Open AccessArticle Extending Fibre Nonlinear Interference Power Modelling to Account for General Dual-Polarisation 4D Modulation Formats by Gabriele LigaGabriele Liga SciProfiles Scilit Preprints.org Google Scholar 1,*, Astrid BarreiroAstrid Barreiro SciProfiles Scilit Preprints.org Google Scholar 1, Hami RabbaniHami Rabbani SciProfiles Scilit Preprints.org Google Scholar 1,2 and Alex AlvaradoAlex Alvarado SciProfiles Scilit Preprints.org Google Scholar 1 1 Information and Communication Theory Lab, Signal Processing Systems Group, Department of Electrical Engineering, Eindhoven University of Technology, 5600 MB Eindhoven, The Netherlands 2 Department of Electrical Engineering, K. N. Toosi University of Technology, Tehran 1355-16315, Iran * Author to whom correspondence should be addressed. Entropy 2020, 22(11), 1324; https://doi.org/10.3390/e22111324 Submission received: 7 September 2020 / Revised: 16 October 2020 / Accepted: 27 October 2020 / Published: 20 November 2020 (This article belongs to the Special Issue Information Theory of Optical Fiber) Download keyboard_arrow_down Download PDF Download PDF with Cover Download XML Download Epub Browse Figures Versions Notes Abstract In optical communications, four-dimensional (4D) modulation formats encode information onto the quadrature components of two arbitrary orthogonal states of polarisation of the optical field. Many analytical models available in the optical communication literature allow, within a first-order perturbation framework, the computation of the average power of the nonlinear interference (NLI) accumulated in coherent fibre-optic transmission systems. However, all such models only operate under the assumption of transmitted polarisation-multiplexed two-dimensional (PM-2D) modulation formats, which only represent a limited subset of the possible dual-polarisation 4D (DP-4D) formats. Namely, only those where data transmitted on each polarisation channel are mutually independent and identically distributed. This paper presents a step-by-step mathematical derivation of the extension of existing NLI models to the class of arbitrary DP-4D modulation formats. In particular, the methodology adopted follows the one of the popular enhanced Gaussian noise model, albeit dropping most assumptions on the geometry and statistic of the transmitted 4D modulation format. The resulting expressions show that, whilst in the PM-2D case the NLI power depends only on different statistical high-order moments of each polarisation component, for a general DP-4D constellation, several other cross-polarisation correlations also need to be taken into account. Keywords: 4D modulation formats; optical communications; channel modelling 1. IntroductionWith the resurgence of polarisation-diverse, optical coherent detection, transmission of information over an optical fibre is typically performed exploiting four degrees of freedom of the optical field: two quadrature components over two orthogonal states of polarisation. The standard approach consists in encoding data independently over the two polarisation channels using the same two-dimensional (2D) modulation format. The resulting four-dimensional (4D) constellation is often referred to as a polarisation-multiplexed 2D (PM-2D) modulation format. The strong point of PM-2D formats is their simplicity of generation and performance analysis: as the two polarisation channels are independent and under the assumption of data-independent cross-polarisation interference in the fibre channel, transmission performance can be evaluated using the 2D component format.Despite the popularity of PM-2D formats, a substantial amount of research work in the literature has been devoted to more general 4D formats, i.e., 4D constellations which are not necessarily generated as Cartesian products of a component 2D constellation [1,2]. These formats have recently regained attention due to their potential power efficiency, nonlinearity tolerance, and ultimately their still unexplored shaping gains. The reason for that relies on the fact that, by exploiting the full 4D space, sensitivity and other relevant performance metrics such as mutual information or generalised mutual information can be improved compared to traditional PM-2D formats [3,4,5,6,7].Previous works on optimised 4D modulation formats have either operated under an additive white Gaussian noise channel hypothesis [1,2,3] or exploited some heuristic approaches to derive nonlinearly tolerant formats in the fibre-optic channel [5,6,7]. However, accurately predicting the amount of nonlinear interference generated by transmission of a given constellation in an optical fibre is key to optimising its shape in N dimensions.Modelling of nonlinear interference (NLI) in optical fibre transmission is quite a mature field of research where an impressive amount of progress was made in the first half of the 2010s, e.g., in [8,9,10,11]. In particular, [10,11] introduced for the first time the possibility of predicting the dependency of nonlinear interference power as a function of the modulation format features, i.e., geometrical shape and statistical properties. Among other assumptions, one underlying key point of all previous models is the transmission of PM-2D modulation formats, where data on the two polarisation channels are assumed to be independent and identically distributed. Under this constraint, one can predict the NLI power using the statistical properties of the 2D component modulation format. It is clear, however, that this approach ceases to be applicable to general DP-4D formats, where a single 2D component format might not even exist.In this work, we extend the existing analytical expressions for NLI power to account for DP-4D constellations where the two 2D polarisation components are not identically distributed or when there is statistical dependency between them. The undertaken approach is the same as in [9], i.e., a frequency-domain, first-order perturbation study. Unlike [9], no assumptions are made on either the marginal or joint statistics of the two polarisation components of the transmitted 4D constellation (besides being zero-mean). The final expressions reveal the impact of several different (nontrivial) cross-polarisation statistics on the NLI power.The formulas presented in this work enable an accurate computation of the NLI power for all possible dual-polarisation formats in optical fibre transmission. As a result, a reliable optimisation of both geometry and symbol probability of occurrence of such 4D formats is also enabled for the optical fibre channel. 2. Organisation of the Manuscript and NotationThe manuscript is organised as follows: (i) in Section 3, the investigated system model is described and the model assumptions are presented; (ii) Section 4, Section 5, Section 6, Section 7 and Section 8 are devoted to a step-by-step analytical derivation of the model; and (iii) ultimately, the main model expression is presented in Section 8. In particular: in Section 4, the regular perturbation (RP) solution to the frequency domain Manakov equation is derived for a multi-span fibre system and its power spectral density (PSD) is evaluated in the case of a transmitted periodic signal; in Section 5, the contributions of the different high-order moments and cross-polarisation correlations of the transmitted 4D modulation format are highlighted; finally, Section 8 derives, via Theorem 2, an expression for the PSD as the signal period is extended into infinity. A flowchart of the main derivation steps performed in this work, with their corresponding references in the manuscript, is shown in Figure 1.Throughout this manuscript, we denote 2D (column) vectors with boldface letters (e.g., a ), whereas 2D column vector functions are indicated with boldface capital letters (e.g., E ( f , z ) , E ˜ ( t , z ) , etc.). For indicating the optical field, the first variable of represents either the time or frequency variable whereas the second one represents the fibre propagation section. An exception is made for the multi-span system case, where second and third variables are assigned to the number of spans and span length, respectively. This highlights the joint dependence of the output optical field on these two variables, as shown later in the paper. F { · } , E { · } , and Re { · } indicate the Fourier transform, the statistical expectation, and the real part operators, respectively. The delta distribution is indicated by δ ( · ) , whereas δ k denotes the Kronecker delta defined as δ k ≜ 1 for k = 0 , 0 elsewhere . Finally, Z , R , and C denote the integer, real, and complex fields, respectively, and j is the imaginary unit. Figure 1. Flowchart of the analytical derivation in this work. Figure 1. Flowchart of the analytical derivation in this work. 3. Model Assumptions 3.1. System ModelThe baseband equivalent model of the optical fibre system under investigation in this work is shown in Figure 2. The fibre channel is a multi-span fibre system using Erbium-doped fibre amplification (EDFA). In this manuscript, it is assumed that a single-channel signal is transmitted. The transmitter is assumed to generate for each symbol period n the 4D symbol a n = [ a x , n , a y , n ] T , where a x , n , a y , n ∈ C are complex symbols modulated on two arbitrary orthogonal polarisation states x and y, respectively. The sequence of symbols a n for n ∈ Z is assumed to be a cyclostationary process of period W. The set of random variables (RVs) within each period of such process are also assumed to be statistically independent. Linear modulation with a single, real pulse p ( t ) on x and y polarisation is adopted. The pulse p ( t ) with spectrum P ( f ) is assumed to be strictly band-limited within the range of frequencies [ − R s / 2 , R s / 2 ] . As discussed in Section 3.3, the transmitted signal E ˜ ( t , 0 ) is assumed to be periodic with period T, such that E ˜ ( t , 0 ) = ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n p ( t − n T s ) , for 0 ≤ t ≤ T , (1) T s = 1 / R s = T / W represents the symbol period, and R s is the symbol rate. A schematic representation of the transmitted signal is shown in Figure 3. Figure 2. System model under investigation in this work which consists of an optical fibre system model and a nonlinear interference (NLI) variance estimation block: the two branches in the NLI variance estimator block indicate alternative ways of estimating the NLI variance Σ NLI . Figure 2. System model under investigation in this work which consists of an optical fibre system model and a nonlinear interference (NLI) variance estimation block: the two branches in the NLI variance estimator block indicate alternative ways of estimating the NLI variance Σ NLI . The signal E ˜ ( t , 0 ) is transmitted over N s (homogeneous) fibre spans, each of length L s and each followed by an ideal lumped optical amplifier for which the gain exactly recovers from the span losses. Since in this work we are only concerned about the prediction of NLI arising from the signal–signal nonlinear interactions along the fibre propagation, the optical noise added by the amplifier plays no role in the model and will be entirely neglected. The signal at the channel output E ˜ ( t , N s , L s ) is ideally compensated for accumulated chromatic dispersion in the link (see Section 4). In the frequency-domain output of the chromatic dispersion compensation (CDC) block E ˚ ( f , N s , L s ) (Figure 2), we ideally isolate the first-order RP term E 1 ( f , N s , L s ) (see Section 4) and we compute its PSD S ( f , N s , L s ) . The vector of the NLI powers Σ NLI ≜ [ σ NLI , x 2 , σ NLI , y 2 ] T for both x and y polarisations is obtained by integrating over the frequency interval [ − R s / 2 , R s / 2 ] the NLI PSD weighted by the function | P ( f ) | 2 , where P ∗ ( f ) is the frequency response of a matched filter (MF) for the system under consideration. As shown in Figure 2, this quantity is equivalent to the variance of the output of the MF followed by symbol-rate sampling, which more naturally arises when assessing the transmission performance of systems employing an MF at the receiver. The model in this manuscript provides an analytical relationship between the statistical features of the transmitted symbols a n and Σ NLI . 3.2. DP-4D vs. PM-2D FormatsThe model presented in this paper allows for prediction of the NLI for generic 4D real modulation formats. A 4D format is defined as a set A ≜ { a ( i ) = [ a x ( i ) , a y ( i ) ] T ∈ C 2 , i = 1 , 2 , … , M } , (2) where a x and a y are the symbols modulated on two orthogonal polarisation states x and y, respectively, and M is the modulation cardinality. It can be seen that the elements in A are 2D vectors in C as opposed to 4D. This is only due the to baseband-equivalent representation of signals used throughout this paper, while it is common to refer to a modulation format dimensionality based on the real signal dimensions, which justifies the 4D format label.Two important particular cases of the formats in (2) are (i) the so-called polarisation-multiplexed 2D (PM-2D) modulation formats, which are characterised by A = X 2 , X ∈ C , where X represents the 2D component constellation, and (ii) polarisation-hybrid 2D modulation formats characterized by A = X × Y , with X , Y ∈ C , X ≠ Y , where X and Y are two distinct component 2D formats in x and y polarisation, respectively. PM-2D formats are the most common ones in optical communications due to their generation’s simplicity. Both PM-2D and polarisation-hybrid 2D formats are often analysed in terms of their 2D polarisation components. This is because A can be factorised in two component formats which are independently encoded. Hence, if the generic transmitted constellation point is regarded as a random variable, in a conventional PM-2D format, the two polarisation components are statistically independent. In the remainder of this paper, no specific assumption on either the geometry or the statistic of the transmitted 4D symbols will be made, except the zero-mean feature E { a ( i ) } = 0 . Figure 3. Schematic representation of the periodic signal assumption, where W symbols are transmitted every T [s], each symbol with a duration of T s [s]: the periodicity assumption will be lifted in Section 8 by letting Δ f → 0 . Figure 3. Schematic representation of the periodic signal assumption, where W symbols are transmitted every T [s], each symbol with a duration of T s [s]: the periodicity assumption will be lifted in Section 8 by letting Δ f → 0 . 3.3. Transmitted Signal FormLet E ˜ ( t , z ) = E ˜ x ( t , z ) i x + E ˜ y ( t , z ) i y be the complex envelope of the optical field vector at time t and fibre section z, and let i x , i y denote 2 orthonormal polarisations of the transversal plane of propagation. Let also E ( f , z ) = E x ( f , z ) i x + E y ( f , z ) i y be the (vector) Fourier transform of E ˜ ( t , z ) defined as E ( f , z ) = F { E ˜ ( t , z ) } ≜ ∫ − ∞ ∞ E ˜ ( t , z ) e − j 2 π f t d t . Because of the periodicity assumption made in (1) (see Figure 3), we can write E ˜ ( t , 0 ) as E ˜ ( t , 0 ) = ∑ k = − ∞ ∞ C k e j 2 π k Δ f t , (3) where C k = [ C x , k , C y , k ] T , C x / y , k are the Fourier series coefficients of E ˜ ( t , 0 ) and Δ f = 1 / T is the frequency spacing of the spectral lines in E x / y ( f , z ) . Hence, E ( f , 0 ) can be then written as E ( f , 0 ) = ∑ k = − ∞ ∞ C k δ ( f − k Δ f ) . (4) Since each component of E ˜ ( t , 0 ) is periodic with period T, we can write E ˜ ( t , 0 ) = ∑ n = − ∞ ∞ E ^ ( t − n T , 0 ) , where, as per assumption in (1), we have E ^ ( t , 0 ) ≜ ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n p ( t − n T s ) , for − T 2 ≤ t ≤ T 2 0 , otherwise , and, W is assumed to be odd without loss of generality. Under the above assumptions, the Fourier coefficients in (3), for k ∈ Z , are given by C k = Δ f ∫ − T 2 T 2 E ^ ( t , 0 ) e − j 2 π k Δ f t d t (5a) = Δ f ∫ − T 2 T 2 ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n p ( t − n T s ) e − j 2 π k Δ f t d t (5b) = Δ f ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n ∫ − T 2 T 2 p ( t − n T s ) e − j 2 π k Δ f t d t (5c) ≈ Δ f ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n P ( k Δ f ) e − j 2 π k Δ f n T s (5d) = Δ f P ( k Δ f ) ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n e − j 2 π k n W (5e) = Δ f P ( k Δ f ) ν k , (5f) where P ( f ) ≜ F { p ( t ) } and ν k = [ ν x , k , ν y , k ] T = Δ f ∑ n = − ( W − 1 ) / 2 ( W − 1 ) / 2 a n e − j 2 π k n W , ∀ k ∈ Z , (6) are the discrete Fourier transforms of the sequence a n , n = 0 , 1 , … , W − 1 . Note that the approximation in (5c)–(5d) is justified only for large enough values of T as lim T → ∞ ∫ − T 2 T 2 p ( t − n T s ) e − j 2 π k Δ f t d t = F { p ( t − n T s ) } | f = k Δ f , for n , k ∈ Z , and letting T → ∞ will be the approach taken at a later stage in this derivation.Finally, combining (4) and (5f), we obtain E ( f , 0 ) = Δ f ∑ k = − ∞ ∞ P ( k Δ f ) ν k δ ( f − k Δ f ) ≈ ∑ k = − ( W − 1 ) / 2 ( W − 1 ) / 2 P ( k Δ f ) ν k δ ( f − k Δ f ) , (7) where the approximate equality on the right-hand side of (7) stems from the fact that p ( t ) is assumed to be strictly or quasi-strictly band-limited (see Section 3.1). Hence, P ( k Δ f ) is effectively equal to zero for k = − W / 2 , − W / 2 + 1 , … , W / 2 . 4. PSD of the First-Order NLI for Periodic Transmitted SignalsTo find an analytical expression for NLI power, first, a solution as explicit as possible to the Manakov equation [12] ∂ E ˜ ( t , z ) ∂ z = − α 2 E ˜ ( t , z ) − j β 2 2 ∂ 2 E ˜ ( t , z ) ∂ t 2 + j 8 9 γ | E ˜ ( t , z ) | 2 E ˜ ( t , z ) , (8) must be found. Equation (8) describes the propagation of the optical field E ˜ ( t , z ) in a single strand of fibre (e.g., a fibre span with no amplifier in the system in Figure 2). In this case, α , β 2 , and γ representing the attenuation, group velocity dispersion, and nonlinearity coefficients, respectively, can be assumed to be spatially constant. As it is well-known, general closed-form solutions are not available for (8). Like most of the existing NLI power models in the literature, the model derived here operates within a first-order perturbative framework. In particular, a frequency-domain first-order regular perturbation (RP) approach in the γ coefficient is performed [13,14], i.e., the Fourier transform of the solution in (8) is expressed as E ( f , z ) = ∑ n = 0 ∞ γ n A n ( f , z ) ≈ A 0 ( f , z ) + γ A 1 ( f , z ) , (9) where E n ( f , z ) = γ n A n ( f , z ) for n = 0 , 1 , … , (10) represents the so-called nth order term of the expansion.In the following theorem, we present the expressions for E 0 ( f , z ) , and E 1 ( f , z ) , when a multiple fibre span system like the one in Figure 2 is considered. These expressions are well-known in the literature (see, e.g., [13]). Nevertheless, we present the proof in Appendix A for completeness.Theorem 1 (First-order frequency-domain RP solution for a multi-span fibre system). Let E ( f , z ) be the solution in the frequency domain of the Manakov equation for the system in Figure 2 with initial condition at distance z = 0 given by the transmitted signal E ( f , 0 ) . Then, the first-order RP solution after N s spans E ( f , N s , L s ) is given by E ( f , N s , L s ) ≈ E 0 ( f , N s , L s ) + E 1 ( f , N s , L s ) , where the zeroth-order term is given by E 0 ( f , N s , L s ) = E 0 ( f , 0 ) e j 2 π 2 f 2 β 2 N s L s , and the first-order term is E 1 ( f , N s , L s ) = − j 8 9 γ e j 2 π 2 f 2 β 2 N s L s ∫ − ∞ ∞ ∫ − ∞ ∞ E T ( f 1 , 0 ) E ∗ ( f 2 , 0 ) E ( f − f 1 + f 2 , 0 ) η ( f 1 , f 2 , f , N s , L s ) d f 1 d f 2 , (11) with η ( f 1 , f 2 , f , N s , L s ) ≜ 1 − e − α L s e j 4 π 2 β 2 ( f − f 1 ) ( f 2 − f 1 ) L s α − j 4 π 2 β 2 ( f − f 1 ) ( f 2 − f 1 ) ∑ l = 1 N s e − j 4 π 2 β 2 ( l − 1 ) ( f − f 1 ) ( f 2 − f 1 ) L s , (12) where N s and L s are the number of spans and the span length of each span, respectively.Proof. See Appendix A. □While Theorem 1 gives an approximation for the field at the output of the fibre, we are interested in the field after ideal CDC (see Figure 2). Ideal CDC ideally removes the exponential e j 2 β 2 π 2 f 2 N s L s from (11), leading to a first-order term in the RP solution for the system in Figure 2 given by E ˚ 1 ( f , N s , L s ) = [ E ˚ 1 , x , E ˚ 1 , y ] T = − j 8 9 γ ∫ − ∞ ∞ ∫ − ∞ ∞ E T ( f 1 , 0 ) E ∗ ( f 2 , 0 ) E ( f − f 1 + f 2 , 0 ) · η ( f 1 , f 2 , f , N s , L s ) d f 1 d f 2 . (13) Substituting the spectrum of the transmitted periodic signal (7) in (13), we obtain, for instance, for the x component in (13), E ˚ 1 , x ( f , N s , L s ) = − j 8 9 γ Δ f 3 / 2 ∑ k = − ∞ ∞ ∑ m = − ∞ ∞ ∑ n = − ∞ ∞ P ( k Δ f ) P ∗ ( m Δ f ) P ( n Δ f ) ν x , k ν x , m ∗ ν x , n + ν y , k ν y , m ∗ ν x , n · ∫ − ∞ ∞ ∫ − ∞ ∞ δ ( f 1 − k Δ f ) δ ( f 2 − m Δ f ) δ ( f − f 1 + f 2 − n Δ f ) η ( f 1 , f 2 , f , N s , L s ) d f 1 d f 2 . (14) Although the product of Dirac’s deltas in (14) is not well-defined in the standard distribution theory framework, in this case, such product can be dealt with in the same way as products between distributions and smooth functions. This approach was formalised by Colombeau in his theory of product between distributions [15]. Thus, integrating in f 1 and f 2 , we obtain E ˚ 1 , x ( f , N s , L s ) = − j 8 9 γ Δ f 3 / 2 ∑ k = − ∞ ∞ ∑ m = − ∞ ∞ ∑ n = − ∞ ∞ P ( k Δ f ) P ∗ ( m Δ f ) P ( n Δ f ) · ν x , k ν x , m ∗ ν x , n + ν y , k ν y , m ∗ ν x , n η ( k Δ f , m Δ f , ( k − m + n ) Δ f , N s , L s ) δ ( f − ( k − m + n ) Δ f ) . (15) Setting i = k − m + n and defining η k , m , n ≜ η ( k Δ f , m Δ f , ( k − m + n ) Δ f , N s , L s ) = 1 − e − α L s e j 4 π 2 Δ f 2 β 2 ( n − m ) ( m − k ) L s α − j 4 π 2 Δ f 2 β 2 ( n − m ) ( m − k ) ∑ l = 1 N s e − j 4 π 2 Δ f 2 β 2 ( l − 1 ) ( n − m ) ( m − k ) L s (16) (15) can be rewritten as E ˚ 1 , x ( f , N s , L s ) = ∑ i = − ∞ ∞ c i δ ( f − i Δ f ) , (17) where c i ≜ − j 8 9 γ Δ f 3 / 2 ∑ ( k , m , n ) ∈ S i P ( k Δ f ) P ∗ ( m Δ f ) P ( n Δ f ) ν x , k ν x , m ∗ ν x , n + ν y , k ν y , m ∗ ν x , n η k , m , n , (18) and S i ≜ { ( k , m , n ) ∈ Z 3 : k − m + n = i } . (19) The PSD of the received nonlinear interference (to the 1st-order) is defined as S ( f , N s , L s ) = [ S x ( f , N s , L s ) , S y ( f , N s , L s ) ] T ≜ E | E ˚ 1 , x ( f , N s , L s ) | 2 , E | E ˚ 1 , y ( f , N s , L s ) | 2 T . For periodic signals, which in the frequency domain can be expressed as in (17), the PSD can be expressed as [16] (Section 4.1.2) S x ( f , N s , L s ) = ∑ i = − ∞ ∞ E { | c i | 2 } δ ( f − i Δ f ) . (20) Substituting the expression (18) for c i in (20), we obtain S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) E { ∑ ( k , m , n ) ∈ S i P ( k Δ f ) P ∗ ( m Δ f ) P ( n Δ f ) ν x , k ν x , m ∗ ν x , n + ν y , k ν y , m ∗ ν x , n η k , m , n ∑ ( k ′ , m ′ , n ′ ) ∈ S i P ∗ ( k ′ Δ f ) P ( m ′ Δ f ) P ∗ ( n ′ Δ f ) ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ + ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k ′ , m ′ , n ′ ∗ } = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) E { ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ ν x , k ν x , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ (21a) + ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ + ν y , k ν y , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ + ν y , k ν y , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , m , n η k ′ , m ′ , n ′ ∗ } , (21b) where we have defined P k , m , n , k ′ , m ′ , n ′ ≜ P ( k Δ f ) P ∗ ( m Δ f ) P ( n Δ f ) P ∗ ( k ′ Δ f ) P ( m ′ Δ f ) P ∗ ( n ′ Δ f ) . (22) The following proposition can be used to make (21b) more compact, and in particular, it will be used to group the two inner correlation terms in (21b) ( ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ and ν y , k ν y , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ ).Proposition 1. For P k , m , n , k ′ , m ′ , n ′ in (22), we have ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , m , n η k ′ , m ′ , n ′ ∗ = ( ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ ν y , k ν y , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ η k , m , n η k ′ , m ′ , n ′ ∗ ) ∗ . (23) Proof. See Appendix B. □Using (23) and (21b) can be written as S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) E { ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ · ν x , k ν x , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ + ν y , k ν y , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , m , n η k ′ , m ′ , n ′ ∗ + 2 Re { P k , m , n , k ′ , m ′ , n ′ ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , n , m η k ′ , n ′ , m ′ ∗ } } = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ E ν x , k ν x , m ∗ ν x , n ν x , k ′ ∗ ν x , m ′ ν x , n ′ ∗ + E ν y , k ν y , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , m , n η k ′ , m ′ , n ′ ∗ + 2 Re { P k , m , n , k ′ , m ′ , n ′ E ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , n , m η k ′ , n ′ , m ′ ∗ } , (24) where the real part operator arises from the sum of the complex conjugate terms discussed in the Proposition section (Section 1).According to (24), calculation of the PSD of the NLI reduces to the computation of a four-dimensional summation (per frequency component i Δ f ) of three sixth-order correlations of the sequence of random variables ν x / y , n , n = 0 , 1 , … , W − 1 . The y-component S y ( f , N s , L s ) of the PSD can be calculated once S x ( f , N s , L s ) is obtained by simply swapping the polarisation labels x → y and y → x . This is due to the invariance of the Manakov equation in (8) to such a transformation. 5. Classification of the Modulation-Dependent Contributions in the 6th-Order Frequency-Domain CorrelationIn this section, we will break down the frequency-domain sixth-order correlation terms in (24) to highlight different contributions in terms of 4D modulation-dependent cross-polarisation correlations. 5.1. Expansion in Terms of the Stochastic Moments of the Transmitted Modulation FormatTo relate the PSD in (24) to the statistical properties of the transmitted modulation format, we replace (6) into (24), obtaining S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i [ P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ · ∑ i ∈ { 0 , 1 , … , W − 1 } 6 S i ( k , m , n , k ′ , m ′ , n ′ ) + 2 Re { P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ · ∑ i ∈ { 0 , 1 , … , W − 1 } 6 T i ( k , m , n , k ′ , m ′ , n ′ ) } ] , (25) where i ≜ ( i 1 , i 2 , … , i 6 ) , S i ( k , m , n , k ′ , m ′ , n ′ ) ≜ Δ f 3 E a x , i 1 a x , i 2 ∗ a x , i 3 a x , i 4 ∗ a x , i 5 a x , i 6 ∗ + E a y , i 1 a y , i 2 ∗ a x , i 3 a y , i 4 ∗ a y , i 5 a x , i 6 ∗ · e − j 2 π W ( k i 1 − m i 2 + n i 3 − k ′ i 4 + m ′ i 5 − n ′ i 6 ) , (26) and T i ( k , m , n , k ′ , m ′ , n ′ ) ≜ Δ f 3 E a x , i 1 a x , i 2 ∗ a x , i 3 a y , i 4 ∗ a y , i 5 a x , i 6 ∗ e − j 2 π W ( k i 1 − m i 2 + n i 3 − k ′ i 4 + m ′ i 5 − n ′ i 6 ) . (27) The terms S i ( k , m , n , k ′ , m ′ , n ′ ) and T i ( k , m , n , k ′ , m ′ , n ′ ) give rise to several correlations among the transmitted symbols a x , i and a y , j at different time-slots i , j , each weighted by a complex exponential. As discussed in Section 3, in this work, we operate under the assumption that the sequence of vector RVs a i for i = 0 , 1 , … , W − 1 are independent, identically distributed (i.i.d.), and with E { a i } = E { a } = 0 . As shown in the following example, this assumption allows us to discard the S i ( k , m , n , k ′ , m ′ , n ′ ) and T i ( k , m , n , k ′ , m ′ , n ′ ) terms which are identically zero for some values of i . Moreover, as it will be shown in Example 2 for all other values of i , S i ( k , m , n , k ′ , m ′ , n ′ ) , and T i ( k , m , n , k ′ , m ′ , n ′ ) can be expressed as a product of high-order statistical moments of the RVs a x and a y , which enables a more compact expression for (25).Example 1. Under the i.i.d. assumption for the sequence of vector RVs a i , i = 0 , 1 , … W − 1 made in this work, in any of the cases where i κ 1 ≠ i κ 2 = i κ 3 = … = i κ 6 for κ 1 , κ 2 , … , κ 6 = 1 , 2 , … , 6 ; κ 1 ≠ κ 2 ≠ … ≠ κ 6 , (28) any of the sixth-order correlations in (26) and (27) degenerate into a product between a first-order moment and a fifth-order correlation. Such a product is equal to zero under our assumption E { a x , i } = E { a x } = 0 . For example, for i 1 ≠ i 2 = i 3 = … = i 6 , we have E { a x , i 1 a x , i 2 ∗ a x , i 3 a x , i 4 ∗ a x , i 5 a x , i 6 ∗ } = E { a x , i 1 } E { | a x , i 2 | 4 a x , i 2 ∗ } = E { a x } E { | a x | 4 a x ∗ } = 0 . From this follows that, for all elements in the set defined in (28), S i ( k , m , n , k ′ , m ′ , n ′ ) = 0 and T i ( k , m , n , k ′ , m ′ , n ′ ) = 0 . This example highlights a zero-contribution region in the 6D space { 0 , 1 , … , W − 1 } 6 , as illustrated in Figure 4.The S i ( k , m , n , k ′ , m ′ , n ′ ) and T i ( k , m , n , k ′ , m ′ , n ′ ) contributions for the set in (28) are identically zero regardless of the values taken by k , m , n , k ′ , m ′ , and n ′ . However, as it will be shown in Section 6, for a specific subset of values k , m , n , k ′ , m ′ , and n ′ , such contributions cancel each other in the inner sums in (25) due to the complex exponential weights.Example 2. Under the i.i.d. assumption for the sequence of vector RVs a i , i = 0 , 1 , … W − 1 made in this work, we have that, for all elements in the set { i ∈ { 0 , 1 , … , W − 1 } 6 , i 1 = i 2 , i 3 = i 4 = i 5 = i 6 , i 1 ≠ i 3 } S i ( k , m , n , k ′ , m ′ , n ′ ) = Δ f 3 [ E { | a x , i 1 | 2 } E { | a x , i 3 | 4 } + E { | a y , i 1 | 2 } E { | a x , i 3 | 2 | a y , i 3 | 2 } ] · e − j 2 π W ( ( k − m ) i 1 + ( n − k ′ + m ′ − n ′ ) i 3 ) = Δ f 3 [ E { | a x | 2 } E { | a x | 4 } + E { | a y | 2 } E { | a x | 2 | a y | 2 } ] e − j 2 π W ( ( k − m ) i 1 + ( n − k ′ + m ′ − n ′ ) i 3 ) , T i ( k , m , n , k ′ , m ′ , n ′ ) = Δ f 3 E { | a x , i 1 | 2 } E { | a x , i 3 | 2 | a y , i 3 | 2 } e − j 2 π W ( k i 1 − m i 2 + n i 3 − k ′ i 4 + m ′ i 5 − n ′ i 6 ) = Δ f 3 E { | a x | 2 } E { | a x | 2 | a y | 2 } e − j 2 π W ( k i 1 − m i 2 + n i 3 − k ′ i 4 + m ′ i 5 − n ′ i 6 ) . It can be noted that (i) the sixth-order correlation degenerates into a product of marginal high-order moments of a x and a y and into the cross-polarisation correlation E { | a x | 2 | a y | 2 } and (ii) all elements within the set in this example contribute to the inner summation in (25) with the same set of moments, cross-polarisation correlations, and products thereof (i.e., E { | a x | 2 } , E { | a x | 4 } , E { | a y | 2 } , a n d E { | a x | 2 | a y | 2 } ). This example illustrates how to break down each instance of the contributions S i ( k , m , n , k ′ , m ′ , n ′ ) and T i ( k , m , n , k ′ , m ′ , n ′ ) , which will be then added up in Section 6.In the remainder of this section, we first partition the six-dimensional space i ∈ { 0 , 1 , … , W − 1 } 6 and list all sets corresponding to nonzero elements of S i ( k , m , n , k ′ , m ′ , n ′ ) and T i ( k , m , n , k ′ , m ′ , n ′ ) . As shown in Example 2, this will help highlight the contribution of a specific set in terms of high-order moments of the transmitted symbols a in (25). Then, we proceed to list all such contributions. 5.2. Set PartitioningThe six-dimensional space i ∈ { 0 , 1 , … , W − 1 } 6 can be partitioned in different subsets, each one uniquely defined by a partition on the set of indices ( i 1 , i 2 , i 3 , i 4 , i 5 , and i 6 ). Each partition defines its corresponding subset in { 0 , 1 , … , W − 1 } 6 as follows: for each index partition, the indices belonging to the same subset all take the same value, whilst the indices belonging to different subsets have distinct values. This is schematically illustrated in Figure 4. For example, the subset of { 0 , 1 , … , W − 1 } 6 labelled by the index partition { ( i 1 , i 2 ) , ( i 3 , i 4 ) , ( i 5 , i 6 ) } is defined as { i ∈ { 0 , 1 , … , W − 1 } 6 : i 1 = i 2 , i 3 = i 4 , i 5 = i 6 , i 1 ≠ i 3 ≠ i 5 } . This subset is shown in Figure 4 as part of L 1 .In Figure 4, the families of subsets of { 0 , 1 , … , W − 1 } 6 labelled L i , i = 1 , 2 , … , 4 , are also highlighted. These families are characterised by subsets sharing the same cardinality of elements associated to their corresponding index partition. For example, in L 1 , all index partitions are characterised by 3 subsets, each one containing 2 indices. As shown in Example 2, this way of partitioning the set { 0 , 1 , … , W − 1 } 6 is useful as it separates out the different contributions of (25) based on the high-order moments of a , as it is highlighted in region L 3 of Figure 4.Since we have 6 different indices, the number of subsets in a partition can vary from 1 to 6. Each of these subsets can contain a number of elements also ranging from 1 to 6. However, the subsets of { 0 , 1 , … , W − 1 } 6 , where the corresponding index partition has one or more index subsets with only one element, bring no contribution to (25) and thus can be discarded. This is illustrated in Example 1. The above class of index partitions then forms a zero contribution region, as shown in Figure 4. Such a region also includes all subsets where the corresponding index partitions contain 4 or more index subsets, as at least one of these subsets will have to contain only one element.As shown in Figure 4, by removing the zero contribution region from { 0 , 1 , … , W − 1 } 6 , only 4 different families of subsets are left:(i) L 1 = { i ∈ { 0 , 1 , … , W − 1 } 6 : i κ 1 = i κ 2 , i κ 3 = i κ 4 , i κ 5 = i κ 6 ; κ 1 , κ 2 , … κ 6 = 1 , 2 , … , 6 ; κ 1 ≠ κ 2 ≠ κ 3 ≠ κ 4 ≠ κ 5 ≠ κ 6 } . This set contains all sets of elements where the indices i 1 , i 2 , … , i 6 , can be grouped in 3 pairs. The indices take up the same value within each pair but different values across different pairs. It can be found that this set can be partitioned in 15 different subsets C 1 ( i ) , i = 1 , 2 , … , 15 , representing all possible distinct ways of pairing the i k indices for k = 1 , 2 , … 6 . These sets are listed in Table A1 in Appendix C, where each column shows a subgroup of indices taking the same value;(ii) L 2 : { i ∈ { 0 , 1 , … , W − 1 } 6 , i κ 1 = i κ 2 = i κ 3 , i κ 4 = i κ 5 = i κ 6 ; κ 1 , κ 2 , … , κ 6 = 1 , 2 , … , 6 ; κ 1 ≠ κ 2 ≠ κ 3 ≠ κ 4 ≠ κ 5 ≠ κ 6 } which can be broken down in 10 subsets C 2 ( i ) , i = 1 , 2 , … , 10 , listed in Table A2 in Appendix C. Each index subgroup identifies a triplet of indices assuming the same value;(iii) L 3 = { i ∈ { 0 , 1 , … , W − 1 } 6 : i κ 1 = i κ 2 , i κ 3 = i κ 4 = i κ 5 = i κ 6 ; κ 1 , κ 2 , … , κ 6 = 1 , 2 , … , 6 , κ 1 ≠ κ 2 ≠ κ 3 ≠ κ 4 ≠ κ 5 ≠ κ 6 } which can be partitioned in 15 subsets C 3 ( i ) , i = 1 , 2 , … , 15 , listed in Table A3 in Appendix C. Each of the two index subgroups identifies the pair and the quadruple of indices assuming the same value;(iv) L 4 : { i ∈ { 0 , 1 , … , W − 1 } 6 : i 1 = i 2 = i 3 = i 4 = i 5 = i 6 } . 6. Evaluation of the L -Based ContributionsIn this section, we provide three examples for the computation of the contributions of a generic element in L 1 , L 2 , and L 3 . The full list of contributions in these three sets and the ones in L 4 are given in Section 6.1, Section 6.2, Section 6.3, Section 6.4.We label each contribution as M g ( h ) ( k , m , n , k ′ , m ′ , n ′ ) and N g ( h ) ( k , m , n , k ′ , m ′ , n ′ ) , where M g ( h ) ( k , m , n , k ′ , m ′ , n ′ ) ≜ ∑ i ∈ C g ( h ) S i ( k , m , n , k ′ , m ′ , n ′ ) , N g ( h ) ( k , m , n , k ′ , m ′ , n ′ ) ≜ ∑ i ∈ C g ( h ) T i ( k , m , n , k ′ , m ′ , n ′ ) , (29) and the subsets C g ( h ) are taken from Table A1, Table A2, Table A3 in Appendix C.Example 3 (Contributions in L 1 ). M 1 ( 1 ) , i.e., one of the 2 contributions for the set C 1 ( 1 ) = { i ∈ { 0 , 1 , … , W − 1 } 6 : i 1 = i 2 , i 3 = i 4 , i 5 = i 6 , i 1 ≠ i 3 , i 1 ≠ i 5 , i 3 ≠ i 5 } is given by M 1 ( 1 ) ≜ ∑ i ∈ C 1 ( 1 ) S i ( k , m , n , k ′ , m ′ , n ′ ) = Δ f 3 E 3 | a x | 2 + E | a y | 2 | E a x a y ∗ | 2 ∑ i 1 = 0 W − 1 e − j 2 π W ( k − m ) i 1 ∑ i 3 ≠ i 1 e − j 2 π W ( n − k ′ ) i 3 · ∑ i 5 ≠ i 1 , i 5 ≠ i 3 e − j 2 π W ( m ′ − n ′ ) i 5 . (30) Since ∑ k = 0 W − 1 e j n k 2 π W = W , for n = p W , p ∈ Z 0 , elsewhere , (31) we can compute (30) using the following approach:we add up the terms for all i 1 , i 3 , i 5 values including all cases when i 1 , i 3 , and i 5 are equal among each other. Because of (31), these terms sum up to W 3 only when k = m + p W , n = k ′ + p W , a n d m ′ = n ′ + p W , p ∈ Z ; otherwise, they sum to 0;we subtract the terms corresponding to the cases: i 1 = i 3 , i 1 ≠ i 5 ; i 1 = i 5 , i 1 ≠ i 3 ; and i 3 = i 5 , i 1 ≠ i 3 . As an example, the number of terms defined by i 1 = i 3 , i 1 ≠ i 5 is given by the difference between the number of all pairs i 1 , i 5 ∈ { 0 , 1 , 2 , … , W − 1 } and the number of terms for i 1 = i 5 . According to (31), the former terms sum to W 2 only for k − m + n − k ′ = p W , m ′ − n ′ = p W , whereas the latter sum to W only for k − m + n − k ′ + m ′ − n ′ = p W , with p ∈ Z . In all other cases, they all bring zero contribution. Similar results are obtained for i 1 = i 5 , i 1 ≠ i 3 and i 3 = i 5 , i 1 ≠ i 3 ;we finally subtract the terms i 1 = i 3 = i 5 , which sum to W only for k − m + n − k ′ + m ′ − n ′ = p W , p ∈ Z ; otherwise, they sum to 0 (see (31)). Hence, we obtain M 1 ( 1 ) = Δ f 3 [ E 3 { | a x | 2 } + 2 E 2 { | a x | 2 } | E { a x a y ∗ } | 2 + E { | a y | 2 } | E { a x a y ∗ } | 2 ] [ W 3 δ k − m − p W δ n − k ′ − p W δ m ′ − n ′ − p W − [ W 2 ( δ k − m + n − k ′ − p W δ m ′ − n ′ − p W + δ k − m + m ′ − n ′ − p W δ n − k ′ − p W + δ m ′ − n ′ + n − k ′ − p W δ k − m − p W ) − 3 W δ k − m + m ′ − n ′ + n − k ′ − p W ] − W δ k − m + m ′ − n ′ + n − k ′ − p W ] = [ E 3 { | a x | 2 } + 2 E 2 { | a x | 2 } | E { a x a y ∗ } | 2 + E { | a y | 2 } | E { a x a y ∗ } | 2 ] [ R s 3 δ k − m + p W δ n − k ′ − p W δ m ′ − n ′ − p W − R s 2 Δ f ( δ k − m + n − k ′ − p W δ m ′ − n ′ − p W + δ k − m + m ′ − n ′ − p W δ n − k ′ − p W + δ m ′ − n ′ + n − k ′ − p W δ k − m − p W ) + 2 R s Δ f 2 δ k − m + m ′ − n ′ + n − k ′ − p W ] , where we have used R s = W Δ f .The same approach can be followed to compute N 1 ( 1 ) , which is, thus, given by N 1 ( 1 ) ≜ ∑ i ∈ C 1 ( 1 ) T i ( k , m , n , k ′ , m ′ , n ′ ) = E 2 { | a x | 2 } | E { a x a y ∗ } | 2 [ R s 3 δ k − m − p W δ n − k ′ − p W δ m ′ − n ′ − p W − R s 2 Δ f ( δ k − m + n − k ′ − p W δ m ′ − n ′ − p W + δ k − m + m ′ − n ′ − p W δ n − k ′ − p W + δ m ′ − n ′ + n − k ′ − p W δ k − m − p W ) + 2 R s Δ f 2 δ k − m + m ′ − n ′ + n − k ′ − p W ] . All other contributions in L 1 can be computed using the approach used in this example.Example 4 (Contributions in L 2 ). M 2 ( 1 ) , i.e., the contribution for the set C 2 ( 1 ) = { i ∈ { 0 , 1 , … , W − 1 } 6 : i 1 = i 2 = i 3 , i 4 = i 5 = i 6 , i 1 ≠ i 4 } is given by M 2 ( 1 ) = ∑ i ∈ C 2 ( 1 ) S i ( k , m , n , k ′ , m ′ , n ′ ) = Δ f 3 [ E { a x , i 1 | a x , i 1 | 2 } E ∗ { a x , i 4 | a x , i 4 | 2 } + E { a x , i 1 | a y , i 1 | 2 } E ∗ { a x , i 4 | a y , i 4 | 2 } ] · ∑ i 1 = 0 W − 1 e − j 2 π W ( k − m + n ) i 1 ∑ i 4 ≠ i 1 e − j 2 π W ( − k ′ + m ′ − n ′ ) i 4 = Δ f 3 [ | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 ] ∑ i 1 = 0 W − 1 e − j 2 π W ( k − m + n ) i 1 ∑ i 4 ≠ i 1 e − j 2 π W ( − k ′ + m ′ − n ′ ) i 4 . (32) Following a similar approach as in Example 3, we compute (32) byadding up the terms for all i 1 and i 4 values including all cases when i 1 and i 4 are equal to each other. These terms sum up to W 2 only when k − m + n = p W and − k ′ + m ′ − n ′ = p W , with p ∈ Z ; otherwise, they sum to 0;subtracting the terms corresponding to the cases i 1 = i 4 . These terms sum to W only for k − m + n − k ′ + m ′ − n ′ = p W , p ∈ Z ; otherwise, they sum to zero. We, thus, obtain M 2 ( 1 ) = [ | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 ] [ R s 2 Δ f δ k − m + n − p W δ k ′ − m ′ + n ′ − p W − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ − p W ] , Following the same approach for N 2 ( 1 ) , we have N 2 ( 1 ) ≜ ∑ i ∈ C 1 ( 1 ) T i ( k , m , n , k ′ , m ′ , n ′ ) = E { a x | a x | 2 } E { a x | a y | 2 } [ R s 2 Δ f δ k − m + n δ k ′ − m ′ + n ′ − p W − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ − p W ] . All other contributions in L 2 can be computed using the approach used in this example.Example 5 (Contributions in L 3 ). M 3 ( 3 ) , i.e., the contribution for the values in the set C 3 ( 3 ) = { i ∈ { 0 , 1 , … , W − 1 } 6 : i 1 = i 4 , i 2 = i 3 = i 5 = i 6 , i 1 ≠ i 4 , i 2 ≠ i 3 , i 5 ≠ i 6 } is given by M 3 ( 3 ) = ∑ i ∈ C 3 ( 3 ) S i ( k , m , n , k ′ , m ′ , n ′ ) = Δ f 3 [ E { | a x , i 1 | 2 } E { | a x , i 2 | 4 } + E { | a y , i 1 | 2 } E { | a x , i 2 | 2 | a y , i 2 | 2 } ] ∑ i 1 = 1 W − 1 e − j 2 π W ( k − k ′ ) i 1 ∑ i 2 ≠ i 1 e − j 2 π W ( − m + n + m ′ − n ′ ) i 2 = Δ f 3 [ E { | a x | 2 } E { | a x | 4 } + E { | a y | 2 } E { | a x | 2 | a y | 2 } ] ∑ i 1 = 1 W − 1 e − j 2 π W ( k − k ′ ) i 1 ∑ i 2 ≠ i 1 e − j 2 π W ( − m + n + m ′ − n ′ ) i 2 . (33) As in the L 2 case described in Example 4, in L 3 , each subset is characterized by 2 subgroups of indices. Hence, the approach followed to compute (33) is identical to (32) and gives M 3 ( 3 ) = [ E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } ] [ R s 2 Δ f δ k − k ′ − p W δ m − n − m ′ + n ′ − p W − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ − p W ] . Similarly, N 3 ( 3 ) = E { a x a y ∗ } E { a x ∗ a y | a x | 2 } [ R s 2 Δ f δ k − k ′ − p W δ m − n − m ′ + n ′ − p W − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ − p W ] . All other contributions in L 3 can be computed using the approach used in this example.As shown in the above examples, each contribution M g ( h ) and N g ( h ) is nonzero only for a specific set of ( k , m , n , k ′ , m ′ , n ′ ) values which is spanned by p ∈ Z . However, the terms ( k , m , n , k ′ , m ′ , n ′ ) arising for all p ≠ 0 bring a total contribution to (25) that can be considered negligible. This is due to our assumption on P ( f ) being strictly band-limited (see Section 3.1) and to the magnitude of the functions product η k , m , n η k ′ , m ′ , n ′ ∗ (see definitions (16) and (22)). Thus, in the computations performed in the following subsections, we will restrict ourselves to the case p = 0 . 6.1. Contributions in L 1 In this section, the contributions M 1 ( i ) , N 1 ( i ) for i = 1 , 2 , … , 15 are computed following Example 3. These contributions are listed in Table 1. 6.2. Contributions in L 2 Following Example 4, the contributions M 2 ( h ) , N 2 ( h ) , h = 1 , 2 , … , 10 , are computed and listed in Table 2. 6.3. Contributions in L 3 Following Example 5, the contributions M 3 ( h ) , N 3 ( h ) , h = 1 , 2 , … , 15 , are computed and listed in Table 3. 6.4. Contributions in L 4 Since L 4 comprises a single subset characterised by the single subgroup of all 6 indices (see Section 5.2), only one pair of contributions M 4 ( 1 ) , N 4 ( 1 ) exists, and it is given by M 4 ( 1 ) ≜ ∑ i ∈ C 4 ( 1 ) S i ( k , m , n , k ′ , m ′ , n ′ ) = ∑ i 1 = 0 W − 1 [ E { | a x | 6 } + E { | a x | 2 | a y | 4 } ] e − j 2 π W ( k − m ) i 1 = [ E { | a x | 6 } + E { | a x | 2 | a y | 4 } ] R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ , N 4 ( 1 ) ≜ ∑ i ∈ C 4 ( 1 ) S i ( k , m , n , k ′ , m ′ , n ′ ) = E { | a x | 4 | a y | 2 } R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ . 7. Sum of All ContributionsIn Section 5, we evaluated all contributions M g ( h ) and N g ( h ) to the PSD in (25). In particular, from (25)–(27), and (29), we have S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f 3 ∑ i = − ∞ ∞ δ ( f − i Δ f ) ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P ∑ g = 1 4 ∑ h = 1 H ( g ) M g ( h ) + 2 Re P ∑ g = 1 4 ∑ h = 1 H ( g ) N g ( h ) , (34) where H ( g ) is the number of subsets in the partitions of L g , g = 1 , 2 , 3 , 4 , described in Section 5.2 ( H ( g ) = 15 , 10 , 15 , 1 for g = 1 , 2 , 3 , 4 , resp.) and P ≜ P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ . (35) In this section, we evaluate ∑ g = 1 4 ∑ h = 1 H ( g ) M g ( h ) and ∑ g = 1 4 ∑ h = 1 H ( g ) N g ( h ) as well as compact the resulting expression as much as possible.Before we proceed with computing the abovementioned summation, we remove the Kronecker deltas in M g ( h ) and N g ( h ) corresponding to contributions in the following subspaces: (i) k = m ; (ii) n = m ; (iii) k ′ = m ′ ; and (iv) n ′ = m ′ . These contributions correspond to so-called bias terms, i.e., they arise from a component of the field E 1 ( f , z ) which is fully correlated with the transmitted field E 0 ( t , 0 ) . This component, after CDC and MF, only results in a deterministic and static complex scaling of the received constellation, which is typically compensated at the receiver even in the presence of other noise sources in the system. Thus, it does not contribute to the power of the additive zero-mean interference component that we observe at the output of the MF + sampling stage once the received constellation is synchronised (in phase and amplitude) with the transmitted one. A more detailed discussion on these bias terms can be found in [8] (Appendix A), [14] (Appendix C). Moreover, the component δ k − m + n δ k ′ − m ′ + n ′ in M g ( h ) and N g ( h ) is also removed as it only gives nonzero contribution to the PSD for frequency f = i Δ f = 0 ; hence, its effect on the total NLI variance vanishes as we let Δ f → 0 (see Section 8). A total of 23 terms from the last columns of Table 1, Table 2 and Table 3 are thus removed. The remaining contributions are given in Table A4 in Appendix D.We now compact the contributions in Table A4 by grouping the Kronecker delta products based on each correlation term they multiply. We use three pairs of curly brackets { · } to denote the terms multiplying R s 3 , R s 2 , and R s . The list of all Kronecker delta products multiplying each correlation term is shown in Table 4. The correlation terms are divided into intra-polarisation (expectations containing only a x ) and cross-polarisation terms (expectations containing both a x and a y ). Moreover, the correlations are categorised based on the specific contribution (either M or N ) in (34) to which they belong.As it can be observed in Table 4, each correlation term is associated with different delta functions. To compact these terms, we exploit a property introduced in the following proposition.Proposition 2. Let D 1 ( k , m , n , k ′ , m ′ , n ′ ) and D 2 ( k , m , n , k ′ , m ′ , n ′ ) be two Kronecker delta products of the kind shown in Table 4. If D 1 ( k , m , n , k ′ , m ′ , n ′ ) = D 2 ( n , m , k , n ′ , m ′ , k ′ ) , (36) then ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 1 ( k , m , n , k ′ , m ′ , n ′ ) = ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k , m , n , k ′ , m ′ , n ′ ) . (37) This property also holds when applying the transformations k = n , n = k , k ′ = n ′ , and n ′ = k ′ , individually.Proof. See Appendix E. □The property in (37) allows us to group many of the Kronecker function products in Table 4 under a single term. Namely, the Kronecker delta products in Table 4 can be grouped in subsets that are closed to property (36), since they all result in the same value of summations in (37). In particular, 14 distinct subsets can be identified for the list of Kronecker delta products in Table 4. We label these subsets, which are shown in Table 5, as D l for l = 1 , 2 , … , 14 .Summing all the contributions in Table 4, using Proposition 2 for the elements in the subsets listed in Table 4, and finally ordering by Kronecker delta product, we obtain from (34) S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f ∑ i = − ∞ ∞ δ ( f − i Δ f ) · ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i [ R s 3 Δ f 2 [ ( a 1 P + 2 Re { a 1 ′ P } ) δ k − k ′ δ m − m ′ δ n − n ′ + ( a 2 P + 2 Re { a 2 ′ P } ) δ k − k ′ δ m + n ′ δ n + m ′ + ( a 3 P + 2 Re { a 3 ′ P } ) δ k + n δ m − m ′ δ k ′ + n ′ ] + R s 2 Δ f 3 [ ( b 1 P + 2 Re { b 1 ′ P } ) δ k − m − k ′ δ n + m ′ − n ′ + ( b 2 P + 2 Re { b 2 ′ P } ) δ k − m + m ′ δ n − k ′ − n ′ + ( b 2 ∗ P + 2 Re { b 3 ′ P } ) δ k + n − k ′ δ m − m ′ + n ′ + ( b 4 P + 2 Re { b 4 ′ P } ) δ k + n + m ′ δ m + k ′ + n ′ + ( c 1 P + 2 Re { c 1 ′ P } ) δ k + n δ m + k ′ − m ′ + n ′ + ( c 2 P + 2 Re { c 2 ′ P } ) δ k − k ′ δ m − n − m ′ + n ′ + ( c 3 P + 2 Re { c 3 ′ P } ) δ k + m ′ δ m − n + k ′ + n ′ + ( c 4 P + 2 Re { c 4 ′ P } ) δ m − m ′ δ k + n − k ′ − n ′ + ( c 3 ∗ P + 2 Re { c 5 ′ P } ) δ m + k ′ δ k + n + m ′ − n ′ + ( c 1 ∗ P + 2 Re { c 6 ′ P } ) δ k ′ + n ′ δ k − m + n + m ′ ] + R s Δ f 4 ( d 1 P + 2 Re { d 1 ′ P } ) δ k − m + n − k ′ + m ′ − n ′ ] , (38) where the coefficients multiplying P are listed in Table A5 in Appendix F and where coset leaders in Table 5 have been used. Table 4. List of Kronecker delta contributions ordered by the corresponding high-order moment or correlation of the transmitted modulation format. Table 4. List of Kronecker delta contributions ordered by the corresponding high-order moment or correlation of the transmitted modulation format. Correlation TermsKronecker Delta ProductsIntra-Polarisation TermsIn M g ( h ) E 3 { | a x | 2 } { δ k − k ′ δ m − m ′ δ n − n ′ , δ k − n ′ δ m − m ′ δ n − k ′ },{ − 2 δ n − k ′ δ k − m + m ′ − n ′ , − 2 δ n − n ′ δ k − m − k ′ + m ′ , − 2 δ k − k ′ δ m − n − m ′ + n ′ , − 2 δ m − m ′ δ k + n − k ′ − n ′ , − 2 δ k − n ′ δ m − n + k ′ − m ′ },{ 12 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 } | E { a x 2 } | 2 { δ k + n δ m − m ′ δ k ′ + n ′ , δ k − k ′ δ m + n ′ δ n + m ′ , δ k + m ′ δ m + k ′ δ n − n ′ , δ k + m ′ δ m + n ′ δ n − k ′ , δ k − n ′ δ m + k ′ δ n + m ′ },{ − δ n − k ′ δ k − m + m ′ − n ′ , − 3 δ m + k ′ δ k + n + m ′ − n ′ , − 3 δ k + n δ m + k ′ − m ′ + n ′ − 3 δ k ′ + n ′ δ k + n − m + m ′ , − δ m − m ′ δ k + n − k ′ − n ′ , − 3 δ m + n ′ δ k + n − k ′ + m ′ , − 3 δ n + m ′ δ k − m − k ′ − n ′ , − δ k − k ′ δ m − n − m ′ + n ′ , − 3 δ k + m ′ δ m − n + k ′ + n ′ , − δ n − n ′ δ k − m − k ′ + m ′ , − δ k − n ′ δ m − n + k ′ − m ′ , } { 18 δ k − m + n − k ′ + m ′ − n ′ } | E { a x | a x | 2 } | 2 {}, { δ k − m − k ′ δ n + m ′ − n ′ , δ k − m + m ′ δ n − k ′ − n ′ , δ k − m − n ′ δ n − k ′ + m ′ , δ k + n − k ′ δ m − m ′ + n ′ , δ k + n − n ′ δ m + k ′ − m ′ , δ k − k ′ + m ′ δ m − n + n ′ , δ k − k ′ − n ′ δ m − n + m ′ , δ k + m ′ − n ′ δ m − n + k ′ }, { − 9 δ k − m + n − k ′ + m ′ − n ′ } | E { a x 3 } | 2 {}, { δ k + n + m ′ δ m + k ′ + n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 4 } E { | a x | 2 } {}, { δ k − k ′ δ m − n − m ′ + n ′ , δ k − n ′ δ m − n + k ′ − m ′ , δ m − m ′ δ k + n − k ′ − n ′ , δ n − k ′ δ k − m + m ′ − n ′ , δ n − n ′ δ k − m − k ′ + m ′ } , { − 9 δ k − m + n − k ′ + m ′ − n ′ } E ∗ { a x 2 | a x | 2 } E { a x 2 } {}, { δ k + n δ m + k ′ − m ′ + n ′ , δ k + m ′ δ m − n + k ′ + n ′ , δ n + m ′ δ k − m − k ′ − n ′ } , { − 3 δ k − m + n − k ′ + m ′ − n ′ } E { a x 2 | a x | 2 } E ∗ { a x 2 } {}, { δ m + k ′ δ k − n + m ′ − n ′ , δ m + n ′ δ k + n − k ′ + m ′ , δ k ′ + n ′ δ k − m + n + m ′ } , { − 3 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 6 } { } , { } , { δ k − m + n − k ′ + m ′ − n ′ } Cross-polarisation termsIn M g ( h ) E { | a x | 2 } E 2 { | a y | 2 } { δ k − k ′ δ m − m ′ δ n − n ′ } , { − 2 δ n − n ′ δ k − m − k ′ + m ′ , − δ m − m ′ δ k + n − k ′ − n ′ , − δ k − k ′ δ m − n − m ′ + n ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 } | E { a y 2 } | 2 { δ k + m ′ δ m + k ′ δ n − n ′ } , { − δ n − n ′ δ k − m − k ′ + m ′ , − δ m + k ′ δ k + n + m ′ − n ′ , − δ k + m ′ δ m − n + k ′ + n ′ } , { 2 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 } E { | a y | 4 } {}, { δ n − n ′ δ k − m − k ′ + m ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 a y ∗ } E { a y | a y | 2 } {}, { δ k − m + m ′ δ n − k ′ − n ′ , δ k − k ′ + m ′ δ m − n + n ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 | a y | 2 } E { | a y | 2 } {}, { δ k − k ′ δ m − n − m ′ + n ′ , δ m − m ′ δ k + n − k ′ − n ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } E { a x a y } E ∗ { a x a y | a x | 2 } {}, { δ k + m ′ δ m − n + k ′ + n ′ , δ m + k ′ δ k − n + m ′ − n ′ , δ n + m ′ δ k − m − k ′ − n ′ , δ k ′ + n ′ δ k − m + n + m ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } E ∗ { | a x | 2 a y 2 } E { a y 2 } {}, { δ k + m ′ δ m − n + k ′ + n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 a y 2 } E ∗ { a y 2 } {}, { δ m + k ′ δ k − n + m ′ − n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 | a y | 4 } {}, {}, { δ k − m + n − k ′ + m ′ − n ′ } | E { a x a y ∗ } | 2 E { | a y | 2 } { δ k − n ′ δ m − m ′ δ n − k ′ } , { − 2 δ n − k ′ δ k − m + m ′ − n ′ , − 2 δ k − n ′ δ m − n + k ′ − m ′ , − δ k − k ′ δ m − n − m ′ + n ′ , − δ m − m ′ δ k + n − k ′ − n ′ } , { 8 δ k − m + n − k ′ + m ′ − n ′ } E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } { δ k − n ′ δ m + k ′ δ n + m ′ } , { − 2 δ m + k ′ δ k + n + m ′ − n ′ , − δ k + n δ m + k ′ − m ′ + n ′ , − δ n + m ′ δ k − m − k ′ − n ′ , − δ k − n ′ δ m − n + k ′ − m ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } { δ k + m ′ δ m + n ′ δ n − k ′ } , { − 2 δ k + m ′ δ m − n + k ′ + n ′ , − δ k ′ + n ′ δ k − m + n + m ′ , − δ n − k ′ δ k − m + m ′ − n ′ , − δ m + n ′ δ k + n − k ′ + m ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } | E { a x a y } | 2 E { | a y | 2 } { δ k + n δ m − m ′ δ k ′ + n ′ , δ k − k ′ δ m + n ′ δ n + m ′ } , { − 2 δ k ′ + n ′ δ k − m + n + m ′ , − 2 δ k + n δ m − m ′ + k ′ + n ′ , − 2 δ n + m ′ δ k − m − k ′ − n ′ , − 2 δ m + n ′ δ k + n − k ′ + m ′ , − δ m − m ′ δ k + n − k ′ − n ′ , − δ k − k ′ δ m − n − m ′ + n ′ } , { 8 δ k − m + n − k ′ + m ′ − n ′ } | E { a x | a y | 2 } | 2 {}, { δ k − m − n ′ δ n − k ′ + m ′ , δ k + n − k ′ δ m − m ′ + n ′ , δ k − k ′ − n ′ δ m − n + m ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } | E { a x a y 2 } | 2 {}, { δ k + n + m ′ δ m + k ′ + n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } | E { a x ∗ a y 2 } | 2 {}, { δ k + m ′ − n ′ δ m − n + k ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } In N g ( h ) E { | a x | 2 } | E { a x a y ∗ } | 2 { δ k − k ′ δ m − m ′ δ n − n ′ , δ k − n ′ δ m − m ′ δ n − k ′ } , { − 2 δ n − k ′ δ k − m + m ′ − n ′ , − 2 δ k − k ′ δ m − n − m ′ + n ′ , − 2 δ m − m ′ δ k + n − k ′ − n ′ , − δ n − n ′ δ k − m − k ′ + m ′ , − δ k − n ′ δ m − n + k ′ − m ′ } , { 8 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 } | E { a x a y } | 2 { δ k + m ′ δ m + k ′ δ n − n ′ , δ k − n ′ δ m + k ′ δ n + m ′ } , { − 2 δ k ′ + n ′ δ k − m + n + m ′ , − 2 δ n + m ′ δ k − m − k ′ − n ′ , − 2 δ k + m ′ δ m − n + k ′ + n ′ , − 2 δ m + k ′ δ k + n + m ′ − n ′ , − δ n − n ′ δ k − m − k ′ + m ′ , − δ k − n ′ δ m − n + k ′ − m ′ } , { 8 δ k − m + n − k ′ + m ′ − n ′ } . E 2 { | a x | 2 } E { | a y | 2 } {}, { − δ n − n ′ δ k − m − k ′ + m ′ , − δ k − n ′ δ m − n + k ′ − m ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 2 } E { | a x | 2 | a y | 2 } {}, { δ k − n ′ δ m − n + k ′ − m ′ , δ n − n ′ δ k − m − k ′ + m ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 4 } E { | a y | 2 } {}, {}, { − δ k − m + n − k ′ + m ′ − n ′ } E { a x | a x | 2 } E { a x | a y | 2 } {}, {}, { − δ k − m + n − k ′ + m ′ − n ′ } E { a y ∗ | a y | 2 } E { | a x | 2 a y } {}, { δ k − m − k ′ δ n + m ′ − n ′ , δ k + n − n ′ δ m + k ′ − m ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } E { a x ∗ | a x | 2 } E { a x | a y | 2 } {}, { δ k − m − n ′ δ n − k ′ + m ′ , δ k + n − n ′ δ m + k ′ − m ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } | E { | a x | 2 a y } | 2 {}, { δ k − m − k ′ δ n + m ′ − n ′ , δ k − m + m ′ δ n − k ′ − n ′ , δ k − k ′ − n ′ δ m − n + m ′ , δ k + m ′ − n ′ δ m − n + k ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } E { a x a y ∗ } E { a x ∗ a y | a x | 2 } {}, { δ k − k ′ δ m − n − m ′ + n ′ , δ m − m ′ δ k + n − k ′ − n ′ , δ n − k ′ δ k − m + m ′ − n ′ } , { − 4 δ k − m + n − k ′ + m ′ − n ′ } E { | a x | 4 | a y | 2 } {}, {}, { δ k − m + n − k ′ + m ′ − n ′ } E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } { δ k + n δ m − m ′ δ k ′ + n ′ } , { − 2 δ k + n δ m + k ′ − m ′ + n ′ , − δ m + k ′ δ k + n + m ′ − n ′ , − δ k ′ + n ′ δ k + n − m + m ′ , − δ m − m ′ δ k + n − k ′ − n ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } { δ k − k ′ δ m + n ′ δ n + m ′ , δ k + m ′ δ m + n ′ δ n − k ′ } , { − 2 δ m + n ′ δ k + n − k ′ + m ′ , − δ n + m ′ δ k − m − k ′ − n ′ , − δ k − k ′ δ m − n − m ′ + n ′ , − δ n − k ′ δ k − m + m ′ − n ′ , − δ k + m ′ δ m − n + k ′ + n ′ } , { 4 δ k − m + n − k ′ + m ′ − n ′ } | E { a x 2 } | 2 E { | a y | 2 } {}, { − δ m + n ′ δ k + n − k ′ + m ′ , − δ k + n δ m + k ′ − m ′ + n ′ } , { 2 δ k − m + n − k ′ + m ′ − n ′ } | E { a x 2 a y ∗ } | 2 {}, { δ k + n − k ′ δ m − m ′ + n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } | E { a x 2 a y } | 2 {}, { δ k + n + m ′ δ m + k ′ + n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { a x 2 } E ∗ { a x 2 | a y | 2 } {}, { δ k + n δ m + k ′ − m ′ + n ′ , δ m + n ′ δ k + n − k ′ + m ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } E { a x a y } E ∗ { a x a y | a y | 2 } {}, { δ k + n δ m + k ′ − m ′ + n ′ , δ n + m ′ δ k − m − k ′ − n ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } E ∗ { a x a y } E { a x a y | a y | 2 } {}, { δ m + n ′ δ k + n − k ′ + m ′ , δ k ′ + n ′ δ k − m + n + m ′ } , { − 2 δ k − m + n − k ′ + m ′ − n ′ } E { a x ∗ a y } E { a x a y ∗ | a y | 2 } {}, { δ k − n ′ δ m − n + k ′ − m ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } E { a x a y ∗ } E { a x ∗ a y | a y | 2 } {}, { δ n − k ′ δ k − m + m ′ − n ′ } , { − δ k − m + n − k ′ + m ′ − n ′ } Table 5. Subsets of Kronecker delta products which are closed to property (36). The terms in boldface are the ones used to group all other elements within each set. Table 5. Subsets of Kronecker delta products which are closed to property (36). The terms in boldface are the ones used to group all other elements within each set. Set NameSet Elements D 1 δ k − k ′ δ m − m ′ δ n − n ′ , δ k − n ′ δ m − m ′ δ n − k ′ D 2 δ k − k ′ δ m + n ′ δ n + m ′ , δ k + m ′ δ m + k ′ δ n − n ′ , δ k + m ′ δ m + n ′ δ n − k ′ , δ k − n ′ δ m + k ′ δ n + m ′ D 3 δ k + n δ m − m ′ δ k ′ + n ′ D 4 δ k − m − k ′ δ n + m ′ − n ′ , δ k − m − n ′ δ n − k ′ + m ′ , δ k + m ′ − n ′ δ m − n + k ′ , δ k − k ′ + m ′ δ m − n + n ′ D 5 δ k − m + m ′ δ n − k ′ − n ′ , δ k − k ′ − n ′ δ m − n − m ′ D 6 δ k + n − k ′ δ m − m ′ + n ′ , δ k + n − n ′ δ m + k ′ − m ′ D 7 δ k + n + m ′ δ m + k ′ + n ′ D 8 δ k + n δ m + k ′ − m ′ + n ′ D 9 δ k − k ′ δ m − n − m ′ + n ′ , δ k − n ′ δ m − n + k ′ − m ′ , δ n − k ′ δ k − m + m ′ − n ′ , δ n − n ′ δ k − m − k ′ + m ′ D 10 δ k + m ′ δ m − n + k ′ + n ′ , δ n + m ′ δ k − m − k ′ − n ′ D 11 δ m − m ′ δ k + n − k ′ − n ′ D 12 δ m + k ′ δ k + n + m ′ − n ′ , δ m + n ′ δ k + n − k ′ + m ′ D 13 δ k ′ + n ′ δ k − m + n + m ′ D 14 δ k − m + n − k ′ + m ′ − n ′ Equation (38) can be further manipulated using the following proposition.Proposition 3. Let D 1 ( k , m , n , k ′ , m ′ , n ′ ) and D 2 ( k , m , n , k ′ , m ′ , n ′ ) be two Kronecker delta products of the kind shown in the second column of Table 4. If D 1 ( k , m , n , k ′ , m ′ , n ′ ) = D 2 ( k ′ , m ′ , n ′ , k , m , n ) , then ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 1 ( k , m , n , k ′ , m ′ , n ′ ) = ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k , m , n , k ′ , m ′ , n ′ ) ∗ . (39) Proof. See Appendix G. □Corollary 1. Let D ( k , m , n , k ′ , m ′ , n ′ ) be a Kronecker delta product for which the following property holds D ( k , m , n , k ′ , m ′ , n ′ ) = D ( k ′ , m ′ , n ′ , k , m , n ) , then ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D ( k , m , n , k ′ , m ′ , n ′ ) ∈ R . Proof. This corollary directly follows from Proposition 3 when D 1 = D 2 = D . □Based on Corollary 1, we obtain from (38) S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f ∑ i = − ∞ ∞ δ ( f − i Δ f ) · ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i [ R s 3 Δ f 2 [ ( a 1 + 2 Re { a 1 ′ } ) P δ k − k ′ δ m − m ′ δ n − n ′ + ( a 2 + 2 Re { a 2 ′ } ) P δ k − k ′ δ m + n ′ δ n + m ′ + ( a 3 + 2 Re { a 3 ′ } ) P δ k + n δ m − m ′ δ k ′ + n ′ ] + R s 2 Δ f 3 [ ( b 1 + 2 Re { b 1 ′ } ) P δ k − m − k ′ δ n + m ′ − n ′ + ( b 2 P + 2 Re { b 2 ′ P } ) δ k − m + m ′ δ n − k ′ − n ′ + ( b 2 ∗ P + 2 Re { b 3 ′ P } ) δ k + n − k ′ δ m − m ′ + n ′ + ( b 4 + 2 Re { b 4 ′ } ) P δ k + n + m ′ δ m + k ′ + n ′ + ( c 1 P + 2 Re { c 1 ′ P } ) δ k + n δ m + k ′ − m ′ + n ′ + ( c 2 + 2 Re { c 2 ′ } ) P δ k − k ′ δ m − n − m ′ + n ′ + ( c 3 P + 2 Re { c 3 ′ P } ) δ k + m ′ δ m − n + k ′ + n ′ + ( c 4 + 2 Re { c 4 ′ } ) P δ m − m ′ δ k + n − k ′ − n ′ + ( c 5 P + 2 Re { c 5 ′ P } ) δ m + k ′ δ k + n + m ′ − n ′ + ( c 6 P + 2 Re { c 6 ′ P } ) δ k ′ + n ′ δ k − m + n + m ′ ] + R s Δ f 4 ( d 1 + 2 Re { d 1 ′ } ) P δ k − m + n − k ′ + m ′ − n ′ ] , where we have used the fact that the sets D i for i = 1 , 2 , 3 , 4 , 7 , 9 , 11 , 14 , are closed to the transformation in Proposition 3. Furthermore, we notice that the set pairs ( D 5 , D 6 ) , ( D 8 , D 13 ) , and ( D 10 , D 12 ) represent pairs of complementary sets under the transformation in Corollary 1; hence, their elements can be grouped. Consequently, S x ( f , N s , L s ) = 8 9 2 γ 2 Δ f ∑ i = − ∞ ∞ δ ( f − i Δ f ) · R s 3 Δ f 2 Φ 1 Q 1 + Φ 2 Q 2 + Φ 3 Q 3 + R s 2 Δ f 3 Ψ 1 Q 4 + 2 Re { Ψ 2 Q 5 + Ψ 3 Q 5 ∗ } + Ψ 4 Q 6 + 2 Re { Λ 1 Q 7 + Λ 2 Q 7 ∗ } + Λ 3 Q 8 + 2 Re { Λ 4 Q 9 + Λ 5 Q 9 ∗ } + Λ 6 Q 10 + R s Δ f 4 Ξ 1 Q 11 , (40) where Q l ≜ ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P D ( l ) = ∑ T l , i P l = 1 , 2 , … , 11 , (41) the coefficients Φ i , i = 1 , 2 , 3 , Ψ i , i = 1 , … , 4 , Λ i , i = 1 , … , 6 , and Ξ 1 in (40) are given in Table 6; the sets S i are defined in (19); and D ( l ) is the coset leaders highlighted in boldface in Table 5 and listed in Table 7 with their corresponding set D . Finally, the sets T l , i are defined as T l , i ≜ { ( k , m , n , k ′ , m ′ , n ′ ) ∈ { 0 , 1 , … , W − 1 } 6 : ( k , m , n ) ∈ S i , ( k ′ , m ′ , n ′ ) ∈ S i , D ( l ) = 1 } . Note how, in the second equality of (41), we have accounted for the multiplication by D ( l ) by restricting the summation set to T l , i . 8. Final ResultEquation (40) expresses the NLI PSD for a periodic signal of period T = 1 / Δ f as a function of the statistical moments and cross-polarisation correlations of a generic 4D modulation format. To generalise this result to aperiodic signals, we take the same approach in [8,17], i.e., we let the period T go to infinity or, equivalently, Δ f → 0 (see Figure 3).The limit of (40) for Δ f → 0 is a limit of a distribution (a Dirac’s delta comb) which is parametric in Δ f . To rigorously evaluate such a limit, we use Lemma 1 and Theorem 2 presented in the following. In particular, Theorem 2 presents the key result of this work.Lemma 1 (Dimensionality of the sets T l , i ). The sets T l , i , for l = 1 , 2 , 3 , for l = 4 , … , 10 , and for l = 11 have dimensionalities 2–4, respectively, ∀ i ∈ Z .Proof. See Appendix H. □Theorem 2 (Limit of the distribution S x ( f , N s , L s ) ). For a generic aperiodic transmitted signal and a fibre transmission system like the one in Figure 2 and under the following assumptions:i.i.d. sequence of zero-mean input DP-4D symbols a n for n ∈ Z (see Section 3.1)rectangular (or quasi-rectangular) spectrum of the transmitted pulse p ( t ) (see Section 3.1)first-order RP framework for the solution of the Manakov equation in (8) the NLI PSD S ¯ x ( f , N s , L s ) ≜ lim Δ f → 0 S x ( f , N s , L s ) , where S x ( f , N s , L s ) is given in (40), is S ¯ x ( f , N s , L s ) = 8 9 2 γ 2 R s 3 Φ 1 χ 1 ( f ) + Φ 2 χ 2 ( f ) + Φ 3 χ 3 ( f ) + R s 2 Ψ 1 χ 4 ( f ) + 2 Re { Ψ 2 χ 5 ( f ) + Ψ 3 χ 5 ∗ ( f ) } + Ψ 4 χ 6 ( f ) + 2 Re { Λ 1 χ 7 ( f ) + Λ 2 χ 7 ∗ ( f ) } + Λ 3 χ 8 ( f ) + 2 Re { Λ 4 χ 9 ( f ) + Λ 5 χ 9 ∗ ( f ) } + Λ 6 χ 10 ( f ) + R s Ξ 1 χ 11 ( f ) , (42) where the coefficients Φ i , i = 1 , 2 , 3 , Ψ i , i = 1 , 2 , … , 4 , Λ i , i = 1 , 2 , … , 6 , and Ξ 1 as well as the integrals χ i ( f ) , i = 1 , 2 , … , 11 , are given in Table 8. As discussed at the end of Section 4, S ¯ y ( f ) can be obtained applying the transformation x → y , y → x to (42).The NLI power vector Σ NLI can be obtained from the PSDs in x and y as Σ NLI ≜ [ σ NLI , x 2 , σ NLI , y 2 ] T = ∫ − ∞ ∞ S ¯ x ( f , N s , L s ) | P ( f ) | 2 d f , ∫ − ∞ ∞ S ¯ y ( f , N s , L s ) | P ( f ) | 2 d f T , (43) where P ( f ) is the transmitted pulse spectrum.Proof. See Appendix I. □The results in (42) and (43) generalise the formulas presented in [9] for PM-2D modulation formats. In particular, assuming that a x and a y are statistically independent, which leads to, e.g., E { a x a y } = E { a x } E { a y } = 0 , a x and a y are identically distributed, which, for example, leads to E { | a | 2 } ≜ E { | a x | 2 } = E { | a y | 2 } , E { a x 2 } = E { a x 3 } = E { a y 2 } = E { a y 3 } = 0 , which applies, for instance, to distributions with a certain degree of symmetry, it can be seen that (42) reduces to S ¯ x ( f , N s , L s ) = 8 9 2 γ 2 [ R s 3 Φ 1 χ 1 ( f ) + R s 2 ( Λ 3 χ 8 ( f ) + Λ 6 χ 10 ( f ) ) + R s Ξ 1 χ 11 ( f ) ] , with Φ 1 = 3 E 3 { | a | 2 } , Λ 3 = 5 E { | a | 4 } E { | a | 2 } − 10 E 3 { | a | 2 } , Λ 6 = E { | a | 4 } E { | a | 2 } − 2 E 3 { | a | 2 } , Ξ 1 = E { | a | 6 } − 9 E { | a | 4 } E { | a | 2 } + 12 E 3 { | a | 2 } , which matches the formulation given in [9] (Equation (41)). Table 8. Table of high-order moments, correlation coefficients, and integrals appearing in (42). The function η ( f 1 , f 2 , f ) is defined in (12). Table 8. Table of high-order moments, correlation coefficients, and integrals appearing in (42). The function η ( f 1 , f 2 , f ) is defined in (12). NameValueCorrelation coefficients Φ 1 2 E 3 { | a x | 2 } + 4 E { | a x | 2 } | E { a x a y ∗ } | 2 + E { | a x | 2 } E 2 { | a y | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } Φ 2 4 E { | a x | 2 } | E { a x 2 } | 2 + E { | a x | 2 } | E { a y 2 } | 2 + 4 E { | a x | 2 } | E { a x a y } | 2 + | E { a x a y } | 2 E { | a y | 2 } + 2 Re { E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } + 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } } Φ 3 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } + 2 Re { E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } Ψ 1 4 | E { a x | a x | 2 } | 2 + 4 | E { | a x | 2 a y } | 2 + E { | a x | 2 a y } E { a y ∗ | a y | 2 } + E { | a x | 2 a y ∗ } E { a y | a y | 2 } + | E { a x | a y | 2 } | 2 + | E { a x ∗ a y 2 } | 2 + 2 Re { E { a x ∗ | a x | 2 } E { a x | a y | 2 } } Ψ 2 2 | E { a x | a x | 2 } | 2 + 2 | E { | a x | 2 a y } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } + | E { a x | a y | 2 } | 2 Ψ 3 E { a x ∗ | a x | 2 } E { a x | a y | 2 } + | E { a x 2 a y ∗ } | 2 Ψ 4 | E { a x 3 } | 2 + 2 | E { a x 2 a y } | 2 + | E { a x a y 2 } | 2 Λ 1 − 3 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x 2 | a x | 2 } E { a x 2 } − | E { a x 2 } | 2 E { | a y | 2 } − 2 | E { a x a y } | 2 E { | a y | 2 } + E { a x 2 } E ∗ { a x 2 | a y | 2 } − 2 E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } + E { a x a y } E ∗ { a x a y | a y | 2 } − E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } Λ 2 − 2 E { | a x | 2 } | E { a x a y } | 2 + E { a x a y } E ∗ { a x a y | a x | 2 } − E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } Λ 3 4 E { | a x | 4 } E { | a x | 2 } − 4 E { | a x | 2 } | E { a x 2 } | 2 − 8 E 3 { | a x | 2 } + 4 E { | a x | 2 } E { | a x | 2 | a y | 2 } − 12 E { | a x | 2 } | E { a x a y ∗ } | 2 − 4 E { | a x | 2 } | E { a x a y } | 2 − 4 E 2 { | a x | 2 } E { | a y | 2 } − 3 E { | a x | 2 } E 2 { | a y | 2 } − E { | a x | 2 } | E { a y 2 } | 2 + E { | a x | 2 | a y | 2 } E { | a y | 2 } + E { | a x | 2 } E { | a y | 4 } − 5 | E { a x a y ∗ } | 2 E { | a y | 2 } − | E { a x a y } | 2 E { | a y | 2 } + 2 Re { 2 E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } + E { a x ∗ a y } E { a x a y ∗ | a y | 2 } − 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } } Λ 4 − 6 E { | a x | 2 } | E { a x 2 } | 2 + 2 E ∗ { a x 2 | a x | 2 } E { a x 2 } + 4 E { | a x | 2 } | E { a x a y } | 2 − E { | a x | 2 } | E { a y 2 } | 2 + E ∗ { | a x | 2 a y 2 } E { a y 2 } + 2 E { a x a y } E ∗ { a x | a x | 2 a y } − 2 | E { a x a y } | 2 E { | a y | 2 } − 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } + E { a x a y } E ∗ { a x a y | a y | 2 } − E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } − 2 Re { E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } } Λ 5 − 2 E { | a x | 2 } | E { a x a y } | 2 + E { a x a y } E ∗ { a x a y | a x | 2 } − | E { a x 2 } | 2 E { | a y | 2 } − E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } − 2 Re { E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } Λ 6 − 2 E 3 { | a x | 2 } + E { | a x | 4 } E { | a x | 2 } − E { | a x | 2 } | E { a x 2 } | 2 − 4 E { | a x | 2 } | E { a x a y ∗ } | 2 − E { | a x | 2 } E 2 { | a y | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } − | E { a x a y ∗ } | 2 E { | a y | 2 } − | E { a x a y } | 2 E { | a y | 2 } + 2 Re { E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } Ξ 1 E { | a x | 6 } − 9 E { | a x | 4 } E { | a x | 2 } + 12 E 3 { | a x | 2 } − 2 E { | a x | 4 } E { | a y | 2 } + E { | a x | 2 | a y | 4 } − 8 E { | a x | 2 } E { | a x | 2 | a y | 2 } − 4 E { | a x | 2 | a y | 2 } E { | a y | 2 } + 2 E { | a x | 4 | a y | 2 } − E { | a x | 2 } E { | a y | 4 } + 4 E { | a x | 2 } E 2 { | a y | 2 } + 8 E 2 { | a x | 2 } E { | a y | 2 } + 18 E { | a x | 2 } | E { a x 2 } | 2 − | E { a x 3 } | 2 − 9 | E { a x | a x | 2 } | 2 + 2 E { | a x | 2 } | E { a y 2 } | 2 − 4 | E { a x | a y | 2 } | 2 − 8 | E { | a x | 2 a y } | 2 + 8 | E { a x a y ∗ } | 2 E { | a y | 2 } + 8 | E { a x a y } | 2 E { | a y | 2 } − | E { a x a y 2 } | 2 − | E { a x ∗ a y 2 } | 2 + 16 E { | a x | 2 } | E { a x a y ∗ } | 2 − 2 | E { a x 2 a y ∗ } | 2 + 16 E { | a x | 2 } | E { a x a y } | 2 + 4 | E { a x 2 } | 2 E { | a y | 2 } − 2 | E { a x 2 a y } | 2 + 2 Re { 4 E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } − 3 E { a x 2 | a x | 2 } E ∗ { a x 2 } − 2 E { | a x | 2 a y } E { a y ∗ | a y | 2 } − E { | a x | 2 a y 2 } E ∗ { a y 2 } − 2 E { a x a y } E ∗ { a x a y | a y | 2 } − E { a x a y ∗ } E { a x ∗ a y | a y | 2 } − 2 E { a x ∗ | a x | 2 } E { a x | a y | 2 } − 2 E { a x 2 } E ∗ { a x 2 | a y | 2 } − E { a x | a x | 2 } E { a x | a y | 2 } − 4 E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − 4 E { a x a y } E ∗ { a x a y | a x | 2 } + 8 E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } Integrals χ 1 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 | P ( f 2 ) | 2 | P ( f − f 1 + f 2 ) | 2 | η ( f 1 , f 2 , f ) | 2 d f 1 d f 2 χ 2 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 | P ( f 2 ) | 2 | P ( f − f 1 + f 2 ) | 2 η ( f 1 , f 2 , f ) η ∗ ( f 1 , f 1 − f 2 − f , f ) d f 1 d f 2 χ 3 ( f ) | P ( f ) | 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 | P ( f 2 ) | 2 η ( f 1 , − f , f ) η ∗ ( f 2 , − f , f ) d f 1 d f 2 χ 4 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 P ( f 1 ) P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ∗ ( f 1 − f 2 ) P ( f 3 ) P ∗ ( f − f 1 + f 2 + f 3 ) η ( f 1 , f 2 , f ) · η ∗ ( f 1 − f 2 , f 3 , f ) d f 1 d f 2 d f 3 χ 5 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 P ( f 1 ) P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ∗ ( f 3 ) P ( f 2 − f 1 ) P ∗ ( f − f 1 + f 2 − f 3 ) η ( f 1 , f 2 , f ) · η ∗ ( f 3 , f 2 − f 1 , f ) d f 1 d f 2 d f 3 χ 6 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 P ( f 1 ) P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ∗ ( f 3 ) P ∗ ( f + f 2 ) P ( f 2 + f 3 ) η ( f 1 , f 2 , f ) · η ∗ ( f 3 , − f − f 2 , f ) d f 1 d f 2 d f 3 χ 7 ( f ) P ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 P ∗ ( f 2 ) P ( f 3 ) P ∗ ( f − f 2 + f 3 ) η ( f 1 , − f , f ) η ∗ ( f 2 , f 3 , f ) d f 1 d f 2 d f 3 χ 8 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ( f 3 ) P ∗ ( f − f 1 + f 3 ) η ( f 1 , f 2 , f ) η ∗ ( f 1 , f 3 , f ) d f 1 d f 2 d f 3 χ 9 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 | P ( f 1 ) | 2 P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ∗ ( f 3 ) P ( f − f 1 − f 3 ) η ( f 1 , f 2 , f ) η ∗ ( f 3 , − f 1 , f ) d f 1 d f 2 d f 3 χ 10 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 P ( f 1 ) | P ( f 2 ) | 2 P ( f − f 1 + f 2 ) P ∗ ( f 3 ) P ∗ ( f + f 2 − f 3 ) η ( f 1 , f 2 , f ) η ∗ ( f 3 , f 2 , f ) d f 1 d f 2 d f 3 χ 11 ( f ) ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 ∫ − R s / 2 R s / 2 P ( f 1 ) P ∗ ( f 2 ) P ( f − f 1 + f 2 ) P ∗ ( f 3 ) P ( f 4 ) P ∗ ( f − f 3 + f 4 ) η ( f 1 , f 2 , f ) · η ∗ ( f 3 , f 4 , f ) d f 1 d f 2 d f 3 d f 4 9. Discussion and ConclusionsIn this paper, we have derived a comprehensive analytical expression for NLI power when a general DP-4D modulation format is transmitted. The transmitted format is only assumed to be zero-mean. The reported result extends the model in [9] by accounting for any constellation geometry and statistic in four dimensions. This extension is performed by lifting two underlying assumptions in [9] (and other existing models): (i) the transmitted formats are PM versions of a 2D format and (ii) some high-order moments of the 2D components of the transmitted modulation format, such as E { a x 2 } and E { a x 3 } , are implicitly assumed to be equal to zero.The presented results are derived in a single-channel transmission scenario. However, as it can be inferred from previous works, extending the expressions to the wavelength-division multiplexing (WDM) case does not lead to a different set of modulation-related statistical quantities in the NLI power expression. An extension of this work to the WDM transmission scenario will be addressed in a future publication.Future work will also focus on comparing the presented model with possible heuristic extensions of existing PM-2D models to the general DP-4D case, for instance by using the 4D constellation standardised fourth-order moment (or so-called kurtosis). For such a study, a numerical validation of the model via the split-step Fourier method will certainly play a key role. Lastly, 4D constellation shaping in the optical fibre channel arguably represents the most attractive application and future research direction for the model derived in this manuscript. Author ContributionsConceptualization, G.L.; investigation, G.L., A.B., and A.A.; methodology, G.L., A.B., and A.A.; writing—original draft preparation, G.L.; writing—review and editing, G.L., A.B., H.R., and A.A.; visualisation, G.L. and A.B. All authors have read and agreed to the published version of the manuscript.FundingThe work of G.L. is funded by the EuroTechPostdoc programme under the European Union’s Horizon 2020 research and innovation programme (Marie Skłodowska-Curie grant agreement No. 754462). This work has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 757791).Conflicts of InterestThe authors declare no conflict of interest. Appendix A. Proof of Theorem 1The Manakov Equation (8) can be written in the frequency domain as ∂ E ( f , z ) ∂ z = − α 2 E ( f , z ) + j 4 π 2 f 2 β 2 2 E ( f , z ) + j γ 8 9 F { | E ˜ ( t , z ) | 2 E ˜ ( t , z ) } = − α 2 + j 4 π 2 f 2 β 2 2 E ( f , z ) + j γ 8 9 F { | E ˜ ( t , z ) | 2 } ∗ E ( f , z ) , (A1) where ∗ denotes a modified convolution operator between a scalar function and a vector function (For a scalar function α and a vector function B = [ B x , B y ] T , the operator α ∗ B is defined here as α ∗ B ≜ α ∗ B x , α ∗ B y T ). Expanding the nonlinear term in (A1), we have F { | E ˜ ( t , z ) | 2 } ∗ E ( f , z ) = F { E ˜ x ( t , z ) E ˜ x ∗ ( t , z ) } + F { E ˜ y ( t , z ) E ˜ y ∗ ( t , z ) } ∗ [ E x ( f , z ) , E y ( f , z ) ] T , which, for instance, for the x component, becomes E x ( f , z ) ∗ E x ∗ ( − f , z ) ∗ E x ( f , z ) + E y ( f , z ) ∗ E y ∗ ( − f , z ) ∗ E x ( f , z ) . (A2) Expanding the first term in (A2), we obtain E x ( f , z ) ∗ E x ∗ ( − f , z ) ∗ E x ( f , z ) = ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , z ) E x ∗ ( f 1 − f 2 , z ) E x ( f − f 2 , z ) d f 1 d f 2 , (A3) which by substitution f 1 − f 2 = f ˜ 2 becomes (for notation’s simplicity, the integration variable f ˜ 2 is relabelled as f 2 ) E x ( f , z ) ∗ E x ∗ ( − f , z ) ∗ E x ( f , z ) = − ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , z ) E x ∗ ( f 2 , z ) E x ( f − f 1 + f 2 , z ) d f 1 d f 2 . (A4) Similar to the steps in (A3) and (A4), the second term in (A2) can be found as E y ( f , z ) ∗ E y ∗ ( − f , z ) ∗ E x ( f , z ) = − ∫ − ∞ ∞ ∫ − ∞ ∞ E y ( f 1 , z ) E y ∗ ( f 2 , z ) E x ( f − f 1 + f 2 , z ) d f 1 d f 2 . The x component in (A1) can be then rewritten as ∂ E x ( f , z ) ∂ z = − α 2 + j 2 π 2 f 2 β 2 E x ( f , z ) − j 8 9 γ ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , z ) E x ∗ ( f 2 , z ) E x ( f − f 1 + f 2 , z ) + E y ( f 1 , z ) E y ∗ ( f 2 , z ) E x ( f − f 1 + f 2 , z ) d f 1 d f 2 . (A5) Following the first-order RP approach to finding the solution to the Manakov equation [13], we replace the x component of the first-order expansion in (9) into (A5) and equate terms with the same power of γ . After some algebra and after substituting the A n terms with the corresponding E n using (10), we find the following set of differential equations ∂ E 0 , x ( f , z ) ∂ z = − α 2 + j 2 π 2 f 2 β 2 E 0 , x ( f , z ) , (A6) ∂ E 1 , x ( f , z ) ∂ z = − j 8 9 γ ∫ − ∞ ∞ ∫ − ∞ ∞ E 0 , x ( f 1 , z ) E 0 , x ∗ ( f 2 , z ) E 0 , x ( f − f 1 + f 2 , z ) + E 0 , y ( f 1 , z ) E 0 , y ∗ ( f 2 , z ) E 0 , x ( f − f 1 + f 2 , z ) d f 1 d f 2 . (A7) The zeroth-order term for a single fibre span of length z is given by E 0 , x ( f , z ) = E ( f , 0 ) e ( − α / 2 + j 2 π 2 β 2 f 2 ) z . (A8) On the other hand, the first-order term (for the x component) E 1 , x ( f , z ) , with initial conditions given by the transmitted signal E ( f , 0 ) , can be found solving the following differential equation ∂ E 1 , x ( f , z ) ∂ z = − α 2 + j 2 π 2 β 2 f 2 E 1 , x ( f , z ) − j 8 9 γ ∫ − ∞ ∞ ∫ − ∞ ∞ E 0 , x ( f 1 , z ) E 0 , x ∗ ( f 2 , z ) E 0 , x ( f − f 1 + f 2 , z ) + E 0 , y ( f 1 , z ) E 0 , y ∗ ( f 2 , z ) E 0 , y ( f − f 1 + f 2 , z ) d f 1 d f 2 . (A9) The solution to (A9) with initial condition E 1 , x ( f , 0 ) = 0 is given by E 1 , x ( f , z ) = − j 8 9 γ e − α z + j 2 β 2 π 2 f 2 z ∫ 0 z e α 2 − j 2 β 2 π 2 f 2 z ′ ∫ − ∞ ∞ ∫ − ∞ ∞ E 0 , x ( f 1 , z ′ ) E 0 , x ∗ ( f 2 , z ′ ) E 0 , x ( f − f 1 + f 2 , z ′ ) + E 0 , y ( f 1 , z ′ ) E 0 , y ∗ ( f 2 , z ′ ) E 0 , x ( f − f 1 + f 2 , z ′ ) d f 1 d f 2 d z ′ (A10a) = − j 8 9 γ e − α z + j 2 β 2 π 2 f 2 z ∫ 0 z e α 2 − j 2 β 2 π 2 f 2 z ′ ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , 0 ) E x ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) + E y ( f 1 , 0 ) E y ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) e − 3 2 α z ′ e j 4 π 2 β 2 2 ( f 1 2 − f 2 2 + ( f − f 1 + f 2 ) 2 ) z ′ d f 1 d f 2 d z ′ , (A10b) where (A8) was used in the step from (A10a) to (A10b).The power profile assumed in Section 3.1 for the multi-span optical link exponentially decays with a lumped amplification at the end of each span, which brings the power back to the transmitted level. This behavior leads to a discontinuity in the function α ( z ) across the interface where an amplifier is located. For such a power profile, we can solve the differential Equations (A6) and (A7) by exploiting the continuity of their coefficients within each span and by imposing the initial conditions at the input of each new fibre span E 0 , x ( f , l L s + ) = e α L s / 2 E 0 , x ( f , l L s − ) and E 1 , x ( f , l L s + ) = e α L s / 2 E 1 , x ( f , l L s − ) , for l = 1 , 2 , … , N s . Here, z = l L s − and z = l L s + indicate the sections at the input and at the output of the lth amplifier, respectively. Thus, we obtain that the zeroth and first-order term after N s fibre spans are given by E 0 , x ( f , N s , L s ) = E ( f , 0 ) e j 2 π 2 β 2 f 2 N s L s , (A11) E 1 , x ( f , N s , L s ) = − j 8 9 γ e j 2 β 2 π 2 f 2 N s L s ∑ l = 1 N s ∫ ( l − 1 ) L s l L s e α 2 − j 2 β 2 π 2 f 2 z ′ · ∫ − ∞ ∞ ∫ − ∞ ∞ E 0 , x ( f 1 , z ′ ) E 0 , x ∗ ( f 2 , z ′ ) E 0 , x ( f − f 1 + f 2 , z ′ ) + E 0 , y ( f 1 , z ′ ) E 0 , y ∗ ( f 2 , z ′ ) E 0 , x ( f − f 1 + f 2 , z ′ ) d f 1 d f 2 d z ′ . (A12) Using (A11) in (A12) and swapping the integral in z ′ with the double integral in d f 1 d f 2 , we obtain E 1 , x ( f , N s , L s ) = − j 8 9 γ e j 2 β 2 π 2 f 2 N s L s ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , 0 ) E x ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) + E y ( f 1 , 0 ) E y ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) · ∑ l = 1 N s ∫ ( l − 1 ) L s l L s e − α + j β 2 ( f − f 1 ) ( f 2 − f 1 ) z ′ d z ′ d f 1 d f 2 = − j 8 9 γ e j 2 β 2 π 2 f 2 N s L s ∫ − ∞ ∞ ∫ − ∞ ∞ E x ( f 1 , 0 ) E x ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) + E y ( f 1 , 0 ) E y ∗ ( f 2 , 0 ) E x ( f − f 1 + f 2 , 0 ) · 1 − e − α z e j β 2 ( f − f 1 ) ( f 2 − f 1 ) z α − j β 2 ( f − f 1 ) ( f 2 − f 1 ) ∑ l = 1 N s e − j 4 π 2 β 2 ( l − 1 ) ( f − f 1 ) ( f 2 − f 1 ) L s d f 1 d f 2 . The y-component of the zeroth-order term E 0 , y ( f , z ) and first-order term E 1 , y ( f , z ) can be found using the transformation x → y , y → x in (A11) and (A12), respectively. Finally, bringing together the x and y components, we have E 0 ( f , N s , L s ) = E 0 ( f , 0 ) e j 2 π 2 f 2 β 2 N s L s , E 1 ( f , N s , L s ) = − j 8 9 γ e j 2 β 2 π 2 f 2 N s L s ∫ − ∞ ∞ ∫ − ∞ ∞ E T ( f 1 , 0 ) E ∗ ( f 2 , 0 ) E ( f − f 1 + f 2 , 0 ) η ( f 1 , f 2 , f , z ) d f 1 d f 2 , where η ( f , f 1 , f 2 , z ) is defined in (12), which proves the theorem. Appendix B. Proof of Proposition 1Applying the variable transformation k ˜ = k ′ , m ˜ = m ′ , n ˜ = n ′ , k ˜ ′ = k , m ˜ ′ = m , a n d n ˜ ′ = n to the left-hand side of (23), we obtain ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ ν x , k ν x , m ∗ ν x , n ν y , k ′ ∗ ν y , m ′ ν x , n ′ ∗ η k , n , m η k ′ , n ′ , m ′ ∗ (A13a) = ∑ ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i ( k ˜ , m ˜ , n ˜ ) ∈ S i P k ˜ ′ , m ˜ ′ , n ˜ ′ , k ˜ , m ˜ , n ˜ ν x , k ˜ ′ ν x , m ˜ ′ ∗ ν x , n ˜ ′ ν y , k ˜ ∗ ν y , m ˜ ν x , n ˜ ∗ η k ˜ ′ , m ˜ ′ , n ˜ ′ η k ˜ , m ˜ , n ˜ ∗ (A13b) = ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ ( ν y , k ˜ ∗ ν y , m ˜ ν x , n ˜ ∗ ν x , k ˜ ′ ν x , m ˜ ′ ∗ ν x , n ˜ ′ η k ˜ , m ˜ , n ˜ η k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ ) ∗ (A13c) = ( ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ν y , k ˜ ν y , m ˜ ∗ ν x , n ˜ ν x , k ˜ ′ ∗ ν x , m ˜ ′ ν x , n ˜ ′ ∗ η k ˜ , m ˜ , n ˜ ∗ η k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∗ , (A13d) where in the step between (A13b) and (A13c), we have used the property P k ˜ ′ , m ˜ ′ , n ˜ ′ , k ˜ , m ˜ , n ˜ = P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ , (A14) which can be easily verified based on definition (22). Using the relabelling k ˜ → k , m ˜ → m , n ˜ → n , k ˜ ′ → k ′ , m ˜ ′ → m ′ , n ˜ ′ → n ′ for (A13d), the proposition is proven. Appendix C. Partition Tables for Sets L 1 , L 2 , and L 3 Table A1. List of all subsets in L 1 : for each subset, the index subgroups identify the corresponding pairs of indices assuming the same value. Table A1. List of all subsets in L 1 : for each subset, the index subgroups identify the corresponding pairs of indices assuming the same value. Index Subgroup123Subset Label C 1 ( 1 ) i 1 , i 2 i 3 , i 4 i 5 , i 6 C 1 ( 2 ) i 1 , i 2 i 3 , i 5 i 4 , i 6 C 1 ( 3 ) i 1 , i 2 i 3 , i 6 i 4 , i 5 C 1 ( 4 ) i 1 , i 3 i 2 , i 4 i 5 , i 6 C 1 ( 5 ) i 1 , i 3 i 2 , i 5 i 4 , i 6 C 1 ( 6 ) i 1 , i 3 i 2 , i 6 i 4 , i 5 C 1 ( 7 ) i 1 , i 4 i 2 , i 3 i 5 , i 6 C 1 ( 8 ) i 1 , i 4 i 2 , i 5 i 3 , i 6 C 1 ( 9 ) i 1 , i 4 i 2 , i 6 i 3 , i 5 C 1 ( 10 ) i 1 , i 5 i 2 , i 3 i 4 , i 6 C 1 ( 11 ) i 1 , i 5 i 2 , i 4 i 3 , i 6 C 1 ( 12 ) i 1 , i 5 i 2 , i 6 i 3 , i 4 C 1 ( 13 ) i 1 , i 6 i 2 , i 3 i 4 , i 5 C 1 ( 14 ) i 1 , i 6 i 2 , i 4 i 3 , i 5 C 1 ( 15 ) i 1 , i 6 i 2 , i 5 i 3 , i 4 Table A2. List of all subsets in L 2 : for each subset, the index subgroups identify the corresponding triplets of indices assuming the same value. Table A2. List of all subsets in L 2 : for each subset, the index subgroups identify the corresponding triplets of indices assuming the same value. Subgroup Index12Subset Label C 2 ( 1 ) i 1 , i 2 , i 3 i 4 , i 5 , i 6 C 2 ( 2 ) i 1 , i 2 , i 4 i 3 , i 5 , i 6 C 2 ( 3 ) i 1 , i 2 , i 5 i 3 , i 4 , i 6 C 2 ( 4 ) i 1 , i 2 , i 6 i 3 , i 4 , i 5 C 2 ( 5 ) i 1 , i 3 , i 4 i 2 , i 5 , i 6 C 2 ( 6 ) i 1 , i 3 , i 5 i 2 , i 4 , i 6 C 2 ( 7 ) i 1 , i 3 , i 6 i 2 , i 4 , i 5 C 2 ( 8 ) i 1 , i 4 , i 5 i 2 , i 3 , i 6 C 2 ( 9 ) i 1 , i 4 , i 6 i 2 , i 3 , i 5 C 2 ( 10 ) i 1 , i 5 , i 6 i 2 , i 3 , i 4 Table A3. List of all subsets in L 3 : for each subset, the index subgroups identify the corresponding pair and quadruple of indices assuming the same value. The set C 3 ( 1 ) corresponds to the case discussed in Example 2. Table A3. List of all subsets in L 3 : for each subset, the index subgroups identify the corresponding pair and quadruple of indices assuming the same value. The set C 3 ( 1 ) corresponds to the case discussed in Example 2. Subgroup Index12Subset Label C 3 ( 1 ) i 1 , i 2 i 3 , i 4 , i 5 , i 6 C 3 ( 2 ) i 1 , i 3 i 2 , i 4 , i 5 , i 6 C 3 ( 3 ) i 1 , i 4 i 2 , i 3 , i 5 , i 6 C 3 ( 4 ) i 1 , i 5 i 2 , i 3 , i 4 , i 6 C 3 ( 5 ) i 1 , i 6 i 2 , i 3 , i 4 , i 5 C 3 ( 6 ) i 2 , i 3 i 1 , i 4 , i 5 , i 6 C 3 ( 7 ) i 2 , i 4 i 1 , i 3 , i 5 , i 6 C 3 ( 8 ) i 2 , i 5 i 1 , i 3 , i 4 , i 6 C 3 ( 9 ) i 2 , i 6 i 1 , i 3 , i 4 , i 5 C 3 ( 10 ) i 3 , i 4 i 1 , i 2 , i 5 , i 6 C 3 ( 11 ) i 3 , i 5 i 1 , i 2 , i 4 , i 6 C 3 ( 12 ) i 3 , i 6 i 1 , i 2 , i 4 , i 5 C 3 ( 13 ) i 4 , i 5 i 1 , i 2 , i 3 , i 6 C 3 ( 14 ) i 4 , i 6 i 1 , i 2 , i 3 , i 5 C 3 ( 15 ) i 5 , i 6 i 1 , i 2 , i 3 , i 4 Appendix D. M g ( h ) and N g ( h ) Contributions Table A4. List of M g ( h ) and N g ( h ) contributions computed in Section 5 without bias terms. Table A4. List of M g ( h ) and N g ( h ) contributions computed in Section 5 without bias terms. ghCorr. Terms in M g ( h ) Corr. Terms in N g ( h ) Delta Products11 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 − R s 2 Δ f δ n − k ′ δ k − m + m ′ − n ′ + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y } | 2 − R s 2 Δ f ( δ k ′ + n ′ δ k − m + n + m ′ + δ n + m ′ δ k − m − k ′ − n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 E 3 { | a x | 2 } + E { | a x | 2 } E 2 { | a y | 2 } E 2 { | a x | 2 } E { | a y | 2 } − R s 2 Δ f δ n − n ′ δ k − m − k ′ + m ′ + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 E { | a x | 2 } | E { a x 2 } | 2 + E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } − R s 2 Δ f ( δ m + k ′ δ k + n + m ′ − n ′ + δ k + n δ m + k ′ − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } R s 3 δ k + n δ m − m ′ δ k ′ + n ′ − R s 2 Δ f ( δ k ′ + n ′ δ k − m + n + m ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k + n δ m − m ′ + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } | E { a x 2 } | 2 E { | a y | 2 } − R s 2 Δ f ( δ m + n ′ δ k + n − k ′ + m ′ + δ k + n δ m + k ′ − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 − R s 2 Δ f δ k − k ′ δ m − n − m ′ + n ′ + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 E 3 { | a x | 2 } + E { | a x | 2 } E 2 { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − k ′ δ m − m ′ δ n − n ′ − R s 2 Δ f ( δ n − n ′ δ k − m − k ′ + m ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k − k ′ δ m − n − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } R s 3 δ k − k ′ δ m + n ′ δ n + m ′ − R s 2 Δ f ( δ n + m ′ δ k − m − k ′ − n ′ + δ m + n ′ δ k + n − k ′ + m ′ + δ k − k ′ δ m − n − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } E { | a x | 2 } | E { a x a y } | 2 − R s 2 Δ f ( δ k ′ + n ′ δ k − m + n + m ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 11 E { | a x | 2 } | E { a x 2 } | 2 + E { | a x | 2 } | E { a y 2 } | 2 E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k + m ′ δ m + k ′ δ n − n ′ − R s 2 Δ f ( δ n − n ′ δ k − m − k ′ + m ′ + δ m + k ′ δ k + n + m ′ − n ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 12 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } R s 3 δ k + m ′ δ m + n ′ δ n − k ′ − R s 2 Δ f ( δ n − k ′ δ k − m + m ′ − n ′ + δ m + n ′ δ k + n − k ′ + m ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 13 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E 2 { | a x | 2 } E { | a y | 2 } − R s 2 Δ f δ k − n ′ δ m − n + k ′ − m ′ + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 14 E { | a x | 2 } | E { a x 2 } | 2 + E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k − n ′ δ m + k ′ δ n + m ′ − R s 2 Δ f ( δ n + m ′ δ k − m − k ′ − n ′ + δ m + k ′ δ k + n + m ′ − n ′ + δ k − n ′ δ m − n + k ′ − m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 15 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − n ′ δ m − m ′ δ n − k ′ − R s 2 Δ f ( δ n − k ′ δ k − m + m ′ − n ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k − n ′ δ m − n + k ′ − m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 21 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 E { a x | a x | 2 } E { a x | a y | 2 } − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 | E { a x | a x | 2 } | 2 + E { a y ∗ | a y | 2 } E { | a x | 2 a y } | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − m − k ′ δ n + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − m + m ′ δ n − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 E { a x ∗ | a x | 2 } E { a x | a y | 2 } R s 2 Δ f δ k − m − n ′ δ n − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 | E { a x 2 a y ∗ } | 2 R s 2 Δ f δ k + n − k ′ δ m − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 | E { a x 3 } | 2 + | E { a x a y 2 } | 2 | E { a x 2 a y } | 2 R s 2 Δ f δ k + n + m ′ δ m + k ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y } E { a y ∗ | a y | 2 } E { a x | a x | 2 } E { a x ∗ | a y | 2 } R s 2 Δ f δ k + n − n ′ δ m + k ′ − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } E { a x | a y | 2 } E { a x ∗ | a x | 2 } R s 2 Δ f δ k − k ′ + m ′ δ m − n + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − k ′ − n ′ δ m − n − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 | E { a x | a x | 2 } | 2 + | E { a x ∗ a y 2 } | 2 | E { | a x | 2 a y } | 2 R s 2 Δ f δ k + m ′ − n ′ δ m − n + k ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 31 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } E { a x 2 } E ∗ { a x 2 | a y | 2 } R s 2 Δ f δ k + n δ m + k ′ − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { a x a y ∗ } E { a x ∗ a y | a x | 2 } R s 2 Δ f δ k − k ′ δ m − n − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E ∗ { | a x | 2 a y 2 } E { a y 2 } E { a x a y } E ∗ { a x a y | a x | 2 } R s 2 Δ f δ k + m ′ δ m − n + k ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 E { | a x | 4 } E { | a x | 2 } + E { a x ∗ a y } E { a x a y ∗ | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ k − n ′ δ m − n + k ′ − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 E { | a x | 4 } E { | a x | 2 } + E { a x a y ∗ } E { a x ∗ a y | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E { | a x | 2 a y 2 } E ∗ { a y 2 } E ∗ { a x a y } E { a x a y | a x | 2 } R s 2 Δ f δ m + k ′ δ k − n + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { a x ∗ a y } E { a x a y ∗ | a x | 2 } R s 2 Δ f δ m − m ′ δ k + n − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E ∗ { a x a y } E { a x a y | a y | 2 } E ∗ { a x 2 } E { a x 2 | a y | 2 } R s 2 Δ f δ m + n ′ δ k + n − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 E { | a x | 4 } E { | a x | 2 } + E { a x a y ∗ } E { a x ∗ a y | a y | 2 } E { a x a y ∗ } E { a x ∗ a y | a x | 2 } R s 2 Δ f δ n − k ′ δ k − m + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 11 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } E { a x a y } E ∗ { a x a y | a x | 2 } R s 2 Δ f δ n + m ′ δ k − m − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 12 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 } E { | a y | 4 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ n − n ′ δ k − m − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 13 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { | a x | 4 } E { | a y | 2 } − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 14 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E ∗ { a x a y } E { a x a y | a y | 2 } E ∗ { a x a y } E { a x a y | a x | 2 } R s 2 Δ f δ k ′ + n ′ δ k − m + n + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 15 E { | a x | 4 } E { | a x | 2 } + E { a x ∗ a y } E { a x a y ∗ | a y | 2 } E { a x ∗ a y } E { a x a y ∗ | a x | 2 − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 41 E { | a x | 6 } + E { | a x | 2 | a y | 4 } E { | a x | 4 | a y | 2 } R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ Appendix E. Proof of Proposition 2Applying the variable transformation k ˜ = n , m ˜ = m , n ˜ = k , k ˜ ′ = n ′ , m ˜ ′ = m ′ , and n ˜ ′ = k ′ to the right-hand side of (37), we have ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k , m , n , k ′ , m ′ , n ′ ) = ∑ ( n ˜ , m ˜ , k ˜ ) ∈ S i ( n ˜ ′ , m ˜ ′ , k ˜ ′ ) ∈ S i P n ˜ , m ˜ , k ˜ , n ˜ ′ , m ˜ ′ , k ˜ ′ η n ˜ , m ˜ , k ˜ η n ˜ ′ , m ˜ ′ , k ˜ ′ ∗ D 2 ( n ˜ , m ˜ , k ˜ , n ˜ ′ , m ˜ ′ , k ˜ ′ ) . (A15) From definitions (16) and (22), it can be easily verified that P n , m , k , n ′ , m ′ , k ′ = P k , m , n , k ′ , m ′ , n ′ and η n , m , k = η k , m , n . Moreover, based on the definition of the set S i in (19), it can be observed that the condition ( k , m , n ) ∈ S i is equivalent to ( n , m , k ) ∈ S i , i.e., generates the same set of triplets ( k , m , n ) . We can thus write (A15) as ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k , m , n , k ′ , m ′ , n ′ ) = ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ η k ˜ , m ˜ , n ˜ η k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ D 2 ( n ˜ , m ˜ , k ˜ , n ˜ ′ , m ˜ ′ , k ˜ ′ ) = ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ η k ˜ , m ˜ , n ˜ η k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ D 1 ( k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ) , which proves the proposition. Appendix F. Coefficients in (38) Table A5. Expressions for the coefficients in (38). Table A5. Expressions for the coefficients in (38). NameValueNameValue a 1 2 E 3 { | a x | 2 } + E { | a x | 2 } E 2 { | a y | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } a 1 ′ 2 E { | a x | 2 } | E { a x a y ∗ } | 2 a 2 4 E { | a x | 2 } | E { a x 2 } | 2 + E { | a x | 2 } | E { a y 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } + 2 Re { E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } } a 2 ′ 2 E { | a x | 2 } | E { a x a y } | 2 + 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } a 3 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } a 3 ′ E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } b 1 4 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y } E { a y ∗ | a y | 2 } + E { | a x | 2 a y ∗ } E { a y | a y | 2 } + | E { a x | a y | 2 } | 2 + | E { a x ∗ a y 2 } | 2 b 1 ′ E { a x ∗ | a x | 2 } E { a x | a y | 2 } + 2 | E { | a x | 2 a y } | 2 b 2 2 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } + | E { a x | a y | 2 } | 2 b 2 ′ 2 | E { | a x | 2 a y } | 2 b 3 ′ E { a x ∗ | a x | 2 } E { a x | a y | 2 } + | E { a x 2 a y ∗ } | 2 b 4 | E { a x 3 } | 2 + | E { a x a y 2 } | 2 b 4 ′ | E { a x 2 a y } | 2 c 1 − 3 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x 2 | a x | 2 } E { a x 2 } − E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } − 2 | E { a x a y } | 2 E { | a y | 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } c 1 ′ − 2 E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } − | E { a x 2 } | 2 E { | a y | 2 } + E { a x 2 } E ∗ { a x 2 | a y | 2 } c 2 − 8 E 3 { | a x | 2 } − 4 E { | a x | 2 } | E { a x 2 } | 2 + 4 E { | a x | 4 } E { | a x | 2 } − 3 E { | a x | 2 } E 2 { | a y | 2 } − E { | a x | 2 } | E { a y 2 } | 2 + E { | a x | 2 } E { | a y | 4 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } − 5 | E { a x a y ∗ } | 2 E { | a y | 2 } − | E { a x a y } | 2 E { | a y | 2 } + 2 Re { E { a x ∗ a y } E { a x a y ∗ | a y | 2 } − E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } } c 2 ′ − 6 E { | a x | 2 } | E { a x a y ∗ } | 2 − 2 E { | a x | 2 } | E { a x a y } | 2 − 2 E 2 { | a x | 2 } E { | a y | 2 } + 2 E { | a x | 2 } E { | a x | 2 | a y | 2 } + 2 E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } c 3 − 6 E { | a x | 2 } | E { a x 2 } | 2 + 2 E ∗ { a x 2 | a x | 2 } E { a x 2 } − E { | a x | 2 } | E { a y 2 } | 2 + E ∗ { | a x | 2 a y 2 } E { a y 2 } − E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } − 2 | E { a x a y } | 2 E { | a y | 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } − 2 Re { E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } } c 3 ′ 4 E { | a x | 2 } | E { a x a y } | 2 + 2 E { a x a y } E ∗ { a x | a x | 2 a y } − 2 E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } c 4 − 2 E 3 { | a x | 2 } − E { | a x | 2 } | E { a x 2 } | 2 − E { | a x | 2 } E 2 { | a y | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } − | E { a x a y ∗ } | 2 E { | a y | 2 } − | E { a x a y } | 2 E { | a y | 2 } + E { | a x | 4 } E { | a x | 2 } c 4 ′ − 2 E { | a x | 2 } | E { a x a y ∗ } | 2 + E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } c 5 ′ − 2 E { | a x | 2 } | E { a x a y } | 2 + E { a x a y } E ∗ { a x a y | a x | 2 } − E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } − | E { a x 2 } | 2 E { | a y | 2 } − 2 Re { E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } c 6 ′ − 2 E { | a x | 2 } | E { a x a y } | 2 + E { a x a y } E ∗ { a x a y | a x | 2 } − E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } d 1 12 E 3 { | a x | 2 } + 18 E { | a x | 2 } | E { a x 2 } | 2 − | E { a x 3 } | 2 − 9 | E { a x | a x | 2 } | 2 − 9 E { | a x | 4 } E { | a x | 2 } + E { | a x | 6 } + 4 E { | a x | 2 } E 2 { | a y | 2 } + 2 E { | a x | 2 } | E { a y 2 } | 2 − E { | a x | 2 } E { | a y | 4 } − 4 E { | a x | 2 | a y | 2 } E { | a y | 2 } − 4 | E { a x | a y | 2 } | 2 + 8 | E { a x a y ∗ } | 2 E { | a y | 2 } + 8 | E { a x a y } | 2 E { | a y | 2 } − | E { a x a y 2 } | 2 − | E { a x ∗ a y 2 } | 2 + E { | a x | 2 | a y | 4 } + 2 Re { 4 E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } − E { a x a y ∗ } E { a x ∗ a y | a y | 2 } − 3 E { a x 2 | a x | 2 } E ∗ { a x 2 } − 2 E { a x a y } E ∗ { a x a y | a y | 2 } − 2 E { | a x | 2 a y } E { a y ∗ | a y | 2 } − E { | a x | 2 a y 2 } E ∗ { a y 2 } } d 1 ′ 8 E { | a x | 2 } | E { a x a y ∗ } | 2 − | E { a x 2 a y ∗ } | 2 + 8 E { | a x | 2 } | E { a x a y } | 2 + 4 E 2 { | a x | 2 } E { | a y | 2 } − 4 E { | a x | 2 } E { | a x | 2 | a y | 2 } − E { | a x | 4 } E { | a y | 2 } − 2 E { a x ∗ | a x | 2 } E { a x | a y | 2 } − 2 E { a x 2 } E ∗ { a x 2 | a y | 2 } − E { a x | a x | 2 } E { a x | a y | 2 } − 4 | E { | a x | 2 a y } | 2 + E { | a x | 4 | a y | 2 } − 4 E { a x a y ∗ } E { a x ∗ a y | a x | 2 } − 4 E { a x a y } E ∗ { a x a y | a x | 2 } + 2 | E { a x 2 } | 2 E { | a y | 2 } − | E { a x 2 a y } | 2 + 8 Re { E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } } Appendix G. Proof of Proposition 3Since D 1 ( k , m , n , k ′ , m ′ , n ′ ) = D 2 ( k ′ , m ′ , n ′ , k , m , n ) , the left-hand side of (39) can be written as ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 1 ( k , m , n , k ′ , m ′ , n ′ ) = ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k ′ , m ′ , n ′ , k , m , n ) . (A16) Using the change of variables k ˜ = k ′ , m ˜ = m ′ , n ˜ = n ′ , k ˜ ′ = k , m ˜ ′ = m , and n ˜ ′ = n , the right-hand side of (A16) can be equivalently expressed as ∑ ( k , m , n ) ∈ S i ( k ′ , m ′ , n ′ ) ∈ S i P k , m , n , k ′ , m ′ , n ′ η k , m , n η k ′ , m ′ , n ′ ∗ D 2 ( k ′ , m ′ , n ′ , k , m , n ) (A17a) = ∑ ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i ( k ˜ , m ˜ , n ˜ ) ∈ S i P k ˜ ′ , m ˜ ′ , n ˜ ′ , k ˜ , m ˜ , n ˜ η k ˜ , m ˜ , n ˜ ∗ η k ˜ ′ , m ˜ ′ , n ˜ ′ D 2 ( k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ) (A17b) = ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ η k ˜ , m ˜ , n ˜ ∗ η k ˜ ′ , m ˜ ′ , n ˜ ′ D 2 ( k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ) (A17c) = ( ∑ ( k ˜ , m ˜ , n ˜ ) ∈ S i ( k ˜ ′ , m ˜ ′ , n ˜ ′ ) ∈ S i P k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ η k ˜ , m ˜ , n ˜ η k ˜ ′ , m ˜ ′ , n ˜ ′ ∗ D 2 ( k ˜ , m ˜ , n ˜ , k ˜ ′ , m ˜ ′ , n ˜ ′ ) ) ∗ , (A17d) where in the step from (A17b) to (A17c), we have used (A14). Equation (A17d) is identical to the right-hand side of (39) up to the variable relabelling k ˜ → k , m ˜ → m , n ˜ → n , k ˜ ′ → k ′ , m ˜ ′ → m ′ , n ˜ ′ → n ′ , which proves the proposition. Appendix H. Proof of Lemma 1To prove the statement about dimensionality of the sets T l , i , we take as an example the cases for l = 1 , 2 , 3 . In these instances, the sets T l , i ∀ i ∈ Z are identified by 5 linear constraints on the set of variables ( k , m , n , k ′ , m ′ , n ′ ) ∈ { 0 , 1 , … , W − 1 } 6 given by (i) the 2 linearly independent constraints, ( k , m , n ) ∈ S i and ( k ′ , m ′ , n ′ ) ∈ S i and (ii) the 3 linearly independent constraints induced by the condition D ( l ) = 1 for l = 1 , 2 , 3 (see Table 7). Then, let A l ≜ [ a 1 T ; a 2 T ; … ; a 5 T ] be a 5 × 6 matrix in which the rows a k , k = 1 , 2 , … , 5 , describe each of these 5 linear combinations, x ≜ [ k , m , n , k ′ , m ′ , n ′ ] , and y i = [ i , i , 0 , 0 , 0 ] . Thus, the set T l , i can be equivalently defined as T l , i = { x ∈ { 0 , 1 , … , W − 1 } 6 : A l x = y i } . (A18) From (A18), it can be seen that T l , i is a vector space for which the number of dimensions is given by dim { T l , i } = 6 − rank ( A l ) . (A19) Due to the construction of the delta products D ( l ) , l ∈ { 1 , 2 , 3 } , it can be shown that the rows of A l are linearly dependent under the relationship a 1 − a 2 = ± a 3 ± a 4 ± a 5 . Hence, ∀ l ∈ { 1 , 2 , 3 } and i ∈ Z , we have rank ( A l ) = 4 . As a result, from (A19), dim { T l , i } = 2 , ∀ l ∈ { 1 , 2 , 3 } , and i ∈ Z .For l ∈ { 4 , 5 , … , 10 } , we have that T l , i is identified by 4 linear constraints, 2 of them related to the S i set and 2 related to the condition D ( l ) = 1 . Furthermore, it can be seen that a 1 − a 2 = ± a 3 ± a 4 , hence leading to rank ( A l ) = 3 , ∀ l ∈ { 4 , 5 , … , 10 } and dim { T l , i } = 3 . Finally, based on similar arguments, one can show that rank ( A l ) = 2 for l = 11 and dim { T l , i } = 4 , which proves the lemma. Appendix I. Proof of Theorem 2The limit of a sequence of distributions f ( Δ f ) is defined as the distribution f ˜ such that [18] (Section 2.2) 〈 f ˜ , ψ 〉 = lim Δ f → 0 〈 f ( Δ f ) , ψ 〉 , ∀ ψ , (A20) where 〈 f , ψ 〉 ≜ ∫ − ∞ ∞ f ( f ) ψ ( f ) d f (A21) denotes the functional corresponding to the distribution f applied to a generic test function ψ [18] (Section 1.1). In particular, the delta distribution centered in f 0 is defined as 〈 δ f 0 , ψ 〉 ≜ ∫ − ∞ ∞ δ ( f − f 0 ) ψ ( f ) d f = ψ ( f 0 ) . (A22) Based on (A21), we have for the distribution S x ( f , N s , L s ) in (40), 〈 S x ( f , N s , L s ) , ψ 〉 = 8 9 2 γ 2 Δ f [ R s 3 Δ f 2 ( Φ 1 ∫ − ∞ ∞ ∑ i = − ∞ ∞ ∑ T 1 , i P δ ( f − i Δ f ) ψ ( f ) d f + … + Φ 3 ∫ − ∞ ∞ ∑ i = − ∞ ∞ ∑ T 3 , i P δ ( f − i Δ f ) ψ ( f ) d f ) + R s 2 Δ f 3 ( Ψ 1 ∫ − ∞ ∞ ∑ i = − ∞ ∞ ∑ T 4 , i P δ ( f − i Δ f ) ψ ( f ) d f + … + Λ 6 ∫ − ∞ ∞ ∑ i = − ∞ ∞ ∑ T 10 , i P δ ( f − i Δ f ) ψ ( f ) d f ) + R s Δ f 4 Ξ 1 ∫ − ∞ ∞ ∑ i = − ∞ ∞ ∑ T 11 , i P δ ( f − i Δ f ) ψ ( f ) d f ] (A23a) = 8 9 2 γ 2 [ R s 3 Δ f 3 ( Φ 1 ∑ i = − ∞ ∞ ∑ T 1 , i P ψ ( i Δ f ) + … + Φ 3 ∑ i = − ∞ ∞ ∑ T 3 , i P ψ ( i Δ f ) ) + R s 2 Δ f 4 ( Ψ 1 ∑ i = − ∞ ∞ ∑ T 4 , i P ψ ( i Δ f ) + … + Λ 6 ∑ i = − ∞ ∞ ∑ T 10 , i P ψ ( i Δ f ) ) + R s Δ f 5 Ξ 1 ∑ i = − ∞ ∞ ∑ T 11 , i P ψ ( i Δ f ) ] , (A23b) where we have used (A22) in the step between (A23a) and (A23b).Now, we want to show that all the terms in (A23b) are multidimensional Riemann sums, which then will converge to multidimensional integrals in the limit for Δ f → 0 . From (16), (22), and (35), it can be seen that the terms P ψ ( i Δ f ) are samples on a multidimensional grid of step Δ f of the multivariate function P ˜ ( f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ) ≜ P ( f 1 ) P ∗ ( f 2 ) P ( f 3 ) P ∗ ( f 1 ′ ) P ( f 2 ′ ) P ∗ ( f 3 ′ ) η ( f 1 , f 2 , f 3 , N s , L s ) η ∗ ( f 1 ′ , f 2 ′ , f 3 ′ , N s , L s ) , f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ∈ R . (A24) Moreover, Δ f t ( l ) , which represents the power of Δ f multiplying the lth element in (A23b), where t ( l ) ≜ 3 for l = 1 , 2 , 3 ; 4 for l = 4 , … , 10 ; 5 for l = 11 , (A25) is a measure of the t ( l ) th dimensional hypercube in R t ( l ) for which the side measures Δ f . Hence, to prove that each term in (A23b) converges to a sum of multiple integrals of the multivariate functions P l ˜ ψ ( f ) , we simply need to show that the dimensionality of the summation sets, i.e., Z × T l , i , is equal to t ( l ) , i.e., dim { T l , i } = t ( l ) − 1 , for l = 1 , … , 11 , and ∀ i ∈ Z . This can be easily verified comparing Lemma 1 to (A25). Defining the subspaces of R 6 Q l ( f ) ≜ { ( f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ) ∈ R 6 ∩ G l : f 1 − f 2 + f 3 = f , f 1 ′ − f 2 ′ + f 3 ′ = f } , (A26) where G l is the set defined by the condition D ( l ) = 1 , and by replacing the variables ( k , m , n , k ′ , m ′ , n ′ ) → ( f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ) , we have lim Δ f → 0 〈 S x ( f , N s , L s ) , ψ 〉 = 8 9 2 γ 2 [ R s 3 ( Φ 1 ∫ − ∞ ∞ ∫ ... ∫ Q 1 ( f ) P ˜ ( f 1 , … , f 3 ′ ) ψ ( f ) d f 1 … d f 3 ′ d f + … + Φ 3 ∫ − ∞ ∞ ∫ ... ∫ Q 3 ( f ) P ˜ ( f 1 , … , f 3 ′ ) ψ ( f ) d f 1 … d f 3 ′ d f ) + R s 2 ( Ψ 1 ∫ − ∞ ∞ ∫ ... ∫ Q 4 ( f ) P ˜ ( f 1 , … , f 3 ′ ) ψ ( f ) d f 1 … d f 3 ′ d f + … + Λ 6 ∫ − ∞ ∞ ∫ ... ∫ Q 10 ( f ) P ˜ ( f 1 , … , f 3 ′ ) ψ ( f ) d f 1 … d f 3 ′ d f ) + R s Ξ 1 ∫ − ∞ ∞ ∫ ... ∫ Q 11 ( f ) P ˜ ( f 1 , … , f 3 ′ ) ψ ( f ) d f 1 … d f 3 ′ d f ] (A27a) = 8 9 2 γ 2 [ R s 3 ( Φ 1 ∫ − ∞ ∞ ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 1 ( f 1 , f 2 , f ) ψ ( f ) d f 1 d f 2 d f + … + Φ 3 ∫ − ∞ ∞ ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 3 ( f 1 , f 2 , f ) ψ ( f ) d f 1 d f 2 d f ) + R s 2 ( Ψ 1 ∫ ... ∫ R 4 P ˜ 4 ( f 1 , … , f 3 , f ) ψ ( f ) d f 1 … d f 3 d f + … + Λ 6 ∫ ... ∫ R 4 P ˜ 10 ( f 1 , … , f 3 , f ) ψ ( f ) d f 1 … d f 3 d f ) + R s Ξ 1 ∫ ... ∫ R 5 P ˜ 11 ( f 1 , … , f 4 , f ) ψ ( f ) d f 1 … d f 4 d f ] . (A27b) In the steps from (A27a) to (A27b), we have replaced in each integral the function P ˜ with its constrained instance over Q l ( f ) P ˜ l ≜ P ˜ ( f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ) | ( f 1 , f 2 , f 3 , f 1 ′ , f 2 ′ , f 3 ′ ) ∈ Q l ( f ) , and explicitly expressed the dimensionality of the integrals based on the dimension of their corresponding integration domains Q l ( f ) . By construction (see (A26)), dim { Q l ( f ) } = t ( l ) − 1 , for l = 1 , … , 11 .Finally, using (A20) and comparing definition (A21) with (A27b), we obtain S ¯ x ( f , N s , L s ) = lim Δ f → 0 S x ( f , N s , L s ) = 8 9 2 γ 2 [ R s 3 ( Φ 1 ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 1 ( f 1 , f 2 , f ) d f 1 d f 2 + … + Φ 3 ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 3 ( f 1 , f 2 , f ) d f 1 d f 2 ) + R s 2 ( Ψ 1 ∫ − ∞ ∞ ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 4 ( f 1 , f 2 , f 3 , f ) d f 1 d f 2 d f 3 + … + Λ 6 ∫ − ∞ ∞ ∫ − ∞ ∞ ∫ − ∞ ∞ P ˜ 10 ( f 1 , f 2 , f 3 , f ) d f 1 d f 2 d f 3 ) + R s Ξ 1 ∫ ... ∫ R 4 P ˜ 11 ( f 1 , … , f 4 , f ) d f 1 … d f 4 ] , which, defining χ l ( f ) ≜ ∫ R 2 P ˜ l ( f 1 , f 2 , f ) d f 1 d f 2 = ∫ − R s 2 R s 2 ∫ − R s 2 R s 2 P ˜ l ( f 1 , f 2 , f ) d f 1 d f 2 , l = 1 , 2 , 3 ; ∫ R 3 P ˜ l ( f 1 , f 2 , f 3 , f ) d f 1 d f 2 d f 3 = ∫ − R s 2 R s 2 ∫ − R s 2 R s 2 ∫ − R s 2 R s 2 P ˜ l ( f 1 , f 2 , f 3 , f ) d f 1 d f 2 d f 3 , l = 4 , … , 10 ; ∫ R 4 P ˜ 11 ( f 1 , … , f 4 , f ) d f 1 … d f 4 = ∫ ... ∫ R 4 P ˜ 11 ( f 1 , … , f 4 , f ) d f 1 … d f 4 , l = 11 , (A28) with R 4 ≜ [ − R s / 2 , R s / 2 ] 4 , proves the theorem. The second equalities in (A28) are justified by the form of the functions P ˜ l (see Table 8) which, due to the assumption of strictly bandlimited pulses, have limited support within the hybercube [ − R s / 2 , R s / 2 ] t ( l ) − 1 . To derive the explicit expressions for χ l ( f ) in Table 8, we used (A28) and the property P ( − f ) = P ∗ ( f ) , which stems from the fact that p ( t ) is assumed to be a real-valued function (see Section 3.1).ReferencesAgrell, E.; Karlsson, M. Power-efficient modulation formats in coherent transmission systems. J. Lightwave Technol. 2009, 27, 5115–5126. [Google Scholar] [CrossRef]Karlsson, M.; Agrell, E. Which is the most power-efficient modulation format in optical links? Opt. Express 2009, 17, 10814–10819. [Google Scholar] [CrossRef] [PubMed]Alvarado, A.; Agrell, E. Four-dimensional coded modulation with bit-wise decoders for future optical communications. J. Lightwave Technol. 2015, 33, 1993–2003. [Google Scholar] [CrossRef]Eriksson, T.A.; Fehenberger, T.; Andrekson, P.A.; Karlsson, M.; Hanik, N.; Agrell, E. Impact of 4D channel distribution on the achievable rates in coherent optical communication experiments. J. Lightwave Technol. 2016, 34, 2256–2266. [Google Scholar] [CrossRef]Kojima, K.; Yoshida, T.; Koike-Akino, T.; Millar, D.S.; Parsons, K.; Pajovic, M.; Arlunno, V. Nonlinearity-tolerant four-dimensional 2A8PSK family for 5–7 bits/symbol spectral efficiency. J. Lightwave Technol. 2017, 35, 1383–1391. [Google Scholar] [CrossRef]Chen, B.; Chigo, O.; Hafermann, H.; Alvarado, A. Polarization-ring-switching for nonlinearity-tolerant geometrically-shaped four-dimensional formats maximizing generalized mutual information. J. Lightwave Technol. 2019, 37, 3579–3591. [Google Scholar] [CrossRef]Chen, B.; Alvarado, A.; van der Heide, S.; van den Hout, M.; Hafermann, H.; Okonkwo, C. Analysis and experimental demonstration of orthant-symmetric four-dimensional 7 bit/4D-sym modulation for optical fiber communication. arXiv 2020, arXiv:2003.12712v2. [Google Scholar]Poggiolini, P.; Bosco, G.; Carena, A.; Curri, V.; Jiang, Y.; Forghieri, F. A detailed analytical derivation of the GN model of non-linear interference in coherent optical transmission systems. arXiv 2012, arXiv:1209.0394v13. [Google Scholar]Carena, A.; Bosco, G.; Curri, V.; Jiang, Y.; Poggiolini, P.; Forghieri, F. On the accuracy of the GN-model and on analytical correction terms to improve it. arXiv 2014, arXiv:1401.6946v7. [Google Scholar]Mecozzi, A.; Essiambre, R. Nonlinear Shannon limit in pseudolinear coherent systems. J. Lightwave Technol. 2012, 30, 2011–2024. [Google Scholar] [CrossRef]Dar, R.; Feder, M.; Mecozzi, A.; Shtaif, M. Properties of nonlinear noise in long, dispersion-uncompensated fiber links. Opt. Express 2013, 21, 25685–25699. [Google Scholar] [CrossRef] [PubMed]Marcuse, D.; Menyuk, C.R.; Wai, P.K.A. Application of the Manakov-PMD equation to studies of signal propagation in optical fibers with randomly varying birefringence. J. Lightwave Technol. 1997, 15, 1735–1745. [Google Scholar] [CrossRef]Vannucci, A.; Serena, P.; Member, S.; Bononi, A. The RP method: A new tool for the iterative solution of the nonlinear Schrödinger equation. J. Lightwave Technol. 2002, 20, 1102–1112. [Google Scholar] [CrossRef]Johannisson, P.; Karlsson, M. Perturbation analysis of nonlinear propagation in a strongly dispersive optical communication system. J. Lightwave Technol. 2013, 31, 1273–1282. [Google Scholar] [CrossRef]Colombeau, J.F. New Generalized Functions and Multiplication of Distributions; North-Holland, Elsevier Science Publishers B.V.: Amsterdam, The Netherlands, 1984. [Google Scholar]Proakis, J.G.; Manolakis, D.G. Digital Signal Processing: Principles, Algorithms, and Applications, 4th ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2006. [Google Scholar]Carena, A.; Curri, V.; Bosco, G.; Poggiolini, P.; Forghieri, F. Modeling of the impact of nonlinear propagation effects in uncompensated optical coherent transmission links. J. Lightwave Technol. 2012, 30, 1524–1539. [Google Scholar] [CrossRef]Strichartz, R. A Guide to Distribution Theory and Fourier Transforms; CRC-Press: Boca Raton, FL, USA, 1994. [Google Scholar] Figure 4. Venn diagram of the partition on the 6D space i = ( i 1 , i 2 , i 3 , i 4 , i 5 , i 6 ) ∈ { 0 , 1 , … , W − 1 } 6 discussed in Section 5.2 Figure 4. Venn diagram of the partition on the 6D space i = ( i 1 , i 2 , i 3 , i 4 , i 5 , i 6 ) ∈ { 0 , 1 , … , W − 1 } 6 discussed in Section 5.2 Table 1. List of contributions M 1 ( h ) and N 1 ( h ) for i = 1 , 2 , … , 15 . Table 1. List of contributions M 1 ( h ) and N 1 ( h ) for i = 1 , 2 , … , 15 . hCorr. Terms in M 1 ( h ) Corr. Terms in N 1 ( h ) Delta Products1 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − m δ n − k ′ δ m ′ − n ′ − R s 2 Δ f ( δ m ′ − n ′ δ k − m + n − k ′ + δ n − k ′ δ k − m + m ′ − n ′ + δ k − m δ m ′ − n ′ + n − k ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k − m δ n + m ′ δ k ′ + n ′ − R s 2 Δ f ( δ k ′ + n ′ δ k − m + n + m ′ + δ n + m ′ δ k − m − k ′ − n ′ + δ k − m δ n − k ′ + m ′ − n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 E 3 { | a x | 2 } + E { | a x | 2 } E 2 { | a y | 2 } E 2 { | a x | 2 } E { | a y | 2 } R s 3 δ k − m δ n − n ′ δ k ′ − m ′ − R s 2 Δ f ( δ k ′ − m ′ δ k − m + n − n ′ + δ n − n ′ δ k − m − k ′ + m ′ + δ k − m δ n − n ′ − k ′ + m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 E { | a x | 2 } | E { a x 2 } | 2 + E { a x a y } E { a x ∗ a y } E ∗ { a y 2 } E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } R s 3 δ k + n δ m + k ′ δ m ′ − n ′ − R s 2 Δ f ( δ m ′ − n ′ δ k + n − m − k ′ + δ m + k ′ δ k + n + m ′ − n ′ + δ k + n δ m + k ′ − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 E { | a x | 2 } | E { a x 2 } | 2 · | E { a x a y } | 2 E { | a y | 2 } E { a x 2 } E ∗ { a x a y } E { a x ∗ a y } R s 3 δ k + n δ m − m ′ δ k ′ + n ′ − R s 2 Δ f ( δ k ′ + n ′ δ k + n − m + m ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k + n δ m − m ′ + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } | E { a x 2 } | 2 E { | a y | 2 } R s 3 δ k + n δ m + n ′ δ k ′ − m ′ − R s 2 Δ f ( δ k ′ − m ′ δ k + n − m − n ′ + δ m + n ′ δ k + n − k ′ + m ′ + δ k + n δ m + k ′ − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − k ′ δ m − n δ m ′ − n ′ − R s 2 Δ f ( δ m ′ − n ′ δ k − k ′ − m + n + δ m − n δ k − k ′ + m ′ − n ′ + δ k − k ′ δ m − n − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 E 3 { | a x | 2 } + E { | a x | 2 } E 2 { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − k ′ δ m − m ′ δ n − n ′ − R s 2 Δ f ( δ n − n ′ δ k − m − k ′ + m ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k − k ′ δ m − n − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 E { | a x | 2 } | E { a x 2 } | 2 + | E { a x a y } | 2 E { | a y | 2 } E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } R s 3 δ k − k ′ δ m + n ′ δ n + m ′ − R s 2 Δ f ( δ n + m ′ δ k − m − k ′ − n ′ + δ m + n ′ δ k + n − k ′ + m ′ + δ k − k ′ δ m − n − m ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k + m ′ δ m − n δ k ′ + n ′ − R s 2 Δ f ( δ k ′ + n ′ δ k − m + n + m ′ + δ m − n δ k − k ′ + m ′ − n ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 11 E { | a x | 2 } | E { a x 2 } | 2 + E { | a x | 2 } | E { a y 2 } | 2 E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k + m ′ δ m + k ′ δ n − n ′ − R s 2 Δ f ( δ n − n ′ δ k − m − k ′ + m ′ + δ m + k ′ δ k + n + m ′ − n ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 12 E { | a x | 2 } | E { a x 2 } | 2 + E ∗ { a x a y } E { a x a y ∗ } E { a y 2 } E ∗ { a x 2 } E { a x a y } E { a x a y ∗ } R s 3 δ k + m ′ δ m + n ′ δ n − k ′ − R s 2 Δ f ( δ n − k ′ δ k − m + m ′ − n ′ + δ m + n ′ δ k + n − k ′ + m ′ + δ k + m ′ δ m − n + k ′ + n ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 13 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E 2 { | a x | 2 } E { | a y | 2 } R s 3 δ k − n ′ δ m − n δ k ′ − m ′ − R s 2 Δ f ( δ k ′ − m ′ δ k − m + n − n ′ + δ m − n δ k − k ′ + m ′ − n ′ + δ k − n ′ δ m − n + k ′ − m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 14 E { | a x | 2 } | E { a x 2 } | 2 + E { a x a y } E { x a ∗ a y } E ∗ { a y 2 } E { | a x | 2 } | E { a x a y } | 2 R s 3 δ k − n ′ δ m + k ′ δ n + m ′ − R s 2 Δ f ( δ n + m ′ δ k − m − k ′ − n ′ + δ m + k ′ δ k + n + m ′ − n ′ + δ k − n ′ δ m − n + k ′ − m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 15 E 3 { | a x | 2 } + | E { a x a y ∗ } | 2 E { | a y | 2 } E { | a x | 2 } | E { a x a y ∗ } | 2 R s 3 δ k − n ′ δ m − m ′ δ n − k ′ − R s 2 Δ f ( δ n − k ′ δ k − m + m ′ − n ′ + δ m − m ′ δ k + n − k ′ − n ′ + δ k − n ′ δ m − n + k ′ − m ′ ) + 2 R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ Table 2. List of contributions M 2 ( h ) and N 2 ( h ) for i = 1 , 2 , … , 10 . Table 2. List of contributions M 2 ( h ) and N 2 ( h ) for i = 1 , 2 , … , 10 . hCorr. Terms in M 2 ( h ) Corr. Terms in N 2 ( h ) Delta Products1 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 E { a x | a x | 2 } E { a x | a y | 2 } R s 2 Δ f δ k − m + n δ k ′ − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 | E { a x | a x | 2 } | 2 + E { a y ∗ | a y | 2 } E { | a x | 2 a y } | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − m − k ′ δ n + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − m + m ′ δ n − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 E { a x ∗ | a x | 2 } E { a x | a y | 2 } R s 2 Δ f δ k − m − n ′ δ n − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 | E { a x 2 a y ∗ } | 2 R s 2 Δ f δ k + n − k ′ δ m − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 | E { a x 3 } | 2 + | E { a x a y 2 } | 2 | E { a x 2 a y } | 2 R s 2 Δ f δ k + n + m ′ δ m + k ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y } E { a y ∗ | a y | 2 } E { a x | a x | 2 } E { a x ∗ | a y | 2 } R s 2 Δ f δ k + n − n ′ δ m + k ′ − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 | E { a x | a x | 2 } | 2 + E { | a x | 2 a y ∗ } E { a y | a y | 2 } E { a x | a y | 2 } E { a x ∗ | a x | 2 } R s 2 Δ f δ k − k ′ + m ′ δ m − n + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 | E { a x | a x | 2 } | 2 + | E { a x | a y | 2 } | 2 | E { | a x | 2 a y } | 2 R s 2 Δ f δ k − k ′ − n ′ δ m − n − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 | E { a x | a x | 2 } | 2 + | E { a x ∗ a y 2 } | 2 | E { | a x | 2 a y } | 2 R s 2 Δ f δ k + m ′ − n ′ δ m − n + k ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ Table 3. List of contributions M 3 ( h ) and N 3 ( h ) for i = 1 , 2 , … , 15 . Table 3. List of contributions M 3 ( h ) and N 3 ( h ) for i = 1 , 2 , … , 15 . hCorr. Terms in M 3 ( h ) Corr. Terms in N 3 ( h ) Delta Products1 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ k − m δ n − k ′ + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 2 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } E { a x 2 } E ∗ { a x 2 | a y | 2 } R s 2 Δ f δ k + n δ m + k ′ − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 3 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { a x a y ∗ } E { a x ∗ a y | a x | 2 } R s 2 Δ f δ k − k ′ δ m − n − m ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 4 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E ∗ { | a x | 2 a y 2 } E { a y 2 } E { a x a y } E ∗ { a x a y | a x | 2 } R s 2 Δ f δ k + m ′ δ m − n + k ′ + n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 5 E { | a x | 4 } E { | a x | 2 } + E { a x ∗ a y } E { a x a y ∗ | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ k − n ′ δ m − n + k ′ − m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 6 E { | a x | 4 } E { | a x | 2 } + E { a x a y ∗ } E { a x ∗ a y | a y | 2 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ m − n δ k − k ′ + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 7 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E { | a x | 2 a y 2 } E ∗ { a y 2 } E ∗ { a x a y } E { a x a y | a x | 2 } R s 2 Δ f δ m + k ′ δ k − n + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 8 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { a x ∗ a y } E { a x a y ∗ | a x | 2 } R s 2 Δ f δ m − m ′ δ k + n − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 9 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E ∗ { a x a y } E { a x a y | a y | 2 } E ∗ { a x 2 } E { a x 2 | a y | 2 } R s 2 Δ f δ m + n ′ δ k + n − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 10 E { | a x | 4 } E { | a x | 2 } + E { a x a y ∗ } E { a x ∗ a y | a y | 2 } E { a x a y ∗ } E { a x ∗ a y | a x | 2 } R s 2 Δ f δ n − k ′ δ k − m + m ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 11 E ∗ { a x 2 | a x | 2 } E { a x 2 } + E { a x a y } E ∗ { a x a y | a y | 2 } E { a x a y } E ∗ { a x a y | a x | 2 } R s 2 Δ f δ n + m ′ δ k − m − k ′ − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 12 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 } E { | a y | 4 } E { | a x | 2 } E { | a x | 2 | a y | 2 } R s 2 Δ f δ n − n ′ δ k − m − k ′ + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 13 E { | a x | 4 } E { | a x | 2 } + E { | a x | 2 | a y | 2 } E { | a y | 2 } E { | a x | 4 } E { | a y | 2 } R s 2 Δ f δ k ′ − m ′ δ k − m + n − n ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 14 E { a x 2 | a x | 2 } E ∗ { a x 2 } + E ∗ { a x a y } E { a x a y | a y | 2 } E ∗ { a x a y } E { a x a y | a x | 2 } R s 2 Δ f δ k ′ + n ′ δ k − m + n + m ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ 15 E { | a x | 4 } E { | a x | 2 } + E { a x ∗ a y } E { a x a y ∗ | a y | 2 } E { a x ∗ a y } E { a x a y ∗ | a x | 2 R s 2 Δ f δ m ′ − n ′ δ k − m + n − k ′ − R s Δ f 2 δ k − m + n − k ′ + m ′ − n ′ Table 6. Correlation coefficients in (40): the values of a 1 , a 1 ′ , b 1 , b 1 ′ , … d 1 ′ are given in Table A5. Table 6. Correlation coefficients in (40): the values of a 1 , a 1 ′ , b 1 , b 1 ′ , … d 1 ′ are given in Table A5. NameValueNameValue Φ 1 a 1 + 2 Re { a 1 ′ } Λ 1 c 1 + c 1 ′ Φ 2 a 2 + 2 Re { a 2 ′ } Λ 2 c 6 ′ Φ 3 a 3 + 2 Re { a 3 ′ } Λ 3 c 2 + 2 Re { c 2 ′ } Ψ 1 b 1 + 2 Re { b 1 ′ } Λ 4 c 3 + c 3 ′ Ψ 2 b 2 + b 2 ′ Λ 5 c 5 ′ Ψ 3 b 3 ′ Λ 6 c 4 + 2 Re { c 4 ′ } Ψ 4 b 4 + 2 Re { b 4 ′ } Ξ 1 d 1 + 2 Re { d 1 ′ } Table 7. Delta products D ( l ) in the Q l terms, l = 1 , 2 , … , 11 , in (41) with their corresponding D set in Table 5. Table 7. Delta products D ( l ) in the Q l terms, l = 1 , 2 , … , 11 , in (41) with their corresponding D set in Table 5. l D ( l ) Set D 1 δ k − k ′ δ m − m ′ δ n − n ′ D 1 2 δ k − k ′ δ m + n ′ δ n + m ′ D 2 3 δ k + n δ m − m ′ δ k ′ + n ′ D 3 4 δ k − m − k ′ δ n + m ′ − n ′ D 4 5 δ k − m + m ′ δ n − k ′ − n ′ D 5 6 δ k + n + m ′ δ m + k ′ + n ′ D 7 7 δ k + n δ m + k ′ − m ′ + n ′ D 8 8 δ k − k ′ δ m − n − m ′ + n ′ D 9 9 δ k + m ′ δ m − n + k ′ + n ′ D 10 10 δ m − m ′ δ k + n − k ′ − n ′ D 11 11 δ k − m + n − k ′ + m ′ − n ′ D 14 Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. © 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/). Share and Cite MDPI and ACS Style Liga, G.; Barreiro, A.; Rabbani, H.; Alvarado, A. Extending Fibre Nonlinear Interference Power Modelling to Account for General Dual-Polarisation 4D Modulation Formats. Entropy 2020, 22, 1324. https://doi.org/10.3390/e22111324 AMA Style Liga G, Barreiro A, Rabbani H, Alvarado A. Extending Fibre Nonlinear Interference Power Modelling to Account for General Dual-Polarisation 4D Modulation Formats. Entropy. 2020; 22(11):1324. https://doi.org/10.3390/e22111324 Chicago/Turabian Style Liga, Gabriele, Astrid Barreiro, Hami Rabbani, and Alex Alvarado. 2020. "Extending Fibre Nonlinear Interference Power Modelling to Account for General Dual-Polarisation 4D Modulation Formats" Entropy 22, no. 11: 1324. https://doi.org/10.3390/e22111324 APA Style Liga, G., Barreiro, A., Rabbani, H., & Alvarado, A. (2020). Extending Fibre Nonlinear Interference Power Modelling to Account for General Dual-Polarisation 4D Modulation Formats. Entropy, 22(11), 1324. https://doi.org/10.3390/e22111324 Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here. Article Metrics No No Article Access Statistics For more information on the journal statistics, click here. Multiple requests from the same IP address are counted as one view.






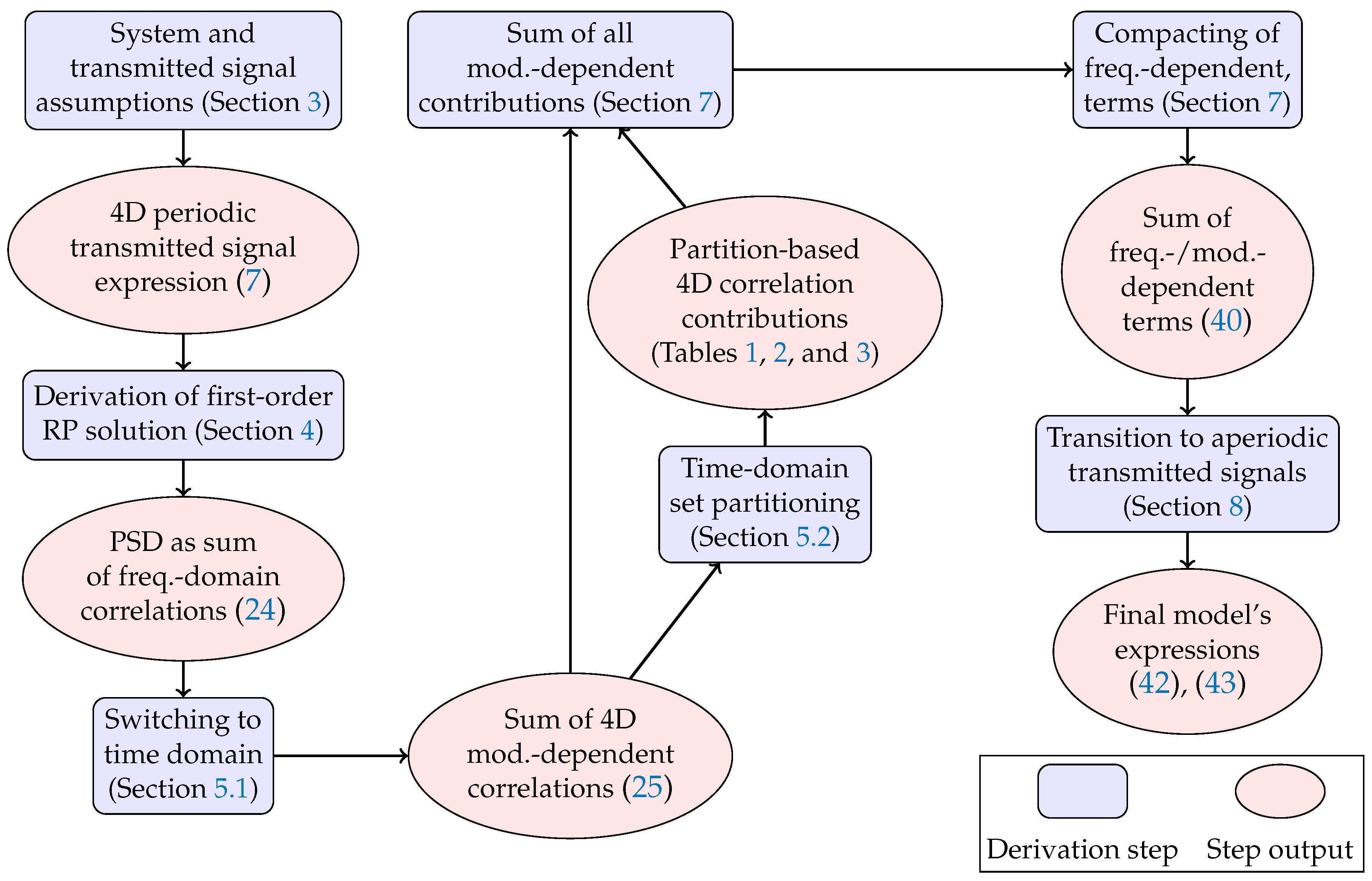{kind=link}
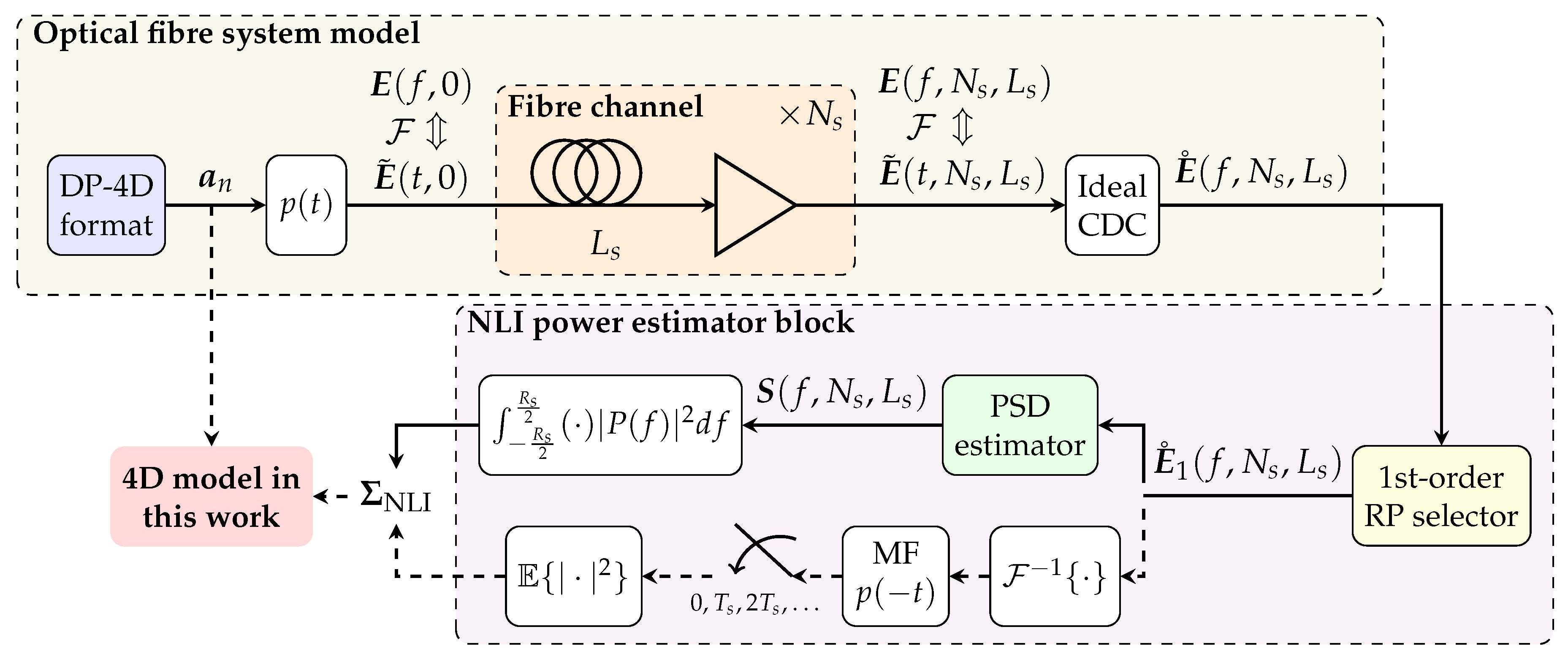{kind=link}
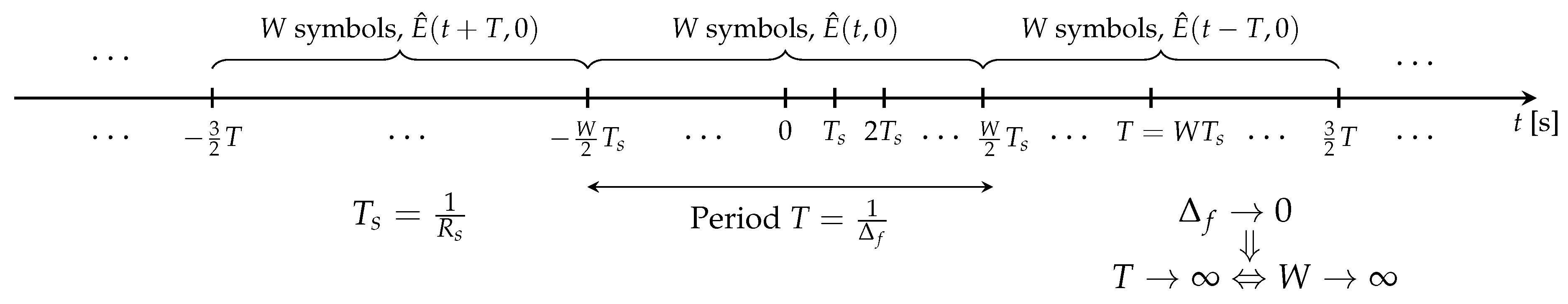{kind=link}
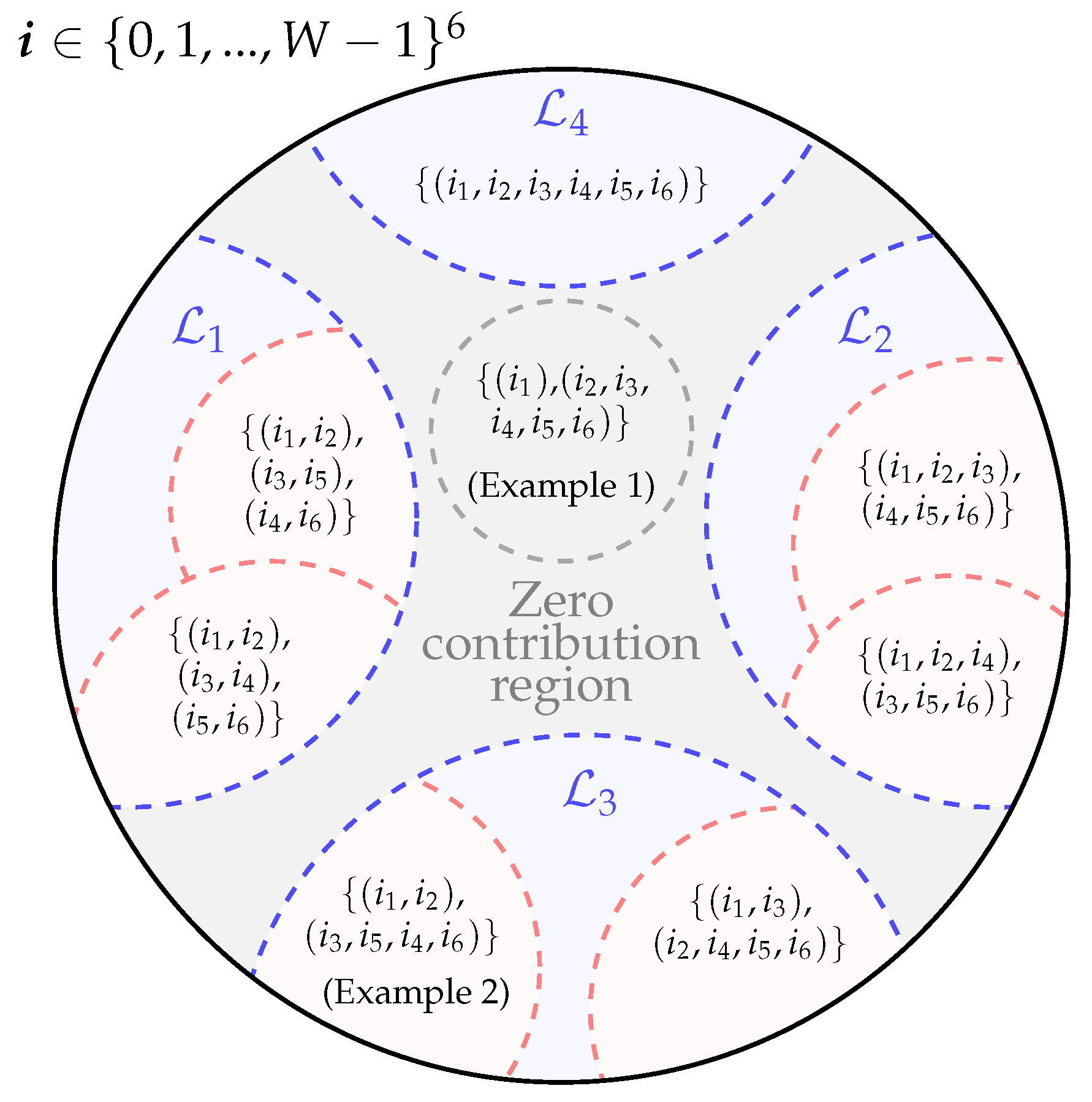{kind=link}
