Salient Object Detection Techniques in Computer Vision—A Survey




Abstract
1. Introduction
2. Motivation and Contribution
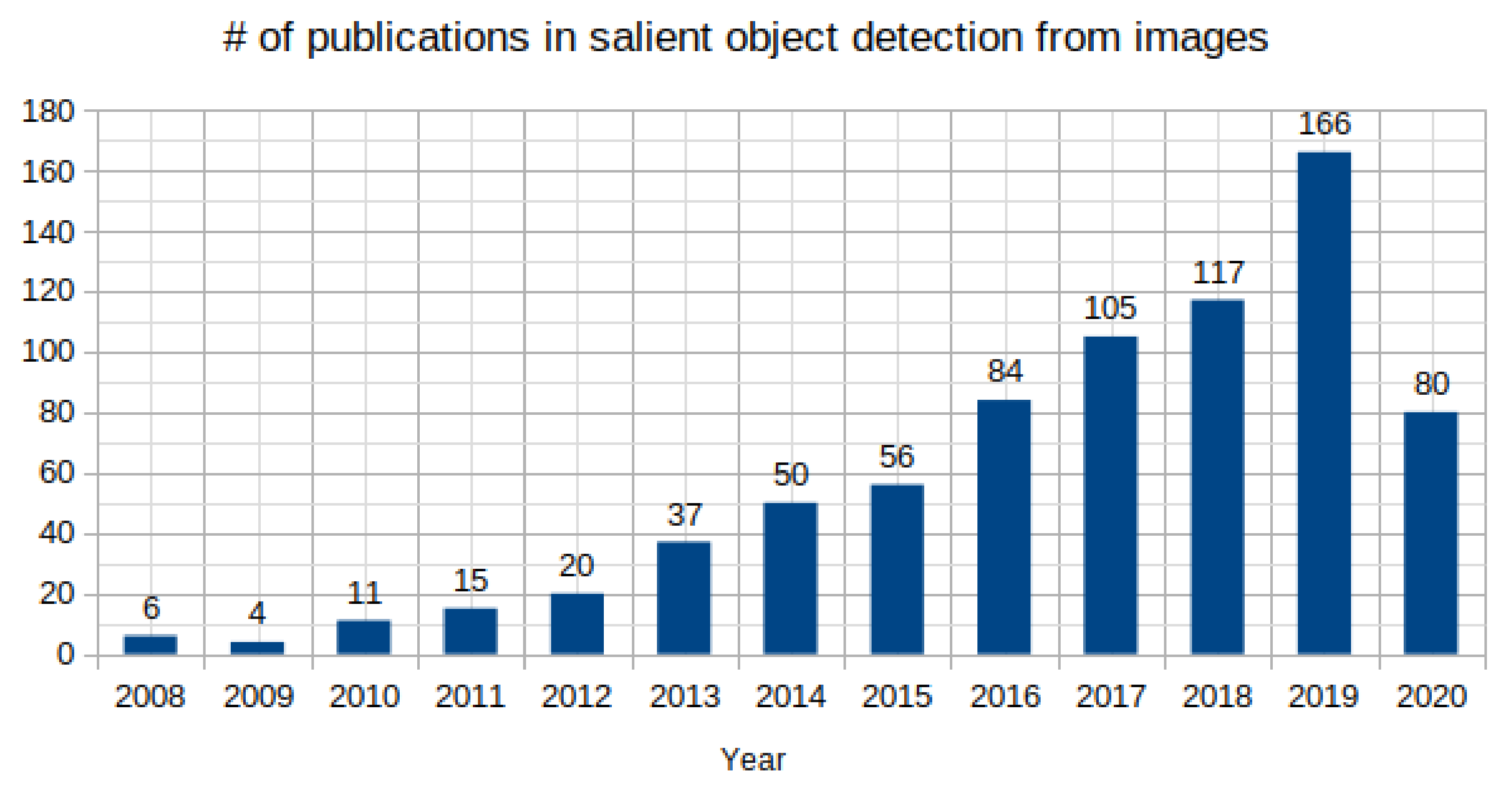
- This is an attempt to cover most of the influential contributions in the past 20 years for SOD in images. Data from Google scholar advanced search with the search constraint as salient object detection from images is collected. The rise of research work as shown in Figure 2 is an indicative of the importance and usefulness of SOD in the current scenario. The present review includes 41 and 50 publications discussed from conventional and deep learning-based SOD, respectively with the aim to help readers to make a broad view of the field necessary to explore future directions for research in SOD.
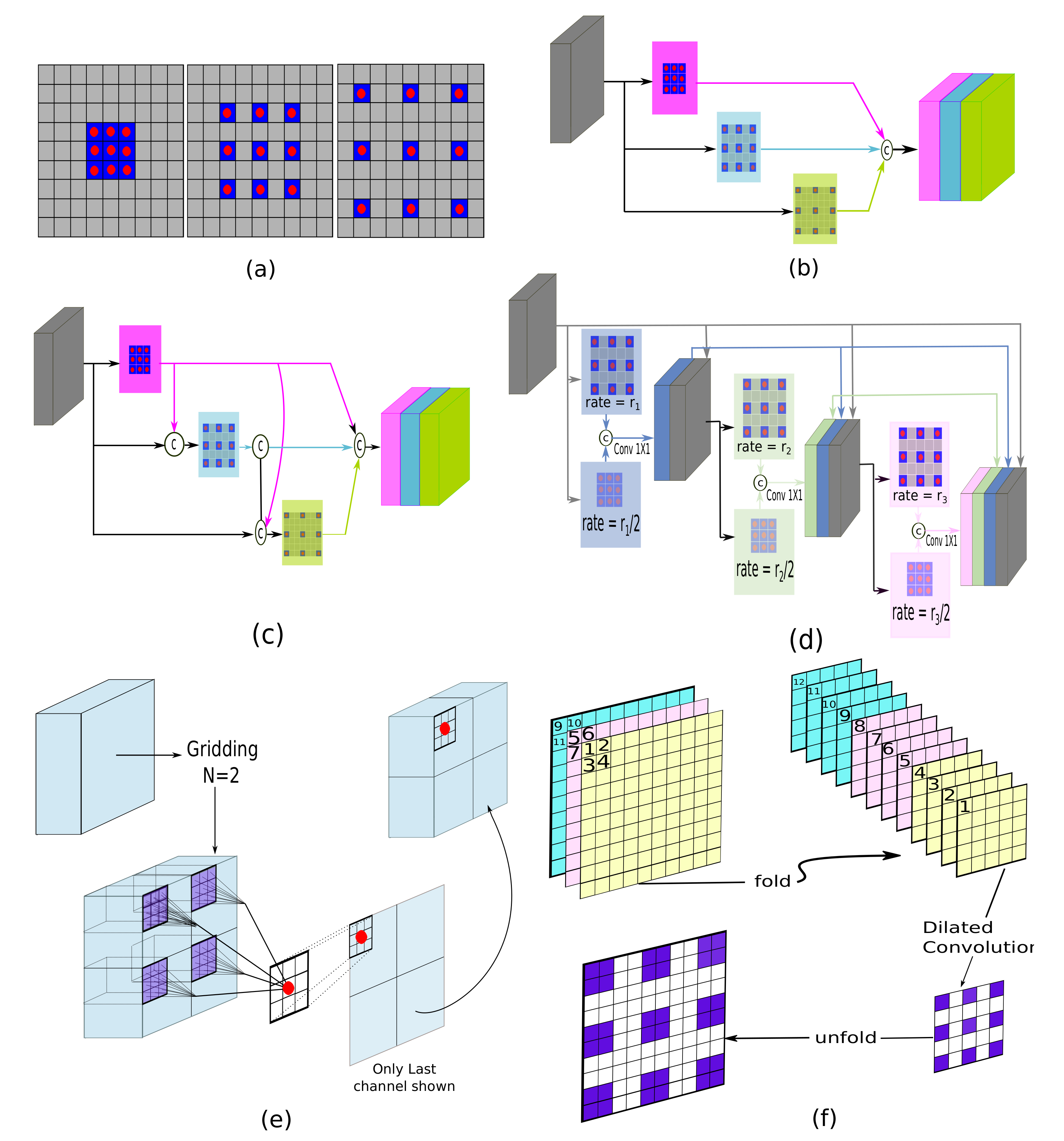
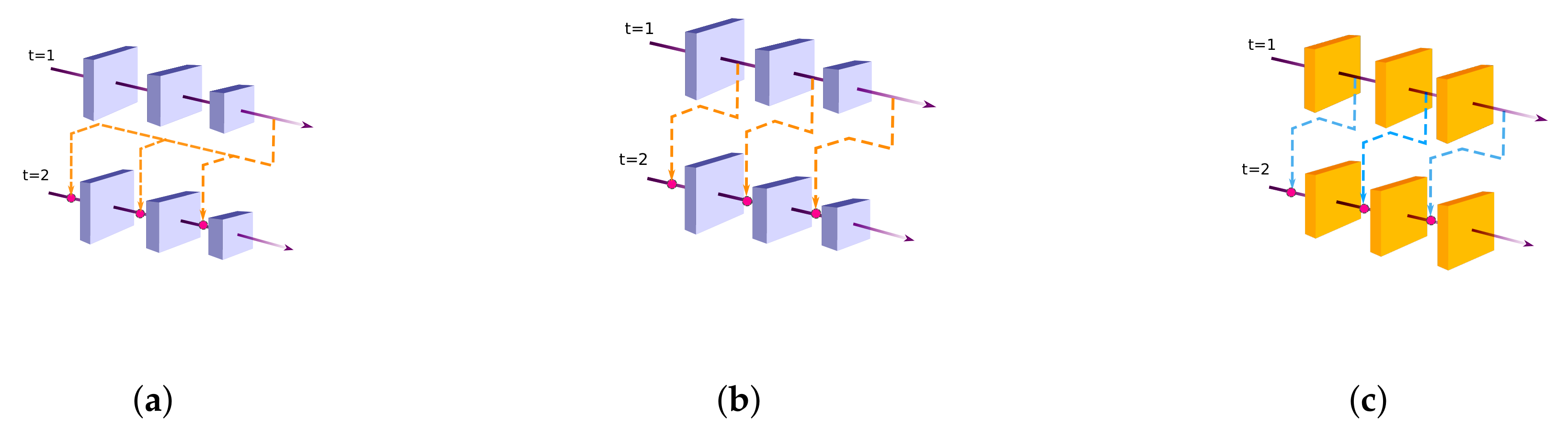
- State-of-the-art SOD models have adopted many techniques from the connected fields such as semantic segmentation. Techniques such as multi-scale contextual extraction and recurrent connections are crucial for extracting advanced features for SOD and therefore, included in this survey in a concise manner.
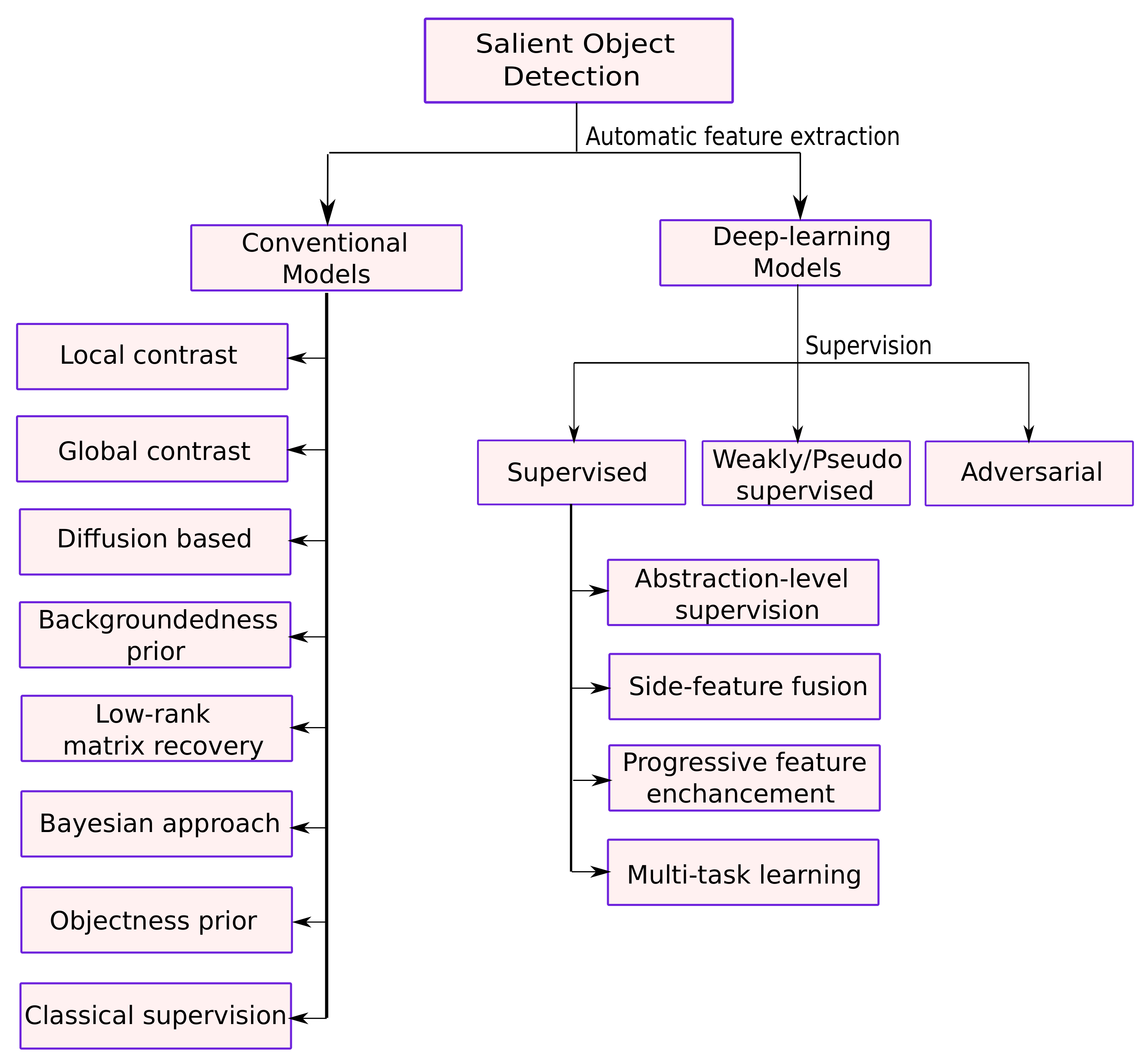
- Deep learning-based SOD models are categorized based on the level of supervision during the model training. The arrangement of the most recent developments in categories of supervised, weakly-supervised, and adversarial learning is useful in understanding the key design issues of SOD models. Figure 3 presents the classification for conventional and deep learning-based methods presented in this work.
3. Overview of Salient Object Detection
4. Conventional Salient Object Detection
4.1. Local Contrast Based SOD
4.2. Global Contrast Based SOD
4.3. Diffusion Based SOD
4.4. Backgroundedness Prior Based Methods
4.5. Low Rank Based SOD
4.6. Bayesian Approach Based SOD
4.7. Objectness Prior Based SOD
4.8. Classical Supervised SOD
5. Deep Learning-Based Salient Object Detection
5.1. Supervised Models
5.1.1. Abstraction-Level Supervision Based

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Publ. | Year | Backbone | Training Dataset | Strategy |
|---|---|---|---|---|---|
| Multi-Context Deep | CVPR | 2015 | GoogleNet | MSRA10K [54] | Superpixel centered deep local |
| Learning (MCDL) [150] | and global context extraction. | ||||
| Encoded Low Level | CVPR | 2016 | VGGNet | MSRA10K [54] | Learned local deep features |
| Distance (ELD) [151] | from heuristic ones. | ||||
| Multi-scale Deep | CVPR | 2017 | VGGNet | MSRA-B [54] + HKU-IS [154] | Learned deep features at various scales. |
| Features (MDF) [154] | + ILSO [157] | ||||
| Local Estimate-Global | CVPR | 2015 | - | MSRA-B [54] + PASCAL-S [158] | Refined local estimate within object |
| Search (LEGS) [152] | proposals, search globally for best proposals. | ||||
| Maximum-a posteriori (MAP) [153] | CVPR | 2016 | VGGNet | SOS [69] | Optimized a set of bounding-box proposals. |
| Shape Saliency Detector (SDD) [156] | ECCV | 2016 | AlexNet | MSRA-B [54] | Utilized pre-defined shapes. |
5.1.2. Side-Feature Fusion Based Models
| Method | Publ. | Year | Backbone | Training Dataset | Strategy |
|---|---|---|---|---|---|
| Deeply Supervised Saliency (DSS) [167] | CVPR | 2017 | VGGNet | MSRA-B [54] + HKU-IS [154] | Introduced short connections. |
| Non-Local Deep features (NLDF) [15] | CVPR | 2017 | VGGNet | MSRA-B [54] | Extracted contrast based features. |
| Aggregate Multi-level (Amulet) [171] | ICCV | 2017 | VGGNet | MSRA10K [54] | Aggregated multi-level features into multiple resolution. |
| Recurrently Aggregated Deep (RADF) [172] | AAAI | 2018 | VGGNet | MSRA10K [54] | Performed aggregation at image resolution and propagate back. |
| Cascaded Partial Decoder (CPD) [173] | CVPR | 2019 | ResNet50 | DUTS [174] | Partial decoders for computational efficiency. |
| Deepside [169] | Neurocomputing | 2019 | CGG | MSRA-B [54] + DUTS [174] | A general framework emphasizing side structures with different depths |
| Sub-region Dilated Block (SRDBNet) [164] | ITCSVT | 2020 | DenseNet | DUTS [174] | Introduced parallel-ASPP for context extraction. |
5.1.3. Progressive Feature Enhancement Models
5.1.4. Multi-Task Learning Based Models
5.1.5. Other Models
5.2. Weakly-Supervised/Pseudo-Supervised
5.3. Adversarial Training Based Models
6. Datasets, Evaluation and Discussion
6.1. SOD Datasets
6.2. SOD Evaluation Metrics
- Precision-Recall (PR) computation demands the conversion of an input saliency map S into a binary map B for comparison with ground-truth annotation G:The most popular method to binarize saliency prediction S into binary map B is to threshold S using a fixated range varying from 0 to 255. Based on the thresholded binary maps, 256 pairs of precision-recall values are then plotted into a precision-recall (PR) curve which serves as a situational model performance descriptor. Contrary to this, precision-recall pair can also be reported at an image-dependent adaptive threshold [14], computed as:which is the double of the mean saliency computed over S with W and H representing the width and the height of S, respectively.
- F-measure [14] is computed as a weighted harmonic mean of Precision and Recall:where is often set to for weighing precision more than recall. Due to the comprehensive nature of F-measure curves, they are preferred over PR-curves to compare the performance of different methods. Alternatively, the values from the F-measure curve or the value at an adaptive threshold such as Equation (6) have also been reported.
- Receiver Operator Characteristics (ROC) curve plotting requires computation of True positive rate (TPR) and False positive rate at all fixed threshold values in the range [0–255]. With B and G representing maps as in Equation (5), TPR and FPR can be defined as:where and . Methods having the ROC curve closer to the upper right achieve better performance.
- Area under ROC curve (AUC) is a scalar quantity calculated as the area under the plotted ROC curve. An AUC score of 1 indicates to a perfect SOD model, while a score around 0.5 indicates random saliency prediction and therefore, a high score is better.
- Mean Absolute Error (MAE) [106] penalizes those SOD methods that do well in salient object regions but additionally switch-on pixels in non-salient regions. MAE computes the mean pixel-wise absolute difference between normalized continuous prediction map S and the binary ground truth G asA smaller MAE score relates to the better performance as it reflects the high similarity between the saliency map S and the ground truth G considering all pixels in the image.
- Weighted measure [223] resolves the flaws caused by dependency between false-negative pixels and the spatial location of false-positive pixels in computation of with non-binary saliency masks. The error re-weighted versions of four basic quantities TP, TN, FP, and FN are defined by incorporating foreground pixel location affinities and background pixels locations w.r.t. foreground into weighing terms. The is defined as:
- Structural measure (S-measure) [224] addresses the shortfall of pixel-wise error based evaluation measures in capturing the structural information by favouring foreground structures in the continuous saliency map. S-measure combines structural similarities computed at region-aware and object-aware levels as:where is set to 0.5.
- E-measure. [225] Enhance-alignment measure is another recently proposed measure which captures the image-level statistics and local pixel matching information of a binary map in a single term named enhanced alignment matrix using which the measure is defined as follows:
6.3. Comparison and Analysis
7. Future Recommendations
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ma, C.; Miao, Z.; Zhang, X.P.; Li, M. A saliency prior context model for real-time object tracking. IEEE Trans. Multimed. 2017, 19, 2415–2424. [Google Scholar] [CrossRef]
- Lee, H.; Kim, D. Salient region-based online object tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1170–1177. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Qin, C.; Zhang, G.; Zhou, Y.; Tao, W.; Cao, Z. Integration of the saliency-based seed extraction and random walks for image segmentation. Neurocomputing 2014, 129, 378–391. [Google Scholar] [CrossRef]
- Fu, H.; Xu, D.; Lin, S. Object-based multiple foreground segmentation in RGBD video. IEEE Trans. Image Process. 2017, 26, 1418–1427. [Google Scholar] [CrossRef] [PubMed]
- Donoser, M.; Urschler, M.; Hirzer, M.; Bischof, H. Saliency driven total variation segmentation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 817–824. [Google Scholar]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient object detection with recurrent fully convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1734–1746. [Google Scholar] [CrossRef]
- Chen, S.; Tan, X.; Wang, B.; Lu, H.; Hu, X.; Fu, Y. Reverse Attention-Based Residual Network for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 3763–3776. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, T.; Dai, Y.; Harandi, M.; Hartley, R. Deep unsupervised saliency detection: A multiple noisy labeling perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9029–9038. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.M. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6609–6617. [Google Scholar]
- Feng, G.; Bo, H.; Sun, J.; Zhang, L.; Lu, H. CACNet: Salient Object Detection via Context Aggregation and Contrast Embedding. Neurocomputing 2020, 403, 33–44. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, C.; Fu, H.; Guo, X.; Tian, Q. Saliency-aware nonparametric foreground annotation based on weakly labeled data. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 1253–1265. [Google Scholar] [CrossRef]
- Gu, K.; Wang, S.; Yang, H.; Lin, W.; Zhai, G.; Yang, X.; Zhang, W. Saliency-guided quality assessment of screen content images. IEEE Trans. Multimed. 2016, 18, 1098–1110. [Google Scholar] [CrossRef]
- Liu, H.; Heynderickx, I. Studying the added value of visual attention in objective image quality metrics based on eye movement data. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3097–3100. [Google Scholar]
- Li, L.; Zhou, Y.; Lin, W.; Wu, J.; Zhang, X.; Chen, B. No-reference quality assessment of deblocked images. Neurocomputing 2016, 177, 572–584. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Song, J.; Shen, H. Beyond frame-level CNN: Saliency-aware 3-D CNN with LSTM for video action recognition. IEEE Signal Process. Lett. 2016, 24, 510–514. [Google Scholar] [CrossRef]
- Qi, M.; Wang, Y.; Qin, J.; Li, A.; Luo, J.; Van Gool, L. stagNet: An attentive semantic RNN for group activity and individual action recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 549–565. [Google Scholar] [CrossRef]
- Jacob, H.; Pádua, F.L.; Lacerda, A.; Pereira, A.C. A video summarization approach based on the emulation of bottom-up mechanisms of visual attention. J. Intell. Inf. Syst. 2017, 49, 193–211. [Google Scholar] [CrossRef]
- Ji, Q.G.; Fang, Z.D.; Xie, Z.H.; Lu, Z.M. Video abstraction based on the visual attention model and online clustering. Signal Process. Image Commun. 2013, 28, 241–253. [Google Scholar] [CrossRef]
- Han, S.; Vasconcelos, N. Image compression using object-based regions of interest. In Proceedings of the International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 3097–3100. [Google Scholar]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Trans. Image Process. 2009, 19, 185–198. [Google Scholar]
- Frintrop, S.; García, G.M.; Cremers, A.B. A cognitive approach for object discovery. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 2329–2334. [Google Scholar]
- Frintrop, S.; Kessel, M. Most salient region tracking. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 1869–1874. [Google Scholar]
- Su, Y.; Zhao, Q.; Zhao, L.; Gu, D. Abrupt motion tracking using a visual saliency embedded particle filter. Pattern Recognit. 2014, 47, 1826–1834. [Google Scholar] [CrossRef]
- Gao, Y.; Shi, M.; Tao, D.; Xu, C. Database saliency for fast image retrieval. IEEE Trans. Multimed. 2015, 17, 359–369. [Google Scholar] [CrossRef]
- Sun, J.; Liu, X.; Wan, W.; Li, J.; Zhao, D.; Zhang, H. Video hashing based on appearance and attention features fusion via DBN. Neurocomputing 2016, 213, 84–94. [Google Scholar] [CrossRef]
- Feng, S.; Xu, D.; Yang, X. Attention-driven salient edge (s) and region (s) extraction with application to CBIR. Signal Process. 2010, 90, 1–15. [Google Scholar] [CrossRef]
- Goldberg, C.; Chen, T.; Zhang, F.L.; Shamir, A.; Hu, S.M. Data-driven object manipulation in images. In Computer Graphics Forum; Wiley Online Library: Oxford, UK, 2012; Volume 31, pp. 265–274. [Google Scholar]
- Chia, A.Y.S.; Zhuo, S.; Gupta, R.K.; Tai, Y.W.; Cho, S.Y.; Tan, P.; Lin, S. Semantic colorization with internet images. ACM Trans. Graph. (TOG) 2011, 30, 6. [Google Scholar] [CrossRef]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. Saliency for image manipulation. Vis. Comput. 2013, 29, 381–392. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Yu, Y.; Ma, K.L. Stereoscopic thumbnail creation via efficient stereo saliency detection. IEEE Trans. Vis. Comput. Graph. 2016, 23, 2014–2027. [Google Scholar] [CrossRef]
- Goferman, S.; Tal, A.; Zelnik-Manor, L. Puzzle-like collage. In Computer Graphics Forum; Wiley Online Library: Oxford, UK, 2010; Volume 29, pp. 459–468. [Google Scholar]
- Fang, Y.; Chen, Z.; Lin, W.; Lin, C.W. Saliency detection in the compressed domain for adaptive image retargeting. IEEE Trans. Image Process. 2012, 21, 3888–3901. [Google Scholar] [CrossRef]
- Fang, Y.; Zeng, K.; Wang, Z.; Lin, W.; Fang, Z.; Lin, C.W. Objective quality assessment for image retargeting based on structural similarity. IEEE J. Emerg. Sel. Top. Circuits Syst. 2014, 4, 95–105. [Google Scholar] [CrossRef]
- Fang, Y.; Wang, J.; Yuan, Y.; Lei, J.; Lin, W.; Le Callet, P. Saliency-based stereoscopic image retargeting. Inf. Sci. 2016, 372, 347–358. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. Scene classification with a sparse set of salient regions. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1902–1908. [Google Scholar]
- Rutishauser, U.; Walther, D.; Koch, C.; Perona, P. Is bottom-up attention useful for object recognition? In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; Volume 2. [Google Scholar]
- Ren, Z.; Gao, S.; Chia, L.T.; Tsang, I.W.H. Region-based saliency detection and its application in object recognition. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 769–779. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Zhao, Q.; Yan, S. Attentive systems: A survey. Int. J. Comput. Vis. 2018, 126, 86–110. [Google Scholar] [CrossRef]
- Cong, R.; Lei, J.; Fu, H.; Cheng, M.M.; Lin, W.; Huang, Q. Review of visual saliency detection with comprehensive information. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2941–2959. [Google Scholar] [CrossRef]
- Borji, A. Saliency prediction in the deep learning era: Successes and limitations. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Zhou, T.; Fan, D.P.; Cheng, M.M.; Shen, J.; Shao, L. RGB-D Salient Object Detection: A Survey. arXiv 2020, arXiv:2008.00230. [Google Scholar]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Cave, K.R.; Franzel, S.L. Guided search: An alternative to the feature integration model for visual search. J. Exp. Psychol. Hum. Percept. Perform. 1989, 15, 419. [Google Scholar] [CrossRef] [PubMed]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Dordrecht, The Netherlands, 1987; pp. 115–141. [Google Scholar]
- Liu, T.; Sun, J.; Zheng, N.; Tang, X.; Shum, H. Learning to Detect A Salient Object. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 7–22 June 2007; pp. 1–8. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Shen, Y.; Ji, R.; Zhang, S.; Zuo, W.; Wang, Y. Generative adversarial learning towards fast weakly supervised detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5764–5773. [Google Scholar]
- Chen, B.; Li, P.; Sun, C.; Wang, D.; Yang, G.; Lu, H. Multi attention module for visual tracking. Pattern Recognit. 2019, 87, 80–93. [Google Scholar] [CrossRef]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Ramanathan, S.; Katti, H.; Sebe, N.; Kankanhalli, M.; Chua, T.S. An eye fixation database for saliency detection in images. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 30–43. [Google Scholar]
- Huang, X.; Shen, C.; Boix, X.; Zhao, Q. Salicon: Reducing the semantic gap in saliency prediction by adapting deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 262–270. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, S.; Sameki, M.; Sclaroff, S.; Betke, M.; Lin, Z.; Shen, X.; Price, B.; Mech, R. Salient object subitizing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4045–4054. [Google Scholar]
- Cao, X.; Tao, Z.; Zhang, B.; Fu, H.; Feng, W. Self-adaptively weighted co-saliency detection via rank constraint. IEEE Trans. Image Process. 2014, 23, 4175–4186. [Google Scholar] [PubMed]
- Huang, R.; Feng, W.; Sun, J. Color feature reinforcement for cosaliency detection without single saliency residuals. IEEE Signal Process. Lett. 2017, 24, 569–573. [Google Scholar] [CrossRef]
- Wei, L.; Zhao, S.; Bourahla, O.E.F.; Li, X.; Wu, F. Group-wise deep co-saliency detection. arXiv 2017, arXiv:1707.07381. [Google Scholar]
- Jacobs, D.E.; Goldman, D.B.; Shechtman, E. Cosaliency: Where people look when comparing images. In Proceedings of the 23nd Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 3–6 October 2010; pp. 219–228. [Google Scholar]
- Wang, W.; Shen, J.; Sun, H.; Shao, L. Video co-saliency guided co-segmentation. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1727–1736. [Google Scholar] [CrossRef]
- Fu, H.; Cao, X.; Tu, Z. Cluster-based co-saliency detection. IEEE Trans. Image Process. 2013, 22, 3766–3778. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Li, Y. Progressively complementarity-aware fusion network for RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3051–3060. [Google Scholar]
- Audet, F.; Allili, M.S.; Cretu, A.M. Salient Object Detection in Images by Combining Objectness Clues in the RGBD Space. In Proceedings of the International Conference Image Analysis and Recognition, Montreal, QC, Canada, 5–7 July 2017; Springer: Cham, Switzerland, 2017; pp. 247–255. [Google Scholar]
- Wang, A.; Wang, M. RGB-D salient object detection via minimum barrier distance transform and saliency fusion. IEEE Signal Process. Lett. 2017, 24, 663–667. [Google Scholar] [CrossRef]
- Sheng, H.; Liu, X.; Zhang, S. Saliency analysis based on depth contrast increased. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1347–1351. [Google Scholar]
- Chen, H.; Li, Y.F.; Su, D. Attention-aware cross-modal cross-level fusion network for RGB-D salient object detection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6821–6826. [Google Scholar]
- Zhao, X.; Zhang, L.; Pang, Y.; Lu, H.; Zhang, L. A single stream network for robust and real-time rgb-d salient object detection. arXiv 2020, arXiv:2007.06811. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D Salient Object Detection: Models, Data Sets, and Large-Scale Benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Dynamically encoded actions based on spacetime saliency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2755–2764. [Google Scholar]
- Li, Z.; Qin, S.; Itti, L. Visual attention guided bit allocation in video compression. Image Vis. Comput. 2011, 29, 1–14. [Google Scholar] [CrossRef]
- Fan, D.P.; Wang, W.; Cheng, M.M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8554–8564. [Google Scholar]
- Ng, R.; Levoy, M.; Brédif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Light Field Photography with a Hand-Held Plenoptic Camera. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2005. [Google Scholar]
- Wang, T.; Piao, Y.; Li, X.; Zhang, L.; Lu, H. Deep learning for light field saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8838–8848. [Google Scholar]
- Fan, D.P.; Lin, Z.; Ji, G.P.; Zhang, D.; Fu, H.; Cheng, M.M. Taking a Deeper Look at Co-Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2919–2929. [Google Scholar]
- Mehrani, P.; Veksler, O. Saliency Segmentation based on Learning and Graph Cut Refinement. BMVC 2010, 41, 1–12. [Google Scholar]
- Kim, J.; Han, D.; Tai, Y.W.; Kim, J. Salient region detection via high-dimensional color transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 883–890. [Google Scholar]
- Wang, Q.; Yuan, Y.; Yan, P.; Li, X. Saliency detection by multiple-instance learning. IEEE Trans. Cybern. 2013, 43, 660–672. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ling, H.; Yu, J.; Peng, J. Salient region detection by ufo: Uniqueness, focusness and objectness. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1976–1983. [Google Scholar]
- Yang, J.; Yang, M.H. Top-down visual saliency via joint CRF and dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 576–588. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.F.; Zhang, H.J. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the eleventh ACM international conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 374–381. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Liu, T.; Zheng, N.; Li, S. Automatic salient object segmentation based on context and shape prior. BMVC 2011, 6, 9. [Google Scholar]
- Rosin, P.L. A simple method for detecting salient regions. Pattern Recognit. 2009, 42, 2363–2371. [Google Scholar] [CrossRef]
- Hu, Y.; Rajan, D.; Chia, L.T. Robust subspace analysis for detecting visual attention regions in images. In Proceedings of the 13th annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 716–724. [Google Scholar]
- Liu, F.; Gleicher, M. Region enhanced scale-invariant saliency detection. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 1477–1480. [Google Scholar]
- Klein, D.A.; Frintrop, S. Center-surround divergence of feature statistics for salient object detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2214–2219. [Google Scholar]
- Li, X.; Li, Y.; Shen, C.; Dick, A.; Van Den Hengel, A. Contextual hypergraph modeling for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3328–3335. [Google Scholar]
- Achanta, R.; Estrada, F.; Wils, P.; Süsstrunk, S. Salient region detection and segmentation. In Proceedings of the International Conference on Computer Vision Systems, Santorini, Greece, 12–15 May 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 66–75. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Cheng, M.M.; Warrell, J.; Lin, W.Y.; Zheng, S.; Vineet, V.; Crook, N. Efficient salient region detection with soft image abstraction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1529–1536. [Google Scholar]
- Liu, Z.; Zou, W.; Le Meur, O. Saliency tree: A novel saliency detection framework. IEEE Trans. Image Process. 2014, 23, 1937–1952. [Google Scholar] [PubMed]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fu, K.; Gong, C.; Yang, J.; Zhou, Y.; Gu, I.Y.H. Superpixel based color contrast and color distribution driven salient object detection. Signal Process. Image Commun. 2013, 28, 1448–1463. [Google Scholar] [CrossRef]
- Margolin, R.; Tal, A.; Zelnik-Manor, L. What makes a patch distinct? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1139–1146. [Google Scholar]
- Gopalakrishnan, V.; Hu, Y.; Rajan, D. Random walks on graphs for salient object detection in images. IEEE Trans. Image Process. 2010, 19, 3232–3242. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Zhang, L.; Ai, J.; Jiang, B.; Lu, H.; Li, X. Saliency detection via absorbing Markov chain with learnt transition probability. IEEE Trans. Image Process. 2017, 27, 987–998. [Google Scholar] [CrossRef]
- Jiang, B.; Zhang, L.; Lu, H.; Yang, C.; Yang, M.H. Saliency detection via absorbing markov chain. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1665–1672. [Google Scholar]
- Filali, I.; Allili, M.S.; Benblidia, N. Multi-scale salient object detection using graph ranking and global–local saliency refinement. Signal Process. Image Commun. 2016, 47, 380–401. [Google Scholar] [CrossRef]
- Sun, J.; Lu, H.; Liu, X. Saliency region detection based on Markov absorption probabilities. IEEE Trans. Image Process. 2015, 24, 1639–1649. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Pan, Z.; Tu, C.; Vasconcelos, N.; Chen, B.; Peng, J. Super diffusion for salient object detection. IEEE Trans. Image Process. 2019, 29, 2903–2917. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M.H. Saliency detection via dense and sparse reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Zou, W.; Kpalma, K.; Liu, Z.; Ronsin, J. Segmentation driven low-rank matrix recovery for saliency detection. In Proceedings of the British Machine Vision Conference (BMVC), Bristol, UK, 9–13 September 2013; pp. 1–13. [Google Scholar]
- Wei, Y.; Wen, F.; Zhu, W.; Sun, J. Geodesic saliency using background priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 29–42. [Google Scholar]
- Gong, C.; Tao, D.; Liu, W.; Maybank, S.J.; Fang, M.; Fu, K.; Yang, J. Saliency propagation from simple to difficult. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2531–2539. [Google Scholar]
- Zhang, J.; Sclaroff, S.; Lin, Z.; Shen, X.; Price, B.; Mech, R. Minimum barrier salient object detection at 80 fps. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1404–1412. [Google Scholar]
- Tu, W.C.; He, S.; Yang, Q.; Chien, S.Y. Real-time salient object detection with a minimum spanning tree. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2334–2342. [Google Scholar]
- Strand, R.; Ciesielski, K.C.; Malmberg, F.; Saha, P.K. The minimum barrier distance. Comput. Vis. Image Underst. 2013, 117, 429–437. [Google Scholar] [CrossRef]
- Shen, X.; Wu, Y. A unified approach to salient object detection via low rank matrix recovery. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 853–860. [Google Scholar]
- Peng, H.; Li, B.; Ji, R.; Hu, W.; Xiong, W.; Lang, C. Salient object detection via low-rank and structured sparse matrix decomposition. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Peng, H.; Li, B.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S.J. Salient object detection via structured matrix decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 818–832. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Lu, H.; Yang, M.H. Bayesian saliency via low and mid level cues. IEEE Trans. Image Process. 2012, 22, 1689–1698. [Google Scholar]
- Sun, J.; Lu, H.; Li, S. Saliency detection based on integration of boundary and soft-segmentation. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 1085–1088. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef]
- Wang, X.; Ma, H.; Chen, X. Geodesic weighted Bayesian model for saliency optimization. Pattern Recognit. Lett. 2016, 75, 1–8. [Google Scholar] [CrossRef]
- Chang, K.Y.; Liu, T.L.; Chen, H.T.; Lai, S.H. Fusing generic objectness and visual saliency for salient object detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 914–921. [Google Scholar]
- Jia, Y.; Han, M. Category-independent object-level saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1761–1768. [Google Scholar]
- Li, H.; Lu, H.; Lin, Z.; Shen, X.; Price, B. Inner and inter label propagation: Salient object detection in the wild. IEEE Trans. Image Process. 2015, 24, 3176–3186. [Google Scholar] [CrossRef]
- Lu, S.; Mahadevan, V.; Vasconcelos, N. Learning optimal seeds for diffusion-based salient object detection. In Proceedings of the IEEE Conference on Computer Vision and PATTERN Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2790–2797. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. IntelligenCe Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Mobile encrypted traffic classification using deep learning: Experimental evaluation, lessons learned, and challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapè, A. MIMETIC: Mobile encrypted traffic classification using multimodal deep learning. Comput. Netw. 2019, 165, 106944. [Google Scholar] [CrossRef]
- Hiransha, M.; Gopalakrishnan, E.A.; Menon, V.K.; Soman, K. NSE stock market prediction using deep-learning models. Procedia Comput. Sci. 2018, 132, 1351–1362. [Google Scholar]
- Rather, A.M.; Agarwal, A.; Sastry, V. Recurrent neural network and a hybrid model for prediction of stock returns. Expert Syst. Appl. 2015, 42, 3234–3241. [Google Scholar] [CrossRef]
- Renton, G.; Chatelain, C.; Adam, S.; Kermorvant, C.; Paquet, T. Handwritten text line segmentation using fully convolutional network. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 5, pp. 5–9. [Google Scholar]
- Sudholt, S.; Fink, G.A. Attribute CNNs for word spotting in handwritten documents. Int. J. Doc. Anal. Recognit. (IJDAR) 2018, 21, 199–218. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wu, R.; Feng, M.; Guan, W.; Wang, D.; Lu, H.; Ding, E. A mutual learning method for salient object detection with intertwined multi-supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8150–8159. [Google Scholar]
- Zhang, L.; Zhang, J.; Lin, Z.; Lu, H.; He, Y. CapSal: Leveraging captioning to boost semantics for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6024–6033. [Google Scholar]
- Wei, J.; Wang, S.; Wu, Z.; Su, C.; Huang, Q.; Tian, Q. Label Decoupling Framework for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13025–13034. [Google Scholar]
- Zhang, J.; Yu, X.; Li, A.; Song, P.; Liu, B.; Dai, Y. Weakly-Supervised Salient Object Detection via Scribble Annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12546–12555. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Lee, G.; Tai, Y.W.; Kim, J. Deep saliency with encoded low level distance map and high level features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 660–668. [Google Scholar]
- Wang, L.; Lu, H.; Ruan, X.; Yang, M.H. Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3183–3192. [Google Scholar]
- Zhang, J.; Sclaroff, S.; Lin, Z.; Shen, X.; Price, B.; Mech, R. Unconstrained salient object detection via proposal subset optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 5733–5742. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Geodesic object proposals. In Proceedings of the European conference on computer vision. Springer, Zurich, Switzerland, 6–12 September 2014; pp. 725–739. [Google Scholar]
- Kim, J.; Pavlovic, V. A shape-based approach for salient object detection using deep learning. In Proceedings of the European Conference on Computer Vision. Springer, Amsterdam, The Netherlands, 8–16 October 2016; pp. 455–470. [Google Scholar]
- Li, G.; Xie, Y.; Lin, L.; Yu, Y. Instance-level salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2386–2395. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A bi-directional message passing model for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1741–1750. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9413–9422. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Stacked Cross Refinement Network for Edge-Aware Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7264–7273. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, L.; Chen, R.; Zhu, L.; Xie, H.; Li, X. Deep Sub-region Network for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and Balance: A Simple Gated Network for Salient Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Fu, K.; Zhao, Q.; Gu, I.Y.H.; Yang, J. Deepside: A general deep framework for salient object detection. Neurocomputing 2019, 356, 69–82. [Google Scholar] [CrossRef]
- Tu, Z.; Ma, Y.; Li, C.; Tang, J.; Luo, B. Edge-guided Non-local Fully Convolutional Network for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Hu, X.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently aggregating deep features for salient object detection. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Zheng, T.; Li, B.; Liu, J. Annular Feature Pyramid Network for Salient Object Detection. In Proceedings of the 2019 Eleventh International Conference on Advanced Computational Intelligence (ICACI), Guilin, China, 7–9 June 2019; pp. 1–6. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1623–1632. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 678–686. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 714–722. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3089–3098. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3127–3135. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3917–3926. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7479–7489. [Google Scholar]
- Wang, W.; Shen, J.; Cheng, M.M.; Shao, L. An iterative and cooperative top-down and bottom-up inference network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5968–5977. [Google Scholar]
- Xu, Y.; Xu, D.; Hong, X.; Ouyang, W.; Ji, R.; Xu, M.; Zhao, G. Structured modeling of joint deep feature and prediction refinement for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3789–3798. [Google Scholar]
- Hu, X.; Fu, C.W.; Zhu, L.; Wang, T.; Heng, P.A. Sac-net: Spatial attenuation context for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Wang, T.; Borji, A.; Wei, G.; Lu, H. A Multistage Refinement Network for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 3534–3545. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Tang, S.; Lin, M.; Li, J.; Yan, S. Global-residual and local-boundary refinement networks for rectifying scene parsing predictions. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3427–3433. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Ke, W.; Chen, J.; Jiao, J.; Zhao, G.; Ye, Q. SRN: Side-output residual network for object symmetry detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1068–1076. [Google Scholar]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Su, J.; Li, J.; Zhang, Y.; Xia, C.; Tian, Y. Selectivity or invariance: Boundary-aware salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3799–3808. [Google Scholar]
- He, S.; Jiao, J.; Zhang, X.; Han, G.; Lau, R.W. Delving into salient object subitizing and detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1059–1067. [Google Scholar]
- Amirul Islam, M.; Kalash, M.; Bruce, N.D. Revisiting salient object detection: Simultaneous detection, ranking, and subitizing of multiple salient objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7142–7150. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L. Joint learning of saliency detection and weakly supervised semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7223–7233. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Amirul Islam, M.; Rochan, M.; Bruce, N.D.; Wang, Y. Gated feedback refinement network for dense image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3751–3759. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Saliency detection with recurrent fully convolutional networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switerland, 2016; pp. 825–841. [Google Scholar]
- Kuen, J.; Wang, Z.; Wang, G. Recurrent attentional networks for saliency detection. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3668–3677. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning uncertain convolutional features for accurate saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 212–221. [Google Scholar]
- Hu, P.; Shuai, B.; Liu, J.; Wang, G. Deep level sets for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2300–2309. [Google Scholar]
- Wang, T.; Borji, A.; Zhang, L.; Zhang, P.; Lu, H. A stagewise refinement model for detecting salient objects in images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4019–4028. [Google Scholar]
- Zeng, Y.; Zhang, P.; Zhang, J.; Lin, Z.; Lu, H. Towards High-Resolution Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7234–7243. [Google Scholar]
- Ju, R.; Liu, Y.; Ren, T.; Ge, L.; Wu, G. Depth-aware salient object detection using anisotropic center-surround difference. Signal Process. Image Commun. 2015, 38, 115–126. [Google Scholar] [CrossRef]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. Rgbd salient object detection: A benchmark and algorithms. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 92–109. [Google Scholar]
- Li, X.; Yang, F.; Cheng, H.; Liu, W.; Shen, D. Contour knowledge transfer for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 355–370. [Google Scholar]
- Tang, M.; Djelouah, A.; Perazzi, F.; Boykov, Y.; Schroers, C. Normalized cut loss for weakly-supervised cnn segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1818–1827. [Google Scholar]
- Yang, J.; Price, B.; Cohen, S.; Lee, H.; Yang, M.H. Object contour detection with a fully convolutional encoder-decoder network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 193–202. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Cai, Y.; Dai, L.; Wang, H.; Chen, L.; Li, Y. A Novel Saliency Detection Algorithm Based on Adversarial Learning Model. IEEE Trans. Image PRocessing 2020, 29, 4489–4504. [Google Scholar] [CrossRef]
- Tang, Y.; Wu, X. Salient object detection using cascaded convolutional neural networks and adversarial learning. IEEE Trans. Multimed. 2019, 21, 2237–2247. [Google Scholar] [CrossRef]
- Zhu, D.; Dai, L.; Luo, Y.; Zhang, G.; Shao, X.; Itti, L.; Lu, J. Multi-scale adversarial feature learning for saliency detection. Symmetry 2018, 10, 457. [Google Scholar] [CrossRef]
- Movahedi, V.; Elder, J.H. Design and perceptual validation of performance measures for salient object segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar]
- Alpert, S.; Galun, M.; Brandt, A.; Basri, R. Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 315–327. [Google Scholar] [CrossRef]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Xia, C.; Li, J.; Chen, X.; Zheng, A.; Zhang, Y. What is and what is not a salient object? Learning salient object detector by ensembling linear exemplar regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4142–4150. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, J.J.; Gao, S.H.; Hou, Q.; Borji, A. Salient objects in clutter: Bringing salient object detection to the foreground. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 186–202. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 724–732. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 248–255. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Xu, X.; Chen, J.; Zhang, H.; Han, G. Dual pyramid network for salient object detection. Neurocomputing 2020, 375, 113–123. [Google Scholar] [CrossRef]
- Zhang, P.; Su, L.; Li, L.; Bao, B.; Cosman, P.; Li, G.; Huang, Q. Training Efficient Saliency Prediction Models with Knowledge Distillation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 512–520. [Google Scholar]











| # | Title | Publ. | Focused Attentive Task | Coverage Span (upto) | Short Description |
|---|---|---|---|---|---|
| 1 | State-of-the-Art in Visual Attention Modeling [46] | TPAMI | Fixation prediction (FP) | 2012 | Reviewed traditional models for visual attention. |
| 2 | Salient Object Detection: A Benchmark [45] | TIP | FP and SOD | 2014 | Qualitatively evaluated selective heuristic FP and SOD models over seven datasets. |
| 3 | Attentive Systems: A Survey [47] | IJCV | General attention | 2017 | Application oriented review of attentive (SOD and FP) techniques. |
| 4 | Review of Visual Saliency Detection with Comprehensive Information [48] | TCSVT | RGB-D, Co-saliency and Video saliency | 2018 | Review of traditional, and learning-based models for all 3 SOD tasks. |
| 5 | Saliency prediction in the deep learning era: Successes and limitations [49] | TPAMI | FP | 2018 | Covered of FP models for still images and videos. |
| 6 | Salient Object Detection: A Survey [7] | CVM | SOD | 2017 | Reviewed early deep learning-based models for RGB images and heuristic models for 2-D, 3-D and 4-D images. |
| 7 | Salient Object Detection in the Deep Learning Era: An In-Depth Survey [44] | arXiv | SOD | 2019 | Compact coverage and attribute-based analysis of deep SOD models for RGB-images. |
| 8 | RGB-D Salient Object Detection: A Survey [50] | arXiv | RGB-D SOD | 2020 | Reviewed RGB-D based SOD and light field SOD models and benchmark their datasets. |
| # | Task | Aim | GT Map | Vs. SOD |
|---|---|---|---|---|
| 1 | Fixation prediction | Finds where human look in a scene. | Several fixation dots in human fixation map. | Pixel-wise GT maps with clear boundaries are seldom used. |
| 2 | Image/Semantic segmentation | Assigns a label to each pixel in the image. | Each pixel has an associated category label. | Scope is the entire image, not just the salient objects. |
| 3 | Object proposals | Generates overlapping candidate region proposals. | Rectangular bounding-box annotation. | Objectness prior have been utilized in heuristic SOD models. |
| 4 | Object detection | To locate object(s) from fixed category list. | Rectangular bounding-box annotation. | Locates all instances of desired type, not just salient. |
| 5 | Salient object subitizing | Find existence and the number of salient objects. | Pixel accurate annotation with a count. | Indexing of individual objects as salient. |
| Model | Objective Function Terms | Short Descriptions | |||
|---|---|---|---|---|---|
| add’l. Constraint | |||||
| ULR model [124] | - | - | is the nuclear norm and is the L1 regularizer. | ||
| SLR model [118] | - | is a feature matrix and is a set of N prior values with one value each for a superpixel. | |||
| LSMD model [125] | – | – | represents a tree-structured sparsity regularizer. weights the node , where, d and represent # of tree levels and # of nodes per level, respectively. | ||
| SMD model [126] | – | represents a Laplacian sparsity regularizer. p is set to ∞, is the Laplacian matrix. | |||
| Architecture | Year | Publication | Key Features | Layers | Representative Model |
|---|---|---|---|---|---|
| VGG [56] | 2014 | ICLR | Small size convolution kernels, More | 13, 16, 19 | [159,160] |
| discriminative decision function. | |||||
| ResNet [145] | 2016 | CVPR | Much deeper network, residual | 18, 34, 50, 101, 152 | [161,162] |
| modeling eases the training process | |||||
| of a very deep network structure. | |||||
| DenseNet [163] | 2017 | CVPR | Less parameters, more reuse of features, | 121,169, 201, 264 | [164] |
| better training relives from the vanishing | |||||
| gradient and model degeneration problems. | |||||
| ResNext [165] | 2017 | CVPR | Homogeneous, multi-branch architecture, | 101 | [166] |
| few hyper-parameter setting required. |
| Method | Publ. | Year | Backbone | Training Dataset | Strategy |
|---|---|---|---|---|---|
| Deep Hierarchical Saliency (DHSNet) [179] | CVPR | 2016 | VGGNet | MSRA10K [54] + DUT-OMRON [110] | Recurrent convolution based refinement. |
| Bi-directional Message Passing (BDMP) [159] | CVPR | 2018 | VGGNet | DUTS [174] | Enabled bi-directional message passing. |
| Progressive Attention Guided Recurrence (PAGR) [180] | CVPR | 2018 | VGGNet19 | DUTS [174] | Spatial-/Channel-wise attention mechanism. |
| Pixel-wise Contextual Attention (PiCANet) [181] | CVPR | 2018 | VGGNet/ResNet50 | DUTS [174] | Learned local and global pixel-wise contextual information. |
| Detect Globally Refine Locally (DGRL) [182] | CVPR | 2018 | ResNet50 | DUTS [174] | Recurrence connections within ResNet50 blocks. |
| Reverse Attention (RAS) [160] | ECCV | 2018 | VGGNet | MSRA-B [54] | Residual connections with reverse attention mechanism. |
| Pooling-based Network (PoolNet) [183] | CVPR | 2019 | ResNet50 | DUTS [174] | Pooling intensive approach. |
| Boundary-Aware Saliency (BASNet) [184] | CVPR | 2019 | ResNet-34 | DUTS [174] | Saliency refinement based on residual network. Introduced novel losses. |
| Attention Feedback (AFNet) [177] | CVPR | 2019 | VGGNet16 | DUTS [174] | Feedback mechanism in scale matching encoder-decoder pair. |
| Iterative Pathways Saliency (IPS) [185] | CVPR | 2019 | ResNet50 | MSRA10K [54] | Iterative top-down/bottom-up inference. |
| Joint Deep features (JDF) [186] | ICCV | 2019 | VGG | MSRA-B [54] | Modelled interaction between side-features and predictions. |
| Gated Network (GateNet) [166] | arXiv | 2020 | ResNet/ResNeXt-101 | DUTS [174] | Gates with encoder-decoder inputs to control message passing. |
| Spatial Attenuation Context (SACNet) [187] | ITCSVT | 2020 | ResNet-101 | DUTS [174] | Used spatial attenuation context for SOD. |
| Multistage Interactive (MINet) [188] | CVPR | 2020 | VGG-16/ResNet-50 | DUTS [174] | Mutual learning based interaction modules. |
| Method | Publ. | Year | Backbone | Training Dataset | Strategy |
|---|---|---|---|---|---|
| Delving salient object subitizing (DSOS) [195] | ICCV | 2017 | VGGNet | SOS [69] | Salient object subitization assists SOD with the count of salient objects. |
| Revisiting Saliency Detection (RSDNet-R) [196] | CVPR | 2018 | ResNet101 | PASCAL-S [158] | Gate based skip connections. |
| Boundary-Aware (BANet) [194] | ICCV | 2019 | ResNet50 | DUTS [174] | Build three streams network to address selectivity-invariance delimma. |
| Stacked Cross refinement (SCRN) [162] | ICCV | 2019 | ResNet50 | DUTS [174] | Let multiple tasks benefit each other. |
| Caption Saliency (CapSal) [147] | CVPR | 2019 | ResNet101 | COCO-CapSal [147]/DUTS[174] | Utilized image captioning for SOD. |
| Saliency Semantic-segmentation (SSNet) [197] | ICCV | 2019 | Densenet169 | PASCAL VOC 2012 [198]/DUTS [174] | Unified framework for weakly supervised semantic segmentation and SOD. |
| Edge Guided (EGNet) [199] | ICCV | 2019 | VGGNet/ResNet | DUTS [174] | Combined SOD features and Edge features at multiple scales. |
| Mutual Learning saliency (MLSL) [146] | CVPR | 2019 | VGGNet16 | DUTS [174] | Mutual learning module based. |
| Pyramid Attention Edge (PAGE-Net) [44] | CVPR | 2019 | VGGNet16 | MSRA10K [54] | Utilized Hierarchical attention mechanism. |
| Label Decomposition Framework (LDF) [148] | CVPR | 2020 | ResNet-50 | DUTS [174] | Saliency mask decoupled for better edge and interior supervision. |
| -Net [193] | PR | 2020 | RSU | DUTS [174] | Two-level nested U-structure which is trained from scratch. |
| Method | Publ. | Year | Backbone | Training Dataset | Strategy |
|---|---|---|---|---|---|
| Recurrent FCN (RFCN) [201] | ECCV | 2016 | VGGNet | PASCAL VOC 2010 [198] + MSRA10K [54] | Utilized conventional saliency maps and recurrent FCN. |
| Recurrent Attention (RACDNN) [202] | CVPR | 2016 | VGGNet | DUT-OMRON [110] + NJU2000 [207] + RGBDSOD [208] | Spatial transform network to attend to image sub-regions. |
| Uncertain Conv Features (UCF) [203] | ICCV | 2017 | VGGNet | MSRA10K [54] | Introduced R-dropouts in encoder. |
| Deep Level-Sets (DLS) [204] | CVPR | 2017 | VGGNet | MSRA10K [54] | Level-set based loss function. |
| Stagewise Refinement Model (SRM) [205] | ICCV | 2017 | ResNet | DUTS [174] | Multi-stage refinement mechanism. |
| Multi-scale Refinement (MSRNet) [157] | CVPR | 2017 | ResNet | DUTS [174] | Multi-scale refinement mechanism. |
| High Resolution SOD (HRSOD) [206] | ICCV | 2019 | VGGNet | DUTS [174] + HRSOD [206] | High resolution SOD utilizing global cues for local refinement. |
| Method | Publ. | Year | Backbone | Training Dataset | Supervision Source |
|---|---|---|---|---|---|
| Image Level Supervision (ILS) [174] | CVPR | 2017 | VGGNet | ImageNet [55] | Image-level tags. |
| Deep Unsupervised Saliency (DUS) [13] | CVPR | 2018 | ResNet101 | MSRA-B [54] | Noisy saliency maps from four heuristic SOD. |
| Contour2Saliency C2S-Net [209] | ECCV | 2018 | VGGNet | MSRA10K [54]+Web | Contour information. |
| Weakly-Supervised Scribble Annotations (WSSA) [149] | CVPR | 2020 | VGGNet | Scribble-DUTS [149] | Scribble annotation based. |
| S.No | Dataset | Year | Publication | Images | Annt | Property | Resolution | ||
|---|---|---|---|---|---|---|---|---|---|
| Object | Bkg | Max(w,h) | Min(w,h) | ||||||
| 1 | MSRA-A [54] | 2007 | CVPR | 20,840 | BB | 1-2, LG, CN | CL, SE | 400 | 165 |
| 2 | MSRA-B [54] | 2007 | CVPR | 2500 (TR) + 2500 (TE) | BB | 1-2, LG, CN | CL, SE | 400 | 126 |
| 3 | SED1 [218] | 2007 | CVPR | 100 | PW | 1 | SE | 465 | 125 |
| 4 | SED2 [218] | 2007 | CVPR | 100 | PW | 2 | CM | 300 | 144 |
| 5 | ASD [14] | 2009 | CVPR | 1000 | PW | 1-2, MD, CN | CL, SE | 400 | 165 |
| 6 | SOD [217,219] | 2010 | CVPR-W | 300 | PW | ML, MD | CM | 481 | 321 |
| 7 | MSRA5K [54,95] | 2011 | CVPR | 5000 | PW | 1 | CL, SE | 400 | 144 |
| 8 | CSSD [103] | 2013 | CVPR | 200 | PW | 1 | CL, SE | 400 | 139 |
| 9 | ECSSD [103] | 2013 | CVPR | 1000 | PW | ML, LG | CL, SE | 400 | 139 |
| 10 | MSRA10K [54] | 2013 | CVPR | 10,000 | PW | 1 | CL, SE | 400 | 144 |
| 11 | DUT-OMRON [110] | 2013 | CVPR | 5168 | PW | ML, SM | CM | 401 | 89 |
| 12 | PASCAL-S [158] | 2014 | CVPR | 850 | PW | ML, MD | CM | 500 | 151 |
| 13 | HKU-IS [154] | 2015 | CVPR | 3000 (TR) +1447 (TE) | PW | ML, MD | CM | 401 | 100 |
| 14 | DUTS [174] | 2017 | CVPR | 10,553 (TR) + 5019 (TE) | PW | ML | CM | 400 | 126 |
| 15 | XPIE [220] | 2017 | CVPR | 10,000 | PWIL | 1, MD | CM | 500 | 130 |
| 16 | ILSO [157] | 2017 | CVPR | 1000 | PWIL | ML, MD | CM | 400 | 142 |
| 17 | SOC [221] | 2018 | ECCV | 6000 | PWIL, OC | 0-4+, MD | CM, TX | 849 | 161 |
| 18 | HRSOD [206] | 2019 | ICCV | 1610 (TR) + 400 (TE) | PW | ML, MD | CM | 10,240 | 600 |
| 19 | DAVIS-S [206,222] | 2019 | ICCV | 92 | PW | ML, MD, SA | CM, RE | 3840 | 720 |
| Model | ECSSD [103] | HKU-IS [154] | DUT-OMRON [110] | DUTS-TE [174] | Pascal-S [158] | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE ↓ | MAE ↓ | MAE ↓ | MAE ↓ | MAE ↓ | ||||||||||||||||
| VGG | ||||||||||||||||||||
| [174] | 0.855 | 0.811 | 0.868 | 0.103 | 0.859 | 0.822 | 0.897 | 0.078 | 0.689 | 0.730 | 0.766 | 0.110 | 0.737 | 0.737 | 0.793 | 0.100 | 0.771 | 0.743 | 0.791 | 0.139 |
| [157] | 0.911 | 0.895 | 0.918 | 0.054 | 0.914 | 0.903 | 0.940 | 0.040 | 0.782 | 0.808 | 0.827 | 0.073 | 0.829 | 0.839 | 0.848 | 0.061 | 0.858 | 0.841 | 0.854 | 0.081 |
| [15] | 0.905 | 0.875 | 0.912 | 0.063 | 0.902 | 0.878 | 0.929 | 0.048 | 0.753 | 0.817 | 0.770 | 0.080 | 0.812 | 0.816 | 0.855 | 0.065 | 0.833 | 0.804 | 0.842 | 0.099 |
| [171] | 0.915 | 0.894 | 0.912 | 0.059 | 0.899 | 0.886 | 0.915 | 0.050 | 0.743 | 0.781 | 0.784 | 0.098 | 0.778 | 0.804 | 0.803 | 0.085 | 0.841 | 0.821 | 0.831 | 0.098 |
| [203] | 0.903 | 0.884 | 0.896 | 0.069 | 0.888 | 0.874 | 0.904 | 0.061 | 0.730 | 0.760 | 0.768 | 0.120 | 0.773 | 0.783 | 0.770 | 0.112 | 0.825 | 0.807 | 0.809 | 0.115 |
| [167] | 0.899 | 0.873 | 0.907 | 0.068 | 0.916 | 0.878 | 0.935 | 0.040 | 0.781 | 0.790 | 0.844 | 0.063 | 0.825 | 0.824 | 0.885 | 0.056 | 0.843 | 0.795 | 0.848 | 0.096 |
| [181] | 0.931 | 0.914 | 0.926 | 0.046 | 0.922 | 0.905 | 0.938 | 0.042 | 0.794 | 0.826 | 0.842 | 0.068 | 0.851 | 0.861 | 0.865 | 0.054 | 0.871 | 0.851 | 0.862 | 0.077 |
| [160] | 0.921 | 0.893 | 0.922 | 0.056 | 0.913 | 0.887 | 0.931 | 0.045 | 0.787 | 0.814 | 0.849 | 0.062 | 0.831 | 0.839 | 0.864 | 0.059 | 0.838 | 0.795 | 0.837 | 0.104 |
| [209] | 0.910 | 0.893 | 0.914 | 0.054 | 0.895 | 0.882 | 0.927 | 0.048 | 0.757 | 0.7981 | 0.828 | 0.072 | 0.806 | 0.874 | 0.816 | 0.063 | 0.842 | 0.836 | 0.845 | 0.081 |
| [180] | 0.927 | 0.889 | 0.917 | 0.061 | 0.919 | 0.889 | 0.941 | 0.047 | 0.771 | 0.775 | 0.843 | 0.071 | 0.854 | 0.838 | 0.883 | 0.055 | 0.858 | 0.817 | 0.854 | 0.093 |
| [186] | 0.927 | 0.906 | 0.931 | 0.049 | 0.920 | 0.903 | 0.943 | 0.039 | 0.801 | 0.821 | 0.862 | 0.057 | 0.832 | 0.825 | 0.860 | 0.058 | 0.856 | 0.841 | 0.853 | 0.082 |
| [159] | 0.929 | 0.910 | 0.915 | 0.044 | 0.927 | 0.906 | 0.938 | 0.039 | 0.792 | 0.809 | 0.839 | 0.064 | 0.854 | 0.850 | 0.862 | 0.048 | 0.854 | 0.845 | 0.845 | 0.073 |
| [173] | 0.936 | 0.910 | 0.943 | 0.040 | 0.924 | 0.904 | 0.952 | 0.033 | 0.794 | 0.818 | 0.868 | 0.057 | 0.864 | 0.867 | 0.908 | 0.043 | 0.873 | 0.843 | 0.884 | 0.074 |
| [146] | 0.928 | 0.911 | 0.916 | 0.045 | 0.920 | 0.907 | 0.938 | 0.039 | 0.774 | 0.809 | 0.839 | 0.064 | 0.852 | 0.862 | 0.863 | 0.049 | 0.864 | 0.845 | 0.847 | 0.075 |
| [44] | 0.931 | 0.912 | 0.943 | 0.042 | 0.920 | 0.904 | 0.948 | 0.036 | 0.792 | 0.825 | 0.860 | 0.062 | 0.838 | 0.854 | 0.886 | 0.052 | 0.859 | 0.840 | 0.879 | 0.078 |
| [177] | 0.935 | 0.912 | 0.940 | 0.042 | 0.925 | 0.905 | 0.948 | 0.036 | 0.797 | 0.826 | 0.859 | 0.057 | 0.863 | 0.855 | 0.892 | 0.046 | 0.871 | 0.849 | 0.885 | 0.071 |
| [183] | 0.941 | 0.917 | 0.942 | 0.041 | 0.931 | 0.911 | 0.951 | 0.033 | 0.820 | 0.832 | 0.863 | 0.056 | 0.879 | 0.866 | 0.894 | 0.041 | 0.868 | 0.851 | 0.873 | 0.071 |
| [199] | 0.942 | 0.918 | 0.941 | 0.041 | 0.926 | 0.911 | 0.940 | 0.035 | 0.808 | 0.836 | 0.864 | 0.056 | 0.877 | 0.877 | 0.894 | 0.044 | 0.870 | 0.847 | 0.872 | 0.077 |
| [161] | 0.943 | 0.919 | 0.947 | 0.036 | 0.932 | 0.914 | 0.955 | 0.030 | 0.794 | 0.822 | 0.864 | 0.057 | 0.877 | 0.875 | 0.912 | 0.039 | 0.882 | 0.855 | 0.898 | 0.065 |
| ResNet-50/ResNet-101/DenseNet/ResNeXt-101/RSU | ||||||||||||||||||||
| [205] | 0.917 | 0.895 | 0.928 | 0.054 | 0.906 | 0.887 | 0.939 | 0.046 | 0.769 | 0.798 | 0.843 | 0.069 | 0.826 | 0.836 | 0.867 | 0.059 | 0.850 | 0.833 | 0.861 | 0.085 |
| [182] | 0.925 | 0.906 | 0.943 | 0.043 | 0.914 | 0.896 | 0.947 | 0.038 | 0.779 | 0.810 | 0.850 | 0.063 | 0.828 | 0.842 | 0.899 | 0.050 | 0.860 | 0.839 | 0.881 | 0.075 |
| [184] | 0.942 | 0.916 | 0.921 | 0.037 | 0.93 | 0.908 | 0.947 | 0.033 | 0.805 | 0.836 | 0.869 | 0.056 | 0.859 | 0.866 | 0.884 | 0.048 | 0.863 | 0.837 | 0.853 | 0.077 |
| [147] | 0.862 | 0.826 | 0.866 | 0.074 | 0.884 | 0.850 | 0.907 | 0.058 | 0.639 | 0.674 | 0.703 | 0.096 | 0.823 | 0.815 | 0.866 | 0.062 | 0.869 | 0.837 | 0.878 | 0.074 |
| [183] | 0.949 | 0.926 | 0.948 | 0.035 | 0.936 | 0.918 | 0.958 | 0.029 | 0.830 | 0.831 | 0.873 | 0.053 | 0.893 | 0.874 | 0.909 | 0.036 | 0.884 | 0.864 | 0.887 | 0.064 |
| [194] | 0.945 | 0.924 | 0.953 | 0.035 | 0.930 | 0.913 | 0.955 | 0.032 | 0.803 | 0.832 | 0.865 | 0.059 | 0.872 | 0.879 | 0.907 | 0.040 | 0.879 | 0.853 | 0.889 | 0.070 |
| [162] | 0.950 | 0.927 | 0.942 | 0.037 | 0.935 | 0.917 | 0.954 | 0.033 | 0.811 | 0.837 | 0.869 | 0.056 | 0.888 | 0.885 | 0.901 | 0.040 | 0.890 | 0.867 | 0.888 | 0.065 |
| [164] | 0.950 | 0.922 | 0.953 | 0.031 | 0.939 | 0.915 | 0.954 | 0.027 | 0.822 | 0.829 | 0.933 | 0.053 | 0.891 | 0.863 | 0.918 | 0.036 | 0.888 | 0.798 | 0.85 | 0.068 |
| [148] | 0.950 | 0.923 | 0.950 | 0.034 | 0.940 | 0.920 | 0.961 | 0.027 | 0.821 | 0.839 | 0.881 | 0.051 | 0.896 | 0.879 | 0.923 | 0.034 | 0.875 | 0.862 | 0.904 | 0.059 |
| [193] | 0.951 | 0.928 | 0.925 | 0.032 | 0.934 | 0.913 | 0.945 | 0.031 | 0.822 | 0.846 | 0.871 | 0.054 | 0.872 | 0.860 | 0.883 | 0.045 | 0.861 | 0.844 | 0.850 | 0.074 |
| [161] | 0.947 | 0.925 | 0.953 | 0.033 | 0.935 | 0.920 | 0.961 | 0.028 | 0.810 | 0.833 | 0.873 | 0.055 | 0.884 | 0.884 | 0.917 | 0.037 | 0.882 | 0.857 | 0.899 | 0.064 |
| [166] | 0.952 | 0.929 | - | 0.035 | 0.943 | 0.925 | - | 0.029 | 0.829 | 0.848 | - | 0.051 | 0.898 | 0.895 | - | 0.035 | 0.888 | 0.865 | - | 0.065 |
| [187] | 0.954 | 0.930 | 0.958 | 0.028 | 0.945 | 0.925 | 0.969 | 0.023 | 0.832 | 0.846 | 0.883 | 0.050 | 0.898 | 0.878 | 0.920 | 0.032 | 0.876 | 0.801 | 0.902 | 0.070 |
| Models | SF [106] | MR [110] | RBD [117] | DRFI [92] | MCDL [150] | AMULet [171] | UCF [203] | C2S-Net [209] |
|---|---|---|---|---|---|---|---|---|
| Time(s) | 0.16 | 0.25 | 0.25 | 9 | 2.41 | 0.07 | 0.046 | 0.034 |
| GPU Support | No | No | No | No | Yes | Yes | Yes | Yes |
| Learning | No | No | No | CML | DL | DL | DL | DL |
| Code | C++ | Matlab | Matlab | Matlab | Caffe | Caffe | caffe | caffe |
| Models | PiCANet [181] | RAS [160] | PoolNet [183] | AFNet [177] | EGNet [199] | SCRN [162] | CPD [173] | BASNet [184] |
| Time(s) | 0.19 | 0.0291 | 0.033 | 0.023 | 0.11 | 0.032 | 0.016 | 0.014 |
| GPU Support | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Learning | DL | DL | DL | DL | DL | DL | DL | DL |
| Code | caffe | caffe | caffe | pytorch | pytorch | pytorch | prtorch | pytorch |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gupta, A.K.; Seal, A.; Prasad, M.; Khanna, P. Salient Object Detection Techniques in Computer Vision—A Survey. Entropy 2020, 22, 1174. https://doi.org/10.3390/e22101174
Gupta AK, Seal A, Prasad M, Khanna P. Salient Object Detection Techniques in Computer Vision—A Survey. Entropy. 2020; 22(10):1174. https://doi.org/10.3390/e22101174
Chicago/Turabian StyleGupta, Ashish Kumar, Ayan Seal, Mukesh Prasad, and Pritee Khanna. 2020. "Salient Object Detection Techniques in Computer Vision—A Survey" Entropy 22, no. 10: 1174. https://doi.org/10.3390/e22101174
APA StyleGupta, A. K., Seal, A., Prasad, M., & Khanna, P. (2020). Salient Object Detection Techniques in Computer Vision—A Survey. Entropy, 22(10), 1174. https://doi.org/10.3390/e22101174