Information-Theoretic Generalization Bounds for Meta-Learning and Applications



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Main Contributions
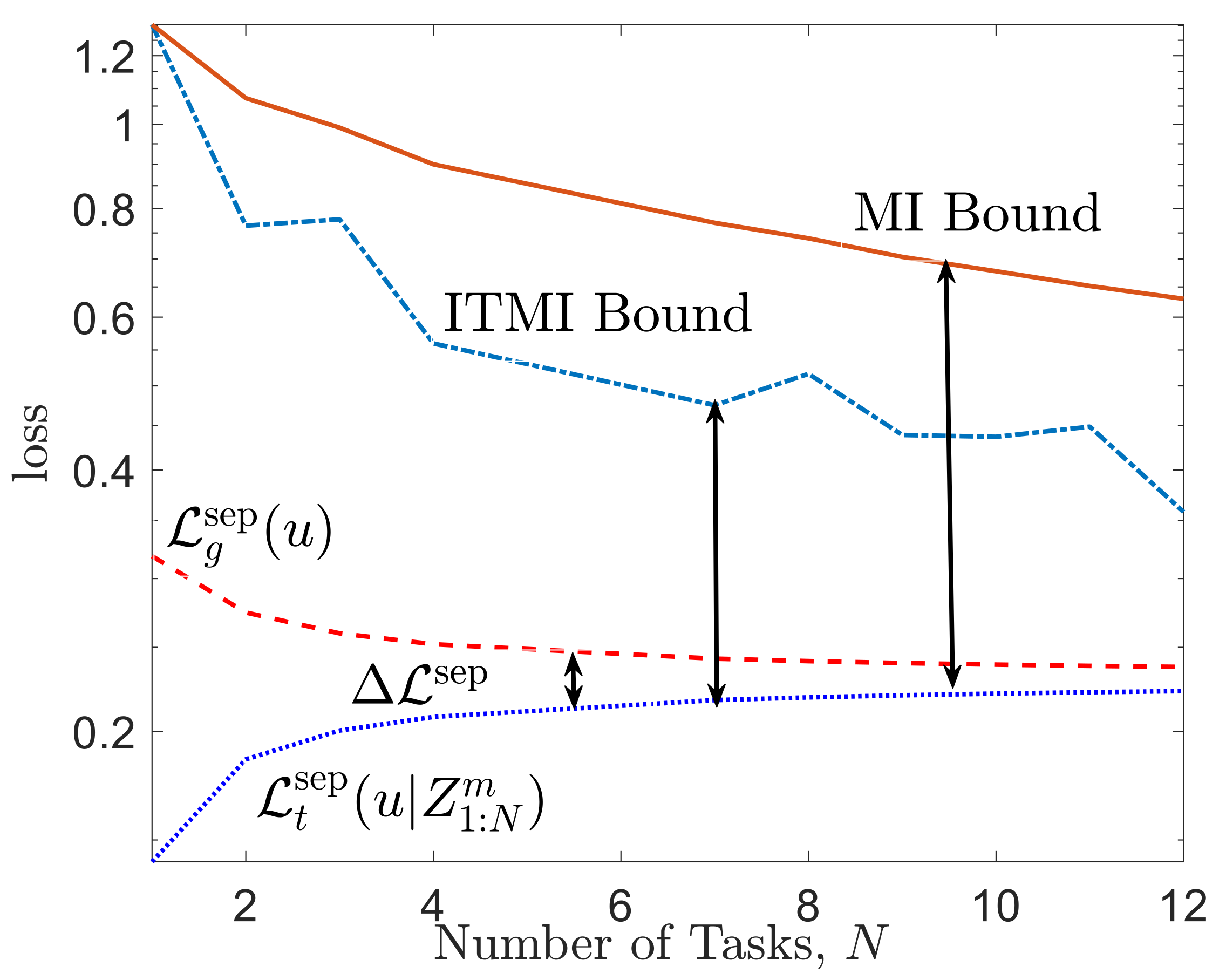
- In Theorem 1, we show that, for the case with separate within-task training and test sets, the average meta-generalization gap contains only the contribution of environment-level uncertainty. This is captured by a ratio of the mutual information (MI) between the output of the meta-learner U and the meta-training set , and the number of tasks N, aswhere is the sub-Gaussianity variance factor of the meta-loss function. This is a direct parallel of the MI-based bounds for single-task learning [25].
- In Theorem 3, we then show that, for the case with joint within-task training and test sets, the bound on the average meta-generalization gap also contains a contribution due to the within-task uncertainty via the ratio of the MI between the output of the base-learner and within-task training data and the per-task data sample size m. Specifically, we have the following boundwhere is the sub-Gaussianity variance factor of the loss function for task T.
- In Theorems 2 and 4, we extend the individual sample MI (ISMI) bound of [26] to obtain novel individual task MI (ITMI)-based bounds on the meta-generalization gap for both separate and within-task training and test sets asand
- Finally, we study the applications of the derived bounds to two meta-learning problems. The first is a parameter estimation setup that involves one-shot meta-learning and base-learning procedures, for which a closed form expression for meta-generalization gap can be derived. The second application covers a broad range of noisy iterative meta-learning algorithms and is inspired by the work of Pensia et al. [27] for conventional learning.
1.2. Related Work
1.3. Notation
2. Problem Definition
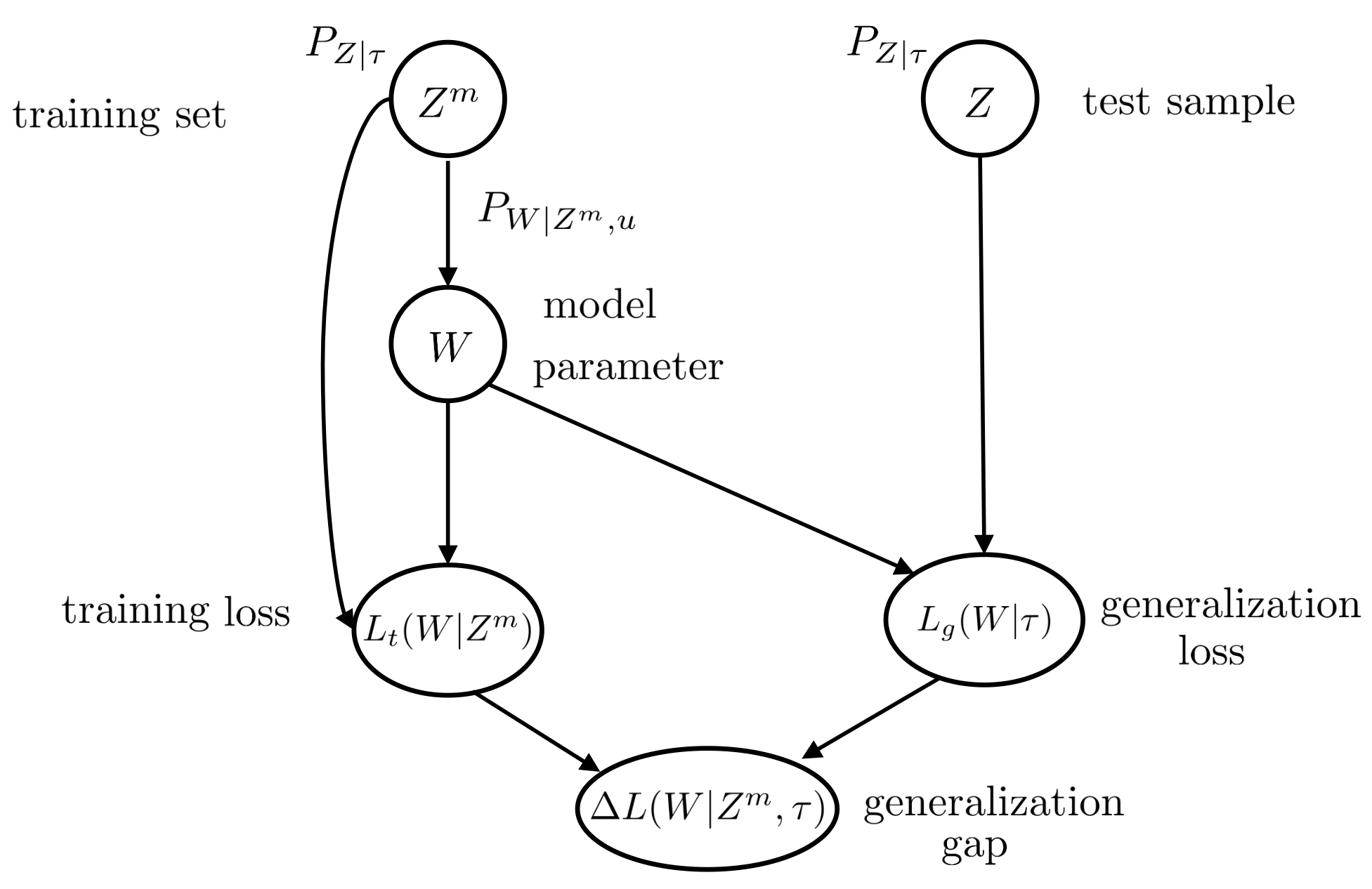
2.1. Generalization Gap for Single-Task Learning
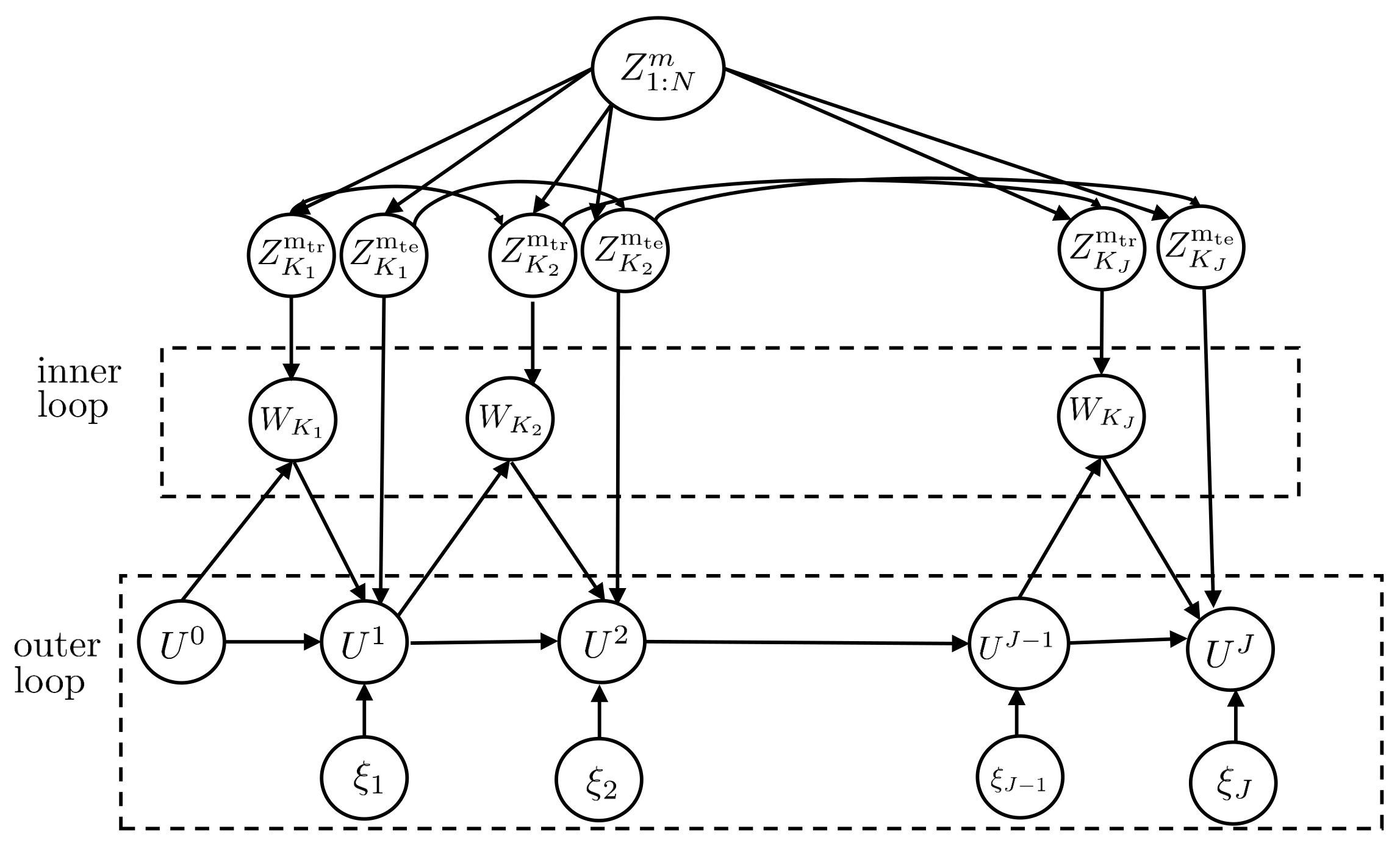
2.2. Generalization Gap for Meta-Learning
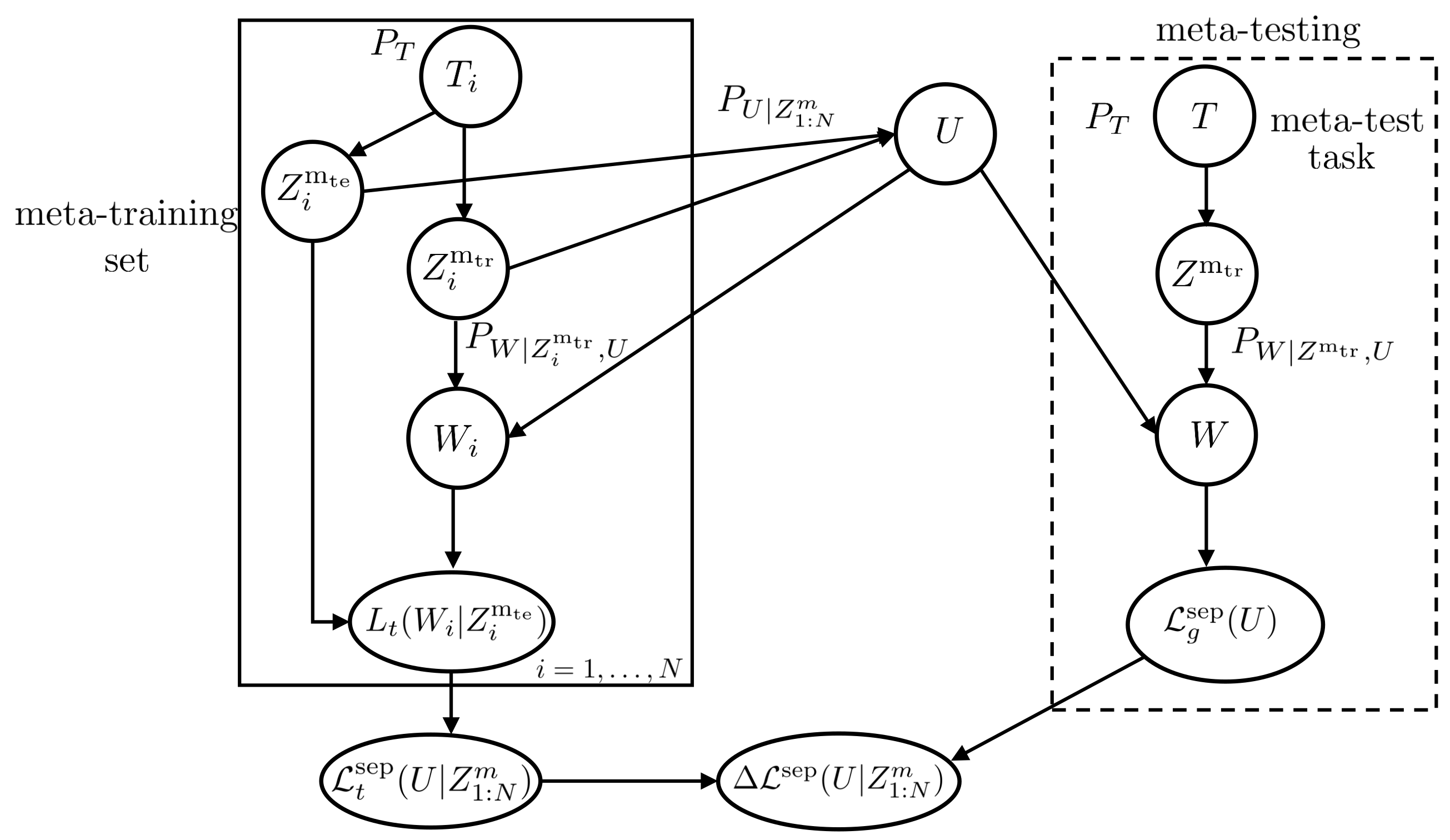
2.2.1. Separate Within-Task Training and Test Sets
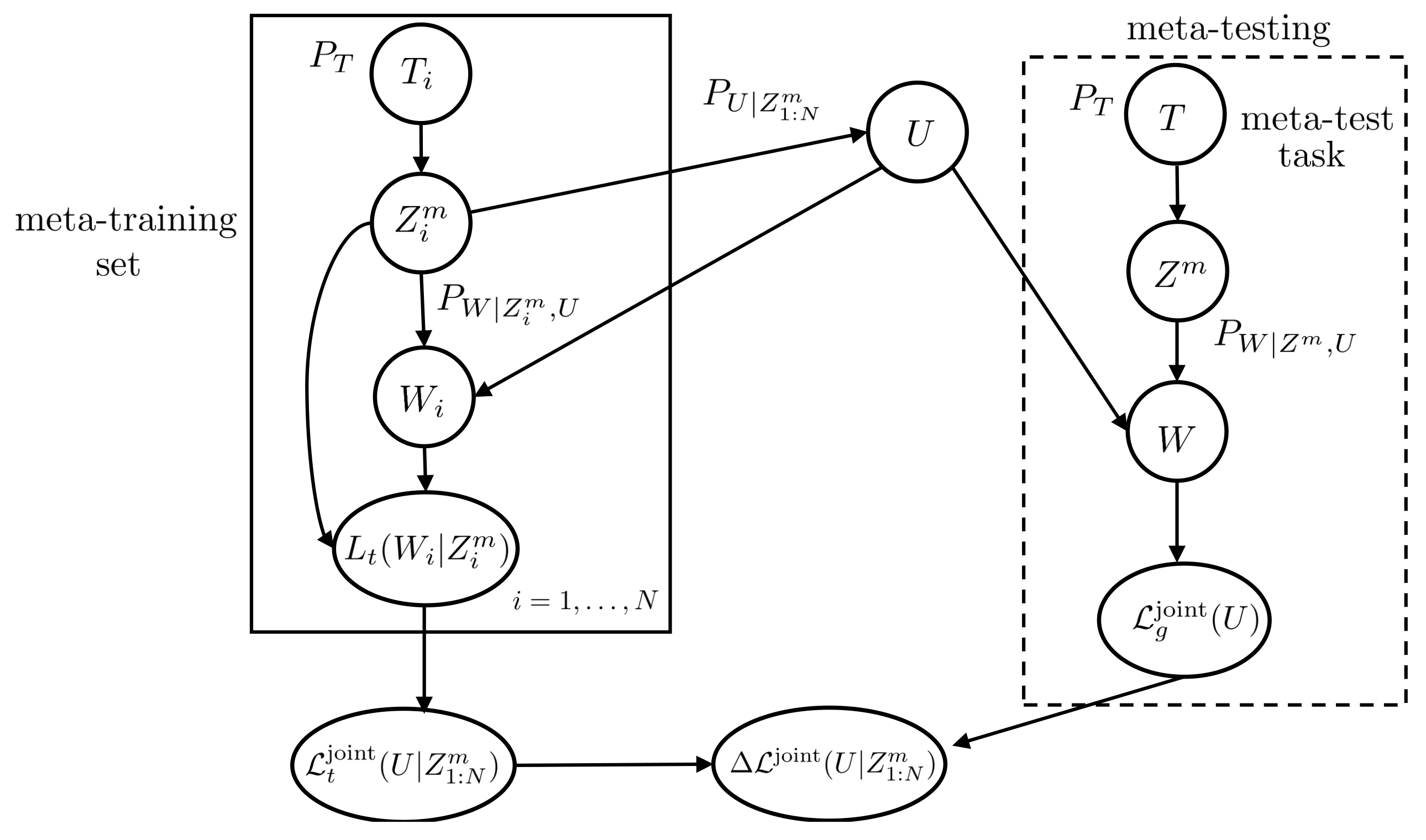
2.2.2. Joint Within-Task Training and Test Sets
3. Information-Theoretic Generalization Bounds for Single-Task Learning
3.1. Preliminaries
3.2. Mutual Information (MI) Bound
3.3. Individual Sample MI (ISMI) Bound
- (a)
- Assumption 1, or
- (b)
- is a -sub-Gaussian random variable when , where is the marginal of the joint distribution .
4. Information-Theoretic Generalization Bounds for Meta-Learning
4.1. Bounds on Meta-Generalization Gap with Separate Within-Task Training and Test Sets
4.1.1. MI-Based Bound
4.1.2. ITMI Bound
- (a)
- satisfies Assumption 3, or
- (b)
- is -sub-Gaussian under , where is the marginal of the joint distribution and is the marginal of the joint distribution .
4.2. Bounds on Generalization Gap with Joint Within-Task Training and Test Sets
4.2.1. MI-Based Bound
- (a)
- For each task , the loss function satisifies Assumption 1, and
- (b)
4.2.2. ITMI Bound on (22)
- (a)
- Assumption 5 holds, or
- (b)
- For each task , the loss function is -sub-Gaussian when , where is the marginal of the joint distribution . The average per-task training loss is -sub-Gaussian when .
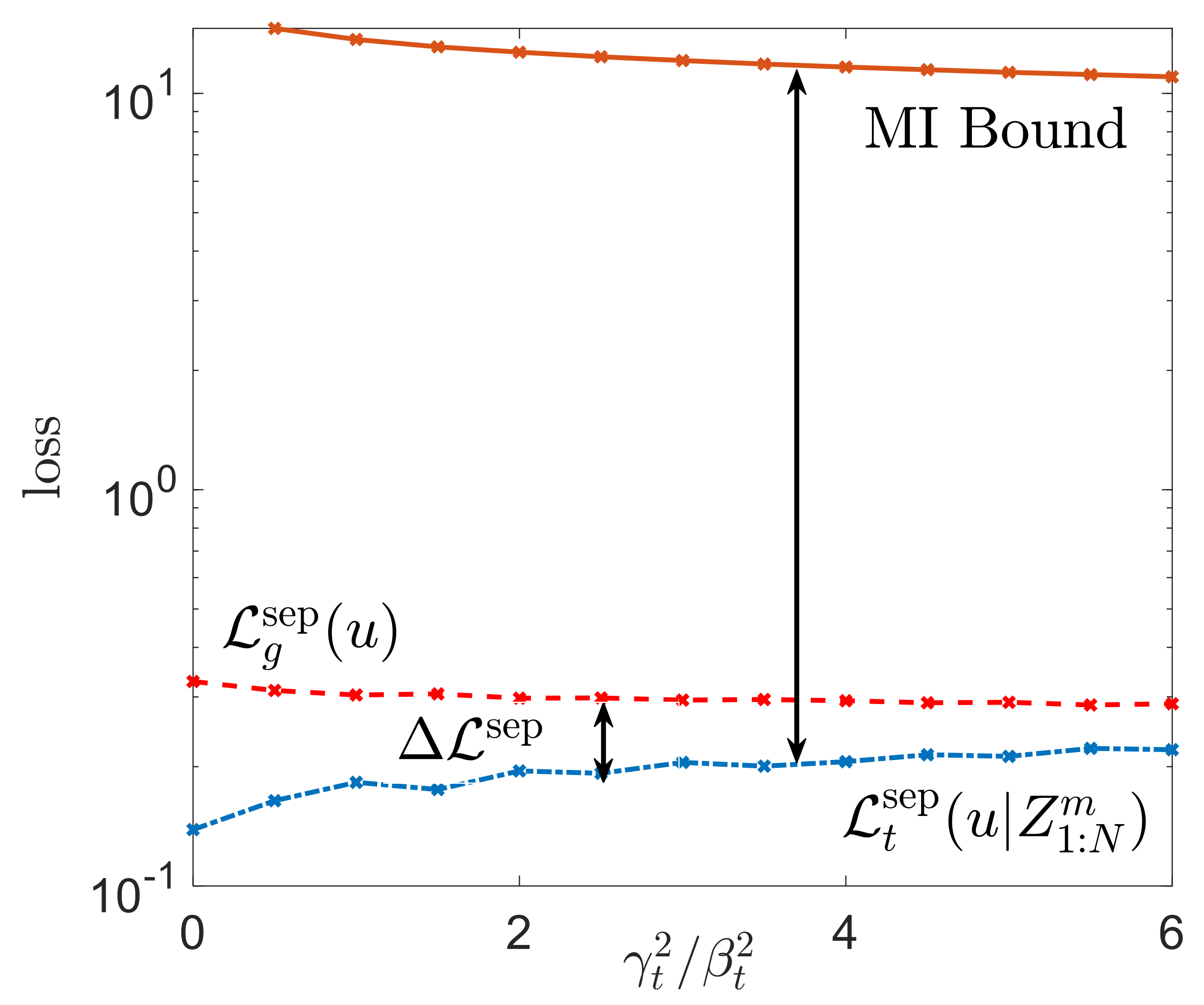
4.3. Discussion on Bounds
5. Applications
5.1. Parameter Estimation
5.1.1. Separate Within-Task Training and Test Sets
5.1.2. Joint Within-Task Training and Testing sets
5.2. Noisy Iterative Meta-Learning Algorithms
- (1)
- (2)
- The meta-training data set sampled at each iteration j is conditionally independent of the history of model-parameter vectors and hyperparameter , i.e.,
- (3)
- The meta-parameter update function is uniformly bounded, i.e., for some .
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Decoupling Estimate Lemmas
Appendix B. Proofs of Theorems 1 and 2
Appendix C. Proofs of Theorems 3 and 4
Appendix D. Details of Example
Appendix E. Proof of Lemma 4
References
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Simeone, O. A Brief Introduction to Machine Learning for Engineers. Found. Trends Signal Process. 2018, 12, 200–431. [Google Scholar] [CrossRef]
- Schmidhuber, J. Evolutionary Principles in Self-Referential Learning, or On Learning How to Learn: The Meta-meta-... Hook. Ph.D. Thesis, Technische Universität München, München, Germany, 1987. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to Learn: Introduction and Overview. In Learning to Learn; Springer: Berlin/Heidelberg, Germany, 1998; pp. 3–17. [Google Scholar]
- Thrun, S. Is Learning the N-th Thing Any Easier Than Learning the First? In Proceedings of the Advances in Neural Information Processing Systems(NIPS); MIT Press: Cambridge, MA, USA, 1996; pp. 640–646. [Google Scholar]
- Vilalta, R.; Drissi, Y. A Perspective View and Survey of Meta-Learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Simeone, O.; Park, S.; Kang, J. From Learning to Meta-Learning: Reduced Training Overhead and Complexity for Communication Systems. arXiv 2020, arXiv:2001.01227. [Google Scholar]
- Kuzborskij, I.; Orabona, F. Fast rates by transferring from auxiliary hypotheses. Mach. Learn. 2017, 106, 171–195. [Google Scholar] [CrossRef]
- Kienzle, W.; Chellapilla, K. Personalized handwriting recognition via biased regularization. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 457–464. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Grazzi, R.; Pontil, M. Learning-to-learn stochastic gradient descent with biased regularization. arXiv 2019, arXiv:1903.10399. [Google Scholar]
- Denevi, G.; Pontil, M.; Ciliberto, C. The advantage of conditional meta-learning for biased regularization and fine-tuning. arXiv 2020, arXiv:2008.10857. [Google Scholar]
- Baxter, J. A Model of Inductive Bias Learning. J. Artif. Intell. Res. 2000, 12, 149–198. [Google Scholar] [CrossRef]
- Russo, D.; Zou, J. Controlling Bias in Adaptive Data Analysis Using Information Theory. In Proceedings of the Artificial Intelligence and Statistics (AISTATS), Cadiz, Spain, 9–11 May 2016; pp. 1232–1240. [Google Scholar]
- Xu, H.; Farajtabar, M.; Zha, H. Learning Granger causality for Hawkes processes. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 20–22 June 2016; pp. 1717–1726. [Google Scholar]
- Maurer, A. Algorithmic Stability and Meta-Learning. J. Mach. Learn. Res. 2005, 6, 967–994. [Google Scholar]
- Devroye, L.; Wagner, T. Distribution-Free Performance Bounds for Potential Function Rules. IEEE Trans. Inf. Theory 1979, 25, 601–604. [Google Scholar] [CrossRef]
- Rogers, W.H.; Wagner, T.J. A Finite Sample Distribution-Free Performance Bound for Local Discrimination Rules. Ann. Stat. 1978, 6, 506–514. [Google Scholar] [CrossRef]
- Pentina, A.; Lampert, C. A PAC-Bayesian Bound for Lifelong Learning. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 991–999. [Google Scholar]
- Amit, R.; Meir, R. Meta-Learning by Adjusting Priors Based on Extended PAC-Bayes Theory. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2018; pp. 205–214. [Google Scholar]
- Rothfuss, J.; Fortuin, V.; Krause, A. PACOH: Bayes-Optimal Meta-Learning with PAC-Guarantees. arXiv 2020, arXiv:2002.05551. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Stamos, D.; Pontil, M. Incremental learning-to-learn with statistical guarantees. arXiv 2018, arXiv:1803.08089. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Xu, A.; Raginsky, M. Information-Theoretic Analysis of Generalization Capability of Learning Algorithms. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 2524–2533. [Google Scholar]
- Bu, Y.; Zou, S.; Veeravalli, V.V. Tightening Mutual Information Based Bounds on Generalization Error. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 587–591. [Google Scholar]
- Pensia, A.; Jog, V.; Loh, P.L. Generalization Error Bounds for Noisy, Iterative Algorithms. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Veil, CO, USA, 17–22 June 2018; pp. 546–550. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities. In Theory of Probability and Its Applications; SIAM: Philadelphia, PA, USA, 1971; Volume 16, pp. 264–280. [Google Scholar]
- Koltchinskii, V.; Panchenko, D. Rademacher Processes and Bounding the Risk of Function Learning. In High Dimensional Probability II; Springer: Berlin/Heidelberg, Germany, 2000; Volume 47, pp. 443–457. [Google Scholar]
- Bousquet, O.; Elisseeff, A. Stability and Generalization. J. Mach. Learn. Res. 2002, 2, 499–526. [Google Scholar]
- Kearns, M.; Ron, D. Algorithmic Stability and Sanity-Check Bounds for Leave-One-Out Cross-Validation. Neural Comput. 1999, 11, 1427–1453. [Google Scholar] [CrossRef]
- Poggio, T.; Rifkin, R.; Mukherjee, S.; Niyogi, P. General Conditions for Predictivity In Learning Theory. Nature 2004, 428, 419–422. [Google Scholar] [CrossRef]
- Kutin, S.; Niyogi, P. Almost-Everywhere Algorithmic Stability and Generalization Error. In Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence (UAI’02); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2002; pp. 275–282. [Google Scholar]
- Dwork, C.; Feldman, V.; Hardt, M.; Pitassi, T.; Reingold, O.; Roth, A.L. Preserving Statistical Validity in Adaptive Data Analysis. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing (STOC), Portland, OR, USA, 15–17 June 2015; pp. 117–126. [Google Scholar]
- Bassily, R.; Nissim, K.; Smith, A.; Steinke, T.; Stemmer, U.; Ullman, J. Algorithmic Stability for Adaptive Data Analysis. In Proceedings of the Forty-Eighth Annual ACM Symposium on Theory of Computing (STOC), Cambridge, MA, USA, 19–21 June 2016; pp. 1046–1059. [Google Scholar]
- McAllester, D.A. PAC-Bayesian Model Averaging. In Proceedings of the Twelfth Annual Conference on Computational Learning Theory (COLT), Santa Cruz, CA, USA, 7–9 July 1999; pp. 164–170. [Google Scholar]
- Seeger, M. PAC-Bayesian Generalization Error Bounds for Gaussian Process Classification. J. Mach. Learn. Res. 2002, 3, 233–269. [Google Scholar]
- Alquier, P.; Ridgway, J.; Chopin, N. On the Properties of Variational Approximations of Gibbs Posteriors. J. Mach. Learn. Res. 2016, 17, 8374–8414. [Google Scholar]
- Asadi, A.; Abbe, E.; Verdú, S. Chaining Mutual Information and Tightening Generalization Bounds. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018; pp. 7234–7243. [Google Scholar]
- Negrea, J.; Haghifam, M.; Dziugaite, G.K.; Khisti, A.; Roy, D.M. Information-Theoretic Generalization Bounds for SGLD via Data-Dependent Estimates. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 11013–11023. [Google Scholar]
- Alabdulmohsin, I. Towards a Unified Theory of Learning and Information. Entropy 2020, 22, 438. [Google Scholar] [CrossRef]
- Jiao, J.; Han, Y.; Weissman, T. Dependence Measures Bounding the Exploration Bias for General Measurements. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1475–1479. [Google Scholar]
- Issa, I.; Gastpar, M. Computable Bounds On the Exploration Bias. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 576–580. [Google Scholar]
- Issa, I.; Esposito, A.R.; Gastpar, M. Strengthened Information-Theoretic Bounds on the Generalization Error. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 582–586. [Google Scholar]
- Steinke, T.; Zakynthinou, L. Reasoning About Generalization via Conditional Mutual Information. arXiv 2020, arXiv:2001.09122. [Google Scholar]
- Knoblauch, J.; Jewson, J.; Damoulas, T. Generalized Variational Inference. arXiv 2019, arXiv:1904.02063. [Google Scholar]
- Bissiri, P.G.; Holmes, C.C.; Walker, S.G. A General Framework for Updating Belief Distributions. J. R. Stat. Soc. Ser. Stat. Methodol. 2016, 78, 1103–1130. [Google Scholar] [CrossRef] [PubMed]
- Yin, M.; Tucker, G.; Zhou, M.; Levine, S.; Finn, C. Meta-Learning Without Memorization. arXiv 2019, arXiv:1912.03820. [Google Scholar]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019; Volume 48. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Learnability, Stability and Uniform Convergence. J. Mach. Learn. Res. 2010, 11, 2635–2670. [Google Scholar]
- Maurer, A.; Pontil, M.; Romera-Paredes, B. The Benefit of Multitask Representation Learning. J. Mach. Learn. Res. 2016, 17, 2853–2884. [Google Scholar]
- Welling, M.; Teh, Y.W. Bayesian Learning via Stochastic Gradient Langevin Dynamics. In Proceedings of the 28th International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011; pp. 681–688. [Google Scholar]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Michalowicz, J.V.; Nichols, J.M.; Bucholtz, F. Handbook of Differential Entropy; CRC Press: New York, NY, USA, 2013. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jose, S.T.; Simeone, O. Information-Theoretic Generalization Bounds for Meta-Learning and Applications. Entropy 2021, 23, 126. https://doi.org/10.3390/e23010126
Jose ST, Simeone O. Information-Theoretic Generalization Bounds for Meta-Learning and Applications. Entropy. 2021; 23(1):126. https://doi.org/10.3390/e23010126
Chicago/Turabian StyleJose, Sharu Theresa, and Osvaldo Simeone. 2021. "Information-Theoretic Generalization Bounds for Meta-Learning and Applications" Entropy 23, no. 1: 126. https://doi.org/10.3390/e23010126
APA StyleJose, S. T., & Simeone, O. (2021). Information-Theoretic Generalization Bounds for Meta-Learning and Applications. Entropy, 23(1), 126. https://doi.org/10.3390/e23010126