CEB Improves Model Robustness


Abstract
1. Introduction
- CEB models are easy to implement and train.
- CEB models show improved generalization performance over deterministic baselines on CIFAR10 and ImageNet.
- CEB models show improved robustness to untargeted Projected Gradient Descent (PGD) attacks on CIFAR10.
- CEB models trained on ImageNet show improved robustness on the ImageNet-C Common Corruptions Benchmark, the ImageNet-A Benchmark, and targeted PGD attacks.
- CEB models trained on ImageNet show improved calibration on the ImageNet validation set and on ImageNet-C.
2. Materials and Methods
2.1. Information Bottlenecks
2.2. Implementing a CEB Model
2.3. Consistent Classifier
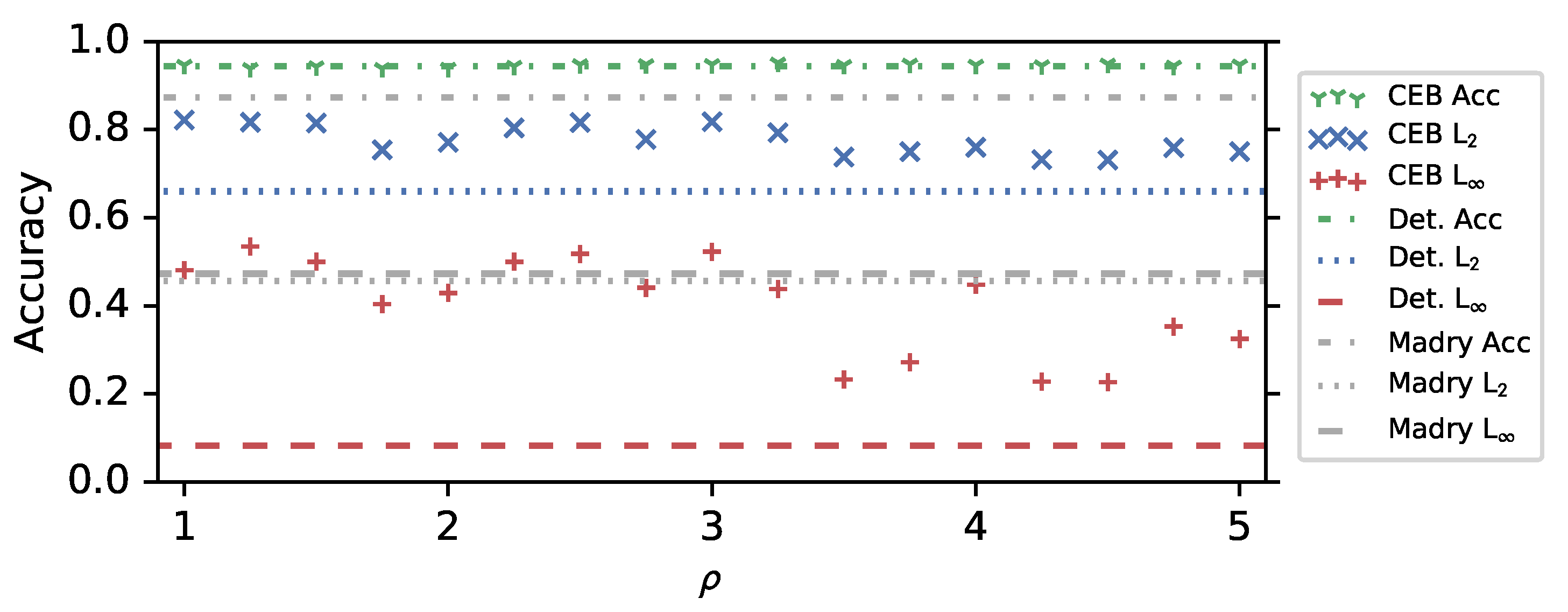
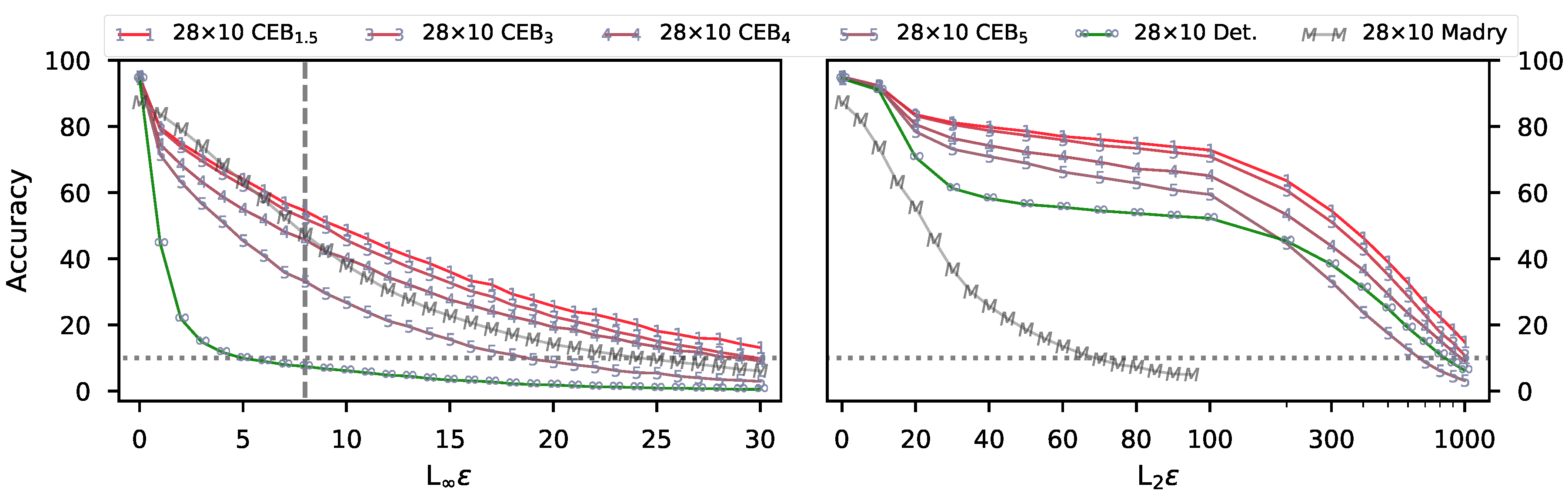
2.4. Adversarial Attacks and Defenses
2.4.1. Attacks
2.4.2. Defenses
2.5. Common Corruptions
2.6. Natural Adversarial Examples
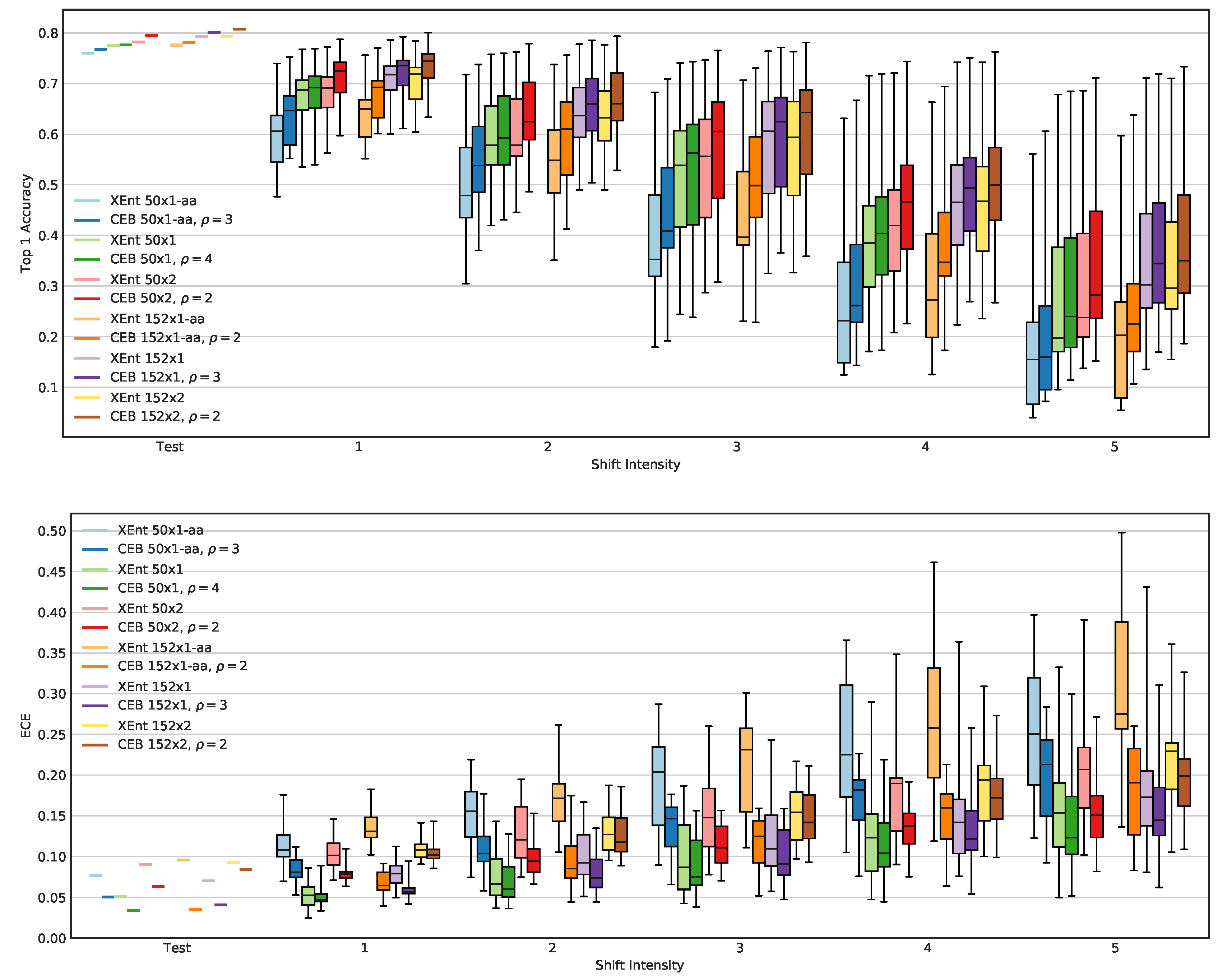
2.7. Calibration
3. Results
3.1. CIFAR10 Experiments
3.2. ImageNet Experiments
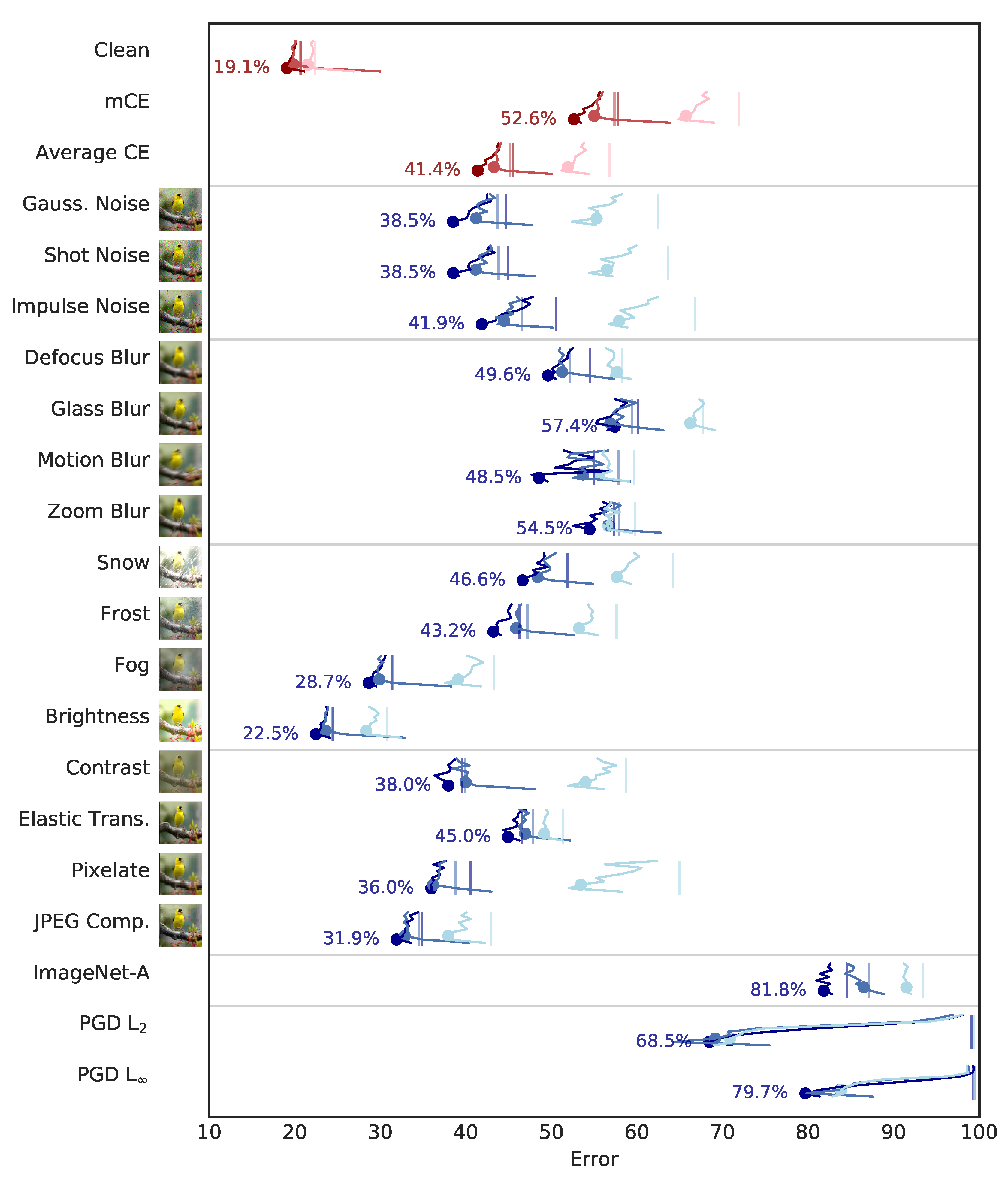
3.2.1. Accuracy, ImageNet-C, and ImageNet-A
3.2.2. Targeted PGD Attacks
3.2.3. Calibration and ImageNet-C
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Experiment Details
Appendix A.1. CIFAR10 Experiment Details
Appendix A.2. ImageNet Experiment Details
Appendix B. CEB Example Code

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #In model.py: |
| defresnet_v1_generator(block_fn, layers, num_classes,…): |
| def model(inputs, is_training): |
| # Build the ResNet model as normal up to the following lines: |
| inputs = tf.reshape( |
| inputs, [−1, 2048 if block_fn is bottleneck_block else 512]) |
| # Now, instead of the final dense layer, just~return inputs, |
| # which for ResNet50 models is a [batch_size, 2048] tensor. |
| return inputs |
| # In resnet_main.py add the following imports and functions: |
| importtensorflow_probabilityastfp |
| tfd = tfp.distributions |
| defezx_dist(x): |
| """Builds the encoder distribution, e(z|x).""" |
| dist = tfd.MultivariateNormalDiag(loc = x) |
| return dist |
| defbzy_dist(y, num_classes = 1000, z_dims = 2048): |
| """Builds the backwards distribution, b(z|y).""" |
| y_onehot = tf.one_hot(y, num_classes) |
| mus =| tf.layers.dense(y_onehot, z_dims, activation = None) |
| dist = tfd.MultivariateNormalDiag(loc = mus) |
| return dist |
| defcyz_dist(z, num_classes = 1000): |
| """Builds the classifier distribution, c(y|z).""" |
| # For the classifier, we~are using exactly the same dense layer |
| # initialization as was used for the final layer that we removed |
| # from model.py. |
| logits = tf.layers.dense( |
| z, num_classes, activation = None, |
| kernel_initializer=tf.random_normal_initializer(stddev = 0.01)) |
| return tfd.Categorical(logits=logits) |
| deflerp(global_step, start_step, end_step, start_val, end_val): |
| """Utility function to linearly interpolate two values.""" |
| interp = (tf.cast(global_step - start_step, tf.float32) |
| / tf.cast(end_step - start_step, tf.float32)) |
| interp = tf.maximum(0.0, tf.minimum(1.0, interp)) |
| return start_val ∗ (1.0 - interp) + end_val ∗ interp |
| # Still in resnet_main.py, modify resnet_model_fn as follows: |
| defresnet_model_fn(features, labels, mode, params): |
| # Nothing changes until after the definition of build_network: |
| def build_network(): |
| # Elided, unchanged implementation of build_network. |
| if params['precision'] == 'bfloat16': |
| #build_network now returns the pre-logits, so~we'll change |
| # the variable name from logits to net. |
| with tf.contrib.tpu.bfloat16_scope(): |
| net = build_network() |
| net = tf.cast(net, tf.float32) |
| elif params['precision'] == 'float32': |
| net = build_network() |
| # Get the encoder, e(z|x): |
| with tf.variable_scope('ezx', reuse=tf.AUTO_REUSE): |
| ezx = ezx_dist(net) |
| # Get the backwards encoder, b(z|y): |
| with tf.variable_scope('bzy', reuse=tf.AUTO_REUSE): |
| bzy = bzy_dist(labels) |
| # Only sample z during training. Otherwise, just~pass through |
| # the mean value of the encoder. |
| if mode == tf.estimator.ModeKeys.TRAIN: |
| z = ezx.sample() |
| else: |
| z = ezx.mean() |
| #Get the classifier, c(y|z): |
| with tf.variable_scope('cyz', reuse=tf.AUTO_REUSE): |
| cyz = cyz_dist(z, params) |
| # cyz.logits is the same as what the unmodified ResNet model would return. |
| logits = cyz.logits |
| # Compute the individual conditional entropies: |
| hzx = −ezx.log_prob(z) # H(Z|X) |
| hzy = −bzy.log_prob(z) # H(Z|Y) (upper bound) |
| hyz = −cyz.log_prob(labels) # H(Y|Z) (upper bound) |
| # I(X;Z|Y) = −H(Z|X) + H(Z|Y) |
| # >= −hzx + hzy =: Rex, the~residual information. |
| rex = −hzx + hzy |
| rho = 3.0 # You should make this a hyperparameter. |
| rho_to_gamma = lambda rho: 1.0 / np.exp(rho) |
| gamma = tf.cast(rho_to_gamma(rho), tf.float32) |
| # Get the global step now, so~that we can adjust rho dynamically. |
| global_step = tf.train.get_global_step() |
| anneal_rho = 12,000 # You should make this a hyperparameter. |
| if anneal_rho > 0: |
| # Anneal rho from 100 down to the target rho |
| # over the first anneal_rho steps. |
| gamma = lerp(global_step, 0, aneal_rho, |
| rho_to_gamma(100.0), gamma) |
| # Replace all the softmax cross-entropy loss computation with the following line: |
| loss = tf.reduce_mean(gamma ∗ rex + hyz) |
| # The rest of resnet_model_fn can remain unchanged. |
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 25 May 2017; pp. 39–57. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the ICLR Workshop, International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm Sweden, 10–15 July 2018. [Google Scholar]
- Engstrom, L.; Gilmer, J.; Goh, G.; Hendrycks, D.; Ilyas, A.; Madry, A.; Nakano, R.; Nakkiran, P.; Santurkar, S.; Tran, B.; et al. A Discussion of ’Adversarial Examples Are Not Bugs, They Are Features’. Distill 2019. Available online: https://distill.pub/2019/advex-bugs-discussion (accessed on 24 September 2020). [CrossRef]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lopes, R.G.; Yin, D.; Poole, B.; Gilmer, J.; Cubuk, E.D. Improving Robustness Without Sacrificing Accuracy with Patch Gaussian Augmentation. arXiv 2019, arXiv:1906.02611. [Google Scholar]
- Yin, D.; Gontijo Lopes, R.; Shlens, J.; Cubuk, E.D.; Gilmer, J. A Fourier Perspective on Model Robustness in Computer Vision. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 13276–13286. [Google Scholar]
- Fischer, I. The Conditional Entropy Bottleneck. Entropy 2020, 22, 999. [Google Scholar] [CrossRef]
- Achille, A.; Soatto, S. Emergence of Invariance and Disentanglement in Deep Representations. J. Mach. Learn. Res. 2018, 19, 1–34. [Google Scholar]
- Achille, A.; Soatto, S. Information dropout: Learning optimal representations through noisy computation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef] [PubMed]
- Pensia, A.; Jog, V.; Loh, P.L. Extracting robust and accurate features via a robust information bottleneck. IEEE J. Select. Areas Inf. Theory 2020. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Google TensorFlow Team. Cloud TPU ResNet Implementation. 2019. Available online: https://github.com/tensorflow/tpu/tree/master/models/official/resnet (accessed on 30 September 2019).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples; ICLR, 2015; Available online: http://arxiv.org/abs/1412.6572 (accessed on 7 September 2020).
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning models. arXiv 2017, arXiv:1707.08945. [Google Scholar]
- Baluja, S.; Fischer, I. Learning to Attack: Adversarial Transformation Networks. In Proceedings of the AAAI Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial Examples Are Not Bugs, They Are Features. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 125–136. [Google Scholar]
- Xie, C.; Wu, Y.; Maaten, L.V.D.; Yuille, A.L.; He, K. Feature denoising for improving adversarial robustness. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 501–509. [Google Scholar]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A.; Madry, A. Robustness May Be at Odds with Accuracy. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural adversarial examples. arXiv 2019, arXiv:1907.07174. [Google Scholar]
- Naeini, M.P.; Cooper, G.; Hauskrecht, M. Obtaining Well Calibrated Probabilities Using Bayesian Binning. In AAAI Conference on Artificial Intelligence; Association for the Advancement of Artificial Intelligence: Menlo Park, CA, USA, 2015. [Google Scholar]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.; Lakshminarayanan, B.; Snoek, J. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 13991–14002. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of Machine Learning Research; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Wu, T.; Fischer, I.; Chuang, I.L.; Tegmark, M. Learnability for the Information Bottleneck. Entropy 2019, 21, 924. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]





| Architecture | ResNet152x2 | ResNet152 | ResNet152-aa | ResNet50x2 | ResNet50 | ResNet50-aa | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Objective | cCEB | CEB | XEnt | CEB | XEnt | CEB | XEnt | cCEB | CEB | XEnt | CEB | XEnt | CEB | XEnt |
| 2 | 2 | NA | 3 | NA | 3 | NA | 4 | 3 | NA | 6 | NA | 4 | NA | |
| Clean | 19.1 | 19.3 | 20.7 | 19.9 | 20.7 | 21.6 | 22.4 | 20.0 | 20.2 | 21.8 | 21.9 | 22.5 | 22.8 | 24.0 |
| mCE | 52.6 | 53.2 | 57.8 | 55.0 | 57.4 | 65.7 | 71.9 | 57.9 | 57.8 | 62.0 | 62.1 | 64.4 | 72.0 | 77.0 |
| Average CE | 41.4 | 41.8 | 45.5 | 43.3 | 45.2 | 51.9 | 56.8 | 45.6 | 45.5 | 48.9 | 49.0 | 50.8 | 56.9 | 60.9 |
| Gauss. Noise | 38.5 | 40.1 | 44.7 | 41.2 | 43.7 | 55.3 | 62.5 | 44.8 | 43.9 | 48.3 | 48.0 | 50.7 | 59.6 | 67.3 |
| Shot Noise | 38.5 | 40.3 | 45.0 | 41.2 | 43.8 | 56.5 | 63.7 | 44.5 | 43.9 | 48.4 | 47.8 | 50.7 | 61.2 | 68.8 |
| Impulse Noise | 41.9 | 43.6 | 50.5 | 44.5 | 46.6 | 57.9 | 66.8 | 48.7 | 48.1 | 53.1 | 51.3 | 54.8 | 64.8 | 72.7 |
| Defocus Blur | 49.6 | 48.8 | 54.5 | 51.3 | 52.1 | 57.7 | 58.3 | 54.4 | 54.2 | 57.3 | 57.4 | 58.8 | 61.5 | 62.7 |
| Glass Blur | 57.4 | 56.7 | 60.1 | 56.9 | 59.4 | 66.2 | 67.7 | 59.9 | 61.0 | 62.6 | 64.2 | 64.9 | 71.5 | 72.3 |
| Motion Blur | 48.5 | 51.4 | 55.0 | 53.7 | 57.8 | 55.6 | 59.7 | 57.0 | 56.6 | 59.5 | 60.0 | 62.3 | 62.7 | 68.1 |
| Zoom Blur | 54.5 | 54.7 | 57.3 | 56.8 | 57.9 | 56.6 | 59.8 | 58.6 | 58.0 | 61.3 | 62.5 | 64.8 | 61.8 | 63.7 |
| Snow | 46.6 | 46.6 | 51.9 | 48.4 | 51.8 | 57.6 | 64.2 | 51.4 | 50.9 | 55.9 | 55.7 | 58.8 | 63.1 | 68.7 |
| Frost | 43.2 | 43.9 | 46.3 | 45.9 | 47.2 | 53.2 | 57.6 | 47.1 | 47.1 | 50.7 | 51.0 | 52.7 | 57.6 | 61.7 |
| Fog | 28.7 | 28.7 | 31.4 | 29.9 | 31.5 | 39.1 | 43.3 | 30.6 | 30.2 | 33.9 | 33.9 | 34.8 | 42.3 | 47.0 |
| Brightness | 22.5 | 22.6 | 24.5 | 23.6 | 24.4 | 28.4 | 30.8 | 23.8 | 24.1 | 26.3 | 26.4 | 26.8 | 30.3 | 33.4 |
| Contrast | 38.0 | 37.7 | 39.5 | 40.0 | 39.9 | 54.0 | 58.7 | 42.0 | 42.4 | 44.9 | 46.7 | 47.6 | 58.5 | 62.8 |
| Elastic Trans. | 45.0 | 45.3 | 46.6 | 46.9 | 47.8 | 49.2 | 51.4 | 49.0 | 48.8 | 52.4 | 51.7 | 53.7 | 53.0 | 56.0 |
| Pixelate | 36.0 | 35.2 | 40.5 | 36.2 | 38.8 | 53.4 | 64.9 | 37.3 | 37.9 | 41.1 | 40.8 | 42.8 | 63.1 | 64.6 |
| JPEG Comp. | 31.9 | 31.8 | 34.9 | 32.9 | 34.5 | 38.0 | 43.0 | 34.7 | 35.1 | 37.4 | 37.0 | 37.9 | 41.8 | 43.5 |
| ImageNet-A | 81.8 | 82.0 | 84.6 | 86.5 | 87.1 | 91.5 | 93.4 | 86.8 | 88.1 | 89.8 | 92.0 | 94.2 | 94.9 | 96.8 |
| PGD L | 68.5 | 68.0 | 99.1 | 69.1 | 99.2 | 70.9 | 99.4 | 86.6 | 84.5 | 99.8 | 89.7 | 99.7 | 80.2 | 99.7 |
| PGD L | 79.7 | 79.3 | 99.3 | 83.8 | 99.4 | 83.8 | 99.4 | 95.1 | 93.2 | 99.4 | 97.3 | 99.4 | 91.0 | 99.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fischer, I.; Alemi, A.A. CEB Improves Model Robustness. Entropy 2020, 22, 1081. https://doi.org/10.3390/e22101081
Fischer I, Alemi AA. CEB Improves Model Robustness. Entropy. 2020; 22(10):1081. https://doi.org/10.3390/e22101081
Chicago/Turabian StyleFischer, Ian, and Alexander A. Alemi. 2020. "CEB Improves Model Robustness" Entropy 22, no. 10: 1081. https://doi.org/10.3390/e22101081
APA StyleFischer, I., & Alemi, A. A. (2020). CEB Improves Model Robustness. Entropy, 22(10), 1081. https://doi.org/10.3390/e22101081