
Spectrum Sensing Implemented with Improved Fluctuation-Based Dispersion Entropy and Machine Learning


Abstract
:1. Introduction
- The implementation of spectrum sensing based on the combination of entropy measures with ML algorithms.
- The novel application of FDE to the spectrum sensing problem.
- An improvement of the FDE and DE to make it more robust to the presence of noise.
- The evaluation of the proposed approach on a data set of real signals in different SNR and fading conditions.
2. Related Work
3. Materials and Methods
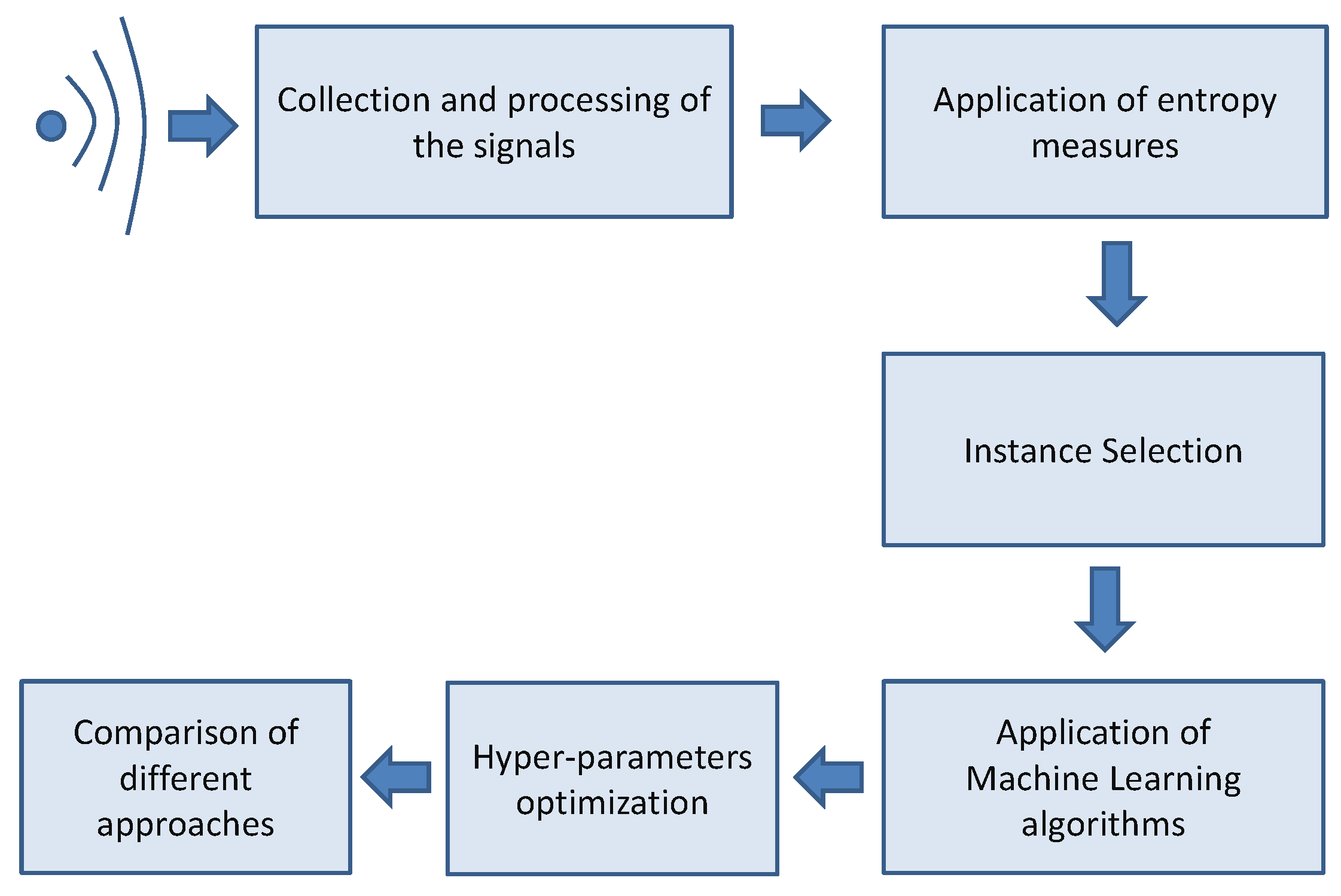
3.1. Overall Methodology
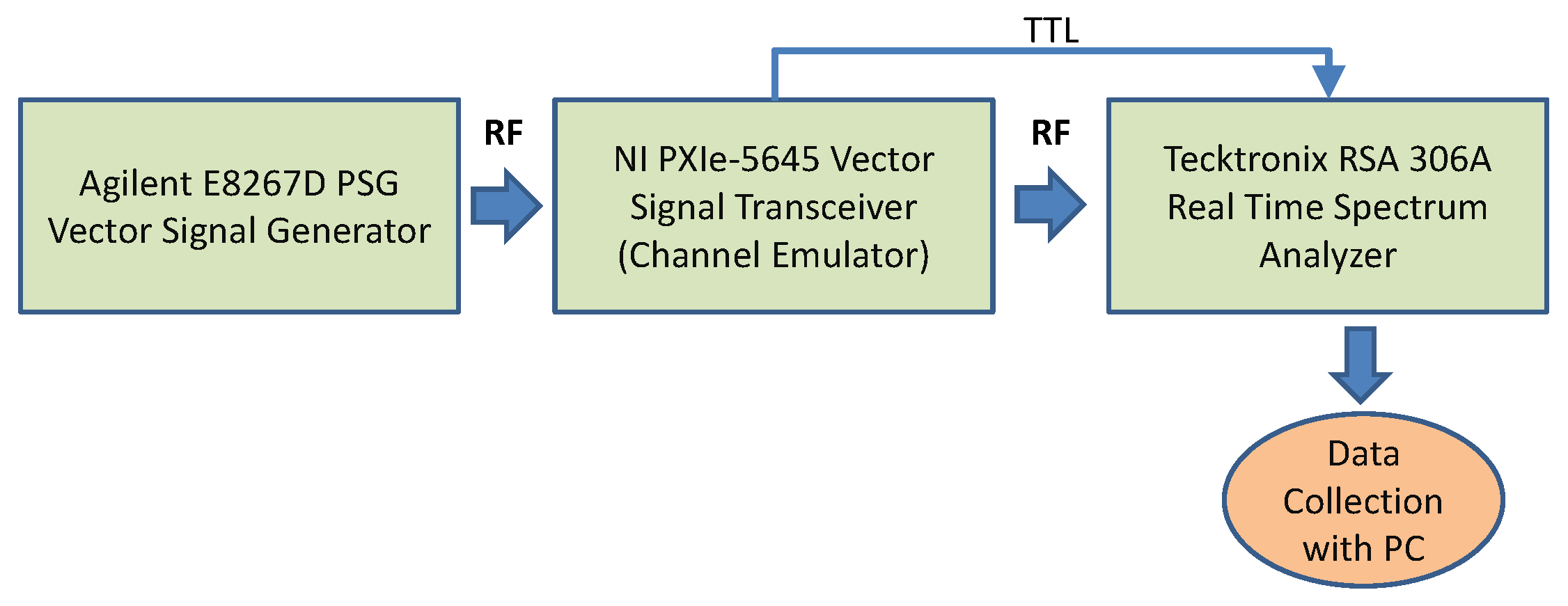
3.2. Materials
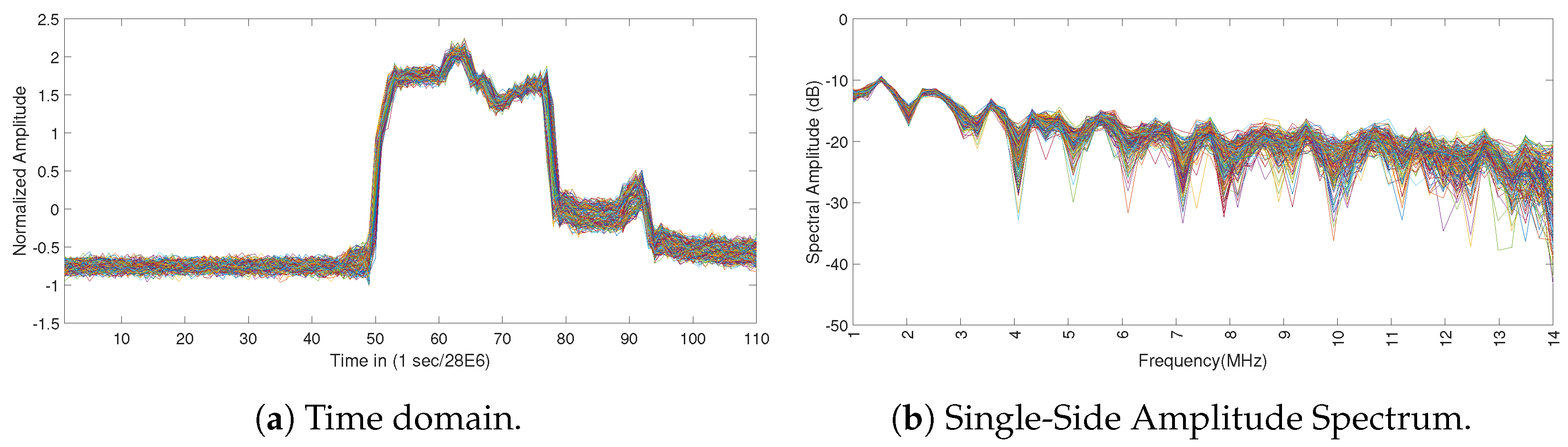
- Agilent E8267D PSG Vector Signal Generator: this signal generator was used to create a simulated radar signal with the following settings which are based on the radar test signal defined in [30] sampling frequency: 40.00 MHz, pulse width: 1 microsecond, the first Pulse Repetition Frequency (PRF1): 800 Hz, the second PRF (PRF2) is 1200 Hz. The number of pulses for each PRF is 18. This configuration creates a sequence of pulses with one pulse lasting 1 microsecond, one pause lasting 1.25 ms, one pulse lasting 1 microsecond, and one pause lasting 0.833 ms. A total of 1920 radar pulses were generated plus the pauses. The carrier frequency for the train of radar pulses is set to 5650 MHz in the PSG Vector Signal Generator since this is the frequency where most of the interferences take place in Europe [29].
- The RF channel emulator based on the NI-VST (Vector Signal Transceiver by National Instruments) PXIe-5645R which was extended with additional fading models and configurations. The channel emulator implements the Tapped Delay Line (TDL) model based on the standard 3GPP TR 38.901 version 14.0.0 Release 14 standard (page 66 to 70) [31].
- Tektronix RSA 306A Real-Time Spectrum Analyzer with 40 MHz of bandwidth, which is used to collect the signal output from the RF channel emulator. A sampling frequency of 28 MHz is used to be well within the limits of the Real-Time Spectrum Analyzer.
3.3. Machine Learning Algorithms and Classification Metrics
3.3.1. Machine Learning Algorithms
- SVM is a supervised learning model with the related learning algorithms that classify data by creating a hyperplane or set of hyperplanes in a high- or infinite-dimensional space, to distinguish the samples belonging to different classes. Various kernels have been tried and the one providing the best performance was the Radial Basis Function (RBF) kernel, where the values of the scaling factor must be optimized together with the parameter C [32].
- KNN is an approach to data classification that estimates how likely a data point is to be a member of one class or another depending on what group the data points nearest to it are in. The KNN is an example of a lazy learner algorithm, meaning that it does not build a model using the training set until a query of the data set is performed. The main hyperparameter in KNN is the K factor, which must be optimized for the specific classification problem. The type of distance metric used to calculate the ’nearest’ must also be chosen carefully.
- Decision tree is a predictive modeling approaches where a decision tree (as a predictive model) analyzes the observations about an item (represented in the branches) to reach conclusions about the item’s target value (represented in the leaves). In this case, we use classification trees where leaves represent class labels and branches represent conjunctions of features that lead to those class labels. The hyper-parameter chosen for optimization is the maximum number of branches at each split. The option in which the algorithm trains the classification tree learners without pruning them was chosen.
3.3.2. Detection Metrics
- The detection probability refers to the numbers of correct detections (PU is present) over the total number of sensing operations. Another definition of is the probability of deciding when is true.
- The probability of false alarm refers to the number of times that the PU is falsely detected over the total number of sensing operations. Another definition of is the probability that the decision is when is true.
4. Entropy Measures
4.1. Shannon Entropy
4.2. Renyi Entropy
4.3. Dispersion Entropy
- ‘LM’ (linear mapping);
- ‘NCDF’ (normal cumulative distribution function);
- ‘TANSIG’ (tangent sigmoid);
- ‘LOGSIG’ (logarithm sigmoid);
- ‘SORT’ (sorting method).
4.4. Fluctuation Dispersion Entropy
4.5. Improved Fluctuation Dispersion Entropy
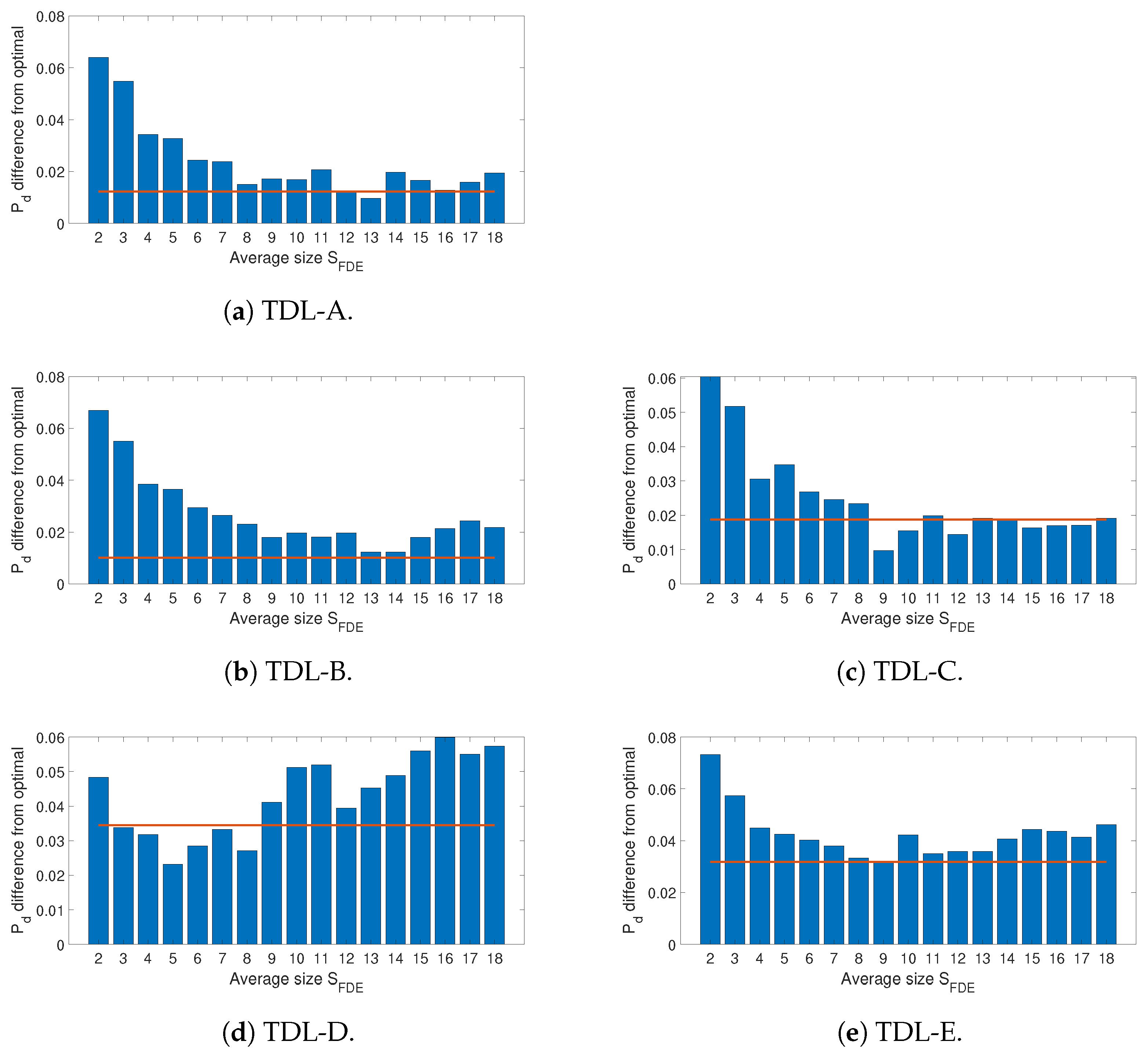
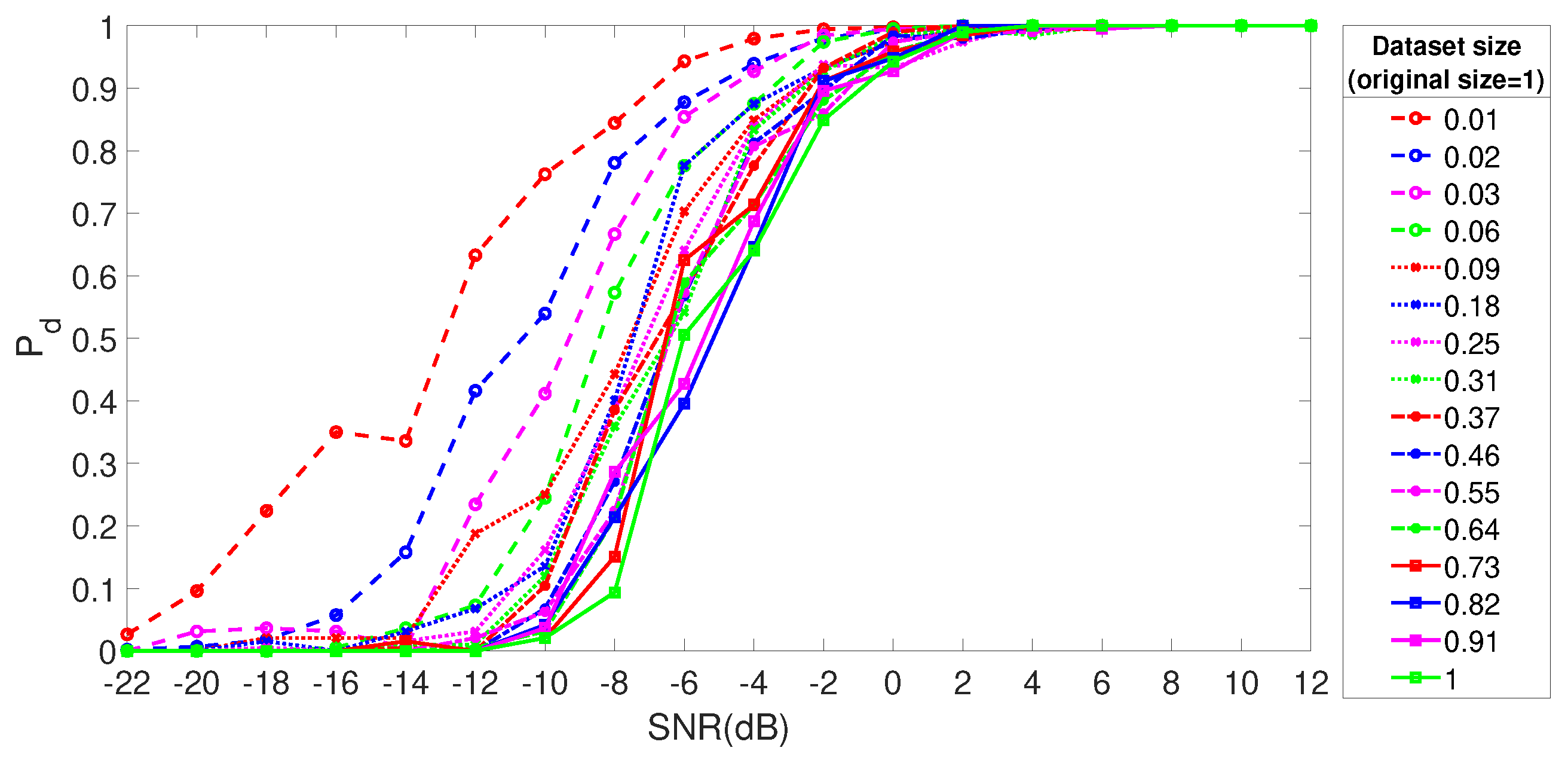
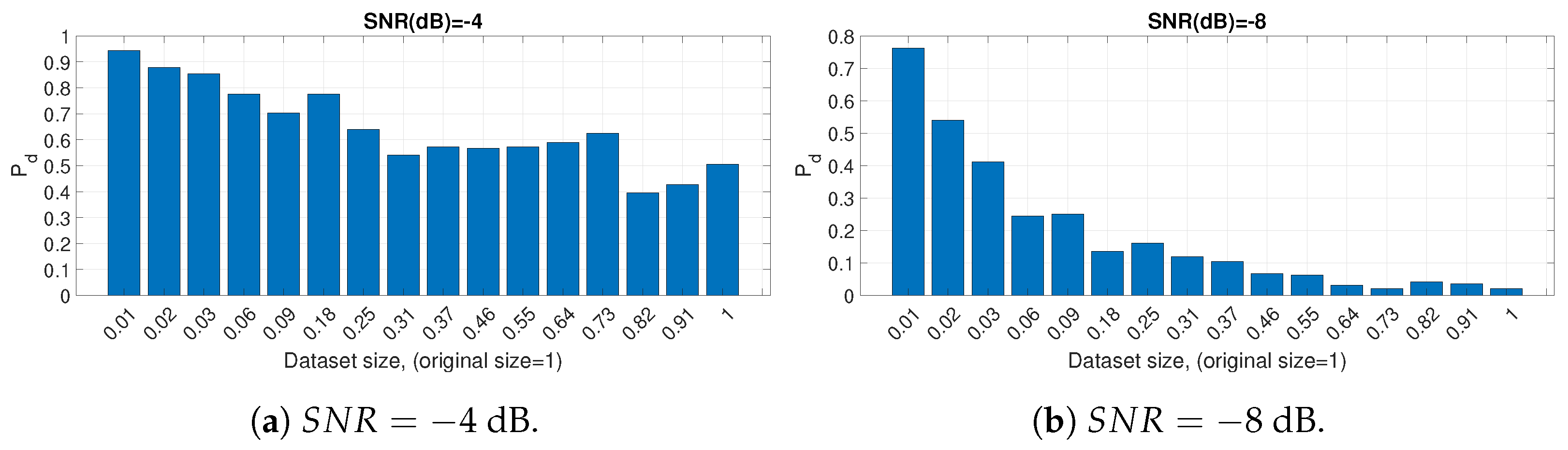
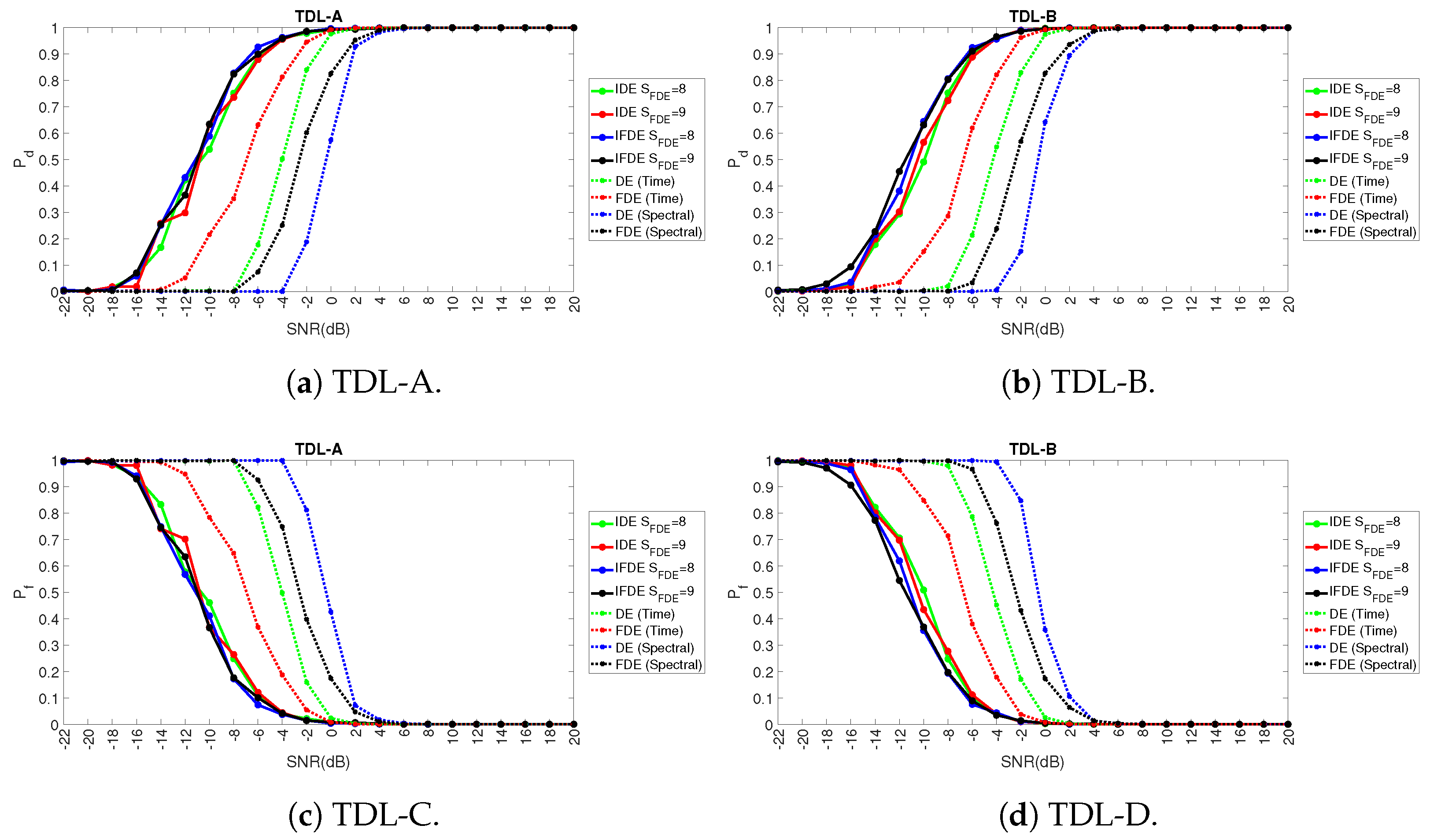
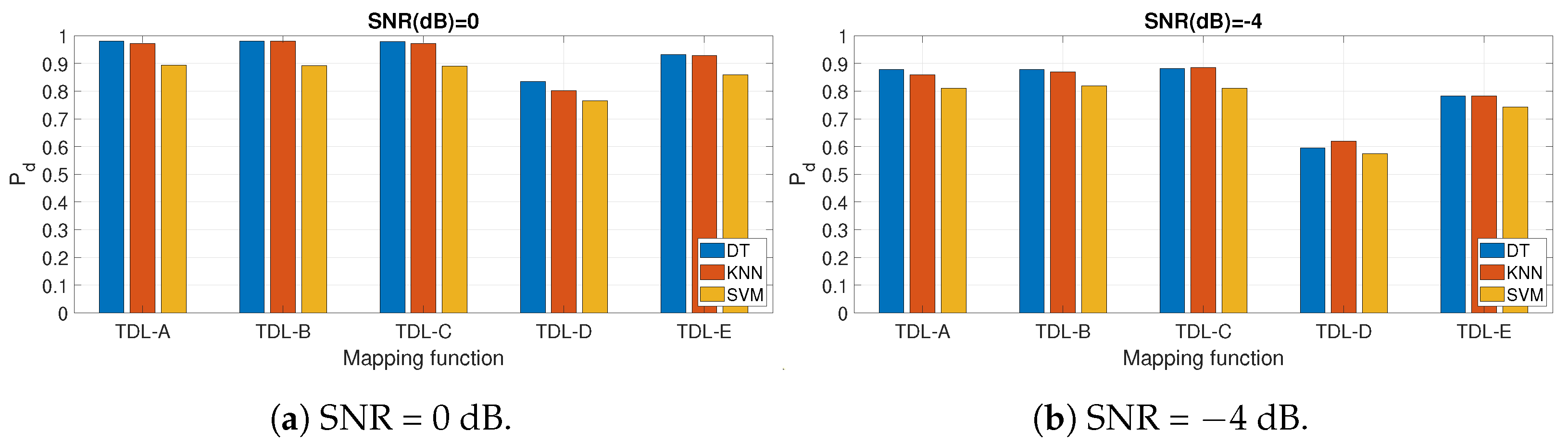
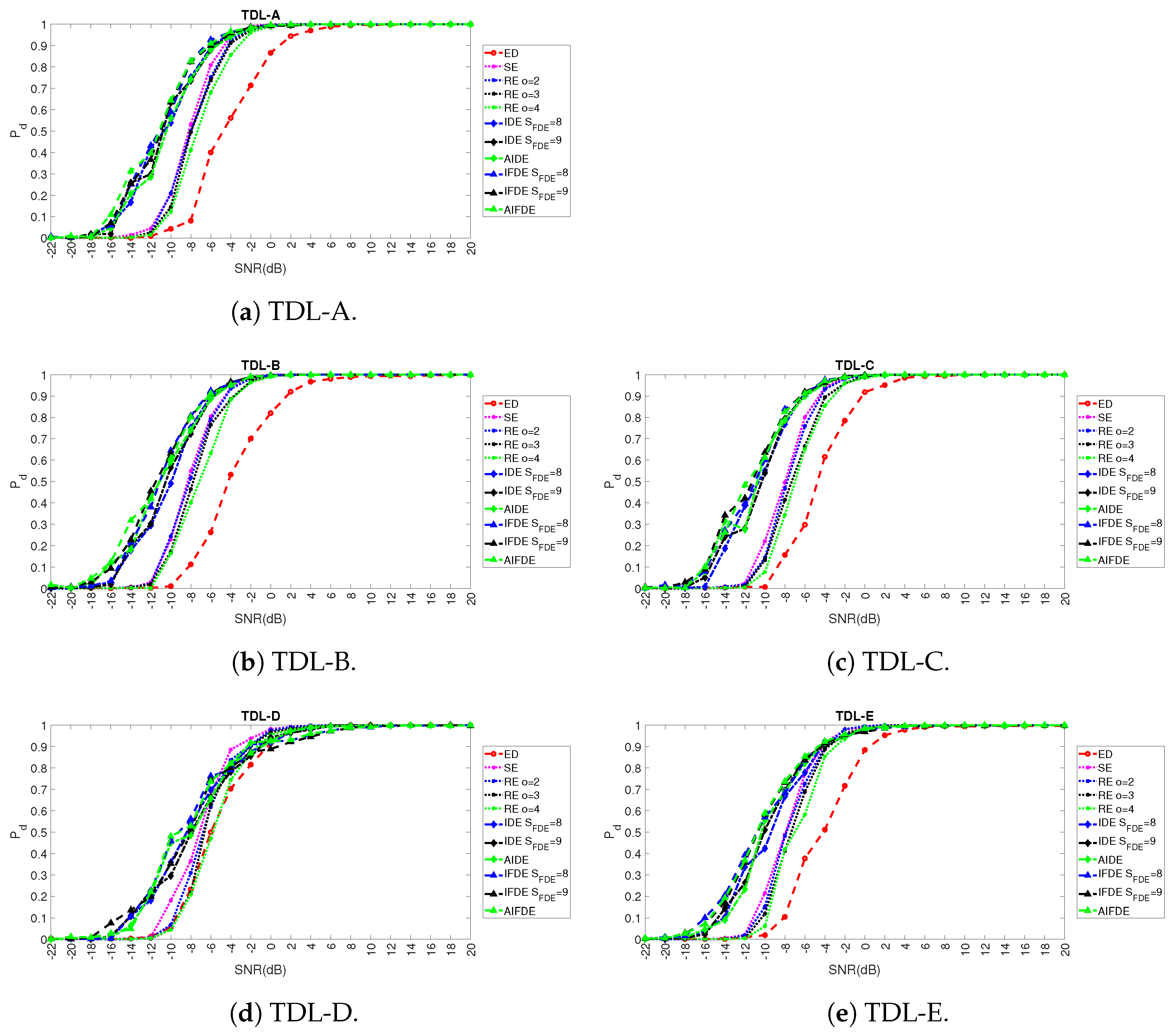
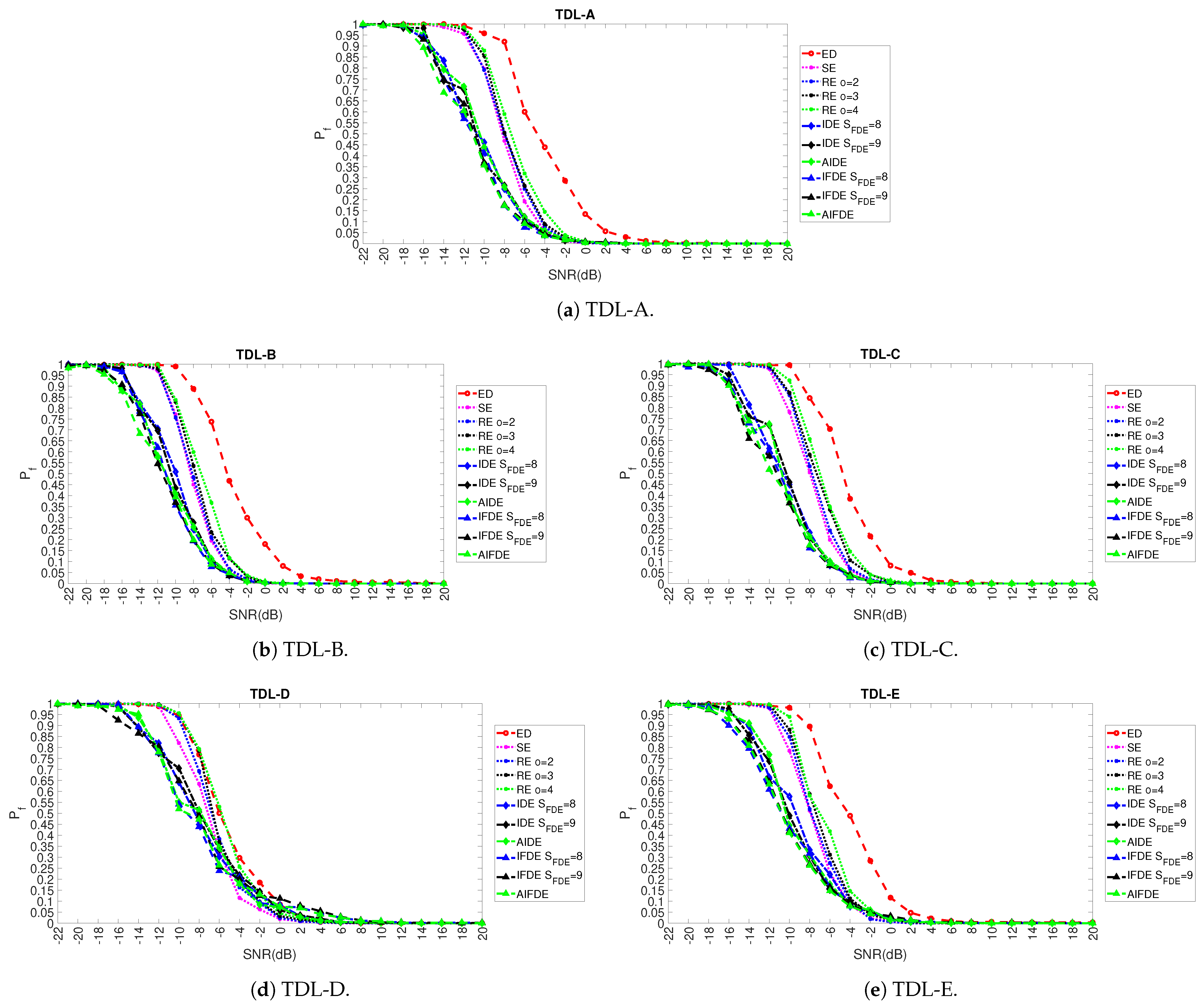
5. Results
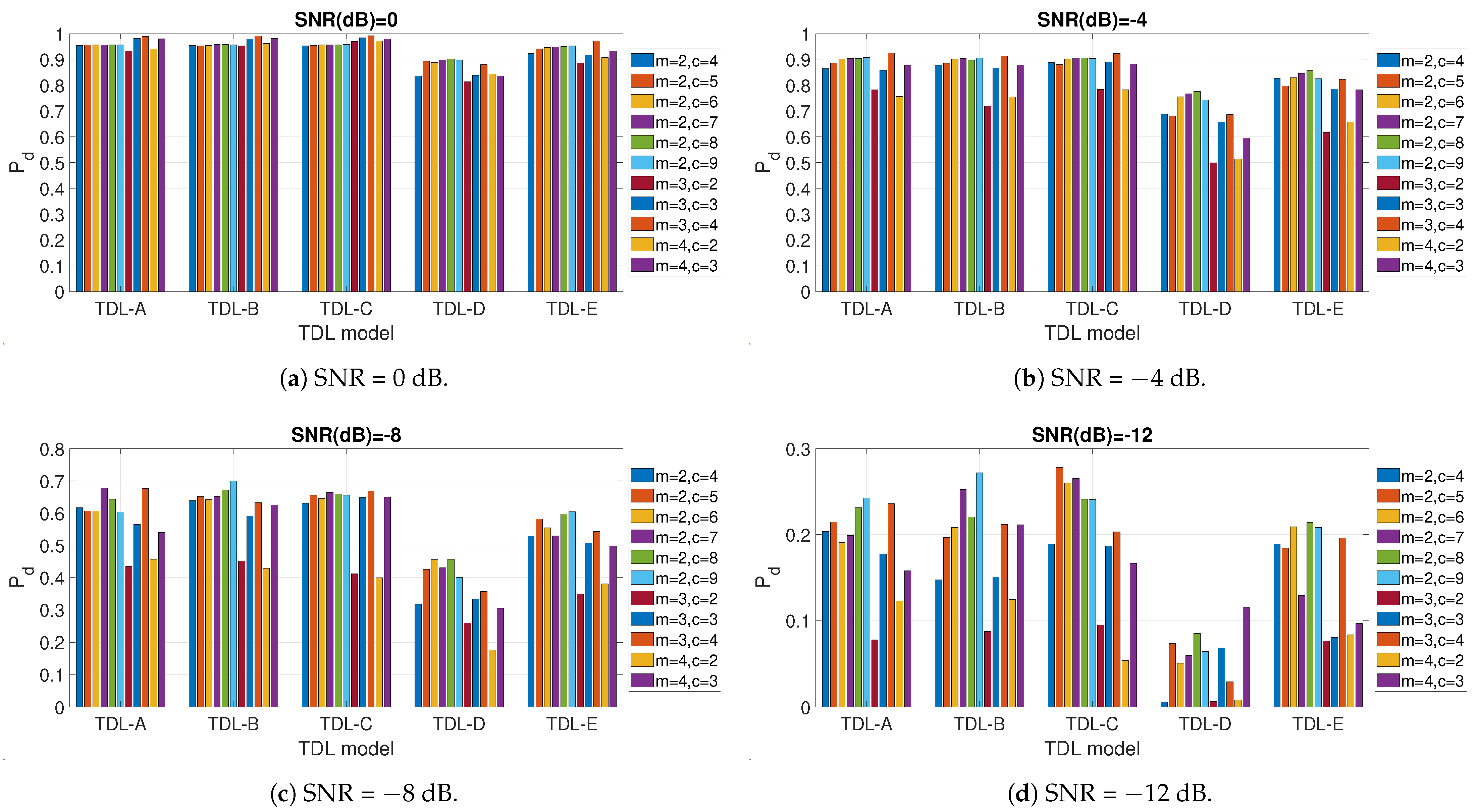
5.1. Hyper-Parameter Optimization
5.2. Comparison with Other Approaches from Literature
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| AIFDE | Adaptive Improved Fluctuation Dispersion Entropy |
| AIDE | Adaptive Improved Dispersion Entropy |
| AWGN | Additive White Gaussian Noise |
| DE | Dispersion Entropy |
| DT | Decision Tree |
| IFDE | Improved Fluctuation Dispersion Entropy |
| IDE | Improved Dispersion Entropy |
| KNN | K Nearest Neighbor |
| NCDF | Normal Cumulative Distribution Function |
| PRF | Pulse Repetition Frequency |
| RBF | Radial Basis Function |
| RE | Renyi Entropy |
| SE | Shannon Entropy |
| SNR | Signal to Noise Ratio |
| SVM | Support Vector Machine |
| TDL | Tapped Delay Line |
References
- Yucek, T.; Arslan, H. A survey of spectrum sensing algorithms for cognitive radio applications. IEEE Commun. Surv. Tutor. 2009, 11, 116–130. [Google Scholar] [CrossRef]
- Awin, F.; Abdel-Raheem, E.; Tepe, K. Blind spectrum sensing approaches for interweaved cognitive radio system: A tutorial and short course. IEEE Commun. Surv. Tutor. 2018, 21, 238–259. [Google Scholar] [CrossRef]
- Tavares, C.H.A.; Marinello, J.C.; Proenca Jr, M.L.; Abrao, T. Machine learning-based models for spectrum sensing in cooperative radio networks. IET Commun. 2020, 14, 3102–3109. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Zhang, Q.Y.; Melodia, T. A frequency-domain entropy-based detector for robust spectrum sensing in cognitive radio networks. IEEE Commun. Lett. 2010, 14, 533–535. [Google Scholar] [CrossRef] [Green Version]
- Swetha, N.; Sastry, P.N.; Rao, Y.R.; Sabat, S.L. Parzen window entropy based spectrum sensing in cognitive radio. Comput. Electr. Eng. 2016, 52, 379–389. [Google Scholar] [CrossRef]
- Cadena Muñoz, E.; Pedraza Martínez, L.F.; Hernandez, C.A. Rényi Entropy-Based Spectrum Sensing in Mobile Cognitive Radio Networks Using Software Defined Radio. Entropy 2020, 22, 626. [Google Scholar] [CrossRef] [PubMed]
- Rostaghi, M.; Azami, H. Dispersion entropy: A measure for time-series analysis. IEEE Signal Process. Lett. 2016, 23, 610–614. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude-and fluctuation-based dispersion entropy. Entropy 2018, 20, 210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baldini, G.; Giuliani, R.; Steri, G.; Neisse, R. Physical layer authentication of Internet of Things wireless devices through permutation and dispersion entropy. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Mitiche, I.; Morison, G.; Nesbitt, A.; Hughes-Narborough, M.; Stewart, B.G.; Boreham, P. Classification of partial discharge signals by combining adaptive local iterative filtering and entropy features. Sensors 2018, 18, 406. [Google Scholar] [CrossRef] [Green Version]
- Lu, L.; Zhou, X.; Onunkwo, U.; Li, G.Y. Ten years of research in spectrum sensing and sharing in cognitive radio. EURASIP J. Wirel. Commun. Netw. 2012, 2012, 28. [Google Scholar] [CrossRef] [Green Version]
- Arjoune, Y.; Kaabouch, N. A comprehensive survey on spectrum sensing in cognitive radio networks: Recent advances, new challenges, and future research directions. Sensors 2019, 19, 126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akyildiz, I.F.; Lo, B.F.; Balakrishnan, R. Cooperative spectrum sensing in cognitive radio networks: A survey. Phys. Commun. 2011, 4, 40–62. [Google Scholar] [CrossRef]
- Ejaz, W.; Shah, G.A.; Hasan, N.U.; Kim, H.S. Optimal entropy-based cooperative spectrum sensing for maritime cognitive radio networks. Entropy 2013, 15, 4993–5011. [Google Scholar] [CrossRef] [Green Version]
- Prieto, G.; Andrade, Á.G.; Martínez, D.M.; Galaviz, G. On the evaluation of an entropy-based spectrum sensing strategy applied to cognitive radio networks. IEEE Access 2018, 6, 64828–64835. [Google Scholar] [CrossRef]
- Nagaraj, S.V. Entropy-based spectrum sensing in cognitive radio. Signal Process. 2009, 89, 174–180. [Google Scholar] [CrossRef]
- Zhao, N. A novel two-stage entropy-based robust cooperative spectrum sensing scheme with two-bit decision in cognitive radio. Wirel. Pers. Commun. 2013, 69, 1551–1565. [Google Scholar] [CrossRef] [Green Version]
- Ernesto, C.M.; Martínez, J.A.R.; Martínez, L.F.P.; Parra, I.P.P. Cooperative Spectrum Sensing with Entropy for Mobile Cognitive Radio Networks. In Proceedings of the 2020 IEEE ANDESCON, Quito, Ecuador, 13–16 October 2020; pp. 1–5. [Google Scholar]
- Janu, D.; Singh, K.; Kumar, S. Machine learning for cooperative spectrum sensing and sharing: A survey. Trans. Emerg. Telecommun. Technol. 2021, e4352. [Google Scholar] [CrossRef]
- Thilina, K.M.; Choi, K.W.; Saquib, N.; Hossain, E. Machine learning techniques for cooperative spectrum sensing in cognitive radio networks. IEEE J. Sel. Areas Commun. 2013, 31, 2209–2221. [Google Scholar] [CrossRef]
- Awe, O.P.; Lambotharan, S. Cooperative spectrum sensing in cognitive radio networks using multi-class support vector machine algorithms. In Proceedings of the 2015 9th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, QLD, Australia, 14–16 December 2015; pp. 1–7. [Google Scholar]
- Li, Z.; Wu, W.; Liu, X.; Qi, P. Improved cooperative spectrum sensing model based on machine learning for cognitive radio networks. IET Commun. 2018, 12, 2485–2492. [Google Scholar] [CrossRef]
- Molina-Tenorio, Y.; Prieto-Guerrero, A.; Aguilar-Gonzalez, R.; Ruiz-Boqué, S. Machine learning techniques applied to multiband spectrum sensing in cognitive radios. Sensors 2019, 19, 4715. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Chen, S.; Qi, P.; Zhou, H.; Yang, X. Spectrum sensing based on deep learning classification for cognitive radios. China Commun. 2020, 17, 138–148. [Google Scholar] [CrossRef]
- Lee, W.; Kim, M.; Cho, D.H. Deep cooperative sensing: Cooperative spectrum sensing based on convolutional neural networks. IEEE Trans. Veh. Technol. 2019, 68, 3005–3009. [Google Scholar] [CrossRef]
- Lees, W.M.; Wunderlich, A.; Jeavons, P.J.; Hale, P.D.; Souryal, M.R. Deep learning classification of 3.5-GHz band spectrograms with applications to spectrum sensing. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 224–236. [Google Scholar] [CrossRef] [PubMed]
- Saravanan, P.; Chandra, S.S.; Upadhye, A.; Gurugopinath, S. A Supervised Learning Approach for Differential Entropy Feature-based Spectrum Sensing. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; pp. 395–399. [Google Scholar]
- Xue, H.; Gao, F. A machine learning based spectrum-sensing algorithm using sample covariance matrix. In Proceedings of the 2015 10th International Conference on Communications and Networking in China (ChinaCom), Shanghai, China, 15–17 August 2015; pp. 476–480. [Google Scholar]
- Saltikoff, E.; Cho, J.Y.; Tristant, P.; Huuskonen, A.; Allmon, L.; Cook, R.; Becker, E.; Joe, P. The threat to weather radars by wireless technology. Bull. Am. Meteorol. Soc. 2016, 97, 1159–1167. [Google Scholar] [CrossRef]
- ETSI. ETSI EN 301 893 V2.1.1 (2017-05) 5 GHz RLAN; Harmonised Standard Covering the Essential Requirements of Article 3.2 of Directive 2014/53/EU. 2020. Available online: https://www.etsi.org/deliver/etsi_en/301800_301899/301893/02.01.01_60/en_301893v020101p.pdf (accessed on 4 October 2021).
- 3GPP. Study on Channel Model for Frequencies from 0.5 to 100 GHz. 2017. Available online: https://www.3gpp.org/ftp//Specs/archive/38_series/38.901/38901-e00.zip (accessed on 4 October 2021).
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Zhao, N.; Yu, F.R.; Sun, H.; Nallanathan, A. Energy-efficient cooperative spectrum sensing schemes for cognitive radio networks. EURASIP J. Wirel. Commun. Netw. 2013, 2013, 120. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters of the Machine Learning Algorithms | Parameters |
|---|---|
| SVM | RBF scaling factor (range: to ), C factor = (range: to ) |
| KNN | (range: 1 to 10), Distance metric = Euclidean Distance (choices: Chebychev, Euclidean, Minkowski) |
| Decision Tree | (range: 2 to 12), Split Criterion = Gini’s diversity index (choices: Gini Index and Cross-Entropy) |
| Hyper-parameters of the entropy measures | |
| DE | embedding dimension (range 2, 3, 4), number of classes (range 2, 3, …, 9). Mapping function equal to TANSIG with range (LM, NCDF, TANSIG, LOGSIG, SORT). |
| IDE and AIDE | embedding dimension (range 2, 3, 4), number of classes (range 2, 3, …, 9), averaging parameter or adaptive calculation of . Mapping function equal to TANSIG with range (LM, NCDF, TANSIG, LOGSIG, SORT). |
| FDE | embedding dimension (range 2, 3, 4), number of classes (range 2, 3, …, 9). Mapping function equal to TANSIG with range (LM, NCDF, TANSIG, LOGSIG, SORT). |
| IFDE and AIFDE | embedding dimension (range 2, 3, 4), number of classes (range 2, 3, …, 9), averaging parameter or adaptive calculation of . Mapping function equal to TANSIG with range (LM, NCDF, TANSIG, LOGSIG, SORT). |
| Approach | (SNR = −12 dB) | (SNR = −8 dB) | (SNR = −12 dB) | (SNR = −8 dB) |
|---|---|---|---|---|
| ED | 0.0083 | 0.08 | 0.9916 | 0.919 |
| Shannon entropy | 0.00447 | 0.5322 | 0.955 | 0.4677 |
| Renyi entropy | 0.0255 | 0.5162 | 0.975 | 0.50 |
| Renyi entropy | 0.028 | 0.4953 | 0.975 | 0.504 |
| Renyi entropy | 0.0156 | 0.4104 | 0.984 | 0.589 |
| IDE () | 0.4229 | 0.7515 | 0.577 | 0.248 |
| IDE () | 0.2984 | 0.735 | 0.714 | 0.264 |
| AIDE | 0.2854 | 0.742 | 0.701 | 0.2578 |
| IFDE () | 0.4322 | 0.826 | 0.567 | 0.1694 |
| IFDE () | 0.365 | 0.823 | 0.634 | 0.1706 |
| AIFDE | 0.3958 | 0.827 | 0.604 | 0.1729 |
| ED | 0.001 | 0.1125 | 0.9989 | 0.8875 |
| Shannon entropy | 0.0029 | 0.5489 | 0.973 | 0.451 |
| Renyi entropy | 0.021 | 0.516 | 0.98 | 0.4833 |
| Renyi entropy | 0.019 | 0.464 | 0.98 | 0.535 |
| Renyi entropy | 0.012 | 0.401 | 0.998 | 0.598 |
| IDE () | 0.294 | 0.752 | 0.705 | 0.247 |
| IDE () | 0.302 | 0.723 | 0.6975 | 0.276 |
| AIDE | 0.42 | 0.741 | 0.575 | 0.258 |
| IFDE () | 0.38 | 0.801 | 0.619 | 0.1937 |
| IFDE () | 0.455 | 0.8 | 0.577 | 0.1963 |
| AIFDE | 0.425 | 0.806 | 0.585 | 0.187 |
| ED | 0.0078 | 0.1567 | 0.992 | 0.843 |
| Shannon entropy | 0.0023 | 0.4953 | 0.976 | 0.5047 |
| Renyi entropy | 0.0177 | 0.467 | 0.982 | 0.5328 |
| Renyi entropy | 0.0093 | 0.414 | 0.986 | 0.5854 |
| Renyi entropy | 0.005 | 0.344 | 0.9948 | 0.6557 |
| IDE () | 0.38 | 0.768 | 0.6135 | 0.2318 |
| IDE () | 0.28 | 0.793 | 0.7198 | 0.2068 |
| AIDE | 0.2755 | 0.786 | 0.7245 | 0.2135 |
| IFDE () | 0.397 | 0.838 | 0.6026 | 0.1615 |
| IFDE () | 0.421 | 0.824 | 0.5781 | 0.1745 |
| AIFDE | 0.4828 | 0.826 | 0.5172 | 0.174 |
| ED | 0.013 | 0.232 | 0.988 | 0.768 |
| Shannon entropy | 0.010 | 0.366 | 0.990 | 0.634 |
| Renyi entropy | 0.007 | 0.309 | 0.993 | 0.691 |
| Renyi entropy | 0.003 | 0.216 | 0.997 | 0.784 |
| Renyi entropy | 0.006 | 0.207 | 0.994 | 0.793 |
| IDE () | 0.180 | 0.535 | 0.820 | 0.465 |
| IDE () | 0.226 | 0.494 | 0.774 | 0.506 |
| AIDE | 0.209 | 0.485 | 0.791 | 0.515 |
| IFDE () | 0.226 | 0.561 | 0.774 | 0.439 |
| IFDE () | 0.197 | 0.513 | 0.803 | 0.488 |
| AIFDE | 0.221 | 0.528 | 0.779 | 0.472 |
| ED | 0.010 | 0.105 | 0.990 | 0.895 |
| Shannon entropy | 0.021 | 0.488 | 0.979 | 0.513 |
| Renyi entropy | 0.019 | 0.481 | 0.981 | 0.519 |
| Renyi entropy | 0.004 | 0.412 | 0.996 | 0.588 |
| Renyi entropy | 0.005 | 0.419 | 0.995 | 0.581 |
| IDE () | 0.336 | 0.667 | 0.664 | 0.333 |
| IDE () | 0.262 | 0.694 | 0.738 | 0.306 |
| AIDE | 0.233 | 0.689 | 0.767 | 0.311 |
| IFDE () | 0.392 | 0.682 | 0.608 | 0.318 |
| IFDE () | 0.357 | 0.731 | 0.643 | 0.269 |
| AIFDE | 0.368 | 0.737 | 0.632 | 0.263 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldini, G.; Chareau, J.-M.; Bonavitacola, F. Spectrum Sensing Implemented with Improved Fluctuation-Based Dispersion Entropy and Machine Learning. Entropy 2021, 23, 1611. https://doi.org/10.3390/e23121611
Baldini G, Chareau J-M, Bonavitacola F. Spectrum Sensing Implemented with Improved Fluctuation-Based Dispersion Entropy and Machine Learning. Entropy. 2021; 23(12):1611. https://doi.org/10.3390/e23121611
Chicago/Turabian StyleBaldini, Gianmarco, Jean-Marc Chareau, and Fausto Bonavitacola. 2021. "Spectrum Sensing Implemented with Improved Fluctuation-Based Dispersion Entropy and Machine Learning" Entropy 23, no. 12: 1611. https://doi.org/10.3390/e23121611
APA StyleBaldini, G., Chareau, J.-M., & Bonavitacola, F. (2021). Spectrum Sensing Implemented with Improved Fluctuation-Based Dispersion Entropy and Machine Learning. Entropy, 23(12), 1611. https://doi.org/10.3390/e23121611