Abstract
We derive finite-length bounds for two problems with Markov chains: source coding with side-information where the source and side-information are a joint Markov chain and channel coding for channels with Markovian conditional additive noise. For this purpose, we point out two important aspects of finite-length analysis that must be argued when finite-length bounds are proposed. The first is the asymptotic tightness, and the other is the efficient computability of the bound. Then, we derive finite-length upper and lower bounds for the coding length in both settings such that their computational complexity is low. We argue the first of the above-mentioned aspects by deriving the large deviation bounds, the moderate deviation bounds, and second-order bounds for these two topics and show that these finite-length bounds achieve the asymptotic optimality in these senses. Several kinds of information measures for transition matrices are introduced for the purpose of this discussion.
1. Introduction
In recent years, finite-length analyses for coding problems have been attracting considerable attention [1]. This paper focuses on finite-length analyses for two representative coding problems: One is source coding with side-information for Markov sources, i.e., the Markov–Slepian–Wolf problem on the system with full side-information at the decoder, where only the decoder observes the side-information and the source and the side-information are a joint Markov chain. The other is channel coding for channels with Markovian conditional additive noise. Although the main purpose of this paper is finite-length analyses, we also present a unified approach we developed to investigate these topics including asymptotic analyses. Since this discussion is spread across a number of subtopics, we explain them separately in the Introduction.
1.1. Two Aspects of Finite-Length Analysis
We explain the motivations of this research by starting with two aspects of finite-length analysis that must be argued when finite-length bounds are proposed. For concreteness, we consider channel coding here even though the problems treated in this paper are not restricted to channel coding. To date, many types of finite-length achievability bounds have been proposed. For example, Verdú and Han derived a finite-length bound by using the information-spectrum approach in order to derive the general formula [2] (see also [3]), which we term as the information-spectrum bound. One of the authors and Nagaoka derived a bound (for the classical-quantum channel) by relating the error probability to binary hypothesis testing [4] (Remark 15) (see also [5]), which we refer to as the hypothesis-testing bound. Polyanskiy et. al. derived the random coding union (RCU) bound and the dependence testing (DT) bound [1] (a bound slightly looser (coefficients are worse) than the DT bound can be derived from the hypothesis-testing bound of [4]). Moreover, Gallager’s bound [6] is known as an efficient bound to derive the exponentially decreasing rate.
Here, we focus on two important aspects of finite-length analysis:
- (A1)
- Computational complexity for the bound and
- (A2)
- Asymptotic tightness for the bound.
Both aspects are required for the bound in finite-length analysis as follows. As the first aspect, we consider the computational complexity for the bound. For the BSC (binary symmetric channel), the computational complexity of the RCU bound is , and that of the DT bound is [7]. However, the computational complexities of these bounds are much larger for general DMCs (discrete memoryless channels) or channels with memory. It is known that the hypothesis testing bound can be described as a linear programming problem (e.g., see [8,9] (in the the case of a quantum channel, the bound is described as a semi-definite programming problem)) and can be efficiently computed under certain symmetry. However, the number of variables in the linear programming problem grows exponentially with the block length, and it is difficult to compute in general. The computation of the information-spectrum bound depends on the evaluation of the tail probability. The hypothesis testing bound gives a tighter bound than the information-spectrum bound, as pointed out by [8], and the computational complexity of the former is much smaller than that of the latter. However, the computation of the tail probability continues to remain challenging unless the channel is a DMC. For DMCs, the computational complexity of Gallager’s bound is since the Gallager function is an additive quantity for DMCs. However, this is not the case if there is a memory (the Gallager bound for finite-state channels was considered in [10] (Section 5.9), but a closed form expression for the exponent was not derived). Consequently, no efficiently computable bound currently exists for channel coding with Markov additive noise. The situation is the same for source coding with side-information.
Since the actual computation time may depend on the computational resource we can use for numerical experiment, it is not possible to provide a concrete requirement of computational complexity. However, in order to conduct a numerical experiment for a meaningful blocklength, it is reasonable to require the computational complexity to be, at most, a polynomial order of the blocklength n.
Next, let us consider the second aspect, i.e., asymptotic tightness. Thus far, three kinds of asymptotic regimes have been studied in information theory [1,11,12,13,14,15,16]:
- A large deviation regime in which the error probability asymptotically behaves as for some ;
- A moderate deviation regime in which asymptotically behaves as for some and ; and
- A second-order regime in which is a constant.
We shall claim that a good finite-length bound should be asymptotically optimal for at least one of the above-mentioned three regimes. In fact, the information-spectrum bound, the hypothesis-testing bound, and the DT bound are asymptotically optimal in both the moderate deviation and second-order regimes, whereas the Gallager bound is asymptotically optimal in the large deviation regime and the RCU bound asymptotically optimal in all the regimes (Both the Gallager and RCU bounds are asymptotically optimal in the large deviation regime only up to the critical rate). Recently, for DMCs, Yang and Meng derived an efficiently computable bound for low-density parity check (LDPC) codes [17], which is asymptotically optimal in both the moderate deviation and second-order regimes.
1.2. Main Contribution for Finite-Length Analysis
We derive the finite-length achievability bounds on the problems by basically using the exponential-type bounds (for channel coding, it corresponds to the Gallager bound.). In source coding with side-information, the exponential-type upper bounds on error probability for a given message size are described by using the conditional Rényi entropies as follows (cf. Lemmas 14 and 15):
and:
Here, is the information to be compressed and is the side-information that can be accessed only by the decoder. is the conditional Rényi entropy introduced by Arimoto [18], which we shall refer to as the upper conditional Rényi entropy (cf. (12)). On the other hand, is the conditional Rényi entropy introduced in [19], which we shall refer to as the lower conditional Rényi entropy (cf. (7)). Although there are several other definitions of conditional Rényi entropies, we only use these two in this paper; see [20,21] for an extensive review on conditional Rényi entropies.
Although the above-mentioned conditional Rényi entropies are additive for i.i.d. random variables, they are not additive for joint Markov chains over and , for which the derivation of finite-length bounds for Markov chains are challenging. Because it is generally not easy to evaluate the conditional Rényi entropies for Markov chains, we consider two assumptions in relation to transition matrices: the first assumption, which we refer to as non-hidden, is that the Y-marginal process is a Markov chain, which enables us to derive the single-letter expression of the conditional entropy rate and the lower conditional Rényi entropy rate; the second assumption, which we refer to as strongly non-hidden, enables us to derive the single-letter expression of the upper conditional Rényi entropy rate; see Assumptions 1 and 2 of Section 2 for more detail (Indeed, as explained later, our result on the data compression can be converted to a result on the channel coding for a specific class of channels. Under this conversion, we obtain certain assumptions for channels. As explained later, these assumptions for channels are more meaningful from a practical point of view.). Under Assumption 1, we introduce the lower conditional Rényi entropy for transition matrices (cf. (47)). Then, we evaluate the lower conditional Rényi entropy for the Markov chain in terms of its transition matrix counterpart. More specifically, we derive an approximation:
where an explicit form of the term is also derived. Using the evaluation (2) with this evaluation, we obtain finite-length bounds under Assumption 1. Under a more restrictive assumption, i.e., Assumption 2, we also introduce the upper conditional Rényi entropy for a transition matrix (cf. (55)). Then, we evaluate the upper Rényi entropy for the Markov chain in terms of its transition matrix counterpart. More specifically, we derive an approximation:
where an explicit form of the term is also derived. Using the evaluation (1) with this evaluation, we obtain finite-length bounds that are tighter than those obtained under Assumption 1. It should be noted that, without Assumption 1, even the conditional entropy rate is challenging to evaluate. For evaluation of the conditional entropy rate of the X process given the Y process, the assumption of the X process being Markov seems to be not helpful. This is the reason why we consider the Y process being Markov instead of the X process being Markov in this paper.
We also derive converse bounds by using the change of measure argument for Markov chains developed by the authors in the accompanying paper on information geometry [22,23]. For this purpose, we further introduce two-parameter conditional Rényi entropy and its transition matrix counterpart (cf. (18) and (59)). This novel information measure includes the lower conditional Rényi entropy and the upper conditional Rényi entropy as special cases. We clarify the relation among bounds based on these quantities by numerically calculating the upper and lower bounds for the optimal coding rate in source coding with a Markov source in Section 3.7. Owing to the second aspect (A2), this calculation shows that our finite-length bounds are very close to the optimal value. Although this numerical calculation contains a case with a very large size , its calculation is not as difficult because the calculation complexity behaves as . That is, this calculation shows the advantage of the first aspect (A1).
Here, we would like to remark about the terminologies because there are a few ways to express exponential-type bounds. In statistics or large deviation theory, we usually use the cumulant generating function (CGF) to describe exponents. In information theory, we employ the Gallager function or the Rényi entropies. Although these three terminologies are essentially the same quantity and are related by the change of variables, the CGF and the Gallager function are convenient for some calculations because of their desirable properties such as convexity. On the other hand, the minimum entropy and collision entropy are often used as alternative information measures of Shannon entropy in the community of cryptography. Since the Rényi entropies are a generalization of the minimum entropy and collision entropy, we can regard the Rényi entropies as information measures. The information theoretic meaning of the CGF and the Gallager function are less clear. Thus, the Rényi entropies are intuitively familiar to the readers’ of this journal. The Rényi entropies have an additional advantage in that two types of bounds (e.g., (152) and (161)) can be expressed in a unified manner. Therefore, we state our main results in terms of the Rényi entropies, whereas we use the CGF and the Gallager function in the proofs. For the readers’ convenience, the relation between the Rényi entropies and corresponding CGFs are summarized in Appendix A and Appendix B.
1.3. Main Contribution for Channel Coding
An intimate relationship is known to exist between channel coding and source coding with side-information (e.g., [24,25,26]). In particular, for an additive channel, the error probability of channel coding by a linear code can be related to the corresponding source coding problem with side-information [24]. Chen et. al. also showed that the error probability of source coding with side-information by a linear encoder can be related to the error probability of a dual channel coding problem and vice versa [27] (see also [28]). Since these dual channels can be regarded as additive channels conditioned on state information, we refer to these channels as conditional additive channels (In [28], we termed these channels general additive channels, but we think “conditional” more suitably describes the situation.). In this paper, we mainly discuss a conditional additive channel, in which the additive noise is operated subject to a distribution conditioned on additional output information. Then, we convert our obtained results of source coding with side-information to the analysis on conditional additive channels. That is, using the aforementioned duality between channel coding and source coding with side-information enables us to evaluate the error probability of channel coding for additive channels. Then, we derive several finite-length analyses on additive channels.
For the same reason as source coding with side-information, we make two assumptions, Assumptions 1 and 2, on the noise process of a conditional additive channel. In this context, Assumption 1 means that the marginal system deciding the behavior of the additive noise is a Markov chain. It should be noted that the Gilbert–Elliott channel [29,30] with state information available at the receiver can be regarded as a conditional additive channel such that the noise process is a Markov chain satisfying both Assumptions 1 and 2 (see Example 6). Thus, we believe that Assumptions 1 and 2 are quite reasonable assumptions.
In fact, our analysis is applicable for a broader class of channels known as regular channels [31]. The class of regular channels includes conditional additive channels as a special case, and it is known as a class of channels that are similarly symmetrical. To show it, we propose a method to convert a regular channel into a conditional additive channel such that our treatment covers regular channels. Additionally, we show that the BPSK (binary phase shift keying)-AWGN (additive white Gaussian noise) channel is included in conditional additive channels.
1.4. Asymptotic Bounds and Asymptotic Tightness for Finite-Length Bounds
We present asymptotic analyses of the large and moderate deviation regimes by deriving the characterizations (for the large deviation regime, we only derive the characterizations up to the critical rate) with the use of our finite-length achievability and converse bounds, which implies that our finite-length bounds are tight in both of these deviation regimes. We also derive the second-order rate. Although this rate can be derived by the application of the central limit theorem to the information-spectrum bound, the variance involves the limit with respect to the block length because of memory. In this paper, we derive a single-letter form of the variance by using the conditional Rényi entropy for transition matrices (An alternative way to derive a single-letter characterization of the variance for the Markov chain was shown in [32] (Lemma 20). It should also be noted that a single-letter characterization can be derived by using the fundamental matrix [33]. The single-letter characterization of the variance in [12] (Section VII) and [11] (Section III) contains an error, which is corrected in this paper.).
As we will see in Theorems 11–14 and 22–25, our asymptotic results have the same forms as the counterparts of the i.i.d. case (cf. [1,6,11,12,13,14]) when the information measures for distributions in the i.i.d. case are replaced by the information measures for the transition matrices introduced in this paper.
We determine the asymptotic tightness for finite-length bounds by summarizing the relation between the asymptotic results and the finite-length bounds in Table 1. The table also describes the computational complexity of the finite-length bounds. “” indicates that those problems are solved up to the critical rates. “Ass. 1” and “Ass. 2” indicate that those problems are solved either under Assumption 1 or Assumption 2. “” indicates that both the achievability and converse parts of those asymptotic results are derived from our finite-length achievability bounds and converse bounds whose computational complexities are . “Tail” indicates that both the achievability and converse parts of those asymptotic results are derived from the information-spectrum-type achievability bounds and converse bounds of which the computational complexities depend on the computational complexities of the tail probabilities.

Table 1.
Summary of asymptotic results and finite-length bounds to derive asymptotic results under Assumptions 1 and 2, which are abbreviated to Ass. 1 and Ass. 2.
In general, the exact computations of tail probabilities are difficult, although they may be feasible for a simple case such as an i.i.d. case. One way to compute tail probabilities approximately is to use the Berry–Esséen theorem [34] (Theorem 16.5.1) or its variant [35]. This direction of research is still ongoing [36,37], and an evaluation of the constant was conducted [37], although its tightness has not been clarified. If we can derive a tight Berry–Esséen-type bound for the Markov chain, this would enable us to derive a finite-length bound that is asymptotically tight in the second-order regime. However, the approximation errors of Berry–Esséen-type bounds converge only in the order of and cannot be applied when is rather small. Even in cases in which the exact computations of tail probabilities are possible, the information-spectrum-type bounds are looser than the exponential type bounds when is rather small, and we need to use appropriate bounds depending on the size of . In fact, this observation was explicitly clarified in [38] for random number generation with side-information. Consequently, we believe that our exponential-type finite-length bounds are very useful. It should be also noted that, for source coding with side-information and channel coding for regular channels, even the first-order results have not been revealed as far as the authors know, and they are clarified in this paper (General formulae for those problems were known [2,3], but single-letter expressions for Markov sources or channels were not clarified in the literature. For the source coding without side-information, the single-letter expression for entropy rate of Markov source is well known (e.g., see [39]).).
1.5. Related Work on Markov Chains
Since related work concerning the finite-length analysis is reviewed in Section 1.1, we only review work related to the asymptotic analysis here. Some studies on Markov chains for the large deviation regime have been reported [40,41,42]. The derivation in [40] used the Markov-type method. A drawback of this method is that it involves a term that stems from the number of types, which does not affect the asymptotic analysis, but does hurt the finite-length analysis. Our achievability is derived by following a similar approach as in [41,42], i.e., the Perron–Frobenius theorem, but our derivation separates the single-shot part and the evaluation of the Rényi entropy, and thus is more transparent. Furthermore, the converse part of [41,42] is based on the Shannon–McMillan–Breiman limiting theorem and does not yield finite-length bounds.
For the second-order regime, Polyanskiy et. al. studied the second-order rate (dispersion) of the Gilbert–Elliott channel [43]. Tomamichel and Tan studied the second-order rate of channel coding with state information such that the state information may be a general source and derived a formula for the Markov chain as a special case [32]. Kontoyiannis studied the second-order variable length source coding for the Markov chain [44]. In [45], Kontoyiannis and Verdú derived the second-order rate of lossless source coding under the overflow probability criterion.
For channel coding of the i.i.d. case, Scarlett et al. derived a saddle-point approximation, which unifies all three regimes [46,47].
1.6. Organization of the Paper
In Section 2, we introduce the information measures and their properties that will be used in Section 3 and Section 4. Then, source coding with side-information and channel coding is discussed in Section 3 and Section 4, respectively. As we mentioned above, we state our main result in terms of the Rényi entropies, and we use the CGFs and the Gallager function in the proofs. We explain how to cover the continuous case in Remarks 1 and 5. In Appendix A and Appendix B, the relation between the Rényi entropies and corresponding CGFs are summarized. The relation between the Rényi entropies and the Gallager function are explained as necessary. Proofs of some technical results are also provided in the remaining Appendices.
1.7. Notations
For a set , the set of all distributions on is denoted by . The set of all sub-normalized non-negative functions on is denoted by . The cumulative distribution function of the standard Gaussian random variable is denoted by:
Throughout the paper, the base of the logarithm is the natural base e.
2. Information Measures
Since this paper discusses the second-order tightness, we need to discuss the central limit theorem for the Markov process. For this purpose, we usually employ advanced mathematical methods from probability theory. For example, the paper [48] (Theorem 4) showed the Markov version of the central limit theorem by using a martingale stopping technique. Lalley [49] employed the regular perturbation theory of operators on the infinite-dimensional space [50] (Chapter 7, #1, Chapter 4, #3, and Chapter 3, #5). The papers [51,52] and [53] (Lemma 1.5 of Chapter 1) employed the spectral measure, while it is hard to calculate the spectral measure in general even in the finite-state case. Further, the papers [36,51,54,55] showed the central limit theorem by using the asymptotic variance, but they did not give any computable expression of the asymptotic variance without the infinite sum. In summary, to derive the central limit theorem with the variance of a computable form, these papers needed to use very advanced mathematics beyond calculus and linear algebra.
To overcome the difficulty of the Markov version of the central limit theorem, we employed the method used in our recent paper [23]. The paper [23] employed the method based on the cumulant generating function for transition matrices, which is defined by the Perron eigenvalue of a specific non-negative-entry matrix. Since a Perron eigenvalue can be explained in the framework of linear algebra, the method can be described with elementary mathematics. To employ this method, we need to define the information measure in a way similar to the cumulant generating function for transition matrices. That is, we define the information measures for transition matrices, e.g., the conditional Rényi entropy for transition matrices, etc, by using Perron eigenvalues.
Fortunately, these information measures for transition matrices are very useful even for large deviation-type evaluation and finite-length bounds. For example, our recent paper [23] derived finite-length bounds for simple hypothesis testing for the Markov chain by using the cumulant generating function for transition matrices. Therefore, using these information measures for transition matrices, this paper derives finite-length bounds for source coding and channel coding with Markov chains and discusses their asymptotic bounds with large deviation, moderate deviation, and the second-order type.
Since they are natural extensions of information measures for single-shot setting, we first review information measures for the single-shot setting in Section 2.1. Next, we introduce information measures for transition matrices in Section 2.2. Then, we show that information measures for Markov chains can be approximated by information measures for transition matrices generating those Markov chains in Section 2.3.
2.1. Information Measures for the Single-Shot Setting
In this section, we introduce conditional Rényi entropies for the single-shot setting. For more a detailed review of conditional Rényi entropies, see [21]. For a correlated random variable on with probability distribution and a marginal distribution on , we introduce the conditional Rényi entropy of order relative to as:
where . The conditional Rényi entropy of order zero relative to is defined by the limit with respect to . When X has no side-information, it is nothing but the ordinary Rényi entropy, and it is denoted by throughout the paper.
One of the important special cases of is the case with , where is the marginal of . We shall call this special case the lower conditional Rényi entropy of order and denote (this notation was first introduced in [56]):
When we consider the second-order analysis, the variance of the entropy density plays an important role:
We have the following property, which follows from the correspondence between the conditional Rényi entropy and the cumulant generating function (cf. Appendix B).
Lemma 1.
Proof.
The other important special case of is the measure maximized over . We shall call this special case the upper conditional Rényi entropy of order and denote (Equation (13) for follows from the Hölder inequality, and Equation (13) for follows from the reverse Hölder inequality [57] (Lemma 8). Similar optimization has appeared in the context of Rényi mutual information in [58] (see also [59]).):
where:
For this measure, we also have the same properties as Lemma 1. This lemma will be proven in Appendix C.
Lemma 2.
We have:
and:
When we derive converse bounds, we need to consider the case such that the order of the Rényi entropy is different from the order of conditioning distribution defined in (15). For this purpose, we introduce two-parameter conditional Rényi entropy, which connects the two kinds of conditional Rényi entropies and in the way as Statements 10 and 11 of Lemma 3:
Next, we investigate some properties of the measures defined above, which will be proven in Appendix D.
Lemma 3.
- 1.
- For fixed , is a concave function of θ, and it is strict concave iff .
- 2.
- For fixed , is a monotonically decreasing (Technically, is always non-increasing, and it is monotonically decreasing iff strict concavity holds in Statement 1. Similar remarks are also applied for other information measures throughout the paper.) function of θ.
- 3.
- The function is a concave function of θ, and it is strict concave iff .
- 4.
- is a monotonically decreasing function of θ.
- 5.
- The function is a concave function of θ, and it is strict concave iff .
- 6.
- is a monotonically decreasing function of θ.
- 7.
- For every , we have .
- 8.
- For fixed , the function is a concave function of θ, and it is strict concave iff .
- 9.
- For fixed , is a monotonically decreasing function of θ.
- 10.
- We have:
- 11.
- We have:
- 12.
- For every , is maximized at .
The following lemma expresses explicit forms of the conditional Rényi entropies of order zero.
Lemma 4.
We have:
Proof.
See Appendix E. □
The definition (6) guarantees the existence of the derivative of . From Statement 1 of Lemma 3, is monotonically decreasing. Thus, the inverse function (Throughout the paper, the notations and are reused for several inverse functions. Although the meanings of those notations are obvious from the context, we occasionally put superscript Q, ↓ or ↑ to emphasize that those inverse functions are induced from corresponding conditional Rényi entropies. This definition is related to the Legendre transform of the concave function .) of exists so that the function is defined as:
for , where and . Let:
Since:
is a monotonic increasing function of . Thus, we can define the inverse function of by:
for .
For , by the same reason as above, we can define the inverse functions and by:
and:
for . For , we also introduce the inverse functions and by:
and:
for .
Remark 1.
Here, we discuss the possibility for extension to the continuous case. Since the entropy in the continuous case diverges, we cannot extend the information quantities to the case when is continuous. However, it is possible to extend these quantities to the case when is continuous, but is a discrete finite set. In this case, we prepare a general measure μ (like the Lebesgue measure) on and probability density function and such that the distributions and are given as and , respectively. Then, it is sufficient to replace ∑, , and by , , and , respectively. Hence, in the n-independent and identically distributed case, these information measures are given as n times the original information measures.
One might consider the information quantities for transition matrices given in the next subsection for this continuous case. However, this is not so easy because it needs a continuous extension of the Perron eigenvalue.
2.2. Information Measures for the Transition Matrix
Let be an ergodic and irreducible transition matrix. The purpose of this section is to introduce transition matrix counterparts of those measures in Section 2.1. For this purpose, we first need to introduce some assumptions on transition matrices:
Assumption 1
(Non-hidden). We say that a transition matrix W is non-hidden (with respect to Y) if the Y-marginal process is a Markov process, i.e., (The reason for the name “non-hidden” is the following. In general, the Y-marginal process is a hidden Markov process. However, when the condition (37) holds, the Y-marginal process is a Markov process. Hence, we call the condition (37) non-hidden.):
for every and . This condition is equivalent to the existence of the following decomposition of :
Assumption 2
(Strongly non-hidden). We say that a transition matrix W is strongly non-hidden (with respect to Y) if, for every and (The reason for the name “strongly non-hidden” is the following. When we compute the upper conditional Rényi entropy rate of the Markov source, the effect of the Y process may propagate infinitely even if it is non-hidden. When (39) holds, the effect of the Y process in the computation of the upper conditional Rényi entropy rate is only one step.):
is well defined, i.e., the right-hand side of (39) is independent of .
Assumption 1 requires (39) to hold only for , and thus, Assumption 2 implies Assumption 1. However, Assumption 2 is a strictly stronger condition than Assumption 1. For example, let us consider the case such that the transition matrix is a product form, i.e., . In this case, Assumption 1 is obviously satisfied. However, Assumption 2 is not satisfied in general.
Assumption 2 has another expression as follows.
Lemma 5.
Assumption 2 holds if and only if, for every , there exists a permutation on such that .
Proof.
Since the part “if” is trivial, we show the part “only if” as follows. By noting (38), Assumption 2 can be rephrased as:
does not depend on for every . Furthermore, this condition can be rephrased as follows. For , if the largest values of and are different, say the former is larger, then for sufficiently large , which contradicts the fact that (40) does not depend on . Thus, the largest values of and must coincide. By repeating this argument for the second largest value of and , and so on, we find that Assumption 2 implies that for every , there exists a permutation on such that . □
Now, we fix an element and transform a sequence of random numbers to the sequence of random numbers . Then, letting , we have . That is, essentially, the transition matrix of this case can be written by the transition matrix . Therefore, the transition matrix can be written by using the positive-entry matrix .
The following are non-trivial examples satisfying Assumptions 1 and 2.
Example 1.
Suppose that is a module (an additive group). Let P and Q be transition matrices on . Then, the transition matrix given by:
satisfies Assumption 1. Furthermore, if transition matrix can be written as:
for permutation and a distribution on , then transition matrix W defined by (41) satisfies Assumption 2 as well.
Example 2.
Suppose that is a module and W is (strongly) non-hidden with respect to . Let Q be a transition matrix on . Then, the transition matrix given by:
is (strongly) non-hidden with respect to .
The following is also an example satisfying Assumption 2, which describes a noise process of an important class of channels with memory (cf. the Gilbert-Elliot channel in Example 6).
Example 3.
Let . Then, let:
for some , and let:
for some . By choosing to be the identity, this transition matrix satisfies the condition given in Remark 5, which is equivalent to Assumption 2.
First, we introduce information measures under Assumption 1. In order to define a transition matrix counterpart of (7), let us introduce the following tilted matrix:
Here, we should notice that the tilted matrix is not normalized, i.e., is not a transition matrix. Let be the Perron–Frobenius eigenvalue of and be its normalized eigenvector. Then, we define the lower conditional Rényi entropy for W by:
where . For , we define the lower conditional Rényi entropy for W by:
and we just call it the conditional entropy for W. In fact, the definition of above coincides with:
where is the stationary distribution of W (cf. [60] (Equation (30))). For , is also defined by taking the limit. When X has no side-information, the Rényi entropy for W is defined as a special case of .
As a counterpart of (11), we also define (Since the limiting expression in (51) coincides with the second derivative of the CGF (cf. (A30)) and since the second derivative of the CGF exists (cf. [22] (Appendix D)), the variance in (51) is well defined. While the definition (51) contains the limit , it can be calculated without this type of limit by using the fundamental matrix [61] (Theorem 4.3.1), [23] (Theorem 7.7 and Remark 7.8).):
Remark 2.
When transition matrix W satisfies Assumption 2, can be written as:
where is the Perron–Frobenius eigenvalue of . In fact, for the left Perron–Frobenius eigenvector of , we have:
which implies that is the Perron–Frobenius eigenvalue of . Consequently, we can evaluate by calculating the Perron–Frobenius eigenvalue of the matrix instead of the matrix when W satisfies Assumption 2.
Next, we introduce information measures under Assumption 2. In order to define a transition matrix counterpart of (12), let us introduce the following matrix:
where is defined by (39). Let be the Perron–Frobenius eigenvalue of . Then, we define the upper conditional Rényi entropy for W by:
where . For and , is defined by taking the limit. We have the following properties, which will be proven in Appendix F.
Lemma 6.
We have:
and:
Now, let us introduce a transition matrix counterpart of (18). For this purpose, we introduce the following matrix:
Let be the Perron–Frobenius eigenvalue of . Then, we define the two-parameter conditional Rényi entropy by:
Remark 3.
Although we defined and by (47) and (55), respectively, we can alternatively define these measures in the same spirit as the single-shot setting by introducing a transition matrix counterpart of as follows. For the marginal of , let . For another transition matrix V on , we define in a similar manner. For V satisfying , we define (although we can also define even if is not satisfied (see [22] for the detail), for our purpose of defining and , other cases are irrelevant):
for , where is the Perron–Frobenius eigenvalue of:
By using this measure, we obviously have:
Furthermore, under Assumption 2, the relation:
holds (see Appendix G for the proof), where the maximum is taken over all transition matrices satisfying .
Next, we investigate some properties of the information measures introduced in this section. The following lemma is proven in Appendix H.
Lemma 7.
- 1.
- The function is a concave function of θ, and it is strict concave iff .
- 2.
- is a monotonically decreasing function of θ.
- 3.
- The function is a concave function of θ, and it is strict concave iff .
- 4.
- is a monotonically decreasing function of θ.
- 5.
- For every , we have .
- 6.
- For fixed , the function is a concave function of θ, and it is strict concave iff .
- 7.
- For fixed , is a monotonically decreasing function of θ.
- 8.
- We have:
- 9.
- We have:
- 10.
- For every , is maximized at , i.e.,
From Statement 1 of Lemma 7, is monotonically decreasing. Thus, we can define the inverse function of by:
for , where and . Let:
Since
is a monotonic increasing function of . Thus, we can define the inverse function of by:
for , where .
For , by the same reason, we can define the inverse function by:
and the inverse function of:
by:
for , where . Here, the first equality in (71) follows from (66).
Since is concave, the supremum of is attained at the stationary point. Furthermore, note that for . Thus, we have the following property.
Lemma 8.
Furthermore, we have the following characterization for another type of maximization.
Lemma 9.
Proof.
See Appendix I. □
Remark 4.
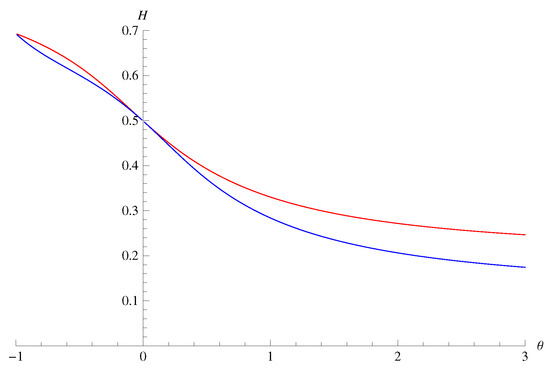
The combination of (49), (51), and Lemma 6 guarantees that both the conditional Rényi entropies expand as:
around . Thus, the difference of these measures significantly appears only when is rather large. For the transition matrix of Example 3 with , , and , we plotted the values of the information measures in Figure 1. Although the values at coincide in Figure 1, note that the values at may differ in general.
Figure 1.
A comparison of (upper red curve) and (lower blue curve) for the transition matrix of Example 3 with , , and . The horizontal axis is , and the vertical axis is the values of the information measures (nats).
Now, let us consider the asymptotic behavior of around . When is close to zero, we have:
Taking the derivative, (67) implies that:
Hence, when R is close to , we have:
i.e.,
2.3. Information Measures for the Markov Chain
Let be the Markov chain induced by transition matrix W and some initial distribution . Now, we show how information measures introduced in Section 2.2 are related to the conditional Rényi entropy rates. First, we introduce the following lemma, which gives finite upper and lower bounds on the lower conditional Rényi entropy.
Lemma 10.
Suppose that transition matrix W satisfies Assumption 1. Let be the eigenvector of with respect to the Perron–Frobenius eigenvalue such that (since the eigenvector corresponding to the Perron–Frobenius eigenvalue for an irreducible non-negative matrix has always strictly positive entries [62] (Theorem 8.4.4, p. 508), we can choose the eigenvector satisfying this condition). Let . Then, for every , we have:
where:
and is defined as .
Proof.
This follows from (A29) and Lemma A2. □
From Lemma 10, we have the following.
Theorem 1.
We also have the following asymptotic evaluation of the variance, which follows from Lemma A3 in Appendix A.
Theorem 2.
Suppose that transition matrix W satisfies Assumption 1. For any initial distribution, we have:
Theorem 2 is practically important since the limit of the variance can be described by a single-letter characterized quantity. A method to calculate can be found in [23].
Next, we show the lemma that gives the finite upper and lower bounds on the upper conditional Rényi entropy in terms of the upper conditional Rényi entropy for the transition matrix.
Lemma 11.
Suppose that transition matrix W satisfies Assumption 2. Let be the eigenvector of with respect to the Perron–Frobenius eigenvalue such that . Let be the -dimensional vector defined by:
Then, we have:
where:
Proof.
See Appendix J. □
From Lemma 11, we have the following.
Theorem 3.
Suppose that transition matrix W satisfies Assumption 2. For any initial distribution, we have:
Finally, we show the lemma that gives the finite upper and lower bounds on the two-parameter conditional Rényi entropy in terms of the two-parameter conditional Rényi entropy for the transition matrix.
Lemma 12.
Suppose that transition matrix W satisfies Assumption 2. Let be the eigenvector of with respect to the Perron–Frobenius eigenvalue such that . Let be the -dimensional vector defined by:
Then, we have:
where:
for and:
for
Proof.
By multiplying in the definition of , we have:
The second term is evaluated by Lemma 11. The first term can be evaluated almost in the same manner as Lemma 11. □
From Lemma 12, we have the following.
Theorem 4.
Suppose that transition matrix W satisfies Assumption 2. For any initial distribution, we have:
3. Source Coding with Full Side-Information
In this section, we investigate source coding with side-information. We start this section by showing the problem setting in Section 3.1. Then, we review and introduce some single-shot bounds in Section 3.2. We derive finite-length bounds for the Markov chain in Section 3.3. Then, in Section 3.5 and Section 3.6, we show the asymptotic characterization for the large deviation regime and the moderate deviation regime by using those finite-length bounds. We also derive the second-order rate in Section 3.4.
3.1. Problem Formulation
A code consists of one encoder and one decoder . The decoding error probability is defined by:
For notational convenience, we introduce the infimum of error probabilities under the condition that the message size is M:
For theoretical simplicity, we focus on a randomized choice of our encoder. For this purpose, we employ a randomized hash function F from to . A randomized hash function F is called a two-universal hash when for any distinctive x and [63]; the so-called bin coding [39] is an example of the two-universal hash function. In the following, we denote the set of two-universal hash functions by . Given an encoder f as a function from to , we define the decoder as the optimal decoder by . Then, we denote the code by . Then, we bound the error probability averaged over the random function F by only using the property of two-universality. In order to consider the worst case of such schemes, we introduce the following quantity:
3.2. Single-Shot Bounds
In this section, we review existing single-shot bounds and also show novel converse bounds. For the information measures used below, see Section 2.
By using the standard argument on information-spectrum approach, we have the following achievability bound.
Lemma 13
(Lemma 7.2.1 of [3]). The following bound holds:
Although Lemma 13 is useful for the second-order regime, it is known to be not tight in the large deviation regime. By using the large deviation technique of Gallager, we have the following exponential-type achievability bound.
Lemma 14
([64]). The following bound holds: (note that the Gallager function and the upper conditional Rényi entropy are related by (A45)):
Although Lemma 14 is known to be tight in the large deviation regime for i.i.d. sources, for Markov chains can only be evaluated under the strongly non-hidden assumption. For this reason, even though the following bound is looser than Lemma 14, it is useful to have another bound in terms of , which can be evaluated for Markov chains under the non-hidden assumption.
Lemma 15.
The following bound holds:
Proof.
To derive this bound, we change the variable in (118) as . Then, , and we have:
where we use Lemma A4 in Appendix C. □
For the source coding without side-information, i.e., when X has no side-information, we have the following bound, which is tighter than Lemma 14.
Lemma 16
((2.39) [65]). The following bound holds:
For the converse part, we first have the following bound, which is very close to the operational definition of source coding with side-information.
Lemma 17
([66]). Let be a family of subsets , and let . Then, for any , the following bound holds:
Since Lemma 17 is close to the operational definition, it is not easy to evaluate Lemma 17. Thus, we derive another bound by loosening Lemma 17, which is more tractable for evaluation. Slightly weakening Lemma 17, we have the following.
Lemma 18
([3,4]). For any , we have (In fact, a special case for corresponds to Lemma 7.2.2 of [3]. A bound that involves was introduced in [4] for channel coding, and it can be regarded as a source coding counterpart of that result.):
By using the change-of-measure argument, we also obtain the following converse bound.
Theorem 5.
Proof.
See Appendix K. □
In particular, by taking in Theorem 5, we have the following.
Remark 5.
Here, we discuss the possibility for extension to the continuous case. As explained in Remark 1, we can define the information quantities for the case when is continuous, but is a discrete finite set. The discussions in this subsection still hold even in this continuous case. In particular, in the n-i.i.d. extension case with this continuous setting, Lemma 14 and Corollary 1 hold when the information measures are replaced by n times the single-shot information measures.
3.3. Finite-Length Bounds for Markov Source
In this subsection, we derive several finite-length bounds for the Markov source with a computable form. Unfortunately, it is not easy to evaluate how tight those bounds are only with their formula. Their tightness will be discussed by considering the asymptotic limit in the remaining subsections of this section. Since we assume the irreducibility for the transition matrix describing the Markov chain, the following bound holds with any initial distribution.
To derive a lower bound on in terms of the Rényi entropy of the transition matrix, we substitute the formula for the Rényi entropy given in Lemma 10 into Lemma 15. Then, we can derive the following achievability bound.
Theorem 6
(Direct, Ass. 1). Suppose that transition matrix W satisfies Assumption 1. Let . Then, for every , we have:
where is given by (91).
For the source coding without side-information, from Lemma 16 and a special case of Lemma 10, we have the following achievability bound.
Theorem 7
(Direct, no-side-information). Let . Then, for every , we have:
To derive an upper bound on in terms of the Rényi entropy of transition matrix, we substitute the formula for the Rényi entropy given in Lemma 10 for Theorem 5. Then, we have the following converse bound.
Theorem 8
Proof.
We first use (124) of Theorem 5 for and Lemma 10. Then, we restrict the range of as and set . Then, we have the assertion of the theorem. □
Next, we derive tighter bounds under Assumption 2. To derive a lower bound on in terms of the Rényi entropy of the transition matrix, we substitute the formula for the Rényi entropy in Lemma 11 for Lemma 14. Then, we have the following achievability bound.
Theorem 9
(Direct, Ass. 2). Suppose that transition matrix W satisfies Assumption 2. Let . Then, we have:
where is given by (98).
Finally, to derive an upper bound on in terms of the Rényi entropy for the transition matrix, we substitute the formula for the Rényi entropy in Lemma 12 for Theorem 5 for . Then, we can derive the following converse bound.
Theorem 10
Proof.
We first use (124) of Theorem 5 for and Lemma 12. Then, we restrict the range of as and set . Then, we have the assertion of the theorem. □
3.4. Second-Order
By applying the central limit theorem to Lemma 13 (cf. [67] (Theorem 27.4, Example 27.6)) and Lemma 18 for and by using Theorem 2, we have the following.
Theorem 11.
Suppose that transition matrix W on satisfies Assumption 1. For arbitrary , we have:
Proof.
The central limit theorem for the Markov process cf. [67] (Theorem 27.4, Example 27.6) guarantees that the random variable asymptotically obeys the normal distribution with average zero and variance , where we use Theorem 2 to show that the limit of the variance is given by . Let . Substituting and in Lemma 13, we have:
□
On the other hand, substituting and in Lemma 18 for , we have:
From the above theorem, the (first-order) compression limit of source coding with side-information for a Markov source under Assumption 1 is given by (although the compression limit of source coding with side-information for a Markov chain is known more generally [68], we need Assumption 1 to get a single-letter characterization):
for any . In the next subsections, we consider the asymptotic behavior of the error probability when the rate is larger than the compression limit in the moderate deviation regime and the large deviation regime, respectively.
3.5. Moderate Deviation
From Theorems 6 and 8, we have the following.
Theorem 12.
Suppose that transition matrix W satisfies Assumption 1. For arbitrary and , we have:
Proof.
We apply Theorems 6 and 8 to the case with , i.e., . For the achievability part, from (88) and Theorem 6, we have:
To prove the converse part, we fix arbitrary and choose to be . Then, Theorem 8 implies that:
□
Remark 6.
In the literature [13,69], the moderate deviation results are stated for such that and instead of for . Although the former is slightly more general than the latter, we employ the latter formulation in Theorem 12 since the order of convergence is clearer. In fact, in Theorem 12 can be replaced by general without modifying the argument of the proof.
3.6. Large Deviation
From Theorems 6 and 8, we have the following.
Theorem 13.
Suppose that transition matrix W satisfies Assumption 1. For , we have:
On the other hand, for , we have:
Proof.
The achievability bound (151) follows from Theorem 6. The converse part (152) is proven from Theorem 8 as follows. We first fix and . Then, Theorem 8 implies:
By taking the limit and , we have:
Thus, (152) is proven. The alternative expression (153) is derived via Lemma 9. □
Under Assumption 2, from Theorems 9 and 10, we have the following tighter bound.
Theorem 14.
Suppose that transition matrix W satisfies Assumption 2. For , we have:
On the other hand, for , we have:
Proof.
The achievability bound (160) follows from Theorem 9. The converse part (161) is proven from Theorem 10 as follows. We first fix and . Then, Theorem 10 implies:
By taking the limit and , we have:
Thus, (161) is proven. The alternative expression (162) is derived via Lemma 9.□
Remark 7.
For , where (cf. (72) for the definition of ):
is the critical rate, the left-hand side of (76) in Lemma 9 is attained by parameters in the range . Thus, the lower bound in (160) is rewritten as:
Thus, the lower bound and the upper bounds coincide up to the critical rate.
Remark 8.
For the source coding without side-information, by taking the limit of Theorem 7, we have:
On the other hand, as a special case of (152) without side-information, we have:
for . Thus, we can recover the results in [40,41] by our approach.
3.7. Numerical Example
In this section, to demonstrate the advantage of our finite-length bound, we numerically evaluate the achievability bound in Theorem 7 and a special case of the converse bound in Theorem 8 for the source coding without side-information. Thanks to the aspect (A2), our numerical calculation shows that our upper finite-length bounds are very close to our lower finite-length bounds when the size n is sufficiently large. Thanks to the aspect (A1), we could calculate both bounds with the huge size because the calculation complexity behaves as .
Figure 2.
The description of the transition matrix in (173).
In this case, the stationary distribution is:
The entropy is:
where is the binary entropy function. The tilted transition matrix is:
The Perron–Frobenius eigenvalue is:
and its normalized eigenvector is:
The normalized eigenvector of is also given by:
From these calculations, we can evaluate the bounds in Theorems 7 and 8. For , , the bounds are plotted in Figure 3 for fixed error probability . Although there is a gap between the achievability bound and the converse bound for rather small n, the gap is less than approximately 5% of the entropy rate for n larger than 10,000. We also plot the bounds in Figure 4 for fixed block length 10,000 and varying . The gap between the achievability bound and the converse bound remains approximately 5% of the entropy rate even for as small as .
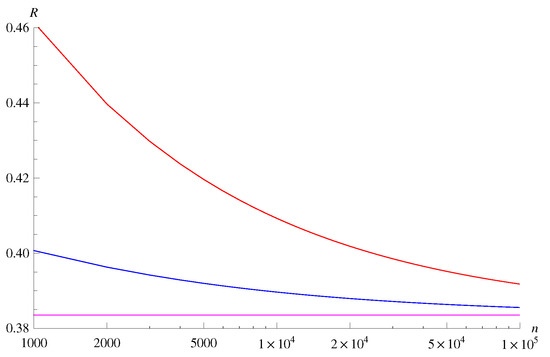
Figure 3.
A comparison of the bounds for , , and . The horizontal axis is the block length n, and the vertical axis is the rate R (nats). The upper red curve is the achievability bound in Theorem 7. The middle blue curve is the converse bound in Theorem 8. The lower purple line is the first-order asymptotics given by the entropy .
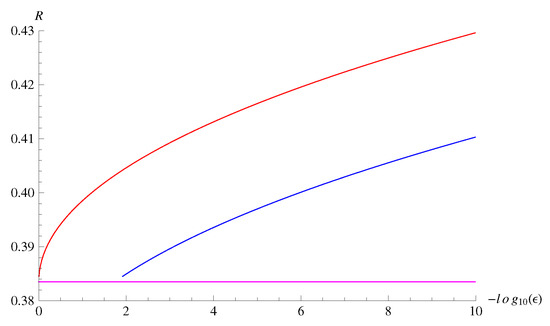
Figure 4.
A comparison of the bounds for , , and 10,000. The horizontal axis is , and the vertical axis is the rate R (nats). The upper red curve is the achievability bound in Theorem 7. The middle blue curve is the converse bound in Theorem 8. The lower purple line is the first-order asymptotics given by the entropy .
The gap between the achievability bound and the converse bound in Figure 3 is rather large compared to a similar numerical experiment conducted in [1]. One reason for the gap is that our bounds are exponential-type bounds. For instance, when the source is i.i.d., the achievability bound essentially reduces to the so-called Gallager bound [64]. However, an advantage of our bounds is that the computational complexity does not depend on the blocklength. The computational complexities of the bounds plotted in [1] depend the blocklength, and numerical computation of those bounds for Markov sources seems to be difficult.
When , an alternative approach to derive tighter bounds is to consider encoding of the Markov transition, i.e., , instead of the source itself (cf. [45] (Example 4)). Then, the analysis can be reduced to i.i.d. case. However, such an approach is possible only when .
3.8. Summary of the Results
The obtained results in this section are summarized in Table 2. The check marks 🗸 indicate that the tight asymptotic bounds (large deviation, moderate deviation, and second-order) can be obtained from those bounds. The marks 🗸 indicate that the large deviation bound can be derived up to the critical rate. The computational complexity “Tail” indicates that the computational complexities of those bounds depend on the computational complexities of tail probabilities. It should be noted that Theorem 8 is derived from a special case () of Theorem 5. The asymptotically optimal choice is , which corresponds to Corollary 1. Under Assumption 1, we can derive the bound of the Markov case only for that special choice of , while under Assumption 2, we can derive the bound of the Markov case for the optimal choice of .
Table 2.
Summary of the bounds for source coding with full side-information. No-side means the case with no side-information.
4. Channel Coding
In this section, we investigate the channel coding with a conditional additive channel. The first part of this section discusses the general properties of the channel coding with a conditional additive channel. The second part of this section discusses the properties of the channel coding when the conditional additive noise of the channel is Markov. The first part starts with showing the problem setting in Section 4.1 by introducing a conditional additive channel. Section 4.2 gives a canonical method to convert a regular channel to a conditional additive channel. Section 4.3 gives a method to convert a BPSK-AWGN channel to a conditional additive channel. Then, we show some single-shot achievability bounds in Section 4.4 and single-shot converse bounds in Section 4.5.
As the second part, we derive finite-length bounds for the Markov noise channel in Section 4.6. Then, we derive the second-order rate in Section 4.7. In Section 4.8 and Section 4.9, we show the asymptotic characterization for the large deviation regime and the moderate deviation regime by using those finite-length bounds.
4.1. Formulation for the Conditional Additive Channel
4.1.1. Single-Shot Case
We first present the problem formulation in the single-shot setting. For a channel with input alphabet and output alphabet , a channel code consists of one encoder and one decoder . The average decoding error probability is defined by:
For notational convenience, we introduce the error probability under the condition that the message size is M:
Assume that the input alphabet is the same set as the output alphabet and they equal an additive group . When the transition matrix is given as by using a distribution on , the channel is called additive.
To extend the concept of the additive channel, we consider the case when the input alphabet is an additive group and the output alphabet is the product set . When the transition matrix is given as by using a distribution on , the channel is called conditional additive. In this paper, we are exclusively interested in the conditional additive channel. As explained in Section 4.2, a channel is a conditional additive channel if and only if it is a regular channel in the sense of [31]. When we need to express the underlying distribution of the noise explicitly, we denote the average decoding error probability by .
4.1.2. n-Fold Extension
When we consider n-fold extension, the channel code is denoted with subscript n such as . The error probabilities given in (183) and (184) are written with the superscript as and , respectively. Instead of evaluating the error probability for given , we are also interested in evaluating:
for given .
When the channel is given as a conditional distribution, the channel is given by:
where is a noise distribution on .
For the code construction, we investigate the linear code. For an linear code , there exists a parity check matrix such that the kernel of is . That is, given a parity check matrix , we define the encoder as the imbedding of the kernel . Then, using the decoder , we define .
Here, we employ a randomized choice of a parity check matrix. In particular, instead of a two-universal hash function, we focus on linear two-universal hash functions, because the linearity is required in the above relation with source coding. Therefore, denoting the set of linear two-universal hash functions from to by , we introduce the quantity:
Taking the infimum over all linear codes associated with (cf. (113)), we obviously have:
When we consider the error probability for conditionally additive channels, we use notation so that the underlying distribution of the noise is explicit. We are also interested in characterizing:
for given .
4.2. Conversion from the Regular Channel to the Conditional Additive Channel
The aim of this subsection is to show the following theorem by presenting the conversion rule between these two types of channels. Then, we see that a binary erasure symmetric channel is an example of a regular channel.
Theorem 15.
A channel is a regular channel in the sense of [31] if and only if it can be written as a conditional additive channel.
To show the conversion from a conditional additive channel to a regular channel, we assume that the input alphabet has an additive group structure. Let be a distribution on the output alphabet . Let be a representation of the group on , and let . A regular channel [31] is defined by:
The group action induces orbit:
The set of all orbits constitutes a disjoint partition of . A set of the orbits is denoted by , and let be the map to the representatives.
Example 4
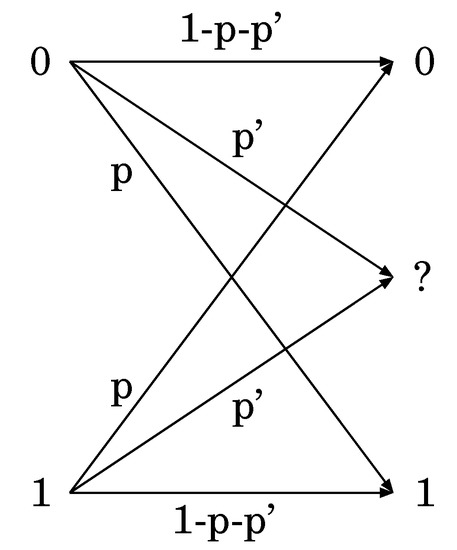
(Binary erasure symmetric channel). Let , , and:
Then, let:
The channel defined in this way is a regular channel (see Figure 5). In this case, there are two orbits: and .
Figure 5.
The binary erasure symmetric channel.
Let and for some joint distribution on . Now, we consider a conditional additive channel, whose transition matrix is given as . When the group action is given by , the above conditional additive channel is given as a regular channel. In this case, there are orbits, and the size of each orbit is , respectively. This fact shows that any conditional additive channel is written as a regular channel. That is, it shows the “if” part of Theorem 15.
Conversely, we present the conversion from a regular channel to a conditional additive channel. We first explain the construction for the single-shot channel. For random variable , let and be the random variable describing the representatives of the orbits. For and each orbit , we fix an element . Then, we define:
Then, we obtain the virtual channel as . Using the conditional distributions and as:
we obtain the relations:
These two equations show that the receiver information of the virtual conditional additive channel and the receiver information of the regular channel can be converted into each other. Hence, we can say that a regular channel in the sense of [31] can be written as a conditional additive channel, which shows the “only if” part of Theorem 15.
Example 5
(Binary erasure symmetric channel revisited). We convert the regular channel of Example 4 to a conditional additive channel. Let us label the orbit as and as . Let and .
When we consider the nth extension, a channel is given by:
where the nth extension of the group action is defined by .
Similarly, for n-fold extension, we can also construct the virtual conditional additive channel. More precisely, for , we set and:
4.3. Conversion of the BPSK-AWGN Channel into the Conditional Additive Channel
Although we only considered finite input/output sources and channels throughout the paper, in order to demonstrate the utility of the conditional additive channel framework, let us consider the additive white Gaussian noise (AWGN) channel with binary phase shift keying (BPSK) in this section. Let be the input alphabet of the channel, and let be the output alphabet of the channel. For an input and Gaussian noise Z with mean zero and variance , the output of the channel is given by . Then, the conditional probability density function of this channel is given as:
Now, to define a conditional additive channel, we choose and define the probability density function on with respect to the Lebesgue measure and the conditional distribution as:
for . When we define for and , we have:
The relations (202) and (206) show that the AWGN channel with BPSK is given as a conditional additive channel in the above sense.
By noting this observation, as explained in Remark 5, the single-shot achievability bounds in Section 3.2 are also valid for continuous Y. Furthermore, the discussions for the single-shot converse bounds in Section 4.5 hold even for continuous Y. Therefore, the bounds in Section 4.4 and Section 4.5 are also applicable to the BPSK-AWGN channel.
In particular, in the n memoryless extension of the BPSK-AWGN channel, the information measures for the noise distribution are given as n times the single-shot information measures for the noise distribution. Even in this case, the upper and lower bounds in Section 4.4 and Section 4.5 are also applicable by replacing the information measures by n times the single-shot information measures. Therefore, we obtain finite-length upper and lower bounds of the optimal coding length for the memoryless BPSK-AWGN channel. Furthermore, even though the additive noise is not Gaussian, when the probability density function of the additive noise Z satisfies the symmetry , the BPSK channel with the additive noise Z can be converted to a conditional additive channel in the same way.
4.4. Achievability Bound Derived by Source Coding with Side-Information
In this subsection, we give a code for a conditional additive channel from a code of source coding with side-information in a canonical way. In this construction, we see that the decoding error probability of the channel code equals that of the source code.
When the channel is given as the conditional additive channel with conditional additive noise distribution as (186) and is the finite field , we can construct a linear channel code from a source code with full side-information whose encoder and decoder are and as follows. First, we assume linearity for the source encoder . Let be the kernel of the linear encoder of the source code. Suppose that the sender sends a codeword and is received. Then, the receiver computes the syndrome , estimates from and , and subtracts the estimate from . That is, we choose the channel decoder as:
We succeed in decoding in this channel coding if and only if equals . Thus, the error probability of this channel code coincides with that of the source code for the correlated source . In summary, we have the following lemma, which was first pointed out in [27].
Lemma 19
([27], (19)). Given a linear encoder and a decoder for a source code with side-information with distribution , let and be the channel encoder and decoder induced by . Then, the error probability of channel coding for the conditionally additive channel with noise distribution satisfies:
Furthermore, (in fact, when we additionally impose the linearity on the random function F in the definition (114) for the definition of , the result in [27] implies that the equality in (209) holds) taking the infimum for chosen to be a linear two-universal hash function, we also have:
By using this observation and the results in Section 3.2, we can derive the achievability bounds. By using the conversion argument in Section 4.2, we can also construct a channel code for a regular channel from a source code with full side-information. Although the following bounds are just a specialization of known bounds for conditional additive channels, we review these bounds here to clarify the correspondence between the bounds in source coding with side-information and channel coding.
From Lemma 13 and (209), we have the following.
Lemma 20
([2]). The following bound holds:
From Lemma 14 and (209), we have the following exponential-type bound.
Lemma 21
([6]). The following bound holds:
From Lemma 15 and (209), we have the following slightly loose exponential bound.
Lemma 22
([3,70]). The following bound holds (The bound (212) was derived in the original Japanese edition of [3], but it is not written in the English edition [3]. The quantum analogue was derived in [70].):
When X has no side-information, i.e., the virtual channel is additive, we have the following special case of Lemma 21.
Lemma 23
([6]). Suppose that X has no side-information. Then, the following bound holds:
4.5. Converse Bound
In this subsection, we show some converse bounds. The following is the information spectrum-type converse shown in [4].
Lemma 24
([4], Lemma 4). For any code and any output distribution , we have:
When a channel is a conditional additive channel, we have:
By taking the output distribution as:
for some , as a corollary of Lemma 24, we have the following bound.
Lemma 25.
When a channel is a conditional additive channel, for any distribution , we have:
Proof.
A similar argument as in Theorem 5 also derives from the following converse bound.
Theorem 16.
Proof.
See Appendix L. □
4.6. Finite-Length Bound for the Markov Noise Channel
From this section, we address the conditional additive channel whose conditional additive noise is subject to the Markov chain. Here, the input alphabet equals the additive group , and the output alphabet is . That is, the transition matrix describing the channel is given by using a transition matrix W on and an initial distribution Q as:
As in Section 2.2, we consider two assumptions on the transition matrix W of the noise process , i.e., Assumptions 1 and 2. We also use the same notations as in Section 2.2.
Example 6
(Gilbert–Elliot channel with state-information available at the receiver). The Gilbert–Elliot channel [29,30] is characterized by a channel state on and an additive noise on . The noise process is a Markov chain induced by the transition matrix W introduced in Example 3. For the channel input , the channel output is given by when the state-information is available at the receiver. Thus, this channel can be regarded as a conditional additive channel, and the transition matrix of the noise process satisfies Assumption 2.
Proofs of the following bounds are almost the same as those in Section 3.3, and thus omitted. The combination of Lemmas 10 and 22 derives the following achievability bound.
Theorem 17
(Direct, Ass. 1). Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 1. Let . Then, we have:
Theorem 16 for and Lemma 10 yield the following converse bound.
Theorem 18
Next, we derive tighter bounds under Assumption 2. From Lemmas 11 and 21, we have the following achievability bound.
Theorem 19
(Direct, Ass. 2). Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 2. Let . Then, we have:
By using Theorem 16 for and Lemma 12, we obtain the following converse bound.
Theorem 20
Finally, when X has no side-information, i.e., the channel is additive, we obtain the following achievability bound from Lemma 23.
Theorem 21
(Direct, no-side-information). Let . Then, we have:
Remark 9.
Our treatment for the Markov conditional additive channel covers Markov regular channels because Markov regular channels can be reduced to Markov conditional additive channels as follows. Let be a Markov chain on whose distribution is given by:
for a transition matrix and an initial distribution Q. Let be the noise process of the conditional additive channel derived from the noise process of the regular channel by the argument of Section 4.2. Since we can write:
the process is also a Markov chain. Thus, the regular channel given by is reduced to the conditional additive channel given by .
4.7. Second-Order
To discuss the asymptotic performance, we introduce the quantity:
By applying the central limit theorem (cf. [67] (Theorem 27.4, Example 27.6)) to Lemmas 20 and 25 for , and by using Theorem 2, we have the following.
Theorem 22.
Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 1. For arbitrary , we have:
Proof.
This theorem follows in the same manner as the proof of Theorem 11 by replacing Lemma 13 with Lemma 20 (achievability) and Lemma 18 with Lemma 25 (converse). □
From the above theorem, the (first-order) capacity of the conditional additive channel under Assumption 1 is given by:
for every . In the next subsections, we consider the asymptotic behavior of the error probability when the rate is smaller than the capacity in the moderate deviation regime and the large deviation regime, respectively.
4.8. Moderate Deviation
From Theorems 17 and 18, we have the following.
Theorem 23.
Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 1. For arbitrary and , we have:
Proof.
The theorem follows in the same manner as Theorem 12 by replacing Theorem 6 with Theorem 17 (achievability) and Theorem 8 with Theorem 18 (converse). □
4.9. Large Deviation
From Theorem 17 and Theorem 18, we have the following.
Theorem 24.
Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 1. For , we have:
On the other hand, for , we have:
Proof.
The theorem follows in the same manner as Theorem 13 by replacing Theorem 6 with Theorem 17 (achievability) and Theorem 8 with Theorem 18 (converse). □
Under Assumption 2, from Theorems 19 and 20, we have the following tighter bound.
Theorem 25.
Suppose that the transition matrix W of the conditional additive noise satisfies Assumption 2. For , we have:
On the other hand, for , we have:
Proof.
The theorem follows the same manner as Theorem 14 by replacing Theorem 9 with Theorem 19 and Theorem 10 with Theorem 20. □
When X has no side-information, i.e., the channel is additive, from Theorem 21 and (245), we have the following.
Theorem 26.
For , we have:
On the other hand, for , we have:
Proof.
The first claim follows by taking the limit of Theorem 21, and the second claim follows as a special case of (245) without side-information. □
4.10. Summary of the Results
The results shown in this section for the Markov conditional additive noise are summarized in Table 3. The check marks 🗸 indicate that the tight asymptotic bounds (large deviation, moderate deviation, and second-order) can be obtained from those bounds. The marks 🗸 indicate that the large deviation bound can be derived up to the critical rate. The computational complexity “Tail” indicates that the computational complexities of those bounds depend on the computational complexities of tail probabilities. It should be noted that Theorem 18 is derived from a special case () of Theorem 16. The asymptotically optimal choice is . Under Assumption 1, we can derive the bound of the Markov case only for that special choice of , while under Assumption 2, we can derive the bound of the Markov case for the optimal choice of . Furthermore, Theorem 18 is not asymptotically tight in the large deviation regime in general, but it is tight if X has no side-information, i.e., the channel is additive. It should be also noted that Theorem 20 does not imply Theorem 18 even for the additive channel case since Assumption 2 restricts the structure of transition matrices even when X has no side-information.
Table 3.
Summary of the finite-length bounds for channel coding.
5. Discussion and Conclusions
In this paper, we developed a unified approach to source coding with side-information and channel coding for a conditional additive channel for finite-length and asymptotic analyses of Markov chains. In our approach, the conditional Rényi entropies defined for transition matrices played important roles. Although we only illustrated the source coding with side-information and the channel coding for a conditional additive channel as applications of our approach, it could be applied to some other problems in information theory such as random number generation problems, as shown in another paper [60].
Our obtained results for the source coding with side-information and the channel coding of the conditional additive channel has been extended to the case when the side-information is continuous like the real line and the joint distribution X and Y is memoryless. Since this case covers the BPSK-AWGN channel, it can be expected that it covers the MPSK-AWGN channel. Since such channels are often employed in the real channel coding, it is an interesting future topic to investigate the finite-length bound for these channels. Further, we could not define the conditional Rényi entropy for transition matrices of continuous Y. Hence, our result could not be extended to such a continuous case. It is another interesting future topic to extend the obtained result to the case with continuous Y.
Author Contributions
Conceptualization, M.H.; methodology, S.W.; formal analysis, S.W. and M.H.; writing, original draft preparation, S.W.; writing, review and editing, M.H. All authors read and agreed to the published version of the manuscript.
Funding
M.H. is partially supported by the Japan Society of the Promotion of Science (JSPS) Grant-in-Aid for Scientific Research (A) No. 23246071, (A) No. 17H01280, (B) No. 16KT0017, the Okawa Research Grant, and Kayamori Foundation of Informational Science Advancement. He is also partially supported by the National Institute of Information and Communication Technology (NICT), Japan. S.W. is supported in part by the Japan Society of the Promotion of Science (JSPS) Grant-in-Aid for Young Scientists (A) No. 16H06091.
Acknowledgments
The authors would like to thank Vincent Y. F. Tan for pointing out Remark 6. The authors are also grateful to Ryo Yaguchi for his helpful comments.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; nor in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| RCU | random coding union |
| BSC | binary symmetric channel |
| DMC | discrete memoryless channel |
| DT | dependence testing |
| LDPC | low-density parity check |
| BPSK | binary phase shift keying |
| AWGN | additive white Gaussian noise |
| CGF | cumulant generating function |
| MPSK | M-ary phase shift keying |
| CC | channel coding |
| SC | source coding |
| SI | side-information |
Appendix A. Preparation for the Proofs
When we prove some properties of Rényi entropies or derive converse bounds, some properties of cumulant generating functions (CGFs) become useful. For this purpose, we introduce some terminologies in statistics from [22,23]. Then, in Appendix B, we show the relation between the terminologies in statistics and those in information theory. For the proofs, see [22,23].
Appendix A.1. Single-Shot Setting
Let Z be a random variable with distribution P. Let:
be the cumulant generating function (CGF). Let us introduce an exponential family:
By differentiating the CGF, we find that:
We also find that:
We assume that Z is not constant. Then, (A6) implies that is a strict convex function and is monotonically increasing. Thus, we can define the inverse function of by:
Let:
be the Rényi divergence. Then, we have the following relation:
Appendix A.2. Transition Matrix
Let be an ergodic and irreducible transition matrix, and let be its stationary distribution. For a function , let:
We also introduce the following tilted matrix:
Let be the Perron–Frobenius eigenvalue of . Then, the CGF for W with generator g is defined by:
Lemma A1.
The function is a convex function of ρ, and it is strict convex iff .
From Lemma A1, is a monotone increasing function. Thus, we can define the inverse function of by:
Appendix A.3. Markov Chain
Let be the Markov chain induced by and an initial distribution . For functions and , let . Then, the CGF for is given by:
We will use the following finite evaluation for .
Lemma A2.
Let be the eigenvector of with respect to the Perron–Frobenius eigenvalue such that . Let . Then, we have:
where:
From this lemma, we have the following.
Corollary A1.
For any initial distribution and , we have:
The relation:
is well known. Furthermore, we also have the following.
Lemma A3.
For any initial distribution, we have:
Appendix B. Relation Between CGF and Conditional Rényi Entropies
Appendix B.1. Single-Shot Setting
For correlated random variable , let us consider . Then, the relation between the CGF and conditional Rényi entropy relative to is given by:
From this, we can also find that the relationship between the inverse functions (cf. (29) and (A7)):
Thus, the inverse function defined in (32) also satisfies:
Similarly, by setting , we have:
Then, the variance (cf. (11)) satisfies:
Let be the CGF of (cf. (15) for the definition of ). Then, we have:
It should be noted that is a CGF for fixed , but cannot be treated as a CGF.
Appendix B.2. Transition Matrix
For transition matrix , we consider the function given by:
Then, the relation between the CGF and the lower conditional Rényi entropy is given by:
Then, the variance defined in (51) satisfies:
Appendix C. Proof of Lemma 2
We use the following lemma.
Lemma A4.
For , we have:
Proof.
The left hand side inequality of (A31) is obvious from the definition of two Rényi entropies (the latter is defined by taking the maximum). The right-hand side inequality was proven in [71] (Lemma 6). □
Furthermore, since , we also have:
Appendix D. Proof of Lemma 3
Statements 1 and 3 follow from the relationships in (A22) and (A25) and the strict convexity of the CGFs.
To prove Statement 5, we first prove the strict convexity of the Gallager function:
for . We use the Hölder inequality:
for such that , where the equality holds iff for some constant c. For , let , which implies:
and:
Then, by applying the Hölder inequality twice, we have:
The equality in the second inequality holds iff:
for some constant c. Furthermore, the equality in the first inequality holds iff . Substituting this into (A44), we find that is irrespective of y. Thus, both the equalities hold simultaneously iff . Now, since:
we have:
for , where the equality holds iff .
Statement 7 is obvious from the definitions of the two measures. The first part of Statement 8 follows from (A27) and the convexity of the CGF, but we need another argument to check the conditions for strict concavity. Since the second term of:
is linear with respect to , it suffices to show the strict concavity of the first term. By using the Hölder inequality twice, for , we have:
where both the equalities hold simultaneously iff , which can be proven in a similar manner as the equality conditions in (A40) and (A43). Thus, we have the latter part of Statement 8.
Statements 10–12 are also obvious from the definitions. Statements 2, 4, 6, and 9, follow from Statements 1, 3, 5, and 8, (cf. [71], Lemma 1).
Appendix E. Proof of Lemma 4
Since (24) and (28) are obvious from the definitions, we only prove (26). We note that:
and:
where:
Appendix F. Proof of Lemma 6
From Lemma A4, Theorems 1 and 3, we have:
for . Thus, we can prove Lemma 6 in the same manner as Lemma 2.
Appendix G. Proof of (63)
First, in the same manner as Theorem 1, we can show:
where is a Markov chain induced by V for some initial distribution. Then, since for each n, by using Theorem 3, we have:
Thus, the rest of the proof is to show that is attainable by some V.
Let be the normalized left eigenvector of , and let:
Then, attains the maximum. To prove this, we will show that is the Perron–Frobenius eigenvalue of:
Since is a positive vector and the Perron–Frobenius eigenvector is the unique positive eigenvector, we find that is the Perron–Frobenius eigenvalue. Thus, we have:
Appendix H. Proof of Lemma 7
Statement 1 follows from (A29) and the strict convexity of the CGF. Statements 5 and 8–10 follow from the corresponding statements in Lemma 3, Theorems 1, 3 and 4.
Now, we prove (the concavity of follows from the limiting argument, i.e., the concavity of (cf. Lemma 3) and Theorem 3. However, the strict concavity does not follow from the limiting argument; Statement 3. For this purpose, we introduce the transition matrix counterpart of the Gallager function as follows. Let:
for , which is well defined under Assumption 2. Let be the Perron–Frobenius eigenvalue of , and let and be its normalized right and left eigenvectors. Then, let:
be a parametrized transition matrix. The stationary distribution of is given by:
We prove the strict convexity of for . Then, by the same reason as (A46), we can show Statement 3. Let . By the same calculation as [22] (Proof of Lemmas 13 and 14), we have:
Furthermore, from the definition of , we have:
Now, we show the convexity of for each . By using the Hölder inequality (cf. Appendix D), for , we have:
Thus, is convex. To check strict convexity, we note that the equality in (A78) holds iff . Since:
does not depend on from Assumption 2, we have for some integer . By substituting this into , we have:
On the other hand, we note that the CGF is defined as the logarithm of the Perron–Frobenius eigenvalue of:
Since:
is the Perron–Frobenius eigenvalue of (A81), and thus, we have when the equality in (A78) holds for every such that . Since is strict convex if , is strict convex if . Thus, is strict concave if . On the other hand, from (57), is strict concave only if .
Statement 6 can be proven by modifying the proof of Statement 8 of Lemma 3 to a transition matrix in a similar manner as Statement 3 of the present lemma.
Finally, Statements 2, 4 and 7 follow from Statements 1, 3 and 6 (cf. [71], Lemma 1).
Appendix I. Proof of Lemma 9
We only prove (75) since we can prove (76) exactly in the same manner by replacing , , and by , , and . Let:
Then, we have:
Since is monotonically increasing and is monotonically decreasing, we have for and for . Thus, takes its maximum at . Furthermore, since for , we have:
where we substituted in the second equality.
Appendix J. Proof of Lemma 11
Let u be the vector such that for every . From the definition of , we have the following sequence of calculations:
which implies the left-hand side inequality, where we used Assumption 2 in . On the other hand, we have the following sequence of calculations:
which implies the right-hand side inequality.
Appendix K. Proof of Theorem 5
For arbitrary , we set and , where:
Then, by the monotonicity of the Rényi divergence, we have:
Thus, we have:
Now, by using Lemma 18, we have:
We also have, for any ,
Thus, by setting so that:
we have
Furthermore, we have the relation:
Thus, by substituting and and by using (A22), we can derive (124).
Now, we restrict the range of so that and take:
Appendix L. Proof of Theorem 16
Let:
and let be a conditional additive channel defined by:
We also define the joint distribution of the message, the input, the output, and the decoded message for each channel:
For arbitrary , let and . Then, by the monotonicity of the Rényi divergence, we have:
Thus, we have:
Here, we have:
On the other hand, from Lemma 25, we have:
Now, we restrict the range of so that and take:
Then, by noting (A22), we have (223).
References
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Verdú, S.; Han, T.S. A general fomula for channel capacity. IEEE Trans. Inform. Theory 1994, 40, 1147–1157. [Google Scholar] [CrossRef]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Hayashi, M.; Nagaoka, H. General formulas for capacity of classical-quantum channels. IEEE Trans. Inf. Theory 2003, 49, 1753–1768. [Google Scholar] [CrossRef]
- Wang, L.; Renner, R. One-shot classical-quantum capacity and hypothesis testing. Phys. Rev. Lett. 2012, 108, 200501. [Google Scholar] [CrossRef] [PubMed]
- Gallager, R.G. A simple derivation of the coding theorem and some applications. IEEE Trans. Inf. Theory 1965, 11, 3–18. [Google Scholar] [CrossRef]
- Polyanskiy, Y. Channel coding: Non-Asymptotic Fundamental Limits. Ph.D. Dissertation, Princeton University, Princeton, NJ, USA, November 2010. [Google Scholar]
- Tomamichel, M.; Hayashi, M. A hierarchy of information quantities for finite block length analysis of quantum tasks. IEEE Trans. Inform. Theory 2013, 59, 7693–7710. [Google Scholar] [CrossRef]
- Matthews, W.; Wehner, S. Finite blocklength converse bounds for quantum channels. IEEE Trans. Inf. Theory 2014, 60, 7317–7329. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons: Hoboken, NJ, USA, 1968. [Google Scholar]
- Hayashi, M. Information spectrum approach to second-order coding rate in channel coding. IEEE Trans. Inf. Theory 2009, 55, 4947–4966. [Google Scholar] [CrossRef]
- Hayashi, M. Second-order asymptotics in fixed-length source coding and intrinsic randomness. IEEE Trans. Inf. Theory 2008, 54, 4619–4637. [Google Scholar] [CrossRef][Green Version]
- Altug, Y.; Wagner, A.B. Moderate deviation analysis of channel coding: Discrete memoryless case. In Proceedings of the IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 265–269. [Google Scholar]
- He, D.; Lastras-Montano, L.A.; Yang, E.; Jagmohan, A.; Chen, J. On the redundancy of slepian-wolf coding. IEEE Trans. Inf. Theory 2009, 55, 5607–5627. [Google Scholar] [CrossRef]
- Tan, V.Y.F. Moderate-deviations of lossy source coding for discrete and gaussian sources. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 920–924. [Google Scholar]
- Kuzuoka, S. A simple technique for bounding the redundancy of source coding with side-information. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 915–919. [Google Scholar]
- Yang, E.; Meng, J. New nonasymptotic channel coding theorems for structured codes. IEEE Trans. Inf. Theory 2015, 61, 4534–4553. [Google Scholar] [CrossRef]
- Arimoto, S. Information measures and capacity of order α for discrete memoryless channels. In Colloquia Mathematica Societatis Janos Bolyai, 16. Topics in Information Theory; Elsevier: Amsterdam, The Netherlands, 1975; pp. 41–52. [Google Scholar]
- Hayashi, M. Exponential decreasing rate of leaked information in universal random privacy amplification. IEEE Trans. Inf. Theory 2011, 57, 3989–4001. [Google Scholar] [CrossRef]
- Teixeira, A.; Matos, A.; Antunes, L. Conditional Rényi entropies. IEEE Trans. Inf. Theory 2012, 58, 4273–4277. [Google Scholar] [CrossRef]
- Iwamoto, M.; Shikata, J. Information theoretic security for encryption based on conditional Rényi entropies. In Information Theoretic Security ICITS 2013; Padró, C., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 103–121. [Google Scholar]
- Hayashi, M.; Watanabe, S. Information geometry approach to parameter estimation in Markov chains. Ann. Stat. 2016, 44, 1495–1535. [Google Scholar] [CrossRef]
- Watanabe, S.; Hayashi, M. Finite-length analysis on tail probability and simple hypothesis testing for Markov chain. Ann. Appl. Probab. 2017, 27, 811–845. [Google Scholar] [CrossRef]
- Wyner, A.D. Recent results in the shannon theory. IEEE Trans. Inf. Theory 1974, 20, 2–10. [Google Scholar] [CrossRef]
- Csiszár, I. Linear codes for sources and source networks: Error exponents, universal coding. IEEE Trans. Inf. Theory 1982, 28, 585–592. [Google Scholar] [CrossRef]
- Ahlswede, R.; Dueck, G. Good codes can be produced by a few permutations. IEEE Trans. Inf. Theory 1982, 28, 430–443. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A.; Lastras-Montano, L.A.; Yang, E. On the linear codebook-level duality between Slepian-Wolf coding and channel coding. IEEE Trans. Inf. Theory 2009, 55, 5575–5590. [Google Scholar] [CrossRef]
- Hayashi, M. Tight exponential analysis of universally composable privacy amplification and its applications. IEEE Trans. Inf. Theory 2013, 59, 7728–7746. [Google Scholar] [CrossRef]
- Gilbert, E.N. Capacity of burst-noise for codes on burst-noise channels. Bell Syst. Tech. J. 1960, 39, 1253–1265. [Google Scholar] [CrossRef]
- Elliott, E.O. Estimates of error rates for codes on burst-noise channels. Bell Syst. Tech. J. 1963, 42, 1977–1997. [Google Scholar] [CrossRef]
- Delsarte, P.; Piret, P. Algebraic construction of shannon codes for regular channels. IEEE Trans. Inf. Theory 1982, 28, 593–599. [Google Scholar] [CrossRef]
- Tomamichel, M.; Tan, V.Y.F. Second-order coding rates for channels with state. IEEE Trans. Inf. Theory 2014, 60, 4427–4448. [Google Scholar] [CrossRef]
- Kemeny, J.G.; Snell, J. Finite Markov Chains; Springer: Berlin/Heidelberg, Germany, 1976. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; Wiley: Hoboken, NJ, USA, 1971. [Google Scholar]
- Tikhomirov, A.N. On the convergence rate in the central limit theorem for weakly dependent random variables. Theory Probab. Appl. 1980, 25, 790–890. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Meyn, P. Spectral theory and limit theorems for geometrically ergodic Markov processes. Ann. Appl. Probab. 2003, 13, 304–362. [Google Scholar] [CrossRef]
- Hervé, L.; Ledoux, J.; Patilea, V. A uniform Berry-Esseen theorem on m-estimators for geometrically ergodic Markov chains. Bernoulli 2012, 18, 703–734. [Google Scholar] [CrossRef]
- Watanabe, S.; Hayashi, M. Non-asymptotic analysis of privacy amplification via Rényi entropy and inf-spectral entropy. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 2715–2719. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Davisson, L.D.; Longo, G.; Sgarro, A. The error exponent for the noiseless encoding of finite ergodic Markov sources. IEEE Trans. Inform. Theory 1981, 27, 431–438. [Google Scholar] [CrossRef]
- Vašek, K. On the error exponent for ergodic Markov source. Kybernetika 1980, 16, 318–329. [Google Scholar]
- Zhong, Y.; Alajaji, F.; Campbell, L.L. Joint source-channel coding error exponent for discrete communication systems with Markovian memory. IEEE Trans. Inf. Theory 2007, 53, 4457–4472. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Dispersion of the Gilbert-Elliott channel. IEEE Trans. Inf. Theory 2011, 57, 1829–1848. [Google Scholar] [CrossRef]
- Kontoyiannis, I. Second-order noiseless source coding theorems. IEEE Trans. Inform. Theory 1997, 43, 1339–1341. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Verdú, S. Optimal lossless data compression: Non-asymptotic and asymptotics. IEEE Trans. Inf. Theory 2014, 60, 777–795. [Google Scholar] [CrossRef]
- Scarlett, J.; Martinez, A.; Fábregas, A.G.i. Mismatched decoding: Error exponents, second-order rates and saddlepoint approximations. IEEE Trans. Inform. Theory 2014, 60, 2647–2666. [Google Scholar] [CrossRef]
- Scarlett, J.; Martinez, A.; i Fabregas, A.G. The saddlepoint approximation: A unification of exponents, dispersions and moderate deviations. arXiv 2014, arXiv:1402.3941. [Google Scholar]
- Ben-Ari, I.; Neumann, M. Probabilistic approach to Perron root, the group inverse, and applications. Linear Multilinear Algebra 2010, 60, 39–63. [Google Scholar] [CrossRef]
- Lalley, S.P. Ruelle’s Perron-Frobenius theorem and the central limit theorem for additive functionals of one-dimensional Gibbs states. Adapt. Stat. Proced. Relat. Top. 1986, 8, 428–446. [Google Scholar]
- Kato, T. Perturbation Theory for Linear Operators; Springer: New York, NY, USA, 1980. [Google Scholar]
- Häggström, O.; Rosenthal, J.S. On the central limit theorem for geometrically ergodic markov chains. Electron. Commun. Probab. 2007, 12, 454–464. [Google Scholar]
- Kipnis, C.; Varadhan, S.R.S. Central limit theorem for additive functionals of reversible markov processes and applications to simple exclusions. Commun. Math. Phys. 1986, 104, 1–19. [Google Scholar] [CrossRef]
- Komorowski, C.L.T.; Olla, S. Fluctuations in Markov Processes: Time Symmetry and Martingale Approximation; Springer: Berlin, Germany, 2012. [Google Scholar]
- Meyn, S.P.; Tweedie, R.L. Markov Chains and Stochastic Stability; Springer: London, UK, 1993. [Google Scholar]
- Jones, G.L. On the Markov chain central limit theorem. Probab. Surv. 2004, 1, 299–320. [Google Scholar] [CrossRef]
- Tomamichel, M.; Berta, M.; Hayashi, M. Relating different quantum generalizations of the conditional Rényi entropy. J. Math. Phys. 2014, 55, 082206. [Google Scholar] [CrossRef]
- Hayashi, M. Large deviation analysis for classical and quantum security via approximate smoothing. IEEE Trans. Inf. Theory 2014, 60, 6702–6732. [Google Scholar] [CrossRef]
- Csiszár, I. Generalized cutoff rates and Rényi’s information measures. IEEE Trans. Inf. Theory 1995, 41, 6–34. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Verdú, S. Arimoto channel coding converse and Rényi divergence. In Proceedings of the 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Allerton, IL, USA, 29 September–1 October 2010; pp. 1327–1333. [Google Scholar]
- Hayashi, M.; Watanabe, S. Uniform random number generation from Markov chains: Non-asymptotic and asymptotic analyses. IEEE Trans. Inform. Theory 2016, 62, 1795–1822. [Google Scholar] [CrossRef]
- Kemeny, J.G.; Snell, J.L. Finite Markov Chains; Springer: New York, NY, USA, 1960. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Express: Cambridge, UK, 1985. [Google Scholar]
- Wegman, M.N.; Carter, J.L. New hash functions and their use in authentication and set equality. J. Comput. Syst. Sci. 1981, 22, 265–279. [Google Scholar] [CrossRef]
- Gallager, R.G. Source coding with side-information and universal coding. Proc. IEEE Int. Symp. Inf. Theory 1976. Available online: http://web.mit.edu/gallager/www/papers/paper5.pdf (accessed on 5 April 2020).
- Hayashi, M. Quantum Information: An Introduction; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Renner, R.; Wolf, S. Simple and tight bound for information reconciliation and privacy amplification. In Advances in Cryptology – ASIACRYPT 2005; ser. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 199–216. [Google Scholar]
- Billingsley, P. Probability and Measure; JOHN WILEY & SONS: Hoboken, NJ, USA, 1995. [Google Scholar]
- Cover, T. A proof of the data compression theorem of Slepian and Wolf for ergodic sources. IEEE Trans. Inf. Theory 1975, 21, 226–228. [Google Scholar] [CrossRef]
- Dembo, A.; Zeitouni, O. Large Deviations Techniques and Applications, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Hayashi, M. Error exponent in asymmetric quantum hypothesis testing and its application to classical-quantum channel coding. Phys. Rev. A 2007, 76, 062301. [Google Scholar] [CrossRef]
- Hayashi, M. Security analysis of ε-almost dual universal2 hash functions. IEEE Trans. Inf. Theory 2016, 62, 3451–3476. [Google Scholar] [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).