On a Class of Tensor Markov Fields


1
Computational Genomics Division, National Institute of Genomic Medicine, 14610 Mexico City, Mexico
2
Centro de Ciencias de la Complejidad, Universidad Nacional Autónoma de México, 04510 Mexico City, Mexico
Entropy 2020, 22(4), 451; https://doi.org/10.3390/e22040451
Submission received: 6 March 2020
/
Revised: 1 April 2020
/
Accepted: 9 April 2020
/
Published: 16 April 2020
(This article belongs to the Special Issue Data Science: Measuring Uncertainties)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Here, we introduce a class of Tensor Markov Fields intended as probabilistic graphical models from random variables spanned over multiplexed contexts. These fields are an extension of Markov Random Fields for tensor-valued random variables. By extending the results of Dobruschin, Hammersley and Clifford to such tensor valued fields, we proved that tensor Markov fields are indeed Gibbs fields, whenever strictly positive probability measures are considered. Hence, there is a direct relationship with many results from theoretical statistical mechanics. We showed how this class of Markov fields it can be built based on a statistical dependency structures inferred on information theoretical grounds over empirical data. Thus, aside from purely theoretical interest, the Tensor Markov Fields described here may be useful for mathematical modeling and data analysis due to their intrinsic simplicity and generality.
1. General Definitions
Here, we introduce Tensor Markov Fields, i.e., Markov random fields [1,2] over tensor spaces. Tensor Markov Fields (TMFs) represent the joint probability distribution for a set of tensor-valued random variables.
Let be one of such tensor-valued random variables. Here may represent either a variable , that may exist in a given context or layer (giving rise to a class of so-called multilayer graphical models or multilayer networks) or a single tensor-valued quantity . A TMF will be an undirected multilayer graph representing the statistical dependency structure of X as given by the joint probability distribution .
As an extension of the case of Markov random fields, a TMF is a multilayer graph formed by a set V of vertices or nodes (the ’s) and a set of edges connecting the nodes, either on the same layer or through different layers (Figure 1). The set of edges represents a neighborhood law N stating which vertex is connected (dependent) to which other vertex in the multilayer graph. With this in mind, a TMF can be also represented (slightly abusing notation) as . The set of neighbors of a given point will be denoted .
1.1. Configuration
It is possible to assign to each point in the multilayer graph, one of a finite set S of labels. Such assignment will be called a configuration. We will assign probability measures to the set of all possible configurations . Hence, represents the configuration restricted to the subset A of V. It is possible to think of as a configuration on the smaller multilayer graph restricting V to points of A (Figure 2).
1.2. Local Characteristics
It is also possible to extend the notion of local characteristics from MRFs. The local characteristics of a probability measure defined on are the conditional probabilities of the form:
i.e., the probability that the point t is assigned the value , given the values at all other points of the multilayer graph. In order to make explicit the tensorial nature of the multilayer graph , let us re-write Equation (1). Let us also recall the fact that the probability measure will define a tensor Markov random field (a TMF) if the local characteristics depend only of the knowledge of the outcomes at neighboring points, i.e., if for every
1.3. Cliques
Given an arbitrary graph (or in the present case a multilayer graph), we shall say that a set of points C is a clique if every pair of points in C are neighbors (see Figure 3). This definition includes the empty set as a clique. A clique is thus a set whose induced subgraph is complete, for this reason cliques are also called complete induced subgraphs or maximal subgraphs (although these latter term may be ambiguous).
1.4. Configuration Potentials
A potential is a way to assign a number to every subconfiguration of a configuration in the multilayer graph . Given a potential, we shall say that it defines (or better, induces) a dimensionless energy on the set of all configurations by
In the preceeding expression, for fixed , the sum is taken over all subsets including the empty set. We can define a probability measure, called the Gibbs measure induced by U as
with Z a normalization constant called the partition function.
In physics, the term potential is often used in connection with the so-called potential energies. Physicists often call a dimensionless potential energy, and they call a potential.
1.5. Gibbs Fields
A potential is called a nearest neighbor Gibbs potential if whenever A is not a clique. It is customary to refer as a Gibbs measure to a measure induced by a nearest neighbor Gibbs potential. However, it is possible to define more general Gibbs measures by considering other types of potentials.
The inclusion of all cliques in the calculation of the Gibbs measure is necessary to establish the equivalence between Gibbs random fields and Markov random fields. Let us see how a nearest neighbor Gibbs measure on a multilayer graph determines a TMF.
Let be a probability measure determined on by a nearest neighbor Gibbs potential :
With the product taken over all cliques C on the multilayer graph . Then,
Here is any configuration which agrees with at all points except .
For any clique C that does not contain , , So that all the terms that correspond to cliques that do not contain the point cancel both from the numerator and the denominator in Equation (10), therefore this probability depends only on the values at and its neighbors. defines thus a TMF.
A more general proof of this equivalence is given by Hammersley-Clifford theorem that will be presented in the following section.
2. Extended Hammersley Clifford Theorem
Here we will outline a proof for an extension of Hammersley-Clifford theorem for Tensor Markov Fields (i.e., we will show that a Tensor Markov Field is equivalent to a Tensor Gibbs Field).
Let be a multilayer graph representing a TMF as defined in the previous section. With , a set of vertices over a tensor field and N a neighborhood law that connects vertices over this tensor field. The field obeys the following neighborhood law given its Markov property (see Equation (2))
Here is any neighbor of . The Hammersley-Clifford theorem states that a MRF is also a local Gibbs field. In the case of a TMF we have the following expression:
In order to prove the equivalence of Equations (11) and (12), we will first bult a deductive (backward direction) part of the proof to be complemented with a constructive (forward direction) part as presented in the following subsections.
2.1. Backward Direction
Let us consider Equation (11) at the light of Bayes’ theorem:
Using a clique-approach to calculate the joint and marginal probabilities (see next subsection to support the following statement):
Let us split the product into two products, one over the set of cliques that contain (let us call it ) and another set formed by cliques not containing (let us call it ):
Factoring out the terms depending on (that do not contribute to cliques in the domain ):
The term does not involve (by construction) so, it can be factored out from the summation over in the denominator.
We can cancel the term in the numerator and denominator:
Then we multiply by
Remembering that ,
2.2. Forward Direction
In this subsection we will show how to express the clique potential functions , given the joint probability distribution over the tensor field and the Markov property.
Consider any subset of the multilayer graph . We define a candidate potential function (following Möbius inversion lemma) [3] as follows:
In order for to be a proper clique potential, it must satisfy the following two conditions:
- (i)
- (ii)
- whenever is not a clique
To prove (i), we need to show that all factors in cancel out, except for .
To do this, it will be useful to consider the following combinatorial expansion of zero:
Here, of course is the number of combinations of B elements from an A-element set.
Let us consider any subset of . Let us consider a factor . For the case of it occurs as . Such factor also occurs in subsets containg and other additional elements. If it includes and one additional element, there are such functions. The additional element creates an inverse factor . The functions over subsets containg and two additional elements contributes with a factor . If we continue this process and consider Equation (22), it is evident that all odd cardinality difference terms cancel out with all even cardinality difference terms so that the only remaining factor corresponds to equal to thus fulfilling condition (i).
In order to show how condition (ii) is fulfilled, we will need to use the Markov property of TMFs. Let us consider that is not a clique. Then it will be possible to find two nodes and in that are not connected to each other. Let us recall Equation (21):
An arbitrary subset may belong to any of the following classes: (i) a generic subset of ; (ii) ; (iii) or (iv) . If we write down Equation (23) factored down to these contributions we get:
Let us consider two of the factors in Equation (24) at the light of Bayes’ theorem:
We can notice that the priors in the numerator and denominator of Equation (25) are the same. We can then cancell them out. Since by definition and are conditionally independent given the rest of the multilayer graph, we can also replace the default value for instead.
Since and are conditionally independent given the rest of the multilayer graph, we can also replace the condition for with any other, without affecting . By adjusting this prior conveniently, we can write out:
3. An Information-Theoretical Class of Tensor Markov Fields
Let us consider again the set of tensor-valued random variables . It is possible to calculate, for every duplex in X, the mutual information function [4]:
Let us consider a multilayer graph scenario. From now on, the indices will refer to the random variables, whereas will be indices for the layers. and are the respective sampling spaces (that may, of course, be equal). In order to discard self-information, let us define the off-diagonal mutual information as follows:
With the bi-delta function defined as:
By having the complete set of off-diagonal mutual information functions for all the random variables and layers, it is possible to define the following hyper-matrix elements:
as well as:
Here is Heavyside’s function and is a lower bound for mutual information (a threshold) to be considered significant.
We call and the adjacency hypermatrix and the strength hypermatrix respectively (notice that ∘ in Equation (33) represents the product of a scalar times a hypermatrix). The adjacency hyper-matrix and the strength hyper-matrix define the (unweighted and weighted, respectively) neighborhood law of the associated TMF, hence the statistical dependency structure for the set of random variables and contexts (layers).
Although the adjacency and strength hypermatrices are indeed, proper representations of the undirected (unweighted and weighted) dependency structure of , it has been considered advantageous to embed them into a tensor linear structure, in order to be able to work out some of the mathematical properties of such fields relying on the methods of tensor algebra. One relevant proposal in this regard, has been advanced by De Domenico and collaborators, in the context of multilayer networks.
Following the ideas of De Domenico and co-workers [5], we introduce the unweighted and weighted adjacency 4-tensors (respectively) as follows:
Here, is a unit four-tensor whose role is to provide the hypermatrices with the desired linear properties (projections, contractions, etc.). Square brackets indicate that the indices and k belong to the and dimensions and ⊗ represents a form of a tensor matricization product (i.e., the one producing a 4-tensor out of a 4-index hypermatrix times a unitary 4-tensor).
3.1. Conditional Independence in Tensor Markov Fields
In order to discuss the conditional independence structure induced by the present class of TMFs, let us analyze Equation (32). As already mentioned, the hyper-adjacency matrix represents the neigborhood law (as given by the Markov property) on the multilayer graph (i.e., the TMF). Every non-zero entry on this hypermatrix represents a statistical dependence relation between two elements on X. The conditional dependence structure on TMFs inferred from mutual information measures via Equation (32) are related not only to the statistical independence conditions (as given by a zero mutual information measure between two elements), but also to the lower bound and in general to the dependency structure of the whole multilayer graph.
The definition of conditional independence (CI) for tensor random variables is as follows:
.
Here represents conditional independence between two random variables, were is the joint conditional cumulative distribution of and given and , and are realization events of the corresponding random variables.
In the case of MRFs (and by extension TMFs), CI is defined by means of (multi)graph separation: in this sense we say that iff separates from in the multilayer graph . This means that if we remove node there are no undirected paths from to in .
Conditional independence in random fields is often considered in terms of subsets of V. Let A, B and C be three subsets of V. The statement , which holds only iff C separates A from B in the multilayer graph , meaning that if we remove all vertices in C there will be no paths connecting any vertex in A to any vertex in B is called the global Markov property of TMFs.
The smallest set of vertices that renders a vertex conditionally independent of all other vertices in the multilayer graph is called its Markov blanket, denoted . If we define the closure of a node as then .
It is possible to show that in a TMF, the Markov blanket of a vertex is its set of first neighbors. This is called the undirected local Markov property. Starting from the local Markov property it is possible to show that two vertices and are conditionally independent given the rest if there is no direct edge between them. This has been called the pairwise Markov property.
If we denote by the set of undirected paths in the multilayer graph connecting vertices and , then the pairwise Markov property of a TMF can be stated as:
It is clear that the global Markov property implies the local Markov property which in turn implies the pairwise Markov property. For systems with positive definity probability densities, it has been probed (in the case of MRFs) that pairwise Markov actually implied global Markov (See [6] p. 119 for a proof). For the present extension this is important since it is easier to assess pairwise conditional independence statements.
3.2. Indepence Maps
Let denote the set of all conditional independence relations encoded by the multilayer graph (i.e., those CI relations given by the Global Markov property). Let be the set of all CI relations implied by the probability distribution . A multilayer graph will be called an independence map (I-map) for a probability distribution , if all CI relations implied by hold for , i.e., [6].
The converse statement is not necessarily true, i.e., there may be some CI relations implied by that are not encoded in the multilayer graph . We may be usually interested in minimal I-maps, i.e., I-maps from which none of the edges could be removed without destroying its CI properties.
Every distribution has a unique minimal I-map (and a given graph representation). Let . Let be the multilayer graph obtained by introducing edges between all pairs of vertices , such that , then is the unique minimal I-map. We call a perfect map of when there is no dependencies which are not indicated by , i.e., [6].
3.3. Conditional Independence Tests
Conditional independence tests are useful to evaluate whether CI conditions apply either exactly or in the case of applications under a certain bounded error. In order to be able to write down expressions for C.I. tests let us introduce the following conditional kernels [7]:
as well as their generalized recursive relations:
The conditional probability of given can be thus written as:
We can then write down expressions for Markov conditional independence as follows:
Following Bayes’ theorem, CI conditions –in this case– will be of the form:
Equation (42) is useful since in large scale data applications is computationally cheaper to work with joint and marginal probabilities rather than conditionals.
Now let us consider the case of conditional independence given several conditional variables. The case for CI given two variables could be written—using conditional kernels—as follows:
Hence,
Using Bayes’ theorem,
In order to generalize the previous results to CI relations given an arbitrary set of conditionals, let us consider the following sigma-algebraic approach:
Let be the -algebra of all subsets of X that do not contain or . If we consider the contravariant index with and the covariant index with , then there are such -algebras in X (let us recall that TMFs are undirected graphical models).
A relevant problem for network reconstruction is that of establishing the more general Markov pairwise CI conditions, i.e., the CI relations for every edge not drawn in the graph. Two arbitrary nodes and are conditionally independent given the rest of the graph iff:
By using conditional kernels, the recursive relations and Bayes’ theorem it is possible to write down expressions of the form:
The family of Equations (48) represent the CI relations for all the non-existing edges in the hypergraph , i.e., every pair of nodes and not-connected in must be conditionally independent given the rest of the nodes in the graph. These expression may serve to implement exact tests or optimization strategies for graph reconstruction and/or graph sparsification in applications considering a mutual information threshold as in Equation (32).
In brief, for every node pair with a mutual information value lesser than , the presented graph reconstruction approach will not draw an edge, hence implying CI between the two nodes given the rest. Such CI condition may be tested on the data to see whether it holds or the threshold itself can be determined by resorting to optimization schemes (e.g., error bounds) in Equation (48).
4. Graph Theoretical Features and Multilinear Structure
Once the probabilistic properties of TMFs have been set, it may be fit to briefly present some of their graph theoretical features, as well as some preliminaries as to the reasons to embed hyperadjecency matrices into multilayer adjacency tensors. Given that TMFs are indeed PGMs, some of their graph characteristics will result relevant here.
Since the work by De Domenico and coworkers [5] covers in great detail how the multilinear structure of the multilayer adjacency tensor allows the calculation of these quantities—usually as projection operations—we will only mention connectivity degree vectors since these are related with the size of the TMF dependency neighborhoods.
Let us recall multilayer adjacency tensors, as defined in Equations (34) and (35). To ease presentation, we will work with the unweighted tensor (Equation (34)). The multidegree centrality vector which contains the connectivity degrees of the nodes spanning different layers can be written as follows:
Here is a rank 2 tensor that contains a 1 in every component and is a rank 1 tensor that contains a 1 in every component—these quantities are called 1—tensors by De Domenico and coworkers [5]. It can be shown that is indeed given by the sums of the connectivity degree vectors corresponding to all different layers:
is the vector of connections that nodes in the set in layer h have to any other nodes in layer k. Whereas is the vector with connections in all the layers. Appropriate projections will yield measures such as the size of the neighborhood to a given vertex , the size of its Markov blanquet , or other similar quantities.
5. Specific Applications
After having considered some of the properties of this class of Tensor Markov Fields, it may become evident that aside from purely theoretical importance, there is a number of important applications that may arise as probabilistic graphical models in tensor valued problems, among the ones that are somewhat evident are the following:
Some of these problems are being treated indeed as multiple instances of Markov fields or as multipartite graphs or hypergraphs. However, it may become evident that when random variables across layers are interdependent (which is often the case), the definitions of potentials, cliques and partition functions, as well as the conditional statistical independence features become manageable (and in some cases even meaninful) under the presented formalism of Tensor Markov Fields.
6. Conclusions
Here we have presented the definitions and fundamental properties of Tensor Markov Fields, i.e., random Markov fields over tensor spaces. We have proved –by extending the results of Dobruschin, Hammersley and Clifford to such tensor valued fields– that tensor Markov fields are indeed Gibbs fields whenever strictly positive probability measures are considered. We also introduced a class of tensor Markov fields obtained by using information theoretical statistical dependence measures inducing local and global Markov properties, and show how these can be used as probabilistic graphical models in multi-context environments much in the spirit of the so-called multilayer network approach. Finally, we discuss the convenience of embedding tensor Markov fields in the multilinear tensor representation of multilayer networks.
Funding
This research received no external funding.
Conflicts of Interest
The author declares no conflict of interest.
References
- Dobruschin, R.L. The description of a random field by means of conditional probabilities and conditions of its regularity. Theory Probab. Appl. 1968, 13, 197–224. [Google Scholar] [CrossRef]
- Grimmett, G.R. A theorem about random fields. Bull. Lond. Math. Soc. 1973, 5, 81–84. [Google Scholar] [CrossRef]
- Rota, G.C. On the foundations of combinatorial theory I: Theory of Möbius functions. Probab. Theory Relat. Fields 1964, 2, 340–368. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- De Domenico, M.; Solé-Ribalta, A.; Cozzo, E.; Kivelä, M.; Moreno, Y.; Porter, M.A.; Gómez, S.; Arenas, A. Mathematical formulation of multilayer networks. Phys. Rev. X 2013, 3, 041022. [Google Scholar] [CrossRef] [Green Version]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques (Adaptive Computation and Machine Learning series). Mit Press. Aug 2009, 31, 2009. [Google Scholar]
- Williams, D. Probability with Martingales; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Hernández-Lemus, E.; Espinal-Enríquez, J.; de Anda-Jáuregui, G. Probabilistic multilayer networks. arXiv 2018, arXiv:1808.07857. [Google Scholar]
- De Anda-Jauregui, G.; Hernandez-Lemus, E. Computational Oncology in the Multi-Omics Era: State of the Art. Front. Oncol. 2020, 10, 423. [Google Scholar] [CrossRef]
- Hernández-Lemus, E.; Reyes-Gopar, H.; Espinal-Enríquez, J.; Ochoa, S. The Many Faces of Gene Regulation in Cancer: A Computational Oncogenomics Outlook. Genes 2019, 10, 865. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McGee, F.; Ghoniem, M.; Melançon, G.; Otjacques, B.; Pinaud, B. The state of the art in multilayer network visualization. In Computer Graphics Forum; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 38, pp. 125–149. [Google Scholar]
- Krejsa, M.; Koubová, L.; Flodr, J.; Protivínskỳ, J.; Nguyen, Q.T. Probabilistic prediction of fatigue damage based on linear fracture mechanics. Fract. Struct. Integr. 2017, 39, 143–159. [Google Scholar] [CrossRef] [Green Version]
- Abe, S.; Suzuki, N. Complex network of earthquakes. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1046–1053. [Google Scholar]
- Liu, F.; Cui, Y.; Wang, J.; Ji, D. Observability of probabilistic Boolean multiplex networks. Asian J. Control. 2020, 1, 1–8. [Google Scholar] [CrossRef]
Figure 1.
A Tensor Markov Field: represented as a multilayer graph spanning over with and . To illustrate, layer I is colored in blue and layer is colored green.
Figure 1.
A Tensor Markov Field: represented as a multilayer graph spanning over with and . To illustrate, layer I is colored in blue and layer is colored green.
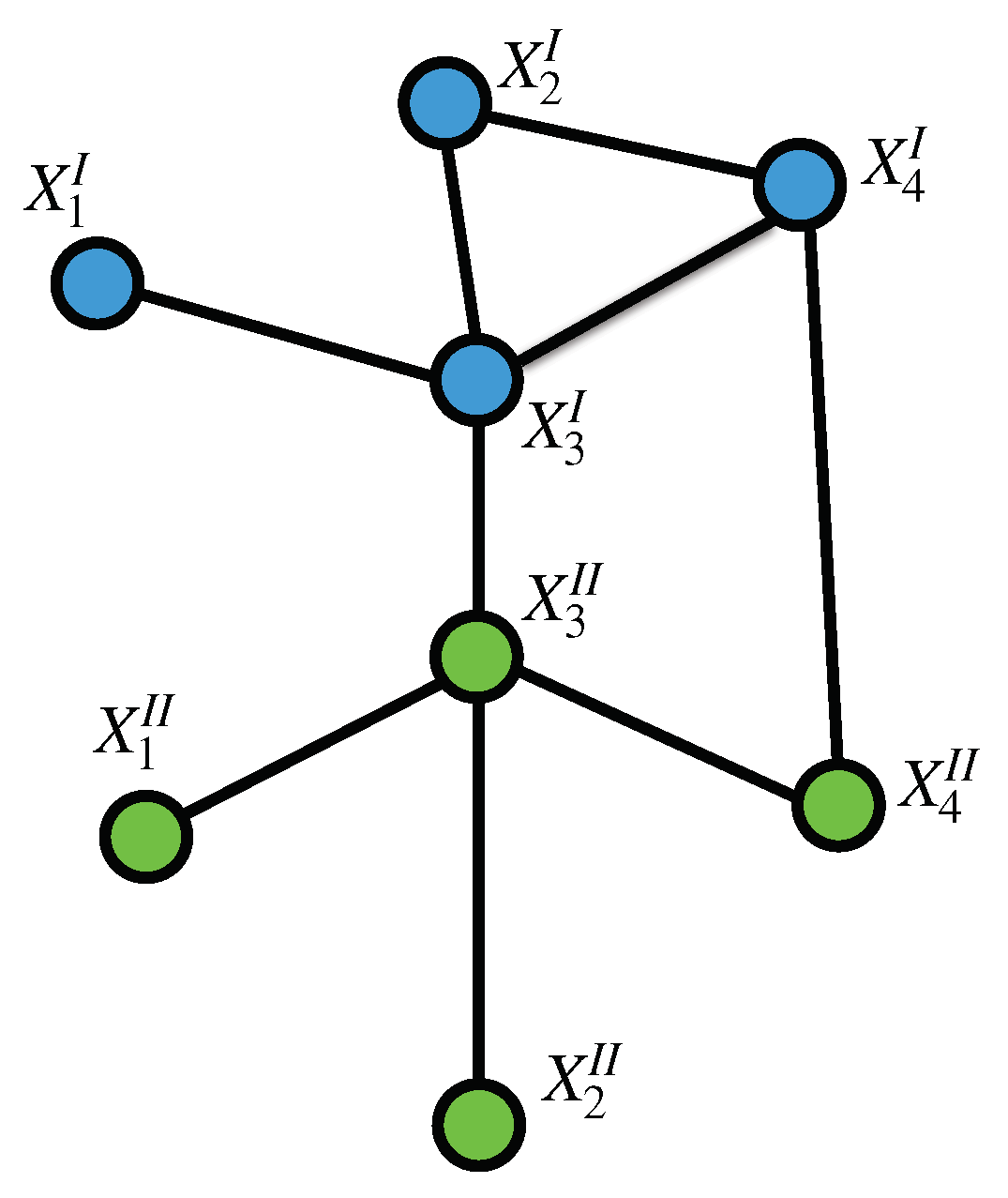
Figure 2.
Three different configurations of a Tensor Markov Fieldpanels (i), (ii) and (iii) present different configurations or states of the TMF. Labels are represented by color intensity.
Figure 2.
Three different configurations of a Tensor Markov Fieldpanels (i), (ii) and (iii) present different configurations or states of the TMF. Labels are represented by color intensity.
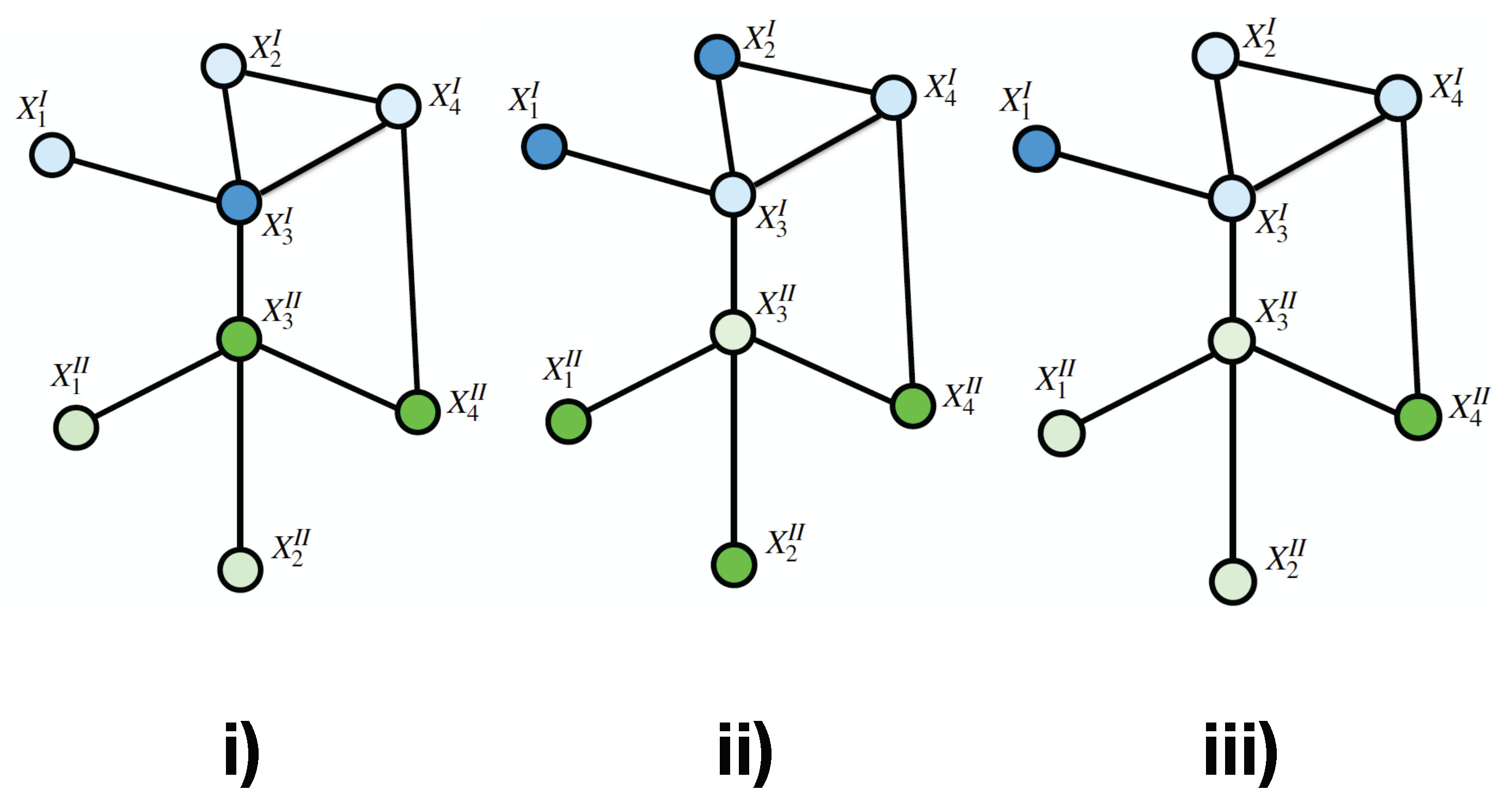
Figure 3.
Cliques on a Tensor Markov Field: The set forms an intra-layer 2-clique (as marked by the red edges, all on layer I), the set forms an inter-layer 1-clique (marked by the blue edge connecting layers I and ). However, the set is not a clique since there are no edges between and nor between and .
Figure 3.
Cliques on a Tensor Markov Field: The set forms an intra-layer 2-clique (as marked by the red edges, all on layer I), the set forms an inter-layer 1-clique (marked by the blue edge connecting layers I and ). However, the set is not a clique since there are no edges between and nor between and .
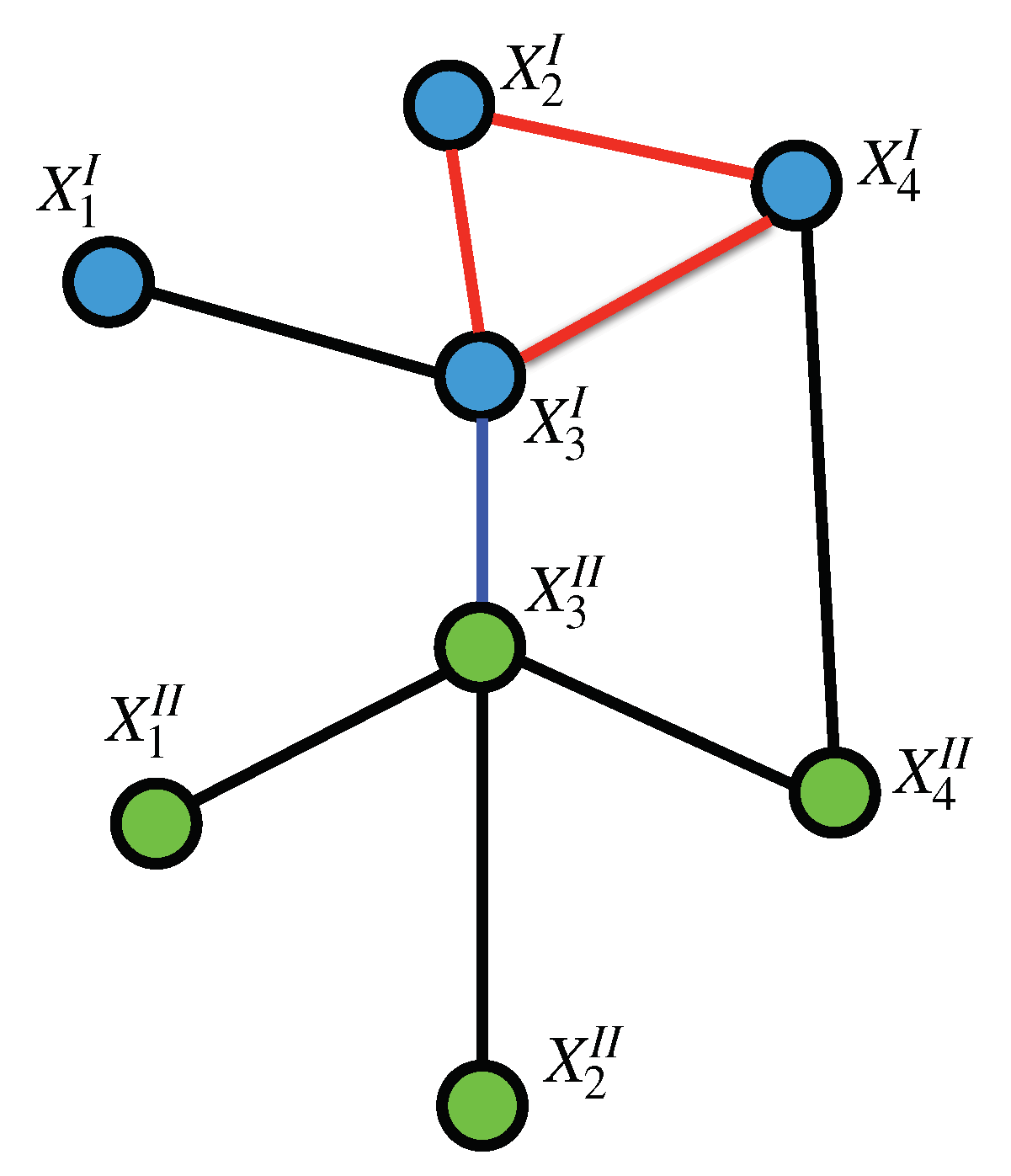
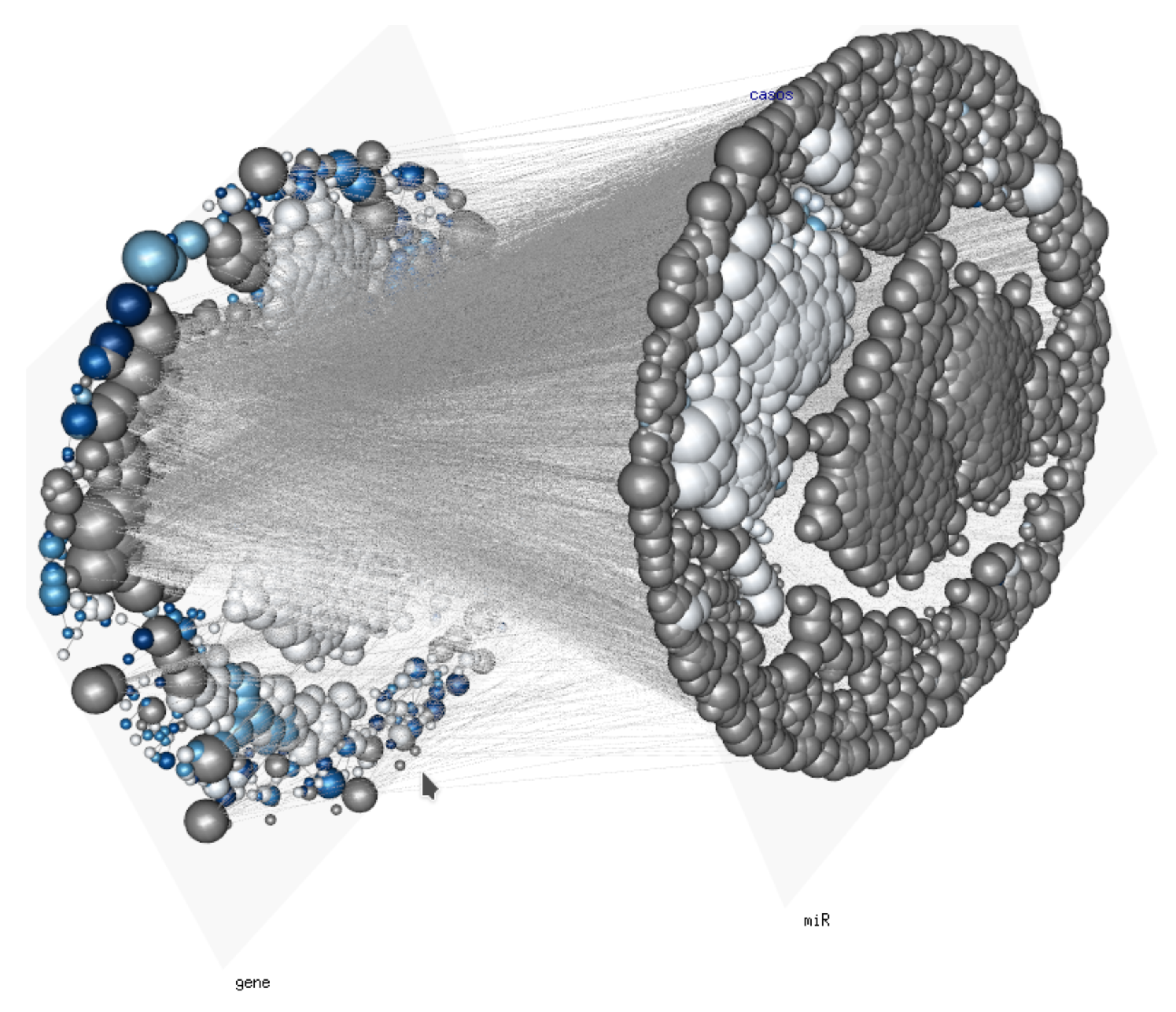
Figure 4.
Gene and microRNA regulatory network: A Tensor Markov Field depicting the statistical dependence of genome wide gene and microRNA (miR) on a human phenotype. Edge width is given by the mutual information between expression levels of genes (layer j) and miRs (layer k) in a very large corpus of RNASeq samples, vertex size is proportional to the degree, i.e., the size of the node’s neighborhood, .
Figure 4.
Gene and microRNA regulatory network: A Tensor Markov Field depicting the statistical dependence of genome wide gene and microRNA (miR) on a human phenotype. Edge width is given by the mutual information between expression levels of genes (layer j) and miRs (layer k) in a very large corpus of RNASeq samples, vertex size is proportional to the degree, i.e., the size of the node’s neighborhood, .
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hernández-Lemus, E. On a Class of Tensor Markov Fields. Entropy 2020, 22, 451. https://doi.org/10.3390/e22040451
AMA Style
Hernández-Lemus E. On a Class of Tensor Markov Fields. Entropy. 2020; 22(4):451. https://doi.org/10.3390/e22040451
Chicago/Turabian StyleHernández-Lemus, Enrique. 2020. "On a Class of Tensor Markov Fields" Entropy 22, no. 4: 451. https://doi.org/10.3390/e22040451
APA StyleHernández-Lemus, E. (2020). On a Class of Tensor Markov Fields. Entropy, 22(4), 451. https://doi.org/10.3390/e22040451
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.