1. Introduction
Natural Language Processing (NLP) has achieved great progress in these years, including text classification [
1,
2,
3,
4], text generation [
5,
6,
7,
8,
9,
10], and sentiment analysis [
11,
12,
13]. At the same time, deep recurrent belief [
14] and capsule networks [
15,
16,
17] also have new challenges in the field of NLP.
Deep neural networks [
18] have achieved great success in the so-called neural generation of text [
5,
6,
7,
8,
9,
10]. In the field of text generation, the most common is the sequence-to-sequence(seq2seq) model [
19], which consists of an encoder and a decoder. The encoder encodes the text into a fixed vector, and the decoder decodes the corresponding text according to this vector. However, since the encoder in seq2seq encodes the text into a fixed vector, the text generated by the decoder is too monotonous and cannot generate diverse text. The Variational AutoEncoder (VAE) [
20,
21] randomly samples the encoded representation vector from the hidden space, and the decoder can generate real and novel text based on the latent variables. VAE provides a tractable method to train generative models of latent variables. In NLP, latent variables may represent higher-level meanings of sentences, such as semantics or topics. These latent variables control the generation of text [
22]. Compared with the traditional seq2seq model, the latent variables in the VAE are considered to make the model more powerful.
In Natural Language Generation, Long Short Term Memory networks (LSTM) [
23] and Transformer structures [
24] are mostly used in the text generation field. The Transformer completely uses the attention mechanism. There are many Transformer-based models, including Bert [
25], UniLM [
26], BART [
27], T5 [
28], and GPT-2 [
8]. Most VAEs use the LSTM structure for text generation [
22,
29,
30,
31], and very few VAEs use the Transformer structure [
32,
33,
34].
At present, VAE is mainly used to generate short text (less than 20 words or one sentence) in text generation, and few people pay attention to the generation of long text. For long texts, words are often composed of sentences, and sentences are composed of text. Each sentence may contain different semantics and other latent variables information, and the latent variables of each sentence may also have a progressive relationship. However, few people focused on it. Therefore, in order to improve long text generation, we proposed a new method for combining the Transformer-Based Hierarchical Variational AutoEncoder and Hidden Markov Model (HT-HVAE) to learn multiple hierarchical latent variables and their relationships.
Humans think about their purpose before writing, which is the meaning of this article. After that, an individual will write by progressing from sentence to sentence. The act of writing these sentences needs to meet the writing purpose, and the previous sentence simultaneously determines the generation of the following sentence. However, the purpose of writing is not observable. For example, when reading a long text, we can only know the author’s writing purpose if we read the entire text. In addition, each sentence in the text has its own semantics or topics. These are also latent variables, but these latent variables, such as semantics or topics, cannot exist without the purpose of writing. It is these latent variables that control the generation of the entire long text. We call the latent variables that control the generation of all sentences similar to the purpose of writing as global latent variables, and the latent variables that specifically control the generation of each sentence (such as semantics or topics) are called local latent variables. In addition, the current local latent variables are also related to the previous local latent variables (for example, semantic conversion, etc.).
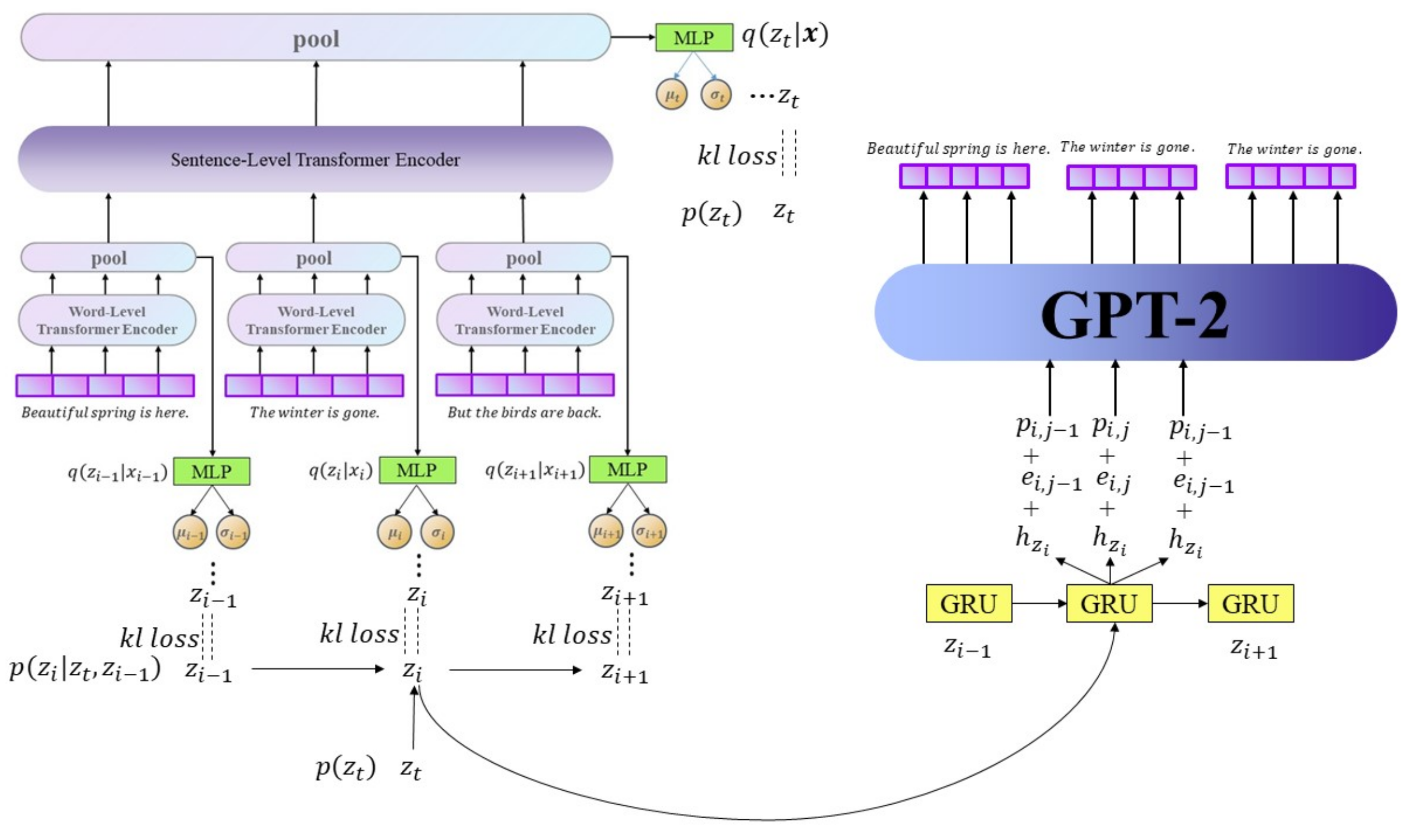
We used a Hierarchical Transformer to encode long text for the encoder of HT-HVAE. We used a word-level Transformer to encode every sentence (we denoted it as sentence-code). All sentence-code passes sentence-level transformers to acquire text representations (we denote the represent as text-code). The sentence-code will be used to learn local latent variables and text-code to learn global latent variables. The decoder also applies hierarchical structure, which combines Gated Recurrent Unit (GRU) [
35] with GPT-2, to reconstruct texts. The input of GRU includes local latent variables, and we denote GRU’s output as plan-vectors. The plan-vector will be copied in n copies, where n is the length of the sentence as the input of GPT-2 to generate the sentence.
We always maximize Evidence Lower Bound (ELBO) in the training process of VAE. Thus, we can use ELBO to approximately calculate the perplexity (PPL) of the language model. However, ELBO always makes the calculated PPL inaccurate. The Importance Weighted AutoEncoder (IWAE) [
36] proposed a method that PPL can calculate a single latent variable as accurately as possible. Many researchers used this method to calculate PPL as accurately as possible [
33]. However, this method is mainly for single latent variables, and HT-HVAE has multiple latent variables. We adopted the idea of IWAE and expanded the method of accurately calculating PPL in the case of multi-level latent variables.
In summary, our work mainly explores the following:
In order to further generate real long texts, we propose a new model that combines VAE, HMM, and hierarchical structure to learn one global latent variable and multiple local latent variables.
The global latent variables (from the entire text) learned by our method control the local latent variables (from each sentence), and the local latent variables at the sentence level also have dependencies. Moreover, this is similar to the way humans write.
According to IWAE, we extend this method for the hierarchical latent variable in order to obtain a more accurate PPL.
Experiments prove that our model alleviates the notorious posterior collapse problem in VAE.
The topic in the first section is the Introduction. The following sections are structured as follows:
Section 2 introduces related work,
Section 3 introduces background knowledge,
Section 4 introduces the methods we use,
Section 5 introduces experimental results, and
Section 6 is the conclusion.
2. Related Work
VAE has made significant progress in text generation [
22,
30,
32,
33,
34,
37,
38,
39,
40,
41,
42,
43]. In this reference [
22], researchers used VAE for text generation for the first time. Researchers proved that learning higher-level text representations (such as semantics or topics) is possible through LSTM-based latent variables generative models, and these higher-level representations control text generation. Due to the sampling process of latent variables, the diversity of the generated text is better. [
44].
However, most of VAE’s work focuses on the generation of short texts (mostly one sentence), and few people use VAE to generate long texts. Shen et al. [
29] proposes a new hierarchical structure named hVAE to learn a generative model of two-layer latent variables to generate long text: the global latent variables of the entire text and the local latent variables at the sentence level. However, hVAE still has some problems: (1) There is only one sentence-level local latent variable, and it does not learn the local latent variables of each sentence. (2) It does not explore the dependency relationship between sentence-level local latent variables, for example, semantic transformation. (3) Its framework does not deviate from the LSTM structure.
Recently, the Transformer has achieved great success in the field of NLP and has surpassed LSTM, and the most famous one in text generation is GPT-2. However, the attention mechanism of GPT-2 only pays attention to the relationship between words and does not pay attention to the relationship between sentences. In addition, few people combine GPT-2 or Transformer and VAE. Liu et al. [
32] combined Transformer and VAE for text generation for the first time; Wang et al. [
34] used Transformer and CVAE for story complement tasks; Li et al. [
33] used Bert as the encoder for VAE, and GPT-2 is used as a VAE decoder to train a large pretraining model to solve various tasks of natural language processing. However, Optimus [
33] only uses the standard VAE method; that is, it only learns one hidden variable. Therefore, its application scenario is still short text, which is not suitable for long text generation. In addition, even though Optimus provides latent variable information in the decoder part, it still fails to make GPT-2 pay attention to the connection between the latent variables at the sentence level.
By considering the shortcomings of hVAE, GPT-2, and Optimus, we proposed HT-HVAE to learn a global latent variable (from the entire text) and multiple local latent variables (from each sentence). Furthermore, we propose it to learn the dependence between global latent variables and local latent variables and the connection between local latent variables. In addition, in the decoder part, we input local latent variables into GPT-2 so that GPT-2 pays attention to the relationship between words and the relationship between sentence-level latent variables.
However, text VAE also has a notorious posterior collapse problem. In recent years, several methods have been working to alleviate this problem, including different Kullback–Leibler (KL) annealing/thresholding schemes [
22,
45,
46,
47], decoder architectures [
38,
48], auxiliary loss [
44], semi amortized inference [
41], aggressive encoder training schedule [
49], and flexible posterior [
50]. However, none of them help to improve the perplexity compared to a plain neural language model. In this article, because the local latent variable sent to the decoder not only contains the information of the global latent variable but also contains the information of the previous local latent variable, it makes the prior distribution function of the local latent variable more flexible. Therefore, the decoder contains more local latent variable information, which alleviates the problem of posterior collapse.
3. Background
3.1. VAE
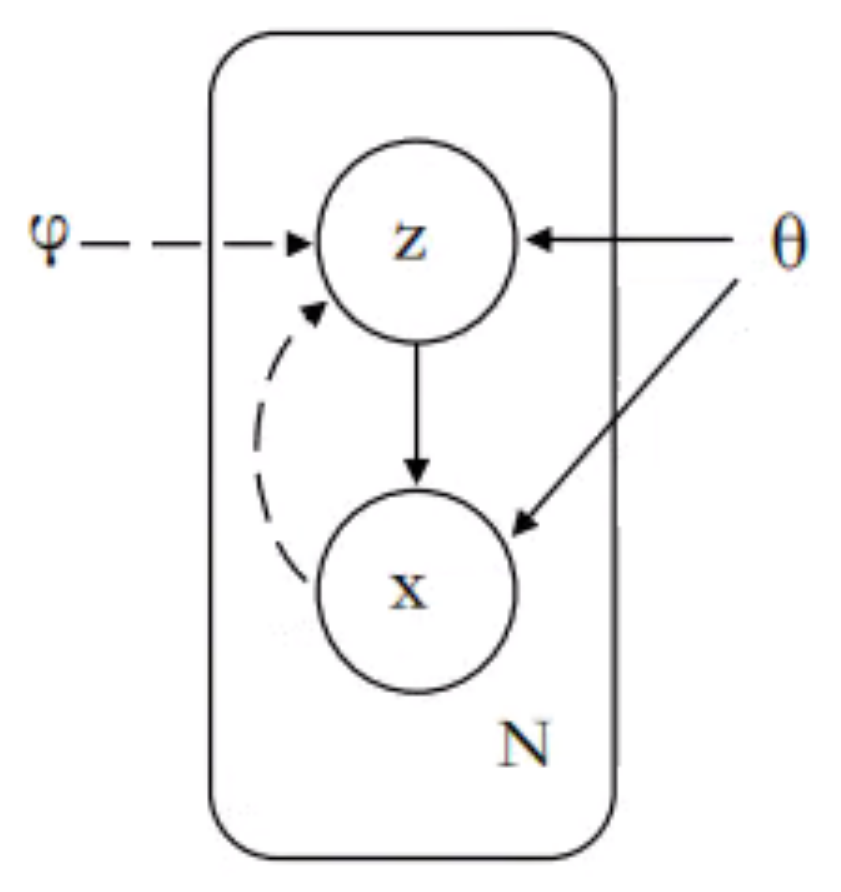
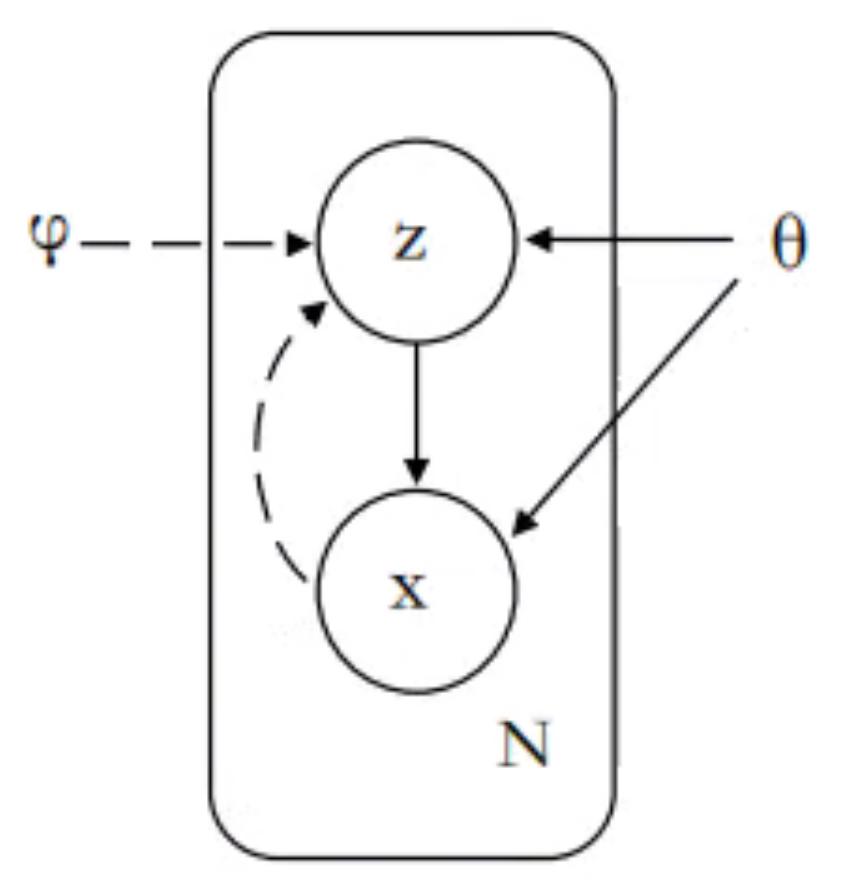
As shown in
Figure 1, VAE mainly includes inference networks and generative networks. In NLP, the inference network mainly represents sentences as low-dimensional latent variables, and the generative network uses this latent variable to generate sentences. In fact, VAE can be regarded as a regularized version of the AutoEncoder (AE) [
18], but the low dimension of the sentence is not a fixed code, unlike AE, and is sampled from a probability distribution.
Suppose
x is the observable data obtained by sampling, such as a sentence, and
z is a low-dimensional latent variable, such as semantics or topics. The joint probability density function of this generative model can be decomposed into the following.
is the prior distribution of the latent variable z, is the conditional probability distribution of x when z is known, and is the parameter of the two probability distributions. We assume that and are a known distribution family, such as a normal distribution. In VAE, we used two neural networks to fit these two distribution families separately. In fact, we assume the standard normal distribution of and use a network to learn the probability distribution . This network is called the generative network, also called decoder, and its input is a latent variable z while the output is the observable variable x.
The purpose of the inference network is to learn the probability distribution , which is used to approximate the true posterior distribution . The input of the inference network is x, and the output is the probability distribution . Similarly, we assume that is Gaussian distribution.
It has been proved in [
20] that the objective function of VAE is
, which is composed of the reconstruction term and the KL divergency.
The first term in is called the reconstruction loss, which is the same as the AE, and the second term is KL loss, which can be regarded as a regularized item. The KL loss forces the distribution of the hidden variable z to approximate as much as possible and to sample from it in order to generate real text.
When VAE is used in the field of text generation, most of the inference network and the generative network utilize the LSTM structure. Due to the strong decoding ability of LSTM, x can be generated without z during the generation process, so the notorious “posterior collapse” problem will occur. In HT-HVAE, we use Transformer as the inference network and the generative network. For single-layer latent variables, the problem of posterior collapse will also occur. However, we have learned two layers of latent variables, namely the global latent variable of the entire text and the local latent variable of each sentence.
Moreover, for each sentence, the prior latent variables are related to prior hidden variables of the previous sentence. The prior distribution of is no longer a simple standard diagonal Gaussian distribution, rendering the local latent variable more important when decoding. Experiments show that HT-HVAE alleviates the problem of posterior collapse.
3.2. Transformer
The Transformer [
24] is a new sequence-to-sequence model, different from Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), and it only relies on the attention mechanism. Since its inception, Transformer has achieved great success in many areas of natural languages, such as machine translation and other natural language understanding tasks.
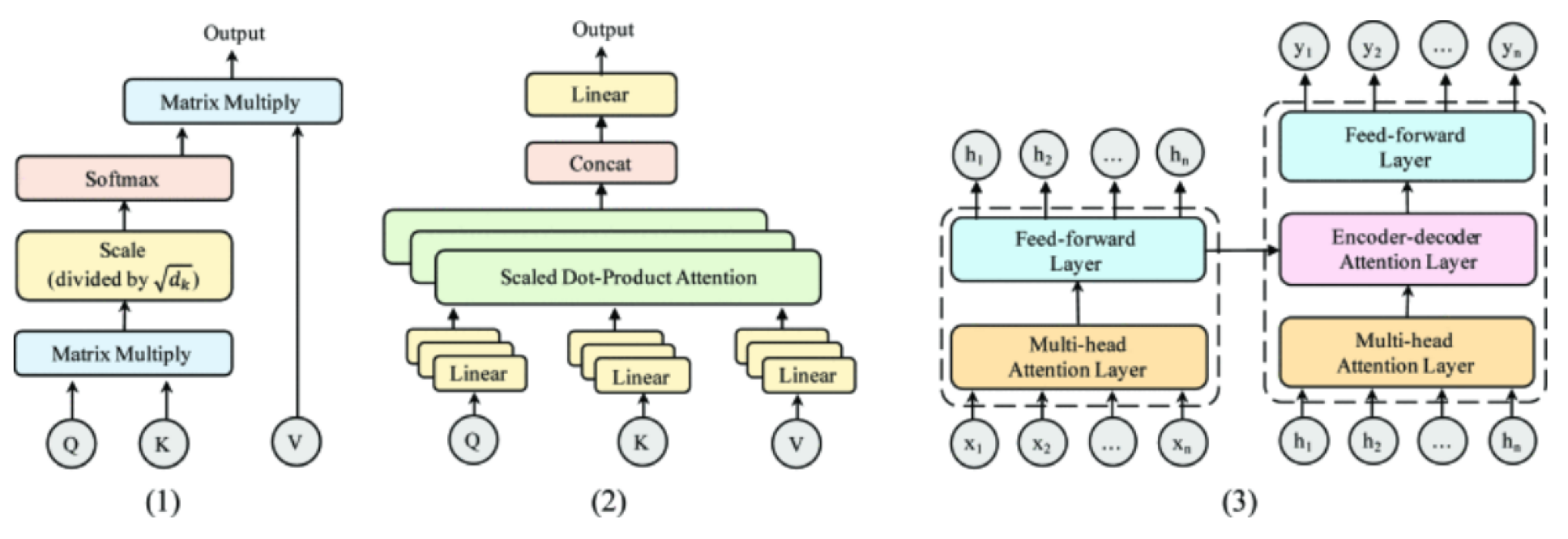
The multi-head self-attention mechanism is the core of the Transformer. It mainly consists of two parts: Scaled Dot-Product Attention and Multi-Head Attention. Generally speaking, the point of Scaled Dot-Product Attention is to map a query and a key-value into an output, as shown in (1) of
Figure 2. This output is the weighted sum of key values, and its weight is calculated from the similarity between query and key. In the self-attention mechanism, the similarity between query and key is scaled dot-product. Its form is as follows.
Q, K, and V are very common in the attention mechanism. They represent Query vector, Key vector, and Value vector, respectively, and they are all learnable parameters. By using this method, Transformer can learn the distribution of attention between words. Moreover, in order to retain a smaller inner product of Q and K, it is usually divided by the dimension of K.
In addition, Transformer uses a method called multi-head self-attention mechanism, shown in the (2) of
Figure 2. First, different linear functions are used to divide
Q,
K, and
V into different h parts. Each part’s self-attention score is then calculated, and these h parts are then concatenated through the linear function as the final output:
where the matrices
,
, and
represent the corresponding linear projections.
(3) In
Figure 2, the entire structure of the Transformer is presented: The left one is the encoder, and the right one is the decoder. In particular, the Transformer’s encoder consists of a multi-head self-attention layer and a feed-forward fully connected layer. Such modules have
N layers in total, and each layer’s module accepts the output of the previous layer as the input of the layer. The encoder’s function is to encode the input
x into H and then to send
H to the decoder.
The decoder is similar to the encoder. The only difference is that an encoder–decoder multi-head self-attention layer is added. An encoder–decoder attention layer is directly added to the multi-head attention layer and the feed-forward fully connected layer. There are also N such modules. The encoder–decoder multi-head self-attention layer’s query is the output of the previous decoder layer, and the key and value come from the output of the encoder.
3.3. HMM
The Hidden Markov Model (HMM) is a relatively classic machine learning model. It is widely used in language recognition, natural language processing, pattern recognition, and other fields.
Of course, with the current rise of deep learning, especially the popularity of neural network sequence models such as RNN and LSTM, the status of HMM has declined.
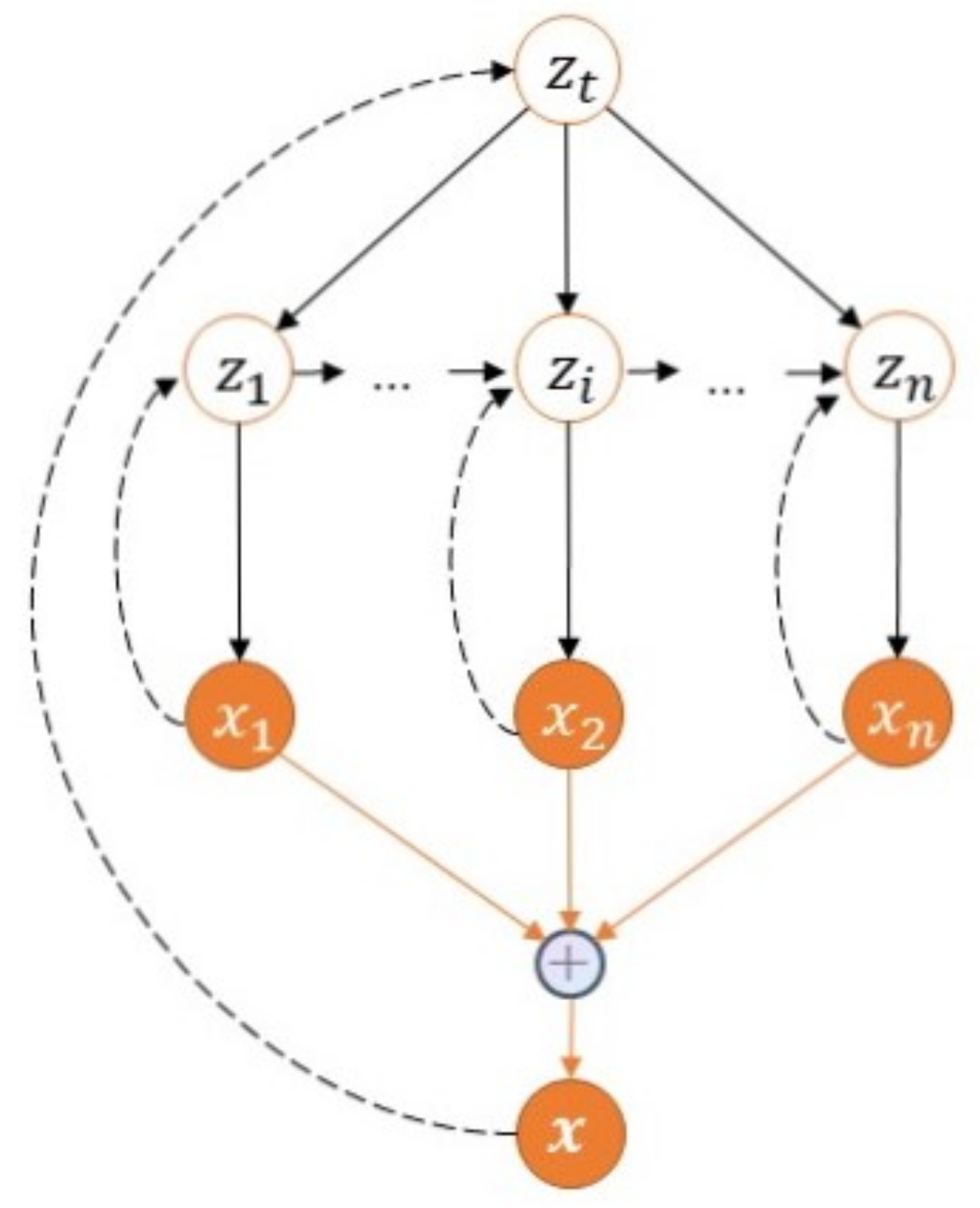
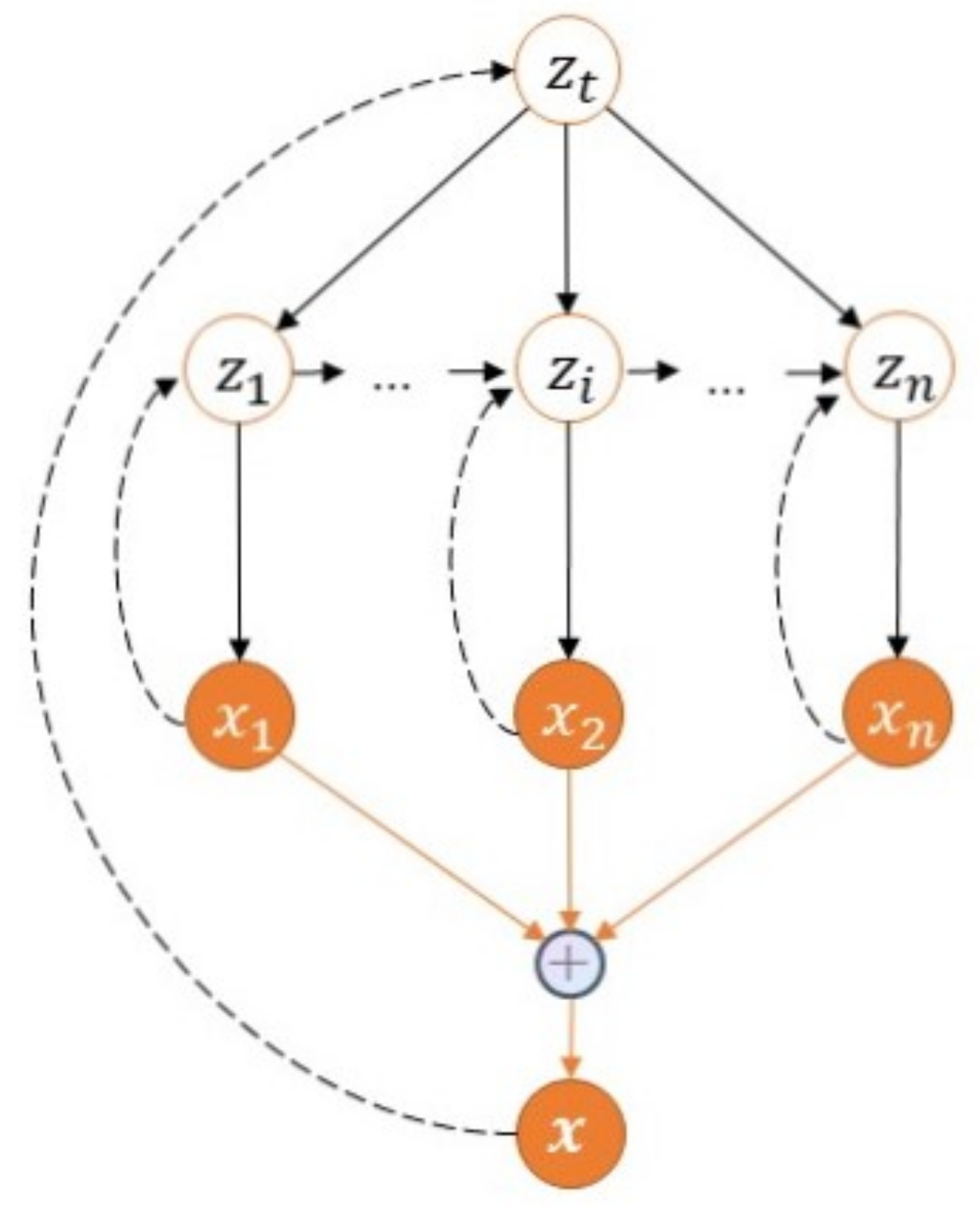
Figure 3 shows the probability graph model of HMM, where
…
represents an observable variable and
…
represents a hidden variable. The latent variables form a Markov chain, and each observable variable
depends on the current latent variable
, and its joint probability distribution is the following.
and , respectively, represent observable variables and hidden variables, represents the output probability, represents the transition probability, and and represent the parameters of both.
5. Experiment
Our experiment mainly includes unconditional long text generation and conditional long text generation. For unconditional text generation, we used the Arxiv paper abstract dataset and Yelp comment dataset; for conditional generation, we used the Arxiv paper abstract dataset. For the evaluation of the model, we mainly evaluated the language model and the generated text. Since our paper mainly studies VAE for the generation of long texts, we only consider similar models. We use hVAE [
29], GPT-2 [
8], and OPTIMUS [
33] as the benchmarks for language models; for the evaluation of generated text, we use ARAE [
51], hVAE, GPT-2, and OPTIMUS as benchmarks.
5.1. Dataset
We used the Arxiv paper abstract dataset and Yelp review dataset to verify the effectiveness of our model. Arxiv paper abstracts are more logical, while Yelp comments are not as logical as Arxiv paper abstracts.
We have performed some processing on the two datasets as we are concerned about the generation of long text: (1) First, use the GPT2 Tokinzer to segment each data text, calculate the number of characters, and select the number of characters between 150 and 300. The average number of characters in the long text is about 200 (much greater than the number of characters in hVAE and Optimus). (2) Use nltk to segment the text for the selected original text data and insert ’<BOS>’ at the beginning of the first sentence, insert ’<EOS>’ at the end of each sentence, and insert ’<|endoftext|>’ at the end of the last sentence. These inserted characters are not used during encoding and are instead used in the decoding stage. (3) We selected 20 million data texts as the training set and 30,000 texts as the test set. From
Table 1, we can observe the specific information of the dataset. Both datasets are divided into a training set of 200,000 long text data and a test set of 30,000 long text data. At the same time, the average number of words in Arxiv is 211, the average number of characters in Yelp is 206, and the average number of sentences in the two datasets is 6.
5.2. Language Model
hVAE: The encoder uses hierarchical CNN encoding, and the decoder uses a hierarchical LSTM network to learn two layers of hidden variables, but there is only one local hidden variable.
GPT-2: Composed of Transformer decoder, we use a model containing 117M parameters here.
OPTIMUS: The encoder is composed of Bert, and the decoder is composed of GPT-2.
This section mainly compares PPL and KL on the Arxiv dataset and Yelp dataset.
When evaluating the language model, we randomly selected 3000 pieces of data from the test set and chose their average PPL and KL as the final result.
However, in the VAE training process, the optimization function we chose was ELBO, which is less than or equal to
, and
cannot be completely obtained. Therefore, PPL can only be approximated in VAE. Here, we used the IWAE method to solve OPTIMUS
as accurately as possible and drew on the idea of IWAE in order to derive a method to solve the PPL of HT-HVAE with two layers of latent variables as accurately as possible:
where
. According to IWAE,
converges to
as k →
∞. We need to decompose
and
to obtain PPL.
, where and are independent of each other, then and can be sampled in and .
We can observe from
Table 2 that the PPL of HT-HVAE is three points lower than that of OPTIMUS, and KL divergence is also improved. If we delete HMM from our model, we will find that the KL divergence is lower than the model with HMM, and PPL is not as good. This shows that our model is better than OPTIMUS in the long text language model, which also proves that our previous assumptions are correct. That is, the latent variable information obtained from the long text as a whole cannot contain the latent variable information of each sentence, and there is a relationship between the hidden variables of each sentence. Similarly to people writing articles, there is always an outline first, and then sentences are written with one sentence after another. Finally, a long text is formed. In our model,
plays the role of outline,
is the latent variable that generates each sentence, and the relationship between sentences is expressed by HMM, which is similar to people’s writing habits.
We calculate the NLL loss of GPT-2, OPTIMUS, HT-VAE, and HT-HVAE on two datasets in order to further illustrate the effectiveness of HMM in decoding. It can be observed from
Table 3 that the NLL loss of the HT-HVAE model is lower than that of other Transformer types, which shows that adding HMM is helpful for language modeling. In particular, it works better on the more logical Arxiv paper abstract data set.
5.3. Evaluation of the Generated Text
We used BLEU [
52] to evaluate the quality of the generated text and self-BLEU to evaluate the diversity of the generated text. BLEU was proposed by IBM in 2002 for the evaluation of machine translation tasks. Its overall idea is accuracy. If a reference is given, the sentence generated by the neural network is a candidate, the sentence length is n, and m words in the candidate appear in the reference. We used this method to generate 1000 sentences as candidates and used all test set data (30,000 items) as references to calculate BLEU-2, BLEU-3, and BLEU-4, respectively.
It can be observed from
Table 4 that our model surpassed the original model in B-2, B-3, and B-4 scores, reaching the state of art. This shows that our model can produce better quality text. We found that in a dataset with strong logic, the BLEU score with HMM is better than the score without HMM; on the contrary, the results of the two are similar.
We use self-BLEU [
53] to evaluate the diversity of the generated text. The lower self-BLEU is, the better text diversity is. Similarly, we randomly generated 1000 yelp comments in order to evaluate the diversity of the text. It can be observed from
Table 5 that our model may not be the best at the B-2 level but surpassed the previous model at the B-3 and B-4 levels. This shows that our model generates better text diversity.
The effect of our model on the yelp dataset is not much different from the baseline model, but it performs better on the Arxiv paper abstract dataset. A possible reason for this is that the corpus of Arxiv paper abstracts is richer than the Yelp dataset, and the abstract is written carefully and logically, so it is more in line with the ideas of our model. In contrast, the corpus of the Yelp comment dataset is not very rich, and the logic is definitely not as good as the Arxiv paper abstract, so our model is not much improved compared to the baseline model. The reason why our model generates better corpus diversity is due to the fact that the hidden variables that control the generation of each sentence are constantly changing, unlike other baseline models that do not change.
5.4. Interpolating Latent Space
According to reference [
22], we measured the continuity of the learned latent variable space. First, we randomly sampled two points (denoted as
and
) from the space of the prior hidden variable
, and then we sent them to the decoder to generate text based on the equidistant intermediate points along the linear trajectory between
and
, that is, the hidden variable input into the decoder is
. As shown in
Table 6, these intermediate samples are all realistic looking reviews that are syntactically and semantically reasonable, demonstrating the smoothness of the learned VAE latent space.
5.5. Conditional Text Generation
We used the Arxiv paper abstract dataset in order to achieve controllable text generation. While encoding each word, the title of the paper is also encoded but not sent to the sentence-level encoder. At the same time, we also changed the prior probability of
, and it is no longer the standard Gaussian distribution but the Gaussian distribution determined by the title code
c. In the generation stage, the word of the title will also be added before ‘<BOS>’, but this part of the title will not add hidden variables unlike the sentence of the text; that is, this part of the hidden variable is zero. Given the title, the generated text is shown in
Table 7.
6. Conclusions
In this paper, we propose a new method combining VAE+HMM+Hierarchical Transformers to generate better long texts. Unlike traditional VAE, our model learns more than one hidden variable including the global hidden variable and multiple local hidden variables. In addition, the global hidden variable and the previous local hidden variable control the current local hidden variable. Another advantage of our model is that the VAE and Transformer are further combined, and each local latent variable is sent to the decoder GPT-2 so that GPT-2 notices the connection between the local latent variables at the sentence level. This is similar to human writing habits. Experimental results prove that our model generates high-quality long texts.
However, our method still has some shortcomings. We only proposed that there are some connections between the global hidden variables and local hidden variables of the long text, which is also proved by the comparison experiment results. However, we did not conduct a quantitative analysis of the relationship between this hidden variable and analyze the strength of the relationship between them. The question of how to quantitatively analyze the relationship between such hidden variables is a difficult one to answer. This is exactly what we aim to study next.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}