1. Introduction
At present, the fifth generation (5G) mobile wireless communication system has begun to be commercially used. In 5G mobile wireless communication, polar codes have been used to transmit signal or synchronize data in control channel. In [
1], Arıkan proposed the definition of polar codes and proved that it can reach the Shannon limit. When the code length goes to infinity, the channels are divided into noisy subchannels and noiseless subchannels, which are known as “channel polarization”. Arıkan also proposed a successive cancellation (SC) algorithm for polar codes, which uses the previously decoded bits as reliable information to assist in decoding subsequent bits. As the code length increases, the decoding performance of the SC algorithm gradually becomes better. However, for short or moderate code length of polar codes, the decoding performance of the SC decoding algorithm deteriorates due to the incomplete channel polarization. In order to improve the performance of the SC decoding algorithm, a successive cancellation list (SCL) decoding algorithm was proposed, which can greatly improve the decoding performance of polar codes [
2]. The CRC-aided SCL (CASCL) algorithm uses the cyclic redundancy check (CRC) to improve the performance of the SCL decoding algorithm [
3].
However, the complexity of the SCL algorithm is high. To reduce the complexity of the SCL algorithm, Orion et al. proposed the successive cancellation flip (SCF) decoding algorithm, which is a combination of the bit-flipping decoding and the SC decoding [
4]. The SCF decoding algorithm needs low storage, which is the same as the storage of the SC decoding algorithm. The SCF decoding algorithm uses log likelihood ratio (LLR) as a metric to determine the flipping position. Chandesris et al. proposed an optimized metric which can improve ability of finding the first error bit in the initial SC decoding for the SCF decoding algorithm [
5]. In order to further improve the performance of the SCF algorithm, they also proposed a dynamic SCF (D-SCF) decoding algorithm; it can dynamically build a list of candidate bits, which can guarantee that the next decoding attempt has the highest probability to correct the decoding error [
6].
To further reduce the decoding complexity, Zhang et al. proposed a critical set, which has a high probability to include the first error bit in the initial SC decoding algorithm based on search tree [
7]. Condo et al. proposed a fixed index selection (FIS) scheme and an enhanced index selection (EIS) criterion to reduce the decoding complexity of the SCF algorithm, which is based on the error distributions [
8]. In [
9], a path-metric-assisted SCF decoding algorithm was proposed, which can prioritize the bits that need to be corrected. Condo et al. proposed an improved SC-Flip multi-error decoding algorithm based on error correlation, which has better decoding performance than the SCF algorithm under the same decoding complexity [
10].
However, the SCF decoding algorithm has a high complexity at low signal-to-noise ratio (SNR). To overcome this shortcoming, Lv et al. in [
11] proposed a modified successive cancellation flip (MSCF) decoding algorithm, which can avoid the unnecessary flipping attempts of the SCF algorithm by using a threshold based on Gaussian approximation. Ercan et al. proposed a threshold SCF (TSCF) decoding algorithm, which uses a comparator to replace the LLR selection and ordering of the SCF algorithm to reduce the complexity of implementation [
12]. Zhang et al. proposed an SCF decoder based on bit error rate evaluation, which can accurately locate the first error bit and correct it [
13]. In addition, some authors in [
14,
15,
16,
17] used the segmented SC decoding algorithm to improve the error correction ability of the SCF decoding algorithm. Some characteristics of polar codes are used to segment the decoding process in these methods. For each segment, the decoding is performed by using a bit-flipping decoding algorithm.
Recently, machine learning (ML) techniques have been widely applied to many industries and research domains. In communication systems, ML-assisted communication systems have been widely studied.
For a deep learning technique, some authors in [
18,
19,
20,
21,
22] used deep learning algorithms to assist in the coding and decoding of polar codes. To enhance the coding of the polar codes, a polar code construction algorithm based on deep learning was proposed [
18], which has better performance than 5G polar codes without CRC [
19]. Its core idea is that the bits of polar codes are regarded as the trainable weights of the neural network. In terms of the decoding algorithm, Gruber et al. achieved maximum a posteriori (MAP) bit error rate (BER) performance of polar codes by using a deep neural network to decode the codeword [
20]. However, as the number of information bits increases, the complexity of learning also exponentially increases. In contrast, a neural SC (NSC) decoder based on the portioning technique decreases the complexity by learning information bits in each subblock of polar codes, and it reduces the decoding delay of the SC algorithm [
21]. In order to improve the performance of the SC algorithm, a weighted successive cancellation (WSC) algorithm was proposed [
22], which uses a neural network to learn the weights.
For reinforcement learning, some authors in [
23,
24,
25] used reinforcement learning algorithms to assist in the coding and decoding of channel codes. In [
23], a deep reinforcement learning method for constructing low-density parity-check (LDPC) codes was proposed, which combines a deep reinforcement learning training and a Monte Carlo tree search (MCTS). It has the potential to improve performance compared with traditional LDPC code construction. For further optimizing the structure of error correction codes (ECC), Huang et al. studied an artificial intelligence (AI)-driven method to design the ECC [
24]. They also proposed a construction-evaluation framework, in which the construction framework can be implemented by various AI algorithms, such as reinforcement learning and genetic algorithm, and the evaluation framework can provide the performance metrics of the ECC. In [
25], reinforcement learning-assisted bit flipping decoding was proposed. The authors studied the effective decoding strategy of Reed–Muller and BCH codes by using reinforcement learning methods. Traditional decoding algorithms are mapped to the Markov decision process (MDP), thereby allowing the optimal decision strategies to be obtained through training.
For the SCF decoding algorithm, it is critical to accurately locate candidate flipping bits and reduce decoding delay. In order to accurately locate the candidate bits, Wang et al. proposed a deep learning-assisted SCF decoding algorithm, using a long short-term memory (LSTM) network and reinforcement learning to find the error bits [
26].
At present, little work has been devoted to applications of reinforcement learning on the SCF decoding of polar codes. The reinforcement learning algorithm can be used in the SC bit-flipping decoding, because the selection of candidate flipping bits can be seen as the decision process. The selection process of candidate bits is modeled as MDP. Compared with the traditional method, the reinforcement learning algorithm can quickly obtain the appropriate strategy. Therefore, the reinforcement learning is used to optimize the SCF decoding of polar codes in our design.
In this paper, we propose a Q-learning-assisted SCF (QLSCF) algorithm which uses the reinforcement learning to reduce decoding delay of the SCF decoding. First, we provide a set of candidate bits as the action space for reinforcement learning, and verify the completeness of the action space. Secondly, we design a one-bit SCF decoding algorithm assisted by reinforcement learning. Finally, the performance of the proposed QLSCF algorithm is compared with that of the traditional decoding algorithms, and the results are discussed. The structure of the paper is as follows.
Section 2 introduces polar codes and reinforcement learning. The reinforcement learning model and the QLSCF decoding algorithm are shown in
Section 3, and
Section 4 discusses the simulation result and analysis. The conclusions are shown in
Section 5.
3. The Q-Learning-Assisted Successive Cancellation Flip Decoding Algorithm
In this section, we propose a new algorithm which uses the Q-learning-assisted SCF decoding to reduce decoding delay. In order to realize this algorithm, we give the model design of the Q-learning-assisted SCF decoding algorithm.
3.1. The Model and Training of the Q-Learning Algorithm
The Q-learning algorithm can be used in the SCF decoding, because the selection procedure of candidate bits is modeled as the MDP process. Selection of candidate bits can be seen as a decision process in general. For the SCF decoding, the decision of the Q-learning is how to select one bit from candidate bits to make the decoded codeword correct.
In the above model, the state corresponds to SNR during the decoding, and the action of the state transition corresponds to a candidate bit. The reward function is determined by whether the decoded codeword is correct. The candidate bits set can be obtained from the Q-table. The QLSCF decoding algorithm is modeled by a single-step MDP with a Q-learning algorithm, as shown in
Figure 1. The state, action, reward and exploration strategy are detailed as follows.
Discrete SNR values are obtained by systematic sampling method from continuous SNR, ranging between 0.5 dB and 2.5 dB. Nine sampled values of SNR are used as states in state space .
We assume that the action space
is an index set, in which action
means that the
-th bit needs to be flipped. Since there are
possible choices, initial action space
is
. However, according to the theory of polar codes, the error probability of each information bit is different, so some indexes of bits are redundant in action space
. Only part of the information indexes is selected as the action space. Therefore, we design an algorithm to obtain the optimized action space, as shown in Algorithm 1. When the code length is 256, the size of initial action space is 128 and the size of the optimized action space is 50. The size of the optimized action space is only half the size of the initial action space. For short polar codes, the frame error rate (FER) of the SC decoding algorithm is greater than 0.5 when SNR is low. Therefore, the decoding codeword has a high error probability. The initial SC decoding is considered as an action in the action space
, which is denoted as
. When SNR is low, the flipping actions may be preferentially performed due to higher FER. Conversely, action
is preferentially performed when SNR is high. Hence, the agent can decide which action to be preferentially performed through interaction with the environment. In Algorithm 1,
is an empirical parameter in the optimized algorithm of action space, which has different values for different code lengths. We use this algorithm to effectively reduce the size of the action space
and further reduce the training complexity. The function
is a traditional SC decoder used to output the index of the first error bit and the decoded codeword. Then, we also verify the completeness of the optimized action space, as shown in
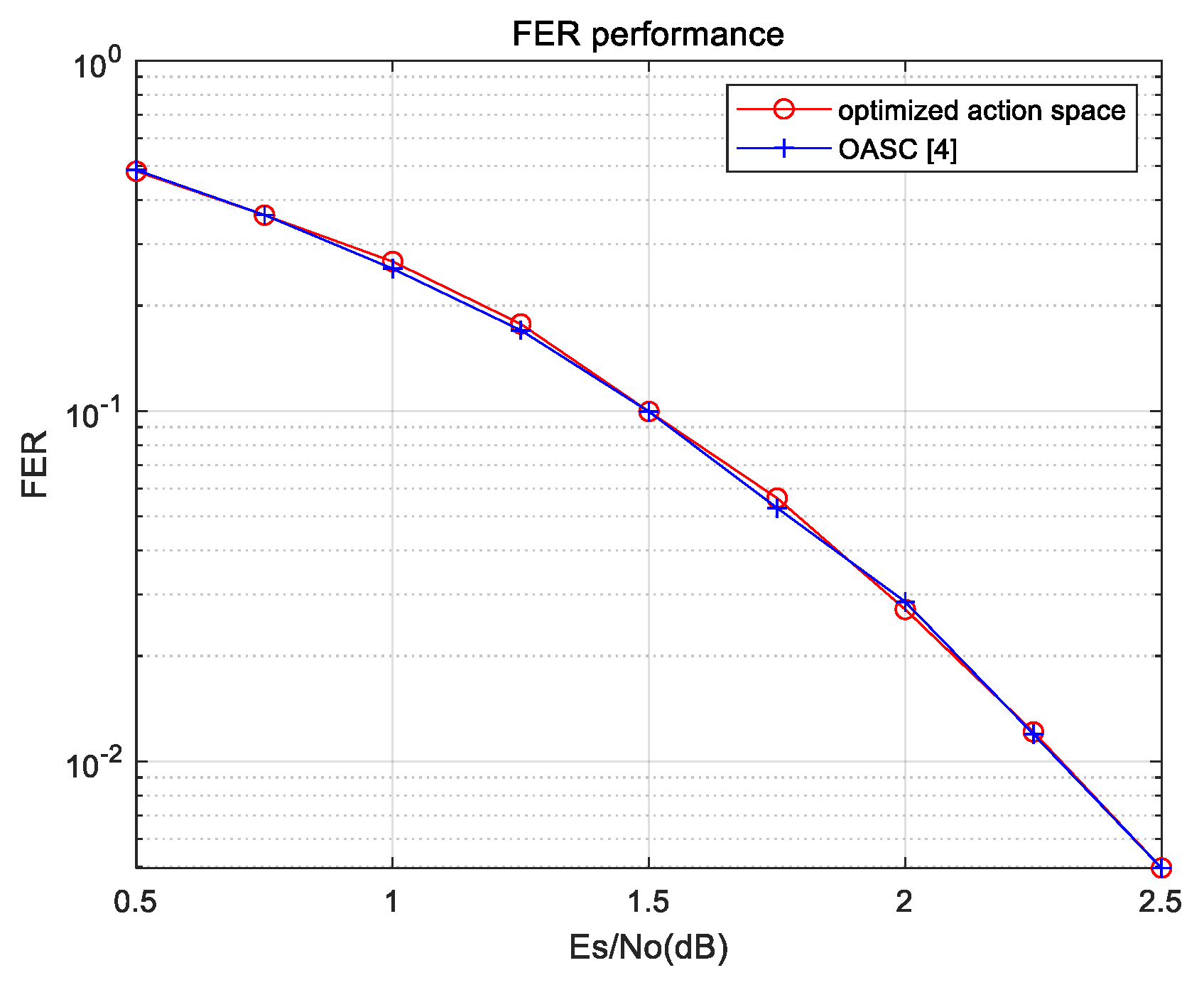
Figure 2. Without considering the decoding delay, the action space is enumerated to participate in bit-flipping decoding, and its decoding performance is compared with the performance lower bound for the one-bit SCF decoding algorithm. The lower bound of the FER performance for the one-bit SCF decoding algorithm is calculated using an Oracle-assisted SC (OASC) decoding algorithm proposed in [
4]. The results show that the FER performance of the action space is the same as that of the OASC decoding algorithm. This shows that the size of the action space is reduced without loss of performance. Therefore, the proposed action space is complete.
| Algorithm 1 Optimized design of action space |
| Input: |
| The number of trials: |
| Information bits length: |
| Discrete SNRs: |
| Output: The action space: |
| Initialization:; ; |
Forin:
;
While:
Updating the received LLR: ;
;
//The is the first error bit index in SC decoding.
;
If is : Continue; else:
;
;
End if
End while
;
For in :
If :
Move into ;
End if
End for
End for |
Reinforcement learning needs the reward to reflect the effect of action execution. The simple reward function returns to “1” when the flipping decoding is successful, and if the flipping decoding fails, the reward function returns to “−1”. This would imply that an optimal policy is maximum decoding accuracy. This reward function cannot reflect the priority of the candidate bits, because every action may make flipping decoding successful. We introduce the LLR into the reward function and
is the absolute value of the LLR at action
, as shown in Equation (5). The reward
consists of two parts. One is the feedback of the decoding result. If the action execution makes the decoding codeword correct, the agent will obtain a positive reward “+1”, otherwise a negative reward “−1”. The other is the absolute value of LLR. Since every action may make decoding codeword correct, the reward
of the proposed model should reflect the priority of candidate bits. LLR is added into the reward
, and the absolute value of LLR at action
is denoted as
. The smaller
is, the higher the error probability of the
-th bit is. Therefore, the reward
can reflect the effect of the action execution, and the
obtained by using this reward
can reflect the priority of the action execution.
Since each action may make the bit-flipping decoding obtain the correct decoded codeword, we hope that the agent can explore full action space in the early stage of learning. Therefore, the
-greedy algorithm is modified. An
-greedy strategy is used as the exploration strategy, where
is the number of training and
represents the decay rate of
, as shown in Equation (6). In the training process of the proposed model,
is 0.004.
The Q-learning algorithm for the QLSCF decoding algorithm is described in Algorithm 2, as well as learning parameters being listed in
Table 1. The training data is obtained by real-time interacting with the environment during the training process. In the environment, the agent chooses an action to perform SCF decoding in current state and obtains a reward. The process of real-time interaction with the decoding environment can directly reflect the reward of the decision made by the agent. The value of the discounting factor is between 0 and 1. The discounting factor determines the impact of the long-term state on the agent. A larger discounting factor can make the agent tend to learn more far-sighted decision strategy, and a smaller discounting factor can make the agent tend to learn more radical decision strategy. Therefore, the value of the discounting factor is 0.9 in the reinforcement learning algorithm. The value of the learning rate is between 0 and 1. A large learning rate may cause the non-convergent learning results, and a small learning rate may cause a slow convergence rate. Therefore, we made a trade-off to select the value of the learning rate. In Algorithm 2, we set a maximum number of episodes to 1000 and each episode requires multiple Q-value updates.
| Algorithm 2 Q-learning algorithm for the QLSCF algorithm |
While < :
Initial observation ;
While :
Initial information of polar codes: ;
If < :
;
Else:
;
End if
;
;
;
;
End while
End while
// The env function
Function :
;
;
If :
;
Else:
;
End if
End function |
The processed Q-table is obtained by sorting the Q-values. In the processed Q-table, each row corresponds to an SNR value. The elements in each row represent actions, in which the actions are sorted according to the Q-value from largest to smallest. This process of the processed Q-table does not participate in the SCF decoding. Therefore, this process does not increase the decoding delay of the proposed QLSCF algorithm.
The detailed description of the proposed functions in Algorithm 2 is as follows.
: It is to select the action at the state. The function has a probability of to randomly select the action , and a probability of to use to select the action .
: It represents the environment of the Q-learning algorithm. The function can be used to generate the state and the reward . The specific details of the function are described in Algorithm 2.
: It is used to get the next state .
: A decoder of polar codes has additional functions. Depending on the input action , the decoder performs different decoding. If action is , the decoder performs the traditional SC decoding. If action is the index of the candidate bits, the decoder performs an additional decoding attempt to decode the codeword with flipping a bit. Finally, the decoder outputs used to judge whether the decoded codeword is correct.
3.2. Q-Learning-Assisted Successive Cancellation Flip Decoding Algorithm
The QLSCF algorithm uses the reinforcement learning algorithm to select the candidate bits. In the SCF algorithm, the selection of the candidate bits is a decision process. Therefore, an optimal selection strategy needs to be obtained. Reinforcement learning technology can solve decision problems in complex environment and obtain optimal selection strategy through a large amount of learning. The selection of the candidate bits can be seen as the MDP process in the complex environment, so Q-learning is used to obtain an optimal selection strategy. For the conventional SCF algorithms, the values of LLR and the set of candidate bits are obtained after the SC decoding, and the values of LLR are sorted to obtain the order of the candidate bits. For the proposed QLSCF algorithm, the order of candidate bits is already obtained in the reinforcement learning. Hence, the proposed QLSCF algorithm only needs to use the sorted set of candidate bits during the decoding process, and the additional sorting process is not needed.
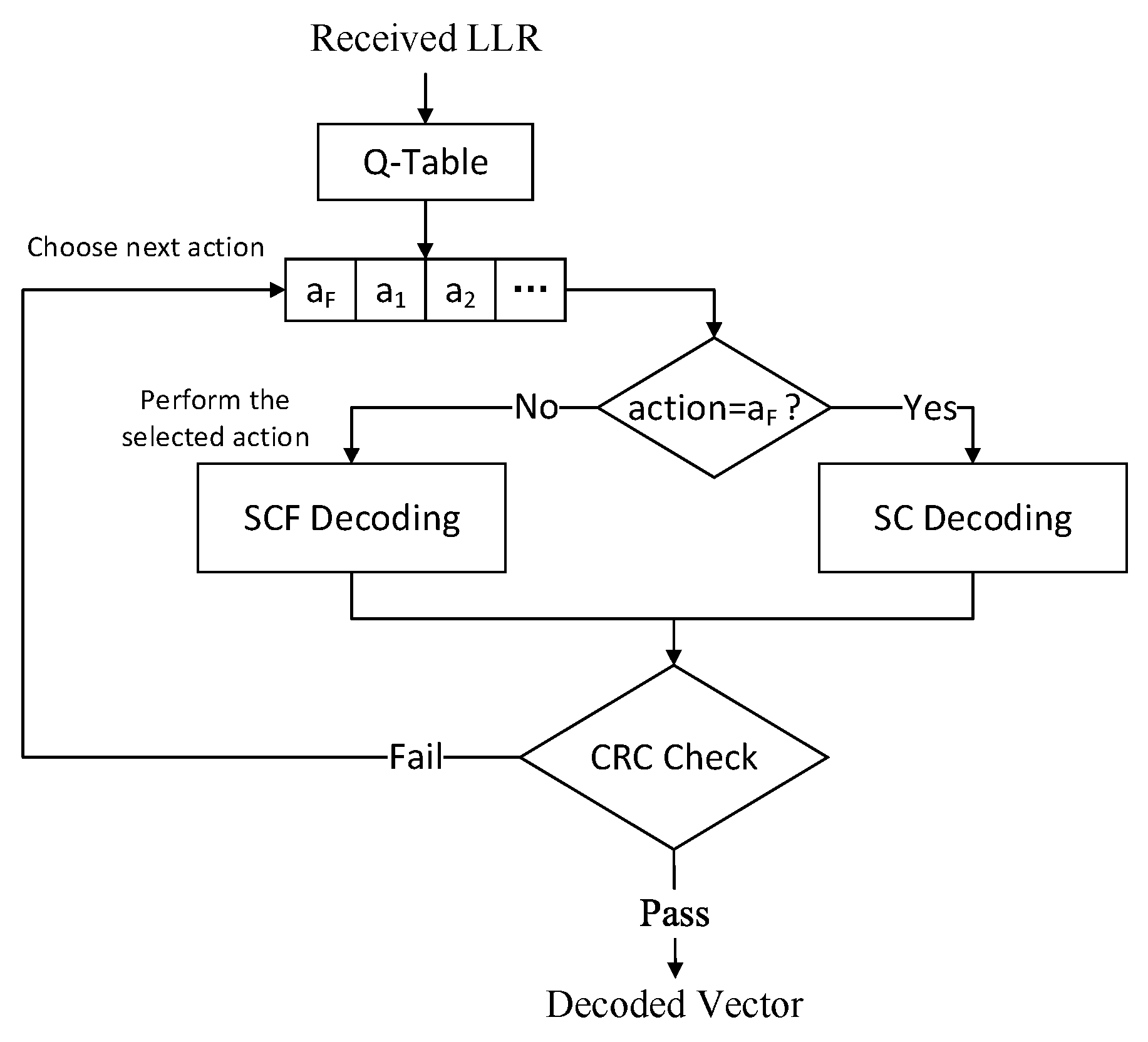
The decoding process of the proposed QLSCF decoding algorithm is shown in
Figure 3 and the QLSCF algorithm is shown in Algorithm 3. The candidate bits obtained from Q-Table have been already sorted. In addition, the SC decoding is considered as a special action
, which means to perform the SC decoding. The conventional SCF algorithm firstly performs the SC decoding to obtain the decoded codeword; if the decoded codeword does not pass CRC check, the conventional SCF algorithm will perform the additional bit-flipping decoding. In contrast, the QLSCF algorithm does not have this process. We add action
into the action space in the Q-learning model. After that, actions are sequentially performed according to the priority of actions after training. Bit-flipping decoding may be firstly performed to reduce the decoding delay when SNR is low.
| Algorithm 3 Q-learning-assisted Successive Cancellation Flip Decoding Algorithm |
| Input: |
| The received LLR: |
| Information bits length: |
| SNR: |
| The processed Q-table: |
| Output: The decoded vector: |
| Initialization:; |
;
Return;
// The QLSCF function
Function:
Forto:
;
;
If successes:
;
End if
End for
Return ;
End function |
The detailed description of the proposed functions in Algorithm 3 is as follows.
: It is to extract the set of candidate bits. is the processed Q-table. In the processed Q-table, the actions corresponding to each state are sorted in a descending order of Q-value. As a result, this function outputs the sorted sequence of actions for state in the processed Q-table.
: A decoder of polar codes has additional functions. The decoder performs different decoding methods for the input . If is , the decoder performs the traditional SC decoding. If is the index of the candidate bits, the decoder performs additional decoding attempt to decode the codeword with flipping a bit. Finally, the decoder outputs the decoded codeword.
4. Experiment and Analysis
In this Section, the proposed QLSCF decoding algorithm is compared with other decoding algorithms in terms of the FER performance and the decoding delay. The experimental results validate the advantage of the proposed QLSCF algorithm. All decoding algorithms are simulated with a 0.5 code rate. The maximum number of flips is equal to the size of the critical set. Error detection performance of CRC is also considered. For different decoding algorithms using the same CRC length, their error detection probabilities of CRC are the same. The longer CRC length is, the higher the error detection probability is. However, the long CRC length has a big impact on code rate of polar codes. Therefore, we make a tradeoff between the error detection probability and code rate. The CRC length for each decoding algorithm is set to 16. In the training process of reinforcement learning, the transmitted codeword is known. The binary phase shift keying (BPSK) modulation and the additive white Gaussian noise (AWGN) channel are used in this experiment.
4.1. The FER Performance Analysis of the QLSCF Decoding Algorithm
The proposed QLSCF decoding algorithm is compared with traditional decoding algorithms, including the SC decoding algorithm [
1], the OASC decoding algorithm [
4], the original SCF decoding algorithm [
4], the SCF-CS decoding algorithm [
7] and the CASCL decoding algorithm with list
and
[
3]. The CASCL decoding algorithm with
is denoted as CASCL-2, so does CASCL-4. The FER performance comparisons and the average number of additional decoding attempts are given. The FER performance of the proposed QLSCF decoding algorithm is compared with that of other decoding algorithms in
Figure 4 and
Figure 5.
Figure 4 shows the FER performance of the proposed QLSCF algorithm with code length of 128 and code rate of 0.5. In
Figure 4, the FER performance of the QLSCF algorithm is better than that of both the CASCL-2 and the SC decoding algorithm, and it is almost consistent with the performance of both the OASC decoding and the SCF-CS decoding algorithm. Furthermore,
Figure 5 illustrates the FER performance of the proposed QLSCF algorithm and the traditional algorithms with code length of 256 and code rate of 0.5 under the same channel and modulation. In
Figure 5, the simulation result shows that the performance of the proposed QLSCF algorithm is better than that of both the CASCL-2 Algorithm and the SC Algorithm. The FER performance of the proposed QLSCF algorithm is less than that of the CASCL-4 decoding algorithm in
Figure 4 and
Figure 5. However, the CASCL decoding algorithm increases the computational complexity and storage space in exchange for the improvement of decoding performance. In general, the proposed QLSCF Algorithm does not have performance loss compared with both the OASC decoding and the SCF-CS decoding Algorithm.
The comparison of the candidate bits set for different algorithms is shown in
Table 2. The candidate bit set of original SCF algorithm contains all information bits. In the simulation, the critical set used by SCF-CS decoding algorithm is obtained at 1.5 dB. The proposed action space includes error positions under multiple SNRs. Therefore, the size of the proposed action space is larger than that of the critical set. The size of the proposed action space is less than that of the bit-flipping set in the original SCF decoding algorithm.
In order to analyze the decoding complexity, we count the average number of additional decoding attempts for different algorithms, which are shown in
Figure 6 and
Figure 7. It can be seen from the results that the average additional decoding attempts of all bit-flipping decoding algorithms decrease as SNR increases and approach 0 at high SNR.
When SNR is less than 1.25 dB, the average additional decoding attempts of the proposed QLSCF algorithm are less than that of both the original SCF and the SCF-CS decoding algorithm in
Figure 6. It can be seen in
Figure 7 that the average additional decoding attempts of the QLSCF algorithm are reduced compared with the SCF-CS decoding algorithm when SNR is less than 1.5 dB. At high SNR, the average additional decoding attempts of the proposed algorithm are the same as that of the SCF-CS decoding algorithm in
Figure 6 and
Figure 7. When SNR is high, the complexity of the proposed QLSCF decoding algorithm is lower than that of the CASCL-4 decoding algorithm in
Figure 6 and
Figure 7. In general, the decoding complexity of the proposed QLSCF algorithm is lower than that of other algorithms when SNR is low.
4.2. Decoding Delay Analysis of the QLSCF Decoding Algorithm
The additional decoding attempts and the acquisition of the priority for the candidate bits cause an increase of decoding delay in the SCF decoding. In this subsection, the delay caused by sorting candidate bits are analyzed, so does the overall decoding delay. The decoding delay is affected by the number of time-steps during decoding process [
29]. The greater the number of time-steps is, the greater the decoding delay is. The traditional SCF decoding algorithms contain the delay caused by the initial SC decoding, the delay caused by the sorting and the delay caused by the additional decoding attempts.
For the delay caused by the sorting, the absolute values of the LLR for information bits need to be sorted in the original SCF algorithm, so the decoding delay caused by the sorting is considered as . In the SCF-CS decoding algorithm, since only values need to be sorted, t, the decoding delay caused by the sorting, is considered as , where is the critical set and is the length of the critical set. In the proposed QLSCF decoding algorithm, the selection of candidate bits is learned by the Q-learning algorithm and the processed Q-table is directly used for the QLSCF decoding. Therefore, the proposed QLSCF decoding algorithm does not need to sort the values of the LLR, and the decoding delay caused by the sorting is considered as 0. Denote the decoding delay caused by the sorting by .
The comparisons of decoding delay caused by sorting are shown in
Table 3. The proposed QLSCF decoding algorithm has the least decoding delay caused by sorting.
For the overall decoding delay, the delay caused by the initial SC decoding and the delay caused by additional decoding attempts need to be considered. The number of decoding time-steps caused by the initial SC decoding process is equal to
[
29]. Additional decoding attempts only need to start decoding after the index of a candidate bit, so each attempt requires
time-steps to decode a codeword, where
is the index of a candidate bit. Denote the number of decoding time-steps caused by additional decoding attempts by
. The general form of
is Equation (7).
where
is the number of information frames,
is the number of additional decoding attempts for the
-th information frame, and
is the index of the candidate bit for the
-th attempt of the
-th information frame.
In summary, the number of total decoding time-steps is equal to
. The comparison of the total decoding delay is shown in
Table 4.
The number of additional decoding attempts is different for different decoding algorithms. In order to intuitively illustrate the comparisons of the QLSCF decoding, the original SCF decoding and the SCF-CS decoding algorithm, the total decoding delay is obtained by counting the average decoding time-steps. The decoding time-steps of the proposed QLSCF algorithm are compared with that of other algorithms in
Figure 8 and
Figure 9.
At low SNR (less than 1.5 dB), the average decoding delay of the proposed QLSCF algorithm is less than that of both the original SCF and the SCF-CS decoding algorithm in
Figure 8. When SNR is greater than 2 dB, the decoding delay of the proposed QLSCF decoding algorithm is lower than that of the CASCL-4 decoding algorithm in
Figure 8. The decoding delay of the proposed QLSCF algorithm is reduced compared with the SCF-CS decoding algorithm when SNR is 1.25 dB.
In
Figure 9, the decoding delay of the proposed QLSCF algorithm is less than that of the SCF-CS decoding algorithm at low SNR (less than 2 dB). When SNR is greater than 2.25 dB, the decoding delay of the proposed QLSCF decoding algorithm is lower than that of the CASCL-4 decoding algorithm. The decoding delay of the proposed QLSCF algorithm is reduced compared with the SCF-CS decoding algorithm when SNR is 1.75 dB.
At high SNR, the decoding delay of the proposed QLSCF algorithm is the same as that of the SCF-CS decoding algorithm and less than that of the original SCF decoding algorithm. The above results imply that we can apply the Q-learning algorithm to an SCF decoding algorithm to reduce decoding delay without loss of performance.
The SCF decoding algorithm based on LSTM network [
26] uses reinforcement learning in the decoding process. However, the decoding delay caused by LSTM network is not given. When the proposed QLSCF algorithm is compared with this algorithm, the average decoding time per frame can be used to evaluate the decoding delay under the same hardware conditions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}