
From Rényi Entropy Power to Information Scan of Quantum States



{kind=link}
{kind=link}
Abstract
1. Introduction
2. Rényi Entropy Based Estimation Theory and Rényi Entropy Powers
2.1. Fisher Information—Shannon’s Entropy Approach
2.2. Fisher Information—Rényi’s Entropy Approach
2.3. Rényi’s Entropy Power and Generalized Isoperimetric Inequality
3. Information Distribution
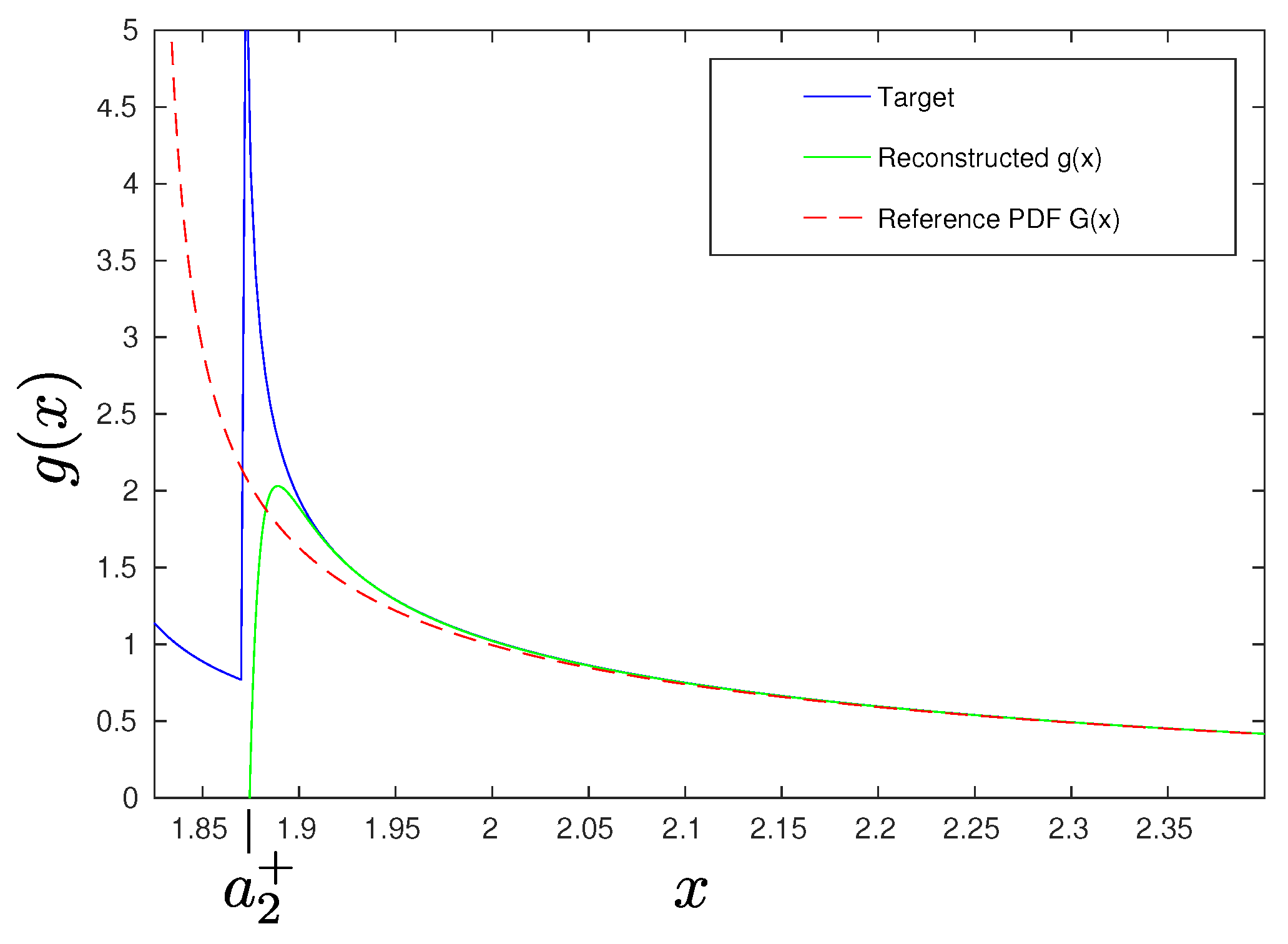
4. Reconstruction Theorem
5. Information Scan of Quantum-State PDF
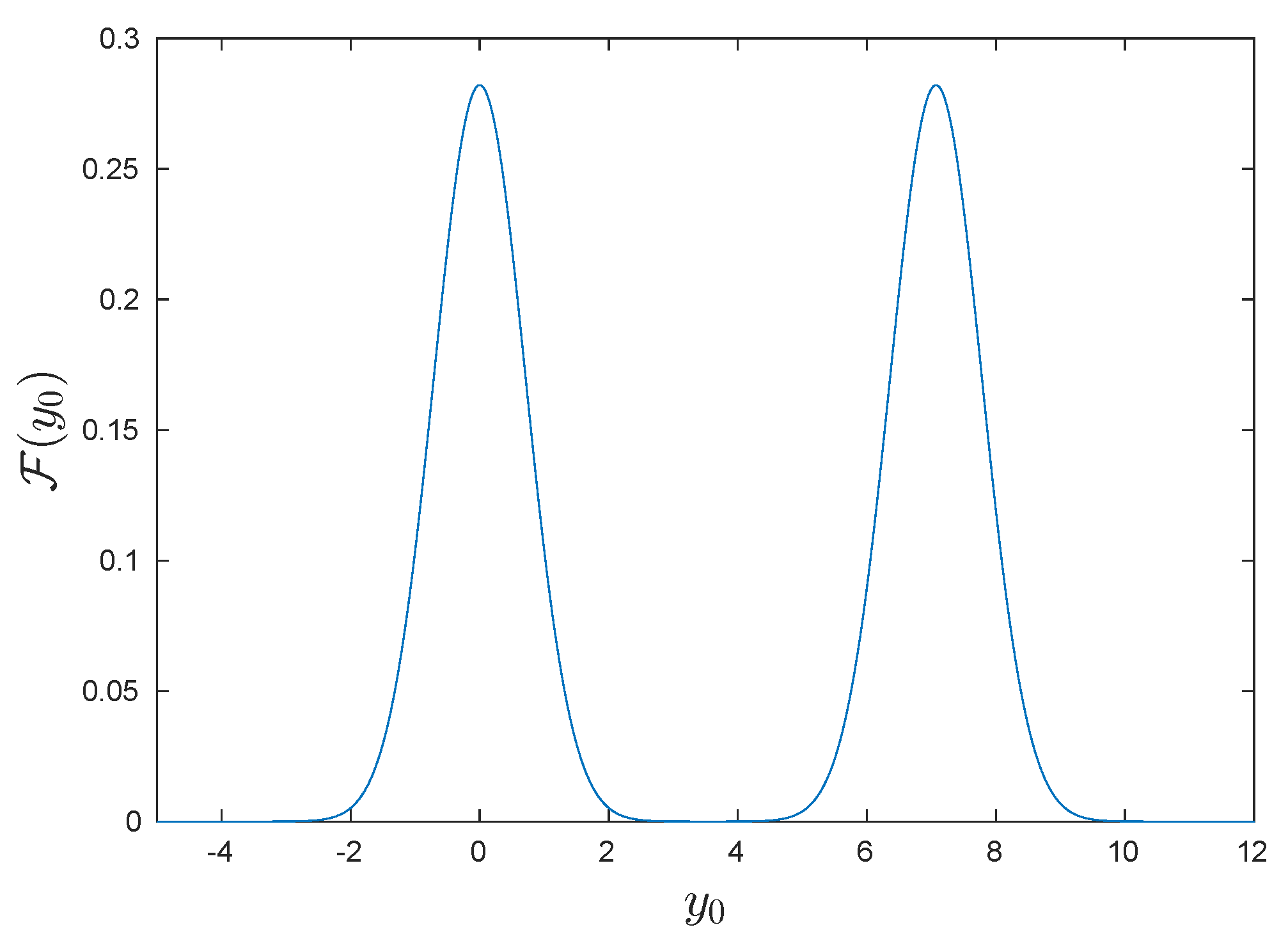
6. Example—Reconstruction Theorem and (Un)Balanced Cat State
7. Entropy Powers Based on Tsallis Entropy
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ITE | Information-theoretic entropy |
| UR | Uncertainty relation |
| RE | Rényi entropy |
| TE | Tsallis entropy |
| REPUR | Rényi entropy-power-based quantum uncertainty relation |
| QM | Quantum mechanics |
| EP | Entropy power |
| FI | Fisher information |
| Probability density function | |
| EPI | Entropy power inequality |
| REP | Rényi entropy power |
| BCS | Balanced cat state |
| UCS | Unbalanced cat state |
Appendix A
Appendix B
Appendix C
References
- Bennaim, A. Information, Entropy, Life in addition, the Universe: What We Know Amnd What We Do Not Know; World Scientific: Singapore, 2015. [Google Scholar]
- Jaynes, E.T. Papers on Probability and Statistics and Statistical Physics; D. Reidel Publishing Company: Boston, MA, USA, 1983. [Google Scholar]
- Millar, R.B. Maximum Likelihood Estimation and Infrence; John Wiley and Soms Ltd.: Chichester, UK, 2011. [Google Scholar]
- Leff, H.S.; Rex, A.F. (Eds.) Maxwell’s Demon 2: Entropy, Classical and Quantum Information, Computing; Institute of Physics: London, UK, 2002. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423; 623–656. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: New York, NY, USA, 1949. [Google Scholar]
- Feinstein, A. Foundations of Information Theory; McGraw Hill: New York, NY, USA, 1958. [Google Scholar]
- Campbell, L.L. A Coding Theorem and Rényi’s Entropy. Inf. Control 1965, 8, 423–429. [Google Scholar] [CrossRef]
- Bercher, J.-F. Source Coding Escort Distributions Rényi Entropy Bounds. Phys. Lett. A 2009, 373, 3235–3238. [Google Scholar] [CrossRef]
- Thurner, S.; Hanel, R.; Klimek, P. Introduction to the Theory of Complex Systems; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics; Approaching a Complex World; Springer: New York, NY, USA, 2009. [Google Scholar]
- Bialynicki-Birula, I. Rényi Entropy and the Uncertainty Relations. AIP Conf. Proc. 2007, 889, 52–61. [Google Scholar]
- Jizba, P.; Ma, Y.; Hayes, A.; Dunningham, J.A. One-parameter class of uncertainty relations based on entropy power. Phys. Rev. E 2016, 93, 060104-1(R)–060104-5(R). [Google Scholar] [CrossRef] [PubMed]
- Maassen, H.; Uffink, J.B.M. Generalized entropic uncertainty relations. Phys. Rev. Lett. 1988, 60, 1103–1106. [Google Scholar] [CrossRef] [PubMed]
- Bialynicki-Birula, I.; Mycielski, J. Uncertainty relations for information entropy in wave mechanics. Commun. Math. Phys. 1975, 44, 129–132. [Google Scholar] [CrossRef]
- Dang, P.; Deng, G.-T.; Qian, T. A sharper uncertainty principle. J. Funct. Anal. 2013, 265, 2239–2266. [Google Scholar] [CrossRef]
- Ozawa, T.; Yuasa, K. Uncertainty relations in the framework of equalities. J. Math. Anal. Appl. 2017, 445, 998–1012. [Google Scholar] [CrossRef]
- Zeng, B.; Chen, X.; Zhou, D.-L.; Wen, X.-G. Quantum Information MeetsQuantum Matter: From Quantum Entanglement to Topological Phase in Many-Body Systems; Springer: New York, NY, USA, 2018. [Google Scholar]
- Melcher, B.; Gulyak, B.; Wiersig, J. Information-theoretical approach to the many-particle hierarchy problem. Phys. Rev. A 2019, 100, 013854-1–013854-5. [Google Scholar] [CrossRef]
- Ryu, S.; Takayanagi, T. Holographic derivation of entanglement entropy from AdS/CFT. Phys. Rev. Lett. 2006, 96, 181602-1–181602-4. [Google Scholar] [CrossRef]
- Eisert, J.; Cramer, M.; Plenio, M.B. Area laws for the entanglement entropy—A review. Rev. Mod. Phys. 2010, 82, 277–306. [Google Scholar] [CrossRef]
- Pikovski, I.; Vanner, M.R.; Aspelmeyer, M.; Kim, M.S.; Brukner, Č. Probing Planck-Scale physics Quantum Optics. Nat. Phys. 2012, 8, 393–397. [Google Scholar] [CrossRef]
- Marin, F.; Marino, F.; Bonaldi, M.; Cerdonio, M.; Conti, L.; Falferi, P.; Mezzena, R.; Ortolan, A.; Prodi, G.A.; Taffarello, L.; et al. Gravitational bar detectors set limits to Planck-scale physics on macroscopic variables. Nat. Phys. 2013, 9, 71–73. [Google Scholar]
- An, S.; Zhang, J.-N.; Um, M.; Lv, D.; Lu, Y.; Zhang, J.; Yin, Z.-Q.; Quan, H.T.; Kim, K. Experimental test of the quantum Jarzynski equality with a trapped-ion system. Nat. Phys. 2014, 11, 193–199. [Google Scholar] [CrossRef]
- Campisi, M.; Hänggi, P.; Talkner, P. Quantum fluctuation relations: Foundations and applications. Rev. Mod. Phys. 2011, 83, 771–791. [Google Scholar] [CrossRef]
- Erhart, J.; Sponar, S.; Sulyok, G.; Badurek, G.; Ozawa, M.; Hasegawa, Y. Experimental demonstration of a universally valid error—Disturbance uncertainty relation in spin measurements. Nat. Phys. 2012, 8, 185–189. [Google Scholar] [CrossRef]
- Sulyok, G.; Sponar, S.; Erhart, J.; Badurek, G.; Ozawa, M.; Hasegawa, Y. Violation of Heisenberg’s error-disturbance uncertainty relation in neutron-spin measurements. Phys. Rev. A 2013, 88, 022110-1–022110-15. [Google Scholar] [CrossRef]
- Baek, S.Y.; Kaneda, F.; Ozawa, M.; Edamatsu, K. Experimental violation and reformulation of the Heisenberg’s error-disturbance uncertainty relation. Sci. Rep. 2013, 3, 2221-1–2221-5. [Google Scholar] [CrossRef] [PubMed]
- Dressel, J.; Nori, F. Certainty in Heisenberg’s uncertainty principle: Revisiting definitions for estimation errors and disturbance. Phys. Rev. A 2014, 89, 022106-1–022106-14. [Google Scholar] [CrossRef]
- Busch, P.; Lahti, P.; Werner, R.F. Proof of Heisenberg’s Error-Disturbance Relation. Phys. Rev. Lett. 2013, 111, 160405-1–160405-5. [Google Scholar] [CrossRef]
- Jizba, P.; Arimitsu, T. The world according to Rényi: Thermodynamics of multifractal systems. Ann. Phys. 2004, 312, 17–59. [Google Scholar] [CrossRef]
- Liu, R.; Liu, T.; Poor, H.V.; Shamai, S. A Vector Generalization of Costa’s Entropy-Power Inequality with Applications. IEEE Trans. Inf. Theory 2010, 56, 1865–1879. [Google Scholar]
- Costa, M.H.M. On the Gaussian interference channel. IEEE Trans. Inf. Theory 1985, 31, 607–615. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Wu, Y. Wasserstein continuity of entropy and outer bounds for interference channels. arXiv 2015, arXiv:1504.04419. [Google Scholar] [CrossRef]
- Bagherikaram, G.; Motahari, A.S.; Khandani, A.K. The Secrecy Capacity Region of the Gaussian MIMO Broadcast Channel. IEEE Trans. Inf. Theory 2013, 59, 2673–2682. [Google Scholar] [CrossRef]
- De Palma, G.; Mari, A.; Lloyd, S.; Giovannetti, V. Multimode quantum entropy power inequality. Phys. Rev. A 2015, 91, 032320-1–032320-6. [Google Scholar] [CrossRef]
- Costa, M.H. A new entropy power inequality. IEEE Trans. Inf. Theory 1985, 31, 751–760. [Google Scholar] [CrossRef]
- Frieden, B.R. Science from Fisher Information: A Unification; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Courtade, T.A. Strengthening the Entropy Power Inequality. arXiv 2016, arXiv:1602.03033. [Google Scholar]
- Barron, A.R. Entropy and the Central Limit Theorem. Ann. Probab. 1986, 14, 336–342. [Google Scholar] [CrossRef]
- Pardo, L. New Developments in Statistical Information Theory Based on Entropy and Divergence Measures. Entropy 2019, 21, 391. [Google Scholar] [CrossRef]
- Biró, T.; Barnaföldi, G.; Ván, P. New entropy formula with fluctuating reservoir. Physics A 2015, 417, 215–220. [Google Scholar] [CrossRef]
- Bíró, G.; Barnaföldi, G.G.; Biró, T.S.; Ürmössy, K.; Takács, Á. Systematic Analysis of the Non-Extensive Statistical Approach in High Energy Particle Collisions—Experiment vs. Theory. Entropy 2017, 19, 88. [Google Scholar] [CrossRef]
- Hanel, R.; Thurner, S. When do generalized entropies apply? How phase space volume determines entropy. Europhys. Lett. 2011, 96, 50003-1–50003-6. [Google Scholar] [CrossRef]
- Hanel, R.; Thurner, S.; Gell-Mann, M. How multiplicity determines entropy and the derivation of the maximum entropy principle for complex systems. Proc. Natl. Acad. Sci. USA 2014, 111, 6905–6910. [Google Scholar] [CrossRef] [PubMed]
- Burg, J.P. The Relationship Between Maximum Entropy Spectra In addition, Maximum Likelihood Spectra. Geophysics 1972, 37, 375–376. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Havrda, J.; Charvát, F. Quantification Method of Classification Processes: Concept of Structural α-Entropy. Kybernetika 1967, 3, 30–35. [Google Scholar]
- Frank, T.; Daffertshofer, A. Exact time-dependent solutions of the Renyi Fokker–Planck equation and the Fokker–Planck equations related to the entropies proposed by Sharma and Mittal. Physics A 2000, 285, 351–366. [Google Scholar] [CrossRef]
- Sharma, B.D.; Mitter, J.; Mohan, M. On measures of “useful” information. Inf. Control 1978, 39, 323–336. [Google Scholar] [CrossRef][Green Version]
- Jizba, P.; Korbel, J. On q-non-extensive statistics with non-Tsallisian entropy. Physics A 2016, 444, 808–827. [Google Scholar] [CrossRef]
- Jizba, P.; Arimitsu, T. Generalized statistics: Yet another generalization. Physics A 2004, 340, 110–116. [Google Scholar] [CrossRef]
- Vos, G. Generalized additivity in unitary conformal field theories. Nucl. Phys. B 2015, 899, 91–111. [Google Scholar] [CrossRef]
- Uffink, J. Can the maximum entropy principle be explained as a consistency requirement? Stud. Hist. Phil. Mod. Phys. 1995, 26, 223–261. [Google Scholar] [CrossRef]
- Jizba, P.; Korbel, J. Maximum Entropy Principle in Statistical Inference: Case for Non-Shannonian Entropies. Phys. Rev. Lett. 2019, 122, 120601-1–120601-6. [Google Scholar] [CrossRef] [PubMed]
- Jizba, P.; Arimitsu, T. Observability of Rényi’s entropy. Phys. Rev. E 2004, 69, 026128-1–026128-12. [Google Scholar] [CrossRef]
- Elben, A.; Vermersch, B.; Dalmonte, M.; Cirac, J.I.; Zoller, P. Rényi Entropies from Random Quenches in Atomic Hubbard and Spin Models. Phys. Rev. Lett. 2018, 120, 050406-1–050406-6. [Google Scholar] [CrossRef]
- Bacco, D.; Canale, M.; Laurenti, N.; Vallone, G.; Villoresi, P. Experimental quantum key distribution with finite-key security analysis for noisy channels. Nat. Commun. 2013, 4, 2363-1–2363-8. [Google Scholar] [CrossRef] [PubMed]
- Müller-Lennert, M.; Dupuis, F.; Szehr, O.; Fehr, S.; Tomamichel, M. On quantum Renyi entropies: A new generalization and some properties. J. Math. Phys. 2013, 54, 122203-1–122203-20. [Google Scholar] [CrossRef]
- Coles, P.J.; Colbeck, R.; Yu, L.; Zwolak, M. Uncertainty Relations from Simple Entropic Properties. Phys. Rev. Lett. 2012, 108, 210405-1–210405-5. [Google Scholar] [CrossRef]
- Minter, F.; Kuś, M.; Buchleitner, A. Concurrence of Mixed Bipartite Quantum States in Arbitrary Dimensions. Phys. Rev. Lett. 2004, 92, 167902-1–167902-4. [Google Scholar]
- Vidal, G.; Tarrach, R. Robustness of entanglement. Phys. Rev. A 1999, 59, 141–155. [Google Scholar] [CrossRef]
- Bengtsson, I.; Życzkowski, K. Geometry of Quantum States. An Introduction to Quantum Entanglement; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Jizba, P.; Dunningham, J.A.; Joo, J. Role of information theoretic uncertainty relations in quantum theory. Ann. Phys. 2015, 355, 87–114. [Google Scholar] [CrossRef]
- Toranzo, I.V.; Zozor, S.; Brossier, J.-M. Generalization of the de Bruijn Identity to General ϕ-Entropies and ϕ-Fisher Informations. IEEE Trans. Inf. Theory 2018, 64, 6743–6758. [Google Scholar] [CrossRef]
- Rioul, O. Information Theoretic Proofs of Entropy Power Inequalities. IEEE Trans. Inf. Theory 2011, 57, 33–55. [Google Scholar] [CrossRef]
- Dembo, A.; Cover, T.M. Information Theoretic Inequalitis. IEEE Trans. Inf. Theory 1991, 37, 1501–1517. [Google Scholar] [CrossRef]
- Lutwak, E.; Lv, S.; Yang, D.; Zhang, G. Extensions of Fisher Information and Stam’s Inequality. IEEE Trans. Inf. Theory 2012, 58, 1319–1327. [Google Scholar] [CrossRef]
- Widder, D.V. The Laplace Transform; Princeton University Press: Princeton, NJ, USA, 1946. [Google Scholar]
- Knott, P.A.; Proctor, T.J.; Hayes, A.J.; Ralph, J.F.; Kok, P.; Dunningham, J.A. Local versus Global Strategies in Multi-parameter Estimation. Phys. Rev. A 2016, 94, 062312-1–062312-7. [Google Scholar] [CrossRef]
- Beck, C.; Schlögl, F. Thermodynamics of Chaotic Systems; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Gardner, R.J. The Brunn-Minkowski inequality. Bull. Am. Math. Soc. 2002, 39, 355–405. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Einstein, A. Theorie der Opaleszenz von homogenen Flüssigkeiten und Flüssigkeitsgemischen in der Nähe des kritischen Zustandes. Ann. Phys. 1910, 33, 1275–1298. [Google Scholar] [CrossRef]
- De Palma, G. The entropy power inequality with quantum conditioning. J. Phys. A Math. Theor. 2019, 52, 08LT03-1–08LT03-12. [Google Scholar] [CrossRef]
- Ram, E.; Sason, I. On Rényi Entropy Power Inequalities. IEEE Trans. Inf. Theory 2016, 62, 6800–6815. [Google Scholar] [CrossRef]
- Stam, A. Some inequalities satisfied by the quantities of information of Fisher and Shannon. Inform. Control 1959, 2, 101–112. [Google Scholar] [CrossRef]
- Rényi, A. Probability Theory; Selected Papers of Alfred Rényi; Akadémia Kiado: Budapest, Hungary, 1976; Volume 2. [Google Scholar]
- Cramér, H. Mathematical Methods of Statistics; Princeton University Press: Princeton, NJ, USA, 1946. [Google Scholar]
- Wilk, G.; Włodarczyk, Z. Uncertainty relations in terms of the Tsallis entropy. Phys. Rev. A 2009, 79, 062108-1–062108-6. [Google Scholar] [CrossRef]
- Schrödinger, E. About Heisenberg Uncertainty Relation. Sitzungsber. Preuss. Akad. Wiss. 1930, 24, 296–303. [Google Scholar]
- Robertson, H.P. The Uncertainty Principle. Phys. Rev. 1929, 34, 163–164. [Google Scholar] [CrossRef]
- Hirschman, I.I., Jr. A Note on Entropy. Am. J. Math. 1957, 79, 152–156. [Google Scholar] [CrossRef]
- D’Ariano, M.G.; De Laurentis, M.; Paris, M.G.A.; Porzio, A.; Solimeno, S. Quantum tomography as a tool for the characterization of optical devices. J. Opt. B 2002, 4, 127–132. [Google Scholar] [CrossRef]
- Lvovsky, A.I.; Raymer, M.G. Continuous-variable optical quantum-state tomography. Rev. Mod. Phys. 2009, 81, 299–332. [Google Scholar] [CrossRef]
- Gross, D.; Liu, Y.-K.; Flammia, S.T.; Becker, S.; Eisert, J. Quantum State Tomography via Compressed Sensing. Phys. Rev. Lett. 2010, 105, 150401-1–150401-4. [Google Scholar] [CrossRef] [PubMed]
- Beckner, W. Inequalities in Fourier Analysis. Ann. Math. 1975, 102, 159–182. [Google Scholar] [CrossRef]
- Babenko, K.I. An inequality in the theory of Fourier integrals. Am. Math. Soc. Transl. 1962, 44, 115–128. [Google Scholar]
- Samko, S.G.; Kilbas, A.A.; Marichev, O.I. Fractional Integrals and Derivatives: Theory and Applications; Gordon and Breach: New York, NY, USA, 1993. [Google Scholar]
- Reed, M.; Simon, B. Methods of Modern Mathematical Physics; Academic Press: New York, NY, USA, 1975; Volume XI. [Google Scholar]
- Wallace, D.L. Asymptotic Approximations to Distributions. Ann. Math. Stat. 1958, 29, 635–654. [Google Scholar] [CrossRef]
- Zolotarev, V.M. Mellin—Stieltjes Transforms in Probability Theory. Theory Probab. Appl. 1957, 2, 444–469. [Google Scholar] [CrossRef]
- Tagliani, A. Inverse two-sided Laplace transform for probability density functions. J. Comp. Appl. Math. 1998, 90, 157–170. [Google Scholar] [CrossRef]
- Lukacs, E. Characteristic Functions; Charles Griffin: London, UK, 1970. [Google Scholar]
- Pal, N.; Jin, C.; Lim, W.K. Handbook of Exponential and Related Distributions for Engineers and Scientists; Taylor & Francis Group: New York, NY, USA, 2005. [Google Scholar]
- Kira, M.; Koch, S.W.; Smith, R.P.; Hunter, A.E.; Cundiff, S.T. Quantum spectroscopy with Schrödinger-cat states. Nat. Phys. 2011, 7, 799–804. [Google Scholar]
- Knott, P.A.; Cooling, J.P.; Hayes, A.; Proctor, T.J.; Dunningham, J.A. Practical quantum metrology with large precision gains in the low-photon-number regime. Phys. Rev. A 2016, 93, 033859-1–033859-7. [Google Scholar] [CrossRef]
- Wei, L. On the Exact Variance of Tsallis Entanglement Entropy in a Random Pure State. Entropy 2019, 21, 539. [Google Scholar] [CrossRef] [PubMed]
- Marcinkiewicz, J. On a Property of the Gauss law. Math. Z. 1939, 44, 612–618. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jizba, P.; Dunningham, J.; Prokš, M. From Rényi Entropy Power to Information Scan of Quantum States. Entropy 2021, 23, 334. https://doi.org/10.3390/e23030334
Jizba P, Dunningham J, Prokš M. From Rényi Entropy Power to Information Scan of Quantum States. Entropy. 2021; 23(3):334. https://doi.org/10.3390/e23030334
Chicago/Turabian StyleJizba, Petr, Jacob Dunningham, and Martin Prokš. 2021. "From Rényi Entropy Power to Information Scan of Quantum States" Entropy 23, no. 3: 334. https://doi.org/10.3390/e23030334
APA StyleJizba, P., Dunningham, J., & Prokš, M. (2021). From Rényi Entropy Power to Information Scan of Quantum States. Entropy, 23(3), 334. https://doi.org/10.3390/e23030334