Abstract
In this paper, variational sparse Bayesian learning is utilized to estimate the multipath parameters for wireless channels. Due to its flexibility to fit any probability density function (PDF), the Gaussian mixture model (GMM) is introduced to represent the complicated fading phenomena in various communication scenarios. First, the expectation-maximization (EM) algorithm is applied to the parameter initialization. Then, the variational update scheme is proposed and implemented for the channel parameters’ posterior PDF approximation. Finally, in order to prevent the derived channel model from overfitting, an effective pruning criterion is designed to eliminate the virtual multipath components. The numerical results show that the proposed method outperforms the variational Bayesian scheme with Gaussian prior in terms of root mean squared error (RMSE) and selection accuracy of model order.
1. Introduction
Channel modeling plays a pivotal role in the design and evaluation of wireless communication networks. In the fifth-generation (5G) mobile communication systems, the diversity of the communication scenarios leads to the urgent need for advanced channel modeling techniques with higher accuracy and lower implementation complexity. In the existing channel measurement campaigns, the channel sounding technique based on pseudo-random (PN) sequences has widely been adopted due to its higher processing gain and delay resolution. As for the estimation of the multipath characteristics such as power delay profile, Doppler power spectrum, and frequency response from the obtained channel responses, super-resolution algorithms such as space-alternating generalized expectation-maximization (SAGE) [1] and subtractive deconvolution technique (CLEAN algorithm) [2] are widely applied. However, since the SAGE and CLEAN algorithms are based on the maximum likelihood criterion, the selection of model order, i.e., the number of multipath, is a nontrivial task. The estimated order of the channel model tends to be overestimated because of the contamination of noise. The unnecessary “virtual paths” will not only affect the accuracy of the channel coefficients estimation but also increase the computational cost of the algorithm. To solve this problem, different techniques such as negative log-evidence (NLE) [3] and Bayesian information criterion (BIC) [4] have been proposed to estimate the model order. However, the estimation performance of these model estimation schemes is far from ideal, especially when considering the low signal-to-noise ratio scenarios [5]. Since considerable computation is needed to find the optimal model order value, the existing techniques also suffer from prohibitive complexity.
Due to the fact that the multipath components (MPC) are sparse in channel impulse responses (CIR) [6], the joint estimation problem of channel parameters and channel model order can be addressed by sparse Bayesian learning (SBL). SBL is a typical machine learning algorithm that was first proposed by Tipping in 2001 [7] and has been developed into an important branch of compressed sensing reconstruction algorithms. The basic idea of SBL is to introduce the sparsity parameter to establish a hierarchical Bayesian model. By defining the priors on the sparse vector, SBL can automatically determine the position and amount of the non-zero elements in the reconstructed signal without pre-specifying the sparsity number. SBL is a promising method for the joint estimation of channel model order and the channel response coefficients. However, even after the hierarchical Bayesian model is established, the posterior PDF cannot be directly derived due to an intractable integral of the joint probability density. Thus, the variational inference is introduced to obtain an approximation of the parameter posterior in the SBL framework. This method, also known as variational sparse Bayesian learning (VSBL) [8], has been widely applied in online spectrum estimation [9], orthogonal time-frequency space (OTFS) detector [10], multi-user joint decoding [11], joint signal detection [12], and high-resolution radar imaging [13], etc. For channel parameter estimation, the idea of complete hidden data is introduced to speed up the convergence in [5]. The simulation result shows that the VSBL scheme outperforms the BIC criterion in both root mean squared error (RMSE) and model order selection. In [14], the delay of MPCs is modeled as the Poisson distribution, which incorporates the Fast VSBL based channel estimation as a priori information and significantly improves the bit error ratio (BER) performance.
Several channel measurement campaigns conducted in high-speed railways [15], airport grounds [16,17], and inland rivers [18] have shown that Weibull and Nakagami-m distributions are more suitable for modeling channel characteristics compared with Rayleigh and Rice distribution. This phenomenon originates from the uneven distribution of scatterers in the mobile communication environment. However, in most VSBL models, the channel taps were assumed to be Gaussian distributed [19,20], which is not appropriate for parameter learning. In this paper, the Gaussian mixture model (GMM) is adopted to describe the statistical characteristics of the MPCs. A GMM is linearly composed of Gaussian PDFs with corresponding means and covariances. By using sufficient Gaussian components, the GMM can be flexible to approximate any given PDF [21], which is suitable for establishing various fading channels models.
The contributions of this paper are summarized as follows:
- The Gaussian mixture model as a powerful method for sparse parameter learning for wireless channels is introduced to the estimation problem of wireless channel parameters under the VSBL framework. The flexibility of GMM is capable of describing the statistical characteristics of both theoretical general channels and complex real-world channels.
- A new variational Bayesian inference scheme for the Gaussian mixture model (VB-GMM) is developed based on multiple channel observations. The corresponding graphical model is given, and the closed-form updates of the model variables are derived. By setting a pruning criterion on the sparsity priors, the joint estimation of channel parameters and model order is achieved with low complexity.
- The simulation results demonstrate that the performance of VB-GMM is superior to the existing algorithms in terms of the estimation error, the convergence rate, and the model order selection accuracy in most non-Gaussian channels.
Throughout the paper, we use the following notations. and denote the Hermitian transpose and the inverse of matrices, respectively. The expression represents the multivariate complex Gaussian distribution with mean vector and covariance matrix . denotes the Gamma distribution in which , and represent shape parameter, scale parameter and Gamma function, respectively. We use calligraphic uppercase letters to represent sets, e.g., denotes the index set of MPCs and is the complement set of . The remainder of the paper is organized as follows. In Section 2, the signal model is introduced, and the graphical model of VB-GMM is presented. In Section 3, the derivations of the VB-GMM estimators are given followed by the initialization algorithm and the pruning criterion. Finally, in Section 4, the numerical results are presented to demonstrate the effectiveness of the proposed scheme.
2. System Model
2.1. Signal Model
Consider a single-input-single-output (SISO) wireless channel measurement system, the sounding signal is denoted as , in which the pseudo-random sequence has chips and the shaped pulse has the duration . Assume that copies of are transmitted periodically to obtain the time-varying channel responses. After passing through the multipath channel, the signal at the receiver is made of duplications of with additive Gaussian white noise , and the received signal corresponding to the n-th can be expressed as
where is the complex coefficient of the -th multipath and denotes the dispersion parameter vector including multipath delay, DoA, DoD, etc. We define as the discrete samples of the n-th received signal in which is the sampling interval at the receiver and represents the number of discrete samples, i.e., . The discrete vector is considered as an observation of the measured channel. In our proposed scheme, an Bayesian probabilistic model is established to infer the posterior probabilities of the channel parameters based on multiple observations.
Since the proposed algorithm is developed based on time-varying channels, it is crucial to determine the wide-sense stationary (WSS) region in which the statistical characteristics of channel parameters are assumed invariant. For vehicle-to-vehicle channel, the spatial distance of 20~40 times the wavelength is considered to be WSS [22]. For convenience, we denote the multiple observation matrix as , where represents the number of channel responses obtained in a WSS region. If the spatial distance of the WSS is chosen properly according to the criterion, the dispersion parameter vector is assumed to be constant for the observations, i.e., . Thus Equation (1) can be rewritten in a discrete form as:
in which is the Gaussian white noise vector.
In the SAGE algorithm, the complete parameter set is divided into several subsets so that the joint estimation for is decomposed into optimizations for in a sequential manner. Let denote the admissible hidden data with respect to , when the equation is satisfied, the likelihood corresponding to the estimation monotonically increases and may converge to the local maximum [23]. In this paper, the concept of admissible hidden data is also adopted. Consider an MPC we have
in which represents the noise that the l-th MPC contribute to the total noise with , , and the likelihood . Then the covariance of the noise that is not related to the -th component is , which can also affect the estimation of when observations are obtained and fixed. The noise covariance has a significant impact on the estimation results of channel parameters. Since the length of the channel sounding frame is generally much longer than the channel delay spread, most of the channel response samples are considered to be measurement noise. In this paper, the noise covariance is computed by the tail of CIRs.
2.2. The GMM Model of Channel Coefficients
Denote the channel coefficients of the -th multipath as . Assume that obeys the Gaussian mixture distribution with components:
where is defined as mixing coefficients. and represent the complex mean and covariance matrix of the -th Gaussian distribution, respectively. For , each sample can only be derived from one component of the Gaussian mixture distribution. Therefore, the discrete hidden variable is introduced. is a 0–1 matrix in which means the channel coefficient corresponds to the -th Gaussian component. Given the mixing coefficients, the probability of hidden variables takes a product form:
For the variable a Dirichlet distribution prior is applied:
where , and is assumed non-informative, i.e., . The Dirichlet distribution is introduced here as the conjugate prior of the polynomial likelihood function , which means the posterior of has the same form of Dirichlet distribution. In variational inference, the application of conjugate priors makes it convenient to merely update the parameters of the density functions with their form unchanged.
The graphical model for the variational Bayesian-based GMM is presented in Figure 1. Denote the parameter set as the joint probability density can be rewritten according to the structure of the graph:
in which
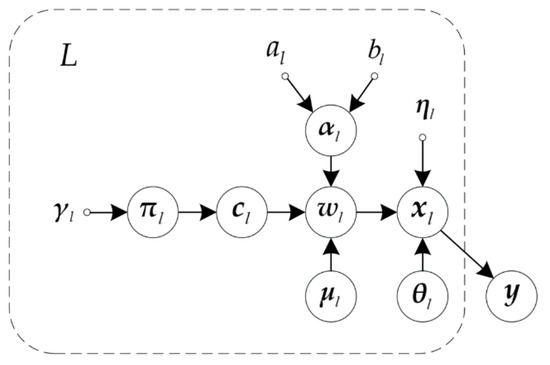
Figure 1.
Graphical Model for VB-GMM algorithm.
The sparsity prior of -th path is a key to restrain the gain of MPCs and implement model order selection. The sparsity prior is usually chosen as Laplace [24] or Gaussian distributed [7]. The Laplace prior leads to a -type sparsity and Gaussian prior a -type sparsity [5]. In the proposed scheme each component of the GMM is specified with an independent Gaussian sparsity prior, i.e., . Thus consider all the observations for the -th path, we define
The nonnegative sparsity parameter is inversely proportional to the width of the Gaussian function. Consider a situation that , the Gaussian function will be concentrated at the mean value , which renders the MAP estimations of channel coefficients to be constant. Due to the time-varying nature of wireless channels, the channel coefficients cannot be a constant value over time, unless they are concentrated at the value of zero, i.e., the -th MPC is considered to be the measurement noise and should be removed. By setting a large threshold for , the irrelevant MPCs are pruned and the sparsity is obtained. The prior of the sparsity parameter is set to be a Gamma distribution with a non-informative hyperprior for all branches, i.e., , . Such choice is proper when no prior information is available, and it has been widely applied in various Bayesian hierarchical models, e.g., [5,7,8].
3. GMM-Based Variational Bayesian Learning
In this section, the VSBL is applied to the estimation problem of the Gaussian mixture channel model. First, the basic principle of variational Bayesian inference is introduced. Then the update expression of each variable in the graphical model is derived. Lastly, the appropriate initialization algorithm and corresponding parameter settings are given.
3.1. Variational Bayesian Inference
Consider a probabilistic model defined by observed variables , hidden variable sets , and the corresponding joint probability density . Our target is to obtain the posterior . However, the computation of the marginal likelihood function is intractable since it involves a multi-dimensional and complicated integral . Therefore, a PDF with a simpler structure is introduced to approximate the posterior distribution, i.e.,
where is the variational posterior distribution (VPD). In the variational Bayesian framework, the Kullback-Leibler (KL) divergence is defined as
To obtain a deterministic approximation of the posterior, (12) should be minimized, and the optimal VPD is achieved only if . Using Bayes theorem to replace , it makes the derivation of VPD a tractable optimization problem:
For simplicity, we adopt the mean-field theory and assume the joint PDF factorizes as
For most of the variables including , (13) is optimized over the exponential family of distributions. In this case, the KL divergence vanishes, and the optimal solution of (13) is assumed to be achievable. For and , the optimization on is restricted on Dirac measures to obtain point estimates. By optimizing (13), the solution that minimizes the KL divergence is:
In (15), denotes the expectation with respect to the distribution , represents the Markov blanket [25] of the variable . In the Bayesian network, the Markov Blanket of a node is the set of the nodes comprised of the node’s parents, its children, and its co-parents. I.e., is the minimal set around which makes independent of the rest of the variables.
3.2. Update of the Estimation Expressions
As discussed in Section 2, a hierarchical Bayesian model is set up to find sparse MPCs and infer the parameter sets from the measurements . A detailed derivation of the VPDs for each factor is given below. The VPDs can be updated in any order during the iteration process.
- 1.
In (16), is the set of all MPCs. Note that scattering parameters should be determined for a specific MPC, thus, we define to be a point estimation, i.e., , where denotes the estimated value for in a former update iteration. Based on the Gaussian noise assumption in Section 2.1, we have
By substituting and (17) into (16), the admissible hidden data of the -th observation obeys a Gaussian distribution with the mean and covariance matrix as follows:
- 2.
- Estimation of: Evaluating (15) with (5) and (10), the VPD of takes the formin whichand represents the di-gamma function. Since is a 0–1 matrix with a discrete VPD, the posterior expectation of is .
- 3.
- Estimation of: From the graph the Markov blanket of is , thus
By integrating the factors in , the VPD can be written as with
- 4.
- Estimation of: Similarly, evaluating (15) leads to . As mentioned above, the proxy PDF is defined as in order to obtain a point estimation. Therefore, we have
- 5.
- Estimation of: From the graphic model the Markov blanket of is and . Due to the gamma hyperprior and the nature of conjugate prior, the VPD also satisfies the Gamma distribution, i.e., with
- 6.
- Estimation of: The only variable related to is , thus, . By substituting (5) and (6) into (15) we obtainwhich indicates that the VPD also satisfies the Dirichlet distribution. The parameter of the VPD can be updated by
- 7.
- Estimation of: The Markov blanket of is , so that
For simplicity, the prior of the mean vector is set to be flat, and a delta VPD is also applied. By maximizing , a point estimation can be obtained as follows:
3.3. Initialization Algorithm
The initialization algorithm is proposed to infer the initial variational variables, including the preliminary estimation of the parameter set and the GMM model parameters. As shown in Algorithm 1, the estimation for multipath parameters and is obtained by cyclically finding and removing the corresponding template function from the remaining observations. The estimation process stops when the number of multipath reaches the preset amount . This method will inevitably result in duplicated estimations with the same scatter parameter vectors. Therefore, the channel taps with the same are checked and combined to be one. After obtaining the multipath coefficients , we use the expectation-maximization (EM) algorithm [21] to estimate the initial parameters of Gaussian clusters. In the E-step, the probability that is classified as the -th Gaussian component, i.e., , is computed by the relative weight of the Gaussian likelihoods. In the M-step, and are updated by the statistics of observations. When the EM process converges, we obtain . Notice that when initializing the EM algorithm, improper mean and variance values may cause the estimation of failing to converge. Thus in this paper, the K-means algorithm [26] is applied to estimate the initial mean and variance of each cluster.
| Algorithm 1: Initialization |
3.4. Pruning and Convergence Condition
A close examination of the sparsity prior (10) for the -th multipath reveals that the sparsity parameter controls the width of the Gaussian prior. When the cluster will be concentrated around the center which tends to be zero for a fading channel. Thus, large values of will make the component “irrelevant” and be removed from the estimation. In the proposed method, we set as a pruning condition where is a preset threshold. In order to halt the iterative variational process, another preset threshold is used to check whether the estimation converges. Define the update rate for the i-th iteration
The iteration process stops when . The general flow chart of the VB-GMM algorithm is shown in Figure 2.
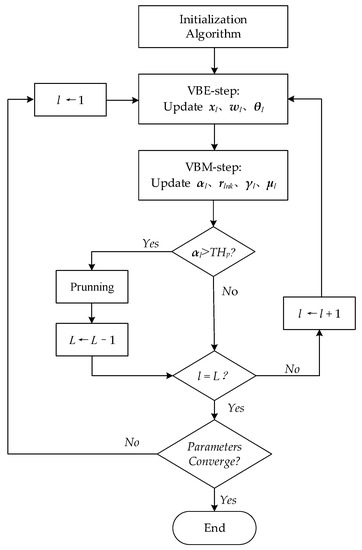
Figure 2.
The flow chart of the VB-GMM algorithm.
3.5. Computational Complexity
The computational complexity of the proposed algorithm is discussed in this section. For the benchmark comparison, we introduce the Gaussian prior-based variational Bayesian estimation scheme proposed in [5] (VB-G). The complex multiplication times (CMT) is used as the comparison metric for the evaluation of the computational complexity in VB-G and VB-GMM. Note that the multiplication of a complex matrix and a complex matrix demands the CMT of . And the CMT required by computing the inversion of a complex matrix is [27]. The computational complexity of each procedure is given in Table 1, in which represents the number of iterations taken by the variational updates in VB-G, the EM process, the K-means algorithm, and the variational updates of the VB-GMM, respectively. Compared with VB-G, the initialization process of VB-GMM has greater complexity due to an iterative estimation for GMM parameters, in which the computational complexity of the K-means algorithm is [28]. In the variational inference procedure, the coefficient of the main complexity term in VB-GMM is much smaller, resulting in the running time of about 1/5 of the VB-G in numerical simulations.

Table 1.
The CMT required by VB-G and VB-GMM algorithms.
4. Simulation Results
In the numerical simulation, the setup of the sounding parameters is given below. We use the constant amplitude zero auto-correlation sequence as the sounding sequence with 256 chips, and the interval is . The sample rate at the receiver is set as which implies that the number of discrete samples per CIR is . The number of observations per WSS region is assumed as . For the multipath channel, a 4-tap model is adopted in which the mean power of each tap is set as 0, −3, −5, −10 dB, and the multipath delay equals 10, 12, 15, 20 μs, respectively. For testing the performance of VB-GMM in various complex environments, three different fading types are considered. In the first scenario, the coefficients of the MPC are generated from Gaussian mixture distributions with . The real and imaginary parts of Gaussian means, covariances, and the mixing coefficients are randomly selected from the interval , and , respectively. In the second scenario, all four multipaths are modeled as Weibull distribution with the shape parameter set as 3, 4, 5, 6, respectively. In the third scenario, we define the channel taps to be Nakagami-m distributed, and the m-parameters are set as 2, 3, 4, 5, respectively, to simulate different fading depths.
The numerical setup for the VB-GMM algorithm is as follows. The preset multipath amount is , and the pruning threshold is set as for all SNR conditions. In the VBE-step, the initial parameters are: , and a flat prior probability . In the VBM-step, the initial values of the parameters are: , . Note that all the numerical simulations are based on over 5000 observations, and the iteration process is terminated when the update rate is smaller than 0.001.
Figure 3a shows a scatter plot of the estimated Gaussian mixture channel taps with the noise level , in which the circles represent cluster centroids and the dots represent the estimated channel taps. The graph indicates that when the channel coefficients are Gaussian mixture distributed, the proposed VB-GMM is capable of classifying channel tap samples that come from different Gaussian components. Meanwhile, the cluster centroids can be precisely located. In Figure 3b,c, we examined the classification capability of the proposed algorithm when the channel taps are assumed to be Weibull and Nakagami distributed, respectively. As shown in Figure 3b,c, the channel coefficients in Weibull and Nakagami scenarios with random phases are clearly clustered into three regions, which indicates that the proposed method can learn and fit the distribution of random channels.
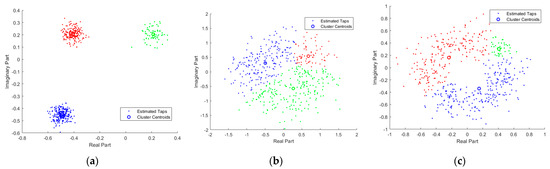
Figure 3.
Scatter plot of estimated channel coefficients in different scenarios. (a) Gaussian mixture distributed channels; (b) Weibull distributed channels; (c) Nakagami distributed channels.
Figure 4a represents the RMSE between the synthetic and reconstructed CIRs versus SNR in different scenarios. Notice that the VB-G scheme adopts a fixed sensitivity level of . For low SNR of −5 dB, the VB-GMM exhibits comparable performance with the VB-G. As SNR increases, the VB-GMM clearly outperforms the VB-G in all three scenarios due to the flexibility in fitting non-Gaussian data. The reason is that for VB-SAGE the estimation errors of , i.e., the delay of MPCs in part of the observations will result in a significant RMSE between the synthetic and reconstructed channel responses. While for VB-GMM, the multipath observations make the estimate of more robust because is assumed invariant in the WSS region. Figure 4b shows the curves of the estimated mean model order versus SNR. In the SNR range of −5 dB to 4 dB, the value of sparsity parameters tends to diverge, resulting in an obvious suppression effect on the MPCs. Under most SNR conditions, the VB-GMM shows accurate model selection for the 4-tap multipath channel, while the VB-G has a positive model order bias. Because for some of the observations if is wrongly estimated, there will be residual in the received signal after removing the template function, which leads to the falsely identified components. From the results of Figure 3 and Figure 4, the proposed method demonstrates its superiority in terms of model complexity and estimation accuracy. In Figure 5 we demonstrate curves of RMSEs that vary with the increasing iteration number in different scenarios for an SNR of 10 dB. The proposed method performs a similar convergence rate to the Gaussian prior-based scheme with smaller RMSEs in all the scenarios.
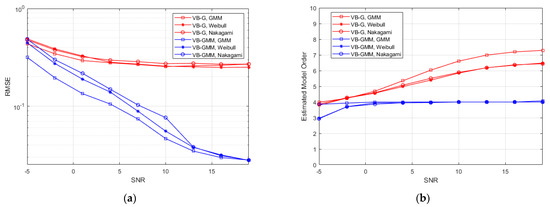
Figure 4.
(a) RMSE between the synthetic and reconstructed channel responses; (b) The mean value of estimated model order.
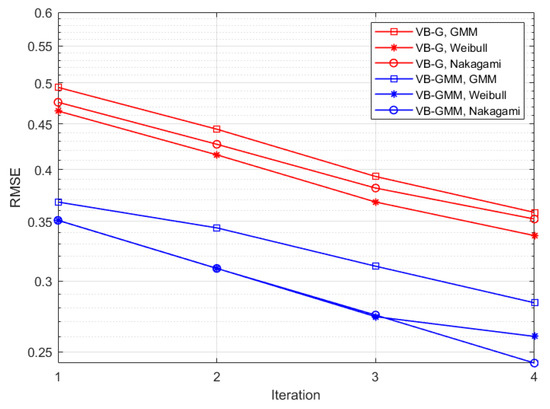
Figure 5.
The RMSE of estimated channel responses versus iteration numbers.
To study the influence of the number of Gaussian components , we generated over 30,000 channel responses from the Weibull and Nakagami channels and the performance of the proposed VB-GMM is given in Figure 6. In the simulation, the SNR is fixed at 10 dB. As depicted in Figure 6a, the RMSEs of the reconstructed channel responses have no significant change as increases in both Weibull and Nakagami channels. From Figure 6b, it can be seen that the estimated model orders are accurate when . Consider that a large cannot bring considerate improvement and may increase the complexity of GMM, we propose to set for most channel conditions.
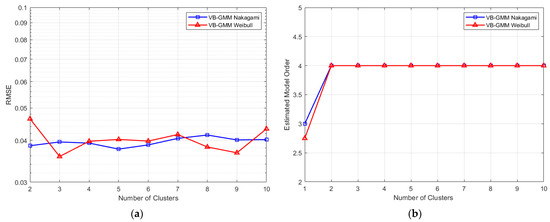
Figure 6.
The performance of VB-GMM versus the number of Gaussian components. (a) RMSE between the synthetic and reconstructed channel responses; (b) The mean value of estimated model order.
5. Conclusions
In this paper, we presented a variational Bayesian-based channel parameter estimation approach for Gaussian mixture distributed wireless channels, which combined the variational Bayesian estimation [5] and the variational GMM training [21]. Compared with the existing Bayesian estimation schemes, the proposed scheme can exploit the sparse solutions of the multipath channel and represent the complicated distribution patterns by the application of GMMs. Experiment results showed that the VB-GMM method can obtain the channel estimates with a small reconstruction RMSE and determine the optimal number of MPCs through a fixed pruning criterion under various SNR conditions. For future works, we will further investigate factors that may affect the algorithm performance in terms of the sparsity and the implementation complexity.
Author Contributions
Conceptualization, J.W.; Data curation, L.K.; Investigation, H.Z. and J.W.; Methodology, X.Z.; Supervision, J.W.; Writing—original draft, L.K.; Writing—review & editing, X.Z. and H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China under Grant 61931020.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fleury, B.H.; Tschudin, M.; Heddergott, R.; Dahlhaus, D.; Pedersen, K.I. Channel parameter estimation in mobile radio envi-ronments using the SAGE algorithm. IEEE J. Sel. Areas Commun. 1999, 17, 434–450. [Google Scholar] [CrossRef]
- Liu, T.C.-K.; Kim, D.I.; Vaughan, R.G. A High-Resolution, Multi-Template Deconvolution Algorithm for Time-Domain UWB Channel Characterization. Can. J. Electr. Comput. Eng. 2007, 32, 1183–1186. [Google Scholar] [CrossRef]
- Lanterman, A.D. Schwarz, Wallace, and Rissanen: Intertwining themes in theories of model order estimation. Int. Stat. Rev. 2000, 69, 185–212. [Google Scholar] [CrossRef]
- Myung, J.I.; Navarro, D.J.; Pitt, M.A. Model selection by normalized maximum likelihood. J. Math. Psychol. 2006, 50, 167–179. [Google Scholar] [CrossRef]
- Shutin, D.; Fleury, B.H. Sparse Variational Bayesian SAGE Algorithm with Application to the Estimation of Multipath Wire-less Channels. IEEE Trans. Signal Process. 2011, 59, 3609–3623. [Google Scholar] [CrossRef]
- Bajwa, W.U.; Haupt, J.; Sayeed, A.M.; Nowak, R. Compressed Channel Sensing: A New Approach to Estimating Sparse Multipath Channels. Proc. IEEE 2010, 98, 1058–1076. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Thomas, B. Variational Sparse Bayesian Learning: Centralized and Distributed Processing. Ph.D. Thesis, Graz University of Technology, Graz, Austria, 2013. [Google Scholar]
- Badiu, M.; Hansen, T.L.; Fleury, B.H. Variational Bayesian Inference of Line Spectra. IEEE Trans. Signal Process. 2017, 65, 2247–2261. [Google Scholar] [CrossRef]
- Yuan, W.; Wei, Z.; Yuan, J.; Ng, D.W.K. A Simple Variational Bayes Detector for Orthogonal Time Frequency Space (OTFS) Modulation. IEEE Trans. Veh. Technol. 2020, 69, 7976–7980. [Google Scholar] [CrossRef]
- Hu, B.; Land, I.; Rasmussen, L.K.; Piton, R.; Fleury, B.H. A Divergence Minimization Approach to Joint Multiuser Decoding for Coded CDMA. IEEE J. Sel. Areas Commun. 2008, 26, 432–445. [Google Scholar]
- Zhong, K.; Wu, Y.; Li, S. Signal Detection for OFDM-Based Virtual MIMO Systems under Unknown Doubly Selective Chan-nels, Multiple Interferences and Phase Noises. IEEE Trans. Wirel. Commun. 2013, 12, 5309–5321. [Google Scholar] [CrossRef]
- Bai, X.; Zhang, Y.; Zhou, F. High-Resolution Radar Imaging in Complex Environments Based on Bayesian Learning with Mixture Models. IEEE Trans. Geosci. Remote Sens. 2018, 57, 972–984. [Google Scholar] [CrossRef]
- Karseras, E.; Dai, W.; Dai, L.; Wang, Z. Fast variational Bayesian learning for channel estimation with prior statistical infor-mation. In Proceedings of the 2015 IEEE 16th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Stockholm, Sweden, 28 June–1 July 2015; pp. 470–474. [Google Scholar]
- He, R.; Zhong, Z.; Ai, B.; Wang, G.; Ding, J.; Molisch, A.F. Measurements and Analysis of Propagation Channels in High-Speed Railway Viaducts. IEEE Trans. Wirel. Commun. 2012, 12, 794–805. [Google Scholar] [CrossRef]
- Matolak, D.W.; Sen, I.; Xiong, W. The 5-GHz Airport Surface Area Channel—Part I: Measurement and Modeling Results for Large Airports. IEEE Trans. Veh. Technol. 2008, 57, 2014–2026. [Google Scholar] [CrossRef]
- Sen, I.; Matolak, D.W. The 5-GHz Airport Surface Area Channel—Part II: Measurement and Modeling Results for Small Airports. IEEE Trans. Veh. Technol. 2008, 57, 2027–2035. [Google Scholar] [CrossRef]
- Yu, J.; Chen, W.; Li, F.; Li, C.; Yang, K.; Liu, Y.; Chang, F. Channel Measurement and Modeling of the Small-Scale Fading Characteristics for Urban Inland River Environment. IEEE Trans. Wirel. Commun. 2020, 19, 3376–3389. [Google Scholar] [CrossRef]
- Tan, S.; Huang, K.; Shang, B. Sparse Bayesian Learning with joint noise robustness and signal sparsity. IET Signal Process. 2017, 11, 1104–1113. [Google Scholar] [CrossRef]
- Pedersen, N.L.; Manchon, C.N.; Shutin, D.; Fleury, B.H. Application of Bayesian Hierarchical Prior Modeling to Sparse Channel Estimation. IEEE Int. Conf. Commun. 2012, 3487–3492. [Google Scholar] [CrossRef]
- Tzikas, D.G.; Likas, A.C.; Galatsanos, N.P. The variational approximation for Bayesian inference. IEEE Signal Process. Mag. 2008, 25, 131–146. [Google Scholar] [CrossRef]
- Lee, W. Estimate of local average power of a mobile radio signal. IEEE Trans. Veh. Technol. 1985, 34, 22–27. [Google Scholar] [CrossRef]
- Fessler, J.A.; Hero, A.O. Space-alternating generalized expectation-maximization algorithm. IEEE Trans. Signal Process. 1994, 42, 2664–2677. [Google Scholar] [CrossRef]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Bayesian Compressive Sensing Using Laplace Priors. IEEE Trans. Image Process. 2009, 19, 53–63. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberger, Germany, 2006. [Google Scholar]
- McQueen, J.B. Some methods of classification and analysis in multivariate observations. In Proceedings of the Fifth Barkley Symposium on Mathematical Statistics and Probability; California University Press: Oakland, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Kusume, K.; Joham, M.; Utschick, W. MMSE block decision-feedback equalizer for spatial multiplexing with reduced com-plexity. In Proceedings of the IEEE Global Telecommunications Conference 2004, Dallas, TX, USA, 29 November–3 December 2004; Volume 4, pp. 2540–2544. [Google Scholar]
- Pakhira, M.K. A Linear Time-Complexity k-Means Algorithm Using Cluster Shifting. In Proceedings of the 2014 International Conference on Computational Intelligence and Communication Networks, Bhopal, India, 14–16 November 2014; pp. 1047–1051. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).