Kernel-Based Approximation of the Koopman Generator and Schrödinger Operator


Abstract
1. Introduction
- We show how the derivative reproducing properties of kernels can be used to approximate differential operators such as the Koopman generator and the Schrödinger operator, as well as their eigenvalues and eigenfunctions from data. Additionally, we derive a kernel-based method tailored to reversible dynamics, which does not require estimating drift and diffusion terms, but only an equilibrated trajectory.
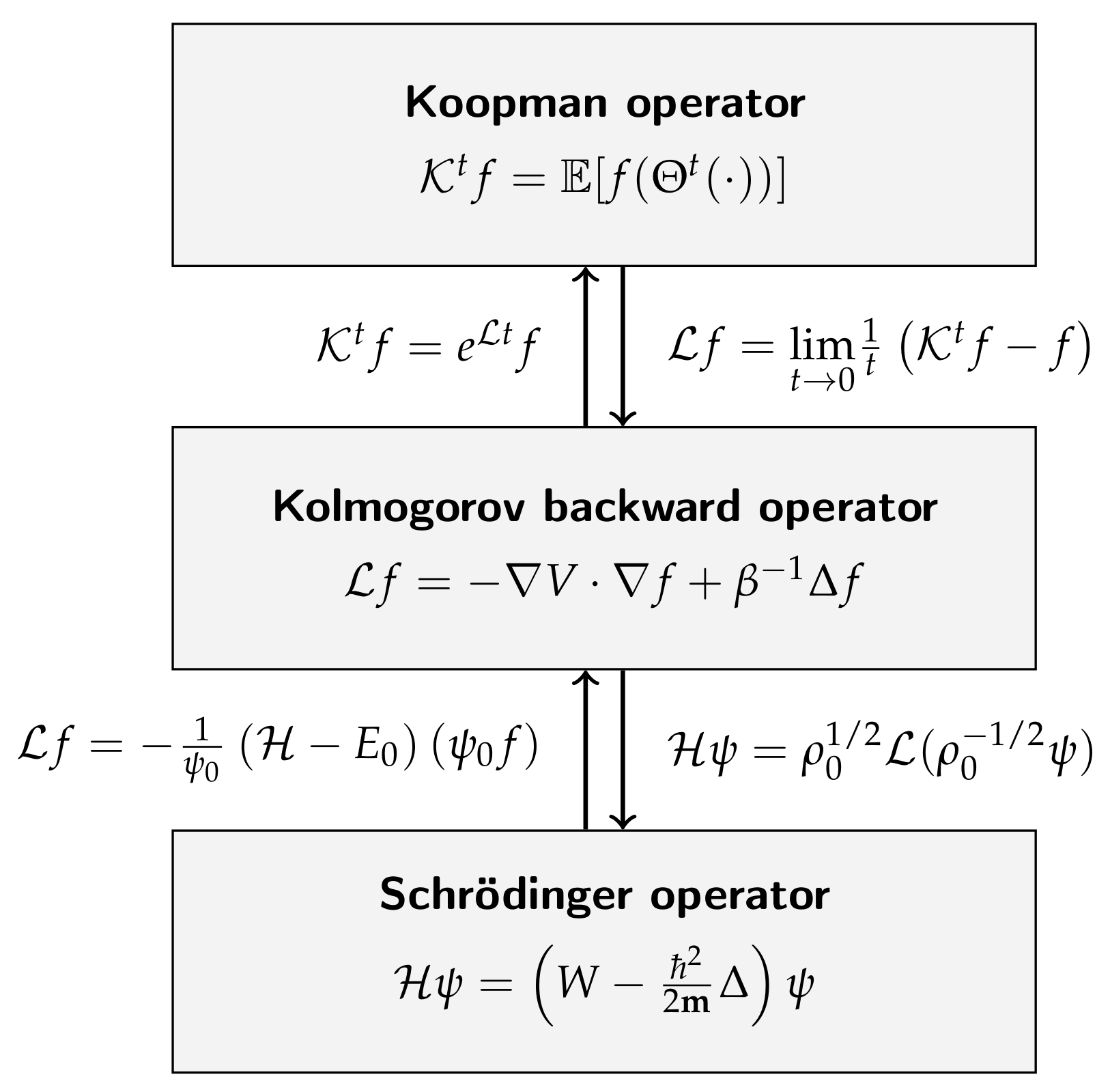
- Furthermore, we exploit the fact that, under certain conditions, the Schrödinger operator can be turned into a Kolmogorov backward operator (see, e.g., [24]), which allows for the interpretation of a quantum-mechanical system as a drift-diffusion process and, as a consequence, the application of methods developed for the analysis of stochastic differential equations or their generators.
- We demonstrate potential applications in molecular dynamics, using the example of a quadruple-well problem, and quantum mechanics, describing how to apply the proposed methods directly to the Schrödinger equation or the associated stochastic process. This will be illustrated with two well-known examples, the quantum harmonic oscillator and the hydrogen atom.
2. Koopman Theory and Reproducing Kernel Hilbert Spaces
2.1. The Koopman Operator and Its Generator
2.2. Generator EDMD
2.3. Second-Order Differential Operators
2.4. Reproducing Kernel Hilbert Spaces and Derivative Reproducing Properties
- (i)
- for all and
- (ii)
- .
- (i)
- for any and .
- (ii)
- for any , , and .
- For the polynomial kernel, we obtain:Thus, and .
- Similarly, for the Gaussian kernel, this results in:, and .
3. Kernel-Based Representation of Differential Operators
3.1. Galerkin Projection of Operators
3.2. Empirical Estimates
3.3. Weak Formulation and Numerical Algorithm
- (i)
- In the general case, u solves , where the entries of the matrices and are given by:
- (ii)
- Analogously, for the symmetric case, we obtain , where we define:and is the column of the matrix .
- (1)
- Choose a kernel k and compute all its required derivatives, either analytically or with the aid of automatic differentiation.
- (2)
- Assemble the Gram matrices and or, if the system is symmetric, , for , and .
- (3)
- Solve the corresponding eigenvalue problem described in Lemma 4 to obtain an eigenvector u.
- (4)
- An eigenfunction is then given by .
3.4. Analysis
- (i)
- The operators , , , and are Hilbert–Schmidt.
- (ii)
- Let . Assume the coefficients of the operator are all globally bounded, and let for all ( in the symmetric case). If the data are drawn i.i.d. from the distribution μ, then there are constants such that with probability at least ,where the is the Hilbert–Schmidt norm.
4. Applications
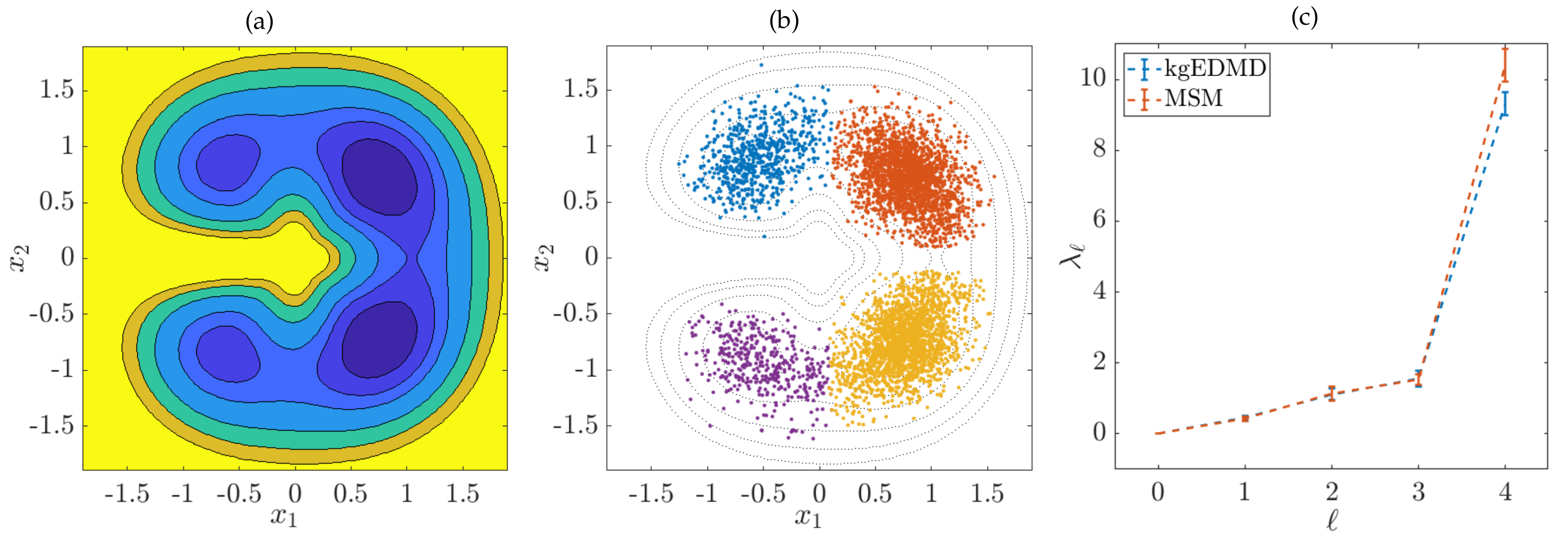
4.1. Molecular Dynamics
4.2. Quantum Mechanics
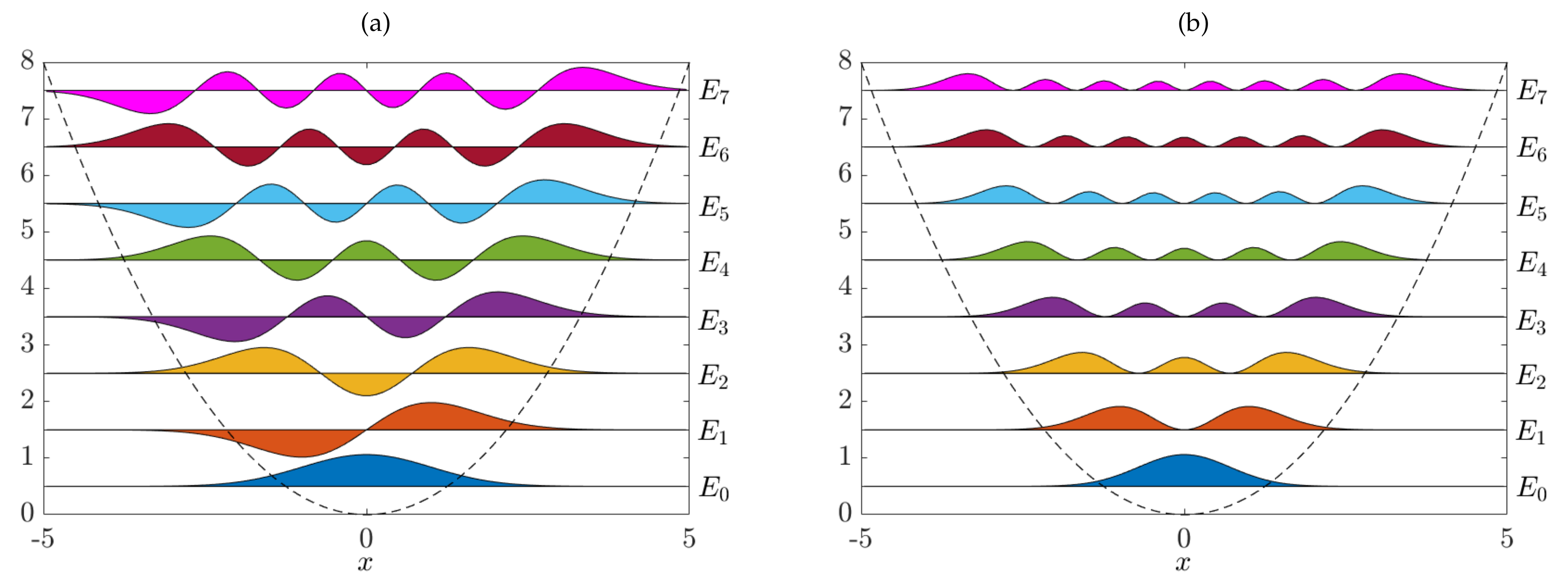
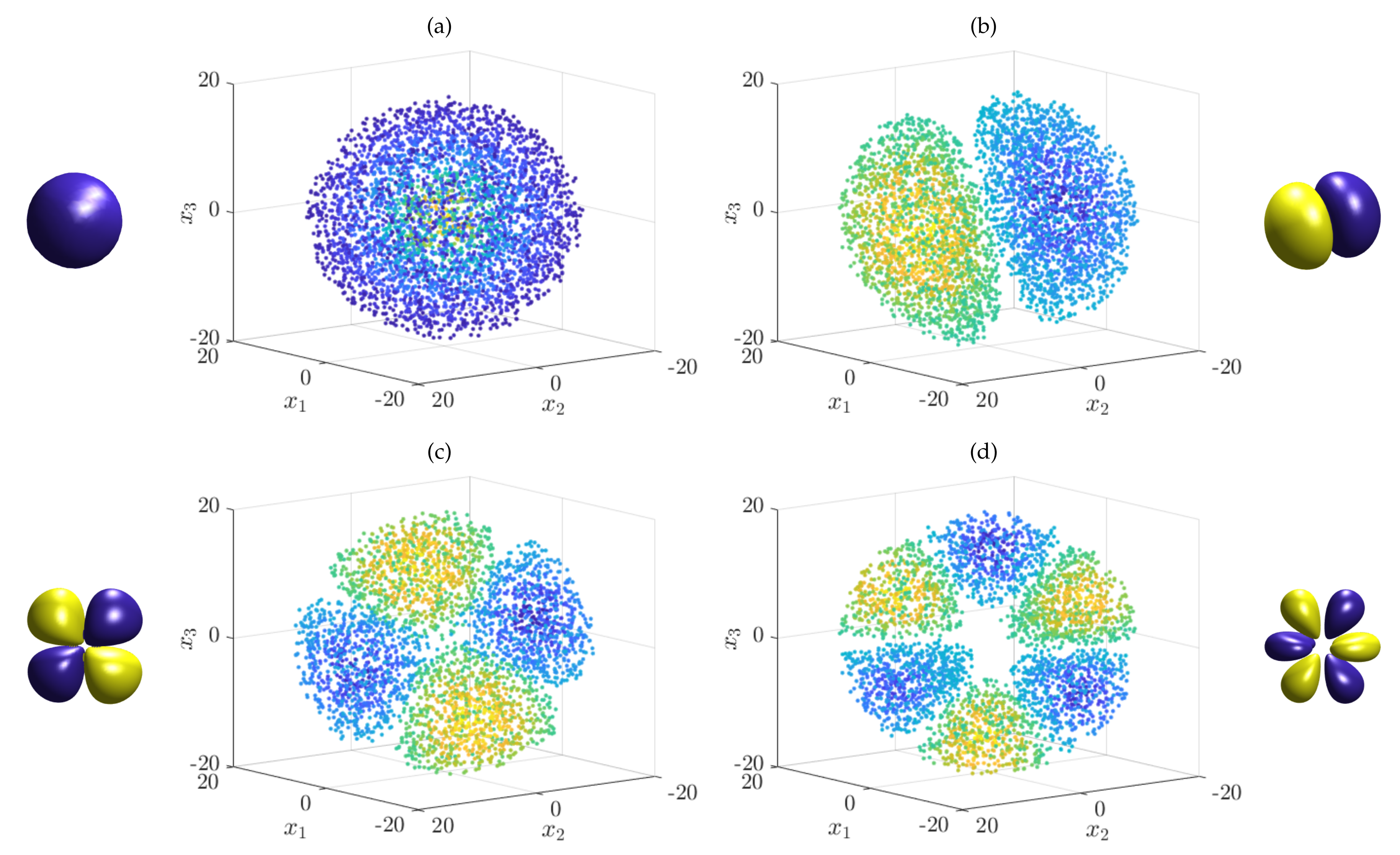
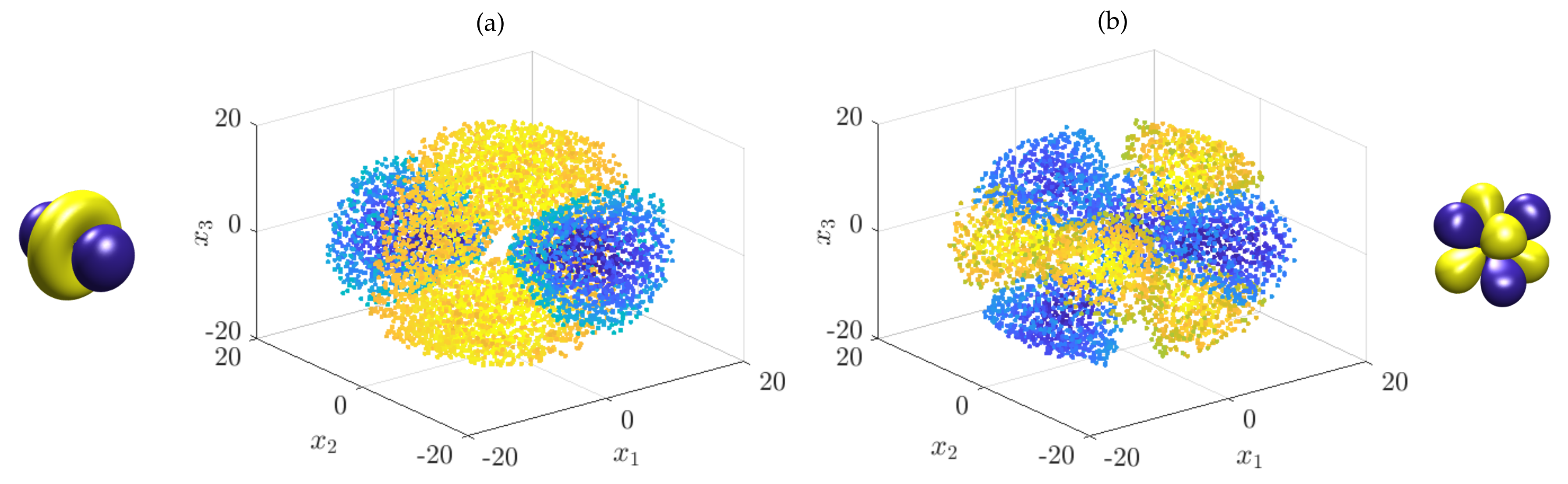
4.2.1. Generator EDMD for the Schrödinger Equation
4.2.2. SDE Formulation of the Schrödinger Equation
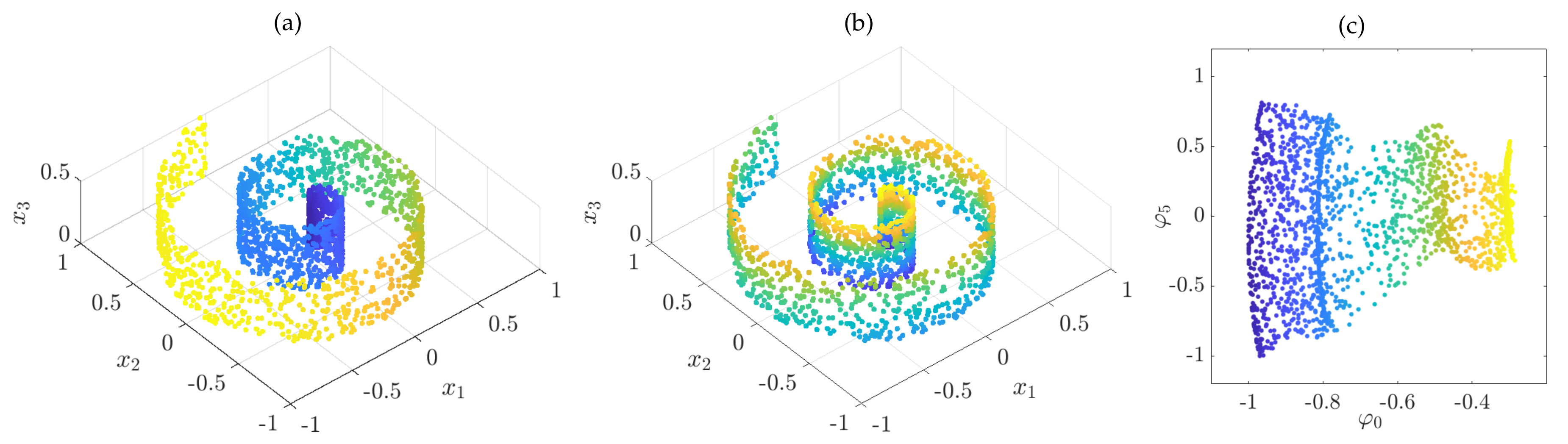
4.3. Manifold Learning
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proofs
References
- Koopman, B. Hamiltonian systems and transformations in Hilbert space. Proc. Natl. Acad. Sci. USA 1931, 17, 315. [Google Scholar] [CrossRef]
- Lasota, A.; Mackey, M.C. Chaos, Fractals, and Noise: Stochastic Aspects of Dynamics, 2nd ed. Probab. Eng. Inf. Sci. 1994, 10, 311. [Google Scholar]
- Mezić, I. Spectral Properties of Dynamical Systems, Model Reduction and Decompositions. Nonlinear Dyn. 2005, 41, 309–325. [Google Scholar] [CrossRef]
- Budišić, M.; Mohr, R.; Mezić, I. Applied Koopmanism. Chaos Interdiscip. J. Nonlinear Sci. 2012, 22. [Google Scholar] [CrossRef]
- Mauroy, A.; Mezić, I. Global stability analysis using the eigenfunctions of the Koopman operator. IEEE Trans. Autom. Control 2016, 61, 3356–3369. [Google Scholar] [CrossRef]
- Klus, S.; Koltai, P.; Schütte, C. On the numerical approximation of the Perron–Frobenius and Koopman operator. J. Comput. Dyn. 2016, 3, 51–79. [Google Scholar] [CrossRef]
- Kaiser, E.; Kutz, J.N.; Brunton, S.L. Data-driven discovery of Koopman eigenfunctions for control. arXiv 2017, arXiv:1707.01146. [Google Scholar]
- Korda, M.; Mezić, I. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control. Automatica 2018, 93, 149–160. [Google Scholar] [CrossRef]
- Peitz, S.; Klus, S. Koopman operator-based model reduction for switched-system control of PDEs. Automatica 2019, 106, 184–191. [Google Scholar] [CrossRef]
- Klus, S.; Husic, B.E.; Mollenhauer, M.; Noé, F. Kernel methods for detecting coherent structures in dynamical data. Chaos 2019. [Google Scholar] [CrossRef]
- Williams, M.O.; Kevrekidis, I.G.; Rowley, C.W. A Data-Driven Approximation of the Koopman Operator: Extending Dynamic Mode Decomposition. J. Nonlinear Sci. 2015, 25, 1307–1346. [Google Scholar] [CrossRef]
- Williams, M.O.; Rowley, C.W.; Kevrekidis, I.G. A Kernel-Based Method for Data-Driven Koopman Spectral Analysis. J. Comput. Dyn. 2015, 2, 247–265. [Google Scholar] [CrossRef]
- Klus, S.; Nüske, F.; Peitz, S.; Niemann, J.H.; Clementi, C.; Schütte, C. Data-driven approximation of the Koopman generator: Model reduction, system identification, and control. Physica D 2020, 406, 132416. [Google Scholar] [CrossRef]
- Mauroy, A.; Goncalves, J. Linear identification of nonlinear systems: A lifting technique based on the Koopman operator. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 6500–6505. [Google Scholar]
- Klus, S.; Schuster, I.; Muandet, K. Eigendecompositions of Transfer Operators in Reproducing Kernel Hilbert Spaces. J. Nonlinear Sci. 2019. [Google Scholar] [CrossRef]
- Zhou, D.X. Derivative reproducing properties for kernel methods in learning theory. J. Comput. Appl. Math. 2008, 220, 456–463. [Google Scholar] [CrossRef]
- Giesl, P.; Hamzi, B.; Rasmussen, M.; Webster, K. Approximation of Lyapunov functions from noisy data. J. Comput. Dyn. 2019. [Google Scholar] [CrossRef]
- Haasdonk, B.; Hamzi, B.; Santin, G.; Witwar, D. Greedy Kernel Methods for Center Manifold Approximation. arXiv 2018, arXiv:1810.11329. [Google Scholar]
- Wendland, H. Scattered Data Approximation; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef]
- Coifman, R.R.; Lafon, S. Diffusion maps. Appl. Comput. Harmon. Anal. 2006, 21, 5–30. [Google Scholar] [CrossRef]
- Nadler, B.; Lafon, S.; Coifman, R.R.; Kevrekidis, I.G. Diffusion maps, spectral clustering and reaction coordinates of dynamical systems. Appl. Comput. Harmon. Anal. 2006, 21, 113–127. [Google Scholar] [CrossRef]
- Coifman, R.R.; Kevrekidis, I.G.; Lafon, S.; Maggioni, M.; Nadler, B. Diffusion Maps, Reduction Coordinates, and Low Dimensional Representation of Stochastic Systems. Multiscale Model. Simul. 2008, 7, 842–864. [Google Scholar] [CrossRef]
- Nadler, B.; Lafon, S.; Coifman, R.R.; Kevrekidis, I.G. Diffusion Maps—A Probabilistic Interpretation for Spectral Embedding and Clustering Algorithms. In Principal Manifolds for Data Visualization and Dimension Reduction; Gorban, A., Kégl, B., Wunsch, D., Zinovyev, A., Eds.; Springer: Heidelberg, Germany, 2008; pp. 238–260. [Google Scholar]
- Pavliotis, G.A. Stochastic Processes and Applications: Diffusion Processes, the Fokker–Planck and Langevin Equations; Springer: New York, NY, USA, 2014. [Google Scholar]
- Levine, I.N. Quantum Chemistry; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Aronszajn, N. Theory of Reproducing Kernels. Trans. Am. Math. Soc. 1950, 68, 337–404. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization and Beyond; MIT press: Cambridge, MA, USA, 2001. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines, 1st ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Baker, C. Mutual Information for Gaussian Processes. SIAM J. Appl. Math. 1970, 19, 451–458. [Google Scholar] [CrossRef]
- Baker, C. Joint Measures and Cross-Covariance Operators. Trans. Am. Math. Soc. 1973, 186, 273–289. [Google Scholar] [CrossRef]
- Davies, E.B. Spectral Theory and Differential Operators; Cambridge University Press: Cambridge, UK, 1996; Volume 42. [Google Scholar]
- Chacon, R.V. An ergodic theorem for operators satisfying norm conditions. J. Math. Mech. 1962, 11, 165–172. [Google Scholar]
- Rosasco, L.; Belkin, M.; Vito, E.D. On Learning with Integral Operators. J. Mach. Learn. Res. 2010, 11, 905–934. [Google Scholar]
- Klus, S. Data-Driven Dynamical Systems Toolbox. Available online: https://github.com/sklus/d3s/ (accessed on 1 May 2020).
- Klus, S.; Bittracher, A.; Schuster, I.; Schütte, C. A kernel-based approach to molecular conformation analysis. J. Chem. Phys. 2018, 149, 244109. [Google Scholar] [CrossRef]
- Froyland, G.; Rock, C.P.; Sakellariou, K. Sparse eigenbasis approximation: Multiple feature extraction across spatiotemporal scales with application to coherent set identification. Commun. Nonlinear Sci. Numer. Simul. 2019, 77, 81–107. [Google Scholar] [CrossRef]
- Okamoto, H. Stochastic formulation of quantum mechanics based on a complex Langevin equation. J. Phys. A Math. Gen. 1990, 23, 5535–5545. [Google Scholar] [CrossRef]
- Reed, M.; Simon, B. Methods of Modern Mathematical Physics. IV Analysis of Operators; Academic Press: San Diego, CA, USA, 1978. [Google Scholar]
- Kosztin, I.; Faber, B.; Schulten, K. Introduction to the diffusion Monte Carlo method. Am. J. Phys. 1996, 64, 633–644. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- McGibbon, R.T.; Pande, V.S. Variational cross-validation of slow dynamical modes in molecular kinetics. J. Chem. Phys. 2015, 142, 03B621_1. [Google Scholar] [CrossRef]
- Owhadi, H.; Yoo, G.R. Kernel Flows: From learning kernels from data into the abyss. J. Comput. Phys. 2019, 389, 22–47. [Google Scholar] [CrossRef]
- Wu, H.; Noé, F. Variational approach for learning Markov processes from time series data. arXiv 2017, arXiv:1707.04659. [Google Scholar] [CrossRef]
- Muandet, K.; Fukumizu, K.; Sriperumbudur, B.; Schölkopf, B. Kernel mean embedding of distributions: A review and beyond. Found. Trends Mach. Learn. 2017, 10, 1–141. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| stochastic process | |
| state space | |
| kernel and associated feature map | |
| reproducing kernel Hilbert space induced by k | |
| Koopman operator with lag time t | |
| generator of the Koopman operator | |
| Schrödinger operator | |
| general differential operator | |
| kernel-based differential operator | |
| covariance operator | |
| empirical estimate of operator | |
| (generalizations of) Gram matrices |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klus, S.; Nüske, F.; Hamzi, B. Kernel-Based Approximation of the Koopman Generator and Schrödinger Operator. Entropy 2020, 22, 722. https://doi.org/10.3390/e22070722
Klus S, Nüske F, Hamzi B. Kernel-Based Approximation of the Koopman Generator and Schrödinger Operator. Entropy. 2020; 22(7):722. https://doi.org/10.3390/e22070722
Chicago/Turabian StyleKlus, Stefan, Feliks Nüske, and Boumediene Hamzi. 2020. "Kernel-Based Approximation of the Koopman Generator and Schrödinger Operator" Entropy 22, no. 7: 722. https://doi.org/10.3390/e22070722
APA StyleKlus, S., Nüske, F., & Hamzi, B. (2020). Kernel-Based Approximation of the Koopman Generator and Schrödinger Operator. Entropy, 22(7), 722. https://doi.org/10.3390/e22070722