Information Processing in the Brain as Optimal Entropy Transport: A Theoretical Approach

{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. The Monge–Kantorovich Problem
2.1. Dual Formulation
2.2. Solution in the Real Line: Optimal Transportation Case
3. Solution in the Real Line: Optimal Entropy Transportation Case
The Monge–Ampère Equation
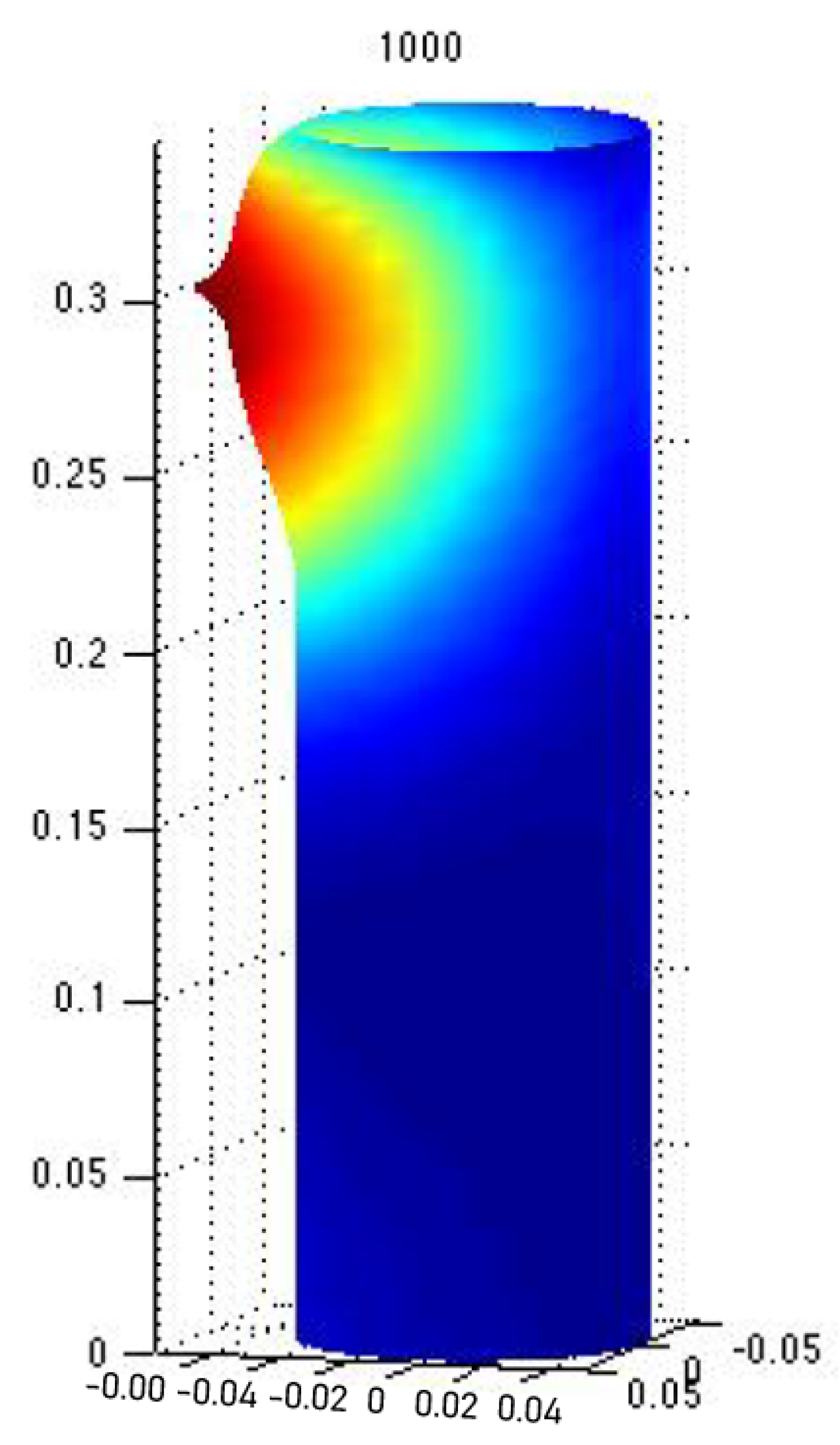
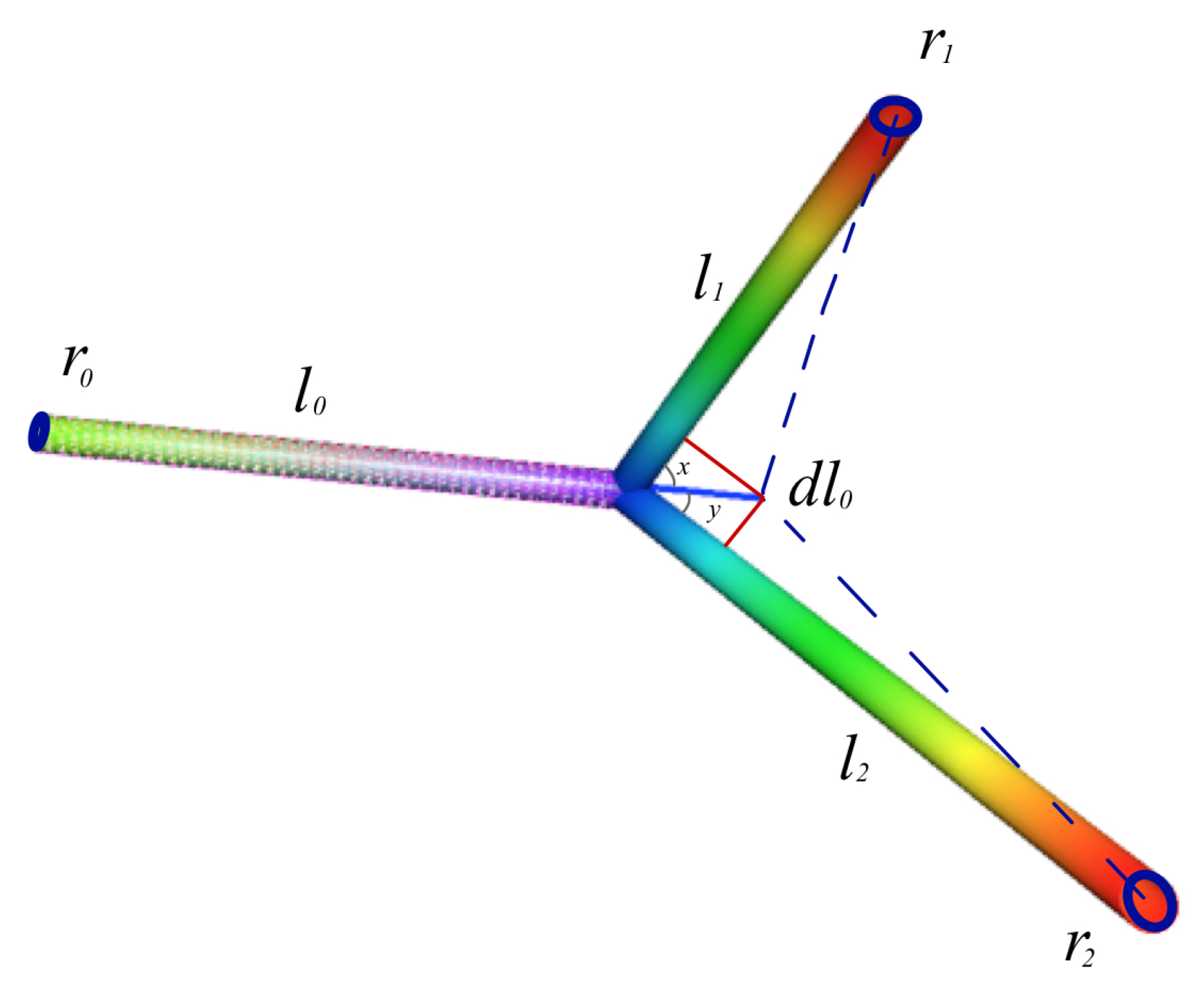
4. Neural Branching Structure and the Linearization of the Monge–Ampère Equation
5. Murray’s Law and Neural Branching
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Relevant Theorems and Some Proofs
- a.
- The function F is strictly increasing in the interval:
- b.
- The inverse function is continuous.
- c.
- The inverse measure is non-atomic.
- d.
- The support of μ, given by:with Σ a σ-algebra defined on , is a closed interval in the real line, finite or not.
- T is well defined:The only problem we might have with the definition of could be when . However, if , then:but if for some , we have , then , which means that and T is well defined, as desired.
- :Let F and G be defined as in observation (1). Then, is non-decreasing, since F and G are non-decreasing. Then:Since T is non-decreasing, is an interval.Claim 1. Since has no atom, F is increasing and continuous, and then, is a closed interval.If has no atom, let and such that . Then, given such that , there exits such that . Then, such that , there exists such that:then for all such that , and so, F is increasing and continuous; Theorem A1 implies that is continuous, and then:is closed. In particular, is closed. Then, we conclude that is a closed interval, as desired.We have proven Claim 1.Now, if , then , and we have:and then, , as desired.
- is optimal:Observe that given by (11) and (12) satisfy:where:and:then as given by (13).Now, observe that:since T and are non-decreasing,for . Then:On the other hand,for , and then:As a consequence, in any case, we have:Set:then (A2) becomes:which implies:as a consequence, is c-concave, according to Definition (1).Hypothesis A1 implies the existence of , such that:Claim 2: and : Observe that:and:hence:then, by (A4) and (A5),now, by Hypothesis A3 and since :therefore, integrating (A6) with respect to , we get:as a consequence:and we can conclude that .Similarly:by (A4) and (A5); using (A3) and (A7), if we integrate with respect to ,therefore:Hence, . We have proven Claim 2.Integrating with respect to , we get:and then:Finally, observe that for every ; if is another entropy transport plan, the associated total entropy transport cost is greater, by the definition of and ; then, the equality holds only for the optimal entropy transport plan and ; hence, it solves Problem (14), and solves Problem (15).We have proven the proposition.□
Appendix B. Linearization of the Monge–Ampère Equation
References
- Jensen, G.; Ward, R.D.; Balsam, P.D. Information: Theory, brain, and behavior. J. Exp. Anal. Behav. 2013, 100, 408–431. [Google Scholar] [CrossRef] [PubMed]
- Pregowska, A.; Szczepanski, J.; Wajnryb, E. Temporal code versus rate code for binary Information Sources. Neurocomputing 2016, 216, 756–762. [Google Scholar] [CrossRef]
- Pregowska, A.; Szczepanski, J.; Wajnryb, E. How Far can Neural Correlations Reduce Uncertainty? Comparison of Information Transmission Rates for Markov and Bernoulli Processes. Int. J. Neural Syst. 2019, 29, 1950003. [Google Scholar] [CrossRef] [PubMed]
- Harris, J.J.; Jolivet, R.; Engl, E.; Attwell, D. Energy-Efficient Information Transfer by Visual Pathway Synapses. Curr. Biol. 2015, 25, 3151–3160. [Google Scholar] [CrossRef]
- Harris, J.J.; Engl, E.; Attwell, D.; Jolivet, R.B. Energy-efficient information transfer at thalamocortical synapses. PLoS Comput. Biol. 2019, 15, 1–27. [Google Scholar] [CrossRef]
- Keshmiri, S. Entropy and the Brain: An Overview. Entropy 2020, 22, 917. [Google Scholar] [CrossRef]
- Salmasi, M.; Stemmler, M.; Glasauer, S.; Loebel, A. Synaptic Information Transmission in a Two-State Model of Short-Term Facilitation. Entropy 2019, 21, 756. [Google Scholar] [CrossRef]
- Crumiller, M.; Knight, B.; Kaplan, E. The Measurement of Information Transmitted by a Neural Population: Promises and Challenges. Entropy 2013, 15, 3507–3527. [Google Scholar] [CrossRef]
- Panzeri, S.; Piasini, E. Information Theory in Neuroscience. Entropy 2019, 21, 62. [Google Scholar] [CrossRef]
- Isomura, T. A Measure of Information Available for Inference. Entropy 2018, 20, 512. [Google Scholar] [CrossRef]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Ramstead, M.J.D.; Badcock, P.B.; Friston, K. Answering Schrodinger’s question: A free-energy formulation. Phys. Life Rev. 2016, 24, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Luczak, A. Measuring neuronal branching patterns using model-based approach. Front. Comput. Neurosci. 2010, 4, 135. [Google Scholar] [CrossRef] [PubMed]
- Bonnotte, N. Unidimensional and Evolution Methods for Optimal Transportation. Ph.D. Thesis, Scuola Normale Superiore di Pisa and Université Paris-Sud XI, Orsay, France, 2013. [Google Scholar]
- Stephenson, D.; Patronis, A.; Holland, D.M.; Lockerby, D.A. Generalizing Murray’s Law: An optimization principle for fluidic networks of arbitrary shape and scale. J. Appl. Phys. 2015, 118, 174302. [Google Scholar] [CrossRef]
- Villani, C. Topics in Optimal Transportation, 1st ed.; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2003; Volume 58. [Google Scholar]
- Villani, C. Optimal Transport Old and New, 1st ed.; Grundlehren der Mathematischen Wissenschaften: A Series of Comprehensive Studies in Mathematics; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar] [CrossRef]
- Evans, L.C. Partial Differential Equations and Monge–Kantorovich Mass Transfer. Curr. Dev. Math. 1997, 1997, 65–126. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Applebaum, D. Probability and Information: An Integrated Approach, 2nd ed.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Alarcón, T.; Castillo, J.; García-Ponce, B.; Padilla, P. Growth rate and shape as possible control mechanisms for the selection of mode development in optimal biological branching processes. Eur. Phys. J. Spec. Top. 2016, 225, 2581–2589. [Google Scholar] [CrossRef]
- Gutierrez, C.E.; Caffarelli, L.A. Properties of the solutions of the linearized Monge-Ampére equation. Am. J. Math. 1997, 119, 423–465. [Google Scholar] [CrossRef]
- Gutiérrez, C.E. The Monge-Ampére Equation, 2nd ed.; Progress in Nonlinear Differential Equations and Their Applications; Birkhäuser: Basel, Switzerland, 2016; Volume 89. [Google Scholar] [CrossRef]
- Ni, W.M. Diffusion, cross-diffusion, and their spike-layer steady states. Not. AMS 1998, 45, 9–18. [Google Scholar]
- Turing, A.M. The Chemical Basis of Morphogenesis. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 1952, 237, 37–72. [Google Scholar]
- Zhu, X.; Yang, H. Turing Instability-Driven Biofabrication of Branching Tissue Structures: A Dynamic Simulation and Analysis Based on the Reaction–Diffusion Mechanism. Micromachines 2018, 9, 109. [Google Scholar] [CrossRef] [PubMed]
- Meinhardt, H.; Koch, A.J.; Bernasconi, G. Models of pattern formation applied to plant development. In Symmetry in Plants; Series in Mathematical Biology and Medicine: Volume 4; World Scientific: Singapore, 1998; pp. 723–758. [Google Scholar] [CrossRef]
- Cortes-Poza, Y.; Padilla-Longoria, P.; Alvarez-Buylla, E. Spatial dynamics of floral organ formation. J. Theor. Biol. 2018, 454, 30–40. [Google Scholar] [CrossRef] [PubMed]
- Barrio, R.A.; Romero-Arias, J.R.; Noguez, M.A.; Azpeitia, E.; Ortiz-Gutiérrez, E.; Hernández-Hernández, V.; Cortes-Poza, Y.; Álvarez-Buylla, E. Cell Patterns Emerge from Coupled Chemical and Physical Fields with Cell Proliferation Dynamics: The Arabidopsis thaliana Root as a Study System. PLoS Comput. Biol. 2013, 9, e1003026. [Google Scholar] [CrossRef] [PubMed]
- Serini, G.; Ambrosi, D.; Giraudo, E.; Gamba, A.; Preziosi, L.; Bussolino, F. Modeling the early stages of vascular network assembly. EMBO J. 2003, 22, 1771–1779. [Google Scholar] [CrossRef]
- Köhn, A.; de Back, W.; Starruß, J.; Mattiotti, A.; Deutsch, A.; Perez-Pomares, J.M.; Herrero, M.A. Early Embryonic Vascular Patterning by Matrix-Mediated Paracrine Signalling: A Mathematical Model Study. PLoS ONE 2011, 6, e24175. [Google Scholar]
- Murray, C. The Physiological Principle of Minimum Work: I. The Vascular System and the Cost of Blood Volume. Proc. Natl. Acad. Sci. USA 1926, 12, 207–214. [Google Scholar] [CrossRef]
- Murray, C. The Physiological Principle of Minim Work Applied to the Angle of Branching of Arteries. J. Gen. Physiol. 1926, 9, 835–841. [Google Scholar] [CrossRef]
- McCulloh, K.A.; Sperry, J.S.; Adler, F.R. Water transport in plants obeys Murray’s law. Nature 2003, 421, 939–942. [Google Scholar] [CrossRef]
- Zheng, X.; Shen, G.; Wang, C.; Li, Y.; Dunphy, D.; Tawfique Hasan, T.; Brinker, C.J.; Su, B.L. Bio-inspired Murray materials for mass transfer and activity. Nat. Commun. 2017, 8, 14921. [Google Scholar] [CrossRef]
- Özdemir, H.I. The structural properties of carotid arteries in carotid artery diseases—A retrospective computed tomography angiography study. Pol. J. Radiol. 2020, 85, e82–e89. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; Childress, A.R.; Detre, J.A. Brain Entropy Mapping Using fMRI. PLoS ONE 2014, 9, e89948. [Google Scholar] [CrossRef] [PubMed]
- Bobkov, S.; Ledoux, M. One-Dimensional Empirical Measures, Order Statistics, and Kantorovich Transport Distances, 1st ed.; Memoirs of the American Mathematical Society; American Mathematical Society: Providence, RI, USA, 2016; Volume 261. [Google Scholar] [CrossRef]
- Evans, L.C.; Gariepy, R.F. Measure Theory and Fine Properties of Functions, Revised ed.; Textbooks in Mathematics; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
Sample Availability: Samples of the compounds are available from the authors. |



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islas, C.; Padilla, P.; Prado, M.A. Information Processing in the Brain as Optimal Entropy Transport: A Theoretical Approach. Entropy 2020, 22, 1231. https://doi.org/10.3390/e22111231
Islas C, Padilla P, Prado MA. Information Processing in the Brain as Optimal Entropy Transport: A Theoretical Approach. Entropy. 2020; 22(11):1231. https://doi.org/10.3390/e22111231
Chicago/Turabian StyleIslas, Carlos, Pablo Padilla, and Marco Antonio Prado. 2020. "Information Processing in the Brain as Optimal Entropy Transport: A Theoretical Approach" Entropy 22, no. 11: 1231. https://doi.org/10.3390/e22111231
APA StyleIslas, C., Padilla, P., & Prado, M. A. (2020). Information Processing in the Brain as Optimal Entropy Transport: A Theoretical Approach. Entropy, 22(11), 1231. https://doi.org/10.3390/e22111231