1. Introduction
This article proposes a novel type of probabilistic inference in quantum-like Bayesian networks [
1] based on the notion of intensity waves. We refer to intensity waves the principle of an electron being represented as a wave under uncertainty: if one does not perform any measurement, then the electron enters into a superposition state and takes the properties of a wave, which evolves through time and which can generate quantum interference effects. The underlying core idea of the proposed model is to provide a novel mathematical formalism that, under probabilistic inference in quantum-like Bayesian networks, will enable the intensity waves to cancel each other during Bayes normalisation. This will result in probabilistic waves that are balanced, contrary to the current approach, where they are skewed in order to meet Bayes normalisation. These intensity waves are highly significant in the literature, because they can provide means to quantify uncertainty during probabilistic inferences, and consequently the prediction of inferences that are either obeying or violating the rules of classical probability theory.
The main motivation of proposing such a model is based on the fact that empirical evidence from the cognitive psychology literature suggest that most human decision-making cannot be adequately modelled using classical probability theory as defined by Kolmogorov’s axioms [
2,
3,
4,
5,
6]. These empirical findings show that, under uncertainty, humans tend to violate the expected utility theory and consequently the laws of classical probability theory (e.g., the law of total probability [
7]), leading to what is known as the “disjunction effect” which, in turn, leads to violation of the Sure Thing Principle.
The concept of human behaviour deviating from the predictions of expected utility theory is not something new. There are many studies suggesting that humans tend to deviate from optimal Bayesian decisions [
8,
9,
10,
11], which is not consistent with expected utility theory. Many approaches have been proposed in the literature in order to overcome these limitations. For instance, recently Peters [
12] criticised the notion of expected utility by showing that it is built under false assumptions, and proposed the concept of ergodicty economics as an alternative model to optimise time-average growth rates. Another work from Schwartenbeck et al. [
13] describes irrational behaviour as a characteristic of suboptimal behaviour of specific groups [
14]. Their main argument is to look at irrational behaviour as a subject-specific generative model of a task, as opposed of having a single optimal model of behaviour (like it is predicted by expected utility theory). Other models have been recently proposed in the literature based on a more general probabilistic framework: the formalism of quantum probability theory, which had led to the emergence of a new research field called quantum cognition [
7,
15,
16,
17,
18,
19,
20,
21].
The main difference between classical and quantum probability theory lies in the fact that in classical probability all properties of events are assumed to be in a definite state. As a consequence, all properties are assumed to have a definite value before measurement, and that this value is the outcome of the measurement [
22]. In quantum probability theory, on the other hand, all properties of events are in an indefinite state prior to measurement and are represented by a wave function, which evolves in a smooth and continuous way according to Schrödinger’s equation. This evolution is deterministic and reversible and is done in parallel. Reversible means that no information is lost. This kind of evolution is described by quantum probabilities that are also called von Neumann probabilities. However, during the observation (measurement), the wave collapses into a definite state. The subsequent observed evolution is described by Kolmogorov’s probabilities, which are neither smooth, nor reversible, since information is lost. In terms of probabilistic inference in quantum-like models, this suggests that probabilities are composed of two terms: one corresponding to the outcome of Kolmogorov’s (classical) probabilities, and another which corresponds to the interference effects between the intensity waves that occur before measurement.
Current models for probabilistic inference in quantum-like Bayesian networks apply Bayes normalisation factor to both the classical terms and interference terms. While it is clear the application of Bayes normalisation to classical outcomes, it is not clear what is the interpretation when it comes to its application to quantum interference terms. One can argue that this is just a way to normalise likelihoods in order to convert them into probabilities, however the resulting intensity waves lack interpretation and become extremely skewed, resulting in a representation that is very sensitive to initial conditions of amplitudes. This can lead to some significant challenges, since one core research question is how to quantify the decision-maker’s uncertainty during probabilistic inferences using the amplitudes of the intensity waves, in such a way that it can predict probabilistic outcomes which are either following a definite Kolmogorovian setting, or disjunction effects, or other violations to the laws of classical probability.
To address these challenges this article extends the initial work conducted in Wichert and Moreira [
23], and investigates the relationship between classical and quantum probabilities and we propose two laws that will allow the representation of the intensity waves. The law of balance which is a way to normalise intensity waves without the need of using Bayes normalisation factor, and the law of maximum uncertainty that enables the quantification of uncertainty within the paradigm of these intensity waves. In short, this article contributes:
A Law of Balance: a novel mathematical formalism for quantum-like probabilistic inferences that enables the cancellation of quantum interference terms upon the application of Bayes normalisation factor. This way, the amplitudes of the probability waves become balanced.
A Law of Maximum Uncertainty: which states that in order to predict disjunction effects, one should choose the amplitude of the wave that contains the maximum uncertainty or the the maximum information.
These laws are validated in quantum-like probabilistic inferences in Bayesian networks in cognitive psychology experiments from the literature, namely the Prisoner’s Dilemma game [
24,
25,
26,
27] and the Two Stage Gambling Game [
28,
29].
We would like to highlight that the purpose of the present paper is not to say that quantum cognition is the best approach to fully understand human behaviour. We see quantum cognition as an approach which is as promising as other approaches in the literature for this end with its advantages and disadvantages. The main goal of this work is simply to continue to develop quantum-like models for cognition, since they still suffer from many gaps, one of them is precisely on how to deal with quantum interference during probabilistic reasoning and how that could be applied in more general structures, not only for cognition, but for general decision-making models.
2. Probabilistic Inference in Bayesian Networks
In this section, we present the fundamental concepts regarding probabilistic inference within Bayesian networks. Bayesian Networks are directed acyclic graphs in which each node represents a random variable from a specific domain, and each edge represents a direct influence from the source node to the target node. The graph represents independence relationships between variables, and each node is associated with a conditional probability table that specifies a distribution over the values of a node given each possible joint assignment of values of its parents [
30].
In these networks, the graphical relationship between random variables is fundamental to determine conditional independence and to compute probabilistic inferences. For instance, consider two events represented by the binary random variables,
X and
Y, which can either be true (
) or false (
. For simplicity, throughout this paper, we will refer to
as
,
as
,
as
and
as
. This translates into
where the law of total probability is given by
Using the chain rule,
The same relationship is obtained for
,
This probabilistic influence that random variables
X exerts
Y can be represented by the Bayesian network depicted in
Figure 1.
If two variables
x and
y are independent, then the probability that the event
x and
y simultaneously occur is
For
N independent random variables, we obtain
When not all events are independent, then we can decompose the probabilistic domain into subsets via conditional independence by using Bayes’ rule,
This translates in the chain rule formula. Assuming that
and
are independent, but
is conditionally dependent given
and
, then
Analogously, if we assume that
is conditionally dependent given
but independent of
and
, then
From this representation, it follows a causal relationship between these events, which is represented by a conditional dependence.
Figure 2 shows a graphical representation indicating the causal influence between events
,
,
and
.
In our example
and
cause
and
also causes
. This kind of decomposition via conditional independence is modelled by Bayesian networks, since they provide a natural representation for (causally induced) conditional independence. These conditional independence assumptions are also represented by the topology of an acyclic directed graph and by sets of conditional probabilities. In the network each variable is represented by a node and the links between them represent the conditional independence of the variable towards its non descendants and its immediate predecessors (see
Figure 2).
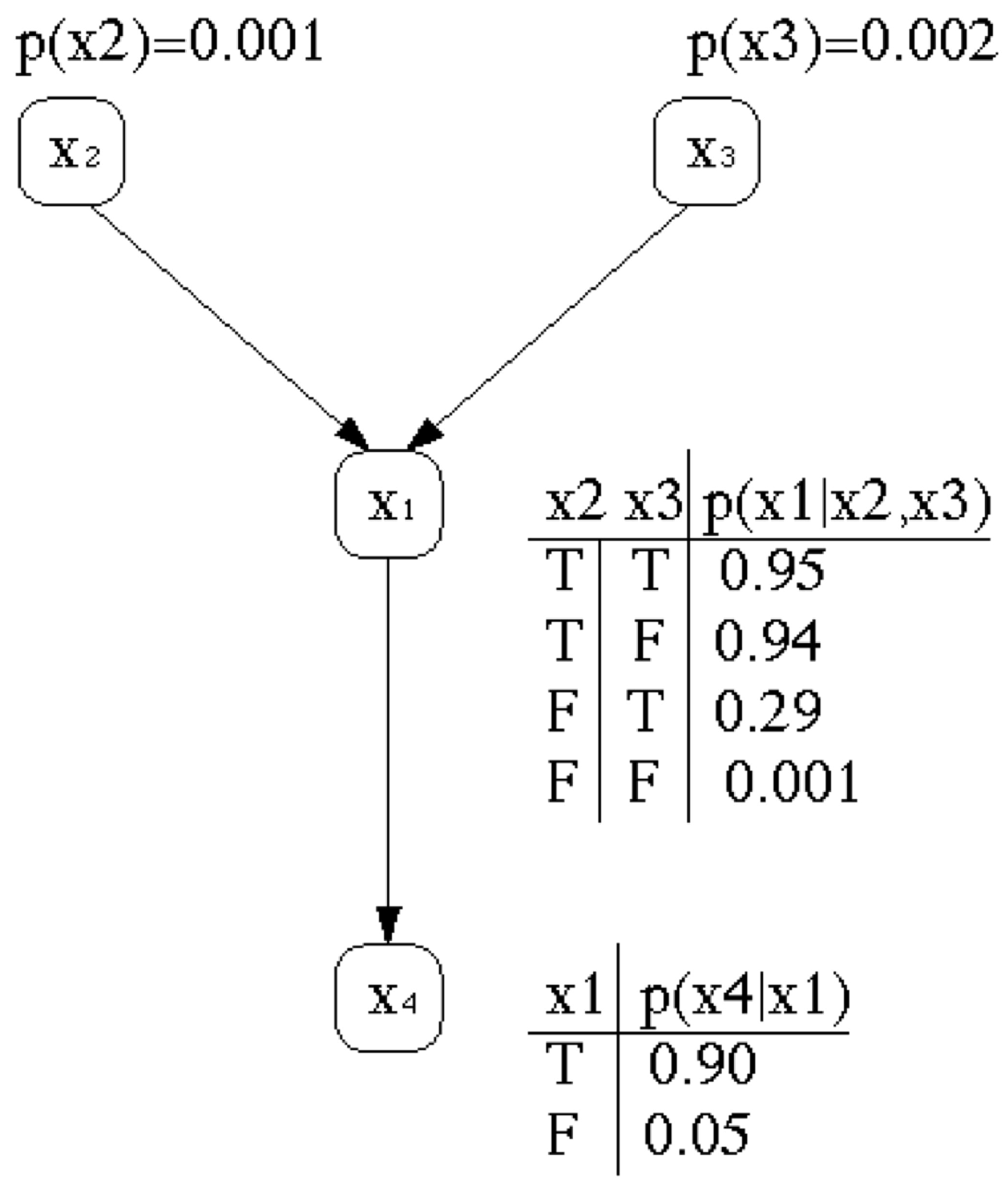
The corresponding network topology reflects our belief in the associated causal knowledge. Consider the well-known example of Judea Perl [
31,
32]. “I am at work in Los Angeles, and neighbour John calls to say that the alarm of my house is ringing. Sometimes minor earthquakes set off the alarm. Is there a burglary?” Constructing a Bayesian network should be easy, because each variable is directly influenced by only a few other variables. In the example, there are four variables, namely,
),
),
) and
). Due to simplicity, we ignore an additional variable
that was present in the original example. The corresponding network topology in
Figure 2 reflects the following “causal” knowledge:
A burglar can set the alarm on.
An earthquake can set the alarm on.
The alarm can cause John to call.
Bayesian networks represent for each variable a conditional probability table which describes the probability distribution of a specific variable given the values of its immediate predecessors. A conditional distribution for each node
given its parents is
with
k representing the number of predecessor nodes (or parent nodes) of node
. Given the query variable
x whose value has to be determined and the evidence variable
e which is known and the remaining unobservable variables
y, we perform a summation over all possible
y. In the following examples, for simplification the variables are binary and describe binary events. All possible values (true/false) of the unobservable variables
y are determined according to the law of total probability
with
3. Quantum Probabilities
Until “recently” quantum physics was the only branch in science that evaluated a probability
of a state
x as the squared magnitude of a probability amplitude
, which is represented by a complex number
This is because the product of a complex number with its conjugate is always a real number. With
Quantum physics by itself does not offer any justification or explanation beside the statement that it just works fine, see Binney and Skinner [
33].
4. The Two-Slit Experiment, Intensity Waves and Probabilisitc Waves
Suppose there are two mutual exclusive events x and y. This means that x and y do not occur together.
The classical probability of an event
x or event
y is just
This is the sum rule for probabilities for exclusive events. For probability amplitudes, it is as well
However converting these amplitudes into probabilities according to Equation (
9) leads to an interference term
,
making both approaches, in general, incompatible
In other words, the summation rule of classical probability theory is violated, resulting in one of the most fundamental laws of quantum mechanics, see [
33]. In the following sections, rather than dealing with binary events, we will introduce the notion of a “state” which corresponds to some states of nature. Logical possibilities of events are usually called the elementary events or states of nature. Here we will refer to them simply as “states”.
The relation between the amplitudes and probabilities in quantum theory is related to an unobservable wave function. The wave function in quantum mechanics represents a superposition of states of which each state
x is represented by
. Suppose that an unobservable state evolves smoothly and continuously. However, during the measurement, it collapses into a definite state with a probability
. For instance, let us imagine a gun that fires electrons and a screen with two narrow slits
x and
y and a photographic plate. An emitted electron can pass through slit
x or slit
y and reaches the photographic plate at the position
z, which is equidistant from both slits. The electron detectors show from which slit the electron went through, and we find that the probability of the electron hitting the photographic plate is
This probability means that, when measured, the electron behaved as a particle.
4.1. Intensity Waves
On the other hand, if we remove the detectors, the electron is unobserved, not knowing through which slit it went through. Now, the electron is represented as a wave with the amplitudes
These amplitudes contain a parameter
, which corresponds to the phase of the wave. The equation then becomes
with
for most values of
. Since the value of
may be bigger than one, we can not identify it with probability values. We call
the intensity wave of the state
z. Since the norm is being positive or more precisely non-negative, the intensity wave of the state
z,
, is always non-negative
It follows
With
we get
At different positions at the photographic plate an interference pattern emerges due to the different phase values
that change with time. They are non-constant contrary to the values
x and
y. This corresponds the wave-particle duality that states that all matter exhibits both wave and particle properties. For binary events,
the law of total quantum probability corresponds to the intensity waves
For simplification we can replace
with
,
and
with
and for certain phase values
In
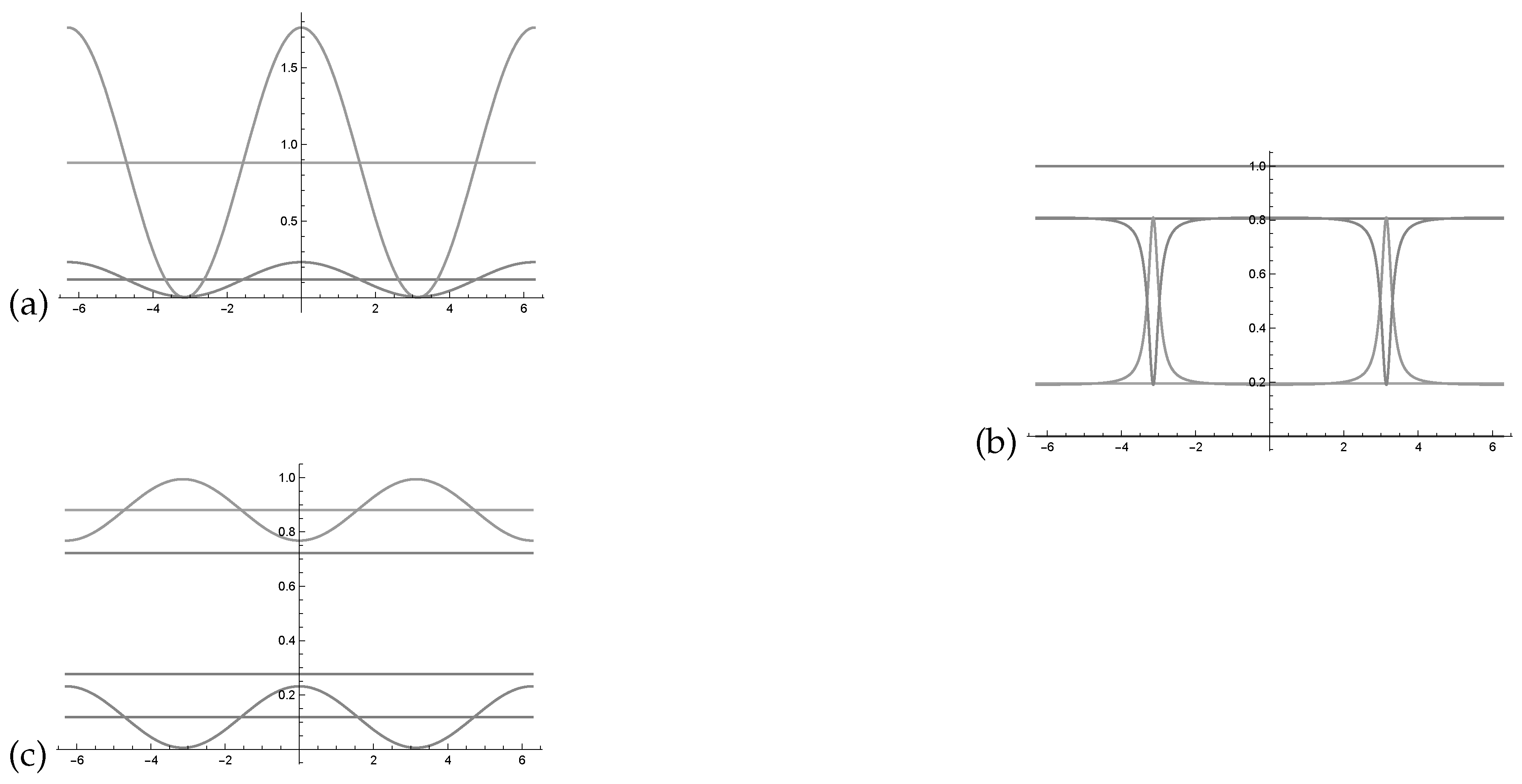
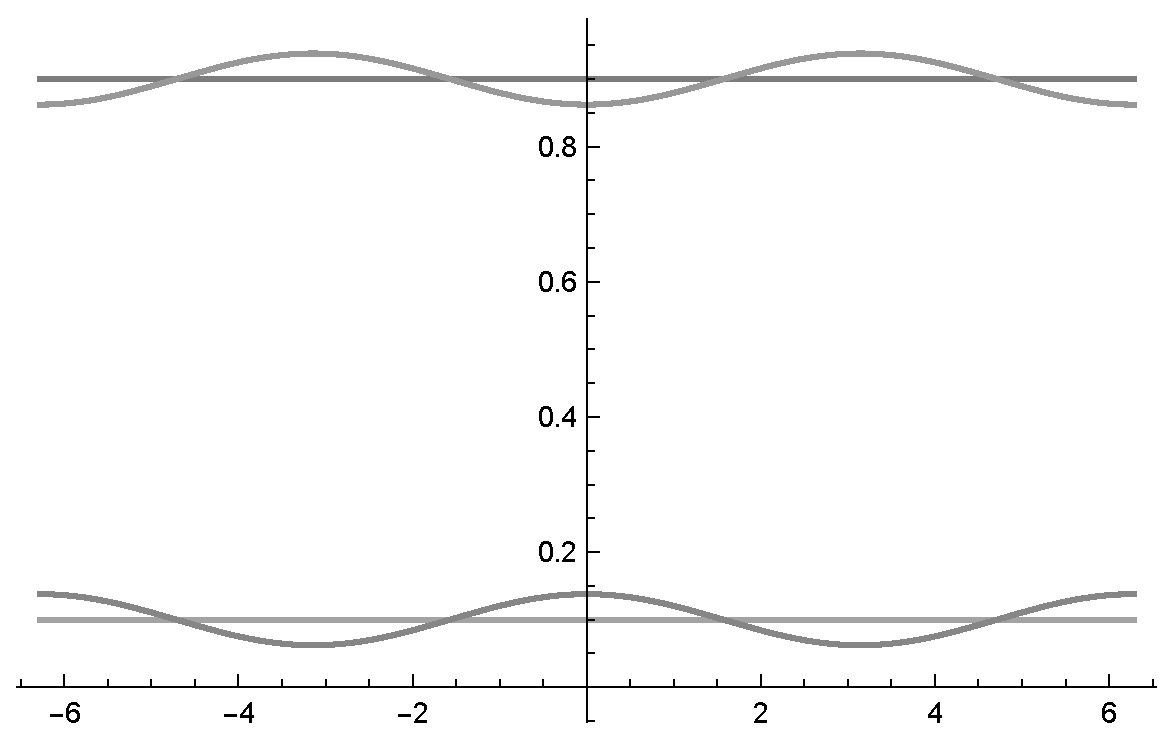
Figure 3a we see two intensity waves in relation to the phase with the parametrisation as indicated in the Bayesian network represented in
Figure 1.
4.2. Probability Waves
Intensity waves and are probability waves and if:
They are bigger or equal than 0 and smaller or equal than one
4.3. Normalisation
During probabilistic inference in quantum-like Bayesian networks, normalisation is done in the following way (see [
1,
34,
35]):
and
with
The probability waves collapse to the classical setting, when the interference term is 0. In other words, when
. Usually it is assumed that
.
Figure 3b shows the two probability waves
and
in relation to the Bayesian network presented in
Figure 1. Using this normalisation formula, one can see that the probability waves become very skewed and extremely sensitive to changes in the waves’
parameter. A more balanced representation of the intensity waves would be beneficial for quantum-like Bayesian networks, to overcome this
deterministic chaos that was pointed out in Moreira and Wichert [
1].
We will now place the preceding conceptual framework and associated formalism from quantum mechanics within the context of human decision-making. As stated previously, human decision-making may violate the law of total probability and indicate a subjective probability
. In quantum cognition, the probability wave
is used to model the subjective probability with a value
with
Usually the value of
is manually fitted for each case, see [
35]. A disadvantage of individual fitting is that it does not allow the possibility to make predictions or frame generalisations.
In Moreira and Wichert [
1] a dynamic heuristic was proposed in which thresholds are determined by learning from the data from a certain domain. In this work, we investigate if there is a straightforward meaningful relationship between the phase,
and the resulting probability
that could explain
. This leads to our first contribution, the
Law of Balance.
5. The Law of Balance
Instead of the simple Bayes normalisation of the intensity waves, we propose a novel normalisation technique based on the law of balance.
In the law of balance, the interference between the two waves is balanced, which means that the interference term of
and the interference term
cancel each out during probabilistic inference. In other words,
We can solve the Equation (
36) in terms of the phase
or
, which results in the three possible cases, which are the core of the proposed Law of Balance.
Case 1: probability wavedominates probability wave. For the constraint
then, we get that the probability wave
dominates (or is bigger than) the probability wave
. This means that the probability wave
determines the other wave as
where
Case 2: probability wavedominates probability wave.
For the constraint,
then, we get that the probability wave
dominates (or is bigger than) the probability wave
. This means that the probability wave
determines the other wave as
where
Case 3: none of the waves dominate each other.
For the constraint
we get
or
This case applies for double stochastic models, like the ones proposed in [
7,
15,
16,
17,
18].
From the constraints derived from the law of balance, one can easily prove that this law is in accordance to the axioms of probability theory, where the probability of an event is a non-negative real number smaller or equal to one, and that it is also in accordance with the current double stochastic models proposed in the literature, namely Busemeyer et al. [
7], Busemeyer and Trueblood [
17].
6. Balanced Probability Waves
In this section, we investigate the boundaries that the phase parameter, and can have, in order to obtain probability waves that do not lose information.
According to the law of balance, the probability waves
and
are defined as
In
Figure 3c, one can see two probability waves in relation to the phase with the parametrisation as indicated in the Bayesian network represented in
Figure 1.
For
, the maximum interference is
For
, the maximum interference is
We can define the intervals that describe the probability waves by
with
From these boundaries, an immediate question arises: How can we choose the phase without losing information about the probability waves?
According to the Bayesian network in
Figure 1, with only two random variables, a wave is fully described by the probability value
or
and the corresponding maximum amplitude is described by the unknown variable,
x.
We propose the law of maximum uncertainty, which is based on two principles, the principle of entropy and the mirror principle, in order to represent this information regarding the unknown variable, x. The main difference between these principles is the fact that, in some decision-making problems, these intervals can overlap and in others they do not.
We validate the proposed law in different experiments in the literature that reported violations to the laws of classical probabilistic theory and logic.
6.1. Principle of Entropy
For the case in which both intervals do not overlap, , the values of the waves that are closest to the equal distribution are chosen. By doing so, the uncertainty is maximised and the information about the probability wave is not lost.
Principle of Maximum Entropy: states that the probability distribution which best represents the current state of knowledge is the one with largest entropy (see [
36,
37,
38]). For the case of a binary random variable, the highest entropy corresponds to an equal distribution,
The value that best represents the state of knowledge is the one with the largest entropy, which is when . This results in the subjective probabilities:
For
,
For
,
For
,
The probability waves in
Figure 3c, which represent the Bayesian network in
Figure 1, since
, then they can be described by the interval,
where the maximum entropy is given by
, and
where the maximum entropy is given by
.
6.2. Mirror Principle
For the case in which both intervals overlap, , then, an equal distribution maximises the uncertainty, but loses the information about the probability wave. To avoid this loss, we do not change the entropy of the system. We use only the positive interference as defined by the law of balance.
When the intervals overlap the positive interference is approximately the size of smaller probability value, since the arithmetic and geometric means approach each other (see Equation (
46)). We maximise the uncertainty by mirroring the “probability values”.
In this sense, the value that best represents the state of knowledge is given by:
For the case
, we define
For the case
, we define
7. Empirical Validation
In this section, we validate the law of balance in psychological experiments from the literature, namely the prisoner’s dilemma game and the two stage gamble game. These experiments report human decisions that violate the Sure Thing Principle [
39], consequently violating the laws of probability theory and logic.
7.1. Prisoner’s Dilemma Game and Probability Waves
In the prisoner’s dilemma game, there are two prisoners, prisoner
x and prisoner
y. They have no means of communicating with each other. Each prisoner is offered by the prosecutors a bargain: (1) testifying against the other one and betray (Defect); (2) refuse the deal and cooperate with the other one by remaining silent (Cooperate). For more information about the general problem description of the Prisoner’s Dilemma game, please consult Moreira and Wichert [
1].
In the experimental setting of the Prisoner’s Dilemma game proposed in Shafir and Tversky [
40], participants were presented with the payoff matrix of the game and they played a set of one-shot prisoner dilemma games each against a different opponent. During these one-shot games, participants were informed that they had randomly been selected to a bonus group, which consisted in having the information about the opponent’s strategy. Participants were able to use this information in their strategies. This means that three conditions were tested in order to verify if there were violations to the Sure Thing Principle:
Participant was informed that the opponent chose to defect, .
Participant was informed that the opponent chose to cooperate, x.
Participant was not informed of the opponents choice.
This allows us to compute the following information:
The probability that the prisoner y defects given x defects, .
The probability that the prisoner y defects given x cooperates, .
The probability that the prisoner
y defects given there is no information present about knowing if prisoner
x cooperates or defects. This can be expressed by
and is represented by a Bayesian network (see
Figure 1) that indicates the influence between events
x and
y.
In
Table 1, we summarise the results of several experiments of the literature concerned with the prisoner’s dilemma experiment, which correspond to slight variations to the one conducted in Shafir and Tversky [
40], using different payoff matrices. In
Table 1,
corresponds to all participants who chose to defect given that they were informed that the opponent also chose to defect, normalised by the total of participants who played this condition;
corresponds to all participants who chose to defect given that they were informed that the opponent chose to cooperate, normalised by the total of participants who played this condition;
corresponds to all participants who chose to defect given that no information about the opponent’s strategy was given, normalised by the total number of participants in this condition. The last row of
Table 1 labelled
Average is simply the average of all the results reported in
Table 1 as it is presented in the work of Pothos and Busemeyer [
19]. The column
Sample size corresponds to the number of participants used in each experiment.
These findings mainly suggest that, under uncertainty, a decision-maker tends to become more cooperative, and for that reason, they will attempt a more cooperative strategy.
7.2. Two Stage Gambling Game
In the two stage gambling game the participants were asked to play two gambles in a row where they had equal chance of winning
$200 or losing
$100 [
1]. In the original experiment conducted by Tversky and Shafir [
27], the authors used a within-subjects design where the participants were told the following:
Imagine that you have just played a game of chance that gave you a 50% chance to win $200 and a 50% chance to lose $100. Imagine that you have already made such a bet. If you won this bet and were up $200, and were offered a chance to make the same bet a second time, would you take it? What if you lost the first bet and were down $100, would you make the same bet again? What if you do not yet know whether you won or lost the first bet and so do not yet know whether you are up or in debt, would you go ahead and make the same bet a second time?.
Three experimental settings were tested:
The participant was informed that he lost the first gamble, , and was asked if he wanted to play the second gamble y.
The participant was informed that he won the first gamble, x, and was asked if he wanted to play the second gamble y.
The participant was not informed about the outcome of the first gamble, and was asked if he wanted to play the second gamble
y. This would by by the law of total probability
In
Table 2, we summarise the results of several experiments of the literature concerned with the two stage gambling game. In
Table 2,
corresponds to all participants who chose to
given that they were informed that they had
the first gamble, normalised by the total of participants who played this condition;
corresponds to all participants who chose to
given that they were informed that they had
the first gamble, normalised by the total of participants who played this condition;
corresponds to all participants who chose to
given that no information about the first gamble was given, normalised by the total number of participants in this condition. The last row of
Table 2 labelled
Average is simply the average of all the results reported in
Table 2. The column
Sample size corresponds to the number of participants used in each experiment.
These findings mainly suggest that, under uncertainty, a decision-maker tends to become more risk-averse, and for that reason, they tend to not bet on the second gamble, leading to a violation of the Sure Thing Principle.
7.3. Probability Waves in the Prisoner’s Dilemma and the Two Stage Gambling Game
Using the values of
Table 1 and
Table 2, we can determine the probability waves
,
as indicated in
Figure 4.
Table 3 summarises the intervals that describe the probability waves, the resulting probabilities,
, that are based on the law of maximum uncertainty, the subjective probability,
, and the classical probability values,
.
We compared the results that are based on probability waves and the law of maximal uncertainty with previous works in the literature that deal with predictive quantum-like models for decision making, see
Table 4. The dynamic heuristic as described by Moreira and Wichert [
1] used quantum-like Bayesian networks. Its parameters are determined by examples from a domain. On the other hand in the Quantum Prospect Decision Theory [
41], the values do not need to be adapted to a domain and the quantum interference term is determined by the Interference Quarter Law. This means that the quantum interference term of total probability is simply fixed to a value equal to 0.25.
The results presented in
Table 4 show that the dynamic heuristic (DH) and the law of maximum uncertainty (MU) are similar, however the dynamic heuristic, originally proposed in Moreira and Wichert [
1], is the result of a domain specific learning function. In other words, this function that is used to compute the quantum interference terms is learned to the specific problem of disjunction effects. The law of maximum uncertainty, on the other hand, is able to address disjunction errors in a more generalised way. The dynamic heuristic performs slightly better than the law of maximum uncertainty, but the first one is the result of a learned domain specific function, while the latter is derived from the hypothesis that quantum interference waves should be balanced, rather than simply normalised with Bayes rule.
Additionally, with respect to the classical counterpart, quantum-like models offer advantages when modelling paradoxical decisions in Bayesian networks. In the study of Moreira and Wichert [
42], the authors demonstrated that in terms of parameters, a classical Bayesian network would require more random variables (and consequently more parameters) to reproduce the paradoxical results reported in the several experiments of the literature showing disjunction effects than its quantum-like counterpart. This suggests that quantum-like models might offer advantages, not only in terms of a cognitive perspective, but also computationally.
8. Quantum-like Bayesian Network
To apply the law of balance to Quantum-Like Bayesian networks, our next step is to generalise the law of balance rule during probabilistic inference from one unknown variable, x, to several, .
8.1. Generalisation
For the binary event
x and non binary event
y, we have that
and the law of total probability is represented by
The intensity wave is defined as
usually there are interference terms during probabilistic inferences in quantum-like Bayesian networks, therefore the intensity waves do not follow the rules of classical probability theory,
The intensity waves,
, is always non negative, since the norm is non-negative,
8.2. Probability Waves Sum to One according by the Law of Balance
For
M unknown events, the interference from the intensity waves cancel each other, if they satisfy the condition,
if
The relationship between different combinations of phases
cannot be simplified. It is not possible to define a
as before. If we decompose Equation (
76) for each
and
we get
parameters and the sub-equations
representing
subsystems that can be solved independently as before.
8.3. Probability Waves are Smaller Equal One only after Normalisation
The general formula for interference effects in quantum-like Bayesian networks is given by
By the inequality of arithmetic and geometric means, if follows that
There are
pairs
, since the summation goes over
M. There are
interference sub-equations
. It means that there are
more interference sub-equations. For
M the intensity wave becomes a probability wave if we normalise the interference part by dividing through
. Note for
, we do not need to normalise since the value is one. The intensity wave is a probability wave by using the law of balance and by normalising the interference part by dividing through
. This results in
The interference, however, is not symmetric, since it is composed out of a sum of sub-equations.
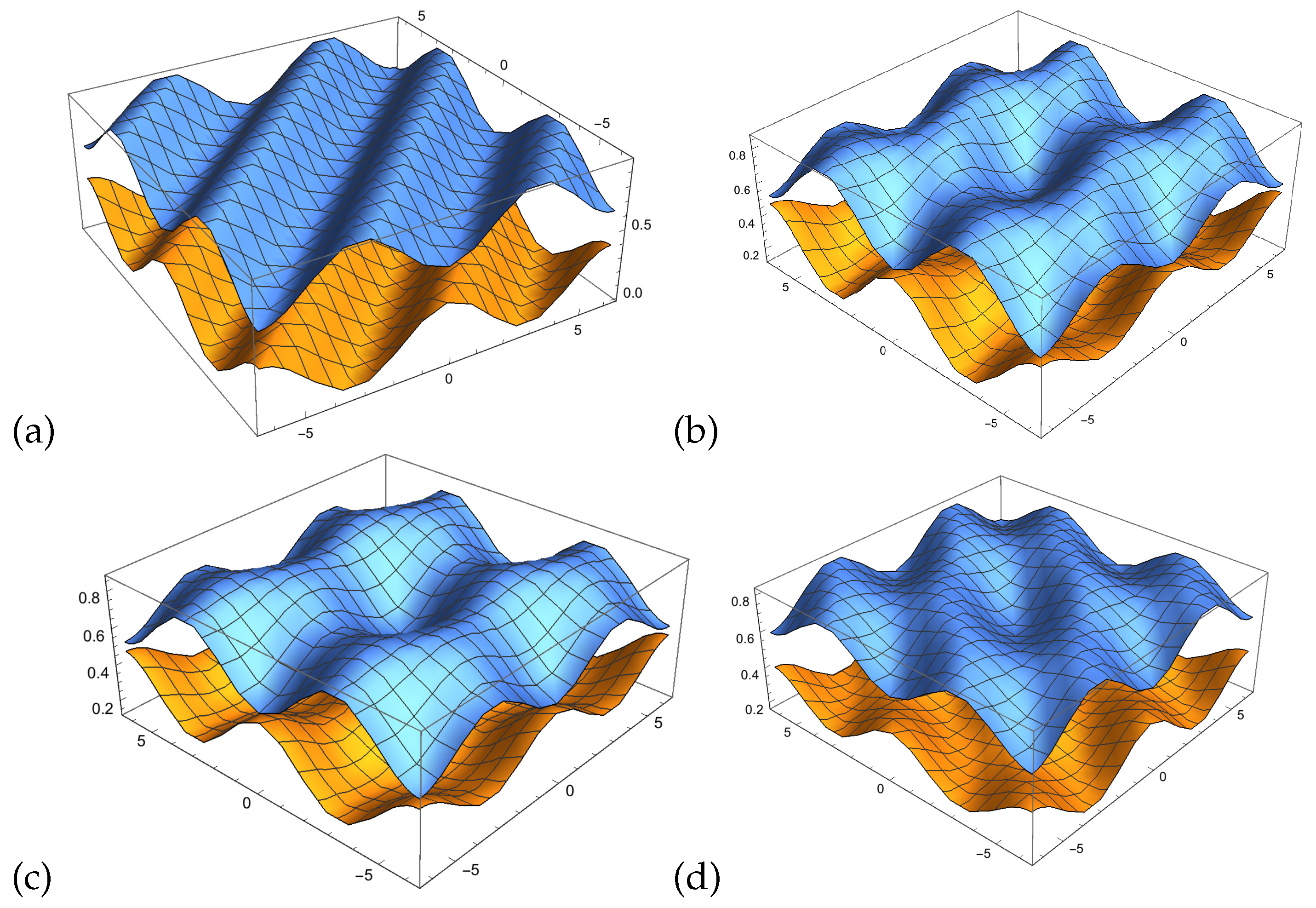
8.4. Example of Estimation of Balanced Phases
In the following example, we present the probability wave
,
with
The relation between different combinations of phases
cannot be simplified. It is not possible to define a
as before since two out of three permutations exist. Having two different phases there is only one combination and we can project the two dimensional function onto one dimension function (see
Figure 5a). With three different phases, a three dimensional function cannot be projected onto one dimension.
If we assume the following values,
and
in
Figure 5b–d, we assume that each of the three phases of
is zero. This results in three different plots which approximate the three dimensional function by three projections onto two dimensions.
Again, we determined
of the three or more dimensional waves numerically. We chose the balanced phases according to Equation (
78) and determined the minima and maxima of the three dimensional Equation (
84) wave numerically by a numerical computing environment. We used
Wolfram Mathematica using the build in functions
and
, the source code will be publicly available in Github:
https://github.com/catarina-moreira/QuLBIT.
When
, then we obtain
8.5. Example of Application in the Burglar / Alarm Bayesian Network
For the Bayesian Network represented in
Figure 2, for unknown variables like
, using the ignorance rule we get Equation (
86)
and Equation (
87).
We use the roman notation for the index of the phase to distinguish between the index of variables. Two solutions exist:
For the constraint,
we get
For the constraint,
we get
Using the parameters of the Bayesian network in
Figure 2, we get
Since the priors are small,
),
), the quantum interference effects will not become noticeable (see
Figure 6).
For
, we obtain
By increasing the parameter values of
) and
), the quantum interference effects become noticeable. Again, we estimated numerically with the new increased parameters. With
, we obtained
In this case, the interference part becomes noticeable (see
Figure 7). However, the increase does not have any effect on the classical probabilities since the values are only dependent on the value
.
For unknown variables
,
we get the four dimensional probability wave we get the Equation (
94). One can clearly see that the interference value diminish since six we multiply for each interference part seven probability values.
With the normalisation factor
,
we get six sub-equations of which each has two solutions with constraints that are defined by three different equations and their symmetrical counterparts
Using the parameters of the Bayesian network in
Figure 2, we can determine the balanced wave
In order to do this, we have to determine the minima or maxima of the four dimensional wave described by Equation (
94) numerically. We used
Mathematica using the build in functions
and
, the source code will be publicly available in Github:
https://github.com/catarina-moreira/QuLBIT. Since the parameter values are small
),
), the interference part becomes nearly not noticeable as before. With,
, we obtain
By increasing the parameter values to
),
), the interference part becomes noticeable. We estimate numerically with the increased parameters with,
, we obtain
It seems that, under the law of balance, the quantum interference tends to diminish with the complexity of the decision scenario as indicated with the examples of balanced quantum-like Bayesian network.
9. Interpretation
According to most physics textbooks, the existence of the wave function and its collapse is only present in the microscopic world and is not present in the macroscopic world. However, there has been an increasing amount of scientific studies indicating that this is not true and that wave functions are indeed present in the macroscopic world (see Vedral [
43]). Additionally, experiments in physics state that the size of atoms does not matter and that a very large number of atoms actually be entangled (see Amico et al. [
44], Ghosh et al. [
45]).
Clues from psychology indicate that human cognition is based on quantum probability rather than the traditional probability theory as explained by Kolmogorov’s axioms [
7,
16,
17,
18]. It seems that under uncertainty, Kolmogorov’s axioms tell what the decision-maker should choose, while quantum probability can indicate what the decision-maker actually chooses [
46]. This could tell us that, under a cognitive point of view, a wave function can indeed be present at the macro scale of our daily life. This implies a unified explanation of human cognition under the paradigm of quantum cognition and quantum interference.
A unified explanation of human interference using quantum probability theory and classical theory was for the first time proposed in Trueblood et al. [
47]. The authors propose a hierarchy of mental representations ranging from quantum-like to classical. This approach allows the combination of both Bayesian and non-Bayesian influences in cognition, where classical representations provide a better account of data as individuals gain familiarity, and quantum-like representations can provide novel predictions and novel insights about the relevant psychological principles involved during the decision process.
Motivated by this model, we propose the distinction between unknown, which can be seen as a truth value, and ignorance as the lack of knowledge or as being unaware. An event can either be true, false or unknown. The proposed balanced quantum-like approach can be integrated in this view in the following way:
For unknown events, the classical law of total probability is applied;
For events of which we are unaware, we apply quantum-like models in which the phase information is related to ignorance. We determine the possible values of the wave using the law of maximum entropy of quantum-like systems.
Note that, an unknown event is not known to the decision-maker, because he does not have enough information. Ignorance means that the decision-maker cannot obtain this information, so ignorance is not a truth value at all and the decision-maker does not know at what the value of the event is. This relationship is analogous to the relation between pseudo randomness and true randomness. Pseudo randomness appears to the decision-maker as being totally random due to his lack of information. True quantum randomness corresponds to ignorance.
This distinction between unknown and ignorance can also be explained by the interference in the two-slit experiment.
In the two-slit experiment, with the electron detectors showing which slit the electron goes through, the electron behaves as a particle. Assuming that the information about the detectors is unknown to us, we apply the law of total probability.
When the detectors are removed, the electron is unobserved and is represented as a wave. In this case, we apply the quantum-like law of total probability.
Under this context, ignorance corresponds to a prediction in the future.
10. Conclusions
This work is motivated by empirical findings from cognitive psychology, which indicate that, in scenarios under high levels of uncertainty, most people tend to make decisions that violate the laws of classical probability and logic. It seems that normative models, like Bayesian inference and the expected utility theory, tend to compute what people
should choose, instead of computing what they actually choose [
46]. In order to address this issue, many models have been proposed in the literature, which are based on quantum probability theory.
In this work, we explored the relationship between the empirical findings from cognitive psychology and quantum probability amplitudes. More specifically, we make use of the notion of intensity waves as the interference effects that result in the double slit experiment, when there are no detectors in the slits. We then investigated the relationship between the phase of these intensity waves and the resulting subjective probabilities that were found in the different experiments reported in the literature, showing paradoxical human decisions. We found that there is indeed a meaningful relationship between the phase and the resulting subjective probability, which is the result of a different, and novel, normalisation method that is summarised into two laws:
The Law of Balance: a novel mathematical formalism for quantum-like probabilistic inferences that enables the cancellation of the quantum interference terms upon the application of Bayes normalisation factor. This way, the amplitudes of the probability waves become balanced.
The Law of Maximum Uncertainty: which states that in order to predict disjunction effects, one should choose the amplitude of the wave that contains most the maximum uncertainty, or the the maximum information.
These laws were used in the formalism of quantum-like Bayesian networks, in a model that we define as the balanced quantum-like Bayesian network, in order to model the disjunction effects and to represent uncertainty. We validated the proposed balanced quantum-like Bayesian network in the different experiments reported in the literature, mainly disjunction effects under the Prisoner’s Dilemma game and the Two-Stage gambling game. Results showed that the proposed quantum-like Bayesian network could predict many of these disjunction effects.
Although we cannot test the proposed approach in more complex decision problems due to the current nonexistence of data, our analysis indicated that the quantum interference seem to diminish with the complexity of the decision scenario as indicated before with the examples of balanced quantum-like Bayesian networks. There are, however, some preliminary studies on real-world complex decision-scenarios of quantum-like Bayesian networks, namely trying to predict the probability of a client receiving a credit or not in a financial institution [
48]. This preliminary analysis shows that, under uncertainty, the quantum-like Bayesian network could fit the data better due to quantum interference effects and was able to reproduce better the underlying credit application process of the financial institution better than the classical network. This study indicates the potential of quantum-like decision technologies, however this is still an open question and more research is needed in this direction.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}