1. Introduction
Differential entropy (DE) has wide applications in a range of fields including signal processing, machine learning, and feature selection [
1,
2,
3]. DE estimation is also related to dimension reduction through independent component analysis [
4], a method for separating data into additive components. Such algorithms typically look for linear combinations of different independent signals. Since two variables are independent if and only if their mutual information vanishes, accurate and efficient entropy estimation algorithms are highly advantageous [
5]. Another important application of DE estimation is quantifying order in out-of-equilibrium physical systems [
6,
7]. In such systems, existent efficient methods for entropy approximation using thermodynamic integration fail and more fundamental approaches for estimating DE using independent samples are required.
The DE of a continuous multi-dimensional distribution with density
is defined as,
Despite a large number of suggested algorithms [
8,
9], the problem of estimating the DE from independent samples of distributions remains a challenge in high dimensions. Broadly speaking, algorithms can be classified as one of two approaches: Binning and sample-spacing methods, or their multidimensional analogues, namely partitioning and nearest-neighbor (NN) methods. In 1D, the most straight-forward method is to partition the support of the distribution into bins and either calculate the entropy of the histogram or use it for plug-in estimates [
8,
10,
11]. This amounts to approximating
as a piece-wise constant function (i.e., assuming that the distribution is uniform in each subset in the partition). This works well if the support of the underlying distribution is bounded and given. If the support is not known or is unbounded, it can be estimated as well, for example using the minimal and maximal observations. In such cases, sample-spacing methods [
8] that use the spacings between adjacent samples are advantageous. Overall, the literature provides a good arsenal of tools for estimating 1D entropy including rigorous bounds on convergence rates (given some further assumptions of
p). See [
8,
9] for reviews.
Estimating entropy in higher dimensions is significantly more challenging [
9,
12]. Binning methods become impractical as having
M bins in each dimension implies
bins overall. Beyond the computational costs, most such bins will often have 1 or 0 samples, leading to the significant underestimating of the entropy. In order to overcome this difficulty, Stowell and Plumbley [
13] suggested partitioning the data using a
k-D partitioning tree-hierarchy (
kDP). In each level of the tree, the data is divided into two parts with an equal number of samples. The splitting continues recursively across the different dimensions (see below for a discussion on the stopping criteria). The construction essentially partitions the support of
p into bins that are multi-dimensional rectangles whose sides are aligned with the principal axes. The DE is then calculated assuming a uniform distribution in each rectangle. As shown below, this strategy works well at low dimensions (typically 2-3) and only if the support is known. The method is highly efficient, as constructing the partition tree has an
efficiency. In particular, it has no explicit dependence on the dimension.
Spacing methods are generalized using the set of
k nearest-neighbors to each sample (
kNN) [
11,
14,
15,
16,
17]. These are used to locally approximate the density, typically using kernels [
10,
18,
19,
20,
21,
22]. As shown below,
kNN schemes preform well at moderately high dimensions (up to 10–15) for distributions with unbounded support. However, they fail completely when
p has a compact support and become increasingly inefficient with the dimension. Broadly speaking, algorithms for approximating
kNN in
D-dimensions have an efficiency of
, where
is the required accuracy [
23]. Other approaches for entropy estimation include variations and improvements of
kNN (e.g., [
4,
19,
22]), Voronoi-based partitions [
24] (which are also prohibitively expensive at very high dimensions), Parzen windows [
1], and ensemble estimators [
25].
Here, we follow the approach of Stowell and Plumbley [
13], partitioning space using trees. However, we add an important modification that significantly enhances the accuracy of the method. The main idea is to decompose the density
into a product of marginal (1D) densities and a copula. The copula is computed over the compact support of the one dimensional cumulative distributions. As such, the multidimensional DE estimates become the combination of one dimensional estimates, and a multi-dimensional estimate on a compact support, even if the support of the original distribution was not compact. We term the proposed method as copula decomposition entropy estimate (CADEE).
Following Sklar’s theorem [
26,
27], any continuous multi-dimensional density
can be written uniquely as:
where,
,
denotes the marginal density of the
k’th dimension with the cumulative distribution function (CDF)
, and
is the density of the copula, i.e., a probability density on the hyper-square
whose marginals are all uniform on
,
for all
k. Substituting Equation (
2) into Equation (
1) yields,
where
is the entropy of the
k’th marginal, to be computed using appropriate 1D estimators, and
is the entropy of the copula. Using Sklar’s theorem has been previously suggested as a method for calculating the mutual information between variables, which is identical to the copula entropy
[
5,
28,
29,
30]. The new approach here is in showing that
can be efficiently estimated recursively, similar to the
kDP approach.
Splitting the overall estimation into the marginal and copula contributions has several major advantages. First, the support of the copula is compact, which is exactly the premise for which partitioning methods are most adequate. Second, since the entropy of the copula is non-positive, adding up the marginal entropies across tree-levels provides an improving approximation (from above) of the entropy. Finally, the decomposition brings-forth a natural criterion for terminating the tree-partitioning and for dimension reduction using pairwise independence.
The following sections are organized as follows.
Section 2 describes the outline of the CADEE algorithm. In order to demonstrate its wide applicability, several examples in which the DE can be calculated analytically are presented. In addition, our results are compared to previously suggested methods.
Section 4 discusses implementation issues and the algorithm’s computational cost. We conclude in
Section 5.
2. CADEE Method
The main idea proposed here is to write the entropy
H as a sum of
D 1D marginal entropies, and the entropy of the copula. Analytically, the copula is obtained by a change of variables,
Let
,
denote
N independent samples from a real
D-dimensional random variable (RV) with density
. We would like to use the samples
in order to obtain samples from the copula density
. From Equation (
5), this can be obtained by finding the rank (in increasing order) of samples along each dimension. In the following, this operation will be referred to as a rank transformation. This is the empirical analogue of the integral transform where one plugs the sample into the CDF. More formally, for each
, let
denote a permutation of
that arranges
in increasing order, i.e.,
for
. Then, taking
yields
N samples
,
from the distribution
. Note that the samples are not independent. In other words, the rank is the emperical CDF, shifted by
. In particular, they correspond to
N distinct points on a uniform grid,
.
1D entropies are estimated using either uniform binning or sample-spacing methods, depending on whether the support of the marginal is known to be compact (bins) or unbounded/unknown (spacing). The main challenge lies in evaluating the DE of high-dimensional copulas [
5,
31]. In order to overcome this difficulty, we compute it recursively, following the
kDP approach. Let
be spatial dimensions, to be chosen using any given order. The copula samples
are split into two equal parts (note that the median in each dimension is
). Denote the two halves as
and
. Scaling the halves as
and
produces two sample sets for two new copulas, each with
points. A simple calculation shows that:
where
is the entropy estimate obtained using the set of points
and
is the entropy estimate obtained using the set of points
. The marginals of each half may no longer be uniformly distributed in
, which suggests continuing recursively, i.e., the entropy of each half is a decomposed using Sklar’s theorem, etc. See
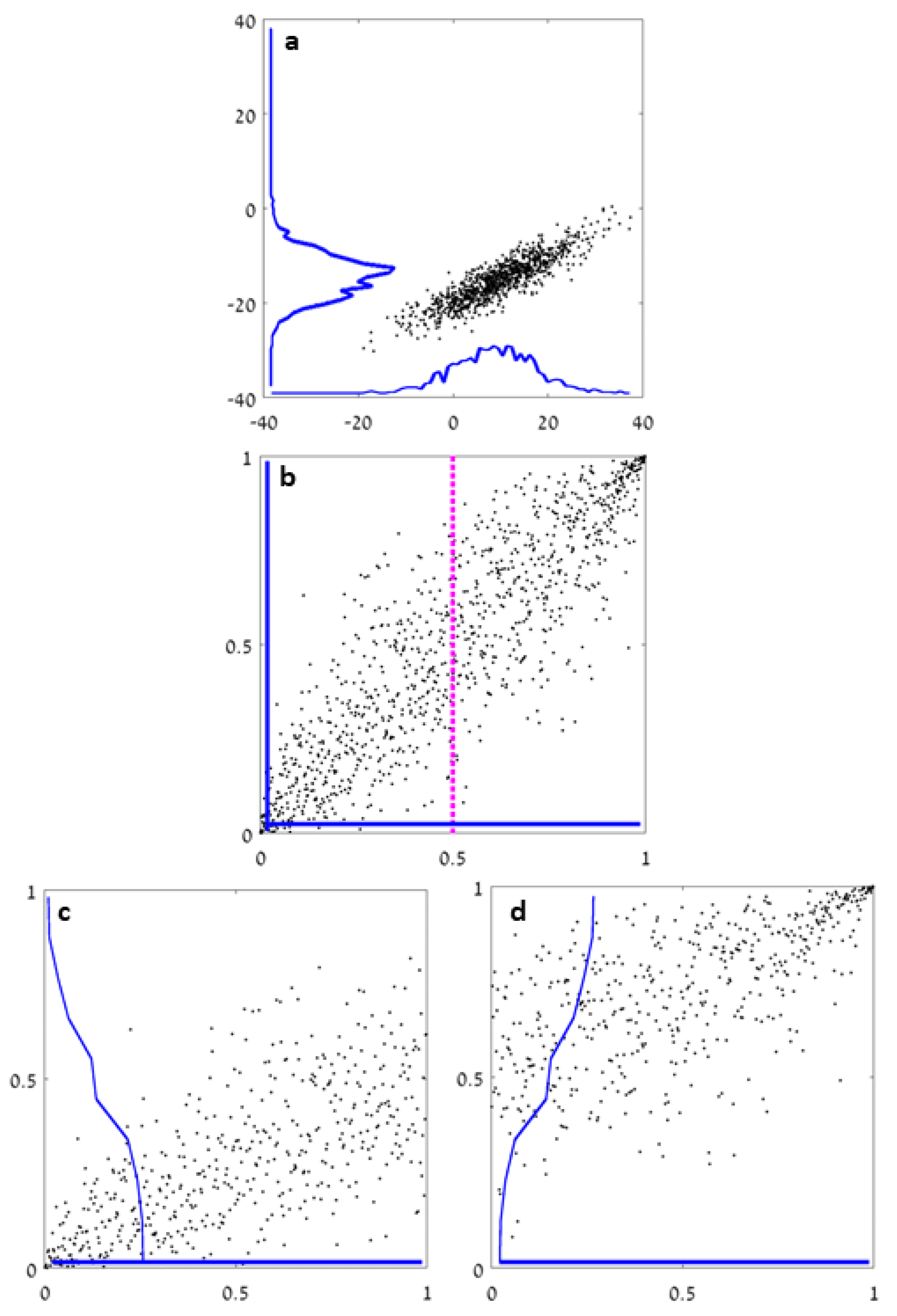
Figure 1 for a schematic sketch of the method.
A key question is finding a stopping condition for the recursion. In [
13], Stowell and Plumbley apply a statistical test for uniformity of
, the dimension used for splitting. This condition is meaningless for our method as copulas have uniform marginals by construction. In fact, this suggests that one reason for the relatively poor
kDP estimates at high
D is the rather simplistic stopping criterion, requiring that only one of the marginals is statistically similar to a uniform RV.
In principle, we would like to stop the recursion once the copula cannot be statistically distinguished from the uniform distribution on
. However, reliable statistical tests for uniformity at high
D are essentially equivalent to evaluating the copula entropy [
5,
18,
31]. As a result, we relax the stopping condition to only test for pairwise dependence. The precise test for that will be further discussed. Calculating pairwise dependencies also allows a dimension reduction approach: If the matrix of pairwise-dependent dimensions can be split into blocks, then each block can be treated independently.
In order to demonstrate the applicability of the method described above, we study the results of our algorithm for several distributions for which the DE in Equation (
1) can be computed analytically.
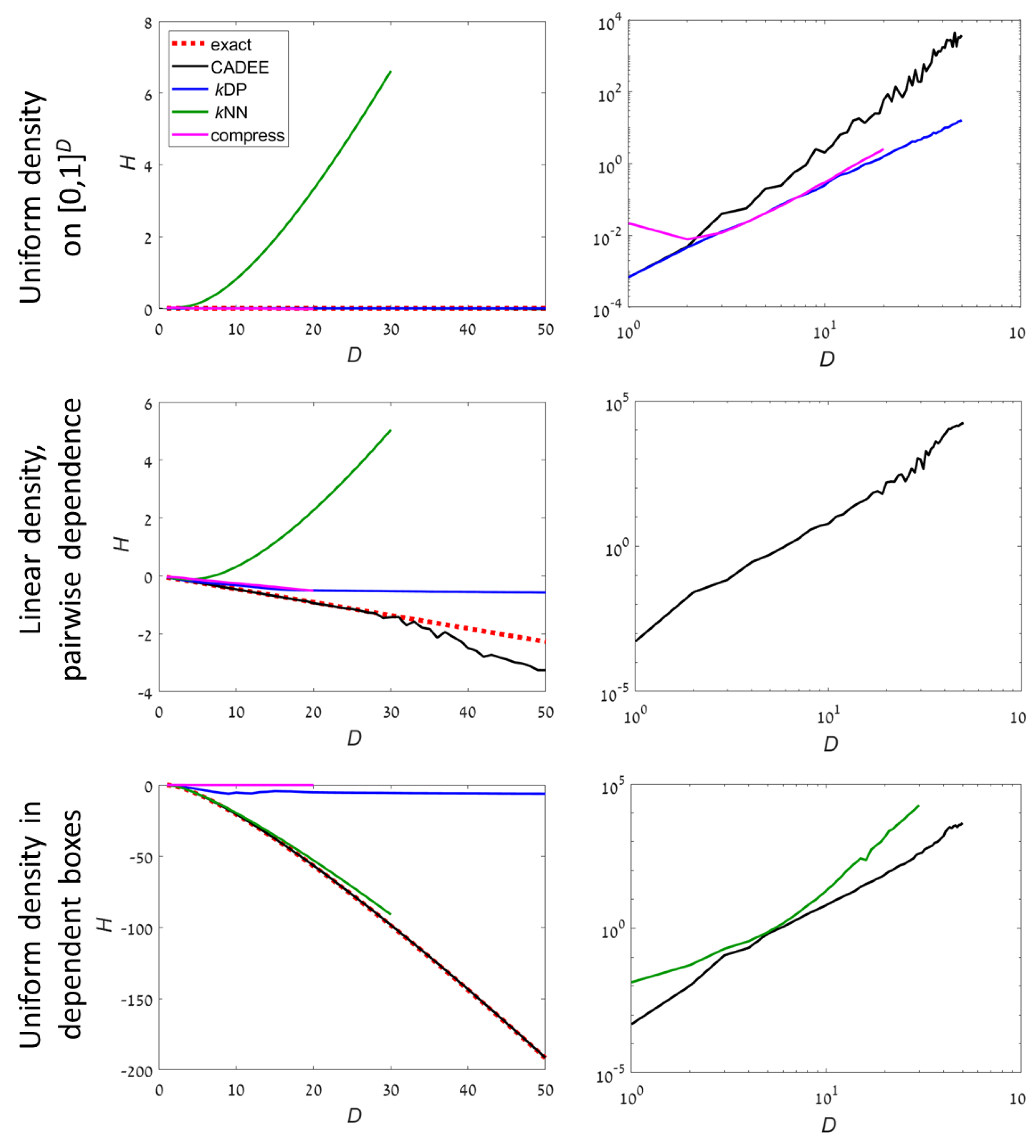
Figure 2 and
Figure 3 show numerical results for
H and the running time as a function of the dimension using an implementation in Matlab. Five different distributions are studied. Three have a compact support in
(
Figure 2):
C1: A uniform distribution;
C2: Dependent pairs. The dimensions are divided into pairs. The density in each pair is , supported on . Different pairs are independent;
C3: Independent boxes. Uniform density in a set consisting of D small hypercubes, .
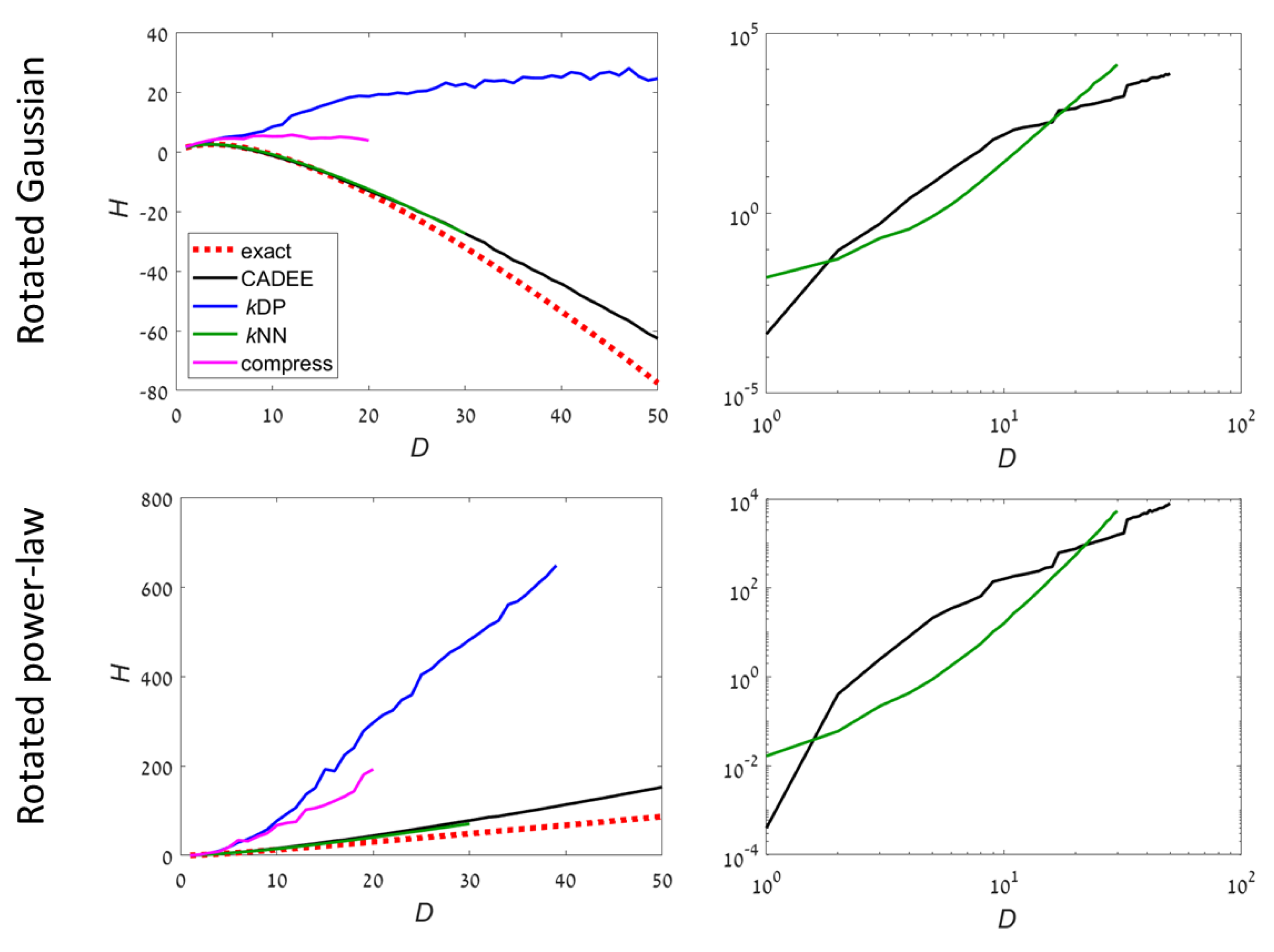
Two examples have an unbounded support (
Figure 3):
UB1: Gaussian distribution. The covariance is chosen to be a randomly rotated diagonal matrix with eigenvalues , . Then, the samples are rotated to a random orthonormal basis in . The support of the distribution is ;
UB2: Power-law distribution. Each dimension k is sampled independently from a density , in . Then, the samples are rotated to a random orthonormal basis in . The support of the distribution is a fraction of that is not aligned with the principal axes.
Results with our method are compared to three algorithms:
The
kDP algorithm [
20]. We use the C implementation available in [
32];
The
kNN algorithm based on the Kozachenko–Leonenko estimator [
14]. We use the C implementation available in [
33];
A lossless compression approach [
6,
7]. Following [
6], samples are binned into 256 equal bins in each dimension, and the data is converted into a
matrix of 8-bit unsigned integers. The matrix is compressed using the Lempel–Ziv–Welch (LZW) algorithm (implemented in Matlab’s imwrite function to a gif file). In order to estimate the entropy, the file size is interpolated linearly between a constant matrix (minimal entropy) and a random matrix with independent uniformly distributed values (maximal entropy), both of the same size.
Theoretically, in order to get rigorous convergence of estimators, the number of samples should grow exponentially with the dimension [
8]. Since this requirement is impractical at very high dimensions, we considered an under-sampled case and only used
samples. Each method was tested at increasing dimensions until a running time of about 3 hours was reached (per run, on a standard PC) or the implementation ran out of memory. In such cases, no results are reported for this and following dimensions. See also
Table 1 and
Table 2 for numerical results for
and 20.
Note that, in principle, it may be advantageous to apply a Principle Component Analysis (PCA) or Singular value Decomposition (SVD) of the sample convariance to decouple dependent directions. Such methods will be particular advantageous for the unbounded problems. We do not apply such conventional pre-processing methods here in order to make it more difficult for the CADEE method. If SVD converges the distribution into a product of independent 1D variables, the copula is close to 1 and the method will be highly exact after a single iteration.
For compact distributions, it is well known than kNN methods may fail completely. This can be seen even for the most simple examples such as uniform distributions (example C1). However, kNN worked well in example C3 because the density occupied a small fraction of the volume, which is optimal for kNN. kDP and compression methods are precise for uniform distribution, which is a reference case for these methods. For examples C2 and C3, both were highly inaccurate at . In comparison, CADEE showed very good accuracy up to D = 30–50, depending on the example.
For unbounded distributions,
kDP and compression methods did not provide meaningful results for
. Both CADEE and
kNN provided good estimates up to
(
kNN was slightly better), but diverged slowly at higher dimensions (CADEE was better). Numerical tests suggest this was primarily due to the relatively small number of samples, which severely under-sampled the distributions at high
D. Comparing running times, the recursive copula splitting method was significantly more efficient at high dimensions. Simulations suggest a polynomial running time (see
Section 4 for details), while
kNN was exponential in
D, becoming prohibitively inefficient at
.
3. Convergence Analysis
In this section, we study the convergence properties of CADEE, i.e., the estimation error as N increases with fixed D. We proceeded along three routes. First, we considered an example in which the first several copula splittings could be preformed analytically. The example demonstrates how, ignoring statistical errors, recursive splitting of the copula and adding up the marginal entropies at the different recursion levels gets close to the exact entropy. Next, we provided a general analytical bound on the error of the model. Although the bound is not tight, it establishes that, in principle, the method provides a valid approximation of the entropy. Finally, we study the convergence of the method numerically for several low dimensional examples, providing empirical evidence that the rate of convergence of the method (the average absolute value of the error) is for some .
3.1. Analytical Example
In order to demonstrate the main idea why splitting the copula iteratively improved the entropy estimate, we worked-out a simple example in which the splittings could be performed analytically. For the purpose of this example, sampling errors in the estimate of the 1D entropy were neglected.
Consider the dependent pairs example (C2) with
. The two dimensional density of the sampled random variable is given by:
The exact entropy is
. In order to obtain the copula, we first write the marginal densities and CDFs,
Since the CDFs are invertible (in
), it can be equivalently written as,
We invert the CDF’s in Equation (
11),
. Then substitute into Equation (
11), hence,
Indeed, one verifies that the marginals are uniform,
Continuing the CADEE algorithm, we computed the entropy of marginals,
. This implies that the copula entropy is
(5.8% of
H). In order to approximate it, we split
into two halves, for example along the
Y axis. Each density is shifted and stretched linearly to have support in
again,
We continue recursively, computing the marginals for
and
,
The marginal entropies are
,
,
, and
. Overall, summing up the marginal entropies of the two iterations, we have
(error = 2.77%).
We similarly continue, calculating the copula of and and then the marginal distributions of their copulas. We found that the entropy after the third iteration is (error = 1.02%).
Indeed, we see that in the absence of statistical errors, the recursive splitting provides in improving upper bound for the entropy.
3.2. Analytical Bound
Here, we provide an analytical estimate of the bias and statistical error incurred by the algorithm. We derive a bound, which is not tight. Detailed analysis of the bias and error in some adequate norm is beyond the scope of the current paper.
The first part of the analysis estimated the worst-case accuracy by iteratively approximating the entropy using q repeated splittings of the copula. In the last iterations, the dimensions are assumed to be independent, i.e., the copula equals 1.
Consider the copula
, which is split, e.g., along
into two halves corresponding to
and
. Linearly scaling back into
, we obtain two densities:
where
. It is easily seen that
, where
and
are the entropies of
and
, respectively. We continue recursively, splitting the resulting copulas along some dimension. After
q iterations, we obtain an expression of the form,
where
is the 1D entropy of the
j’th marginal and
is the entropy of the copula, obtained after
k splittings along the dimensions
. For simplicity, we assume that the dimensions are chosen sequentially and suppose that
, i.e., each dimension was split
r times.
Let
and suppose that the copula
is constant on small hyper-rectangles with sides:
where
. This implies that within these rectangles all dimensions are independent. Then,
and the last sum in Equation (
17) vanishes.
Next, we approximate
in each small rectangle using Taylor. Without loss of generality, we focus on the case
. To first order,
, with
are
. Scaling to
,
, where
Z is a normalization constant. Assuming that
are continuously differentiable and strictly increasing,
are also continuously differentiable and
. Then, since the total mass in each rectangle is exactly
, we have that
. Finally, the entropy of the normalized density
can be estimated. Expanding the log to order 1 in
,
From this, one needs to subtract
to compensate for the scaling. Therefore, for any continuously differential, strictly positive (in its support) density,
. We conclude that the entire last sum in Equation (
17) sums to order
. The prefactor is typically proportional to
D.
Next, we consider statistical errors. Using the Kolmogorov–Smirnov statistics, the distance between the empirical CDF and the exact one is of order
. Suppose 1D entropy estimates use a method with accuracy (absolute error) of order
,
. Then, in the worst case, if all errors are additive, then each estimate in the
k’th iterate has an error (in absolute value) of order
. Overall, we have,
For fixed
q, the statistical error decreases like
. Typically, for an unbiased 1D estimator in which the variance of the estimator is of order
, the variance of the overall estimation using CADEE is,
However, the prefactor depends linearly on the dimension D and exponentially on the number of iterations q. Recall that the bias decreases exponentially with . Hence, the two sources of errors should be balanced in order to obtain a convergent approximation.
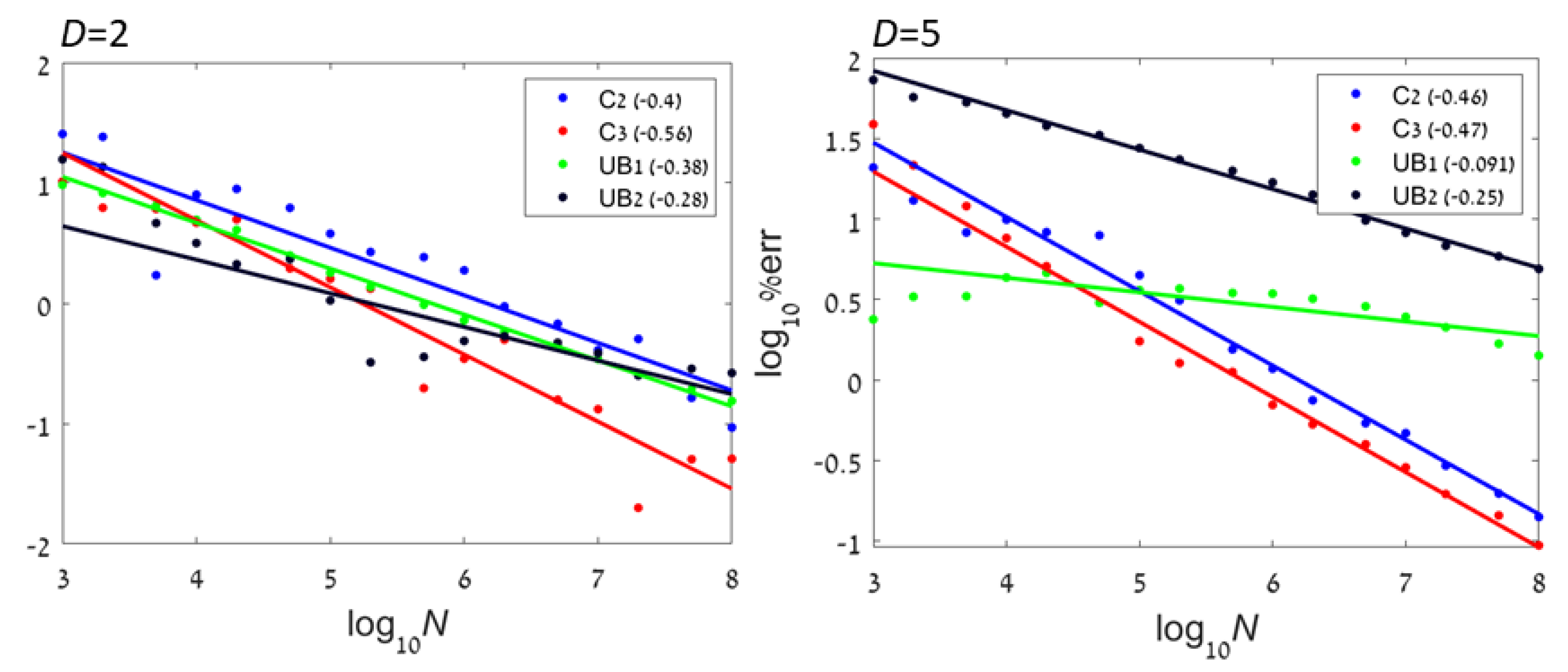
3.3. Numerical Examples
In order to demonstrate the convergence of the method, we test the error of the estimate obtained using CADEE for small
D examples.
Figure 4 shows numerical results with four types of distributions (dependent pairs, independent boxes, Gaussian, and power-law) with
and
and
–
samples. As discussed above, larger dimensions require significantly more samples in order to guarantee that the entire support is sampled at appropriate frequencies. We see that for all examples, the method indeed converged. For non-bounded distributions, the rate decreased with dimension.
4. Implementation Details
The following is a pseudo-code implementation of the algorithm described above (Algorithm 1). Several aspects of the codes, such as choice of constants, stopping criterion, and estimation of pair-wise independence are rather heuristic approaches, which were found to improve the accuracy and efficiency of our method. See
Appendix A for details. Recall that for every
i,
is an independent sample.
| Algorithm 1 Recursive entropy estimator |
- 1:
functioncopulaH(, D, N, ) - 2:
- 3:
for k = 1 to D do - 4:
rank()/N ▹ Calculate rank (by sorting) - 5:
H1D(, N, ) ▹ entropy of marginal k - 6:
end for - 7:
- 8:
if or min #samples then - 9:
return H - 10:
end if - 11:
- 12:
▹A is the matrix of pairwise independence - 13:
true if and are statistically independent - 14:
# of blocks in A. - 15:
if then ▹ Split dimensions - 16:
for to do - 17:
elements in block j - 18:
copulaH(,dim(v),N,) - 19:
end for - 20:
return H - 21:
else ▹ No independent blocks - 22:
choose a dim for splitting - 23:
- 24:
- 25:
copulaH(,D,,) /2 - 26:
- 27:
- 28:
- 29:
copulaH(,D,,) /2 - 30:
end if - 31:
end function
|
Several steps in the above algorithm should be addressed.
The rank of an array x is the order in which values appear. Since the support of all marginals in the copula is , we take . For example, . This implies that the minimal and maximal samples are not mapped into , which would artificially change the support of the distribution. The rank transformation is easily done using sorting;
1D entropy: One-dimensional entropy of compact distributions (whose support is
) is estimated using a histogram with uniformly spaced bins. The number of bins can be taken to depend of
N, and order
is typically used (we used
or
for spacing or bin-based methods, respectively. For additional considerations and methods for choosing the number of bins see [
34]. At the first iteration, the distribution may not be compact, and the entropy is estimated using
-spacings (see [
8], Equation (
16));
Finding blocks in the adjacency matrix
A: Let
A be a matrix whose entries are 0 and 1, where
implies that
and
are independent. By construction,
A is symmetric. Let
D denote the diagonal matrix whose diagonal elements are the sums of rows of
A. Then,
is the Laplacian associated with the graph described by
A. In particular, the sum of all rows of
L is zero. We seek a rational basis for the kernel of a matrix
L: Let ker(
L) denote the kernel of a matrix
L. By a rational basis we mean an orthogonal basis (for ker(
L)), in which all the coordinates are either 0 or 1 and the number of 1’s is minimal. In each vector in the basis, components with 1’s form a cluster (or block), which is pair-wise independent of all other marginals. In Matlab, this can be obtained using the command null(
L,’r’). For example, consider the adjacency matrix:
whose graph Laplacian is:
A rational basis for the kernel of
L (which is 2D) is:
which corresponds to two blocks: Components 1+3 and component 2.
Pairwise independence is determined as follows:
Calculate the Spearman correlation matrix of the samples , denoted R. Note that this is the same as the Pearson correlation matrix of the ranked data ;
Assuming normality and independence (which does not hold), the distribution of elements in
R is asymptotically given by the t-distribution with
degrees of freedom. Denoting the CDF of the t-distribution with
n degrees of freedom by
, two marginals
are considered uncorrelated if
, where
is the acceptance threshold. We take the standard
. Note that because we do
tests, the probability of observing independent vectors by chance grows with
D. This can be corrected by looking at the statistics of the maximal value for
R (in absolute value), which tends to a Gumbel distribution [
35]. This approach (using Gumbel) is not used because below we also consider independence between blocks;
Pairwise independence using mutual information: Two 1D RVs
X and
Y are independent if and only if their mutual information vanishes,
[
10]. In our case, the marginals are
and
, hence
. This suggests a statistical test for the hypothesis that
X and
Y are independent as follows. Suppose
X and
Y are independent. Draw
N independent samples and plot the density of the 2D entropy
. For a given acceptance threshold
, find the cutoff value
such that
.
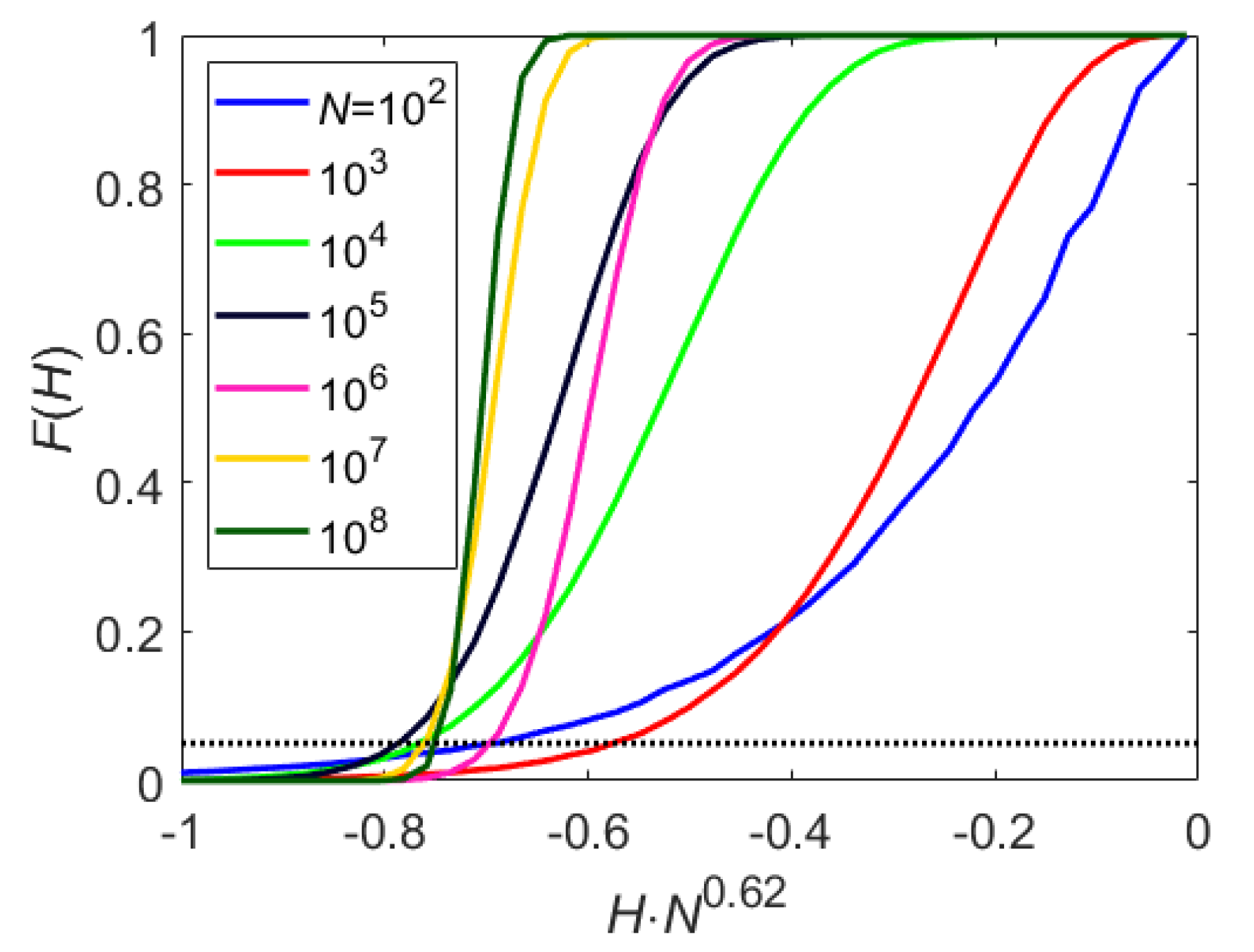
Figure A1 shows the distribution for different values of
N. With
, the cutoff can be approximated by
. Accordingly, any pair of marginals which were found to be statistically uncorrelated, are also tested for independence using they mutual information (see below);
2D entropy: Two-dimensional entropy (which, in our case, is always compact with support ) is estimated using a 2D histogram with uniformly spaced bins in each dimension.
As a final note, we address the choice of which dimension should be used for splitting in the recursion step. We suggest splitting the dimension which shows the strongest correlations with other marginals. To this end, we square the elements in the correlation matrix R and sum the rows. We pick the column with the largest sum (or the first of them if several are equal).
Lastly, we consider the computational cost of the algorithm, which has four components whose efficiency requires consideration:
Sorting of 1D samples: In the first level, samples may be unbounded and sorting can cost . However, for the next levels, the samples are approximately uniformly distributed in and bucket sort works with an average cost of . This is multiplied by the number of levels, which is . As all D dimensions need to be sorted, the overall cost of sorting is ;
Calculating 1D entropies. Since the data is already sorted, calculating the entropy using either binning or spacing has a cost per dimension, per level. Overall ;
Pairwise correlations: pre-sorted pairs, each costs per level. Overall ;
Pairwise entropy: The worst-case is that all pairs are uncorrelated but dependent, which implies that all pairwise mutual information need to be calculated at all levels. However, pre-sorting again reduces the cost of calculating histograms to per level. With levels, the cost is .
Overall, the cost of the algorithm is . The bottleneck is due to the stopping criterion for the recursion. A simpler test may reduce the cost by a factor D. However, in addition to the added accuracy, checking for pairwise independence allows, for some distributions, splitting the samples into several lower dimensional estimates which is both efficient and more accurate.
5. Summary
We presented a new algorithm for estimating the differential entropy of high-dimensional distributions using independent samples. The method applied the idea of decoupling the entropy to a sum of 1D contributions, corresponding to the entropy of marginals, and the entropy of the copula, describing the dependence between the variables. Marginal densities were estimated using known methods for scalar distributions. The entropy of the copula was estimated recursively, similar to the k-D partitioning tree method. Our numerical examples demonstrated the applicability of our method up to a dimension of 50, showing improved accuracy and efficiency compared to previously suggested schemes. The main disadvantage of the algorithm was the assumption that pair-wise independent components of the data were truly independent. This approximations may clearly fail for particularly chosen setups. Rigorous proofs of consistency and analysis of convergence rates were beyond the scope of the present manuscript.
Our tests demonstrated that compression-based methods did not provide accurate estimates of the entropy, at least for the synthetic examples tested. Nonetheless, it was surprising that some quantitative estimate of entropy could be obtained using such simple-to-implement method. Moreover, this approach could be easily applied to high-dimensional distributions. Under some ergodic or mixing properties, independent sampling could be easily replaced by larger ensembles. Thus, for dimension 100 or higher (e.g., a 50 particles system in 2D), all the direct estimation methods (kDP, kNN, and CADEE) were prohibitively expensive.
To conclude, our numerical experiments suggest that
kNN methods were favorable for unbounded distributions up to about dimension 20. At higher dimensions,
kNN may become inaccurate, in particular for distributions with compact support (e.g., examples C1 and C2 in
Figure 2). In addition, we found that
kNN methods become inefficient at dimensions higher than 30 (e.g., examples UB1 and UB2 in
Figure 3). For distribution with compact support, or when the support is mixed or unknown, the proposed CADEE method was significantly more robust. Our simple numerical examples suggest that the CADEE method may provide reliable estimates at relatively high dimensions (up to 100), even under severe under-sampling and at a reasonable computational cost. Here, we focused on the presentation of the algorithm and demonstrated its advantages for relatively simple analytically tractable examples. Applications to more realistic problems, for example estimating the entropy of physical systems that were out of equilibrium will be presented in a future publication. We suggest using the recursive copula splitting scheme for other applications requiring estimation of copulas and evaluation of mutual dependencies between RVs, for example, in financial applications and neural signal processing algorithms.
A Matlab code is available in Matlab’s File Exchange.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}