Bayesian3 Active Learning for the Gaussian Process Emulator Using Information Theory


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Bayesian Inference with Information Theory for a Gaussian Process Emulator
2.1. Construction and Training of Gaussian Process Emulators
2.2. Bayesian Updating on Observation Data Using GPE
2.3. Bayesian Model Evidence
2.4. Relative Entropy
2.5. Information Entropy
3. Bayesian Active Learning for Gaussian Process Emulators in Parameter Inference
3.1. Bayesian Inference of Gaussian Process Emulator Incorporating Observation Data
3.2. Model Evidence-Based Bayesian Active Learning
3.3. Relative Entropy-Based Bayesian Active Learning
3.4. Information Entropy-Based Bayesian Active Learning Criterion
4. Application of GPE-Based Bayesian Active Learning
4.1. Bayesian Active Learning for an Analytical Test Case
4.1.1. Scenario Set up
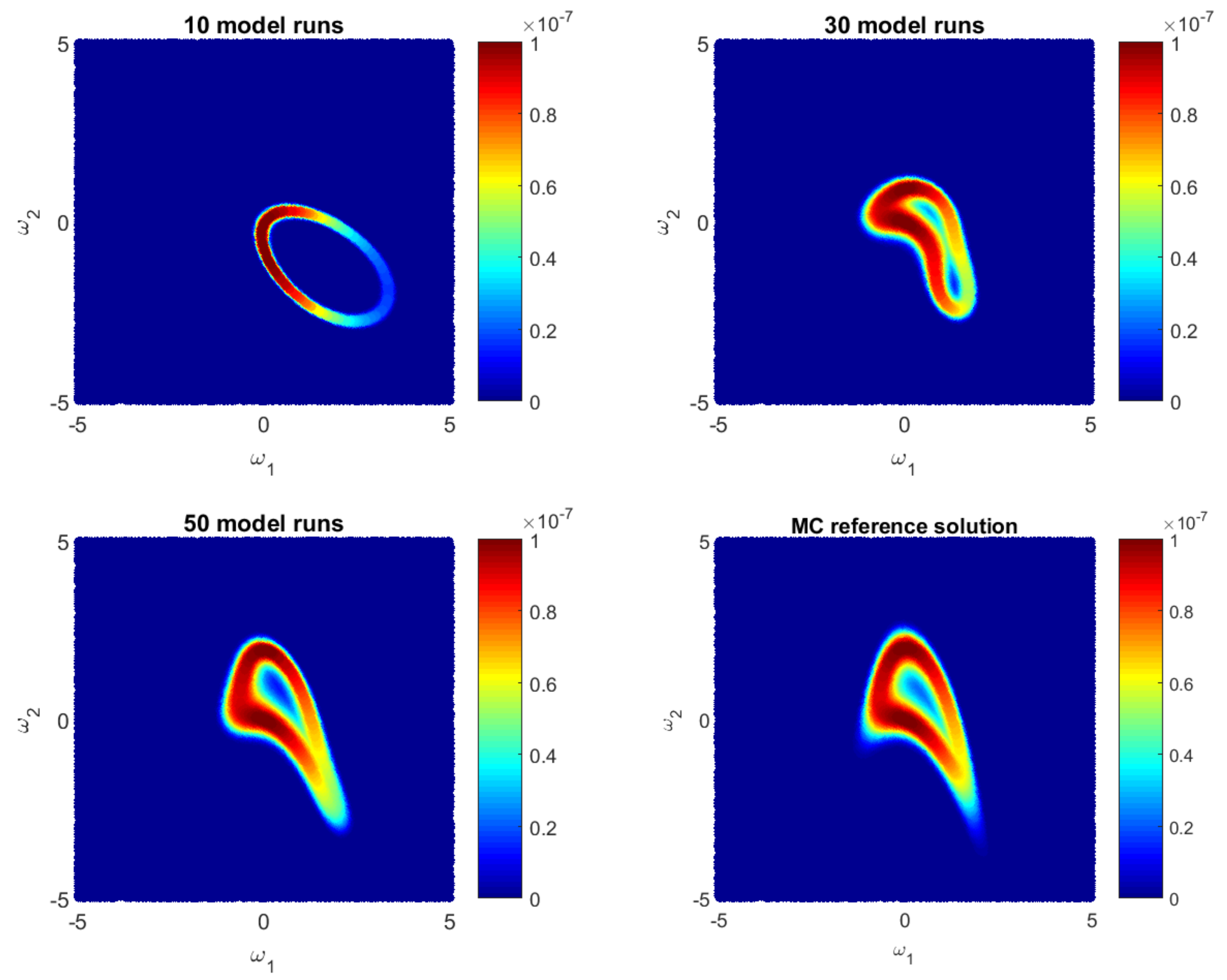
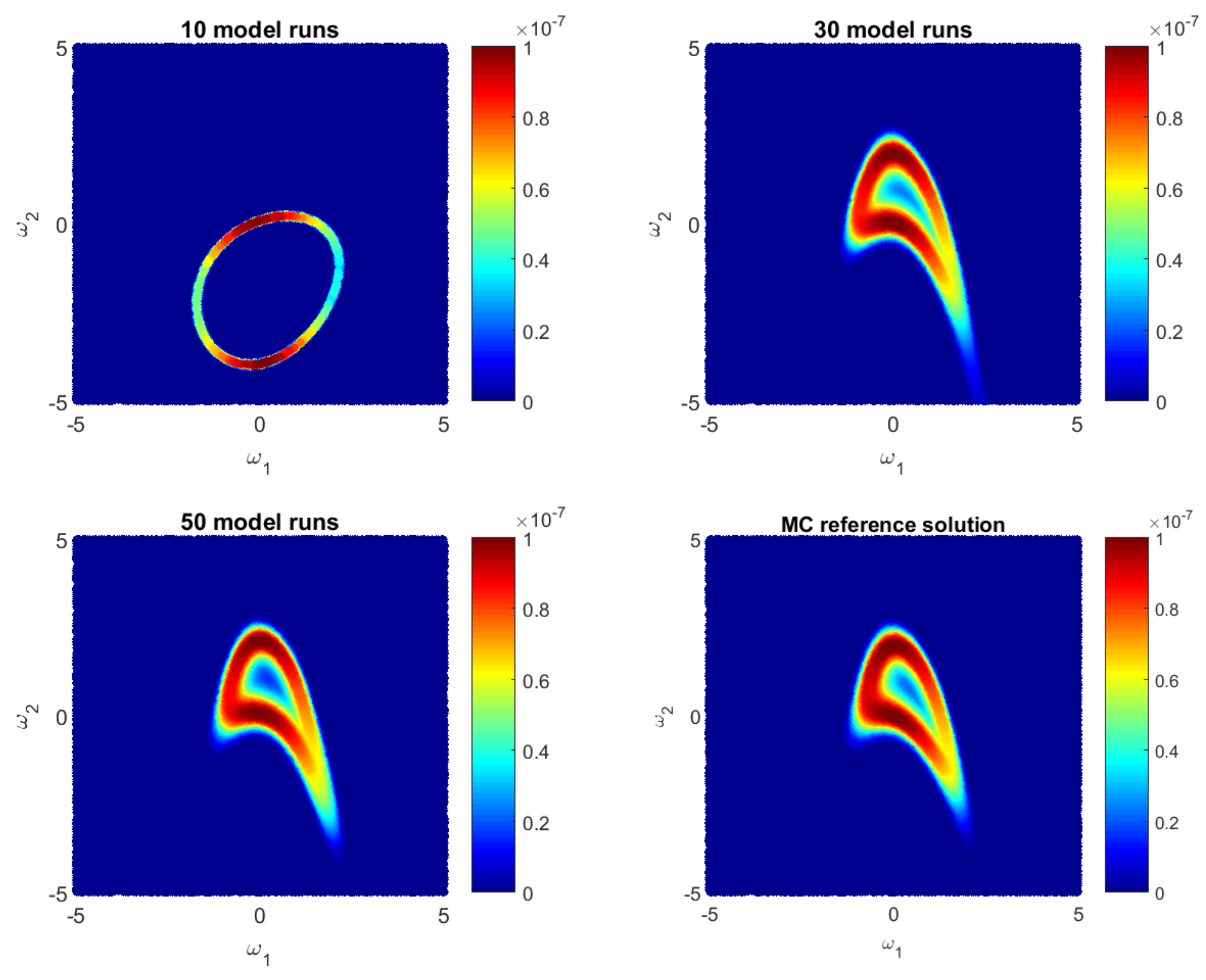
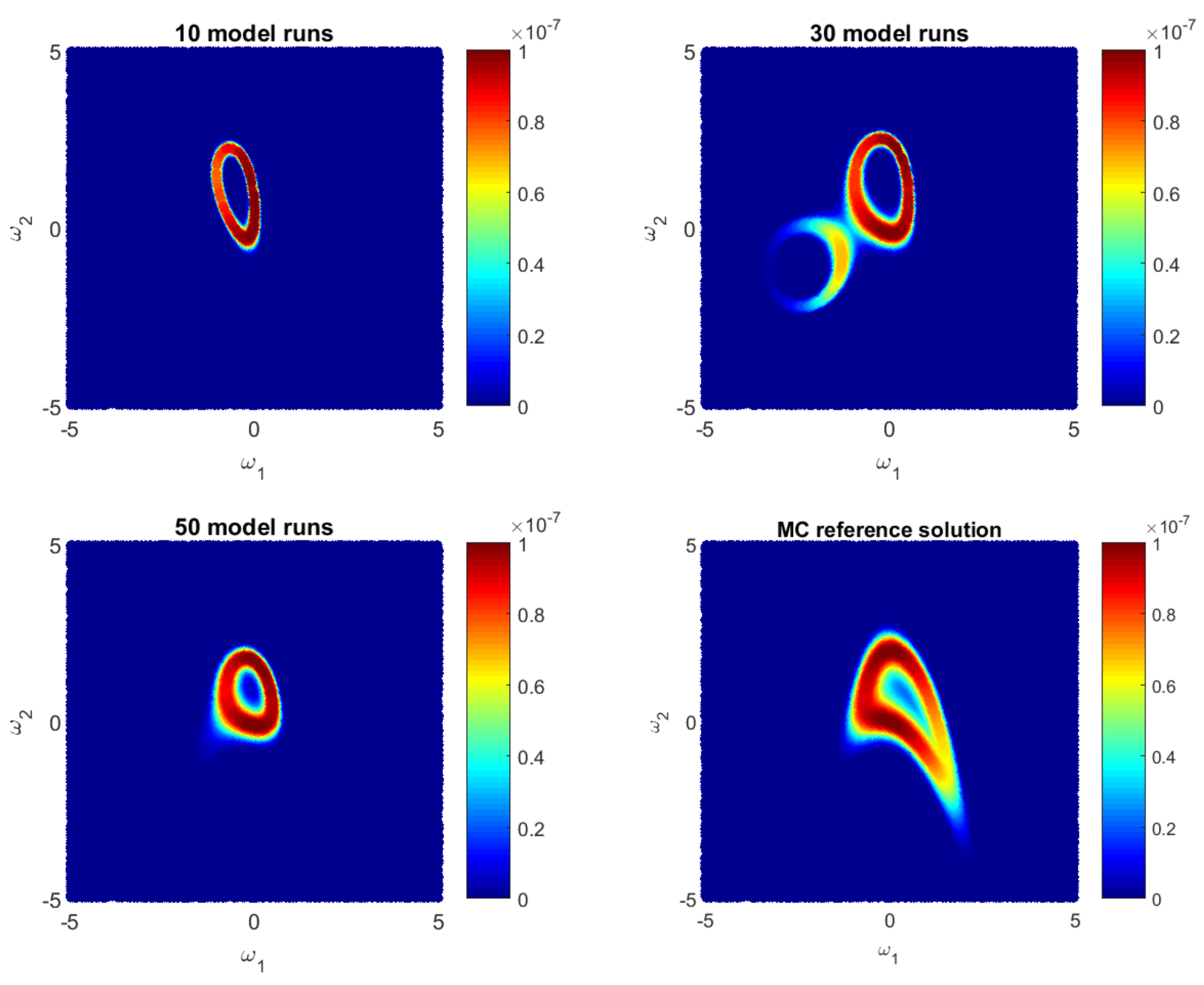
4.1.2. Likelihood Reconstruction during Bayesian Active Learning
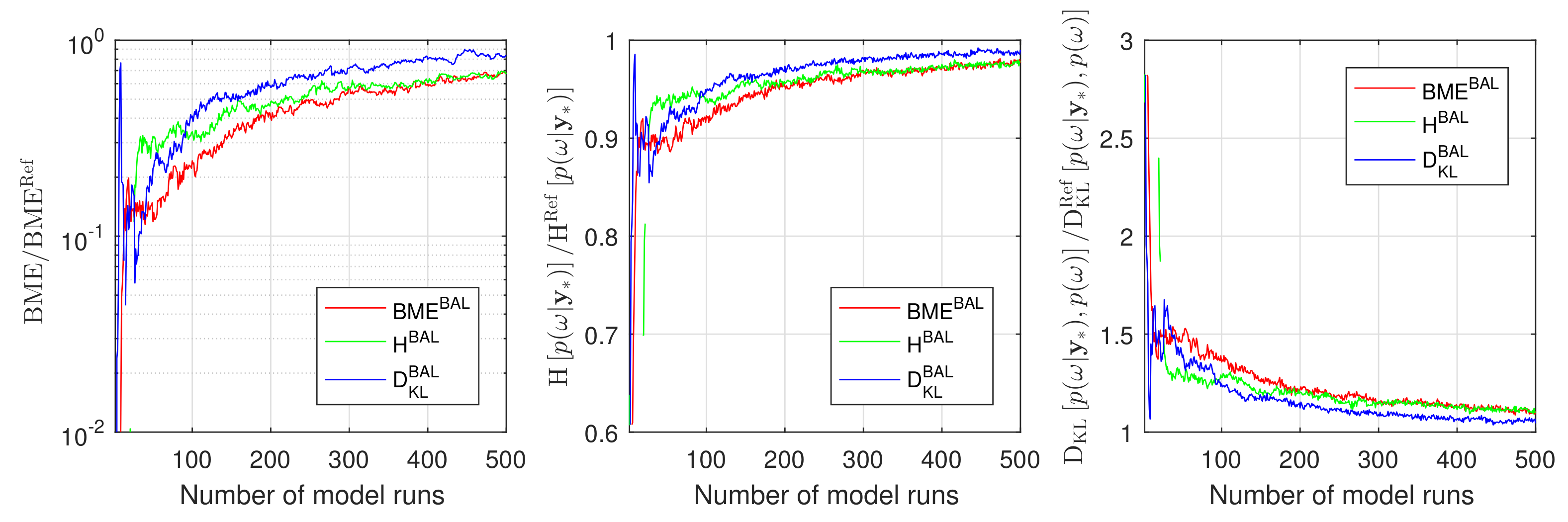
4.1.3. Assessment of Information Arguments during Bayesian Active Learning
4.2. Bayesian Active Learning for Carbon Dioxide Benchmark Problem
4.2.1. CO2 Benchmark Set up
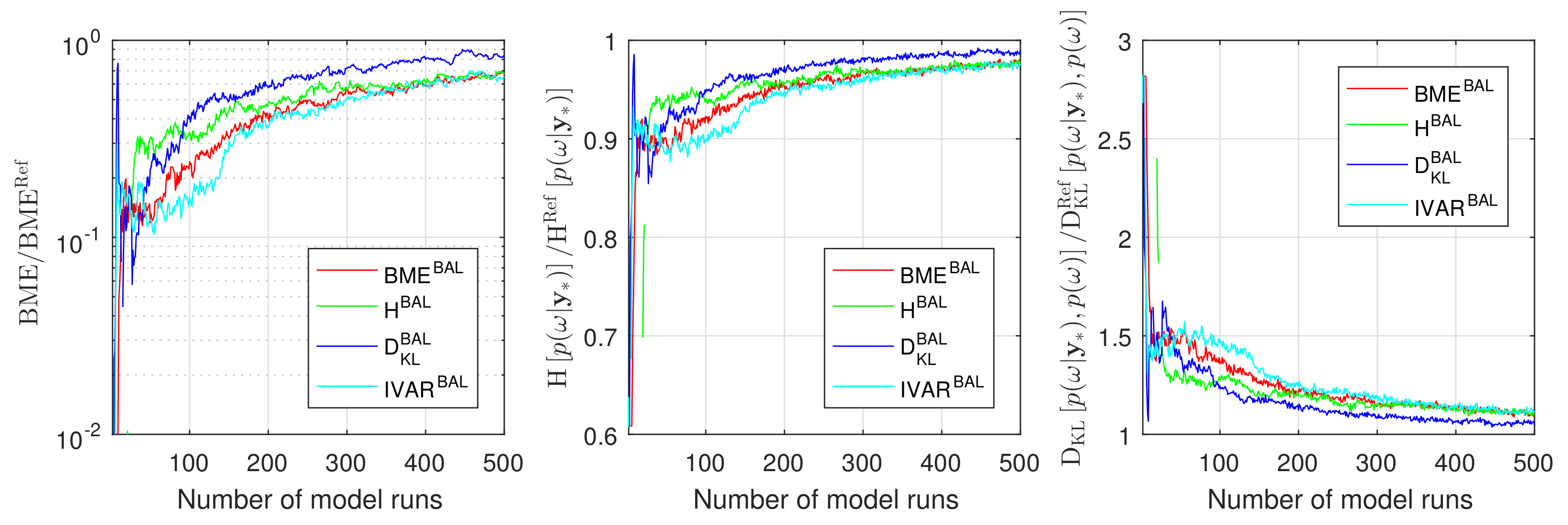
4.2.2. Assessment of Information Arguments during Bayesian Active for CO2 Benchmarks
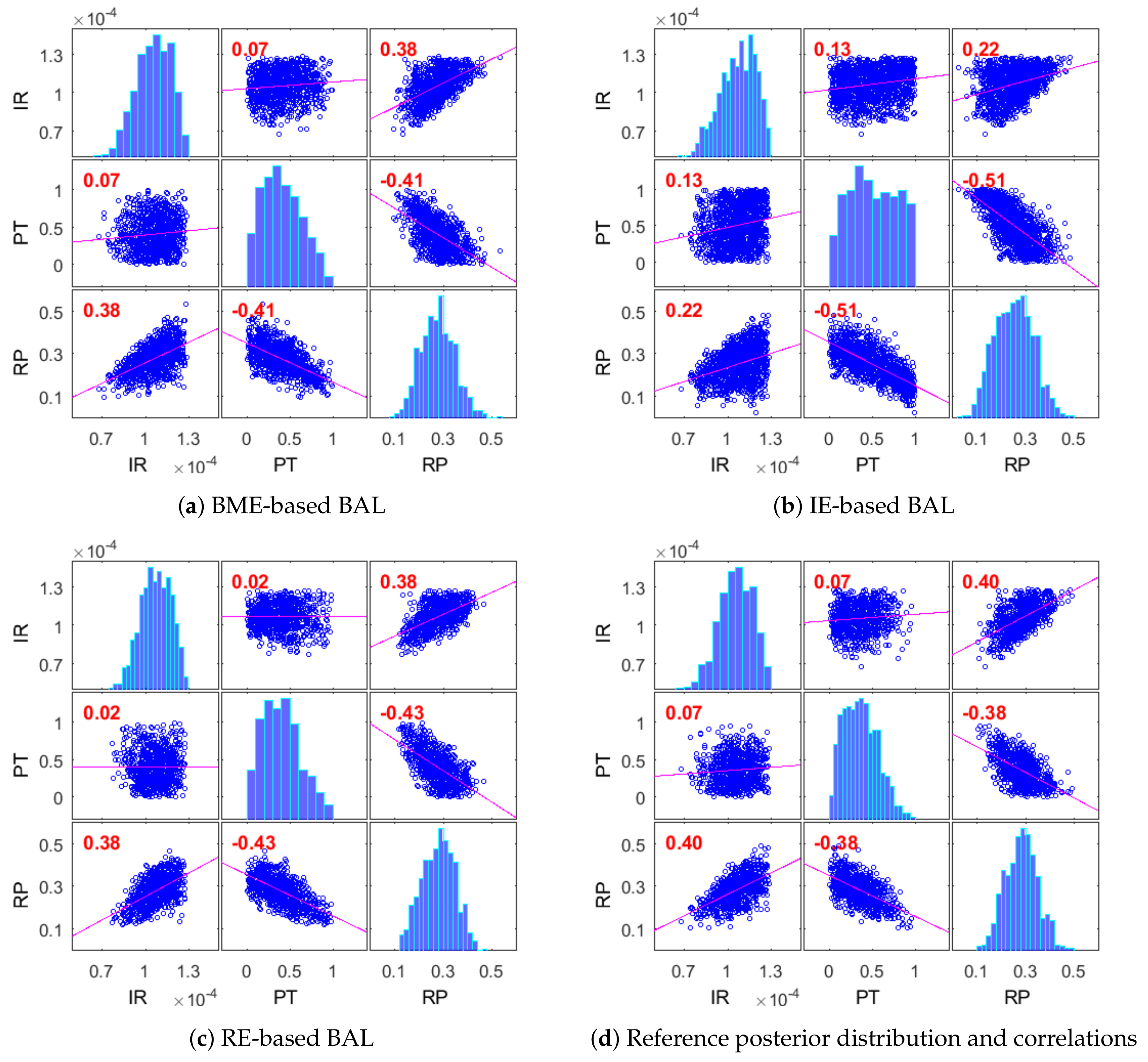
4.2.3. Posterior Distribution of Modeling Parameters for CO2 Benchmarks
4.3. Discussion
5. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. List of Approximative Active Learning Strategies

Appendix A.1. Maximum a Posteriori Estimates
Appendix A.1.1. Chib’s Estimates
Appendix A.1.2. Estimates via Akaike Information Criterion
Appendix A.1.3. Estimates via Second-Order bias Correction for Akaike Information Criterion
Appendix A.1.4. Estimates via Bayesian Information Criterion
Appendix A.1.5. Estimates via Kashyap Information Criterion
Appendix A.1.6. Estimates via Re-Scaled Kashyap Information Criterion
Appendix A.1.7. Estimates via Gelfand and Dey Sampling
Appendix A.1.8. Multivariate Gaussian Estimates
References
- Wirtz, D.; Nowak, W. The rocky road to extended simulation frameworks covering uncertainty, inversion, optimization and control. Environ. Model. Softw. 2017, 93, 180–192. [Google Scholar] [CrossRef]
- Wiener, N. The homogeneous chaos. Am. J. Math. 1938, 60, 897–936. [Google Scholar] [CrossRef]
- Ghanem, R.G.; Spanos, P.D. Stochastic Finite Elements: A Spectral Approach; Springer: New York, NY, USA, 1991. [Google Scholar]
- Lin, G.; Tartakovsky, A. An efficient, high-order probabilistic collocation method on sparse grids for three-dimensional flow and solute transport in randomly heterogeneous porous media. Adv. Water Res. 2009, 32, 712–722. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Nowak, W. Data-driven uncertainty quantification using the arbitrary polynomial chaos expansion. Reliab. Eng. Syst. Safe 2012, 106, 179–190. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Nowak, W. Incomplete statistical information limits the utility of high-order polynomial chaos expansions. Reliab. Eng. Syst. Saf. 2018, 169, 137–148. [Google Scholar] [CrossRef]
- Foo, J.; Karniadakis, G. Multi-element probabilistic collocation method in high dimensions. J. Comput. Phys. 2010, 229, 1536–1557. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Pau, G.; Oladyshkin, S.; Finsterle, S. Evaluation of multiple reduced-order models to enhance confidence in global sensitivity analyses. Int. J. Greenh. Gas Control 2016, 49, 217–226. [Google Scholar] [CrossRef][Green Version]
- Oladyshkin, S.; Class, H.; Helmig, R.; Nowak, W. An integrative approach to robust design and probabilistic risk assessment for CO2 storage in geological formations. Comput. Geosci. 2011, 15, 565–577. [Google Scholar] [CrossRef]
- Keese, A.; Matthies, H.G. Sparse quadrature as an alternative to Monte Carlo for stochastic finite element techniques. Proc. Appl. Math. Mech. 2003, 3, 493–494. [Google Scholar] [CrossRef]
- Blatman, G.; Sudret, B. Sparse polynomial chaos expansions and adaptive stochastic finite elements using a regression approach. C. R. Mécanique 2008, 336, 518–523. [Google Scholar] [CrossRef]
- Ahlfeld, R.; Belkouchi, B.; Montomoli, F. SAMBA: Sparse approximation of moment-based arbitrary polynomial chaos. J. Comput. Phys. 2016, 320, 1–16. [Google Scholar] [CrossRef]
- Sinsbeck, M.; Nowak, W. Sequential Design of Computer Experiments for the Solution of Bayesian Inverse Problems. SIAM/ASA J. Uncertain. Quantif. 2017, 5, 640–664. [Google Scholar] [CrossRef]
- Alkhateeb, O.; Ida, N. Data-Driven Multi-Element Arbitrary Polynomial Chaos for Uncertainty Quantification in Sensors. IEEE Trans. Magn. 2017, 54, 1–4. [Google Scholar] [CrossRef]
- Kröker, I.; Nowak, W.; Rohde, C. A stochastically and spatially adaptive parallel scheme for uncertain and nonlinear two-phase flow problems. Comput. Geosci. 2015, 19, 269–284. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Class, H.; Helmig, R.; Nowak, W. A concept for data-driven uncertainty quantification and its application to carbon dioxide storage in geological formations. Adv. Water Res. 2011, 34, 1508–1518. [Google Scholar] [CrossRef]
- Köppel, M.; Kröker, I.; Rohde, C. Intrusive uncertainty quantification for hyperbolic-elliptic systems governing two-phase flow in heterogeneous porous media. Comput. Geosci. 2017, 21, 807–832. [Google Scholar] [CrossRef]
- Wendland, H. Scattered Data Approximation; Cambridge University Press: Cambridge, UK, 2005; Volume 17. [Google Scholar]
- Schölkopf, B.; Smola, A. Learning with Kernels; The MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Cressie, N.A. Spatial prediction and kriging. Statistics for Spatial Data, Cressie NAC, ed.; John Wiley & Sons: New York, NY, USA, 1993; pp. 105–209. [Google Scholar]
- Kolmogorov, A.N.; Bharucha-Reid, A.T. Foundations of the Theory of Probability: Second English Edition; Courier Dover Publications: Mineola, NY, USA, 2018. [Google Scholar]
- Xiao, S.; Oladyshkin, S.; Nowak, W. Reliability analysis with stratified importance sampling based on adaptive Kriging. Reliab. Eng. Syst. Saf. 2020, 197, 106852. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian processes for regression. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1996; pp. 514–520. [Google Scholar]
- Köppel, M.; Franzelin, F.; Kröker, I.; Oladyshkin, S.; Santin, G.; Wittwar, D.; Barth, A.; Haasdonk, B.; Nowak, W.; Pflüger, D.; et al. Comparison of data-driven uncertainty quantification methods for a carbon dioxide storage benchmark scenario. Comput. Geosci. 2019. [Google Scholar] [CrossRef]
- Lia, O.; Omre, H.; Tjelmeland, H.; Holden, L.; Egeland, T. Uncertainties in reservoir production forecasts. AAPG Bull. 1997, 81, 775–802. [Google Scholar]
- Smith, A.F.; Gelfand, A.E. Bayesian statistics without tears: A sampling–resampling perspective. Am. Stat. 1992, 46, 84–88. [Google Scholar]
- Gilks, W.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapmann & Hall: London, UK, 1996. [Google Scholar]
- Liu, P.; Elshall, A.S.; Ye, M.; Beerli, P.; Zeng, X.; Lu, D.; Tao, Y. Evaluating marginal likelihood with thermodynamic integration method and comparison with several other numerical methods. Water Resour. Res. 2016, 52, 734–758. [Google Scholar] [CrossRef]
- Xiao, S.; Reuschen, S.; Köse, G.; Oladyshkin, S.; Nowak, W. Estimation of small failure probabilities based on thermodynamic integration and parallel tempering. Mech. Syst. Signal Process. 2019, 133, 106248. [Google Scholar] [CrossRef]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Elsheikh, A.; Oladyshkin, S.; Nowak, W.; Christie, M. Estimating the probability of co2 leakage using rare event simulation. In Proceedings of the ECMOR XIV-14th European Conference on the Mathematics of Oil Recovery, Catania, Italy, 8–11 September 2014. [Google Scholar]
- Au, S.K.; Beck, J.L. Estimation of small failure probabilities in high dimensions by subset simulation. Probabilistic Eng. Mech. 2001, 16, 263–277. [Google Scholar] [CrossRef]
- Zuev, K.M.; Beck, J.L.; Au, S.K.; Katafygiotis, L.S. Bayesian post-processor and other enhancements of Subset Simulation for estimating failure probabilities in high dimensions. Comput. Struct. 2012, 92, 283–296. [Google Scholar] [CrossRef]
- Volpi, E.; Schoups, G.; Firmani, G.; Vrugt, J.A. Sworn testimony of the model evidence: Gaussian mixture importance (GAME) sampling. Water Resour. Res. 2017, 53, 6133–6158. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Class, H.; Nowak, W. Bayesian updating via Bootstrap filtering combined with data-driven polynomial chaos expansions: Methodology and application to history matching for carbon dioxide storage in geological formations. Comput. Geosci. 2013, 17, 671–687. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Schroeder, P.; Class, H.; Nowak, W. Chaos expansion based Bootstrap filter to calibrate. CO2 injection models. Energy Procedia 2013, 40, 398–407. [Google Scholar] [CrossRef][Green Version]
- Li, J.; Marzouk, Y.M. Adaptive construction of surrogates for the Bayesian solution of inverse problems. SIAM J. Sci. Comput. 2014, 36, A1163–A1186. [Google Scholar] [CrossRef]
- Sinsbeck, M.; Cooke, E.; Nowak, W. Sequential Design of Computer Experiments for the Computation of Bayesian Model Evidence. Submitted.
- Beckers, F.; Heredia, A.; Noack, M.; Nowak, W.; Wieprecht, S.; Oladyshkin, S. Bayesian Calibration and Validation of a Large-Scale and Time-Demanding Sediment Transport Model. Water Resour. Res. 2020, 56, e2019WR026966. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Nowak, W. The Connection between Bayesian Inference and Information Theory for Model Selection, Information Gain and Experimental Design. Entropy 2019, 21, 1081. [Google Scholar] [CrossRef]
- Wiener, N. Cybernetics; John Wiley & Sons Inc.: New York, NY, USA, 1948. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Good, I. Some terminology and notation in information theory. Proc. IEE-Part C Monogr. 1956, 103, 200–204. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The mathematical theory of communication. Ill. Press. Urbana I 1949, 11, 117. [Google Scholar]
- Murari, A.; Peluso, E.; Cianfrani, F.; Gaudio, P.; Lungaroni, M. On the use of entropy to improve model selection criteria. Entropy 2019, 21, 394. [Google Scholar] [CrossRef]
- Gresele, L.; Marsili, M. On maximum entropy and inference. Entropy 2017, 19, 642. [Google Scholar] [CrossRef]
- Cavanaugh, J.E. A large-sample model selection criterion based on Kullback’s symmetric divergence. Stat. Probab. Lett. 1999, 42, 333–343. [Google Scholar] [CrossRef]
- Vecer, J. Dynamic Scoring: Probabilistic Model Selection Based on Utility Maximization. Entropy 2019, 21, 36. [Google Scholar] [CrossRef]
- Cliff, O.; Prokopenko, M.; Fitch, R. Minimising the Kullback–Leibler divergence for model selection in distributed nonlinear systems. Entropy 2018, 20, 51. [Google Scholar] [CrossRef]
- Chaloner, K.; Verdinelli, I. Bayesian experimental design: A review. Stat. Sci. 1995, 10, 273–304. [Google Scholar] [CrossRef]
- Lindley, D.V. On a measure of the information provided by an experiment. Ann. Math. Stat. 1956, 27, 986–1005. [Google Scholar] [CrossRef]
- Fischer, R. Bayesian experimental design—studies for fusion diagnostics. Am. Inst. Phys. 2004, 735, 76–83. [Google Scholar]
- Nowak, W.; Guthke, A. Entropy-based experimental design for optimal model discrimination in the geosciences. Entropy 2016, 18, 409. [Google Scholar] [CrossRef]
- Richard, M.D.; Lippmann, R.P. Neural network classifiers estimate Bayesiana posterio probabilities. Neural Comput. 1991, 3, 461–483. [Google Scholar] [CrossRef]
- Rubinstein, R.Y.; Kroese, D.P. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation and Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Granziol, D.; Ru, B.; Zohren, S.; Dong, X.; Osborne, M.; Roberts, S. MEMe: An accurate maximum entropy method for efficient approximations in large-scale machine learning. Entropy 2019, 21, 551. [Google Scholar] [CrossRef]
- Mohammad-Djafari, A. Entropy, information theory, information geometry and Bayesian inference in data, signal and image processing and inverse problems. Entropy 2015, 17, 3989–4027. [Google Scholar] [CrossRef]
- Laws, F.; Schätze, H. Stopping criteria for active learning of named entity recognition. In Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1; Association for Computational Linguistics: Strawsburg, PA, USA, 2008; pp. 465–472. [Google Scholar]
- Fu, L.; Grishman, R. An efficient active learning framework for new relation types. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 692–698. [Google Scholar]
- Schreiter, J.; Nguyen-Tuong, D.; Eberts, M.; Bischoff, B.; Markert, H.; Toussaint, M. Safe Exploration for Active Learning with Gaussian Processes. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD 2015), Porto, Portugal, 7–11 September 2015. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Bayesian calibration of computer models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 425–464. [Google Scholar] [CrossRef]
- O’Hagan, A. Bayesian analysis of computer code outputs: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 1290–1300. [Google Scholar] [CrossRef]
- Busby, D. Hierarchical adaptive experimental design for Gaussian process emulators. Reliab. Eng. Syst. Saf. 2009, 94, 1183–1193. [Google Scholar] [CrossRef]
- Handcock, M.S.; Stein, M.L. A Bayesian Analysis of Kriging. Technometrics 1993, 35, 403–410. [Google Scholar] [CrossRef]
- Diggle, P.J.; Ribeiro, P.J.; Christensen, O.F. An Introduction to Model-Based Geostatistics. In Spatial Statistics and Computational Methods; Møller, J., Ed.; Springer: New York, NY, USA, 2003; pp. 43–86. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. The Matérn function as a general model for soil variograms. Geoderma 2005, 128, 192–207. [Google Scholar] [CrossRef]
- Echard, B.; Gayton, N.; Lemaire, M. AK-MCS: An active learning reliability method combining Kriging and Monte Carlo simulation. Struct. Saf. 2011, 33, 145–154. [Google Scholar] [CrossRef]
- Sundar, V.; Shields, M.D. Reliability analysis using adaptive kriging surrogates with multimodel inference. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2019, 5, 04019004. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, J.; Li, R.; Tong, C. LIF: A new Kriging based learning function and its application to structural reliability analysis. Reliab. Eng. Syst. Saf. 2017, 157, 152–165. [Google Scholar] [CrossRef]
- Krause, A.; Singh, A.; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Zhang, J.; Li, W.; Zeng, L.; Wu, L. An adaptive Gaussian process-based method for efficient Bayesian experimental design in groundwater contaminant source identification problems. Water Resour. Res. 2016, 52, 5971–5984. [Google Scholar] [CrossRef]
- Conrad, P.R.; Marzouk, Y.M.; Pillai, N.S.; Smith, A. Accelerating asymptotically exact MCMC for computationally intensive models via local approximations. J. Am. Stat. Assoc. 2016, 111, 1591–1607. [Google Scholar] [CrossRef]
- Wang, H.; Li, J. Adaptive Gaussian process approximation for Bayesian inference with expensive likelihood functions. Neural Comput. 2018, 30, 3072–3094. [Google Scholar] [CrossRef]
- Gramacy, R.B.; Apley, D.W. Local Gaussian process approximation for large computer experiments. J. Comput. Graph. Stat. 2015, 24, 561–578. [Google Scholar] [CrossRef]
- Gorodetsky, A.; Marzouk, Y. Mercer kernels and integrated variance experimental design: Connections between Gaussian process regression and polynomial approximation. SIAM/ASA J. Uncertain. Quantif. 2016, 4, 796–828. [Google Scholar] [CrossRef]
- MATLAB. Version 9.7.0.1216025 (R2019b). 2019. Available online: https://www.mathworks.com/help/stats/fitrgp.html (accessed on 10 July 2020).
- Mohammadi, F.; Kopmann, R.; Guthke, A.; Oladyshkin, S.; Nowak, W. Bayesian selection of hydro-morphodynamic models under computational time constraints. Adv. Water Resour. 2018, 117, 53–64. [Google Scholar] [CrossRef]
- Soofi, E.S. Information theory and Bayesian statistics. In Bayesian Analysis in Statistics and Econometrics: Essays in Honor of Arnold Zellnge; John Wiley & Sons: New York, NY, USA, 1996; pp. 179–189. [Google Scholar]
- Kass, R.E.; Raftery, A.E. Bayes Factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Hammersley, J.M. Monte Carlo Methods for solving multivariable problems. Ann. N. Y. Acad. Sci. 1960, 86, 844–874. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. In Selected Papers of Hirotugu Akaike; Springer: Berlin/Heidelberg, Germany, 1974; pp. 215–222. [Google Scholar]
- Oladyshkin, S. BAL-GPE Matlab Toolbox: Bayesian Active Learning for GPE, MATLAB Central File Exchange. 2020. Available online: https://www.mathworks.com/matlabcentral/fileexchange/74794-bal-gpe-matlab-toolbox-bayesian-active-learning-for-gpe (accessed on 12 August 2020).
- Class, H.; Ebigbo, A.; Helmig, R.; Dahle, H.K.; Nordbotten, J.M.; Celia, M.A.; Audigane, P.; Darcis, M.; Ennis-King, J.; Fan, Y.; et al. A benchmark study on problems related to CO2 storage in geologic formations. Comput. Geosci. 2009, 13, 409. [Google Scholar] [CrossRef]
- Chib, S. Marginal likelihood from the Gibbs output. J. Am. Stat. Assoc. 1995, 90, 1313–1321. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Sugiura, N. Further analysts of the data by Akaike’s information criterion and the finite corrections: Further analysts of the data by Akaike’s. Commun. Stat.-Theory Methods 1978, 7, 13–26. [Google Scholar] [CrossRef]
- Kashyap, R.L. Optimal choice of AR and MA parts in autoregressive moving average models. IEEE Trans. Pattern Anal. Mach. Intell. 1982, PAMI-4, 99–104. [Google Scholar] [CrossRef]
- Gelfand, A.E.; Dey, D.K. Bayesian model choice: Asymptotics and exact calculations. J. R. Stat. Soc. Ser. B (Methodol.) 1994, 56, 501–514. [Google Scholar] [CrossRef]
- Oladyshkin, S.; De Barros, F.; Nowak, W. Global sensitivity analysis: A flexible and efficient framework with an example from stochastic hydrogeology. Adv. Water Resour. 2012, 37, 10–22. [Google Scholar] [CrossRef]
- Xiao, S.; Oladyshkin, S.; Nowak, W. Forward-reverse switch between density-based and regional sensitivity analysis. Appl. Math. Model. 2020, 84, 377–392. [Google Scholar] [CrossRef]
- Goldman, S. Information Theory; Prentice-Hall: Englewood Cliffs, NJ, USA, 1953. [Google Scholar]
- McEliece, R.; Mac Eliece, R.J. The Theory of Information and Coding; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]








© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oladyshkin, S.; Mohammadi, F.; Kroeker, I.; Nowak, W. Bayesian3 Active Learning for the Gaussian Process Emulator Using Information Theory. Entropy 2020, 22, 890. https://doi.org/10.3390/e22080890
Oladyshkin S, Mohammadi F, Kroeker I, Nowak W. Bayesian3 Active Learning for the Gaussian Process Emulator Using Information Theory. Entropy. 2020; 22(8):890. https://doi.org/10.3390/e22080890
Chicago/Turabian StyleOladyshkin, Sergey, Farid Mohammadi, Ilja Kroeker, and Wolfgang Nowak. 2020. "Bayesian3 Active Learning for the Gaussian Process Emulator Using Information Theory" Entropy 22, no. 8: 890. https://doi.org/10.3390/e22080890
APA StyleOladyshkin, S., Mohammadi, F., Kroeker, I., & Nowak, W. (2020). Bayesian3 Active Learning for the Gaussian Process Emulator Using Information Theory. Entropy, 22(8), 890. https://doi.org/10.3390/e22080890