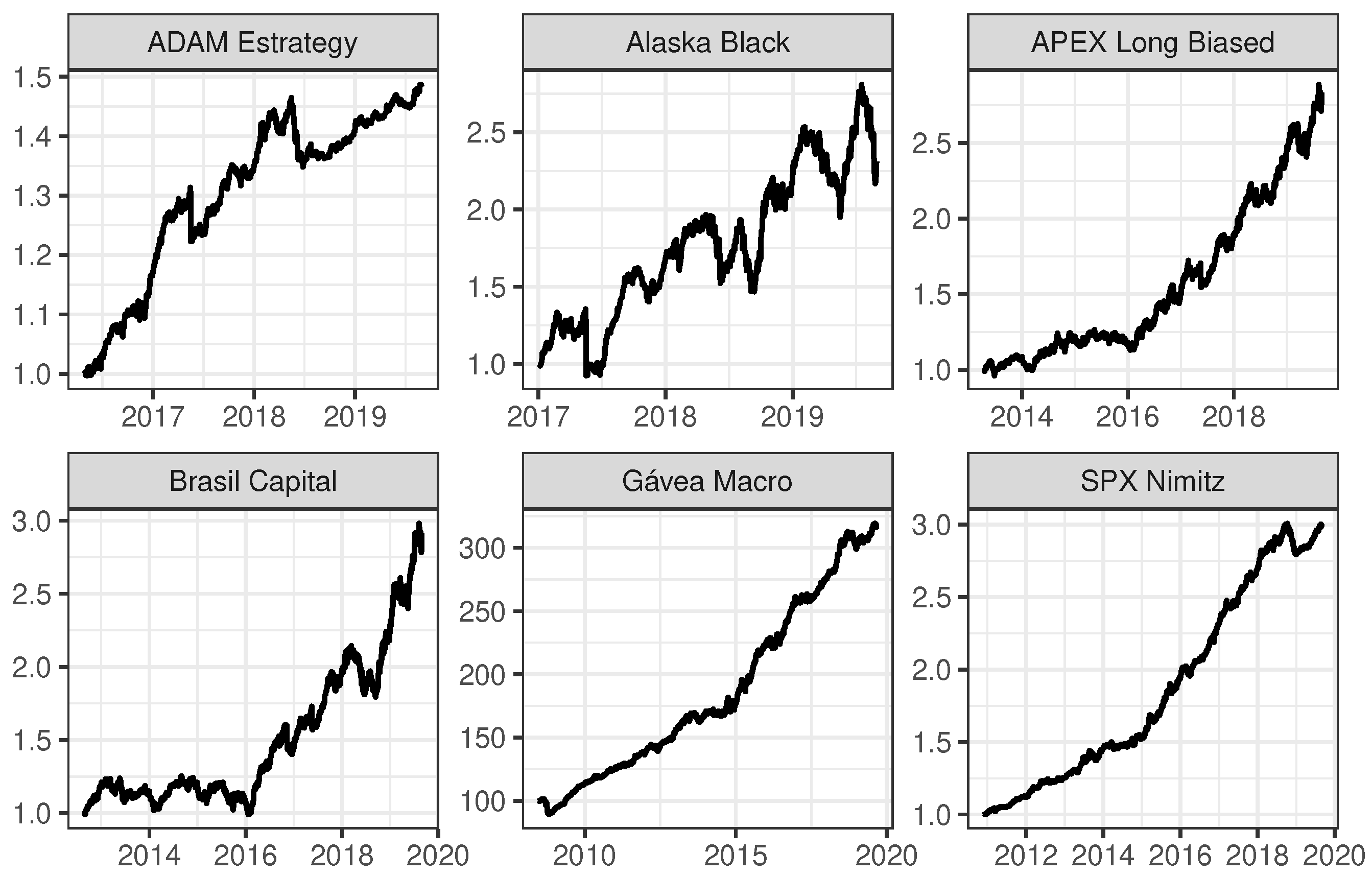
In this section, comparisons are made between the classical ARIMA model, the classical SSA algorithm, and the robust SSA algorithms, in terms of computational time and accuracy for model fit and model forecast. These comparisons for decomposing and forecasting time series are done by considering a simulation example and the time series of six mutual investment funds.
3.1. Model Fit
The models/algorithms under comparison for model fit are: (i) ARIMA, (ii) SSA, (iii) robust SSA based on the norm (RLSSA), and (iv) robust SSA based on the Huber function (RHSSA).
The parameters of the ARIMA model for each of the six mutual investment funds were estimated with the function “auto.arima” from the R package “forecast” [
36].
For the SSA and robust SSA algorithms, there are two choices to be made by the researcher: (i) the window length
L; and (ii) the number of eigentriples used for reconstruction
r. Three values of
L were chosen for each time series, as defined in
Table 2—
,
, and
—being the
obtained from the periodogram, based on the largest cycle for each time series [
37] (i.e., about one trimester for ADAM Strategy, one semester for Alaska Black, one year for APEX Long Biased, one quadrimeter for Brasil Capital, one quadrimeter for Gavea Macro, and one quadrimester for SPX Nimitz), and
N being the time series length. The choice of the number of eigentriples used for reconstruction
r, for each of the considered window lengths and each of the time series, was done by taking into consideration the the w-correlations among components [
5].
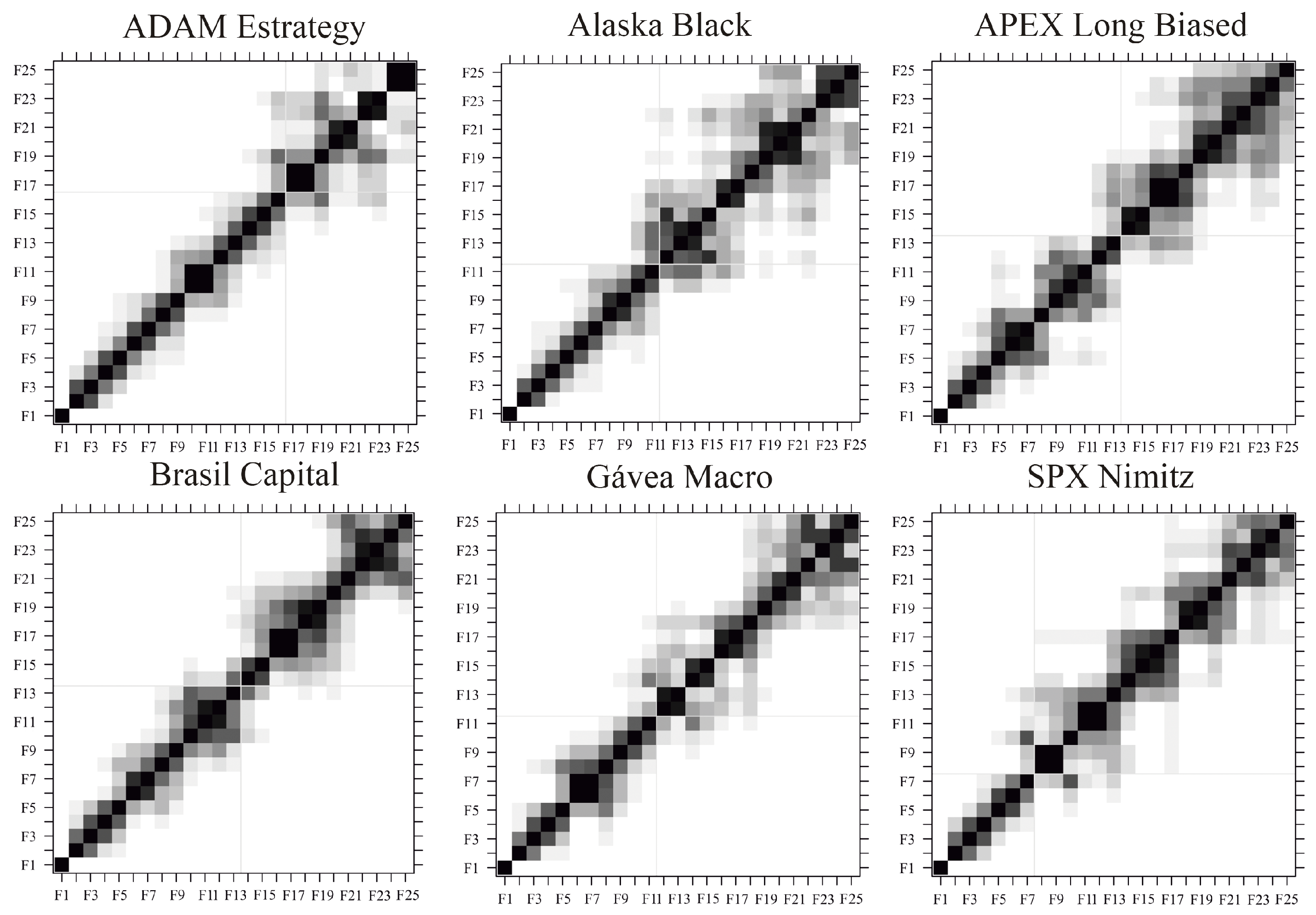
Figure 2 shows the w-correlation matrices for each of the six mutual investment funds, considering an window length
, and
Figure A1 of the appendix shows the w-correlation matrices for each of the six mutual investment funds, considering an window length
. The w-correlation matrices can be obtained with the function “wcor” of the R package “Rssa” [
38] and the number of eigentriples
r should be chosen in order to maximize the separability between signal and noise components; i.e., maximize the w-correlation among signal components, maximize the w-correlation among noise components, and minimize the w-correlation between signal and noise components. A summary of the number of eigentriples used for the reconstruction of each time series for each of the window length considered can be seen in
Table 2.
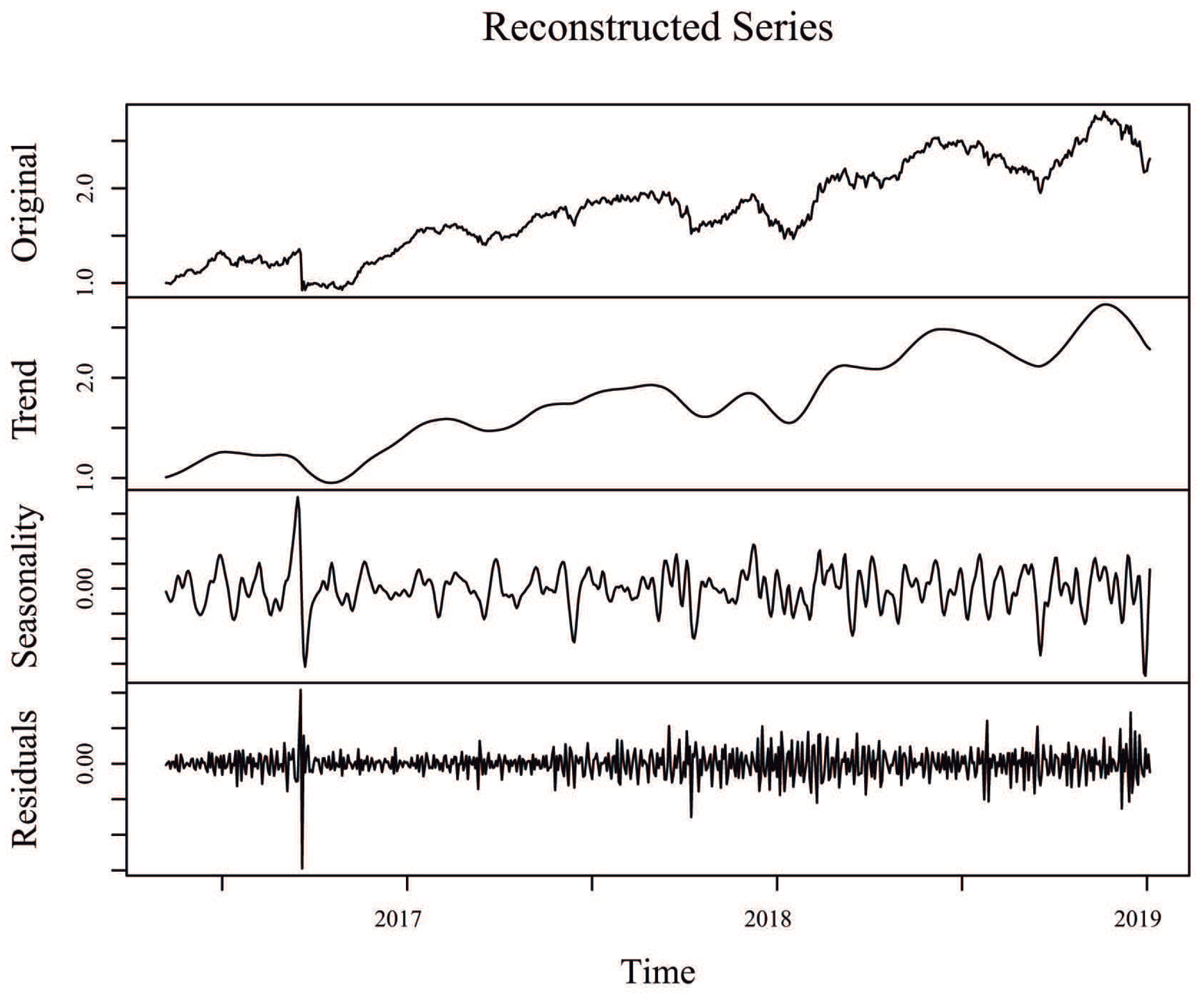
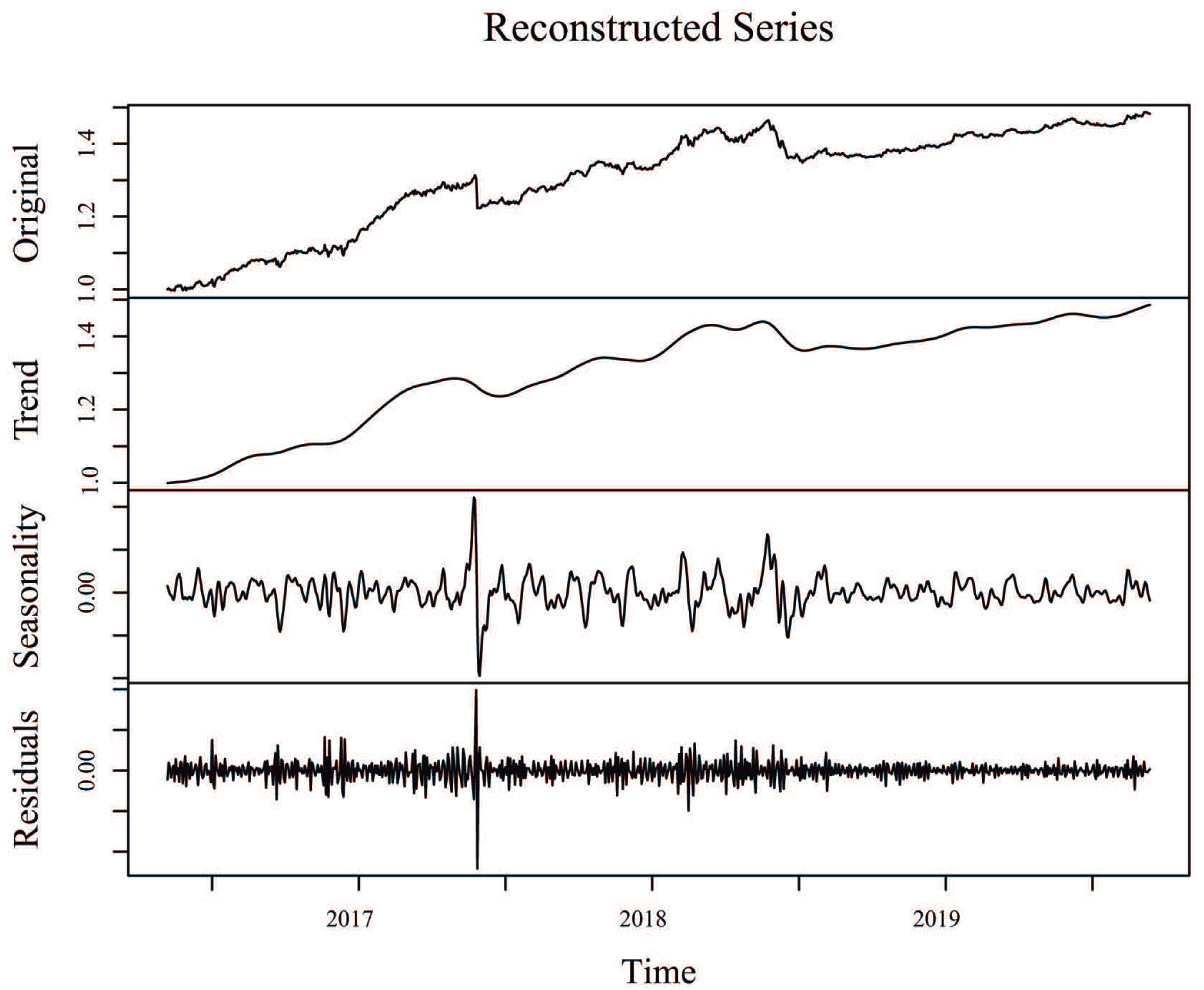
Since one of the objectives in SSA is to decompose the original time series into interpretable components such as trend and seasonality, plus the noise component that is then discarded,
Figure 3 shows the original time series for the Alaska Black mutual investment fund, its trend component (sum of individual trend components), its seasonal component (sum of individual seasonal components), and its residuals (sum of the remaining components associated to noise), considering an window length
and
eigentriples for reconstruction. Similar SSA decompositions for ADAM Strategy, APEX Long Biased, Brasil Capital, ADAM Strategy, Gavea Macro, and SPX Nimitz—considering the values of window length
and
eigentriples used for reconstruction, as defined in
Table 2—can be found in
Figure A2,
Figure A3,
Figure A4,
Figure A5 and
Figure A6 of the appendix, respectively.
In order to evaluate and compare the ability for model fit using the four models, ARIMA, SSA, robust SSA based on the
norm (RLSSA), and robust SSA based on the Huber function (RHSSA), the root mean square error (RMSE) was calculated for each time series.
Table 3 shows the RMSE for model fit by each of the four models applied to each of the six mutual investment funds, considering a window length
(
Table 2).
Table 4 shows the RMSE for model fit by each of the four models applied to each of the six mutual investment funds, considering a window length
(
Table 2).
Table 5 shows the RMSE for model fit by each of the four models applied to each of the six mutual investment funds, considering a window length obtained based on the largest cycle for each time series (
Table 2). From the analyzes of these tables, we can conclude that the ARIMA model shows an overall better performance when the window length in the SSA related algorithms is set to be half of the time series (
Table 3). However, when the window length is set to be
or
(i.e., equal to the length of the largest cycle), the classical SSA provides the best results, while the ARIMA model and the robust SSA algorithms alternate for the second best performances. For all choices of window length, the two robust SSA algorithms behaved similarly.
Table 6,
Table 7 and
Table 8 show the computational times for each combination of model/algorithm and mutual investment fund, as presented in
Table 3,
Table 4 and
Table 5, respectively. From the analyzes of these tables, we can conclude that the best performance was obtained by the ARIMA and SSA algorithms. The computational time, for the classic and robust SSA algorithms, increases with the increase of the length
L. Moreover, for larger trajectory matrices (i.e., considering
) the robust SSA algorithm based on the Huber function has a lower computational time than the robust SSA algorithm based on the
norm (
Table 6). However, when the trajectory matrices are more rectangular (i.e., considering
,
Table 7, or
,
Table 8), the robust SSA algorithm based on the
norm has a much lower computational time (comparable to the ARIMA and SSA computational times) than the robust SSA algorithm based on the Huber function).
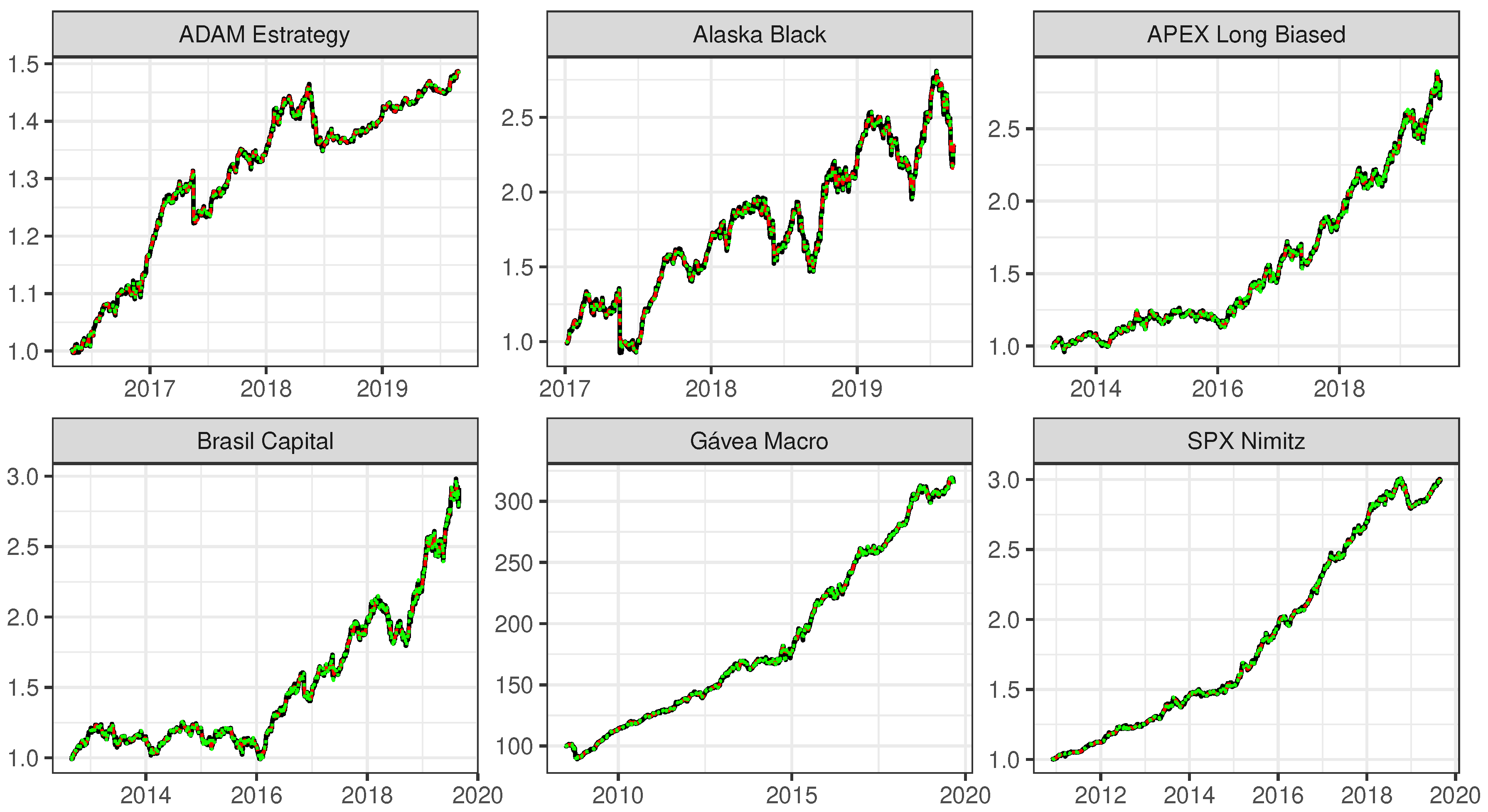
Figure 4 shows the original time series and the model fit by the SSA model with
and by the ARIMA model. We can confirm that both fits are almost overlapped and very near to the original time series, which was expected from the small RMSE showed in
Table 4.
3.2. Model Forecasting
In this section we compare the forecasting abilities of ARIMA, SSA with
, SSA with
, SSA with
based on the largest cycle for each time series, and robust SSA based on the
norm with
and
. The decision for not considering the robust SSA algorithm based on the Huber function was because of its similarity in terms of RMSE with the robust SSA based on the
norm (
Table 3,
Table 4 and
Table 5) and the much higher computational time (
Table 6,
Table 7 and
Table 8). A similar argument was considered for not presenting the results for the robust SSA algorithm based on the
norm with
.
Table 9 shows the RRMSE for model forecasting for each of the six mutual investment funds, considering each of the four models, ARIMA, SSA with
, SSA with
, SSA with
, and robust SSA based on the
norm (RLSSA) with
and
, considering the window length and engentriples used for reconstruction as defined in
Table 2. These values were obtained based on the forecasting of the
observations from each time series, obtained for one, five, and ten steps ahead out-of-sample forecast; i.e., one day ahead, one week ahead, and two weeks ahead.
The overall best performance was obtained with the classic SSA algorithm that considers a lower value for the window length, either
or
, followed closely by ARIMA and the robust SSA algorithm based on the
norm. The ARIMA model obtained the best performance in three cases for one-step-ahead forecasting, and the robust SSA algorithm based on the
norm with
yielded the best performance in a couple of time series for five-steps-ahead forecasting. As expected, the RMSE shows an overall increase when increasing the number of steps ahead to be forecast. A possible justification for the similarity between the SSA and robust SSA algorithm can be explained by the possible lack of outliers in the data.
Table 10 shows the computational time for model forecasting for each of the six mutual investment funds, considering each of the five models shown in
Table 9. As expected, after analyzing the computational times for model fit (
Table 6,
Table 7 and
Table 8), the best performance in terms of computational time for model forecasting was obtained by the the ARIMA and SSA (with lower values for the window length) models and the worse by the robust SSA algorithm based on the
norm.
3.3. Simulation Example
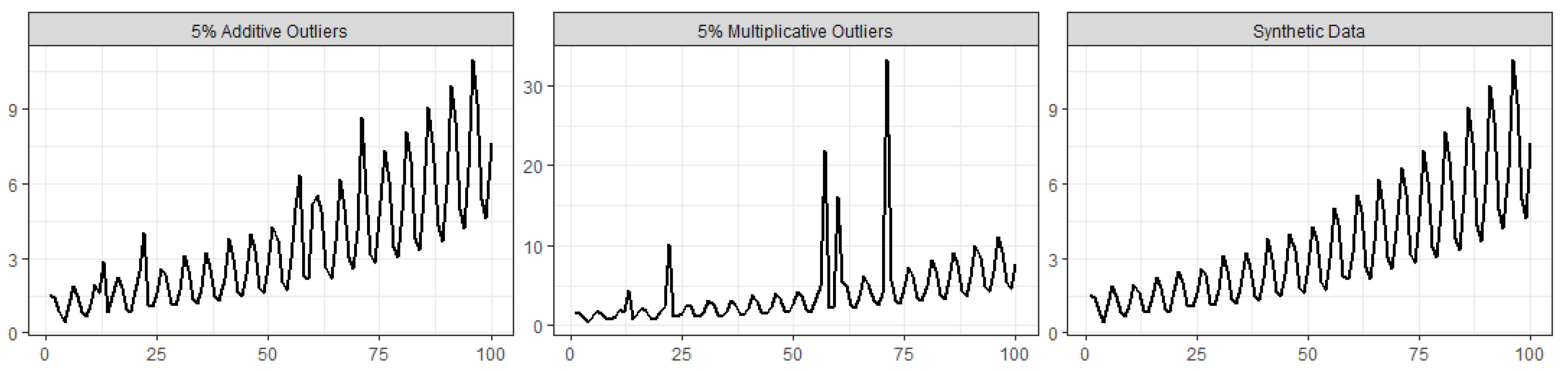
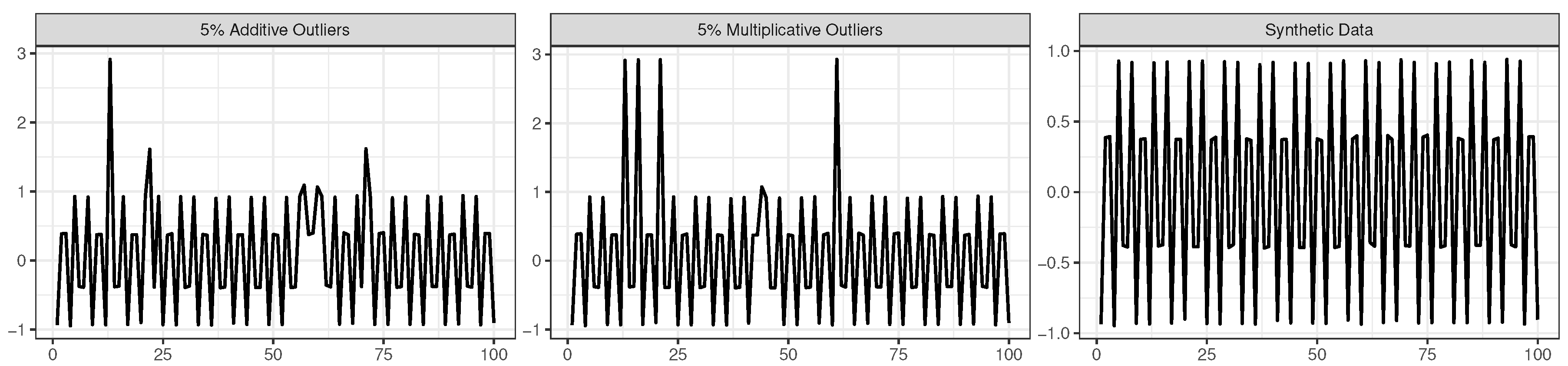
To verify the hypothesis raised in the previous subsection that the similarity between the results from SSA and the robust SSA algorithm can be due to the lack of outliers in the time series, in this subsection we present a simulation example where the methods are compared while analyzing a time series contaminated with outlying observations. The synthetic data were obtained by generating random values from the following function, and then we transformed them into a time series (right-hand plot in
Figure 5):
where
is the noise generated from the
. A total of 100 simulated time series were considered.
The data contamination, for illustration purposes, was made by considering additive outliers and magnitude increase outliers in the following way:
Additive outliers: 2%, 5%, and 10% of the time points
are randomly chosen to be replaced by
; i.e., the values of
are increased by a constant value of 2, resulting in a mild contamination scenario (e.g., (left-hand plot in
Figure 5));
Magnitude increase: 2%, 5%, and 10% of the time points
are randomly chosen to be replaced by
; i.e., the time point magnitude of
is increased by a factor of 5, resulting in an a quite extreme contamination scenario (e.g., central plot in
Figure 5).
Table 11 shows the mean of the root mean square errors for model fit, computed for each of the four models, ARIMA, SSA, robust SSA based on the
norm, and robust SSA based on the Huber function, for the simulated data, based on 100 runs, using
and
, and considering both contamination scenarios with 2, 5, and 10% outliers. As expected, when there is no data contamination, the classic SSA model is the most appropriated. For the mild contamination scenario with additive outliers, the robust SSA algorithms outperform both ARIMA and SSA models, the better performance being more evident when the percentage of the outliers increases. For the more extreme contamination scenario with multiplicative outliers, a similar patters was obtained, the RLSSA being the best robust algorithm, in this simulation example.
Appendix B includes a second simulation scenario where robust SSA algorithm based on the Huber function (RHSSA) outperforms the classic ARIMA and SSA models and the robust SSA algorithm based on the
norm (RLSSA).
Table 12 shows mean of the root mean square errors for model forecasting (
steps- ahead), computed for each of ARIMA, SSA, and robust SSA based on the
norm, for the simulated data, based on 100 runs, using
and
. The results for the robust SSA based on the Huber function were not included because of their computational cost and out-performance when compared with the robust SSA based on the
norm. Again, as expected, the SSA model yielded the best performance for no data contamination. For scenarios with data contamination, the best performance was obtained by the robust SSA forecasting algorithm, with a very large decrease in RMSE in many scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




