Complex Contagion Features without Social Reinforcement in a Model of Social Information Flow


Abstract
1. Introduction
2. Background
2.1. Measuring Information Flow
2.2. Quoter Model
2.3. Other Models of Information Flow
3. Materials and Methods
3.1. The Quoter Model
3.2. Measuring Information Flow over the Network
3.3. Simulating Contagion Models
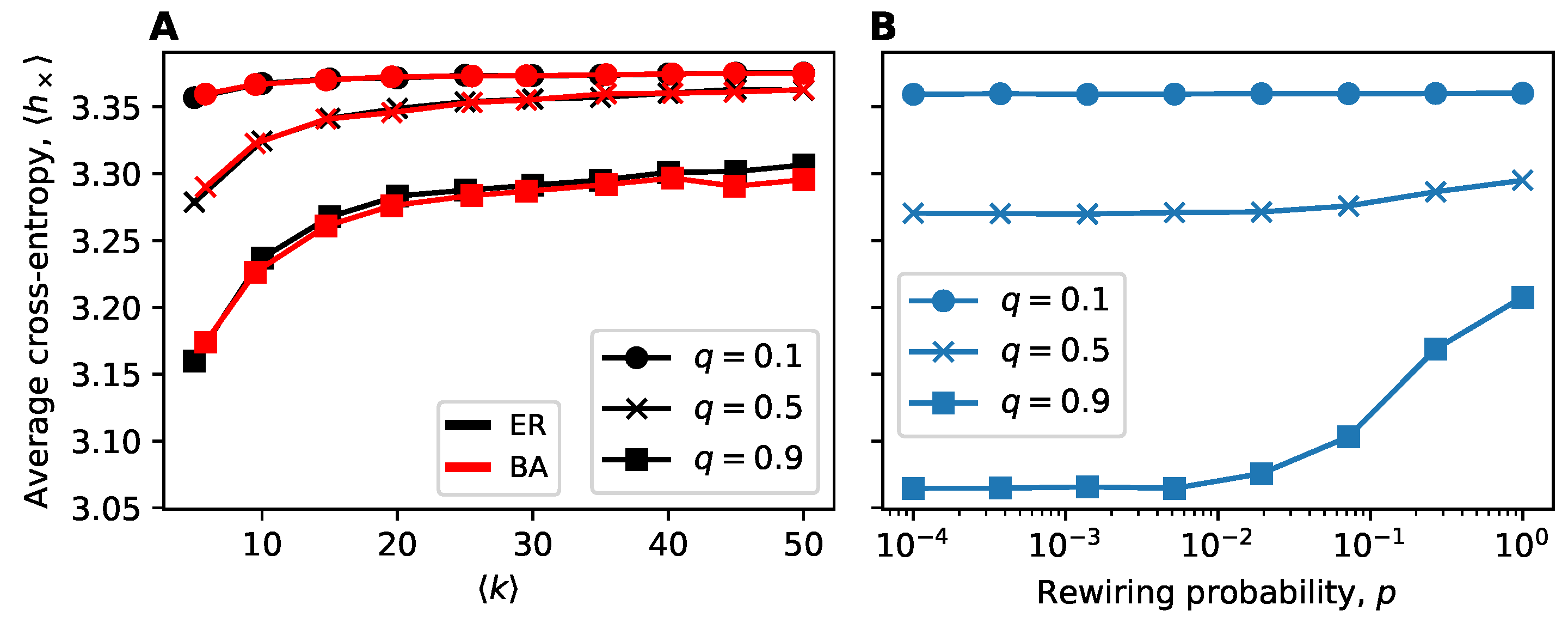
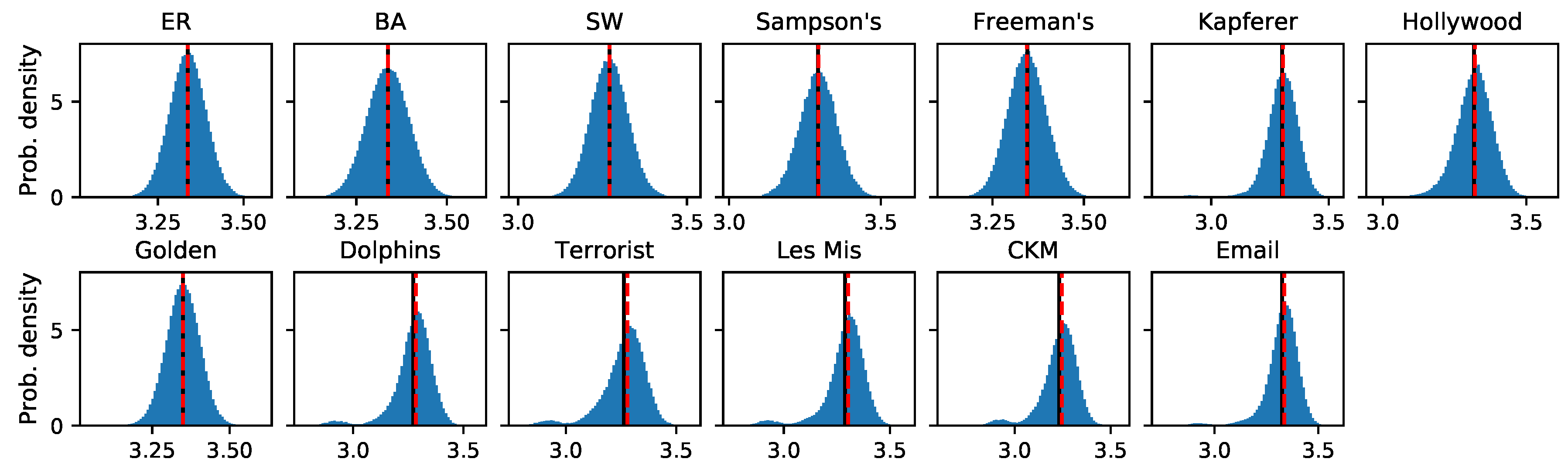
3.4. Assessing the Impact of Structure on Dynamics
3.5. Network Datasets
4. Results
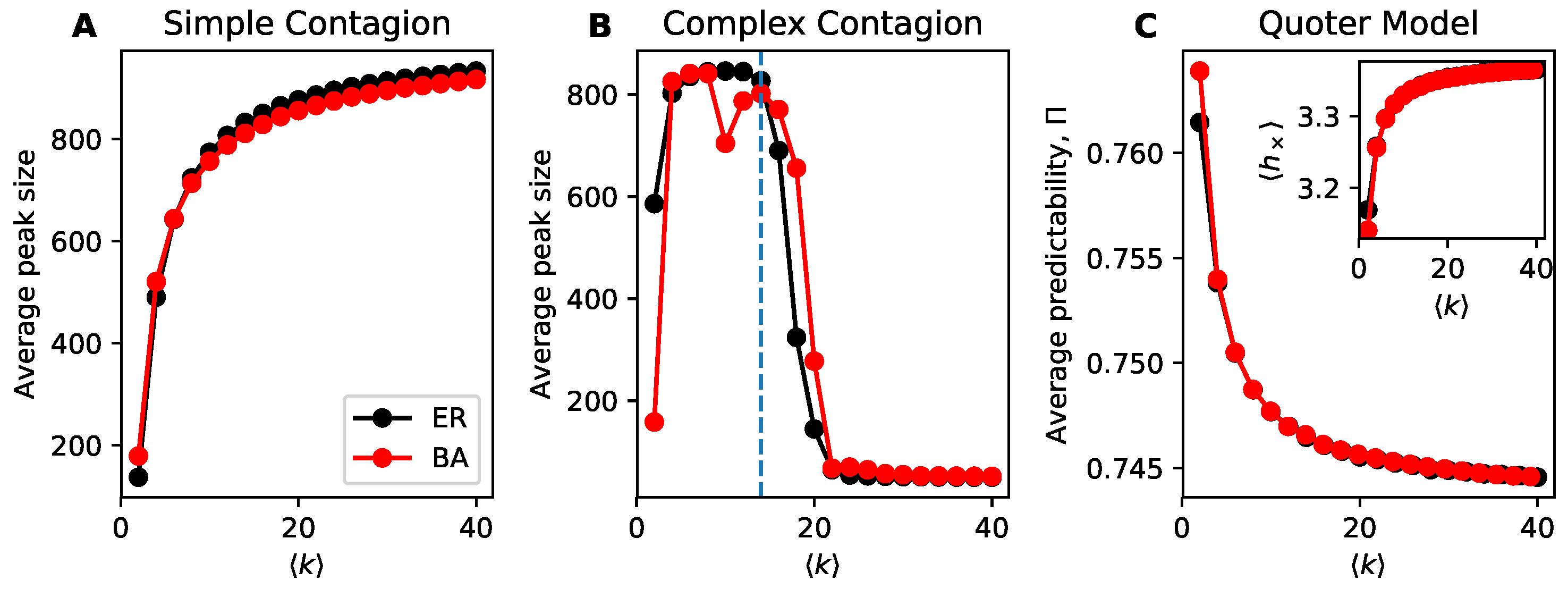
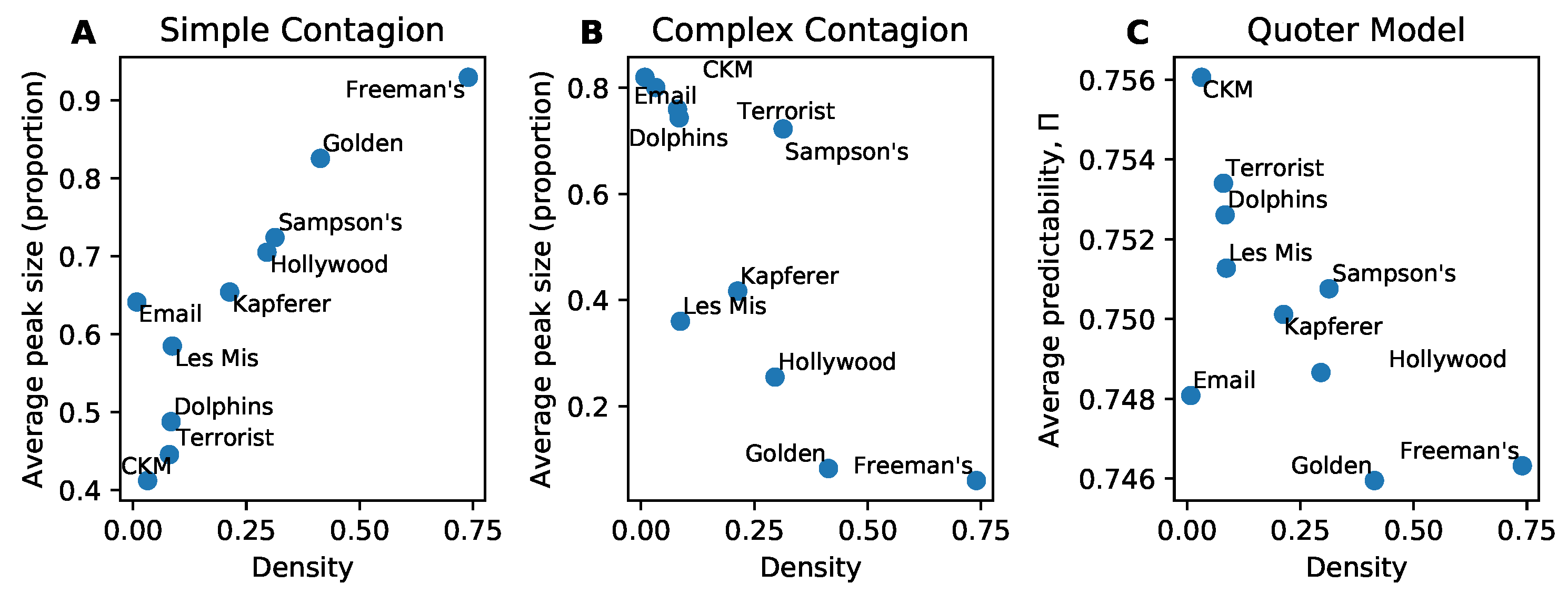
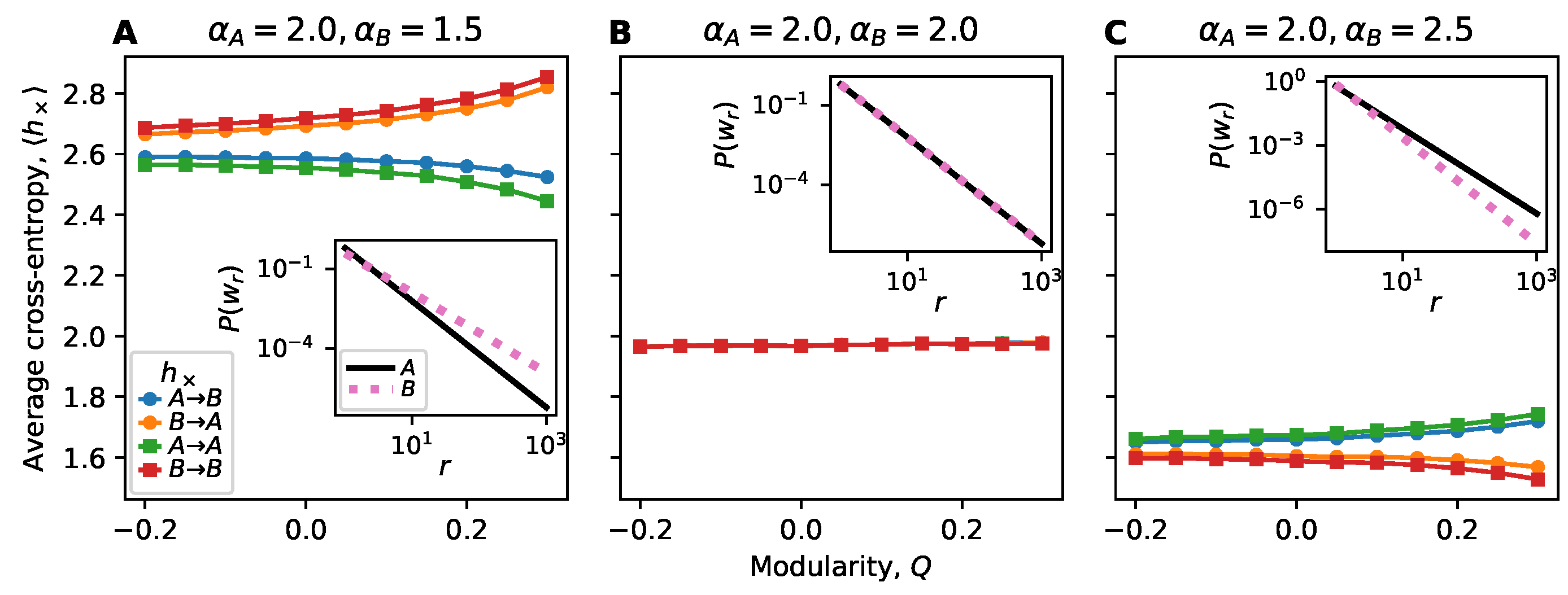
4.1. Information Flow and Models of Contagion
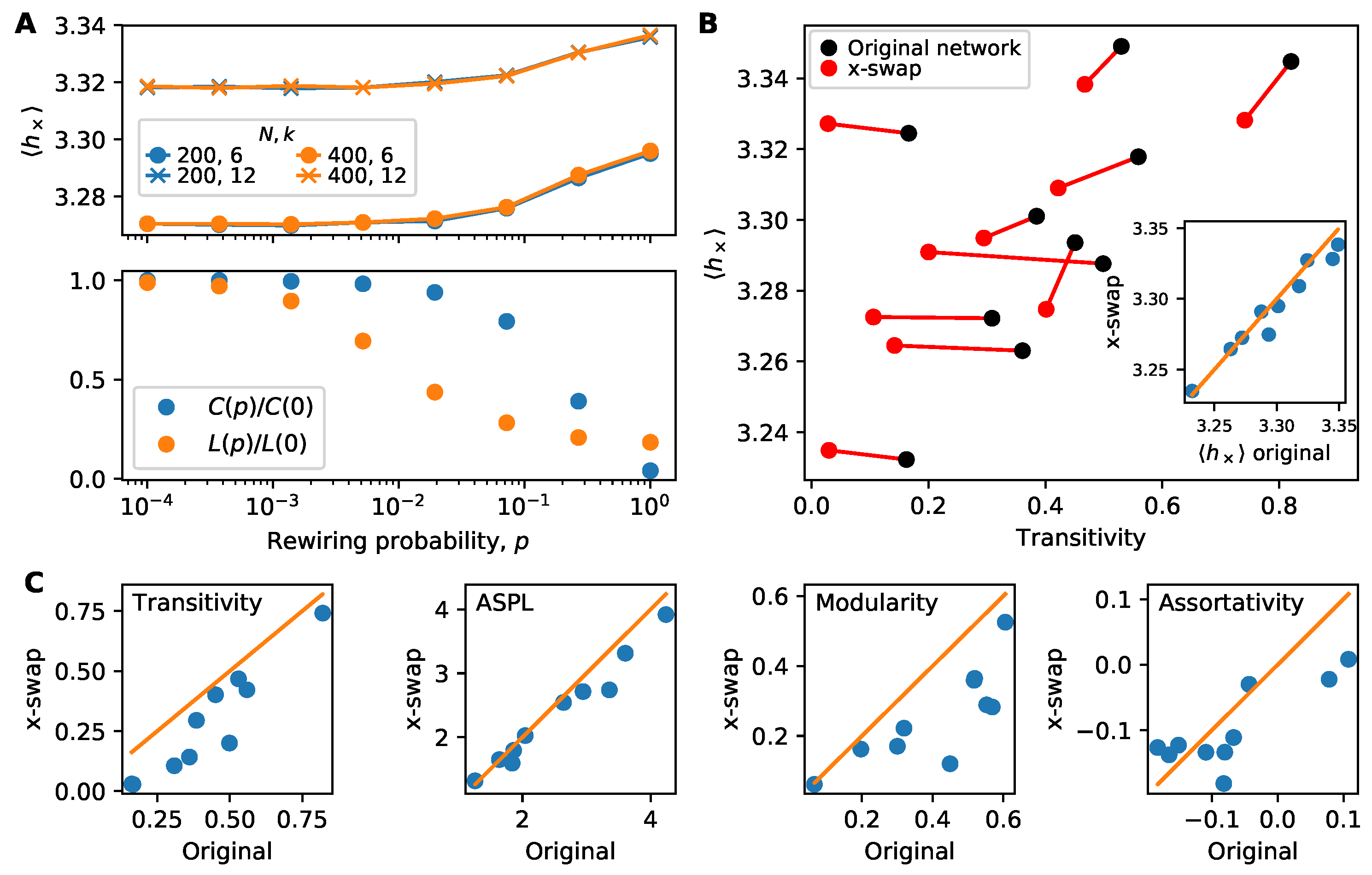
4.2. Interplay of Clustering and Information Flow
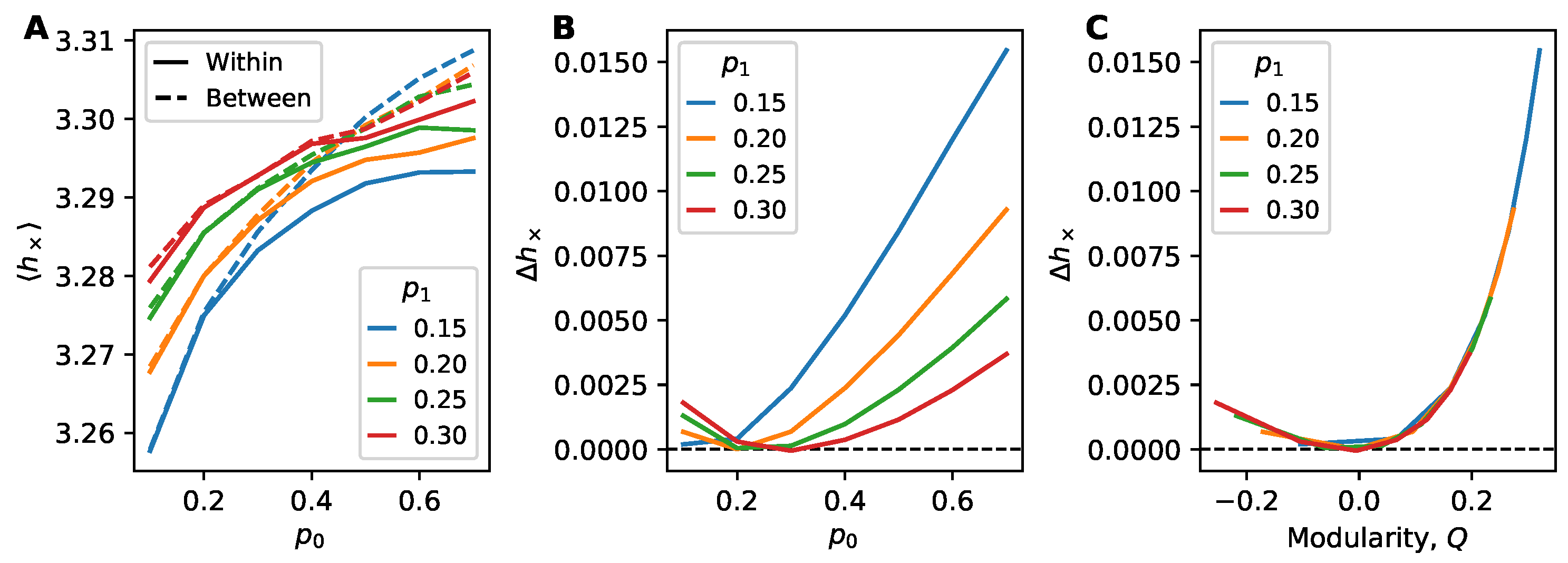
4.3. Community Structure and the Weakness of Long Ties
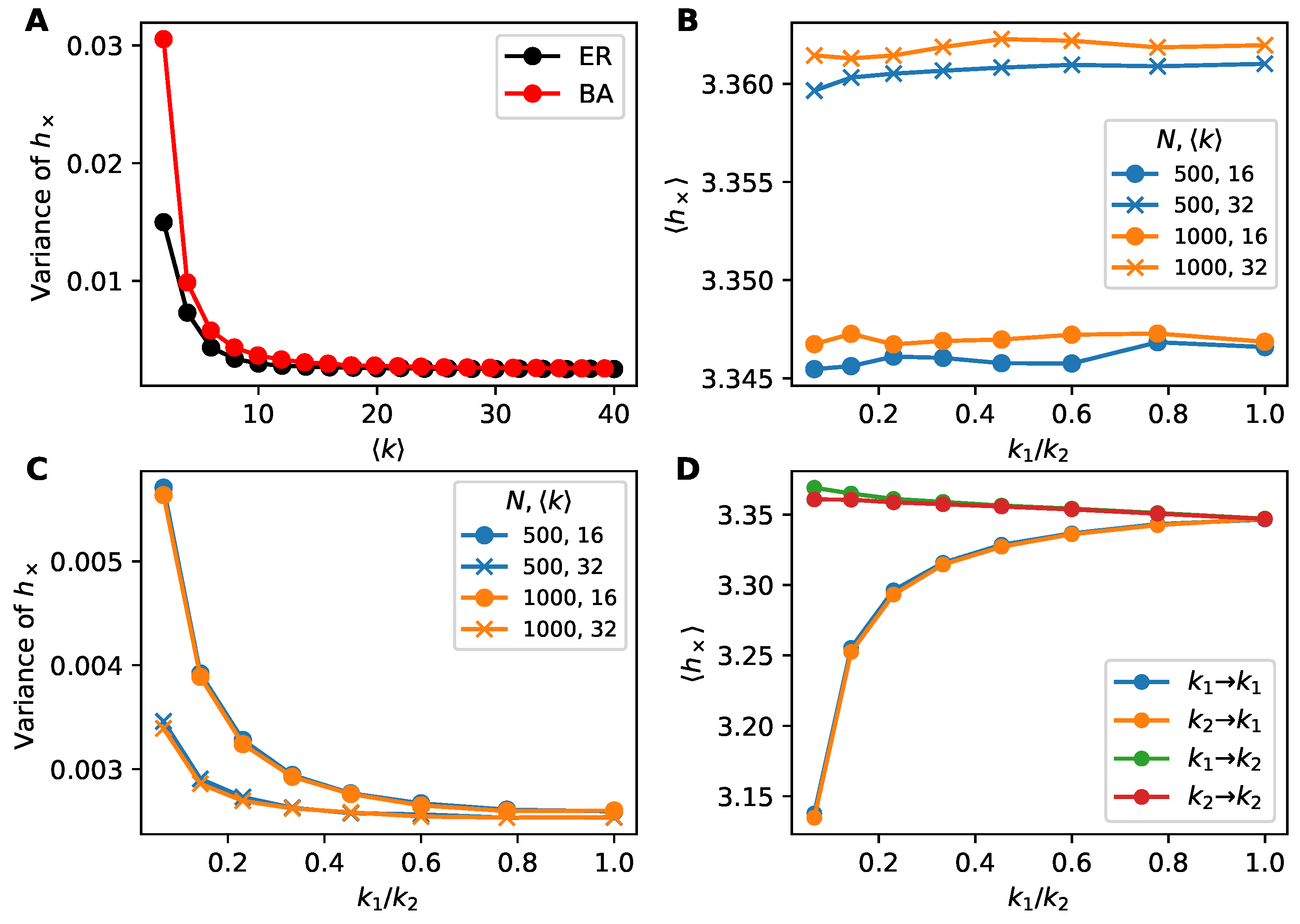
4.4. The Role of Dynamic Heterogeneity
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ASPL | Average Shortest Path Length |
| BA | Barabási-Albert |
| ER | Erdos-Rényi |
| SBM | Stochastic Block Model |
| SI | Susceptible-Infected |
| SIR | Susceptible-Infected-Recovered |
| WS | Watts–Strogatz |
Appendix A. Further Exploring Quoter Model Parameters


Appendix B. Summarizing

Appendix C. Network Corpus
- Les Miserables co-appearances [44] [Undirected, Weighted].
- Hollywood film music [45] [Undirected, Weighted]. This is a bipartite network; we converted it to a one-mode projection (nodes are composers and two composers are linked if they worked with the same producer).
- Freeman’s EIES dataset [46] [Directed, Weighted]. We used the “personal relationships (time 1)” network.
- Sampson’s monastery [47] [Directed, Weighted]. We used the Pajek dataset. The weight of a directed link represents how an individual rates the other. The rating can be positive (1,2,3 = top 3 ranked) or negative (-1,-2,-3 = worst 3 ranked). We chose to only keep links which were positive.
- Golden Age of Hollywood [48] [Directed, Weighted]. We used the aggregated network over 1909-2009.
- 9-11 terrorist network [49] [Undirected, Unweighted].
- CKM physicians social network [50] (1966) [Directed, Unweighted]. We used “CKM physicians Freeman” networks hosted by Linton Freeman, and chose the “friend” network (i.e., the third adjacency matrix). We took only the giant component.
- Kapferer tailor shop [51] (1972) [Undirected, Unweighted]. We used the “Kapferer tailor shop 1” Pajek dataset (kapfts1.dat).
- Dolphin social network [52] (1994-2001) [Undirected, Unweighted].
- Email network (Uni. R-V, Spain, 2003) [53] [Directed, Unweighted]. We used the “email-uni-rv-spain-arenas” network.
References
- Lazer, D.; Pentland, A.; Adamic, L.; Aral, S.; Barabasi, A.L.; Brewer, D.; Christakis, N.; Contractor, N.; Fowler, J.; Gutmann, M.; et al. SOCIAL SCIENCE: Computational Social Science. Science 2009, 323, 721–723. [Google Scholar] [CrossRef]
- Tumasjan, A.; Sprenger, T.O.; Sandner, P.G.; Welpe, I.M. Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010; pp. 178–185. [Google Scholar]
- Conover, M.D.; Ferrara, E.; Menczer, F.; Flammini, A. The Digital Evolution of Occupy Wall Street. PLoS ONE 2013, 8, e64679. [Google Scholar] [CrossRef]
- Castells, M. Networks of Outrage and Hope: Social Movements in the Internet Age; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- De Montjoye, Y.A.; Radaelli, L.; Singh, V.; Pentland, A. Unique in the shopping mall: On the reidentifiability of credit card metadata. Science 2015, 347, 536–539. [Google Scholar] [CrossRef] [PubMed]
- Garcia, D. Leaking privacy and shadow profiles in online social networks. Sci. Adv. 2017, 3, e1701172. [Google Scholar] [CrossRef] [PubMed]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Bollt, E.M. Causation entropy identifies indirect influences, dominance of neighbors and anticipatory couplings. Phys. D 2014, 267, 49–57. [Google Scholar] [CrossRef]
- Borge-Holthoefer, J.; Perra, N.; Gonçalves, B.; González-Bailón, S.; Arenas, A.; Moreno, Y.; Vespignani, A. The dynamics of information-driven coordination phenomena: A transfer entropy analysis. Sci. Adv. 2016, 2, e1501158. [Google Scholar] [CrossRef]
- Wang, D.; Wen, Z.; Tong, H.; Lin, C.Y.; Song, C.; Barabási, A.L. Information spreading in context. In Proceedings of the 20th international conference on World wide web (WWW 2011), Hyderabad, India, 28 March–1 April 2011; pp. 735–744. [Google Scholar]
- Bagrow, J.P.; Liu, X.; Mitchell, L. Information flow reveals prediction limits in online social activity. Nat. Hum. Behav. 2019, 3, 122–128. [Google Scholar] [CrossRef]
- Bagrow, J.P.; Mitchell, L. The quoter model: A paradigmatic model of the social flow of written information. Chaos 2018, 28, 075304. [Google Scholar] [CrossRef]
- Centola, D. The Spread of Behavior in an Online Social Network Experiment. Science 2010, 329, 1194–1197. [Google Scholar] [CrossRef]
- Borge-Holthoefer, J.; Banos, R.; Gonzalez-Bailon, S.; Moreno, Y. Cascading behaviour in complex socio-technical networks. J. Complex Netw. 2013, 1, 3–24. [Google Scholar] [CrossRef]
- Shannon, C. Prediction and Entropy of Printed English. Bell Labs Tech. J. 1951, 30, 50–64. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Algoet, P.; Suhov, Y.; Wyner, A. Nonparametric entropy estimation for stationary processes and random fields, with applications to English text. IEEE Trans. Inf. Theory 1998, 44, 1319–1327. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabasi, A.L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Ziv, J.; Merhav, N. A Measure of Relative Entropy between Individual Sequences with Application to Universal Classification. In Proceedings of the IEEE International Symposium on Information Theory, San Antonio, TX, USA, 17–22 January 1993; p. 352. [Google Scholar]
- Sun, J.; Taylor, D.; Bollt, E.M. Causal Network Inference by Optimal Causation Entropy. SIAM J. Appl. Dyn. Syst. 2015, 14, 73–106. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1991. [Google Scholar]
- Granovetter, M. Threshold Models of Collective Behavior. Am. J. Sociol. 1978, 83, 1420–1443. [Google Scholar] [CrossRef]
- Watts, D. A simple model of global cascades on random networks. Proc. Natl. Acad. Sci. USA 2002, 99, 5766–5771. [Google Scholar] [CrossRef]
- Centola, D.; Eguíluz, V.M.; Macy, M.W. Cascade dynamics of complex propagation. Phys. A 2007, 374, 449–456. [Google Scholar] [CrossRef]
- Ugander, J.; Backstrom, L.; Marlow, C.; Kleinberg, J. Structural diversity in social contagion. Proc. Natl. Acad. Sci. USA 2012, 109, 5962–5966. [Google Scholar] [CrossRef]
- Miller, J.C. Percolation and epidemics in random clustered networks. Phys. Rev. E 2009, 80, 020901. [Google Scholar] [CrossRef]
- Pastor-Satorras, R.; Castellano, C.; Van Mieghem, P.; Vespignani, A. Epidemic processes in complex networks. Rev. Mod. Phys. 2015, 87, 925–979. [Google Scholar] [CrossRef]
- O’Sullivan, D.J.; O’Keeffe, G.J.; Fennell, P.G.; Gleeson, J.P. Mathematical modeling of complex contagion on clustered networks. Front. Phys. 2015, 3, 71. [Google Scholar] [CrossRef]
- Gray, C.; Mitchell, L.; Roughan, M. Super-blockers and the effect of network structure on information cascades. In Proceedings of the Companion Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1435–1441. [Google Scholar]
- Centola, D.; Macy, M. Complex Contagions and the Weakness of Long Ties. Am. J. Sociol. 2007, 113, 702–734. [Google Scholar] [CrossRef]
- Granovetter, M.S. The Strength of Weak Ties. In Social Networks; Elsevier: New York, NY, USA, 1977; pp. 347–367. [Google Scholar]
- Miller, J.; Ting, T. EoN (Epidemics on Networks): A fast, flexible Python package for simulation, analytic approximation, and analysis of epidemics on networks. J. Open Source Softw. 2019, 4, 1731. [Google Scholar] [CrossRef]
- Lambiotte, R. How does degree heterogeneity affect an order-disorder transition? Europhys. Lett. 2007, 78, 68002. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Singh, P.; Sreenivasan, S.; Szymanski, B.; Korniss, G. Threshold-limited spreading in social networks with multiple initiators. Sci. Rep. 2013, 3, 2330. [Google Scholar] [CrossRef]
- Milo, R.; Kashtan, N.; Itzkovitz, S.; Newman, M.E.; Alon, U. On the uniform generation of random graphs with prescribed degree sequences. arXiv 2003, arXiv:cond-mat/0312028. [Google Scholar]
- Blitzstein, J.; Diaconis, P. A Sequential Importance Sampling Algorithm for Generating Random Graphs with Prescribed Degrees. Internet Math. 2011, 6, 489–522. [Google Scholar] [CrossRef]
- Newman, M.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef]
- Danon, L.; Díaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Karrer, B.; Newman, M. Stochastic blockmodels and community structure in networks. Phys. Rev. E 2011, 83, 016107. [Google Scholar] [CrossRef] [PubMed]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- De Arruda, G.F.; Petri, G.; Rodrigues, F.A.; Moreno, Y. Impact of the distribution of recovery rates on disease spreading in complex networks. Phys. Rev. Res. 2020, 2, 013046. [Google Scholar] [CrossRef]
- Nematzadeh, A.; Ferrara, E.; Flammini, A.; Ahn, Y.Y. Erratum: Optimal Network Modularity for Information Diffusion. Phys. Rev. Lett. 2014, 113, 088701. [Google Scholar] [CrossRef] [PubMed]
- Clauset, A.; Tucker, E.; Sainz, M. The Colorado index of complex networks. Retrieved July 2016, 20, 2018. Available online: https://icon.colorado.edu (accessed on 25 February 2020).
- Knuth, D.E. Stanford GraphBase: A platform for Combinatorial Computing; Addison-Wesley: Boston, MA, USA, 1993. [Google Scholar]
- Faulkner, R.R. Music on Demand: Composers and Careers in the Hollywood Film Industry; Transaction Books: New Brunswick, NJ, USA, 1983. [Google Scholar]
- Freeman, S.C.; Freeman, L.C. The Networkers Network: A Study of the Impact of a New Communications Medium on Sociometric Structure; University of California: Irvine, CA, USA, 1979. [Google Scholar]
- Sampson, S.F. A novitiate in a Period of Change: An Experimental and Case Study of Social Relationships. Ph.D. Thesis, Cornell University, Ithaca, NY, USA, 1968. [Google Scholar]
- Taylor, D.; Myers, S.A.; Clauset, A.; Porter, M.A.; Mucha, P.J. Eigenvector-Based Centrality Measures for Temporal Networks. Multiscale Model. Simul. 2017, 15, 537–574. [Google Scholar] [CrossRef]
- Krebs, V. Uncloaking Terrorist Networks. First Monday 2002, 7, 43–52. [Google Scholar] [CrossRef]
- Burt, R.S. Social Contagion and Innovation: Cohesion versus Structural Equivalence. Am. J. Sociol. 1987, 92, 1287–1335. [Google Scholar] [CrossRef]
- Kapferer, B. Strategy and Transaction in an African Factory: African Workers and Indian Management in a Zambian Town; Manchester University Press: Manchester, UK, 1972. [Google Scholar]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Guimerà, R.; Danon, L.; Díaz-Guilera, A.; Giralt, F.; Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 2003, 68, 065103. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Density | Transitivity | ASPL | Modularity | Assortativity | |||
|---|---|---|---|---|---|---|---|---|
| Sampson’s monastery | 18 | 71 | 7.9 | 0.464 | 0.53 | 1.54 | 0.29 | −0.07 |
| Freeman’s EIES | 34 | 415 | 24.4 | 0.740 | 0.82 | 1.26 | 0.07 | −0.15 |
| Kapferer tailor | 39 | 158 | 8.1 | 0.213 | 0.39 | 2.04 | 0.32 | −0.18 |
| Hollywood music | 39 | 219 | 11.2 | 0.296 | 0.56 | 1.86 | 0.20 | −0.08 |
| Golden Age | 55 | 564 | 20.5 | 0.380 | 0.53 | 1.64 | 0.45 | −0.13 |
| Dolphins | 62 | 159 | 5.1 | 0.084 | 0.31 | 3.36 | 0.52 | −0.04 |
| Terrorist | 62 | 152 | 4.9 | 0.080 | 0.36 | 2.95 | 0.52 | −0.08 |
| Les Miserables | 77 | 254 | 6.6 | 0.087 | 0.50 | 2.64 | 0.56 | −0.17 |
| CKM physicians | 110 | 193 | 3.5 | 0.032 | 0.16 | 4.24 | 0.61 | −0.11 |
| Email Spain | 1133 | 5452 | 9.6 | 0.009 | 0.17 | 3.61 | 0.57 | −0.08 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pond, T.; Magsarjav, S.; South, T.; Mitchell, L.; Bagrow, J.P. Complex Contagion Features without Social Reinforcement in a Model of Social Information Flow. Entropy 2020, 22, 265. https://doi.org/10.3390/e22030265
Pond T, Magsarjav S, South T, Mitchell L, Bagrow JP. Complex Contagion Features without Social Reinforcement in a Model of Social Information Flow. Entropy. 2020; 22(3):265. https://doi.org/10.3390/e22030265
Chicago/Turabian StylePond, Tyson, Saranzaya Magsarjav, Tobin South, Lewis Mitchell, and James P. Bagrow. 2020. "Complex Contagion Features without Social Reinforcement in a Model of Social Information Flow" Entropy 22, no. 3: 265. https://doi.org/10.3390/e22030265
APA StylePond, T., Magsarjav, S., South, T., Mitchell, L., & Bagrow, J. P. (2020). Complex Contagion Features without Social Reinforcement in a Model of Social Information Flow. Entropy, 22(3), 265. https://doi.org/10.3390/e22030265