1. Introduction
Networks are useful tools to visualize the relational information among a large number of variables. An undirected graphical model belongs to a rich class of statistical network models that encodes conditional independence [
1]. Canonically, Gaussian graphical models (or their normalized version partial correlations [
2]) can be represented by the inverse covariance matrix (i.e., the precision matrix), where a zero entry is associated with a missing edge between two vertices in the graph. Specifically, two vertices are not connected if and only if they are conditionally independent, given the value of all other variables.
On one hand, there is a large volume of literature on estimating the (static) precision matrix for graphical models in the high-dimensional setting, where the sample size and the dimension are both large [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. Most of the earlier work along this line assumes that the underlying network is time-invariant. This assumption is quite restrictive in practice and hardly plausible for many real-world applications, such as gene regulatory networks, social networks, and stocking market, where the underlying data generating mechanisms are often dynamic. On the other hand, dynamic random networks have been extensively studied from the perspective of large random graphs, such as community detection and edge probability estimation for dynamic stochastic block models (DSBMs) [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30]. Such approaches do not model the sampling distributions of the error (or noise), since the “true” networks are connected with random edges sampled from certain probability models, such as the Erdős–Rényi graphs [
31] and random geometric graphs [
32].
In this paper, we view the (time-varying) networks of interests as non-random graphs. We adopt the graph signal processing approach for denoising the nonstationary time series and target on estimating the
true unknown underlying graphs. Despite the recent attempts towards more flexible time-varying models [
33,
34,
35,
36,
37,
38,
39,
40], there are still a number of major limitations in the current high-dimensional literature. First, theoretical analysis was derived under the fundamental assumption that the observations are either temporally
independent, or the temporal dependence has very specific forms, such as Gaussian processes or (linear) vector autoregression (VAR) [
14,
33,
34,
37,
41,
42,
43]. Such dynamic structures are unduly demanding in view that many time series encountered in real applications have very complex nonlinear spatial-temporal dependency [
44,
45]. Second, most existing work assumes the data have time-varying distributions with sufficiently light tails, such as Gaussian graphical models and Ising models [
33,
34,
36,
41,
42]. Third, in change point estimation problems for high-dimensional time series, piecewise constancy is widely used [
41,
42,
46,
47], which can be fragile in practice. For instance, financial data often appears to have time-dependent cross-volatility with structural breaks [
48]. For resting-state fMRI signals, correlation analysis reveals both slowly varying and abruptly changing characteristics corresponding to modularities in brain functional networks [
49,
50].
Advances in analyzing high-dimensional (stationary) time series have been made recently to address the aforementioned nonlinear spatial-temporal dependency issue [
14,
37,
43,
51,
52,
53,
54,
55,
56,
57]. In [
53,
56,
57], the authors considered the theoretical properties of regularized estimation of covariance and precision matrices, based on various dependence measures of high-dimensional time series. Reference [
38] considered the non-paranormal graphs that evolve with a random variable. Reference [
37] discussed the joint estimation of Gaussian graphical models based on a stationary VAR(1) model with special coefficient matrices, which may also depend on certain covariates. The authors applied a constrained
-minimization for inverse matrix estimation (CLIME) estimator with a kernel estimator of covariance matrix and developed consistency in the graph recovery at a given time point. Reference [
14] studied the recovery of the Granger causality across time and nodes assuming a stationary Gaussian VAR model with unknown order.
In this paper, we focus on the recovery of time-varying undirected graphs on the basis of the regularized estimation of the precision matrices for a general class of nonstationary time series. We simultaneously model two types of dynamics: abrupt changes with an unknown number of change points and the smooth evolution between the change points. In particular, we study a class of high-dimensional piecewise locally stationary processes in a general nonlinear temporal dependency framework, where the observations are allowed to have a finite polynomial moment.
More specifically, there are two main goals of this paper: first, to estimate the change point locations, as well as the number of change points, and second, to estimate the smooth precision matrix functions between the change points. Accordingly, our proposed method contains two steps. In the first step, the maximum norm of the local difference matrix is computed at each time point and the jumps in the covariance matrices are detected at the location where the maximum norms are above a certain threshold. In the second step, the precision matrices before and after the jump are estimated by a regularized kernel smoothing estimator. These two steps are recursively performed until a stopping criterion is met. Moreover, a boundary correction procedure based on data reflection is considered to reduce the bias near the change point.
We provide an asymptotic theory to justify the proposed method in high dimensions: point-wise and uniform rates of convergence are derived for the change point estimation and graph recovery under mild and interpretable conditions. The convergence rates are determined via subtle interplay among the sample size, dimensionality, temporal dependence, moment condition, and the choice of bandwidth in the kernel estimator. Our results are significantly more involved than problems for sub-Gaussian tails and independent samples. We highlight that uniform consistency in terms of time-varying network structure recovery is much more challenging and difficult than pointwise consistency. For the multiple change point detection problem, we also characterize the threshold of the difference statistic that gives a consistent selection of the number of change points.
We fix some notations: Positive, finite, and non-random constants, independent of the sample size n and dimension p, are denoted by , whose values may differ from line to line. For the sequence of real numbers, and , we write or if for some constant and if . We say if and . For a sequence of random variables and a corresponding set of constants , denote if for any there is a constant such that for all n. For a vector , we write . For a matrix , , , , and . For a random vector , write , , if . Let . Denote and .
The rest of the paper is organized as follows:
Section 2 presents the time series model, as well as the main assumptions, which can simultaneously capture the smooth and abrupt changes. In
Section 3, we introduce the two-step method that first segments the time series based on the difference between the localized averages on sample covariance matrices and then recovers the graph support based on a kernelized CLIME estimator. In
Section 4, we state the main theoretical results for the change point estimation and support recovery. Simulation examples are presented in
Section 5 and a real data application is given in
Section 6. Proof of main results can be found in
Section 7.
2. Time Series Model
We first introduce a class of causal vector stochastic processes. Next, we state the assumptions to derive an asymptotic theory in
Section 4 and explain their implications. Let
be independent and identically distributed (i.i.d.) random vectors and
be a shift process. Let
be a
p-dimensional nonstationary time series generated by
where
is an
-valued jointly measurable function. Suppose we observe the data points
at the evenly spaced time intervals
,
We drop the subscription n in in the rest of this section. Since our focus is to study the second-order properties, the data is assumed to have a mean of zero.
Model (
1) is first introduced in [
58]. The stochastic process
can be thought of as a triangular array system, double indexed by
i and
t, while the observations
are sampled from the diagonal of the array. On one hand, when fixing the time index
t, the (vertical) process
is stationary. On the other hand, since
is allowed to vary with
, the diagonal process (
2) is able to capture nonstationarity.
The process
is causal or non-anticipative as
is an output of the past innovations
and does not depend on future innovations. In fact, it covers a broad range of linear and nonlinear, stationary and non-stationary processes, such as vector auto-regressive moving average processes, locally stationary processes, Markov chains, and nonlinear functional processes [
53,
58,
59,
60,
61].
Motivated by real applications where nonstationary time series data can involve both abrupt breaks and smooth varies between the breaks, we model the underlying processes as piecewise locally stationary with a finite number of structural breaks.
Definition 1 (Piecewise locally stationary time series model)
. Define as the collection of mean-zero piecewise locally stationary processes on , if for each , there is a nonnegative integer ι such that is piecewise stochastic Lipschitz continuous in t with Lipschitz constant L on the interval , where . A vector stochastic process if all coordinates belong to . For the process defined in (1), this means that there exists a non-negative integer ι and a constant , such that Remark 1. If we assume , then it follows that for each , where , and that for some , we have In other words, within a locally stationary time period, in a local window of i, can be approximated by the stationary process for each . This justifies the terminology of local stationarity.
The covariance matrix function of the underlying process is
,
, where
, and the precision matrix function is
. The graph at time
t is denoted by
, where
is the vertex set and
. Note that
implies piecewise Lipschitz continuity in
except at the breaks
. In particular, if
for some constant
, then
The reverse direction is not necessarily true, i.e., (
3) does not indicate
,
in general. As a trivial example, let
with probability
and
with probability
i.i.d for all
. At time
, let
. Then for any
k and
such that
is odd,
, while
.
Assumption 1 (Piecewise smoothness)
. (i) Assume for each , where and are constants independent of n and p. (ii) For each , and , we have .
Now we introduce the temporal dependence measure. We quantify the dependence of
by the dependence adjusted norm (DAN) (cf. [
62]). Let
be an independent copy of
and
. Denote
, where
,
. Here
is a coupled version of
, with the same generating mechanism and input, except that
is replaced by an independent copy
.
Definition 2 (Dependence adjusted norm (DAN))
. Let constants . Assume . Define the uniform functional dependence measure for the sequences of form (1) asand . The dependence adjusted norm of is defined aswhenever . Intuitively, the physical dependence measure quantifies the adjusted stochastic difference between the random variable and its coupled version by replacing past innovations. Indeed, measures the impact on uniform over t by replacing while freezing all the other inputs, while quantifies the cumulative influence of replacing on uniform over t. Then controls the uniform polynomial decay in the lag of the cumulative physical dependence, where a depends on the the tail of marginal distributions of and A quantifies the polynomial decay power and thus the temporal dependence strength. It is clear that is a semi-norm, i.e., it is subaddative and absolutely homogeneous.
Assumption 2 (Dependence and moment conditions)
. Let be defined in (1) and in (2). There exist and such that We let and write , . The quantities and measure the -norm aggregated effect and the largest effect of the element-wise DANs respectively. Both quantities play a role in the convergence rates of our estimator.
Obviously, we have and for all . In contrast to other works in a high-dimensional covariance matrix and network estimation, where sub-Gaussian tails and independence are the keys to ensure consistent estimation. Assumption 2 only requires that the time series have a finite polynomial moment, and it allows linear and nonlinear processes with short memory in the time domain.
Example 1 (Vector linear process)
. Consider the following vector linear process modelwhere and are i.i.d. with mean 0 and variance 1, and for each and with some constants and . The vector linear process is commonly seen in literature and application [63]. It includes the time-varying VAR model where as a special example. Suppose that the coefficient matrices satisfy the following condition.
- (A1)
For each ,
- (A2)
For each , there is a constant such that for each , for all .
- (A3)
For any , for each .
Note thatwhere is the jth row of . Under conditions (A1)–(A3), one can easily verify that for each , the process satisfies: (1) ; (2) (due to Burkholder’s inequality, cf. [64]); (3) . Conditions (A1)–(A3) implicitly impose smoothness in each entry of the coefficient matrices, sparseness in each column of the entry and evolution, and polynomial decay rate in the lag m of each entry and its derivative.
For
, let
and
, where
is well-defined in view of (
3). We assume that the change points are separated and sizeable.
Assumption 3 (Separability and sizeability of change points)
. There exist positive constants and independent of n and p such that and .
In the high-dimensional context, we assume that the inverse covariance matrices are sparse in the sense of their norms.
Assumption 4 (Sparsity of precision matrices)
. The precision matrix for each , where is allowed to grow with p.
If we further assume that the eigenvalues of the covariance matrices are bounded from below and above, i.e., there exists a constant , such that , then the covariance matrices and precision matrices are well-conditioned. In particular, as , a small perturbation in the covariance matrix would guarantee a small change of the same order in the precision matrix under the spectral norm.
3. Method: Change Point Estimation and Support Recovery
In graphical models (such as the Gaussian graphical model or partial correlation graph), network structures relevant to correlations or partial correlations are second-order characteristics of the data distributions. Specifically, the existence of edges coincides with non-zero entries of the inverse covariance matrix. We consider the dynamics of time series with both structural breaks and smooth changes. The piecewise stochastic Lipschitz continuity in Definition 1 allows the time series to have discontinuity in the covariance matrix function at time points (i.e., change points), while only smooth changes (i.e., twice continuous differentiability of the covariance matrix function in Assumptions 1) can occur between the change points.
In the presence of change points, we must first remove the change points before applying any smoothing procedures since , i.e., a non-negligible abrupt change in the covariance matrix will result in a substantial change of the graph structure for sparse and smooth covariance matrices. Thus our proposed graph recovery method consists of two steps: change point detection and support recovery.
Let
be a bandwidth parameter such that
and
, and
be a search grid in
. Define
To estimate the change points, compute
The following steps are performed recursively. For
, let
until the following criterion is attained:
where
is an early stopping threshold. The value of
is determined in
Section 4, which depends on the dimension and sample size, as well as the serial dependence level, tail condition, and local smoothness. Since our method only utilizes data in the localized neighborhood, multiple change points can be estimated and ranked in a single pass, which offers some computational advantage than the binary segmentation algorithm [
41,
46].
Once the change points are claimed, in the second step, we consider recovering the networks from the locally stationary time series before and after the structural breaks. In [
11], where
are assumed with an identical covariance matrix, the precision matrix
is estimated as,
where
is the sample covariance matrix. Inspired by (
10), we apply a kernelized time-varying (tv-) CLIME estimator for the covariance matrix functions of the multiple pieces of locally stationary processes before and after the structural breaks. Let
where
and
. The bandwidth parameter
b satisfies that
and
. Denote
. The kernel function
is chosen to have properties as follows.
Assumption 5 (Regularity of kernel function)
. The kernel function is non-negative, symmetric, and Lipschitz continuous with bounded support in , and that .
Assumption 5 is a common requirement on the kernel functions and can be fulfilled by a range of kernel functions, such as the uniform kernel, triangular kernel, and the Epanechnikov kernel. Now the tv-CLIME estimator of the precision matrix
is defined by
, where
, and
,
Similar hybridized kernel smoothing and the CLIME method for estimating the sparse and smooth transition matrices in high-dimensional VAR model has been considered in [
65], where change point is not considered. Thus in the current setting we need to carefully control effect of (consistently) removing the change points before smoothing.
Then, the network is estimated by the “effective support” defined as follows.
It should be noted that the (vanilla) kernel smoothing estimator (
11) of the covariance matrix does not adjust for the boundary effect due to the change points in the covariance matrice function. Thus, in the neighborhood of the change points, a larger bias can be induced in estimating
by
. As a remedy, we apply the following reflection procedure for boundary correction. Suppose
for
, Denote
for
. We replace (
11) by
and then apply the rest of the tv-CLIME approach. Here
4. Theoretical Results
In this section, we derive the theoretical guarantees for the change point estimation and graph support recovery. Roughly speaking, Proposition 1 and 2 below show that under appropriate conditions, if each element of the covariance matrix varies smoothly in time, one can obtain an accurate snapshot estimation of the precision matrices as well as the time-varying graphs with high probability via the proposed kernel smoothed constrained minimization approach.
Define , where if , , and , respectively.
Proposition 1 (Rate of convergence for estimating precision matrices: pointwise and uniform)
. Suppose Assumptions 2, 4, and 5 hold with . Let for and .
- (i)
Pointwise.Choose the parameter in the tv-CLIME estimator in (13), where C is a sufficiently large constant independent of n and p. Then for any , we have - (ii)
Uniform.Choose in the tv-CLIME estimator in (13), where C is a sufficiently large constant independent of n and p. Then we have
The optimal order of the bandwidth parameter
in (
17) is the solution to the following equation:
which implies that the closed-form expression for
is given by
for some constants
and
that are independent of
n and
p.
Given a finite sample, to distinguish the small entries in the precision matrix from the noise is challenging. Since a smaller magnitude of a certain element of the precision matrix implies a weaker connection of the edge in the graphical model, we instead consider the estimation of
significant edges in the graph. Define the set of
significant edges at level
u as
, where
Then, as a consequence of (
17), we have the following support recovery consistency result.
Proposition 2 (Consistency of support recovery: significant edges)
. Choose u as , where is taken as a sufficiently large constant independent of n and p. Suppose that as . Then under conditions of Proposition 1, we have that as , Proposition 2 shows that the pattern of significant edges in the time-varying true graphs , can be correctly recovered with high probability. However, it is still an open question to what extent the edges with magnitude below u can be consistently estimated, which can be naturally studied in the multiple hypothesis testing framework. Nonetheless, hypothesis testing for graphical models on the nonstationary high-dimensional time series is rather challenging. We leave it as a future problem.
Propositions 1 and 2 together yield that the consistent estimation of the precision matrices and the graphs can be achieved before and after the change points. Now, we provide the theoretical result of the change point estimation. Theorem 1 below shows that if the change points are separated and sizable, then we can consistently identify them via the single pass segmentation approach under suitable conditions. Denote
where
and
are constants independent of
n and
p.
Theorem 1 (Consistency of change point estimation)
. Assume admits the form (2). Suppose that Assumptions 2 to 3 are satisfied. Choose the bandwidth , and in (5) and (9) respectively. Assume that as . We find that there exist constants independent of n and p, such that Furthermore, in the event , the ordered change-point estimator defined in (7) satisfies Proposition 2 and Theorem 1 together indicate the consistency in the snapshot estimation of the time-varying graphs before and after the change points. In a close neighborhood of the change points, we have the following result for the recovery of the time-varying network. Denote as the time intervals between the estimated change points, and as the recoverable neighborhood of the jump.
Theorem 2. Let Assumptions 2 to 5 be satisfied. We have the following results as .
- (i)
Between change points.For , take and , where and are defined in Proposition 2. Suppose . We have Choose the penalty parameter as , where is a constant independent of n and p. Then - (ii)
Around change points.For , take , and , where , and are constants independent of n and p. Suppose . We have Choose the penalty parameter as , where is a constant independent of n and p. Then
Note that the convergence rates for the covariance matrix entries and precision matrix entries in case (ii) around the jump locations are slower than those for points well separated from the jump locations in case (i). This is because on the boundary due to the reflection, the smooth condition may no longer hold true. Indeed, we only take advantage of the Lipschitz continuous property of the covariance matrix function. Thus, we lose one degree of regularity in the covariance matrix function, and the bias term in the convergence rate of the between-jump area becomes b around the jumps. We also note that around the smaller neighborhood of the jump , due to the larger error in the change point estimation, consistent recovery of the graphs is not achievable.
5. A Simulation Study
We simulate data from the following multivariate time series model:
where
, and
, with
,
,
generated as i.i.d. standardized
random variables. In the simulation, we fix
and vary
and
. For each
, the coefficient matrices
, where
, and
is an
block diagonal matrix. The
diagonal blocks in
are fixed with i.i.d.
entries and all the other entries are 0.
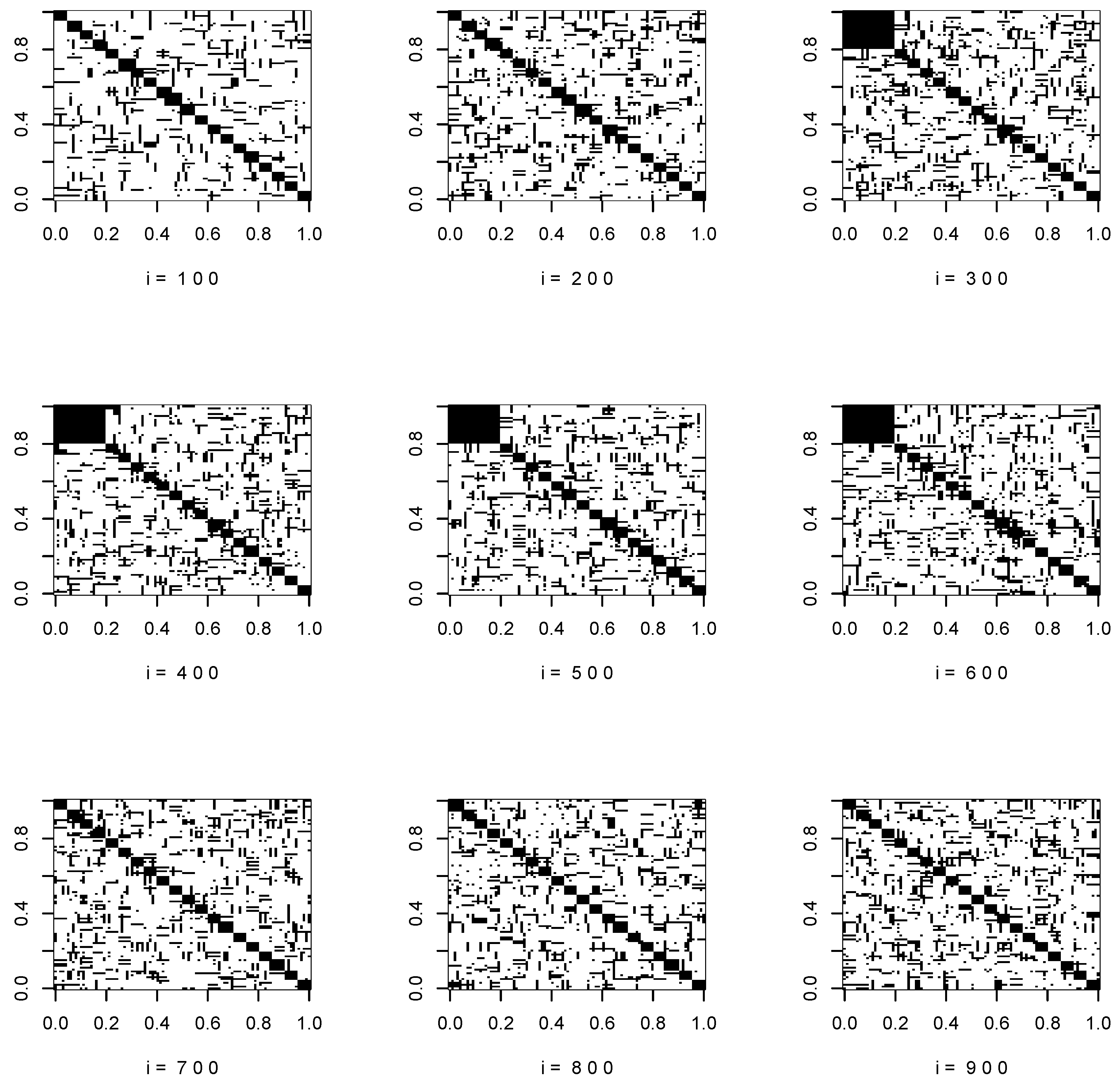
We consider the number of abrupt changes is and . The matrix is set to be a zero matrix for , while , , and , , where the first 20 entries in are taken to be a constant and the others are 0.
We let the coefficient matrices evolve at each time point, such that two entries are soft-thresholded and another two elements increase. Specifically, at time i, we randomly select two elements from the support of , which are denoted as and that , and set them to . We also randomly select two elements from and increase their values by .
Figure 1 and
Figure 2 show the support of the true covariance matrices at
.
In detecting the change points, the cutoff value
of detection is chosen as follows. After removing the neighborhood of detected change points, we obtain
by ordering
, where
is obtained from (
9) with
. For
, compute
We let and set .
We report the number of estimated jumps and the average absolute estimation error, where the average absolute estimation error is the mean of the distance between the estimated change points and the true change points. As is shown in
Table 1 and
Table 2, there is an apparent improvement in the estimation accuracy as the jump magnitude increases and dimension decreases. The detection is relatively robust to the choice of bandwidth.
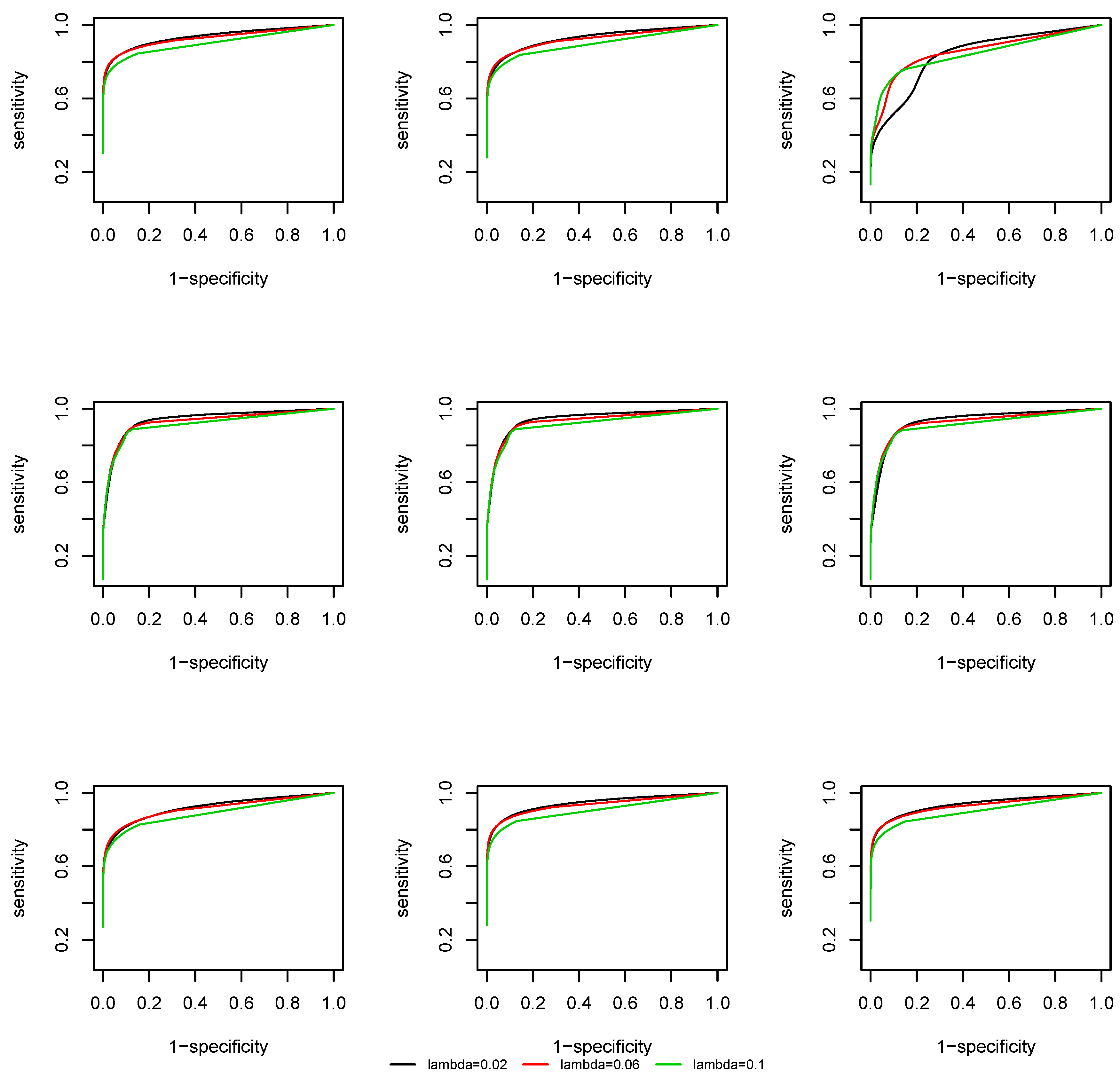
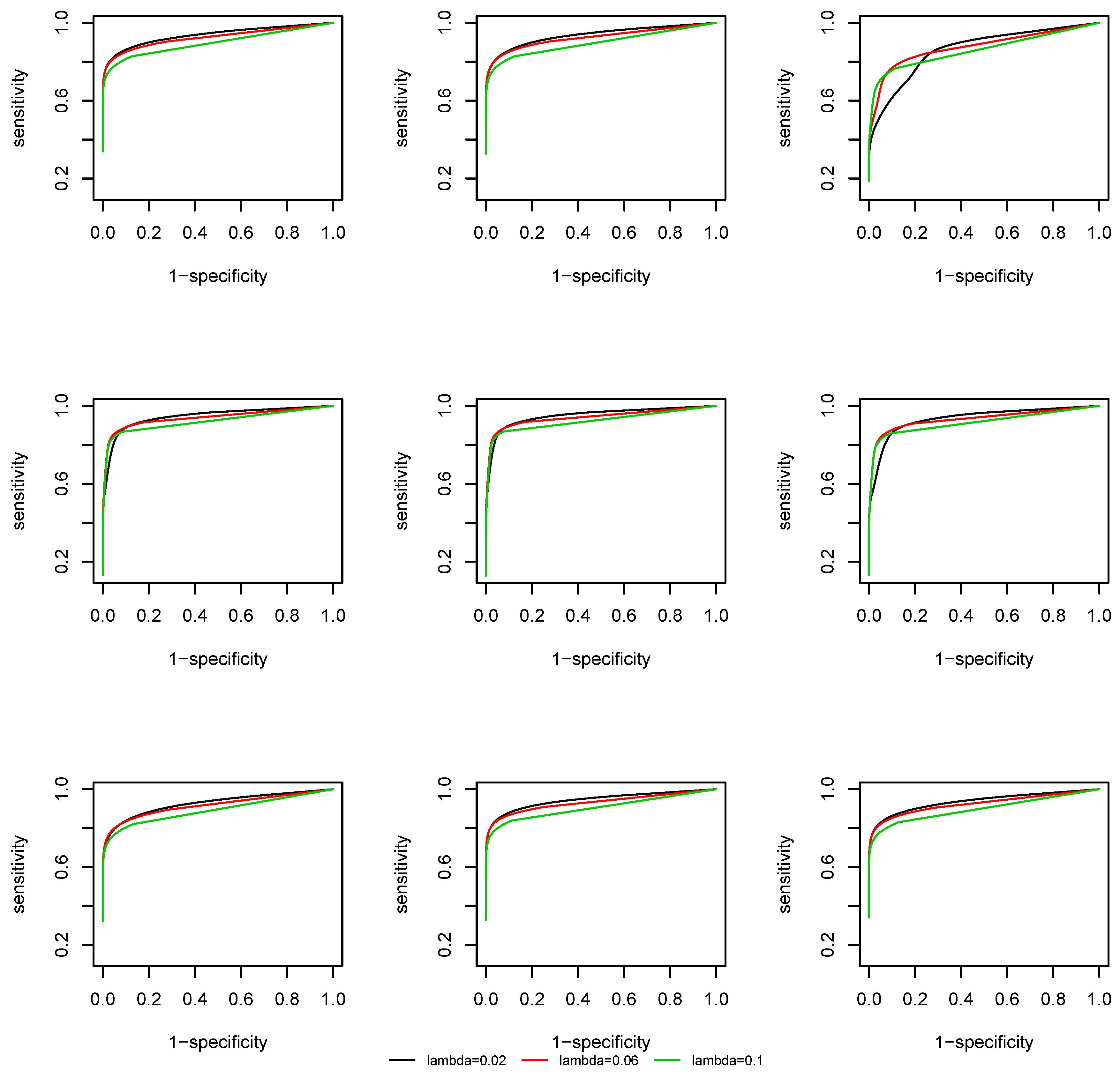
We evaluate the support recovery performance of the time-varying CLIME at the lattice
with
. We take the uniform kernel function and the bandwidth is fixed as
. At each time point
, two quantities are computed: sensitivity and specificity, which are defined as:
We plot the Receiver Operating Characteristic (ROC) curve, that is, sensitivity against 1-specificity. From
Figure 3 and
Figure 4 we observe that, due to a screening step, the support recovery is robust to the choice of
, except at the change points, where a non-negligible estimation error of the covariance matrix is induced and the overall estimation is less accurate. As the effective dimension of the network remains the same at
and
by the construction of the coefficient matrix
, there is no significant difference in the ROC curves at different dimensions.
6. A Real Data Application
Understanding the interconnection among financial entities and how they vary over time provides investors and policy makers with insights into risk control and decision making. Reference [
66] presents a comprehensive study of the applications of network theory in financial systems. In this section, we apply our method to a real financial dataset from Yahoo! Finance (
finance.yahoo.com). The data matrix contains daily closing prices of 420 stocks that are always in the S&P 500 index between 2 January 2002 through 30 December 2011. In total, there are
time points. We select 100 stocks with the largest volatility and consider their log-returns; that is, for
,
where
is the daily closing price of the stock
j at time point
i. We first compute the statistic (
5) and (
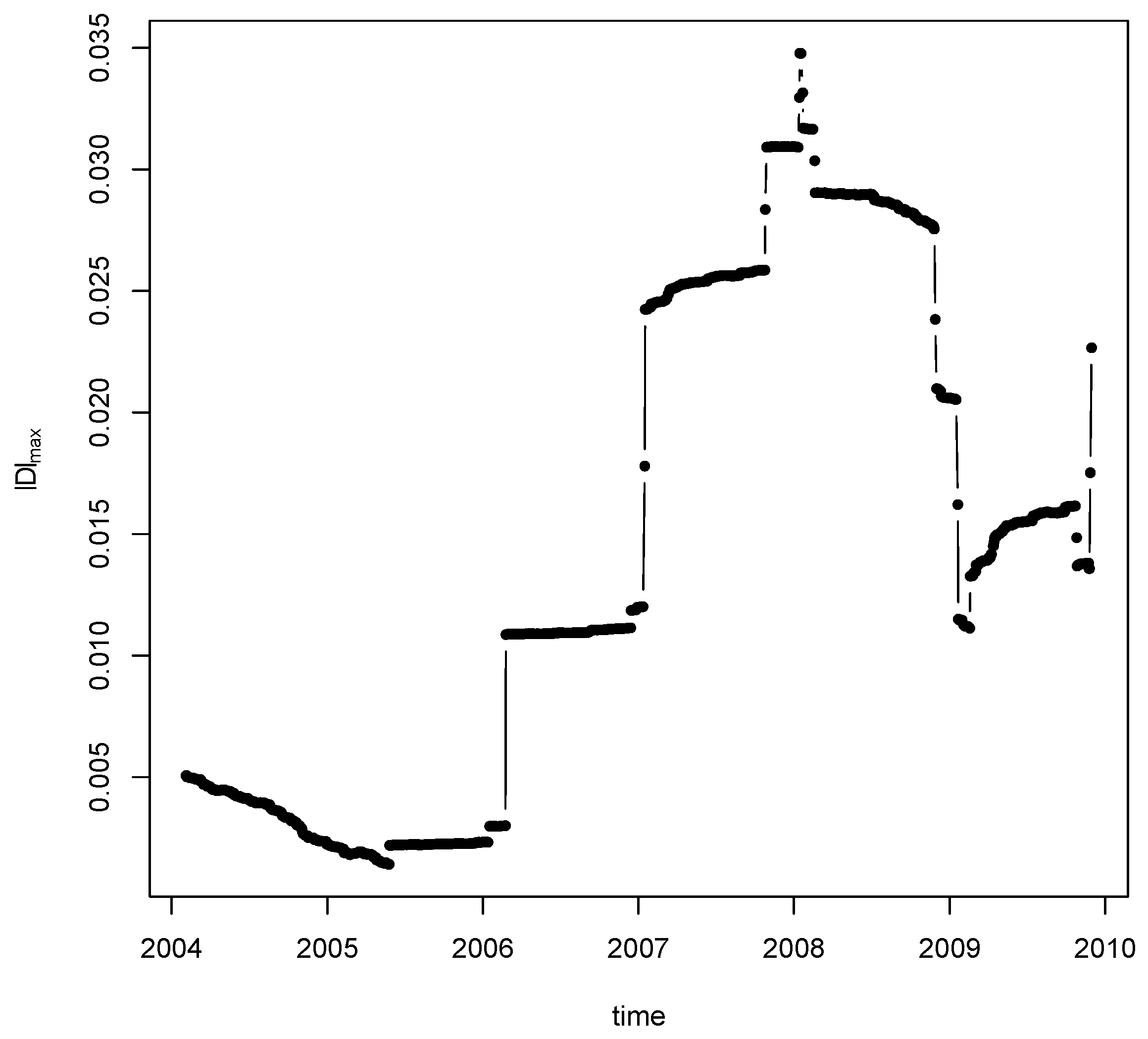
6) for the change point detection. We look at the top three statistics for different bandwidths. For bandwidth
, we rank the test statistic and find that the location for the top change point is: 7 February 2008 (
), which is shown in
Figure 5. The detected change point is quite robust to a variety of choices of bandwidth. Our result is partially consistent with the change point detection method in [
48]. In particular, the two breaks in 2006 and 2007 were also found in [
48] and it is conjectured that the 2007 break may be associated to the U.S. house market collapse. Meanwhile, it is interesting to observe the increased volatility before the 2008 financial crisis.
Next, we estimate the time-varying networks before and after the change point at 26 May 2006 with the largest jump size. Specifically, we look at four time points at: 813, 828, 888, and 903, corresponding to 23 March 2006, 13 April 2006, 11 July 2006, and 1 August 2006. We use tv-CLIME (
13) with the Epanechnikov kernel with the same bandwidth as in the change point detection to estimate the networks at the four points. Optimal tuning parameter
is automatically selected according to the stability approach [
67]. The following matrix shows the number of different edges at those four time points. It is observed that the time of the first two time points (813 and 828) and the last two (888 and 903) has a higher similarity than across the change point at time 858. The estimated networks are shown in
Figure 6. Networks in the first and second row are estimated before and after the estimated change point at time 858, respectively. It is observed that at each time point the companies in the same section tend to be clustered together such as companies in the
Energy section: OXY, NOV, TSO, MRO, and DO (highlighted in cyan). In addition, the distance matrix of estimated networks is estimated as
7. Proof of Main Results
7.1. Preliminary Lemmas
Lemma 1. Let be a sequence that admits (2). Assume for , and the dependence adjusted norm (DAN) of the corresponding underlying array satisfies for and . Let be defined in (12) and suppose that the kernel function satisfies Assumption 5. Denote if , , and , respectively. Then there exist constants and independent of n, such that for all , Proof. Let
. Note that
where the last inequality follows from the fact that
, due to Assumption 5.
To see (
29), it suffices to show
Now, we develop a probability deviation inequality for
, where
,
are constants such that
. Denote
and
Note that
is an independent sequence. By Nagaev’s inequality and Ottaviani’s inequality, we have that
where the last inequality holds because
by Jensen’s inequality. Since
is a martingale difference sequence with respect to
, we have that
is a non-negative sub-martingale. Then by Doob’s inequality and Burkholder’s inequality, we have
Now, we deal with the term
. Define
and
. Then
Let
and
. We have
where we have that
is independent of
for
, as
is
-dependent. Therefore, we can apply Ottaviani’s inequality and Nagaev’s inequality for independent variables. As a consequence,
Again, by Burkholder’s inequality, we have that for
,
Note
. Let
, and we have
as
. In respect to (
34), we have that
Note
, and
Combining (
31), (
32), (
33) and (
35), we obtain
Now, we have (
30) by taking
for
. Note that since
has bounded support, for any given
, we have
Therefore (
28) follows from (
36) by taking
, and note that for any
,
for a constant
. □
Lemma 2. Suppose satisfys Assumption 2. Furthermore, let Assumption 5 hold. Let be defined as in Lemma 1. Then there exist constants , and independent of n and p, such that for all , we haveand Proof. For
, let
. We now check the conditions in Lemma 1 for
. Denote
. Then the uniform functional dependence measure of
is
Thus the DAN of the process
satisfies that
The result follows immediately from Lemma 1 and the Bonferroni inequality. □
Lemma 3. We adopt the notation in Lemma 2. Suppose Assumptions 2, 1, and 5 hold with . Recall , where and as . Then there exists a constant C independent of n and p such that in (11) satisfies that for any , Proof. Approximating the discrete summation with integral, we obtain for all
,
Thus we have
, in view of Assumption 5. By Lemma 2, we have
Denote
for a large enough constant
, then for any
,
Thus (
39) is proved. The result (
40) can be obtained similarly. □
7.2. Proof of Main Results
Proof of Proposition 1. Given (
39) and (
40), the proof of (
16) is standard. (See, e.g., Theorem 6 of [
11]). For
and
given in Proposition 1, by Lemma 3, we have that, respectively,
Then note that for any
, for any
,
where by construction, we have
and
. Consequently,
Then (
16) and (
17) follow from (
41) to (
43). □
Proof of Proposition 2. Theorem 2 is an immediate result of (
17). □
Proof of Theorem 1. Denote as the time point(s) of the time of jump ordered decreasingly in the sense of the infinite norm of covariance matrices, i.e., for . (Temporal order is applied if there is a tie.) Let . For , as a result of Assumption 3, if for n sufficiently large. That is to say, each time point is in the neighborhood of, at most, one change point.
For any
,
, denote
and
Then, for
, by (
3), we have
we can easily verify that
Note that
is maximized at
and
. By the triangle inequalities, we have that for some positive constant
C, for any
,
On the other hand, since
, we have
Denote the event
and let
,
. Note that
By Lemma 2, we have for any
,
Let
for some
. Assume
. Under
we have that
for
and
as a consequence of Assumption 3. According to (
46) and (
47), we have if
is true,
, which implies
. The result (
21) follows from deduction.
Suppose
holds. By the choice of
, as a consequence of (
45) and (
49), and that
, we have that
As a result,
i.e.,
. On the other hand, since
is excluded from the searching region for
, we have
In other words,
. Thus (
20) is proved. □
Proof of Theorem 2. We adopt the notations in the proof of Theorem 1 and assume that
holds. Similar to Lemma 3, we have that by Lemma 2, for any
,
where
for a large enough constant
.
Since under
,
. For
, we have that for all
,
On the other hand, for
, due to reflection, we no longer have that differentiability. As a result of the Lipschitz continuity, we get
The result (
22) follows by the choices of
b. The rest of the proof are similar to that of Proposition 1 and Theorem 2. □








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}