Multi-Modal Medical Image Fusion Based on FusionNet in YIQ Color Space


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We preprocessed two images before fusion, reconstructed the non-membership function according to the relevant knowledge of fuzzy set theory, and obtained their membership hesitation images, which perfectly solved the uncertainty problem caused by the input images coming from different sensors.
- In view of the serious loss of image information in multi-mode medical image fusion, we proposed a new feature enhancement network inspired by DenseNet. At the same time, the gradient disappearance and model degradation are alleviated to some extent by using the new excitation function.
- In the fusion method, we use the trace of matrix to calculate the weight coefficient of each feature graph. The trace is the sum of eigenvalues of each characteristic graph. The eigenvalue is regarded as the importance value of different features in the matrix and can cover the fusion features in the most comprehensive way.
- As far as we know, it is the first time that the combined loss of sensible cross-entropy and structural similarity has been introduced in the training of a CNN-based multi-modal medical image fusion model. Cross entropy can better express the degree of retention of visual color information in fused images. However, the structure similarity is better in expressing edge and texture information in fusion images. Through introducing the combined loss of cross entropy and structural similarity, the trained multi-mode medical image fusion model has obvious advantages in both visual information retention and texture information acquisition.
2. Related Work
2.1. Intuitionistic Fuzzy Sets
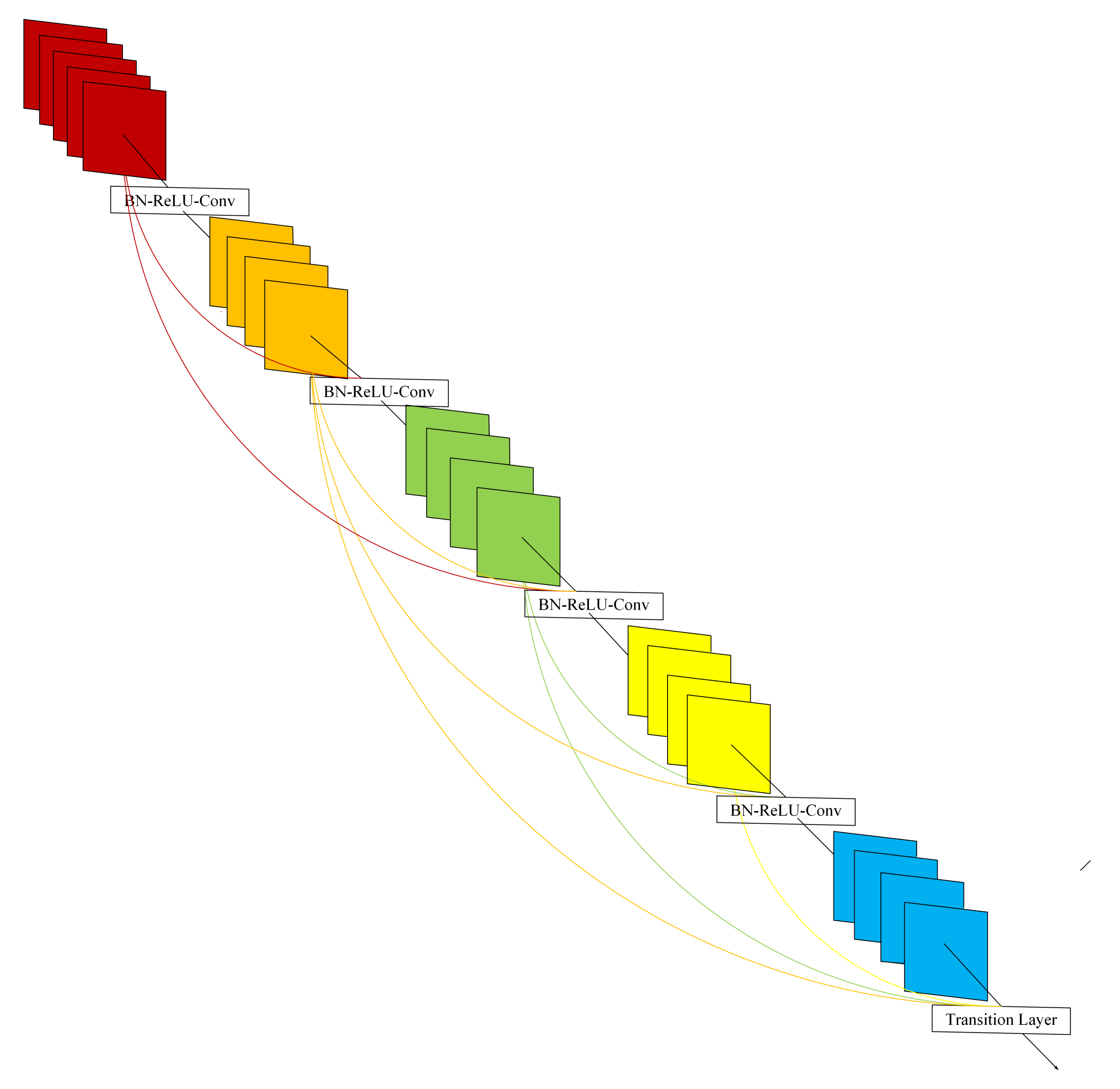
2.2. DenseNet
- This architecture can save as much information as possible in the process of image fusion.
- Due to the regularization effect of density connection, this model reduces the overfitting of experimental tasks.
- The model can improve the gradient of the network, making it easier to train.
2.3. YIQ Color Space
3. A New Framework for Image Fusion
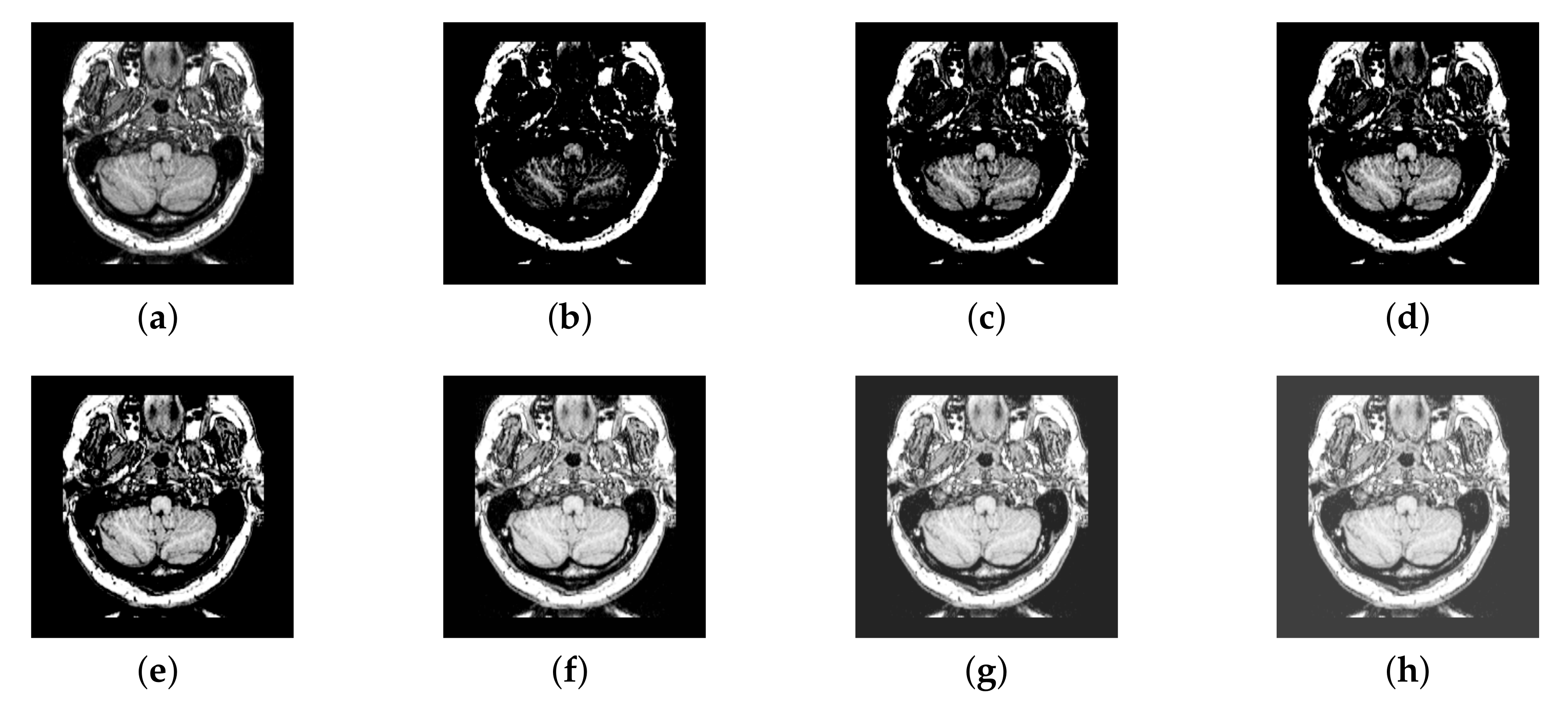
3.1. Intuitive Fuzzy Processing (IFP)
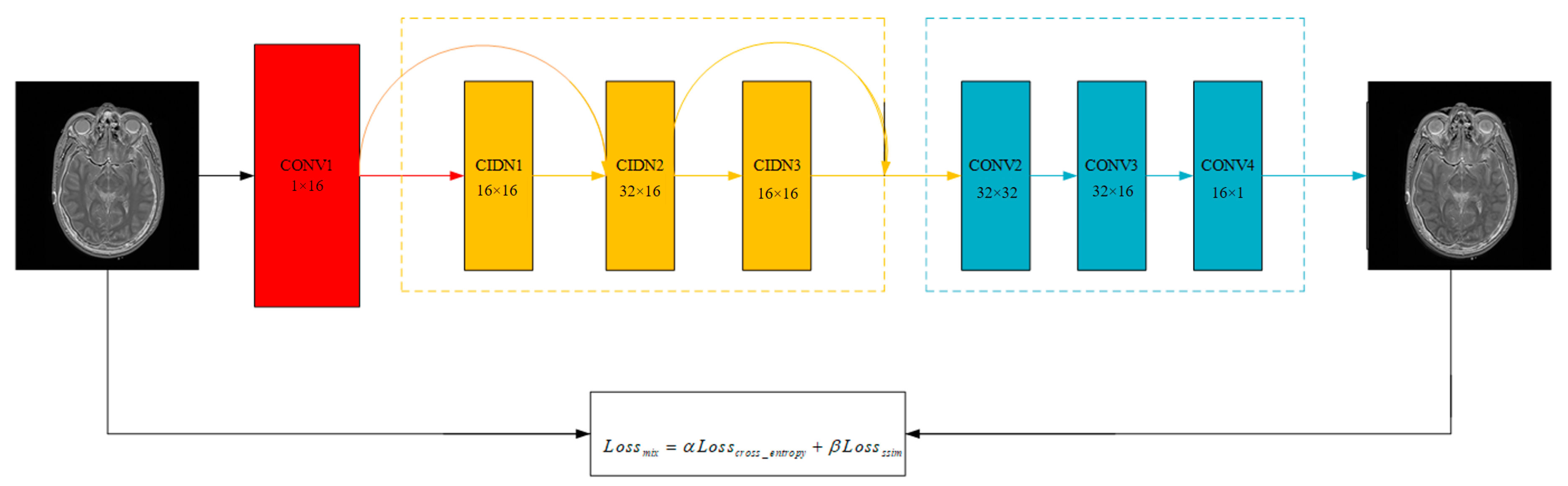
3.2. FusionNet
3.2.1. CIDN
3.2.2. Loss Function
3.2.3. Fusion Strategy
4. Experimental Results and Discussion
4.1. Experimental Settings
4.1.1. Data Set and Compared Algorithms
4.1.2. Training Settings and Fusion Metrics
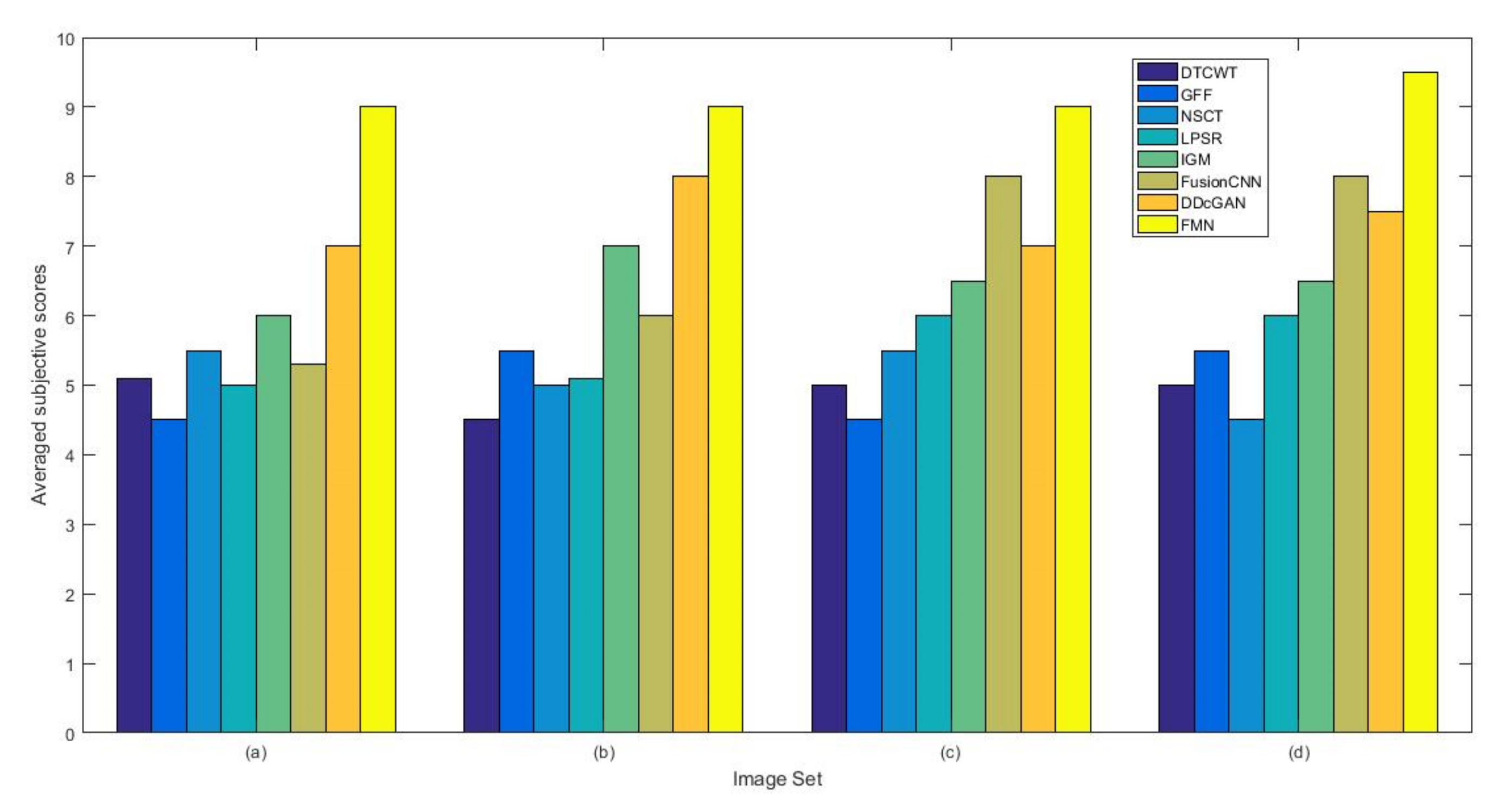
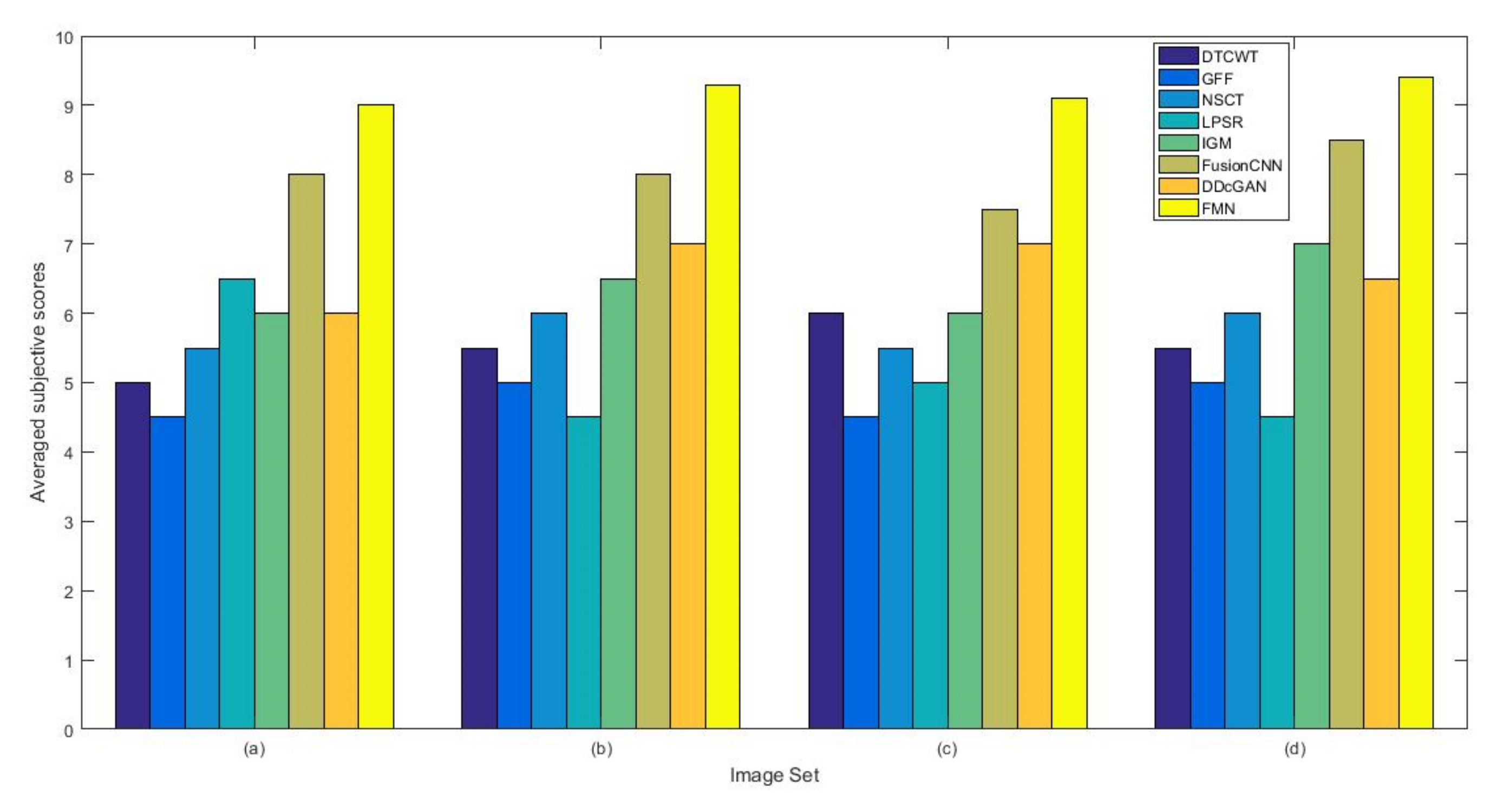
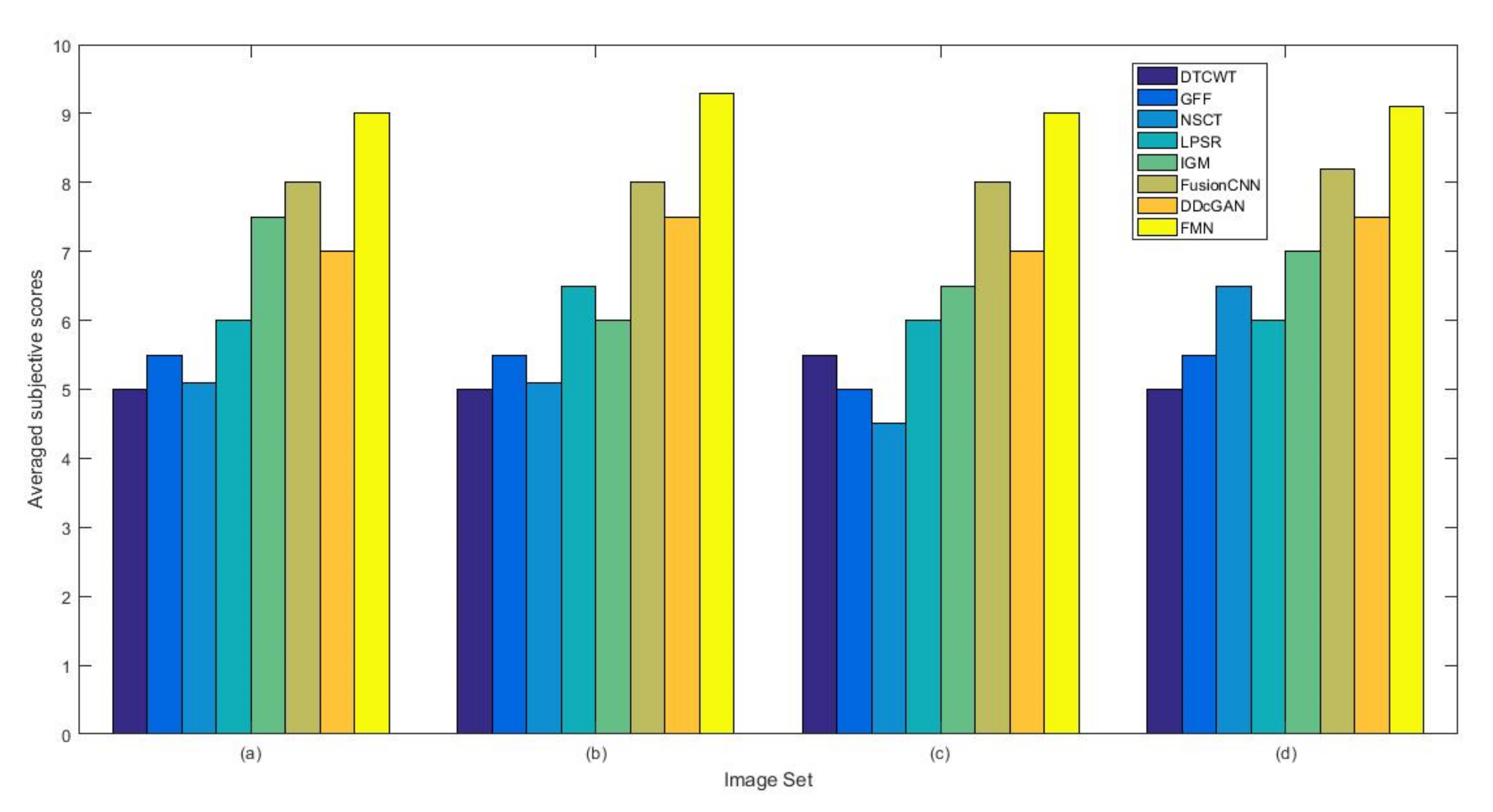
4.1.3. Subjective Evaluation Methods
4.1.4. Parameters Selection
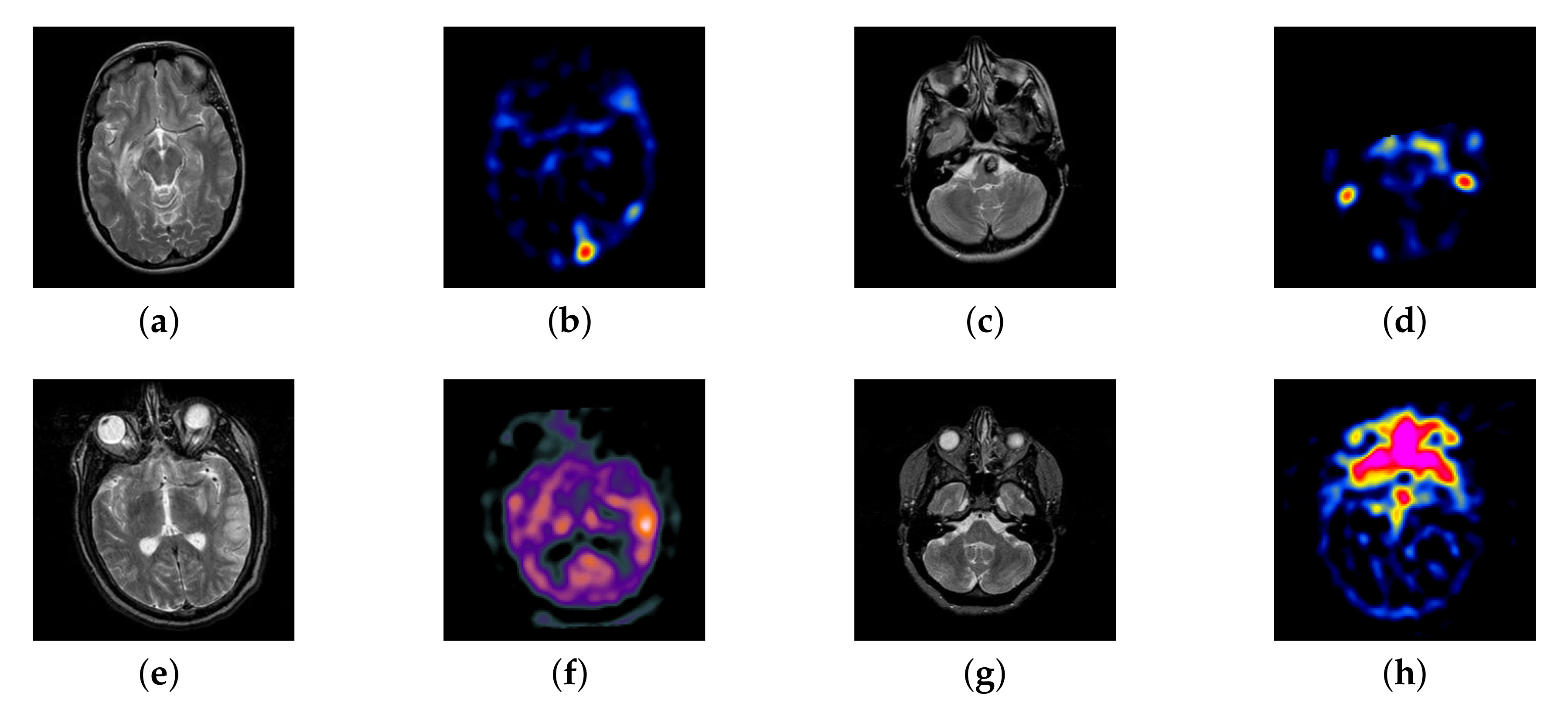
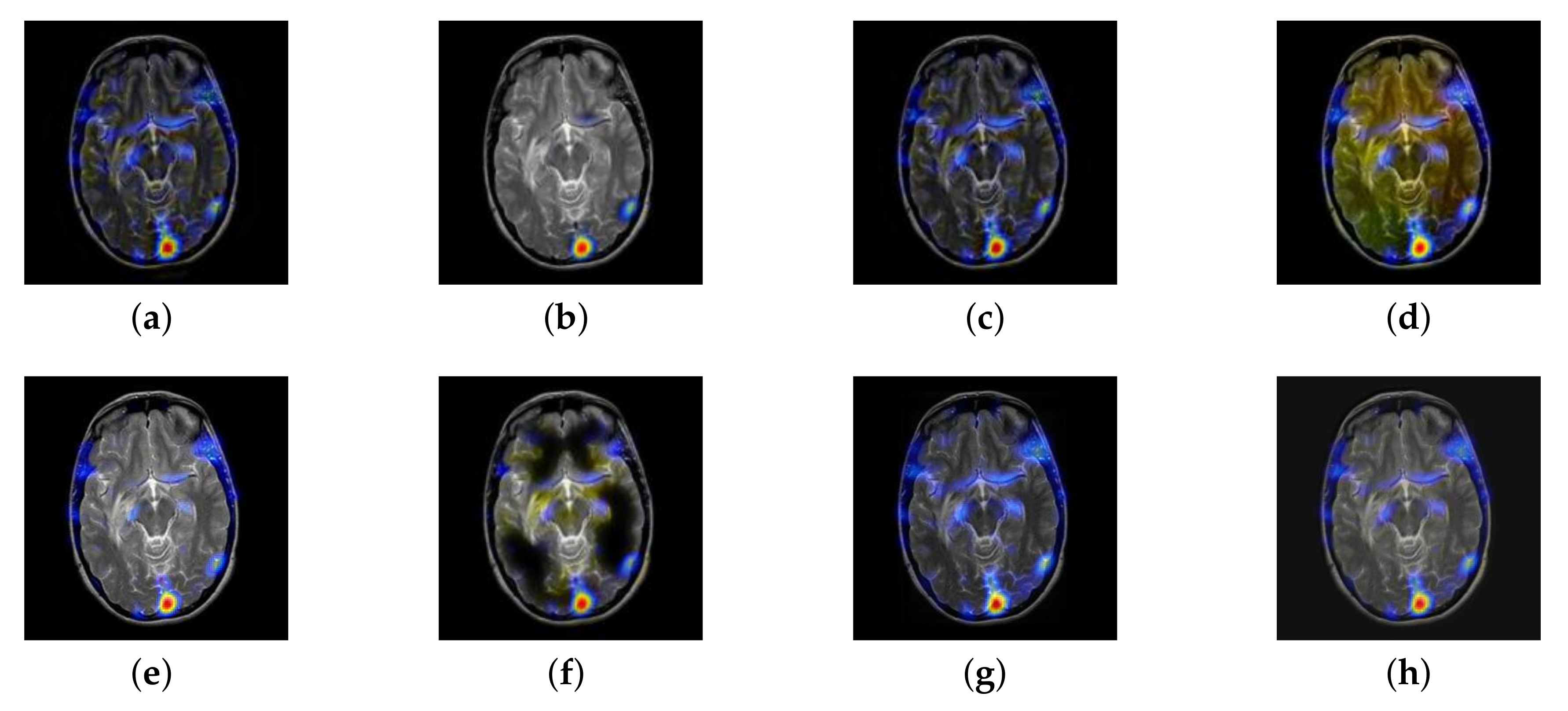
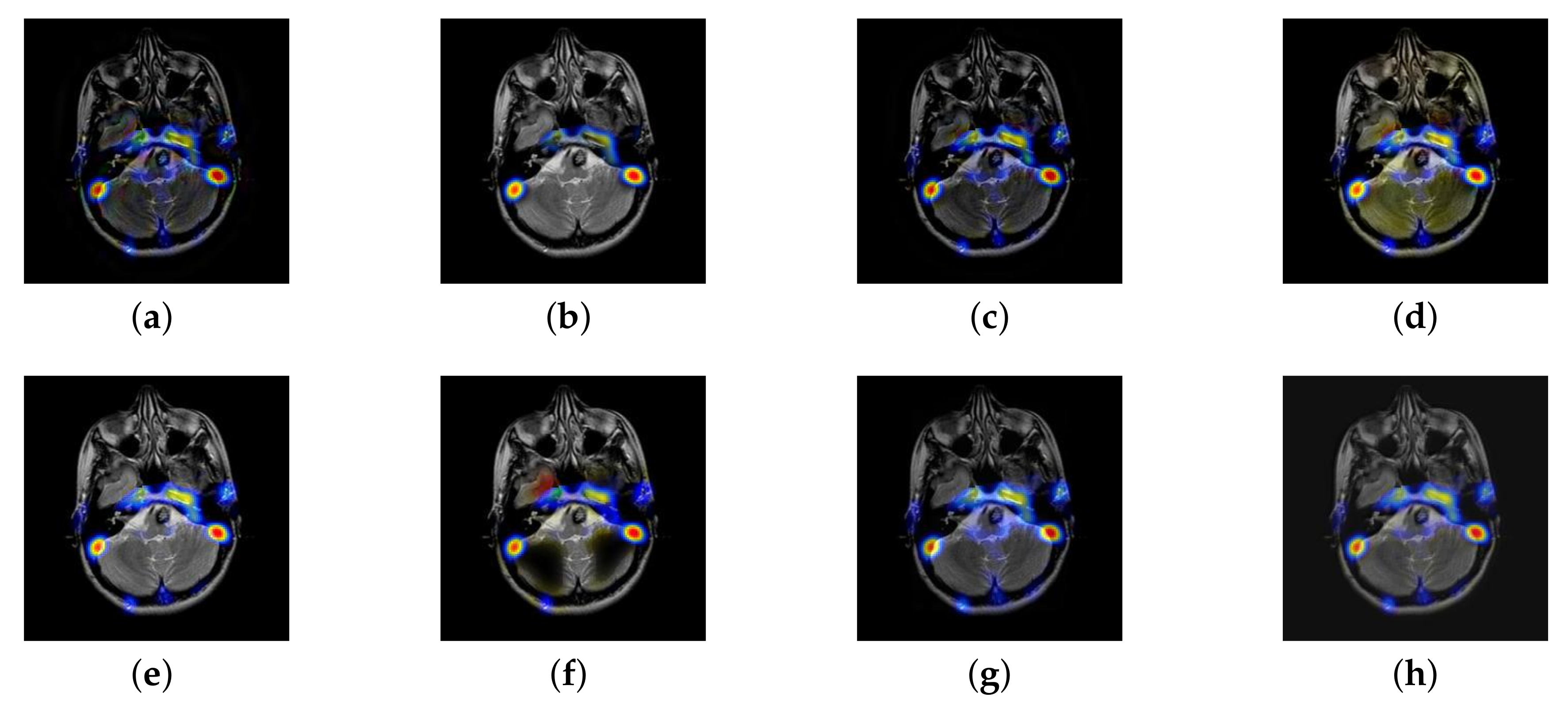
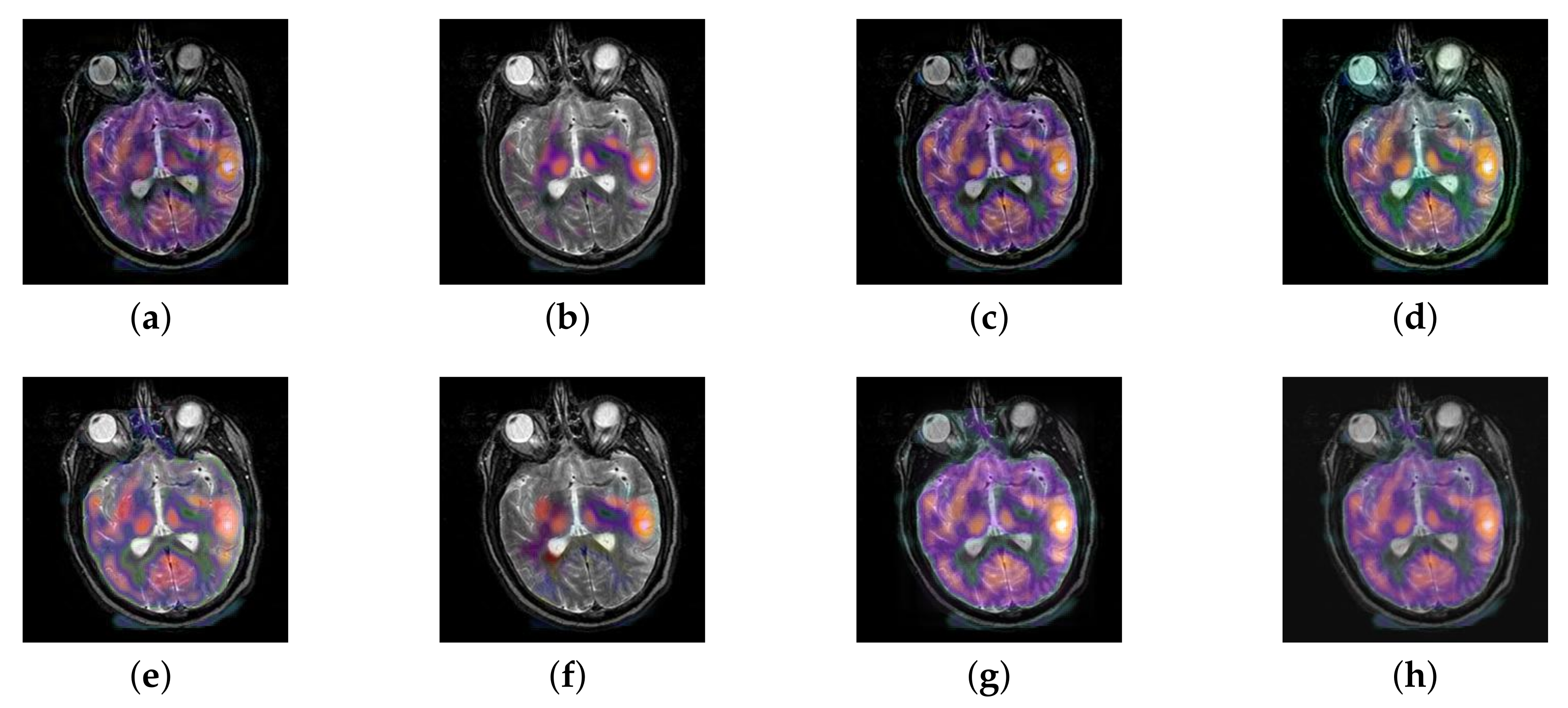
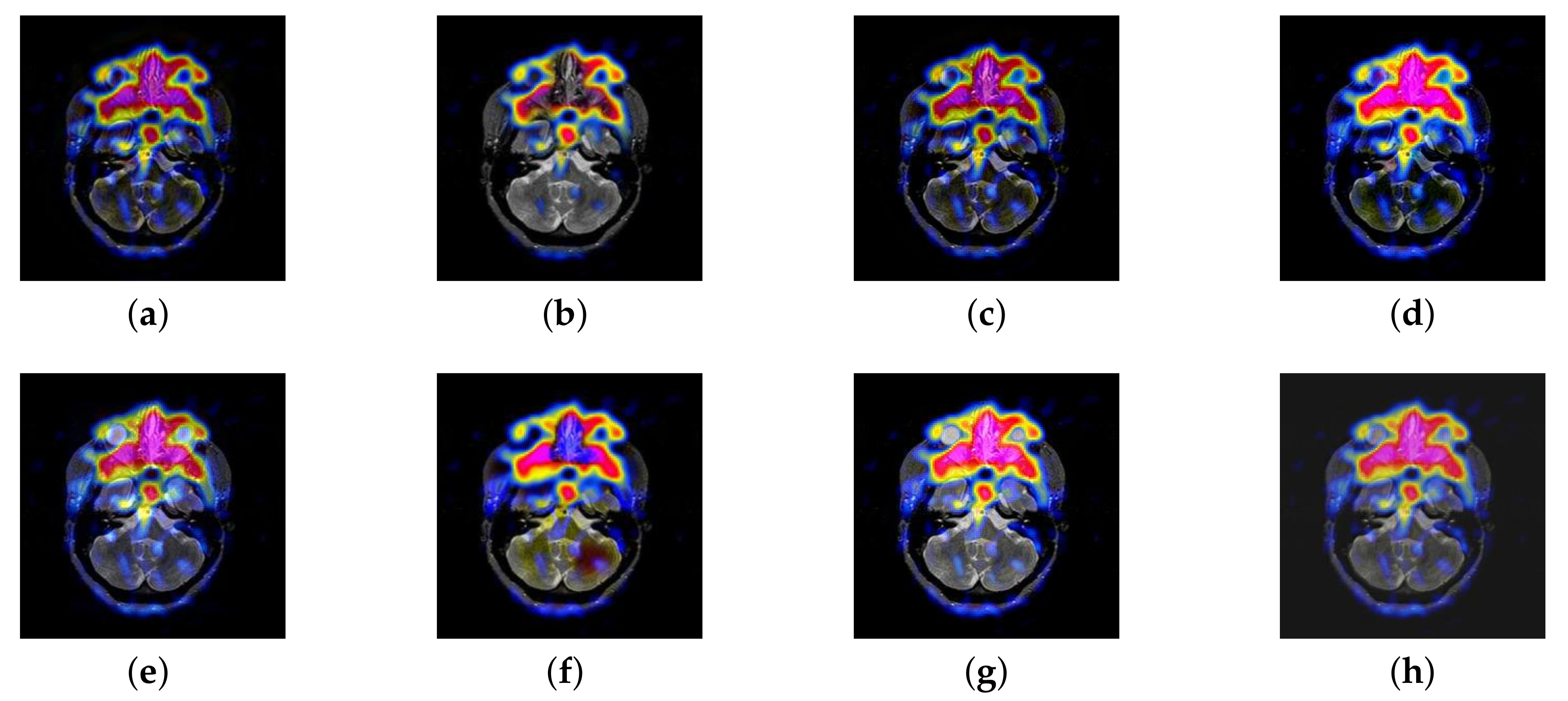
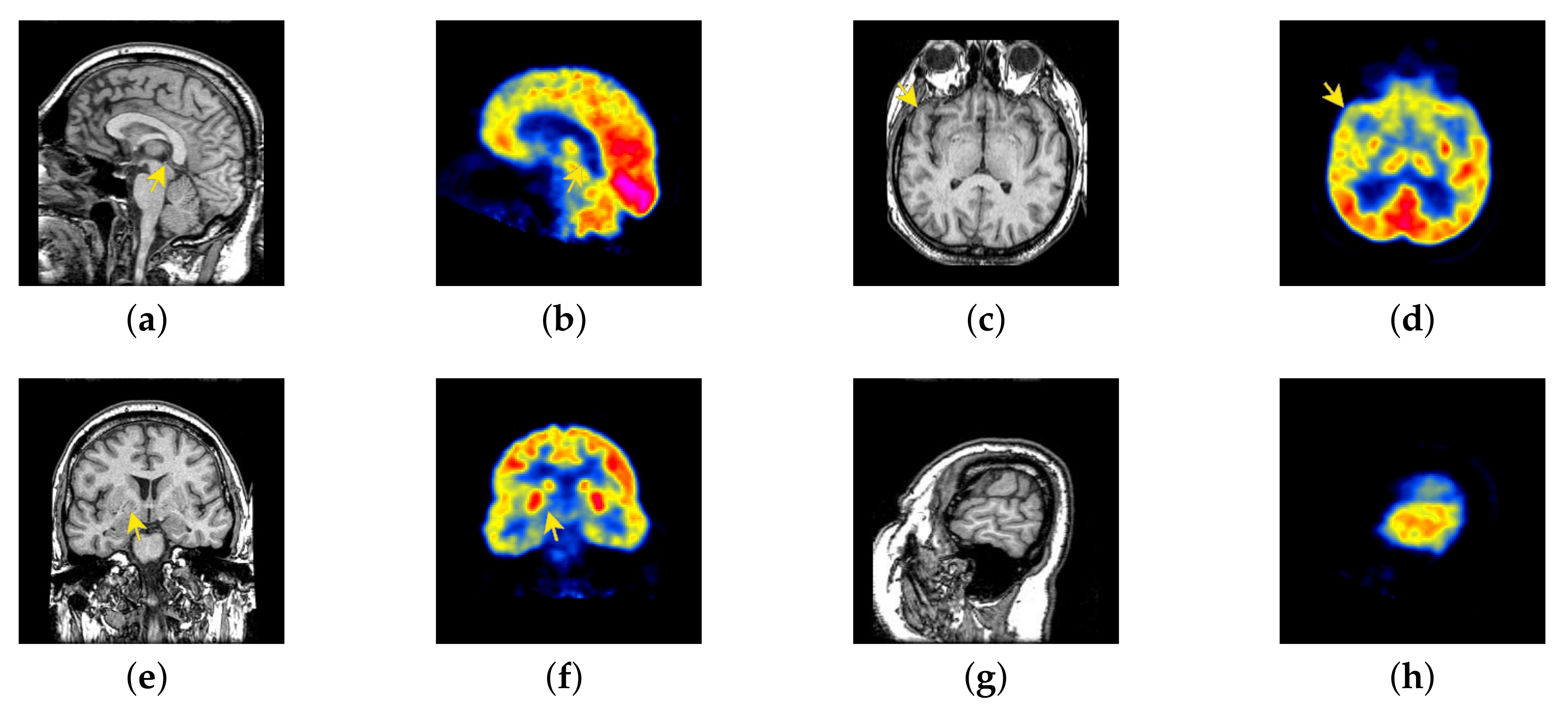
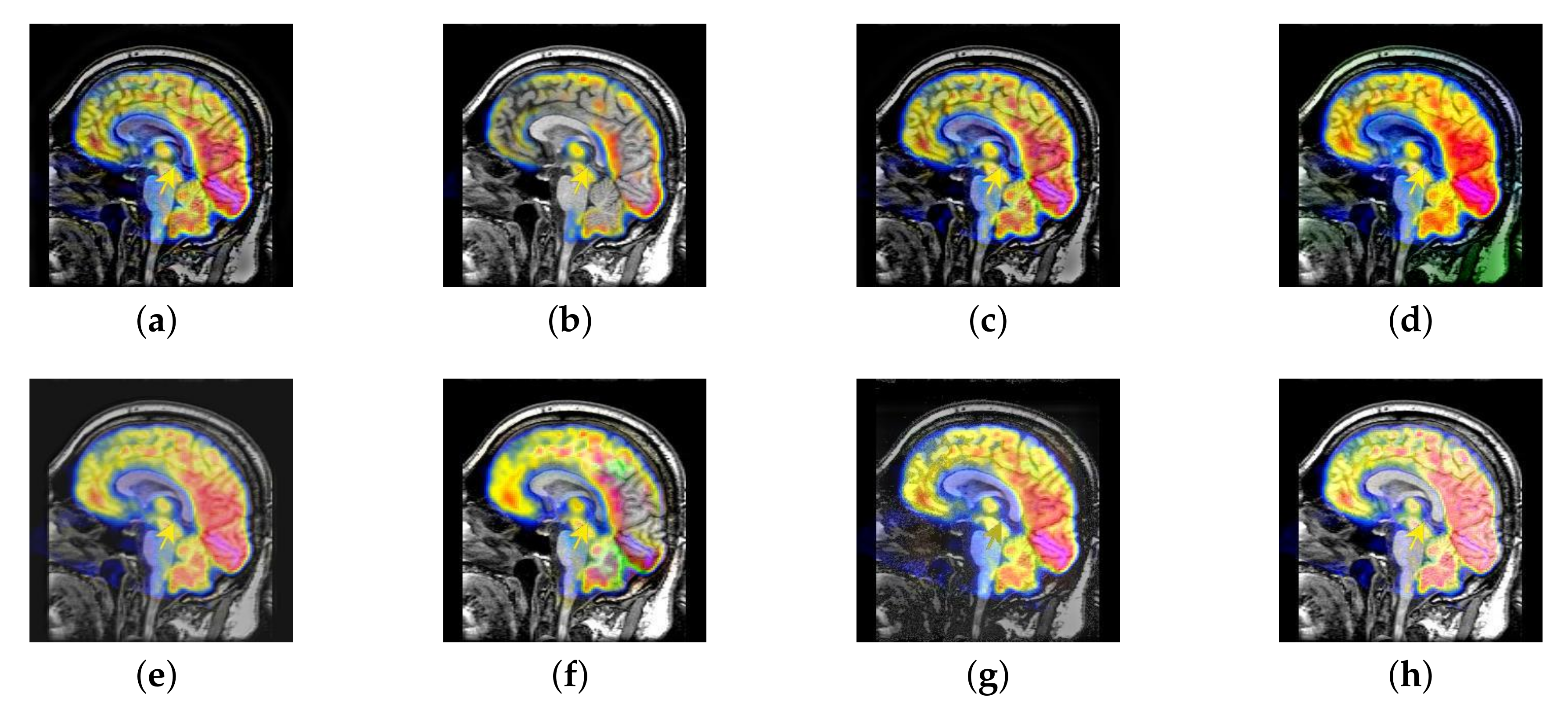
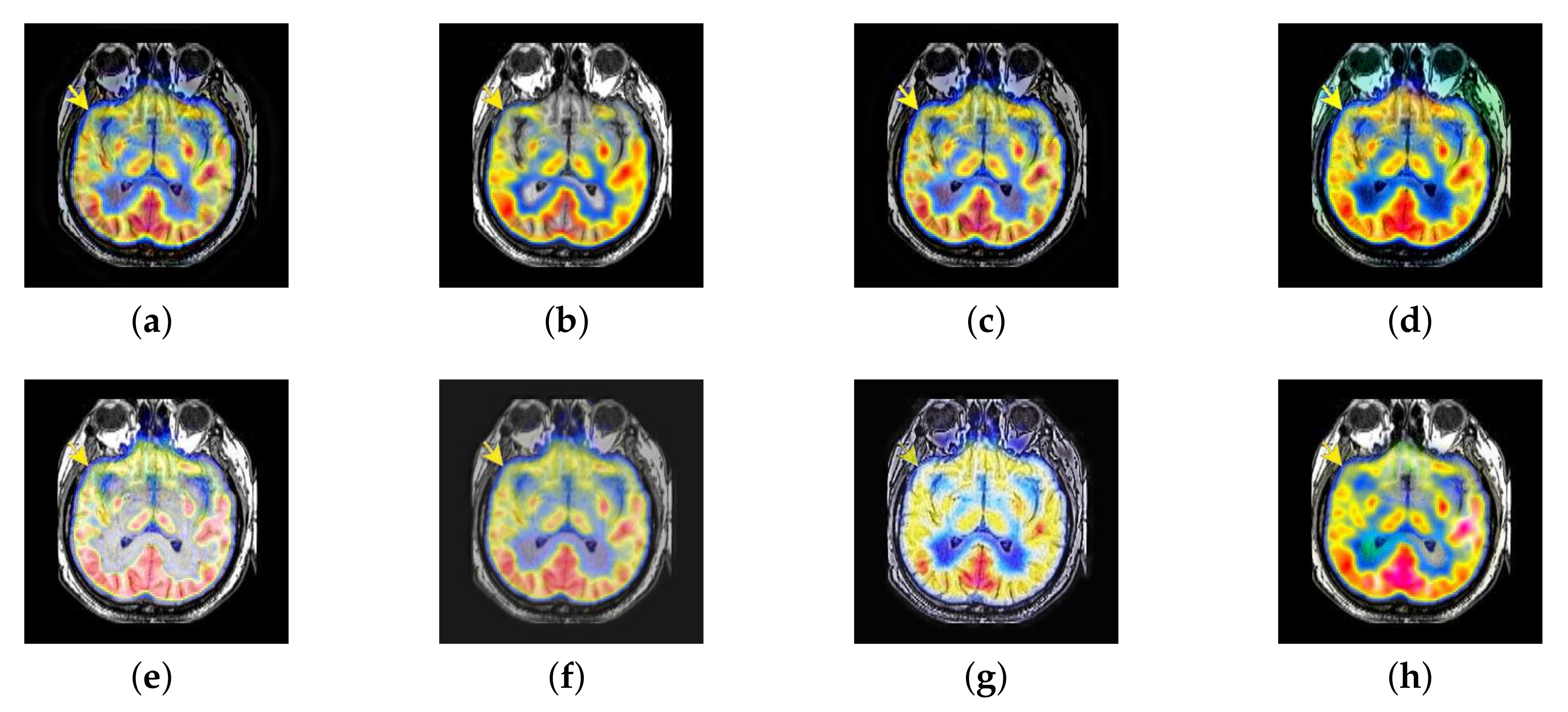
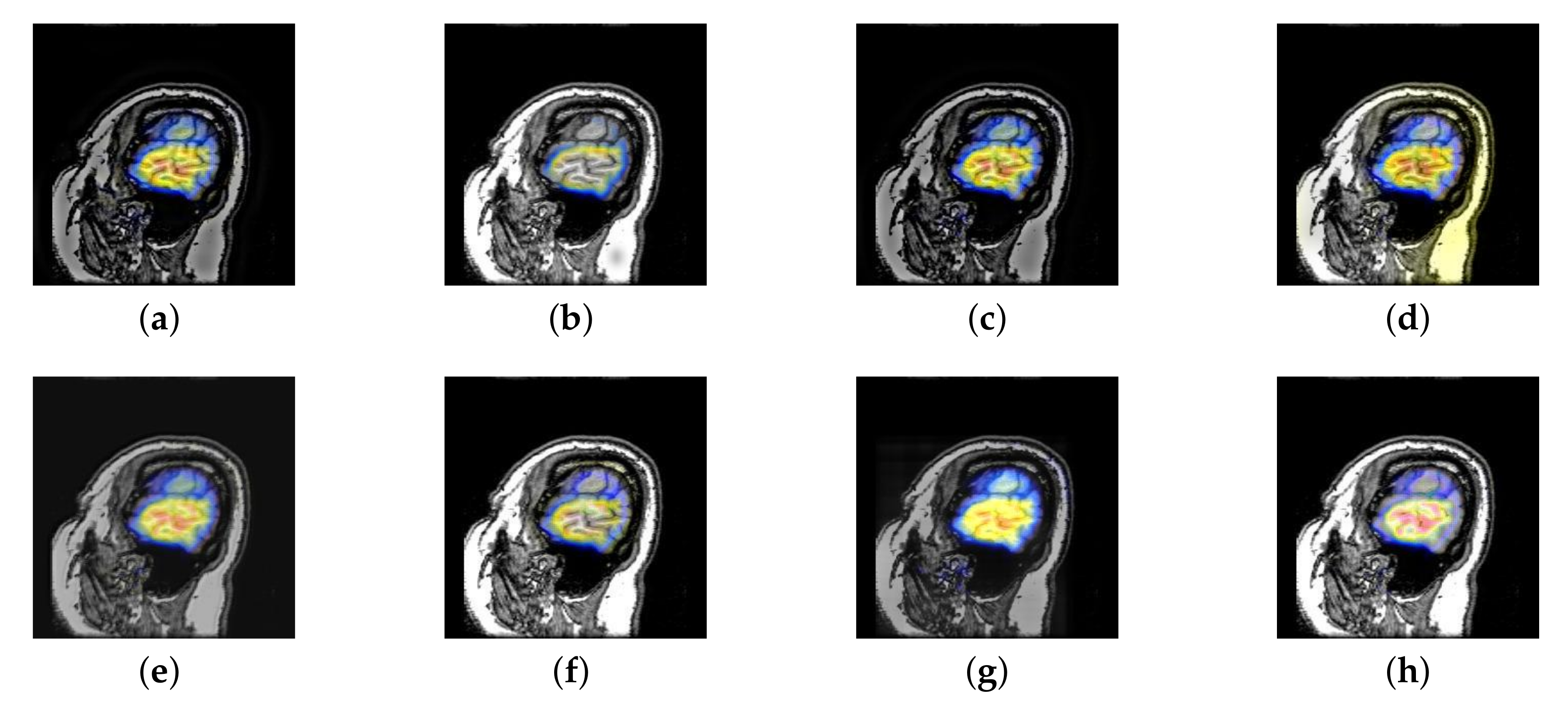
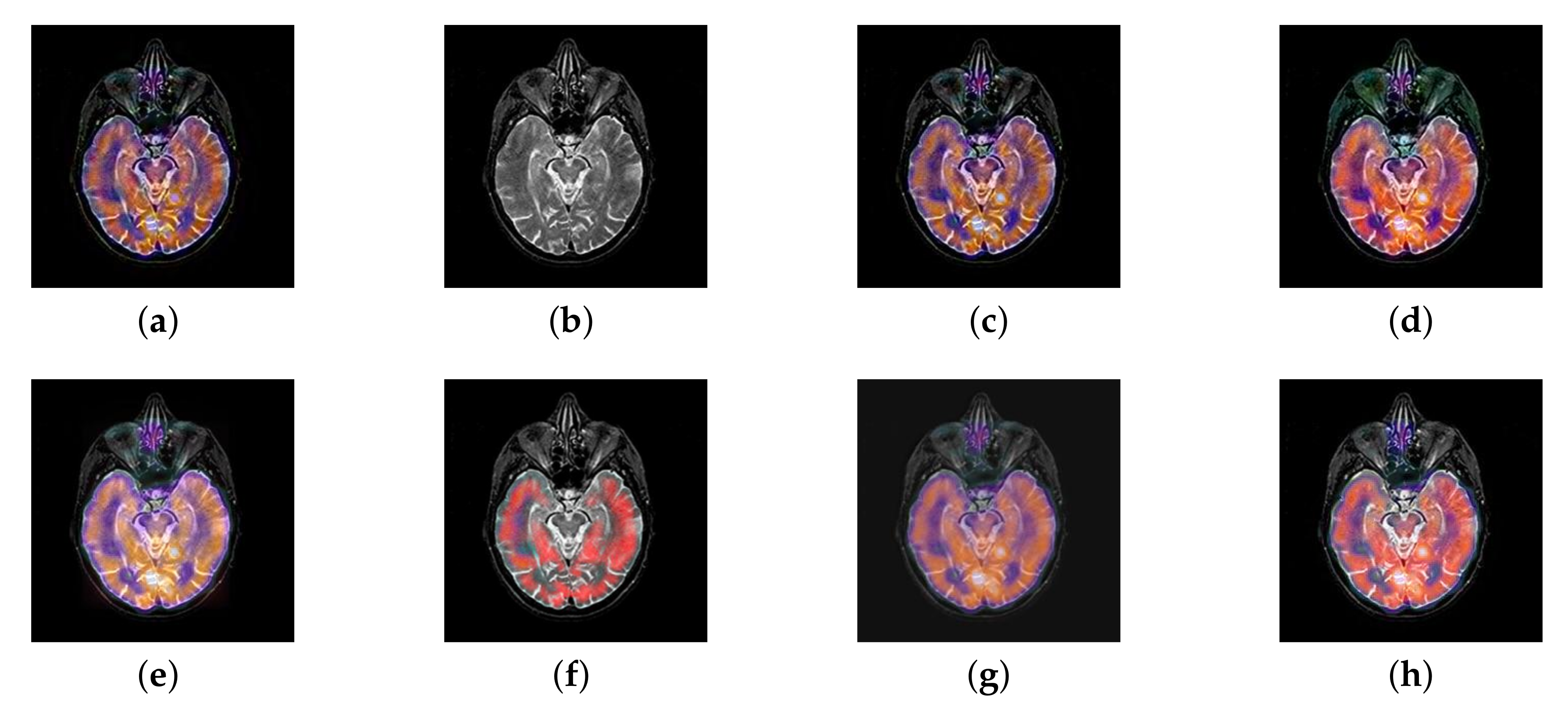
4.2. The Fusion of MRI-SPECT
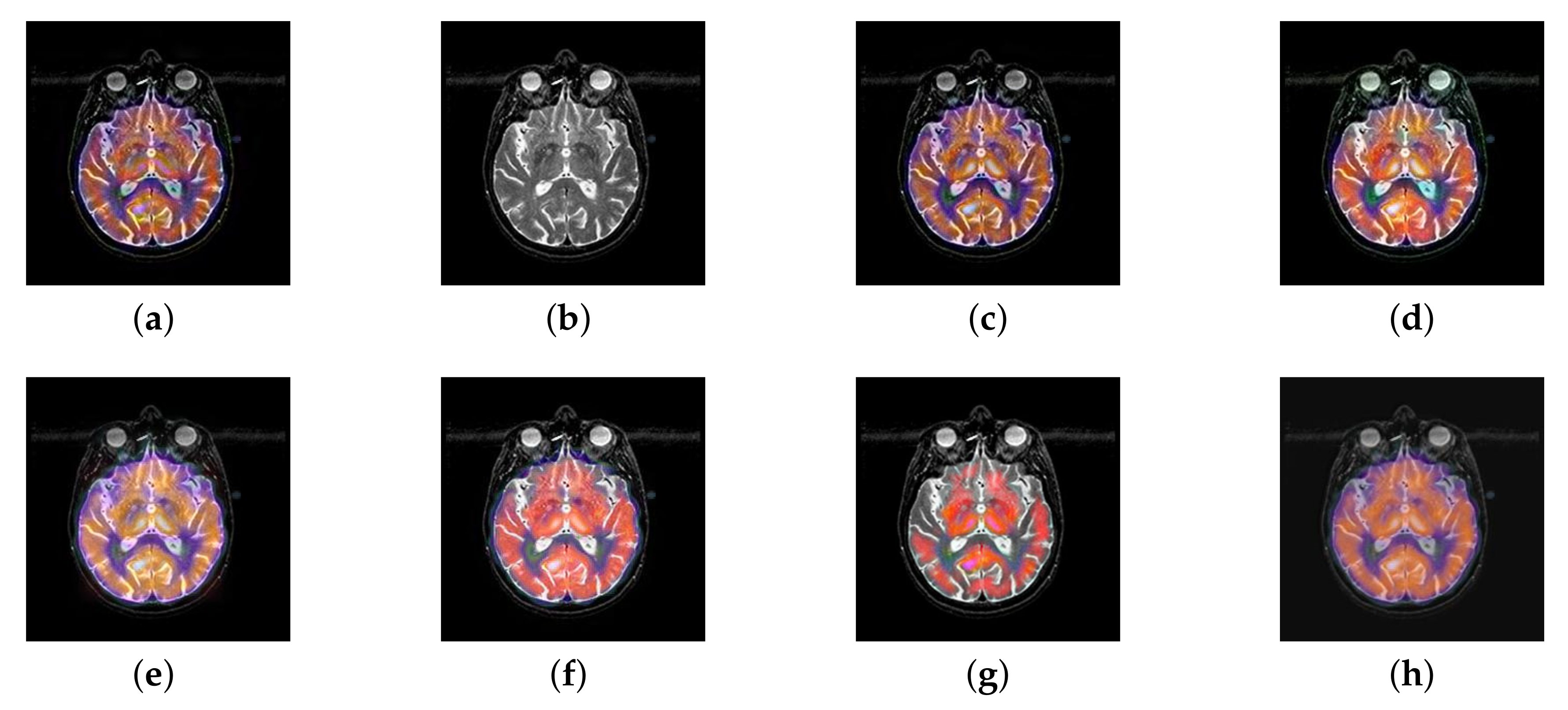
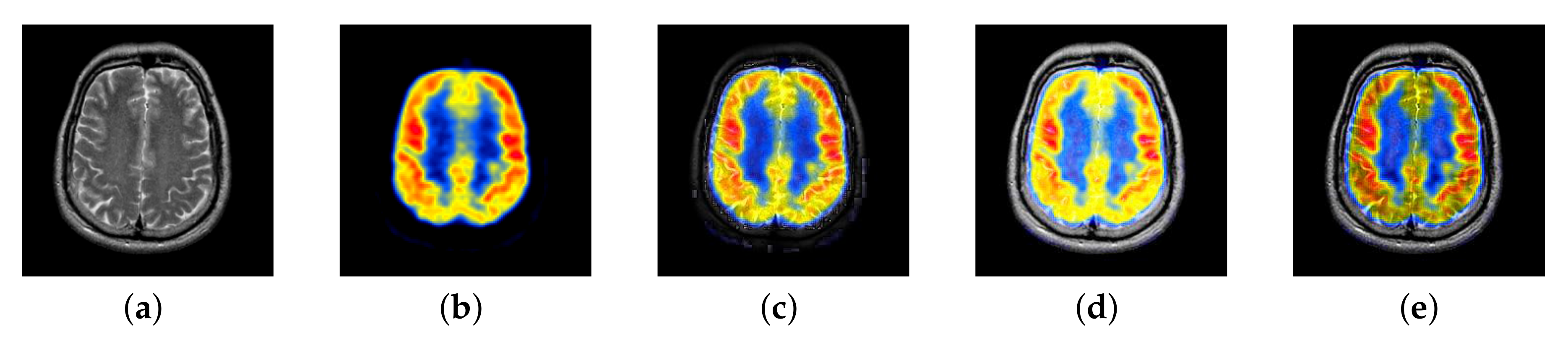
4.3. The Fusion of MRI-FDG
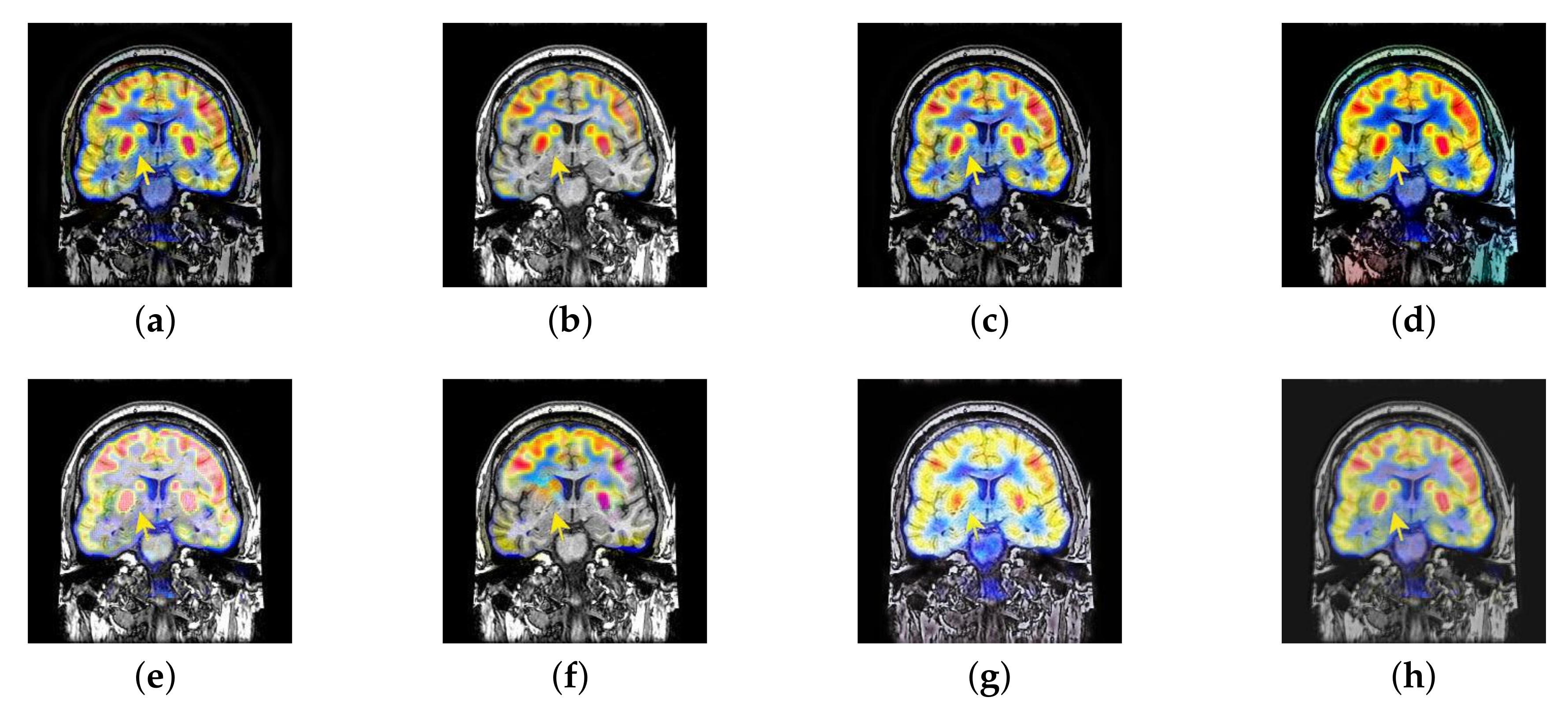
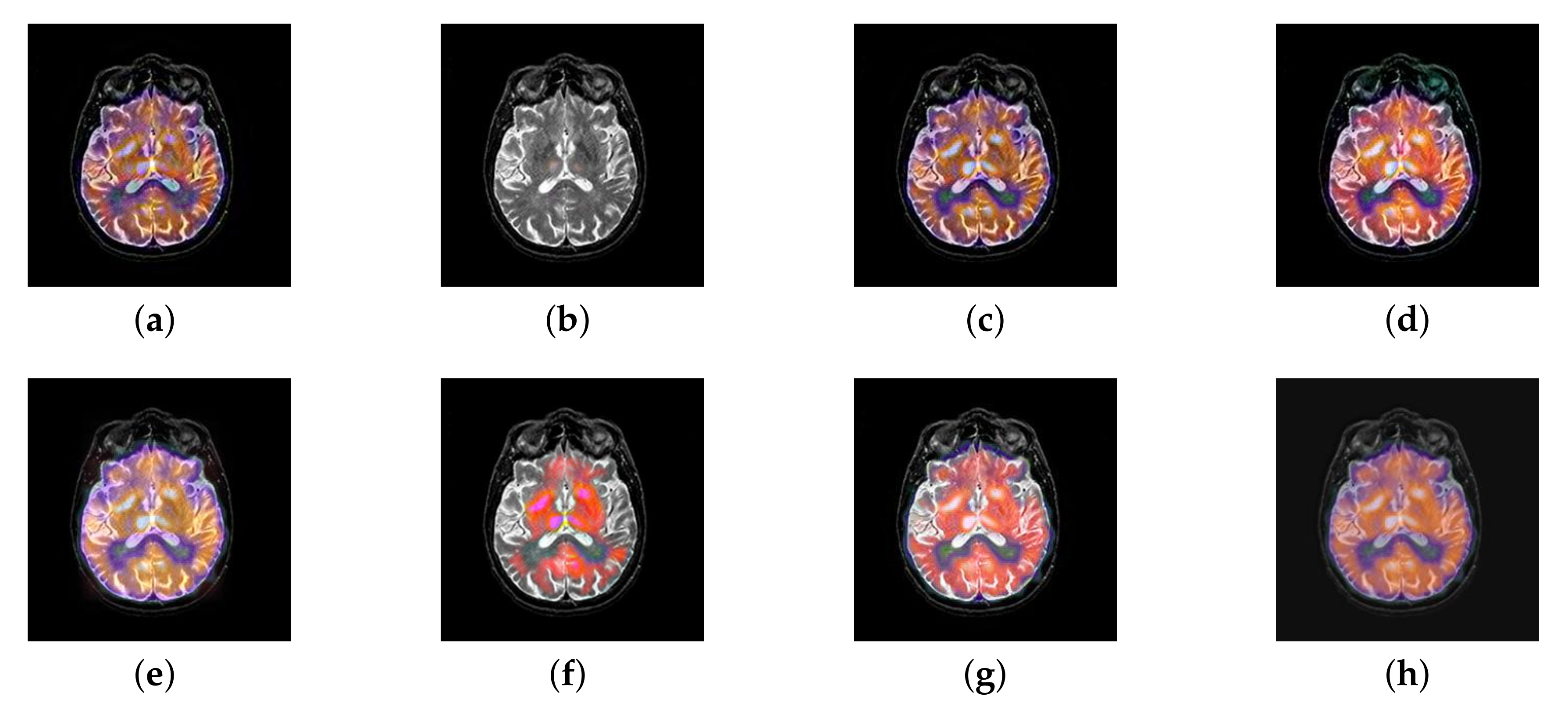
4.4. The Fusion of MRI-CBF
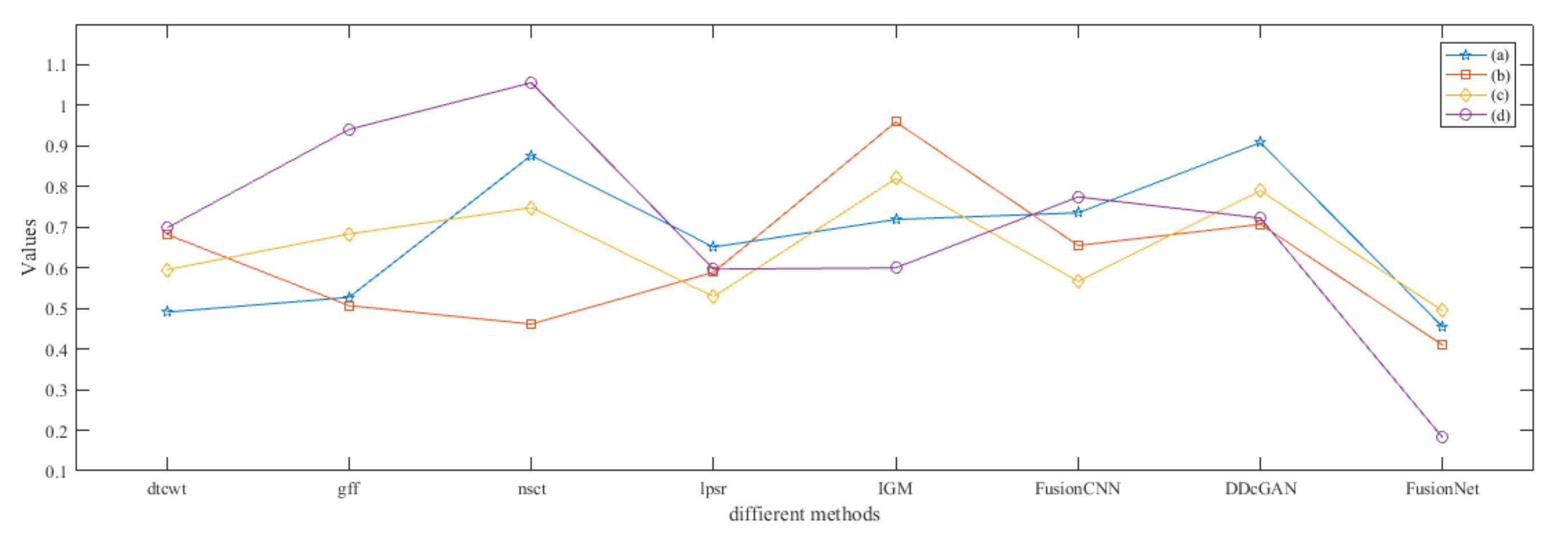
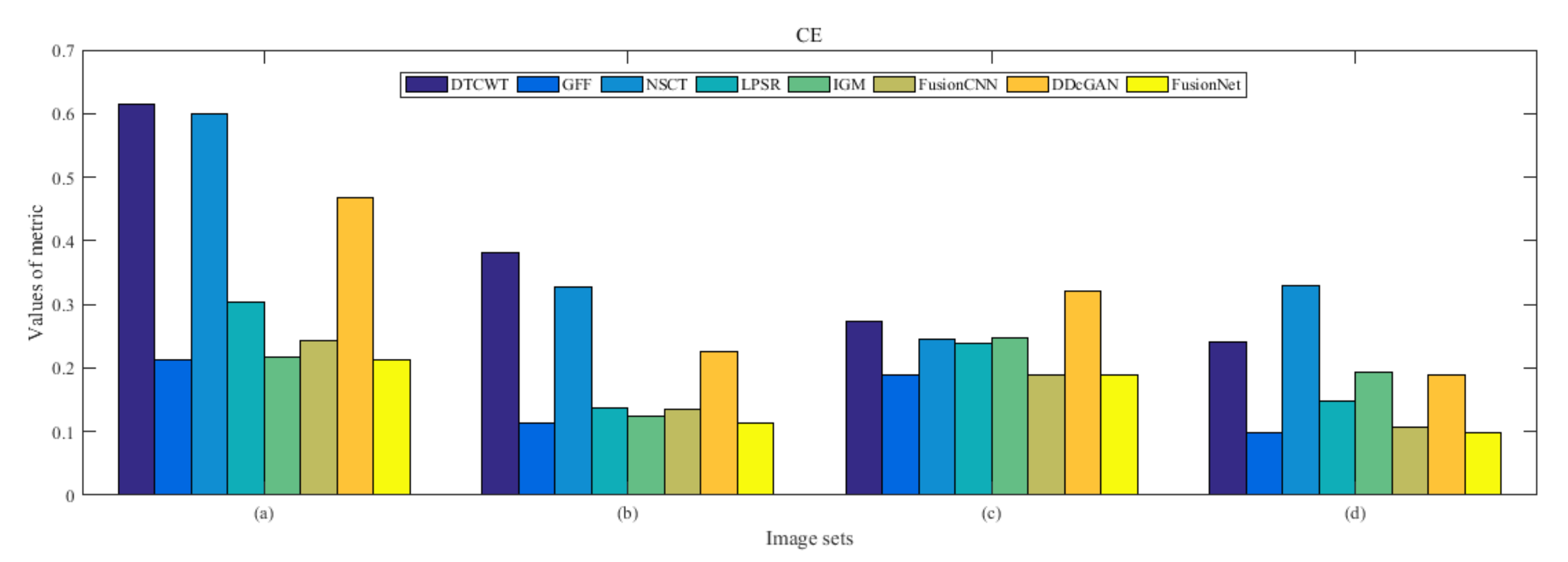
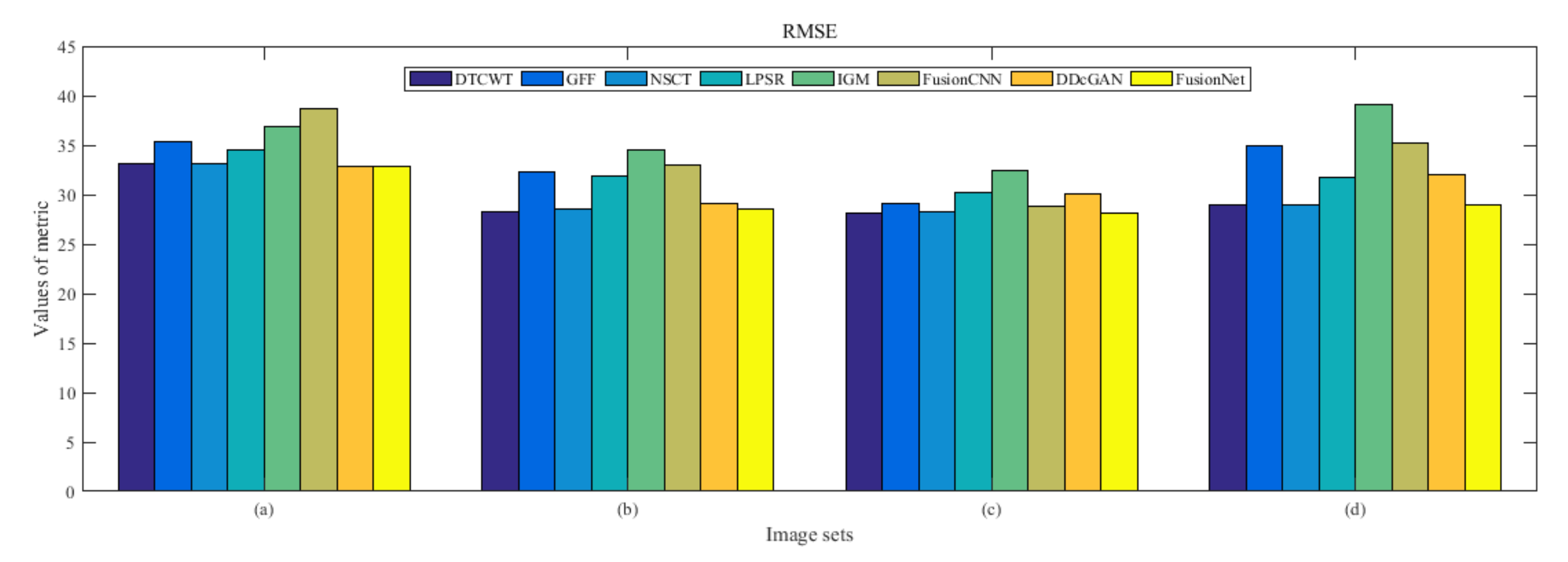
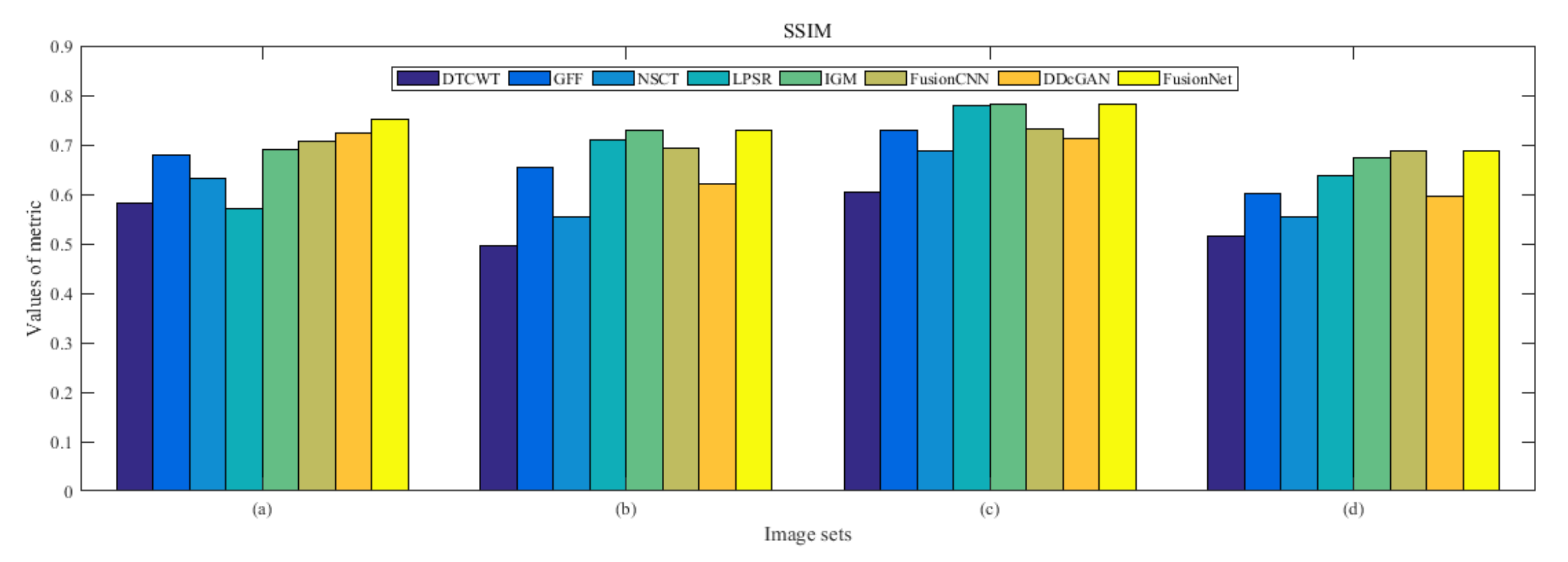
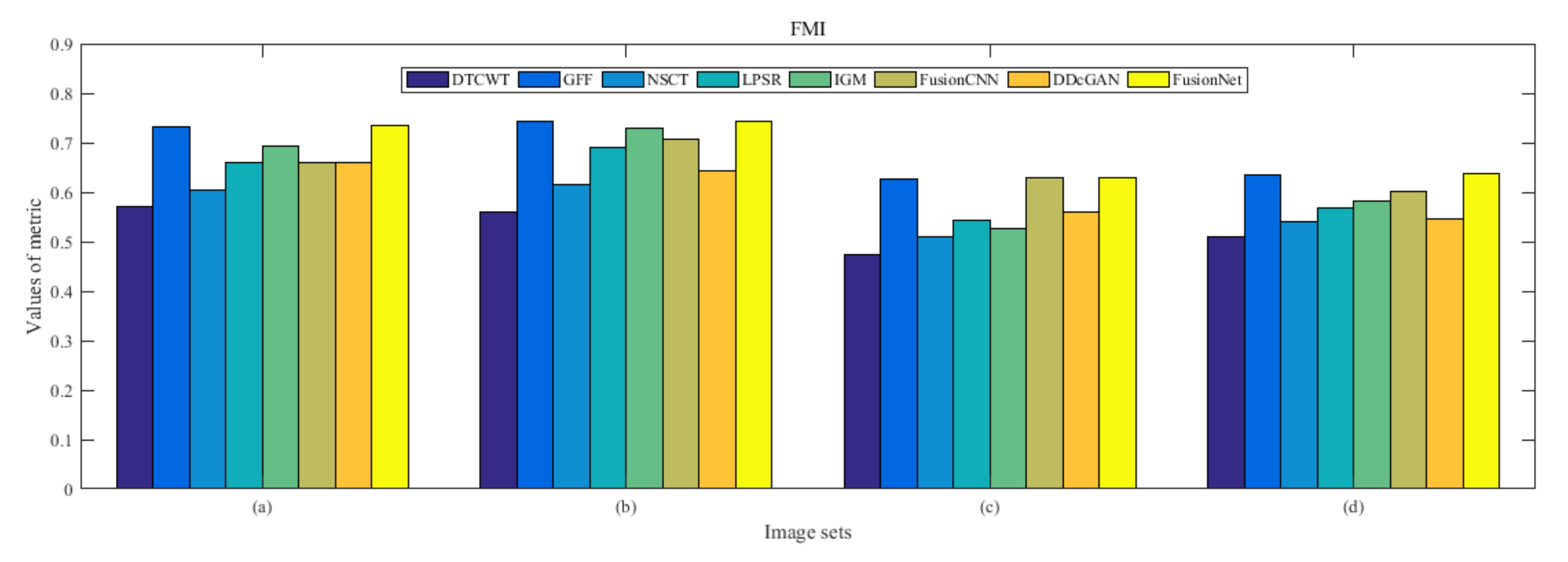
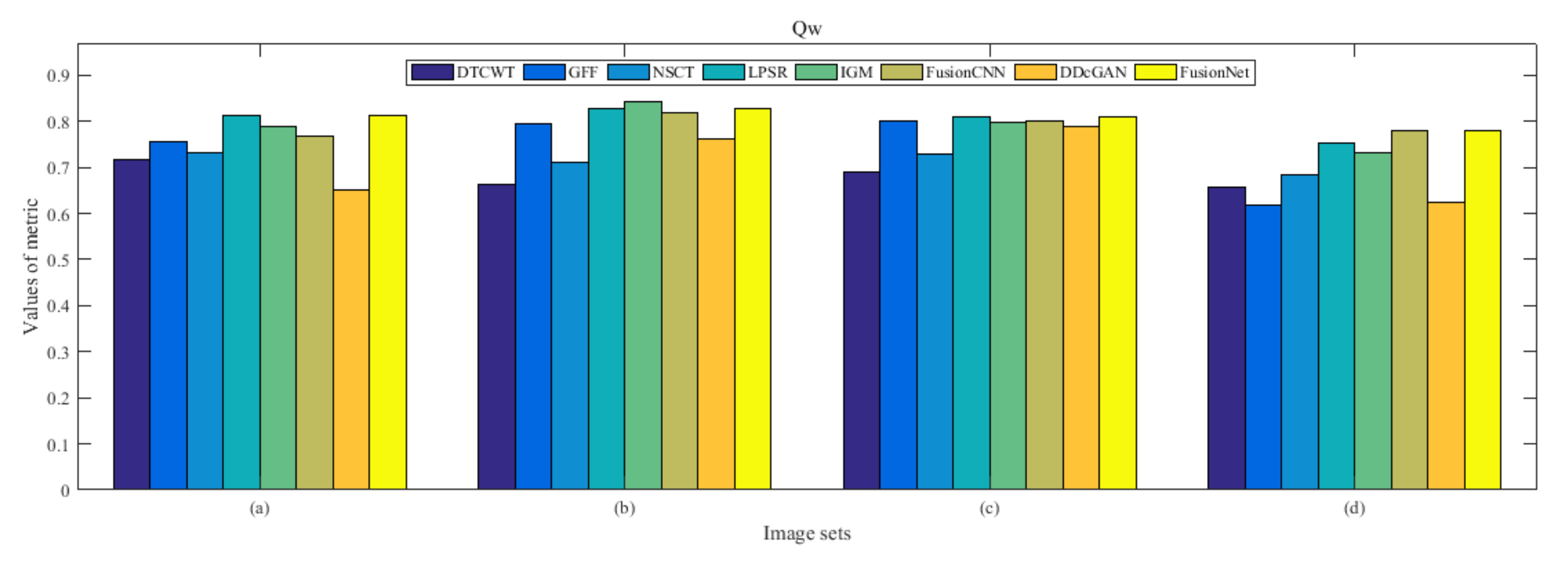
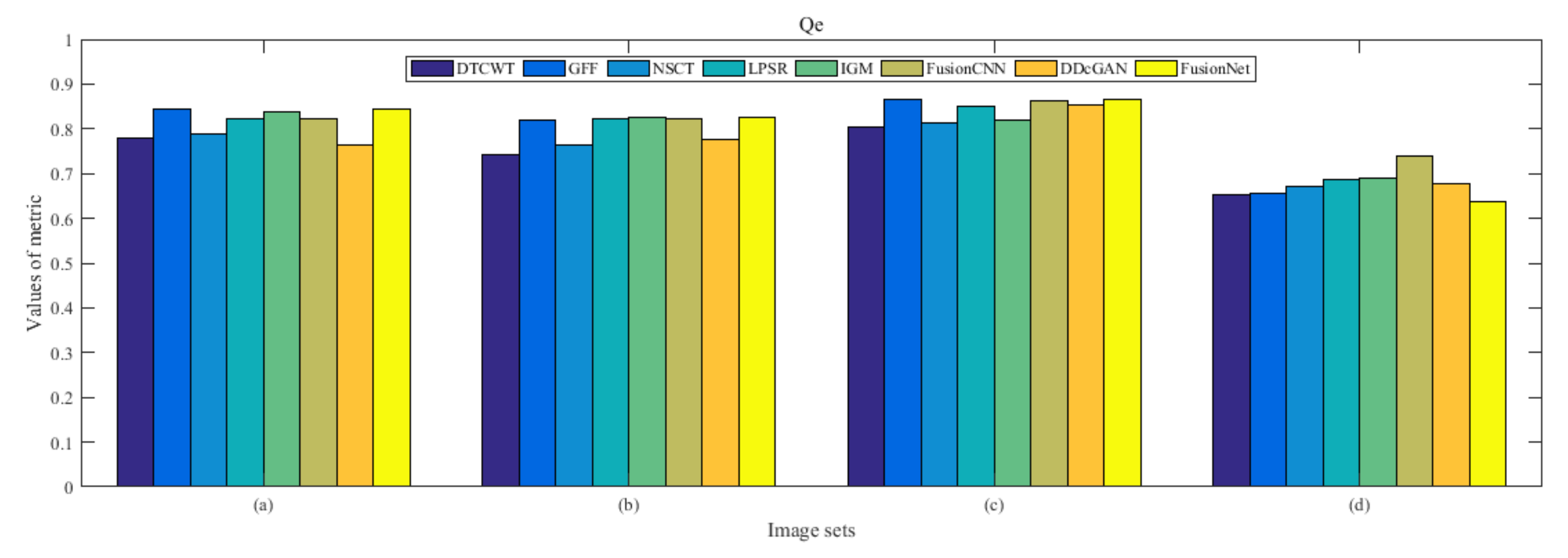
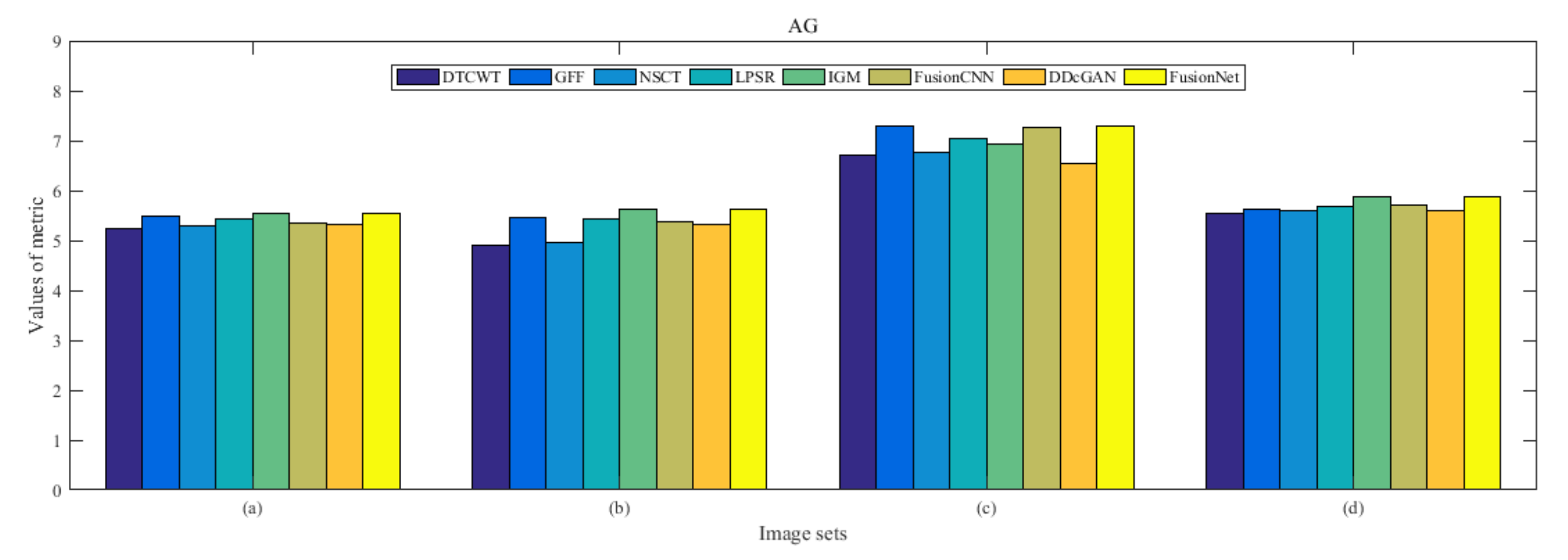
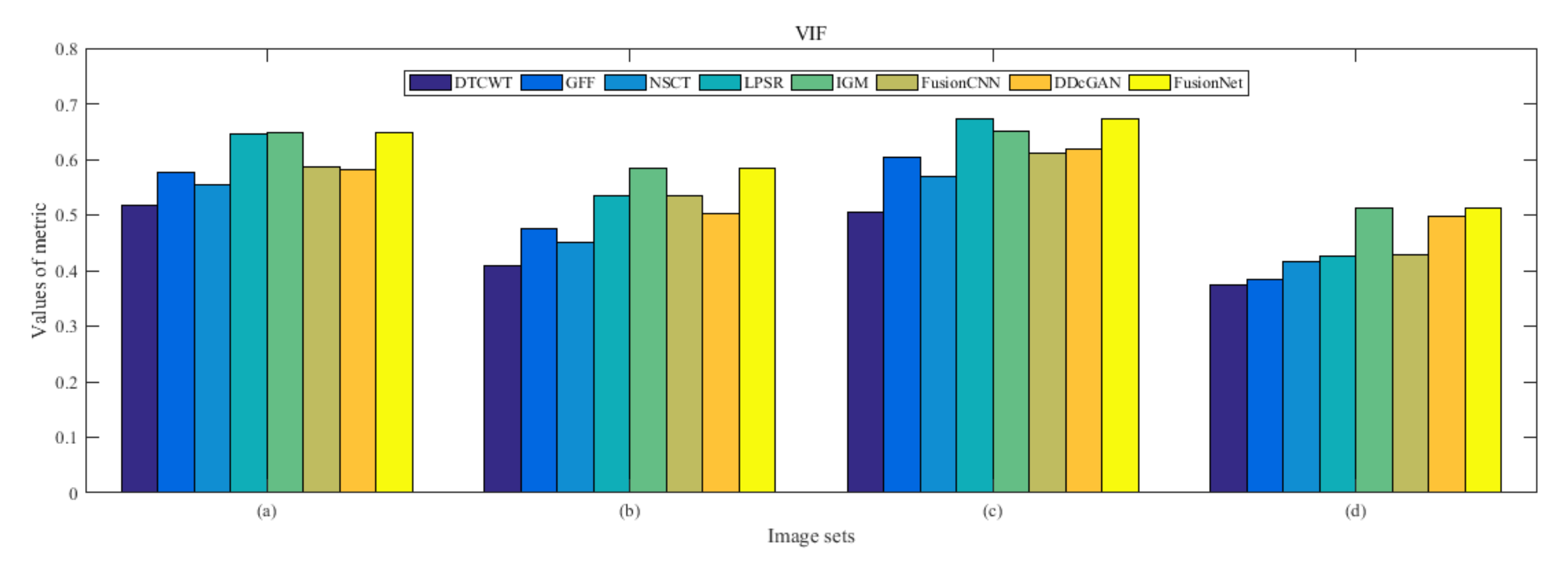
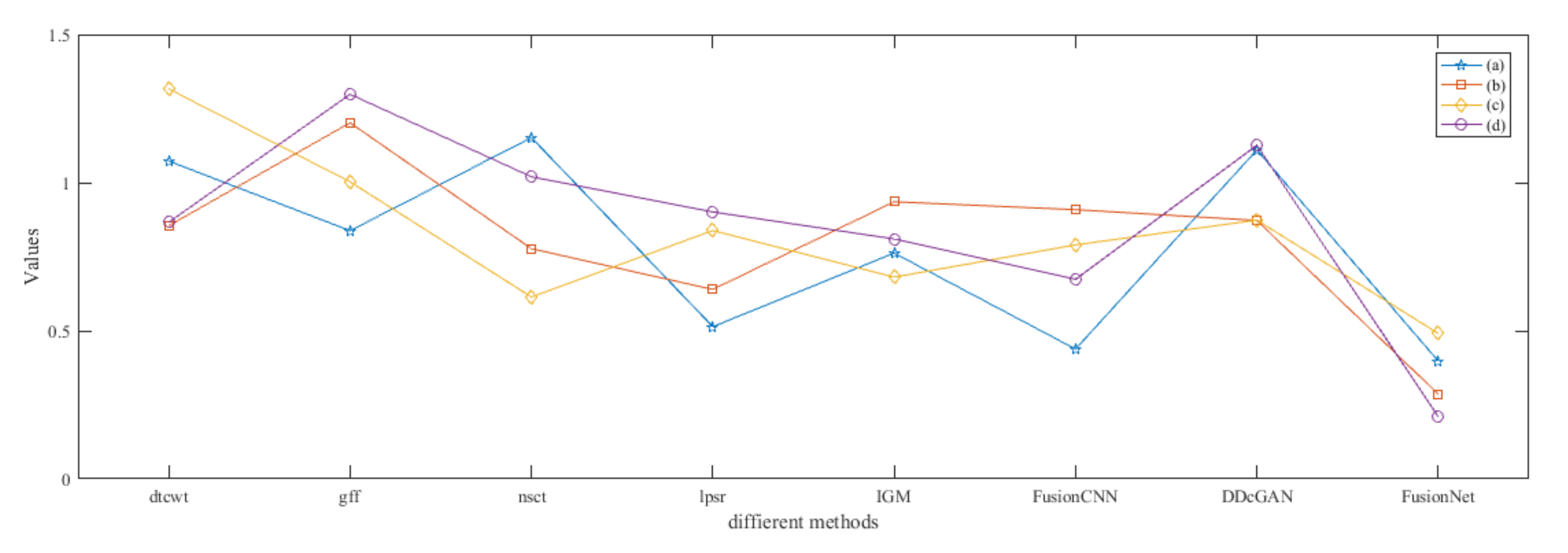
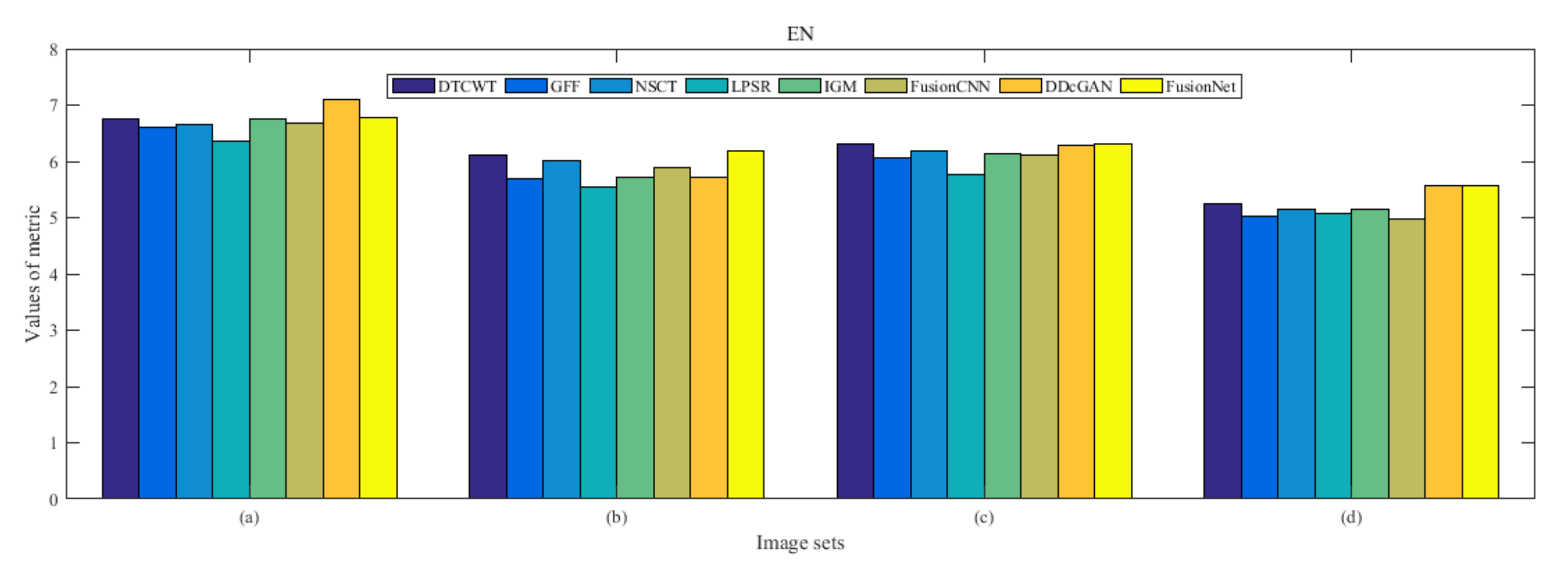
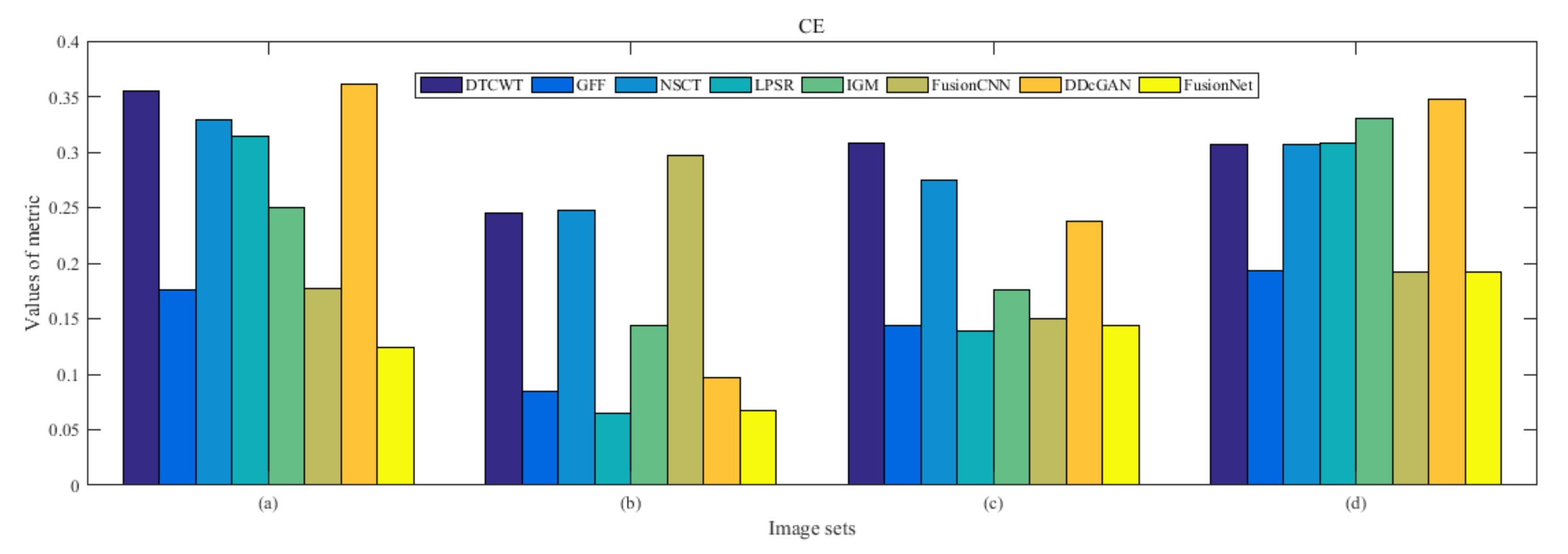
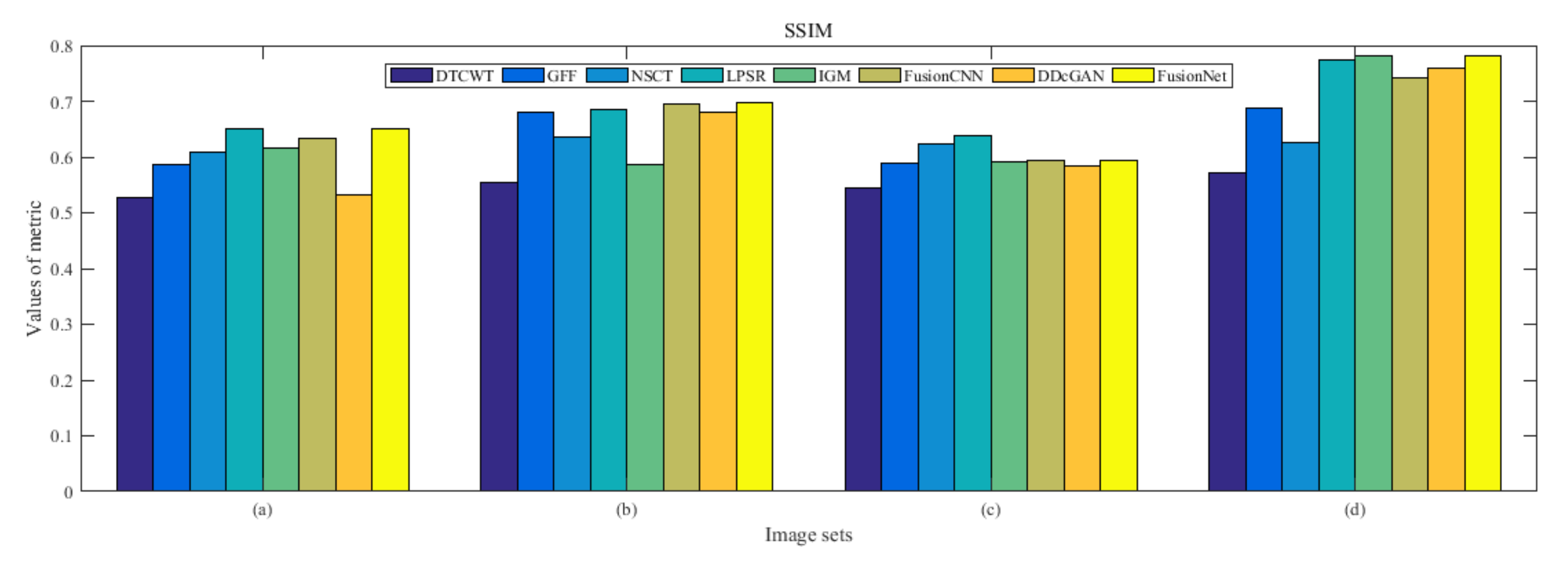
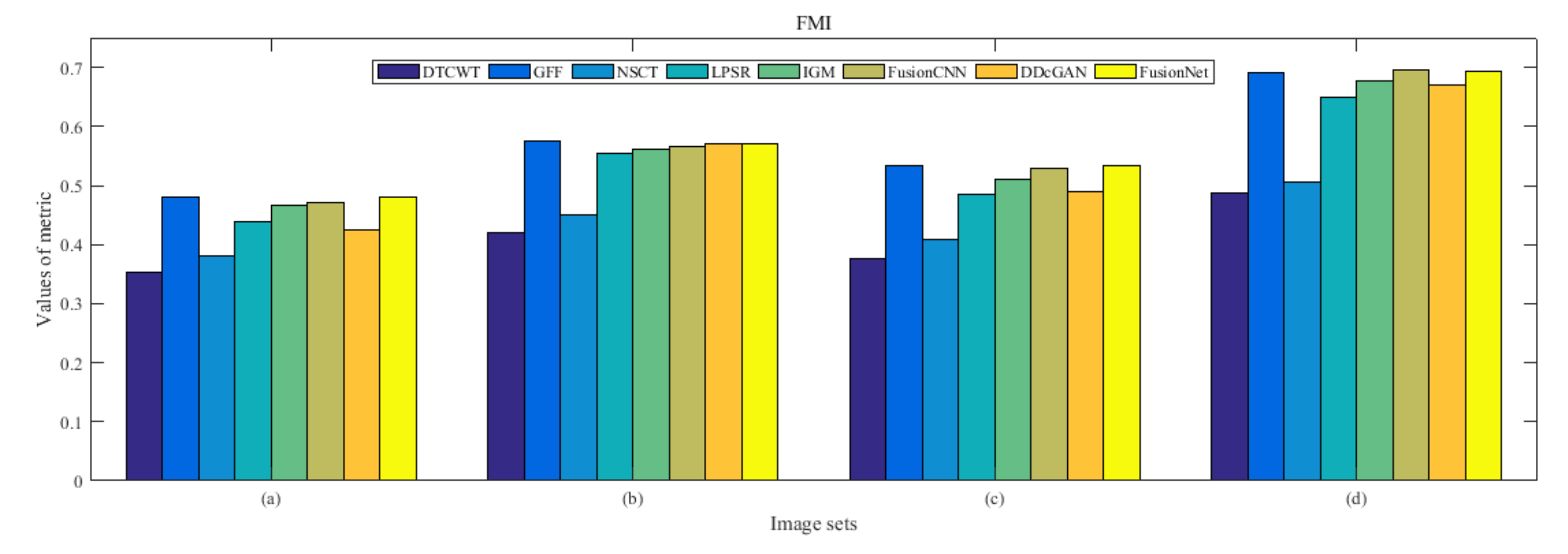
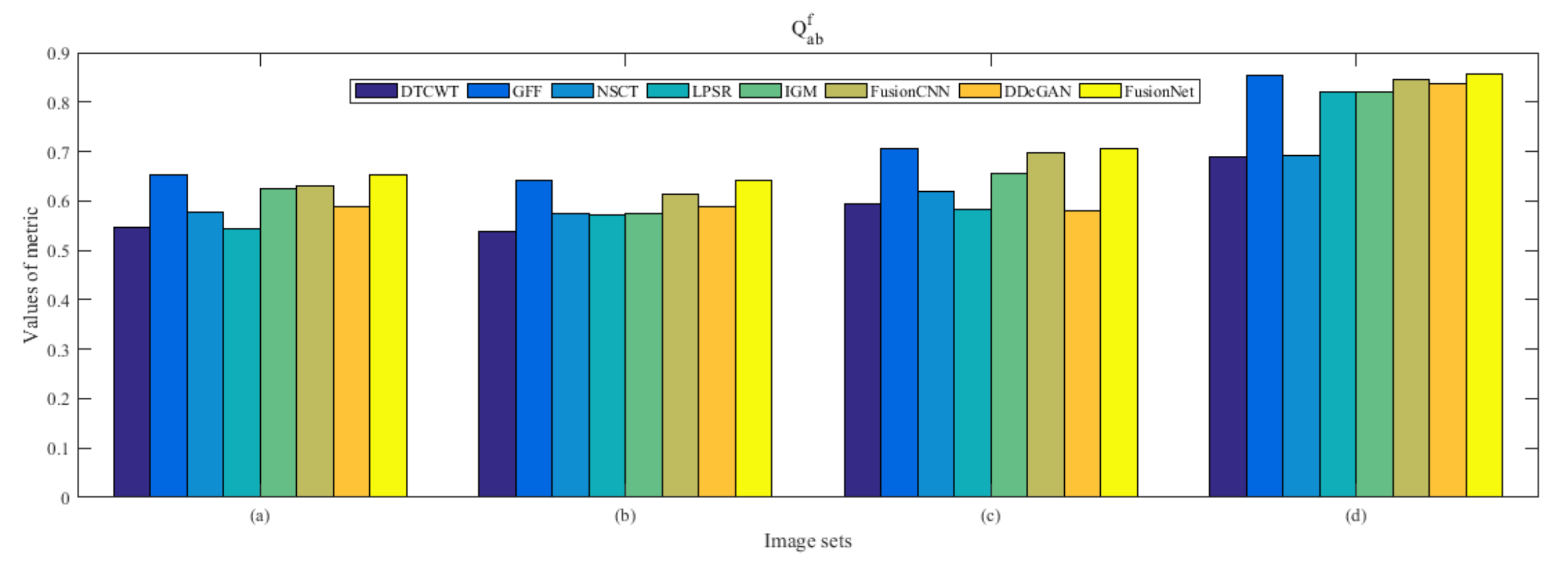
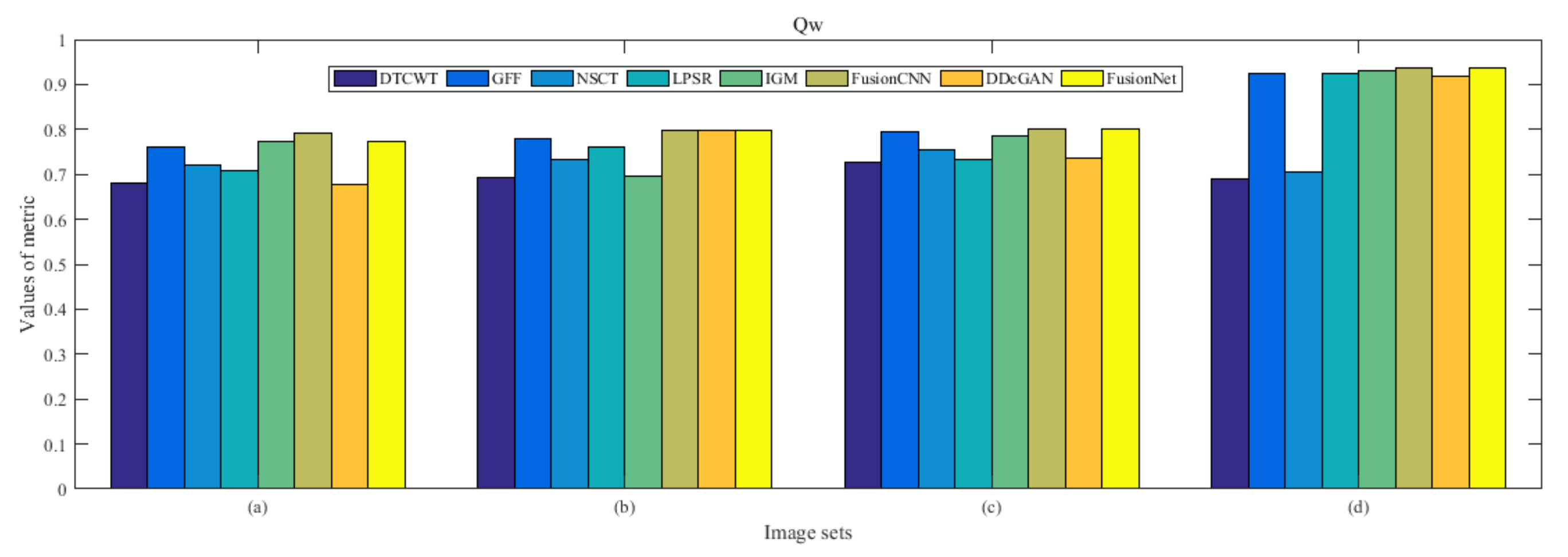
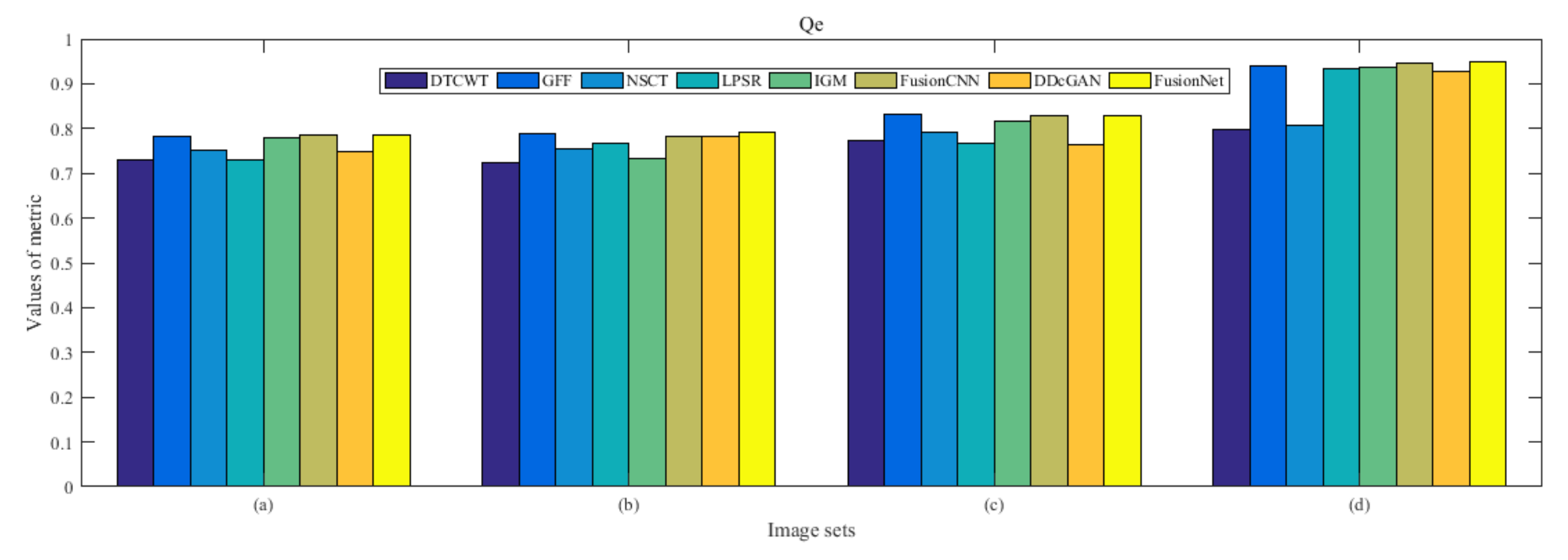
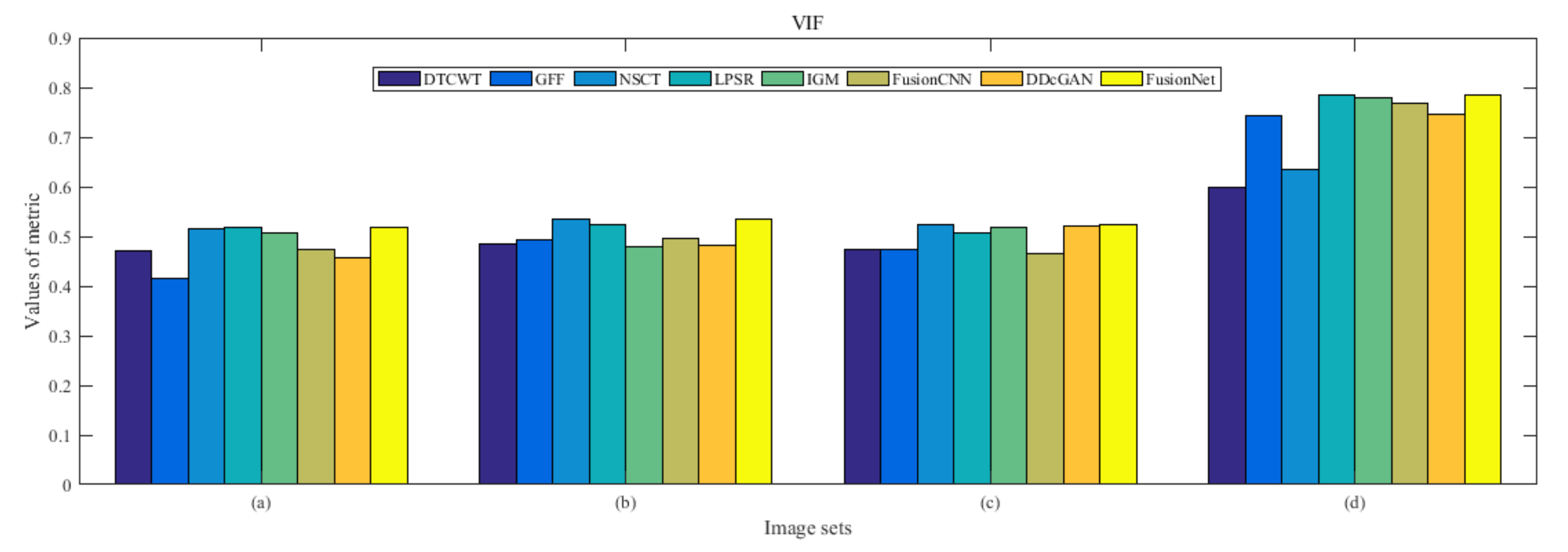
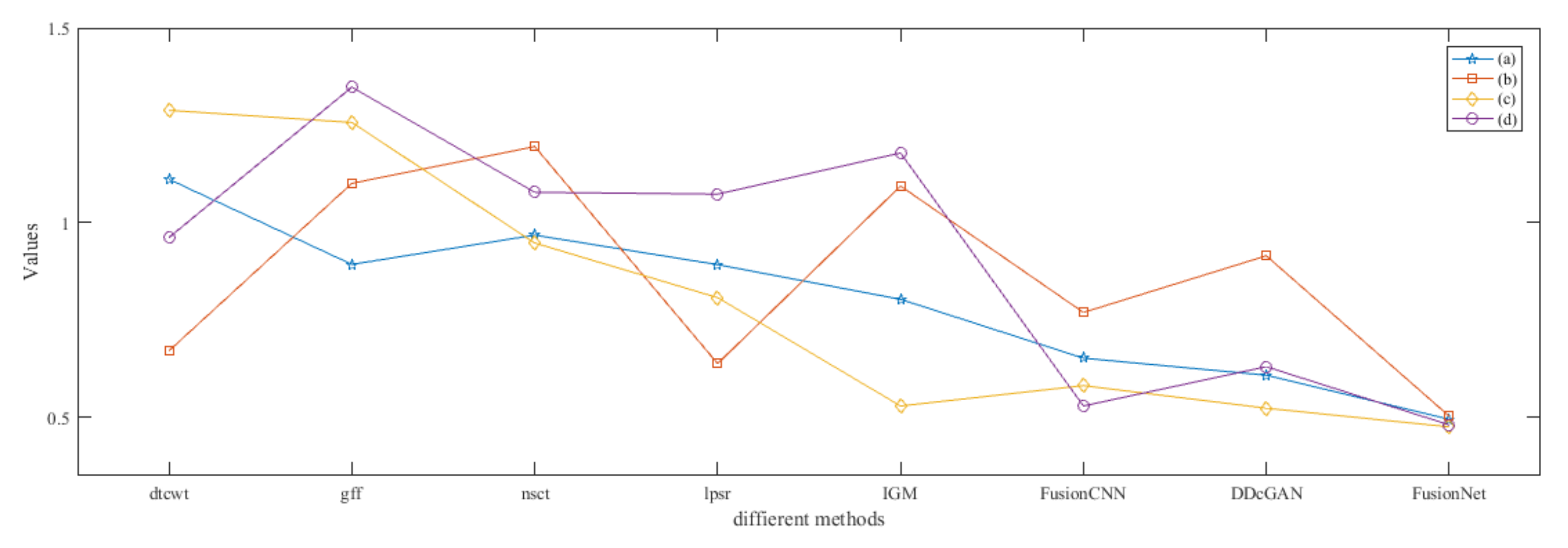
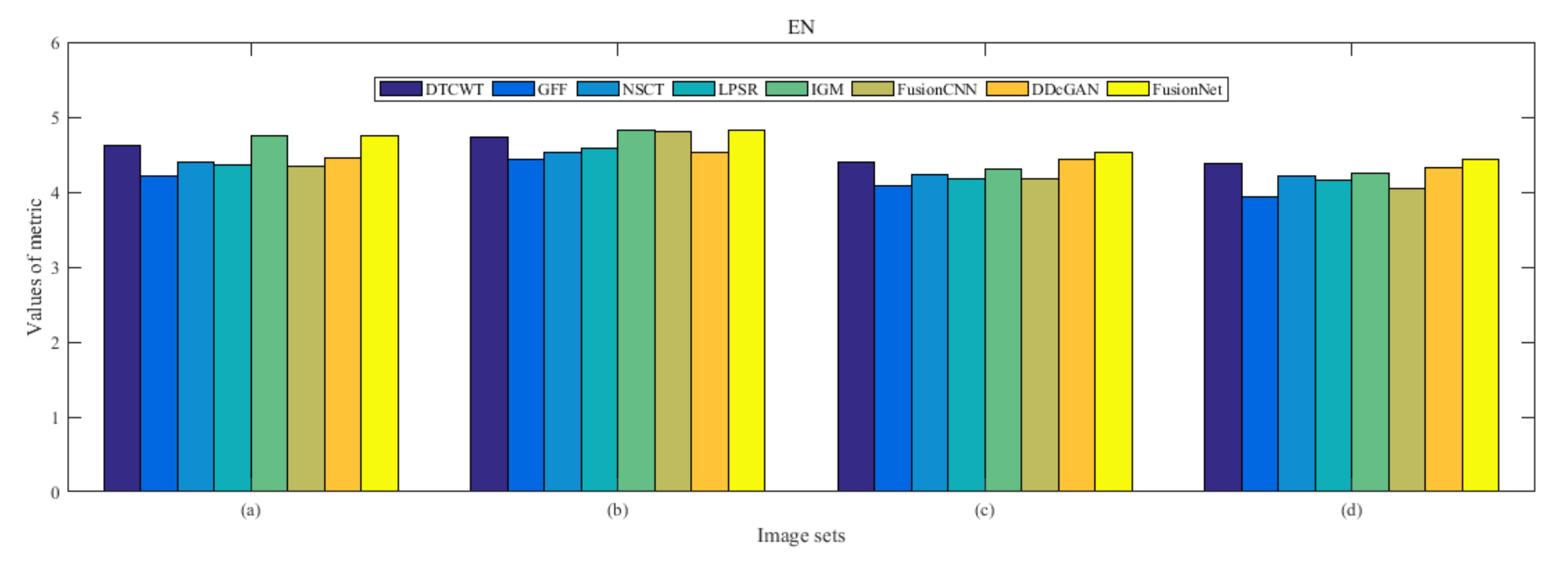
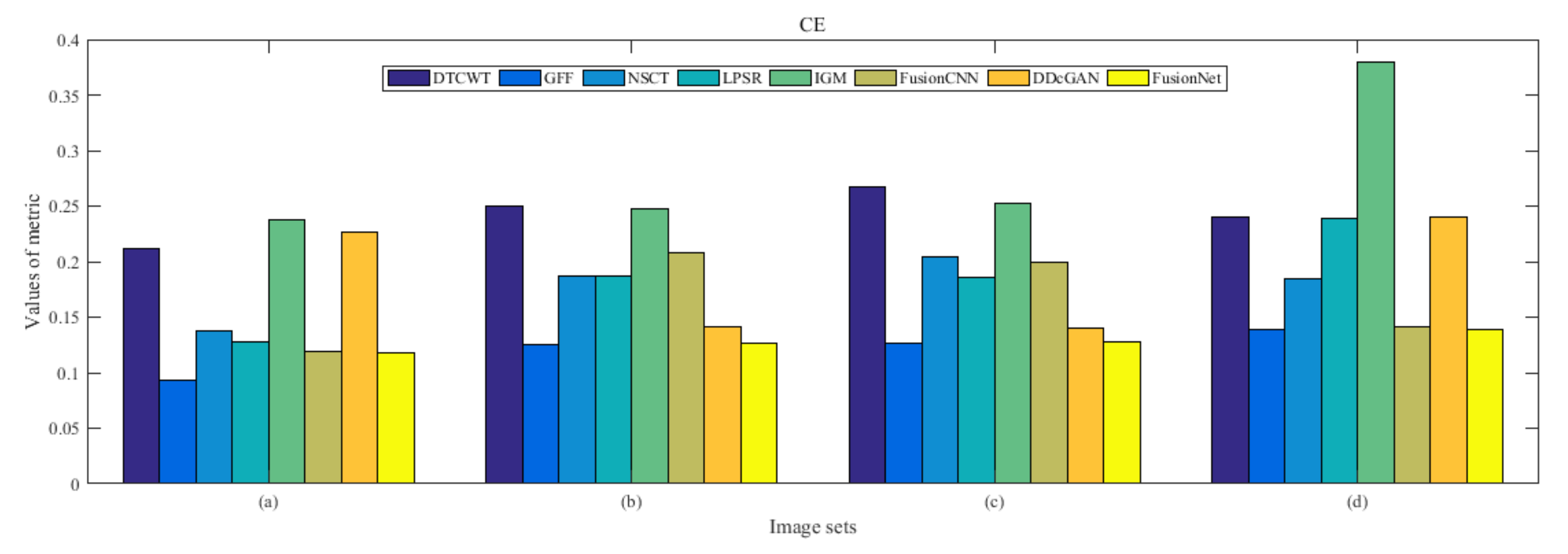
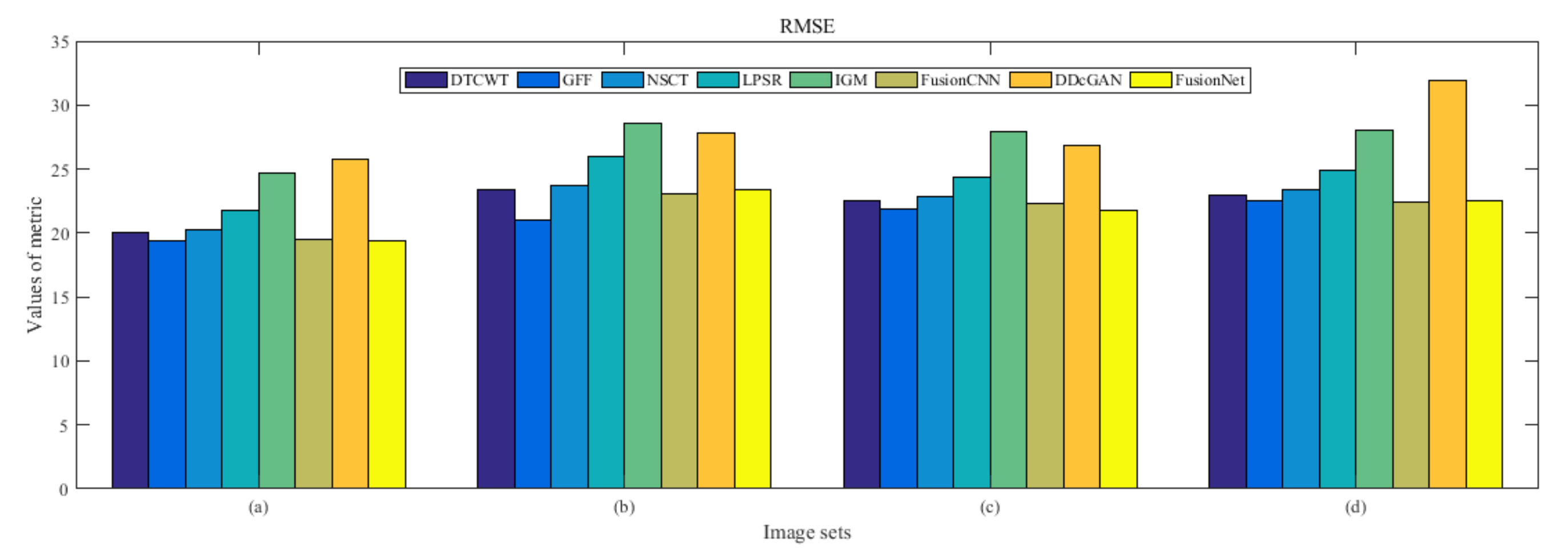
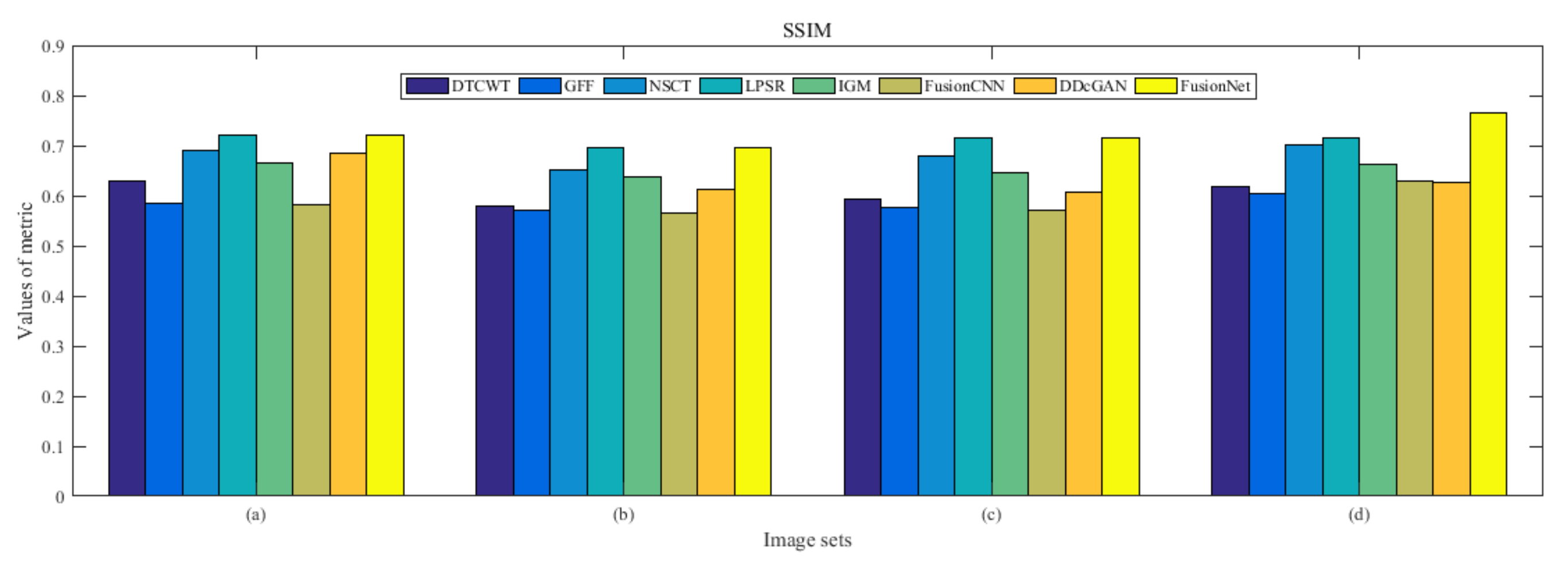
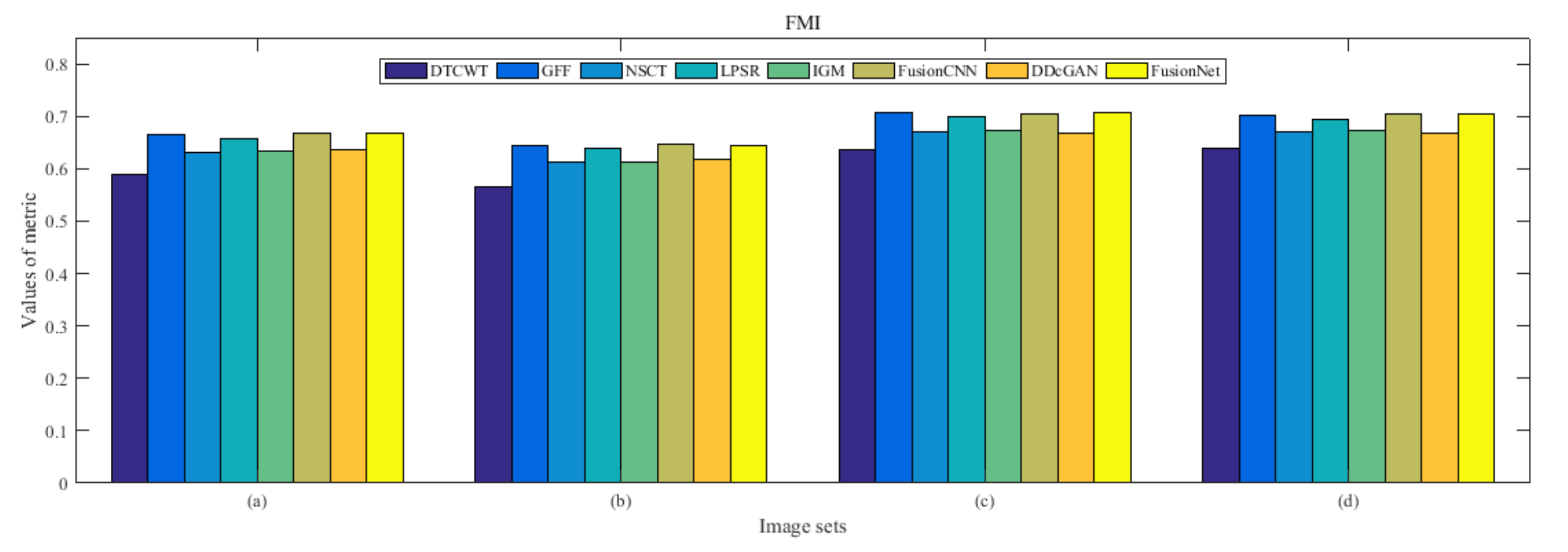
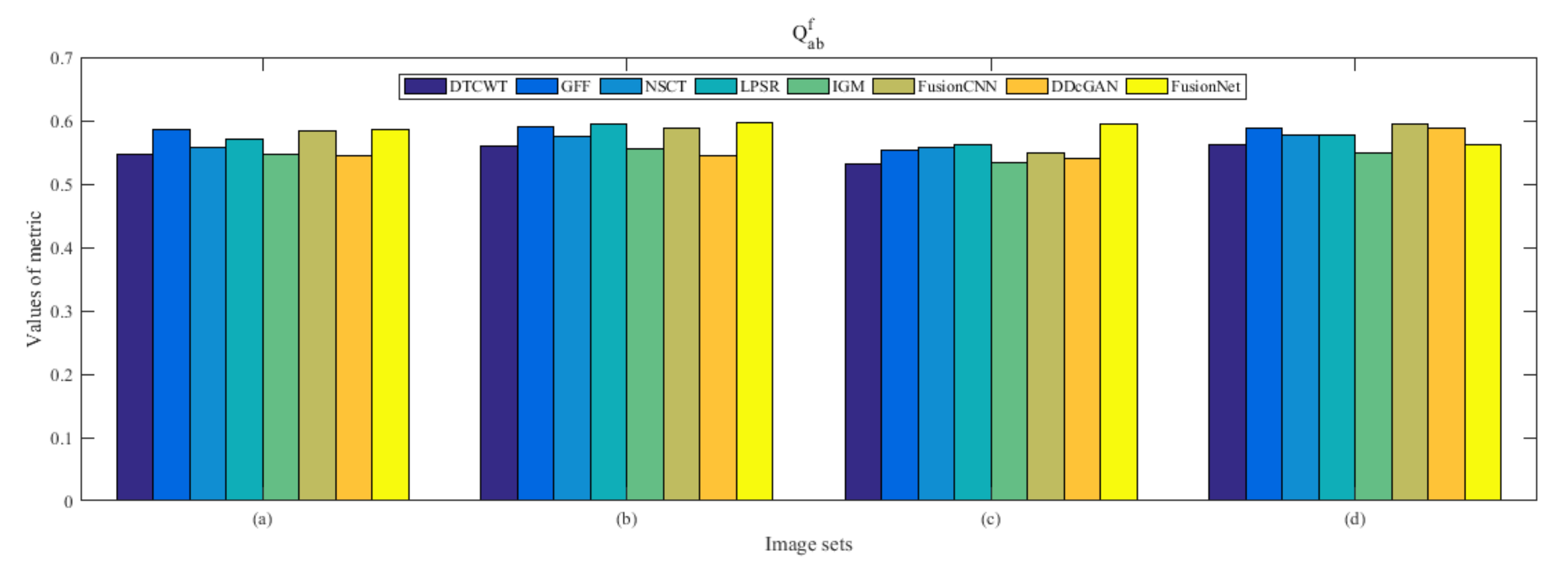
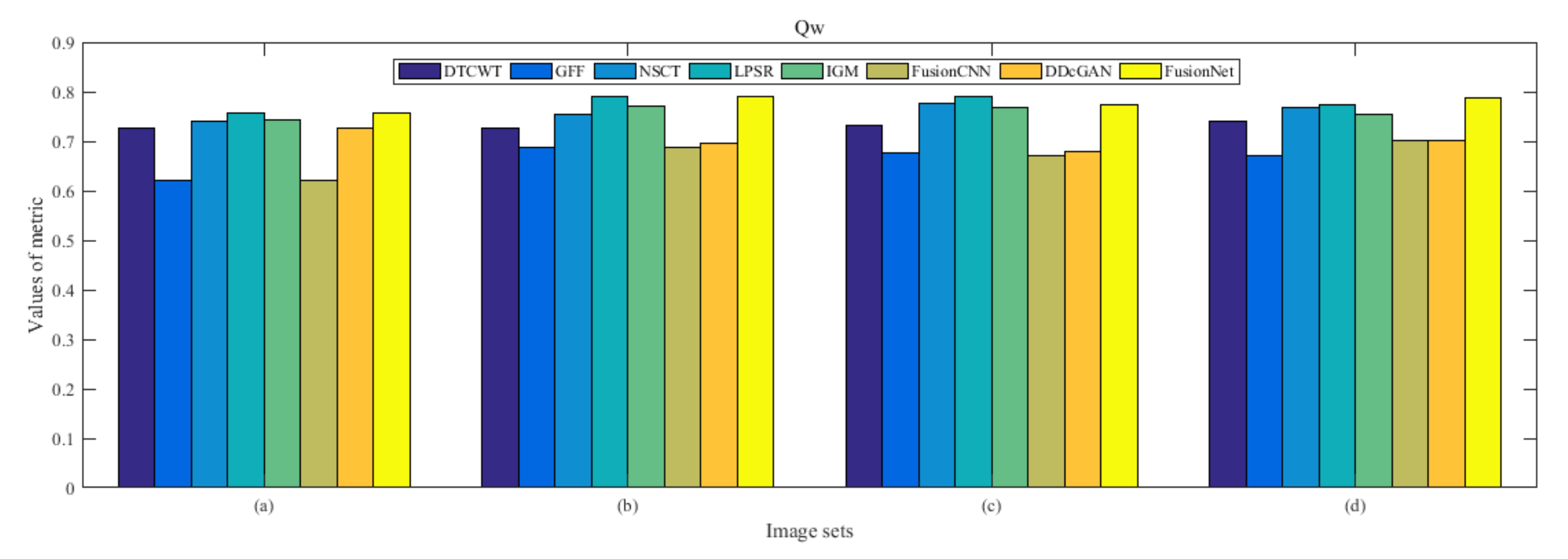
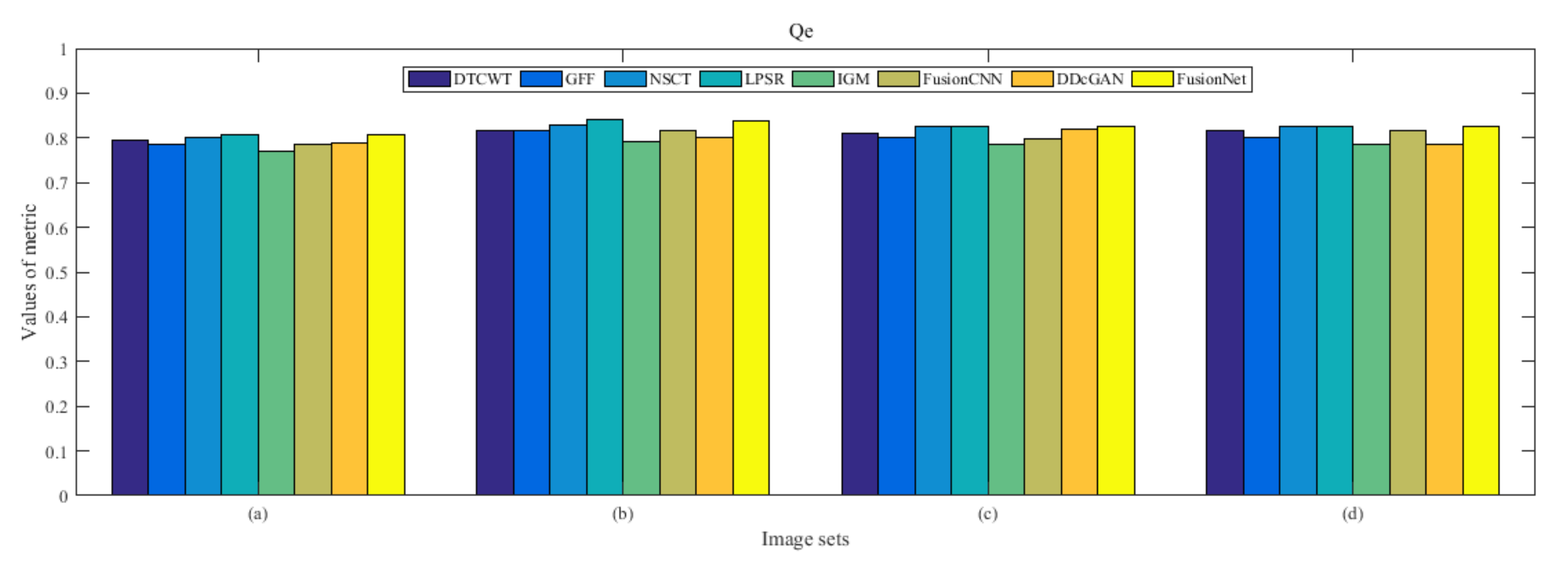
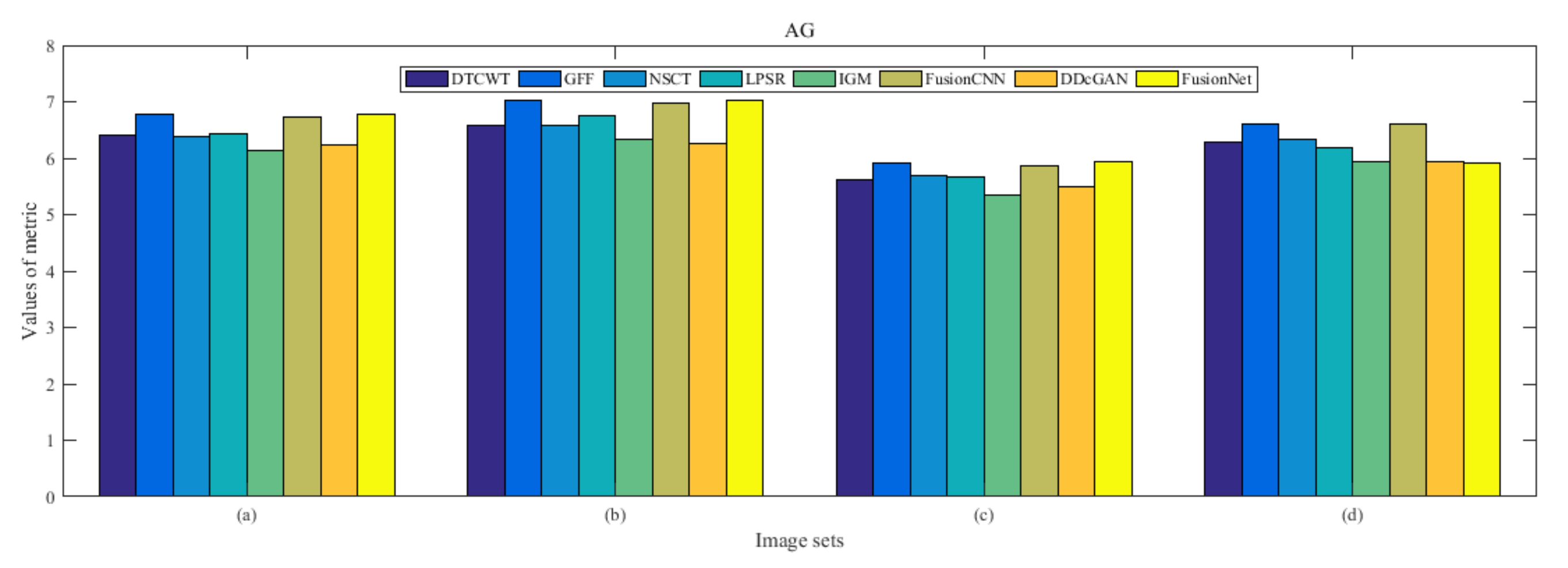
4.5. Metrics Discussion
4.6. Proposed Framework Analysis
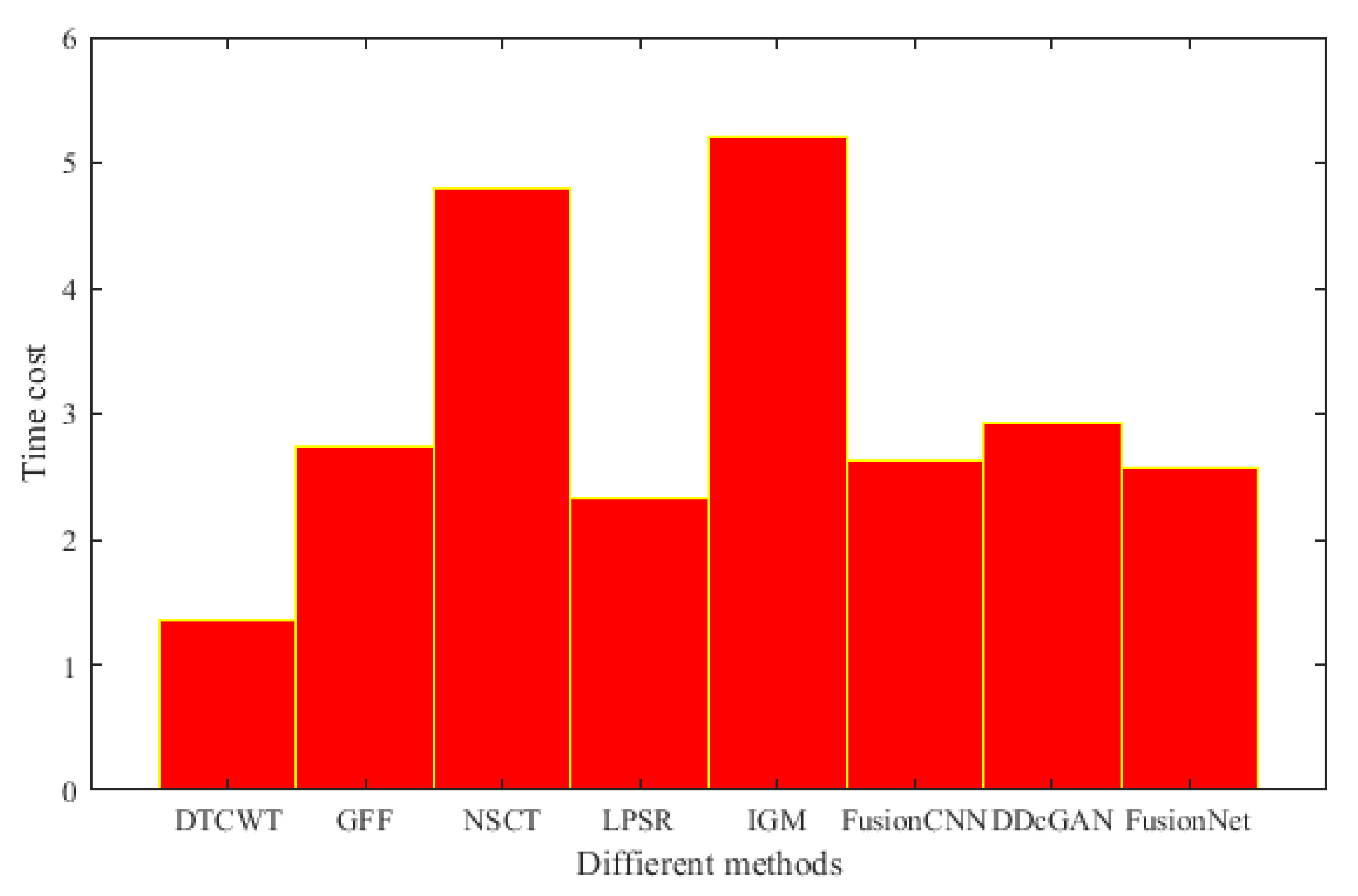
4.7. Computational Time Comparison
5. Conclusions and Future Development
Author Contributions
Funding
Conflicts of Interest
References
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 9, 4–19. [Google Scholar] [CrossRef]
- Liu, Y.; Xun, C.; Cheng, J.; Hu, P. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion, Xi’an, China, 10–13 July 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 1–7. [Google Scholar]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Zribi, M. Non-parametric and region-based image fusion with Bootstrap sampling. Inf. Fusion 2010, 11, 85–94. [Google Scholar] [CrossRef]
- Li, H.; Qiu, H.; Yu, Z.; Li, B. Multifocus image fusion via fixed window techniqueof multiscale images and non-local means filtering. Signal Process. 2017, 138, 71–85. [Google Scholar] [CrossRef]
- Yang, Y. A novel DWT based multi-focus image fusion method. Procedia Eng. 2011, 24, 177–181. [Google Scholar] [CrossRef]
- Yang, S.; Wang, M.; Jiao, L.; Wu, R.; Wang, Z. Image fusion based on a newcontourlet packet. Inf. Fusion 2010, 11, 78–84. [Google Scholar] [CrossRef]
- Yu, B.; Jia, B.; Ding, L.; Cai, Z.; Wu, Q.; Law, R.; Huang, J.; Song, L.; Fu, S. Hybrid dual-tree complex wavelet transform and support vector machine for digital multi-focus image fusion. Neurotoxinmenge 2016, 182, 1–9. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Li, H.; Qiu, H.; Yu, Z.; Zhang, Y. Infrared and visible image fusion scheme basedon NSCT and low-level visual features. Infrared Phys. Technol. 2016, 76, 174–184. [Google Scholar] [CrossRef]
- Paris, S.S.; Hasinoff, W.S.; Kautz, J. Local Laplacian filters: Edgeaware image processing with a Laplacian pyramid. ACM Trans. Graph. 2011, 30, 1244–1259. [Google Scholar] [CrossRef]
- Wang, J.; Zha, H.; Cipolla, R. Combining interest points and edges for content-based image retrieval. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 14 September 2005; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2005; pp. 1256–1259. [Google Scholar]
- Li, H.; Wu, X. Multi-focus image fusion using dictionary learning and low-rank representation. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; Springer: Cham, Switzerland, 2017; pp. 675–686. [Google Scholar]
- Chen, Z.; Wu, X.; Kittler, J. A sparse regularized nuclear norm based matrix regression for face recognition with contiguous occlusion. Pattern Recogn. lett. 2019, 125, 494–499. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, X.; Yin, H.F.; Kittler, J. Robust Low-Rank Recovery with a Distance-Measure Structure for Face Recognition. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Nanjing, China, 28–31 August 2018; Springer: Cham, Switzerland, 2018; pp. 464–472. [Google Scholar]
- Yang, B.; Li, S. Multifocus Image Fusion and Restoration with Sparse Representation. Inf. Fusion 2010, 59, 884–892. [Google Scholar]
- Yin, H.; Li, Y.; Chai, Y.; Liu, Z.; Zhu, Z. A novel sparse-representation-based multi-focus image fusion approach. Neurocomputing 2016, 216, 216–229. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal Satellite Image Fusion Using Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.; Kittler, J. Infrared and Visible Image Fusion using a Deep Learning Framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 2705–2710. [Google Scholar]
- Prabhakar, K.R.; Srikar, V.S.; Babu, R.V. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 4724–4732. [Google Scholar]
- Li, H.; Wu, X. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-II. Inform. Sci. 1975, 8, 301–357. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inform. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-III. Inform. Sci. 1975, 9, 43–80. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy set. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K.T.; Stoeva, S. Intuitionistic fuzzy set. In Proceedings of the Polish Symposium on Interval & Fuzzy Mathematics, Poznań, Poland, 26–29 August 1983; pp. 23–26. [Google Scholar]
- Szmidt, E.; Kacpryzyk, J. Distances between intuitionistic fuzzy sets. Fuzzy Sets Syst. 2000, 114, 505–518. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In European conference on computer vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham. Switzerland, 2016; pp. 630–645. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 14th International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Du, J.; Li, W.; Lu, K.; Xiao, B. An overview of multi-modal medical image fusion. J. Mach. Learn. Res. 2016, 215, 3–20. [Google Scholar] [CrossRef]
- Chao, Z.; Kim, D.; Kim, H.J. Multi-modality image fusion based on enhanced fuzzy radial basis function neural networks. Physica Med. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- El-Gamal, E.Z.A.; Elmogy, M.; Atwan, A. Current trends in medical image registration and fusion. Egypt. Inf. J. 2016, 17, 99–124. [Google Scholar] [CrossRef]
- Jin, X.; Chen, G.; Hou, J.; Jiang, Q.; Zhou, D.; Yao, S. Multimodal sensor medical image fusion based on nonsubsampled shearlet transform and s-pcnns in hsv space. Signal Process. 2018, 153, 379–395. [Google Scholar] [CrossRef]
- Ouerghi, H.; Mourali, O.; Zagrouba, E.; Jiang, Q.; Zhou, D.; Yao, S. Non-subsampled shearlet transform based MRI and PET brain image fusion using simplified pulse coupled neural network and weight local features in YIQ colour space. IET Image Process. 2018, 12, 1873–1880. [Google Scholar] [CrossRef]
- Ullah, H.; Ullah, B.; Wu, L.; Abdalla, F.Y.O.; Ren, G.; Zhao, Y. Multi-modality medical images fusion based on local-features fuzzy sets and novel sum-modified-Laplacian in non-subsampled shearlet transform domain. Biomed Signal Process. 2020, 57, 101724. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. A definition of non probabilistic entropy in the setting of fuzzy set theory. Inform. Control 1972, 20, 301–312. [Google Scholar] [CrossRef]
- Vlachos, I.K.; Sergiadis, G.D. The Role of entropy in intuitionistic fuzzy contrast enhancement. Lect. Notes Artif. Intell. 2007, 4529, 104–113. [Google Scholar]
- Chaira, T. A novel intuitionistic fuzzy C means clustering algorithm and its application to medical images. Appl. Soft Comput. 2011, 11, 1711–1717. [Google Scholar] [CrossRef]
- Burillo, P.; Bustince, H. Entropy on intuitionistic fuzzy sets and on inter-valued fuzzy sets. Fuzzy Sets Syst. 1996, 78, 305–316. [Google Scholar] [CrossRef]
- Zhang, Q.; Guo, B. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Ye, F.; Li, X.; Zhang, X. FusionCNN: A remote sensing image fusion algorithm based on deep convolutional neural networks. Multimed Tools Appl. 2019, 78, 14683–14703. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans Image Process. 2015, 29, 4980–4995. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Zhang, X.; Li, X.; Feng, Y.; Zhao, H.; Liu, Z. Image fusion with internal generative mechanism. Expert Syst. Appl. 2015, 42, 2382–2391. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Lawrence Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision, Zürich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies, Astana, Kazakhstan, 15–17 October 2014; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2014; pp. 1–3. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error measurement to structural similarity. IEEE Trans Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2003; pp. 173–176. [Google Scholar]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Tixier, F.; Le Rest, C.C.; Hatt, M.; Albarghach, N.; Pradier, O.; Metges, J.P.; Corcos, L.; Visvikis, D. Intratumor heterogeneity characterized by textural features on baseline 18F-FDG PET images predicts response to concomitant radiochemotherapy in esophageal cancer. J. Nucl. Med. 2011, 52, 369–378. [Google Scholar] [CrossRef] [PubMed]
- Naqa, I.E.; Grigsby, P.W.; Apte, A.; Kidd, E.; Donnelly, E.; Khullar, D.; Chaudhari, S.; Yang, D.; Schmitt, M.; Laforest, R.; et al. Exploring feature-based approaches in PET images for predicting cancer treatment outcomes. Pattern Recog. 2009, 42, 1162–1171. [Google Scholar] [CrossRef] [PubMed]



























































Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, K.; Li, X.; Zang, H.; Fan, T. Multi-Modal Medical Image Fusion Based on FusionNet in YIQ Color Space. Entropy 2020, 22, 1423. https://doi.org/10.3390/e22121423
Guo K, Li X, Zang H, Fan T. Multi-Modal Medical Image Fusion Based on FusionNet in YIQ Color Space. Entropy. 2020; 22(12):1423. https://doi.org/10.3390/e22121423
Chicago/Turabian StyleGuo, Kai, Xiongfei Li, Hongrui Zang, and Tiehu Fan. 2020. "Multi-Modal Medical Image Fusion Based on FusionNet in YIQ Color Space" Entropy 22, no. 12: 1423. https://doi.org/10.3390/e22121423
APA StyleGuo, K., Li, X., Zang, H., & Fan, T. (2020). Multi-Modal Medical Image Fusion Based on FusionNet in YIQ Color Space. Entropy, 22(12), 1423. https://doi.org/10.3390/e22121423