1. Introduction
Forecasting extreme losses is at the forefront of quantitative management of market risk. More and more statistical methods are being released with the objective of adequately monitoring and predicting large downturns in financial markets, which is a safeguard against severe price swings and helps to manage regulatory capital requirements. We aim to contribute to this strand of research by proposing a new self-exciting probability peaks-over-threshold (SEP-POT) model with the prerogative of being adequately tailored to the dynamics of real-world extreme events in financial markets. Our model can capture the strong clustering phenomenon and the discreteness of times between the days of extreme events.
Market risk models that account for catastrophic movements in security prices are the focal point in the practice of risk management, which can clearly be demonstrated by repetitive downturns in financial markets. The truth of this statement cannot be more convincing nowadays as global equity markets have very recently reacted to the COVID-19 pandemic with a plunge in prices and extreme volatility. The coronavirus fear resulted in panic sell-outs of equities and the U.S. S&P 500 index plummeted 9.5% on 12 March 2020, experiencing its worst loss since the famous Black Monday crash in 1987. Directly 2, 4, 6, and 7 business days later, the S&P 500 index registered additional huge price drops amounting to, correspondingly, 12%, 5.2%, 4.3%, and 2.9%, respectively. At the same time, the toll that the COVID-19 pandemic took on European markets was also unprecedented. For example, the German bluechip index DAX 30 plunged 12.2% on 12 March 2020, which was followed by a further 5.3%, 5.6%, 2.1% losses, correspondingly, 2, 4, and 7 business days later. The COVID-19 aftermath is a real example that highlights the strong clustering property of extreme losses.
One of the most well-recognized and widely used measures of exposure to market risk is the value at risk (VaR). VaR summarizes the quantile of the gains and losses distribution and can be intuitively understood as the worst expected loss over a given investment horizon at a given level of confidence [
1]. VaR can be derived as a quantile of an unconditional distribution of financial returns, but it is much more advisable to model VaR as the conditional quantile, so that it can capture the strongly time-varying nature of volatility inherent to financial markets. The volatility clustering phenomenon provides the reason for using the generalized autoregressive conditional heteroskedasticity (GARCH) models to derive the conditional VaR measure [
2]. However, over the last decade, the conventional VaR models have been subject to massive criticism, as they failed to predict huge repetitive losses that devastated financial institutions during the global crisis of 2007–2008. Therefore, special focus and emphasis is now placed on adequate modeling of extreme quantiles for the conditional distribution of financial returns rather than the distribution itself.
One of the relatively recent and intensively explored approaches to modeling extreme price movements is a dynamic version of the POT model which relies on the concept of the marked self-exciting point process. Unlike the GARCH-family models, POT-family models do not act on the entire conditional distribution of financial returns. Instead, their focus moves to the distribution tails where—in order to account for their heaviness—the probability mass is usually approximated with the generalized Pareto distribution. Early POT models described the occurrence of extreme returns as realizations of an independent and identically distributed (i.i.d.) variable, which led to VaR estimates in the form of unconditional quantiles. One of the first dynamic specifications of POT models that took into account the volatility clustering phenomenon and allowed economists to perceive VaR as a conditional quantile was a two-stage method developed in [
3]. This method required estimating an appropriately specified GARCH-family model in the first stage and fitting the POT model to GARCH residuals. A new avenue for forecasting VaR was opened up when the point-process approach to POT models was released in [
4]. This methodology was later extended in several publications [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14]. The benefit of this model is that it does not require prefiltering returns using GARCH-family estimates while at the same time it can capture the clustering effects of extreme losses and maintain the merits of the extreme value theory. The point-process POT model approximates the time-varying conditional probability of an extreme loss over a given day with the help of a conditional intensity function that characterizes the arrival rate of such extreme events. The intensity function can either be formulated in the spirit of the self-exciting Hawkes process [
4,
5,
10,
11,
12] (which is extensively used in geophysics and seismology), in the form of the observation-driven autoregressive conditional intensity (ACI) model [
13], or using the autoregressive conditional duration (ACD) models [
6,
7,
8] (the last two methodologies were very popular in the area of market microstructure and the modeling of financial ultra-high-frequency data [
15,
16,
17]). In all cases, the timing of extreme losses depends on the timing of extreme losses observed in the past.
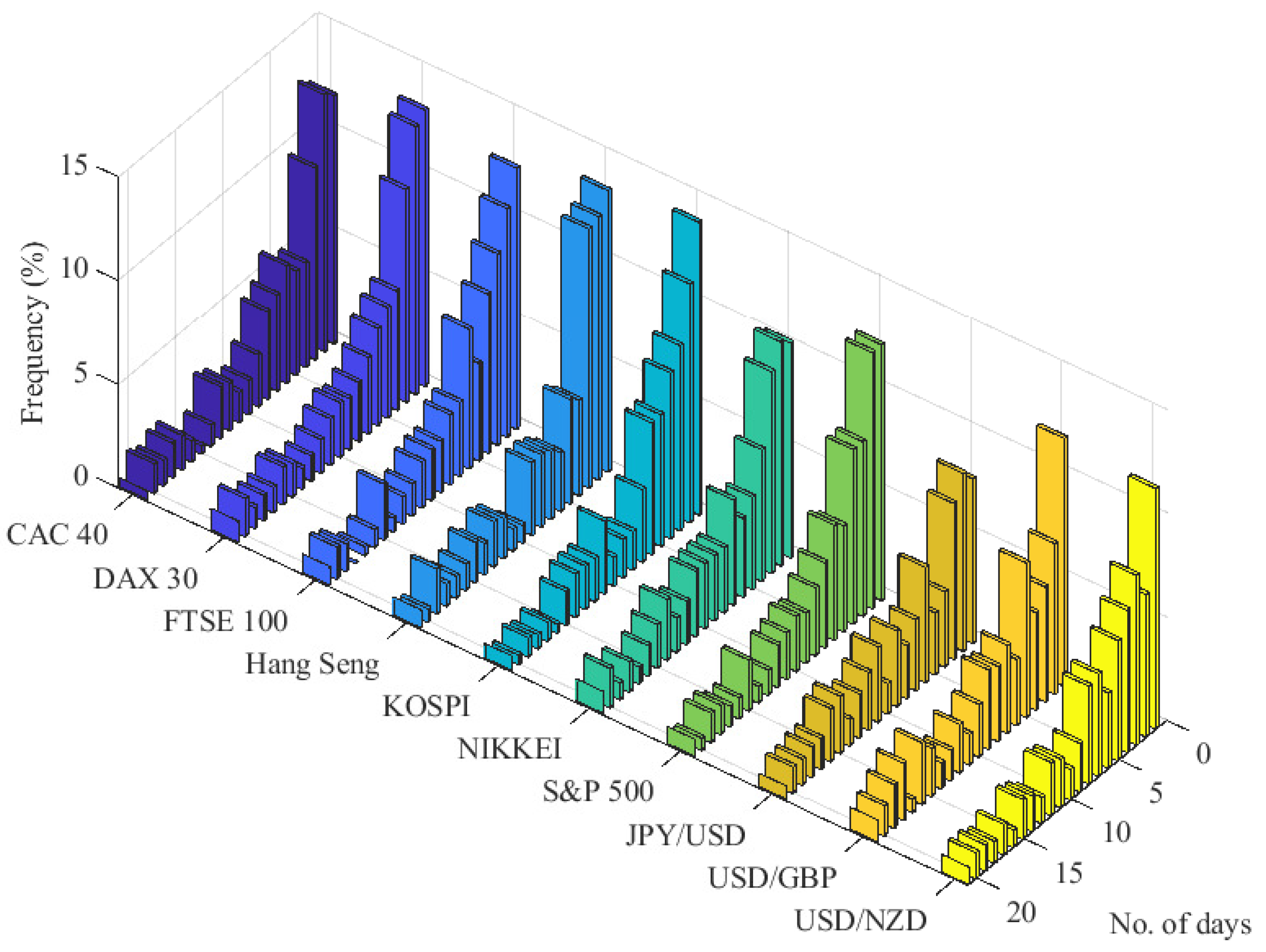
This study does not strictly rely on the above mentioned point process approach to POT models. The discrete-time framework of our SEP-POT model is motivated by observation of real-world financial data measured daily, which is the most common frequency used in POT models of risk. The empirical analysis put forward in this paper is based on the daily log returns of seven international stock indexes (i.e., CAC 40 (France), DAX 30 (Germany), FTSE 100 (United Kingdom), Hang Seng (Hong Kong), KOSPI (Korea), NIKKEI (Japan), and S&P 500 (U.S.)) as well as the daily log returns of three currency pairs (JPY/USD, USD/GBP, USD/NZD). The daily log returns for the equity market were calculated from the adjusted daily closing prices downloaded from the Refinitiv Datastream database. The foreign exchange (FX) rates were obtained from the Federal Reserve Economic Data repository and are measured in following units: Japanese Yen to one U.S. Dollar (JPY/USD), U.S. Dollars to one British Pound (USD/GBP), U.S. Dollars to one New Zealand Dollar (USD/NZD). Extreme losses are defined as the daily negated log returns (log returns pre-multiplied by
) whose magnitudes (in absolute terms) are larger than a sufficiently large threshold,
u.
Figure 1 shows that for
u corresponding to the 0.95-quantile of the unconditional distribution of negated log returns, the daily measurement frequency, and the broad set of financial instruments, the relative frequency mass of the time interval between subsequent extreme losses is concentrated on small integer values. Indeed, about 45% of all such durations is distributed on distinct discrete values of 1–5 days, and the most frequent time span between subsequent extreme losses is one day (about 12–13% of cases).
The SEP-POT model relates to the published work on the point-process approach to POT models but is consistent with the observed discreteness of threshold exceedance durations. Thus, in our model, the values of the time variable are treated as indivisible time units upon which extreme losses can be observed. As a result that the extreme losses are clustered, the model incorporates the self-exciting component. Accordingly, the extreme loss probability is affected by the series of time spans (in number of days) that have elapsed since all past extreme loss events. We apply the weighting function in the form of the at-zero-truncated Negative Binomial (NegBin) distribution that allows the influence of previous extreme losses to decay over time. The functional form of the extreme loss probability in our SEP-POT model is drawn from [
18], where a very similar specification was proposed to depict the self-exciting nature of terrorist attacks in Indonesia and forecasted the probability of future terrorist attacks as a function of attacks observed in the past. Inspired by this work, we check the adequacy of such a discrete-time approach in the framework of POT models of risk. To this end, we perform an extensive validation of the SEP-POT model both in and out of sample and compare it with three widely-recognized VaR measures: one based on the self-exciting intensity (Hawkes) POT model, one derived from the exponential GARCH model with skewed Student’s t distribution (skewed-t-EGARCH) model, and the last one was delivered by the Gaussian GARCH model. The results for VaR at high confidence levels (>99%) remain in favor of the SEP-POT model, and hence, the model constitutes a real alternative for measuring the risk of large losses.
Section 2 outlines the point process approach to POT models, introduces the SEP-POT model, and outlines the backtesting methods used for model validation.
Section 3 presents the empirical findings and discusses the extensive backtesting results. Finally,
Section 4 concludes the paper and proposes areas for future research.
3. Results and Discussion
In our empirical study we use daily log-returns from seven major stock indexes worldwide (CAC 40, DAX 30, FTSE 100, Hang Seng, KOSPI, NIKKEI, and S&P 500) and three currency pairs (JPY/USD, USD/GBP, USD/NZD). The CAC 40, DAX 30, and FTSE 100 are the major equity indexes in France, Germany, and U.K., respectively, and they are often perceived as the proxies or the real-time indicators for a much broader European stock market. The Hang Seng, KOSPI, and NIKKEI demonstrate the investment opportunity on the largest Asian equity markets in Hong Kong, South Korea, and Japan, respectively. S&P 500 constitutes a widely-investigated benchmark stock index reflecting the state of the overall U.S. economy. These seven indices monitor the state of the international equity market in its three global financial centers—western Europe, eastern Asia, and the U.S. As far as selection of the FX rates is concerned, according to [
29], the JPY/USD and USD/GBP are the second and third most traded currency pair in the world, after EUR/USD (We did not investigate the EUR/USD currency pair due to a much smaller number of observations when comparing to the other time series; the euro was launched on 1 January 1999). The NZD/USD, often nicknamed as the Kiwi by FX traders, is a classical example of the commodity currency pair that co-fluctuates with the world prices of primary commodities (i.e., New Zealand exports oil, metals, dairy, and meat products). The New Zealand Dollar is also treated by international investors as a carry trade currency—therefore, it is very sensitive to interest rate risk. For each of these financial instruments we split the data spanning over a four-decades-long period into: (1) the in-sample data (i.e., 2 January 1981–31 December 2014) dedicated to the estimation and evaluation of our models and (2) the out-of-sample data (i.e., 2 January 2015–31 March 2020) which is reserved for VaR backtesting purposes. For each of the time series, the initial threshold
u was set as the 95%-quantile of the in-sample unconditional distribution of negated log returns. Hence, the 5% largest negated returns were defined as extreme losses, which means that, on average, an extreme loss can be observed with probability 0.05. The selection of the threshold value
u was a compromise between (1) the desired number of observations in the tail of the distribution to reduce noise and to ensure stability in parameter estimates (i.e., the lower the
u, the more observations used for estimation) and (2) the goodness-of-approximation of the threshold exceedance distribution with the GP distribution (i.e., the higher the
u, the better the approximation with the GP distribution). The latter issue was solved using two diagnostic tools, that confirmed the adequate goodness-of-fit of the conditional GP distribution. We used the D-test proposed in Ref. [
30] and the
test for uniformity of probability integral transforms (PIT) based on the GP density estimates.
Figure 3 illustrates extreme losses corresponding to the German DAX 30 index between January 1981 and March 2020. The examination of panels [a] and [b] allows us to conclude that the periodic volatility bursts are paralleled with the strong clustering effects for both (1) the magnitudes of extreme losses and (2) the days that they occur. Indeed, the quantile-quantile (QQ) plot (panel [c]) comparing empirical quantiles of the time intervals between subsequent extreme-loss days against the quantiles of an exponential distribution proves that the times of extreme losses are not distributed according to the homogeneous Poisson point process. Clustering of extreme events is also demonstrated by the shape of the autocorrelation function (ACF), indicating significant positive autocorrelations in both time intervals between successive threshold exceedances and the observed magnitudes of such exceedances.
The descriptive statistics of the CAC 40, DAX 30, and FTSE 100 data are summarized in
Table 1 (analogical results for the remaining time series can be obtained from the author upon request). We see that for the CAC 40, DAX 30, and FTSE 100, the threshold exceedances were obtained as the losses surpassing
u that is equal to 0.021, 0.021, and 0.017, respectively. Out of 8574 (CAC 40), 8563 (DAX 30), and 7826 (FTSE 100) daily log returns in-sample, these threshold values allow us to expose, correspondingly, 429, 428, and 391 extreme losses that were used for the model estimation purposes. For the FTSE 100 index, we have less observations (corresponding to three years: 1981–1983), because the in-sample period starts on 3 January 1984, when the FTSE 100 index was established. Although the official base date for the DAX 30 index is 31 December 1987, the DAX 30 index was linked with the former DAX index which dates back to 1959. The official base date for the CAC 40 also begins on 31 December 1987, but between 2 January 1981 and 30 December 1987 it could be measured as the “Insee de la Bourse de Paris.” The threshold-exceedance durations cover a very wide range of observed values. For example, for the FTSE 100 index, the range spans from one day (with the relative frequency equal to 12.8% in-sample and 11.3% out-of-sample) up to 304 days in-sample or 205 days out-of-sample. In-sample, the largest threshold exceedance, equal to 0.114, was observed on the Black Monday of 20 October 1987 and it corresponded to a 12.22% decrease of the index. Out-of-sample, the maximum threshold exceedance is equal to 0.099 (a 10.87% plunge in the index) and was observed on the Black Thursday of 12 March 2020, being a single day in a chain of stock market crashes induced by the COVID-19 pandemic.
Realized gains and losses are measured over distinct days, and hence, the time spans between extreme losses are comprised of discrete time units (i.e., days). The scale of this phenomenon can be seen by looking at the considerable proportion of threshold exceedance durations equal to one, two, or three (business) days. Moreover, about 45% of such durations is less than or equal to five days and over 60% are less than or equal to ten days. Another striking observation from
Table 1 is the clustering of extreme losses. Large losses tend to occur in waves, which is seen from the Ljung-Box test statistics
(where
) for the lack of up to
kth-order serial correlation. These test statistics are significantly different from zero, and hence, the null hypothesis of no autocorrelation in threshold exceedance durations must be rejected. Indeed, due to the COVID-19 outbreak, between 24 Februry and 31 March 2020 (i.e., over 27 business days) the CAC 40, DAX 30, and FTSE 100 suffered from as many as 10 (CAC40 and DAX 30) or 11 (FTSE 100) extreme losses (with the shortest and the longest threshold exceedance durations equal to one and five business days only, respectively). Extreme loss days tended to occur very close to each other, but this phenomenon is paralleled by the significant autocorrelation in the magnitudes of observed threshold exceedances. Based on the Ljung-Box test results, the null hypothesis of no autocorrelation in the threshold exceedance sizes needs to be rejected. The observed threshold exceedance durations are by their very nature discrete and feature strong positive autocorrelation. Therefore, our SEP-POT model is suitably tailored to this data.
The SEP-POT model was estimated by maximizing the log likelihood function given in Equations (
17)–(
19). To this end, we used the constrained maximum likelihood (CML) library of the Gauss mathematical and statistical system. The standard errors of the parameter estimates were derived from the asymptotic covariance matrix based on the (inverse) of a computed Hessian.
Table 2 presents the estimation results for the CAC 40, DAX 30, and FTSE 100 (analogical results for the remaining time series can be obtained from the author upon request). The parameter estimates responsible for the self-excitement mechanism, both in the probability of threshold exceedances (i.e.,
,
,
) and the magnitudes of these exceedances (i.e.,
,
) are highly statistically significant. The parameter estimates for DAX 30 and CAC 40 indices look very much alike, especially for the conditional probability of threshold exceedances, which means that these two stock markets are closely related to each other.
Obtained series for
,
, and
are illustrated in
Figure 4. The extreme loss probability (i.e.,
) features a strong self-excitation property because it reacts to extreme-loss days with abrupt increases and, if there are no further intervening events, it slowly wanders in the downward direction. In calm and prosperous periods of the stock market history, the path of
rests on very low levels. However, in turbulent periods, when the location of extreme-loss days is very dense,
tends to involve very high numbers. More specifically, persistently elevated
levels can be seen during the market downturn of 2002–2003 and the global crisis of 2008–2009. For the CAC 40 and FTSE 100, the highest in-sample
level, equal to 0.2834 (CAC 40) and 0.3082 (FTSE 100), was reached on Monday, 24 November 2008. Both maximum values were triggered by a self-excitation mechanism during the prevailing stock market turmoil. Directly before 24 November 2008 the market suffered three consecutive extreme-loss days–November 19. (Wednesday), 20. (Thursday) and 21. (Friday). For the DAX 30 index, the in-sample
peaked to its highest level (0.3126) on 11 November 1987, in the aftermath of 10 steep losses that started on the Black Monday of 19 October. The last three were observed on three business days, 6–10 November 1987. Out-of-sample, the highest
levels of 0.2298 (CAC 40), 0.2416 (DAX 30), and 0.2339 (FTSE 100) corresponded to 24 March 2020 (CAC 40 and DAX 30) and 19 March 2020 (FTSE 100). COVID-19-induced anxiety before 24 March, resulted in the concentration of six threshold exceedances for CAC 40 and DAX 30 in March 2020 alone, where the last of these threshold exceedances took place just one day before the highest
level was reached on 23 March 2020.
Observed fluctuations of are accompanied with the strongly time-varying behavior of (i.e., the estimate of the dispersion parameter in the conditional distribution of threshold exceedances). The losses exceeding u trigger upward jumps in both numbers, boosting the awaited probability and the size of a threshold exceedance. For the CAC 40 index, peaked to its highest level (0.059) on 15 May 1981, due to enormous panic and sell-offs on the Paris Bourse just days before Francois Mitterand announced hostile reforms for the stocks quoted at the Bourse. Indeed, the preceding days saw the CAC 30 index plunge by over 30%. The UK and German markets were mostly untouched by these French policy-oriented events, and the highest was registered on 27 October 1987 (FTSE 100) and 29 October 1987 (DAX 30) at the levels of 0.051 (FTSE 100) and 0.042 (DAX 30), just after a few huge price drops were observed including the famous Black Monday on 19 October 1987. Note, that the maximum levels do not have to coincide with those of . This is because is also affected by the magnitude of past threshold exceedances. For all data in this study, the highest out-of-sample levels were registered in the second half of March 2020.
The self-triggering nature of
and
give rise to variations in daily VaR, as shown in the panel [c] of
Figure 4. What catches special attention is that the obtained path of VaR estimates tends to adjust to both periods of calm and turmoil in the history of equity markets—it quickly reacts to price jumps and bursts in volatility and accounts for persistent swings in stock prices.
We verified whether the SEP-POT model is appropriate for forecasting the daily VaR. To ensure a big-picture perspective over its usefulness in diverse practical applications, we derived the daily VaR levels for six assumed theoretical coverage rates (i.e., for
), and compared them with corresponding VaR numbers from three competing risk models (i.e., the self-exciting intensity (Hawkes) POT model (SEI-POT), the EGARCH(1,1) model with the skewed-t distributed innovations and the standard GARCH(1,1) model with normally-distributed innovations). For the sake of fair comparison between the four risk models under study, the accuracy of VaR forecasts was validated with four backtesting procedures. Moreover, each of these statistical routines was distinctly applied to examine the following: (1) the in-sample goodness-of-fit and (2) the out-of-sample accuracy. Considering ten financial instruments under study, six coverage levels for VaR (
q) and four models (SEP-POT VaR, SEI-POT VaR, skewed-t-EGARCH VaR, and Gaussian GARCH VaR), we ended up with 240 VaR series in-sample and 240 series out-of-sample. Therefore, for clarity of exposition, the backtesting results were summarized in the form of heatmap graphs (cf.,
Figure 5,
Figure 6,
Figure 7 and
Figure 8). Heatmaps use a grid of colored rectangles across two axes where the horizontal axis corresponds to the assumed VaR coverage level and the vertical axis corresponds to the financial instrument under study. The color of each little rectangle (in shades of red and green) reflects the
p-value of a backtesting procedure. The white colour corresponds to a
p-value equal to 0.05. The darker the red color indicates an increasingly smaller
p-value, one that it is less than 0.05. The darker the tone of green indicates an increasingly higher
p-value, one that it is larger than 0.05. For example, panel [a] of
Figure 5 presents the
p-values corresponding to the UC test statistics. Each of the four heatmaps in panel [a] refers to the VaR delivered from a different model: the SEP-POT, SEI-POT, skewed-t-EGARCH, and Gaussian GARCH.
According to the UC test results, the VaR based on the SEP-POT, SEI-POT, and skewed-t-EGARCH models produce, in-sample, a rather accurate proportion of violations. The best in-sample results were delivered by the skewed-t-EGARCH model; however, its superiority diminishes out-of-sample, where the skewed-t-EGARCH model failed in 13 out of 60 instances. Out-of-sample, the SEP-POT VaR and SEI-POT VaR models rejected the null of correct coverage only three times. The EGARCH model seems to produce good VaR forecasts for high coverage levels (i.e., ). For , the EGARCH VaR model is left behind the SEI-POT VaR model and SEP-POT VaR model. As expected, the advantage of VaR models based on POT methodology is most visible for the extreme quantiles. As far as the Gaussian GARCH VaR model is concerned, its performance is dramatically worse than other risk models both in-sample and out-of-sample. The model produces incorrect VaR forecasts for small q (i.e., ), which can be explained by insufficient probability mass in the tails of Gaussian distribution.
The results of the CC test checking both the correct coverage and the lack of dependence of order one in VaR violations seem to support the SEP-POT VaR model (cf.,
Figure 6). The poorest fit corresponds to the highest
q levels (i.e.,
) because in such cases, the null of proper specification had to be rejected both in-sample and out-of-sample for FTSE 100, KOSPI, NIKKIEI, and S&P 500. However, the SEP-POT VaR model seems to be slightly superior than the SEI-POT VaR model. In sample, only in six instances out of 60 did the SEP-POT VaR model fail. For the SEI-POT VaR model, the number of failures was 10 and for the skewed-t-EGARCH VaR model it was nine. As in the case of the UC test, the CC test results indicate that the Gaussian GARCH VaR model rendered the worst fit—the null was not rejected in only seven cases, mainly for the lowest quantiles (i.e., for
). Out-of-sample, the SEP-POT and the SEI-POT models deliver the similar quality of daily VaR forecasts and both win over GARCH-family models.
Turning our attention to
Figure 7, which illustrates the results of the DQ test, the first striking observation is that a much larger area of all heatmaps is marked with shades of red when compared to the results of the CC tests. Indeed, the DQ test is more demanding than the CC test because checks not only whether a VaR violation today is uncorrelated with the fact of a VaR violation yesterday but it also checks whether VaR violations are affected by some covariates from a wider information set, where we used the current VaR and the
variable observations from one to four days ago (as in original work [
27]). The superiority of the SEP-POT VaR model over its competitors is clearly visible. Although the SEP-POT VaR model has a clear tendency to mis-specify VaR at the highest
q levels (i.e.,
), the DQ test results for the SEI-POT VaR and the VaR based on the GARCH family models are inferior. In-sample, the DQ test rejected 14 SEP-POT VaR models, 21 SEI-POT VaR models, 26 skewed-t-EGARCH VaR and 57 (i.e., nearly all) Gaussian GARCH VaR models. Out-of-sample, the advantage of the SEP-POT VaR model over the SEI-POT VaR model is less vivid—the first model failed in 12 instances and the latter failed in 14.
Figure 8 illustrates the results of the dynamic logit CC test. We can observe a systematic pattern as far as the SEP-POT VaR and SEI-POT VaR models are concerned. The area marked in red concentrates on the left-hand side of the heatmaps both in and out-of-sample, which means that VaR is mis-specified if derived for high coverage rates (i.e.,
). This deficit of POT VaR models is recouped by their accuracy at low
q levels. Indeed, for
in-sample and for
out-of-sample, both POT models are not able to reject the null. The SEP-POT VaR model was still slightly more successful than the remaining risk models. In-sample, it failed only 10 times (mainly for
), whereas the SEI-POT VaR model failed 18 times, the skewed-t-GARCH model failed ten times, yet the Gaussian GARCH VaR model managed to pass this test only two times. Out-of-sample, both POT VaR models were equally correct. For the SEP-POT and SEI-POT VaR model, the null of correct conditional coverage was rejected nine times. The dynamic logit CC test rejected the skewed-t-EGARCH model in 16 and the Gaussian GARCH in majority of cases.
The practical implications of the SEP-POT model stem from its suitability to provide adequate VaR and ES predictions. The VaR forecasts can be used by financial institutions as internal control measures of market risk. The adequacy of risk models used by financial institutions is of utmost importance for the market regulator. Commercial banks have used VaR models for several years to calculate regulatory capital charges using the internal model-based approach of the Basel II regulatory framework. According to the more recent recommendations of the Basel Committee on Banking Supervision (BCBS), banks should use ES to ensure a more prudent capture of “tail risk” and capital adequacy during periods of significant stress in the financial markets [
31]. This attitude remains in line with the core objective of the dynamic POT models (including the SEP-POT model), as they focus on the quantification of both the forecasted probability and the awaited size of huge losses, also producing the time-varying ES forecasts. The recent Basel III accord, comprising a set of regulations developed by the BCBS, further reinforces the role of bank units responsible for internal model validations. For more about the current regulatory framework of market risk management see [
32]. Despite the recent shift from VaR to ES models in the calculation of capital requirements, ES forecasts remain highly sensitive to the quality of VaR predictions.
All in all, our findings pinpoint that the SEP-POT model constitutes a reasonable promising alternative for forecasting extreme quantiles of financial returns and the daily VaR, especially for very small coverage rates. Undoubtedly, further examination of the theoretical properties of the SEP-POT model and its forecasting accuracy is needed. The model should be backtested using other classes of financial instruments and compared against other extreme risk models. However, there is a plethora of VaR models in the literature—therefore, there are no two or three candidate specifications against which the SEP-POT model should be benchmarked and compared. Only among the point process-based POT models there have been variants put forward, including the ACD-POT model (which is based on the dynamic specifications of time, i.e., duration, that elapses between consecutive extreme losses [
6,
7,
8]) or the ACI-POT model (with its multivariate extensions) that provides an explicit autoregressive specification for the intensity function [
13]. All these dynamic versions of POT models exploit both strands of the literature: the point process theory and the EVT, accounting for the clustering of extreme losses and the heavy-tailness of the loss distribution. The SEP-POT model is also suitable tailored to these features but also explicitly accounts for the discreteness of times between extreme losses. The empirical findings in this paper provide much support for our SEP-POT model. However, further efforts should be focused on benchmarking and comparison with a broader range of methods under the same settings (i.e., the same data and the same period).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}