1. Introduction
With the dramatic growing number of wireless devices, more stringent requirements are put forward for performance and energy efficiency of heterogeneous networks (HetNets) [
1]. With the increasing complexity of HetNets, the optimization of energy efficiency has more and more challenges and is one of the hot spots of communication network research, especially for the HetNets with 5G BSs. Therefore, in this paper, the efficiency of resource allocation algorithm is studied, in which the reinforcement learning (RL) is utilized and the parameters such as ABS (almost blank sub-frame), CRE (Cell range expansion), and SI-SBSs (sleeping indicaton of small BSs) are jointly considered simultaneously to optimize the energy efficiency of the whole network.
In general, the optimization problems with multi-variables are non-convex NP problems, it is hard to be solved directly. Some can be processed by dividing the original problem into sub-problems which can be iteratively solved with an acceptable complexity. Baidas et al. [
2] jointly considered subcarriers assignment and global energy-efficient (GEE) power allocation, and the original problem was divided into two subproblems as subcarrier allocation by many to many matching and GEE maximizing power allocation. By designing a two-stage solution program, the original problem was effectively solved with the ensured stability. Chen et al. [
3] jointly investigated the task allocation and CPU-cycle frequency, in order to achieve the minimum energy consumption which scaled down to the sum of two deterministic optimization subproblems by Lyapunov optimization theory. The optimal solutions of the two sub-problems separately which were local computation allocation (LCA) and offloaded computation allocation (OCA) were found to obtain the optimal solution of the upper bound of the original problem. Although decomposition and iteration are efficient to solve the non-convex NP problems in many cases, the complexity of modeling and computing is still high in most cases.
As the AI technologies are developing with a very high speed in the recent years, some learning methods are introduced to solve some complicated optimization problems. As shown in [
4,
5,
6,
7,
8,
9], model-free RL methods can be an efficient way to solve the energy efficiency optimization problem of HetNets, since the precise model process was not necessary. In [
4,
5], the Actor–Critic (AC) algorithm was applied to optimize energy efficiency of HetNets while the authors did not conduct in-depth research on the selections of basis functions which are challenging for the application of RL. Roohollah et al. [
6] introduced a Q-Learning (QL) based distributed power allocation algorithm (Q-DPA) as a self-organizing mechanism to solve the power optimization problem in the networks. In [
7], a method based on QL was proposed to solve the energy efficiency and delay problems of smart grid data transmission in HetNets, in which, however, the dimension of action and state space was too large. Ayala-Romero et al. [
8,
9] combined dynamic programming, neural networks, and data-driven methods to solve problem of energy saving and interference coordination in HetNets.
In this paper, inspired from the previous works [
2,
4,
5,
6,
7,
8,
9,
10], referring to RL and the idea of converting non-convex NP hard problem into several sub-problems, a turbo QL (TQL) scheme is proposed to optimize energy efficiency in which the traditional QL algorithm is decomposed into several sub-Q-Learning algorithms and has a loop iteration structure, each sub-Q-learning solving each sub-problem. In our scheme, the parameters ABS, CRE, and SI-SBSs are jointly taken into account as action vectors, the user positions are taken as the states in order to fully consider the randomness of users in BSs, and the reward function is designed as a negative reciprocal of the system energy efficiency. The problem of dimensional explosion with increased action space is solved by our proposed TQL structure, and it is acceptable for the complexity of the algorithm. For the states, a fully connected deep neural network is designed to identify state type. The contributions of this paper are summarized as follows.
(1) The reward function is designed as a negative reciprocal of the system energy efficiency to avoid the slow speed of convergence and the possibility of fulling into local optimum. If the magnitude of the reward in RL is too large, it is easy to fall into the local optimization, and too small value can cause the problem of system oscillation or slow speed of convergence. In this paper, directly using energy efficiency as the reward function causes the reward value too large and it is easy to fall into the local optimum. As shown in our experimental results, our designed reward function works well.
(2) The TQL is proposed by combining traditional Q-Learning and multistage decision process which has a loop iteration structure, each sub-Q-Learning solving each sub-problem which is from an original optimization problem. It effectively deals with the dimensional explosion problem caused by the action space increasing in RL and greatly reduces the complexity of optimization problems.
(3) The relevant parameters of each sub-problem can be adjusted independently. Thus, the complexity is low in our proposed TQL algorithm. Simulation results show that the TQL algorithm can solve the original problem with efficiency and flexibility.
The rest of the paper is organized as follows. Related works are summarized in
Section 2.
Section 3 introduces the system model. In
Section 4, the energy efficiency model is formulated. Our proposed algorithm is presented in
Section 5.
Section 6 shows the simulation framework and numerical results, and conclusions are drawn in
Section 7.
3. System Model
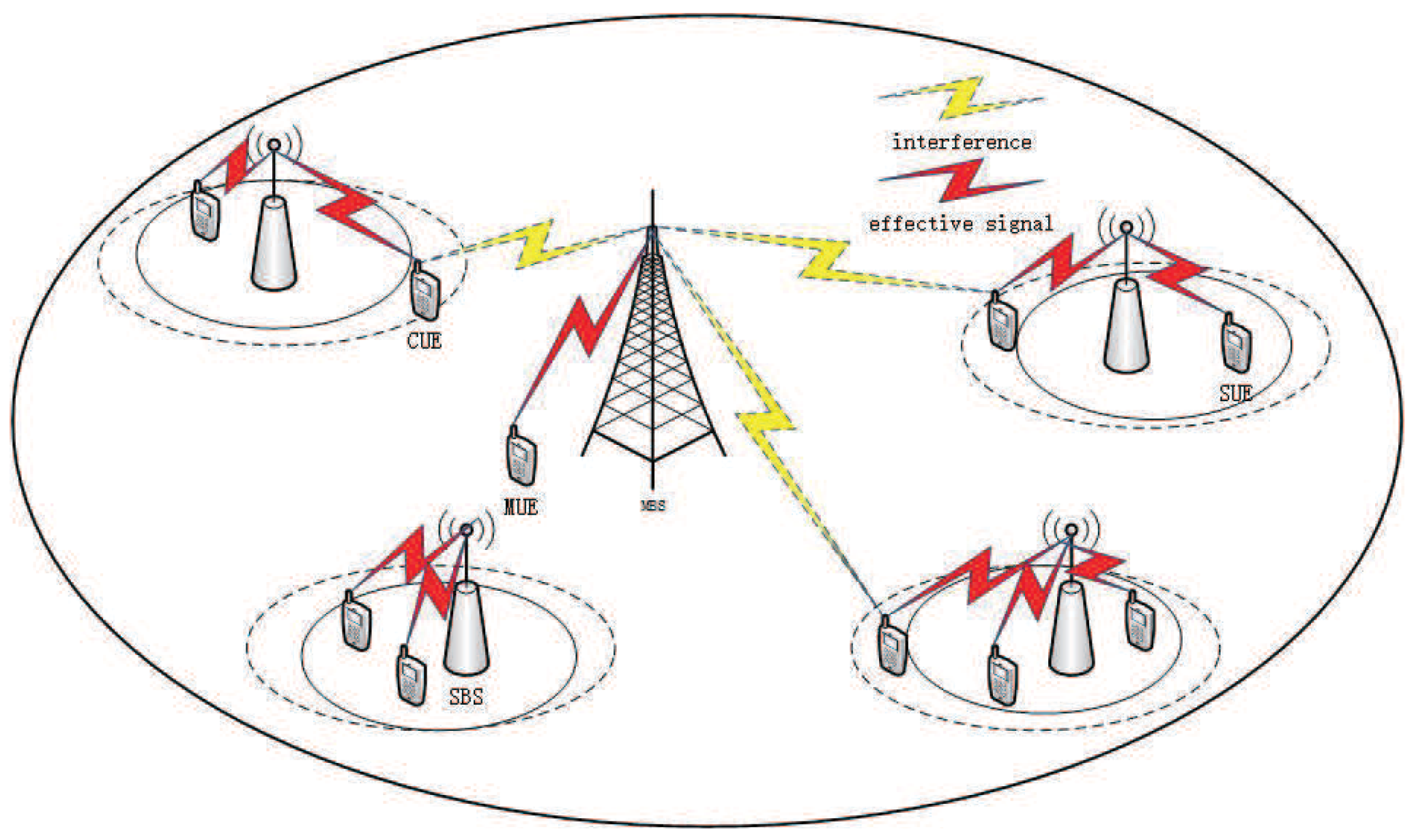
We consider a two-layer HetNets scenario as shown in
Figure 1, in which a cell contains the macro base stations (MBSs) and SBSs. The SBSs are randomly deployed within the coverage of MBSs. The sets of the SBSs and the MBSs are denoted as
S and
M, respectively. The users (UEs) randomly enter the cell. According to a set of UEs association with BSs, UEs are divided into SBS UEs (SUEs) and MBS UEs (MUEs) who are associated with SBSs and MBS, respectively.
In order to balance the load of the entire system network and reduce cross-layer interference by offloading the users of MBSs to SBSs, the enhanced Inter-cell Interference Coordination (eICIC) technology was proposed with two important parameters as ABS and CRE according to [
34]. To reduce signal interference, MBSs and SBSs use radio resources in different time periods (subframes) according to eICIC. A frame is divided into some sub frames as ABS and non-ABS subframes, and MBSs normally transmit normal power in nABS (non-ABS) subframes and keep silent or transmit low power in ABS subframes, where the ratio of ABS in a frame is donated as
α. The SBSs keep normal transmit power in the whole frames. In the time domain, since the MBSs are allowed to be muted in an ABS subframe period, the interference of the MBSs to the users serviced by SBSs is reduced. Therefore, the SINR of UEs with poor channel condition is improved since there is no interference from MBSs in these ABS subframes.
In general, the power of MBSs is much higher than that of SBSs, and some UEs should be accessed to the MBSs according to the reference signal receiving power (RSRP). This is because the UEs in LTE networks are associated with the BSs based on RSRP policy where the UEs are connected to the BSs with the highest reference signal. To balance load and improve the system capacity, SBSs are designed to enhance the frequency multiplexing of the network. CRE was proposed to support SBSs to extend their coverage by adding a bias to their RSRP in which users outside the edge of the SBSs can be connected to the SBSs. The UEs located in the extended area of the SBSs receive less interference from MBSs in ABS subframes and get better channel gain to improve their SINR.
Due to the two operating modes of the MBSs in the ABS subframes and non-ABS subframes (nABS), there are also two interference modes for the UEs in the downlink in the HetNets. When the MBSs are in the ABS subframes, the UEs receive only the signal transmitted by the SBSs. However, the MBSs are in the nABS subframes, and the UEs are interfered by the transmitted signal from the SBSs and the MBSs.
The
of the UE
n connected to the MBS
k can be expressed as
where
is the transmission power from the MBS
k to the UE
n in the nABS subframes,
is the transmission power from the MBS
j to the UE
n in the ABS subframes,
represents the channel gain from the MBS
k to UE
n,
denotes the transmission power from the SBS
j to the UE
n,
indicates noise variance of the additive white Gaussian,
and
are denoted as MBSs in the ABS and nABS subframes periods, respectively. Note that
m and
M are short for
and
, respectively.
The
of the UE
n connected in the SBS
k can be written as
where
and
are denoted as the SBSs sets in the ABS subframes and nABS subframes, respectively. Hence, the transmission rate of UE
n connected to the BS
k can be given as
where
B is the system bandwidth.
4. Problem Formulation
For comprehensively optimizing the energy efficiency of HetNets, the parameters such as SI-SBSs, ABS, and CRE should be jointly considered. The optimization problem is modeled by setting the energy efficiency of the system as the optimization objective function. Based on the above analysis, we can establish a joint optimization energy efficiency problem as
where the relationship during state
, the CRE setting size of the SB
k and transmission power
is closely related.
is closely related to the number of active SBSs.
Let
represent the connection status between BS
k and UE
n, which is expressed as
where
indicates that a connection is established between BS
k and UE
n, otherwise 0. Equation (
6) represents that each UE in the cell can only be connected to one BS.
The transmission power from the BS
k to the UE
n at different subframe times can be expressed as
where
where
is the number of BS transceivers,
indicates MBSs consumption power in sleep state, and
represents maximum transmission power of the MBSs,
denotes the load factor of the BSs, which depends on ABS, CRE, and the load density of the BSs, and
is
where
represents active state which is 1, and otherwise 0,
denotes the maximum RF output power of the SBSs, and
indicates the power when there is no RF of SBSs,
is the power consumption when the BSs transceiver station are in sleep state, and
is
where
represents the proportion of the BSs that wake up the transceiver from sleep to activation state.
Note that ABS, CRE, and the number of active SBSs all affect the load factor of the BSs, which makes problem (
4) become complicated and be a non-convex problem. In order to fully consider the complexity and unknown characteristics of the real environment, the optimization problem (
4) can be changed as
where
f function is unknown,
represents the CRE parameter,
represents the number of SBSs activations.
5. Solution with a Tql Algorithm
It is difficult to solve (
12) directly because the complexity of the target optimization system is an unknown non-convex problem. In [
12], the Gauss–Seidel method needs too much prior knowledge, which is not as convenient as reinforcement learning. In this paper, the table reinforcement learning method QL is used to optimize the system energy efficiency and then our TQL algorithm is proposed to optimize it.
5.1. Q-Learning Algorithm
The environment is typically formulated as a finite-state Markov Decision Process (MDP) and we set a finite discrete time series
. ABS and CRE are denoted by
and
, respectively. The activation state of the SBSs in the state
is
, where
, and
represents the number of SBSs in a cell. According to the Control Space Augmentors (CSA) concept mentioned in [
9], the SBSs states
can be derived based on the number of SBSs activations
in the cell, where A, B, and
represent a limited set of all parameter configurations. Let
be a discrete set of environment states and
be a discrete set of actions. At each step
t, the agent senses the environment state
and selects an action
to be performed, where
s is the position of a certain number of UEs in the cell,
represents the set of cell UEs positions,
a is optimal
,
and
parameter configurations to optimize the energy efficiency of the system, and
represents the set of parameter configurations. As a result, the environment makes a transition to the new state
according to probability
and thereby generates a reward
passing to the agent. MDP is denoted as a tople (
,
,
,
), where
- •
is the set of finite state space;
- •
is the set of finite action space;
- •
is the set of transition probabilities;
- •
represents the set of reward funtion.
(1) State: The position of users at step t is considered as state , and the set of states is denoted as .
(2) Action: The ABS configuration , the CRE bias , and the number of SBS activations are considered as action at state where , and . The action space size is .
(3) State transition: The location of users in the cell changes is considered irregularly, and the state transition is random.
(4) Reward function: The optimization problem is system energy efficiency which is used as reward function, but, in the actual simulation process, the reward is too large, which causes the system to fall into the local optimum easily. Our proposed solution is that negative reciprocal of energy efficiency is designed as the reward.
The goal of RL is to find out the expectation of the strategy with the greatest cumulative reward, which can be expressed as
where discount factor
indicates the degree of influence of successor states on current state, and
represents the reward of state
selecting
and then transiting to state
.
The best decision sequence of MAP is solved by the Bellman equation. The state-action value function
can evaluate the current state. The value of each state-action is not only determined by the current state but also by the successor states. Therefore, the state-action value function
of the current s can be obtained by the cumulative reward expectation of the state. Bellman’s equation can be given as [
35]
which is also equivalent to
Optimal action-value function
can be written as
The update process of Q-value using a time difference method is expressed as [
35]
where
is the learning rate. According to the Formula (
17), the QL algorithm is utilized to solve problem (
12) as shown in Algorithm 1:
| Algorithm 1: The QL for optimizing original problem. |
| Require: the set of state K, the set of action X, earning rate , greedy probability , |
| discount factor , and . |
| Ensure: Q table. |
| 1: Initialize , state s and n = 0 and setting ; |
| 2: while n <= do |
|
| 3: In state s, select the optimal action a with greedy probability ; |
| 4: Observe r; |
| 5: randomly transfer from s to ; |
| 6: Update according to Formula (17); |
| 7: ; |
| 8: ; |
| 9: end while |
| 10: Output: Q table; |
5.2. Tql Algorithm
If QL is directly utilized to solve the original problem (
12) as shown in Algorithm 1, we can see the action size
is too large, where
represents a cardinality of set. Since the action is represented by a vector of three dimensions, the optimization problem can be decomposed into three subproblems. We propose the TQL algorithm which decomposes the objective optimization problem into three sub-problems as optimizing the ratio of ABS
, CRE bias
, and the number of SBS activations
to reduce action space size.
5.2.1. Sub-Problem A: Given the Cre Bias and the Number of Sbs Activation for Optimizing the Abs Ratio
The action of the sub-problem A is
where
and
are given.
and the action space size is
. State
s =
. The tabular method of Q-learning can be used to solve sub-problem A and the updating rule of sub-Q-value can be written as
and shown in Algorithm 2.
| Algorithm 2: The CRE bias and the number of SBSs activation are given to optimize the ABS ratio . |
| Require: . |
| Ensure: Optimized ABS ratio . |
| 1: Initialize , state s and n = 0; |
| 2: Setting learning rate , greedy probability , discount factor and ; |
| 3: while n <= do |
| 4: In state s, select the optimal action a with greedy probability ; |
| 5: Observe r; |
| 6: randomly transfer from s to ; |
| 7: Update according to Formula (18); |
| 8: ; |
| 9: ; |
| 10: end while |
| 11: Output: ; |
5.2.2. Sub-Problem B: Given the Abs Ratio and the Number of Sbs Activation for Optimizing the Cre Bias
The action of the sub-problem B is
where
and
are known.
and the action space size is
. State
s =
. Like Formula (
18), the updating rule of sub-Q-value can be written as
and shown in Algorithm 3.
| Algorithm 3: The ABS ratio and the number of SBSs activation are given to optimize the CRE bias . |
| Require: . |
| Ensure: Optimized CRE bias . |
| 1: Initialize , state s and n = 0; |
| 2: Setting learning rate , greedy probability , discount factor , and ; |
| 3: while n<= do |
| 4: In state s, select the optimal action a with greedy probability ; |
| 5: Observe r; |
| 6: randomly transfer from s to ; |
| 7: Update according to Formula (19); |
| 8: ; |
| 9: ; |
| 10: end while |
| 11: Output: ; |
5.2.3. Sub-Problem C: Given the Abs Ratio and the Cre Bias for Optimizing the Number of Sbs Activation
The action of the sub-problem B is
where
and
are known.
and the action space size is
. State
s =
. It is similar to Formula (
18) and the updating rule of sub-Q-value can be written as
and shown in Algorithm 4.
| Algorithm 4: The ABS ratio and the CRE bias are given to optimize the number of SBS activation . |
| Require: . |
| Ensure: Optimized ABS ratio . |
| 1: Initialize , state s and n = 0; |
| 2: Setting learning rate , greedy probability , discount factor , and |
| 3: while n <= do |
| 4: In state s, select the optimal action a with greedy probability ; |
| 5: Observe r; |
| 6: randomly transfer from s to ; |
| 7: Update according to Formula (20); |
| 8: ; |
| 9: ; |
| 10: end while |
| 11: Output: ; |
The TQL algorithm solves the original problem (11) shown in Algorithm 5.
| Algorithm 5: The algorithm for optimizing initial problems. |
| Require: , , , Reward r, Learning rate , |
| Greedy probability and Discount factor . |
| Ensure: Optimal action configuration in each state. |
| 1: Initialize , , , , |
| 2: while n <= do |
| 3: Fixed the CRE bias and the number of SBS activation , calculate the ABS ratio |
| according to Algorithm 2. Pass the solved to step (4) and step (5); |
| 4: Fixing the ABS ratio and the number of SBS activation , calculate the CRE bias |
| according to Algorithm 3. Pass the solved to step (3) and step (4); |
| 5: Fix the ABS ratio and the CRE bias , calculate the number of SBS activation |
| according to Algorithm 4. Pass the solved to step (4) and step (3); |
| 6: ; |
| 7: end while |
| 8: Output: , , ; |
In summary, our scheme has changed the size of action space from traditional exponential increase as to linear increase as , which greatly reduces the dimension and size of the action space.
Algorithm 5 can be considered as a multi-stage decision process optimization problem which is shown in
Figure 2. The action spaces of the third, fourth, and fifth step in Algorithm 5, which are the optimization problem of Algorithms 2–4, are set to
,
, and
where
,
,
are limited and denoted as set
A,
B, and
, respectively. It can be seen in
Figure 2 that the state spaces of the third, fourth, and fifth step in Algorithm 5 are the Cartesian product of the other two action spaces and the state spaces size are
,
and
, respectively. The state transition equation refers to the transition probability from state
to state
conditioned on taking action
. The state transition probability is written as
, where
,
and
. We assume with the condition that there is no interference in the transition process, so the transition probability here is 1. If the multi-stage decision-making process is a closed loop that
or
or
exists, Algorithm 5 is stable. Since
,
, and
are all bounded,
or
or
appears at most
transitions during the whole stage. Therefore, it indicates that Algorithm 5 is stable. In
Section 6, Figure 6 further illustrates that Algorithm 5 converges to a near optimal solution.
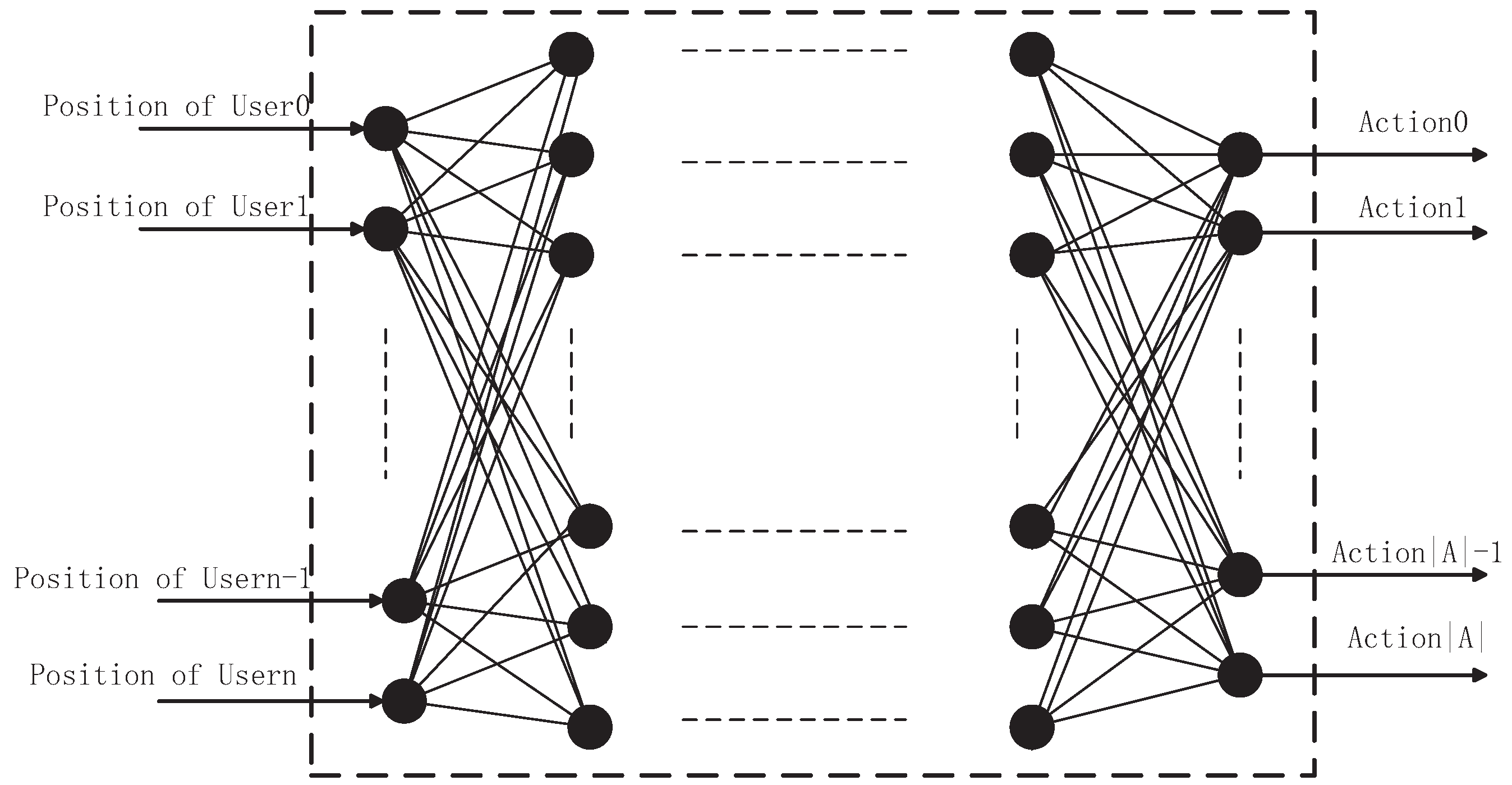
5.3. Neural Network for the Classification of States
In subsection B, the TQL algorithm solves the problem of action space dimension explosion. In order to have the ability to classify the state for the agent, a DNN whose structure is shown in
Figure 3, in which there are two hidden layers and each hidden layer has 512 nodes. The activation function for each hidden layer is a rectified linear unit (ReLU), and ADAM (adaptive moment estimation) [
36] is utilized as updating algorithm and learning-rate is equal to 0.001. The optimal strategy of TQL is to label the samples and specify optimal action in each state. Samples are the set of users position which are gathered from TQL algorithm. The input is the location information of users and the optimal action is encoded according to the index in the action space as the output.
We tried a one-layer, two-layer, and three-layer hidden layer network, and the experimental results showed that it had similar performance on the training performance. Two hidden layers DNN performed relatively more effective with respect to training speed and performance, which is why we use two hidden layers of DNN.
6. Numerical Simulation
The parameters of experimental simulation are set according to the 3GPP LTE-A HetNets framework [
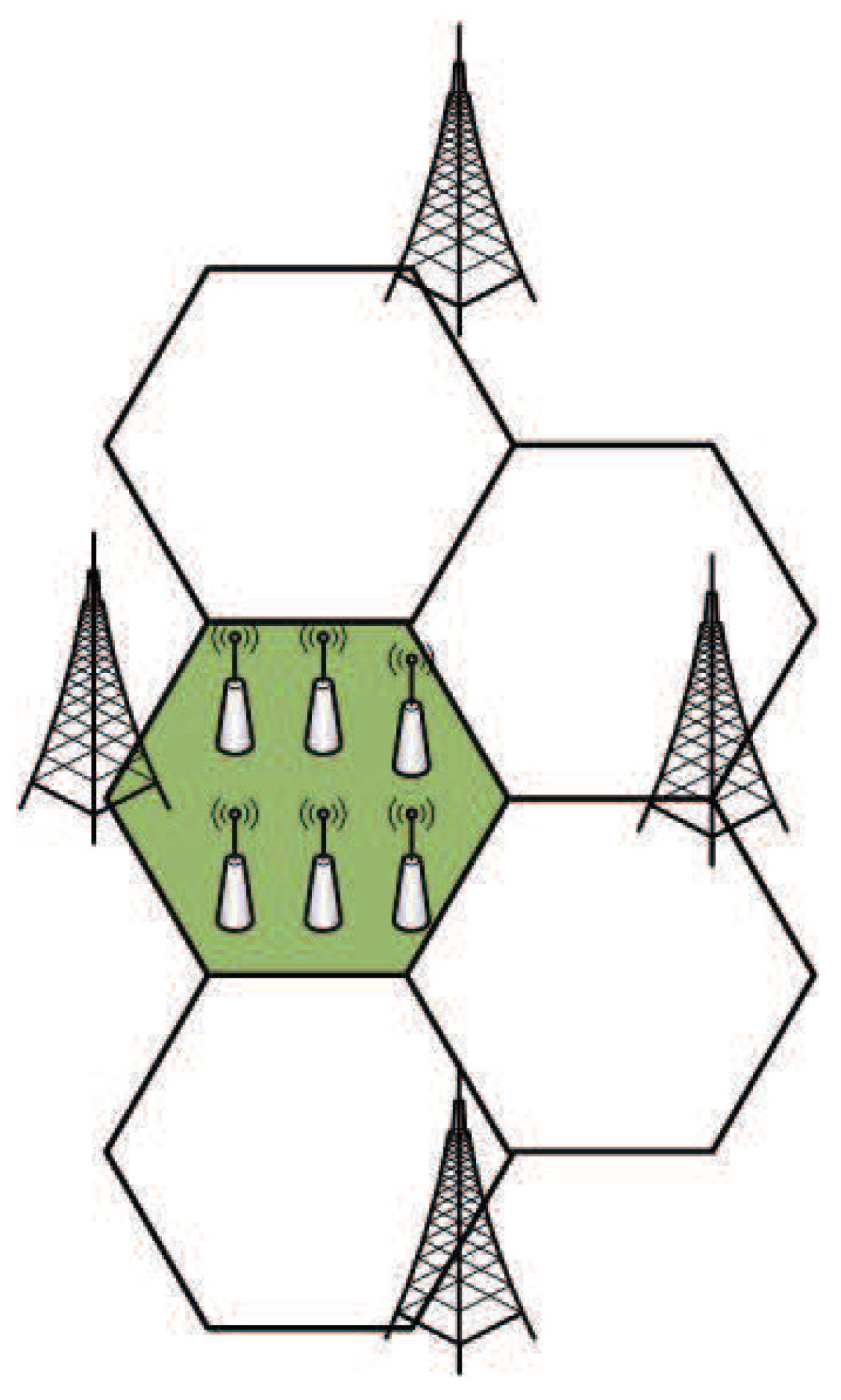
37], and the wireless channel is modeled as deterministic path loss attenuation and random shadow fading models. In this part, the scenario we deployed is that each MBS covers the users in a 120° cell as shown as shadow part in
Figure 4 and is interfered by three other MBSs. We deployed a field where six SBSs are randomly deployed within the coverage of the MBS in the green shaded part of
Figure 4 and select working mode according to load conditions.
The coverage radius of the MBS and the SBSs are 500 m and 100 m, respectively. The thermal noise power is −176 dBm, the system spectrum bandwidth is 10 MHz and the antenna gains of the MBSs, SBSs, and the UE are 14 dBi, 5 dBi, and 0 dBi, respectively. The maximum transmission power of the MBSs and the SBSs are set to 46 dBm and 30 dBm, respectively. The probability of a user entering a cell to access a MBS and a SBS are 1/3 and 2/3, respectively. The proportion
of the BSs that wake up is set here to 0.5. Although LTE frame includes 10 subframes, the ABS mode has a periodicity of eight subframes. The ABS ratio of protected subframe to traditional subframe
belongs to the set
. CRE is denoted by
, where
. The specific parameters are listed in
Table 1.
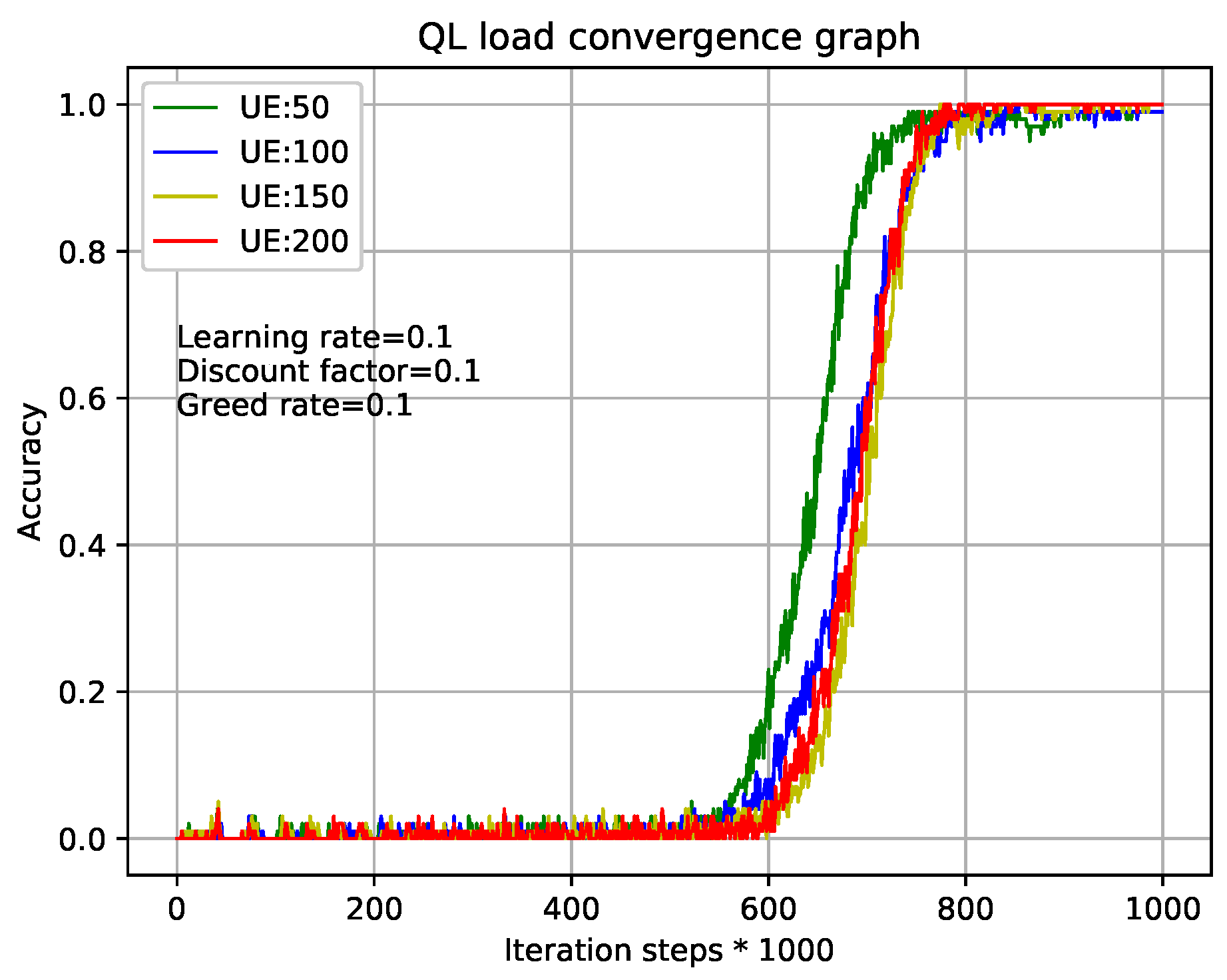
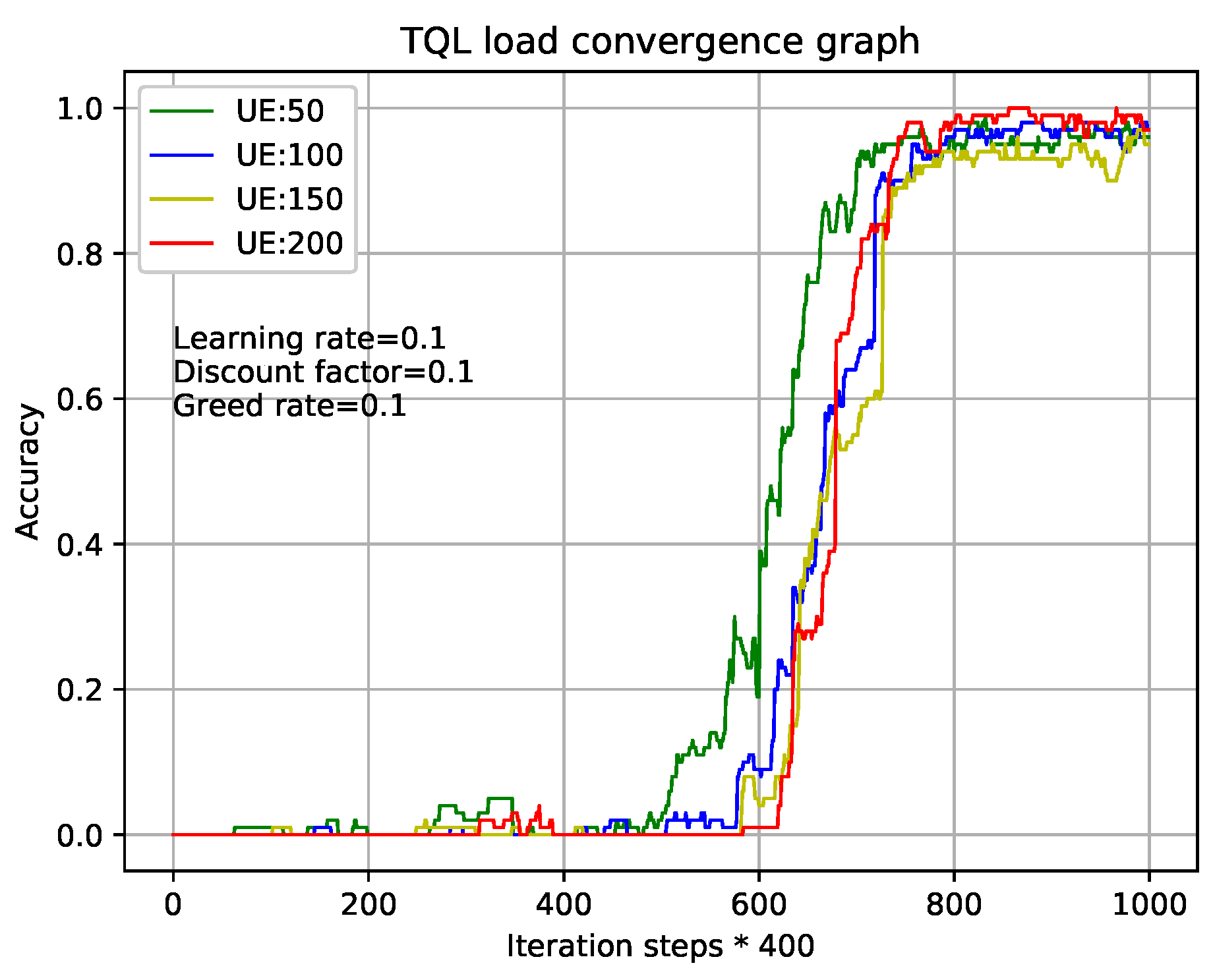
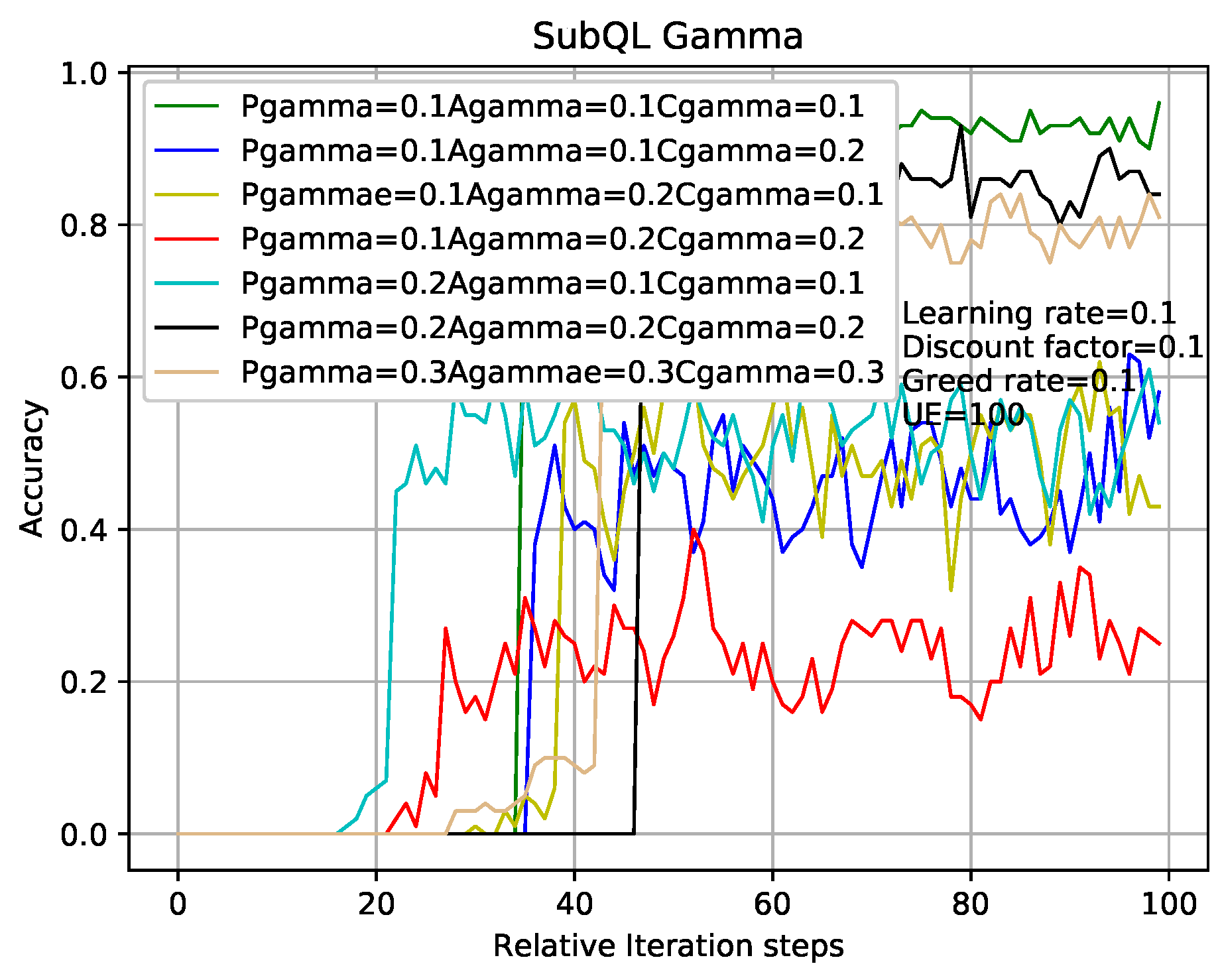
Figure 5 and
Figure 6 show the relationship during iterations and accuracy of Q-Learning algorithm and our TQL algorithm where learning rate, discount factor, and greed rate are all set to 0.1, and the number of users are set to 50, 100, 150, and 200, respectively.
Figure 5 shows that the tabular method of the Q-Learning algorithm converges after
800,000 iterations under different load conditions. Our proposed TQL algorithm converges after
320,000 iterations as shown in
Figure 6. We can see that the convergence speed of our proposed TQL algorithm is increased by about 60% compared with the Algorithm 1. Note that the convergence speed of TQL algorithm proposed in this paper is still much faster than that of Algorithm 1, especially in the case where the action space cardinality is very large from the analysis of Algorithm 5.
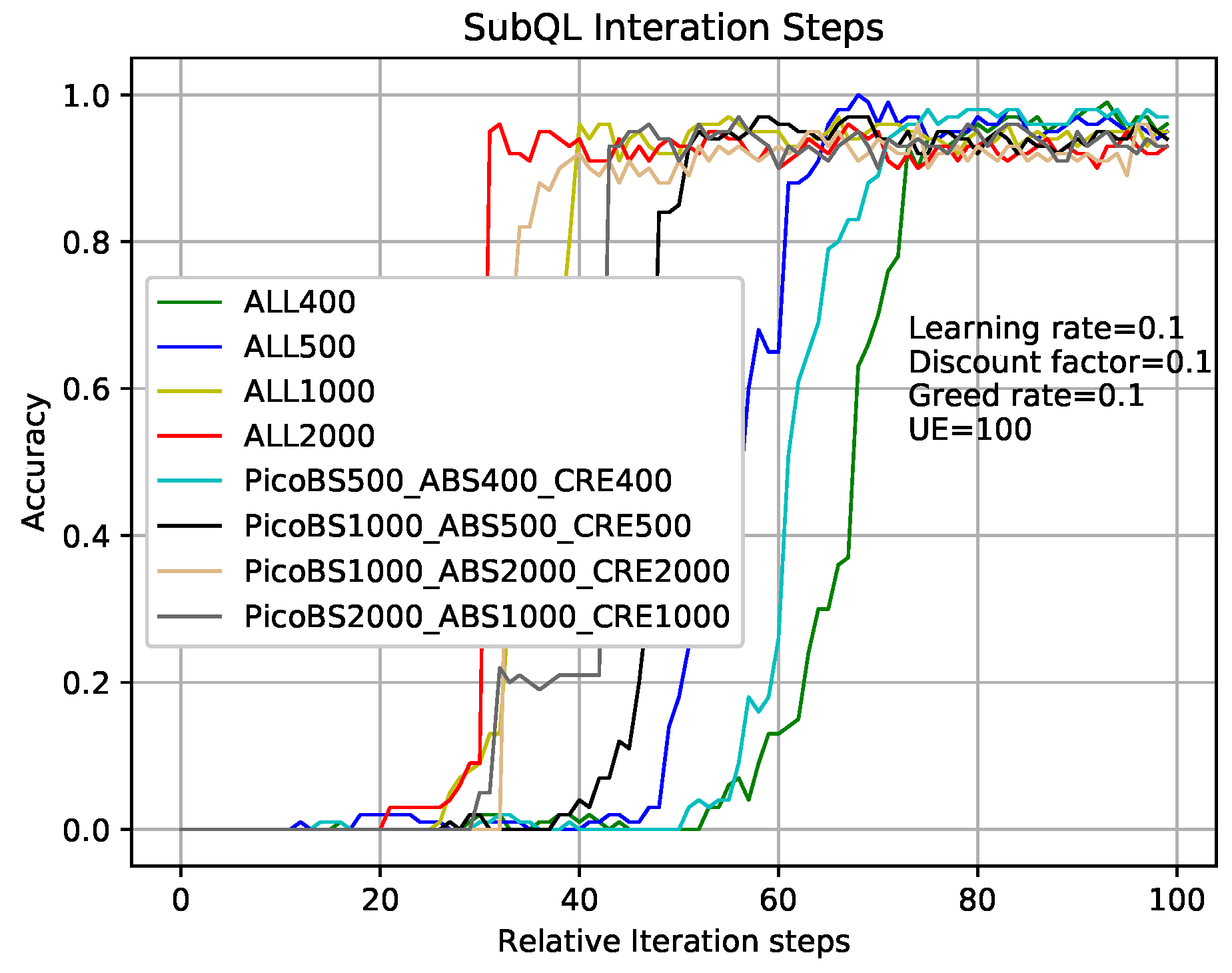
Figure 7 shows that the comparison of sub-QLs (Algorithms 2–4) iterations in the TQL algorithm give different results where relative parameters are the same as that in analysis of
Figure 5 and the number of users is 100. Take the greed line and red line as examples which indicate the number of sub-QL iterations of SBSs (
in Algorithm 4), ABS (
in Algorithm 2), and CRE (
in Algorithm 3) are all set to 400 and 2000, respectively. When the iteration number of TQL represented by the green line and red line is more than about 75 and 30, our proposed TQL algorithm is convergent, but the final accuracy rates are about 98% and 90%, respectively. We can see that, although the convergence speed respected by green line is relatively slower, the final correct rate is higher and the performance is better than that respected by the red line. Our proposed TQL algorithm can make a balance between performance and convergence speed according to actual requirements by adjusting the iterations of the subsystems such as the black line indicated case where the numbers of sub-QL iterations of SBSs, ABS, and CRE are set to 1000, 500, and 500, respectively. The number of iterations for TQL represented by cyan line is more than about 50 and the final correct rate is about 93%.
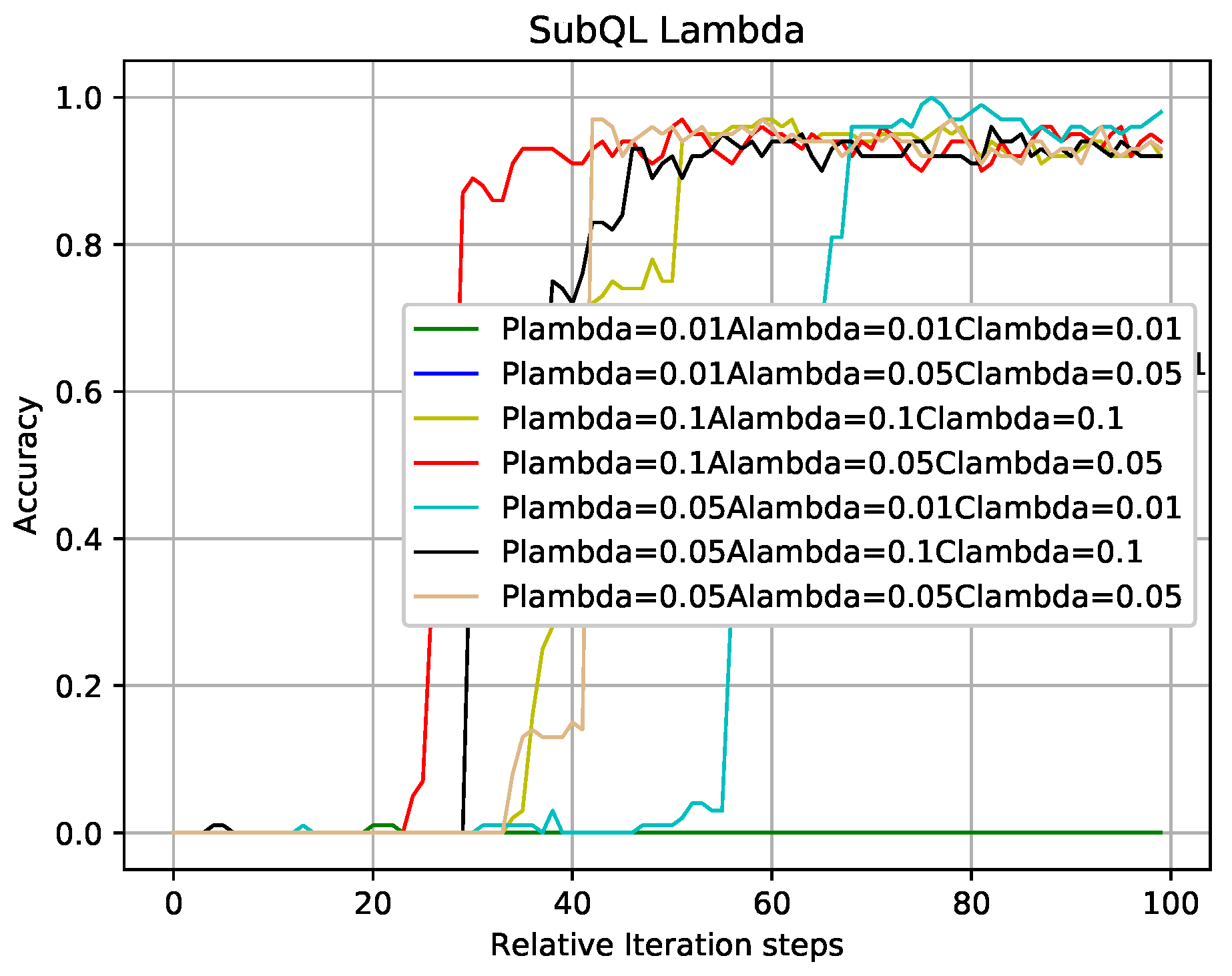
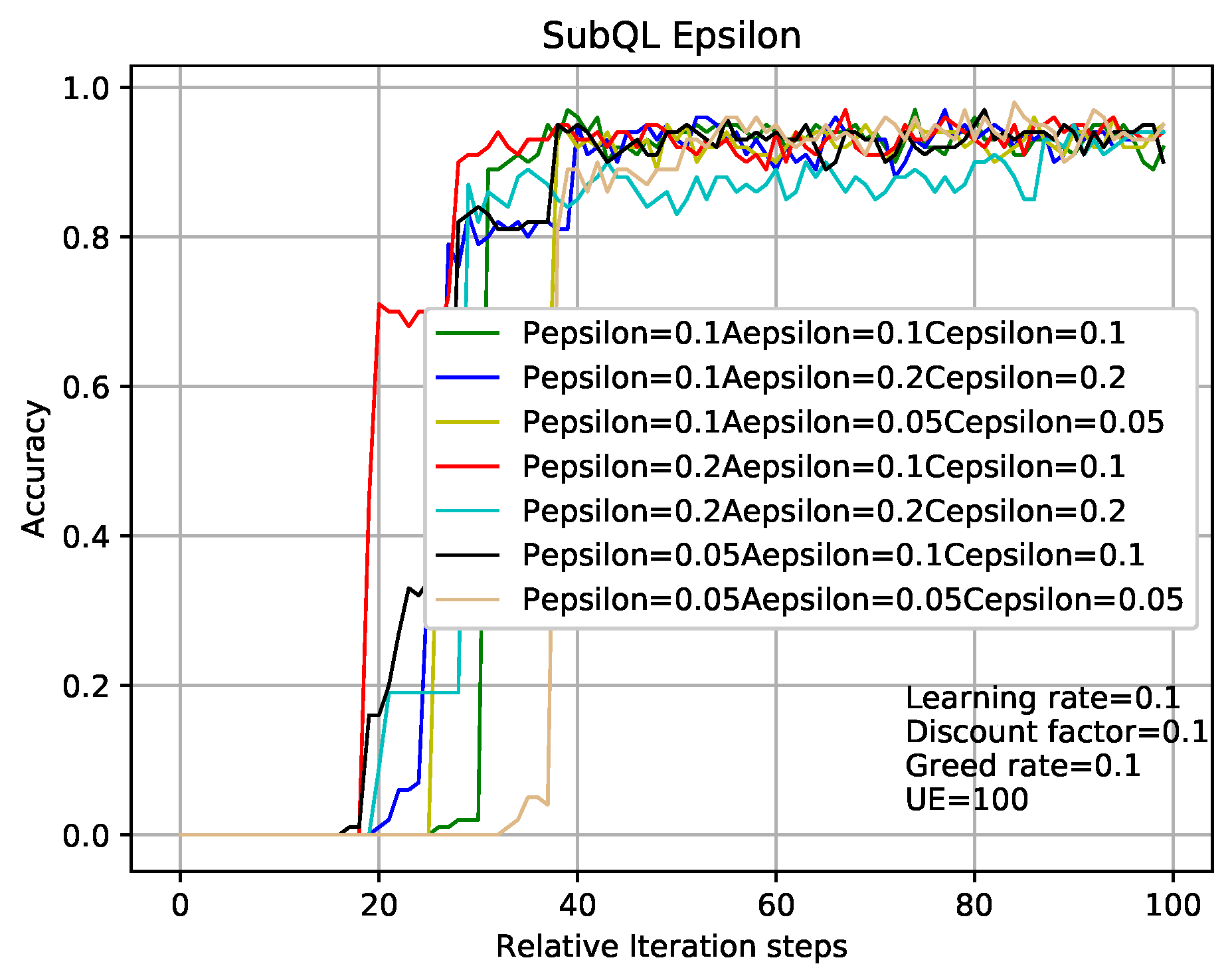
In the case where other experimental parameters are the same as that of
Figure 7,
Figure 8 shows the influence of different learning rates of sub-QL algorithms on convergence speed and correct rate. Take the red line and the cyan line as examples which indicate that the learning rates of sub-QL of SBSs, ABS, and CRE are set to 0.1, 0.05, 0.05 and 0.05, 0.01, 0.01, respectively. We can see that, when the iteration numbers of TQL respected by the red line and cyan line are about 30 and 70, our TQL algorithm is convergent and the final accuracy rate are about 95% and 99%, respectively. The convergence speed respected by the red line is faster than that respected by the cyan line, but the final accuracy rate is otherwise. Pay attention to the problem caused by the setting learning rates respected by the green line which are all set to 0.01, if the learning rate is set too low, the system falls into the local optimum, and the global optimum cannot be found. It is easy to make this mistake in the RL.
In the case where other experimental parameters the same as that in analysis of
Figure 7 and
Figure 8, the methods of analyzing
Figure 9 and
Figure 10 are like that in
Figure 7 and
Figure 8. The results obtained from
Figure 7,
Figure 8,
Figure 9 and
Figure 10 are that the balance can be obtained between performance and convergence speed by changing the corresponding parameters of the sub-QL in our TQL algorithm. It can be seen that our TQL algorithm has greater flexibility in parameter adjustment compared to the general system where only one set of parameters is set.
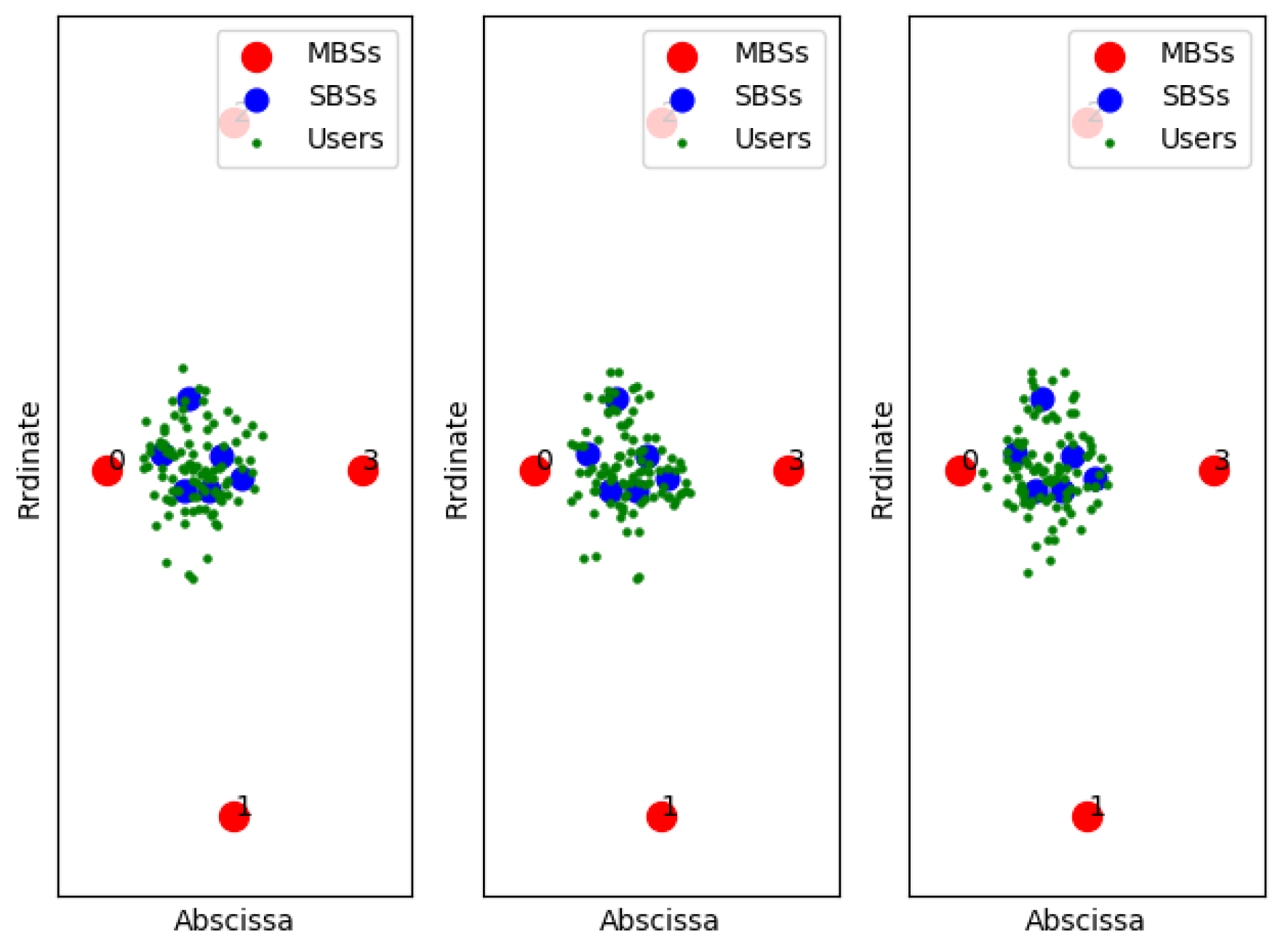
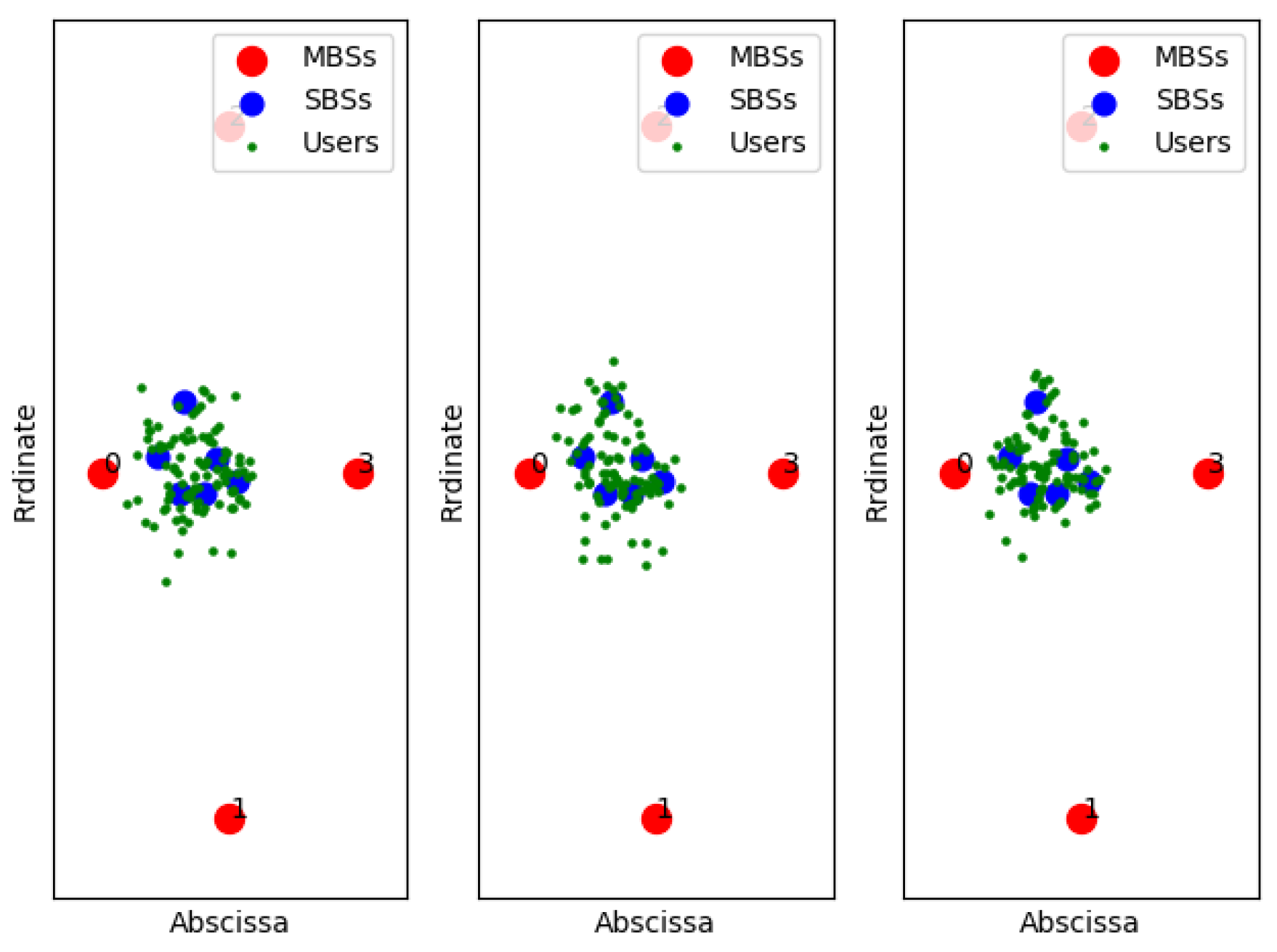
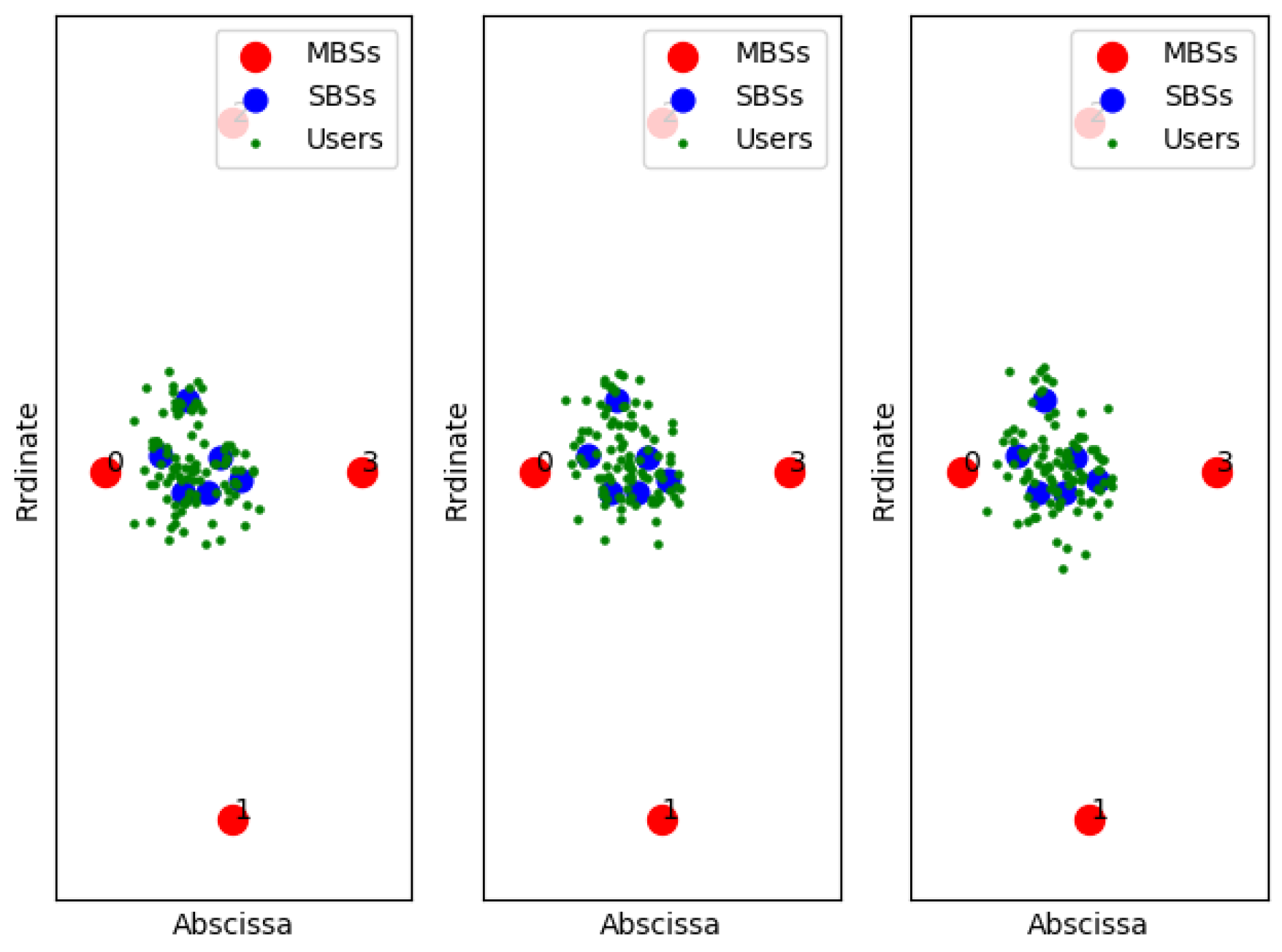
Figure 11,
Figure 12 and
Figure 13 show examples of the sample classification of our designed DNN when the ABS, CRE, and the number of SBSs activations are set to (0, 0, 6), (3/8, 6, 6) and (7/8, 18, 6), respectively. The labeled samples are obtained from the optimal strategy of TQL algorithm, in which 90% of them are training samples and the rest are test samples. The red dots represent the macro base stations where the macro base station with the number 0 is the cell signal source, and the macro base stations with the other numbers are the interference signal sources. Blue and green dots indicate the location of SBSs and users in the cell, respectively.
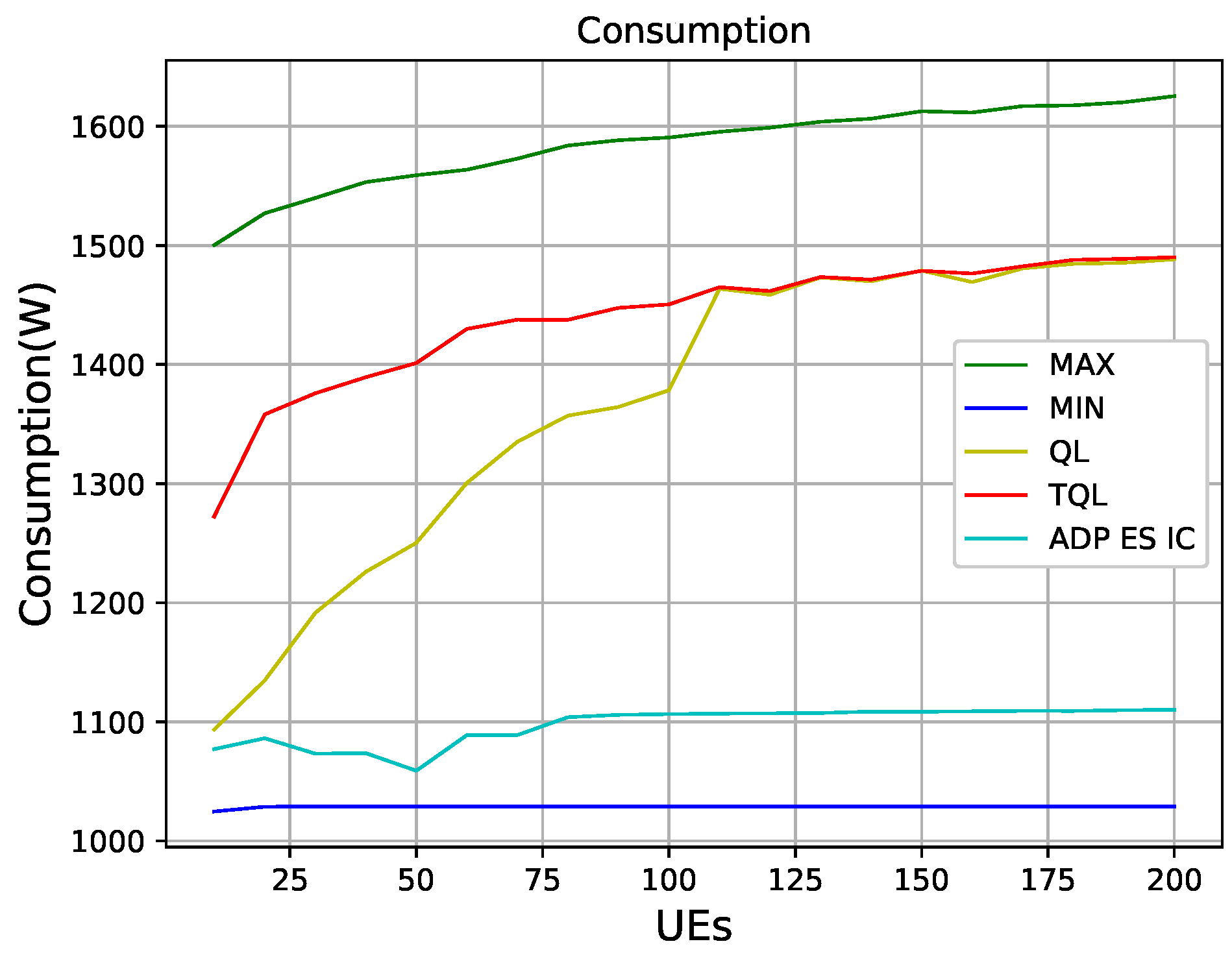
Figure 14 shows that QL, TQL, and the ADP ES IC algorithm in [
9] optimize the power consumption of HetNets. We can see that, under the condition that the number of users being less than 100, the power consumption obtained by the QL algorithm is lower than the TQL proposed in this paper. However, when the number of users is greater than 100, the power consumptions of the two algorithms are the same, which are between the maximum power consumption and the minimum power consumption. The algorithm of ADP ES IC optimizes the power consumption best in the case of 50 users, and it is seen in
Figure 14 that the power consumption control of the entire system is better than QL and TQL in the entire 10–200 users interval. However, it can be seen that such good results is obtained at the premise of sacrificing energy efficiency in
Figure 15.
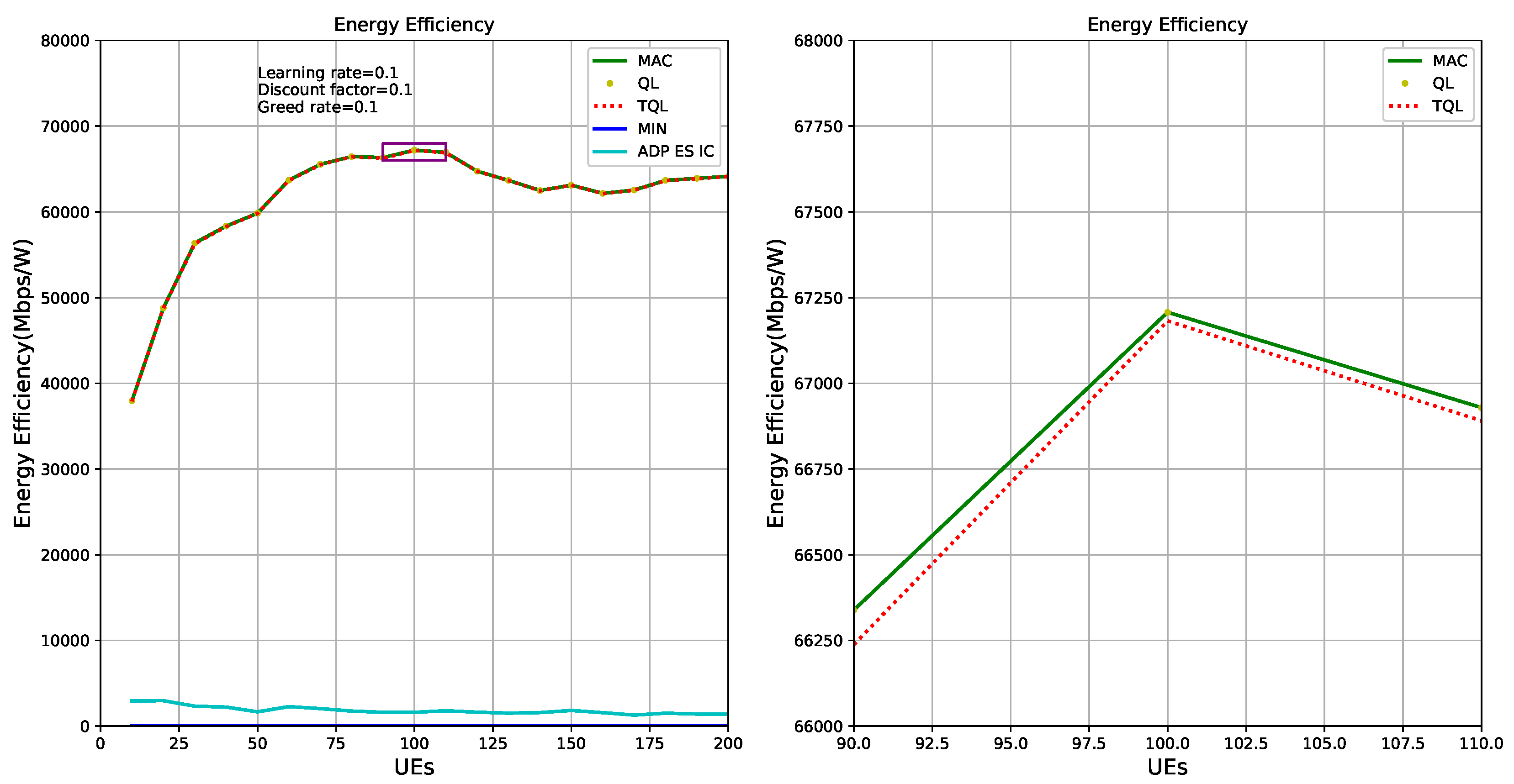
Figure 15 shows the energy efficiency of HetNets is optimized by QL, TQL, and ADP ES IC algorithms, respectively. Green solid line and red dotted line represent the theoretical optimal energy efficiency and the energy efficiency obtained by our TQL algorithm, respectively. The sub-picture on the left of
Figure 15 shows that the optimized energy efficiency of our TQL algorithm is very close to the theoretical optimal, and the sub-picture on the right of
Figure 15 shows that the index of energy efficiency of our algorithm optimization system is slightly lower than the theoretical optimal. According to the analysis of
Figure 6, because the TQL algorithm has not found the optimal solutions (i.e., Pico BS, ABS, and CRE configuration) in some states, the gap exists between theoretical optimal and TQL algorithm, as shown in the sub-picture on the right of
Figure 15. However,
Figure 15 proves that the TQL energy efficiency performance is very close to the theoretical optimal energy efficiency, indicating that the TQL algorithm proposed in this paper has not been optimized in some states, but the solution found is also a relatively optimal solution, which may be a suboptimal solution. For the system, the performance loss is small. The ADP ES IC algorithm is poor in energy efficiency optimization, mainly because the authors focus on power optimization of the system in HetNets.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}