1. Introduction
The modeling of dynamical processes is at the forefront of research in numerous branches of science, including political science [
1], sociology [
2] and social psychology [
3]. The aim of modeling a social system is not to reproduce it with its whole complexity, but rather to postulate causal relations which could be next confronted with statistical observations on selected aspects of the system [
4]. Here, we are interested in consequences of the process of removal of cognitive dissonance for the characteristics of opinions, collected in social surveys. Our aim is to present and discuss a computational scheme, which seems appropriate here.
According to Andrew Heywood ([
5], p. 217), there are four rival models of voting: the party identification model, the sociological model, the rational choice model and the dominant ideology model. In a nutshell, the first three models explore the attachments of voters to political parties, social classes or their personal self-interests, respectively. The fourth model admits that voter behavior is shaped by ideological manipulation through education and mass media. This perspective has been well established in political sciences since the famous essay by Philip E. Converse in 1964 [
6,
7]. As it is argued therein, the majority of voters are unable to analyze political facts abstractly. Instead, they make decisions basing upon rough associations related to ideology. The process of reaching decisions was investigated also in more general frames by Cristina Bicchieri ([
8], p. 4): apart from the rational path, individuals can associate a given situation with their past experience and react almost subconsciously, basing upon such a categorization. Our view here is that these ideologies and categorizations, even if irrational, should be internally consistent.
A specific kind of consistency—with respect to friendly and hostile interpersonal relations—is known in social psychology under the name of Heider (or structural) balance (HB) [
9,
10,
11,
12]. In a fully connected social network, states which are balanced in this sense consist of two subsets of nodes: internally friendly but mutually hostile. In such a state, every triad (three nodes and three relations between them) contains either two or zero hostile relations. Balanced states are commonly interpreted as being devoid of cognitive dissonance [
13], which is perceived by an actor at a node if any of the following rules [
14] are broken:
A friend of my friend is my friend;
An enemy of my friend is my enemy;
A friend of my enemy is my enemy;
An enemy of my enemy is my friend.
In its earliest formulation [
9], the concept of HB was applied to relations of actors to actors and objects. Soon, this application was expanded to relations that are exclusively interpersonal [
11,
12,
15,
16,
17], and to relations between political entities, such as governments of different states [
18,
19,
20,
21,
22,
23]. Our goal here is to apply HB to statements, which are answered in interviews about political issues. We postulate two statements to be ’friendly’ if they are positively correlated in the interviews. In this way, we intend to gain knowledge about the consistency of given sets of statements as perceived by interviewees.
We should not expect that the answers will be logically consistent in our perspective, as the perspective of our interviewees is different from ours. Neither should we expect that the collected material will be already equivalent to a balanced state. Then, our first task will be to find an algorithm which is optimal, in the sense that it drives the system to a balanced state that is as close as possible to the initial state. A final state obtained with this algorithm should be simultaneously (i) balanced, then consistent; and (ii) only minimally distorted with respect to the initial state. Having the algorithm, we intend to apply it to data from interviews, available in the literature. The goal will be to identify statements that co-occur. We expect to gain insight to portraits of voters: sets of statements which seem to them to be consistent.
We underline that this program of research is most coherent with the dominant ideology model, the last out of the four models specified by Heywood [
5]. In the other three, one needs information about the structure of parties, classes or interests of voters. Consequently, any algorithm should be able to make use of these data, including realistic values of numerous parameters. Such an approach is out of the scope of this paper. On the other hand, the binomial character of relations in any balanced state is a natural consequence of a white–black view of the world. Therefore we consider the Heider balance to be properly framed within the model of dominant ideology. Finally, to identify a group of enemies is known to be the best method to consolidate one’s own group. As was famously stated by Alexis de Tocqueville,
In politics, shared hatreds are almost always the basis of friendships ([
24], p. 73). It is here where the fourth rule of an enemy of one’s own enemy applies.
We note that the most prominent application of the Monte Carlo method to locate the minima of a work function is the algorithm of simulated annealing [
25]. The target there was to locate a global minimum, the deepest of all of them. Here, our aim is different: we search for a local minimum that is most close to the initial state in the space of states. The issue that the minima are of the same or different depth is of secondary importance here.
In the next section, we report four algorithms known in the literature, which lead a fully connected network to a balanced state. Section III is meant to describe the set of data, taken from literature [
26]. In Section IV, we compare the performance of the algorithms, and we apply the selected one to this dataset. The last section is devoted to discussion.
2. Algorithms
There are four algorithms which lead a complete graph to a balanced state. Two of them are discrete, i.e. they operate on signed links: a link
between nodes
i and
j can be positive or negative,
[
18]. Both of these algorithms are based on the Monte Carlo method. The next two algorithms operate on real numbers (
), and they are deterministic [
27]. The algorithms can be briefly described as follows.
In the first algorithm, termed local triad dynamics (LTD) [
18,
28], a triad of nodes is selected randomly. If the triad is balanced, it remains unchanged. If it contains three negative links, the sign of one of them is switched to be positive. If one link is negative, it is switched to be positive with probability
p, or one of two positive links is switched to be negative with probability
. Next, another triad is updated, and so on. Once all triads are balanced, the algorithm is stopped. It is clear that each balanced state is absorbing. Yet, under LTD, the total number
F of imbalanced triads can temporarily increase.
In the second algorithm, termed constrained triad dynamics (CTD) [
18,
28], a link is selected randomly, and an attempt is made to change its sign. If this leads to a decrease in
F, the change remains; if
F increases, the change is withdrawn; if
F is not changed, the change of the link remains with probability 1/2. It is clear that under CTD,
F cannot increase. Yet the system can be trapped in an unbalanced state, commonly termed “jammed”.
The third algorithm (let us call it DE—differential equations) relies on a set of
equations, with one per each link:
where
N is the total number of nodes. Here, jammed states are possible, too [
29]. As each configuration of links
is a fixed point, we use
as the initial states, where
is a random number. This setting ensures that the values of the variables
remain in the range
; once the limit is reached, the time derivative is zero. Numerical experiments show that the results do not change visibly as long as
.
The fourth algorithm (let us call it DE’) is a modified version of DE, without the prefactor
. The set of equations is solved analytically [
30]. Its another advantage is that the obtained equations are equivalent to an overdamped motion in a potential:
which is minimal in balanced states. However, these equations lead the links
to infinity in finite time. Therefore, we apply it in combination with the additional condition that
[
31]. This condition is executed numerically: once some variable
reaches the value +1 (−1), it is prevented from further increasing (decreasing). The correction
is applied also here to evade an artificial symmetry, where the same value is assigned to all links.
For all four algorithms, each balanced state is absorbing; once the system falls there, it remains there. As each triad is balanced,
, and the energy
U is of minimal value. Both LTD and CTD remain inactive there. Further, for DE, it appears that all nondiagonal matrix elements of the Jacobian are zero, as
for each link. The eigenvalues are equal just to the diagonal matrix elements as follows:
and their negativity in a balanced state is a consequence of the condition of balance of each particular triad
. (We note that two indices in
are necessary because the Jacobian is the matrix for links, not for nodes.) In
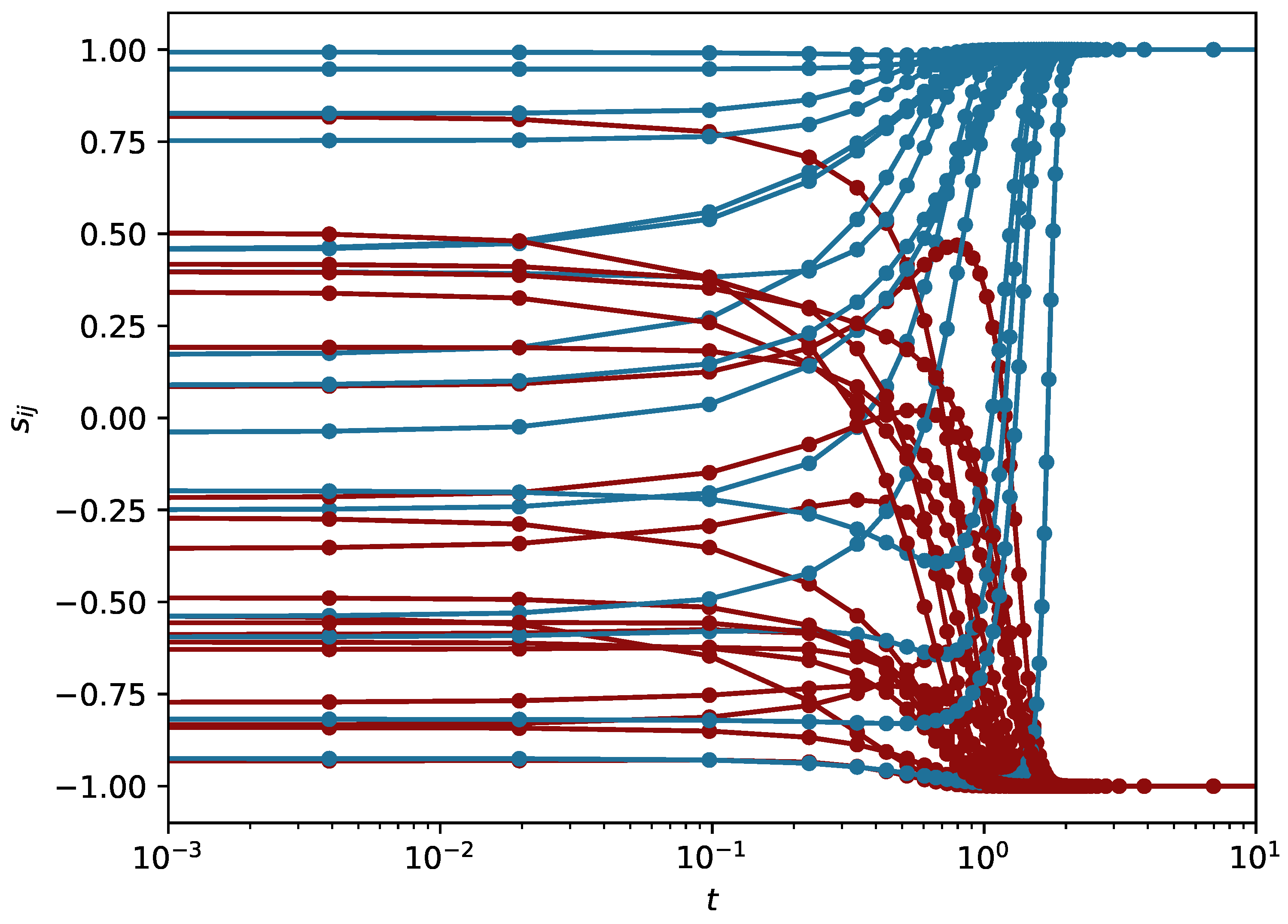
Figure 1, a set of trajectories is shown:
, for
. As we can see, the trajectories tend to values
. The stable sets of these values are the balanced states. We note that when time is reversed, the system is driven to states where all eigenvalues are positive, i.e.
. The number of such states is equal to the number of balanced states. In other words, the dynamics with reversed time and all links with reversed sign cannot be distinguished from the original dynamics.
The challenge is to drive an initial state of the system with randomly selected values of links to the balanced state, which is most close to this initial state. The distance
between states
and states
is measured as follows:
As the compared states are , this definition is equivalent to the Hamming distance, i.e., just the number of different matrix elements, normalized by the number L of links. Note that to calculate the distance, we take .
To identify the balanced configuration minimally distant from , we check all balanced configurations. This is feasible for N not larger than, say, 25. To construct the set, we prepare all possible chains of length N. For such a chain, the relation between nodes i and j in a balanced state is just the product of ws, i.e., . Ideally, the balanced state most close to the initial state is just the final state obtained by the best of the algorithms. In this case, the obtained value of the distance between the final state and the balanced state most close to the initial state is zero.
4. Results
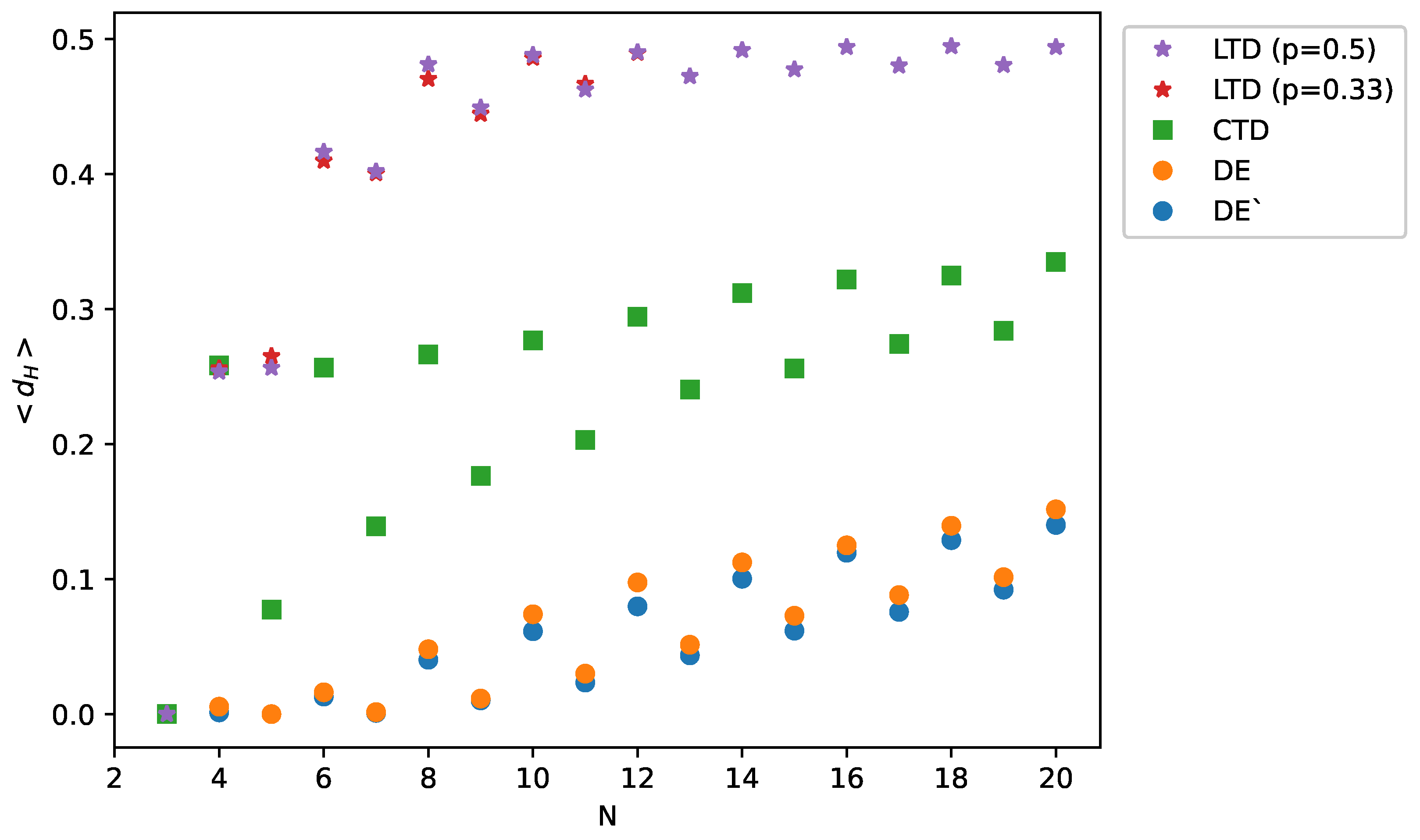
In
Figure 2, we show the data on the mean distance
between the final (balanced) state and this balanced state that is most close to the initial state, for all four algorithms: LTD, CTD, DE and DE’. To make these plots, we need to fix three parameters: the probability
p for LTD, the initial fraction of positive links, and
for DE. The initial fraction of positive links is set to be 0.5 to ensure maximal diversity of states. When this initial fraction is between 0.4 and 0.6, the results are approximately constant. The values of
are selected randomly from the uniform distribution between 0.1 and 0.3, separately for each link. Again, in this range of
, the results do not vary. The probability
p is set to be 0.3 or 0.5; above the value 0.5, all links are expected to be positive [
18]. For all algorithms, the results are averaged over 2000 initial configurations for each value of the number of nodes
N. The exception is LTD for
, the case that is particularly time consuming [
18], where the statistics is 1000.
The results presented in
Figure 2 indicate that the mean distance
between a final state and a balanced state most close to an initial state is shorter when the system is driven by the deterministic algorithms DE and DE’ than in the case of the algorithms LTD and CTD. In other words, DE and DE’ better reproduce the initial state of the system. We calculated also the probability that the final state obtained by each algorithm drives the system exactly to the state most near to the initial state. These results, shown in
Figure 2, allow to conclude that the initial state is better reproduced by the deterministic algorithms DE and DE’. The results can be interpreted as a consequence of the randomness of the Monte Carlo algorithms LTD and CTD. On the other hand, the dynamics of DE and DE’ reveal seemingly non-ordered behavior [
30,
32]—an example is shown in
Figure 1—and therefore, the above test is advisable. We also note that in most cases, the differences between the results of DE and DE’ are minimal.
If we treat the number
F of imbalanced triads as a work function, each balanced state is at a local minimum of
F with the same value
. To pass from one minimum to another is equivalent to shifting a node from one group to another, which means that all
links connecting this node to other nodes change their signs. Indeed, we observe that a minimal distance between the nearest-to-initial state and next-to-nearest state (not shown here) is
. On the other hand, the effectiveness of DE (and of any other algorithm) decreases with
N. This is observed in
Figure 2 and in particular in
Figure 3, where we see that the probability of reaching the distance zero between the final and closest-to-initial state decreases with the number of nodes
N. This is an indication that the boundaries in the
L-dimensional space of states between basins of attraction of particular balanced states are more complex for larger
N.
In
Figure 2 and
Figure 3, a systematic difference is observed in the performance of all algorithms between even and odd values of
N; for odd values, the system works better. The origin of this effect is that for even values of
N, the right side of Equation (
1) is sometimes close to zero. This effect slows down the evolution of some links and makes them more susceptible to be shifted to a local minimum of energy
U that is different from the original one. We note that for LTD, the distance
reaches 0.5 already for
, which means that the correlation between an initial and a final state vanishes.
Now we move to the results of the application of DE and DE’ to the data, described in
Section 3. The obtained balanced state most close to the matrix
in the sense of the minimal Hamming distance is equivalent to the following partition of the issues: “welfare spending” plus “religiosity” vs. all other issues. When using numbers as in the list of issues given above, the partition is 4,8 vs. 1,2,3,5,6,7,9. On the other hand, the evolution, started from the initial state
and driven by both DE and DE’, leads to the balanced state equivalent to the same partition: 4,8 vs. 1,2,3,5,6,7,9. This coincidence indicates that our deterministic algorithms properly identify the split between two groups of statements, collected in [
26]. We note that, as the matrix
is real and not integer, the difference between even and odd values of
N is less important.
5. Discussion
The advantage of the deterministic algorithms DE and DE’ over the Monte Carlo methods of having a more faithful reproduction of the initial state allows to expect that they could also be successful in a reproduction of a state that is initially balanced and then subject to a noise. This application adds the differential equations DE and DE’ to the list of methods of identification of communities [
33], with the specific condition that the number of communities is not larger than two. This condition is a consequence of the duality “friendly–hostile”, imposed by the sociological aspect of the problem. Up to our knowledge, our extension of the method to communities of statements is original.
The partition “welfare spending” plus “religiosity” vs. all other issues, obtained from DE and DE’, is not accidental. It is consistent with the unfulfilled need of safety, which is basic in the hierarchy of needs [
34]. It is also supplementary to the comfort hypothesis, which states that “Parishioners whose life situations most deprive them of satisfaction and fulfillment in the secular society turn to the church for comfort and substitute rewards” (Ref. [
35]; see also [
36] pp. 107–108). The obtained partition indicates that anticipation of reward in heaven does not exclude the expectation of help from Earthly institutions.
The applicability of the deterministic algorithms DE and DE’ to the data reported in [
26] indicates that the concept of Heider balance, usually applied to interpersonal relations, can be extended to sets of opinions, gathered in social surveys. We note that the correlations between answers to particular issues are not mutually bound with any logical relations, imposed by the construction of a survey. Therefore, the method of active data handling, described above, can be useful to identify types of collective opinions and beliefs, which are characteristic for a given society [
37,
38].





{kind=link}
{kind=link}
{kind=link}