1. Introduction
Sentiment polarity refers to the opinion people have about an entity (e.g., film, service, news, etc.). Several machine learning methods have been used to automatically determine polarity of text published on Internet [
1,
2,
3,
4]. In general, polarity is automatically determined in various domains using different approaches, for example, in health prediction [
5,
6,
7,
8] or transportation [
9].
The task of sentiment polarity task can be tackled as a supervised classification problem, where classes correspond to the polarity expressed in opinions (v. gr. positive or negative); classifiers are trained on tagged examples and they generate a model that relates features to the corresponding tag. Some classifiers are able to learn better particular features, while other classifiers that fail on particular cases perform well on others. Ensemble learning uses a set of classifiers to combine their predictions in different ways. [
10] showed that an ensemble of classifiers is more accurate than its individual members if each of these members has an error rate less than 0.5, and they generate different errors when classifying new instances—i.e., members are accurate and diverse. A way to combine their predictions is to apply a voting strategy than can give the same weight to each classifier (hard voting) or different weights (soft voting). There are two determining factors concerning a voting ensemble that have been studied, the set of classifiers to be combined [
11] and the weight assigned to each classifier [
12]. This work focuses on the second problem.
Our main goal is to find the best weights assigned to each classifier in ensemble learning while using a soft voting scheme to improve sentiment polarity classification in a multiclass, unbalanced corpus. Particularly, we focus on the Spanish TASS task [
13] organized by the Spanish Society for Natural Language Processing (SEPLN) (
www.sepln.org). There are several challenges to tackle in this task:
The fact that polarities are specified in four labels: positive, negative, neutral, and none. Thus, this task has to be modeled as a multiclass problem.
The corpus we experiment with, possesses several difficulties: it is designed to have a small training subset (approximately 10%), while the test set is around 90%.
Classes are not uniformly represented, and their distribution varies in the two subsets.
Hence, in this work, the weighting scheme for Twitter sentiment polarity in an unbalanced corpus with four possible polarity values (positive, negative, neutral, and none) is addressed through an optimization approach. This approach involves the formulation of an optimization problem, where its solution is based on the use of the differential evolution algorithm.
Despite that several works [
14,
15] have proposed different strategies for calculating the weighting scheme of an ensemble, the corpora used for their experiments are balanced, so that, to our knowledge, the effects of applying a weighting scheme on an unbalanced corpus have not been explored. In addition, classifiers of previous works are designed to only learn two possible outputs (positive or negative). Adjusting the weighting scheme for multiclass classification, unlike binary classification, could be more challenging when considering the number of possible combinations in the solutions. Therefore, this paper proposes a solution to optimize the weighting scheme of an ensemble to tackle a multiclassification problem with unbalanced classes.
The rest of this paper is structured, as follows:
Section 2 gives details of current methods dealing with this problem.
Section 3 describes some preliminaries, such as details on the selected task, classifiers, and a formal definition of ensemble learning;
Section 4 presents the main proposal of this work—the evolutionary optimization of the weighted ensemble classification. In
Section 5, the experiments and results are presented, and finally in
Section 6 our conclusions are drawn.
2. Related Work
The problem of learning from unbalanced datasets has been addressed in early works, such as [
16]. With the aim of improving the performance of SVMs in the imbalanced dataset context, the authors integrate over-sampling and under-sampling to balance the data and propose the ensemble of SVM (EnSVM) model in order to integrate the classification results of weak classifiers constructed individually on the processed data, and develop a genetic algorithm-based model called EnSVM+ to improve the performance of classification through classifier selection. Inspired by this work, we aimed to propose an ensemble, but focused both on linguistic features and multiclass problems.
Regarding linguistic features, ref. [
17] describes a linguistic analysis framework, in which a number of similarity or dissimilarity features are extracted for each entailment pair in a data set and various classifier methods are evaluated based on the instance data that were derived from the extracted features. They compare and contrast the performance of single and ensemble based learning algorithms of datasets from the RTE1 to RTE5 challenges. They show that only one heterogeneous ensemble approach demonstrated a slight improvement over the technique of Naïve Bayes and none of the homogeneous methods were more accurate than Naïve Bayes. Nevertheless, finding an optimal combination of classifiers is still an important issue.
Over the past few years, the use of evolutionary computing techniques in classification tasks has increased because these techniques help finding an approximate solution closer to the global solution, while retaining, at the same time, independence to particular characteristics of the optimization problem, such as discontinuities, nonlinearities, the need of discrete design variables, etc. Additionally, evolutionary computing techniques are flexible in the sense that they allow merging diverse strategies in order to improve the exploration and exploitation capabilities of the algorithm in the evolutionary process. In [
18], the multi-objective version of Binary Bat Algorithm with local search strategies employing social learning concepts in designing random walks is used on three widely-used micro array cancer datasets to explore significant bio-markers. A bio-inspired hierarchical model for analyzing musical timbre is presented in [
19]; the model extracts three profiles for timbre: time-averaged spectrum, global temporal envelope, and instantaneous roughness. Different weight assignment for each features in ensemble learning-based classification has been applied in [
20].
Related to text classification, the Arabic Text Classification system (ATC-FA) is proposed in [
21]; this system combines the algorithm of Support Vector Machines (SVM) with an intelligent Feature Selection method (FS) based on the Firefly Algorithm (FA). Genetic programming has been used in [
22] to generate alternative term-weighting schemes (TWSs) in text classification, allowing to improve the performance of current schemes in text classification by combining TWSs, terms (TRs), and term-document (TDRs) with a predefined set of operators.
In [
23], a hybrid ensemble pruning scheme that is based on clustering and randomized search for text sentiment classification is proposed. A consensus clustering scheme is presented to deal with the instability of clustering results that consists of self-organizing map algorithm (SOM), expectation maximization (EM), and K-means++ (KM++). The classifiers of the ensemble are initially clustered into groups according to their predictive characteristics. Subsequently, two classifiers from each cluster are selected as candidate classifiers based on their pairwise diversity. The search space of candidate classifiers is explored by the elitist Pareto-based multi-objective evolutionary algorithm for diversity reinforcement (ENORA).
In [
24], a model is introduced in order to predict whether a tweet contains a location or not and show that location prediction is a useful pre-processing step for location extraction. To evaluate the model, the Ritter dataset and MSM2013 dataset were used. To train the model, they tried different machine learning algorithms: the Naive Baiyes (NB), Support Vector Machine (SMO), and Random Forest (RF) using 10-folds cross validation. To optimize accuracy and true positives, the thresholds were varied (0.05, 0.20, 0.50, 0.75) for NB and RF, and for SMO was varied epsilon (0.05, 0.20, 0.50, 0.75). The conclusion was that RF and NB are the best machine learning solutions for this problem they perform better than SMO.
Usually, sets of classifiers are more accurate than the individual classifiers that integrate them when any of their individual members has an error rate of less than
, and, in general, individual members have different errors when classifying new examples—that is, they are precise and diverse [
10]. In recent years, deep learning methods have achieved high performance for several tasks; however, there are several problems for which a traditional machine learning approach is able to obtain state of the art results, given that an appropriate ensemble is constructed [
15,
25,
26,
27,
28].
In this sense, different schemes have been tried to combine the predictions of the base classifiers that form the ensemble classification. Particularly, for the soft weighting scheme, there has been two main approaches: the use of meta-heuristic algorithms proposed by [
14] and the estimation of a weighting scheme based on the probabilities of classifiers and their accuracy, as described by [
15].
In [
14], the use of meta-heuristic algorithms in the weighting of ensemble learning improves classification’s performance. Onan et al. proposed including a weighted ensemble learning for the analysis of the polarity opinion (positive and negative) based on differential evolution. Ensemble learning incorporates the following classifiers: Bayesian Logistic Regression (BLR), NB, Linear Discriminant Analysis (LDA), LR, and SVM. The allocation of the appropriate weighting values to classifier outputs is established as an optimization problem where precision and recall are the objective functions. Their proposal improves the accuracy of the base classifiers and other classic methods of ensemble learning.
In [
15], the polarity of opinion is determined in two classes (positive and negative) of tweets of the
Stanford Sentiment140 English corpus, proposing a combination scheme of the ensemble learning of the weights for the base classifiers NB, RandomForest (RF), SVM, and LR. The proposal considers the weighting of the accuracies of each base classifier along with their probabilities of predict a negative or positive class to calculate prediction scores. According to these scores, the authors determine the polarity of the training data. If negative and positive scores are equal, the cosine similarity is calculated with other tweets in test data and the most similar tweet prediction is chosen. With ensemble learning, the accuracy of the base classifier with better precision (SVM) is improved by 0.2%.
A multiobjective optimization-based weighted voting scheme was presented in [
29]. Zhang et al. [
30] propose adjusting the weight values of each base classifier by using the DE algorithm. Onan et al. [
14] present a static classifier selection involving majority voting error and forward search; and, Ankit and Seleena [
15] consider the weighting of the accuracies of each base classifier along with their probabilities of predict a negative or positive class to calculate prediction scores. It is important to recall that the corpora used for all these experiments are balanced (Except for
First GOP debate twitter sentiment dataset used in [
15]). Additionally, classifiers of previous works are designed to only learn two possible outputs (positive or negative). This is why this paper proposes estimating an optimal weighting scheme using a Differential Evolution algorithm focused in dealing with particular issues that multiclass classification and unbalanced corpora pose.
4. Evolutionary Optimization of the Weighted Ensemble Classification
A mono-objective optimization problem is considered in order to maximize the accuracy of the ensemble classifier. This can be described in a general way as maximizing
subject to (
10) and (
11).
The design goal
considers the
e matches between the set of predictions
of the ensemble learning, and the set of real classes
of the test tweets
, where
are the weights that must be adjusted to maximize
J, as defined in (
4).
The design variables are the weights that are assigned to classifiers . The set of design variables are grouped in vector .
It is necessary to narrow the search space, establishing boundaries for the design variables, in order to find optimal solutions to real-world problems. In the case of this problem, these limits are established as the inequality constraints (
10).
Another restriction that must be met is that the sum of the weights
assigned to classifiers
must be equal to 1. This constraint is described in (
11).
4.1. Differential Evolution Algorithm
Differential Evolution (DE) is an evolutionary algorithm proposed by Rainer Storn and Kenneth Price to solve global optimization problems in continuous search spaces [
39]. DE has characteristics of robustness, precision, and speed of convergence that have made it attractive, not only to solve problems with continuous search spaces [
40,
41], but also discrete spaces [
42,
43]. DE begins with a set of solutions, called parents population, to which processes of crossing, mutation and selection are applied to create child populations that approach optimum solutions in an iterative process. The parameters of DE are: population size
NP, maximum number of generations
, number of crossings
, and a factor of scale
F.
There are different variants of DE, being the most popular
—the one used in this work. The word
indicates that the three individuals selected to calculate the mutation value are selected randomly, 1 the number of pairs of solutions chosen, and
that a binomial recombination is used [
44].
In this work, DE creates an initial matrix population
with
NP individuals, called population of parents. Each individual of
contains the design variables
generated randomly, as described in (
12) and (
13), respecting the inequality constraints (
10) and the equality constraint (
11). In the mutation process a mutant individual
is created with three parent individuals (
,
and
) different to the current father
and the scale factor
F. In the crossing process, the crossing factor
is considered to determine whether the gene inherited from the individual child
is taken from the mutant individual
or from the parent individual
. Subsequently, it is verified if the child individual
complies with constraints (
10) and (
11). If not,
is randomly generated with (
12) and (
13). Finally, in the selection process, the individual parent of the next generation
will be the individual with greater accuracy comparing the child individual
and the parent individual
. These processes continue iteratively while
. The population of the maximum generation
has the individuals with better accuracy for
Max generations. Algorithm 1 shows the complete pseudo-code of the implementation of the
algorithm in order to optimize the weights of the ensemble classifier.
| Algorithm 1: Pseudocode of the DE algorithm for the evolutionary optimization of the ensemble classifier. |
 |
4.2. K-Fold Cross-Validation and Stratified K-Fold Cross-Validation
It is important to estimate the performance of classifiers in order to select the most appropriate scheme. A common strategy for this purpose is to use
k-fold cross-validation, in which a dataset
S is split in
k mutually exclusive subsets, called folds,
,
, …,
of approximately the same size [
45]. Subsequently, classifiers are trained and tested
k times; each time
, it is trained on the training subset
, and tested on
(testing subset).
A variation of this strategy, called stratified
k-fold cross-validation, considers the distribution of classes to create the folds [
45]. The folds in this strategy are evenly distributed, so that they contain approximately the same proportions of labels as the original dataset. In our proposal, for both strategies
k is equal to 10, which is, the training set is divided in 10 folds.
Both of the strategies show the robustness of classifiers and the average accuracy of folds is a good estimator of expected performance on the test set. Therefore, we apply the evolutionary optimization method described in Algorithm 1 on each fold to calculate the best weighting scheme. Selection of the best weighting scheme is described in the following subsection.
4.3. Best Weights Selection Strategy
Evolutionary optimization algorithms provide a set of good solutions. From these solutions, the one that maximizes (or minimizes, depending on the problem) the objective function must be selected. A simple solution could just select the weighting scheme that maximizes accuracy, but this weighting scheme would have been calculated on a single fold of a test set, and there is no certainty that it could obtain the same good results in the test subsets from other folds. To avoid this bias in selecting the best solution, the next next steps are followed:
Train the classifiers described in
Section 3.3 with each of the 10 training sets.
Use Algorithm 1 to determine the weighting schemes that maximizes accuracy on each of the 10 testing sets. In this step 10 candidates for best weighting scheme are obtained, one for each testing fold.
Use the obtained weighting schemes of each test set on the ensemble to classify the tweets of remaining nine test sets.
Calculate the average accuracy obtained by each weighting scheme of the ensemble on the test sets.
Select the weighting scheme with the best average accuracy.
As well as cross-validation ensures the robustness of the classifiers, we consider that the selection strategy described above takes advantage of the diversity of samples on the folds to provide a global solution (The apparently straightforward selection strategy of averaging weights from the best weighting vectors in each fold was also tested, with no satisfactory results.).
The complexity of Algorithm 1 is calculated as , where is the number of generations for crossover and mutation of individuals of the population, and n is the number of design variables that corresponds to the number of weights to be assigned to the classifiers (in this case, 3).
5. Experiments And Results
Our goal is to be able to correctly classify the polarity of tweets of the test set
Z of the TASS corpus, as described in
Section 3.1. In order to do so, first the classifiers are trained and adjusted on the training corpus
E. Experiments and results on this set are described in
Section 5.1; afterwards, the experiments on the test set
Z are described in
Section 5.2.
5.1. Experiments on the E Set
Several strategies can be explored for training and adjusting the ensemble learning scheme with differential evolution weight selection. The number of individuals and generations can be changed (See
Section 5.1.1), as well as the way of creating folds (see
Section 5.1.2). With these experiments, the optimal weighting scheme
is sought. Subsequently, it will be applied to classify the TASS test set
Z, as described in
Section 5.2.
5.1.1. Random Folds
Table 5 shows the results of the first experiment with the training set of the TASS corpus
E and 10 folds. From rows one to three, the accuracy obtained by the NB, LR, and SVM classifiers is observed independently. The fourth row (
Hard w) shows the accuracy obtained by ensemble classification with the same classifiers using a hard weighting (same weights for all classifiers). Row 5 (
Soft w:20–300) shows the accuracy obtained by the ensemble classification using the weighting scheme of the best individual after the process of evolutionary optimization. For this selection a random initial population of 20 individuals over 300 generations was used and the experiment was run 30 times in order to ensure robustness in the results. The total execution time was about 16 h in a 20 core dual-processor Intel Xeon E5-2690V2 Server (TEN CORE @ 3.0 GHz). The average of these 30 runs is reported. For results shown in Row 6 (
Soft w:200–1000) the population was increased from 20 individuals to 200, and generations were increased from 300 to 1000 with the intention of achieving greater diversity in the population. As well as in Row 5 (
Soft w:20–300), the experiment was run 30 times. The execution time was similar to the previous experiment. Because these changes did not have a significant effect in results, no more increases in generations or individuals were tested. Row 7 (
TA) shows the maximum theoretical accuracy that was obtained by ideally selecting the correct result, if provided by any classifier (see
Section 3.6). The last column shows the average accuracy of the classifiers and the ensemble learning. The highest accuracy for each independent classifier on each fold is highlighted in italics, while the best overall accuracy (without considering TA) is shown in bold.
5.1.2. Stratified Folds
The folding strategy in previous experiments consisted of randomly selecting tweets from the
E set of the TASS corpus. As can be seen in
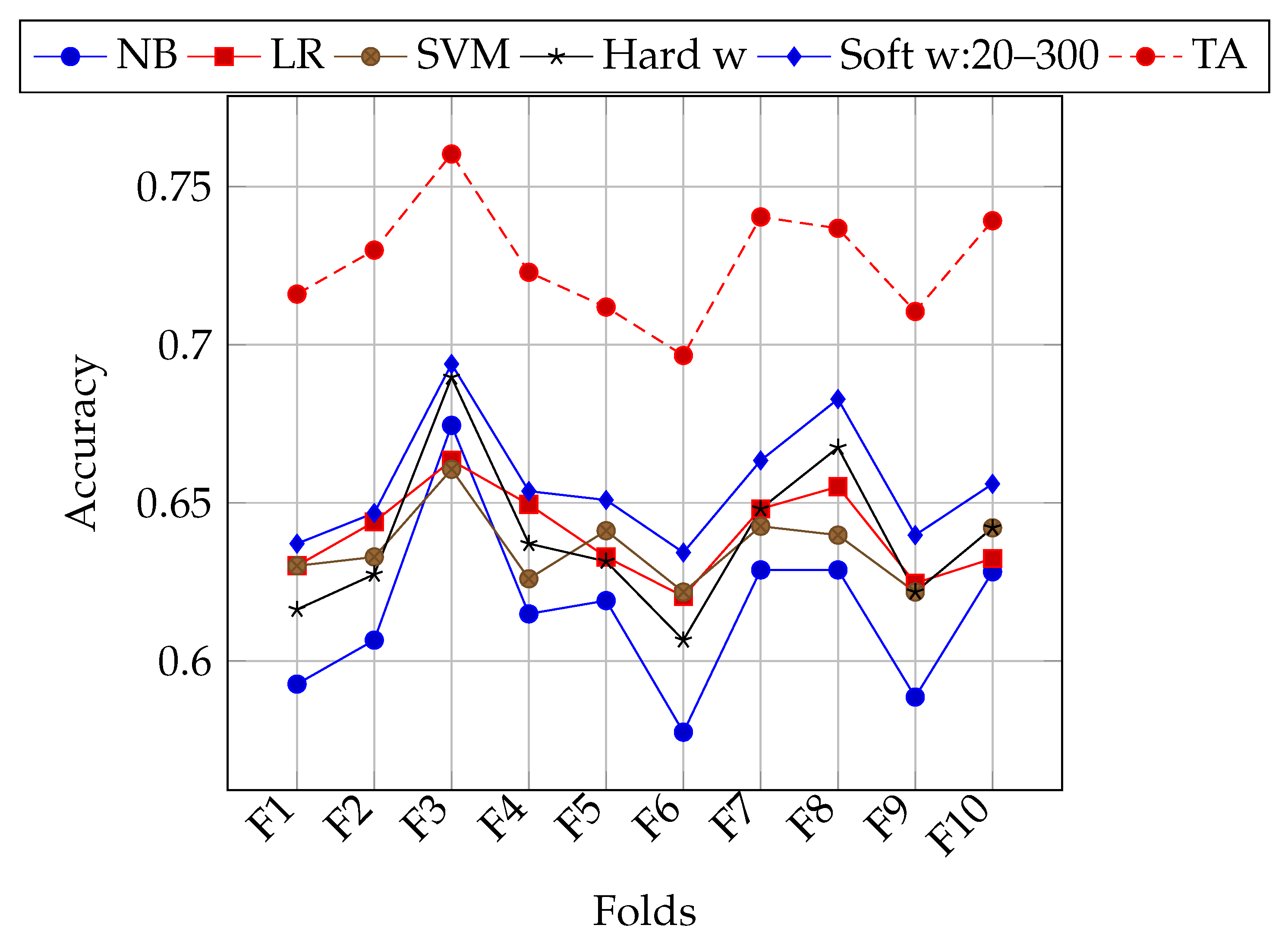
Figure 1, for some folds all classifiers in general achieve better accuracy. This might be due to the class bias of tweet polarities (unbalanced number of classes). Experiments with stratified k-folding were performed in order to lessen the impact of this bias on classification accuracy. In
Table 6, results of using stratified k-folding are shown.
Figure 2 shows performance for each fold using stratification. Both of the configurations of 20 individuals and 300 generations, and 200 individuals and 1000 generations were used. In general, soft weighting improves the classification accuracy on stratified folds as well. Nevertheless, there is still an heterogeneous performance for different folds.
Figure 3 shows a comparison of accuracy obtained by
Soft w:20–300 on both folding strategies, random and stratified. Stratified folding improved the performance on most of the folds, but decreased on others. On average, the accuracy on random folds was 0.6558, while average accuracy on stratified folds was 0.6618.
For each fold, different soft weights were found. In the next section it is explained how the best weight on each folding strategy is selected in order to classify the tweets of the final test on the Z set.
5.2. Experiments on the Z Set
For each experiment described in the previous sections, a vector of optimal weights
was obtained for each fold. The strategy detailed in
Section 4.3 was applied for each experiment in order to select the best set of weights. The selected weighting vector on the random folds (from the
soft w:20–300 experiment) was
= [0.1713, 0.0380, 0.7905], while the vector corresponding to the stratified folds (using 20 individuals and 300 generations) was
= [0.1345, 0.0340, 0.8313]. Each value in this vector corresponds to the weight of each classifier, namely NB, LR, and SVM.
It can be seen that, in both and , SVM is given a predominant weight (0.7905 and 0.8313 respectively); this is interesting, because this classifier obtained better average accuracy than NB, but lower than LR.
Once the weights were determined, tweets in the test set were classified with each classifier, and they were then assembled in a voting scheme with
and
weights, respectively. The results are shown in
Table 7. As can be seen
based on stratified folds (which obtained better results in the training set
E) also yielded the best result in the test set
Z.
5.3. Comparison with Other Works
Table 8 presents the best results reported by other systems on the same task. To our knowledge, the best accuracy reported so far is 0.726 by the LIF system. However, in order to fairly compare these systems, it is necessary to consider the external resources they are using to improve classification. For example, the LIF system uses external affective lexicons, such as ElhPolar [
46], SSL [
47], LYSA [
48], MPQA [
49], and HGI [
50]. A similar situation occurs with the first four systems with the highest accuracies. Isolation from the effect of other resources is desirable, as, in principle, we aim to improve classification accuracy by adjusting weights of a classification ensemble. In that sense, we are comparable to the LYS, SINAI-DW2Vec, and INGEOTEC systems. Our proposed classification method with soft weights on stratified k-folds overcomes the accuracy of these systems.
Additionally,
Table 9 gives a brief description of the tools used by the best methods for classifying polarity tweets on the TASS task. The first column after accuracy shows the maximum number of n-gram features being used. In our work, we used only bag of words, which is equivalent to using unigrams. We are not using a Named-Entity-Recognizer module or NLP techniques (such as lemmatization, using parts-of-speech tags, etc.). We do not handle negation with any particular method. Other works use feature augmenting methods that are based on deep learning (Word2Vec [
55], Doc2Vec [
56], GloVe [
57]), distributional methods (LDA [
58], LSI [
59]), or other feature weighing methods (TF·IDF [
60]). In this work, none of these was used.
The last column of
Table 9 shows a very compact survey of the classifiers used by each system. Most works use Support Vector Machines (SVM). The first system (LIF) uses a ensemble of SVM, and Convolutional networks with skipgrams, bag of words, and vectors obtained from GloVe [
57]. These results are fed to an SVM classifier. ELiRF, the second best system combines the output of several SVM classifiers with different parameters, and then this information is classified in cascade with another SVM classifier.
5.4. Discussion
The Differential Evolution strategy for optimizing the weights in a soft-voting ensemble was able to overcome performance of the individual classifiers. As expected, in the E set performance was better for the soft voting scheme, compared with hard weighting. Specifically, this latter achieves 66.57% accuracy, while the best weights obtained by Differential Evolution reach 67.71%.
Additionally, two different ways of partitioning information for finding the best weights were explored. One was based on random k-folds, and other on stratified k-folding. Stratified k-folds tend to improve the final classification. The latter strategy had better performance on the E set (66.19% vs. 65.61%), and the weight vector Soft calculated on these folds slightly contributed to obtain a better classification on the Z corpus (67.71% vs. 67.68%). In both folding strategies, the soft weighting always outperformed the hard weighting scheme.
We experimented with the InterTASS corpus of 2018 (Spanish) in order to test our solution with a different corpus [
61]. We applied the DE:Soft
method without recalculating weights. The results are shown in
Table 10. From this table, it can be seen that despite the full process of adjusting weights was not carried out, our method outperformed some of the neural-network-based methods (retuyt-cnn).
We have calculated the statistical significance of our experiments while using the STAC platform [
62] considering the different results we obtained separately with each classifier, hard weights, and soft weights. With the Shapiro–Wilk test [
63], we obtained that the null hypothesis is rejected with a level of significance of 0.093, while for the Kolmogorov–Smirnov test [
64], it is rejected with
.
6. Conclusions
In this paper, we presented a method to optimize weights for a classification ensemble. When compared with other methods, DE:Soft is able to obtain state of the art accuracy, given that no external resources are being used. As a future work, it would be interesting to assess the effect of using our proposed method along with external resources in order to further improve scores for this task.
In general, this proposal could be used for problems where training data are relatively small when compared with the amounts required for other state of the art methods, such as deep learning. Automatic optimization of weights for different classifiers allows for easily adapting this method for other problems, including those with multiclass labels.
In both
and
,
is notoriously given a predominant weight, although it is interesting to see that this is not the best overall classifier if used alone. In this case,
would be a better choice (see
Table 5 and
Table 6). Additionally, one of the best reported systems (GTI-GRAD) uses
as its main classifier. This suggests a deeper by-case analysis that may enable classifiers to specialize in particular cases, along with a meta-classifier that dynamically adjusts weights for each case. Another option is to create separate classifiers per class; this is left as future work. Other improvements to the Differential Evolution algorithm, such as different ways of partitioning data, are also considered for further exploration.


 and
and 





{kind=link}
{kind=link}
{kind=link}