Probabilistic Models with Deep Neural Networks


 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Probabilistic Models within the Conjugate Exponential Family
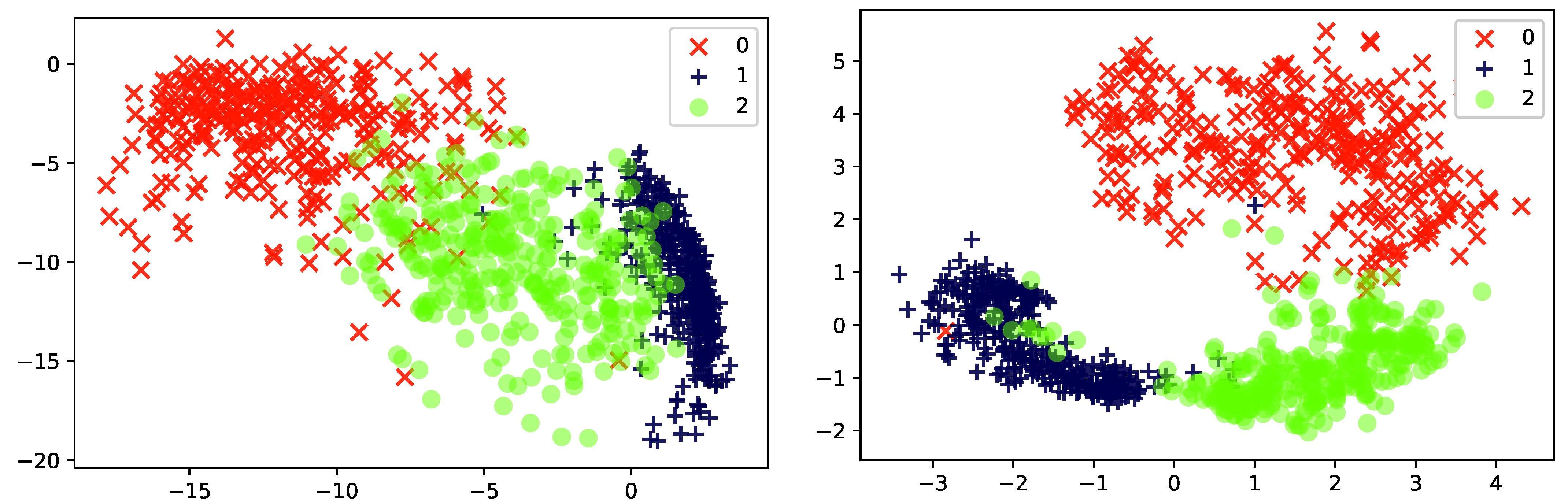
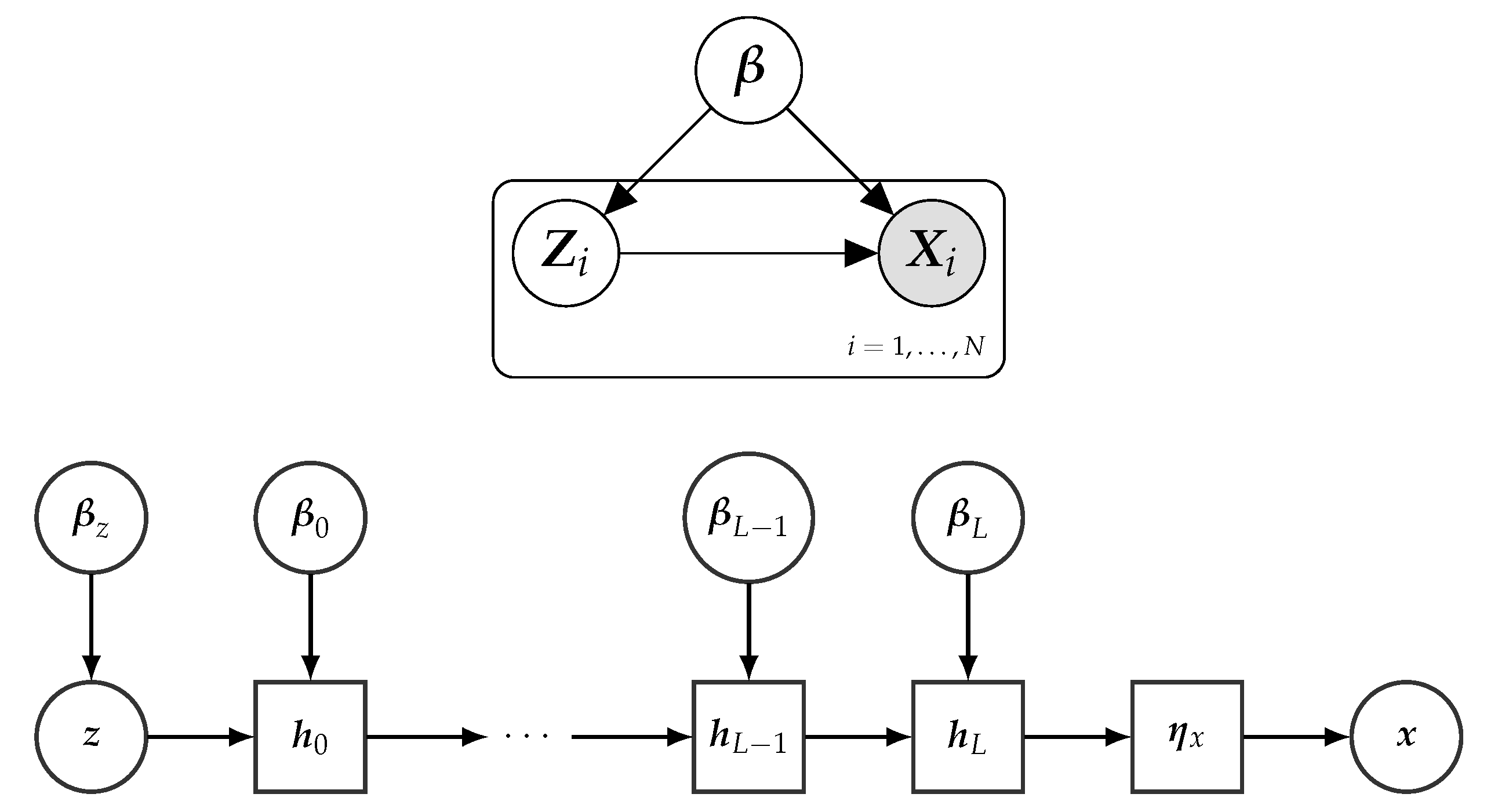
2.1. Latent Variable Models
| Algorithm 1 Pseudo-code of the generative model of a probabilistic PCA model. |
|
2.2. Mean-Field Variational Inference
2.3. Scalable Variational Inference
2.4. Variational Message Passing
3. Deep Neural Networks and Computational Graphs
3.1. Deep Neural Networks
3.2. Computational Graphs
| Algorithm 2 Pseudo-code of the definition and learning of a simple neural network. |
inputx, y the labels.
|
4. Probabilistic Models with Deep Neural Networks
4.1. Deep Latent Variable Models
| Algorithm 3 Pseudo-code of the generative model of a variational auto-encoder (or non-linear probabilistic PCA). |
|
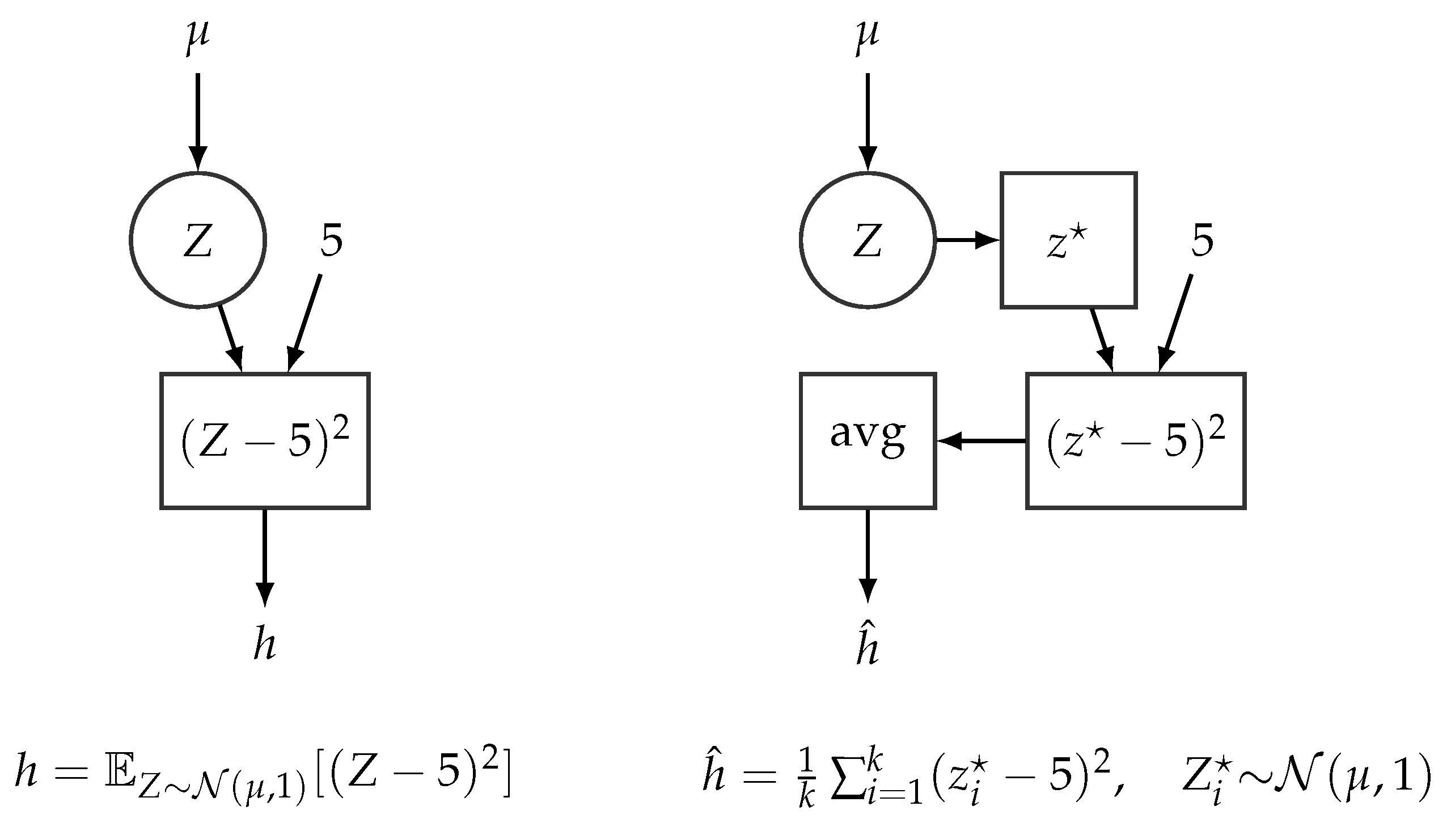
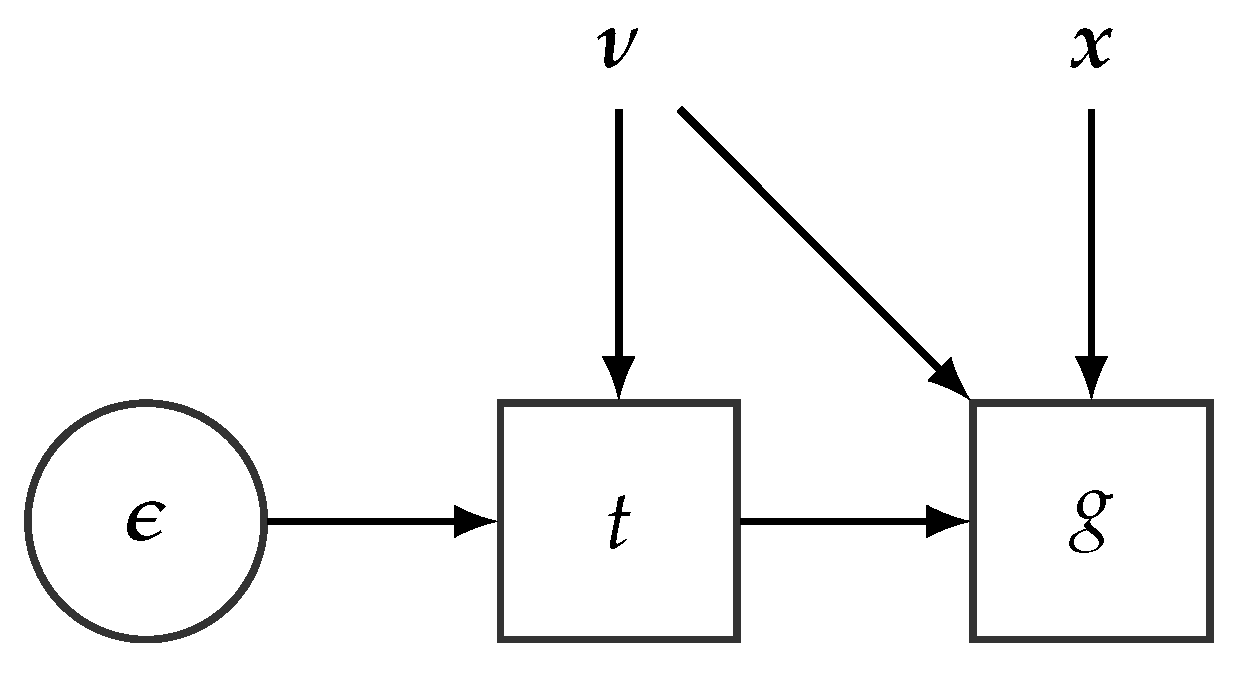
4.2. Stochastic Computational Graphs
5. Variational Inference with Deep Neural Networks
5.1. Black Box Variational Inference
5.1.1. Pathwise Gradients
| Algorithm 4 Pseudo-code for defining the ELBO function , and by translation the SCG, of a VAE with no encoder network (see Algorithm 3). We use a single sample to compute the Monte Carlo estimate of (see Equation (21)). denotes the log-probability function of a normal distribution. |
input Data: xtrain, Variational Parameters:
|
5.1.2. Score Function Gradients
5.2. ELBO Optimization with Amortized Variational Inference
| Algorithm 5 Pseudo-code for the estimation of the ELBO function of a Variational Auto-encoder. We use a single sample to compute the Monte Carlo estimation of (see Equation (21)). denotes the log-probability function of a Normal distribution. |
input Data: xI a single data-sample, N size of the data, Variational Parameters:
|
5.3. Discussion
6. Probabilistic Programming Languages
- Turing.jl [98] is a Julia library for probabilistic programming inference. Originally, Mote Carlo methods were only considered, but recent releases of this library also provide support for variational inference.
7. Conclusions and Open Issues
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1988. [Google Scholar]
- Lauritzen, S.L. Propagation of probabilities, means, and variances in mixed graphical association models. J. Am. Stat. Assoc. 1992, 87, 1098–1108. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: Upper Saddle River, NJ, USA, 2016. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs; Springer: Berlin, Germany, 2007. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Salmerón, A.; Rumí, R.; Langseth, H.; Nielsen, T.; Madsen, A. A review of inference algorithms for hybrid Bayesian networks. J. Artif. Intell. Res. 2018, 62, 799–828. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Salmerón, A.; Cano, A.; Moral, S. Importance sampling in Bayesian networks using probability trees. Comput. Stat. Data Anal. 2000, 34, 387–413. [Google Scholar] [CrossRef]
- Plummer, M. JAGS: A program for analysis of Bayesian graphical models using Gibbs sampling. In Proceedings of the 3rd International Workshop on Distributed Statistical Computing, Vienna, Austria, 20–22 March 2003; Volume 124. [Google Scholar]
- Blei, D.M. Build, compute, critique, repeat: Data analysis with latent variable models. Annu. Rev. Stat. Its Appl. 2014, 1, 203–232. [Google Scholar] [CrossRef]
- Murphy, K.P.; Weiss, Y.; Jordan, M.I. Loopy belief propagation for approximate inference: An empirical study. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 30 July–1 August 1999; Morgan Kaufmann Publishers: San Fransisco, CA, USA, 1999; pp. 467–475. [Google Scholar]
- Minka, T.P. Expectation propagation for approximate Bayesian inference. In Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, Seattle, WA, USA, 2–5 August 2001; Morgan Kaufmann Publishers: San Fransisco, CA, USA, 2001; pp. 362–369. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical Models, Exponential Families, and Variational Inference; Foundations and Trends® in Machine Learning; Now Publishers Inc.: Norwell, MA, USA, 2008; Volume 1, pp. 1–305. [Google Scholar]
- Jordan, M.I.; Ghahramani, Z.; Jaakkola, T.S.; Saul, L.K. An introduction to variational methods for graphical models. Mach. Learn. 1999, 37, 183–233. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Hoffman, M.D.; Blei, D.M.; Wang, C.; Paisley, J. Stochastic Variational Inference. J. Mach. Learn. Res. 2013, 14, 1303–1347. [Google Scholar]
- Barndorff-Nielsen, O. Information and Exponential Families in Statistical Theory; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Winn, J.M.; Bishop, C.M. Variational Message Passing. J. Mach. Learn. Res. 2005, 6, 661–694. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ranganath, R.; Gerrish, S.; Blei, D. Black box variational inference. In Proceedings of the Artificial Intelligence and Statistics, Reykjavic, Iceland, 22–25 April 2014; pp. 814–822. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Salakhutdinov, R. Learning deep generative models. Annu. Rev. Stat. Its Appl. 2015, 2, 361–385. [Google Scholar] [CrossRef]
- Tran, D.; Kucukelbir, A.; Dieng, A.B.; Rudolph, M.; Liang, D.; Blei, D.M. Edward: A library for probabilistic modeling, inference, and criticism. arXiv 2016, arXiv:1610.09787. [Google Scholar]
- Tran, D.; Hoffman, M.W.; Moore, D.; Suter, C.; Vasudevan, S.; Radul, A. Simple, distributed, and accelerated probabilistic programming. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 7608–7619. [Google Scholar]
- Bingham, E.; Chen, J.P.; Jankowiak, M.; Obermeyer, F.; Pradhan, N.; Karaletsos, T.; Singh, R.; Szerlip, P.; Horsfall, P.; Goodman, N.D. Pyro: Deep Universal Probabilistic Programming. arXiv 2018, arXiv:1810.09538. [Google Scholar]
- Cabañas, R.; Salmerón, A.; Masegosa, A.R. InferPy: Probabilistic Modeling with TensorFlow Made Easy. Knowl.-Based Syst. 2019, 168, 25–27. [Google Scholar] [CrossRef]
- Cózar, J.; Cabañas, R.; Salmerón, A.; Masegosa, A.R. InferPy: Probabilistic Modeling with Deep Neural Networks Made Easy. Neurocomputing 2020, 415, 408–410. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Software. Available online: https://www.tensorflow.org (accessed on 15 January 2021).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS AutoDiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Zhang, C.; Bütepage, J.; Kjellström, H.; Mandt, S. Advances in variational inference. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2008–2026. [Google Scholar] [CrossRef]
- Gordon, A.D.; Henzinger, T.A.; Nori, A.V.; Rajamani, S.K. Probabilistic programming. In Proceedings of the on Future of Software Engineering; ACM: New York, NY, USA, 2014; pp. 167–181. [Google Scholar]
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452. [Google Scholar] [CrossRef]
- Bishop, C.M. Latent variable models. In Learning in Graphical Models; Springer: Berlin/Heidelberg, Germany, 1998; pp. 371–403. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Masegosa, A.; Nielsen, T.D.; Langseth, H.; Ramos-Lopez, D.; Salmerón, A.; Madsen, A.L. Bayesian Models of Data Streams with Hierarchical Power Priors. arXiv 2017, arXiv:1707.02293. [Google Scholar]
- Masegosa, A.; Ramos-López, D.; Salmerón, A.; Langseth, H.; Nielsen, T. Variational inference over nonstationary data streams for exponential family models. Mathematics 2020, 8, 1942. [Google Scholar] [CrossRef]
- Kucukelbir, A.; Tran, D.; Ranganath, R.; Gelman, A.; Blei, D.M. Automatic differentiation variational inference. J. Mach. Learn. Res. 2017, 18, 430–474. [Google Scholar]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 2000, 155, 945–959. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Amari, S.I. Natural gradient works efficiently in learning. Neural Comput. 1998, 10, 251–276. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 661–670. [Google Scholar]
- Masegosa, A.R.; Martinez, A.M.; Langseth, H.; Nielsen, T.D.; Salmerón, A.; Ramos-López, D.; Madsen, A.L. Scaling up Bayesian variational inference using distributed computing clusters. Int. J. Approx. Reason. 2017, 88, 435–451. [Google Scholar] [CrossRef]
- Hopfield, J.J. Artificial neural networks. IEEE Circuits Devices Mag. 1988, 4, 3–10. [Google Scholar] [CrossRef]
- Hahnloser, R.H.; Sarpeshkar, R.; Mahowald, M.A.; Douglas, R.J.; Seung, H.S. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 2000, 405, 947–951. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence And Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Griewank, A. On automatic differentiation. Math. Program. Recent Dev. Appl. 1989, 6, 83–107. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Pless, R.; Souvenir, R. A survey of manifold learning for images. IPSJ Trans. Comput. Vis. Appl. 2009, 1, 83–94. [Google Scholar] [CrossRef]
- Kulkarni, T.D.; Whitney, W.F.; Kohli, P.; Tenenbaum, J. Deep convolutional inverse graphics network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 2539–2547. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. Draw: A recurrent neural network for image generation. arXiv 2015, arXiv:1502.04623. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 3483–3491. [Google Scholar]
- Pu, Y.; Gan, Z.; Henao, R.; Yuan, X.; Li, C.; Stevens, A.; Carin, L. Variational autoencoder for deep learning of images, labels and captions. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2352–2360. [Google Scholar]
- Semeniuta, S.; Severyn, A.; Barth, E. A hybrid convolutional variational autoencoder for text generation. arXiv 2017, arXiv:1702.02390. [Google Scholar]
- Hsu, W.N.; Zhang, Y.; Glass, J. Learning latent representations for speech generation and transformation. arXiv 2017, arXiv:1704.04222. [Google Scholar]
- Gómez-Bombarelli, R.; Wei, J.N.; Duvenaud, D.; Hernández-Lobato, J.M.; Sánchez-Lengeling, B.; Sheberla, D.; Aguilera-Iparraguirre, J.; Hirzel, T.D.; Adams, R.P.; Aspuru-Guzik, A. Automatic chemical design using a data-driven continuous representation of molecules. ACS Cent. Sci. 2018, 4, 268–276. [Google Scholar] [CrossRef]
- Johnson, M.; Duvenaud, D.K.; Wiltschko, A.; Adams, R.P.; Datta, S.R. Composing graphical models with neural networks for structured representations and fast inference. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2946–2954. [Google Scholar]
- Linderman, S.W.; Miller, A.C.; Adams, R.P.; Blei, D.M.; Paninski, L.; Johnson, M.J. Recurrent switching linear dynamical systems. arXiv 2016, arXiv:1610.08466. [Google Scholar]
- Zhou, M.; Cong, Y.; Chen, B. The Poisson Gamma belief network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 3043–3051. [Google Scholar]
- Card, D.; Tan, C.; Smith, N.A. A Neural Framework for Generalized Topic Models. arXiv 2017, arXiv:1705.09296. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A recurrent latent variable model for sequential data. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 2980–2988. [Google Scholar]
- Jiang, Z.; Zheng, Y.; Tan, H.; Tang, B.; Zhou, H. Variational deep embedding: An unsupervised and generative approach to clustering. arXiv 2016, arXiv:1611.05148. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Louizos, C.; Shalit, U.; Mooij, J.M.; Sontag, D.; Zemel, R.; Welling, M. Causal effect inference with deep latent-variable models. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6446–6456. [Google Scholar]
- Ou, Z. A Review of Learning with Deep Generative Models from Perspective of Graphical Modeling. arXiv 2018, arXiv:1808.01630. [Google Scholar]
- Schulman, J.; Heess, N.; Weber, T.; Abbeel, P. Gradient estimation using stochastic computation graphs. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 3528–3536. [Google Scholar]
- Dillon, J.V.; Langmore, I.; Tran, D.; Brevdo, E.; Vasudevan, S.; Moore, D.; Patton, B.; Alemi, A.; Hoffman, M.; Saurous, R.A. TensorFlow Distributions. arXiv 2017, arXiv:1711.10604. [Google Scholar]
- Wingate, D.; Weber, T. Automated variational inference in probabilistic programming. arXiv 2013, arXiv:1301.1299. [Google Scholar]
- Mnih, A.; Gregor, K. Neural variational inference and learning in belief networks. arXiv 2014, arXiv:1402.0030. [Google Scholar]
- Dayan, P.; Hinton, G.E.; Neal, R.M.; Zemel, R.S. The Helmholtz machine. Neural Comput. 1995, 7, 889–904. [Google Scholar] [CrossRef]
- Gershman, S.; Goodman, N. Amortized inference in probabilistic reasoning. In Proceedings of the Annual Meeting of the Cognitive Science Society, Quebec City, QC, Canada, 23–26 July 2014; Volume 36, pp. 517–522. [Google Scholar]
- Glasserman, P. Monte Carlo Methods in Financial Engineering; Springer: Berlin/Heidelberg, Germany, 2013; Volume 53. [Google Scholar]
- Fu, M.C. Gradient estimation. Handbooks Oper. Res. Manag. Sci. 2006, 13, 575–616. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. arXiv 2014, arXiv:1401.4082. [Google Scholar]
- Titsias, M.; Lázaro-Gredilla, M. Doubly stochastic variational Bayes for non-conjugate inference. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1971–1979. [Google Scholar]
- Figurnov, M.; Mohamed, S.; Mnih, A. Implicit Reparameterization Gradients. arXiv 2018, arXiv:1805.08498. [Google Scholar]
- Tucker, G.; Mnih, A.; Maddison, C.J.; Lawson, J.; Sohl-Dickstein, J. Rebar: Low-variance, unbiased gradient estimates for discrete latent variable models. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2627–2636. [Google Scholar]
- Grathwohl, W.; Choi, D.; Wu, Y.; Roeder, G.; Duvenaud, D. Backpropagation through the void: Optimizing control variates for black-box gradient estimation. arXiv 2017, arXiv:1711.00123. [Google Scholar]
- Glynn, P.W. Likelihood ratio gradient estimation for stochastic systems. Commun. ACM 1990, 33, 75–84. [Google Scholar] [CrossRef]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Ruiz, F.; Titsias, M.; Blei, D. The generalized reparameterization gradient. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 460–468. [Google Scholar]
- Mnih, A.; Rezende, D.J. Variational inference for Monte Carlo objectives. arXiv 2016, arXiv:1602.06725. [Google Scholar]
- Foerster, J.; Farquhar, G.; Al-Shedivat, M.; Rocktäschel, T.; Xing, E.P.; Whiteson, S. DiCE: The Infinitely Differentiable Monte-Carlo Estimator. arXiv 2018, arXiv:1802.05098. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2, e55. [Google Scholar] [CrossRef]
- Carpenter, B.; Gelman, A.; Hoffman, M.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.A.; Guo, J.; Li, P.; Riddell, A. Stan: A probabilistic programming language. J. Stat. Softw. 2016, 20, 1–37. [Google Scholar] [CrossRef]
- Ge, H.; Xu, K.; Ghahramani, Z. Turing: A Language for Flexible Probabilistic Inference. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Spain, 9–11 April 2018; Storkey, A., Perez-Cruz, F., Eds.; Proceedings of Machine Learning Research; PMLR: Playa Blanca, Lanzarote, Spain, 2018; Volume 84, pp. 1682–1690. [Google Scholar]
- Ketkar, N. Introduction to keras. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 97–111. [Google Scholar]
- Bergstra, J.; Breuleux, O.; Bastien, F.; Lamblin, P.; Pascanu, R.; Desjardins, G.; Turian, J.; Warde-Farley, D.; Bengio, Y. Theano: A CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), Austin, TX, USA, 28 June–3 July 2010; Volume 4, pp. 3–10. [Google Scholar]
- Baudart, G.; Burroni, J.; Hirzel, M.; Kate, K.; Mandel, L.; Shinnar, A. Extending Stan for deep probabilistic programming. arXiv 2020, arXiv:1810.00873. [Google Scholar]
- Murray, L.M.; Schön, T.B. Automated learning with a probabilistic programming language: Birch. Annu. Rev. Control 2018, 46, 29–43. [Google Scholar] [CrossRef]
- Tehrani, N.; Arora, N.S.; Li, Y.L.; Shah, K.D.; Noursi, D.; Tingley, M.; Torabi, N.; Masouleh, S.; Lippert, E.; Meijer, E.; et al. Bean machine: A declarative probabilistic programming language for efficient programmable inference. In Proceedings of the 10th International Conference on Probabilistic Graphical Models, Aalborg, Denmark, 23–25 September 2020. [Google Scholar]
- Minka, T.; Winn, J.; Guiver, J.; Webster, S.; Zaykov, Y.; Yangel, B.; Spengler, A.; Bronskill, J. Infer.NET. 2014. Available online: https://research.microsoft.com/infernet (accessed on 15 January 2021).
- Maddison, C.J.; Mnih, A.; Teh, Y.W. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. arXiv 2016, arXiv:1611.00712. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masegosa, A.R.; Cabañas, R.; Langseth, H.; Nielsen, T.D.; Salmerón, A. Probabilistic Models with Deep Neural Networks. Entropy 2021, 23, 117. https://doi.org/10.3390/e23010117
Masegosa AR, Cabañas R, Langseth H, Nielsen TD, Salmerón A. Probabilistic Models with Deep Neural Networks. Entropy. 2021; 23(1):117. https://doi.org/10.3390/e23010117
Chicago/Turabian StyleMasegosa, Andrés R., Rafael Cabañas, Helge Langseth, Thomas D. Nielsen, and Antonio Salmerón. 2021. "Probabilistic Models with Deep Neural Networks" Entropy 23, no. 1: 117. https://doi.org/10.3390/e23010117
APA StyleMasegosa, A. R., Cabañas, R., Langseth, H., Nielsen, T. D., & Salmerón, A. (2021). Probabilistic Models with Deep Neural Networks. Entropy, 23(1), 117. https://doi.org/10.3390/e23010117