Provably Secure Symmetric Private Information Retrieval with Quantum Cryptography


Abstract
1. Introduction
2. Preliminaries
2.1. Quantum and Classical Systems
2.2. Trace Distance and Distinguishability
3. SPIR
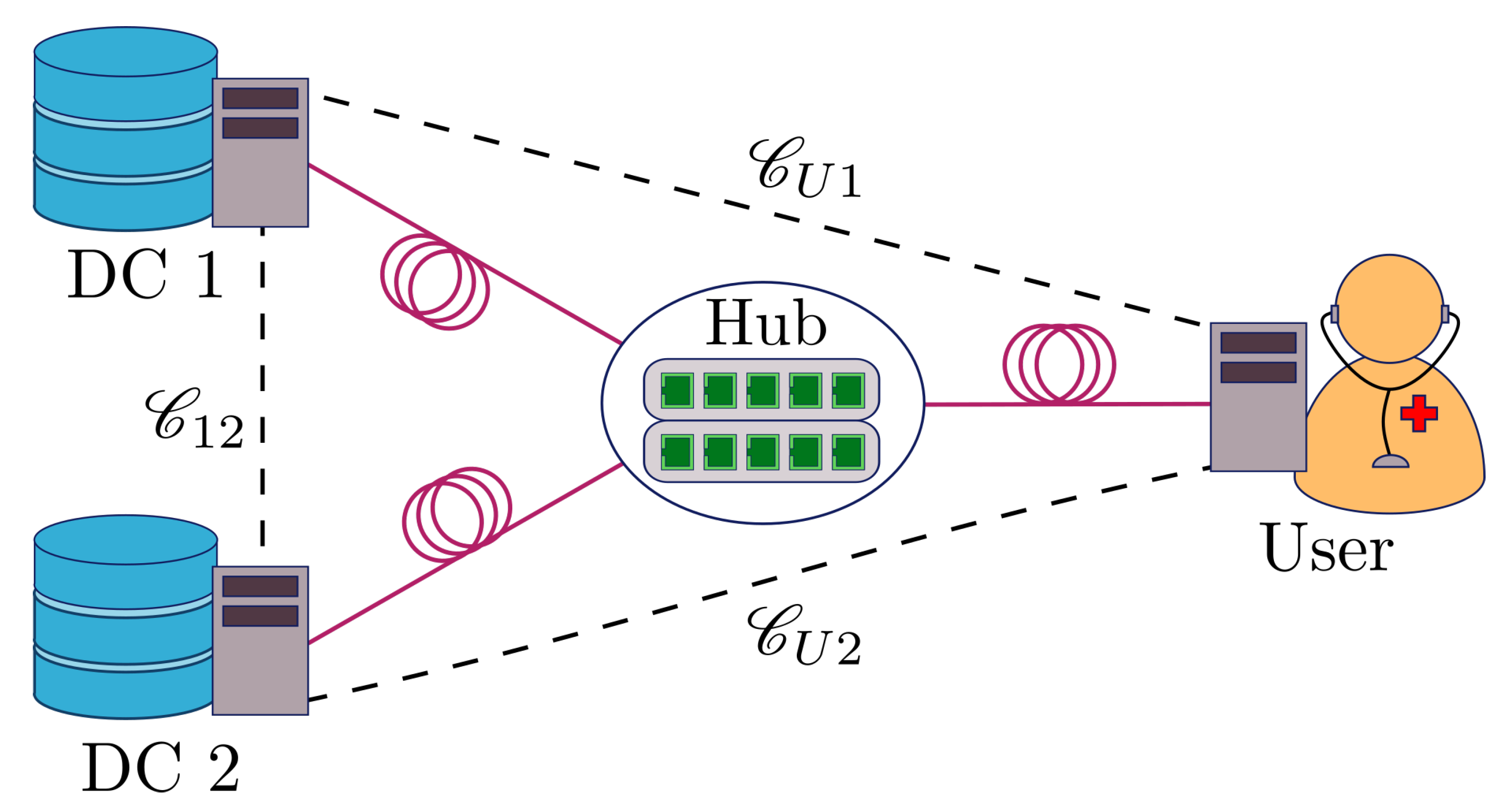
3.1. Generic One-Round SPIR Protocol
- Establishing secure channels: Using pre-established secret keys, perfectly secure channels are established between the user and data centres using one-time pad (OTP) encryption. We use , , to represent the secret key pair between data centre 1 and user, between data centre 2 and user, and between the data centres, respectively. For example, with this arrangement, the user holds and and data centre 1 holds and . Secure channels connecting the user and data centres are denoted by and , respectively. Note that the data centres are not allowed to communicate and hence we do not need to define any channel for them. To allow for two-way secure communication with a single secret key, we split into two halves, namely (for encryption) and (for decryption).
- Query: The user generates queries for data centres 1 and 2, with and , respectively, and sends them to the data centres using the secure channels and .
- Answer: Upon receiving the query (which could be different from ), (resp. ) determines a reply (resp. and sends it to the user via the secure channels.
- Retrieval: The user retrieves the desired database entry value using .
3.2. Original SPIR Security Definition
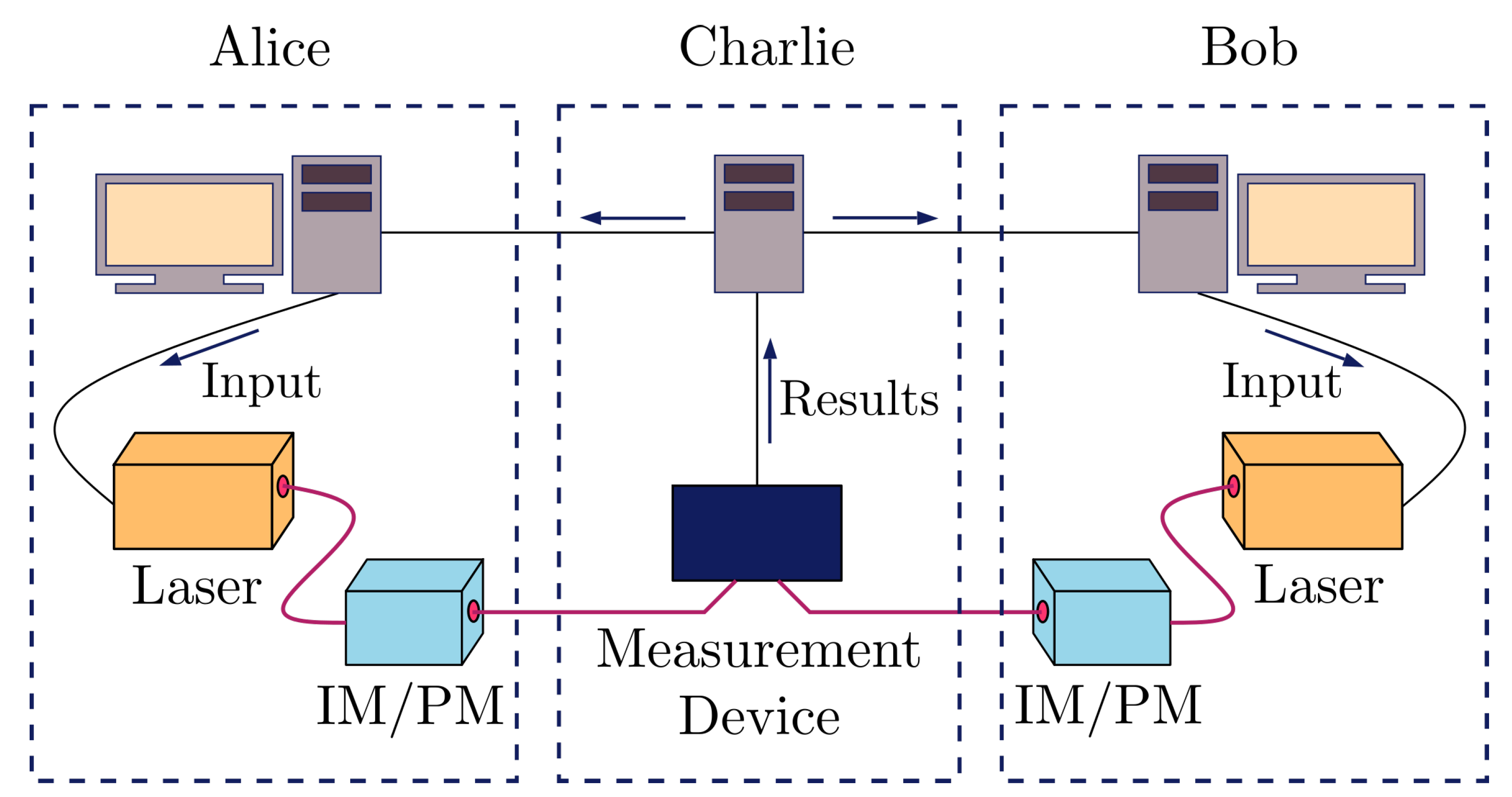
4. SPIR with QKD
4.1. QKD Channel
4.2. QKD Security Definition
4.3. SPIR with QKD Security Definition
4.4. Quantum View Modelling
5. Security Analysis
6. Numerical Simulation
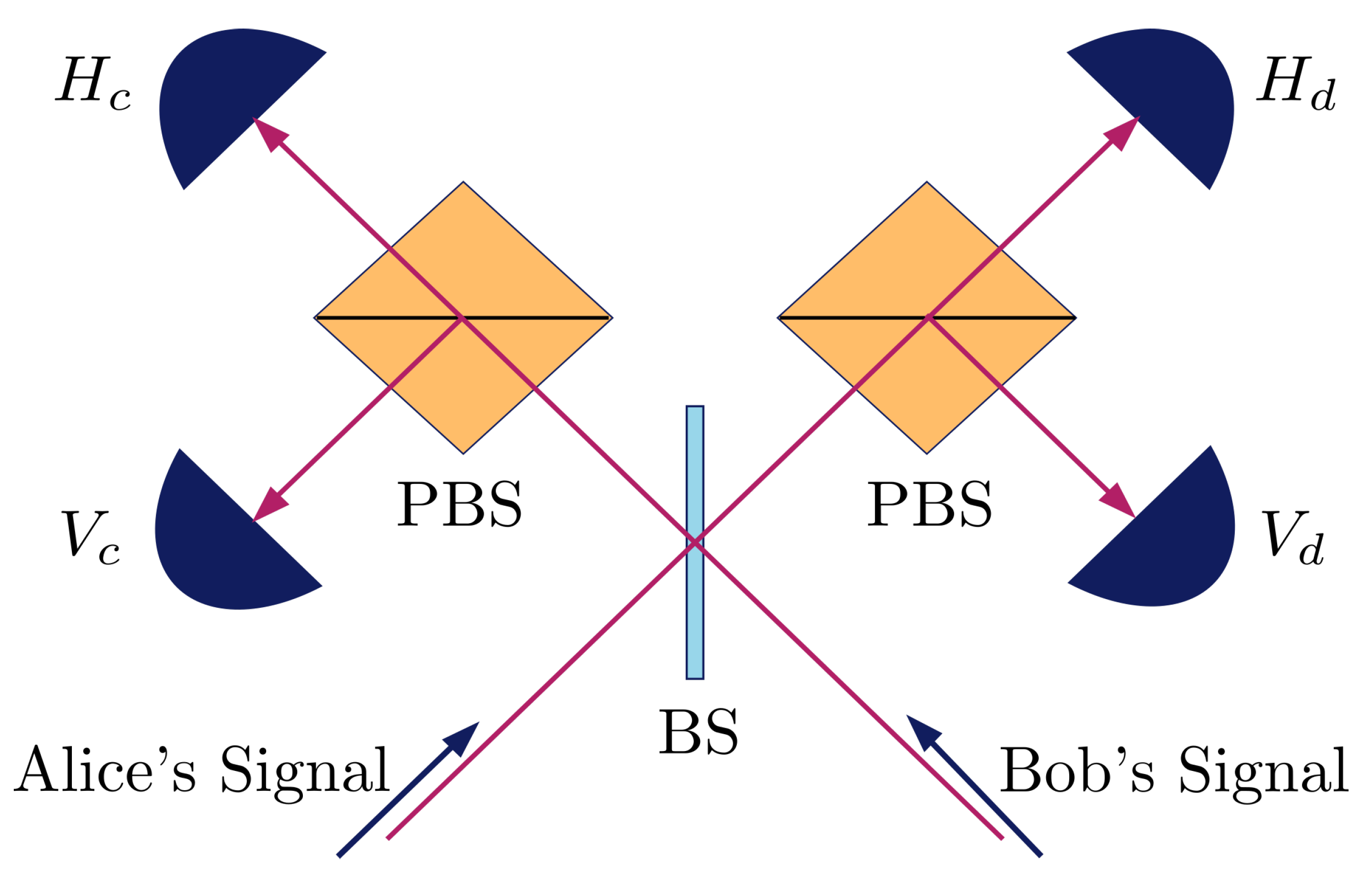
6.1. MDI-QKD
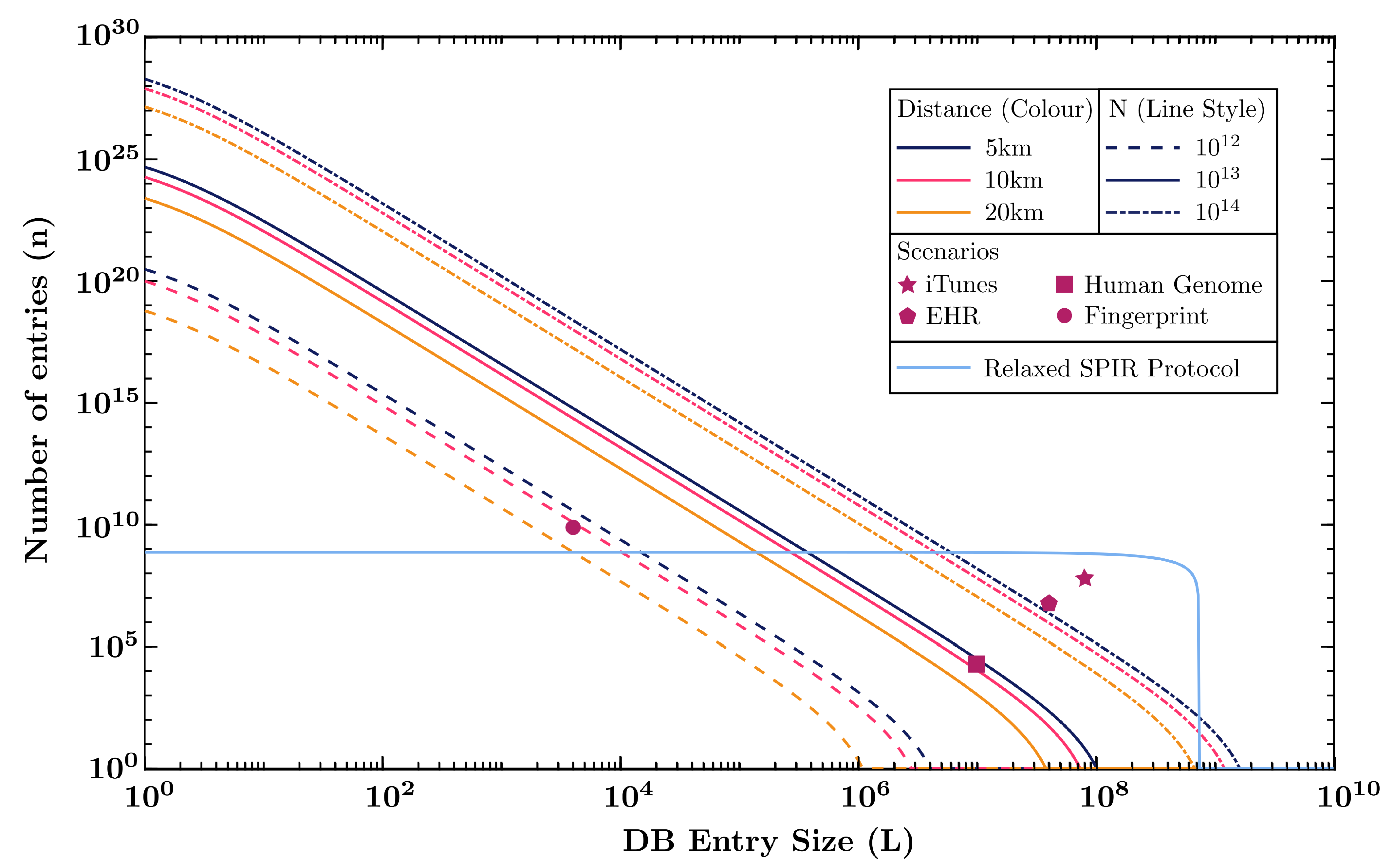
6.2. SPIR Resource
- iTunes: A consumer wants to purchase a song from the iTunes catalogue, which contains 60 million songs. (Assume each music file is 10 MB) [, ]
- Genetic Data: A doctor requests for a gene in a patient’s genome data to analyse disease risk. (Human genome contains 19,116 protein-coding genes, with the maximum size of a single gene being 2.47 million base pairs [46]. Since humans have two alleles for most genes and there are 4 possible bases, each gene entry can be encoded as 9.88 million bits). [ = 19,116, ]
7. Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PIR | Private information retrieval |
| SPIR | Symmetric private information retrieval |
| QKD | Quantum key distribution |
| CPTP | Completely positive and trace preserving |
| POVM | Positive operator value measurement |
| OTP | One-time pad |
| CDS | Conditional disclosure of secrets |
| MDI | Measurement-device independent |
Appendix A. Detailed Security Proof
Appendix B. Protocol
References
- Chor, B.; Kushilevitz, E.; Goldreich, O.; Sudan, M. Private Information Retrieval. J. ACM 1998, 45, 965–981. [Google Scholar] [CrossRef]
- Mittal, P.; Olumofin, F.; Troncoso, C.; Borisov, N.; Goldberg, I. PIR-Tor: Scalable Anonymous Communication Using Private Information Retrieval. In Proceedings of the 20th USENIX Conference on Security, San Francisco, CA, USA, 8–12 August 2011; p. 31. [Google Scholar]
- Khoshgozaran, A.; Shirani-Mehr, H.; Shahabi, C. SPIRAL: A Scalable Private Information Retrieval Approach to Location Privacy. In Proceedings of the Ninth International Conference on Mobile Data Management Workshops, MDMW, Beijing, China, 27–30 April 2008. [Google Scholar]
- Bringer, J.; Chabanne, H.; Pointcheval, D.; Tang, Q. Extended Private Information Retrieval and Its Application in Biometrics Authentications. In Cryptology and Network Security; Bao, F., Ling, S., Okamoto, T., Wang, H., Xing, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 175–193. [Google Scholar]
- Gertner, Y.; Ishai, Y.; Kushilevitz, E.; Malkin, T. Protecting Data Privacy in Private Information Retrieval Schemes. J. Comput. Syst. Sci. 2000, 60, 592–629. [Google Scholar] [CrossRef]
- Stern, J.P. A New and Efficient All-Or-Nothing Disclosure of Secrets Protocol. In Advances in Cryptology—ASIACRYPT’98; Ohta, K., Pei, D., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 1998; pp. 357–371. [Google Scholar]
- Lipmaa, H. An Oblivious Transfer Protocol with Log-Squared Communication. In Information Security; Zhou, J., Lopez, J., Deng, R.H., Bao, F., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2005; pp. 314–328. [Google Scholar]
- Naor, M.; Pinkas, B. Efficient oblivious transfer protocols. In Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms, Washington, DC, USA, 7–9 January 2001; Society for Industrial and Applied Mathematics: Washington, DC, USA, 2001; pp. 448–457. [Google Scholar]
- Chou, T.; Orlandi, C. The Simplest Protocol for Oblivious Transfer. In Progress in Cryptology—LATINCRYPT 2015; Lauter, K., Rodríguez-Henríquez, F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 40–58. [Google Scholar]
- Lo, H.K. Insecurity of quantum secure computations. Phys. Rev. A 1997, 56, 1154–1162. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum Private Queries. Phys. Rev. Lett. 2008, 100, 230502. [Google Scholar] [CrossRef]
- Jakobi, M.; Simon, C.; Gisin, N.; Bancal, J.D.; Branciard, C.; Walenta, N.; Zbinden, H. Practical private database queries based on a quantum-key-distribution protocol. Phys. Rev. A 2011, 83, 022301. [Google Scholar] [CrossRef]
- Panduranga Rao, M.V.; Jakobi, M. Towards communication-efficient quantum oblivious key distribution. Phys. Rev. A 2013, 87, 012331. [Google Scholar] [CrossRef]
- Zhang, J.L.; Guo, F.Z.; Gao, F.; Liu, B.; Wen, Q.Y. Private database queries based on counterfactual quantum key distribution. Phys. Rev. A 2013, 88, 022334. [Google Scholar] [CrossRef]
- Wei, C.Y.; Wang, T.Y.; Gao, F. Practical quantum private query with better performance in resisting joint-measurement attack. Phys. Rev. A 2016, 93, 042318. [Google Scholar] [CrossRef]
- Wei, C.; Cai, X.; Wang, T.; Qin, S.; Gao, F.; Wen, Q. Error Tolerance Bound in QKD-Based Quantum Private Query. IEEE J. Sel. Area Commun. 2020, 38, 517–527. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum Private Queries: Security Analysis. IEEE Trans. Inf. Theory 2010, 56, 3465–3477. [Google Scholar] [CrossRef]
- Olejnik, L. Secure quantum private information retrieval using phase-encoded queries. Phys. Rev. A 2011, 84, 022313. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y.G.; Chen, X.B.; Zhou, Y.H.; Shi, W.M. Practical Quantum Private Database Queries Based on Passive Round-Robin Differential Phase-shift Quantum Key Distribution. Sci. Rep. 2016, 6, 31738. [Google Scholar] [CrossRef]
- Gao, F.; Qin, S.; Huang, W.; Wen, Q. Quantum private query: A new kind of practical quantum cryptographic protocol. Sci. China Phys. Mech. Astron. 2019, 62, 70301. [Google Scholar] [CrossRef]
- Kent, A. Unconditionally Secure Bit Commitment by Transmitting Measurement Outcomes. Phys. Rev. Lett. 2012, 109, 130501. [Google Scholar] [CrossRef]
- Pitalúa-García, D. Spacetime-constrained oblivious transfer. Phys. Rev. A 2016, 93, 062346. [Google Scholar] [CrossRef]
- Wang, Q.; Skoglund, M. Secure symmetric private information retrieval from colluding databases with adversaries. In Proceedings of the 55th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 3–6 October 2017; pp. 1083–1090. [Google Scholar]
- Yekhanin, S. Towards 3-query locally decodable codes of subexponential length. J. ACM 2008, 55, 1:1–1:16. [Google Scholar] [CrossRef]
- Kerenidis, I.; de Wolf, R. Quantum symmetrically private information retrieval. Inf. Process. Lett. 2004, 90, 109–114. [Google Scholar] [CrossRef]
- Song, S.; Hayashi, M. Capacity of Quantum Private Information Retrieval with Multiple Servers. IEEE Trans. Inf. Theory 2020, 67, 452–463. [Google Scholar] [CrossRef]
- Diffie, W.; Hellman, M. New directions in cryptography. IEEE Trans. Inf. Theory 1976, 22, 644–654. [Google Scholar] [CrossRef]
- Bennett, C.H.; Brassard, G. Quantum cryptography: Public key distribution and coin tossing. Theor. Comput. Sci. 1984, 560, 7–11. [Google Scholar] [CrossRef]
- Gisin, N.; Ribordy, G.; Tittel, W.; Zbinden, H. Quantum cryptography. Rev. Mod. Phys. 2002, 74, 145–195. [Google Scholar] [CrossRef]
- Deng, F.G.; Long, G.L.; Liu, X.S. Two-step quantum direct communication protocol using the Einstein-Podolsky-Rosen pair block. Phys. Rev. A 2003, 68, 042317. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, W.; Sheng, Y.; Huang, Y. Experimental long-distance quantum secure direct communication. Sci. Bull. 2017, 62, 1519–1524. [Google Scholar] [CrossRef]
- Qi, R.; Sun, Z.; Lin, Z.; Niu, P.; Hao, W.; Song, L.; Huang, Q.; Gao, J.; Yin, L.; Long, G.L. Implementation and security analysis of practical quantum secure direct communication. Light. Sci. Appl. 2019, 8, 22. [Google Scholar] [CrossRef]
- Lo, H.K.; Curty, M.; Qi, B. Measurement-Device-Independent Quantum Key Distribution. Phys. Rev. Lett. 2012, 108, 130503. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, T.Y.; Wang, L.J.; Liang, H.; Shentu, G.L.; Wang, J.; Cui, K.; Yin, H.L.; Liu, N.L.; Li, L.; et al. Experimental Measurement-Device-Independent Quantum Key Distribution. Phys. Rev. Lett. 2013, 111, 130502. [Google Scholar] [CrossRef]
- Yin, H.L.; Chen, T.Y.; Yu, Z.W.; Liu, H.; You, L.X.; Zhou, Y.H.; Chen, S.J.; Mao, Y.; Huang, M.Q.; Zhang, W.J.; et al. Measurement-Device-Independent Quantum Key Distribution Over a 404 km Optical Fiber. Phys. Rev. Lett. 2016, 117, 190501. [Google Scholar] [CrossRef]
- Tang, Y.L.; Yin, H.L.; Zhao, Q.; Liu, H.; Sun, X.X.; Huang, M.Q.; Zhang, W.J.; Chen, S.J.; Zhang, L.; You, L.X.; et al. Measurement-Device-Independent Quantum Key Distribution over Untrustful Metropolitan Network. Phys. Rev. X 2016, 6, 011024. [Google Scholar] [CrossRef]
- Fernández-Aleman, J.L.; Senor, I.C.; Lozoya, P.A.O.; Toval, A. Security and privacy in electronic health records: A systematic literature review. J. Biomed. Inform. 2013, 46, 541–562. [Google Scholar] [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information: 10th Anniversary Edition, 10th ed.; Cambridge University Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Portmann, C.; Renner, R. Cryptographic Security of Quantum Key Distribution. arXiv 2014, arXiv:1409.3525. [Google Scholar]
- Curty, M.; Xu, F.; Lim, C.C.W.; Tamaki, K.; Lo, H.K. Finite-key analysis for measurement-device-independent quantum key distribution. Nat. Commun. 2014, 5, 3732. [Google Scholar] [CrossRef]
- Xu, F.; Curty, M.; Qi, B.; Lo, H.K. Practical aspects of measurement-device-independent quantum key distribution. New J. Phys. 2013, 15, 113007. [Google Scholar] [CrossRef]
- Healthcare Broadband in America; OBI Technical Paper 5; Federal Communications Commission: Washington, DC, USA, 2010.
- Population Trends; Technical Report; Singapore Department of Statistics: Singapore, 2019.
- ISO/IEC 19794-2:2011. Information Technology—Biometric Data Interchange Formats—Part 2: Finger Minutiae Data; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- World Population Prospects 2019, Volume I: Comprehensive Tables; Technical Report ST/ESA/SER.A/426; Department of Economic and Social Affairs, Population Division, United Nations: New York, NY, USA, 2019.
- Piovesan, A.; Antonaros, F.; Vitale, L.; Strippoli, P.; Pelleri, M.C.; Caracausi, M. Human protein-coding genes and gene feature statistics in 2019. BMC Res. Notes 2019, 12, 315. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | |||||
|---|---|---|---|---|---|
| Input: | w | R, x | w | ||
| Key pair (): | |||||
| Key pair (): | |||||
| Key pair (): | |||||
| Query: | , | ||||
| OTP (): | |||||
| OTP (): | |||||
| Answer: | |||||
| OTP (): | |||||
| OTP (): | |||||
| Decoding: | |||||
| Step | ||||||
|---|---|---|---|---|---|---|
| Input: | w | R, x | w | |||
| QKD (): | ||||||
| QKD (): | ||||||
| QKD (): | ||||||
| Query: | ||||||
| OTP (): | ||||||
| OTP (): | ||||||
| Answer: | ||||||
| OTP (): | ||||||
| OTP (): | ||||||
| Decoding: | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kon, W.Y.; Lim, C.C.W. Provably Secure Symmetric Private Information Retrieval with Quantum Cryptography. Entropy 2021, 23, 54. https://doi.org/10.3390/e23010054
Kon WY, Lim CCW. Provably Secure Symmetric Private Information Retrieval with Quantum Cryptography. Entropy. 2021; 23(1):54. https://doi.org/10.3390/e23010054
Chicago/Turabian StyleKon, Wen Yu, and Charles Ci Wen Lim. 2021. "Provably Secure Symmetric Private Information Retrieval with Quantum Cryptography" Entropy 23, no. 1: 54. https://doi.org/10.3390/e23010054
APA StyleKon, W. Y., & Lim, C. C. W. (2021). Provably Secure Symmetric Private Information Retrieval with Quantum Cryptography. Entropy, 23(1), 54. https://doi.org/10.3390/e23010054