Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset and Feature Extraction
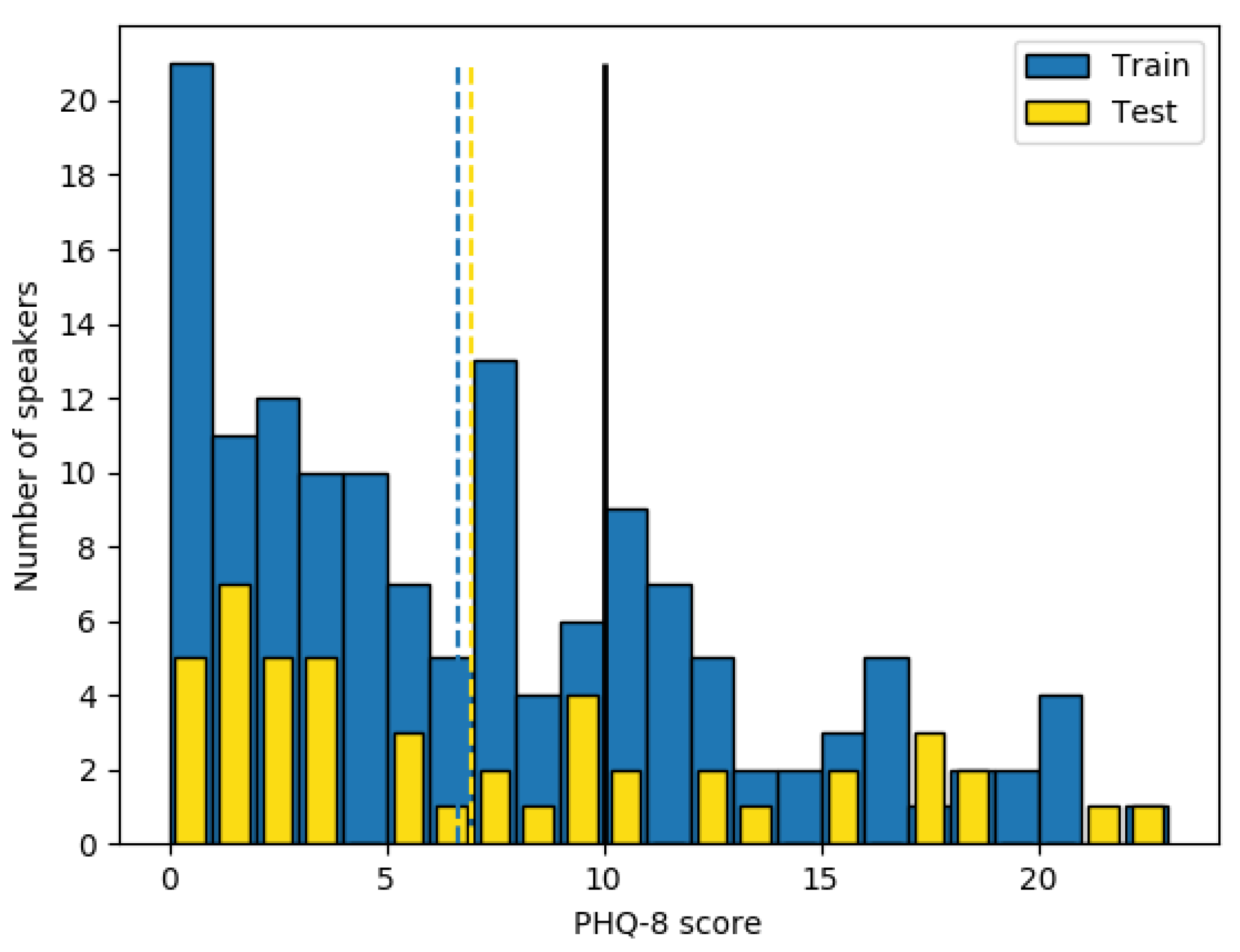
3.1.1. Database Description
3.1.2. Pre-Processing
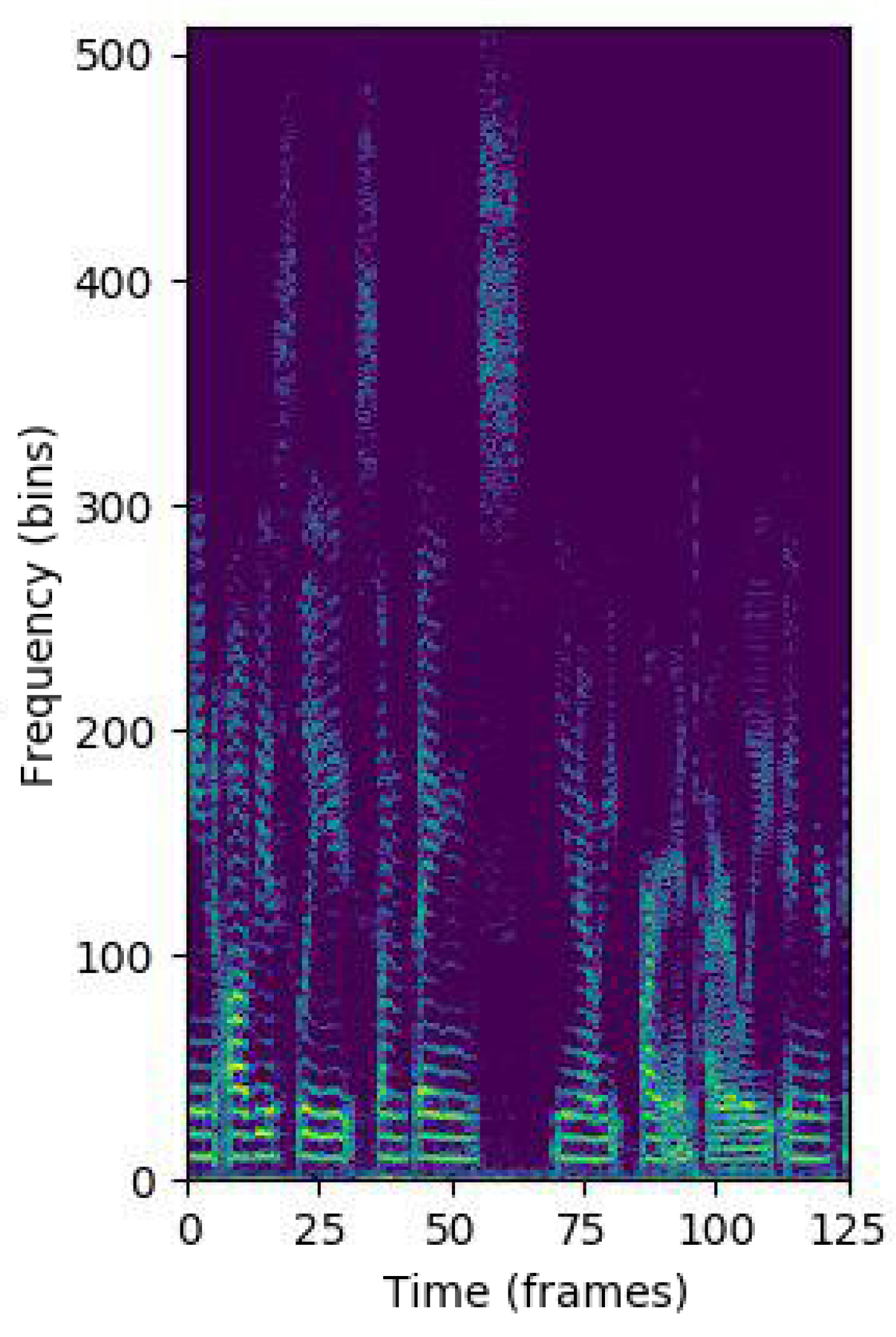
3.1.3. Feature Extraction
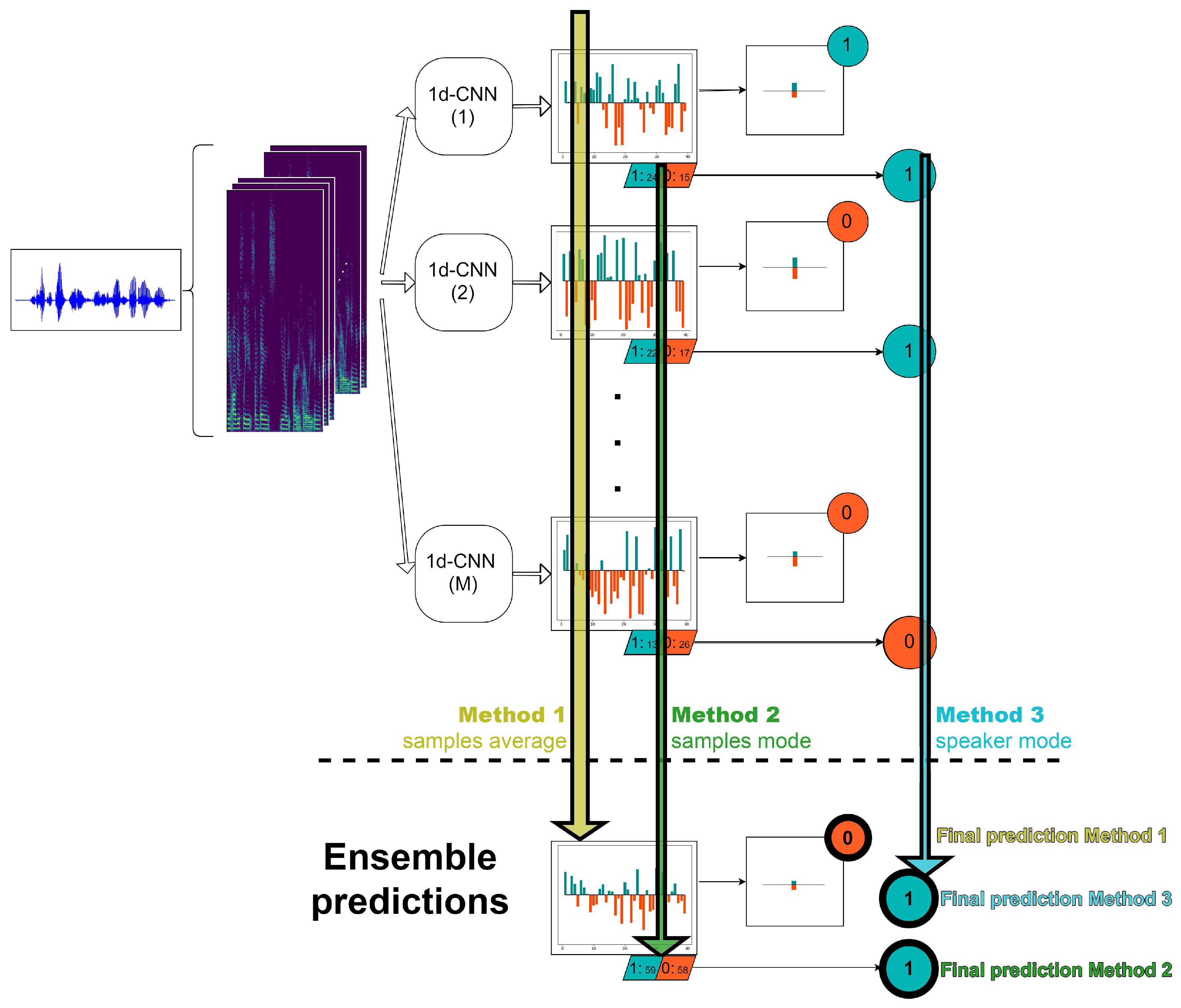
3.2. Depression Detection System
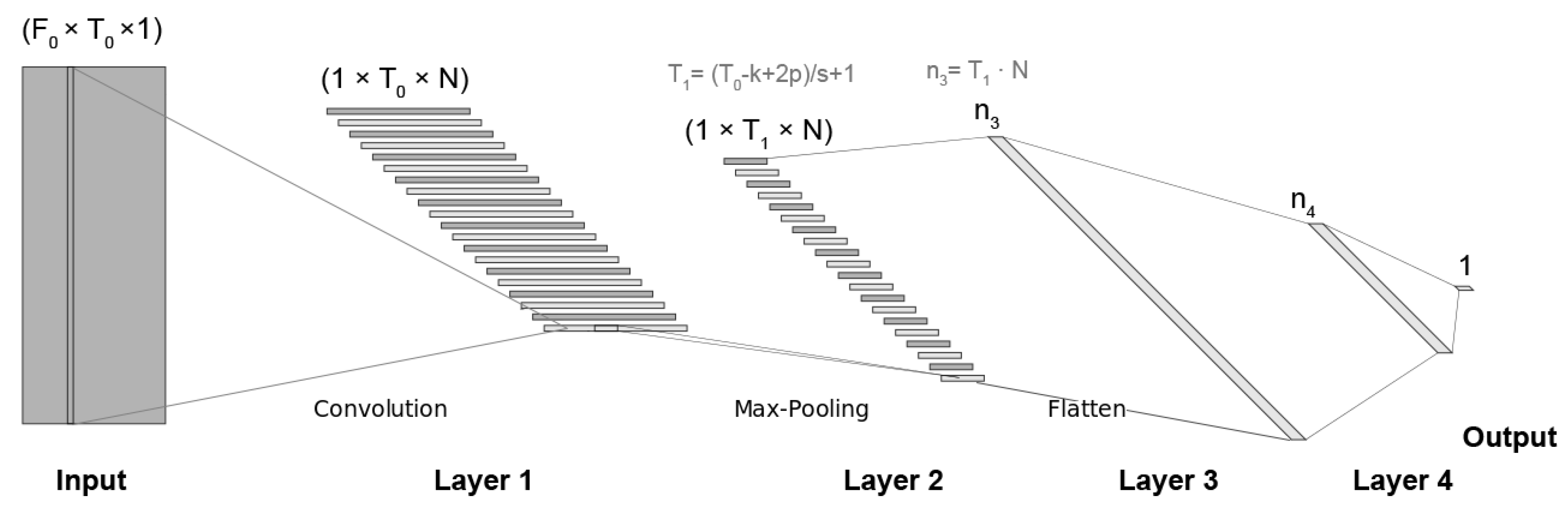
3.2.1. 1d-CNN Model
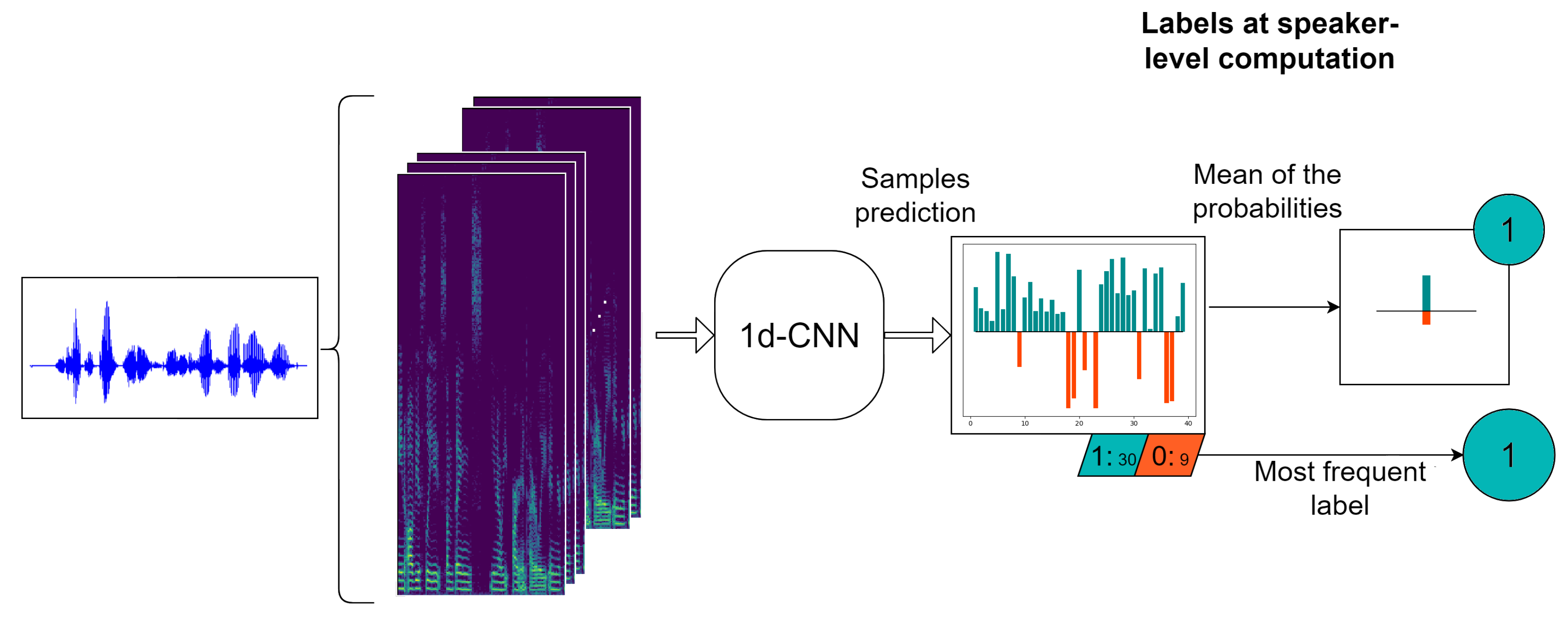
3.2.2. Ensemble Method
- Method 1. In this alternative, first we average the probabilities at sample level of the M 1d-CNN. After that, as in the case of a single classifier, we compute the probability at speaker level by averaging the probabilities of the samples belonging to this particular speaker and with a threshold, we are able to decide the final speaker label.
- Method 2. In this strategy, we start from the hard labels at sample level over all the M classifiers and then, we assign to each speaker the most frequent value of all of his/her corresponding samples, where is the number of log-spectrograms belonging to the ith speaker.
- Method 3. In this approach, first we obtain the predictions at speaker level of each of the M machines as the mode of the corresponding sample labels. Finally, we decide the final speaker label by computing the mode of the M predictions for this particular speaker.
4. Results and Discussion
4.1. Experimental Protocol
4.2. Results
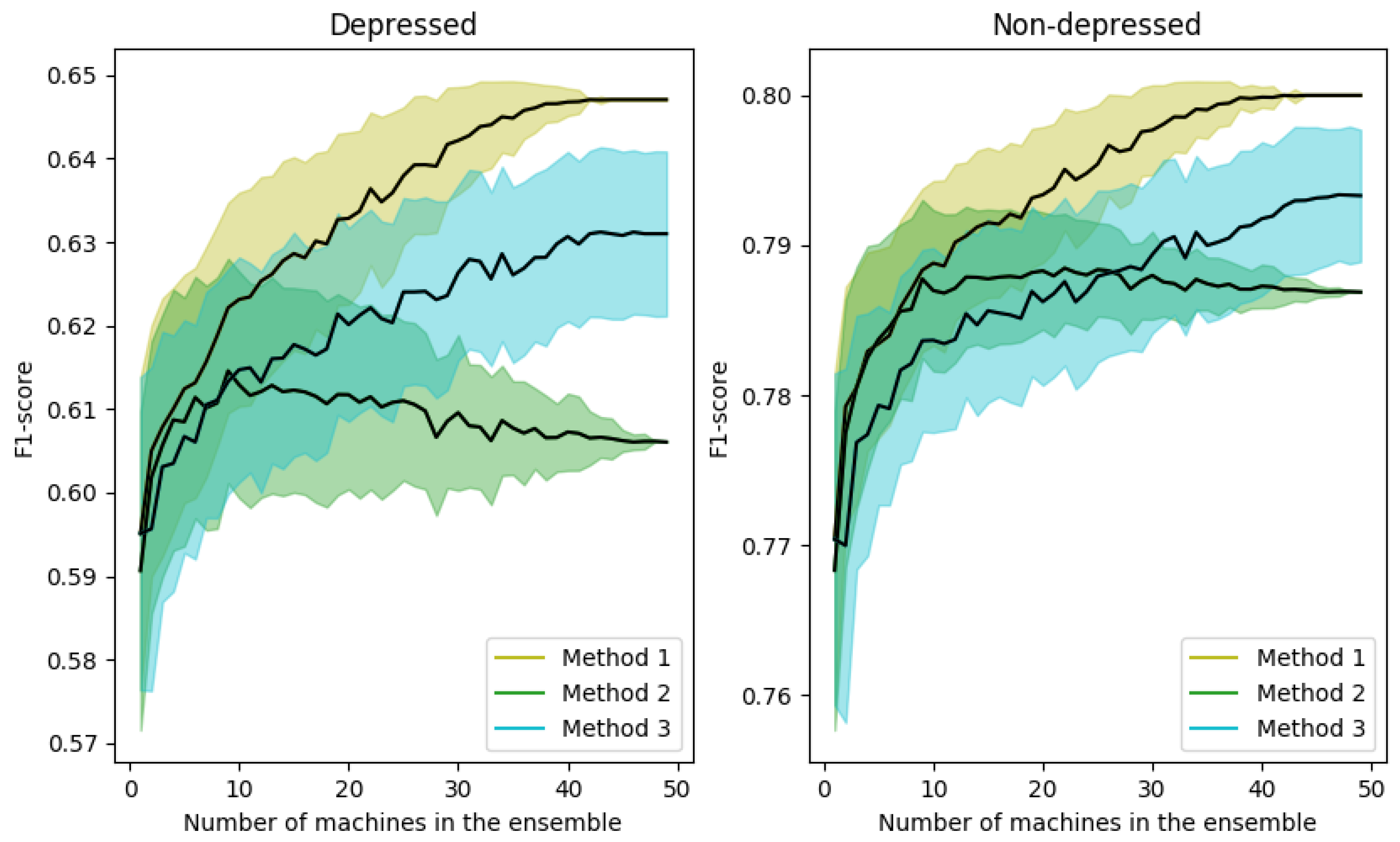
4.2.1. Results with Different Ensemble Methods
4.2.2. Number of Filters in the Layer 1 and Size of the Layer 4
4.3. Size of the Max-Pooling Window
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 1d-CNN | One-Dimensional Convolutional Neural Network |
| ADD | Automatic Depression Detection |
| AAM | Active Appearance Model |
| ANN | Artificial Neural Network |
| AVEC | Audio–Visual Emotion Challenge |
| BDI-II | Beck’s Depression Inventory |
| CNN | Convolutional Neural Network |
| DAIC-WOZ | Distress Analysis Interview Corpus - Wizard of Oz |
| DCC | Depression Classification Sub-Challenge |
| eGeMAPS | Geneva Minimalistic Acoustic Parameter Set |
| FACS | Facial Action Coding System |
| GDS | Geriatric Depression Scale |
| HRSD | Hamilton Rating Scale for Depression |
| LPQ-TOP | Local Phase Quantization at Three Orthogonal Planes |
| LSTM | Long Short-Term Memory |
| MDD | Major Depressive Disorder |
| MFCC | Mel-Frequency Cepstral Coefficients |
| PHQ-8 | Patient Health Questionnaire |
| ReLU | Rectified Linear Unit |
| STFT | Short-Time Fourier Transform |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| WHO | World Health Organization |
References
- World Health Organization. Depression and Other Common Mental Disorders: Global Health Estimates; Technical Report; World Health Organization: Geneva, Switzerland, 2017. [Google Scholar]
- Bachmann, S. Epidemiology of suicide and the psychiatric perspective. Int. J. Environ. Res. Public Health 2018, 15, 1425. [Google Scholar] [CrossRef]
- Beck, A.T.; Steer, R.A.; Carbin, M.G. Psychometric properties of the Beck Depression Inventory: Twenty-five years of evaluation. Clin. Psychol. Rev. 1988, 8, 77–100. [Google Scholar] [CrossRef]
- Yesavage, J.A.; Brink, T.L.; Rose, T.L.; Lum, O.; Huang, V.; Adey, M.; Leirer, V.O. Development and validation of a geriatric depression screening scale: A preliminary report. J. Psychiatr. Res. 1982, 17, 37–49. [Google Scholar] [CrossRef]
- Hamilton, M. The Hamilton rating scale for depression. In Assessment of Depression; Springer: Berlin/Heidelberg, Germany, 1986; pp. 143–152. [Google Scholar]
- Kroenke, K.; Strine, T.W.; Spitzer, R.L.; Williams, J.B.; Berry, J.T.; Mokdad, A.H. The PHQ-8 as a measure of current depression in the general population. J. Affect. Disord. 2009, 114, 163–173. [Google Scholar] [CrossRef]
- Cohn, J.F.; Kruez, T.S.; Matthews, I.; Yang, Y.; Nguyen, M.H.; Padilla, M.T.; Zhou, F.; De la Torre, F. Detecting depression from facial actions and vocal prosody. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–7. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Eyben, F.; Jiang, B.; Bilakhia, S.; Schnieder, S.; Cowie, R.; Pantic, M. AVEC 2013: The continuous audio/visual emotion and depression recognition challenge. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21–25 October 2013; ACM: New York, NY, USA, 2013; pp. 3–10. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. AVEC 2014: 3d dimensional affect and depression recognition challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 3–10. [Google Scholar]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Cowie, R.; Pantic, M. Summary for AVEC 2016: Depression, Mood, and Emotion Recognition Workshop and Challenge. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; ACM: New York, NY, USA, 2016; pp. 1483–1484. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A.; et al. AVEC 2018 workshop and challenge: Bipolar disorder and cross-cultural affect recognition. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Korea, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 3–13. [Google Scholar]
- Schuller, B.; Valstar, M.; Eyben, F.; McKeown, G.; Cowie, R.; Pantic, M. AVEC 2011–the first international audio/visual emotion challenge. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Memphis, TN, USA, 9–12 October 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 415–424. [Google Scholar]
- Gratch, J.; Artstein, R.; Lucas, G.; Stratou, G.; Scherer, S.; Nazarian, A.; Wood, R.; Boberg, J.; DeVault, D.; Marsella, S.; et al. The Distress Analysis Interview Corpus of human and computer interviews. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014; LREC: Reykjavik, Iceland, 2014; pp. 3123–3128. [Google Scholar]
- Jiang, B.; Valstar, M.; Martinez, B.; Pantic, M. A dynamic appearance descriptor approach to facial actions temporal modeling. IEEE Trans. Cybern. 2013, 44, 161–174. [Google Scholar] [CrossRef]
- Cummins, N.; Joshi, J.; Dhall, A.; Sethu, V.; Goecke, R.; Epps, J. Diagnosis of depression by behavioural signals: A multimodal approach. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21–25 October 2013; pp. 11–20. [Google Scholar]
- Wen, L.; Li, X.; Guo, G.; Zhu, Y. Automated depression diagnosis based on facial dynamic analysis and sparse coding. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1432–1441. [Google Scholar] [CrossRef]
- Ooi, K.E.B.; Low, L.S.A.; Lech, M.; Allen, N. Prediction of clinical depression in adolescents using facial image analysis. In Proceedings of the 12th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS 2011), Delft, The Netherlands, 13–15 April 2011; pp. 1–4. [Google Scholar]
- Kächele, M.; Glodek, M.; Zharkov, D.; Meudt, S.; Schwenker, F. Fusion of audio-visual features using hierarchical classifier systems for the recognition of affective states and the state of depression. In Proceedings of the 3rd International Conference on Pattern Recognition Applications and Methods, Angers, France, 6–8 March 2014; pp. 671–678. [Google Scholar]
- Yang, L.; Jiang, D.; He, L.; Pei, E.; Oveneke, M.C.; Sahli, H. Decision tree based depression classification from audio video and language information. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 89–96. [Google Scholar]
- Cummins, N.; Baird, A.; Schuller, B.W. Speech analysis for health: Current state-of-the-art and the increasing impact of deep learning. Methods 2018, 151, 41–54. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.H.; Tsao, Y.; Hsiao, M.J.; Chen, J.Y.; Lai, Y.H.; Lin, F.C.; Wang, C.T. Detection of pathological voice using cepstrum vectors: A deep learning approach. J. Voice 2019, 33, 634–641. [Google Scholar] [CrossRef] [PubMed]
- Zlotnik, A.; Montero, J.M.; San-Segundo, R.; Gallardo-Antolín, A. Random Forest-based prediction of Parkinson’s disease progression using acoustic, ASR and intelligibility features. Proc. Interspeech 2015, 2015, 503–507. [Google Scholar]
- Braga, D.; Madureira, A.M.; Coelho, L.; Ajith, R. Automatic detection of Parkinson’s disease based on acoustic analysis of speech. Eng. Appl. Artif. Intell. 2019, 77, 148–158. [Google Scholar] [CrossRef]
- Gosztolya, G.; Vincze, V.; Tóth, L.; Pákáski, M.; Kálmán, J.; Hoffmann, I. Identifying Mild Cognitive Impairment and mild Alzheimer’s disease based on spontaneous speech using ASR and linguistic features. Comput. Speech Lang. 2019, 53, 181–197. [Google Scholar] [CrossRef]
- Lopez-de Ipina, K.; Martinez-de Lizarduy, U.; Calvo, P.M.; Mekyska, J.; Beitia, B.; Barroso, N.; Estanga, A.; Tainta, M.; Ecay-Torres, M. Advances on automatic speech analysis for early detection of Alzheimer disease: A non-linear multi-task approach. Curr. Alzheimer Res. 2018, 15, 139–148. [Google Scholar] [CrossRef] [PubMed]
- An, K.; Kim, M.; Teplansky, K.; Green, J.; Campbell, T.; Yunusova, Y.; Heitzman, D.; Wang, J. Automatic early detection of amyotrophic lateral sclerosis from intelligible speech using convolutional neural networks. Proc. Interspeech 2018, 2018, 1913–1917. [Google Scholar] [CrossRef]
- Gallardo-Antolín, A.; Montero, J.M. A saliency-based attention LSTM model for cognitive load classification from speech. Proc. Interspeech 2019, 2019, 216–220. [Google Scholar] [CrossRef]
- Gallardo-Antolín, A.; Montero, J.M. External attention LSTM models for cognitive load classification from speech. In International Conference on Statistical Language and Speech Processing; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; pp. 139–150. [Google Scholar] [CrossRef]
- Cho, S.; Liberman, M.; Ryant, N.; Cola, M.; Schultz, R.T.; Parish-Morris, J. Automatic detection of autism spectrum disorder in children using acoustic and text features from brief natural conversations. Proc. Interspeech 2019, 2019, 2513–2517. [Google Scholar] [CrossRef]
- Cummins, N.; Scherer, S.; Krajewski, J.; Schnieder, S.; Epps, J.; Quatieri, T.F. A review of depression and suicide risk assessment using speech analysis. Speech Commun. 2015, 71, 10–49. [Google Scholar] [CrossRef]
- Asgari, M.; Shafran, I.; Sheeber, L.B. Inferring clinical depression from speech and spoken utterances. In Proceedings of the 2014 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Reims, France, 21–24 September 2014; pp. 1–5. [Google Scholar]
- Quatieri, T.F.; Malyska, N. Vocal-source biomarkers for depression: A link to psychomotor activity. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Darby, J.K.; Simmons, N.; Berger, P.A. Speech and voice parameters of depression: A pilot study. J. Commun. Disord. 1984, 17, 75–85. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Golik, P.; Tüske, Z.; Schlüter, R.; Ney, H. Convolutional neural networks for acoustic modeling of raw time signal in LVCSR. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Deng, L.; Li, J.; Huang, J.T.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.; Zweig, G.; He, X.; Williams, J.; et al. Recent advances in deep learning for speech research at Microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 8604–8608. [Google Scholar]
- Lee, M.; Lee, J.; Chang, J.H. Ensemble of jointly trained deep neural network-based acoustic models for reverberant speech recognition. Digit. Signal Process. 2019, 85, 1–9. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, C.; Jia, N. An ensemble model for multi-level speech emotion recognition. Appl. Sci. 2019, 10, 205. [Google Scholar] [CrossRef]
- Hajarolasvadi, N.; Demirel, H. 3D CNN-based speech emotion recognition using k-means clustering and spectrograms. Entropy 2019, 21, 479. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Nguyen, T.; Pernkopf, F. Acoustic scene classification using a convolutional neural network ensemble and nearest neighbor filters. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; pp. 34–38. [Google Scholar]
- Ma, X.; Yang, H.; Chen, Q.; Huang, D.; Wang, Y. DepAudioNet: An Efficient Deep Model for Audio Based Depression Classification. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, AVEC ’16, Amsterdam, The Netherlands, 16 October 2016; ACM: New York, NY, USA, 2016; pp. 35–42. [Google Scholar]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Kumar, A.; Kim, J.; Lyndon, D.; Fulham, M.; Feng, D. An ensemble of fine-tuned convolutional neural networks for medical image classification. IEEE J. Biomed. Health Inform. 2016, 21, 31–40. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Peng, H.; Hussain, A.; Howard, N.; Cambria, E. Ensemble application of convolutional neural networks and multiple kernel learning for multimodal sentiment analysis. Neurocomputing 2017, 261, 217–230. [Google Scholar] [CrossRef]
- Hwang, I.; Park, H.M.; Chang, J.H. Ensemble of deep neural networks using acoustic environment classification for statistical model-based voice activity detection. Comput. Speech Lang. 2016, 38, 1–12. [Google Scholar] [CrossRef]
- Faurholt-Jepsen, M.; Busk, J.; Frost, M.; Vinberg, M.; Christensen, E.M.; Winther, O.; Bardram, J.E.; Kessing, L.V. Voice analysis as an objective state marker in bipolar disorder. Transl. Psychiatry 2016, 6, e856. [Google Scholar] [CrossRef]
- Low, D.M.; Bentley, K.H.; Ghosh, S.S. Automated assessment of psychiatric disorders using speech: A systematic review. Laryngoscope Investig. Otolaryngol. 2020, 5, 96–116. [Google Scholar] [CrossRef]
- Little, B.; Alshabrawy, O.; Stow, D.; Ferrier, I.N.; McNaney, R.; Jackson, D.G.; Ladha, K.; Ladha, C.; Ploetz, T.; Bacardit, J.; et al. Deep learning-based automated speech detection as a marker of social functioning in late-life depression. Psychol. Med. 2020, 1–10. [Google Scholar] [CrossRef]
- Giannakopoulos, T. pyAudioAnalysis: An Open-Source Python Library for Audio Signal Analysis. PLoS ONE 2015, 10, 0144610. [Google Scholar] [CrossRef]
- Degottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP, A collaborative voice analysis repository for speech technologies. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 960–964. [Google Scholar]
- Nasir, M.; Jati, A.; Shivakumar, P.G.; Nallan Chakravarthula, S.; Georgiou, P. Multimodal and multiresolution depression detection from speech and facial landmark features. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 43–50. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2015, 7, 190–202. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; CRC Press: London, UK, 2014. [Google Scholar]
- Deng, L.; Abdel-Hamid, O.; Yu, D. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 6669–6673. [Google Scholar] [CrossRef]
- Berk, R.A. An introduction to ensemble methods for data analysis. Sociol. Methods Res. 2006, 34, 263–295. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. LibROSA: Audio and music signal analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 19 June 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source Scientific Tools for Python. 2001. Available online: https://www.scipy.org (accessed on 19 June 2020).
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N/ | Method | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| Baseline (SVM) | - (-) | 0.41 (0.58) | 0.27 (0.94) | 0.89 (0.42) | |
| DepAudionet | 0.65 (0.65) | 0.50 (0.73) | 0.44 (0.80) | 0.60 (0.68) | |
| 64/64 | 1 1d-CNN | 0.70 (0.70) | 0.56 (0.77) | 0.49 (0.83) | 0.65 (0.71) |
| Ensemble 50 1d-CNN | 0.70 (0.70) | 0.56 (0.77) | 0.50 (0.83) | 0.64 (0.73) | |
| 128/128 | 1 1d-CNN | 0.70 (0.70) | 0.59 (0.76) | 0.50 (0.85) | 0.72 (0.69) |
| Ensemble 50 1d-CNN | 0.74 (0.74) | 0.65 (0.80) | 0.55 (0.89) | 0.79 (0.73) | |
| 256/256 | 1 1d-CNN | 0.71 (0.71) | 0.61 (0.77) | 0.50 (0.86) | 0.73 (0.70) |
| Ensemble 50 1d-CNN | 0.72 (0.72) | 0.63 (0.78) | 0.52 (0.88) | 0.79 (0.70) | |
| 512/512 | 1 1d-CNN | 0.70 (0.70) | 0.60 (0.76) | 0.51 (0.86) | 0.75 (0.68) |
| Ensemble 50 1d-CNN | 0.72 (0.72) | 0.63 (0.78) | 0.52 (0.88) | 0.79 (0.70) |
| Kernel Size | Method | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| Baseline (SVM) | - (-) | 0.41 (0.58) | 0.27 (0.94) | 0.89 (0.42) | |
| DepAudionet | 0.65 (0.65) | 0.50 (0.73) | 0.44 (0.80) | 0.60 (0.68) | |
| (1, 1) | 1 1d-CNN | 0.69 (0.69) | 0.55 (0.76) | 0.48 (0.82) | 0.65 (0.71) |
| Ensemble 50 1d-CNN | 0.68 (0.68) | 0.55 (0.75) | 0.47 (0.82) | 0.64 (0.70) | |
| (1, 3) | 1 1d-CNN | 0.69 (0.69) | 0.57 (0.75) | 0.51 (0.84) | 0.68 (0.72) |
| Ensemble 50 1d-CNN | 0.72 (0.72) | 0.61 (0.79) | 0.53 (0.86) | 0.71 (0.73) | |
| (1, 5) | 1 1d-CNN | 0.70 (0.70) | 0.59 (0.76) | 0.50 (0.85) | 0.72 (0.69) |
| Ensemble 50 1d-CNN | 0.74 (0.74) | 0.65 (0.80) | 0.55 (0.89) | 0.79 (0.73) | |
| (1, 7) | 1 1d-CNN | 0.69 (0.69) | 0.56 (0.75) | 0.48 (0.84) | 0.68 (0.69) |
| Ensemble 50 1d-CNN | 0.72 (0.72) | 0.61 (0.79) | 0.53 (0.86) | 0.71 (0.73) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vázquez-Romero, A.; Gallardo-Antolín, A. Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks. Entropy 2020, 22, 688. https://doi.org/10.3390/e22060688
Vázquez-Romero A, Gallardo-Antolín A. Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks. Entropy. 2020; 22(6):688. https://doi.org/10.3390/e22060688
Chicago/Turabian StyleVázquez-Romero, Adrián, and Ascensión Gallardo-Antolín. 2020. "Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks" Entropy 22, no. 6: 688. https://doi.org/10.3390/e22060688
APA StyleVázquez-Romero, A., & Gallardo-Antolín, A. (2020). Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks. Entropy, 22(6), 688. https://doi.org/10.3390/e22060688