1. Introduction
Closure modeling aims for computationally efficiently reduced models for tasks requiring repeated simulations such as Bayesian uncertainty quantification [
1,
2] and data assimilation [
3,
4]. Consisting of low-dimensional resolved variables, the closure model must take into account the non-negligible effects of unresolved variables so as to capture both the short-time dynamics and large-time statistics. As suggested by the Mori–Zwanzig formalism [
5,
6,
7], trajectory-wise approximation is no longer appropriate, and the approximation is in a statistical sense. That is, the reduced model aims to generate a process that approximates the target process in distribution, or at least, reproduce the key statistics and dynamics for the quantities of interest. For general nonlinear systems, such a reduced closure model is out of the reach of direct derivations from first principles.
Data-driven approaches, which are based on statistical learning methods, provide useful and practical tools for model reduction. The past decades witness revolutionary developments of data-driven strategies, ranging from parametric models (see, e.g., [
8,
9,
10,
11,
12,
13,
14] and the references therein) to nonparametric and machine learning methods (see, e.g., [
15,
16,
17,
18]). These developments demand a systematic understanding of model reduction from the perspectives of dynamical systems (see, e.g., [
7,
19,
20]), numerical approximation [
21,
22], and statistical learning [
17,
23].
With 1D stochastic Burgers equation as a prototype model, we aim to further the understanding of model reduction from an interpretable statistical inference perspective. More specifically, we consider a stochastic Burgers equation with a periodic solution on
:
from an initial condition
. We consider a stochastic force
that is smooth in space, residing on
low wavenumber Fourier modes, and white in time, given by
where
are independent Brown motions. Here
is the viscosity constant and
represents the strength of the stochastic force.
Our goal is to find a discrete-time closure model for the first K Fourier modes, so as to efficiently reproduce the energy spectrum and other statistics of these modes.
We present a class of efficient parametric reduced closure models for 1D stochastic Burgers equations. The key idea is to approximate the discrete-in-time flow map statistically, in particular, to represent the unresolved high wavenumber Fourier modes as functionals of the resolved variable’s trajectory. The reduced models are nonlinear autoregression (NAR) time series models, with coefficients estimated from data simply by least squares. We test the NAR models in four settings: reduction of deterministic responses () vs. reduction involving unresolved stochastic force (), and small vs. large scales of stochastic force (with and ), where is the number of Fourier modes of the white-in-time stochastic force and is the scale of the force. In all these settings, the NAR models can accurately reproduce the energy spectrum, invariant densities, and autocorrelation functions (ACF). We also discuss model selection, consistency of estimators, and memory length of the reduced models.
Taking advantage of our NAR models’ simplicity, we further investigate a critical issue in model reduction of (stochastic) partial differential equations: maximal space-time reduction. The space dimension can be reduced arbitrarily in our parametric inference approach: NAR models with two Fourier modes perform well. The time reduction is another story. The maximal time step is limited by the NAR model’s stability and is smaller than those of the K-mode Galerkin system. Numerical tests indicate that the NAR models achieve the minimal relative error at the time step where the K-mode Galerkin system’s mean CFL (Courant–Friedrichs–Lewy) number agrees with the full model’s, suggesting a potential criterion for optimal space-time reduction.
One can readily extend our parametric closure modeling strategy to general nonlinear dissipative systems beyond quadratic nonlinearities. Along with [
14], we may view it as a parametric inference extension of the nonlinear Galerkin methods [
24,
25,
26,
27]. However, it does not require the existence of an inertial manifold (and the stochastic Burgers equation does not satisfy the spectral gap condition that is sufficient for the existence of an inertial manifold [
28]), and it applies to resolved variables of any dimension (e.g., lower than the dimension of the inertial manifold if it exists [
14]). Notably, one may use NAR models that are linear in parameters and estimate them by least squares. Therefore, the algorithm is computationally efficient and is scalable for large systems.
The limitation of the parametric modeling approach is its reliance on the derivation of a parametric form using the Picard iteration, which depends on the nonlinearity of the unresolved variables (see
Section 3.1). When the nonlinearity is complicated, a linear-in-parameter ansatz may be out of reach. One can overcome this limitation by nonparametric techniques [
23,
29] and machine learning methods (see, e.g., [
16,
17,
30]).
The stochastic Burgers equation is a prototype model for developing closure modeling techniques for turbulence (see e.g., [
31,
32,
33,
34,
35,
36,
37]). In particular, Dolaptchiev et al. [
37] propose a closure model for stochastic Burgers equation in a similar setting, based on local averages of finite-difference discretization, reproducing accurate energy spectrum similar to this study. We directly construct a simple yet effective NAR model for the Fourier modes, providing the ground of a statistical inference examination of model reduction.
We note that the closure reduced models based on parametric inference are different from the widely studied proper orthogonal decomposition (POD)-based reduced order models (ROM) for parametric full models [
38,
39]. These POD-ROMs seek new effective bases to capture the effective dynamics by a linear system for the whole family of parametric full models. The inference-based closure models focus on nonlinear dynamics in a given basis and aim to capture both short-time dynamics and large-time statistics. In a probabilistic perspective, both approaches approximate the target stochastic process: the POD-ROMs are based on Karhunen-Loéve expansion, while the inference-based closure models aim to learn the nonlinear flow-map. One may potentially combine the two and find nonlinear closure models for the nonlinear dynamics in the POD basis.
The exposition of our study proceeds as follows. We first summarize the notations in
Table 1. Following a brief review of the basic properties of the stochastic Burgers equation and its numerical integration, we introduce in
Section 2 the inference approach to closure modeling and compare it with the nonlinear Galerkin methods.
Section 3 presents the inference of NAR models: derivation of the parametric form, parameter estimation, and model selection. Examining NAR models’ performance in four settings in
Section 4, we investigate the space-time reduction.
Section 5 concludes our main findings and possible future research.
3. Inference of Reduced Models
We present here the parametric inference of NAR models: derivation of parametric forms, estimation of the parameters, and model selection.
3.1. Derivation of Parametric Reduced Models
We derive parametric reduced models by extracting basis functions from numerical integration of Equation (6). The combination of these basis functions will give us
in (
11), which approximates the flow maps
in (
8) in a statistical sense.
We first write a closed integro-differential system for the low-mode process
. In view of Equation (6), this can be simply done by integrating the equation of the high modes
w in Equation (7):
where
. Note that in addition to the trajectories
and
, which we can assume to be known, the state
also depends on the initial condition
. Therefore, this equation is not strictly closed. However, as
increases, the effect of the initial condition decays exponentially, allowing for possible finite time approximate closure. Given
and
, the Picard iteration can provide us an approximation of
w as a functional of the trajectory of
v. That is, the sequence of functions
, defined by
with
for
, will converge to
w as
. In particular, the first Picard iteration
provides us a closed representation: from its numerical integrator, we can derive parametric terms for the reduced model. We emphasize that the goal is to derive parametric terms for statistical inference, but not to have a trajectory-wise approximation. Thus, high-order numerical integrators or high-order Picard iterations are helpful but may complicate the parametrization. For simplicity, we shall consider only the first Picard iteration and Riemann sum approximation of this integral.
We can now propose parametric numerical reduced models from the above integro-differential equation. In a simple form, we parametrize both the Riemann sum approximation of the first Picard iteration and a numerical scheme of the differential equation to obtain
Here
denotes the time step-size, the nonlinear function
comes from a numerical integration of the deterministic truncated Galerkin equation
at time
and with time step-size
, and the coefficients
are to be estimated by fitting to data in a statistical sense. To distinguish the approximate process in the reduced model from the original process, we denote it by
, and write the reduced model as
where
is a process representing the residual, can be assumed to be stochastic force for simplicity, but can also be assumed to be a moving average part to better capture the time correlation as in [
13,
46]. The second Equation (14b) does not have a residual term, as its goal is to provide a set of basis functions for the approximation of the forward map
as in Equation (
8), not to model the high modes.
Note that the time step-size can be relatively large, as long as the truncated Galerkin equation of the slow variable v can be reasonably resolved. In general, such a step-size can be much larger than the time step-size needed to resolve the fast process w, because the effect of the unresolved fast process is “averaged” statistically when fitting the coefficients to data. Furthermore, the numerical error in the discretization is taken into account statistically.
Theoretically, the right-hand side of Equation (14a) is an approximation of the conditional expectation , which is the optimal estimator of the forward map conditional on the information up time . Here, the is with respect to the joint measure of the vector , which is approximated by their joint empirical measure when fitting to data.
To avoid nonlinear optimization, the parametric form may be further simplified to be linearly dependent on the coefficients by dropping the terms that are nonlinear in the parameter, which is quadratic. In fact, recall that in the Burgers equation
and
. By dropping the interaction between the high modes
and approximating
in (14a), we obtain a reduced model that depends linearly on the coefficients
.
3.2. The Numerical Reduced Model in Fourier Modes
We now write the reduced model in terms of the Fourier modes as in Equation (
10).
As discussed in the above section, the major task is to parametrize the truncation error
. Recall that the operator
P projects
u to modes with wavenumber
and that the bilinear function
(hereafter, to simplify notation, we also denote
P and
Q on the corresponding vector spaces of Fourier modes).
Since the quadratic term
can only propagate energy from
to modes with wave numbers less than
, we get only the high modes with wave numbers
when we compute
w by a single iteration of
. (We use a single iteration for simplicity, but one can reach higher wave numbers by multiple iterations at the price of more complicated parametric forms.) Therefore, in a single iteration approximation, the truncated error will involve the first
Fourier modes:
Dropping the interaction between the high-modes to avoid nonlinear optimization in parameter estimation, we have
We approximate the high modes
by a functional of low modes as in (14b),
where
is the high modes of the nonlinear function
:
Here
only represents the modes up to wavenumber
, due to the fact that quadratic nonlinearity only involves interaction between double wave-numbers. One can reach higher wave numbers by iterations of the quadratic interaction.
The truncation error term can now be linearly parametrized as
where we also denote
for
for simplicity of notation.
We have now reached a parametric numerical reduced model for the Fourier modes. Denote
the low-modes in the reduced model that approximates the original low modes
. The reduced model is
with the convention that
(with the sup-script
denoting complex conjugate), and where the notion
represents the high modes and is defined by
The reduced model is in the form of a nonlinear auto-regression moving average (NARMA) model:
The map is the 1-step forward of the deterministic K-mode Galerkin truncation equation using a numerical integration scheme with a time step-size , i.e., . We use the ETDRK4 scheme.
The term denotes the increment of the k-th Fourier modes of the stochastic force in the time interval , scaled by , and it is separated from so that the reduced model can linearly quantify the response of the low-modes to the stochastic force.
The function is a function with parameters to be estimated from data. In particular, the coefficients and act as a correction to the integration of the truncated equation.
The new noise terms
are assumed for simplicity to be a white noise independent of the original stochastic force
. That is, we assume that
is a sequence of independent identically distributed (iid) Gaussian random vectors, with independent real and imaginary parts, distributed as
with
to be estimated from data. Under such a white noise assumption, the parameters can be estimated simply by least squares (see next section). In general, one can also assume other distributions for
, or other structures such as moving average
with
being a white noise sequence [
13,
46].
3.3. Data Generation and Parameter Estimation
We estimate the parameters of the NAR model by maximizing the likelihood of the data.
Data for the NAR model. To infer a reduced model in form of Equation (17), we generate relevant data from a numerical scheme that sufficiently resolve the system in space and time, as introduced in
Section 2.2. The relevant data are trajectories of the low-modes of the state and the stochastic force, i.e.,
for
and
, which are taken as
in the reduced model. Here, the time instants are
, where
can be much larger than the time step-size
needed to resolve the system. Furthermore, the data do not include the high modes. In short, the data are generated by a downsampling, in both space and time, of the high-resolution solutions of the system.
The data can be either a long trajectory or many independent short trajectories. We denote the data consisting of
M independent trajectories by
where
m indexes the trajectories,
with
being the time interval between two observations, and
denotes the number of steps for each trajectory,
Parameter estimation. The parameters in the discrete-time reduced model Equation (17) is estimated by maximum likelihood methods. Our discrete-time reduced model has a few attractive features: (i) the likelihood function can be computed exactly, avoiding possible approximation error that could lead to biases in estimators; (ii) the maximum likelihood estimator (MLE) may be computed by least squares under the assumption that the process is white noise, avoiding time-consuming nonlinear optimizations.
Under the assumption that
is white noise, the parameters can be estimated simply by least squares, because the reduced model in Equation (17) depends linearly on the parameters. More precisely, the log-likelihood of the data
in (
19) can be written as
where
denotes the absolute value of a complex number,
and
. To compute the maximum likelihood estimator (MLE) of the parameter
, we note that
in (17b) depends linearly on the parameter
. Therefore, the estimators of
and
can be analytically computed by finding a zero of the gradient of the likelihood function. More precisely, denoting
with
denoting the parameterized terms in (17b), we compute the MLE as
where the normal matrix
and vector
are defined by
In practice,
may be singular and it can be dealt with by pseudo inverse or regularization. We assume for simplicity that the stochastic force
g has independent components, so that the coefficients can be estimated by simple least square regression. One may further improve the NAR model by considering spatial correlation between the components of
g or by using moving average models [
13,
46,
47].
3.4. Model Selection
The parametric form in Equation (17b) leaves a family of reduced models with many freedoms underdetermined, such as the time lag p and possible redundant terms. To avoid overfitting and redundancy, we proposed to select the reduced model by the following criterion.
Cross validation: the reduced model should be stable and can reproduce the distribution of the resolved process, particularly the main dynamical-statistical properties. We will consider the energy spectrum, the marginal invariant densities, and temporal correlations:
for
.
Consistency of the estimators. If the model is perfect and the data are either independent trajectories or a long trajectory from an ergodic measure, the estimators should converge as the data size increases (see e.g., [
45,
48]). While our parametric model may not be perfect, the estimators should also become less oscillatory as the data size increases, so that the algorithm is robust and can yield similar reduced models from different data sets.
Simplicity and sparsity. When there are multiple reduced models performing similarly, we prefer the simplest model. We remove the redundant terms and enforce sparsity by LASSO (least absolute shrinkage and selection operator) regression [
49]. Particularly, a singular normal matrix (
22) indicates the redundancy of the terms and the need to remove strongly correlated terms.
These criteria are by no means exhaustive. Other methods include Bayesian information criterion (BIC, see, e.g., [
50]), and the error reduction ratio [
51] may be applied, but in our experience, they provide limited help for the selection of reduced models [
7,
14,
46].
In view of statistical learning of the high-dimensional nonlinear flow map in (
8), each linear-in-parameter reduced model provides an optimal approximation to the flow map in the hypothesis space spanned by the proposed terms. A possible future direction is to select adaptive-to-data hypothesis spaces in a nonparametric fashion [
23] and analyze the distance between the flow map and the hypothesis space [
52,
53].
4. Numerical Study on Space-Time Reduction
We examine the inference and performance of NAR models for the stochastic Burgers equation in (
1) and (
2). We will consider two settings of the full model: the stochastic force has a scale of either
or
, representing that the stochastic force either dominates or subordinates to the dynamics, respectively. We will also consider two settings for reduction: the number of the Fourier modes of the reduced model is either
or
, representing a reduction of the deterministic responses and a reduction involving stochastic force, respectively.
4.1. Settings
As reviewed in
Section 2.2, we integrate the Equation (
4) of
Fourier modes by ETD-RK4 with a time-stepping
that the solution is resolved accurately. We call this discretized system the full model and its configuration is specified in
Table 3. We will consider two different scales for the stochastic force, with standard deviations
, leading to a dynamics dominated by the stochastic force, and
, representing dynamics dominated by the deterministic drift.
We generate data in (
19) from the full model as described in
Section 3.3. We generate an ensemble of initial conditions by first integrating the system for
time units from an initial condition
and draw
samples uniformly from this long trajectory. Then, we generate either a long trajectory or an ensemble of trajectories starting from randomly picked initial conditions, and we save data with the time-stepping
. Numerical tests show that the invariant densities and the correlation functions vary little when the data are generated from different initial conditions.
We then infer NAR models for the first K Fourier modes with a time step . We will consider two values for K (recall that is the number of Fourier modes in the stochastic force)
. In this case,
, i.e., the stochastic force does not act on the unresolved Fourier modes
w in (7), so
w is a deterministic functional of the history of the resolved Fourier modes. In view of (14b), the reduced model mainly quantifies this deterministic map. We call this case “reduction of the deterministic response” and present the results in
Section 4.3.
. In this case,
, and
w in (7) depend on the unobserved Fourier modes of the stochastic force. Thus, the reduced model has to quantify the effects of the unresolved Fourier modes of both the solution and the stochastic force. We call this case “reduction involving unresolved stochastic force” and present the results in
Section 4.4.
In either case, we explore the maximal time step that NAR models can reach by testing time steps .
We summarize the configurations and notations in
Table 3.
4.2. Model Selection and Memory Length
We demonstrate model selection and the effect of memory length for reduced models with time step . We aim to select a universal parametric form of the NAR model for different setting of , where is the number of Fourier modes in the NAR model and is the standard deviation of the full model’s stochastic force. Such a parametric form will be used later for the exploration of maximal time reduction by NAR models in the next sections.
We select the model according to
Section 3.4: for each pair
, we test a pool of NAR models and select the simplest model that best reproduces the statistics and has consistent estimators. The statistics are computed along a long trajectory of
time units. We say that an NAR is numerically unstable if it blows up (e.g.,
exceeding
) before reaching
time units.
We estimate the coefficients in (17b) for a few time lag
ps. Numerical tests show that the normal matrix in regression is almost singular, either when the stochastic force
presents or when the lag for
or
is bigger than two. Thus, for simplicity, we remove them by setting:
and estimate only
for
.
That is, in (17b), the terms and have a time lag 1, the stochastic force term is removed, and only the high-order (the fourth) term has a time lag p. The memory length is .
Memory length. To select a memory length, we test NAR models with time lags
and consider their reproduction of the energy spectrum in (
23).
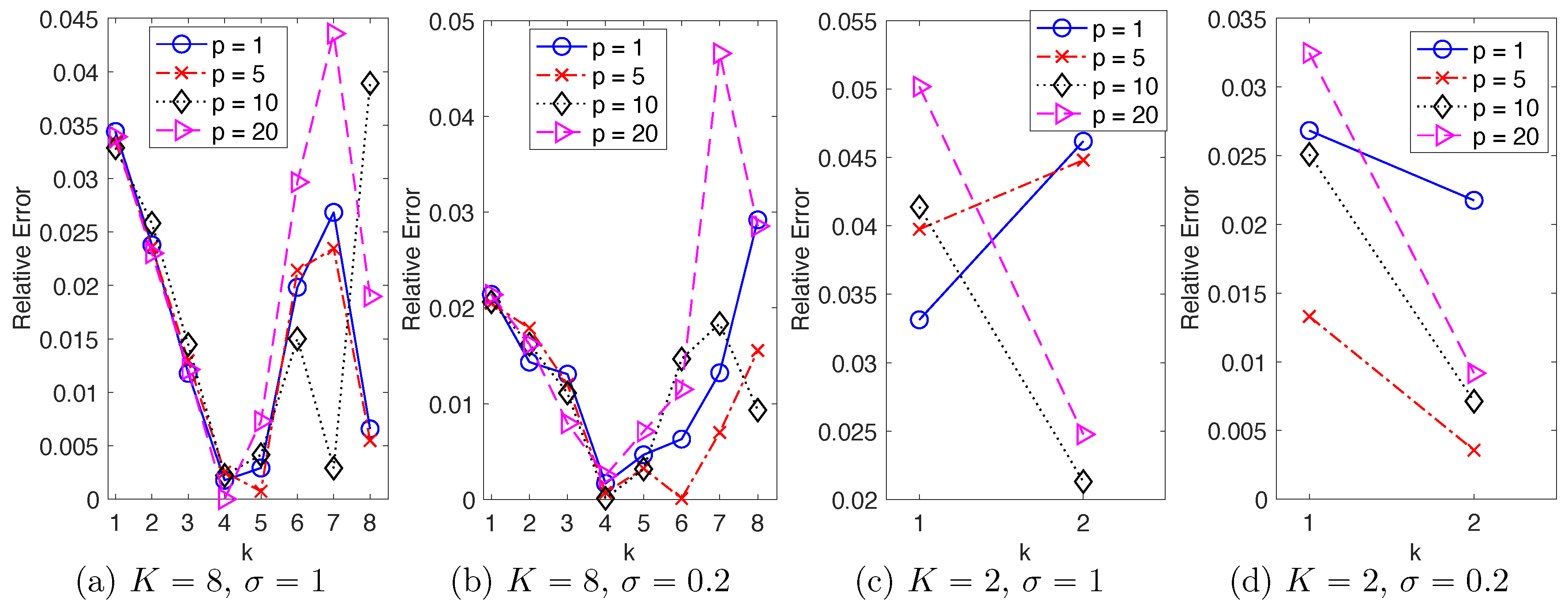
Figure 1 shows the relative error in energy spectrum of these NAR models. It shows that as
p increases: (1) when the scale of the stochastic force is large (
), the error oscillates without a clear pattern; (2) when
, the error first decreases and then increases. Thus, a longer memory does not necessarily lead to a better reduced model when the stochastic force dominates the dynamics; but when deterministic flow dominates the dynamics, a proper memory can be helpful.
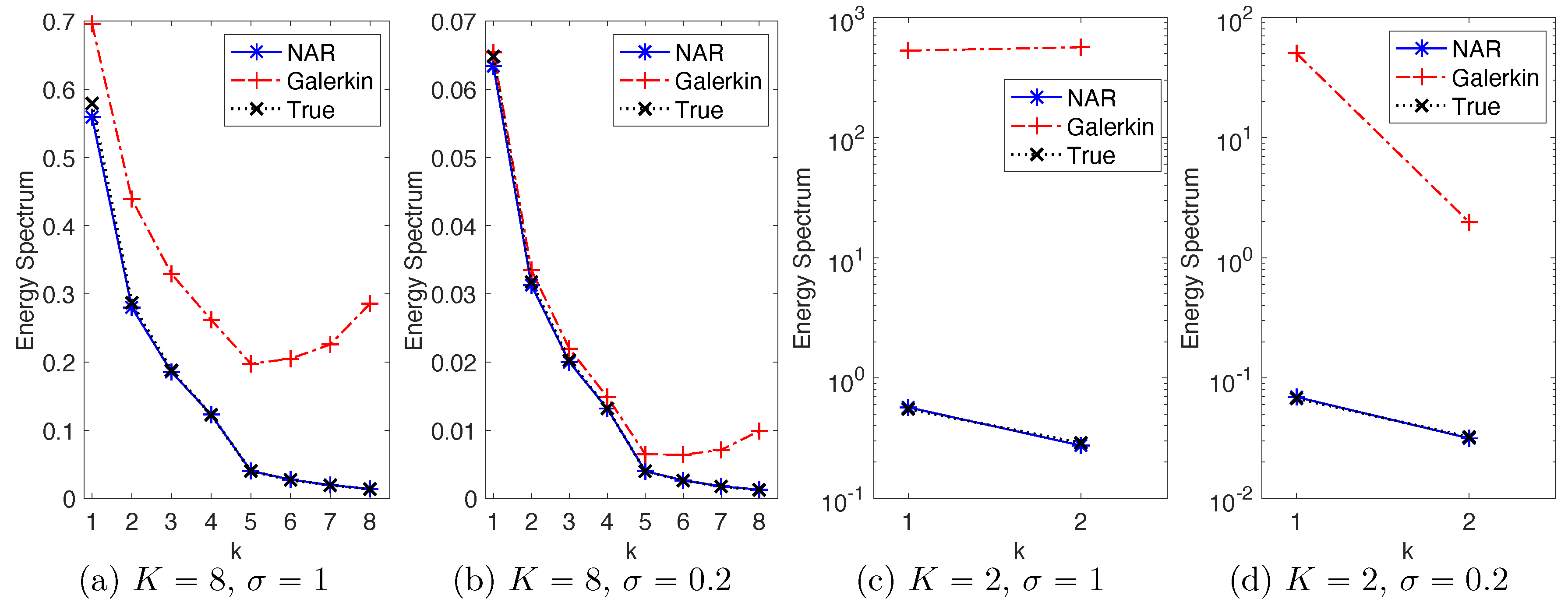
In all four settings, the simplest NAR models with
can consistently reproduce the energy spectrum with relative errors within 5%. Remarkably, the accuracy remains when the true energy spectrum is at the scale of
for the modes with
in
Figure 2a,b and
in
Figure 2d.
Figure 2 also shows that the truncated
K-mode Galerkin systems cannot reproduce the true energy spectrum in any of these settings, with upward tails, due to the lack of fast energy dissipation from the high modes. Thus, the NAR model has introduced additional energy dissipation through
.
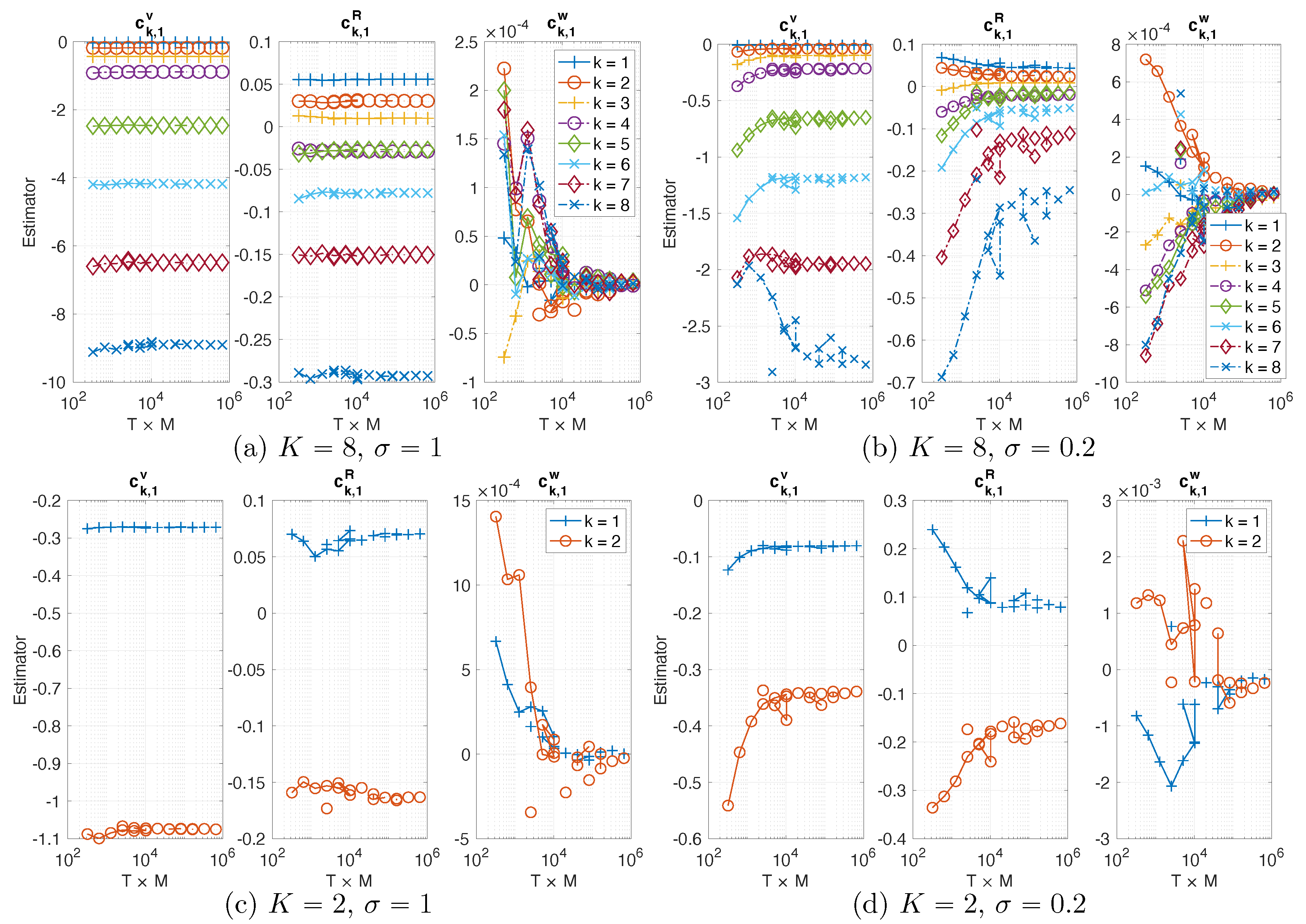
Consistency of estimators. The estimator of the NAR models tends to converge as data size increases.
Figure 3 shows that the estimated coefficients of NAR with
from data consisting of
M trajectories, each with length
T, where
and
. As
increases, all the estimators tend to converge (note that the coefficients
are at the scale of
or
). In particular, they converge faster when
than when
: the estimators in (a)–(c) oscillate little after
, indicating that different trajectories lead to similar estimators, while the estimators (take
for example) in (b)–(d) oscillate until
. This agrees with the fact that a larger stochastic force makes the system mix faster, so each trajectory provides more effective samples driving the estimator to converge faster.
Numerical tests also show that an NAR model can be numerically unstable, while its coefficient estimator was consistent (i.e., tending to converge as above). Thus, consistency is not sufficient for the selection of an NAR model.
In our tests, sparse regression algorithms such as LASSO (see e.g., [
49]) or sequential thresholding (see e.g., [
54,
55]) have difficulty in proper thresholding, because the coefficient
of the high order terms are small and can vary in scales in different settings, but these high order terms are important for the NAR model.
Since the NAR models with perform well in all the four settings, and since they are the simplest, we use them in the next sections to explore the maximal time reduction.
4.3. Reduction of the Deterministic Response
We explore in this and the next section the maximal time step that the NAR models can reach. We consider only the simplest models with time lag .
We consider first the models with
Fourier modes. Since the stochastic force acts directly only on the first
Fourier modes, the unresolved variable
w in (
12) is a deterministic functional of the path of the
K modes, so is the truncation error
in (14b). Thus, the NAR model mainly reduces the deterministic response of the resolved variables to the unresolved variables. In particular, the term
in the NAR model (17a) optimally approximates this deterministic response on the function space linearly spanned by the terms in (17b).
We consider time steps with . For each , we first estimate the coefficients of the NAR model from the data with the same time step. We then validate the estimated NAR model by its statistics.
Numerical tests show that the NAR models with
are numerically unstable for the setting
, and the number is
for the setting
.
Figure 4a,b shows the relative error in energy spectrum reproduced by NAR models with those stable time steps. The relative errors increase as the
increases. Note that the relative errors for modes
change little, but those with
increase significantly. In particular, note that in (b), the relative errors at
are about 8% for
, but the relative errors at
increase sharply to form a peak at
when
. We will discuss connections with CFL numbers in
Section 4.5.
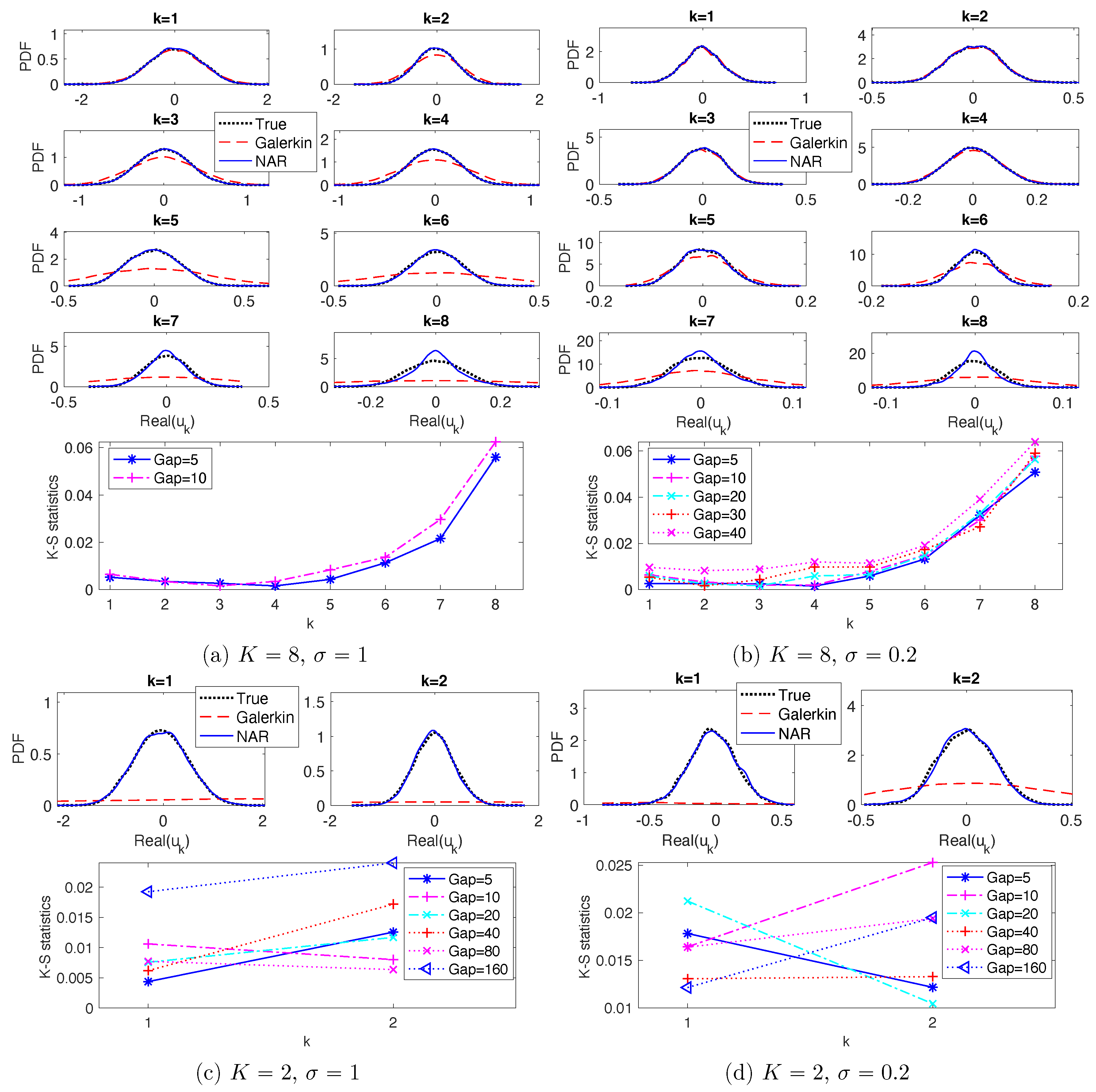
These NAR models reproduce the PDFs and ACFs relatively accurately.
Figure 5 shows the marginal PDFs of the real parts of the modes. The top row shows the marginal PDFs for the NAR models with
, in comparison with those of the full model and the Galerkin truncated system (solved with time step
). For the modes with wave numbers
, the NAR model captures the shape and spread of the PDFs almost perfectly, improving those of the Galerkin truncated system. For the modes with
, the NAR model still performs well, significantly improving those of the truncated Galerkin system. The discrepancy between the PDFs becomes larger as the wavenumber increases, because these modes are affected more by the unresolved modes. The bottom row shows that the Kolmogorov–Smirnov statistics (the maximal difference between the cumulative distribution functions) increase slightly as the
increases.
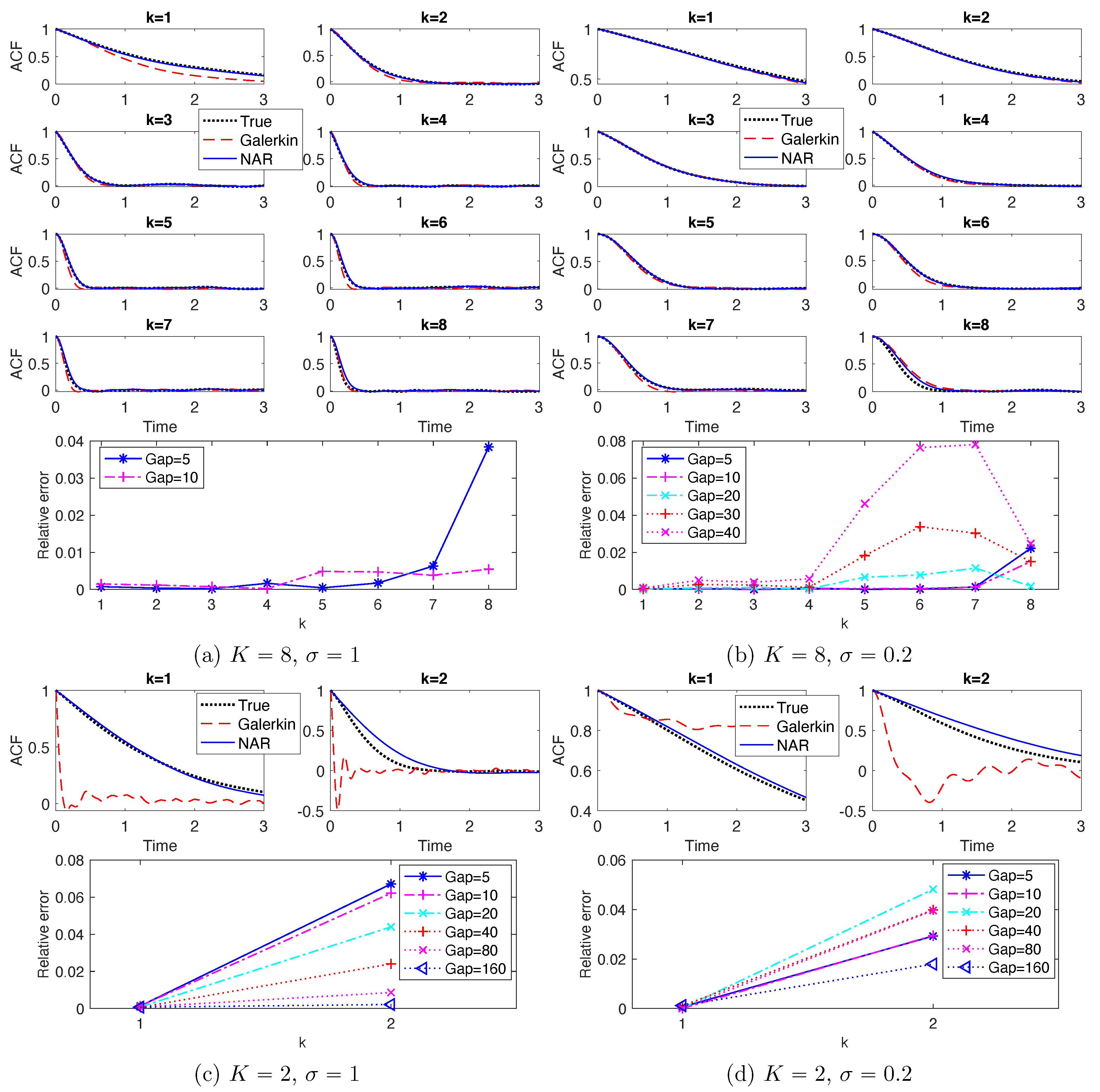
Figure 6 shows the ACFs. The top row shows that both the NAR model (with
) and the Galerkin system can reproduce the ACFs accurately. The bottom row shows that the relative error of the ACF, in
-norm, increases as
increases (particularly in the case
). Recall that the truncated Galerkin system produces PDFs with support much wider than the truth for the high modes (see
Figure 5), and that
becomes less accurate as
increases. Thus, the terms
u and
in the NAR model (17) preserve the temporal correlation, and the high order term helps to dissipate energy and preserve the invariant measure.
In summary, when , the maximal time steps are and when and , respectively, for NAR models with . All these NAR models can accurately reproduce the energy spectrum, the invariant measure and the temporal autocorrelation.
4.4. Reduction Involving Unresolved Stochastic Force
We consider next NAR models with
. In this case, the unresolved variable
w in (
12) is a functional of both the path of the
K modes and the unresolved stochastic force. Thus, in view of (14b), (
16) and (17), the NAR model quantifies the response of the
K-modes to both the unresolved Fourier modes and the unresolved stochastic force.
Note first that
is too small for the
K-mode Galerkin system to meaningfully reproduce any of the statistical or dynamical properties; see
Figure 2c,d for the energy spectrum,
Figure 5c,d for the marginal PDFs and
Figure 6c,d for the ACFs. On the contrary, the NAR models with
, whose term
comes from the
K-mode Galerkin, reproduce these statistics accurately. Remarkably, the NAR models remain accurate even when the time step is as large as
, with the K-S statistics being less than
in
Figure 5c,d, and with the relative error in ACFs less than 6% in
Figure 6c,d.
To explore the maximal time step that NAR models can reach, we consider time steps
with
. Numerical tests show that the NAR models are numerically stable for all of them in both settings of
and
.
Figure 4c,d shows the relative error in energy spectrum reproduced by NAR models with these time steps. The relative error first decreases and then increases as
increases, reaching the lowest when
and
for the settings
and
, respectively. In particular, all of these relative errors remain less than 9%, except when
in the setting
.
In summary, when , NAR models can tolerate large time steps. The maximal time steps are at least and when and , respectively, for the NAR models to reproduce the energy spectrum with relative error less than 9%.
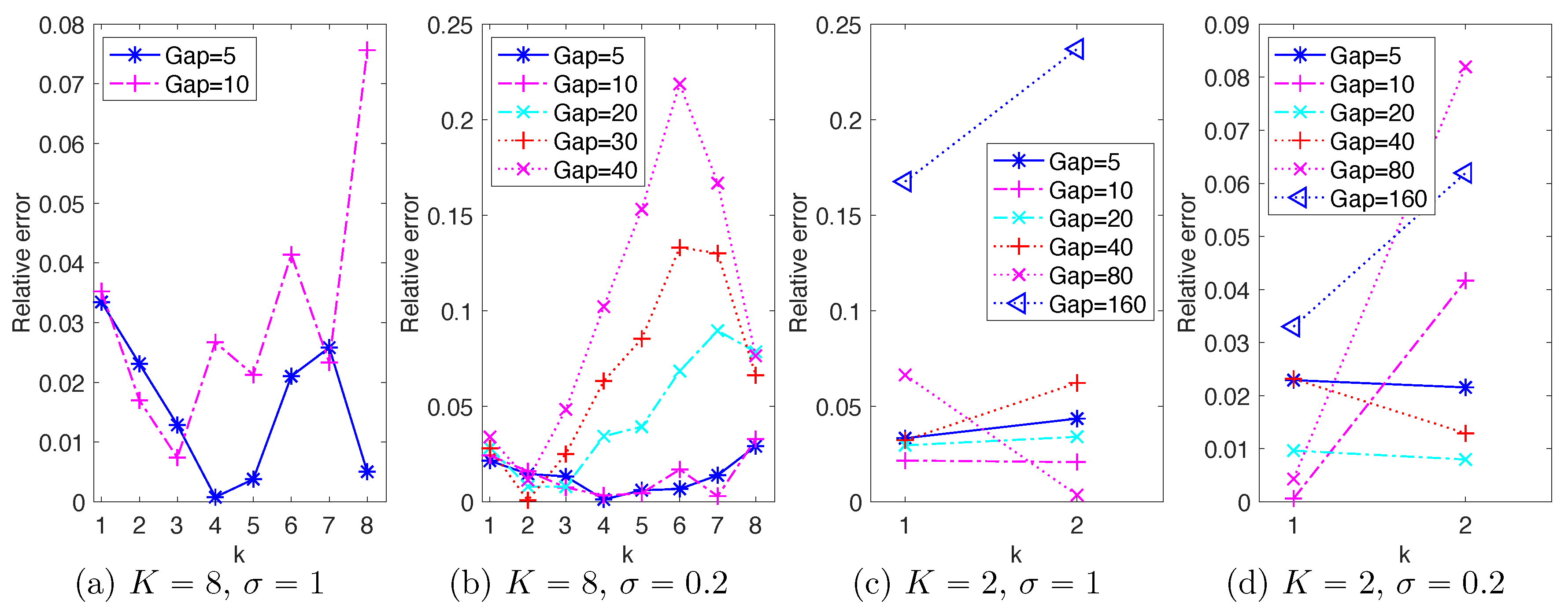
4.5. Discussion on Space-Time Reduction
Since model reduction aims for space-time reduction, it is natural to consider the maximal reduction in space-time; in other words, the minimum “spatial” dimension K and maximum time step . We have the following observations from the previous sections:
Space dimension reduction, memory length of the reduced model and the stochastic force are closely related. As suggested by the discrete Mori–Zwanzig formalism for random dynamics (see e.g., [
7]), space dimension reduction would lead to non-Markovian closure models.
Figure 1 suggests that a proper medium length of the memory leads to best NAR model. It also suggests that the scale of the white in time stochastic force can affect the memory length, and a larger scale of stochastic force leads to shorter memory. We leave it as future work to investigate the relations between memory length (colored or white in time), stochastic force, and energy dissipation.
Maximal time step depends on the space dimension and the scale of the stochastic force, mainly limited by the stability of the nonlinear reduced model.
Figure 4 shows that the maximum time step when
is at least
with
, much larger than those of the case of
. It also shows that as the scale of stochastic force increases from
to
, the NAR models’ maximal time step decreases (because the NAR models either become unstable or have larger errors in energy spectrum). It is noteworthy to mention that these maximal time steps of NAR models are smaller than those that the
K-mode Galerkin system can tolerate.
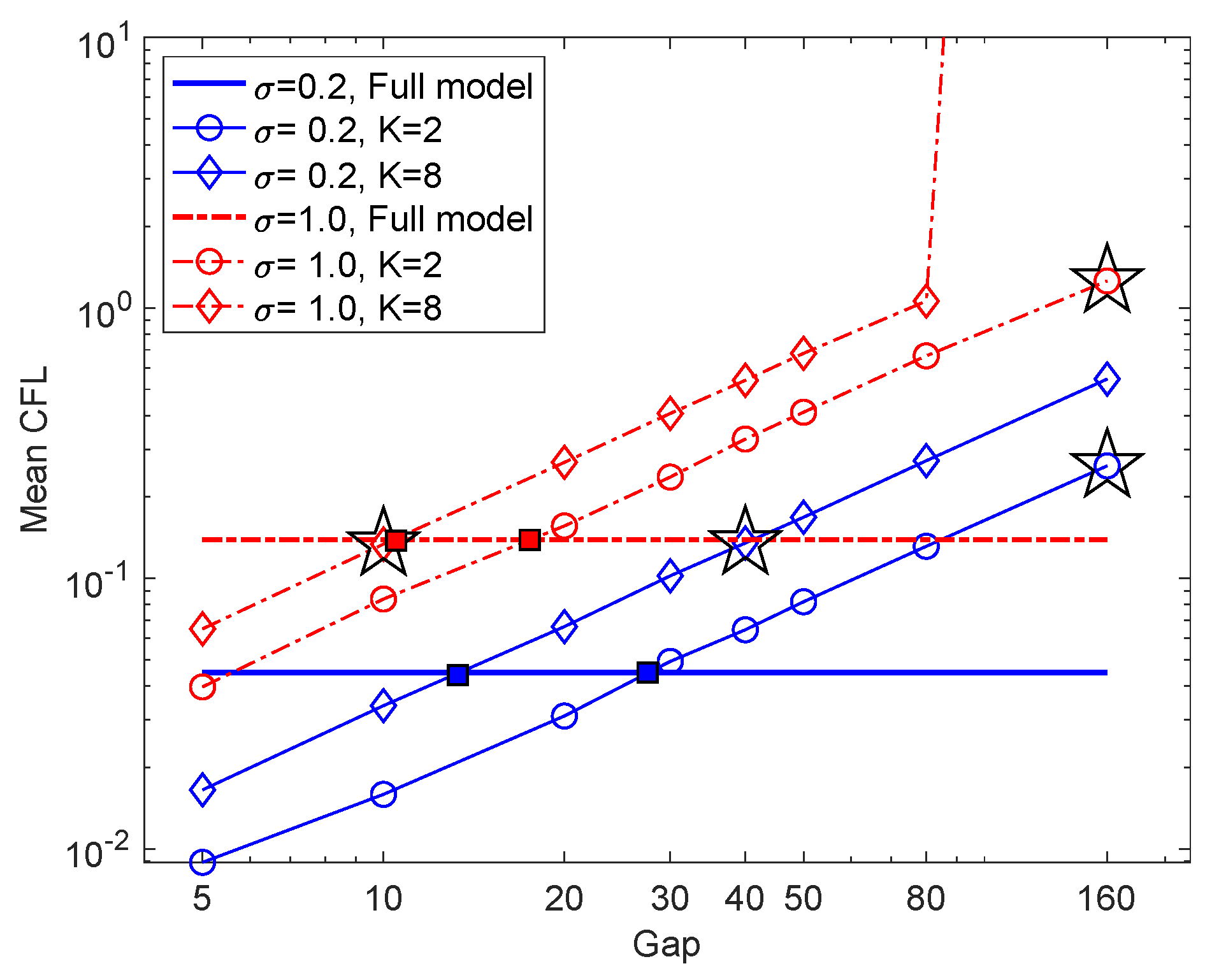
Figure 7 shows that the
K-mode Galerkin system can be stable for time steps much larger than those of the NAR models: the maximal time step for the K-mode Galerkin system is when the mean CFL number (which increases linearly) reaches 1, but the maximal time step for the NAR models to be stable is smaller. For example, in the setting
, the maximal time gap for the Galerkin system is
(the end of the red diamond line), but the maximal time gap for the NAR model is about
. The increased numerical instability of the NAR model is likely due to the nonlinear terms
, which are important for the NAR model to preserve energy dissipation and the energy spectrum (see
Figure 2 and the coefficients in
Figure 3).
Beyond maximal reduction, an intriguing question arises: when does the reduced model perform the best (i.e., the least relative error in energy spectrum)? We call it optimality of space-time reduction. It is more interesting and relevant to model reduction than maximal reduction in space-time, because one may achieve a large time step or a small space dimension at the price of a large error in the NAR model, as we have seen in
Figure 4. We note that the relative errors in energy spectrum in
Figure 4c,d are the smallest when the
s are the closest to the squares in
Figure 7, where the full model’s mean CFL numbers agree with those of the
K-mode Galerkin system. We conjecture that optimal space-time reduction can be achieved by an NAR model when the
K-mode Galerkin system preserves the CFL number of the full model.
5. Conclusions
We consider a data-driven model reduction for stochastic Burgers equations, casting it as a statistical learning problem on approximating the flow map of low-wavenumber Fourier modes. We derive a class of efficient parametric reduced closure models, based on representing the high modes as functionals of the resolved variables’ trajectory. The reduced models are nonlinear autoregression (NAR) time series models, with coefficients estimated from data by least squares. In various settings, the NAR models can accurately reproduce the statistics such as the energy spectrum, the invariant densities, and the autocorrelations.
Using the simplest NAR model, we investigate the maximal space-time reduction in four settings: reduction of deterministic responses () vs. reduction involving unresolved stochastic force (), and small vs. large scales of stochastic force (with and ), where is the number of Fourier modes of the white-in-time stochastic force, and is the scale of the force. Reduction in space dimension is unlimited, and NAR models with Fourier modes can reproduce the energy spectrum with relative errors less than 5%. The time reduction is another story. Maximal time reduction depends on both the dimension reduction and the stochastic force’s scale, as they affect the stability of the NAR model. The NAR model’s stability limits the maximal time step to be smaller than those of the K-mode Galerkin system. Numerical tests indicate that the NAR models achieve the minimal relative error at the time step where the K-mode Galerkin system’s mean CFL number agrees with the full model’s. This is a potential criterion for optimal space-time reduction.
The simplicity of our NAR model structure opens various fronts for a further understanding of data-driven model reduction. Future directions include: (1) studying the connection between optimal space-time reduction, the CFL number, and quantification of the accuracy of reduced models; (2) investigating the relation between memory length, dimension reduction, the stochastic force, and the energy dissipation of the system; (3) developing post-processing techniques to efficiently recover information of the high Fourier modes, so as to predict the shocks using the reduced models.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}