2. Materials and Methods
In this section we propose our novel method, present the data set we used for training and validation and explain robustness tests we have done.
2.1. Eigenfaces and Eigenfaces-Based Steganography
An eigenface is a
k-dimensional vector of real values that represents features of pre-aligned facial image. Eigenfaces are based on principal component analysis (PCA). Let us suppose that we have a set of
l images
with uniform dimensionality
. Each face image being initially a two-dimensional matrix is “flattened” by placing its columns one below another, thereby becoming a single column vector. Then we use PCA to perform variance analysis and to recalculate current coordinates of those vectors into PCA coordinates systems where axes are ordered from those that represent highest variance to those that represent lowest variance. Let us assume that we have matrix
D with dimensionality
in which each column is a flattened image:
Next we calculate a column vector
M (so called mean face) in which each row is a mean value of a corresponding row in matrix
D
where
is the
j-th pixel of
i-th image. This mean face is then subtracted from each column of matrix
D to calculate new matrix called
:
Then a covariance matrix is created:
Because
C is symmetric and positively defined, all eigenvalues have real positive values. Eigenfaces
E are calculated as:
where
are eigenvectors of
C ordered from the highest to the lowest eigenvalue.
In order to generate eigenfaces-based features
of face image
one has to perform following operation:
The inverse procedure that recalculates image vector coordinates to original coordinate system is:
We can use k first eigenvectors where . In this case and keeps at least percentage of variance equals to scaled cumulative sum of eigenvalues cooresponding to k first eigenvectors. In other words when , vector represents “compressed” facial image in respect to overall variance. features are coefficients of linear combination of E. Coefficients with lower indices corresponds to dimensions with higher variance.
Eigenface-based feature calculation is performed after designation of
in (
5). We have to subtract mean vector
M from the face image
in the same manner, as it was performed in (
3). Image
may be replaced by any face image, also not included in
D, however it has to have the same resolution as images in
D, namely
. When
is not from data set
D, then we can safely assume that
.
The idea of eigenface-based steganography is to replace range of coefficients
with a binary encoded message
s with the length
o.
j is an offset from the beginning of the eigenface-based features vector. The message is stored by changing original values of linear combination to binary values:
where
represents 0,
represents 1 and
is a scaling parameter. Transformation of original binary message
s into values of message
, which is directly inserted into eigenfaces coefficients, goes as follows:
where
is
i-th binary coefficient of vector
s that contains a message to hide. The inverse procedure is:
where round denotes rounding to the closest integer.
The offset value
j and the maximum value of secret length
o need to be determined. It is a subject of discussion in following sections. The message hiding algorithm is presented in Algorithm 1. Message recovering algorithm is presented in Algorithm 2.
| Algorithm 1: Message encoding algorithm. |
| Data: J—image containing a face, |
| s—message to hide with length o bits, |
| j—offset from which the coefficients will be replaced by message, |
| —divider parameter. |
| Result: Image with hidden data. |
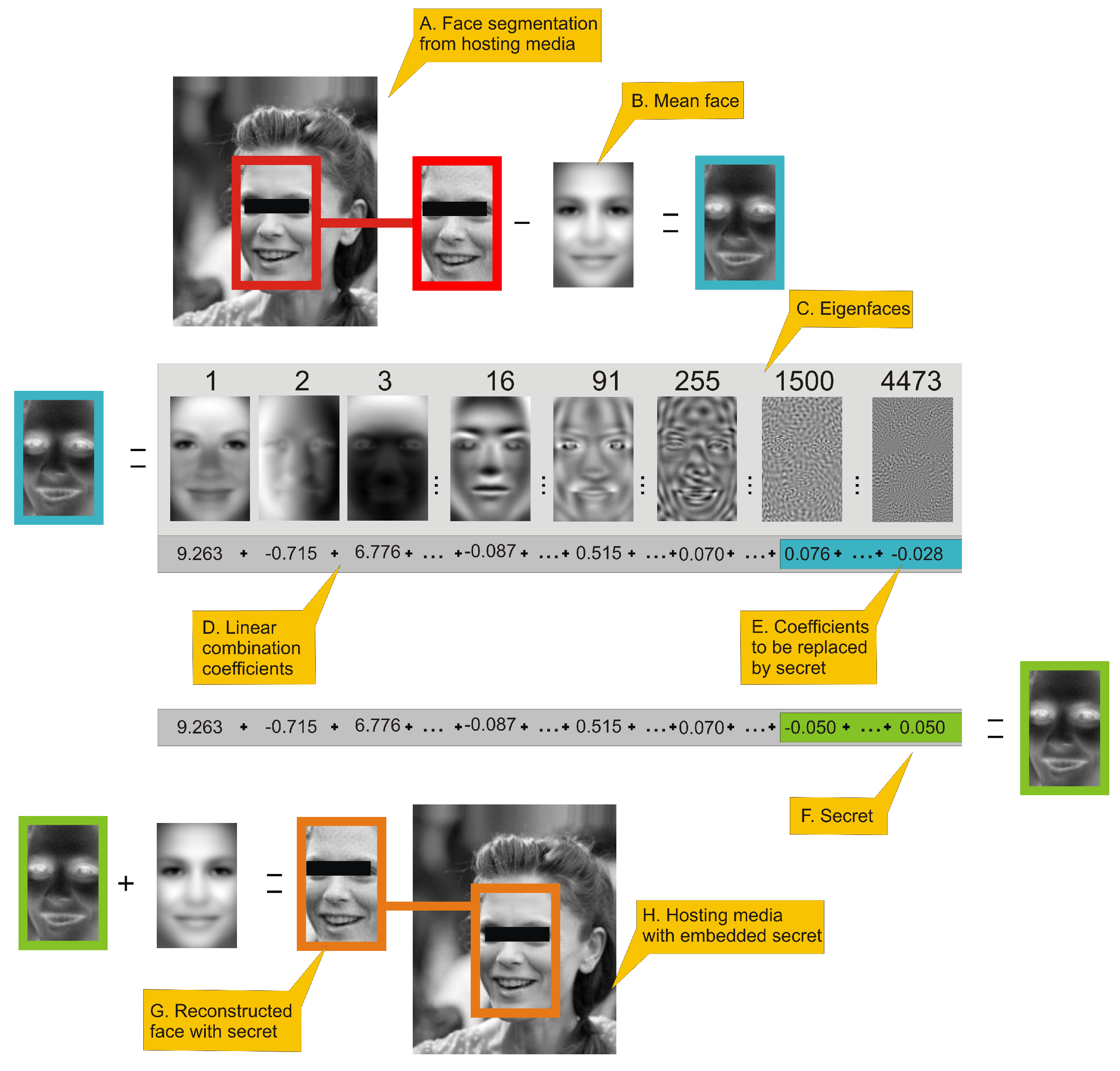
| 1. Extract face image from J (Figure 1A); |
| 2. Perform aligning of extracted face and store it in matrix ; |
| 3. Generate from using (6) (Figure 1B,D); |
| 4. Starting from index j replace original o values in by , which are scaled coefficients that represents binary message data (8) (Figure 1E,F); |
| 5. By application of (7) generate using modified (Figure 1G); |
| 6. Insert into J replacing original face, image is created (Figure 1H); |
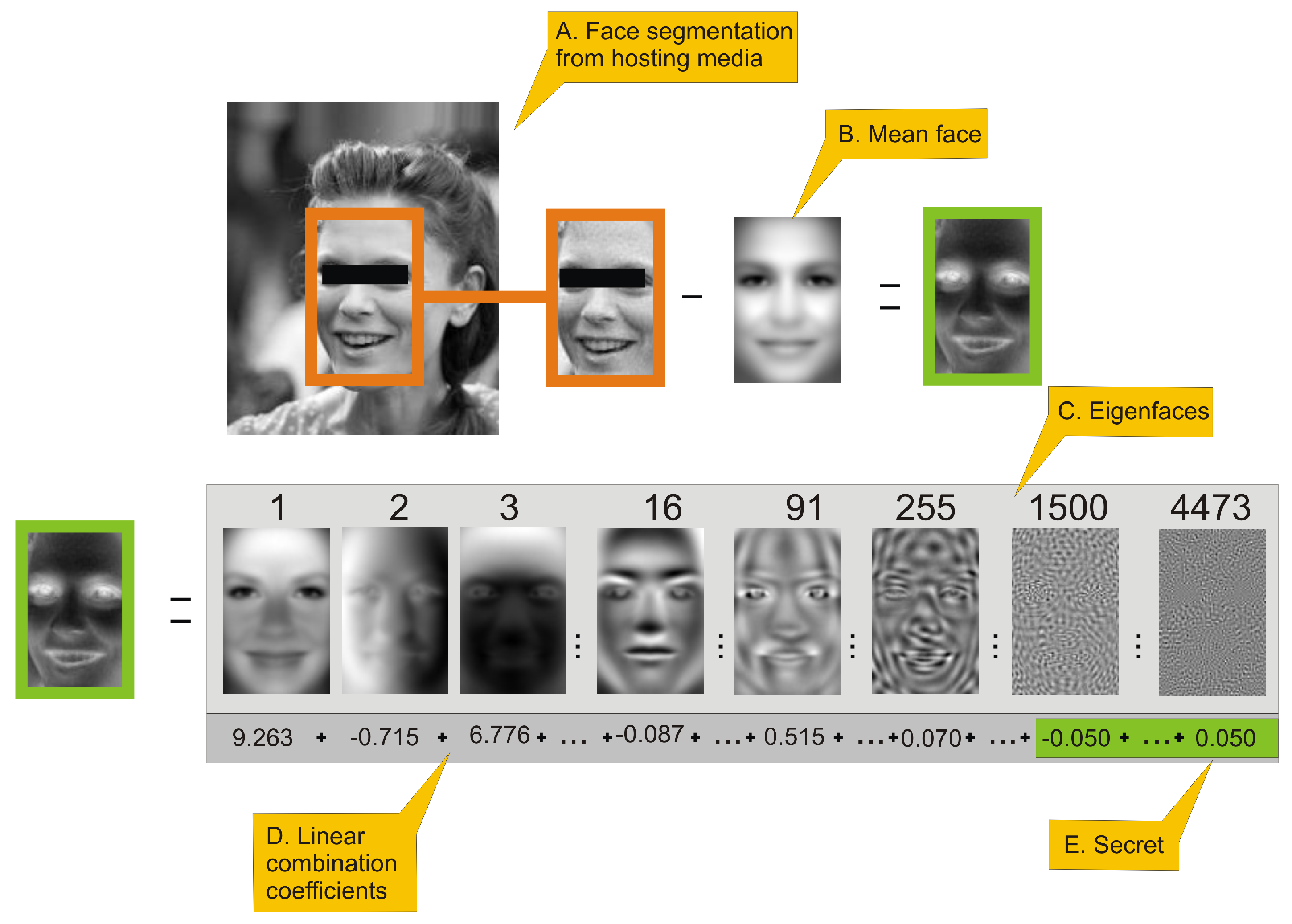
Figure 1.
This figure presents an outline of eigenface-based steganography secret encoding framework. (
A.) a face image is extracted from an image; (
B.) a mean face is subtracted from face image. (
C.) presents selected eigenfaces visualized as 2D images. (
D.) By applying Equation (
6) we can generate eigenfaces-based features of a face, which is a linear combination of coefficients. Values in sum (
D.) are actual coefficients of the face in turquoise frame. High-order coefficients (
E.) of that linear combination have fractional influence on reconstructed image visual quality and can be used to hide the secret. Hiding can be done simply be replacing those coefficients by rescaled secret with Equation (
8). (
F.) is a linear combination coefficient with high-order coefficients replaced by a secret. That linear combination is used to reconstruct face image using Equation (
7), which is represented as the face inside green frame. The last two steps is: (
G.) adding mean face to face with hidden data and: (
H.) inserting face image to original hosting media.
Figure 1.
This figure presents an outline of eigenface-based steganography secret encoding framework. (
A.) a face image is extracted from an image; (
B.) a mean face is subtracted from face image. (
C.) presents selected eigenfaces visualized as 2D images. (
D.) By applying Equation (
6) we can generate eigenfaces-based features of a face, which is a linear combination of coefficients. Values in sum (
D.) are actual coefficients of the face in turquoise frame. High-order coefficients (
E.) of that linear combination have fractional influence on reconstructed image visual quality and can be used to hide the secret. Hiding can be done simply be replacing those coefficients by rescaled secret with Equation (
8). (
F.) is a linear combination coefficient with high-order coefficients replaced by a secret. That linear combination is used to reconstruct face image using Equation (
7), which is represented as the face inside green frame. The last two steps is: (
G.) adding mean face to face with hidden data and: (
H.) inserting face image to original hosting media.

Figure 1 presents the procedure of encoding a secret. All numerical values presented in this figure will be justified in the
Section 3. Person in image has been anonymized. The number above eigenface is its index. Eigenfaces are ordered by decreasing eigenvalues that corresponds to them. As can be seen several first eigenfaces represents global properties of image (i.e., lighting), next eigenfaces are responsible for high-frequency details.
| Algorithm 2: Message decoding algorithm. |
| Data: J—image containing a face, |
| j—offset from which the coefficients have been replaced by message, |
| —divider parameter |
| Result: s—decoded message with length o bits. |
| 1. Extract face image from J; |
| 2. Perform aligning of extracted face and store it in matrix ;
|
| 3. Generate from using (6);
|
| 4. Starting from index j extract o values from which are rescaled message’s values (), then restore the binary message by rescaling with parameter (9); |
The procedure of decoding a secret, which is presented in
Figure 2, is very similar to process of encoding.
2.2. The Data Set
In order to successfully generate eigenfaces with a strong descriptive power and to validate our approach, we needed a sufficiently large collection of faces. Among the largest publicly available open faces repositories we have chosen Large-scale CelebFaces Attributes (CelebA) Dataset [
25] which may be downloaded from Internet (
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html, accessed on 1 January 2021). It consisted of 202,598 images of celebrities, actors, sportspersons etc. In this research we have used aligned and cropped version of those images. Each of aligned and cropped photos has the same resolution and the face is centered so that eyes of each person are located nearly in the same position. There is no information how the alignment has been done; however it can be very closely reproduced with Histogram of Oriented Gradients (HOG) method [
26]. The face position estimator can be created using Python dlib’s library implementation of the work of Kazemi et al. [
27] with face landmark data set (
https://github.com/davisking/dlib-models, accessed on 1 January 2021.) trained on [
28]. In order to reduce the complexity of further computations, we have limited the size of images to resolution
, cropping all regions of image beside very face. For the same reason we have also converted images from RGB to grayscale. We have to remember, however, that proposed steganography approach may also be applied to RGB data, because eigenfaces are calculated in the same way on multiple colour channels as on single channel. Nonetheless, this discussion is out of scope of this paper.
2.3. Comparison of Covariance Matrices
The very heart of eigenfaces approach is preparation of a representative data set that is used to calculate linear transform from original coordinates to space (obtained by principal component analysis). Theoretically the more face samples we take (provided that the data set covers representative sample of images for future encoding), the better variance analysis we get. However, given that we operate on personal computers with limited RAM, we have to keep in mind that solving eigenvalue problem is complex and time demanding task, especially for relatively large matrices (i.e., or larger). Due to this we wanted to estimate the size of training set above which the covariance matrix will not change much. In order to do so, we compared the geodesic distance between covariance matrix generated from whole training data set and covariance matrices generated from subsets of validation data set of different sizes where are subsets of validation data set.
In order to calculate covariance matrix
we used formula:
where
has the same dimension
no matter how many images
l were used in calculation.
Due to the fact that covariance matrices are symmetric positive definite, we can measure distance between them using the Log-Euclidean Distance (LED) [
29]. Let as assume that
A and
B are symmetric positive definite. The geodesic distance between
A and
B can be expressed in the domain of matrix logarithms [
30] as:
In the above equation
is a Frobenius norm which is calculated for
n by
m matrix
A as [
31]:
Let us assume that
C and
D are square matrices. A matrix
C is a logarithm of
D when:
where matrix exponential is defined as:
Any non-singular matrix has infinitely many logarithms. As the covariance matrix does not have negative eigenvalues, we can use method described in [
32] to calculate the logarithm.
Another approach for calculating influence of correlation matrix size on quality of reconstruction from limited number of PCA coefficients is based on two measures: averaged mean square error (MSE) (
15) between actual (
) and reconstructed (
) image and averaged Pearson correlation coefficient (CC) (
16) between actual and PCA compressed image. Mean square error between actual and reconstructed image is defined as:
The Pearson correlation coefficient (CC) between actual
and reconstructed
image is defined as:
where
is covariance coefficient between
and
and
,
are standard deviations of
and
.
To better visualize relationship of LED and size of covariance matrix, we can also use relative values of LED coefficient:
Relative MSE and Relative CC may be calculated similarly as in (
17).
LED geodesic distances were compared with averaged mean square error (MSE) and averaged Pearson correlation coefficient (CC) between actual and reconstructed images from validation data set generated by PCA. The goal of this test was to check if the geodesic distance corresponds to averaged MSE and CC of PCA-compressed data.
2.4. Robustness Tests
We tested the robustness of proposed steganography method to common transformations. Each test has been applied to the image that contained hidden data.
Rotation of image about its centre element using third-order spline interpolation.
Salt and pepper—replacing given number of randomly chosen pixels with either 0 (black) or 255 (white) value.
JPEG compression with various quality settings [
33].
Linear scaling with bicubic pixels interpolation.
Image cropping—for obvious reasons the eigenfaces method is very sensitive to image cropping, however it seems to be resistant to mixing encoded signal with an original image. We can do it with following steps. At first we create a matrix
, which elements
are defined using following formulas:
We can use that matrix to mix the original image
I with image with encoded data
E by linearly scaling the amount of
E using threshold parameter
t:
Figure 3 presents how changes the shape of circular elements when the value of threshold
t increases.
Messages retrieved from disturbed images were compared with the original message using following similarity coefficients or measures:
We have also used two following metrics to compare results obtained by our solution to state-of-the-art method: Pearson correlation (CC) and peak-signal-to-noise-ratio (PSNR). CC is used to evaluate the similarity between the original secret and the secret message and PSNR in dB is used to evaluate the similarity of the original image and the stegoimage.
where
is the maximum value of vector pixels over the original image (in our case 255) and the
is represents the mean square error between the stegoimage and the original image.
2.5. Hiding Data in Larger Images
When the facial image is a part of larger photo (which is true in most cases), it should first be extracted, then encoded and decoded using eigenfaces and finally inserted back into the photo. As the modified face is not identical to the original, it may be possible to spot visual artifacts in a rectangular region containing a face. In order to blur the manipulation, we can use the clipping procedure described in Equations (
18)–(
21). Then, step 5 of the message encoding algorithm (Algorithm 1) is extended in following manner:
5. By application of (
7) generate
using (
8), apply (
18)–(
21) to blur borders of inserted data.
The algorithm has one additional parameter
t (threshold from (
20)). The message decoding algorithm (Algorithm 2) remains unchanged.
3. Results
The proposed solution was implemented in Python 3.8 (however it seemed there were no obstacles to run it on lower version of this language). Among the most important packages we used was OpenCV-python 4.1.2.30 for general purpose image processing. For algorithms training and evaluation we used a PC computer equipped with Intel i7-9700F 3.00 GHz CP, 64 GB RAM, NVIDIA GeForce RTX 2060 GPU with Windows 10 OS, and the second PC with similar hardware architecture, however with 128 GB RAM with Linux OS.
We used data set described in
Section 2.2 to evaluate this research. The faces data set was divided into halves. The first half (101,299 faces) was used as the training data set; the second half (101,300 faces) was a validation/test data set.
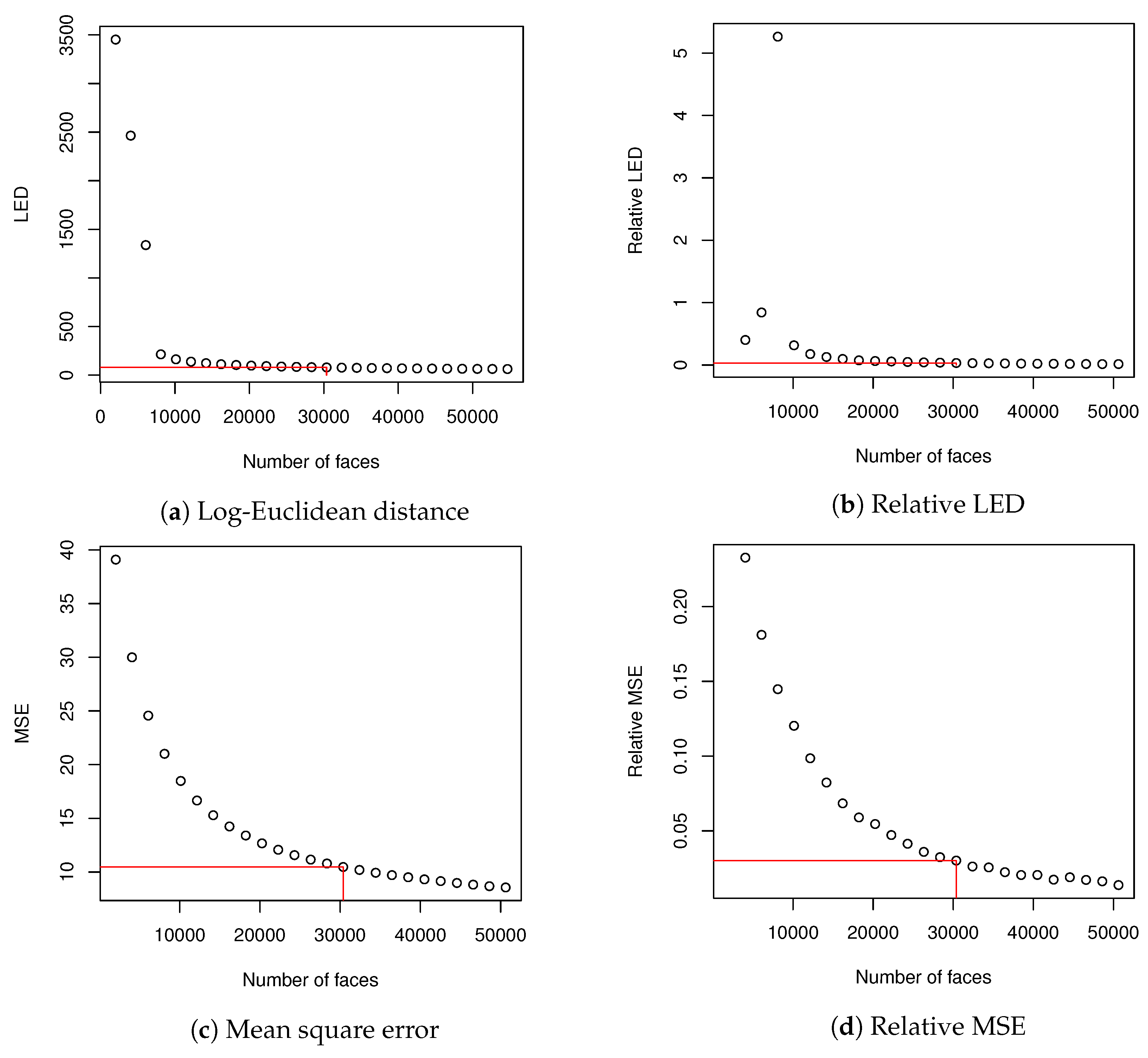
At first we estimated how many images we should use to create eigenfaces. In order to do so, we compared covariance matrices using methodology described in
Section 2.3. To create
(9) matrix, we used the whole validation dataset. In order to create
matrices, we used training dataset that was divided into subsets. Subset with index
a contained
faces (2025 is about 2% of training dataset), where
.
and
were compared using Log-Euclidean Distance (10). It was possible because both matrices had identical dimensions. Then, for each
, every image
in training data set was encoded and then decoded using eigenfaces that explained at least
of variance; as a result an image
was created. MSE (
15) and CC (
16) were calculated for
and corresponding
(they were calculated for images from the test data set because
were generated from validation data set). Averaged values of MSE and CC showed how well eigenfaces of various
described the data set. We also made calculations of relative values of LED and MSE according to Equation (
16). CC coefficient had a high value from the beginning and did not change much and due to this we skipped calculation of relative CC. When we used 30,375 images to create correlation matrix for PCA, both relative LED and relative MSE dropped below
. Basing on this fact, we decided that it might be a sufficient size of the training data set to evaluate our methodology. What is more, calculation of eigen decomposition for
matrix could be done in a reasonable time and further increase of data set did not change much in LED and averaged MSE. We have marked our choice of dataset size in
Table 1 with two horizontal lines.
Results from
Table 1 (beside CC, which did not change much during the experiment) are visualized in
Figure 4.
There was a limited amount of data to be hidden within eigenfaces, which were constrained the most by the face image resolution that was used to produce matrix
D (
1) and then
(
5). The second constraint was distribution of variance among eigenfaces, the influence of which on the capacity of the medium is discussed later on.
Typically steganography algorithms are evaluated on set of benchmark images like Lena, Pepper, Airplane etc. In our case however eigenfaces-based steganography operates only on face data. Because of it we need different validation dataset. Evaluation of robustness of proposed steganography algorithm was performed with methodology described in
Section 2.4. We used training data set containing
faces and validation data set with 101,300 faces. Scaling parameter
in binary data encoding was arbitrary set to 20.
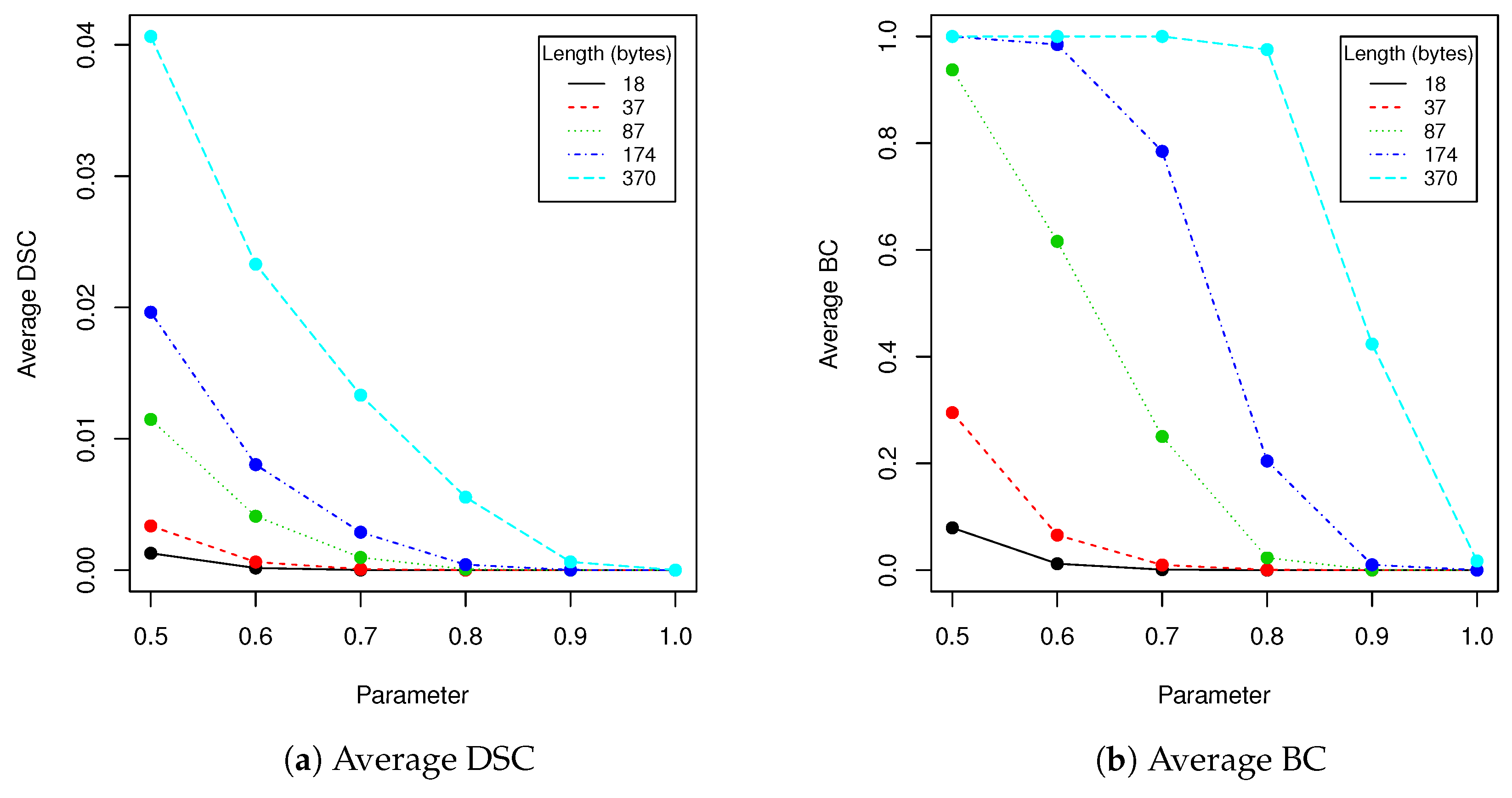
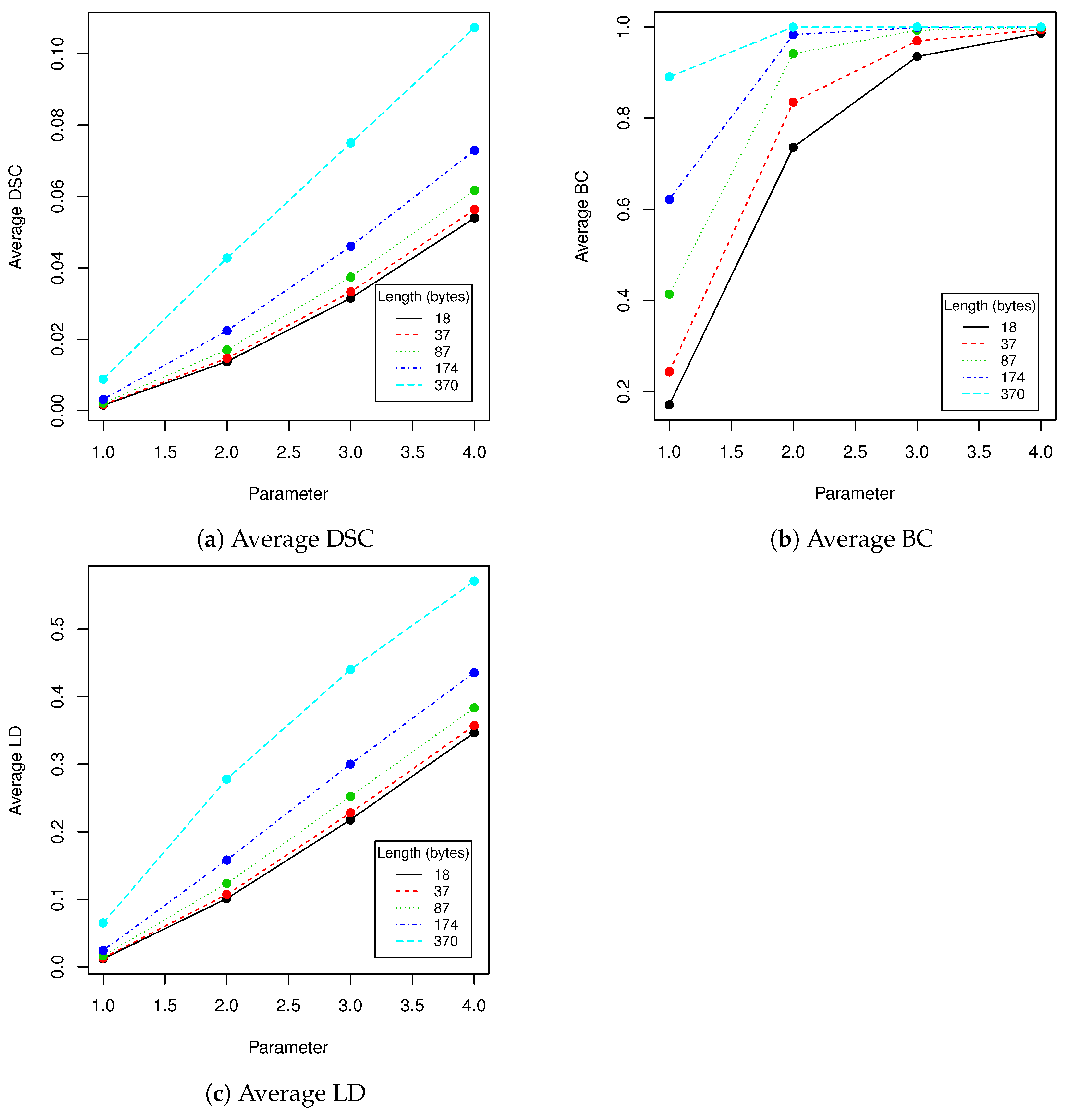
After applying PCA, we have calculated the number of dimensions that describe variance in test data set (consisting of 30,375 faces). 0.75 of variance was explained by 15 dimensions, 0.9 variance by 90 dimensions, 0.95 variance by 254 dimensions, 0.99 variance by 1499 dimensions and finally 0.999 variance by 4473 dimensions. Larger number of dimensions used for image encoding may introduce some high-frequency noises caused by not statistically significant data fluctuations in training data set. We can encode data in any eigenfaces coefficients between first and 4473rd value; however changes in linear combination of coefficients that are more important for variance explanation will be clearly visible in the encoded image. Because of that we decided to modify data between 1499 and 4473 coefficients. In this configuration potential maximal capacity of the image is Bytes. In further tests we have considered following lengths of messages: 18 bytes (∼5% of capacity), 37 bytes (∼10% of capacity), 87 bytes (∼23% of capacity), 174 (∼47% of capacity) and 370 (∼100% of capacity). We have chosen those values for convenience of calculations; also distribution of lengths allows to nicely plot the dependencies of proposed steganography method performance as a function of robustness tests parameters. Using five possible values of messages length unevenly distributed in data set allows visualizing general characteristics of proposed method. Of course it is possible to evaluate method using more sample points, however it would not introduce much new information. Additionally, evaluation of such large validation data set (approximately 100,000 images) lasted 24 to even 36+ h for each robustness test on hardware that we have used.
In robustness tests, besides various parameters described in
Section 2.4, we used five mentioned lengths of encoded messages (18, 37, 87, 174 and 370). Obtained results are presented in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 and
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
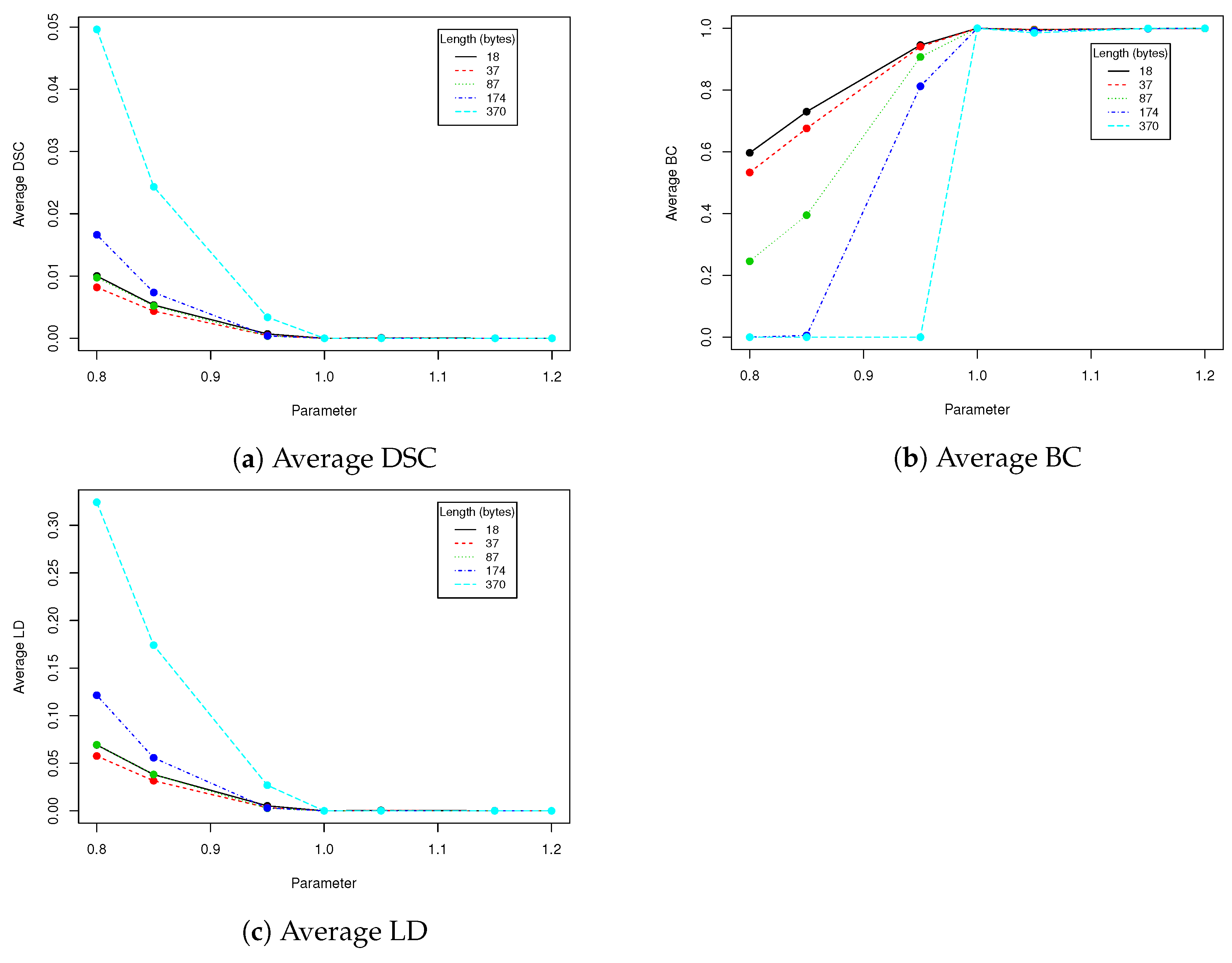
Figure 9 using averaged values of Binary coefficient (BC), Levenshtein distance (LD) and Sørensen–Dice coefficient (DSC) on all images from validation data set.
Next we have tested performance of algorithms described in
Section 2.1 and
Section 2.5 using various lengths of encoded messages and
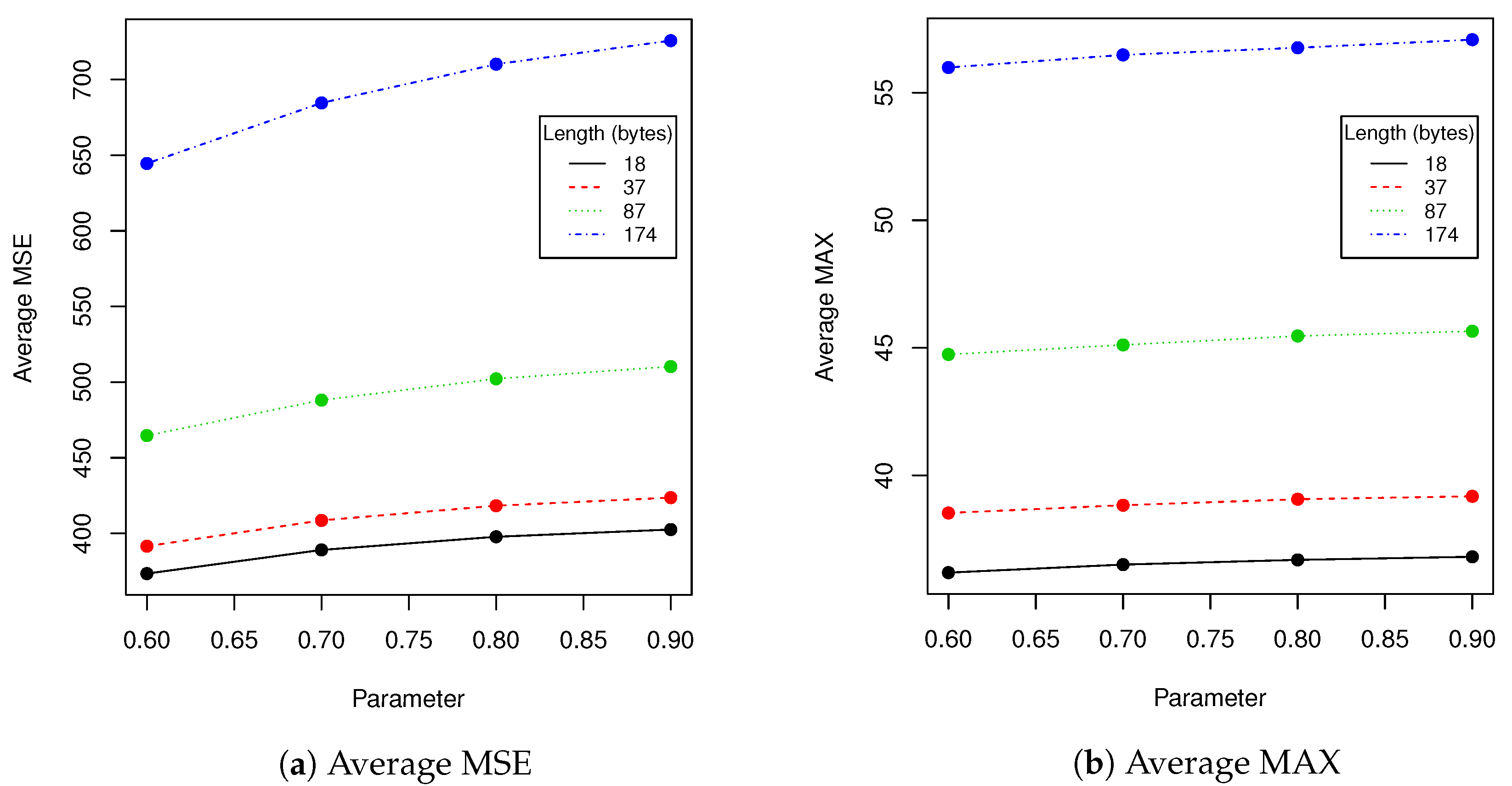
t parameter. We have calculated following statistics between original image and image with hidden data: averaged MSE, averaged maximal difference of pixels and averaged Pearson correlation coefficient of pixels. Results are presented in
Table 7 and
Figure 10.
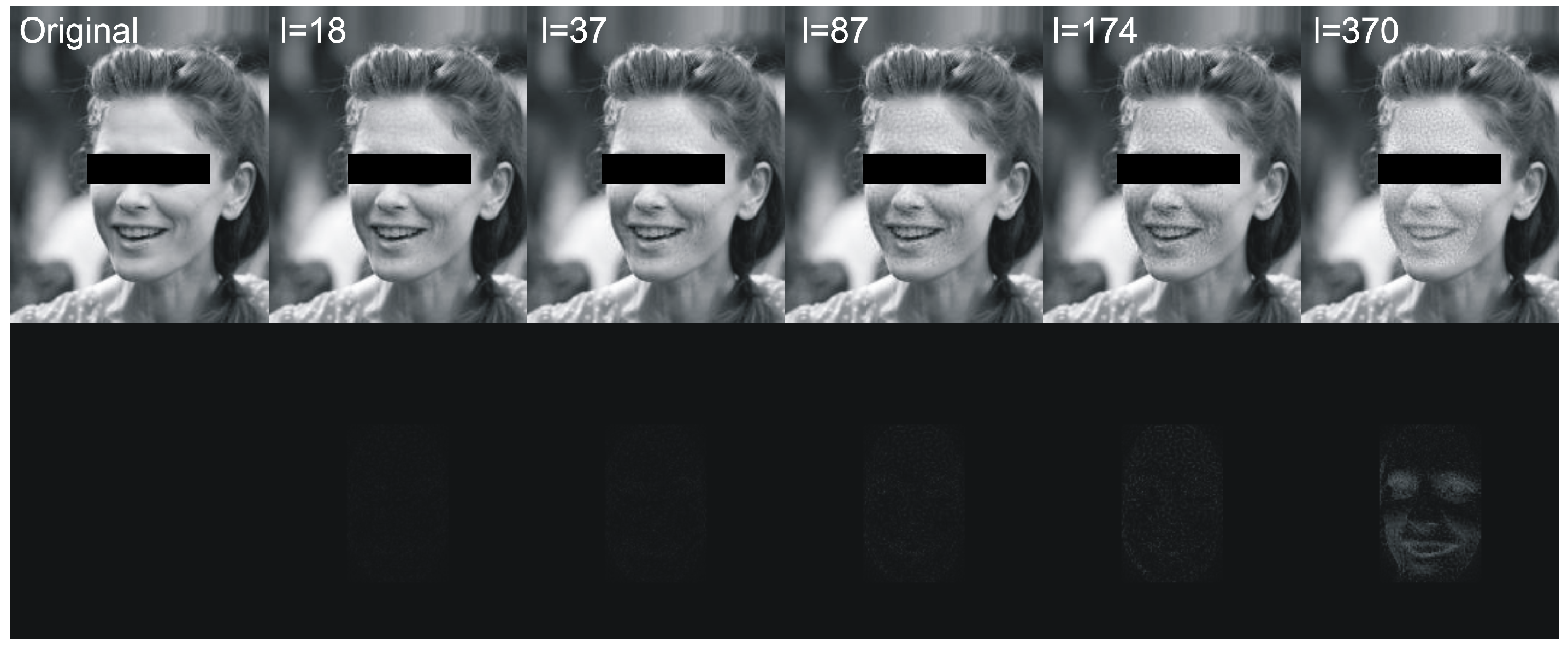
Figure 11 visualizes example differences between original image and image with hidden data. In some tables we have skipped certain zero-filled ranges in order to make results shorter and more comprehensible for reader. The larger ranges of values are presented in figures.
The proposed method has been compared with following contemporary algorithms [
11,
12,
13,
14] in terms of CC and PSNR—see
Table 8. We have evaluated robustness of the proposed steganography method (PM) against compression attack, which seems to be most common scenario in case of publishing stego images in social media.
4. Discussion
For the reasons described in
Section 3, we have selected training data set containing 30,375 faces to generate eigenfaces. This value might have been different if the calculation had been done on images with different resolution or on different data set, however the reasoning remains unchanged. In order to make eigenfaces descriptive enough for particular resolution, we need to take data set for which Relative LED (or/and Relative MSE) is below certain threshold. In our case
seems to be adequate value—as can be seen in
Figure 2, it introduces plateau on the Relative MSE and Relative LED plots. Taking more faces to generate covariance matrix would not change much in obtained results. The rest of calculations and discussion is conducted on eigenfaces generated from selected data set.
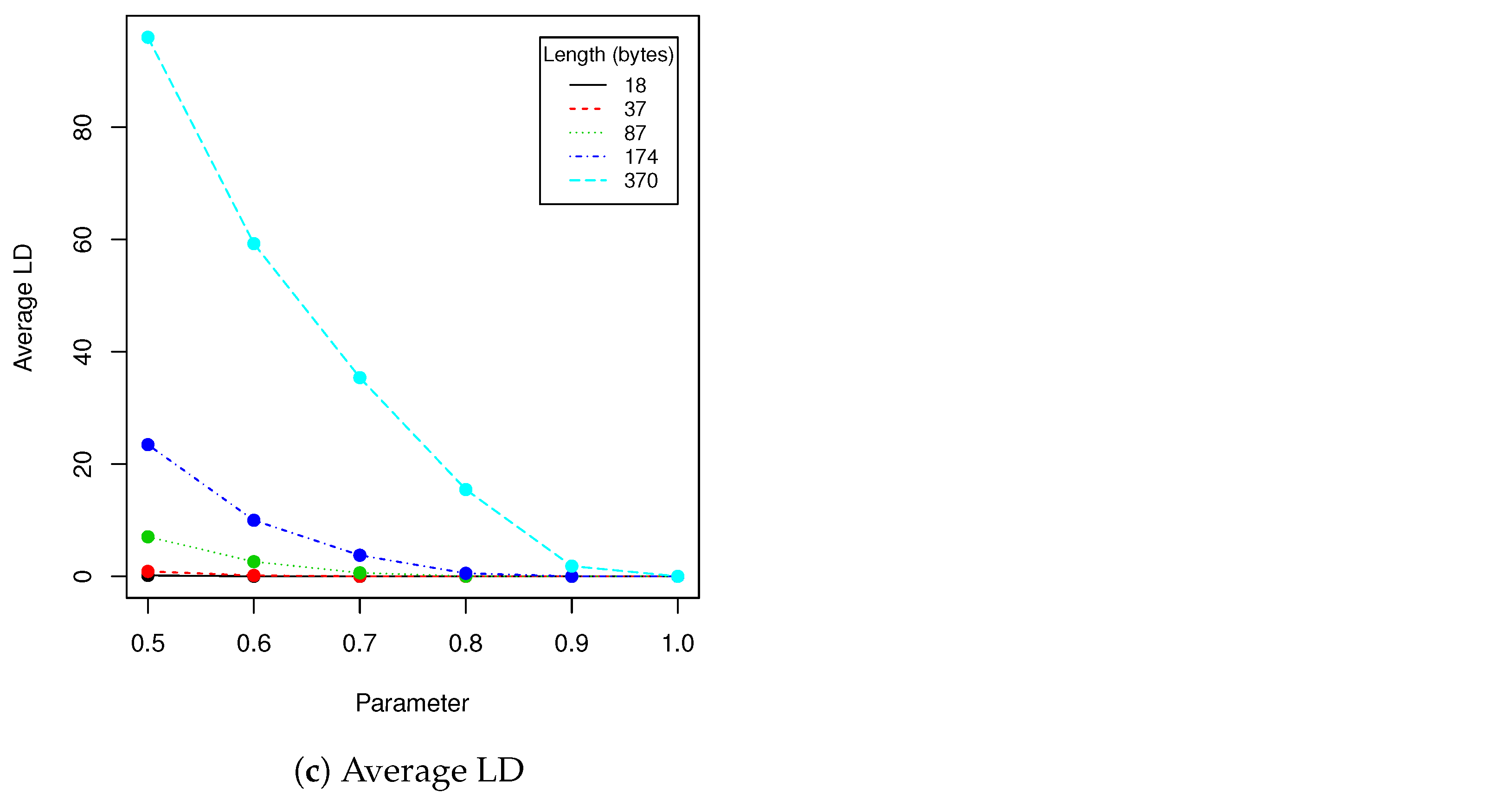
The proposed steganography method exhibits differing resistance to robustness tests. Although it it quite vulnerable to salt and paper disturbance (see
Table 3), it seems to deal very nice with changes applied to whole image domain. Both clipping and JPEG compression do not damage the message if the whole possible capacity is not exhausted. The study found that when message length is set to 87 bytes, we can safely use a quality coefficient equal to 89, which only affects 0.041 (4.1%) of messages (see
Table 5).
When image quality equals to 92 or more, no changes are observed for all validation data set (containing more than 100,000 of various faces images!). Result for BC measure corresponds to DSC and LD coefficients. The longer the message becomes, the more errors are introduced by compression. This situation is very similar if we take into account clipping (see
Table 2). When the message length is set to 37 bytes and
, the BC equals 0.066 which means that over
of messages have been successfully recovered. When
t increases to
, the successful recovery rate rises to 100%. However the larger
t we take, the more visible is a rectangular region in which message is hidden. Due to this fact, when the message lenght is set to 37 (
of image capacity), we suggest using
t in range of
in order to increase difficulty of message detection. More details will be provided together with performance tests.
The limitation of the proposed method is basically the same as in the original eigenfaces approach [
37]. The descriptive power of the method is determined by the variance of images in dataset
D that was used to generate eigenfaces. There might be a face with a certain facial features which are not represented in D and reconstructed face
might differ from the original face
. Those differences will be visible as high frequency noises and they might be easily spotted. The most straightforward solution to this issue is to use large dataset D with diversified face features. From the same reason face of the person wearing heavy, untypical makeup might be inappropriate carrier of hidden data. Additionally, it is recommended that a person on the photo should face the camera, which is an additional limitation.
Because rotation affects face aligning, eigenfaces are not robust to rotation (or robustness is on very low level—see
Table 4). However this weakness may be compensated by face image aligning. The HOG-based face features detection, which is often used for this task, is a robust and repeatable technique that performs translation, rotation and scaling of original image. Due to this fact those three linear transformations, which might be used to change images with encoded data, might be then compensated by face image aligning. This, however, depends of face aligning procedure that we apply and it is not in the scope of this paper.
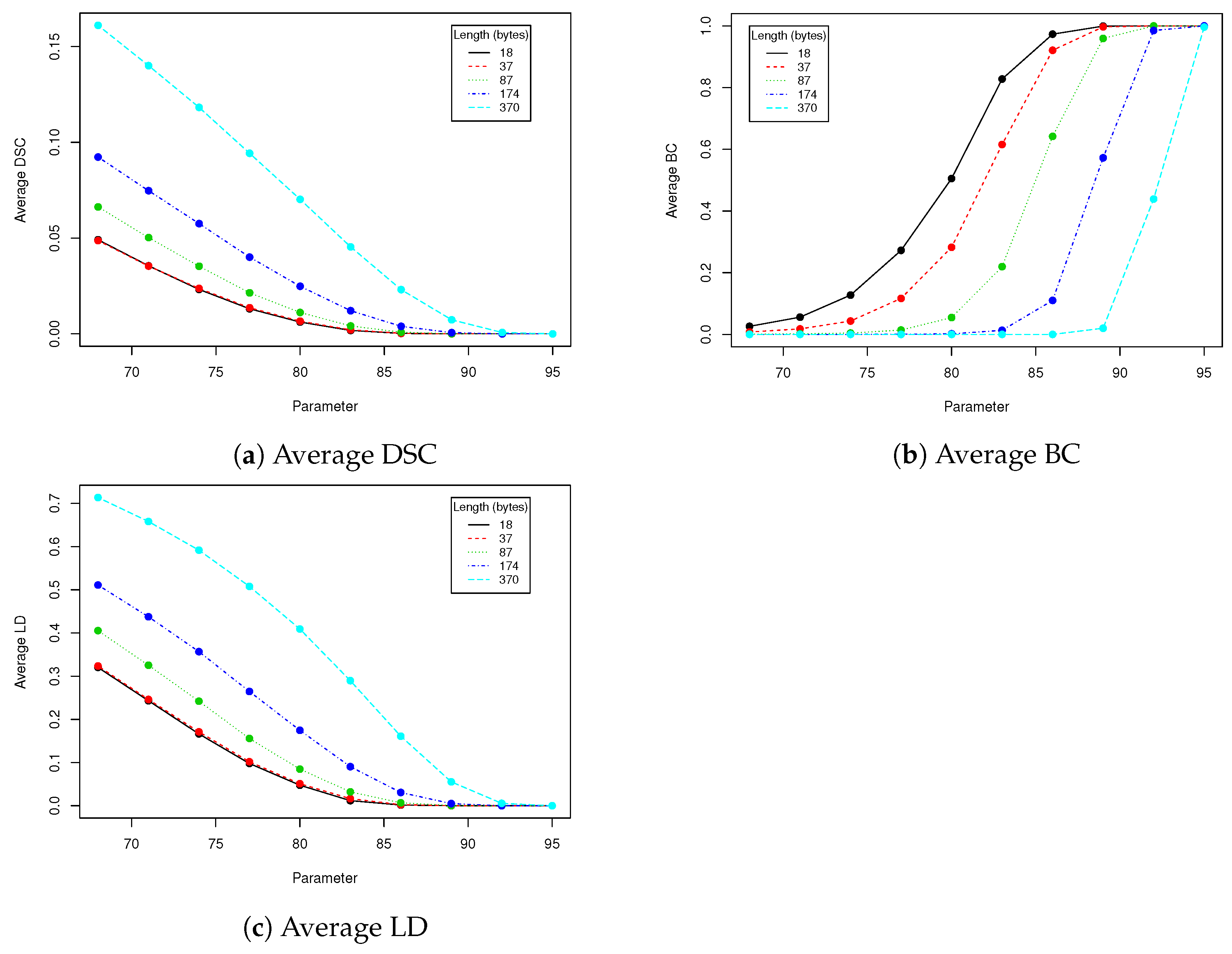
Eigenfaces technique requires that a facial image need to have the same resolution as faces in training dataset that was used to generate eigenfaces. We have to check if scaling the image with hidden data and then returning to the old resolution affects the payload, provided that we use bicubic pixels interpolation. Results in
Table 6 show that our method has limited robustness for downscaling and very good robustness for upscaling. For upscaling by 5%, more than 98% messages were unaffected for all tested lengths; the more we upscale the better results we get. This means that we can use eigenfaces generated from images with lower resolution to hide data into facial images with higher resolution. A facial image has to be downscaled and then upscaled to old resolution. This is very important information, because thanks to that our method can be used in a certain range of facial images resolutions without necessity to generate eigenfaces to each possible resolution. Of course if we upscale image too much, a person observing the face might spot artifacts caused by interpolation.
The next experiment we have done was evaluation of the performance of the proposed algorithm with various encoded message lengths and
t parameter (cropping size) values. Obtained results are presented in
Table 7 and
Figure 10. We have compared over 100,000 original images from the validation data set with images with encoded data using MSE, maximal difference between corresponding pixels and CC averaged. Those results confirmed observations we have made in robustness evaluation. Parameters in range
resulted in a relatively small value of distance between original image and one with encoded data. As can be seen in second row of
Figure 11, when message size is set to 37 (
of source image capacity) and
, the differences are virtually impossible to notice. Those parameters are our recommendation for this particular image resolution we have evaluated. After message encoding we need to check if it can be recovered (according to
Table 2 in
faces there might be a problem with it). To overcome this situation, we have to increase
t value or use another facial image. When message length is close to
of image capacity, we can even visually spot that some changes has been applied to the region of the face. We do not recommend exploiting full possible image capacity: it is better to split message between several faces and then put it together again.
The peak signal-to-noise ratio (PSNR) is the most common metric used to evaluate the stego image quality. The PSNR measures the similarity between two images (how two images are close to each other—higher value means better results) [
38]. As can be seen in
Table 8, our algorithm has obtain very similar results to best state-of-the-art approaches. CC and PSNR are getting worse with decreasing quality of compression and increasing of stego message length. In terms of CC our method has overperformed [
11,
12] and has slightly worse results than [
13,
14]. In terms of PSNR our method has over performed all but [
12]. We can conclude that our method is among most robust algorithms against compression attack.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
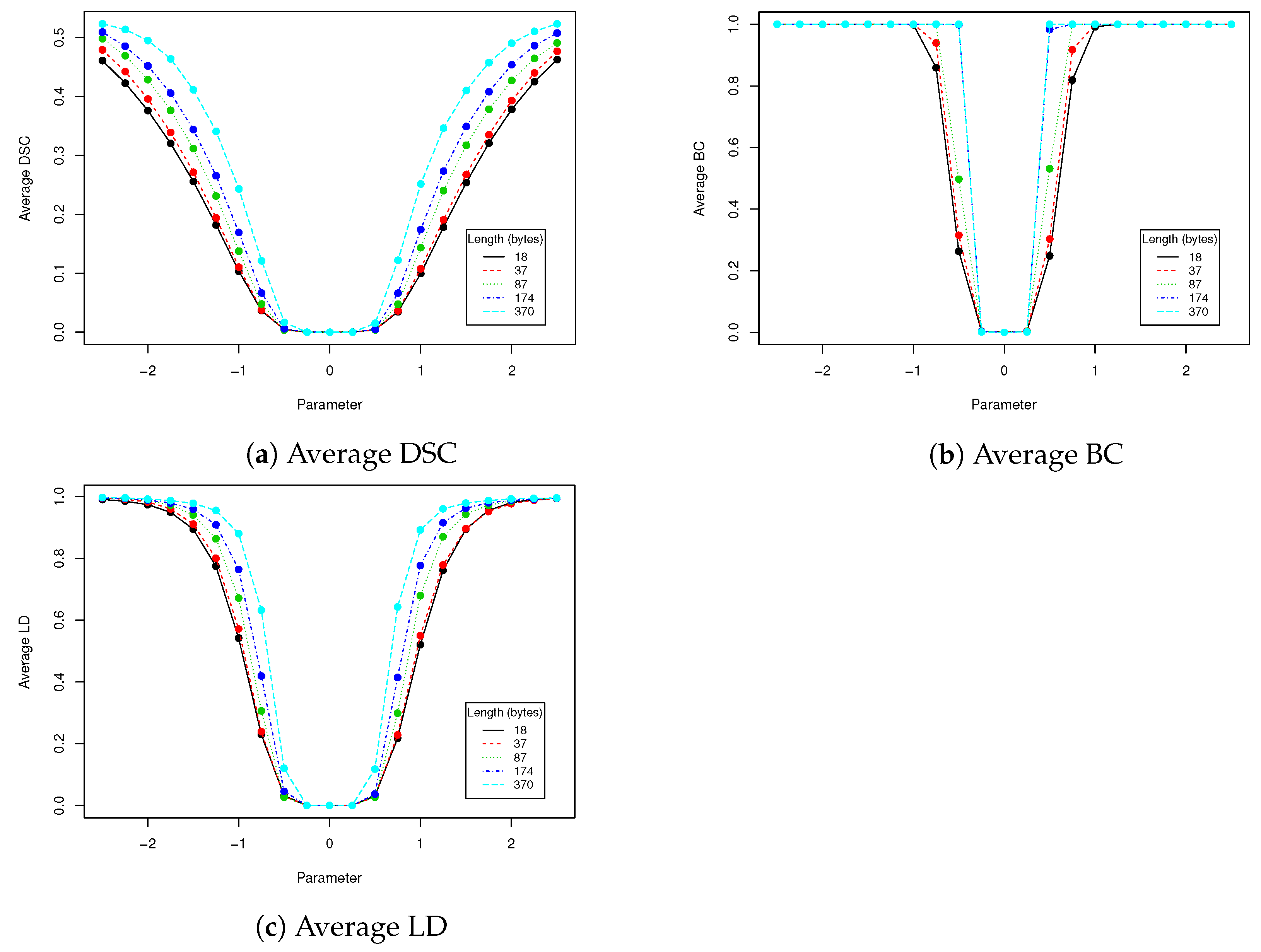{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}