecewise linear activation function and (in red) its partial derivative. We note that , and is the weight associated with the similarity value , is the signum function and is a small number – ensuring that is always above 0 and below 1. (b): represents the binary entropy function in blue and its partial derivative in orange.
3.2.1. Fuzziness Index
The fuzziness index of the pairwise similarity vector = , also known as the entropy of the fuzzy set [45], and defined from to , is given as follows:
The smaller the value of , the better the clustering performance, and vice-versa. In fact, reducing the fuzziness of the pairwise similarities will lead to a more crisp decision making when it comes to finding the optimal partitioning of the n multiple databases. Particularly, the fuzziness of the similarity matrix increases when the pairwise values are centered around , resulting in more confusion when we need to decide whether two databases should be in the same cluster or not.
3.2.2. Proposed Model and Algorithm
To reduce the fuzziness associated with the pairwise similarities between the n transaction databases = , we need to make the similarity values that are above the mean value go closer to 1, and adjust the similarity values that are below to go closer to 0. To do so, we consider the minimization of the sum of the binary entropy loss functions over the weighed similarity values as follows:
such that n is the number of databases, represents the model weight vector, represents the weighted similarity and is the activation function defined in (7). The graph plots of and with respect to are depicted in Figure 1b. Since the fuzziness of the similarity matrix is influenced by the weights associated with the pairwise similarities, the degree to which a pair of databases belongs to the same cluster could be changed by adjusting the corresponding weight , which is learned by minimizing (10) via gradient descent and back-propagation. The training equations are derived as follows:
where
Let and be the initial learning rate and the maximum number of learning iterations, respectively. At each epoch i, the current learning rate decreases as follows:
We note that selecting a large learning rate value may cause global minimum overshooting, whereas choosing a small learning rate may necessitate many iterations for the algorithm to converge. Hence, it is reasonable to let the learning rate decrease over time as the algorithm converges to the global minimum. In Figure 2 and Algorithm 1, we present in detail, the framework and the algorithm of the proposed fuzziness reduction model. The proposed learning Algorithm 1: SimFuzzinessReduction keeps adjusting the weight vector by moving in the opposite direction to the gradient of the loss function until it reaches the maximum number of iteration or until the magnitude of the gradient vector becomes below the minimum value . After convergence, we can feed the new similarity values to any similarity-based clustering algorithm in order to improve the quality of the produced clustering when the latter is trivial or irrelevant.
| Algorithm 1: SimFuzzinessReduction |
 |
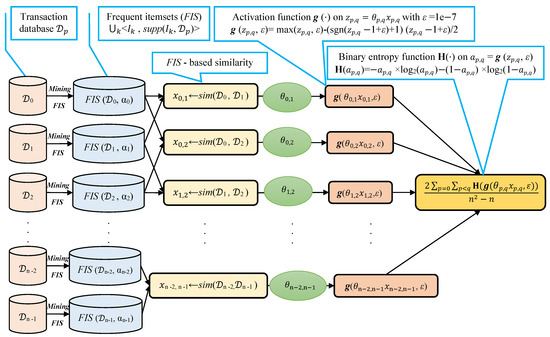
Figure 2.
Proposed fuzziness reduction model on the pairwise similarities , . We note that the graphs corresponding to the activation function and the binary entropy function are plotted in Figure 1.
3.3. Proposed Coordinate Descent-Based Clustering
In this subsection, we present and discuss our proposed loss function and our coordinate descent-based clustering approach in detail. Unlike the gradient-based clustering in [25,26], our algorithm is learning-rate-free and needs to run at most learning cycles to converge to the global minimum, such that n is the number of transaction databases. In fact, at each iteration, the largest coordinate variable is selected and popped from a max-heap data structure (initially built by pushing the pairwise similarities onto the heap). Then, we minimize our quadratic convex hinge-based loss over which is then adjusted by moving in the opposite direction to the gradient of . This process continues until satisfying a convergence test, which will be defined later in this subsection. Each bloc of selected coordinate variables that have the same value will form a set of edges to be added to our graph . Determining the disjoint connected components in G after convergence will allow us to discover the optimal database clusters maximizing the intra-cluster similarity and the inter-cluster distance.
3.3.1. Proposed Loss Function and Algorithm
In order to implement our coordinate descent-based clustering, we propose a quadratic version of the hinge loss , which is a convex function (see proof of Theorem 1) whose minimization problem is formulated as follows:
A simplified 3D graph plot of is depicted in Figure 3.
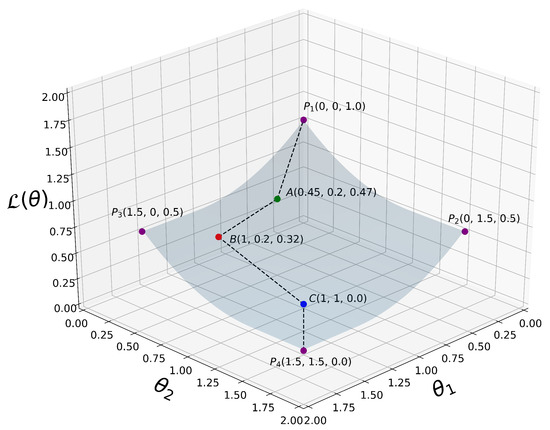
Figure 3.
A simplified 3D plot of our proposed loss function as defined in (14), where for visualization purposes. are some selected 3D points at which is evaluated. From all the way down to , we can clearly see that decreases monotonically when the coordinate variables and increase their values. That is, , where i is an integer representing the current iteration in our algorithm.
Initially, the weight vector is set to the pairwise similarities , and then each weight component of is pushed onto a max-heap data structure. At each iteration , the weight (, ) associated with the current largest similarity value is popped from the max-heap and is updated as follows:
Such that is a differentiable activation function defined as follows:
and its partial derivative with respect to the weight is:
We note that is the signum function. The usage of ensures that each weight is within the range . As there is no learning rate and schedule to choose for our coordinate descent-based algorithm, we set to 1.
Theorem 1.
Proof.
To prove the convexity of , we can show that its Hessian matrix is positive semi-definite as follows:
Since is positive semi-definite satisfying for all , is convex, and therefore guarantees convergence to the global minimum. □
In order to reach the global minimum of (i.e., ), our learning algorithm needs to set the weight vector to (i.e., the unit vector). Consequently, the intra-cluster similarity will reach its maximum value and all the n databases will be put into the same cluster resulting in a meaningless partitioning. Therefore, in order to prevent this scenario from occurring, we need to assess the clustering quality after popping all the coordinate variables that have the same weight (i.e., a block of weights having the same value) from the max-heap. This corresponds to generating one candidate clustering by adding the list of edges satisfying to the graph . Afterward, we need a stopping condition to terminate our algorithm if the current candidate clustering quality is judged to be the optimal one in terms of the similarity-intra cluster and the number of clusters . For this purpose, we define the following quasi-convex loss function evaluated at the i-th iteration:
where , .
Our algorithm terminates right after it reaches the global minimum of . In other words, if , then we continue updating the weight vector, the clustering labels and save the optimal partitioning found so far. Otherwise, the algorithm terminates as it has reached the global minimum , and therefore, the optimal partitioning saved so far is returned as the ideal clustering of the n transactional databases. This stopping condition is only possible due to the quasi-convexity of .
Theorem 2.
Proof.
To prove the quasi-convexity of , we need to demonstrate the validity of (20). First, since is a decreasing function on the range [0,1], it is then both quasi-concave and quasi-convex satisfying the following: for all with . Since is an increasing function on the range [0,1], it is then both quasi-concave and quasi-convex satisfying the following: for all with . By subtracting the two last inequalities, we obtain: . Since and , the right side of the resulting inequality is equal to , which could be set equal to . Finally, by squaring and dividing both sides of the inequality by 2, we get a variation on the Jensen inequality for quasi-convex functions [46] as defined in (20). Hence, is quasi-convex. □
3.3.2. Time Complexity Analysis
In this subsection, we analyze the time complexity of our coordinate descent-based clustering algorithm presented in Algorithm 2, named CDClustering, which depends on the two subroutines presented in Algorithm 3: and Algorithm 4: . We note that the superscript i enclosed in round brackets, i.e., , is used to indicate the iteration number at which a given variable has been assigned a value. The proposed algorithm takes as argument the pairwise similarities and outputs the optimal clustering minimizing our proposed loss function (14). First, the weight vector is initially set equal to . Afterward, coordinate descent and back-propagation are used to search for the optimal weight vector , which minimizes our hinge-based objective . Through each learning cycle i, one coordinate variable is popped from a max-heap. Then, is updated by making the optimal step in the opposite direction to the gradient of . The weights () attaining the maximum value of 1 will have their corresponding database pairs put into the same cluster. By using a max-heap data structure within our coordinate descent algorithm, we optimally choose the current largest variable at each iteration i such that taking the partial derivative of our loss with respect to allows us to attain the next steepest descent minimizing without using a learning rate. This way, the maximum number of iterations required for our algorithm to converge is less than or equal to , i.e., the number of the pairwise similarities. Initially, the number of clusters is set equal to the number of transactional databases n. Then, in order to keep track of the database clusters, their number and their sizes, we implement a disjoint-set data structure [47], which consists of an array A[] of n integers managed by two main operations: cluster and union. Each cluster is represented by a tree whose root index p satisfies , and a database belonging to the cluster satisfies . Therefore, the cluster function is called recursively to find the label assigned to the database index p (passed in as argument) by moving down the tree towards the root (i.e., ). On the other hand, the union procedure links two disjoint clusters and by making the root of the smaller tree point to the root of the larger one in A[]. The algorithms corresponding to union and cluster are presented in Algorithm 3 and Algorithm 4, respectively. Let be the size of the weight vector . The time complexity of building the max-heap is and the time complexity of the proposed Algorithm 2: CDClustering is , such that is the number of learning cycles run until global minimum convergence, and is the time complexity of one pop operation from the heap. The proposed model is also illustrated in Figure 4. Since it is meaningless to return a single cluster consisting of all the n databases, if the clustering obtained at step (10a) is trivial (i.e., all the n databases are put together in one class or each single database stands alone in its own cluster), then we first need to run the model proposed in Figure 2 on the pairwise similarities to reduce the associated intrinsic fuzziness measured in (9). Afterward, we can apply the proposed model Figure 4 on the new adjusted similarity values to obtain more relevant results.
| Algorithm 2: CDClustering |
 |
| Algorithm 3: union |
 |
| Algorithm 4: cluster |
 |
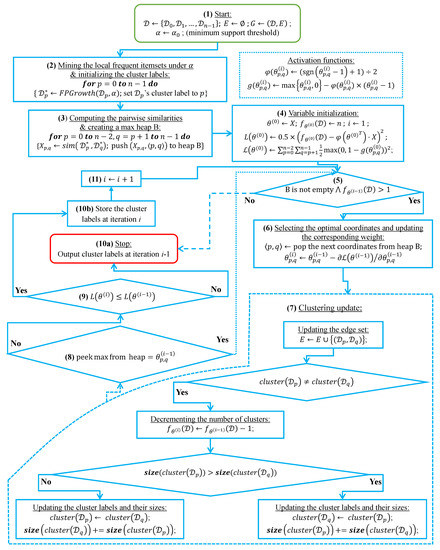
Figure 4.
The coordinate descent-based clustering model depicted in eleven steps.
4. Performance Evaluation
To assess the performance of the proposed clustering algorithm, we carried out numerous experiments on real and synthetic datasets, including Zoo [48], Iris [48], Mushroom [48] and T10I4D100K [49]. To simulate a multi-database environment, we have partitioned each dataset horizontally into n partitions , such that . Afterward, given a minimum support threshold , we run FP-Growth [1] on each partition () to discover the local frequent itemsets (FIs) corresponding to each partition. All the details related to the partition sizes and their corresponding FIs are shown in Table A1. We note that the fifth column of Table A1 reports the number of FIs discovered in the entire dataset, whereas the most right column of the same table reports the number of FIs aggregated from the local FIs mined from the partitions in each cluster.
The proposed similarity measure (3) is called on the pairs of FIs to compute the similarity matrices shown in Figure A1a, Figure A2a, Figure A3a, Figure A4a, Figure A5a, Figure A6a, and Figure A7a. Next, using the obtained pairwise similarities, candidate clusterings are produced via the process described in Section 3.1.2, and then evaluated using the clustering quality measures defined in Table 3, including [43], [21], [23], [20] and our proposed loss function (14). The graphs corresponding to the studied goodness measures are shown in Figure A1b, Figure A2b, Figure A3b, Figure A4b, Figure A5b, Figure A6b, and Figure A7b, where the optimal point (maximum or minimum) of each objective function is depicted as a black dot on its corresponding graph, except that for the graph of our loss function , there is a red dot representing the value (i.e., the optimal point at which our algorithm terminates). It is worth mentioning that due to scale differences, we sometimes multiply or divide our loss function , [21] and [23] by a scaling number to stretch or shrink their graphs in the direction of the y-axis. The experimental results depicted in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7 are summarized in Table A2, such that is the ideal similarity threshold for which a goodness measure attains its optimal point. Python version 3.9.2 was used to implement all the algorithms, and the codes were run on a Ubuntu-20.04 server equipped with an Intel(R) Xeon(R) CPU clocked at 2.30 GHz with 50 GB available Disk capacity and 12 GB of available RAM.
4.1. Similarity Accuracy Analysis
To demonstrate the efficiency of (3), let us have three transaction databases, = 200, = 300 and = 200 with their corresponding local frequent itemsets: = , = and = mined at different minimum support threshold values , and , respectively. Now, clustering the three databases using the algorithm BestDatabaseClustering [22] equipped with two different similarity measures, proposed in [20] and our proposed similarity measure (3), shows the results reported in Table 4. We note that [20] is a clustering quality measure, such that the higher the value of for a given candidate clustering , the better the quality of .
Table 4.
Clustering the three databases , and under the similarity measure [20] against our proposed measure (3).
From Table 4, we notice that using our similarity measure (3), we have obtained a larger intra-cluster similarity, a larger inter-cluster distance and a larger [20]. Now, let us synthesize the global frequent itemsets from the clusters containing more than one database, i.e., and . The obtained results are shown in Table 5, such that and are the minimum support thresholds corresponding to and respectively. As we can see, the similarity measure [20] captures only high frequency itemsets (), such as E, and neglects low support frequent itemsets (i.e., whose supports are immediately above the minimum threshold with and is a very small number), such as A, B and C. This characteristic gives a high similarity value to database pairs sharing only one or very few high frequency itemsets. On the other hand, database pairs sharing many frequent itemsets with a low support will be assigned a lower similarity. However, once the clustering is done, we will be interested in the patterns discovered from each cluster individually, such as the high-vote patterns [32] and the exceptional patterns [31]. That is why our similarity measure estimates the patterns post-mined from each cluster in order to compute . Since our similarity measure focuses on maximizing the number of frequent itemsets synthesized from each cluster , only relevant clusters will be assigned a large similarity value.
Table 5.
Itemsets synthesized from discovered under [20] against the itemsets synthesized from discovered under (3).
4.2. Fuzziness Reduction Analysis
To demonstrate the importance of reducing the fuzziness associated with a similarity matrix, we run the clustering algorithm BestDatabaseClustering [22] on two similarity matrices in Figure 5a and Figure 6a. The obtained results in terms of the optimal clustering, [20], the optimal similarity level (i.e., the similarity level at ) and the silhouette coefficient [43] at are shown in Figure 5b,c and Figure 6b,c corresponding to rows 1 and 2 of Table 6, respectively. From the obtained results, we can clearly see that when the similarity matrices are centered around the mean value 0.5, the fuzziness index becomes larger and closer to 1, and BestDatabaseClustering [22] could not return a meaningful clustering since it has put all the n databases into the same cluster.
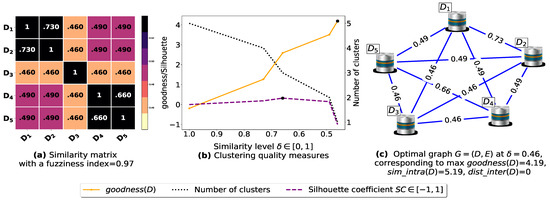
Figure 5.
(a) A 5 × 5 similarity matrix between five transactional databases before applying our fuzziness reduction model. (b) Represents the graph plots corresponding to [20], the silhouette coefficient [43] and the number of clusters. (c) Represents the optimal graph obtained at [20].
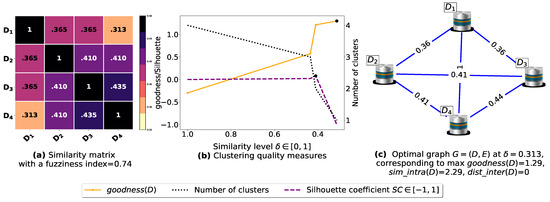
Figure 6.
(a) Represents a similarity matrix between four databases partitioned from the Mushroom dataset [48]. We note that (a) is built by calling sim (3) on the frequent itemsets (FIs) mined from Dp (p = 1, …, 4) under a threshold α = 0.5. (b) Represents the graph plots corresponding to [20], the silhouette coefficient [43] and the number of clusters. (c) Represents the optimal graph obtained at [20].
Now, let us run our fuzziness reduction model on the previous similarity matrices and depict the adjusted similarity matrices in Figure 7a and Figure 8a, respectively. Afterward, we run BestDatabaseClustering [22] on the new similarity matrices and show the clustering results in Figure 7b,c and Figure 8b,c corresponding to rows 3 and 4 of Table 6, respectively. As we can see, after reducing the fuzziness index associated with the previous similarity matrices in Figure 5a and Figure 6a, the algorithm BestDatabaseClustering [22] was able to produce meaningful non-trivial clusterings with an increase in the silhouette coefficient [43] for both similarity matrices in Figure 7a and Figure 8a.
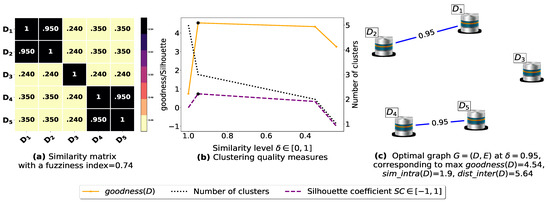
Figure 7.
(a) A 5 × 5 similarity matrix obtained after applying our fuzziness reduction model on Figure 5a. (b) Represents the graph plots corresponding to [20], the silhouette coefficient [43] and the number of clusters. (c) Represents the optimal graph obtained at [20].
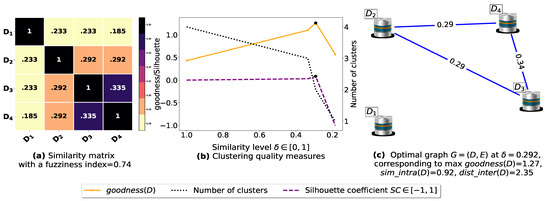
Figure 8.
(a) Represents the similarity table generated after applying our fuzziness reduction model on Figure 6a. (b) Represents the graph plots corresponding to [20], the silhouette coefficient [43] and the number of clusters. (c) Represents the optimal graph obtained at [20].
4.3. Convexity and Clustering Analysis
In this part of our experiments, we analyze the convex behavior of the proposed clustering quality functions (19) and (14), and we also examine the non-convexity of the existing goodness measures in [20,21,23,43]. Additionally, we compare the clustering produced by our algorithm and the ones generated at the optimal points of the previous compared goodness measures (i.e., at [20], [23] and [21]) with the underlying ground-truth cluster labels. When the actual clustering is unknown, we replace it with the partitioning obtained at the maximum value of the silhouette coefficient [43], that is, at . All the graphs corresponding to our loss functions and the compared goodness measures in Table 3 are plotted in Figure A1b, Figure A2b, Figure A3b, Figure A4b, Figure A5b, Figure A6b, and Figure A7b, where the x-axis represents the similarity levels at which multiple candidate clusterings are generated and evaluated.
Consider the similarity matrix shown in Figure A1a. From the graphs plotted in Figure A1b and according to the results shown in the first row of Table A2, we can see that using our loss function and [20], we were able to find the optimal clustering at a similarity level where the silhouette coefficient reaches its maximum value . On the other hand, [21] and [23] did not successfully discover the partitioning maximizing the silhouette coefficient. Additionally, we observe that the proposed convergence test function has a quasi-convex behavior (see proof of Theorem 2). This allows us to terminate the clustering process right after reaching the global minimum. Conversely, the graphs corresponding to [23] and [20] have local optima. Consequently, it is required to explore about similarity levels in order to generate and evaluate all the candidate clusterings possible.
Now, let us examine the results of some experiments that we have conducted on the synthetic and real-world datasets shown in Table A1. From Figure A2b and Figure A7b (the last and second rows of Table A2), we observe that [21] and [23] attain their optimal values when all the partition databases are clustered together in one class. The same phenomenon is observed in Figure A3b, Figure A6b and Figure A7b (the last, the sixth and the third rows of Table A2), where both [23] and [20] have put all the databases into one cluster.
In contrast, the proposed loss function has successfully identified the clustering for which the silhouette coefficient is maximum. Precisely, in Figure A7b, which corresponds to the last row of Table A2), was the only clustering quality measure which has properly identified the ideal 7-class clustering at .
From the obtained graphs in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7, we notice that [21], [23] and [20] are neither quasi-concave nor quasi-convex on the domain . As a result, we observe the existence of local optimum points on their corresponding graphs, which makes the search of the global optimum a difficult problem to solve without exploring all the local solutions.
Conversely, we observe that our loss function (14) is monotonically decreasing all the time and at . This corresponds to the similarity level where all the n databases are put into the same single cluster. To avoid this case from occurring, we used the quasi-convex function (19) as a convergence test function to terminate our algorithm at the point corresponding to the red dot on the graph of our loss function . Moreover, it is worth noting that for every two real -dimensional vectors and , where , the line that joins the points () and () remains above , which is observed in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. Therefore, using the proposed loss function (14) along with (19) guarantees global minimum convergence.
In the fifth and the most right columns of Table A1, we compare the number of frequent itemsets (FIs) mined from all the partitions of a given dataset with the FIs mined from each single cluster consisting of similar partitions from the same dataset, where and . We notice that mining all the partitions from datasets Iris [48] and Zoo [48] did not result in discovering any valid frequent itemset. Whereas, mining each individual cluster of partitions from the datasets Iris and Zoo has led to the discovery of new patterns in each cluster .
In Table A3, we report the similarity levels at which the clustering evaluation measures [20], [23], [21], the silhouette coefficient [43] and our proposed loss function attain their optimal values in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. We note that, the fraction in Table A3 represents the number of similarity levels required to test the convergence and terminate divided by the number of all similarity levels m. We note that is the index of the optimal similarity level according to a given clustering quality measure. Since our proposed algorithm is based on a convex loss function, we notice that . On the other hand, as for the compared algorithms, which are based on non-convex objectives, we notice that . Therefore, our algorithm requires the least number of similarity levels ( out of m) in order to converge and terminate, which makes our algorithm faster than the compared algorithms in [21,22,23], requiring to generate and evaluate all the m candidate clusterings in order to return the optimal one.
All the previous results confirm that using our loss function (14) along with (19), we have identified the ideal clustering for which the silhouette coefficient [43] is maximum and we have also improved the quality of the frequent itemsets (FIs) mined from the multiple databases partitioned from the datasets in Table A1.
4.4. Clustering Error and Running Time Analysis
In this experimental part, we compare the running time of the proposed clustering algorithm with the execution times of two clustering algorithms for multi-database mining (MDM), namely GDMDBClustering [25] and BestDatabaseClustering [22], all run on the same random data samples. We also calculate how the clusterings produced by our algorithm and the compared models are different from the ground-truth clustering. For this purpose, we propose an error function in (21), which measures the difference between two given clusterings and .
First, we generated n = 30 to N = 120 isotropic Gaussian blobs using the scikit-learn generator [50], such that the number of features for each n blobs is set to , while the number of clusters is set to . In Table 7, we present a brief summary of the random blobs generated via scikit-learn [50].
Table 7.
A brief summary of the random blobs generated via scikit-learn [50].
Afterward, we use the min-max scaling [51] to normalize each feature (out of the m features) into the interval [0,1]. Then, for each n blobs, every pair of m-dimensional blobs is passed as arguments to the function (3) in order to compute the pairwise similarities between the n blobs. We then run the proposed algorithm, GDMDBClustering [25] (with three different learning rate values) and BestDatabaseClustering [22] on each of the pairwise similarities () and plot their running time graphs in Figure A8a, Figure A9a and Figure A10a, and then plot the clustering error graphs in Figure A8b, Figure A9b and Figure A10b.
Without loss of generality, assume is the ground-truth clustering (i.e., the actual clusters) of the current n blobs generated via scikit-learn [50], and assume is the partitioning of produced by a given clustering algorithm. To measure how far is from , we propose the error function to be defined as follows:
where is the number of all the database pairs obtained from every cluster in and is the number of all the database pairs that only exist in and that cannot be found in . We note that approaches the maximum value of 1 (i.e., ) when and are too different and do not share many database pairs in common (i.e., ). Conversely, when the clustering and are too similar, i.e., they share the maximum number of pairs .
We also define the average of the clustering errors, which could also be seen as the mean absolute clustering error:
From the obtained results in Figure A8a, Figure A9a and Figure A10a, we observe a rapid increase in the running time of BestDatabaseClustering [22] as the number of generated blobs (n) increases linearly. This is due to the fact that BestDatabaseClustering needs to generate and evaluate approximately candidate clusterings in order to find the optimal clustering for which the non-convex function [20] is maximum. In fact, suffers from the existence of local maxima, which requires exploring all the local candidate solutions in order to find the global maximum. On the other hand, using the proposed convex loss function and the quasi-convex convergence test function allows us to stop the clustering process at . Consequently, this avoids generating unnecessary candidate clusterings, and hence reduces the CPU overhead. Since our algorithm is independent of the learning rate , the running time of our algorithm is the same in all Figure A8a, Figure A9a and Figure A10a. Whereas, the running time of GDMDBClustering [25] increases for smaller learning rate values (e.g., Figure A10) and decreases when we set larger learning rate values (e.g., Figure A9), but this comes at the cost of having an increased clustering error.
Next, by examining the three clustering error graphs in Figure A8b, Figure A9b and Figure A10b, we observe that BestDatabaseClustering [22] has the largest clustering error among the three algorithms with a clustering average error . In fact, on average, BestDatabaseClustering [22] tends to group all the current n blobs () in one single cluster. On the other hand, our proposed algorithm and GDMDBClustering [25] produce clusterings that are close to the ground-truth clustering predetermined by the scikit-learn generator [50]. In fact, the average clustering error due to our algorithm is . For GDMDBClustering [25], we get when the learning rate or , and the error increases to when . The average running times and clustering errors of our algorithm, GDMDBClustering [25] and BestDatabaseClustering [22] are summarized in Table A4.
Our algorithm and GDMDBClustering [25] terminate once we reach the global minimum of the convergence test function . Consequently, the running times of our algorithm and GDMDBClustering [25] are most of the time shorter than that of BestDatabaseClustering [22]. Overall, the running time of GDMDBClustering [25] stays relatively steady with respect to n. However, GDMDBClustering depends strongly on the learning step size and its decay rate. On the other hand, our algorithm is learning-rate-free and needs at most (in the worst case) iterations to converge. Consequently, our proposed algorithm is faster than both BestDatabaseClustering [22] and GDMDBClustering [25].
To illustrate the statistically significant superiority of the proposed clustering model in terms of running time and clustering accuracy, we have applied the Friedman test [52] (under a significance level ) on the measurements (execution times and clustering errors depicted in Figure A8, Figure A9 and Figure A10) obtained by our algorithm, BestDatabaseClustering [22] and GDMDBClustering [25] (with three different values for the learning rate ) considering all the random samples in Table 7.
After conducting the Friedman test [52], we obtained the results shown in Table A5, Table A6 and Table A7, namely the average running time, the average clustering error (22), the standard deviation (SD), the variance (Var), the critical value (stat) and its p-value for all the tested clustering algorithms, considering all 91 random samples generated via scikit-learn [50].
We notice that all the obtained results in Table A5, Table A6 and Table A7 show p-values that are below the significance level . Consequently, the test suggests a rejection of the null hypothesis, stating that the compared clustering models have a similar performance. In fact, the proposed clustering algorithm significantly outperforms the other compared models, as it has the shortest average running time (6.367 milliseconds) and the lowest average clustering error () among all the compared models.
4.5. Clustering Comparison and Assessment
In the third part of our experiments, we are interested in using some information retrieval measures to compare the clusterings produced by our algorithm and some other clustering algorithms with the ground-truth data.
Let be n transactional databases. Let be a k-class clustering of produced by any given clustering algorithm, and let be the ground-truth clustering of the databases in , such that and . Let us define and as the set of database pairs obtained from each cluster of the same clustering. That is, and . To compare the two clusterings with , few methods method [53,54,55] could be used. In this paper, we use a pair counting [56,57,58,59] to calculate some information retrieval measures [60,61], including precision, recall, F-measure (i.e., harmonic mean of recall and precision), Rand index [62] and Jaccard index [63] over pairs of databases being clustered together in and/or . This will allow us to assess whether the predicted database pairs from cluster together in , i.e., are the discovered database pairs in correct with respect to the underlying true pairs in from the ground-truth clustering .
In Table A9, we show the categories of database pairs which represent the working set of all pair counting measures cited in Table A10. Precisely, a: represents the number of pairs that exist in both clusterings and , d: represents the number of pairs that do not exist in either clustering, b: is the number of pairs present only in clustering , and c: is the number of pairs present only in clustering . By counting the pairs in each category, we get an indicator for agreement and disagreement of the two clusterings being compared. The following example illustrates how to compute the measures defined in Table A10 for two given clusterings and the ground-truth partitioning of seven transaction databases . First, let us calculate the following pairing categories:
Then, , , , . Therefore, we get the following measures: , , , , . We note that the higher the values of the evaluation measures given in Table A10, the better the matching of the clustering to its corresponding ground-truth clustering .
In Table A8 and Table A11, we report the F-measure [60,61], precision [60,61], recall [60,61], Rand [62] and Jaccard [63] reached by the clustering algorithms in [21,22,23], and our proposed algorithm on the datasets shown in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. From Table A8 and Table A11, we notice that our algorithm achieves the best scores against the compared clustering algorithms, considering all the experiments in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7.
5. Conclusions
An improved similarity-based clustering algorithm for multi-database mining was proposed in this paper. Unlike the previous works, our algorithm requires fewer upper-bounded iterations to minimize a convex clustering quality measure. In addition, we have proposed a preprocessing layer prior to clustering where the pairwise similarities between multiple databases are first adjusted to reduce their fuzziness. This will help the clustering process to be more precise and less confused in discriminating between the different database clusters. To assess the performance of our algorithm, we conducted several experiments on real and synthetic datasets. Compared to the existing clustering algorithms for multi-database mining, our algorithm achieved the best performance in terms of accuracy and running time. In this paper, we have used the most frequent itemsets mined from each transaction database as feature sets to compute the pairwise similarities between the multiple databases. However, when the sizes of these input vectors become large, building the similarity matrix will increase the CPU overhead drastically. Moreover, the existence of some noisy frequent itemsets (FIs) may largely influence how databases are clustered together. In future work, we will investigate the impact of compressing the size of the FIs into a latent variable represented in a lower dimensional space with discriminative features. Practically, reconstituting the input vectors from the embedding space using deep auto-encoders and non-linear dimensionality reduction techniques, such as T-SNE (t-distributed stochastic neighbor embedding) and UMAP (uniform manifold approximation and projection), will force the removal of the noisy features present in the input data while keeping only the meaningful discriminative ones. Consequently, this may help improve the accuracy and running time of the clustering algorithm. Additionally, we are interested in exploring new ways to reduce the computational time used to calculate the similarity matrix via locality sensitive hashing (LSH) techniques, such as BagMinHash for weighted sets. These methods aim to encode the feature-set vectors into hash-code signatures in order to efficiently estimate the Jaccard similarity between the local transactional databases. Last but not least, in order to design a parallel version of the proposed algorithm, we will study and explore some high-performance computing tools, such as MapReduce and Spark, as an attempt to improve the clustering performance for multi-database mining.
Author Contributions
Conceptualization, S.M.; methodology, S.M.; software, S.M.; validation, S.M.; formal analysis, S.M.; investigation, S.M.; resources, S.M.; data curation, S.M.; writing—original draft preparation, S.M.; writing—review and editing, S.M.; visualization, S.M., W.D.; supervision, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All datasets are available at http://fimi.ua.ac.be/data/ (accessed on 25 April 2021) and https://archive.ics.uci.edu/ml/datasets (accessed on 25 April 2021).
Acknowledgments
We would like to thank the anonymous reviewers for their time and their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FIs | Frequent Itemsets |
| FIM | Frequent Itemset Mining |
| MDB | Multiple Databases |
| MDM | Multi-database Mining |
| CD | Coordinate Descent |
| CL | Competitive Learning |
| BMU | Best Matching Unit |
| T-SNE | t-Distributed Stochastic Neighbor Embedding |
| UMAP | Uniform Manifold Approximation and Projection |
| LSH | Locality Sensitive Hashing |
Appendix A
Table A1.
Description of the datasets used in our experiments with their database partitions and the number frequent itemsets (FIs) mined from each database partition and the number of FIs mined from each cluster under a threshold .
Table A1.
Description of the datasets used in our experiments with their database partitions and the number frequent itemsets (FIs) mined from each database partition and the number of FIs mined from each cluster under a threshold .
| Dataset Name/Ref | Number of Rows | Number of Rows in Partition | Number of from Partition | Number of from Dataset | Ground Truth Clustering | Number of from Cluster |
|---|---|---|---|---|---|---|
| Mushroom [48] (2 classes) | 8124 | () () () () | ||||
| Zoo [48] (7 classes) | 101 | () () () () () () () () () () () () | ||||
| Iris [48] (3 classes) | 150 | () () () () () () | ||||
| T10I4D100K [49] (unknown classes) | 100,000 | rows, | Seven clusters found via the silhouette coefficient [43] | |||
| Figure A1 [20] (unknown classes) | 24 | Three clusters found via the silhouette coefficient [43] |
Table A2.
Clustering results illustrated in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7 after using the clustering quality measures [21], [23], the silhouette coefficient [43], [20] and our proposed objective function , where is the level of similarity at which each clustering evaluation/loss function reaches its optimal value.
Table A2.
Clustering results illustrated in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7 after using the clustering quality measures [21], [23], the silhouette coefficient [43], [20] and our proposed objective function , where is the level of similarity at which each clustering evaluation/loss function reaches its optimal value.
| Dataset Name/Ref | Silhouette Coefficient | Clustering Result Using Proposed Objective | Clustering Result/ Optimal Value | Clustering Result/ Optimal Value | Clustering Result/ Optimal Value | ||||
|---|---|---|---|---|---|---|---|---|---|
| Clusters | Clusters | Clusters | Clusters | ||||||
| Figure A1 [20] | 0.46 at | 2.004 at | 15.407 at | 0.259 at | 0.728 at | ||||
| Figure A2 [48] | 0.41 at | 7.71 at | 32.98 at | 0.57 at | 0.42 at | ||||
| Figure A3 [48] | 0.08 at | 0.43 at | 1.672 at | 0.55 at | 0.68 at | ||||
| Figure A4 [48] | 0.304 at | 1.10 at | 9.64 at | 0.55 at | 0.44 at | ||||
| Figure A5 & [48] | 0.63 at | 0.5 at | 9.96 at | 0.40 at | 0.85 at | ||||
| Figure A6 [39] | 0.34 at | 1.12 at | 2.708 at | 0.38 at | 0.81 at | ||||
| Figure A7 T10I4D100K [49] | 0.115 at | 0.71 at | 35.275 at | 0.193 at | 0.806 at | ||||

Figure A1.
(a): represents a similarity matrix between 7 databases from [25]. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A2.
(a): represents a similarity matrix between 12 databases partitioned from Zoo dataset [48]. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A3.
(a): represents a similarity matrix between 4 databases partitioned from Mushroom dataset [48] without applying the fuzziness reduction model in Figure 2. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A4.
(a): represents a similarity matrix between 6 databases partitioned from Iris dataset [48]. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A5.
(a): represents a similarity matrix between 6 databases including 4 databases partitioned from the real dataset Mushroom [48] and 2 databases partitioned from the real dataset Zoo [48]. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A6.
(a): represents a similarity matrix between 4 databases from [39]. (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.

Figure A7.
(a): represents a similarity matrix between 10 databases partitioned from T10I4D100K [49]. We note that (a) is built by calling (3) on the frequent itemsets (FIs) mined from () under a threshold . (b): represents the graph plots corresponding to [21], [23], [20], the silhouette coefficient [43], our convergence test function , our proposed loss function and the number of generated clusters.
Table A3.
The similarity levels at which the clustering evaluation measures [21], [23], the silhouette coefficient [43], [20] and our proposed objective function attain their optimal values in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. The fraction represents the number of similarity levels required to test the convergence and terminate divided by the number of total similarity levels m.
Table A3.
The similarity levels at which the clustering evaluation measures [21], [23], the silhouette coefficient [43], [20] and our proposed objective function attain their optimal values in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. The fraction represents the number of similarity levels required to test the convergence and terminate divided by the number of total similarity levels m.
| Dataset | Silhouette Coefficient | Proposed Loss Function | Goodness Measure | Goodness Measure | Goodness Measure | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Figure A1 [20] | 0.444 | 0.444 | 0.444 | 0.065 | 0.086 | |||||
| Figure A2 [48] | 0.559 | 0.559 | 0.559 | 0.348 | 0.348 | |||||
| Figure A3 [48] | 0.41 | 0.41 | 0.365 | 0.365 | 0.41 | |||||
| Figure A4 [48] | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | |||||
| Figure A5 & [48] | 0.384 | 0.384 | 0.384 | 0.384 | 0.384 | |||||
| Figure A6 [39] | 0.429 | 0.429 | 0.25 | 0.25 | 0.429 | |||||
| Figure A7 T10I4D100K [49] | 0.846 | 0.846 | 0.737 | 0.737 | 0.737 | |||||
Table A4.
Summary of the average running times and the average clustering errors (22) for the proposed algorithm, BestDatabaseClustering [22] and GDMDBClustering [25] (with three different values for the learning rate ) on the random samples described in Table 7.
| Experiment (Figure) | Proposed Algo | BestDatabaseClustering [22] | GDMDBClustering [25] | |||
|---|---|---|---|---|---|---|
| Average Running Time | Average Clustering Error | Average Running Time | Average Clustering Error | Average Running Time | Average Clustering Error | |
Figure A8 | 6.367 | 0.285 | 47.208 | 0.936 | 14.825 | 0.285 |
Figure A9 | 6.367 | 0.285 | 47.208 | 0.936 | 7.305 | 0.290 |
Figure A10 | 6.367 | 0.285 | 47.208 | 0.936 | 28.479 | 0.285 |
Table A5.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A8.
Table A5.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A8.
Algorithm | Measurements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Running Time | Clustering Error | |||||||||
| Average | SD | Var | Stat | p-Value | Average | SD | Var | Stat | p-Value | |
| Proposed Algo | 6.367 | 3.018 | 9.107 | 0.285 | 0.080 | 0.006 | ||||
| BestDatabaseClustering [22] | 47.208 | 27.537 | 758.313 | 135.707 | 3.40–30 | 0.936 | 0.066 | 0.004 | 150 | –33 |
| GDMDBClustering [25] () | 14.825 | 1.743 | 3.037 | 0.285 | 0.080 | 0.006 | ||||
Table A6.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A9.
Table A6.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A9.
Algorithm | Measurements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Running Time | Clustering Error | |||||||||
| Average | SD | Var | Stat | p-Value | Average | SD | Var | Stat | p-Value | |
| Proposed Algo | 6.367 | 3.018 | 9.107 | 0.285 | 0.080 | 0.006 | ||||
| BestDatabaseClustering [22] | 47.208 | 27.537 | 758.313 | 121.62 | 3.88–27 | 0.936 | 0.066 | 0.004 | 131 | –29 |
| GDMDBClustering [25] () | 7.305 | 1.766 | 3.118 | 0.290 | 0.086 | 0.007 | ||||
Table A7.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A10.
Table A7.
Statistical Friedman test results [52] for the measurements obtained by all the compared clustering algorithms in Figure A10.
Algorithm | Measurements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Running Time | Clustering Error | |||||||||
| Average | SD | Var | Stat | p-Value | Average | SD | Var | Stat | p-Value | |
| Proposed Algo | 6.367 | 3.018 | 9.107 | 0.285 | 0.080 | 0.006 | ||||
| BestDatabaseClustering [22] | 47.208 | 27.537 | 758.313 | 118.90 | –26 | 0.936 | 0.066 | 0.004 | 150 | 2.67–33 |
| GDMDBClustering [25] () | 28.479 | 4.655 | 21.669 | 0.285 | 0.080 | 0.006 | ||||

Figure A8.
(a): represents the running times corresponding to GDMDBClustering [25] (with a learning rate ), BestDatabaseClustering [22] and the proposed algorithm obtained when executed on isotropic Gaussian blobs generated using scikit-learn generator [50]. (b): represents the clustering error graphs (21) due to GDMDBClustering [25], BestDatabaseClustering [22] and the proposed algorithm.

Figure A9.
(a): represents the running times corresponding to GDMDBClustering [25] (with a learning rate ), BestDatabaseClustering [22] and the proposed algorithm obtained when executed on isotropic Gaussian blobs generated using scikit-learn generator [50]. (b): represents the clustering error graphs (21) due to GDMDBClustering [25], BestDatabaseClustering [22] and the proposed algorithm.

Figure A10.
(a): represents the running times corresponding to GDMDBClustering [25] (with a learning rate ), BestDatabaseClustering [22] and the proposed algorithm obtained when executed on isotropic Gaussian blobs generated using scikit-learn generator [50]. (b): represents the clustering error graphs (21) due to GDMDBClustering [25], BestDatabaseClustering [22] and the proposed algorithm.
Table A8.
F-measure [60,61], precision [60,61] and recall [60,61] reached by the compared clustering algorithms in [21,22,23], and our proposed algorithm on the datasets shown in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. Notice that our algorithm gets the best scores for all the datasets.
Table A8.
F-measure [60,61], precision [60,61] and recall [60,61] reached by the compared clustering algorithms in [21,22,23], and our proposed algorithm on the datasets shown in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. Notice that our algorithm gets the best scores for all the datasets.
| Dataset | F-Measure [60,61] | Precision [60,61] | Recall [60,61] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proposed Algo | Algo [22] | Algo [23] | Algo [21] | Proposed Algo | Algo [22] | Algo [23] | Algo [21] | Proposed Algo | Algo [22] | Algo [23] | Algo [21] | |
| Figure A1 7 × 7 [20] | 1 | 1 | 0.44 | 0.8 | 1 | 1 | 0.28 | 0.66 | 1 | 1 | 1 | 1 |
| Figure A2 12 × 12 [48] | 1 | 1 | 0.14 | 0.14 | 1 | 1 | 0.075 | 0.075 | 1 | 1 | 1 | 1 |
| Figure A3 4 × 4 [48] | 1 | 0.66 | 0.66 | 1 | 1 | 0.5 | 0.5 | 1 | 1 | 1 | 1 | 1 |
| Figure A4 6 × 6 [48] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Figure A5 6 × 6 & [48] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Figure A6 4 × 4 [39] | 1 | 0.66 | 0.66 | 1 | 1 | 0.5 | 0.5 | 1 | 1 | 1 | 1 | 1 |
| Figure A7 10 × 10 T10I4D100K [49] | 1 | 0.16 | 0.16 | 0.16 | 1 | 0.088 | 0.088 | 0.088 | 1 | 1 | 1 | 1 |
Table A9.
Contingency matrix showing the categories in pairing clustered databases.
Table A9.
Contingency matrix showing the categories in pairing clustered databases.
| Clustering | Predicted Clusters | |
|---|---|---|
| Pairs in | Pairs Not in | |
| Actual clusters | ||
| Pairs in | (True Positive) | (False Negative) |
| Pairs not in | (False Positive) | Pairs in none (True Negative) |
Table A10.
Pair counting measures used for clustering assessment and comparison.
Table A10.
Pair counting measures used for clustering assessment and comparison.
| Precision [60,61] | Recall [60,61] | F-Measure [60,61] | Rand [62] | Jaccard [63] |
|---|---|---|---|---|
Table A11.
Rand index [62] and Jaccard index [63] reached by the clustering algorithms in [21,22,23] and our proposed algorithm on the datasets shown in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. Notice that our algorithm gets the best scores for all the datasets.
Table A11.
Rand index [62] and Jaccard index [63] reached by the clustering algorithms in [21,22,23] and our proposed algorithm on the datasets shown in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, and Figure A7. Notice that our algorithm gets the best scores for all the datasets.
| Dataset | Rand [62] | Jaccard [63] | ||||||
|---|---|---|---|---|---|---|---|---|
| Proposed Algo | Algo [22] | Algo [23] | Algo [21] | Proposed Algo | Algo [22] | Algo [23] | Algo [21] | |
| Figure A1 [20] | 1 | 1 | 0.28 | 0.85 | 1 | 1 | 0.28 | 0.66 |
| Figure A2 [48] | 1 | 1 | 0.075 | 0.075 | 1 | 1 | 0.075 | 0.075 |
| Figure A3 [48] | 1 | 0.5 | 0.5 | 1 | 1 | 0.5 | 0.5 | 1 |
| Figure A4 [48] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Figure A5 & [48] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Figure A6 [39] | 1 | 0.5 | 0.5 | 1 | 1 | 0.5 | 0.5 | 1 |
| Figure A7 T10I4D100K [49] | 1 | 0.088 | 0.088 | 0.088 | 1 | 0.088 | 0.088 | 0.088 |
References
- Han, J.; Pei, J.; Yin, Y.; Mao, R. Mining frequent patterns without candidate generation: A frequent-pattern tree approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 849–856. [Google Scholar] [CrossRef]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 27 December 1965–7 January 1966; Volume 1, pp. 281–297. [Google Scholar]
- Zhang, Y.J.; Liu, Z.Q. Self-splitting competitive learning: A new on-line clustering paradigm. IEEE Trans. Neural Netw. 2002, 13, 369–380. [Google Scholar] [CrossRef]
- Yair, E.; Zeger, K.; Gersho, A. Competitive learning and soft competition for vector quantizer design. IEEE Trans. Signal Process. 1992, 40, 294–309. [Google Scholar] [CrossRef]
- Hofmann, T.; Buhmann, J.M. Competitive learning algorithms for robust vector quantization. IEEE Trans. Signal Process. 1998, 46, 1665–1675. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer Science & Business Media: Berlin/Heidelberg, Germany; New York, NY, USA, 2012; Volume 30. [Google Scholar]
- Pal, N.R.; Bezdek, J.C.; Tsao, E.K. Generalized clustering networks and Kohonen’s self-organizing scheme. IEEE Trans. Neural Netw. 1993, 4, 549–557. [Google Scholar] [CrossRef]
- Mao, J.; Jain, A.K. A self-organizing network for hyperellipsoidal clustering (HEC). Trans. Neural Netw. 1996, 7, 16–29. [Google Scholar]
- Anderberg, M.R. Cluster Analysis for Applications: Probability and Mathematical Statistics: A Series of Monographs and Textbooks; Academic Press: Cambridge, MA, USA, 2014; Volume 19. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. Data clustering. Algorithms and Application; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Wang, C.D.; Lai, J.H.; Philip, S.Y. NEIWalk: Community discovery in dynamic content-based networks. IEEE Trans. Knowl. Data Eng. 2013, 26, 1734–1748. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, D.; Zhou, X.; Yang, D.; Yu, Z.; Yu, Z. Discovering and profiling overlapping communities in location-based social networks. IEEE Trans. Syst. Man Cybern. Syst. 2013, 44, 499–509. [Google Scholar] [CrossRef]
- Huang, D.; Lai, J.H.; Wang, C.D.; Yuen, P.C. Ensembling over-segmentations: From weak evidence to strong segmentation. Neurocomputing 2016, 207, 416–427. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Zhao, Q.; Wang, C.; Wang, P.; Zhou, M.; Jiang, C. A novel method on information recommendation via hybrid similarity. IEEE Trans. Syst. Man Cybern. Syst. 2016, 48, 448–459. [Google Scholar] [CrossRef]
- Symeonidis, P. ClustHOSVD: Item recommendation by combining semantically enhanced tag clustering with tensor HOSVD. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 1240–1251. [Google Scholar] [CrossRef]
- Rafailidis, D.; Daras, P. The TFC model: Tensor factorization and tag clustering for item recommendation in social tagging systems. IEEE Trans. Syst. Man Cybern. Syst. 2012, 43, 673–688. [Google Scholar] [CrossRef]
- Adhikari, A.; Adhikari, J. Clustering Multiple Databases Induced by Local Patterns. In Advances in Knowledge Discovery in Batabases; Springer: Cham, Switzerland, 2015; pp. 305–332. [Google Scholar]
- Liu, Y.; Yuan, D.; Cuan, Y. Completely Clustering for Multi-databases Mining. J. Comput. Inf. Syst. 2013, 9, 6595–6602. [Google Scholar]
- Miloudi, S.; Hebri, S.A.R.; Khiat, S. Contribution to Improve Database Classification Algorithms for Multi-Database Mining. J. Inf. Proces. Syst. 2018, 14, 709–726. [Google Scholar]
- Tang, H.; Mei, Z. A Simple Methodology for Database Clustering. In Proceedings of the 5th International Conference on Computer Engineering and Networks, SISSA Medialab, Shanghai, China, 12–13 September 2015; Volume 259, p. 19. [Google Scholar]
- Wang, R.; Ji, W.; Liu, M.; Wang, X.; Weng, J.; Deng, S.; Gao, S.; Yuan, C.A. Review on mining data from multiple data sources. Pattern Recognit. Lett. 2018, 109, 120–128. [Google Scholar] [CrossRef]
- Miloudi, S.; Wang, Y.; Ding, W. A Gradient-Based Clustering for Multi-Database Mining. IEEE Access 2021, 9, 11144–11172. [Google Scholar] [CrossRef]
- Miloudi, S.; Wang, Y.; Ding, W. An Optimized Graph-based Clustering for Multi-database Mining. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 807–812. [Google Scholar] [CrossRef]
- Zhang, S.; Zaki, M.J. Mining Multiple Data Sources: Local Pattern Analysis. Data Min. Knowl. Discov. 2006, 12, 121–125. [Google Scholar] [CrossRef][Green Version]
- Adhikari, A.; Rao, P.R. Synthesizing heavy association rules from different real data sources. Pattern Recognit. Lett. 2008, 29, 59–71. [Google Scholar] [CrossRef]
- Adhikari, A.; Adhikari, J. Advances in Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Adhikari, A.; Jain, L.C.; Prasad, B. A State-of-the-Art Review of Knowledge Discovery in Multiple Databases. J. Intell. Syst. 2017, 26, 23–34. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C.; Wu, X. Identifying Exceptional Patterns. Knowl. Discov. Multiple Datab. 2004, 185–195. [Google Scholar]
- Zhang, S.; Zhang, C.; Wu, X. Identifying High-vote Patterns. Knowl. Discov. Multiple Datab. 2004, 157–183. [Google Scholar]
- Ramkumar, T.; Srinivasan, R. Modified algorithms for synthesizing high-frequency rules from different data sources. Knowl. Inf. Syst. 2008, 17, 313–334. [Google Scholar] [CrossRef]
- Djenouri, Y.; Lin, J.C.W.; Nørvåg, K.; Ramampiaro, H. Highly efficient pattern mining based on transaction decomposition. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1646–1649. [Google Scholar]
- Savasere, A.; Omiecinski, E.R.; Navathe, S.B. An Efficient Algorithm for Mining Association Rules in Large Databases; Technical Report GIT-CC-95-04; Georgia Institute of Technology: Zurich, Switzerland, 1995. [Google Scholar]
- Zhang, S.; Wu, X. Large scale data mining based on data partitioning. Appl. Artif. Intel. 2001, 15, 129–139. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, M.; Nie, W.; Zhang, S. Identifying Global Exceptional Patterns in Multi-database Mining. IEEE Intell. Inform. Bull. 2004, 3, 19–24. [Google Scholar]
- Zhang, S.; Zhang, C.; Yu, J.X. An efficient strategy for mining exceptions in multi-databases. Inf. Sci. 2004, 165, 1–20. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, C.; Zhang, S. Database classification for multi-database mining. Inf. Syst. 2005, 30, 71–88. [Google Scholar] [CrossRef]
- Li, H.; Hu, X.; Zhang, Y. An Improved Database Classification Algorithm for Multi-database Mining. In Frontiers in Algorithmics; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 346–357. [Google Scholar]
- Na, S.; Xumin, L.; Yong, G. Research on k-means clustering algorithm: An improved k-means clustering algorithm. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Jian, China, 2–4 April 2010; pp. 63–67. [Google Scholar]
- Selim, S.Z.; Ismail, M.A. K-means-type algorithms: A generalized convergence theorem and characterization of local optimality. IEEE Trans. Pattern Anal. Mach. Intel. 1984, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- De Luca, A.; Termini, S. A Definition of a Nonprobabilistic Entropy in the Setting of Fuzzy Sets Theory. In Readings in Fuzzy Sets for Intelligent Systems; Dubois, D., Prade, H., Yager, R.R., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1993; pp. 197–202. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Data structures for disjoint sets. In Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2009; pp. 498–524. [Google Scholar]
- Center for Machine Learning and Intelligent Systems. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/ (accessed on 10 October 2020).
- IBM Almaden Quest Research Group. Frequent Itemset Mining Dataset Repository. Available online: http://fimi.ua.ac.be/data/. (accessed on 10 October 2020).
- Thirion, G.; Varoquaux, A.; Gramfort, V.; Michel, O.; Grisel, G.; Louppe, J. Nothman. Scikit-learn: Sklearn.datasets.makeblobs. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_blobs.html (accessed on 10 October 2020).
- Gramfort, A.; Blondel, M.; Grisel, O.; Mueller, A.; Martin, E.; Patrini, G.; Chang, E. Scikit-Learn: Sklearn.preprocessing.MinMaxScaler. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 10 October 2020).
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Meilǎ, M. Comparing clusterings: An axiomatic view. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 577–584. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Günnemann, S.; Färber, I.; Müller, E.; Assent, I.; Seidl, T. External evaluation measures for subspace clustering. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–28 October 2011; pp. 1363–1372. [Google Scholar]
- Banerjee, A.; Krumpelman, C.; Ghosh, J.; Basu, S.; Mooney, R.J. Model-based overlapping clustering. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 532–537. [Google Scholar]
- Pfitzner, D.; Leibbrandt, R.; Powers, D. Characterization and evaluation of similarity measures for pairs of clusterings. Knowl. Inf. Syst. 2009, 19, 361–394. [Google Scholar] [CrossRef]
- Achtert, E.; Goldhofer, S.; Kriegel, H.P.; Schubert, E.; Zimek, A. Evaluation of clusterings–metrics and visual support. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1285–1288. [Google Scholar]
- Shafiei, M.; Milios, E. Model-based overlapping co-clustering. In Proceedings of the SIAM Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006. [Google Scholar]
- Chinchor, N. MUC-4 evaluation metrics. In Proceedings of the of the Fourth Message Understanding Conference, McLean, VA, USA, 16–18 June 1992. [Google Scholar]
- Mei, Q.; Radev, D. Information retrieval. In The Oxford Handbook of Computational Linguistics, 2nd ed.; Oxford University Press: New York, NY, USA, 1979. [Google Scholar]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Jaccard, P. Distribution de la flore alpine dans le bassin des Dranses et dans quelques régions voisines. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 241–272. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).