1. Introduction
Causality is the relationship between cause and effect. In other words, there is a causal relationship between two situations when it is certain that the second one arose due to the first one. The causal link is not mentioned exclusively in the relationship between two events or situations alone, but a causal chain may exist between causes and effects. The key component of causality is the succession of cause and effect. Reinchenbach [
1] was the first to point out that the hypothesis of causality in real phenomena should be questioned and not taken a priori as granted. The perspective that the future is indeterminate and the connection between indeterminism and a dynamic view of the world are discussed in this work. Reichenbach [
2] also postulated the principle of common cause, i.e., the dependence of two variables can be explained by at least one of the following cases: there is a unidirectional or bidirectional causation between the variables, or there exists a common cause of the two variables.
Identifying the connectivity pattern in complex multivariate systems is an issue that has seen enormous advances recent years. A variety of methods has been developed and compared, leading sometimes to contradictory conclusions [
3,
4,
5,
6,
7,
8]. Understanding the pros and cons, the estimation accuracy and computational cost of each causal discovery method are of great importance in exploiting the optimal one for experimental and empirical tasks.
A traditional way to discover causal relations is to use interventions or randomized experiments. If this is not possible, causal information is revealed by analyzing the statistical properties of purely observational data [
9]. Probabilistic causation characterizes the relationship between cause and effect based on probability theory. The key idea is that causes raise the probabilities of their effects. Probabilistic theories of causality rely on the basic intuitions in Good [
10] and Suppes [
11], pointing out the temporal priority of the cause and the statistical relevance requirement, which serves as a measure of the strength of a causal chain.
The benchmark work of Spirtes et al. [
12] utilized Bayesian network models for causal discovery. A review of causal discovery methods based on graphical models can be found in [
13]. Recently, additional causal discovery methods have been proposed in the literature. Algorithmic information dynamics is an algorithmic probabilistic framework for causal discovery and causal analysis, which does not rely on graphical models or empirical estimation of mass probability distributions, as traditional probabilistic methods do [
14,
15,
16].
Granger’s concept of causality is based on Wiener’s study [
17], according to which, if the forecast of a time series is improved by incorporating the information of a second one, then the latter exerts a causal effect on the first. Granger formalized this idea in the context of linear regression [
18]. A variable
X Granger causes
Y, if all the recent and previous information on
X values helps in the better prediction of the
Y values.
The notion of Granger causality has been very popular the last few decades, and various extensions of its original form have been introduced and applied in an ensemble of scientific fields. However, such approaches have also been intensively criticized [
19,
20]. Temporal precedence alone is not a sufficient condition for establishing directional relationships. One key problem is that such methods lead to spurious causal influences by the omission of relevant variables. In a review paper on the concept of Granger causality for causal inference from time series data, Eichler [
21] concluded that: “Causal inference based on Granger causality is indeed legitimate, but in many cases provides only sparse identification of true causal relationships, that is, for most links among the variables it cannot be determined whether the link is truly causal or not. Correct learning accumulates knowledge obtained from the large variety of possible submodels. This imposes feasibility constraints in the size of the networks that can be practically analyzed. Any analysis claiming full identification of the causal structure either must be based on very strong assumptions or prior information or—on closer inspection—turns out to be unwarranted.”
Recently, methods of nonlinear time series analysis [
22,
23] and complex networks [
24,
25] have been jointly examined. In a mathematical formulation, the set of observed time series constitutes the observed variables of a complex system of which the interdependence structure is to be investigated. Further, graph theory [
26] offers a tool to visualize the structure of a complex system as a complex network, where the nodes are the observed variables and the connections can be formed utilizing an interdependence measure.
Pairwise causality measures indicate the direct and indirect causal effects between two time series. In [
27], the authors pointed out some pitfalls in applying pairwise measures in the case of mutually dependent time series, while noting that commonly used pairwise measures often lead to erroneous results. On the other hand, conditional (or direct) causality measures exploit all the available information of the observed data to infer the connectivity. Granger [
28] addressed the problem of missing information and stated that a test for causality is impossible unless the set of interacting channels is complete.
The standard Granger causality test [
18] quantifies the directed interrelationships based on vector auto-regressive (VAR) models for prediction. Its nonlinear analogue from information theory is transfer entropy (TE) [
29]. Partial transfer entropy (PTE) extends the pairwise TE and indicates only direct causal influences. The computation of PTE relies on uniform state space reconstruction. Different estimators of PTE have been introduced, with
k-nearest neighbors (KNN) being one of the most effective ones [
30].
In the framework of information theory, the computation of conditional causality measures requires the estimation of marginal and joint probability densities. The prediction of the future of the response variable is done using entropy terms. In the case of a large number of observed variables, the problem of estimating high-dimensional densities arises, which is commonly called the “curse of dimensionality” and affects the reliability of causal inference.
The non-uniform embedding (NUE) scheme has been developed to address this problem along with the problem of irrelevance and redundancy. It was originally introduced for the pairwise case [
31] and later expanded to the conditioned one [
32,
33]. This method progressively builds an optimal mixed embedding vector allowing for different variables and delays using a conditional mutual information (CMI) criterion. Information causality measures exploiting the NUE scheme have been examined on empirical and real datasets with very promising results [
33,
34].
Estimating CMI in multivariate systems requires the computation of high-dimensional joint probability distributions. To circumvent this hurdle, a low-dimensional approximation (LA) methodology has been proposed that helps compute CMI as the sum of mutual information quantities of lower dimensionality. The LA methodology has been combined with the NUE scheme for unraveling causality problems; however, the empirical findings do not seem to be clear regarding the effectiveness of such measures [
35,
36].
In this paper, we examine the performance of conditional information causality measures in correctly identifying the connectivity network of coupled systems and demonstrate the necessity of using dimension reduction techniques. We shed light on the importance of the NUE scheme and also demonstrate the combined effectiveness of the NUE scheme with an LA method. In particular, we compare partial transfer entropy (PTE) defined on the standard uniform embedding scheme, with two dimension reduction measures, PTE utilizing the NUE scheme (PTENUE) [
34] and PTE based on the NUE scheme and an LA algorithm (LATE) [
35,
36]. The three causality measures are evaluated on synthetic time series with different characteristics, focusing on discrete systems. Numerical outcomes demonstrate the superiority of PTENUE, in terms of its strength and power, but also regarding its computational cost. Novel results are presented, emphasizing high-dimensional simulation systems. The superiority of PTENUE over the other two measures is manifested with a financial application, where the goal is to identify the leading forces among the examined variables.
In
Section 2, the three causality measures, namely PTE, PTENUE, and LATE, are reviewed. The simulation analysis for the evaluation of the causality measures is presented in
Section 3. Then,
Section 4 highlights the efficiency of PTENUE on financial data. Finally, the findings are summarized in
Section 5.
2. Methodology
Without loss of generality, let us consider the multivariate dataset in K variables, where X is the driving variable, Y is the response variable, and there are confounding variables, collectively denoted by . The future of the response variable, , is predicted for one step ahead.
2.1. Partial Transfer Entropy
Partial transfer entropy (PTE) is a causality measure from information theory that defines Granger causality based on entropy instead of VARs. It is model free and indicates both linear and nonlinear causal effects. The computation of PTE involves the formulation of uniformly spaced embedding vectors from each variable, e.g., for
X, the corresponding embedding vector is
, where
m is the embedding dimension and
is the time lag. PTE accounts for the direct coupling of
X to
Y conditioning on the remaining variables of the multivariate system [
30,
37,
38]:
where
represents the conditional mutual information and
Shannon entropy. For a discrete variable
X, Shannon entropy is defined as
, where
is the probability mass function of the outcome
, typically estimated by the relative frequency of
.
Entropy estimation can be performed based on random variable discretization by partitioning [
39] or by estimating the probability mass according to the pdf [
40,
41]. For the estimation of the probability densities, the
k-nearest neighbors’ estimator (KNN) is used [
42]. The KNN estimator uses the distances between the reconstructed state space vectors to estimate the joint and marginal densities. For each reference point, viewed in the largest state space, the distance length
is defined as the distance to the
nearest neighbor. Then, densities, at projected subspaces, are locally formed by the number of points within
from each reference point. The KNN estimator has been shown to be stable, not significantly affected by the choice of
k, and specifically effective for high-dimensional data [
30,
31,
42,
43].
PTE requires a significance test for the non-causality null hypothesis (H
0). Surrogate time series are generated by randomly time-shifting the values of the driving time series, while the other series remain unchanged [
44]. The time-shifted surrogates preserve the dynamics of the original time series (such as the histogram and autocorrelations), while the couplings between the driving variable
X and the response
Y are destroyed. They are formed by cyclically time-shifting the components of the driving time series
: an integer
d is randomly chosen, and the
d first values of the time series are moved to the end, giving the time-shifted surrogate time series
. The random number
d is randomly drawn from the discrete uniform distribution in the range
in order to maintain disruption of the time order of the original time series even in the presence of strong autocorrelations. PTE is then estimated from 100 realizations per simulation system and time series length. For each realization, one-hundred surrogate time series are generated using the described time-shifting scheme. Let us denote
the original PTE value from one realization of a system and
the PTE values from the surrogate time series. The rejection of H
0 is decided by the rank ordering of the estimated PTE values. If
is the rank of
when ranking the list
in ascending order, then the
p-value of the one-sided test is
, by applying the correction in [
45]. The significance level is set equal to
.
2.2. Partial Transfer Entropy on Non-Uniform Embedding
The estimation procedure of PTENUE is based on the non-uniform embedding (NUE) scheme. In order to best explain the future of the response variable Y, a mixed embedding vector is formed, where lagged terms from all observed variables are chosen based on a conditional mutual information (CMI) criterion. Therefore, the lagged terms entering are not necessarily uniform over time, and dimension reduction is accomplished.
For a predefined maximum lag
, the ensemble of lagged terms for forming the mixed embedding vector
is
. To formulate
, start with an empty vector. At each step
j, form a new vector
by adding a new component
(lagged term from any observed variable) that gives the most information about the future of the response variable
, conditioning on the mixed embedding vector of the previous step
(CMI criterion):
The stopping criterion relies on randomization of the driving variable. The decision for a significant CMI is made by comparing the CMI of the original data with the
percentile of the surrogate CMI values. PTENUE measures the direct effect of
X on
Y in the presence of the “appropriate” past terms of the remaining variables:
PTENUE was computed using the ITStoolbox (
http://www.lucafaes.net/its.html). The free parameters for the computation of PTENUE were set as suggested in the ITS toolbox, i.e., the significance level for the stopping criterion was set to be
.
2.3. Low-dimensional Approximation of Transfer Entropy
The low-dimensional approximation (LA) methodology has been examined in the framework of feature selection [
46,
47,
48]. Feature selection techniques aim to reduce the number of features, in order to resolve over-fitting problems and increase the computational speed for learning [
49]. Model-independent filter procedures for feature selection are classifier agnostic, simple, and computationally efficient. The conditional mutual information (CMI) has been considered as a criterion for feature selection, e.g., by identifying the best subset of features that together have the highest CMI with the class variable.
Exploiting the LA methodology and the non-uniform embedding (NUE) scheme, we end up with another variant of partial transfer entropy (PTE), denoted as LATE [
35]. The estimation procedure of LATE is similar to PTENUE’s; however, the selection of the lagged terms that form the mixed embedding vector is based on the sum of mutual information terms and low-dimensional CMIs instead of considering a high-dimensional CMI. Suppose that the set of conditioning vectors we have step-wisely built up to step
is
V. Then, the selection of the term
in step
j is extracted on the basis of the LA scheme as:
After defining the mixed embedding vector
, LATE is expressed as:
In the termination criterion, the same low-dimensional approximation scheme is considered for the computation of the surrogate values of LATE. The MATLAB code for the estimation of LATE is available upon request.
3. Simulation Study
The effectiveness of the three causality measures, namely PTE, PTENUE, and LATE, in identifying the true connectivity network of multivariate systems was evaluated in a simulation study, where 100 realizations of each system were considered. The artificial time series were derived from known coupled systems with different characteristics. Additional parameters taken into consideration were the number of variables of the examined system, the time series length, and the coupling strength. The considered time series lengths were , and 4096.
For the estimation of PTE, we set the time delay
(as in the original definition of TE [
29]) and the embedding dimension
m based on each system’s equation, i.e., equal to the maximum delay in the equations of each system. The free parameter
for the computation of PTENUE and LATE was always fixed slightly larger than
m. We note that if
took a sufficiently large value, this did not affect the performance of the measure, while a too large
would only increase the computational cost of the estimation [
33]. The number of nearest neighbors was
(
k did not affect the performance of the KNN estimator [
42]). The number of surrogates for the significance test of PTE and for the stopping criteria of PTENUE and LATE was equal to
.
For each realization of a multivariate coupled system in
K variables, there were
possible causal influences between the variables. For the identification of the connectivity network of a multivariate system, all possible causal effects were estimated. True positives (
s) quantify the correct causal influences detected by a causality measure; false positives (
s) indicate the incorrect link detections; true negatives (
s) count the correctly identified uncoupled variables; and false negatives (
s) express the causal links that are spuriously indicated as uncoupled ones by the measure. Eventually, the performance of each causality measure is discussed in terms of its true positive rate:
and its true negative rate:
Finally, the F1-score is an indicator of the overall performance of a causality measure:
The empirical findings are discussed in terms of the mean exported sensitivity, specificity, and F1-score of each causality measure over the 100 realizations of each system and each time series length.
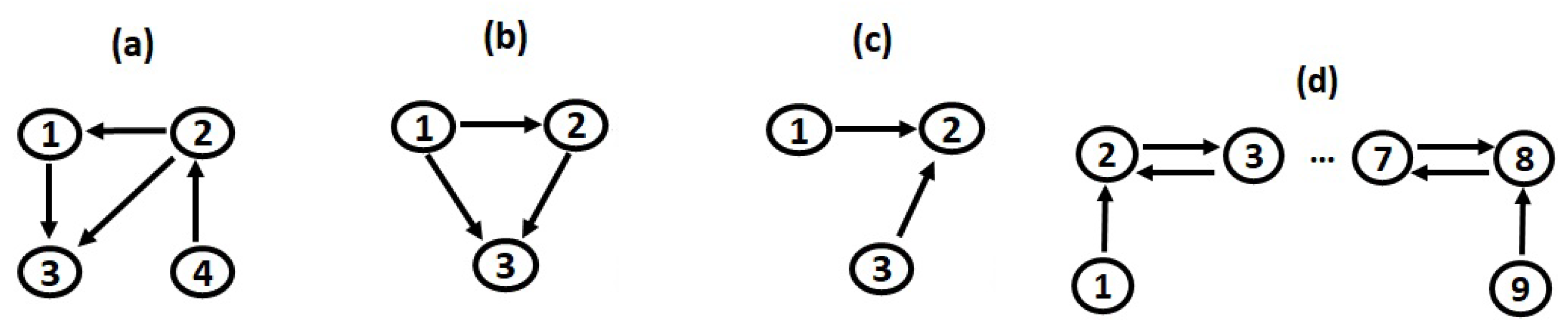
3.1. Linear Stochastic Process
The first simulation system, denoted as S1, was a linear vector auto-regressive (VAR) model of order five in four variables (Model 1 in [
50]):
where
,
, are Gaussian white noise processes independent of each other with the unit the standard deviation. The true connections of the system are known;
,
,
, and
are unidirectional causal relationships (see
Figure 1a). Although the three examined causality measures were nonlinear, we considered this simulation system in order to examine their ability in identifying linear causal influences.
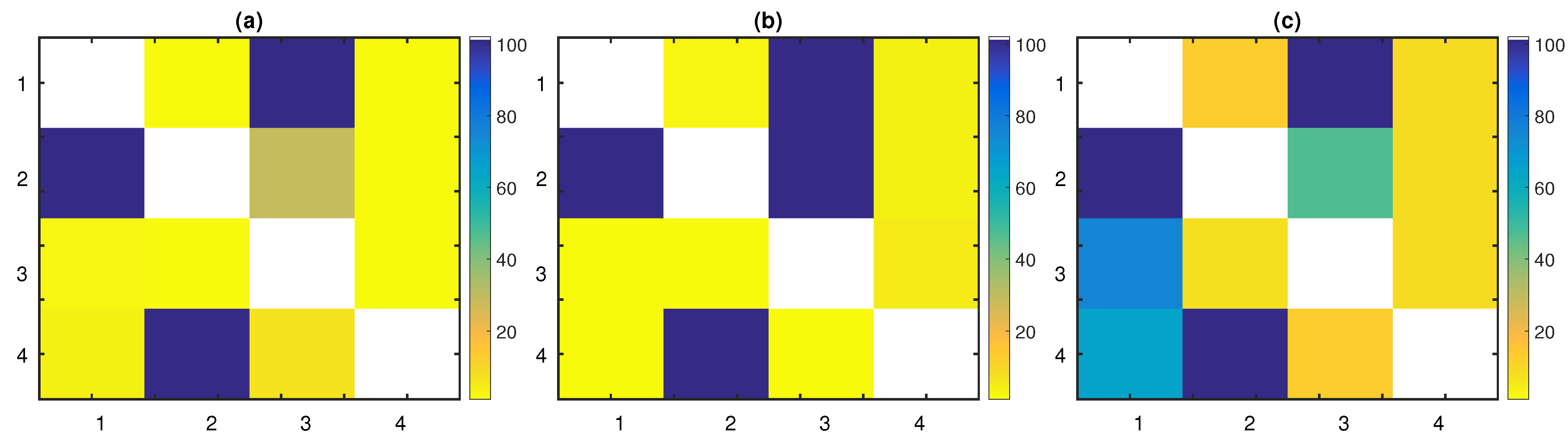
PTE had an increasing sensitivity as the the time series length grew, affecting its overall performance. It detected all the true connections with a percentage of 100% over all realizations for all
n, except for the link
, for which a large time series length was required in order to achieve a high percentage; varying from 16% for
up to 95% for
. The specificity of PTE was high for all time series lengths, with percentages of the uncoupled directions taking values close to the nominal level (from 0% up to 7%). Since the dimensionality of this system was intermediate, the full conditioning of PTE affected its sensitivity only for small time series lengths.
Figure 2a displays the percentage of significant PTE values over the 100 realizations of the linear stochastic process with
.
PTENUE outperformed the other measures, scoring the highest sensitivity, specificity, and subsequently, the highest F1-score for all time series lengths. It captured all the true couplings with a percentage of 100%, but for the link
; for
, the achieved percentage was 49% and for
96%. The corresponding percentages of the uncoupled directions were all close to the nominal level, varying from 0% up to 8%. Empirical findings indicated that partial conditioning did not lead to decreased specificity. On the contrary, PTENUE improved the performance of PTE, achieving higher scores in terms of sensitivity and specificity. In
Figure 2b, the percentage of significant PTENUE values over the 100 realizations of the linear stochastic process with
is presented.
Finally, LATE captured the true causal influences
,
, and
of the linear stochastic system, with high percentages for all time series lengths (varying from 97% up to 100%). However, the link
was detected with increasing percentages with the time series length; we obtained the percentages 43% (
), 38% (
), 46% (
), 74% (
), and 94% (
), respectively. LATE had the smallest specificity among the three causality measures, which affected its overall performance. The low specificity of LATE was due to the approximation scheme for the computation of the high-dimensional CMI. This approximation also caused the detection of the spurious causal effects
(with percentages varying from 12% to 20% for the different time series lengths) and
(with percentages varying from 51% to 75% for the different time series lengths). Additional false causal influences were detected by LATE, but with lower percentages and mainly for small
n, e.g., LATE suggested the link
(percentage of detection around 15% for all time series lengths) and
(21% for
, 16% for
). Further, the indirect coupling
was revealed with increasing percentages as the time series length grew (from 30% for
up to 83% for
) and
(with percentages varying from 6% to 16% for the different time series lengths). The aforementioned findings are summarized in
Figure 2c, where this matrix representation of the percentages of significant causal effects over the 100 realizations of the system with
highlights the fact that LATE captured spurious links and performed poorer than PTE and PTENUE.
The findings regarding the sensitivity, specificity, and F1-score of the three measures, for the linear stochastic system, are revealed in
Table 1. The overall performance of each measure was quantified as the mean over all realizations and time series lengths. The mean F1-score for PTE, PTENUE, and LATE was 90.60%, 96.41%, and 76.27%, respectively. Conclusively, the worst performance was obtained by LATE, while PTENUE outperformed the other measures. Most importantly, only LATE gave erroneous causal influences.
3.2. Nonlinear Stochastic Process
The second simulation system, denoted as S2, was a nonlinear VAR of order one in three variables (Model 7 in [
51]):
where
,
, are Gaussian white noise processes independent of each other with the unit the standard deviation. The causal link
was linear, while
and
were nonlinear unidirectional ones (see
Figure 1b). Therefore, this system incorporated linear and nonlinear causal influences. Additionally, we demonstrated the performance of the examined measures in the case of low-dimensions, where full conditioning was feasible.
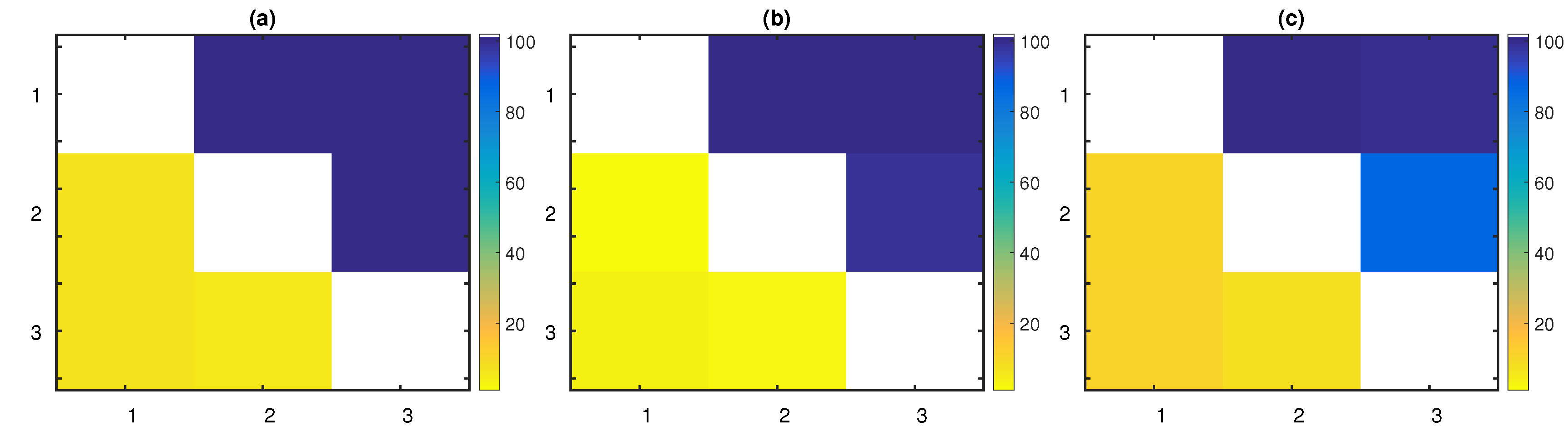
As expected, PTE was effective in this low-dimensional system, achieving high sensitivity and specificity, even for small time series lengths. PTENUE also performed well. Although partial conditioning was not required in such a low-dimensional system, PTENUE slightly outperformed PTE, but for
. In this case, PTENUE had somewhat smaller sensitivity than PTE, which affected its overall performance. LATE performed also well, but placed again last among the three causality measures. This was due to the slightly lower specificity of LATE compared to that of the other two measures. The percentage of capturing the causal effects
and
was above the nominal level for LATE; varying from 5% up to 11%. On the other hand, for PTENUE, these percentages stayed very low (between 0% and 3%), while for PTE, they took values from 2% up to 7%. These findings are demonstrated in
Figure 3 for
.
In conclusion, all the considered measures performed well for low-dimensional systems, achieving high F1-scores, even for small time series lengths (see
Table 2). The mean F1-score over all realizations and time series lengths for PTE, PTENUE, and LATE was 97.32%, 97.05%, and 92.82%, respectively. PTE was in first place for
, while for larger
n, PTENUE seemed to be the most effective measure.
3.3. Chaotic System: Coupled Hénon Maps
The last simulation system, denoted as S3, consisted of
K coupled Hénon maps [
52]:
This is a chaotic system in K variables. The parameter c controls the coupling strength between the variables, while the performance of the causality measures is examined for increasing values of K. In particular, we set , , and .
3.3.1. Coupled Hénon Maps in Three Variables
First, we considered a low-dimensional case and set
variables. Additionally, a moderate coupling strength
was assumed. The causal network is presented in
Figure 1c; the unidirectional links
and
existed.
All measures scored high, since a small
K and a moderate coupling strength were selected (
Table 3). PTENUE outranked the other two measures with a mean F1-score over all realizations and time series lengths equal to 99.89%. LATE closely followed, accomplishing a mean F1-score equal to 98.05%. Finally, PTE scored last, achieving a mean F1-score equal to 86.42%. Although PTE captured the direct causal influences, it spuriously indicated additional ones. In particular, the links
and
were falsely indicated. Thus, PTE had a decreasing specificity with
n, which influenced its overall outcome.
3.3.2. Coupled Hénon Maps in Nine Variables, Coupling Strength c = 0.3
The performance of the three causality measures was then examined for a higher dimensional case. We set the number of variables equal to
, while the coupling strength was fixed to
. The system was chaotic, while both unidirectional and bidirectional nonlinear causal effects existed (
Figure 1d).
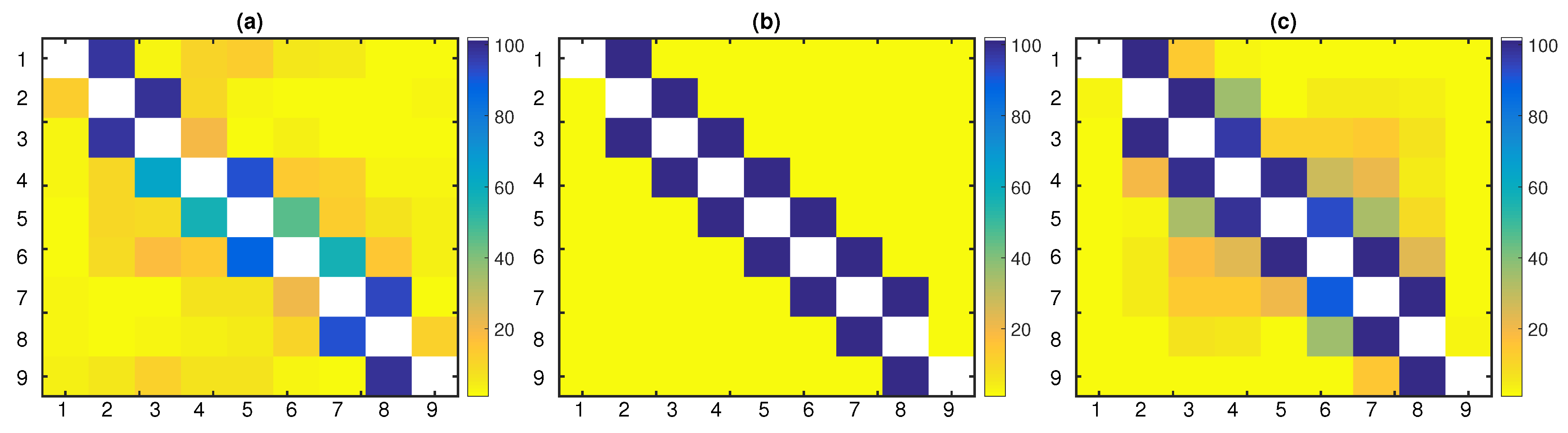
As the dimensionality of the chaotic system increased, PTE required larger time series lengths to detect the true connections with a high percentage over the 100 realizations. Indirect causal effects were obtained with low, but slightly increasing percentages as the time series length grew. The spurious couplings
and
also arose as
n grew. The matrix representation of the extracted significant causal influences based on PTE as a percentage over the 100 realizations of this system with
is displayed in
Figure 4a. The sensitivity of PTE increased from 32% (for
) to 99.79% (for
) and affected its overall performance (
Table 4). The highest mean F1-score for PTE was achieved for
. Its specificity was high; however, it started to decrease from
.
LATE scored second, accomplishing a mean F1-score equal to 84.48% over all realizations and time series lengths. Its performance was improved as the time series length increased and reached the highest F1-score for
. Specificity was high, however lower than PTENUE’s and PTE’s. LATE indicated some indirect causal influences, such as
and
(see
Figure 4c for
).
PTENUE placed at the top with a very high mean F1-score over all realizations and time series lengths, equal to 98.57%. It was the only causality measure that did not indicate indirect or spurious causal effects (see
Figure 4b for
).
3.3.3. Coupled Hénon Maps in Nine Variables, Coupling Strength
In order to evaluate the effectiveness of the three causality measures in the case of weak couplings, we considered the chaotic system in
variables, while the coupling strength was fixed to
. The connectivity pattern was the same (as in
Figure 1d). The considered time series length for this case was
and 2048.
PTE seemed to be completely ineffective in the case of weak couplings (
Table 5). On the other hand, LATE and PTENUE achieved a high mean F1-score. For
, LATE outperformed PTENUE, while the opposite was the case for
. Both measures were able to detect the true causal effects, despite the weak coupling strength. As
n increased, the extracted scores of both measures improved. Overall, the optimal performance was by LATE, with a mean F1-score of 92.41%, while PTENUE closely followed with a mean F1-score equal to 92.21%.
3.3.4. Coupled Hénon Maps in Variables
Finally, we set variables and kept the coupling strength fixed to . Since the number of variables was pretty large, we refrained from making calculations for all time series lengths and extracted results only for . To reduce the computational cost, the number of realizations was also limited to 10.
PTE failed to capture the connectivity network of this high-dimensional system (
Table 6). On the other hand, results indicated the efficiency of PTENUE to capture only the true causal influences, achieving a high sensitivity, specificity, and eventually, F1-score. LATE detected the true couplings, but with lower percentages over all the realizations compared to PTENUE. The percentages of significant LATE values for the true connections varied from 40% to 100% over the 10 realization. Further, LATE indicated some indirect and spurious links, e.g., the spurious link
was obtained with a percentage equal to 20%.
Based on the empirical findings, the performance of PTE substantially deteriorated as the dimension of the examined system increased, while seeming to be ineffective in the case of weak couplings. The full conditioning in PTE resulted in a decreased sensitivity in the case of high dimensions. Additionally, PTE may indicate spurious couplings. On the other hand, PTENUE outperformed the other measures in the majority of the examined cases. A sufficient time series length was required to achieve its optimal performance. Partial conditioning was performed taking into consideration the higher order informational contributions, and redundant lagged terms were excluded from the mixed embedding vector. This way, dimension reduction was efficiently performed, and PTENUE effectively faced the “curse of the dimensionality”. LATE performed satisfactorily for the majority of the simulated systems. It outperformed the other measures in the case of weak coupling and small time series length. However, LATE achieved in general lower sensitivity and specificity compared to PTENUE, while indicating spurious couplings, due to the CMI approximation.
To summarize the above results, all measures performed satisfactorily in the case of low-dimensional systems and sufficiently large time series lengths. The exported mean F1-scores over all realizations, time series lengths, and simulation systems for PTE, PTENUE, and LATE were 63.37%, 96.73%, and 83.86%, respectively. PTENUE prevailed over the other two measures; it correctly identified the causal influences of both low- and high-dimensional multivariate systems, accomplishing high scores in all examined cases.
3.4. Computational Cost
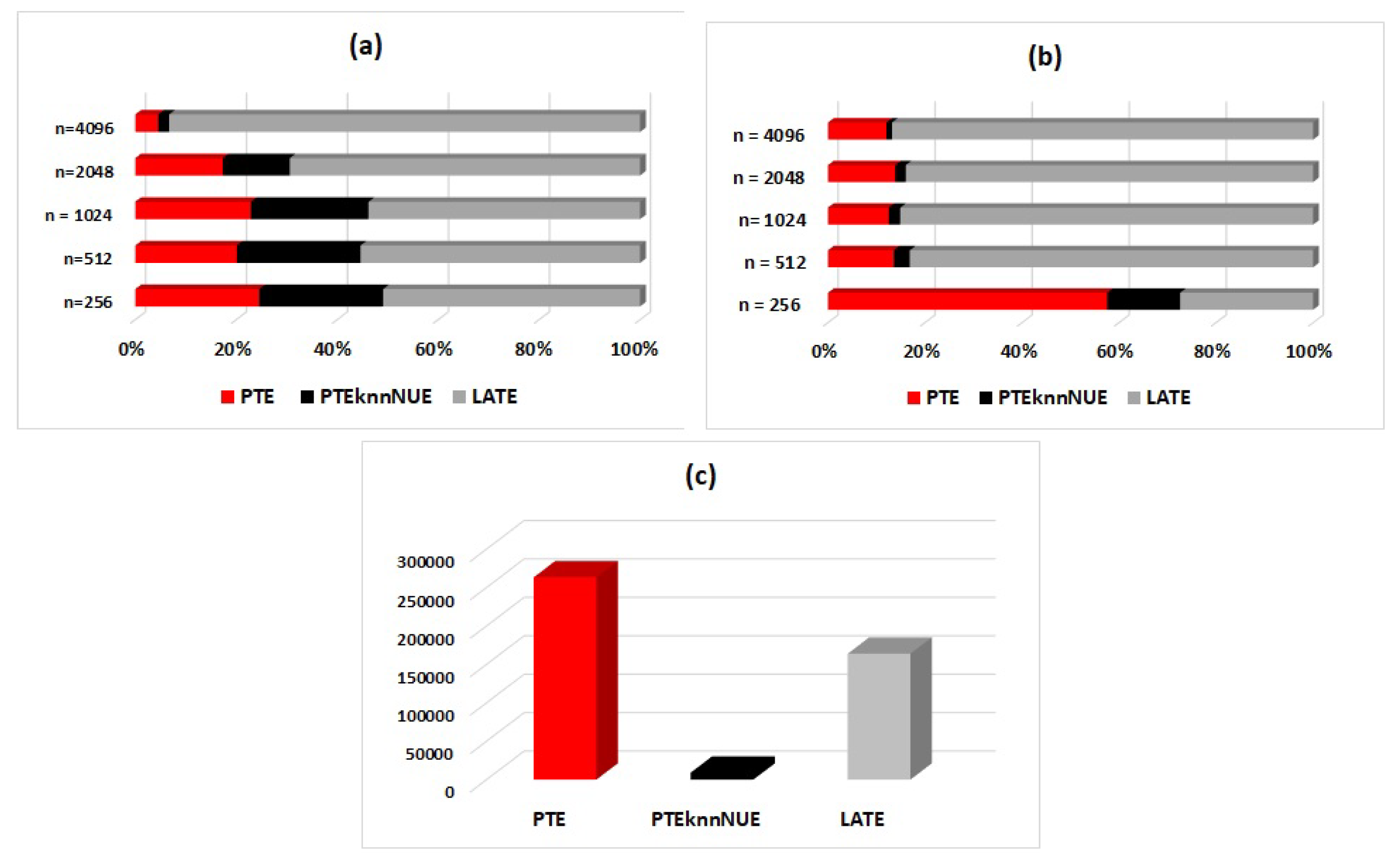
The computational cost of the three measures was also essential, especially in the case of high-dimensional systems. PTENUE had the least computational cost due to its dimension reduction computational scheme. As the dimensionality and the time series length increased, its computational superiority over the other two measures was even more pronounced. In the case of low-dimensional systems, LATE seemed to be the most burdensome one; the estimation of many low-dimensional CMI terms was more demanding than the estimation of a higher dimensional CMI. Raising the time series length and the dimensionality, PTE became the most demanding measure, since full conditioning was performed.
To better demonstrate the corresponding findings from the analysis, we also display the seconds required by each measure in order to complete the estimations for one realization of a multivariate system, i.e., for identifying its connectivity network. Outcomes were observed in regards to the time series lengths. Results are indicatively displayed in
Figure 5 for S2 in
variables (a low-dimensional system), for S3 in
variables (intermediate dimensionality), and for S3 in
variables (a high-dimensional system).
The specifications of the computer used to run the simulations are as follows. MATLAB version: R2015a; Operating system: Windows 10 Pro (64 bit); Processor: Intel(R) Core(TM) i5-3470CPU @ 3.20GHz; RAM: 4GB.
4. Application
In this section, we demonstrate the applicability of the three causality measures to financial time series. In particular, we examine the connectivity pattern between stocks of index CAC40. The stock market index CAC40 is a reference point for the French stock market Euronext (ex Paris Bourse) and consists of the weighted capitalization of the 40 companies (among the 100 highest market caps) with the highest capitalization traded in this stock market. The companies that form the CAC40 index can be reviewed at
https://en.wikipedia.org/wiki/CAC_40.
The examined time period was 2001-12-14 to 2018-09-04. The composition of the index was quarterly reviewed. The number of the observations was . Two variables were excluded from the analysis due to too many missing observations. Therefore, the number of variables of the analysis was . To achieve stationarity, analysis was performed based on the logarithmic returns. All series were obtained from Yahoo finance.
For the calculations, the embedding dimension for the computation of PTE was , and the delay was . We set the number of neighbors , the number of surrogates , the significance level for PTENUE , while for PTE, . Finally, we fixed for the estimation of PTENUE and LATE.
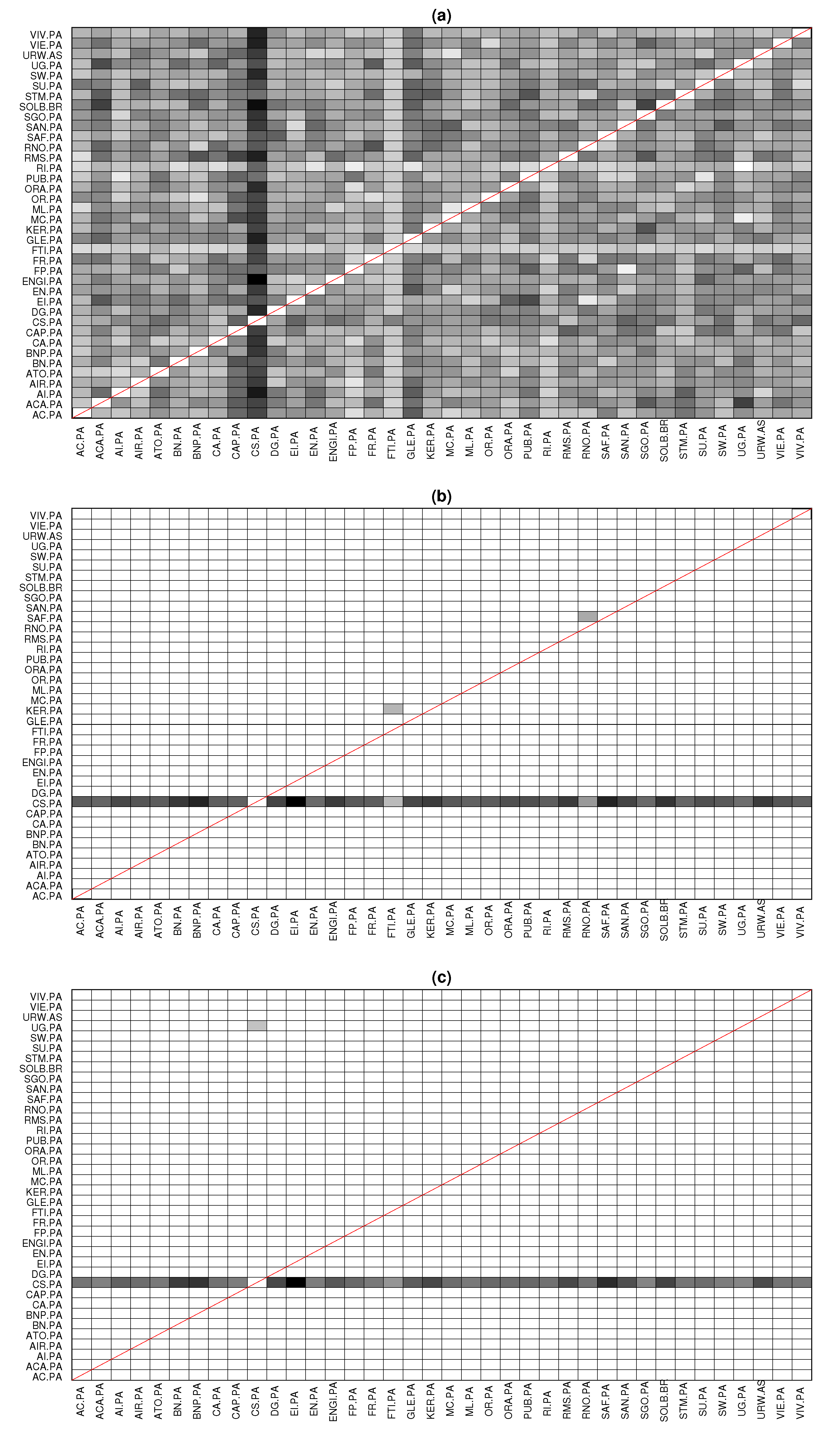
The goal of this application was to determine the leading forces in CAC40, i.e., we were seeking to find the most significant driving variables. PTE identified all couplings as significant, and therefore, the results suggested an almost fully connected network. On the other hand, PTENUE and LATE determined the most significant leading variable to be CS.PA (AXA SA, a French multinational insurance firm), influencing all the other observed variables. Although PTENUE and LATE indicated the same leading driving variable, few different additional links were obtained. Specifically, PTENUE indicated two additional links: FTI.PA → KER.PA, where FTI.PA represents in the stock market TechnipFMC (a Franco-American oil services firm) and KER.PA represents KERING S.A. (a world-class luxury group that develops, designs, manufactures, markets, and sells apparel and accessories), and RNO.PA → SAF.PA, where RNO.PA represents Renault S.A. (a vehicle manufacturing and distribution company) and SAF.PA represents Safran S.A. (a company that engages in the design, manufacture, and sale of aircraft, defense, and communication equipment and technologies). On the other hand, LATE suggested the coupling UG.PA → CS.PA, where UG.PA represents Peugeot (a French car manufacturer firm and part of Groupe PSA). The connectivity pattern obtained by the three causality measures is displayed in
Figure 6.
We note that consistent results were identified using the partial mutual information on mixed embedding (PMIME) [
33] in [
53], when analyzing the same dataset. In particular, CS.PA was identified as the most significant driving variable by observing the extracted connectivity network and calculating the in- and out-degree of the variables.
The most common analyses for constructing financial networks were based on the linear Granger causality [
18,
54], e.g., [
55,
56,
57], and on correlation analysis [
58,
59,
60]. For comparative reasons, we also report the exported results based on standard linear approaches. Utilizing the conditional Granger causality index, 242 causal links were obtained if the order of the VAR was equal to
(as suggested by the Bayesian information criterion [
61]), while 348 links were obtained for
(as suggested by the Akaike information criterion [
62]). Based on the partial correlation coefficient, six-hundred ten links were detected. Thus, both methods seemed to overestimate the number of connections in the examined financial network.
5. Conclusions
In this paper, three conditional causality measures were briefly reviewed and evaluated on artificial datasets. In particular, we examined the performance of partial transfer entropy (PTE) computed based on the standard uniform embedding scheme, PTE estimated using the non-uniform embedding (NUE) scheme, denoted as PTENUE, and PTE using the NUE scheme and also a low-dimensional approximation (LA) method for the computation of conditional mutual information (CMI), denoted as LATE. We assessed the effectiveness of each causality measure in identifying the causal influences among the variables of complex coupled systems based on the extracted sensitivity, specificity, and F1-score. In the simulation analysis, we controlled the dimension of the data, the sample size, the coupling strength, and its nature (linear or nonlinear, unidirectional, or bidirectional). The dimensionality of the chaotic simulation system advanced up to 50 variables in order to reflect the complexity of the real data. Finally, the applicability of the three causality measures in real applications was demonstrated using financial time series.
Based on the empirical findings, partial transfer entropy (PTE) was mainly efficient in the case of low-dimensional systems. LATE improved the performance of PTE in the case of high-dimensional coupled systems. LATE had an overall good performance and was particularly effective in the case of weak couplings and small time series lengths. However, it was computationally expensive and may indicate spurious causal influences.
We should note here that the simulation results displayed in [
35] substantially deviated from the outcomes of this study regarding the performance of LATE; however, our results seemed to be in agreement with the reported results in [
36], where also low-dimensional approximation methods for CMI were employed.
PTENUE outperformed the other measures by accurately identifying the connectivity network of all the examined scenarios and achieving the highest mean F1-score over all the examined scenarios. As the dimension of the examined systems progressively increased, the necessity of using dimension reduction techniques, such as the NUE scheme, was profound. Novel simulation results were presented for both low- and high-dimensional systems, where the number of variables varied from up to . PTENUE did not seem to be significantly affected by the “curse of dimensionality”, while remaining effective also in case of weakly coupled variables. Additionally, PTENUE was the least computationally demanding measure among the three examined measures.
In the financial applications, the connectivity network of CAC40 was examined in order to determine the leading forces. Both PTENUE and LATE indicated the most significant leading variable to be CS.PA (AXA SA, a French multinational insurance firm), influencing all the other observed variables. PTE failed to identify the connectivity relationships of CAC40, tending to identify a fully coupled network.
Subsequently, PTENUE was the most effective causality measure for identifying the connectivity network of multivariate systems among the three examined measures. It was robust, and it was unaffected by the “curse of dimensionality” and the nature, and the strength of the connections. However, the sample size should be sufficiently large, and this should be jointly considered with the dimensionality of the examined data. Finally, it had the least computational cost.
The presented outcomes concerned multivariate systems with a sparse causality structure. The examined causality measures were probabilistic approaches that required the stationarity of the time series and could be applied only to time-invariant networks. Additionally, contemporaneous relationships were not considered. Future work involves the identification of the efficiency of PTENUE on multivariate systems of higher dimensions and with denser causality structures, which will be utilized in financial applications, such as for portfolio construction. A forthcoming work will examine the robustness of PTENUE in the case of noisy data, where preliminary results seemed very promising.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}