Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding

Abstract
1. Introduction
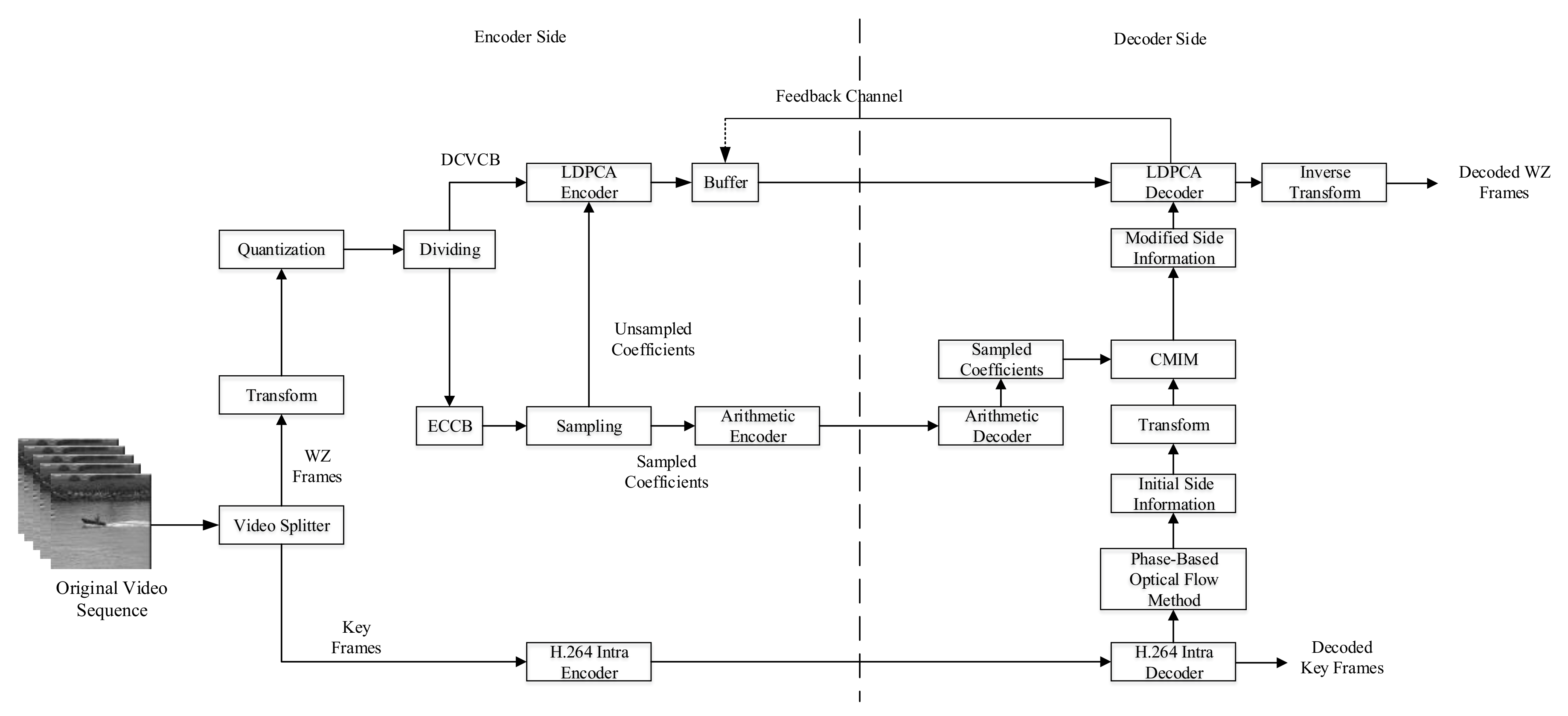
2. Distributed Video Coding System
3. DVC System Based on the Proposed Side Information Generation Scheme
3.1. Video Splitter, Transform, and Quantization
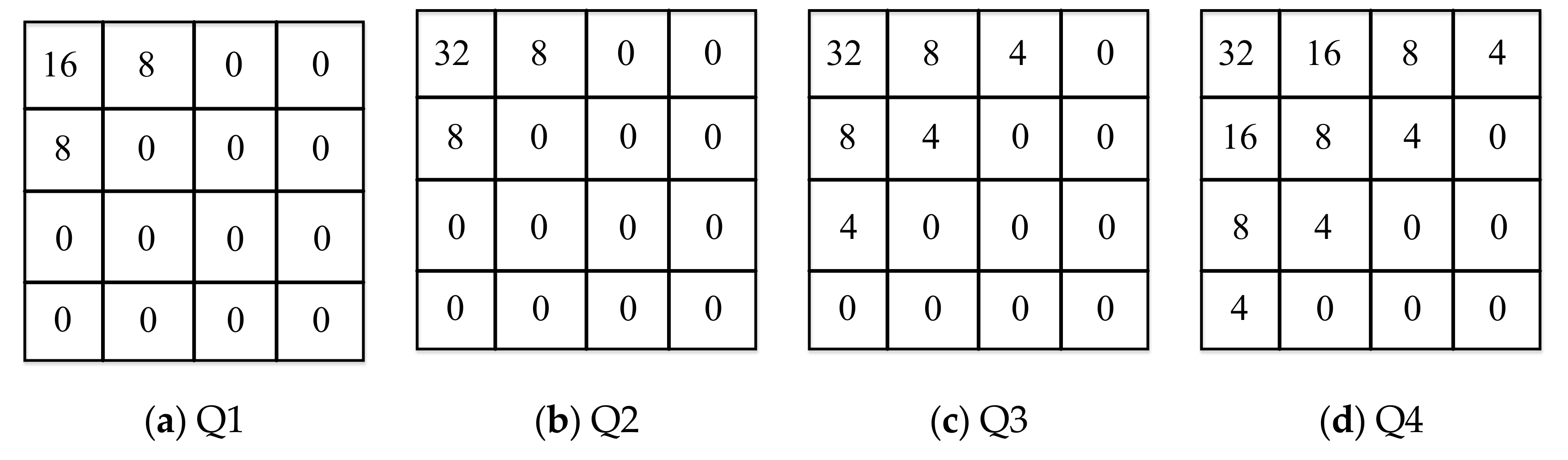
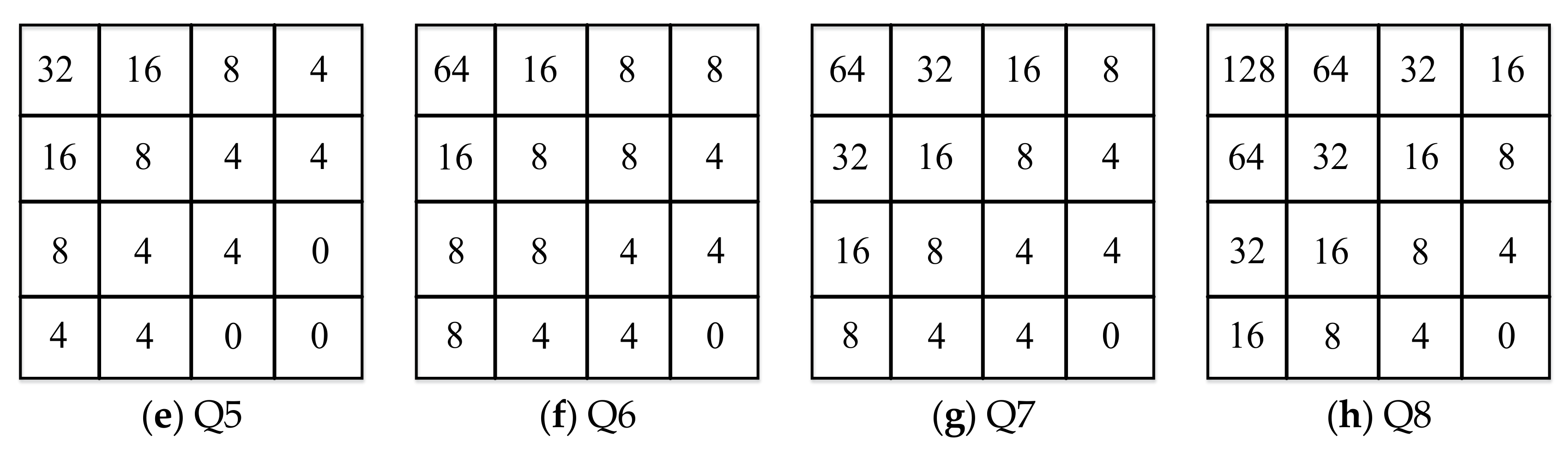
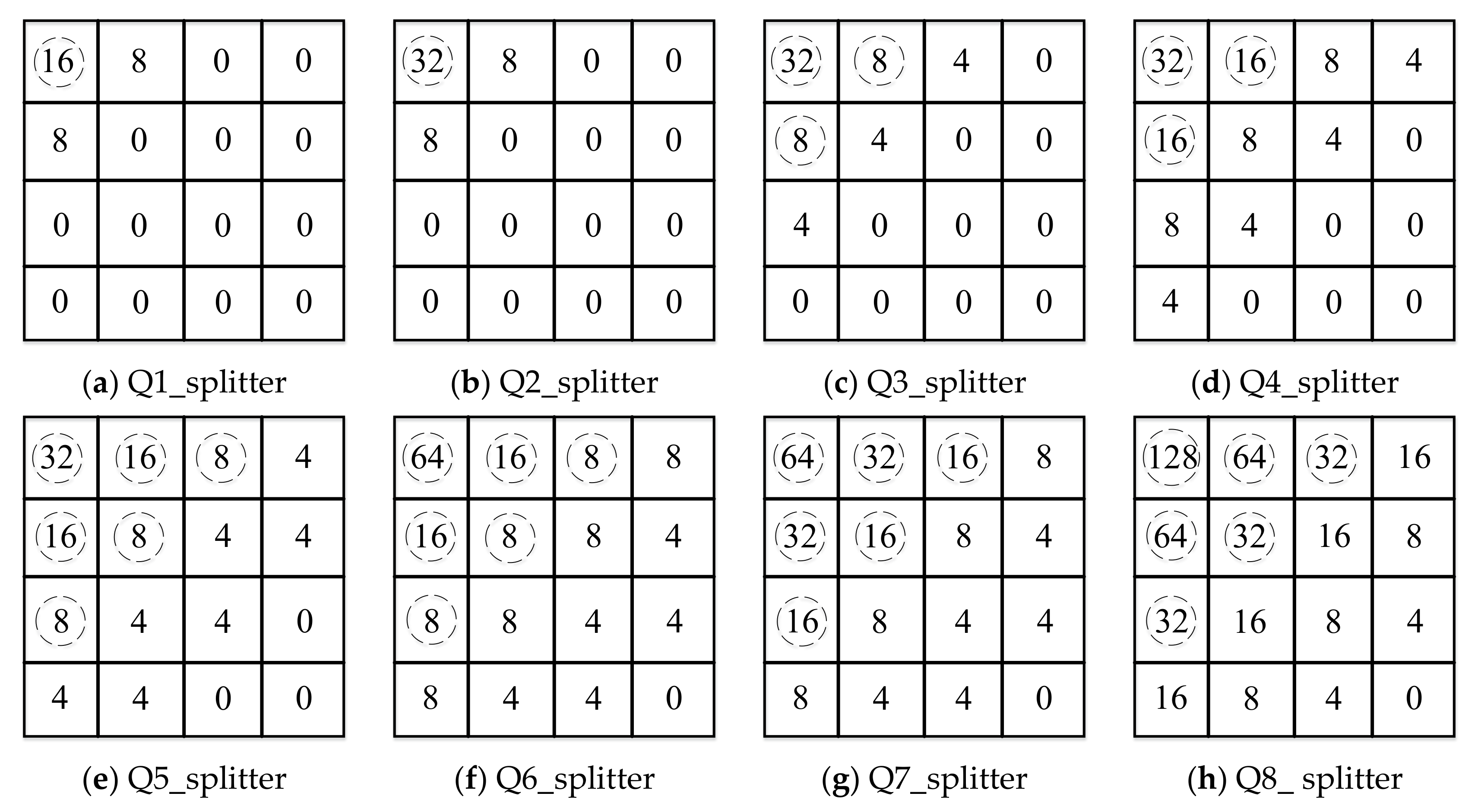
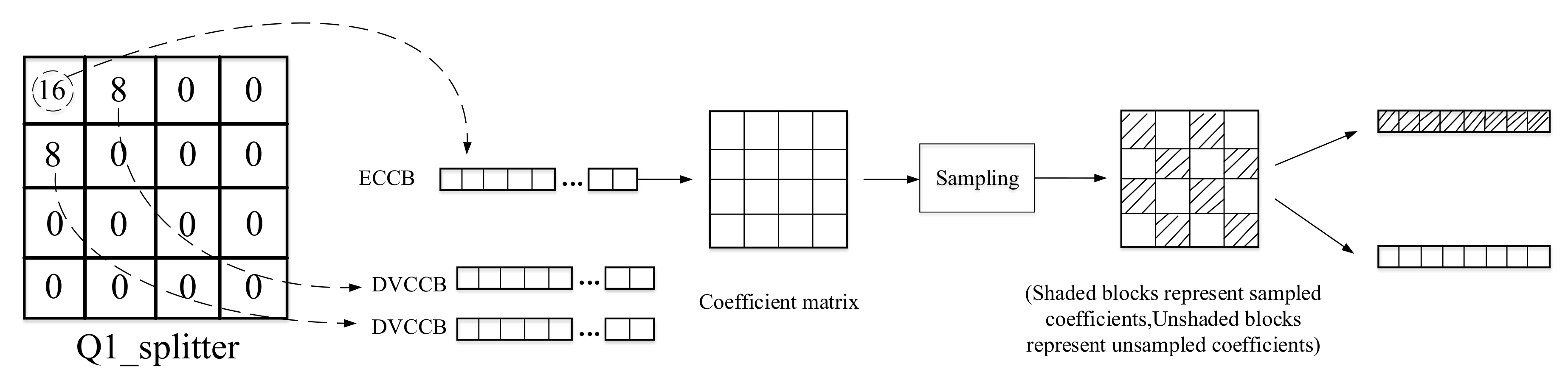
3.2. DCT Coefficient Bands Dividing and Sampling Process
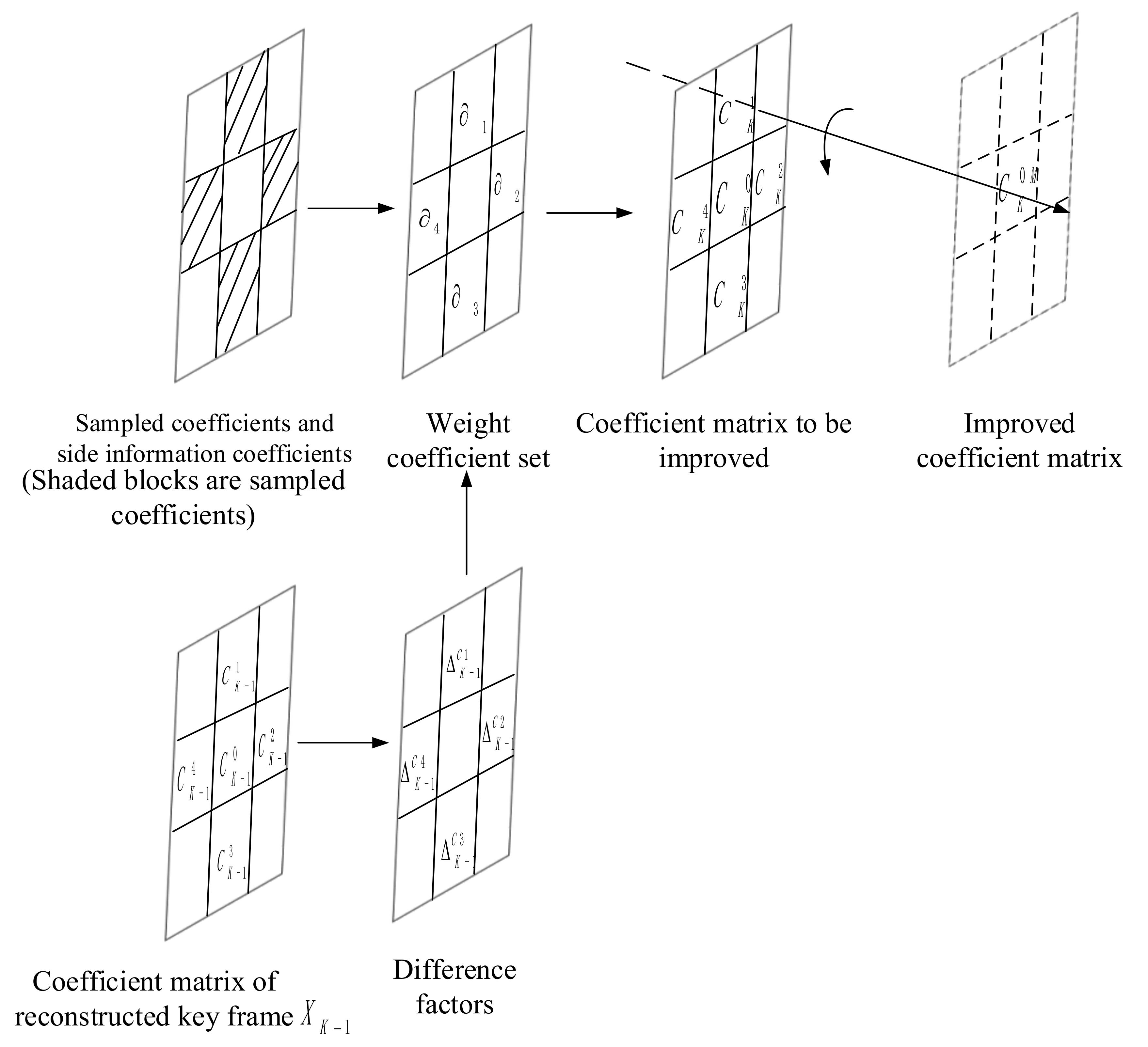
3.3. Coefficient Matrix Improvement Model (CMIM)
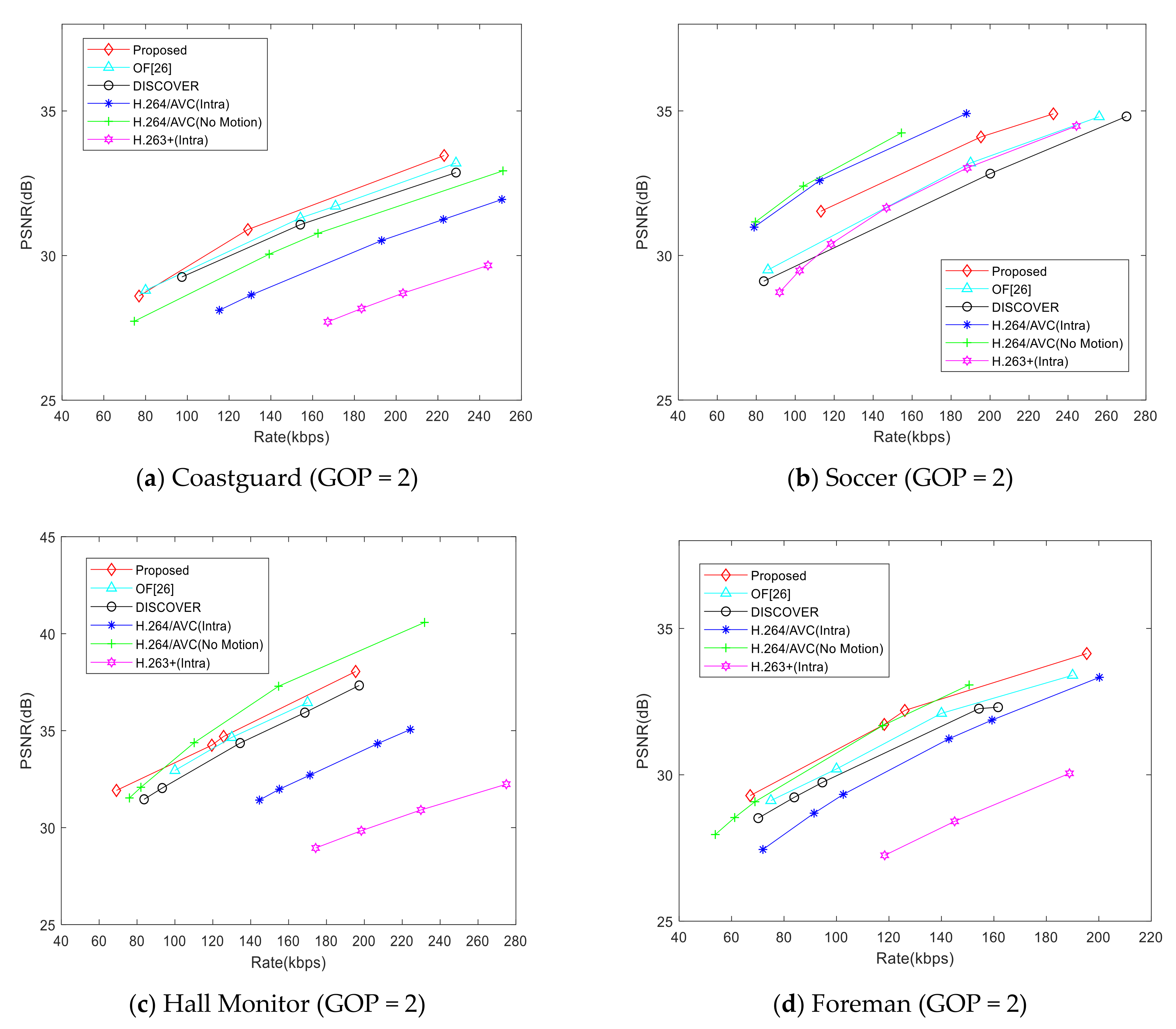
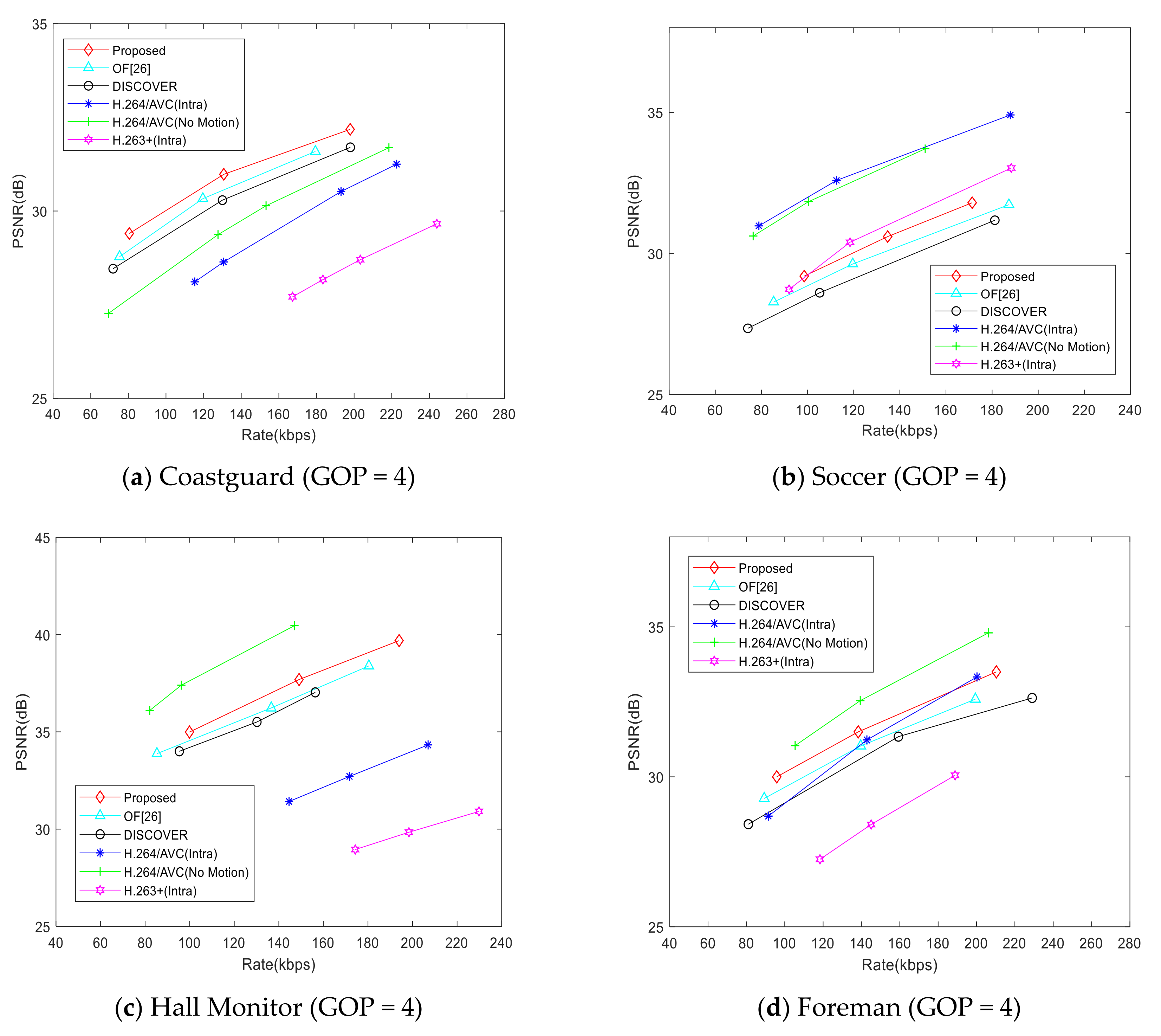
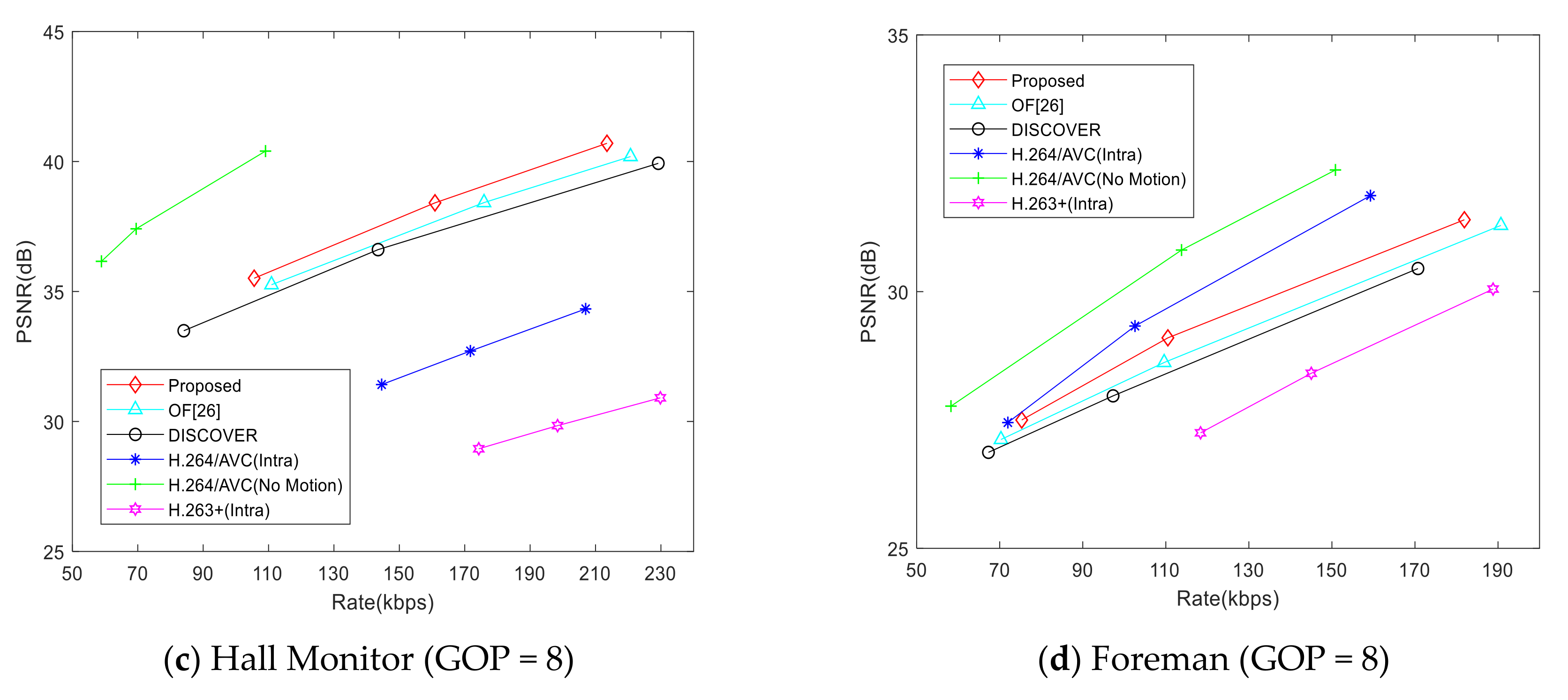
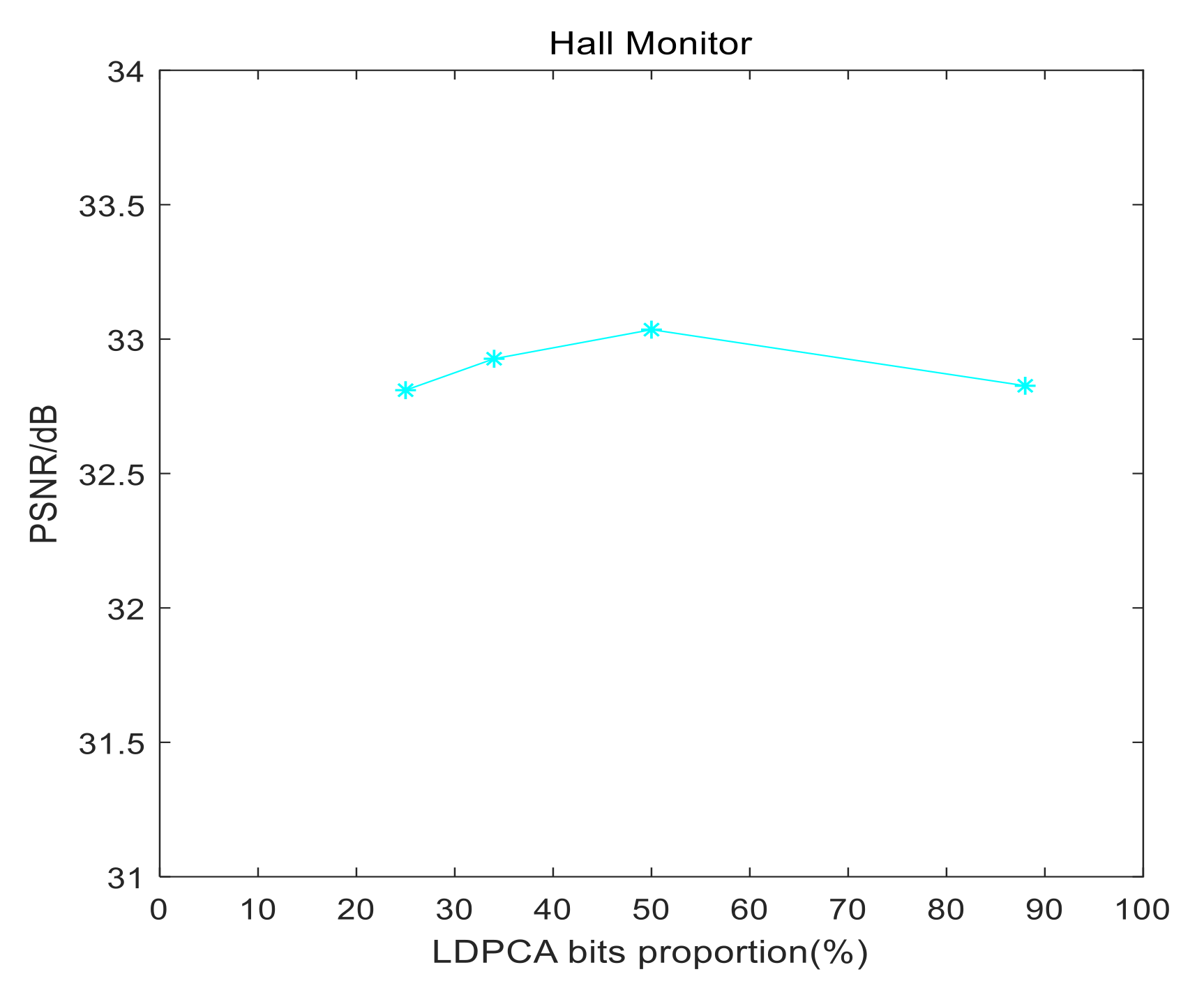
4. Experiment Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Battista, S.; Conti, M.; Orcioni, S. Methodology for modeling and comparing video codecs: HEVC, EVC, and VVC. Electronics 2020, 9, 1579. [Google Scholar] [CrossRef]
- Pan, T.-M.; Fan, K.-C.; Wang, Y.-K. Object-based approach for adaptive source coding of surveillance video. Appl. Sci. 2019, 9, 2003. [Google Scholar] [CrossRef]
- Marpe, D.; Schwarz, H.; Wiegand, T. Context-based adaptive binary arithmetic coding in the H.264/AVC video compression standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 620–636. [Google Scholar] [CrossRef]
- Imran, N.; Seet, B.-C.; Fong, A.C.M. Distributed video coding for wireless video sensor networks: A review of the state-of-the-art architectures. SpringerPlus 2015, 4, 513. [Google Scholar] [CrossRef]
- Puri, R.; Majumdar, A.; Ishwar, P.; Ramchandran, K. Distributed video coding in wireless sensor networks. IEEE Signal Process. Mag. 2006, 23, 94–106. [Google Scholar] [CrossRef]
- Slepian, D.; Wolf, J. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Wyner, A.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Benierbah, S.; Khamadja, M. Symbol positions-based Slepian–Wolf coding with application to distributed video coding. IET Image Process. 2020, 14, 2301–2309. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, S.; Hu, Q.; Kuo, Y. A frame-level encoder rate control scheme for transform domain Wyner-Ziv video coding. Multimed. Tools Appl. 2016, 76, 20567–20585. [Google Scholar] [CrossRef]
- Taheri, Y.M.; Ahmad, O.; Swamy, M.N.S. Successive refinement of side information frames in distributed video coding. Multimed. Tools Appl. 2019, 78, 20697–20722. [Google Scholar] [CrossRef]
- Cao, Y.; Sun, L.; Han, C.; Guo, J. Improved side information generation algorithm based on naive Bayesian theory for distributed video coding. IET Image Process. 2018, 12, 354–360. [Google Scholar] [CrossRef]
- Dash, B.; Rup, S.; Mohapatra, A.; Majhi, B.; Swamy, M.N.S. Decoder driven side information generation using ensemble of MLP networks for distributed video coding. Multimed. Tools Appl. 2017, 77, 15221–15250. [Google Scholar] [CrossRef]
- Jun, D. Distributed video coding with adaptive two-step side information generation for smart and interactive media. Displays 2019, 59, 21–27. [Google Scholar] [CrossRef]
- Yang, H.; Qing, L.; He, X.; Xiong, S. Scalable Distributed Video Coding for Wireless Video Sensor Networks. IEICE Trans. Inf. Syst. 2018, 2, 20–27. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, D.; Liu, H.; Li, Y.; Ma, S.; Gao, W. Side information generation with auto regressive model for low-delay distributed video coding. J. Vis. Commun. Image Represent. 2012, 23, 229–236. [Google Scholar] [CrossRef]
- Zhou, J.; Fu, Y.; Yang, Y.; Ho, A.T. Distributed video coding using interval overlapped arithmetic coding. Signal Process. Image Commun. 2019, 76, 118–124. [Google Scholar] [CrossRef]
- Belyaev, E. Compressive sensed video coding having Jpeg compatibility. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, UAE, 25–28 October 2020; pp. 1128–1132. [Google Scholar]
- Xiaoli, G.; Liu, H.; Xue, R.; Li, Y. Compressive-sensing-based video codec by autoregressive prediction and adaptive residual recovery. Int. J. Distrib. Sens. Netw. 2015, 11, 562840–19. [Google Scholar] [CrossRef]
- Gautama, T.; Van Hulle, M. A phase-based approach to the estimation of the optical flow field using spatial filtering. IEEE Trans. Neural Netw. 2002, 13, 1127–1136. [Google Scholar] [CrossRef]
- Zeng, Y.; Cheng, L.; Bi, G.; Kot, A. Integer DCTs and fast algorithms. IEEE Trans. Signal Process. 2001, 49, 2774–2782. [Google Scholar] [CrossRef]
- Reza, A.M. System level design of adaptive arithmetic encoder/decoder for JPEG 2000 standard. Int. J. Signal Imaging Syst. Eng. 2016, 9, 105. [Google Scholar] [CrossRef]
- Artigas, X.; Ascenso, J.; Dalai, M.; Klomp, S.; Kubasov, D.; Ouaret, M. The DISCOVER codec: Architecture, techniques and evaluation. In Picture Coding Symposium; EPFL: Lisbon, Portugal, November 2007. [Google Scholar]
- Liveris, A.; Xiong, Z.; Georghiades, C. Compression of binary sources with side information at the decoder using LDPC codes. IEEE Commun. Lett. 2002, 6, 440–442. [Google Scholar] [CrossRef]
- Li, X. Video processing via implicit and mixture motion models. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 953–963. [Google Scholar] [CrossRef]
- Huang, X.; Raket, L.L.; Van Luong, H.; Nielsen, M.; Lauze, F.; Forchhammer, S. Multi-hypothesis transform domain Wyner-Ziv video coding including optical flow. In Proceedings of the 2011 IEEE 13th International Workshop on Multimedia Signal Processing, Hangzhou, China, 17–19 October 2011; pp. 1–6. [Google Scholar]
- Taheri, Y.M.; Ahmad, O.; Swamy, M.N.S. Side information generation using optical flow and block matching in Wyner-Ziv video coding. In Proceedings of the 2014 21st IEEE International Conference on Electronics, Circuits and Systems (ICECS), Marseille, France, 7–10 October 2014; pp. 722–725. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Extra [25] | OF [26] | Optical Flow [19] | Hybrid | CMIM |
|---|---|---|---|---|---|
| Coastguard | 28.55 dB | 31.77dB | 30.02 dB | 33.08 dB | 33.51 dB |
| Soccer | 19.26 dB | 23.51 dB | 22.11 dB | 23.91 dB | 24.29 dB |
| Hall Monitor | 33.24 dB | 35.90 dB | 33.89dB | 36.65 dB | 36.86 dB |
| Foreman | 25.20 dB | 31.41 dB | 29.43 dB | 32.02 dB | 32.46 dB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Chen, J. Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding. Entropy 2020, 22, 1427. https://doi.org/10.3390/e22121427
Wang W, Chen J. Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding. Entropy. 2020; 22(12):1427. https://doi.org/10.3390/e22121427
Chicago/Turabian StyleWang, Wei, and Jianhua Chen. 2020. "Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding" Entropy 22, no. 12: 1427. https://doi.org/10.3390/e22121427
APA StyleWang, W., & Chen, J. (2020). Side Information Generation Scheme Based on Coefficient Matrix Improvement Model in Transform Domain Distributed Video Coding. Entropy, 22(12), 1427. https://doi.org/10.3390/e22121427