1. Introduction
One of the most important aims of an integrated pest management programme (IPM) is to provide an accurate estimation of the pest population size at the typical agricultural area. IPM can be defined as the incorporation of several different methods of pest management, which work together in a more sustainable way to protect food production from pest attacks [
1]. This importance of obtaining an accurate estimation of pest population density has been discussed in [
2]. After estimating the pest population abundance in an agricultural field, a decision of implementing a control action will be taken depending on the comparison of the estimation to some threshold value(s). For instance, if this estimate falls below the value of threshold, the decision in this case would be that no action is needed. However, according to the work in [
3], if the estimation exceeds this threshold, then the decision is to implement a control action immediately. Many studies have proven that the application of pesticides is a widely used in order to reduce damage from pest attacks [
4,
5]. Thus, it can be seen from the above that precision is of utmost importance in order to arrive at the correct decision with regards to whether to implement a control action. If the true value of population density is known, then the decision can be made easily; however, this cannot be known, therefore reliable information with which to make an evaluation of population density is required.
There are several techniques that have been used to improve the measurement of accuracy. One method is to increase the number of samples in an agricultural field to calculate the value of pest abundance with a sufficiently large number of traps in statistical equation, given as
where
denotes the individual sample counts and
N is the number of sample counts in an agricultural field [
6], and then to consider it as the exact value of the pest population. In ecological research, the number of traps can be increased to hundreds per given agricultural area. However, in real-life pest monitoring programmes, the number of traps does not exceed twenty [
6], and in some cases, it ranges between one and a few per typical agricultural area [
7].
Numerical integration methods present an alternative to statistical methods of evaluation. In recent years, many studies have been carried out on these methods in order to present an overall view of their application to ecological problems [
2,
8,
9,
10,
11]. These studies have shown that numerical integration methods are more reliable than standard statistical methods (
1), which can be considered as a simple form of numerical integration. It has been demonstrated that advanced numerical integration methods tend to provide a more effective estimation of pest density. Generally, from a mathematical viewpoint, the problem of estimating the pest population size is considered as a problem of calculation of the following integral,
where the integrand
is the pest population density.
Clearly, in ecological problems the function
is only known at discrete points
, and in this situation, it is impossible to find the analytical solution. In order to evaluate this integral, numerical integration methods must be used to approximate the solution [
12,
13,
14,
15,
16].
In the
cases, integral (
1) becomes
where
. According to the work in [
7], the general form of numerical integration can be obtained by the weighted sum as follows,
where
,
rely on numerical integration methods.
The evaluation error has to be introduced as a result of replacing the exact population size
I by approximation value
where the relative error is defined as
It can be seen from the above that Formula (
4) gives an accurate definition of the integration error only if the value of the integral
I is known. However, in real-life applications, the exact value of the integral
I is not available, and so Formula (
4) can not be applied. Therefore, according to the work in [
7], in order to overcome this obstacle, it is beneficial to present the asymptotic error estimate of the numerical integration method as follows,
where
, and
r are constants.
The evaluation accuracy will improve depending on the amount of available data. In other words, in order to achieve a more accurate estimation of the pest population size, the amount of data must increase accordingly [
17]. In this case, the approximated solution will converge to the analytical solution. This means that accurate evaluation of the approximated solution requires a vast array of data to be available. However, in pest monitoring, a large amount of data requires more equipment and labour to perform the physical measurements. Furthermore, in terms of trying to generate simulated data, this will require a high computational effort. Therefore, the amount of data may be limited in various types of application and we have to deal with sparse data.
It has been shown in [
9,
17] that the standard evaluation technique does not work when the available data is sparse because of insufficient information in data collected on coarse grids. Another approach must be applied when dealing with high aggregation density distribution under various conditions. One common example of biological invasion which represents high aggregation density distribution, is that spreading the pest species at the beginning of invasion from a small area to reach as time progresses the entire domain. Within an agriculture field, the pest population is aggregated to a single subregion, and outside that subregion the density is zero. From a mathematical viewpoint, this pattern of distribution is known as a peak function. It is beneficial to make decision about the application of pesticides before the density become dominant over the whole agriculture field. In order to protect the production of the agriculture field, timely and accurate evaluation of the total number of pest insects at the beginning of invasion is very important. In this problem, the exact location of the peak is not known previously, as a result the application of numerical integration methods is hampered. Therefore, in order to overcome this obstacle, the number of traps must be increased uniformly over the entire domain instead of installing traps locally. However, in reality this procedure has failed to work with peak function due to insufficient information about the density function. It was discussed in [
10,
11] that the whole peak may be completely missed when peak is located between nodes of coarse grid. Consequently, the accuracy of evaluation the pest density can be affected severely and negatively. Therefore, instead of applying standard evaluation methods, a probabilistic approach is used to evaluate the total population size on coarse sampling grids. Recent cross-disciplinary research has accelerated in the field of computational and numerical algorithms, including methods for solving real-world ordinary differential equations, numerical integrals, and optimisation, which can be expressed as estimation algorithms. They are utilised to approximate the value of a variable, numerical, or stochastic integral, the solution of a differential equation, or the location of a maximum, as well as to optimise a multi-objective algorithm. Such techniques utilise principles of statistical inference and generalised probability theory. As such, they have been applied to these concepts in computer science, most notably artificial intelligence and modern machine learning.
Understanding and developing numerical techniques such as learning algorithms can be powerful in a wide range of multi-disciplinary research areas and industries. Combining such platforms encourages cross-fertilisation of research in computation, probability, and numerical methods. The interface of research between probabilistic and numerical methods has been applied to diverse and wide-ranging areas such as the Internet of Things, the development of algorithms for neural networks used in self-driving vehicles, and intelligent analysis systems, such as big data, stochastic methods in finance, and Monte Carlo simulation [
18,
19,
20,
21].
The paper is presented as follows. In
Section 2, we will consider the evaluation error as a random variable and calculate probabilistic characteristics of the total population size. In
Section 3, we will use the standard approach to calculate the mean and standard deviation of random variables. The probability of accurate evaluation at random location of the first grid node on a sampling grid will discuss in
Section 4. We consider
probability analysis at regular and random locations of first grid node with ecological example in
Section 5 and
Section 6. In
Section 7, we conclude our experience with probabilistic approach in the problem of accurate evaluation of the total population size.
2. Characteristics of the Probabilistic Approach for Higher Aggregated Population Density
In this section, the probability approach will be used to illustrate that when the number of grid nodes is very small, the accuracy is probabilistic rather than deterministic (i.e., achieving an accurate estimation becomes a matter of chance) [
2]. Let us consider a peak function which represents an early stage of patchy invasion [
2]. The population density function over interval
will be presented as a single peak function located within sub-interval
, and the density will be zero elsewhere. Therefore, a highly aggregated density distribution
can be defined as
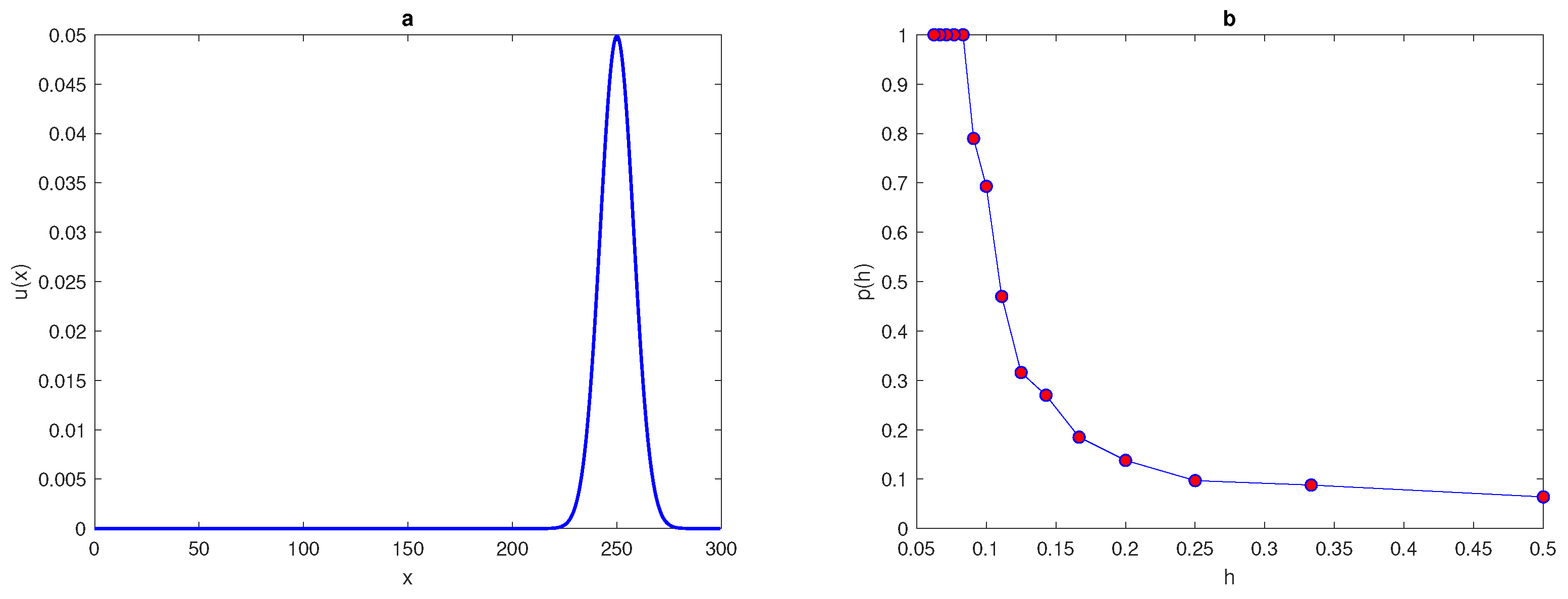
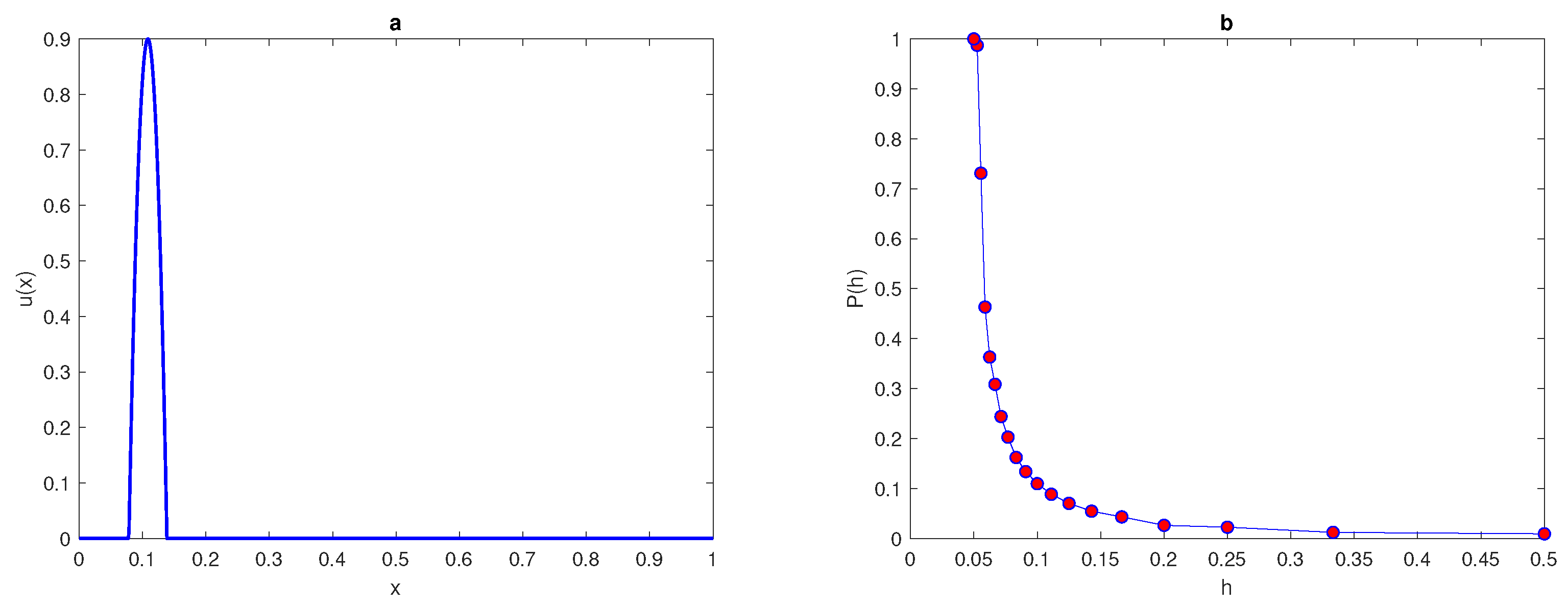
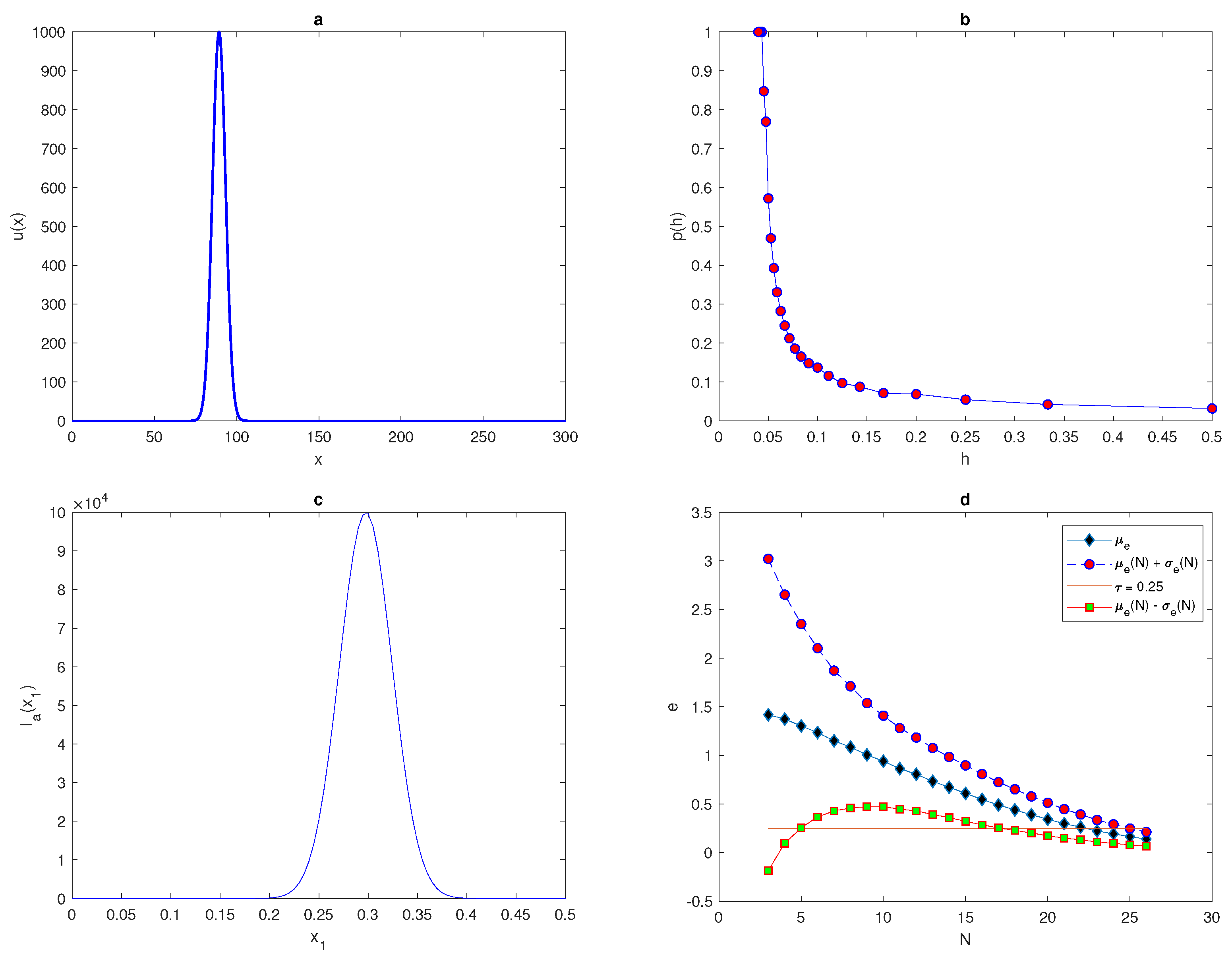
The maximum of the peak is only obtained from the construction
and it is assumed to be located within this construction. An example of a
peak function is shown in
Figure 1a. The location of the peak must be considered randomly within a truncated sub-interval
taken from the original interval
(i.e.,
). The restriction imposed on the location of the peak function is to prevent any important information on the population density being missed if the peak is located at the endpoints of the original interval
or at the boundaries of domain.
A standard example of a peak function is given by substituting
in Equation (
6) as follows,
where the location of the peak maximum
is a random variable within the truncated sub-interval and
is the standard deviation. The definition of the peak width as a function of the standard deviation is represented as follows [
22],
Now, let us generate peak function by using Formula (
7) over interval
where
,
, and the locations of peak will be changed randomly within
where
At a very small number of grid nodes, and when the function of highly aggregated density distributions is considered, the accuracy of the estimate cannot be determined and the integration error is dependent on the location of a random point
. Then, the error becomes a random variable as a result.
The generated function will be integrated over the interval
and a series of an increasingly refined number of regular grid nodes
, by applying statistical rule (
1). Then, the relative error (
4) will be computed to assess the accuracy of the method used, by using the criterion
where
is a fixed tolerance number. The condition (
9) must hold, where in ecological applications a good level of accuracy lies between
, in some cases,
may be considered acceptable level of accuracy, where
is the accuracy tolerance [
23,
24].
At each number of grid node, the computations will be repeated for
realisations of the random variable
. Then, the probability
of accurate numerical integration is computed as follows,
where
is the probability obtained numerically,
h is the grid step size on the number
N of grid nodes
, and
is the number of realisations for which the integration error satisfies the condition
where
. We repeat the computations by increasing the number of grid nodes until the grid step size becomes
then, the computations will be stopped. The peak function (
7) is shown in
Figure 1 for the peak width
. The probability
when the condition (
9) of the function (
7) holds is presented in
Figure 1b.
The computation started from a grid of
nodes and ended on a grid of
, nodes where the condition
holds. It can be seen from
Figure 1b that the integration error when integrating the function (
7) on a very coarse grid of nodes will depend on the location of the peak, and the probability of achieving an accurate estimate is
. Meanwhile, on a grid of
nodes
, the error is deterministic and the error is
no matter where the peak is located. Therefore, it follows from the results of integrating the function of highly aggregated density distributions that the integration error becomes a random variable, and the accuracy of numerical integration at a very small number of grid nodes is probabilistic rather than deterministic, even if an acceptable degree of accuracy is acquired.
The above discussion leads us to introduce a new type of grid to be added to the grid classification, which is defined as an ultra-coarse grid. Therefore, there are now three types of computational grid: fine grid, coarse grid, and ultra-coarse grid. With fine grids, the asymptotic error estimate (
5) always holds. For coarse grid, the asymptotic error estimates do not hold; however, the error will be deterministic and it will satisfy the condition (
9) for a chosen
. In the ultra-coarse grid, the asymptotic error estimate does not hold and the accuracy is not deterministic. The accuracy can only described in terms of the probability of achieving an error within a prescribed tolerance
. The probability satisfies
when the condition
holds for a chosen tolerance
. Therefore, the threshold number
of grid nodes must be determined, where at any number of grid node less than
, the probability is
and the computational grid is defined as an ultra-coarse grid. At the number of grid nodes
, the transition from ultra-coarse to coarse grid takes place and the error becomes deterministic.
Now, let us vary the value of standard deviation
in the peak function (
7) to investigate the impact of choosing different values of
on the probability of achieving an accurate estimation. The peak function (
7) will be considered and the value of
will vary as follows
. Then, at each value of
, the above computations will be repeated. All values of threshold numbers of grid nodes, alongside their value of
, are presented in
Table 1.
It can be seen from
Table 1 that the number of grid nodes required for the condition
to hold depends on the width of the peak function
. By comparing the critical number of grid nodes required to achieve an accurate estimate at two different values of
, it can be noted from
Table 1 that there is an inverse relationship between peak width
and
. For a wide peak, the critical number of grid nodes required is small, whereas this number becomes bigger at narrow peaks, as shown in
Table 1 and
Figure 2b. Furthermore, the number of grid nodes to fulfil the accuracy requirements in the probabilistic approach depends on the value of tolerance
, where from
Table 1 it can be seen that for a low level of accuracy
, the required number of grid nodes is considerably less than the number required at
at the same values of peak width
, as can be seen from
Figure 3.
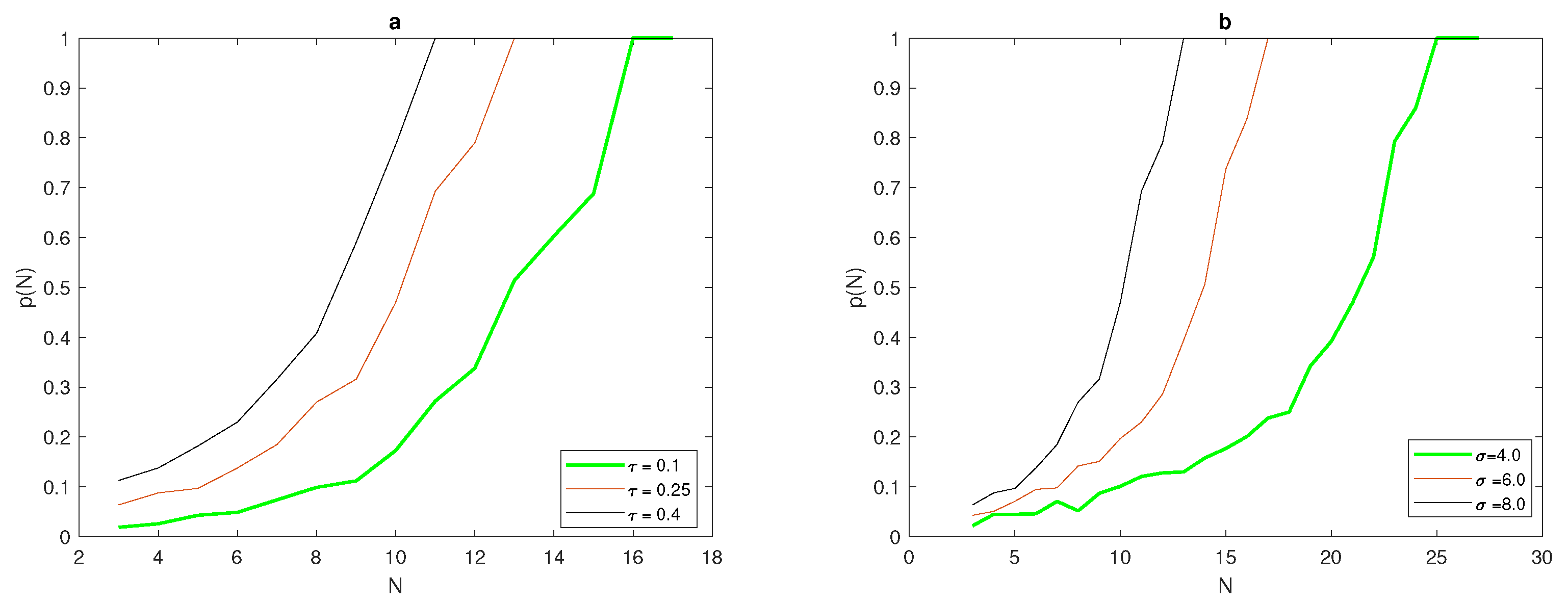
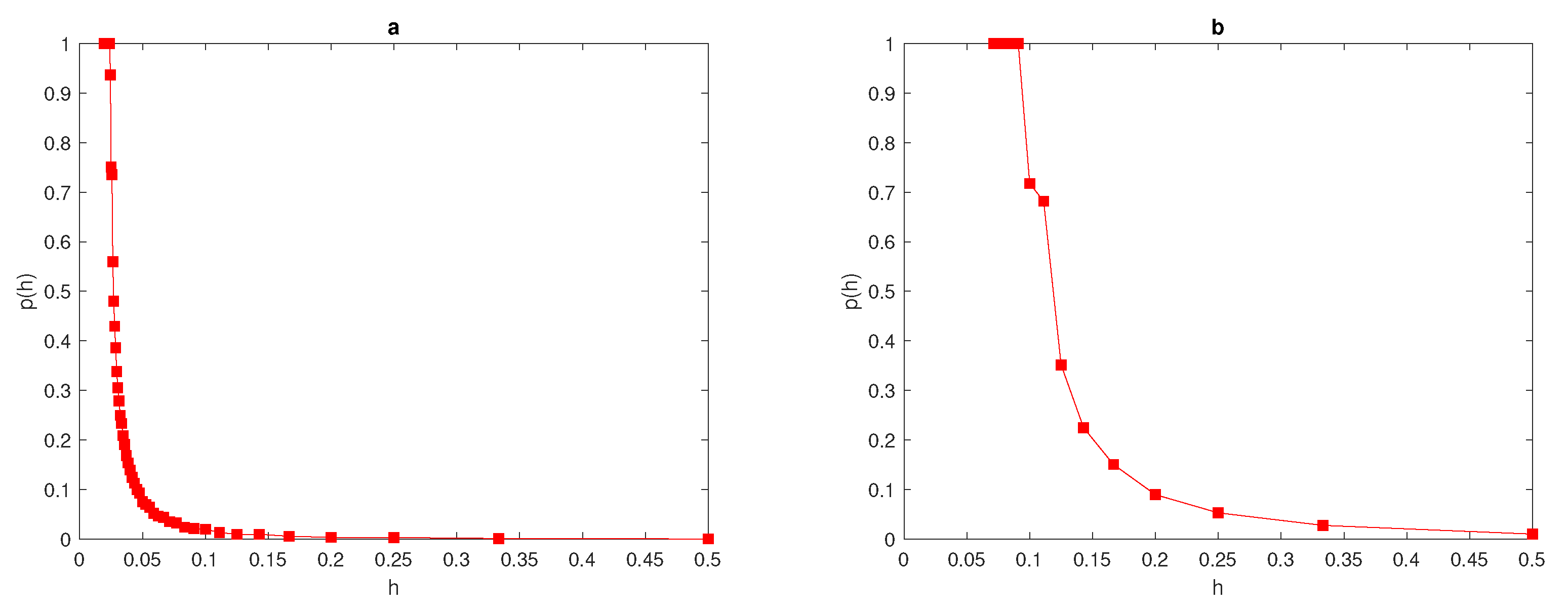
An instructive example is depicted in
Figure 2a, where at fixed width
in (
7), the probability function
depends on the chosen tolerance
: where at the high level of accuracy
, the critical number of grid nodes
required for
to hold is considerably bigger than the numbers required for
and
, respectively.
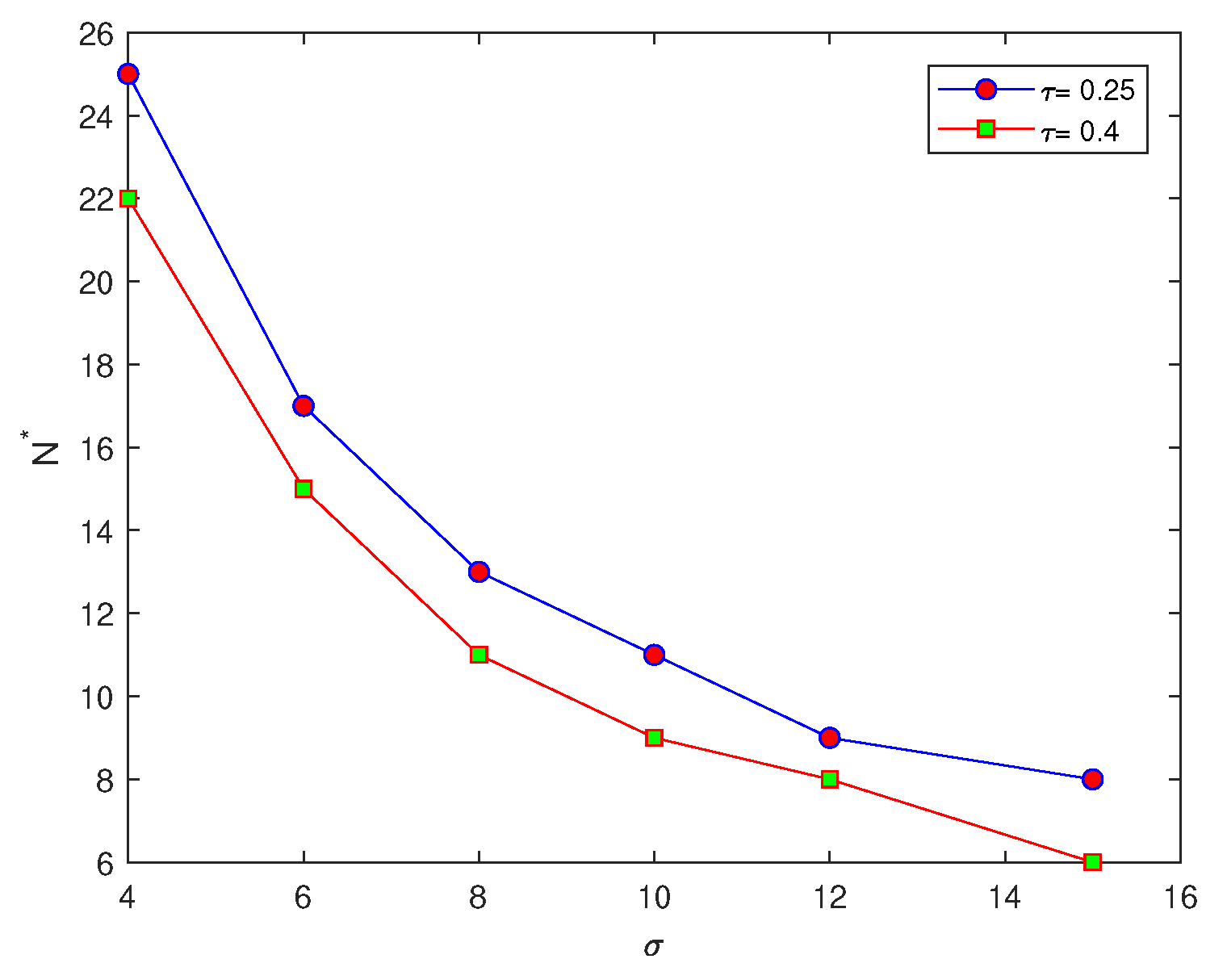
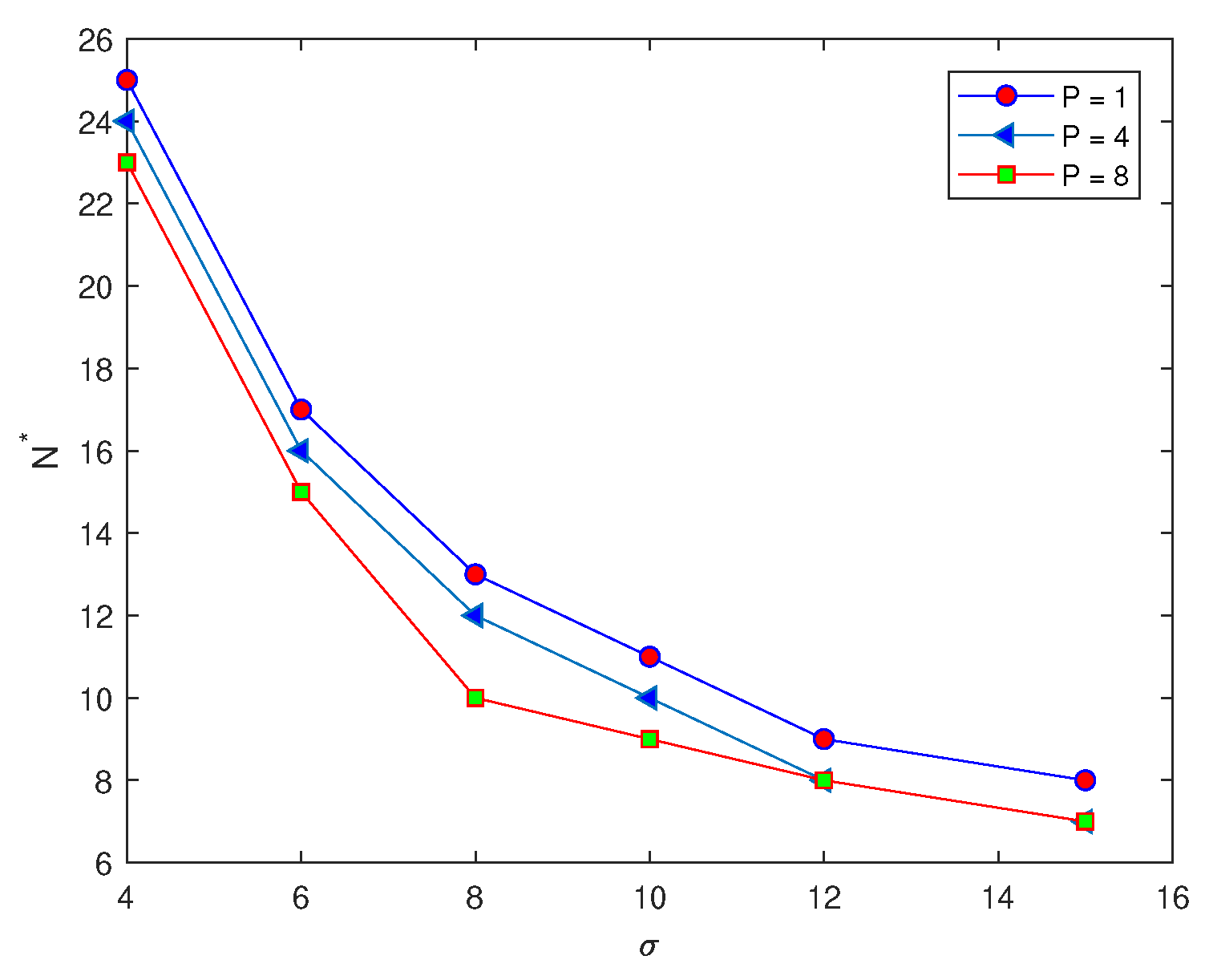
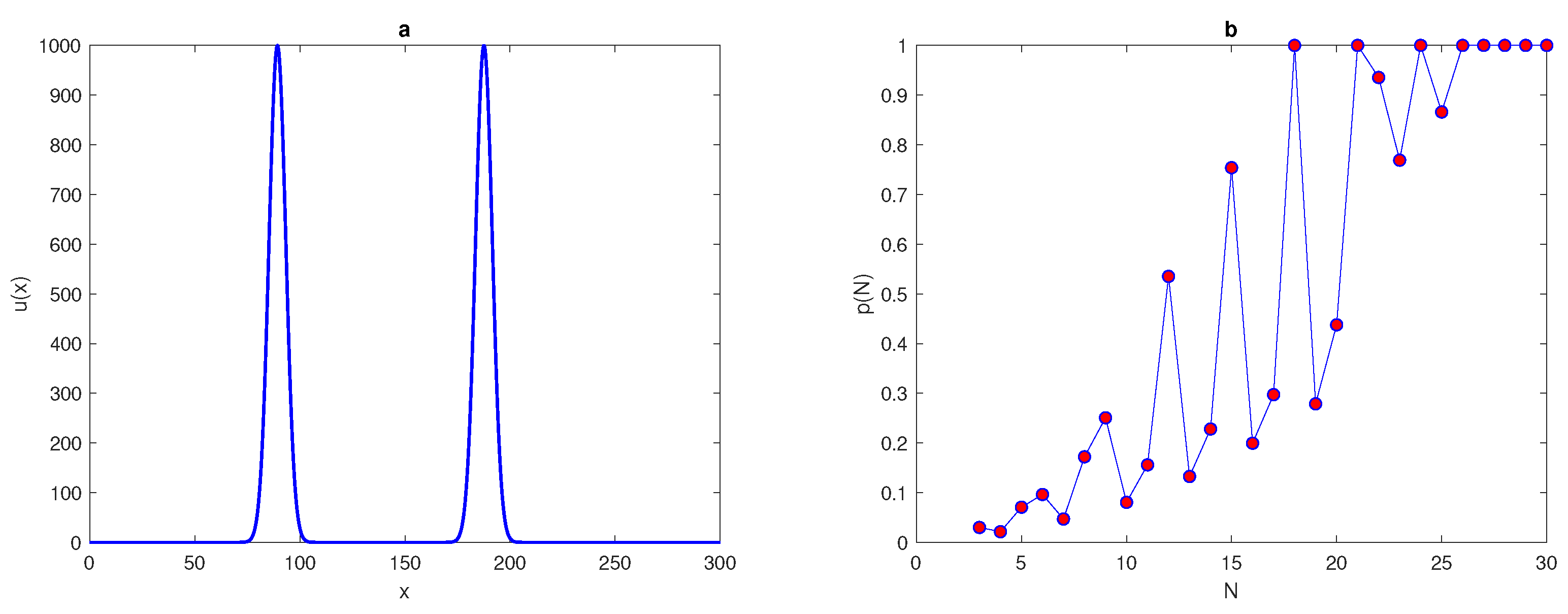
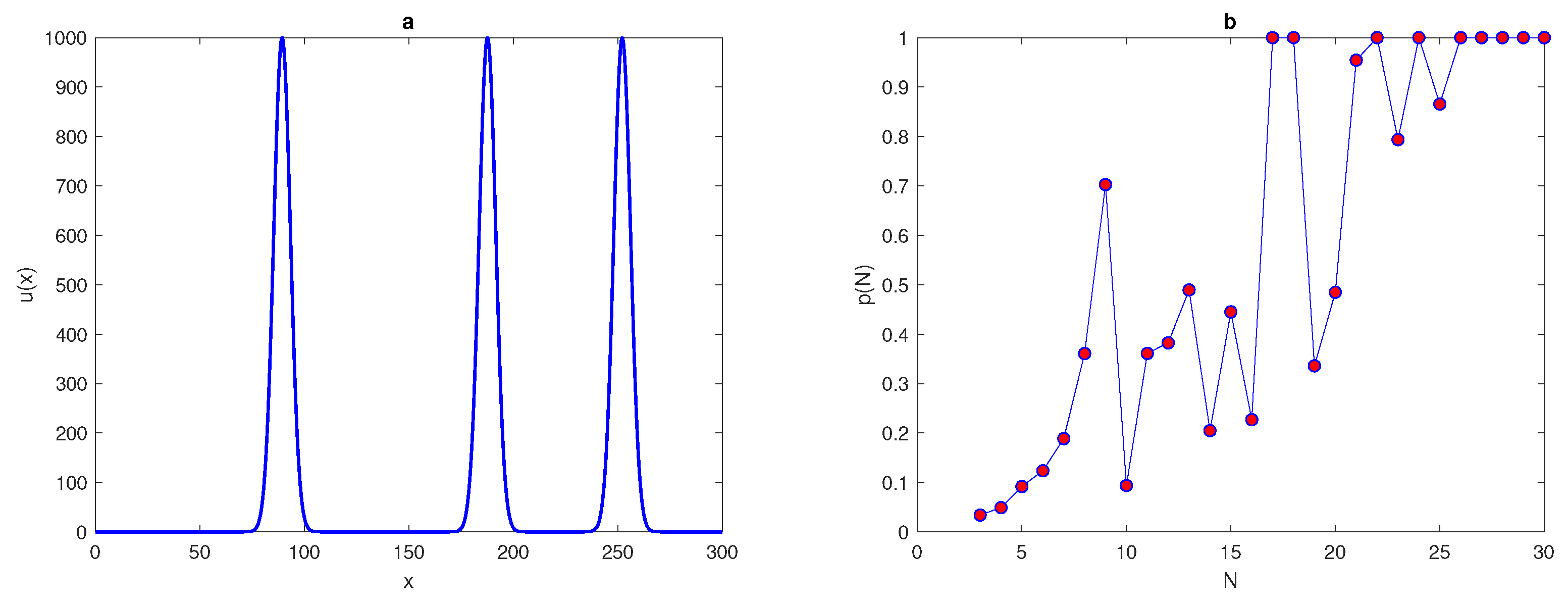
We now consider the superposition of normal distributions given by the following equations,
where
This generates functions of four and eight peaks by substituting the value of
P as
, or
. The previous computations, which are applied to the peak function (
7) at several values of standard deviation
, will be repeated for functions with four and eight peaks, respectively. The main aim of this variation in the number of peaks is to determine the effect of increasing the number of peaks on the probability of achieving an accurate estimate on a coarse grid nodes. For each value of
at different numbers of peaks,
in the function, the number of grid nodes required for the probability condition
to hold is recorded in
Table 2. It can be noted from
Table 2, by comparing the values of the number of grid nodes
with different numbers of peaks, that when the number of peaks becomes
, the number of grid nodes
required to achieve an accurate estimate is slightly less than that number
required at number of peaks
, respectively, as shown in
Figure 4. Therefore, when the number of peaks is increased we have a higher probability of obtaining an accurate estimate.
Let us now expand the population density function given by (
6) in the vicinity of the location of the maximum
as follows,
In the vicinity of the peak, the remainder term
can be ignored, so that the density peak function is given by the quadratic function as follows,
where
,
. The maximum value of the peak coincides with the maximum value of the quadratic function, which is symmetric around the location of
. The quadratic function
must be always non-negative over sub-interval
, i.e.,
. Then, the following condition must hold,
Let us now use the quadratic function given in Equation (
14) to generate data over unit interval
. A uniform grid of
N nodes is generated in the domain
, as
where the grid step size
,
. The population density in the vicinity of the peak will be considered, where for the interval
,
is the width of the peak function. From Equation (
15), the width of the peak function becomes
and the roots are
. The grid step size
h can be defined in terms of peak width as
, where the parameter
. The exact value of abundance
I can be computed by treating the peak as a quadratic function, as follows:
In order to ensure that the relative error satisfies the condition
, in the quadratic function (
14), the chosen value for the peak is always positive, i.e.,
and the grid step size
h should satisfy the following condition
.
Now, let us consider the quadratic function given by (
14). As demonstrated in the previous section, the probability of achieving a sufficiently accurate estimate when modelling a peak function with normal distribution will be computed. The width of the peak is fixed as
, and the location of peak
is a random variable distributed uniformly over the interval
, where the entire peak must be stationed within the unit interval
. By fixing the tolerance
, the probability of achieving an accurate estimate at different values of peak widths can be calculated from Equation (
10). The density of quadratic function (
14) at
is shown in
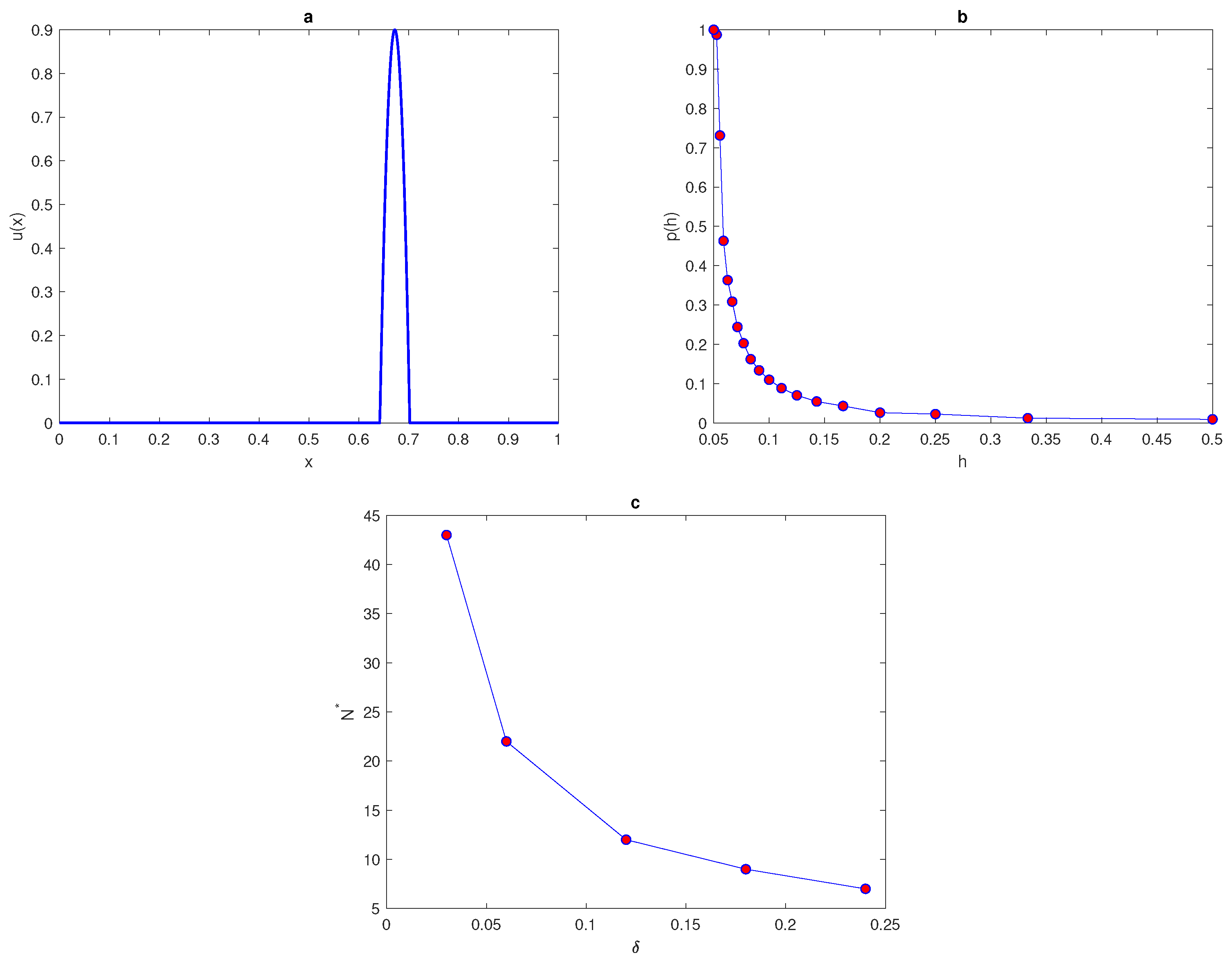
Figure 5a.
Figure 5b shows the probability
of obtaining an accurate answer at peak width
; from this figure, it can be seen that for a very small number of grid nodes, the probability is
and the integration error itself is a random variable with a high magnitude. The probability becomes equal to one at the critical number of grid nodes
. This required critical number of grid nodes
increase as the value of the peak width decreases (i.e., a narrower peak) and it decreases as the peak width increases, as can be seen from
Table 3.
Table 3 presents the number of grid nodes required to achieve an accurate estimate of the quadratic function at different values of peak widths
. The probability curves for approximating the quadratic function with peak widths
are displayed in
Figure 6a,b. It can be deduced from
Figure 5b and
Figure 6a,b that at different values of peak width, the required value of probability when the number of grid nodes
N is very small has not been achieved, and the integration errors become random variables with high magnitudes, due to inadequate information about the integrand quadratic function. Furthermore, the relative error when the number of grid nodes is very small tends to be large (i.e.,
), the accuracy in this case is probabilistic rather than deterministic, and achieving an acceptable level of accuracy will become a matter of chance in this case. By considering a peak as a quadratic function and the integration error as a random variable, the threshold number of grid nodes
required to achieve a prescribed level of accuracy has been determined, where at each regular grid with
, an adequate level of accuracy holds.
3. Evaluating the Arithmetic Mean and Probabilistic Mean Population Density on Coarse Grids
Let us now consider the standard approach to calculating the mean and standard deviation of random variables
given by (
1), and the relative error
e given by (
4) on a grid of
N nodes. Formulas (
17) and (
18) give us the arithmetic mean and standard deviation for uniform variables
as follows [
6],
where
is the total number of realisations of the random variables,
is a random evaluation of the total population size
, or a random evaluation error
e,
for a random
is the probability density function, and the subscript
i can be
or
e. According to the work in [
6], the following formulas are true,
where
is the arithmetic mean of a random variable of the total population size
,
is the arithmetic mean of a random variable of the evaluation error
e,
is the standard deviation of a random variable of the total population size
, and
is the standard deviation of a random variable of the evaluation error
e. Let us now consider the quadratic function given in Equation (
14) to generate data over the unit interval
. The width of the peak will be fixed as
, and the location of peak
is a random variable distribute uniformly over the interval
, where the entire peak must be located within the unit interval
. The above computations are then repeated.
The density (
14) at
is shown in
Figure 5. The computation starts with a fixed number of grid nodes
, and then the number of grid nodes increases as
,
. At each number of grid nodes, the computations will be repeated until the following condition holds,
Once the data has been obtained, the arithmetic mean of approximate integrals
and numerical integration errors
e will be computed by using Equations (
17) and (
18). It can be noted from
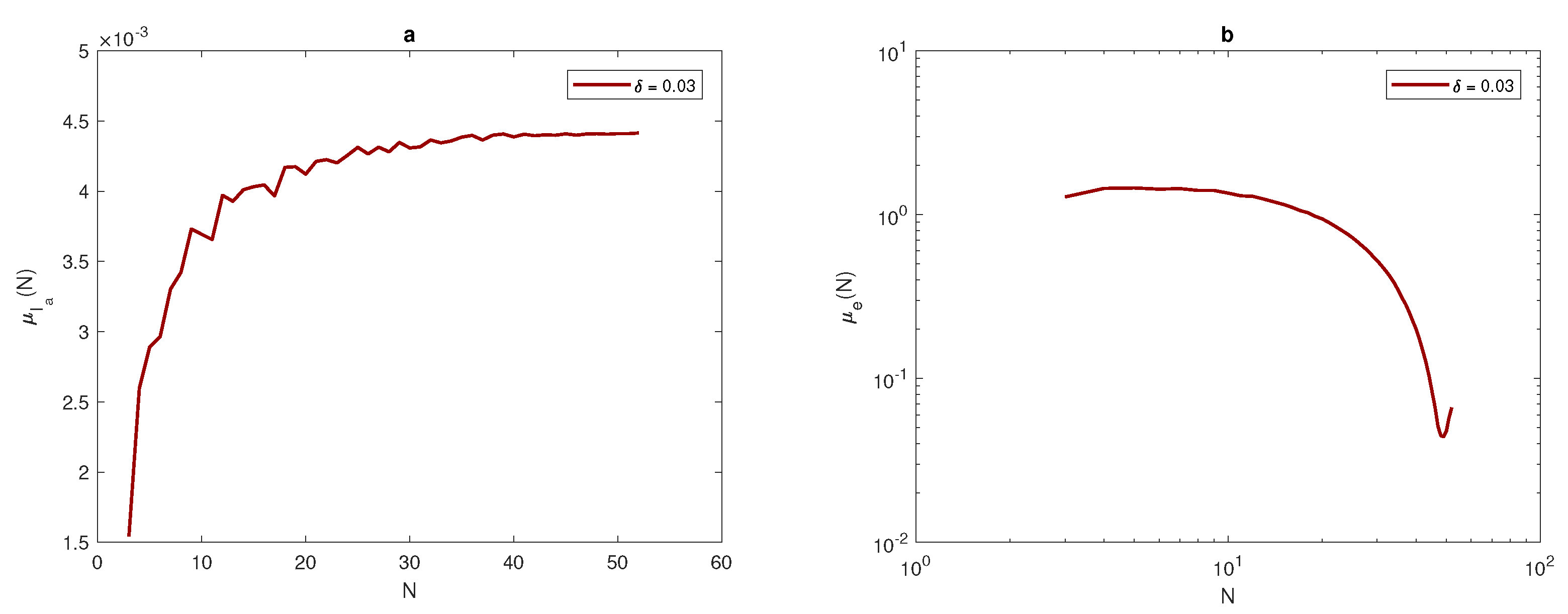
Figure 7,
Figure 8 and
Figure 9, that at each value of peak width
, the arithmetic mean of the approximated integral values tend to be very close to the exact value of the integral when the number of sample units is increased. Furthermore, at a narrow peak
, the arithmetic mean converges slowly to the exact value of integral
. It also has a slightly oscillating feature, as shown in
Figure 8a. At a wider peak width, the approximate value
converges to the exact values of integrals
, and
faster when the width of the peak increases to
, and
, as depicted in
Figure 7a and
Figure 9a. It can be observed from
Figure 7b,
Figure 8b and
Figure 9b that the sample mean
tends to be zero when the number of grid nodes increases, and the approximation converges faster to reach zero when the width of peak in the quadratic function becomes wider, as shown in
Figure 7b,
Figure 8b and
Figure 9b.
Table 4 introduces the number of grid nodes required for the condition (
23) to hold at different peak widths for quadratic function (
14) and when the probability
. It appears from
Table 4 that the number of grid nodes required for condition (
23) to hold is slightly less than the number of grids required for condition
to hold.
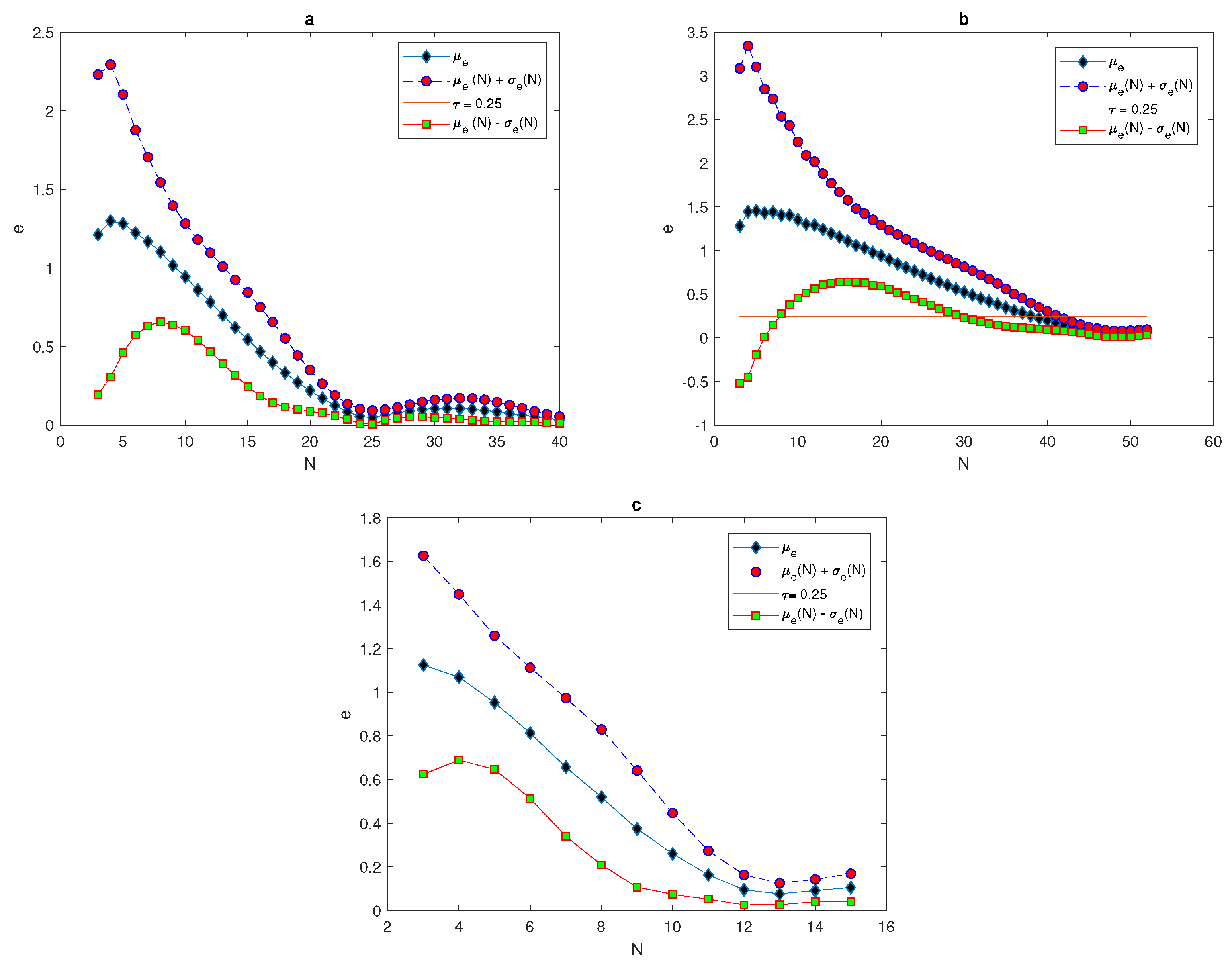
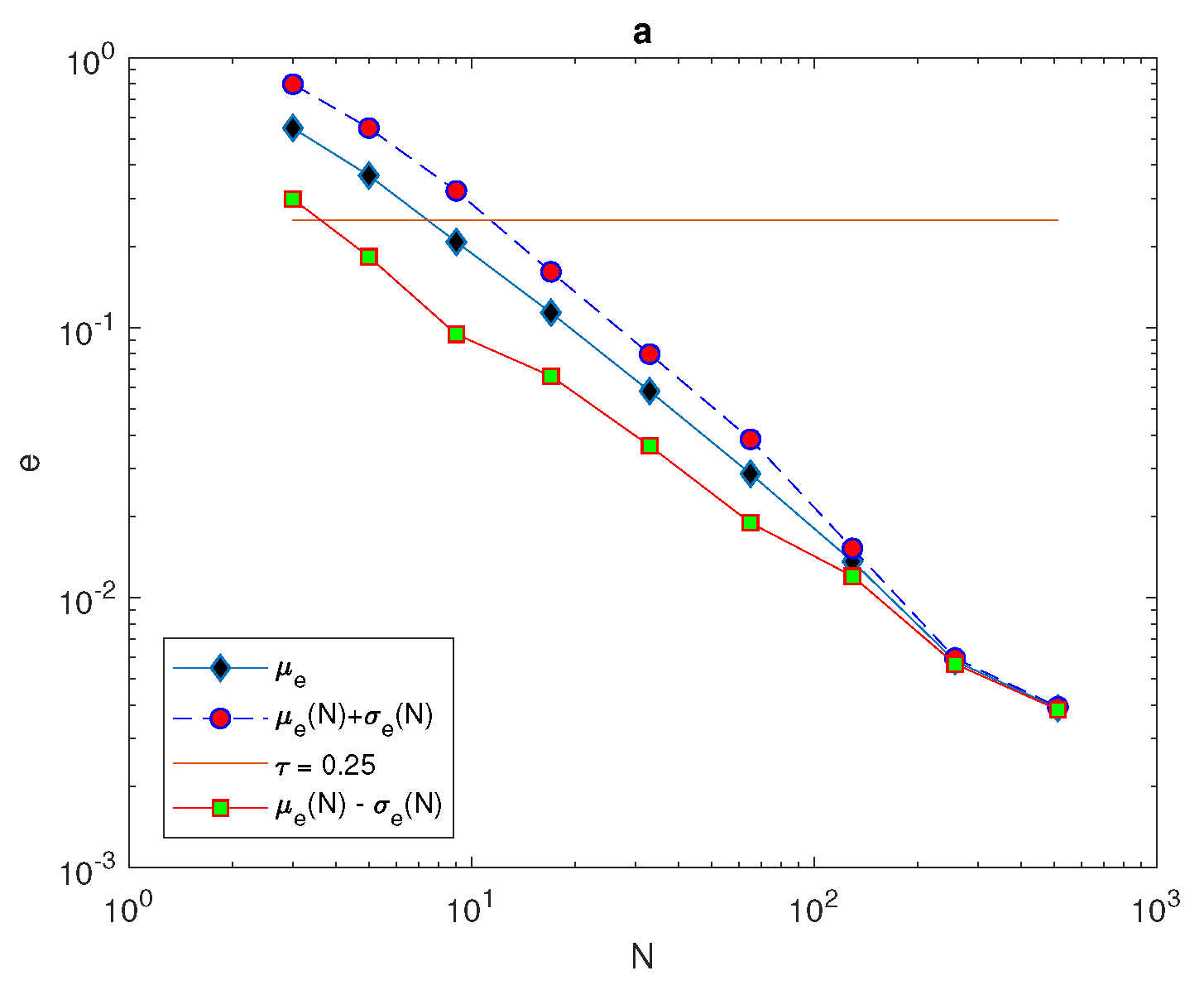
For the population density given by (
14),
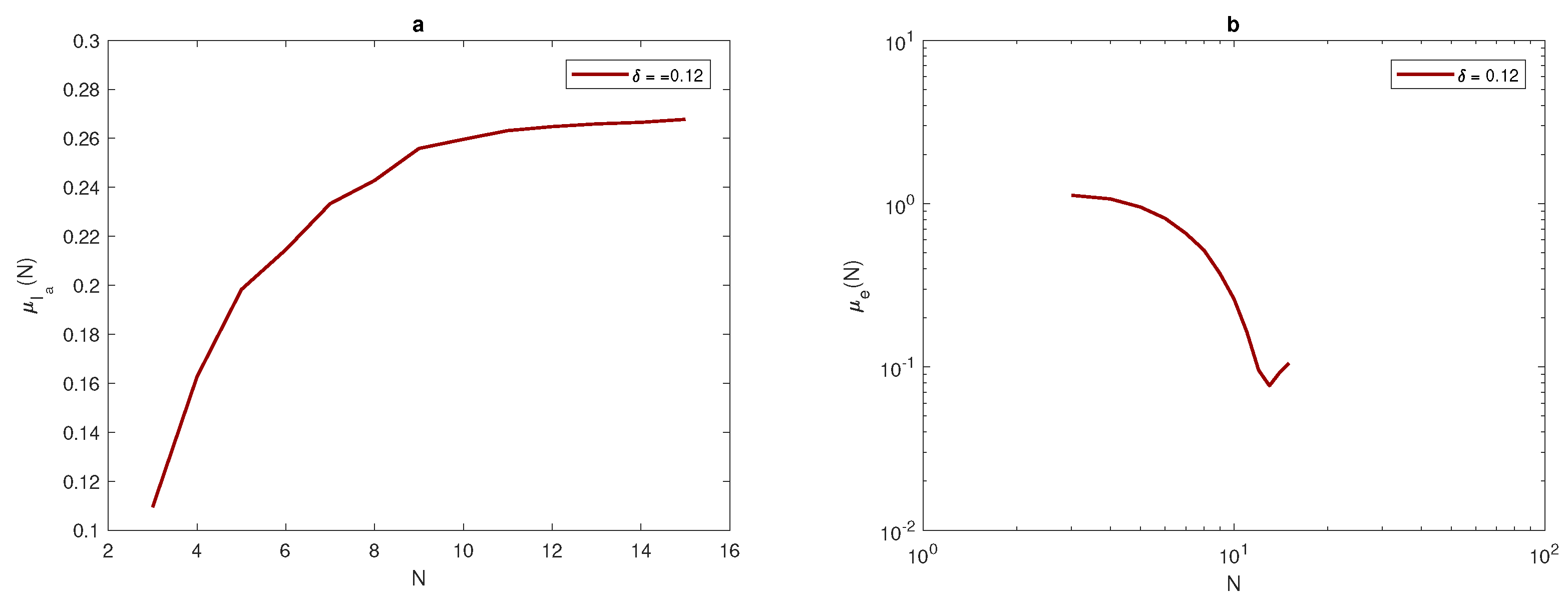
Figure 10 compares the arithmetic mean of error
and upper and lower bounds
with a tolerance of
. When considering the peak function, the graphs of arithmetic mean error and bounds of error for different values of peak widths show the impact of peak width on the number of grid nodes needed to achieve the desirable accuracy
. At the narrowest considered peak function
, the number of grid nodes
N required to fulfill the accuracy requirements is a significant
points, as shown in
Figure 10b, whereas this number decays gradually while increasing the width of the peak as
and
to be
and
, as shown in
Figure 10a,c. Therefore, in order to achieve a desirable accuracy, the grid has to be refined when dealing with a quadratic function that has different peak widths, and the degree of refinement depends on the width of the peak, as demonstrated above.
As we are dealing with continuous random variables, the probabilistic approach of computing the mean and standard deviation of variables
or
e given by (
19) and (
20) will be used. Let us consider the range of variable
y to be
. The interval
will be divided into
M sub-intervals, where the size of each sub-interval is
. The following approximation will be considered
, for
and
, which is the midpoint of the sub-interval
. Now, let us consider the value of variable
y that denotes the approximate value of integral
. The range of
is be
and will be extracted to determine the frequencies
of having the value
. Then, the probability of having
at each sub-interval will be computed using the following formula,
where
provides the number of random realisations. The probability of having
in each sub-interval with a coarse number of grid nodes
is very low, whereas the probability increases when dealing with fine number of grid points
, as shown in
Figure 11a,b. In the coarse sampling grid, the range
of random variable
is very small and only some realisations can be considered as a good approximation to the true population abundance
. The probability distribution in
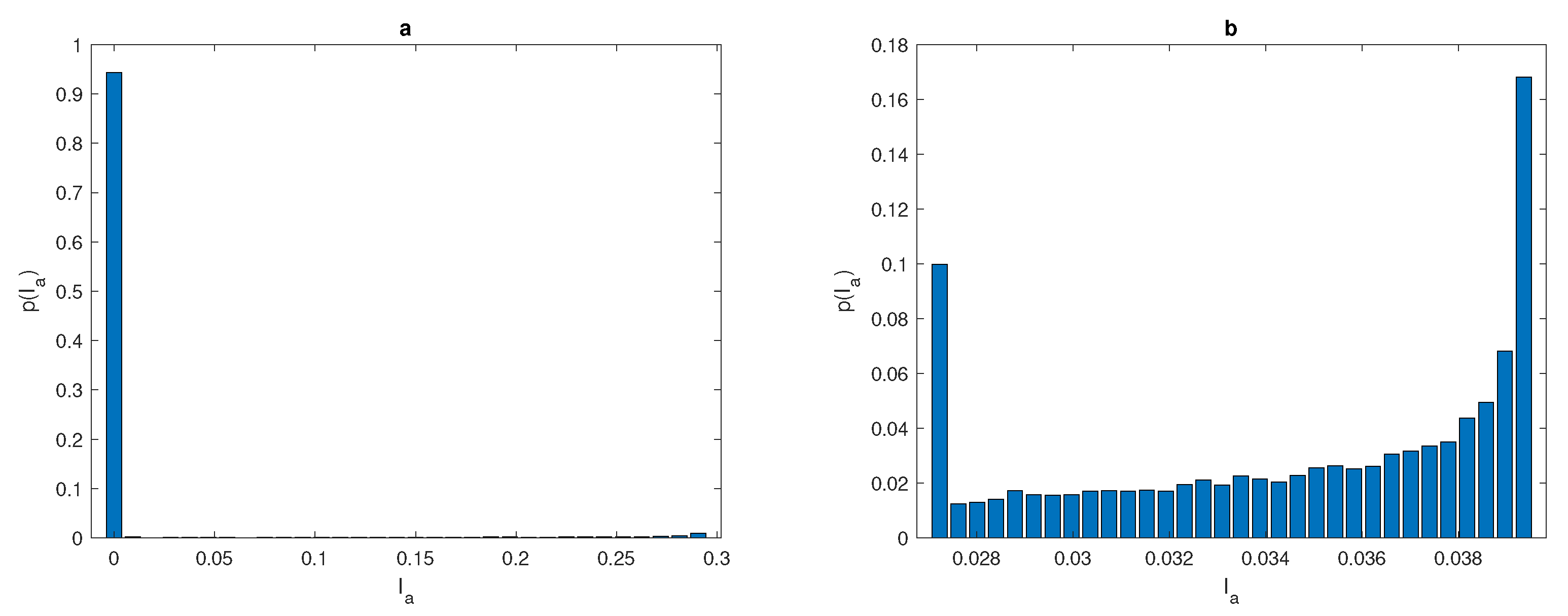
Figure 11a, is not quasi-uniform, therefore as a result of sampling procedure inaccurate realisations of random variable
are more likely to appear. When increasing the number of grid points, the range of
becomes bigger. The probability distribution computed on a grid of
points has the range of
within approximately
of the true population
I as depicted in
Figure 11b. This range is greater than the range of
computed for the population density distribution (
14) on the grid of
points only.
Table 5 shows combinations of statistical approaches used to investigate the difference between the arithmetic mean and standard deviation of
, and the probabilistic mean and standard deviation. From
Table 5, it can be noted that the probability
at coarse grid nodes remains very small and the condition
is achieved when intensively refining the grid nodes. The threshold number of grid points required is
, and at any number of grid nodes less than
, the condition
does not hold. The arithmetic mean
converges to the exact size of population density
I, as predicted in (
21), but the probabilistic mean
converges slightly quicker than
to the exact size
I, as it accounts for random variables
, as shown in
Table 5. It is known from (
22) that the probabilistic standard deviation of
tends to be zero while
, as illustrated in
Table 5. Furthermore, the difference between the exact value of the integral and the probabilistic mean of the integral tends to be zero when the number of grid nodes increases incrementally. Therefore, from these results, the following conclusion is true; the probabilistic approach is more effective than the deterministic approach when dealing with continuous random variables.
4. The Probability of Accurate Evaluation at Random Choice of the First Grid Node on a Sampling Grid
In previous sections, the probability of obtaining an accurate estimate was computed for regular computation grids and a random location of the maximum peak. The probability will now be computed for a quadratic peak function at a fixed location of the maximum peak, and the location on the uniform computational grid will be moved randomly within sub-domain , where h is the grid step size on a grid of N points and a is the left-hand endpoint of interval .
Let us consider the quadratic peak function given by (
14) as the first test case for computing the probability of achieving a sufficiently accurate estimate, as demonstrated in the previous section. The width of the peak is fixed as
, and the location of peak
is fixed as
within the unit interval
. Now the location of grid node
is randomly moved over interval
, where
is the grid step size. The grid nodes must be stationed within the unit interval
; therefore, the last grid node
will be excluded. We provide
realisations of the random variable
on a grid with a fixed location of the maximum peak at
. Then, the value of integral will be estimated by applying statistical method (
1) at each realisation of
. The integration error will be computed by using the relative error (
4). By fixing the tolerance
, the probability of achieving an accurate estimate at different values of grid node
is calculated by Equation (
10), where in the probability equation
represents the number of realisations where the integration error is
. The quadratic peak function (
14) with
is depicted in
Figure 12a.
Figure 12b shows the curve
for the probability of obtaining an accurate answer at peak width
. From this figure, it can be seen that at a very small number of grid nodes, the probability is
and the integration error is a random variable with the high magnitude. The probability becomes equal to one at a critical number of grid nodes
. This required critical number of grid nodes
increases as the value of the peak width decreases (i.e., a narrow peak) and it decreases as peak width increases.
Table 6 shows the number of grid nodes required to achieve an accurate estimate of the quadratic peak function at different values of peak widths
. The numbers of grid nodes required for the condition
to hold for the quadratic peak function (
14) with peak widths
,
,
,
is displayed in
Figure 12c. It can be deduced from
Figure 12c that at different values of peak width, the required condition
does not hold when the number of grid nodes
N is very small, and the integration errors become random variables with high magnitudes, due to inadequate information about the integrand quadratic peak function. Furthermore, the relative error when the number of grid nodes is very small tends to be quite large (i.e.,
), so the accuracy in this case is probabilistic rather than deterministic, and achieving an acceptable level of accuracy becomes a matter of chance in this case. The findings obtained at regular computational grid nodes with random locations of the maximum peak
are almost identical to the results acquired at a fixed position of the maximum peak and a random location of grid node
, as shown in
Figure 5b and
Figure 12b.
Let us now reproduce some of the results of the
test cases introduced in [
9,
25] in order to compare them with the
test cases. We first consider the numerical test case that represents the
counterpart of the continuous front spatial density distribution [
25], which is given by
The function
shown in
Figure 13a represents a spatiotemporal distribution spread throughout the domain from the left boundary of the region, where the population density is originally zero. The location of grid
will vary with a fixed number of grid nodes
N from
to
, where
h is the grid step size. The exact value of the population size in the domain is given by
. Grid nodes must be generated within the region
; therefore, the last grid node
will be excluded. On a grid of
points, when the value of
increases from 0 to
h, the approximated total population size
is given by a continuous monotone function, as shown in
Figure 13c. The range of variable
for
occurs within the interval
, where
and
. Therefore, any random location of
will generate a randomly approximated
taken from
[
25]. It can be seen from
Figure 13b that at the fixed tolerance
and a random location of
, the probability
of obtaining an accurate evaluation holds for a small number of grid nodes
. Increasing or decreasing the value of tolerance
will decrease or increase this threshold number of grid nodes
, as demonstrated in [
25].
In the sequence of regular number
N grid nodes with
random locations of
, the mean of variable error
and the standard deviation of variable error
will be computed from Equations (
19) and (
20). The upper
and lower
bounds of the error will be computed in order to compare them with the tolerance
. In order to approach the required level of accuracy, the following condition must hold,
For Function (
25), the condition (
26) first holds at the number of grid nodes
, as shown in
Figure 13d. The results obtained from
Figure 13d prove that a good accuracy can be acquired with a coarse grid of
, where the upper bound of error falls below the tolerance
. Therefore, for the distribution given by (
25), at any grid node
, the population density is considered to be a uniform distribution and the random variable
e at any realisation will be within a desirable level of accuracy. Furthermore,
provides a good evaluation of the total population density for any realisation on a grid of
points.
Consider now a function with a more sophisticated pattern that represents the
counterpart to the ecological phenomenon of highly aggregated spatial distribution [
26,
27].
Let us consider a single peak function introduced in the [
25], which is given by
where
, and
are selected parameters.
Figure 14a depicts the shape of Function (
27) where
,
, and
. By increasing the value of
continuously from 0 to
h on a grid of
points, the approximated total population size
is not a continuous monotone function of
, as shown in
Figure 14c, and so it differs from the monotone function
Figure 13c for function (
25). It can be seen from
Figure 14c that the range of random variable
is very large, and only for some realisations approximated values can provide a good approximation to the exact value of the population density
. The accuracy can be improved by increasing the number of grid nodes to, for instance
, to reduce the range of the random variable
, as shown in work [
25].
It can be seen from
Figure 14b that at a fixed tolerance
and a random location of
, the probability
of obtaining an accurate evaluation holds for a number of grid nodes
, which is much larger than the number required for
to hold for function (
25). Increasing or decreasing the value of tolerance
will decrease or increase the probability of achieving an accurate evaluation for a fixed number of nodes
N, respectively, as demonstrated in [
25]. It has been illustrated in [
25] that the required threshold number of grid nodes
at
is
, and at
is
, which does not provide significant differences between them. The probability
of the condition
holding depends on the shape of the population density distribution
, as proven in [
9].
The upper
and lower
bounds of the error are computed in order to compare them with the tolerance
. In order to approach the required level of accuracy, condition (
26) must hold. For the function (
27), condition (
26) first holds at the number of grid nodes
, as shown in
Figure 14d. The results obtained from
Figure 14d prove that we require a high number of grid nodes to provide an acceptable level of accuracy when the upper bound of the error falls below the tolerance
. Therefore, for the distribution given by (
27), the probability density is considered as a nonuniform distribution of the random variable
e on coarse grid nodes. On a grid of
N nodes, a significant number of realisations of the random variable
e may satisfy the condition
, even when the upper bound of the error is very close to the tolerance curve
. Furthermore, significant values of random variable
will provide inaccurate approximations of the total population density on a grid of coarse points.
We want to extend the results in [
25] and consider more computationally challenging examples. Let us now consider an exponent function with several peaks, by using the following equation,
where
A,
P,
, and
are the chosen parameters. Let us fix the location of peaks
as
,
, and
. At
in (
28), the single peak function (
25) will be obtained and two-peak and three-peak functions are generated by fixing
, respectively, in (
28). We now repeat the computations undertaken for (
25) on the density distributions (
28) of the two-peak and three-peak functions. The probabilities of obtaining an accurate estimation for in each case are shown in
Figure 15b and
Figure 16b. The shape of the two-peak and three-peak functions are depicted in
Figure 15a and
Figure 16a. It can be seen from
Figure 15b and
Figure 16b that the probability curves
oscillate on a coarse grid node, and for the condition
to hold, a great deal of grid refinement is required. The probability of obtaining an accurate estimate of the total population size satisfies the condition
at a significant number of grid nodes,
, in both cases, as shown in
Figure 15b and
Figure 16b. The results obtained from (
28) support the belief that the probability
p depends on the shape of the population density distribution, as demonstrated by [
9], and the probability function
while dealing with exponent heterogeneous density distributions with more than one peak shows more sophisticated behaviour, as shown in
Figure 15b and
Figure 16b.
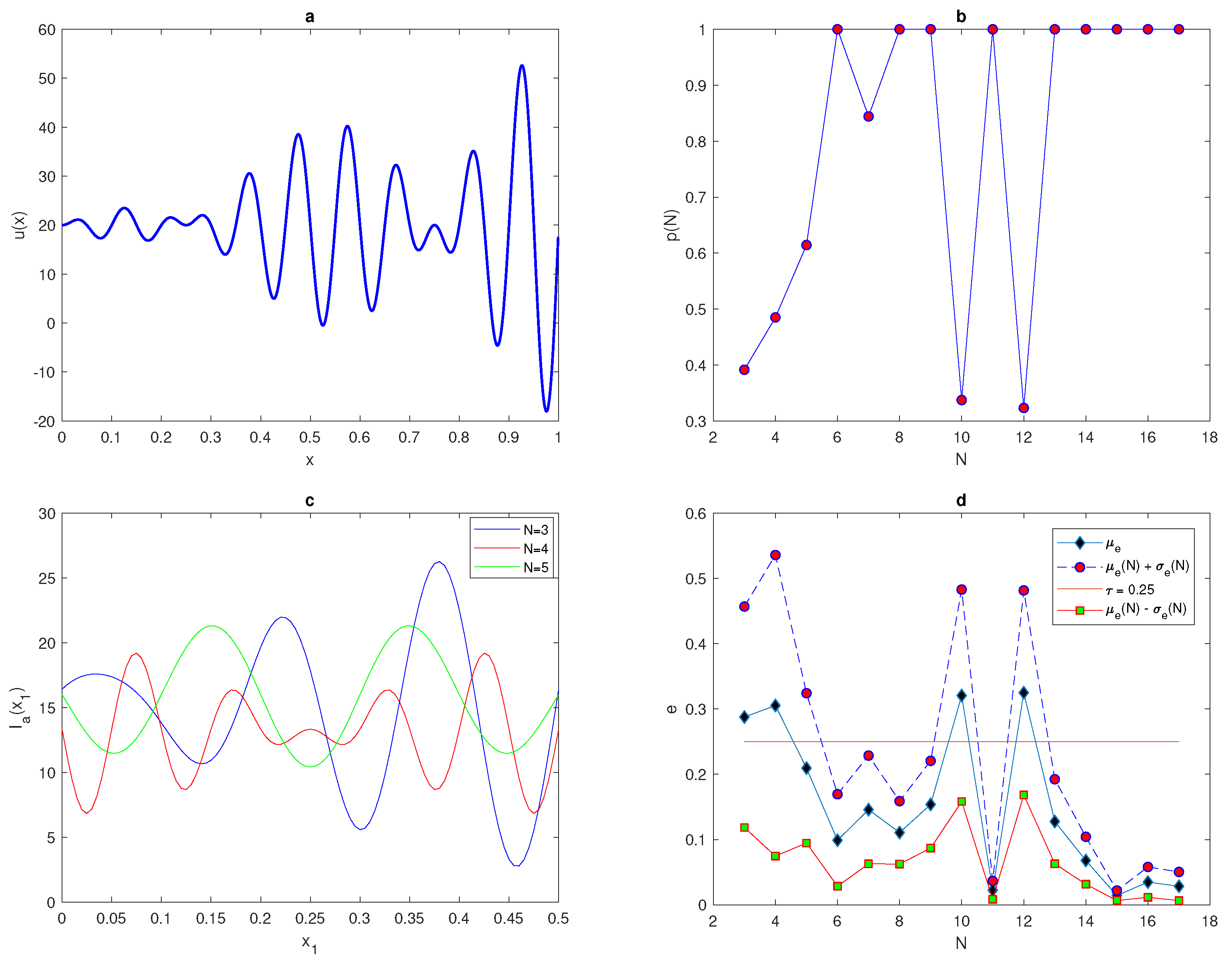
Let us consider heterogeneous population density with multiple peaks to investigate its convergence behaviour. The
function that represents a pattern of patchy density distribution is considered as follows [
25],
where parameters in (
29) are taken as
. The population density distribution given by Function (
29) is shown in
Figure 17a. Changing the value of
continuously from
to
provides the range of variable
, as shown in
Figure 17c. It can be seen from
Figure 17c that for an odd number of grid nodes
, 5, the shapes of variable
are approximate, which is different from the shape at even number of grid nodes
. Therefore, we expect that the probability of obtaining an accurate estimate of population density for random variable
on coarse grids will show different behaviour for odd or even numbers of points. The shape of function
is depicted in
Figure 17b. From
Figure 17b, it can be noticed that
does not provide a monotone function, as presented in some previous test cases. Instead, it has oscillatory behaviour before hold the condition
at critical number of grid nodes
then monotone behaviour will be acquired.
Now let us see how close the probability density distribution
is to the evaluation error
e, by computing the mean of error
and the standard deviation
of random variable
e on a sequence of regular grids.
Figure 17d shows a comparison between
and upper and lower bounds
for the tolerance
. For the function with patchiness behaviour, the graph of mean error and bounds of error exhibit oscillating behaviour on coarse grids. Furthermore, as a result of increasing the number of grid nodes, the mean of error
does not always guarantee an approximation close to the true population size, and the approximation of
does not necessary to decrease. However, an interesting observation is that the graph of
shown in
Figure 17b presents a strong form of synchronisation with the graphs of the mean of error
and upper bound of error, as can be seen from
Figure 17c, where the peaks of the probability
obviously correspond to troughs of the upper bound
.
The probability
of obtaining an accurate evaluation will depend on the level of accuracy required, which is given by tolerance
. It has been demonstrated in [
9] that choosing different values of tolerance
will present different behaviours of the probability function
when a heterogeneous population density distribution (
29) is considered. It has been shown in [
9] that when the level of accuracy is low (i.e., for a large value of tolerance
) the critical number of grid nodes required for
to hold is
. The critical number
will increase as a result of increasing the level of accuracy to
, where in this case
. The probability
does not present a monotone function, but has oscillatory behaviour on a grid of coarse points, before the condition
holds at
. This oscillating behavior of
becomes more obvious when the value of required tolerance decreases to
, where the probability
exhibits strongly oscillating behaviour on a coarse grid
. Therefore, it has been proven in [
9] that at
, the evaluation procedure becomes deterministic and the required accuracy of over
is obtained even on a grid of coarse points. Meanwhile, this evaluation procedure is probabilistic rather than deterministic on coarse grid nodes at
and a fine grid has to be used to fulfill the required level of accuracy. In the next section, we expand the results obtained in [
9,
25] by considering
density distribution for the purpose of comparison, as mentioned previously.
5. The Probability Analysis
After analysing the probability of obtaining an accurate estimation for the
problems, our analysis is expanded to involve a more realistic
problem. Let us consider a peak function given by spatial distribution for the
counterpart of the normal distribution (
7), where the function
is given by
The domain of interest is represented by the unit square
. In the equation (
30),
provides information about the peak maximum and is chosen randomly. The sub-domain
of the peak represents a circular disc of radius
R, which is centered at
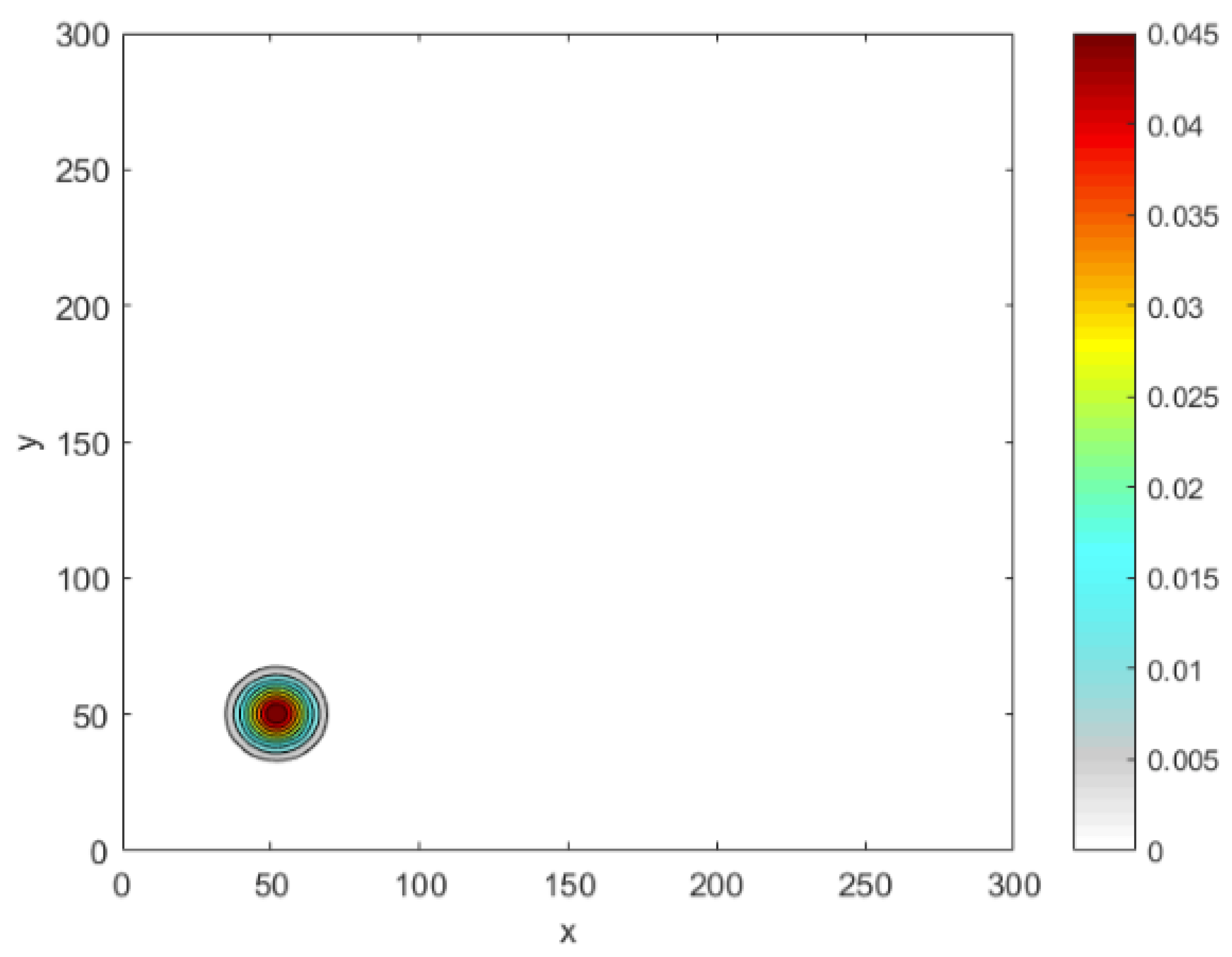
. The peak width is given by
, which in the
distribution is fixed at
. The
normal distribution given by (
30) is depicted as a single peak in
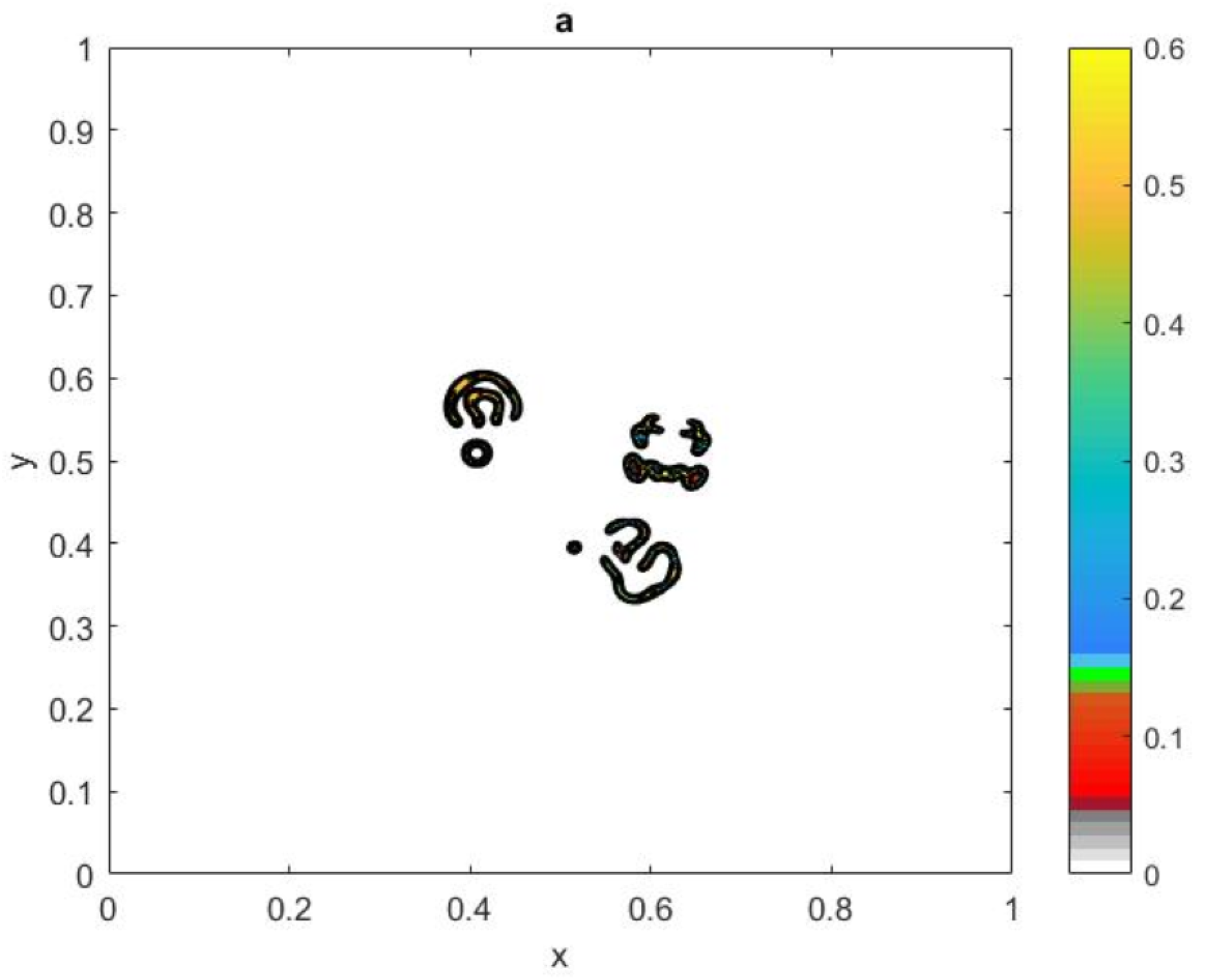
Figure 18.
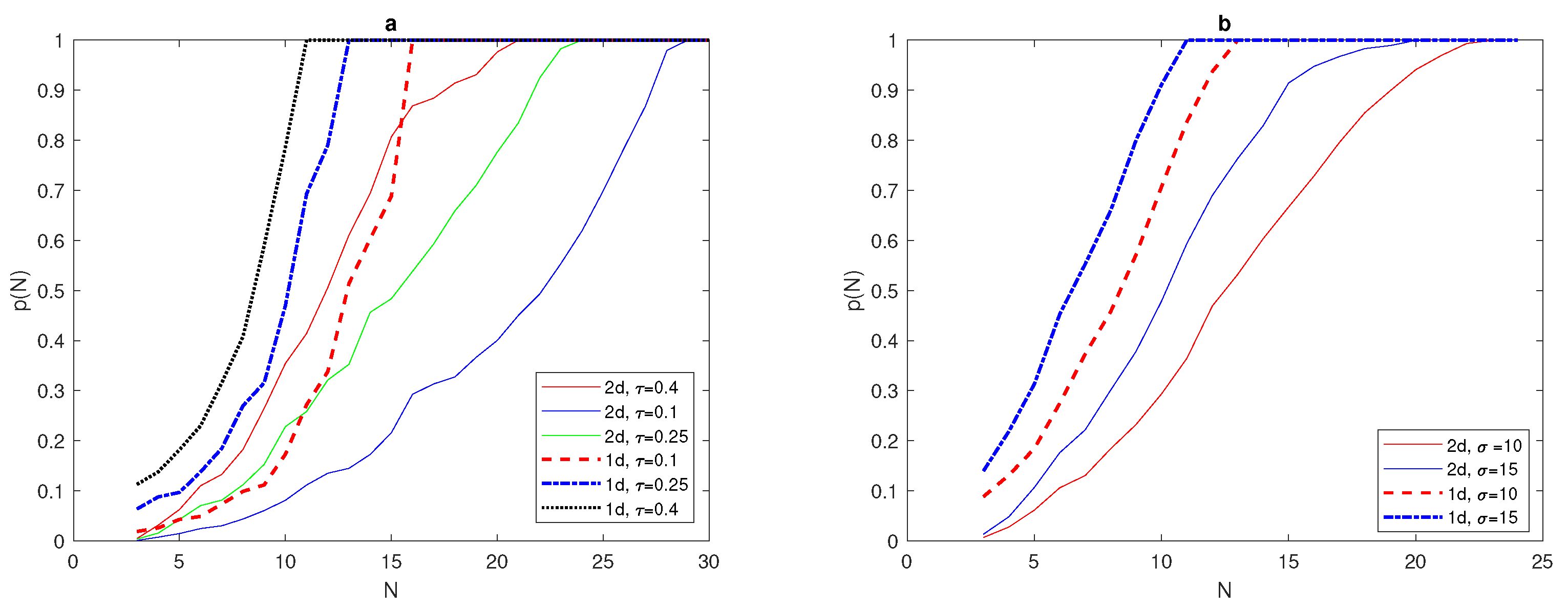
We have determined the critical number of grid nodes required to satisfy
at
for a
normal distribution (
7) with
. The computation will now be extended to obtain
for a
normal distribution given by (
30) with
. Although we expect the probability graphs of
to be the same for both
and
problems, the results obtained for the
normal distribution are shifted from the probability graph
for the
normal distribution (
7), as depicted in
Figure 19a, where the critical number needed to gain
is
, as can also be seen from
Figure 19a.
Table 7 shows how the critical number
depends on the values of the chosen tolerances
and
in both
and
normal distributions. Furthermore,
Table 7 supports the previous observation that the
probability graph for normal distribution shifts in the case of a
problem.
From
Figure 19, it can readily be noticed that the width of the peak and the value of tolerance
play important roles in deciding the critical number of grid nodes
required to satisfy
in both dimensions for normal distributions. However, this critical number is higher in the case of
normal distributions, and it increases as the values of tolerances
and
decrease, as shown in
Figure 19 and
Table 7.
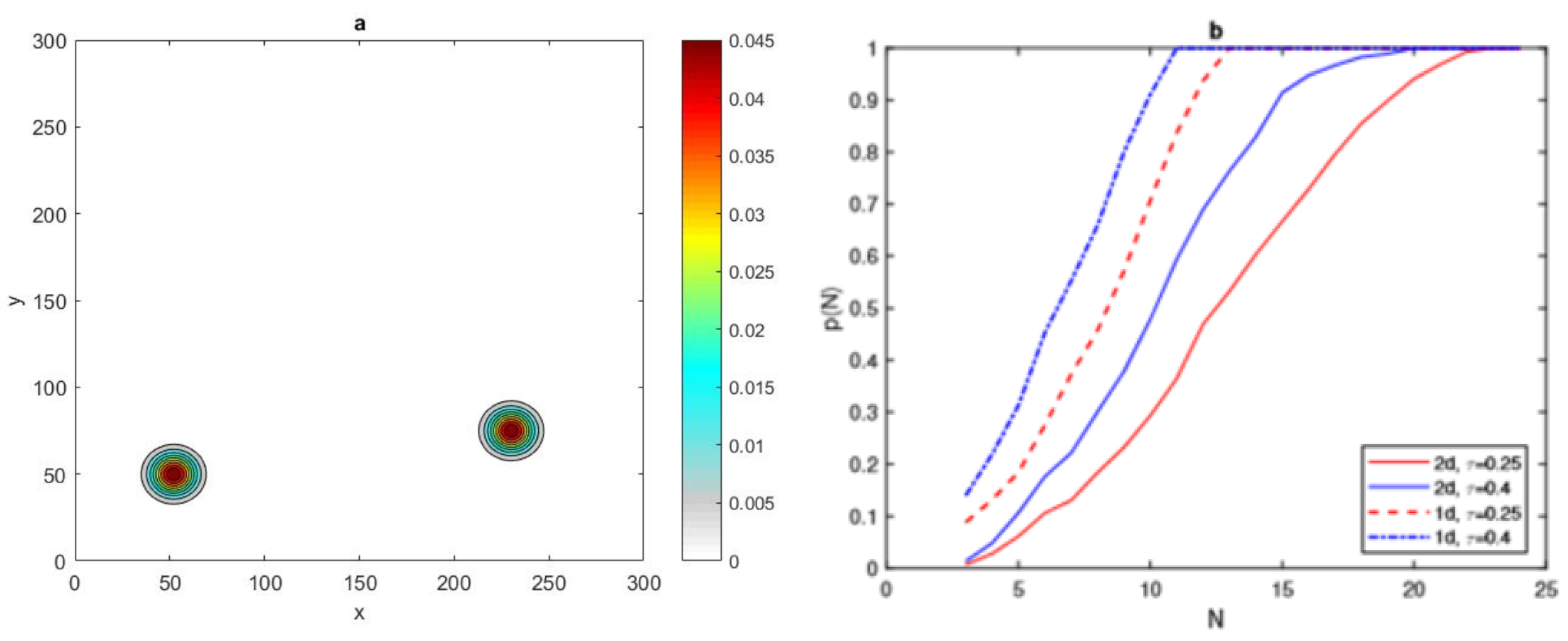
We now consider the superposition of
normal distributions to be given by:
where
denotes the random location of peaks and
P is the number of peaks. Let us first consider
, then the spatial population distribution density appears as two peaks, as shown in
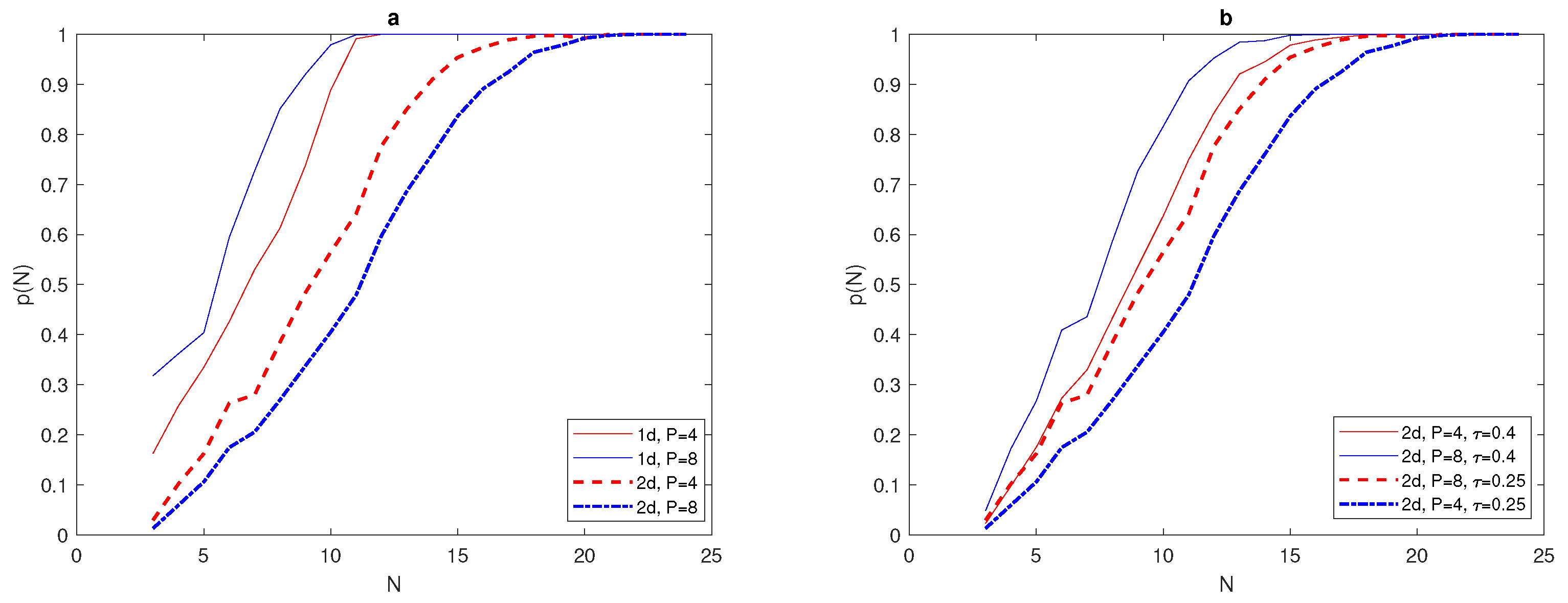
Figure 20a.
It can be seen in
Figure 20b that the value of critical number
for the condition
to hold for a
normal distribution of two patches
is similar to the value for one patch
, where it is equal to
= 24, for
=
, and
for
. Furthermore, the
normal distribution required fewer grid nodes to reach
than in the
case, as depicted in
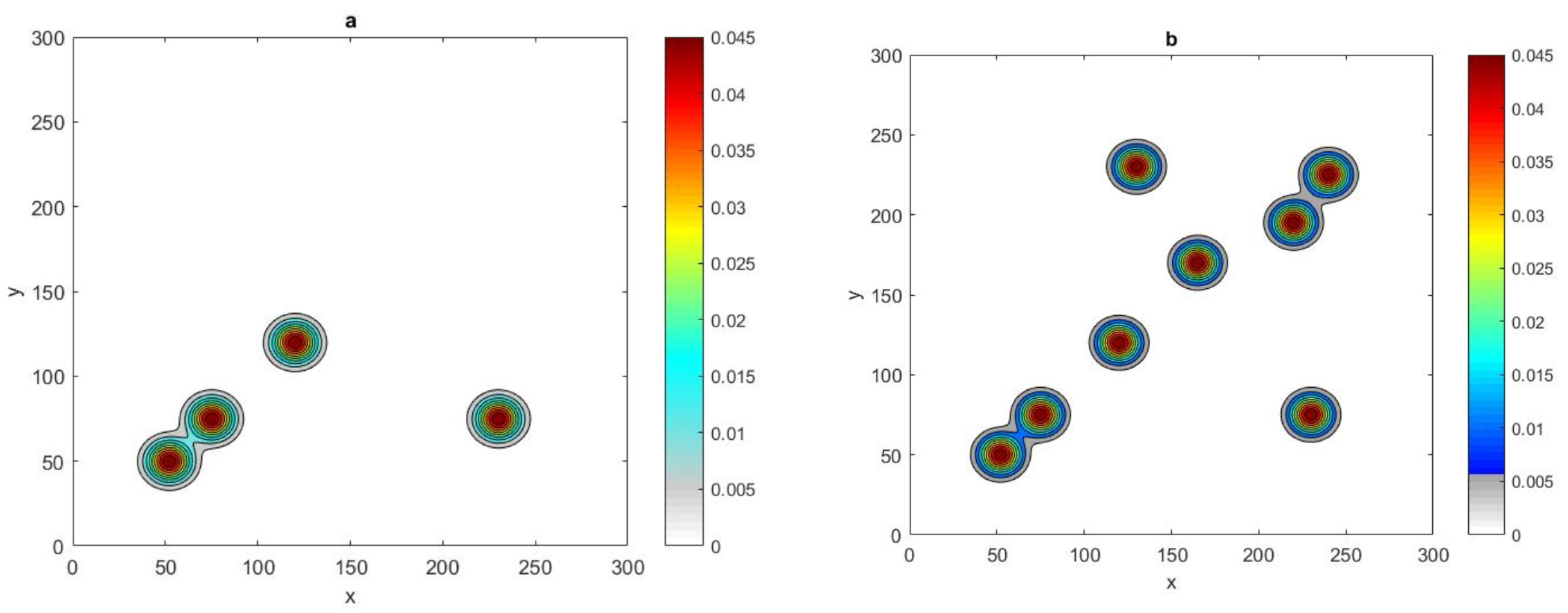
Figure 20b. The investigation was then expanded to involve
normal distributions with four and eight peaks
, and
, as shown in
Figure 21.
It can be seen from
Figure 22a that the probability graph
of
and
normal distributions at fixed peak width
and fixed tolerance
has been computed for different numbers of peaks. By inspecting
Figure 22a, it can be readily seen that the critical number
required to have
depends clearly on the number of peaks, where this number at
is bigger than
at
. Moreover, the critical number needed for a
superposition of normal distribution is obviously lower than for the
problem. By varying the value of tolerance
and number of peaks
P for a
normal distribution with fixed
, it can be seen from
Figure 22b that a lower value of
with
and requires more grid nodes
to achieve
, and this number decreases at
, to be
. When the degree of accuracy required decreases at
, we expect that the critical number
will decrease accordingly, as shown in
Figure 22b, where it is equal to
= 20, for
and
for
.
6. The Probability Analysis at Random Locations of First Grid Node : Ecological Example
Let us now investigate the probability of obtaining an accurate evaluation of
ecological data generated from a system of diffusion—reaction equations given as
where the dimensionless parameters are introduced as
,
,
and
. Consider a spatial population density distributions in a squire domain
, shown in
Figure 23. The spatial distribution depicted in
Figure 23 introduces a highly aggregated pattern of spatial distribution, which was obtained from Equations (
32) and (
33) for
and
.
The exact value of the population density is obtained from (
1) at the finest grid nodes
. Let us now consider a simulation procedure for sampling in domain
. The values of the population density are taken from the nodes of the regular grid sampling procedure, as taking sampling at the nodes of a regular grid is a common situation in ecological applications [
26,
28]. The computational grid nodes in the x-direction,
over interval
are generated as follows:
, where we require that
where
L is the linear size of the domain and the grid step size
. Let us now consider a set of points in the y-direction,
over interval
, generated as
, where the grid step size
for some
. We require the location of the new grid node
to be sufficiently close to the original grid node
of the domain
D; therefore, the conditions
must hold to make sure that the simulated sampling corner grid is located close to the corner in the domain
D.
The location of grid node
is randomly moved over the domain
, where
and
are the grid step size and the number of grid nodes in each direction, respectively. The grid nodes must be generated within the unit domain
; therefore, the last grid node
will be excluded. We provide
realisations of the random variable
. As we are dealing with simulated ecological data, and the density is only known at grid points, we therefore need to find the closest node to the new grid node
from the original computational grid nodes in the domain
. Once the data for the population density is extracted at the new first grid node
, the value of the integral is estimated by applying the statistical method (
1) at each realisation of
. The integration error is computed by using the relative error (
4). By fixing the tolerance
, the probability of achieving an accurate estimate with
random locations of
will be calculated from Equation (
10).
It has been shown in [
25] that, considering the bottom-left corner point of the sampling grid depicted in
Figure 23 to be
, a very accurate evaluation of the integration error
is provided for the continuous front population density distribution. However, an inaccurate estimation of the integration error for the same sampling grid is provided for the patchy invasion. The integration error becomes much greater for a highly aggregated distribution. The degree of accuracy decreases dramatically from
to
for the patchy invasion and the highly aggregated distribution respectively, when the location of grid
A is moved slightly within the limited domain given above. Remarkably, choosing a random grid location
improved the degree of accuracy when dealing with all distributions of zero and non-zero patches. This procedure enables ecologists to increase the probability of catching high density value to gather these values with zero values, to eventually give us an accurate estimate of the population density.
The number of points required to achieve the condition
depends on the level of complexity within the ecological data. For the ecological distributions (
23) the number of grid nodes required is
in each direction to hold the probability condition, as depicted in
Figure 24. A grid with a number of nodes below the value
represent an ultra-coarse grid, where the evaluation of the integration error is probabilistic and is a matter of chance. Once the required number of grid nodes
satisfies the probability condition, the integration error becomes deterministic and the asymptotic error (
5) holds for a fine number of grid nodes.
In the sequence of regular number
N of grid nodes with
random locations of
, the mean of variable error
and the standard deviation of variable error
can be computed from Equations (
19) and (
20). The upper
and lower
bounds of error are computed to be compared with the tolerance
. In order to achieve the required level of accuracy, the condition (
26) must hold. It can be seen from
Figure 25 that the condition (
26) holds at
the patchy invasion distributions, which is in fact the same number of grid nodes required to hold the probability condition
. It can be concluded from this that, for ultra-coarse grid nodes, it is not possible to provide the information required to provide a reliable degree of accuracy; therefore, the integration error will be probabilistic rather than deterministic. Therefore, the probabilistic approach is used to estimate the size of population density for each ecological distribution.
7. Conclusions
A simple evaluation of the population density provides a deterministic level of accuracy when information about population density is sufficient. When dealing with a grid with a very small number of points, the information required to evaluate the population density is insufficient, which means that it is impossible to guarantee the required accuracy. Therefore, the probabilistic approach should be applied to evaluate population abundance. The probability p of achieving a sufficiently small error is used to assess accuracy, rather than considering the error itself; therefore, achieving the desired accuracy will be a matter of chance, rather than being deterministic, by considering the integration error as a random variable. The probabilistic approach requires series of statistical computations, e.g., the mean and the standard deviation, that in turn require repetitive and resource-heavy data collection techniques, which render the sampling procedure impossible.
For homogeneous density distributions, or density distributions slowly changing in space, any single realisation of a random variable obtained from the sampling procedure may possibly provide an accurate estimate of the true population density. In this case, any individual realisation can be considered to be a desired approximation of the population density, and the mean value will be close to the true population size. Moreover, at any realisation, the standard deviation value will tend to be small. However, when dealing with heterogeneous population density, the above observations are incorrect. It has been shown in this chapter that there is a significant difference between a single realisation and the true population size in heterogeneous distributions. The probability of producing an accurate evaluation of population density on ultra-coarse grids is low and is a matter of chance.
On ultra-coarse grids, the conventional approach of convergence analysis do not work, as it does not distinguish between the performance of different numerical integration methods. Therefore, the probability approach has been considered as a measurement of accuracy instead of conventional convergence analysis. A desirable level of accuracy is achieved if the condition holds, where is the probability of obtaining . In order to achieve the above condition, the threshold number of grid nodes is required, where . Determining the threshold number of grid nodes is an important process in order to utilise the probabilistic approach, which depends on computations of random variables with the deterministic approach based on the results obtained from the sampling procedure.
As a result of the above conclusions, the classification of computational grid nodes can be redefined according to the threshold number of grid point
. For a spatial pattern of population density distributions, a grid is considered ultra-coarse if the number of grid nodes
, the transmission from ultra-coarse to coarse grids will be at
and the error will be deterministic. Finally, a fine grid is defined as a grid in which
and the asymptotic error (
5) always holds. Thus, reliable approaches to evaluating the threshold number
must be determined, especially as we are dealing with unknown features of spatial density distribution. In the numerical experiments, it has been proven that the estimation of the threshold number
is a reliable means of determining the minimum number of grid nodes required to achieve sufficient accuracy.
On coarse grids, the locations of essential features of the spatial density distribution are not known in advance, which is an intrinsic property of the problem. Therefore, this paper has investigated the probability on a sample of coarse grid where a random location was provided for the first grid node, which reflects the lack of information about density patterns with several humps, patches or nonzero population densities. To deal with this uncertainty, the threshold number for reliable spatial distribution data, available in real-world settings, must be determined.
The analysis of the probabilistic approach was expanded to involve
problems. The
form of the normal distribution, with a varying number of patches and several values for the chosen tolerance, are considered with the purpose of comparing to the
problem. The critical number
required to achieve an accurate estimate in
cases was considerably lower than the number required in
cases for the condition
to hold. Furthermore, it has been demonstrated that the value of the critical number
depends on the number of patches, where for a small number of patches,
increases, but it decreases gradually when the number of patches
P increases from
to
. The width of each patch and the values of the chosen tolerance
obviously affect the required value of the critical number
. It has been explained in this paper that with a wide patch,
becomes smaller than
at narrow patch. The required number
relies on the value of the chosen tolerance
, where at a low level of accuracy (i.e., at a large value of
),
is quite small; this number increases when greater precision is required. The process of slightly altering the position of the bottom left corner grid node
within a limited domain
in the application of
ecological distributions is beneficial and highly recommended for complicated distribution pattern. In a
ecological distribution, we often do not have any prior information about the properties of the pattern and the location of the domain of non-zero density. The optimal positions of the grid nodes are difficult to discern, therefore the choice of point
A will be random. In other words, at each random location of grid
A, the evaluation of the total population size is considered as a single realisation of the random variable
, and different position of
A will result in different values of
. Let us emphasis that, the location of
A is not important on a sampling of very fine grid nodes, because uncertainty about the optimal location of grid nodes no longer applies.It is worth to mention in our paper that several studies applied the probabilistic approach to deal with sampling of coarse grid. It was suggested in [
9] that the total population size on coarse sampling grids is a random variable and it has to be treated by applying probabilistic approaches. It was introduced in [
9] the concept of ultra-coarse grids and the definition of an ultra-coarse grid implies that the probability
p of achieving an integration error smaller than the given tolerance rather than to evaluate the error itself. The approach suggested in [
9] the minimum number
must be obtained to achieve desirable accuracy of integration which is guaranteed on a grid of
nodes. In addition, it confirmed that the uniform refinement of an ultra-coarse grid will not reduce the value of integration error, on contrary the integration error can be even bigger than the error on the original grid unless the number
of nodes is reached. Moreover, approximately the same result was obtained in [
25], and this issue was discussed and introduced reliability criterion required to reconcile the probabilistic and deterministic approaches when the total population size is evaluated. These mentioned studies are supported to our results in this paper.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
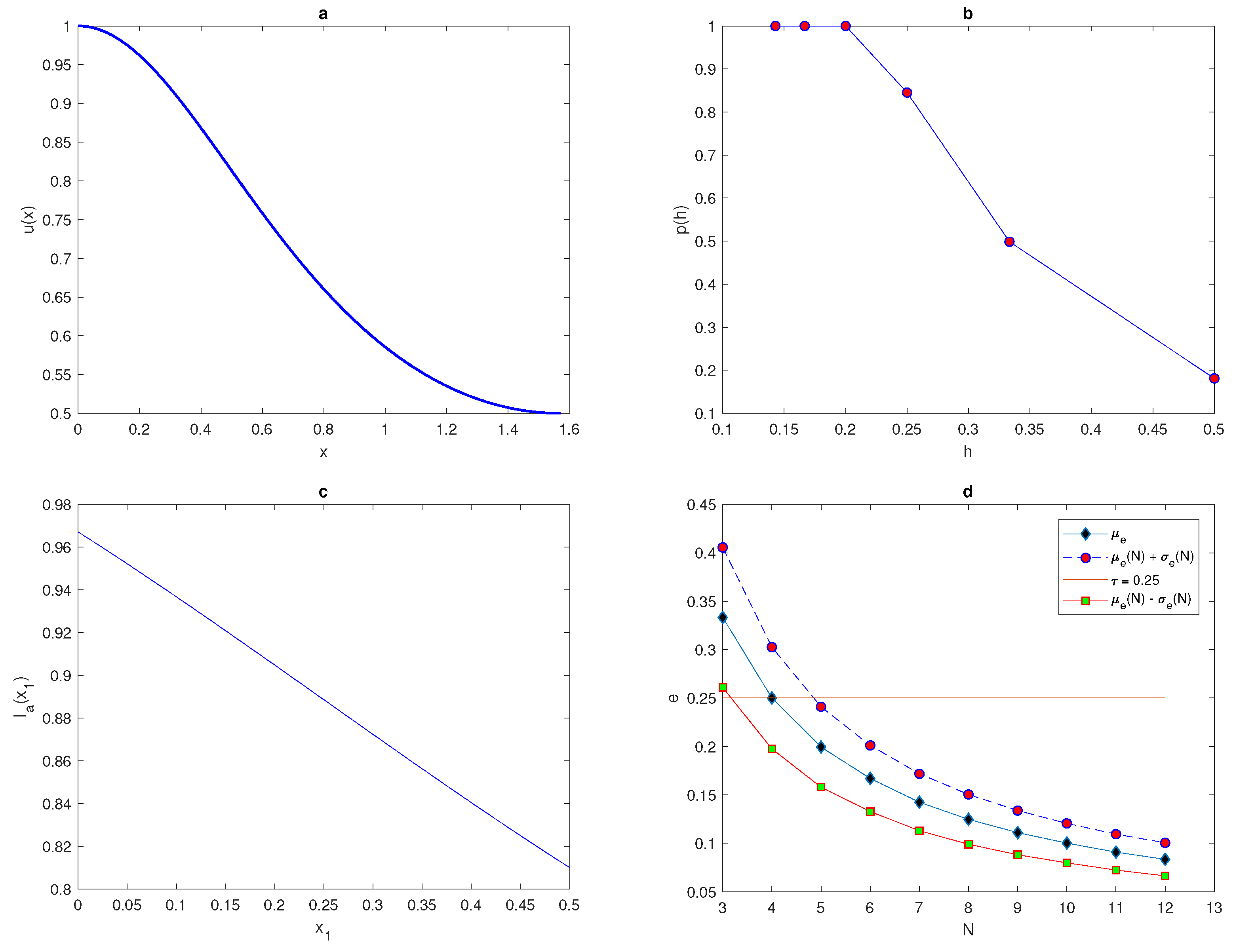{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}