
TIPS: A Framework for Text Summarising with Illustrative Pictures



Abstract
:1. Introduction
1.1. State-of-the-Art on Image-Text Matching
1.2. Study Motivation
2. Material and Methods
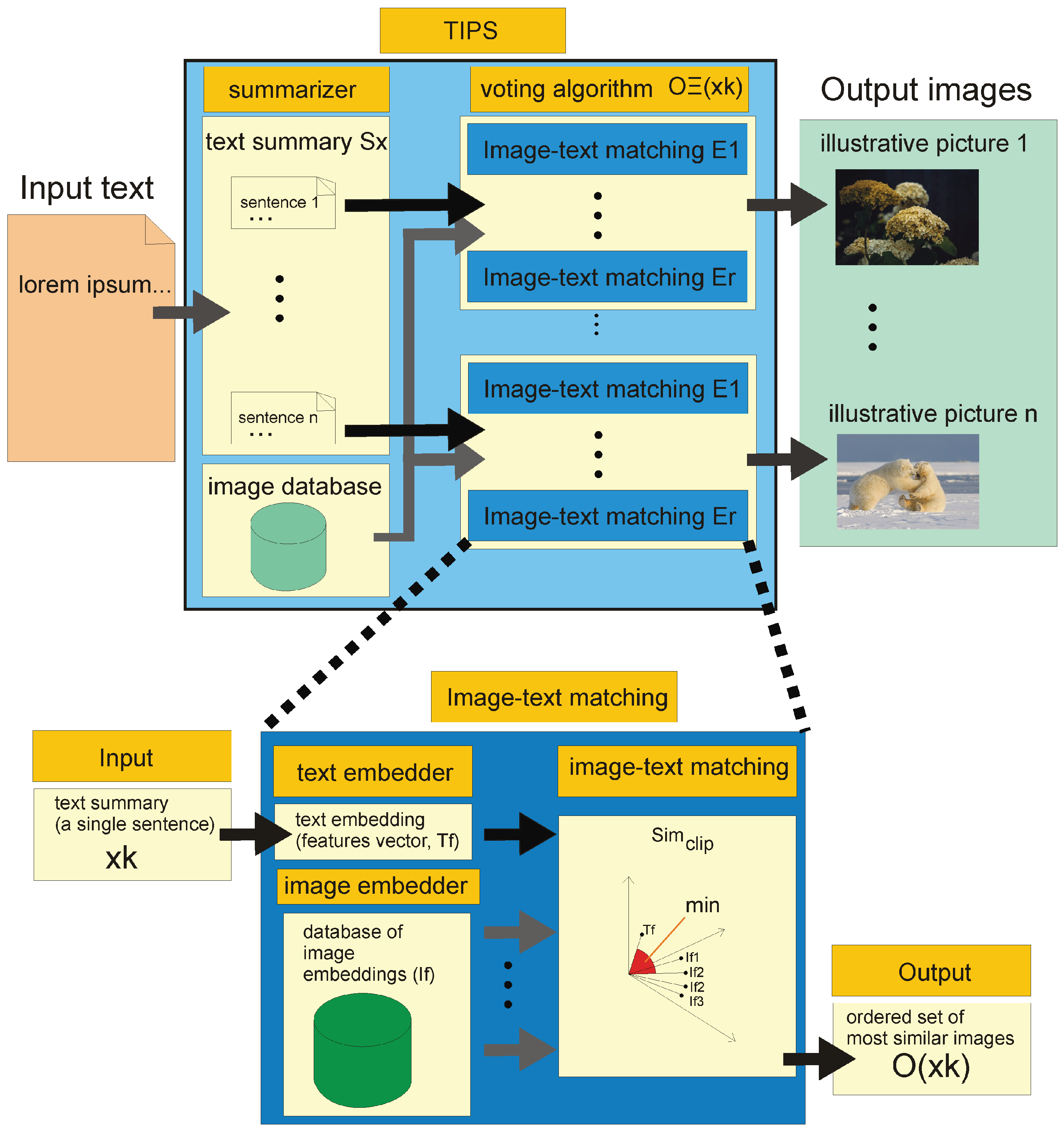
2.1. Text and Image Processing Framework
2.1.1. Text Summarising
2.1.2. Sentence Transformer
2.1.3. Image Embedding
2.1.4. Image-Text Matching
2.2. Data Sets
2.2.1. Text Data Set
2.2.2. Image Data Set
2.3. Proposed Method for Text Summarising with Illustrative Pictures (TIPS)
2.4. Evaluation and Comparison of Image-Text Matching Algorithms
- JS = 0: the image is not relevant to the text;
- JS = 1: the image is relevant to the text;
- JS = 2: the image is highly relevant to the text.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Yan, S.; Yu, L.; Xie, Y. Discrete-continuous Action Space Policy Gradient-based Attention for Image-Text Matching. arXiv 2021, arXiv:2104.10406. [Google Scholar]
- Hu, W.; Dang, A.; Tan, Y. A Survey of State-of-the-Art Short Text Matching Algorithms; Springer Nature: Singapore, 2019; pp. 211–219. [Google Scholar] [CrossRef]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual Semantic Reasoning for Image-Text Matching. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4653–4661. [Google Scholar] [CrossRef] [Green Version]
- Jogin, M.; Mohana, M.; Madhulika, M.; Divya, G.; Meghana, R.; Apoorva, S. Feature Extraction Using Convolution Neural Networks (CNN) and Deep Learning; IEEE: Piscataway, NJ, USA, 2018; pp. 2319–2323. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.; Le, Q. Rethinking Pre-training and Self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Chawla, P.; Jandial, S.; Badjatiya, P.; Chopra, A.; Sarkar, M.; Krishnamurthy, B. Leveraging Style and Content Features for Text Conditioned Image Retrieval; IEEE: Piscataway, NJ, USA, 2021; pp. 3973–3977. [Google Scholar] [CrossRef]
- Conde, M.; Turgutlu, K. CLIP-Art: Contrastive Pre-training for Fine-Grained Art Classification; IEEE: Piscataway, NJ, USA, 2021; pp. 3951–3955. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, M.; Liu, D.; Hu, Z.; Zhang, H. More Grounded Image Captioning by Distilling Image-Text Matching Model; IEEE: Piscataway, NJ, USA, 2020; pp. 4776–4785. [Google Scholar] [CrossRef]
- Joshi, D.; Wang, J. The Story Picturing Engine—A system for automatic text illustration. TOMCCAP 2006, 2, 68–89. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, X.; Li, Z.; Zhao, Z. Bi-Directional Spatial-Semantic Attention Networks for Image-Text Matching. IEEE Trans. Image Process. 2018, 28, 2008–2020. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Conneau, A.; Kiela, D. SentEval: An Evaluation Toolkit for Universal Sentence Representations. arXiv 2018, arXiv:1705.02364. [Google Scholar]
- Devillers, B.; Bielawski, R.; Choski, B.; VanRullen, R. Does language help generalization in vision models? arXiv 2021, arXiv:2104.08313v3. [Google Scholar]
- Zhu, J.; Li, H.; Liu, T.; Zhou, Y.; Zhang, J.; Zong, C. MSMO: Multimodal Summarization with Multimodal Output. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4154–4164. [Google Scholar] [CrossRef]
- Rudinac, S.; Chua, T.S.; Díaz Ferreyra, N.; Friedland, G.; Gornostaja, T.; Huet, B.; Kaptein, R.; Lindén, K.; Moens, M.F.; Peltonen, J.; et al. Rethinking Summarization and Storytelling for Modern Social Multimedia; Springer: Cham, Switzerland, 2018; pp. 632–644. [Google Scholar] [CrossRef] [Green Version]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A Survey on Deep Learning for Multimodal Data Fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef] [PubMed]
- Ramachandram, D.; Taylor, G.W. Deep Multimodal Learning: A Survey on Recent Advances and Trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Huddar, M.; Sannakki, S.; Rajpurohit, V. A Survey of Computational Approaches and Challenges in Multimodal Sentiment Analysis. Int. J. Comput. Sci. Eng. 2019, 7, 876–883. [Google Scholar] [CrossRef]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Cai, Q.; Wang, H.; Li, Z.; Liu, X. A Survey on Multimodal Data-Driven Smart Healthcare Systems: Approaches and Applications. IEEE Access 2019, 7, 133583–133599. [Google Scholar] [CrossRef]
- Liu, Y. Fine-tune BERT for Extractive Summarization. arXiv 2019, arXiv:1903.10318. [Google Scholar]
- Cheng, J.; Lapata, M. Neural Summarization by Extracting Sentences and Words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 484–494. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking Sentences for Extractive Summarization with Reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1747–1759. [Google Scholar] [CrossRef]
- Zhou, Q.; Yang, N.; Wei, F.; Huang, S.; Zhou, M.; Zhao, T. Neural Document Summarization by Jointly Learning to Score and Select Sentences. arXiv 2018, arXiv:1807.02305. [Google Scholar]
- Ba, J.; Kiros, J.; Hinton, G. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Celikyilmaz, A.; Bosselut, A.; He, X.; Choi, Y. Deep Communicating Agents for Abstractive Summarization. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1662–1675. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the KDD04: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar] [CrossRef] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv 2015, arXiv:1503.03832. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Tanti, M.; Gatt, A.; Camilleri, K. Where to put the Image in an Image Caption Generator. Nat. Lang. Eng. 2017, 24, 467–489. [Google Scholar] [CrossRef] [Green Version]
- Amirian, S.; Rasheed, K.; Taha, T.; Arabnia, H. Automatic Image and Video Caption Generation With Deep Learning: A Concise Review and Algorithmic Overlap. IEEE Access 2020, 8, 218386–218400. [Google Scholar] [CrossRef]
- Bernardi, R.; Cakici, R.; Elliott, D.; Erdem, A.; Erdem, E.; Ikizler, N.; Keller, F.; Muscat, A.; Plank, B. Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures. J. Artif. Intell. Res. 2016, 55. [Google Scholar] [CrossRef]
- Wang, J.; Dong, Y. Measurement of Text Similarity: A Survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar]
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Miller, D. Leveraging BERT for Extractive Text Summarization on Lectures. arXiv 2019, arXiv:1906.04165. [Google Scholar]
- Qiu, Y.; Jin, Y. Engineering Document Summarization Using Sentence Representations Generated by Bidirectional Language Model. In Proceedings of the ASME 2021 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Virtual, 17–19 August 2021. [Google Scholar] [CrossRef]
- To, H.; Nguyen, K.; Nguyen, N.; Nguyen, A. Monolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization. arXiv 2021, arXiv:2108.13741. [Google Scholar]
- Srikanth, A.; Umasankar, A.S.; Thanu, S.; Nirmala, S.J. Extractive Text Summarization using Dynamic Clustering and Co-Reference on BERT. In Proceedings of the 2020 5th International Conference on Computing, Communication and Security (ICCCS), Virtual, 14–16 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Marcelino, G.; Semedo, D.; Mourão, A.; Blasi, S.; Mrak, M.; Magalhães, J. A Benchmark of Visual Storytelling in Social Media. arXiv 2019, arXiv:1908.03505. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Volume 8693. [Google Scholar] [CrossRef] [Green Version]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P. ManiGAN: Text-Guided Image Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 7877–7886. [Google Scholar] [CrossRef]
- Nag Chowdhury, S.; Cheng, W.; de Melo, G.; Razniewski, S.; Weikum, G. Illustrate Your Story: Enriching Text with Images. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 849–852. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.; Song, R.; Wang, C.; Zhou, J.; Sakai, T. Composing a Picture Book by Automatic Story Understanding and Visualization. In Proceedings of the Second Workshop on Storytelling, Florence, Italy, 1 August 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Hu, J.; Cheng, Y.; Gan, Z.; Liu, J.; Gao, J.; Neubig, G. What Makes A Good Story? Designing Composite Rewards for Visual Storytelling. arXiv 2019, arXiv:1909.05316. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
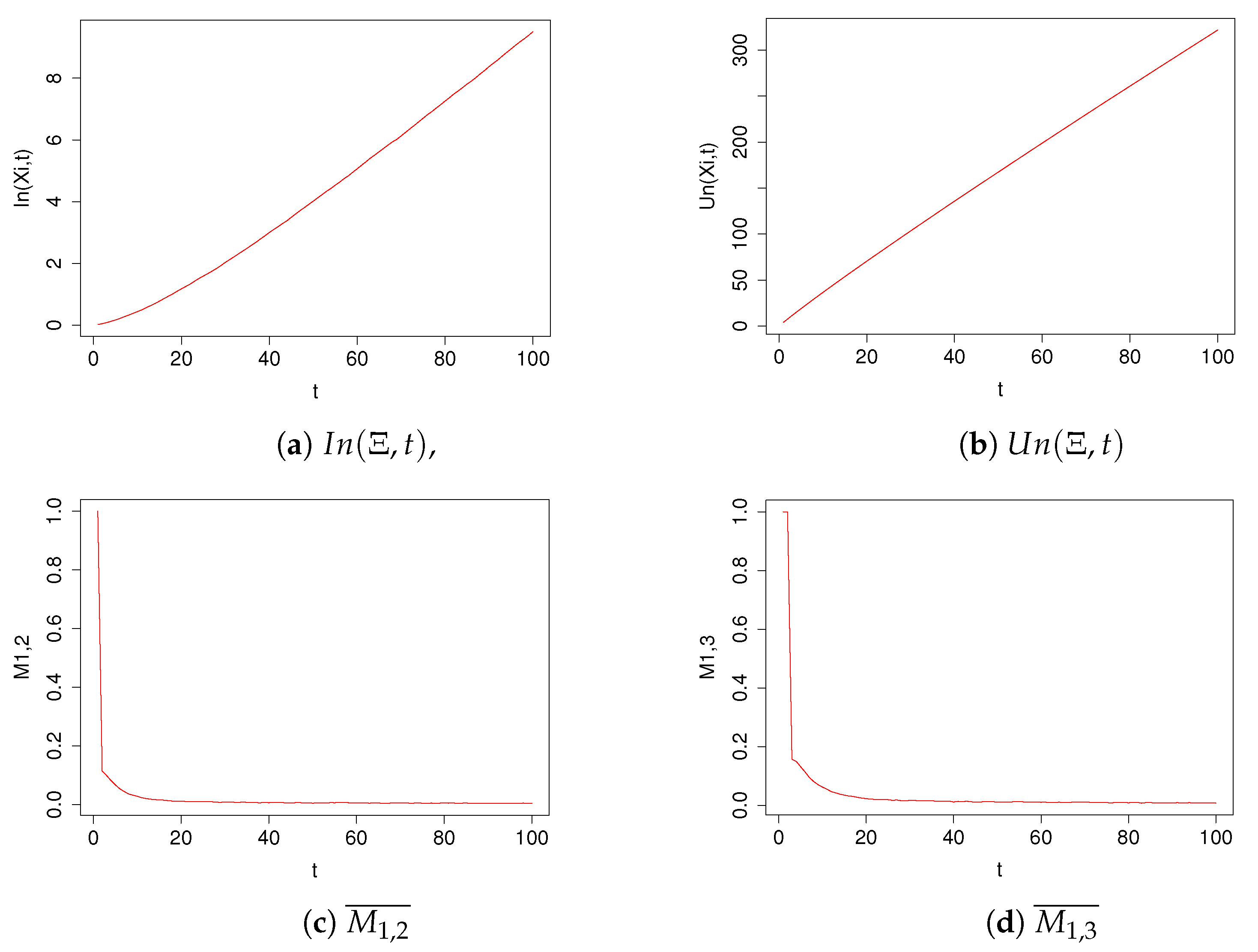{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||
|---|---|---|
| ViT16 | 0.017 | 0.026 |
| ViT32 (SBERT) | 0.017 | 0.026 |
| RN50 | 0.021 | 0.032 |
| RN101 | 0.01 | 0.015 |
| RN50x4 | 0.013 | 0.02 |
| TIPS | 0.013 | 0.03 |
| TIPS | 0.008 | 0.015 |
| TIPS | 0.005 | 0.011 |
| TIPS | 0.004 | 0.008 |
| t | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.02 | 4.13 | 0.40 | 1.89 | 0.53 | 0.65 |
| 2 | 0.05 | 7.93 | 0.40 | 1.91 | 0.74 | 0.82 |
| 3 | 0.08 | 11.69 | 0.40 | 1.91 | 0.86 | 0.93 |
| 17 | 0.93 | 60.53 | 0.55 | 1.91 | 1.37 | 1.35 |
| 22 | 1.33 | 77.22 | 0.65 | 1.91 | 1.47 | 1.39 |
| 52 | 4.23 | 173.77 | 0.69 | 1.91 | 1.53 | 1.49 |
| 86 | 7.91 | 279.14 | 0.79 | 1.91 | 1.54 | 1.52 |
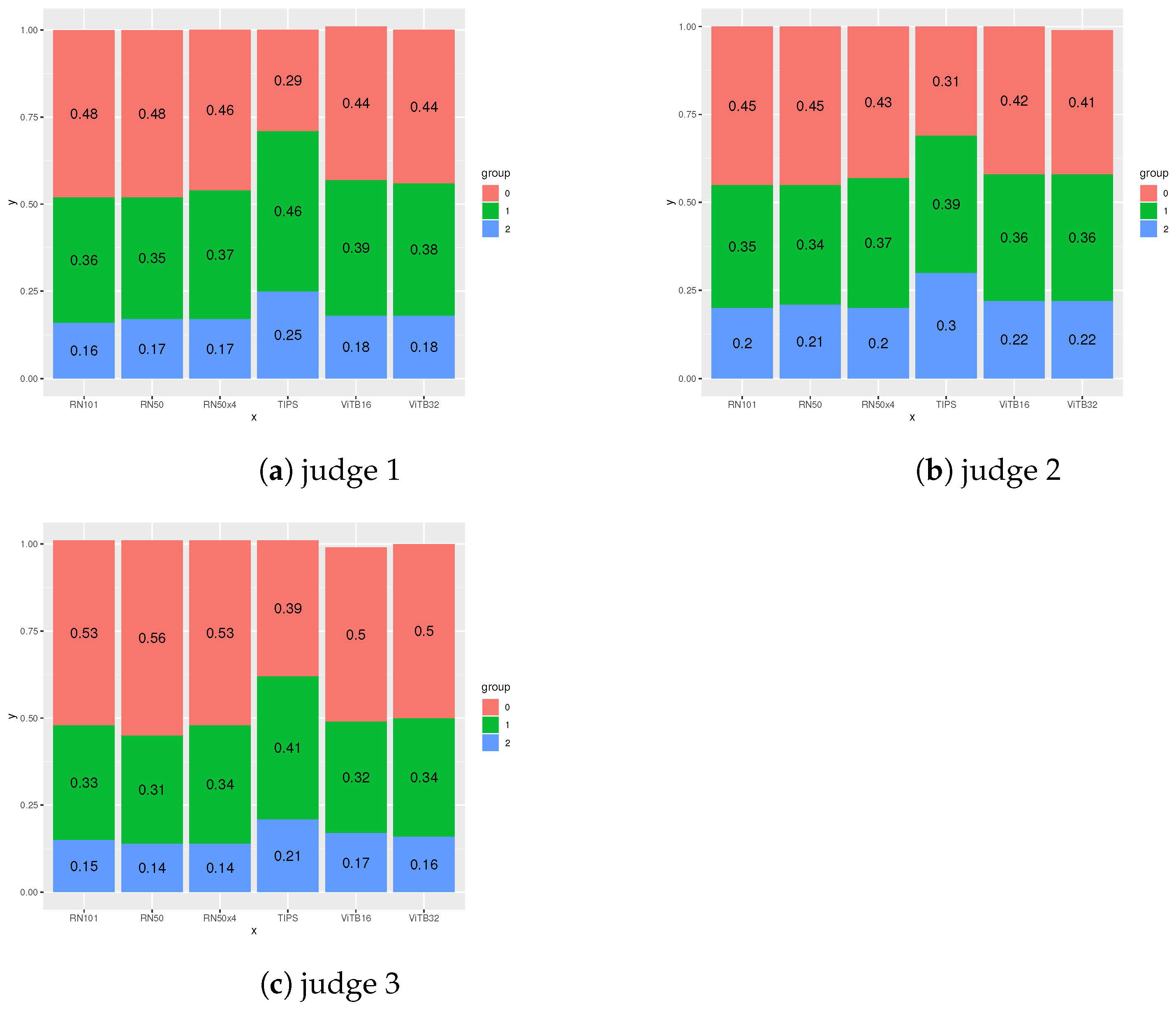
| Judge 1 | Judge 2 | Judge 3 | |
|---|---|---|---|
| TIPS | 0.96 | 0.98 | 0.82 |
| ViTB32 | 0.74 | 0.81 | 0.66 |
| ViTB16 | 0.74 | 0.80 | 0.67 |
| RN101 | 0.68 | 0.75 | 0.62 |
| RN50x4 | 0.71 | 0.77 | 0.61 |
| RN50 | 0.69 | 0.75 | 0.58 |
| TIPS | ViTB32 | ViTB16 | RN101 | RN50x4 | RN50 | |
|---|---|---|---|---|---|---|
| TIPS | 1.00 | 0.55 | 0.52 | 0.55 | 0.57 | 0.52 |
| ViTB32 | 0.55 | 1.00 | 0.47 | 0.46 | 0.47 | 0.45 |
| ViTB16 | 0.52 | 0.47 | 1.00 | 0.44 | 0.45 | 0.41 |
| RN101 | 0.55 | 0.46 | 0.44 | 1.00 | 0.44 | 0.44 |
| RN50x4 | 0.57 | 0.47 | 0.45 | 0.44 | 1.00 | 0.48 |
| RN50 | 0.52 | 0.45 | 0.41 | 0.44 | 0.48 | 1.00 |
| Judge 1 | Judge 2 | Judge 3 | |
|---|---|---|---|
| judge 1 | 1.00 | 0.76 | 0.77 |
| judge 2 | 0.76 | 1.00 | 0.66 |
| judge 3 | 0.77 | 0.66 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golec, J.; Hachaj, T.; Sokal, G. TIPS: A Framework for Text Summarising with Illustrative Pictures. Entropy 2021, 23, 1614. https://doi.org/10.3390/e23121614
Golec J, Hachaj T, Sokal G. TIPS: A Framework for Text Summarising with Illustrative Pictures. Entropy. 2021; 23(12):1614. https://doi.org/10.3390/e23121614
Chicago/Turabian StyleGolec, Justyna, Tomasz Hachaj, and Grzegorz Sokal. 2021. "TIPS: A Framework for Text Summarising with Illustrative Pictures" Entropy 23, no. 12: 1614. https://doi.org/10.3390/e23121614
APA StyleGolec, J., Hachaj, T., & Sokal, G. (2021). TIPS: A Framework for Text Summarising with Illustrative Pictures. Entropy, 23(12), 1614. https://doi.org/10.3390/e23121614