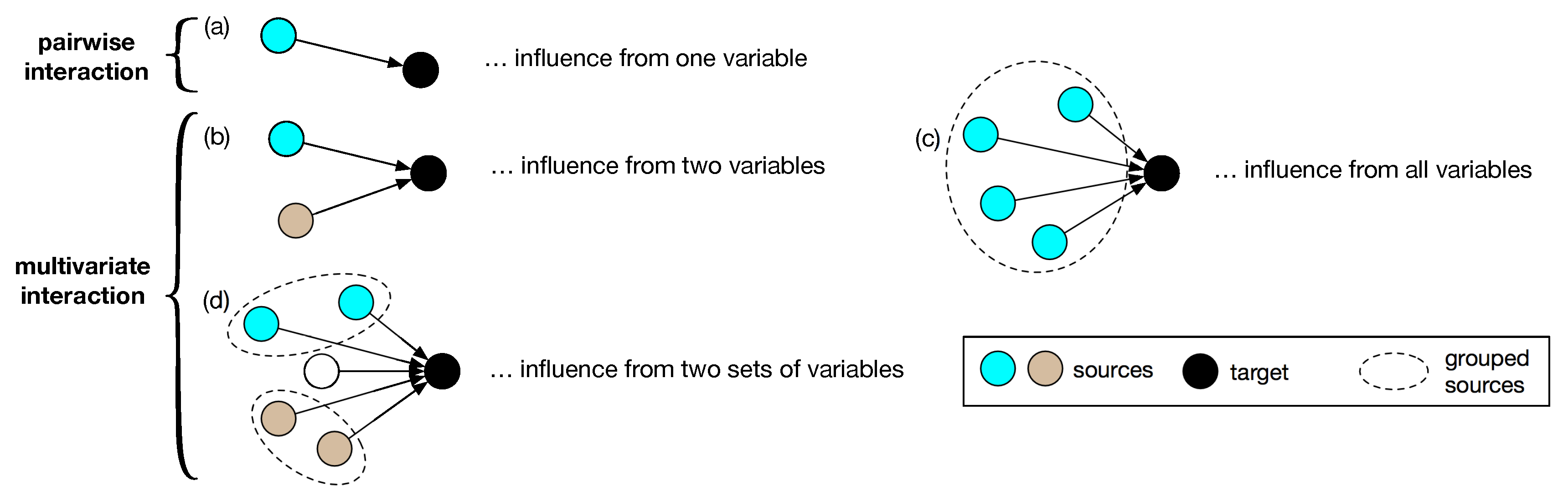
We consider complex systems that can be conceptualized as a multivariate system consisting of
N variables
, varying in time
t. The current state of a target variable,
, is an outcome of interactions in the entire evolutionary dynamics in the causal history [
10] prior to time
t,
. Among the influence from the entire causal history in
, here, we investigate the joint effect from the historical states of two specific groups of variables in
on
. We denote a bundled set containing
variables at time
t as
. The entire historical states of
is represented as
. Now, the aim of our study is to characterize how
is jointly driven by causal histories of two bundled sets,
and
, where
.
In the rest of this section, we first develop the information measures for delineating the information flow from the two bundled sets, and , to the target . Then, to achieve reliable information measure estimation, we introduce a two-stage dimensionality reduction approach to reduce the cardinality of the proposed measures.
2.1. Interactive Information Flow from Two Bundled Variables
Let us denote the remaining variables in the system outside of the two chosen bundles as
with \ as the exclusion symbol. The total information,
, given by the evolutionary dynamics of two bundled sets to the target
can then be expressed as a conditional mutual information (CMI) [
13] between the two bundled sets given the knowledge of
, which is given by:
where
. The conditioning on
is to exclude the influence from the interactions of the rest of the system in the quantification of the interaction between the two bundles. Note that
can belong to any variable in one of the bundled sets or to that in
. When
, Equation (
1) can be considered as a generalized transfer entropy [
7]. Transfer entropy captures the reduction in the uncertainty associated with the prediction of the current state of a variable given the knowledge of another variable that is in addition to that from the knowledge of its own history. This generalization allows us to characterize the reduction in uncertainty from multiple variables that are in addition to those provided by the variables own history or that of a set to which it belongs.
To characterize the information contents in
, we take advantage of Partial Information Decomposition (PID) [
11], which allows us to decompose
into: (1) redundant information
—the overlapping information given by two bundled causal histories,
and
; (2) synergistic information
—the joint information given by
and
; and (3) unique information
and
—the information provided by each bundled set,
and
, respectively. This is given by:
Before we develop quantitative estimation, we ask another related question: Do all the historical states in the bundled sets provide information to
? If the answer is no, then when does such influence end as the lag between
and any source node in
increases? Otherwise, how much information is given by very early dynamics in
? Answering these questions requires the assessment of the memory dependencies due to the bundled causal history
on
. Therefore, we partition the entire bundled causal history into two complementary components: (1) a recent dynamics from all the states up to a positive time lag
,
, termed immediate bundled causal history; and (2) the remaining earlier dynamics,
, termed distant bundled causal history. By using the chain rule of CMI [
14], we can decompose
in Equation (
1) into the information from the immediate (
) and distant (
) bundled causal histories, which are given by:
that is,
Note that information flow from the two partitioned histories,
and
in Equation (
3), are functions of
. Quantifying
and
along with
allows the investigation of the memory dependency due to the evolutionary interactions of the two bundled set [
10].
Partitioning
into immediate and distant causal histories further highlights the need to characterize the joint interactions of the two bundled sets in the two complementary historical states. This, again, can be achieved by using the PID approach, and is given by:
where the last equation reflects the sum of the corresponding terms in the previous two equations. Therefore, Equation (
4) illustrates the additive contribution of each information content (i.e., synergistic, redundant, and unique components) in the two partitioned histories,
and
, to the entire bundled causal history,
.
2.2. Two-Stage Dimensionality Reduction
Computing information flows in Equations (
1)–(
4) is infeasible due to the possibly infinite length of historical states involved, resulting in a joint probability density with infinite dimensions. To resolve this issue, we represent the temporal dependencies of the system as a Directed Acyclic Graph (DAG), where the dimensionality reduction is performed in the following two stages. First, we employ the probabilistic graphical model approach developed by Eichler and Runge [
8,
15] that allows a reduction of the infinite historical states in the above equations into a finite set, by assuming Markov property for the DAG. Then, a further dimension reduction is achieved through reducing the DAG by eliminating “redundant” edges. This elimination is performed by using weighted transitive reduction [
16] with momentary information transfer serving as the weights. This approach is called Momentary Information Weighted Transitive Reduction (MIWTR) [
12]. The second stage of dimensionality reduction is to avoid potential high albeit finite cardinalities of the joint probability in computing the information measures after the first round of reduction.
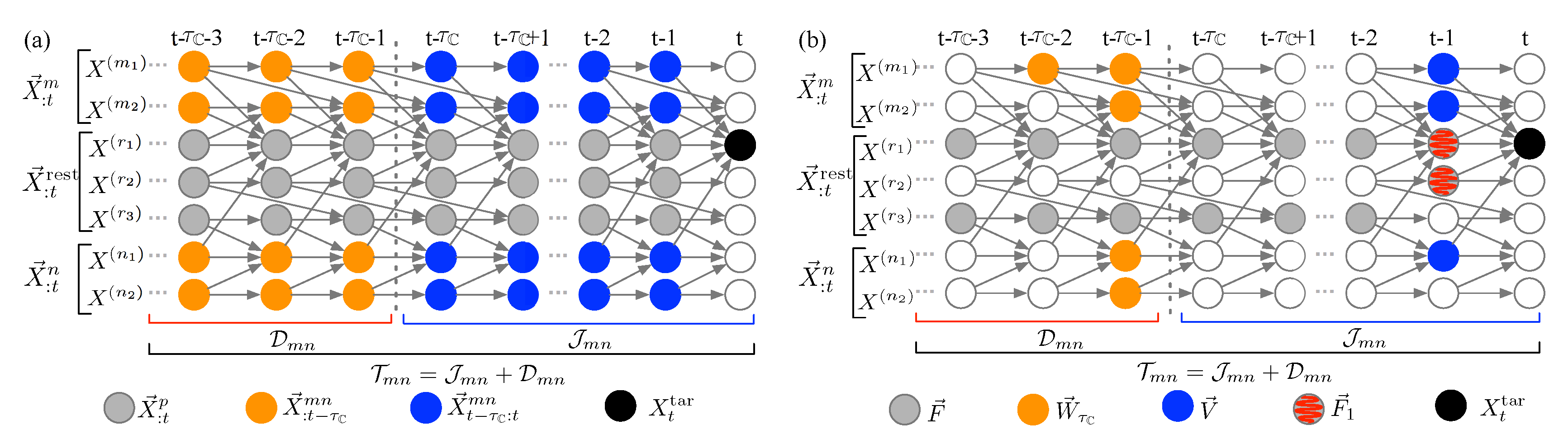
Stage 1: From infinite to finite cardinality—a probabilistic graphical model approach.Figure 2 illustrates the use of a DAG for time-series representation. The DAG,
, includes a set of directed edges
E and a set of nodes
connected by edges in
E. Every state in
is represented by a node in
, and a directed edge in
E connecting from an earlier node
to a recent node
(
),
, refers to the direct influence from
to
. An illustration of using the DAG for time-series to depict the temporal multivariate dynamics is shown in
Figure 2a through a system consisting of seven components,
. We consider
as the target,
as the first bundled causal history, and
as the second bundled causal history. The nodes involved in the bundled causal histories are highlighted in blue for immediate bundled causal history
up to the partitioning time lag
, and in orange for the remaining distant bundled causal history
. The historical states outsize of those two bundled sets in the system,
, are denoted as gray nodes.
Estimation of the quantities in Equations (
1) and (
3), and therefore the corresponding Equations (
2) and (
4), are challenging because the condition set has a large dimension due to its potentially very long history. Therefore, to avoid the curse of dimensionality in computing Equations (
1)–(
4), the Markov property for the DAG for time-series, as developed by Lauritzen et al. [
17], is assumed. Loosely speaking, the Markov property for the graphical model states that a node
is independent of its non-descendants in
given the knowledge of its parents, denoted by
. By using the Markov property, the information flow from the entire (
), the immediate (
), and the distant (
) bundled causal histories in Equations (
1) and (
3) can be revised as (see
Figure 2b):
where
is the parent set of all the nodes in the bundled causal history
and the target
;
is the intersection of the parents of the target,
, and the immediate bundled causal history,
; and
is the parent set of the immediate history belonging to the distant history.
Figure 2b illustrates
,
, and
in blue, orange, and gray nodes, respectively, in the seven-component system. Equation (
5) states that while information from immediate and distant bundled causal histories is aggregated at
and
influencing
, respectively, the conditioning on
blocks the information from the remaining dynamics in the system,
, on the interaction between
and
.
The usage of the Markov property successfully reduces the infinite nodes in immediate (
) and distant (
) bundled causal histories into two finite sets,
and
in Equation (
5), respectively. However, the condition set
in Equation (
5) still contains possibly infinite nodes, making the computation infeasible. Therefore, we now further adopt two orders of approximations on
, and explore the corresponding implications. At the zeroth order (Order-0), we assume the condition set to be empty, i.e.,
. This approach of not conditioning on the states in the remaining variables
allows the information from
to influence the estimation of the interaction between the target
and the bundled causal history. At the first order (Order-1) approximation, the condition set is allowed to include the parents of the target in the remaining variables
, i.e.,
, denoted as gray hatched nodes in
Figure 2b. The Order-0 approximation mimics the idea of mutual information, which aims at capturing the shared dependency between
and
. On the other hand, the Order-1 approximation is consistent with the insight of transfer entropy [
7], such that we prevent the influence of the states in the remaining system directly affecting the target, represented by
, from characterizing the information flowing from the bundled causal history. Note that the simplification due to the Markov property in Equation (
5) and the two approximations in the condition set
and
can be also used in computing the synergistic, redundant, and unique information in Equation (
4).
Stage 2: From high to low cardinality—MIWTR approach. The cardinality of Equation (
5) can be potentially high in a strongly interacting multivariate system, leading to higher uncertainty in the estimation of information measures. Here, we adopt a recently-proposed Momentary Information Weighted Transitive Reduction approach [
12] to further reduce the dimensionality of Equation (
5) by simplifying the DAG. The basic idea of MIWTR is to first exclude any “redundant” edges connecting a node in
with node in immediate history
by using weighted transitive reduction, and then remove any node in
which are now not directly linked to the nodes in
, thereby resulting in reduced cardinality of
. Here, the edge weight, representing the information flowing through the edge, is measured by momentary information transfer [
8] which quantifies the shared dependency between two linked nodes conditioned on their parents. The “redundancy” of a directed edge linking two nodes by using WTR, say
to
, is assessed according to the existence of an indirect path connecting
and
as well as the weights of the edges involved. That is, a directed edge,
, is considered “redundant” and thus removed, if and only if there exists a path indirectly linking
and
and the minimum weight of all the edges in this indirect pathway is larger than that of
. In other words, the existence of an indirect pathway, whose capacity of conveying information from
to
is stronger than the direct channel between the two nodes, makes the direct edge
obsolete. More details of MIWTR can be found in [
12].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




