Single Real Goal, Magnitude-Based Deceptive Path-Planning

Abstract
1. Introduction
2. Background and Related Work
2.1. Deception and Deceptive Path-Planning
2.2. Probabilistic Goal Recognition
3. The Single, Real Goal, Magnitude-based Deceptive Path-Planning
- N is a non-empty set of nodes (or locations);
- is a set of edges between nodes;
- returns the length of each edge.
- is the road network;
- is the source;
- is the single goal/destination/target.
- is the road network;
- is the source;
- is the possible goal set, where is the single real goal, and is the set of bogus goals;
- is the observation sequence;
- are the prior probabilities upon the possible goal set G.
- is the road network;
- is the source;
- is the possible goal set;
- is the single real goal;
- denotes the posterior probability distribution upon G given O.
- is the single real goal deceptive path-planning problem;
- returns the deception magnitude value assigned to each node;
- R is the total amount of distance allowed for the deceiver traversing path.
4. The Single Real Goal Magnitude-Based Deception Maximization
4.1. Model Formulation
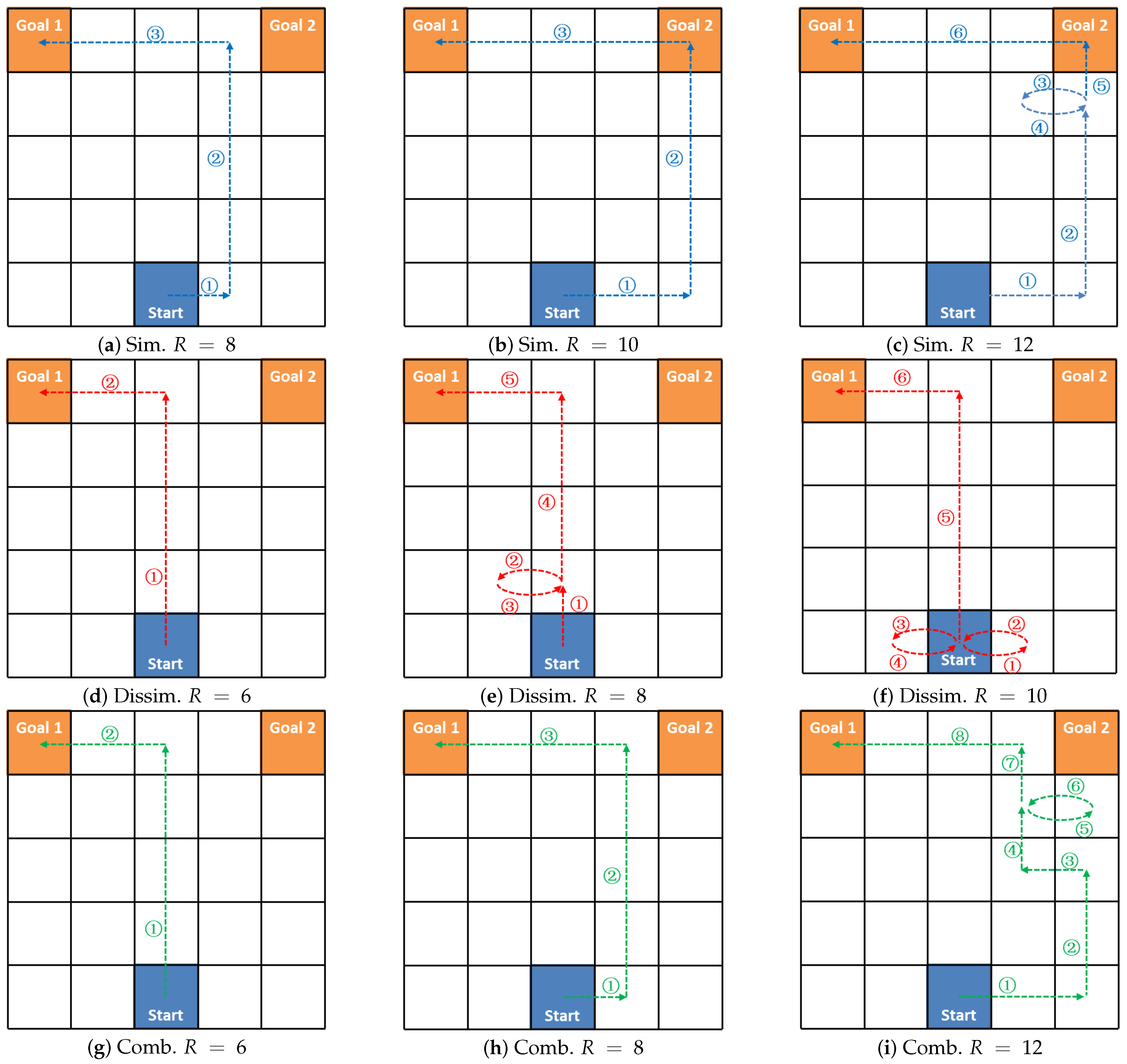
4.2. Deceptive Strategy
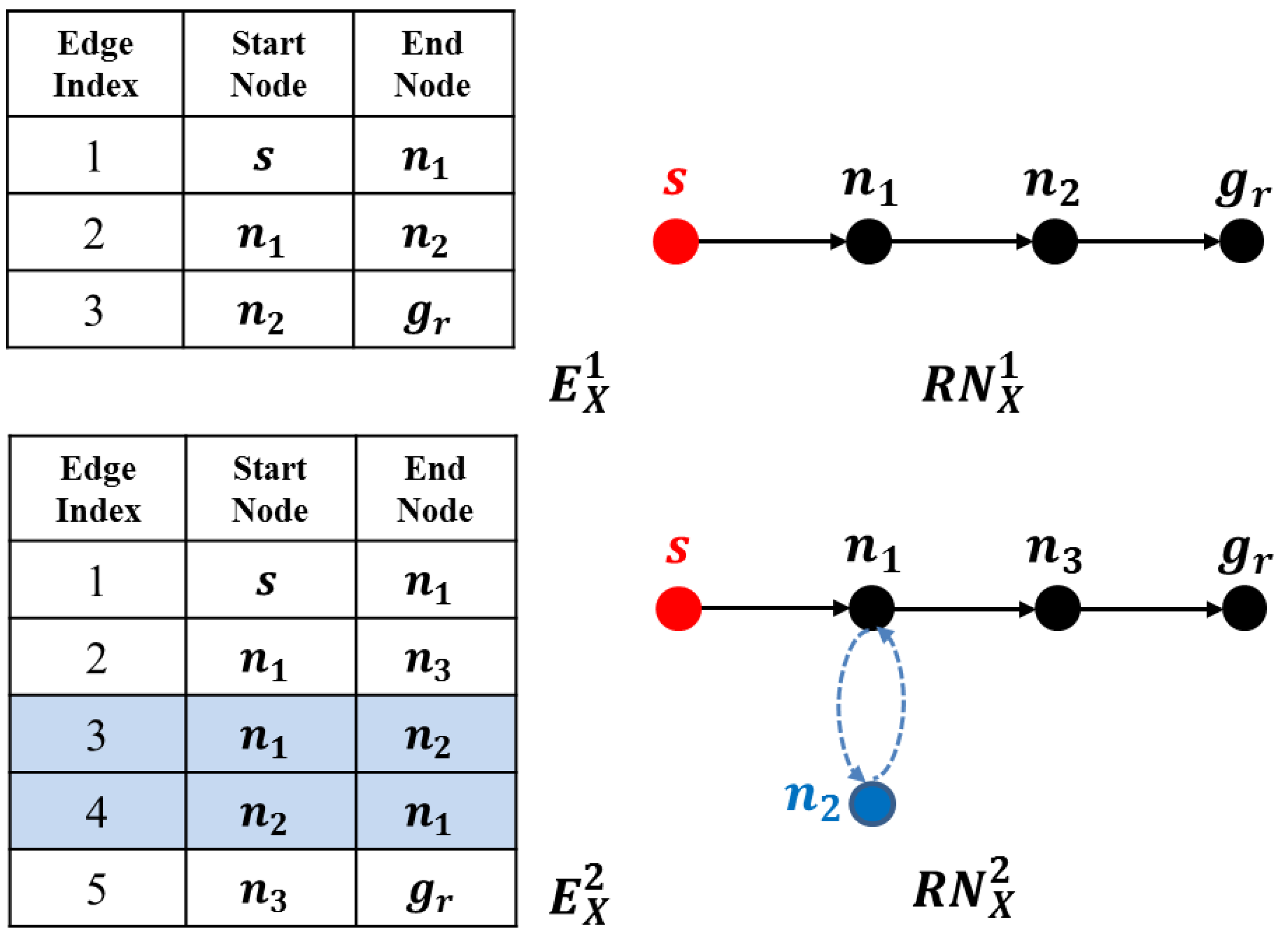
4.3. Cyclic Deceptive Path Identification
- , and ;
- .
| Algorithm 1:Cyclic-path-identify algorithm |
 |
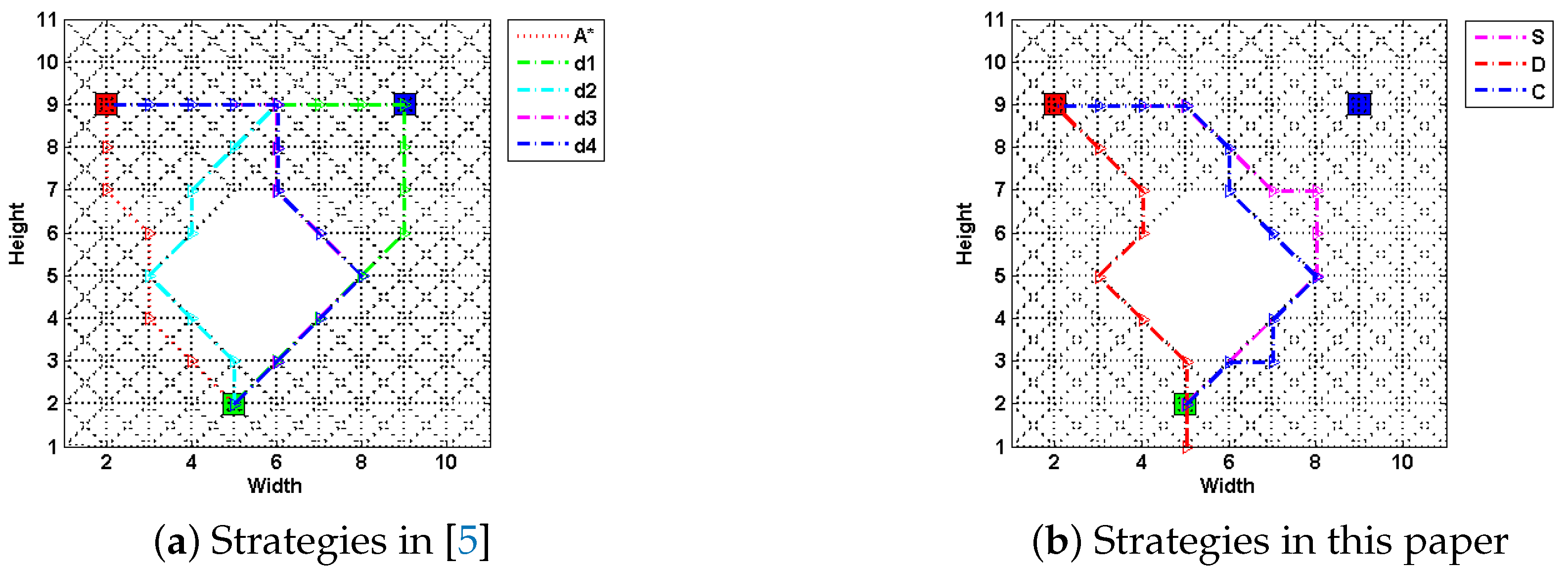
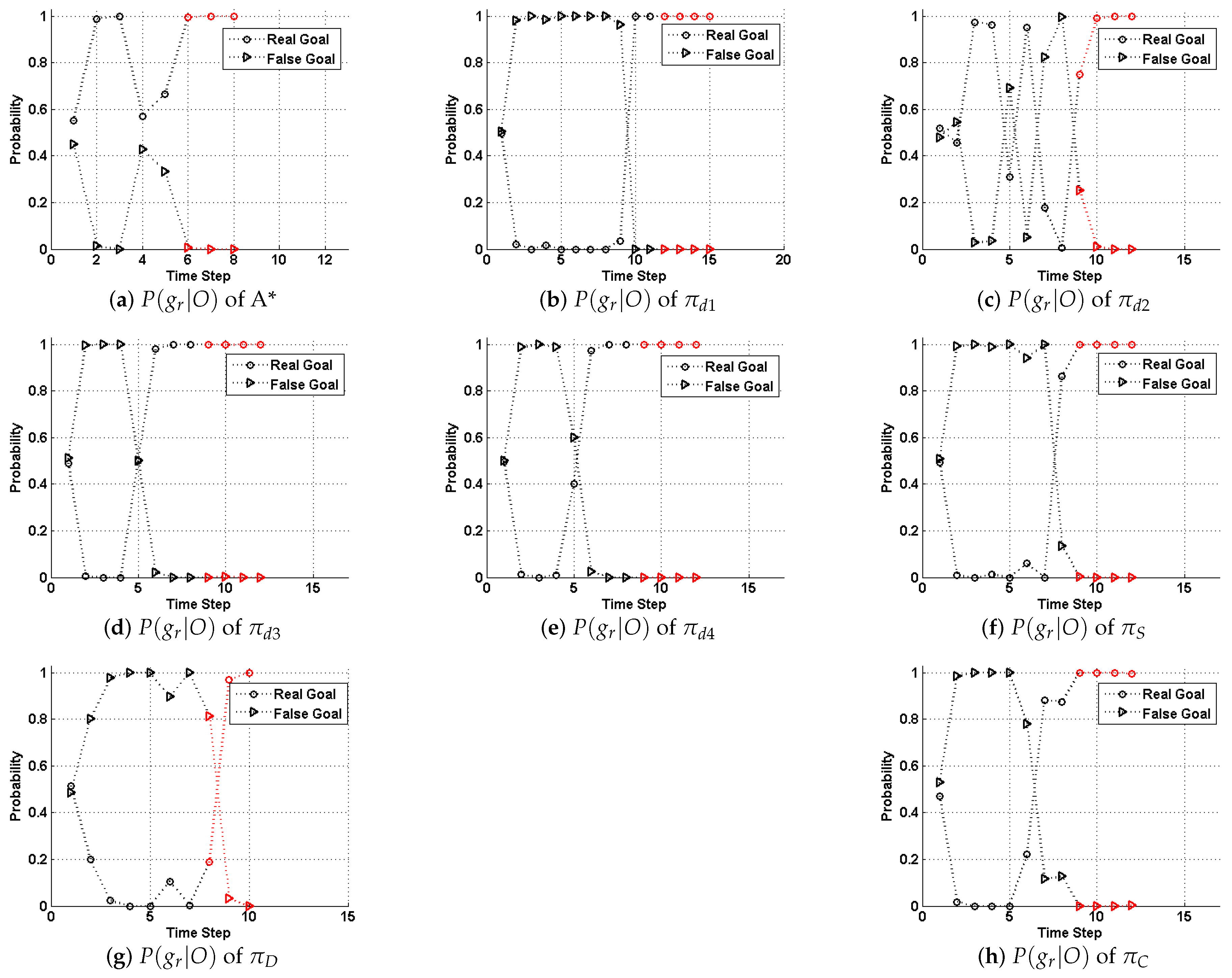
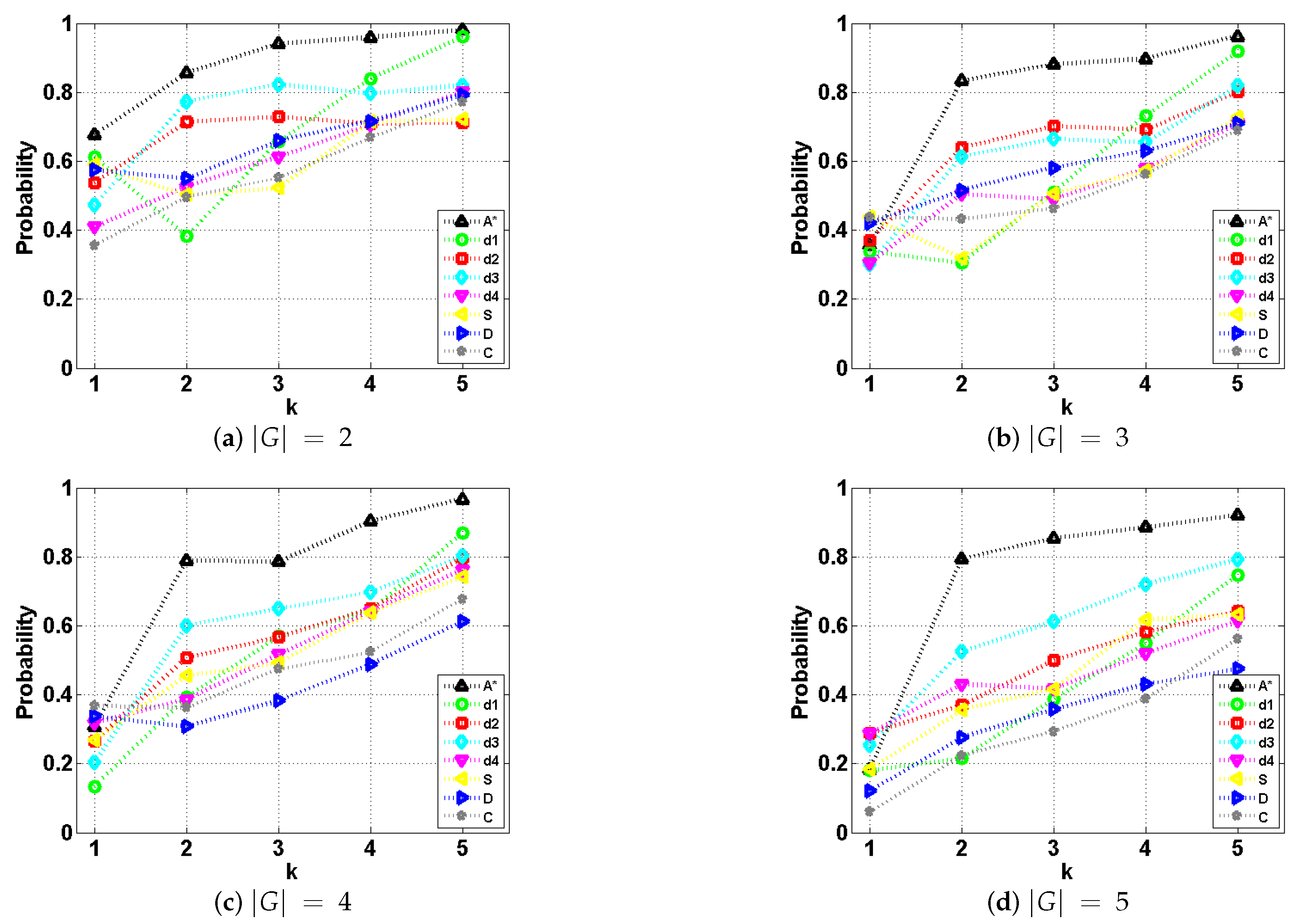
5. Experiments
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| UAV | Unmanned Aerial Vehicle |
| LDP | Last Deceptive Point |
| AHMM | Abstract Hidden Markov Models |
| GRD | Goal Recognition Design |
| wcd | worst-case distinctiveness |
| RN | Road Network |
| SGPP | Single Goal Path-Planning |
| PGR | Probabilistic Goal Recognition |
| SRGDPP | Single Real Goal Deceptive Path-Planning |
| SRGMDPP | Single Real Goal Magnitude-based Deceptive Path-Planning |
| SRGMDM | Single Real Goal Magnitude-based Deception Maximization |
References
- Geib, C.W.; Goldman, R.P. Plan recognition in intrusion detection systems. In Proceedings of the DARPA Information Survivability Conference and Exposition II. DISCEX’01, Anaheim, CA, USA, 12–14 June 2001; Volume 1, pp. 46–55. [Google Scholar]
- Kitano, H.; Asada, M.; Kuniyoshi, Y.; Noda, I.; Osawa, E. Robocup: The robot world cup initiative. In Proceedings of the First International Conference on Autonomous Agents, Marina del Rey, CA, USA, 2–5 February 1997; pp. 340–347. [Google Scholar]
- Root, P.; De Mot, J.; Feron, E. Randomized path planning with deceptive strategies. In Proceedings of the 2005, American Control Conference, Portland, OR, USA, 8–10 June 2005; pp. 1551–1556. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Privacy Preserving Plans in Partially Observable Environments. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 3170–3176. [Google Scholar]
- Masters, P.; Sardina, S. Deceptive Path-Planning. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 7–11 July 2017; pp. 4368–4375. [Google Scholar]
- Masters, P. Goal Recognition and Deception in Path-Planning. Ph.D. Thesis, RMIT University, Melbourne, Australia, 2019. [Google Scholar]
- Ramırez, M.; Geffner, H. Probabilistic plan recognition using off-the-shelf classical planners. In Proceedings of the Conference of the Association for the Advancement of Artificial Intelligence (AAAI 2010), Atlanta, GA, USA, 11–15 July 2010; pp. 1121–1126. [Google Scholar]
- Masters, P.; Sardina, S. Cost-based goal recognition for path-planning. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, International Foundation for Autonomous Agents and Multiagent Systems, Sao Paulo, Brazil, 8–12 May, 2017; pp. 750–758. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Korf, R.E. Real-time heuristic search. Artif. Intell. 1990, 42, 189–211. [Google Scholar] [CrossRef]
- LaValle, S.M. Planning Algorithms; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Bui, H.H. A general model for online probabilistic plan recognition. IJCAI 2003, 3, 1309–1315. [Google Scholar]
- Geib, C.W.; Goldman, R.P. Partial Observability and Probabilistic Plan/Goal Recognition. 2005. Available online: http://rpgoldman.real-time.com/papers/moo2005.pdf (accessed on 2 December 2019).
- Sukthankar, G.; Geib, C.; Bui, H.H.; Pynadath, D.; Goldman, R.P. Plan, Activity, and Intent Recognition: Theory and Practice; Newnes: London, UK, 2014. [Google Scholar]
- Whaley, B. Toward a general theory of deception. J. Strateg. Stud. 1982, 5, 178–192. [Google Scholar] [CrossRef]
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: New York, NY, USA, 2009; pp. 23–65. [Google Scholar]
- Hespanha, J.P.; Ateskan, Y.S.; Kizilocak, H. Deception in Non-Cooperative Games with Partial Information. 2000. Available online: https://www.ece.ucsb.edu/hespanha/published/deception.pdf (accessed on 2 December 2019).
- Hespanha, J.P.; Kott, A.; McEneaney, W. Application and value of deception. Adv. Reason. Comput. Approaches Read. Opponent Mind 2006, 145–165. [Google Scholar]
- Ettinger, D.; Jehiel, P. Towards a Theory of Deception. 2009. Available online: https://ideas.repec.org/p/cla/levrem/122247000000000775.html (accessed on 2 December 2019).
- Arkin, R.C.; Ulam, P.; Wagner, A.R. Moral decision making in autonomous systems: Enforcement, moral emotions, dignity, trust, and deception. Proc. IEEE 2012, 100, 571–589. [Google Scholar] [CrossRef]
- Alloway, T.P.; McCallum, F.; Alloway, R.G.; Hoicka, E. Liar, liar, working memory on fire: Investigating the role of working memory in childhood verbal deception. J. Exp. Child Psychol. 2015, 137, 30–38. [Google Scholar] [CrossRef]
- Dias, J.; Aylett, R.; Paiva, A.; Reis, H. The Great Deceivers: Virtual Agents and Believable Lies. 2013. Available online: https://pdfs.semanticscholar.org/ced9/9b29b53008a285296a10e7aeb6f88c79639e.pdf (accessed on 2 December 2019).
- Greenberg, I. The effect of deception on optimal decisions. Op. Res. Lett. 1982, 1, 144–147. [Google Scholar] [CrossRef]
- Matsubara, S.; Yokoo, M. Negotiations with inaccurate payoff values. In Proceedings of the International Conference on Multi Agent Systems (Cat. number 98EX160), Paris, France, 3–7 July 1998; pp. 449–450. [Google Scholar]
- Hausch, D.B. Multi-object auctions: Sequential vs. simultaneous sales. Manag. Sci. 1986, 32, 1599–1610. [Google Scholar] [CrossRef]
- Yavin, Y. Pursuit-evasion differential games with deception or interrupted observation. Comput. Math. Appl. 1987, 13, 191–203. [Google Scholar] [CrossRef]
- Hespanha, J.P.; Prandini, M.; Sastry, S. Probabilistic pursuit-evasion games: A one-step nash approach. In Proceedings of the 39th IEEE Conference on Decision and Control (Cat. number 00CH37187), Sydney, Australia, 12–15 December 2000; Volume 3, pp. 2272–2277. [Google Scholar]
- Shieh, E.; An, B.; Yang, R.; Tambe, M.; Baldwin, C.; DiRenzo, J.; Maule, B.; Meyer, G. Protect: A Deployed Game Theoretic System to Protect the Ports of the United States. 2012. Available online: https://www.ntu.edu.sg/home/boan/papers/AAMAS2012-protect.pdf (accessed on 2 December 2019).
- Billings, D.; Papp, D.; Schaeffer, J.; Szafron, D. Poker as a Testbed for AI Research. In Conference of the Canadian Society for Computational Studies of Intelligence; Springer: New York, NY, USA, 1998; pp. 228–238. [Google Scholar]
- Bell, J.B. Toward a theory of deception. Int. J. Intell. Count. 2003, 16, 244–279. [Google Scholar] [CrossRef]
- Kott, A.; McEneaney, W.M. AdversariaL Reasoning: Computational Approaches to Reading The Opponent’S Mind; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Jian, J.Y.; Matsuka, T.; Nickerson, J.V. Recognizing Deception in Trajectories. 2006. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.489.165rep=rep1type=pdf (accessed on 2 December 2019).
- Shim, J.; Arkin, R.C. Biologically-inspired deceptive behavior for a robot. In International Conference on Simulation of Adaptive Behavior; Springer: New York, NY, USA, 2012; pp. 401–411. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Goal Recognition Design. In Proceedings of the ICAPS, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Goal Recognition Design for Non-Optimal Agents; AAAI: Menlo Par, CA, USA, 2015; pp. 3298–3304. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Goal Recognition Design with Non-Observable Actions; AAAI: Menlo Par, CA, USA, 2016; pp. 3152–3158. [Google Scholar]
- Wayllace, C.; Hou, P.; Yeoh, W.; Son, T.C. Goal Recognition Design With Stochastic Agent Action Outcomes. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Mirsky, R.; Gal, Y.K.; Stern, R.; Kalech, M. Sequential plan recognition. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, International Foundation for Autonomous Agents and Multiagent Systems, Singapore, 9–13 May, 2016; pp. 1347–1348. [Google Scholar]
- Almeshekah, M.H.; Spafford, E.H. Planning and integrating deception into computer security defenses. In Proceedings of the 2014 New Security Paradigms Workshop, Victoria, BC, Canada, 15–18 September 2014; pp. 127–138. [Google Scholar]
- Lisỳ, V.; Píbil, R.; Stiborek, J.; Bošanskỳ, B.; Pěchouček, M. Game-theoretic approach to adversarial plan recognition. In Proceedings of the 20th European Conference on Artificial Intelligence, Montpellier, France, 27–31 August 2012; pp. 546–551. [Google Scholar]
- Rowe, N.C. A model of deception during cyber-attacks on information systems. In Proceedings of the IEEE First Symposium onMulti-Agent Security and Survivability, Drexel, PA, USA, 31 August 2004; pp. 21–30. [Google Scholar]
- Brafman, R.I. A Privacy Preserving Algorithm for Multi-Agent Planning and Search. In Proceedings of the IJCAI, Buenos Aires, Argentina, 25–31 July 2015; pp. 1530–1536. [Google Scholar]
- Kulkarni, A.; Klenk, M.; Rane, S.; Soroush, H. Resource Bounded Secure Goal Obfuscation. In Proceedings of the AAAI Fall Symposium on Integrating Planning, Diagnosis and Causal Reasoning, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kulkarni, A.; Srivastava, S.; Kambhampati, S. A unified framework for planning in adversarial and cooperative environments. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, FA, USA, 2–7 February 2018. [Google Scholar]
- Kautz, H.A.; Allen, J.F. Generalized Plan Recognition; AAAI: Menlo Par, CA, USA, 1986; Volume 86, p. 5. [Google Scholar]
- Pynadath, D.V.; Wellman, M.P. Generalized queries on probabilistic context-free grammars. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 65–77. [Google Scholar] [CrossRef]
- Pynadath, D.V. Probabilistic Grammars for Plan Recognition; University of Michigan: Ann Arbor, MI, USA, 1999. [Google Scholar]
- Pynadath, D.V.; Wellman, M.P. Probabilistic State-Dependent Grammars for Plan Recognition. 2000. Available online: https://arxiv.org/ftp/arxiv/papers/1301/1301.3888.pdf (accessed on 2 December 2019).
- Geib, C.W.; Goldman, R.P. A probabilistic plan recognition algorithm based on plan tree grammars. Artif. Intell. 2009, 173, 1101–1132. [Google Scholar] [CrossRef]
- Wellman, M.P.; Breese, J.S.; Goldman, R.P. From knowledge bases to decision models. Knowl. Eng. Rev. 1992, 7, 35–53. [Google Scholar] [CrossRef]
- Charniak, E.; Goldman, R.P. A Bayesian model of plan recognition. Artif. Intell. 1993, 64, 53–79. [Google Scholar] [CrossRef]
- Bui, H.H.; Venkatesh, S.; West, G. Policy recognition in the abstract hidden markov model. J. Artif. Intell. Res. 2002, 17, 451–499. [Google Scholar] [CrossRef]
- Liao, L.; Patterson, D.J.; Fox, D.; Kautz, H. Learning and inferring transportation routines. Artif. Intell. 2007, 171, 311–331. [Google Scholar] [CrossRef]
- Xu, K.; Xiao, K.; Yin, Q.; Zha, Y.; Zhu, C. Bridging the Gap between Observation and Decision Making: Goal Recognition and Flexible Resource Allocation in Dynamic Network Interdiction. In Proceedings of the IJCAI, Melbourne, Australia, 7–11 July 2017; Volume 4477. [Google Scholar]
- Baker, C.L.; Saxe, R.; Tenenbaum, J.B. Action understanding as inverse planning. Cognition 2009, 113, 329–349. [Google Scholar] [CrossRef] [PubMed]
- Ramırez, M.; Geffner, H. Plan recognition as planning. In Proceedings of the 21st international joint conference on Artifical intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1778–1783. [Google Scholar]
- Ramırez, M.; Geffner, H. Goal recognition over POMDPs: Inferring the intention of a POMDP agent. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 2009–2014. [Google Scholar]
- Sohrabi, S.; Riabov, A.V.; Udrea, O. Plan Recognition as Planning Revisited. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 3258–3264. [Google Scholar]
- Albrecht, D.W.; Zukerman, I.; Nicholson, A.E. Bayesian models for keyhole plan recognition in an adventure game. User Model. User-Adapt. Interact. 1998, 8, 5–47. [Google Scholar] [CrossRef]
- Goldman, R.P.; Geib, C.W.; Miller, C.A. A New Model of Plan Recognition. 1999. Available online: https://arxiv.org/ftp/arxiv/papers/1301/1301.6700.pdf (accessed on 2 December 2019).
- Doucet, A.; De Freitas, N.; Murphy, K.; Russell, S. Rao-Blackwellised particle filtering for dynamic Bayesian networks. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, Stanford, CA, USA, 30 June–3 July 2000; pp. 176–183. [Google Scholar]
- Saria, S.; Mahadevan, S. Probabilistic Plan Recognition in Multiagent Systems. 2004. Available online: https://people.cs.umass.edu/mahadeva/papers/ICAPS04-035.pdf (accessed on 2 December 2019).
- Blaylock, N.; Allen, J. Fast Hierarchical Goal Schema Recognition. 2006. Available online: http://www.eecs.ucf.edu/gitars/cap6938/blaylockaaai06.pdf (accessed on 2 December 2019).
- Singla, P.; Mooney, R.J. Abductive Markov Logic for Plan Recognition; AAAI: Menlo Park, CA, USA, 2011; pp. 1069–1075. [Google Scholar]
- Yin, Q.; Yue, S.; Zha, Y.; Jiao, P. A semi-Markov decision model for recognizing the destination of a maneuvering agent in real time strategy games. Math. Problems Eng. 2016, 2016. [Google Scholar] [CrossRef]
- Yue, S.; Yordanova, K.; Krüger, F.; Kirste, T.; Zha, Y. A Decentralized Partially Observable Decision Model for Recognizing the Multiagent Goal in Simulation Systems. Discret. Dyn. Nat. Soc. 2016, 2016. [Google Scholar] [CrossRef]
- Min, W.; Ha, E.; Rowe, J.P.; Mott, B.W.; Lester, J.C. Deep Learning-Based Goal Recognition in Open-Ended Digital Games. AIIDE 2014, 14, 3–7. [Google Scholar]
- Bisson, F.; Larochelle, H.; Kabanza, F. Using a Recursive Neural Network to Learn an Agent’s Decision Model for Plan Recognition. Available online: http://www.dmi.usherb.ca/larocheh/publications/ijcai15.pdf (accessed on 2 December 2019).
- Tastan, B.; Chang, Y.; Sukthankar, G. Learning to intercept opponents in first person shooter games. In Proceedings of the 2012 IEEE Conference on Computational Intelligence and Games (CIG), Granada, Spain, 11–14 September 2012; pp. 100–107. [Google Scholar]
- Zeng, Y.; Xu, K.; Yin, Q.; Qin, L.; Zha, Y.; Yeoh, W. Inverse Reinforcement Learning Based Human Behavior Modeling for Goal Recognition in Dynamic Local Network Interdiction. In Proceedings of the AAAI Workshops on Plan, Activity and Intent Recognition, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Agotnes, T. Domain Independent Goal Recognition. Stairs 2010: Proceedings of the Fifth Starting AI Researchers Symposium. 2010. Available online: http://users.cecs.anu.edu.au/ssanner/ICAPS2010DC/Abstracts/pattison.pdf (accessed on 2 December 2019).
- Pattison, D.; Long, D. Accurately Determining Intermediate and Terminal Plan States Using Bayesian Goal Recognition. In Proceedings of the ICAPS, Freiburg, Germany, 11–16 June 2011. [Google Scholar]
- Yolanda, E.; R-Moreno, M.D.; Smith, D.E. A Fast Goal Recognition Technique Based on Interaction Estimates. 2015. Available online: https://www.ijcai.org/Proceedings/15/Papers/113.pdf (accessed on 2 December 2019).
- Pereira, R.F.; Oren, N.; Meneguzzi, F. Landmark-based heuristics for goal recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Cohen, P.R.; Perrault, C.R.; Allen, J.F. Beyond question answering. Strateg. Nat. Lang. Process. 1981, 245274. [Google Scholar]
- Jensen, R.M.; Veloso, M.M.; Bowling, M.H. OBDD-Based Optimistic and Strong Cyclic Adversarial Planning. 2014. Available online: https://pdfs.semanticscholar.org/59f8/fd309d95c6d843b5f7665bbf9337f568c959.pdf (accessed on 2 December 2019).
- Avrahami-Zilberbrand, D.; Kaminka, G.A. Keyhole adversarial plan recognition for recognition of suspicious and anomalous behavior. Plan Activ. Int. Recognit. 2014, 87–121. [Google Scholar]
- Avrahami-Zilberbrand, D.; Kaminka, G.A. Incorporating Observer Biases in Keyhole Plan Recognition (Efficiently!); AAAI: Menlo Park, CA, USA, 2007; Volume 7, pp. 944–949. [Google Scholar]
- Braynov, S. Adversarial Planning and Plan Recognition: Two Sides of the Same Coin. 2006. Available online: https://csc.uis.edu/faculty/sbray2/papers/SKM2006.pdf (accessed on 2 December 2019).
- Le Guillarme, N.; Mouaddib, A.I.; Gatepaille, S.; Bellenger, A. Adversarial Intention Recognition as Inverse Game-Theoretic Planning for Threat Assessment. In Proceedings of the 2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI), San Jose, CA, USA, 6–8 November 2016; pp. 698–705. [Google Scholar]
- Lofberg, J. YALMIP: A toolbox for modeling and optimization in MATLAB. In Proceedings of the CACSD Conference, New Orleans, LA, USA, 2–4 September 2005; pp. 284–289. [Google Scholar]
- Sturtevant, N.R. Benchmarks for grid-based pathfinding. IEEE Trans. Comput. Intell. AI Games 2012, 4, 144–148. [Google Scholar] [CrossRef]
- Xu, K.; Yin, Q. Goal Identification Control Using an Information Entropy-Based Goal Uncertainty Metric. Entropy 2019, 21, 299. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| St | C | T | 10% | 25% | 50% | 75% | 99% |
|---|---|---|---|---|---|---|---|
| A* | 8.24 | 0.69 | 1 | 1 | 0 | 0 | 0 |
| d1 | 15.66 | 2.37 | 1 | 1 | 1 | 1 | 1 |
| d2 | 13.07 | 4.93 | 1 | 0 | 0 | 0 | 1 |
| d3 | 13.07 | 3.81 | 1 | 1 | 1 | 1 | 1 |
| d4 | 13.07 | 66.08 | 1 | 1 | 1 | 1 | 1 |
| S | 13.07 | 849.81 | 1 | 1 | 1 | 1 | 1 |
| D | 11.07 | 220.79 | 1 | 1 | 1 | 0 | 0 |
| C | 13.07 | 145.23 | 1 | 1 | 1 | 1 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Zeng, Y.; Qin, L.; Yin, Q. Single Real Goal, Magnitude-Based Deceptive Path-Planning. Entropy 2020, 22, 88. https://doi.org/10.3390/e22010088
Xu K, Zeng Y, Qin L, Yin Q. Single Real Goal, Magnitude-Based Deceptive Path-Planning. Entropy. 2020; 22(1):88. https://doi.org/10.3390/e22010088
Chicago/Turabian StyleXu, Kai, Yunxiu Zeng, Long Qin, and Quanjun Yin. 2020. "Single Real Goal, Magnitude-Based Deceptive Path-Planning" Entropy 22, no. 1: 88. https://doi.org/10.3390/e22010088
APA StyleXu, K., Zeng, Y., Qin, L., & Yin, Q. (2020). Single Real Goal, Magnitude-Based Deceptive Path-Planning. Entropy, 22(1), 88. https://doi.org/10.3390/e22010088