1. Introduction
With the rapid growth of information technology, multimedia management is a very crucial task. Multimedia is needed to classify different data types for efficient accessing and/or retrieving. Knowing how to build a management of multimedia information for AV (audio/video) indexing and retrieval is becoming extremely important. In the field of AV indexing and retrieval, the speech/music discrimination (SMD) is a very crucial task for the audio content classification (ACC) system or general audio detection and classification (GADC) [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]. In recently, the SMD literatures have been presented in different application [
19,
20,
21,
22,
23,
24] and closely related to retrieval of audio content indexing [
20]. In general, audio feature extraction and audio segmentation are two main parts of a content-based classifier. Different features are presented to describe audio data. These features are mainly categories characteristic of time-domain and frequency-domain. In terms of feature extraction, the very common time-domain features are short-time energy (STE) [
25,
26] and the zero-crossing rate (ZCR) [
27,
28]. Signal energy [
29,
30,
31], fundamental frequency [
32], Mel frequency cepstral coefficients (MFCC) [
19,
33,
34] are the most used frequency-domain features. Recently, a few studies focused on speech and song/music discrimination [
35,
36,
37]. Some features such as loudness and sharpness have been incorporated in the human hearing process to describe sounds [
38,
39]. In a study by [
40], a novel feature extraction method based on the visual signature extraction is presented. The well-known “spectrogram reading” is regarded as visual information and displays the representation of time-frequency. In the visual domain, the representation of time-frequency successfully stands for the audio signal pattern [
40,
41]. In addition, various techniques of audio classification are used for characterizing music signals, such as threshold-based methods or combining the string tokenization method and data mining technique [
42]. Neural network [
43], clustering [
44], and k-nearest neighbor (k-NN) are used for speech/music classification, and the decision is made based on a heuristic-based approach [
45]. In [
46], the decision relies on the k-NN for classification by using perceptually weighted Euclidean distance. Gaussian mixture models (GMM) [
47], support vector machine (SVM) [
48], and fuzzy-rule [
49] are also used for speech/music classification. Such new trends include temporal feature integration and classifiers aggregation [
8,
9,
10,
11,
12,
13,
14,
15], novelty audio detection and bimodal segmentation [
7,
9,
16], and deep learning [
5,
17]. In recent years deep learning algorithms have been successfully used to solve numerous speech/noise classification problems, especially the development of deep convolutional neural networks without any need for careful feature selection [
50,
51]. However, deep neural networks are generally known to be more computationally expensive and slower than other more conventional methods [
52]. Apart from the above, innovative techniques utilizing one-class classifiers, perceptual wavelet-cepstral parameters, hierarchical/multi-resolution thresholding, and other adaptive detection mechanisms were recently reported [
7,
9,
10,
11].
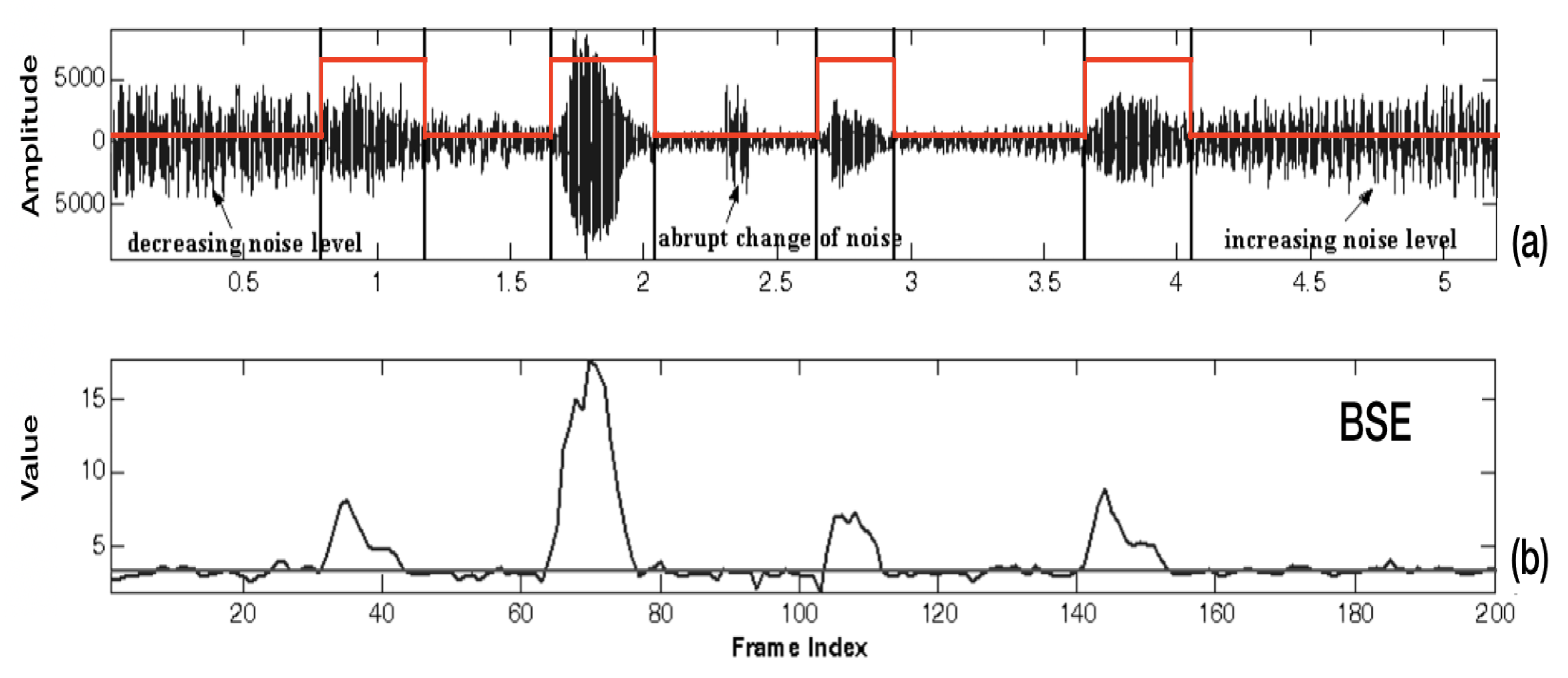
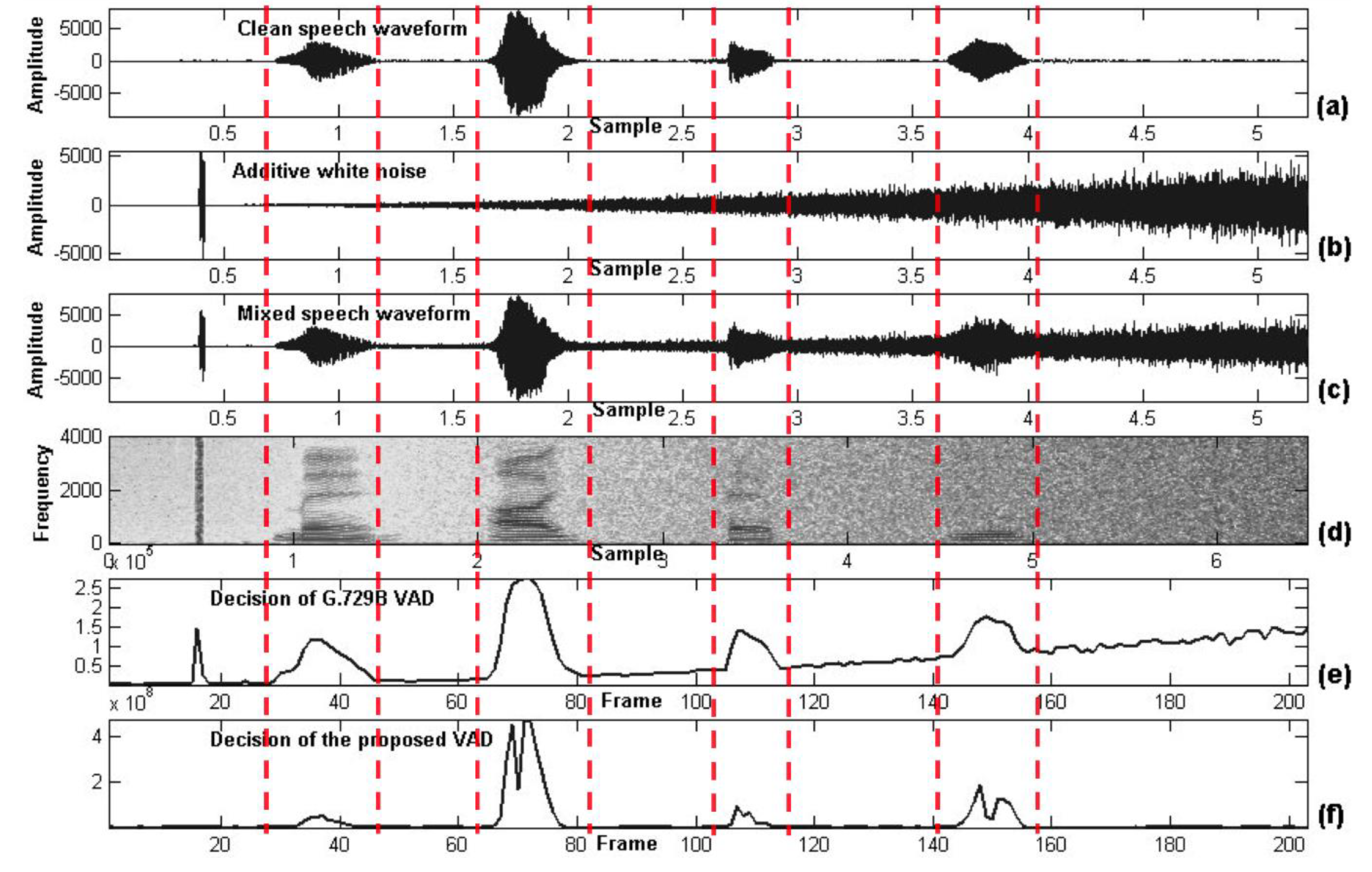
Up to now, in a real-life environment, the problem of a variable-noise level environment is not considered for the above-mentioned works. To alleviate this problem, the robust spectral entropy-based scheme of voice-activity detection (VAD) which distinguishes speech and non-speech segments from the incoming audio signal is combined with the utilized SMD approach as a front-end of the proposed system of ACC application. Especially for the VAD case, the idea of using spectral entropy and other related parameters that monitor spectral variability or flatness has been used for many years [
1,
3,
4]. Our previous research article [
53] proved that spectral entropy-based VAD can be successfully applied to a variable noise-level environment. In addition, the differences on the sound spectrogram between music and speech are significant. In music, the spectrum’s peak tends to change relatively slowly even though music is played with various tempos as shown in
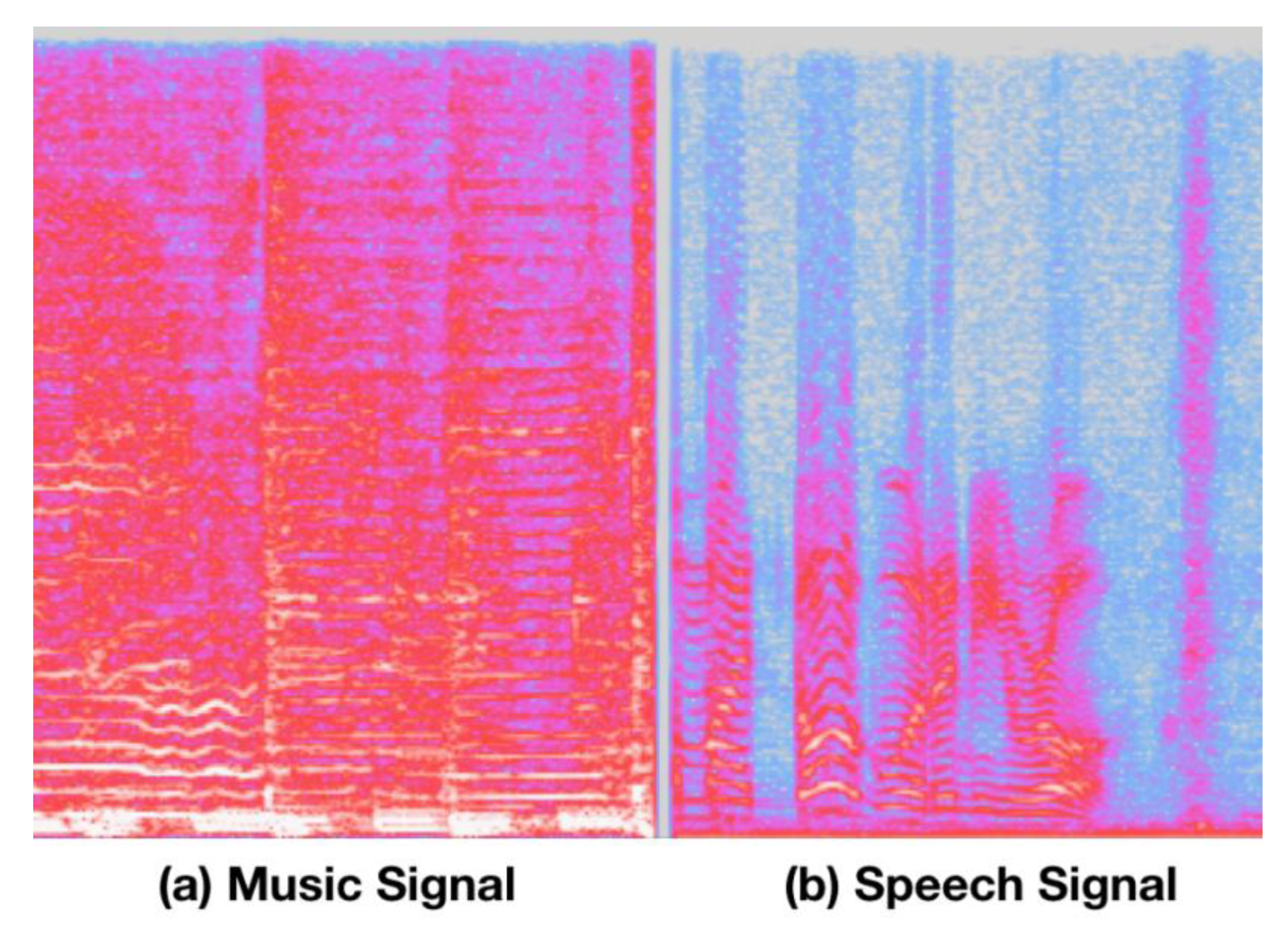
Figure 1. On the contrary, shorter durations occur in speech sound events. We know that the spectral envelope of speech varies more frequently than the spectral envelope of music. Consequently, the rate of change of the spectral envelope (or called texture diversity) is one of the valid features for characterizing the differences between speech and music. This type of texture diversity suggests that perceptual wavelet analysis on a spectrogram will generate highly discriminate features for audio discrimination. Texture diversity is also regarded as 2D textual image information on a spectrogram and was successfully applied in studies by [
54] and [
55].
Extended from our previous work [
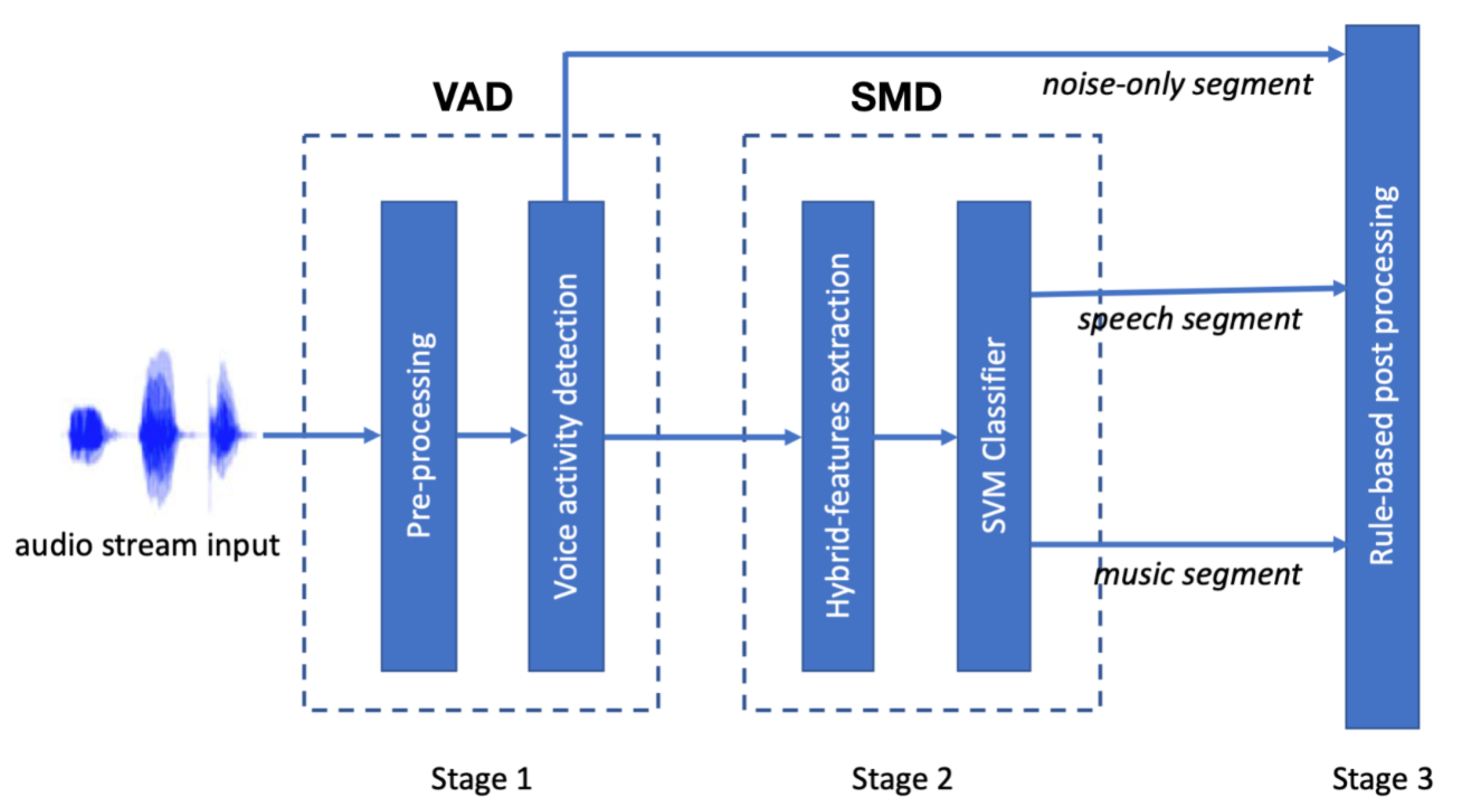
56], a hierarchical scheme of the ACC system is proposed in this paper. In general, audio hierarchically categorizes silence/background noise, various music genres, and speech signals. As a result, a three-stage scheme involving speech, music, and other is adopted herein [
9]. In the first stage of the proposed ACC, the incoming audio signal is pre-emphasized and partitioned. Next, the scheme of VAD is utilized with the Mel-scale spectral entropy to classify the emphasized audio signal into silence segments and non-silence segments. In the second stage, the SMD approach comprises of the extraction of hybrid features and SVM-based classification. A novel technique of hybrid feature extraction is derived from wavelet-spectrogram textual information and energy information to obtain a set of features including the 1D subband energy information (1D-SEI) and 2D texture image information (2D-TII).
In order to extract the 2D-TII parameter, we first generated the spectrogram in grayscale. Then, the local information was captured by zoning the range from 0 kHz to 4 kHz in order to characterize the discrimination between speech and music [
57]. This is so the 2D-texture information [
54] can be analyzed upon the wavelet-spectrogram. Next, the 2D-TII parameter is accurately obtained by using Laws’ mask through 2D-perceptual wavelet packet transform (PWPT). Consequently, we let three hybrid feature inputs into an SVM classifier. During the second stage, the noisy audio segments are classified into speech segments and music segments. In the third stage we improved the discrimination accuracy, and a rule-based post-processing method was applied to reflect the continuity of audio data in time.
This paper is organized as follows. In
Section 2, we introduce the proposed approach of the three-stage ACC. The approach includes three main stages: pre-processing/VAD, SMD, and post-processing. The VAD uses the measure of band-spectral entropy to distinguish non-noise segments (noisy audio segment) from noise segments (silence).
Section 3 presents the hybrid-based SMD algorithm. The hybrid features include 1D subband energy information (1D-SEI) and 2D texture image information (2D-TII). Through the combination of 1D signal processing and 2D image processing, the hybrid features characterize the discrimination between speech and music. In
Section 4, the rule-based post-processing is presented to improve the segmentation results in different noise types and levels. Finally, the experiments and results are presented in
Section 5. In this section, the evaluation of the proposed ACC approach is performed on well-known speech and music databases (e.g., GTZAN dataset) at well-defined signal-to-noise ratio (SNR) levels.
Section 6 provides the discussion and conclusions.
3. Hybrid-Based Speech/Music Discrimination (SMD)
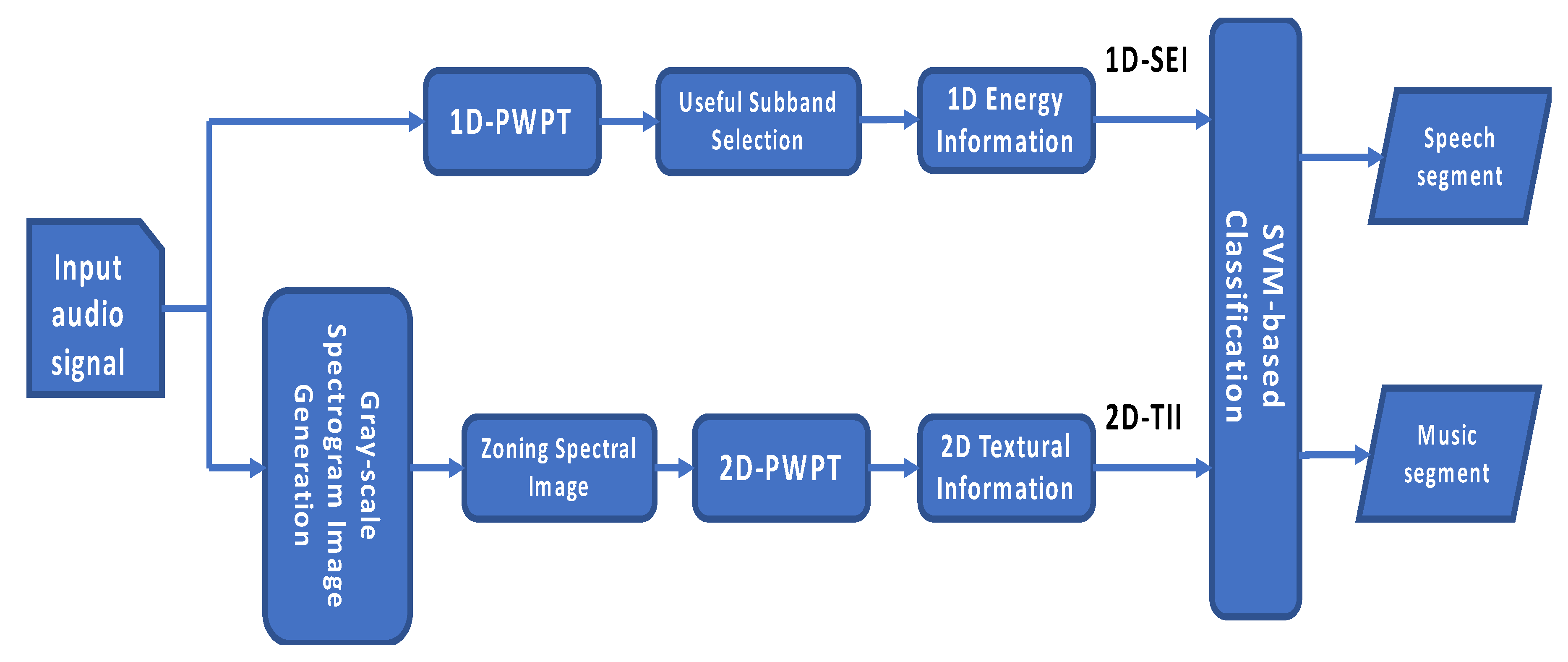
The processing flow of the hybrid-based SMD is shown in
Figure 4. The SMD is based on a hybrid feature set, which contains 1D subband energy information (1D-SEI) and 2D texture information (2D-TII) parameters. For noisy segmented audio input, the composed features are extracted from the 1D-PWPT and Bark scale spectrogram image, respectively. The hybrid features include 1D-SEI feature set and 2D-TII feature set. For the feature extraction of 1D-SEI, we used 1D-PWPT (perceptual wavelet packet transform) to get 24 critical subbands. Through the useful subband selection, the correct energy information was used to discriminate the difference between speech and music. In the feature extraction of 2D-TII, gray-scale spectrogram was first generated. Zoning the range from 0 kHz to 4 kHz, the local information is enough to characterize speech and music, respectively. Using 2D-PWPT, we can get the 2D textural information. Finally, the hybrid features are then fed into the SVM-based classifier to discriminate their types (speech or music).
3.1. D-PWPT (Perceptual Wavelet Packet Transform)
In order to mimic the hearing characteristics of human cochlea, the Bark scale, a psychoacoustical scale proposed by Eberhard Zwicker in 1961, was used [
62]. It was found that for the auditory quality of a speech signal, an analysis on non-uniform frequency resolution is better than on uniformly spaced frequency resolution [
63]. In fact, the selection of the “optimal” decomposition is a classical problem in order to suppress audible noise and eliminate audible artefacts. According to the Bark scale rules, the 1D-perceptual wavelet packet transform (PWPT) implemented with an efficient five-stage tree structure is utilized to split 24 critical subbands for input speech signal. For each stage, the high-pass filter and low-pass filter are implemented with the Daubechies family wavelet, where the symbol ↓2 denotes an operator of down-sampling by 2 [
53]. In
Table 1, we see that the Bark scale-based wavelet decomposition lets every frequency band limit become more and more linear when frequencies are below 500 Hz; this scale is more or less equal to a logarithmic frequency axis when above about 500 Hz.
3.2. Optimal Subband Selection for Useful Information
In previous works [
64], an extraction of selecting useful frequency subbands was proposed to suppress the noise effect on the ACC system, especially at a poor SNR (signal-to-noise ratio). The process of pure energy on the useful frequency is shown below.
During the initialization period, the noisy signal was assumed to be noise-only, and the noise spectrum was estimated by averaging the initial 10 frames. To recursively estimate the noise power spectrum, the subband noise power, , was adaptively estimated by smoothing filtering.
For the
frame, the spectral energy of the
subband is evaluated by the sum of squares:
where
means the
wavelet coefficient.
and
denote the lower boundaries and the upper boundaries of the
subband, respectively.
The
frequency subbands energy of pure speech signal of the
frame
is estimated:
where
is the noise power of the
frequency subband.
According to Wu et al. [
65], subbands with a higher energy
can stand for a greater amount of pure speech information. So, the frequency subband should be sorted according to its value of
.
That is,
where
is the index of the frequency subband with the
max energy.
denotes the number of useful subbands on the
frame.
.
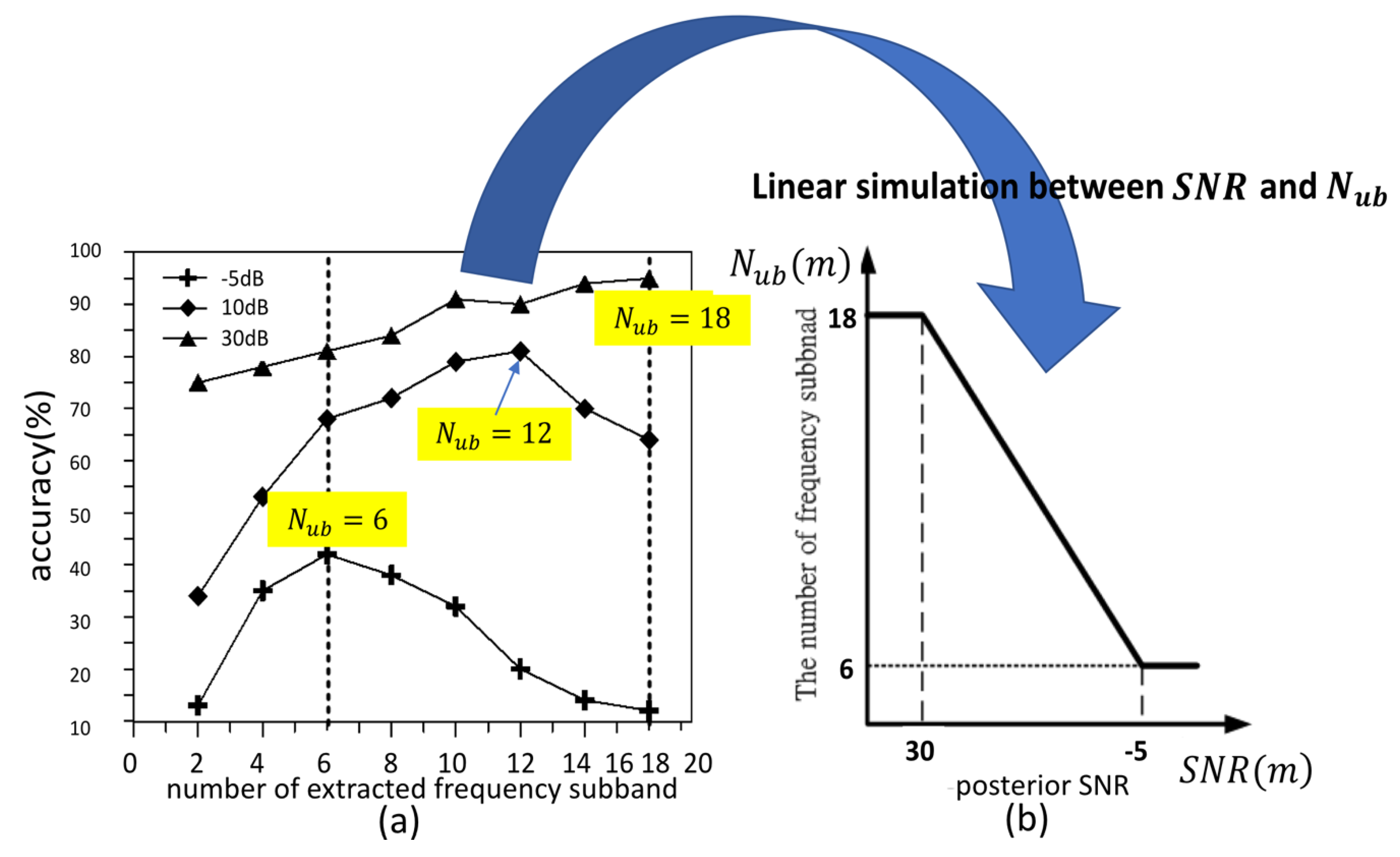
In fact, the relation between the number of useful frequency subbands,
, and the posterior SNR,
, has a negative-correlation, as shown in
Figure 5.
We see that the number of useful frequency subbands increases with the increase of
in
Figure 5a. When
,
and
, the highest accuracy of VAD appears as
,
and
, respectively. In order to simulate the relationship between
and
, a linear function is in the boundary between −5 dB and 30 dB, while the duration between
to
is shown in
Figure 5b:
where
is the round off operator and
denotes a frame-based posterior
for the
frame.
is dependent on the summation of subband-based posterior SNR
on the
useful subband, defined as:
where
.
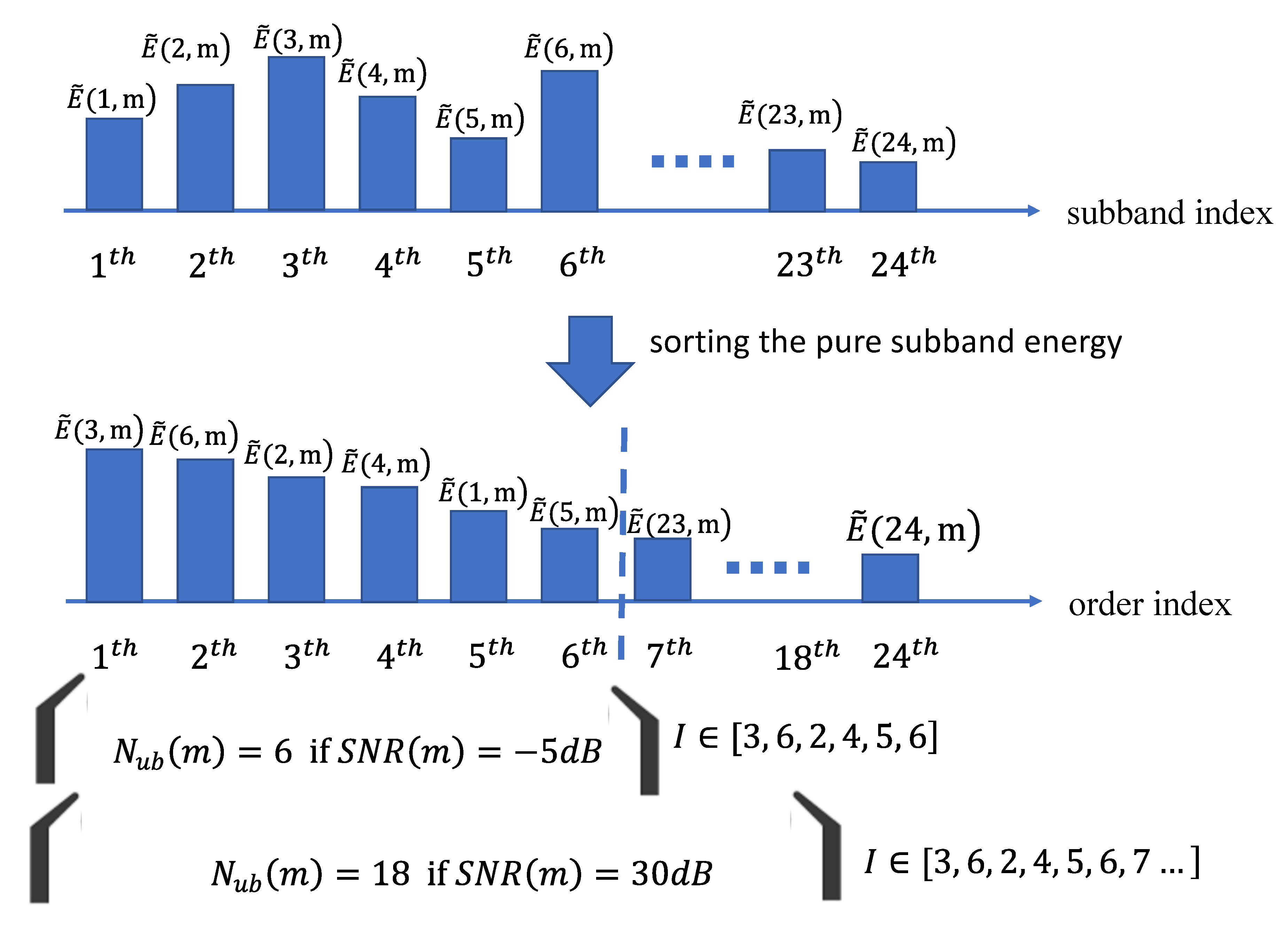
Figure 6 clearly illustrates the example of extracting useful subbands under a different posterior SNR. We see that the pure subband energy is rearranged after sorting processing among all 24 subbands. Originally, the first subband index
is 1, but the updated first index
is 3 when sorting the energy. Consequently, the useful subband index and number are extracted according to the value of the posterior SNR.
3.3. The 1D Subband Energy Informations (1D-SEIs)
It is well-known that the distribution of energy on each frequency band is a very relevant acoustic cue. After selecting a useful subband, the wavelet energy was calculated from 1D-PWPT to form a 1D subband energy informations (1D-SEIs): the average of subband energy (ASE), the standard deviation of subband energy (SDSE), and Teager energy. So, the 1D-SEIs derived from three parameters are investigated below:
- --
The average of subband energy (ASE)
- --
The standard deviation of subband energy (SDSE)
We see that the speech’s energy exists in a lower frequency band mainly and the music’s energy is in a wide range of the frequency band.
- --
The discrete Teager energy operator (TEO), introduced by Kaiser [
66], allows modulation energy tracking and gives a better representation of the formant information in the feature vector. So, we can also successfully use the characteristic to discriminate speech from music.
3.4. Gray-Scale Spectrogram Image Generation
In this subsection, a novel feature extraction is derived from the gray-scale spectrogram images. As mentioned above, we see the difference between speech and music while relying on the virtual representation of audio data by spectrogram. In fact, the gray-scale spectrogram images are regarded as a time-frequency-intensity representation. Since the human perception of sound is logarithmic, the log-spectrogram is defined as:
The time-frequency-intensity representation is normalized into a grayscale normalized image, within the range of 0 to 1:
3.5. The Zoning for Spectrogram Image
To achieve good results for SMD, the zoning method for spectrogram image was applied [
67]. In fact, the textural image information between speech signals and music data is different [
68]. It was found that the music audio data consist of a few silent intervals, and have continuous energy peaks for a short time and fewer frequency variations, while the speech audio data consist of many silent intervals and most of the energy is located at the lower frequencies [
69]. Accordingly, the spectrogram image from 0 kHz to 4 kHz is separated to extract textural features as local features by the zoning method. The feature extraction for the 2D textural image information (2D-TII) is discussed in the next subsection.
3.6. The 2D Textural Image Information (2D-TII)
In fact, the differences on the sound spectrogram between music and speech are significant. In music, the spectrum’s peak tends to change relatively slowly even though the music is played with various tempos. On the contrary, in speech, sound events often have shorter durations but with more distinctive time-frequency representations. For the above reason, the 2D-TII features can be successfully derived from the audio spectrogram image through Laws’ masks based on the principle of texture energy measurement [
54] to find the difference between speech and music. It is known that Laws’ masks are well described for texture energy variation in image processing, and the masks consist of five masks derived from one-dimensional vectors, such as edge
, level
, spot
, ripple
and wave
expressed as Equations (14)–(18):
The two-dimensional filters of the size 5 × 5 were generated by convoluting any vertical one-dimensional vector with a horizontal one. Finally, the 25 combinations of two-dimensional masks are determined [
70].
First, we convoluted the image with each two-dimensional mask to extract texture information from an image
of size
. For example, if we used
to filter the image
, the result was a texture image,
, as seen in Equation (19).
All the two-dimensional masks, except
, had a zero mean. According to Laws, texture image
was used to normalize the contrast of all the texture images
, as seen in Equation (20).
Next, the outputs (TI) from Laws’ masks were passed to “texture energy measurement” (TEM) filters. We calculate the non-linear interval by processing TI normalized and yield through “Texture Energy Measurements, (TEM)” filter. This consisted of a moving non-linear window average of absolute values, as seen in Equation (21).
Since not all mask energy is used as the input basis of texture energy, we take out unchangeable
values before and after rotation to obtain a valid
The
derived from
is represented in Equation (22).
After Equation (22), the results of the three texture feature values: mean, standard deviance (SD), and entropy are extracted via Equations (23)–(25) to exploit the variation of texture information.
Each equation produces feature vectors with 14-dimensional size. Finally, a total of three feature vectors with 42-dimensional sizes are used as the input data for training the SVM classifier.
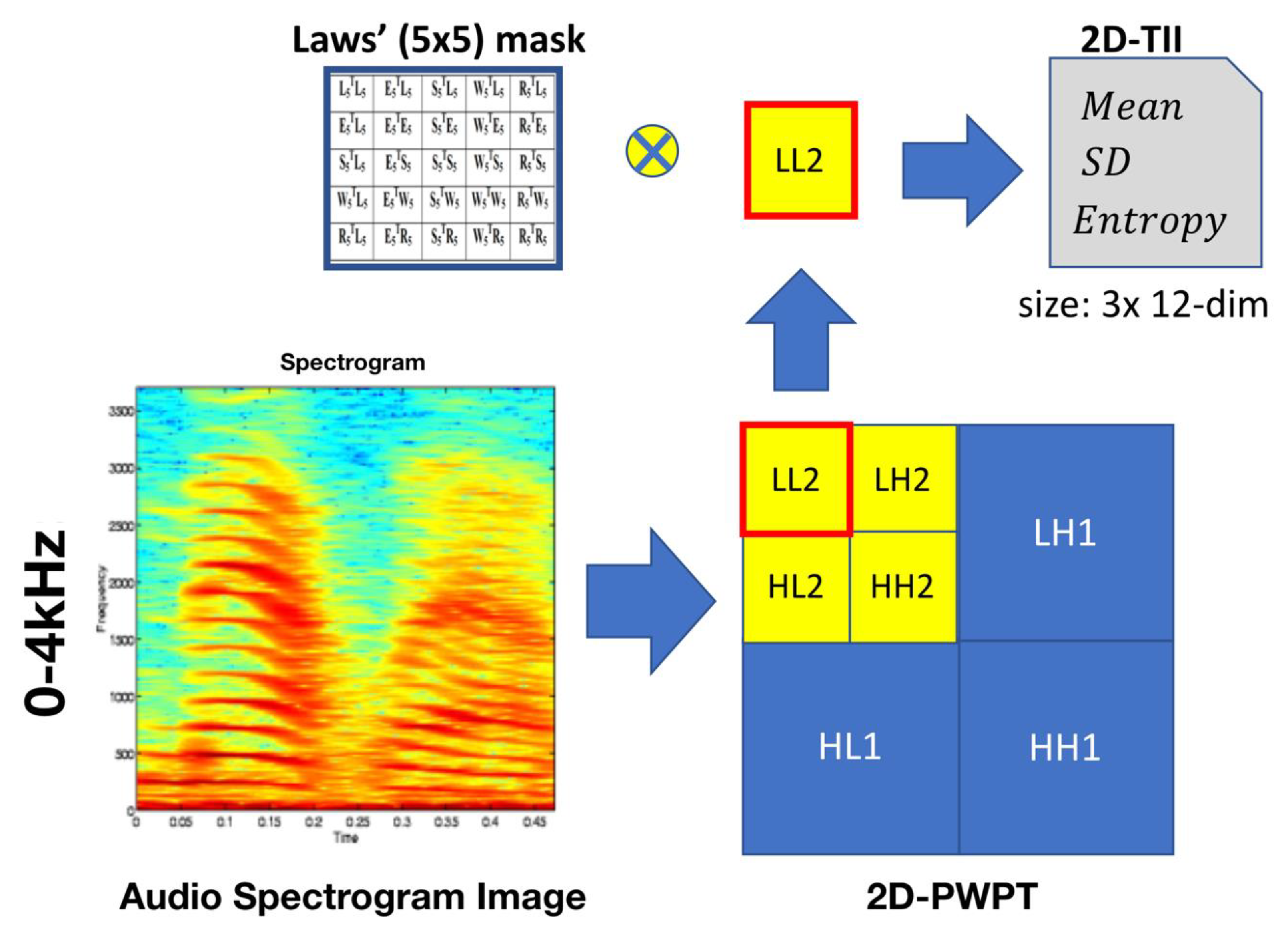
3.7. From 2D-PWPT to 2D-TII
To perform texture analysis on multi-resolution, 2D-PWPT is utilized into an audio spectrogram image, which ranges from 0 to 4 KHz.
Figure 7 shows an audio spectrogram image decomposition. In
Figure 7, these subbands are first obtained using one-level wavelet decomposition. These subbands are labeled as LH1, HL1, and HH1 and represent the detail images, while the sub-band labeled as LL1 is regarded as the approximation image. The detail images represent the finest scale wavelet coefficients. Conversely, the approximation image corresponds to coarse level coefficients. The sub-band LL1 alone is further decomposed and critically sampled in order to obtain the next coarse level of wavelet coefficients. So, this results in two-level wavelet decomposition. Similarly, LL2 is used to obtain further decomposition. Lastly, the spectrogram image of LL2 is only convoluted by the two-dimensional Laws’ mask to determine the 2D-TII. Compared to the original image size of the spectrogram within 0 to 4 kHz, the LL2 is de-sized. Thus, we can decrease the computing time and get good information derived from LL2 sub-image that is better than the original image.
3.8. SVM-Based Classification
Support vector machine (SVM) is well-known effective bi-classification [
71,
72,
73]. In actuality, the SVM is better than other conventional classifiers in terms of classification accuracy, computational time, and stability. In this subsection, the hybrid feature set including 1D-subband energy information and 2D-texture information,
, are imported into a discriminative classifier of the SVM to classify either the speech segment or music segment. Suppose a set
of
is the training set, where
is the input signal vector,
is the class label for speech or audio,
, and
denotes
-dimensional space.
To find the optimal hyper-plane, the support vectors of the dataset maximize the margin, which is the distance between the hyper-plane and support vectors as follows:
The solution to the optimization problem of SVM is given by the Lagrange function as follows:
with constraint
and
, where
is upper bound of the Lagrange multipliers
and the constant
.
As for the kernel function, we consider ERBF and Gaussian function as shown below:
where
is the variance.
is the additional control parameter.
Potentially, the ERBF function is usually used as the kernel function and vastly improves the results [
74]. Therefore, the SVM which adopts ERBF as a kernel function will be compared to other classification.
6. Conclusions
In this paper, we presented a new algorithm of audio content classification (ACC) for applications under a variable noise-level environment. A novel hierarchical scene of a three-stage scheme of the proposed ACC algorithm was described in detail for classifying audio stream into speech, music, and background noise. In addition, we introduced the hybrid-based feature, which investigates the use of 1D-subband energy information (1D-SEI) and 2D textural image information (2D-TII) as hybrid features to classify speech or music. It was found that using hybrid-based features can easily discriminate the noisy audio signal into speech and music. Further, the entropy-based VAD segment indeed provides high accuracy for application of the ACC. In summary, we conclude that the proposed ACC based on hybrid features SMD scheme and entropy-based VAD segment can achieve a low error value of below 13% at a low SNR and variable noise-level according to the above experimental results. It was shown that hybrid-based SMD and entropy-based VAD segments can be successfully applied into the system of audio content classification (ACC). The system was tested with different combinations of audio styles and different SNR levels. The experimental evaluations were also performed with real radio recordings from BBC, NHK, and TTV news.
In addition, the proposed hierarchical ACC system was compared with other systems on publicly available audio datasets. This paper proves that the hierarchical classification is one of the great methodologies for audio content analysis. Compared to the spectrogram-based CNN, the proposed hierarchical ACC system using hybrid feature-based SMD and entropy-based VAD can provide a great trade-off in terms of computing complexity and accuracy. Moreover, a combination of voice activity detection (VAD), speech/music discrimination (SMD), and post-processing is a novel idea, applied into the hierarchical classification. Especially, the voice activity detection (VAD) demonstrates a novel use of entropy. The proposed hierarchical classification system provides a reliable, stable, and low-performance architecture for contribution of audio content analysis.
In future work, the proposed ACC approach using hybrid-based manner will be appended to discriminate more audio types with lower SNR levels. In order to apply audio content retrieval, we will also focus on developing an effective scheme.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}