1. Introduction
Deep learning has substantially impacted technology over the last years, becoming an important center of attention for researchers all over the world. Such a great impact stems from the versatility it offers as well as the excellent results that DNNs achieve on multiple tasks, like image classification or speech recognition, which often reach and even surpass human-level performance [
1,
2].
However, far from being a simple task, the design of new DNNs is generally expensive not only in terms of human effort and time needed to build effective model architectures but mostly because of the large volume of suitable data that must be gathered and the vast amount of computational resources and power used for training. Consequently, businesses owning costly models are interested in protecting them from any illicit use, and this growing need has recently led researchers to a common concern on how to embed watermarks on DNNs. As a result, several frameworks for protecting the intellectual property of neural networks were proposed in the literature, and can be classified as black-box or white-box approaches. The first kind of methods (i.e., black-box) do not need to access model parameters for detecting the presence of watermarks. Instead, key inputs are introduced as special triggers to identify the original network, either by the use of the so-called adversarial examples [
3] or backdoor poisoning [
4].
White-box approaches, in contrast, directly affect the model parameters in order to embed watermarks. One of the most significant white-box contributions was proposed by Uchida et al. in [
5,
6], the algorithm under study in this paper. This watermarking framework employs a regularization term that defines a cost function for embedding the secret message. This regularizer, which transforms weights into bits by means of a projection matrix in a similar way to spread–spectrum techniques used in watermarking [
7], is added to the main loss function and can be applied either at the beginning of the training phase (i.e., from scratch) or during fine-tuning steps.
On the other hand, when training a DNN, there are several optimization algorithms to choose from. With their pros and cons, some of the most popular are the classic Stochastic Gradient Descent (SGD) [
8] and Adaptive Moment Estimation (Adam) [
9]. We found that, in order to perform watermarking following the approach in [
5,
6], it is necessary to pay close attention to the optimization algorithm being used. In this paper, we prove that Adam, although being an appealing algorithm for lots of applications—especially because of its efficiency and training speed—poses a big problem when implementing this watermarking method.
As any other watermarking algorithm, it is important to meet some minimal requirements regarding fidelity, robustness, payload, efficiency, and undetectability [
5,
6,
10]. This latter property involves the need for concealing any clue that would let unauthorized parties know if a watermark was embedded, along with its further consequences. In other words, from a steganographic point of view, watermarks should be embedded into the DNN without leaving any detectable footprint.
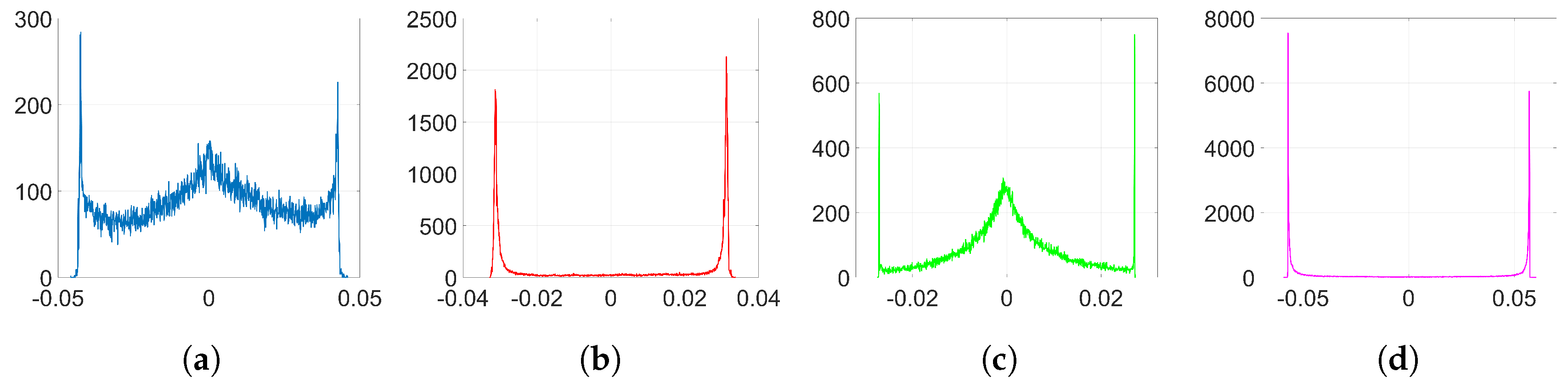
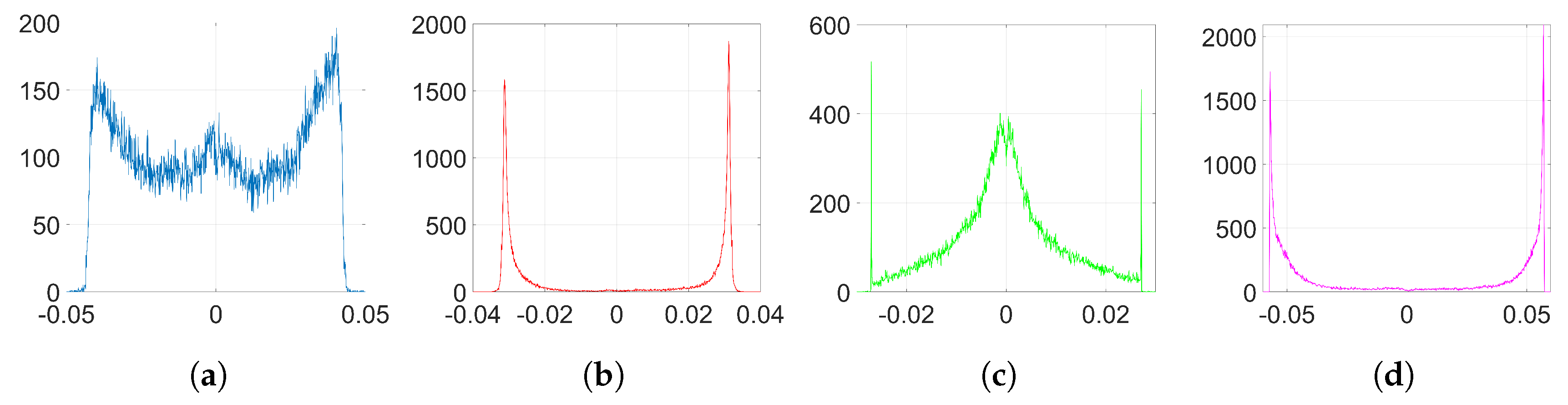
We show that, unlike SGD, Adam significantly alters the distribution of the coefficients at the embedding layer in a very specific way and, thus, it compromises the undetectability of the watermark. In particular, when using Adam, the histogram of the weights at the embedding layer shows that these coefficients tend to group together at both sides of zero, originating two visible spikes that grow in magnitude with the number of iterations, so that the initial distribution ends up changing completely. As we will see later, the update direction given by Adam depends on the projection matrix used for watermarking; specifically, it is based on the sign function, responsible for the symmetric two-spiked shape that emerges. This behavior is somewhat surprising, as with a pseudorandom projection matrix, one might expect that the weights evolve with random speeds; in contrast, the weights tend to move in unison in a way that is reminiscent of ants after they have established a solid path from the nest to a food source. Then, the statistical dependence of the weights with the projection matrix is weak, and this is mainly due to the information collapse induced by the sign function; this loss is invested in making the weights more conspicuous and, therefore, the watermark more easily detectable. As we will confirm, the sign phenomenon does not occur in other algorithms like SGD. The appearance of the sign was already pointed out and studied—without considering watermarking applications—by the authors in [
11], who explained the adverse effects of Adam on generalization [
12] as a consequence of this aspect. However, instead of delving into the general performance of the optimization algorithm itself, we show that the sign function which is involved in Adam’s update direction is detrimental for watermarking purposes, so we highlight the need for being careful with the selection of the optimization algorithm in these cases.
In this paper, we carry out a theoretical and experimental analysis and compare the results using Adam and SGD optimization. The analysis can be extended to other optimization algorithms. As a way to measure the similarity between the original weight distribution and the resulting one after the watermark embedding, we will use the Kullback–Leibler divergence (KLD) [
13]. We will show that, as expected, when we use Adam, the KLD between both distributions is considerably larger than when we use SGD, thus confirming that, as opposed to SGD, Adam modifies the original distribution to a great extent. Furthermore, in order to perform this kind of watermarking and, at the same time, enjoy the advantages that Adam optimization provides, we propose a new method called Block-Orthonormal Projections (BOP), which uses a secret transformation matrix in order to reduce the detectability of the watermark generated by Adam. As we will see, BOP allows us to considerably reduce the KLD to small values which are comparable to those obtained with SGD. Therefore, we show that BOP allows us to preserve the original shape of the weight distribution.
In summary, this work makes the following two-fold contribution:
The remainder of this paper is organized as follows:
Section 1.1 introduces the notation and
Section 2 explains the frameworks and algorithms used in this study—host network, optimization algorithms, and watermarking method—in more detail.
Section 3 presents the mathematical core that allows us to model the observed effects on the histograms of weights once the embedding process has finished. Then, in
Section 4, we introduce BOP as a solution for using Adam and watermarking simultaneously,
Section 5 presents the information-theoretic measures that we will implement, and
Section 6 shows the experimental results. Finally, we point out some concluding remarks in
Section 7. Two appendices give additional details on mathematical derivations (
Appendix A) and the validity of certain assumptions (
Appendix B).
Notation
In this paper, we use the following notation. Matrices and vectors are denoted by upper-case and lower-case boldface characters, respectively, while random variables and their realizations are respectively represented by upper-case and lower-case characters.
For matrix and vector operations, we proceed as follows. As an example, let
be a matrix. Then, its transpose is denoted by
. Moreover, we use
to represent the trace of
and
to denote the
th element of
.
refers to the
identity matrix. We use column vectors unless otherwise stated. In addition, we use
to denote a column vector of zeros and
for a column vector of ones. Let
be a column vector of length
N; then,
is the gradient operator with respect to
that is:
We use the operator ∘ to denote the Hadamard (i.e., sample-wise) product and ⊗ for the Kronecker product. Finally, and denote the mathematical expectation and the variance, respectively.
3. Theoretical Analysis
From now on, we will omit the sub-index
l for the sake of clarity although we are always addressing the coefficients of the embedding layer. The experiments clearly illustrate that the use of Adam optimization together with the watermarking algorithm proposed in [
5,
6] originates noticeable changes in the distribution of weights, as we see in
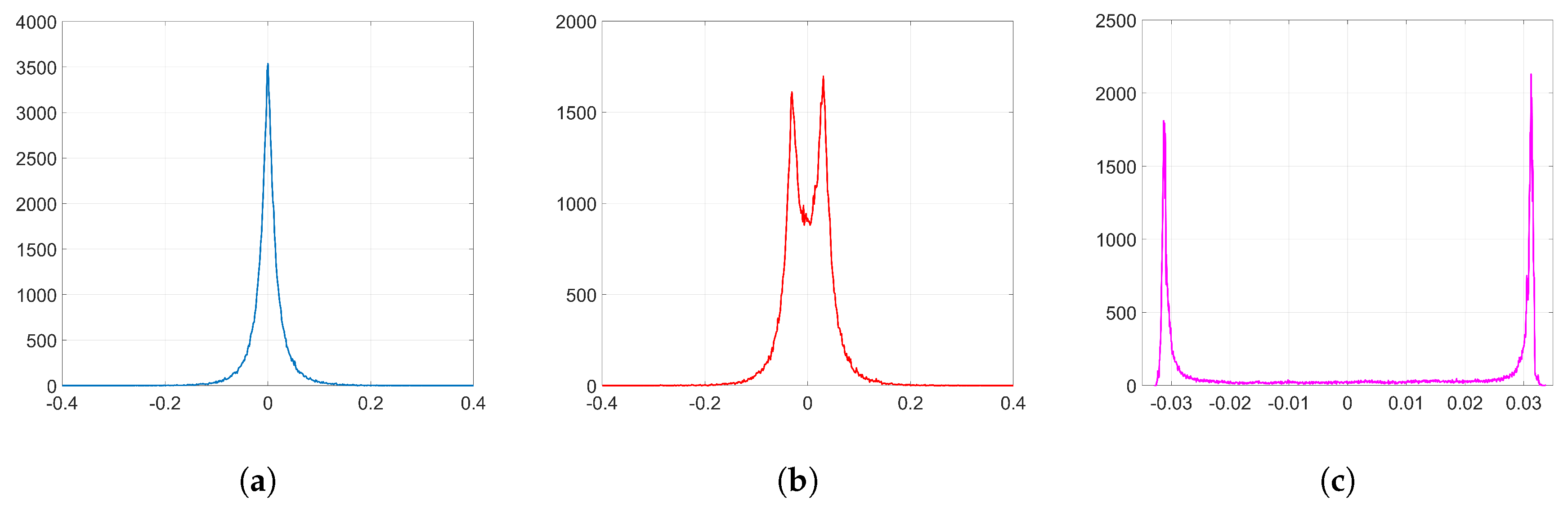
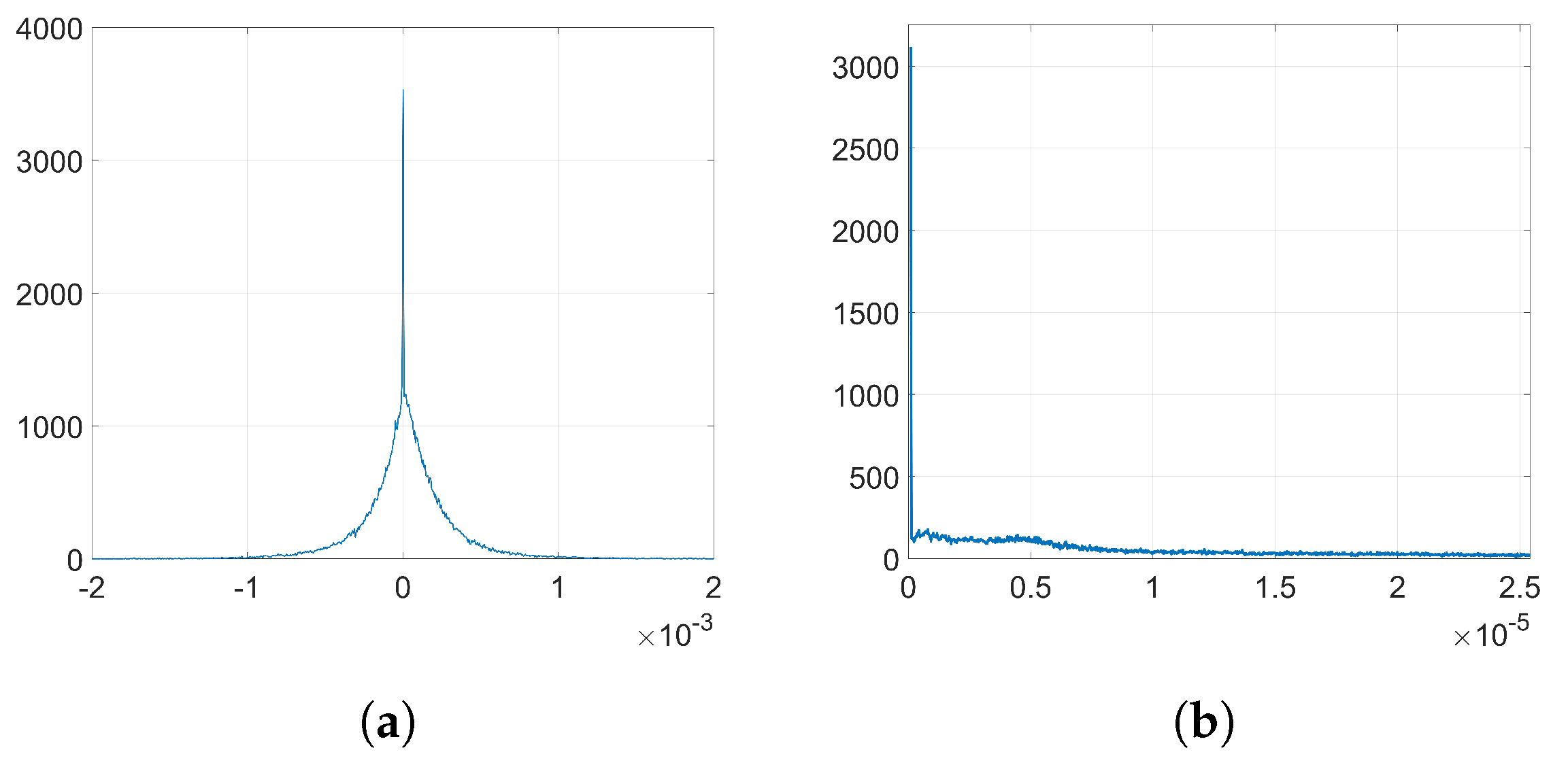
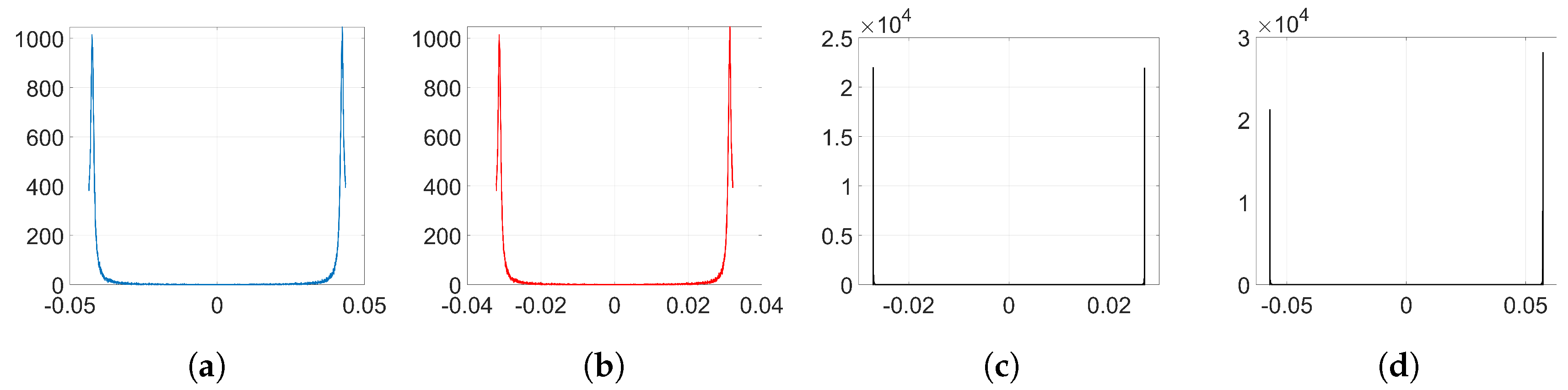
Figure 2. In the following analysis, we delve into the reasons why this happens. To that end, we aim to get a theoretical expression of
. This will allow us to prove and understand the nature of the observed behavior of the weights when watermark embedding is carried out. We start off by defining vector
and matrix
:
Notice that
. In addition, for the case of orthogonal projectors, the following properties can be straightforwardly proven:
These properties will come in handy later on in several theoretical derivations.
Firstly, in order to simplify the analysis and understand more clearly how the watermarking cost function impacts on the movement of the weights when using both SGD and Adam optimization, we will just consider the presence of the regularization term, that is, we will not include the denoising cost function for now. The influence of the denoising part will be studied in
Section 3.3. Therefore, given our embedding cost function in (
10) and assuming for simplicity (and without loss of generality) that all embedded symbols are
, we have:
If we compute the gradient of this function, we obtain:
In order to simplify the subsequent analysis, we introduce a series of assumptions which are based on empirical observations or hypotheses that will be duly verified.
By construction, it is possible to show that the mean of
is zero and its variance is
for Gaussian projectors and
for orthogonal projectors (see
Appendix A.1). Since the variance of the weights at the initial iteration is generally very small—in our experiments, it is
—it can be considered that the variance of
will also be small enough so that we can assume
for all
. Although this assumption might not be strictly true for all
k—especially once we have crossed the linear region of the sigmoid function—it is reasonably good and it allows us to use a first-order Taylor expansion for
around
:
Plugging (
16) into (
15) and using the definitions given above, we can write:
We introduce now one important hypothesis in this theoretical analysis to handle the previous equation: we assume that
grows approximately affinely with
k:
where
is a vector that contains the slopes for each weight, and it is to be determined in the following sections. We hypothesize this affine-like growth for the weights and, later, we will verify that this is consistent with the rest of the theory and the experiments (see
Appendix B.1 for more details). Therefore, we can write the weight variations as:
3.1. Analysis for SGD
We first analyze the behavior of SGD optimization when we implement digital watermarking as proposed in [
5,
6]. Recall the SGD update rule in (
2). If we use the approximation for the gradient in (
17) and the affine growth hypothesis for the weights introduced in (
18), we have:
To simplify the analysis, we consider from now on that
. We confirm the validity of this assumption in
Appendix B.2. Then, we can write:
If we consider orthogonal projectors, we can arrive at a more explicit expression for
. In particular, if we multiply (
21) by
and use the properties (
13) and (14), we obtain:
Then, substituting (
22) into (
21), we can get a more concise expression for
:
Thus, if
F is large compared to
—this certainly holds for our experimental set-up, cf.
Section 6.1—
will be approximately proportional to
. Then, the coefficients will follow an affine-like growth as we hypothesized in (
18) (see
Appendix B.1 for the empirical confirmation of this hypothesis). Now, the weight variations can be expressed as:
As we can see, when we use SGD,
will approximately follow a zero-mean Gaussian distribution, as induced by [
9]. Because of this, and unlike Adam (as we will see later), the weights will evolve with random speeds when we embed watermarks using SGD optimization. Therefore, the impact on the original shape of the weight distribution will be small. However, the variance of the weight distribution may change considerably as stated in [
20]. Since we have
for orthogonal projectors, the variance of
can be computed as:
Thus, considering that
and
are uncorrelated—we check this statement in
Section 6.2.2—we arrive at the following expression for the variance of the weights at the
kth iteration:
As we can see from (
25), when implementing the digital watermarking algorithm in [
5,
6] with SGD optimization and orthogonal projectors, the variance of the resulting weight distribution might change considerably. In order to preserve the original weight distribution when using SGD, it is important to take care with the values of
T,
F and
N, especially. In addition, the standard deviation of the weights will (approximately) increase linearly with the number of iterations so it may be also important to limit the value of
k. This is in line with the expected behavior: the weights will move away from their original value and they will be further if we perform more iterations.
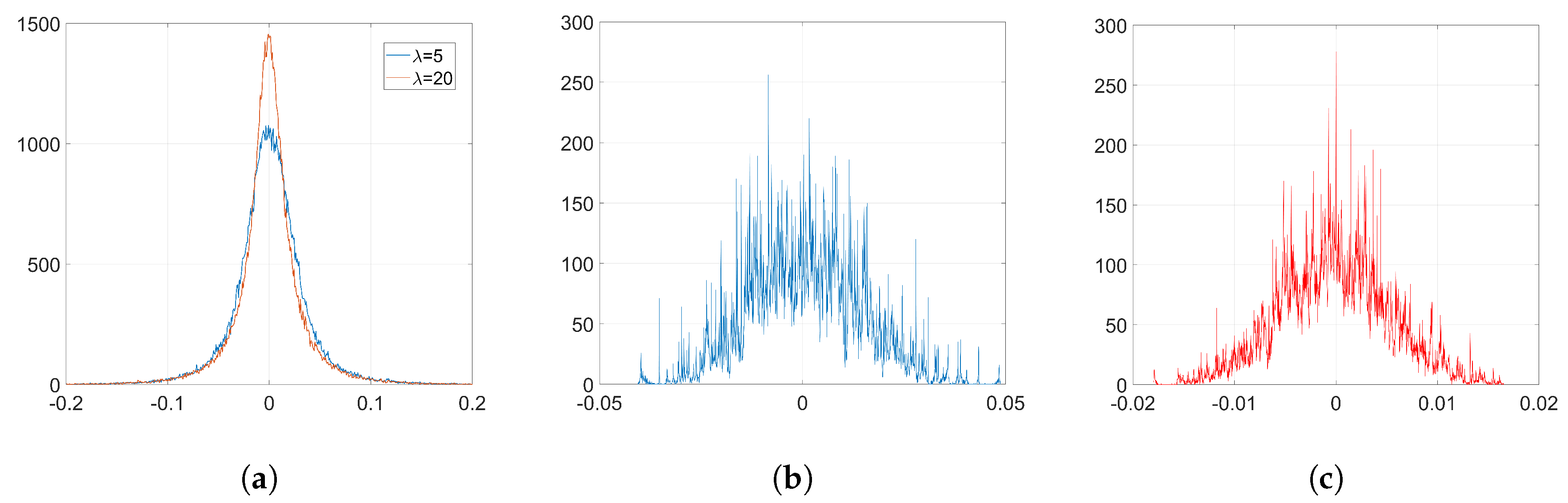
Because the analysis for Gaussian projectors becomes considerably difficult, in this paper, we just address the study of SGD with orthogonal projectors. A more comprehensive analysis for Gaussian projectors that can be linked to the results obtained in [
20] is left for future research. Regardless of this, the whole analysis for both kinds of projection vectors will be developed in the next section for Adam optimization.
3.2. Analysis for Adam
In the next sections, we will delve into the theory behind Adam optimization for DNN watermarking. In particular, we will obtain an expression for the mean and the variance of the gradient and then, as we did with SGD, we will analyze the update term to get an expression of the weight variations.
3.2.1. Mean of the Gradient
We are interested in computing the mean of the gradient that is used in Adam. Considering
as the global cost function, then, from (4), we can rewrite the mean at the
kth iteration as:
We use the gradient in (
17) and do some derivations to find an explicit expression for
under the hypothesis in (
18). Finally, we arrive at the following expression for the bias-corrected mean gradient when
k is sufficiently large (see
Appendix A.2 for all the mathematical details):
where
and
. As we see from (
27), the mean of the gradient also grows affinely with
k.
3.2.2. Variance of the Gradient
Let
. The approximation in (
17) for the
jth element of this vector
, denoted by
, is the following:
where:
Following the hypothesis in (
18), we can write:
In summary, for this affine-like growth, the square gradient vector can be written as:
for some vectors
whose
jth component can be defined as:
Now, from (5), we can rewrite the variance of the gradient that is used in Adam as:
The bias-corrected term
is obtained after dividing
by
. Applied to the special case of (
31), this yields (see
Appendix A.3):
3.2.3. Update Term
Because
is usually very small—we use
in our experiments—we can assume that
will be small enough to obtain an approximation of the update used in Adam. Recall that, for the
jth weight, this is
, implying that
. Let:
Then, assuming that
, we can make a zero-order approximation of the update term, i.e.,:
This approximation is accurate enough for the set of experiments we perform. In particular, for the orthogonal case, we could deal with
= 625,000 and still get a correlation coefficient of
between
and
. In our experiments, we actually reach a BER of zero for values of
k quite below
(cf.
Section 6.2).
From (
36), we observe that the updated
jth coefficient approximately follows the hypothesized growth, i.e.,
, where
. Notice that, as expected, the update does not depend on
, following Adam’s property that the update is invariant to rescaling the gradients [
9]. Finding a more explicit expression runs into the problem that
depends on
, which in turn is a function of
through (
32) and (33). The following subsections are devoted to solving this problem by conjecturing a form for
and refining it.
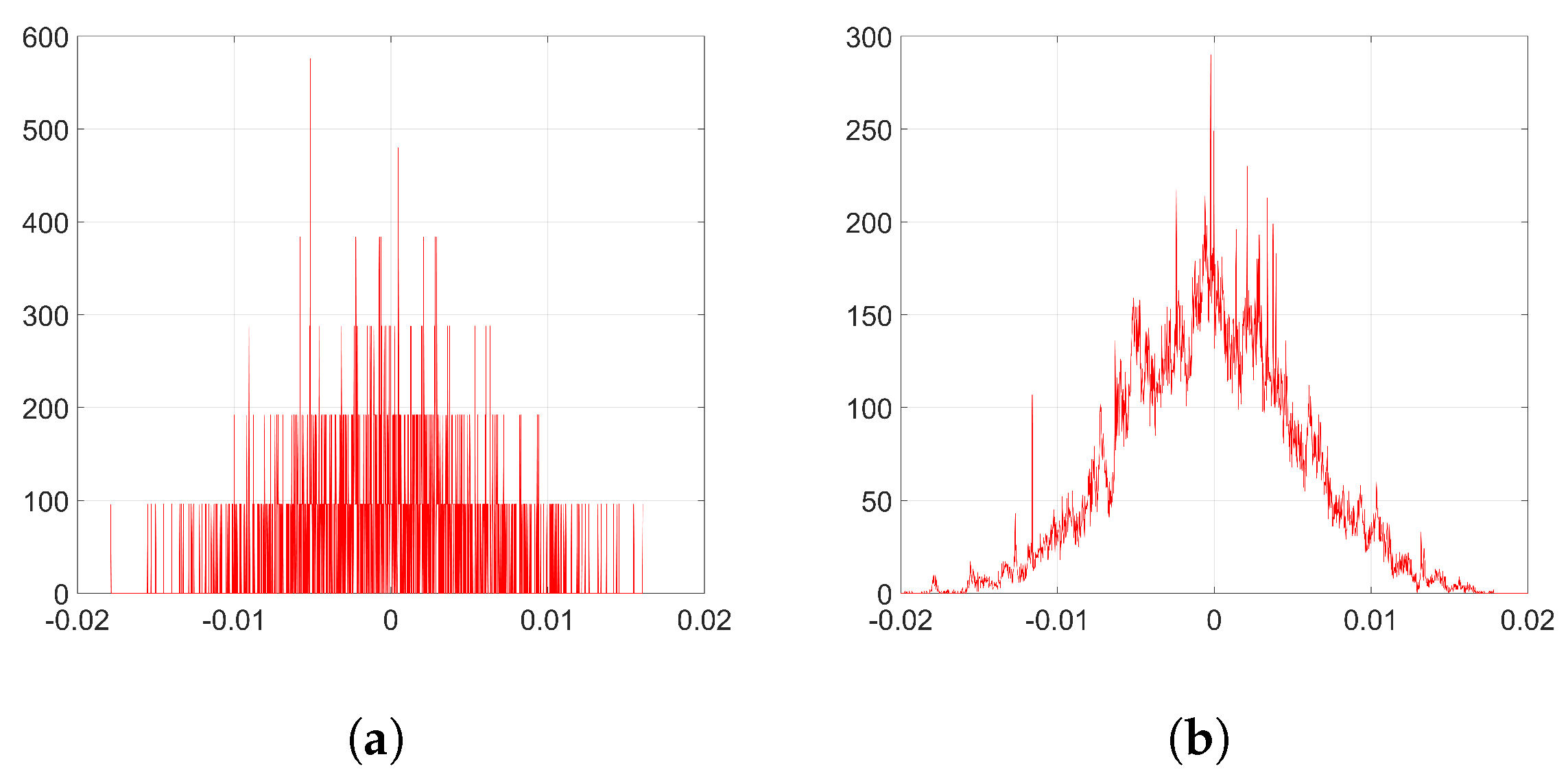
To simplify the analysis, we consider from now on that
since most of the values of the weights at the initial iteration are very small (see
Figure 2a). We will verify the accuracy of this approximation in
Appendix B.2.
3.2.4. Rationale for the Sign Function
Recall the expression (
23) that we obtained for
when analyzing SGD, where we found
to be approximately proportional to
. Now, for Adam, we take this as a starting point, so we conjecture first that
, for some real positive
. Here, we consider orthogonal projection vectors and use the property introduced in (
13) and the following:
In this particular case, we have the following identities:
Substituting these values into (
35), we find that
When we divide
by
, we obtain:
It is then clear that cannot be written in the form , as was conjectured at the beginning of this section.
3.2.5. A Theoretical Expression for
Although the conjectured form for
in
Section 3.2.4 does not hold, the appearance of the sign function in (
37) gives a key clue for an alternative approach, since the sign seems to reveal the reason behind the two-spiked histograms like the one shown in
Figure 2c.
Therefore, let us write
to explicitly contain the sign of
and allow
to take different (non-negative) values with
j to reflect the varying magnitude (recall that even in
Section 3.2.4 the conjectured value could be written as
). Let
be the column vector containing
,
, then
. Since
, we can write:
In addition, thus, in order to meet the condition
, the following nonlinear equation should be solved for all
,
:
This equation can be solved with a fixed-point iteration method [
21]. To that end, we should initialize
and then iterate the following: (1) compute the right-hand side of (
38), and (2) use it to update
on the left-hand side. This process will converge to the solution of (
38). Even though this method can be implemented to give the specific values for each
, we are more interested in obtaining a statistical characterization rather than a deterministic one. As we will see, the statistical approach offers a deeper explanation for the two-spiked distribution of
which we ultimately seek.
We thus aim at finding the pdf of
, now considered as a random variable for which
,
are nothing but realizations. Once again, Equation (
38) can be solved iteratively (e.g., with Markov-chain Monte Carlo methods [
22]) to yield the equilibrium distribution for
. Instead, we can resort to the results in
Section 6 where we conclude that the pdf of
is strongly concentrated around its mode. With this observation, it is possible to consider that
approximately corresponds to realizations of
.
In order to simplify the analysis even further, we are interested in decomposing
using its statistical projection onto
, i.e.,
. Here,
is a real multiplier and
is zero-mean noise uncorrelated with
. More generally, if we define matrix
, then we seek to write
. We do the analysis for the cases of Gaussian projectors and orthogonal projectors separately (refer to
Appendix A.4 for the derivations). For the Gaussian case, we get:
On the other hand, for the orthogonal projectors, we get instead:
Recall that, by construction,
can be seen as a random vector. In fact, we have
for Gaussian projection vectors, and
approximately follows
for orthogonal projectors. Let
,
Z be random variables with the distribution of a single element of
and
, respectively, then
and
can be seen as realizations of (approximately):
and
, so a stochastic version of (
38) is:
Squaring both sides, we find that, for a given realization (
,
z) of (
,
Z),
must take the positive value
that satisfies the following fourth degree equation:
From (
43), it is easy to generate samples
of
and, accordingly, samples of
, by recalling that:
We note that, for the particular case when
is very close to 1,
. This simplification allows us to approximate (
43) as
which leads to the following fixed-point equation:
When the noise term
z is very small compared to
(which occurs with a fairly large probability, especially for the case of orthogonal projectors), then the solution to (
46), denoted by
, will be independent of the value of
. This will cause the probability of
to be concentrated around
, and in turn this will make the pdf
have two spikes centered at
. We will see these spikes appearing time and again in the experiments carried out with Adam (
Section 6).
3.3. The Denoising Term
Thus far, we have considered only that our cost function is ; however, as we know, there is an additional term, the original denoising function, so our real cost function is: .
The gradients corresponding to this function,
, will try to pull the weight vector towards the original optimal
in a relatively hard to model way. In order to analyze this behavior, we can approximate the gradient of the denoising function at the
kth iteration with respect to the
jth coefficient as a sum of a constant term,
, and a noisy one,
, which follows a zero-mean Gaussian distribution and is associated with the use of different training batches on each step. We will refer to this noise as batching noise. Thus, for each coefficient
j, we can write:
Like we did in the previous section, we can formulate a stochastic version of (
47). To that end, we notice that the constant term of this gradient,
, can take different values with
j, as well as the variance of the batching noise,
that is,
is drawn from
. Therefore, in order to reflect the variability of these terms along the
j-elements, we introduce two random variables with the distribution of the mean gradient and the variance of the batching noise,
D and
H, respectively, for which
and
are realizations. The pdf of these distributions will be obtained empirically in
Section 6.2. Then, we can see
as a realization of
.
3.3.1. SGD
Similarly to
Section 3.2.5, let
be a random variable with the distribution of
. Let (
,
,
) be a realization of (
,
D,
), respectively, then for SGD using orthogonal projectors we can compute samples of
adding both functions, i.e., denoising and watermarking:
3.3.2. Adam
The variance of the batching noise computed by Adam will be approximately given by the random variable
V, whose realizations can be expressed as
. Notice that, for each realization of
V, as the sum takes places over
i, we must work with a fixed value
for the variance of the batching noise. Then, with this variance, we generate
k samples of
to be used in the sum that produces
. With this characterization, we can easily analyze how the denoising cost function shapes the distribution of the weight variations. Notice that this analysis could be adapted for any host network. Let
and
be realizations of
D and
V, respectively, then, we can generate samples of
without including the gradients from the watermarking function as:
Moreover, in order to get a more accurate description of the problem, we can combine both functions: denoising and watermarking. The analysis becomes somewhat complicated, but, as we will check in
Section 6, the distributions resulting from this analysis do capture better the shapes observed in the empirical ones. See
Appendix A.5 for the results of this analysis.
4. Block-Orthonormal Projections (BOP)
Here, we discuss BOP, the solution we propose to solve the detectability problem posed by Adam optimization when implementing the watermarking algorithm proposed in [
5,
6]. In order to hide the noticeable weight variations that appear when we use Adam—as seen in
Figure 2—we introduce a prior transformation using a secret
matrix
(the details for its construction are given below). The procedure we follow has three steps per each iteration of Adam.
Firstly, we project the weights and gradients from the embedding layer using
:
Then, we run Adam optimization on the projected weights,
, using the projected gradients,
, as well, i.e., steps (
3)–(8) are taken using
and
instead of
and
, respectively. The key of BOP relies on the following: if we execute Adam on
instead of
, we can break the natural bond created by Adam between
and
—as we saw in the previous sections—responsible for the ant-like behavior of the weights and, consequently, the appearance of side spikes in their histograms. These undesired effects disappear when we de-project
using
to get back to the weight vector
:
In order to reduce the computational complexity and the memory requirements of this method—recall that
N is generally a very large number and we must project and de-project the weights on each iteration—we consider
to be a block diagonal matrix with
B identical
blocks. In this way, we only have to build and work with a single block
, for which we can choose the size by simply adjusting the value of
B. The values of this block are drawn from a standard normal distribution. In addition,
is built as an orthonormal matrix so that
. Let
and
be the
ith block of
and
, respectively, both of them of length
; therefore, we just compute:
After executing Adam, we can get back to
:
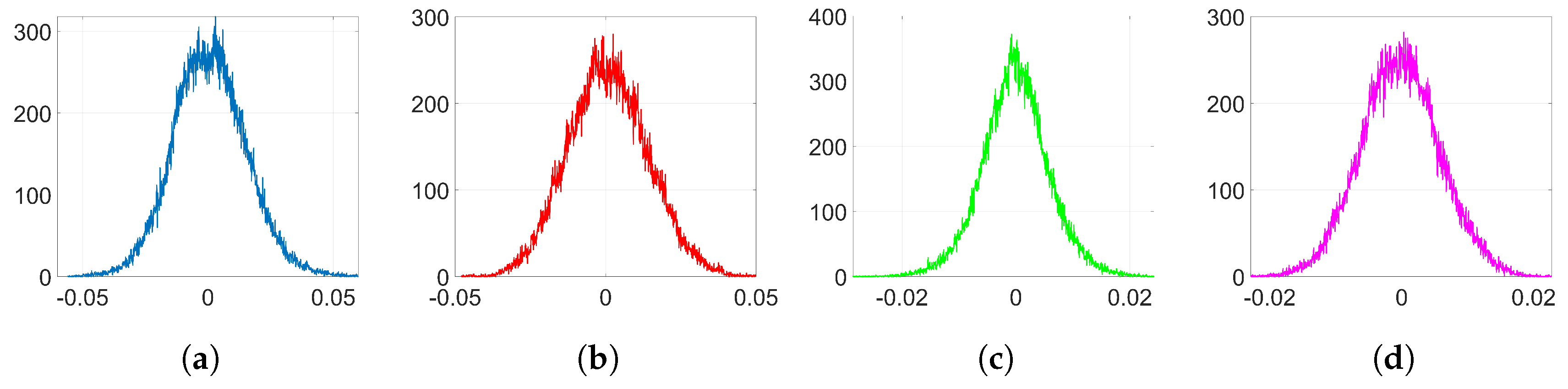
As we will see in
Section 6.2.4, BOP does not significantly alter the original distribution of weights, as opposed to standard Adam. This makes it possible to enjoy the advantages of Adam optimization when we implement the watermarking algorithm in [
5,
6] with a minimal increase in the detectability of the watermark. In addition, this has an advantage in terms of robustness: if the adversary is not able to infer which layer is watermarked, then he/she will have to exert his/her attack (e.g., noise addition, weight pruning) on
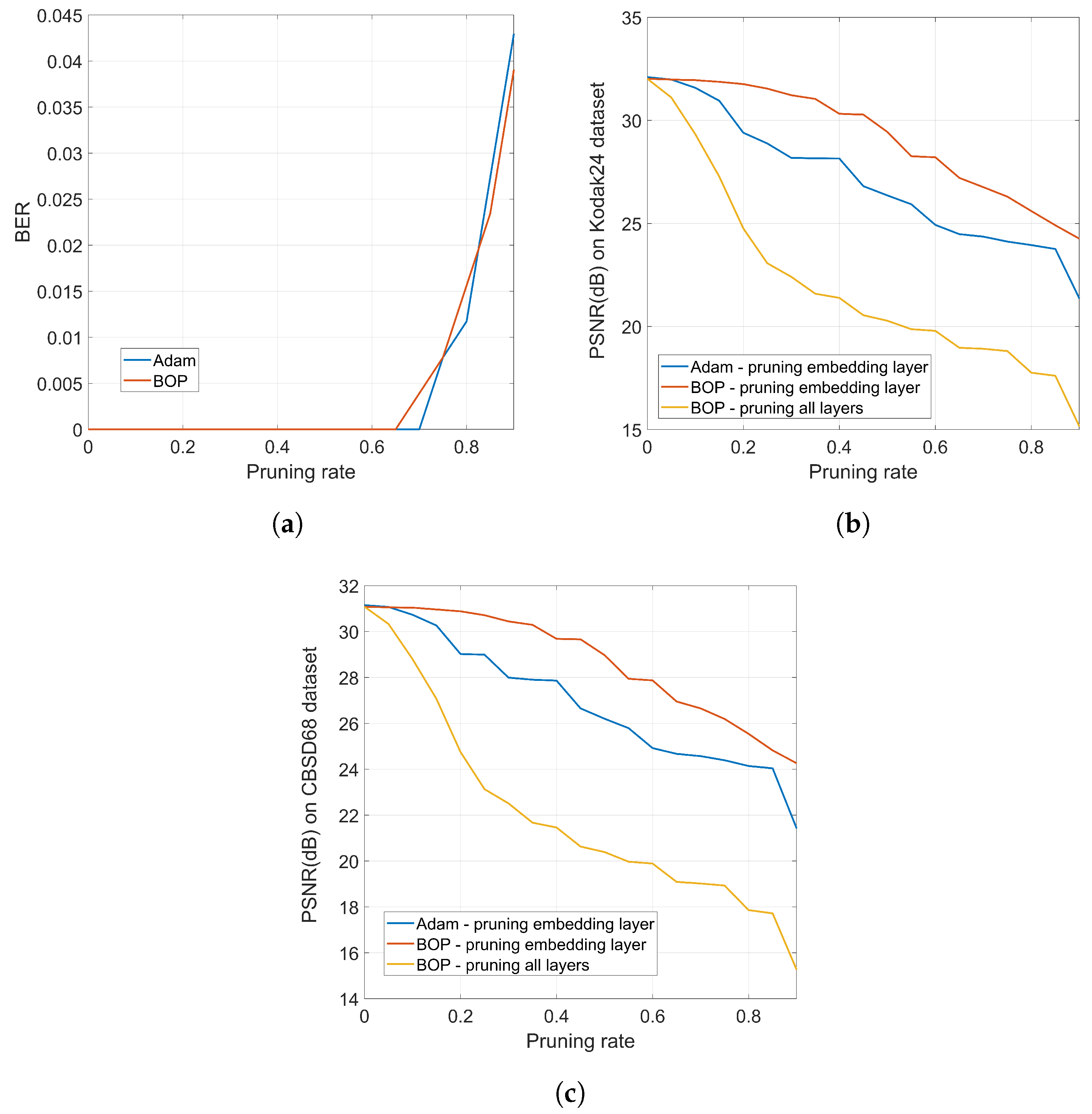
every layer thus producing a larger impact on the performance of the network as measured by the original cost function. We will discuss this fact in the experimental section.
5. Information-Theoretic Measures
As already discussed, one of the potential weaknesses of any neural network watermarking algorithm is the detectability of the watermark. An adversary that detects the presence of a watermark on a certain subset of the weights can initiate an attack to remove or alter the watermark. For this reason, it is important that the weights statistically suffer the least modification possible while of course being able to convey the desired hidden message. To measure this statistical closeness, we propose using the KLD [
13] between the distributions of weights before and after the watermark embedding. Let
P and
Q be two discrete probability distributions defined on the same alphabet
; then, the KLD from
Q to
P is (notice that it is not symmetric):
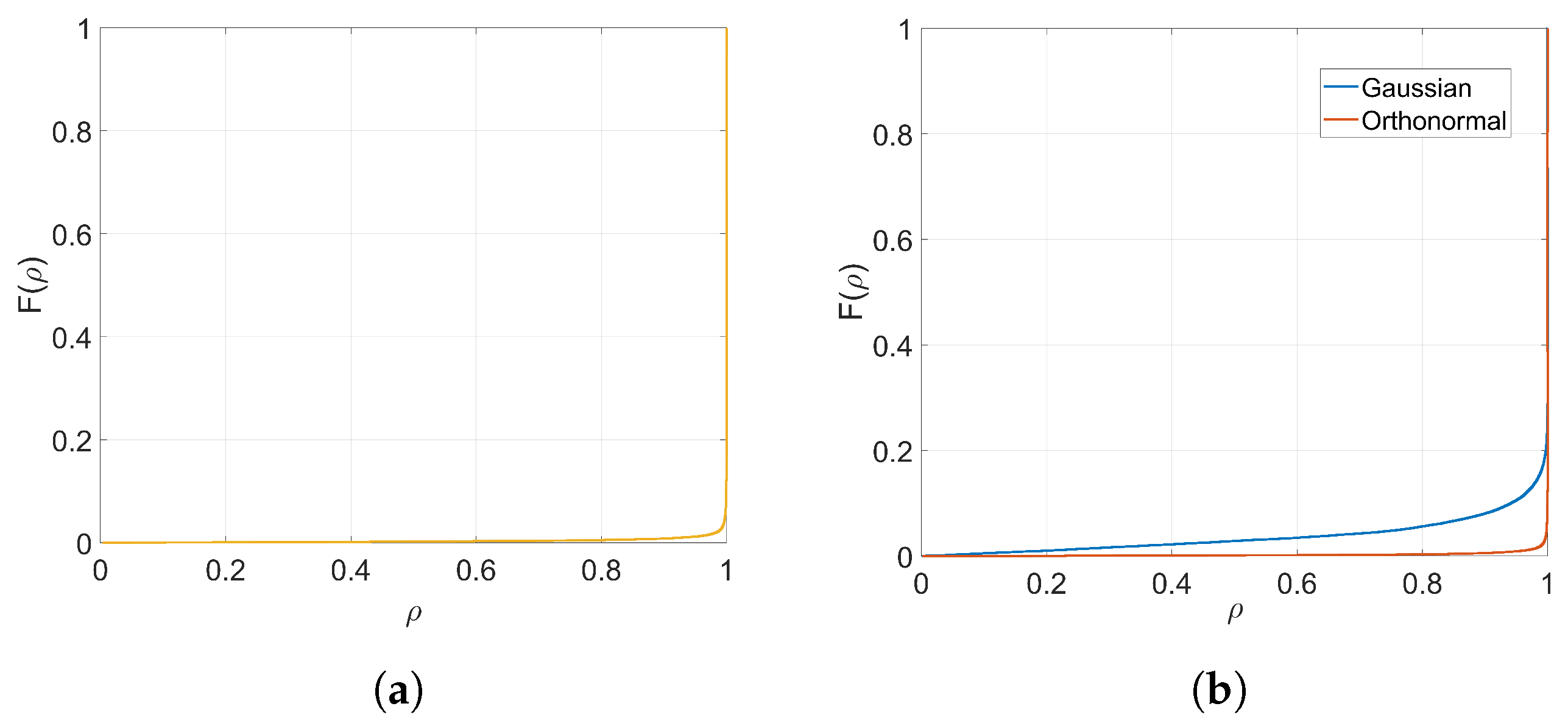
The KLD is always non-negative. The more similar the distributions P and Q are, the smaller the divergence. In the extreme case of two identical distributions, the divergence is zero.
It is interesting to note that the KLD has been proposed for similar problems in forensics, including steganographic security [
23], distinguishability between forensic operators [
24], or more general source identification problems [
25].
In our case, the two compared distributions are those of
and
, for
k just producing convergence with no decoding errors. Since the KLD is not symmetric, it remains to assign those distributions to
P and
Q so that the measure is as informative as possible. In particular, we are interested in properly accounting for the possible lateral spikes in the pdf of
. As those spikes often appear where the pdf of
is small if not negligible, this suggests assigning the latter pdf to
Q and the former to
P. However, this choice creates a problem in practice, as for some
, the empirical probabilities are such that
and
, potentially leading to an infinite divergence. To circumvent this issue related to insufficient sampling, we use an analytical approximation to
Q with infinite support, after noticing that the empirical distribution of
with 1000 discrete bins (see
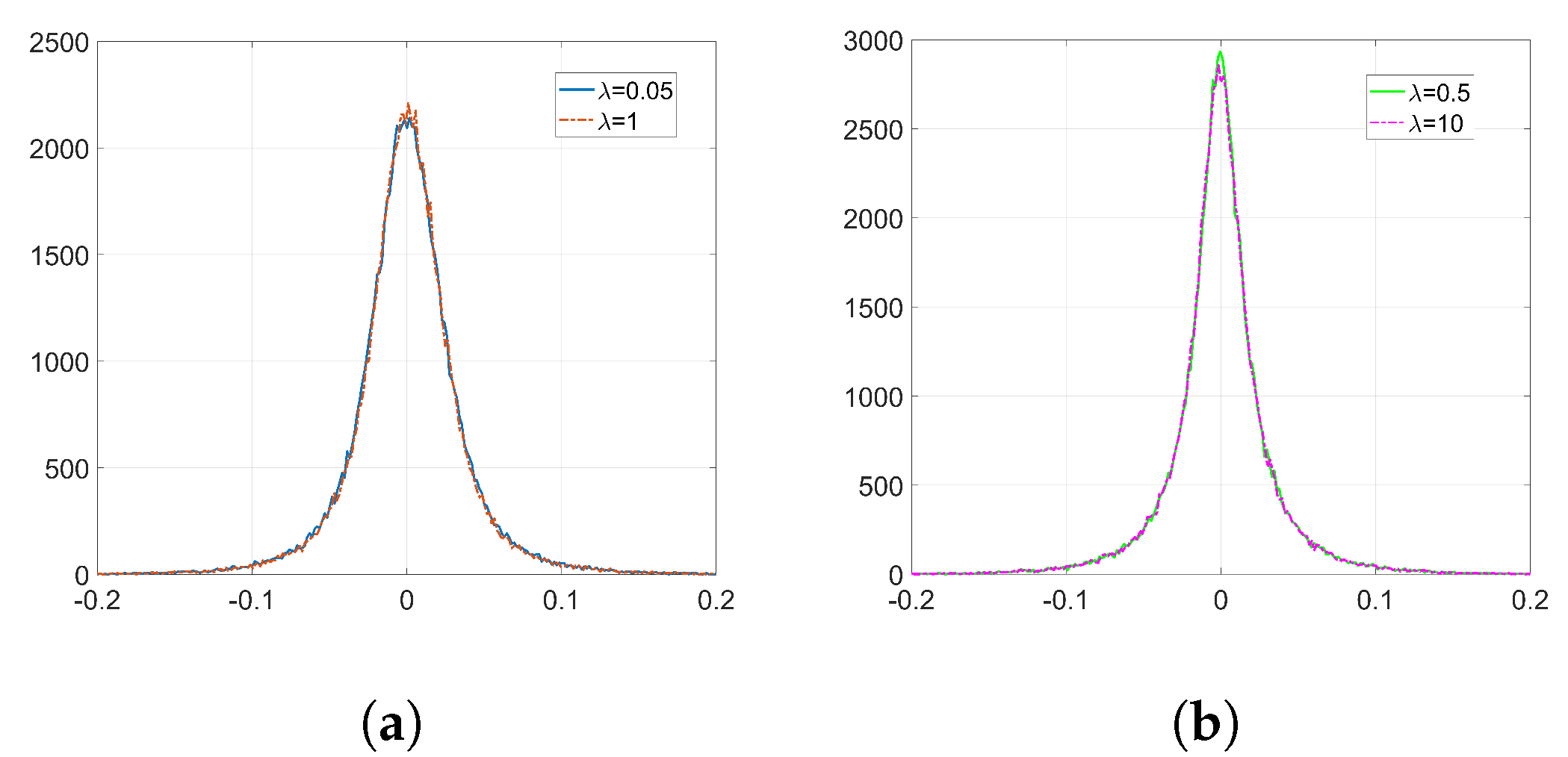
Figure 2a) can be approximated by a zero-mean Generalized Gaussian Distribution (GGD) with shape parameter
and scale parameter
, (for notational coherence with the literature,
is used in this section to denote a different quantity than in the rest of the paper.) for which the latter controls the spread of the distribution. As a reference, the KLD between the empirical distribution of
and its GGD best-fit is
, which is smaller than any of the KLDs that we find in
Table 2. In order to compute the KLD in our experiments, we use this infinite-support symmetric distribution for
Q and the empirical one of
for
P after quantizing both to 1000 discrete bins.
The use of the KLD is adequate to measure the detectability in those cases where the adversary has access to information about the ’expected’ distribution of the weights. For instance, when only one layer is modified, the expected distribution can be inferred from the weights of other layers. However, this may be still too optimistic in terms of adversarial success, as while the expected shape may be preserved—and thus, inferred—across layers, the scale (directly affecting the variance) may be not so. For instance, if the original weights were expected to be zero-mean Gaussian and they still are after watermarking, the KLD (which depends on the ratio of the respective variances) may be quite large, but the adversary will not be able to determine if watermarking took place if he/she does not know what the variance should be and only measures divergence with respect to a Gaussian. To reflect this uncertainty, quite realistic in practical situations, we minimize the KLD with respect to the scale parameter
. This puts the adversary in a scenario where only the shape is used for detectability. Thus, let
correspond to a GGD with scale parameter
, then we define the Scale Invariant KLD (SIKLD) as:
7. Conclusions
Throughout this paper, we have shown the importance of being careful with the optimization algorithm when we embed watermarks following the approach in [
5,
6]. The choice of certain optimization algorithms whose update direction is given by the sign function can originate footprints in the distributions of weights that are easily detectable by adversaries, thus compromising the efficacy of the watermarking algorithm.
In particular, we studied the mechanisms behind SGD and Adam optimization and found that the sign phenomenon that occurs in Adam is detrimental for watermarking, since it causes the appearance of two salient side spikes on the histograms of weights. As opposed to Adam, the sign function does not appear when we use SGD. Therefore, SGD does not significantly alter the original shape of the distribution of weights although, as we showed in the theoretical analysis, it slightly increases its variance. The analysis in this paper can be extended to other optimization algorithms.
In addition, we introduced orthogonal projectors and observed that, compared to the Gaussian case, they generally preserve the original performance and weight distribution better. However, a deeper analysis on this subject is left for further research.
Finally, we presented a novel method that uses orthogonal block projections to address the use of Adam optimization together with the watermarking algorithm under study. As we checked in the empirical section, this method allows us to solve the detectability problem posed by Adam and still enjoy the rest of advantages of this optimization algorithm.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
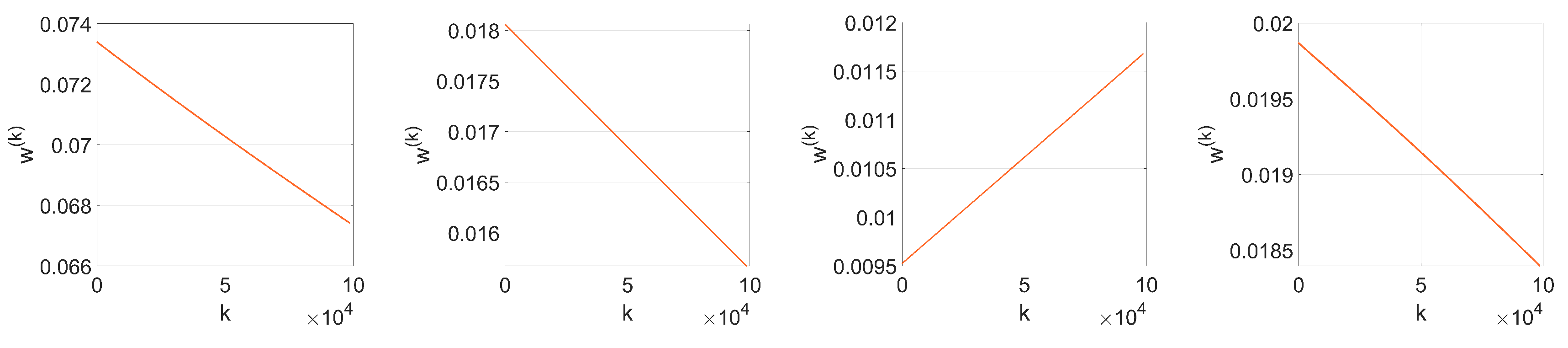{kind=link}
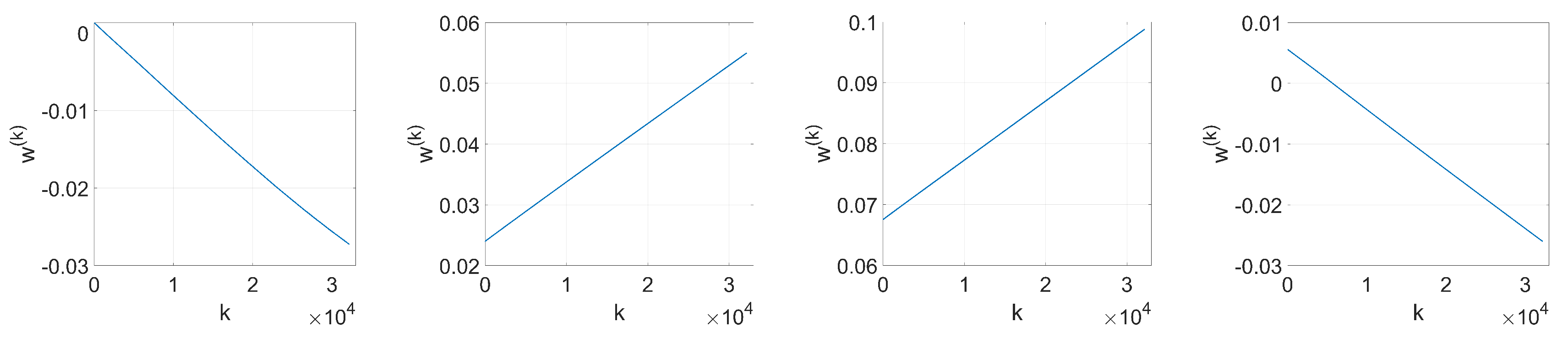{kind=link}
{kind=link}