Construction and Application of Functional Brain Network Based on Entropy

Abstract
1. Introduction
2. Materials and Methods
2.1. Entropy-Based FBN Model Architecture
2.2. Implementation Method of FBN Model Based on Entropy
2.2.1. Entropy Feature Calculation
- •
- Given a N-dimensional time series , and define phase space dimensions and similarity tolerance , reconstruct phase space:where is ;
- •
- Fuzzy membership function is introduced as:where r is the similarity tolerance. Calculate as:
- •
- Where is the maximum absolute distance between the window vectors and , calculated as:
- •
- After calculating the average for each i, the following formula can be obtained:
- •
- Define:
- •
- The fuzzy entropy formula of the original time series is:For a finite data set, the fuzzy entropy formula is:
2.2.2. The Required Method of FBN Construction
- (1)
- Synchronization correlation coefficient
- •
- Define the CORE of random variables X and Y as: , where E represents the expectation operator, represents the kernel function, and is the kernel width. The Gaussian kernel is usually selected as the kernel function:The selection criteria of the kernel function is very strict, and the selection of is based on Silverman’s rule of thumb [21]: , where A is the minimum value of the data standard deviation, and N is the number of data samples.
- •
- Assuming that the joint distribution function of random variables X and Y is expressed as , the CORE is expressed as: . For the limited amount of data and the joint distribution function is unknown, the CORE can be estimated by averaging two finite samples:where are N sampling points of the joint distribution function .
- (2)
- Threshold selection
- (3)
- Network measurement
2.2.3. Verification Standard of “Small World” Property of Network
2.2.4. Classifer
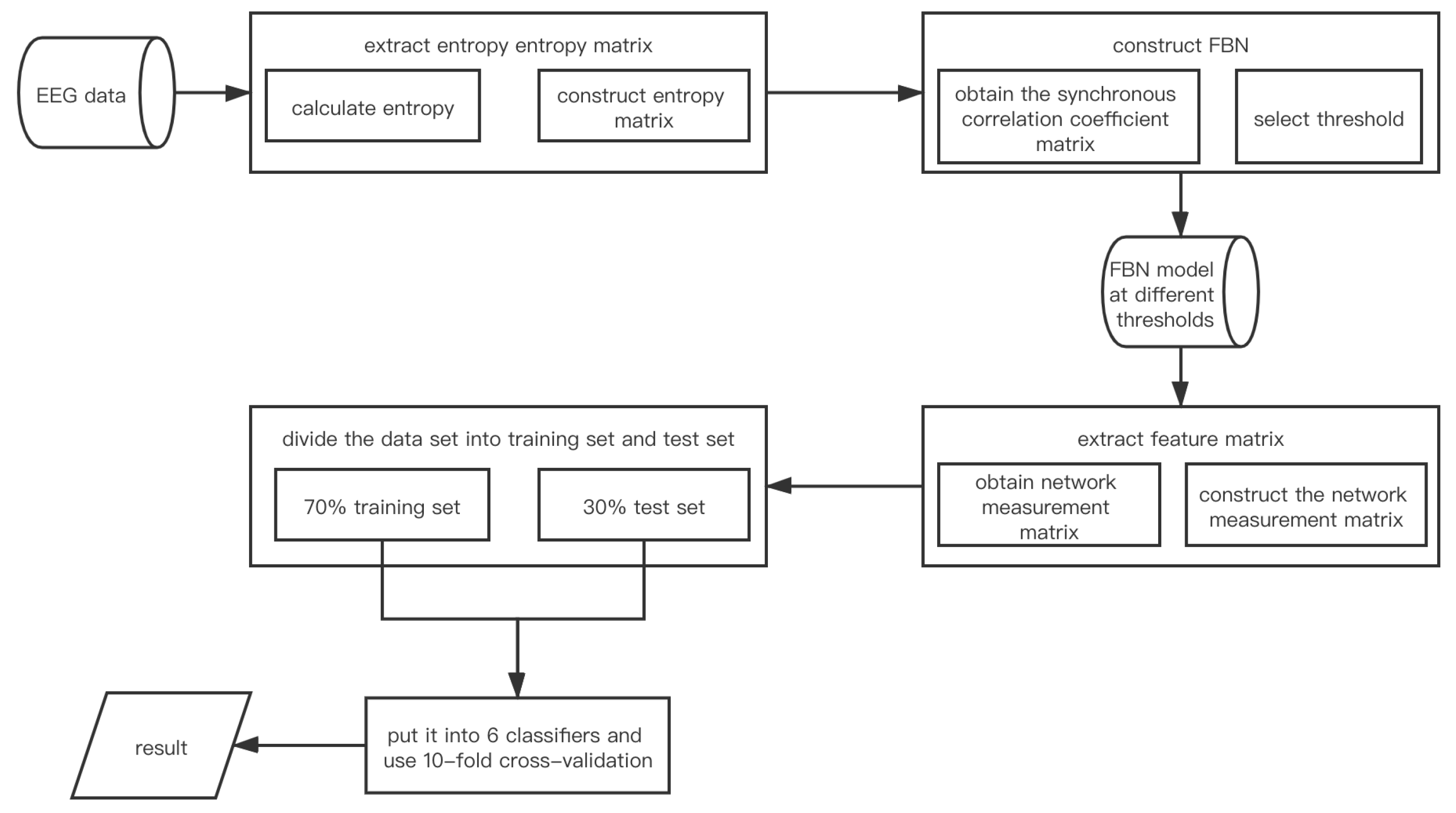
2.3. The Model Framework Construction Flow of EN_FBN
- •
- Calculate entropy under different fatigue driving states in S seconds of R individuals and construct the matrix. Suppose the entropy is . stands for the size of row of E. l stands for size of column of E and the electrode numbers;
- •
- Construct synchronization correlation coefficient matrix. The adjacent matrix is assumed to be , where m and n stand for rows and columns of C, and n represents the electrode numbers;
- •
- Construct the model EN_FBN;
- •
- Extract the network measurement matrix as the feature matrix. The network measurement matrix is assumed to be , where i and j stand for rows and columns of M, and j represents the electrode numbers;
- •
- Put the feature matrix into classifier and get the test result through 10-fold cross-validation.
2.4. Data Matrix Construction and EN_FBN Model Construction Algorithm Based on the Real Data Set of Fatigue Driving
2.4.1. Experiment Data
2.4.2. Construction of Data Matrix
- (1)
- Construction of the entropy matrix
- (2)
- Construction of adjacent matrix
- (3)
- Construction of network measurement matrix
2.4.3. Construction Algorithm of EN_FBN Model Based on the Real Data Set of Fatigue Driving
- (1)
- The first algorithm: Sparse-based FBN algorithm
- •
- The algorithm begins;
- •
- Set the threshold minimum value d and the maximum value through the method mentioned in Section 2.2.1;
- •
- Define the loop invariant , and the loop begins;
- •
- Calculate the number of edges V of the matrix , and sort the weights of the edges of the matrix from large to small;
- •
- Select the sparsity d, and generate the number of network edges according to the formula ;
- •
- Reserve the front side of the matrix , and round off the rest (set the corresponding position of the matrix to 0). Then, generate an FBN ;
- •
- Increase value d by the formula , and compare the sparsity d and . If , jump back to the third step to continue the calculation;
- •
- If , the loop ends;
- •
- The algorithm ends.
- (2)
- The second algorithm: EN_FBN construction algorithm
- •
- Calculate the entropy features under different fatigue driving states in seconds of individuals (the specific method is mentioned in Section 2.2.1) and construct entropy matrix (the specific method is mentioned in Section 2.4.2). Suppose the entropy is , where stands for the size of row of E, and 30 stands for size of column of E, which represents the electrode numbers;
- •
- Construct the synchronous correlation coefficients matrix based on the matrix (the specific method is mentioned in Section 2.2.2) and construct adjacent matrix (the specific method is mentioned in Section 2.4.2). The adjacent matrix is assumed to , where stands for the size of row of C, and 30 stands for size of column of C, which represents the electrode numbers;
- •
- Construct the sparse-based FBN model according to the first algorithm;
- •
- Construct the network measurement matrix (the specific method is mentioned in Section 2.4.2). The network measurement matrix is assumed to , where stands for the size of row of M, and 30 stands for size of column of M, which represents the electrode numbers;
- •
- Input each pair matrix and to the classifiers proposed in Section 2.2.3, and get the test result through 10-fold cross-validation.
3. Results and Discussion
3.1. Experiment and Result Analysis of FBN Based on Four Different Entropy
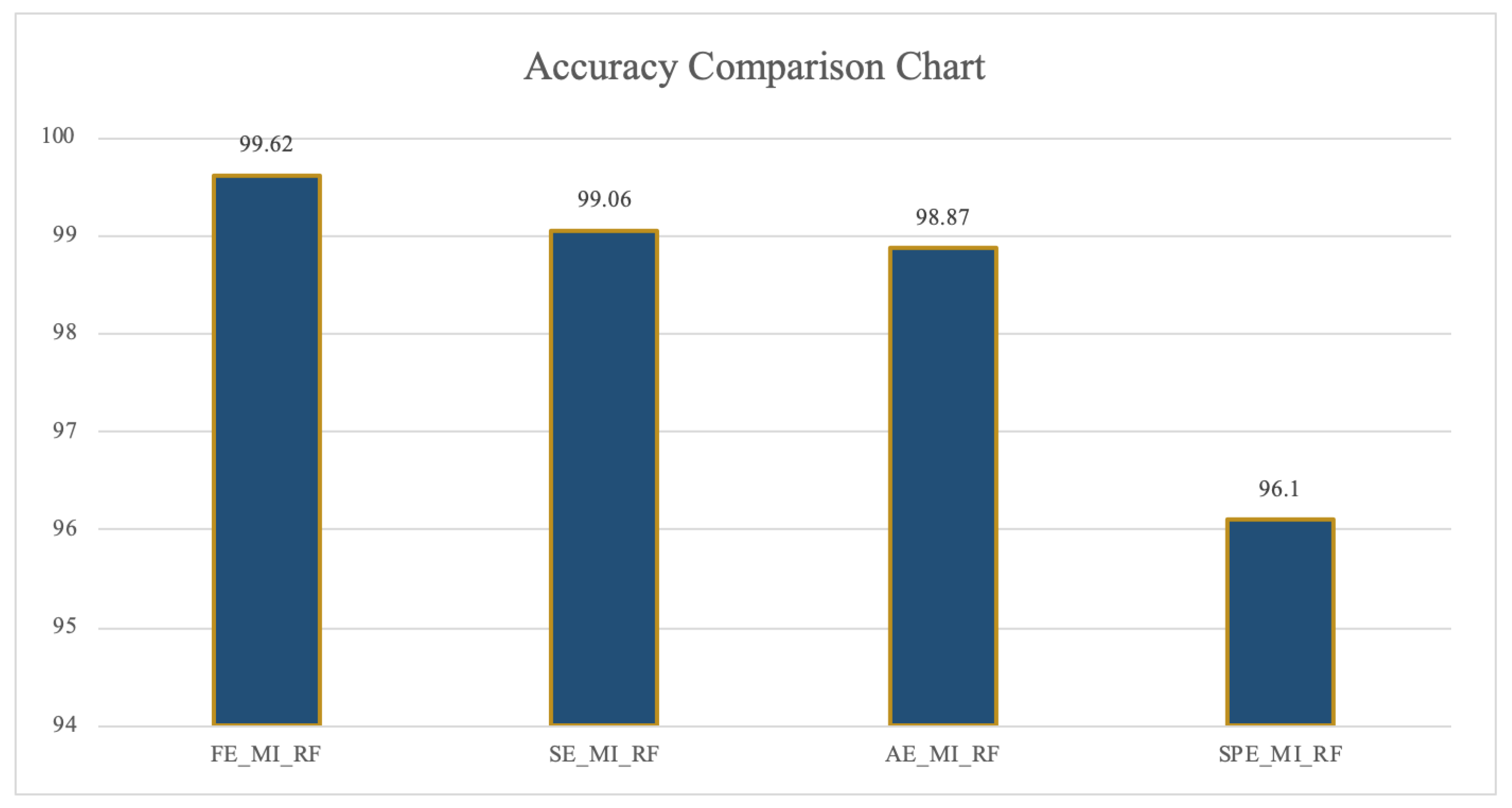
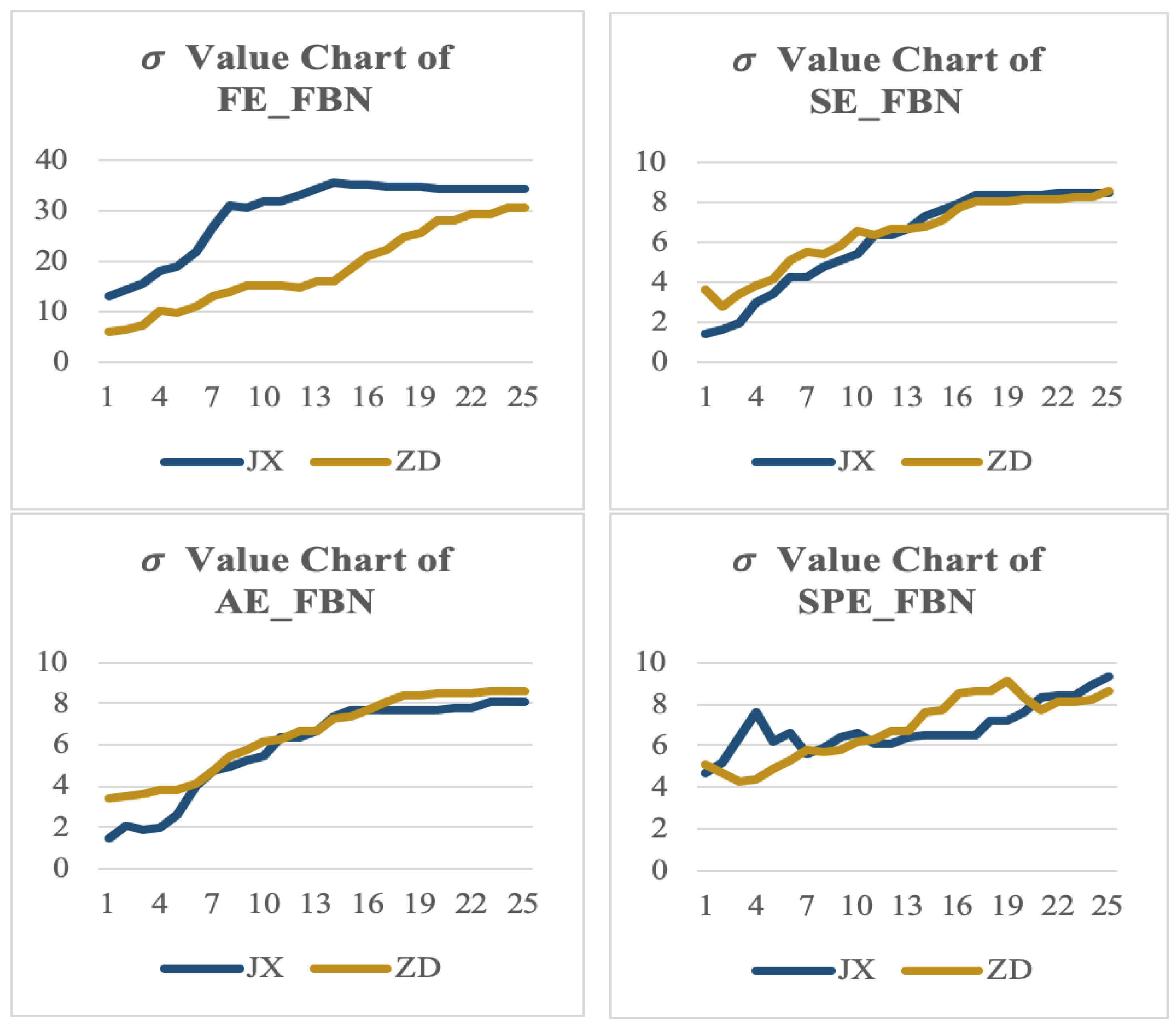
3.1.1. Comparison Test Results of Classification Recognition Rate among FE/AE/SE/SPE_FBN
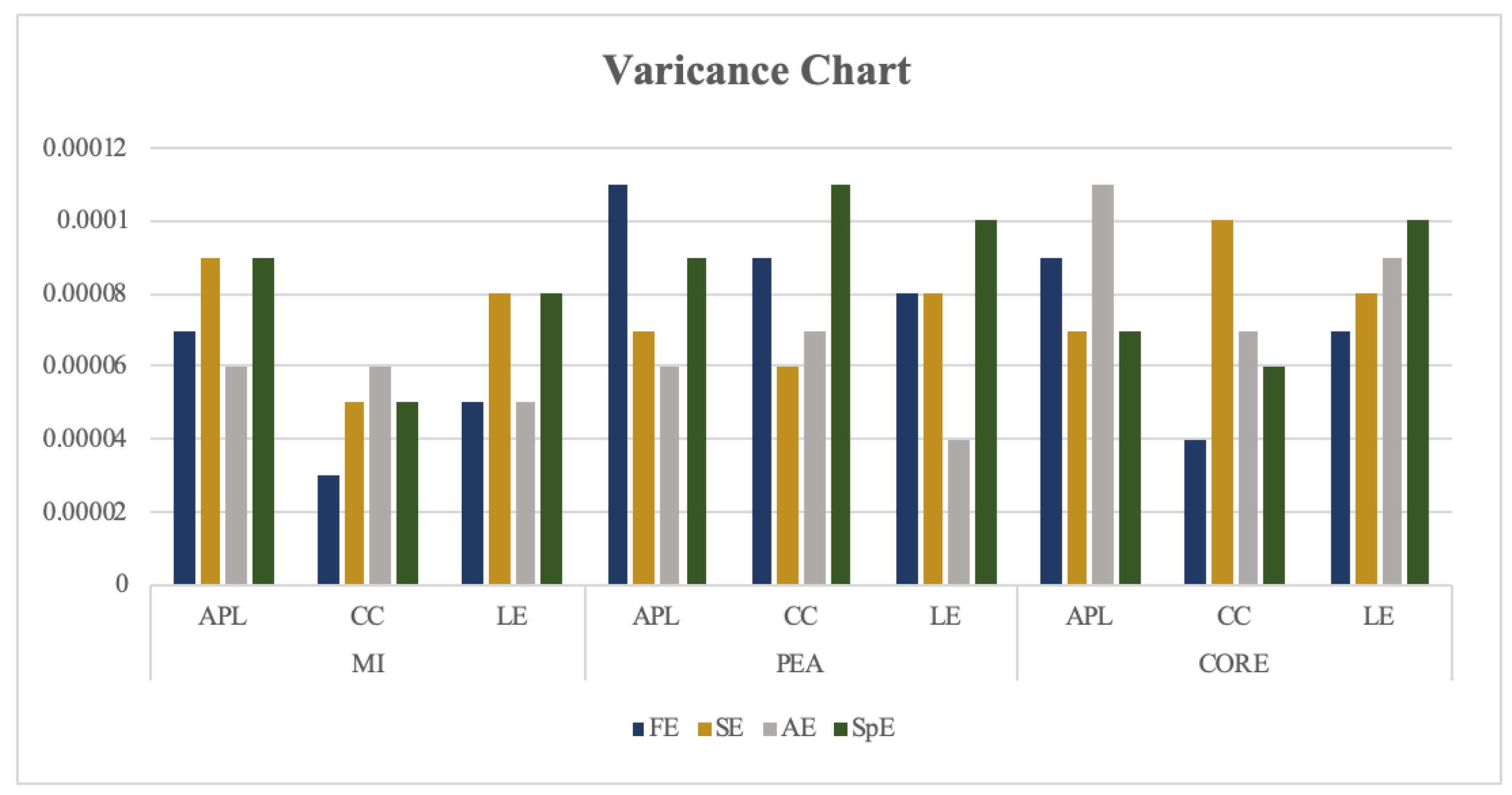
3.1.2. The Stability Test Results of Each Threshold Recognition Rate of FE/SE/AE/SPE_FBN
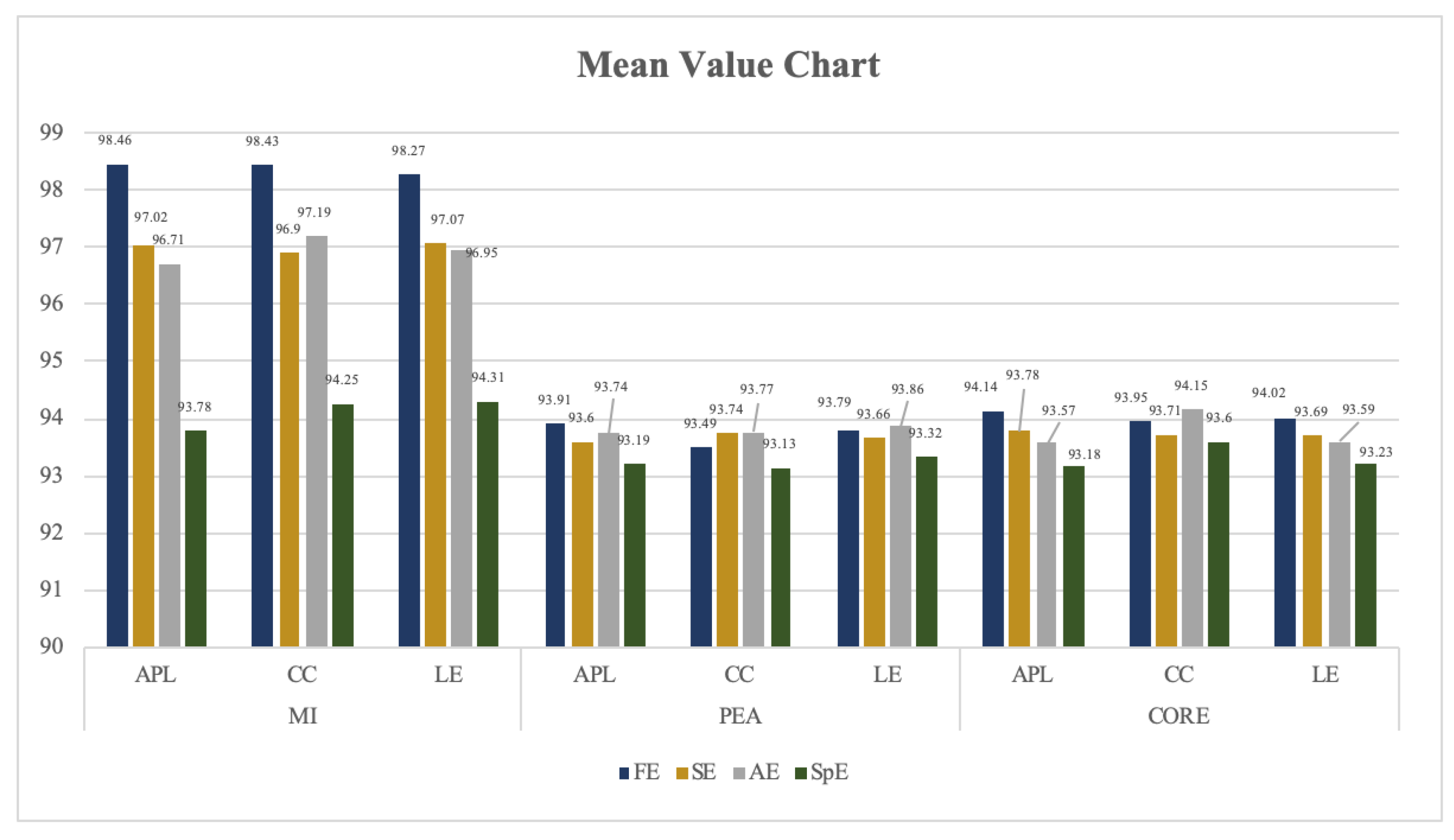
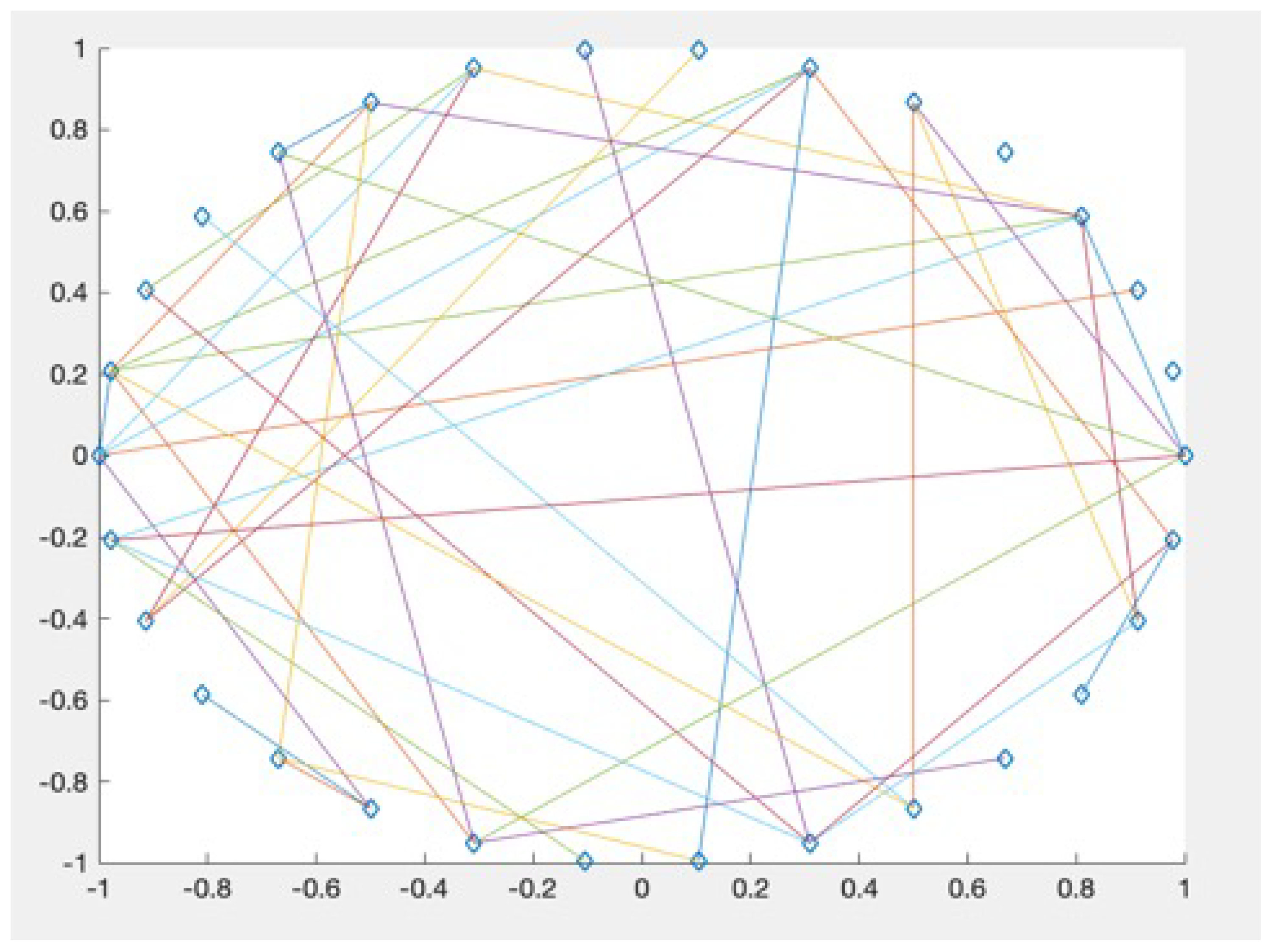
3.2. “Small World” Property Analysis of EN_FBN
3.3. Threshold Selection of FE_FBN
3.4. Stability Comparison between SE_T_KPCA and FE_FBN
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liang, X.; Wang, J.H.; He, Y. Human brain connection group research: Brain structure network and brain function network. Chin. Sci. Bull. 2010, 55, 1565–1583. [Google Scholar] [CrossRef]
- Meier, J.; Tewarie, P.; Mieghem, P. The Union of Shortest Path Trees of Functional Brain Networks. Brain Connect. 2015, 5, 575–581. [Google Scholar] [CrossRef] [PubMed]
- Kabbara, A.; Eid, H.; Falou, W.E.; Khalil, M.; Hassan, M. Reduced integration and improved segregation of functional brain networks in alzheimer’s disease. J. Neural Eng. 2018, 15, 026023. [Google Scholar] [CrossRef] [PubMed]
- Zou, S.L.; Qiu, T.R.; Huang, P.F.; Luo, H.W.; Bai, X.M. The functional brain network based on the combination of shortest path tree and its application in fatigue driving state recognition and analysis of the neural mechanism of fatigue driving. Biomed. Signal Process. Control 2020, 62, 102129. [Google Scholar] [CrossRef]
- Conrin, S.D.; Zhan, L.; Morrissey, Z.D.; Xing, M.; Forbes, A.; Maki, P.M.; Milad, M.R.; Ajilore, O.; Leow, A. Sex-by-age differences in the resting-state brain connectivity. arXiv 2018, arXiv:1801.01577. [Google Scholar]
- Zhao, C.L.; Zhao, M.; Yang, Y. The Reorganization of Human Brain Network Modulated by Driving Mental Fatigue. IEEE J. Biomed. Health Inform. 2017, 21, 743–755. [Google Scholar] [CrossRef]
- Rifkin, H. Entropy: A New World View; Shanghai Translation Publishing House: Shanghai, China, 1987. [Google Scholar]
- Min, J.; Wang, P.; Hu, J. Driver fatigue detection through multiple entropy fusion analysis in an EEG-based system. PLoS ONE 2017, 12, e0188756. [Google Scholar] [CrossRef] [PubMed]
- Ye, B.G. Research on Recognition Method of Fatigue Driving State Based on KPCA; Nanchang University: Nanchang, China, 2019. [Google Scholar]
- Vladimir, M.; Kevin, J.M.; Jack, R.; Kimberly, A.C. Changes in EEG multiscale entropy and power-law frequency scaling during the human sleep cycle. Hum. Brain Mapp. 2019, 40, 538–551. [Google Scholar]
- Zou, S.L.; Qiu, T.R.; Huang, P.F.; Bai, X.M.; Liu, C. Constructing Multi-scale Entropy Based on the Empirical Mode Decomposition(EMD) and its Application in Recognizing Driving Fatigue. J. Neurosci. Methods 2020, 341, 108691. [Google Scholar] [CrossRef]
- Kumar, Y.; Dewal, M.L.; Anand, R.S. Epileptic seizure detection using DWT based fuzzy approximate entropy and support vector machine. Neurocomputing 2014, 133, 271–279. [Google Scholar] [CrossRef]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol. 2002, 283, R789–R797. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Luo, M.W.; Luo, Y. Wavelet transform and sample entropy feature extraction methods for EEG signals. CAAI Trans. Intell. Syst. 2012, 7, 339–344. [Google Scholar]
- Pincus, M.S. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Ma, J.H.; Zhang, X.Y. EEG Emotional Recognition Based on Nonlinear Global Features and Spectral Features. J. Comput. Eng. Appl. 2018, 54, 116–121. [Google Scholar]
- Kraskov, A.; Stgbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Hanieh, B.; Sean, F.; Azinsadat, J.; Tyler, G.; Kenneth, P. Detecting synchrony in EEG: A comparative study of functional connectivity measures. Comput. Biol. Med. 2019, 105, 1–15. [Google Scholar]
- Pearson, K. On the Criterion that a Given System of Deviations from the Probable in the Case of a Correlated System of Variables is Such that it Can be Reasonably Supposed to have Arisen from Random Sampling. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992. [Google Scholar]
- Gunduz, A.; Principe, J.C. Correntropy as a novel measure for nonlinearity tests. Signal Process. 2009, 89, 14–23. [Google Scholar] [CrossRef]
- Silverman, B.M. Destiny Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1996; Volume 26. [Google Scholar]
- Guo, H. Analysis and Classification of Abnormal Topological Attributes of Resting Function Network in Depression; Taiyuan University of Technology: Taiyuan, China, 2013. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of “small-world” networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Humphries, M.D.; Gurney, K.; Prescott, T.J. The brainstem reticular formation is a small-world, not scale-free, network. Proc. R. Soc. B Biol. Sci. 2006, 273, 503–511. [Google Scholar] [CrossRef]
- Erdos, P.; Renyi, A. On random graphs. Publ. Math. Debrecen 1959, 6, 290–297. [Google Scholar]
- Mu, Z.D.; Hu, J.F.; Min, J.L. Driver Fatigue Detection System Using Electroencephalography Signals Based on Combined Entropy Features. Appl. Sci. 2017, 7, 150. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| FE_MI_APL | 98.36 | 98.52 | 99.62 | 98.97 | 74.60 | 93.79 | |
| FE_MI_CC | 97.74 | 99.10 | 99.43 | 98.44 | 81.79 | 98.77 | |
| FE_MI_LE | 93.74 | 98.13 | 99.43 | 99.12 | 76.83 | 98.66 | |
| FE_PEA_APL | 92.33 | 93.89 | 95.53 | 88.12 | 86.18 | 93.96 | |
| FE_PEA_CC | 89.11 | 93.85 | 95.28 | 88.29 | 92.13 | 84.39 | |
| FE_PEA_LE | 89.41 | 93.41 | 95.19 | 86.65 | 94.72 | 88.47 | |
| FE_CORE_APL | 90.35 | 94.58 | 96.04 | 87.42 | 86.13 | 95.53 | |
| FE_CORE_CC | 90.76 | 93.89 | 95.19 | 87.55 | 93.38 | 85.00 | |
| FE_CORE_LE | 86.94 | 93.53 | 96.13 | 88.06 | 96.04 | 88.53 |
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| SE_MI_APL | 96.19 | 97.44 | 99.06 | 95.56 | 72.93 | 96.02 | |
| SE_MI_CC | 95.25 | 96.71 | 98.30 | 96.69 | 80.20 | 97.20 | |
| SE_MI_LE | 93.28 | 96.81 | 98.21 | 96.18 | 94.44 | 95.91 | |
| SE_PEA_APL | 90.87 | 94.53 | 94.95 | 87.95 | 83.37 | 94.72 | |
| SE_PEA_CC | 89.34 | 93.32 | 95.00 | 87.96 | 92.41 | 86.28 | |
| SE_PEA_LE | 89.16 | 94.32 | 95.19 | 87.91 | 95.28 | 89.07 | |
| SE_CORE_APL | 91.14 | 93.69 | 94.91 | 87.51 | 86.43 | 94.12 | |
| SE_CORE_CC | 88.72 | 95.49 | 96.23 | 87.61 | 92.18 | 84.31 | |
| SE_CORE_LE | 87.21 | 93.44 | 95.00 | 86.76 | 94.90 | 87.53 |
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| AE_MI_APL | 94.81 | 96.57 | 97.92 | 96.13 | 74.87 | 95.78 | |
| AE_MI_CC | 94.63 | 96.32 | 98.87 | 96.32 | 82.38 | 96.64 | |
| AE_MI_LE | 93.01 | 96.69 | 98.30 | 95.72 | 89.52 | 95.6 | |
| AE_PEA_APL | 90.33 | 94.09 | 94.81 | 87.7 | 85.11 | 95.09 | |
| AE_PEA_CC | 90.62 | 93.08 | 95.57 | 88.58 | 92.29 | 85.53 | |
| AE_PEA_LE | 87.17 | 93.66 | 95.75 | 88.33 | 95.28 | 87.84 | |
| AE_CORE_APL | 89.99 | 93.94 | 95.94 | 88.93 | 83.87 | 95.09 | |
| AE_CORE_CC | 89.43 | 94.25 | 95.44 | 87.13 | 94.09 | 83.43 | |
| AE_CORE_LE | 90.26 | 93.49 | 95.13 | 88.21 | 95.42 | 87.02 |
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| SPE_MI_APL | 90.57 | 93.47 | 96.04 | 88.88 | 68.44 | 92.9 | |
| SPE_MI_CC | 88.08 | 93.34 | 95.72 | 89.24 | 73.7 | 91.75 | |
| SPE_MI_LE | 87.62 | 94.10 | 96.10 | 89.67 | 87.47 | 89.47 | |
| SPE_PEA_APL | 90.00 | 94.12 | 95.57 | 87.67 | 87.87 | 93.68 | |
| SPE_PEA_CC | 89.8 | 93.42 | 95.16 | 88.89 | 93.64 | 86.31 | |
| SPE_PEA_LE | 89.86 | 93.99 | 95.38 | 85.81 | 95.09 | 86.8 | |
| SPE_CORE_APL | 91.18 | 94.67 | 94.75 | 87.01 | 85.61 | 94.62 | |
| SPE_CORE_CC | 93.02 | 93.22 | 95.44 | 88.17 | 92.15 | 85.39 | |
| SPE_CORE_LE | 86.93 | 93.18 | 95.47 | 87.36 | 94.99 | 87.86 |
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| FE_MI_APL | 0.00245 | 0.00009 | 0.00007 | 0.00018 | 0.00219 | 0.00091 | |
| FE_MI_CC | 0.00059 | 0.00008 | 0.00003 | 0.00009 | 0.00755 | 0.00173 | |
| FE_MI_LE | 0.00064 | 0.00007 | 0.00005 | 0.00023 | 0.00726 | 0.00553 |
| Classifiers | ANN | DT | RF | KNN | AD | SVM | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| FE_MI_APL | 92.11 | 97.15 | 98.46 | 96.84 | 65.86 | 87.87 | |
| FE_MI_CC | 93.58 | 97.15 | 98.43 | 96.45 | 60.97 | 92.42 | |
| FE_MI_LE | 90.45 | 96.84 | 98.27 | 96.07 | 58.72 | 87.51 |
| Threshold | 1 (8%) | 2 (9%) | 3 (10%) | 4 (11%) | 5 (12%) | 6 (13%) | 7 (14%) | 8 (15%) | 9 (16%) | |
|---|---|---|---|---|---|---|---|---|---|---|
| Feature | ||||||||||
| APL | 98.23 | 98.66 | 98.11 | 99.62 | 97.17 | 96.49 | 96.67 | 97.92 | 99.12 | |
| CC | 98.87 | 98.23 | 99.25 | 98.3 | 98.49 | 98.65 | 97.07 | 98.48 | 98.53 | |
| LE | 98.87 | 98.23 | 98.11 | 98.87 | 99.06 | 97.32 | 97.26 | 99.12 | 98.34 |
| Threshold | 10 (17%) | 11 (18%) | 12 (19%) | 13 (20%) | 14 (21%) | 15 (22%) | 16 (23%) | 17 (24%) | |
|---|---|---|---|---|---|---|---|---|---|
| Feature | |||||||||
| APL | 98.93 | 99.25 | 98.49 | 97.33 | 97.92 | 99.43 | 99.06 | 98.74 | |
| CC | 98.62 | 98.68 | 97.95 | 97.54 | 98.23 | 98.3 | 98.3 | 98.96 | |
| LE | 97.78 | 98.58 | 99.06 | 98.11 | 97.66 | 98.68 | 98.02 | 98.36 |
| Threshold | 18 (25%) | 19 (26%) | 20 (27%) | 21 (28%) | 22 (29%) | 23 (30%) | 24 (31%) | 25 (32%) | |
|---|---|---|---|---|---|---|---|---|---|
| Feature | |||||||||
| APL | 99.25 | 98.84 | 98.96 | 99.25 | 98.87 | 98.96 | 98.68 | 97.92 | |
| CC | 97.85 | 98.21 | 98.3 | 99.43 | 98.33 | 99.06 | 98.34 | 98.87 | |
| LE | 98.2 | 97.74 | 98.01 | 99.43 | 97.74 | 98.3 | 97.31 | 98.68 |
| Method | SE_T_KPCA | FE_MI_APL | FE_MI_CC | FE_MI_LE | |
|---|---|---|---|---|---|
| Second | LDA | RF, tree=2 | RF, tree=2 | RF, tree=2 | |
| 10 s | 75.61 | 97.57 | 97.96 | 98.10 | |
| 20 s | 85.19 | 97.98 | 98.50 | 98.33 | |
| 30 s | 99.27 | 99.39 | 98.97 | 99.25 | |
| 40 s | 86.96 | 99.21 | 98.73 | 99.33 | |
| 50 s | 90.55 | 98.92 | 98.93 | 97.94 | |
| 60 s | 94.61 | 98.56 | 99.10 | 98.27 | |
| Method | SE_T_KPCA | FE_MI_APL | FE_MI_CC | FE_MI_LE | |
|---|---|---|---|---|---|
| Second | LDA | RF, tree=4 | RF, tree=4 | RF, tree=4 | |
| 10 s | 80.33 | 98.60 | 99.52 | 99.03 | |
| 20 s | 87,60 | 99.41 | 99.19 | 99.41 | |
| 30 s | 85.08 | 99.19 | 99.68 | 99.31 | |
| 40 s | 90.46 | 99.35 | 99.48 | 99.03 | |
| 50 s | 92.36 | 99.00 | 99.35 | 98.92 | |
| 60 s | 94.74 | 99.35 | 99.19 | 99.52 | |
| Method | SE_T_KPCA | FE_MI_APL | FE_MI_CC | FE_MI_LE | |
|---|---|---|---|---|---|
| Group | Mean|Var | Mean|Var | Mean|Var | Mean|Var | |
| Group one | 88.70%|0.00674 | 98.61%|0.00005 | 98.70%|0.00002 | 98.54%|0.00004 | |
| Group two | 88.43%|0.00274 | 99.15%|0.000009 | 99.40%|0.000004 | 99.23%|0.000006 | |
| Measurement | APL | CC | LE | |
|---|---|---|---|---|
| Second | Mean|Var | Mean|Var | Mean|Var | |
| 10 s | 95.57%|0.00016 | 95.35%|0.00027 | 95.30%|0.00021 | |
| 20 s | 96.15%|0.00013 | 95.94%|0.00033 | 95.47%|0.00026 | |
| 30 s | 96.39%|0.00016 | 96.11%|0.00019 | 96.06%|0.00026 | |
| 40 s | 96.07%|0.00033 | 95.80%|0.00019 | 95.73%|0.00025 | |
| 50 s | 96.74%|0.00012 | 95.95%|0.00017 | 95.96%|0.00015 | |
| 60 s | 96.23%|0.00016 | 96.02%|0.00020 | 96.12%|0.00028 | |
| Measurement | APL | CC | LE | |
|---|---|---|---|---|
| Second | Mean|Var | Mean|Var | Mean|Var | |
| 10 s | 96.88%|0.00011 | 97.27%|0.00016 | 97.11%|0.00015 | |
| 20 s | 97.62%|0.00011 | 97.54%|0.00010 | 97.62%|0.00011 | |
| 30 s | 97.49%|0.00016 | 97.72%|0.00014 | 97.91%|0.00020 | |
| 40 s | 97.83%|0.00020 | 97.62%|0.00011 | 97.58%|0.00011 | |
| 50 s | 97.12%|0.00014 | 97.62%|0.00001 | 97.50%|0.00010 | |
| 60 s | 97.62%|0.00014 | 97.66%|0.00010 | 97.54%|0.00017 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Qiu, T.; Lin, Z.; Zou, S.; Bai, X. Construction and Application of Functional Brain Network Based on Entropy. Entropy 2020, 22, 1234. https://doi.org/10.3390/e22111234
Zhang L, Qiu T, Lin Z, Zou S, Bai X. Construction and Application of Functional Brain Network Based on Entropy. Entropy. 2020; 22(11):1234. https://doi.org/10.3390/e22111234
Chicago/Turabian StyleZhang, Lingyun, Taorong Qiu, Zhiqiang Lin, Shuli Zou, and Xiaoming Bai. 2020. "Construction and Application of Functional Brain Network Based on Entropy" Entropy 22, no. 11: 1234. https://doi.org/10.3390/e22111234
APA StyleZhang, L., Qiu, T., Lin, Z., Zou, S., & Bai, X. (2020). Construction and Application of Functional Brain Network Based on Entropy. Entropy, 22(11), 1234. https://doi.org/10.3390/e22111234